Embed Size (px)
Citation preview

Etude de faisabilité pourl’évaluation d’impact de l’INDH
Jean-Louis A�����
CERDI-CNRS, Université d’Auvergneet European Union Development Network (EUDN)
12 décembre 2007
Table des matières
1 Résumé 71.1 Faisabilité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.1.1 Les données existantes . . . . . . . . . . . . . . . . . . 71.1.2 Rural . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81.1.3 Urbain . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.2 Timing et coûts . . . . . . . . . . . . . . . . . . . . . . . . . . 91.3 Structure de ce rapport . . . . . . . . . . . . . . . . . . . . . . 10
2 Introduction 122.1 Qu’est-ce qu’une évaluation d’impact ? . . . . . . . . . . . . . 122.2 Qu’est-ce qui n’est pas une évaluation d’impact ? . . . . . . . 13
3 Une approche unifiée au problème : Le modèle de traitement 143.1 Ecriture en termes d’une régression linéaire : Y = α+Dβ + ε 153.2 Détermination du statut de traitement : le modèle d’indexe . . 16
4 Les trois sources de biais dans une évaluation d’impact 164.1 Source de biais No. 1 : D est corrélé avec ε . . . . . . . . . . . 174.2 Source de biais No. 2 : β est corrélé avec D . . . . . . . . . . . 174.3 Source de biais No. 3 : β est corrélé avec ε . . . . . . . . . . . 17
1

4.4 Organisation de l’évaluation d’impact autour de ces trois sourcesde biais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
5 Partenaires sectoriels 205.1 Ministère de la santé, Division de la population . . . . . . . . 225.2 Education nationale, Direction de la stratégie et de la planifi-
cation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 235.3 Direction de l’éducation non-formelle . . . . . . . . . . . . . . 245.4 Haut Commissariat au Plan . . . . . . . . . . . . . . . . . . . 255.5 Lutte contre l’analphabétisme . . . . . . . . . . . . . . . . . . 265.6 Coordination nationale de l’INDH . . . . . . . . . . . . . . . . 265.7 Développement social, de la famille et de la solidarité . . . . . 275.8 Agence de développement social . . . . . . . . . . . . . . . . . 285.9 Inspection générale de l’administration territoriale . . . . . . 285.10 Utilisation des données administratives . . . . . . . . . . . . . 29
6 Construire un contrefactuel afin de purger la source de biaisNo. 1 316.1 La source de biais No. 1 est forcément présente . . . . . . . . 316.2 Stratégies d’identification . . . . . . . . . . . . . . . . . . . . . 32
6.2.1 Regression discontinuity design . . . . . . . . . . . . . 326.2.2 Appariement par score de propension . . . . . . . . . . 33
7 Les communes rurales 347.1 Statistiques descriptives . . . . . . . . . . . . . . . . . . . . . 347.2 Détermination du statut d’éligibilité en milieu rural . . . . . . 36
7.2.1 Un modèle probit standard . . . . . . . . . . . . . . . . 367.2.2 Estimation non-paramétrique . . . . . . . . . . . . . . 40
7.3 Construction du contrefactuel . . . . . . . . . . . . . . . . . . 44
8 Les communes urbaines 458.1 Statistiques descriptives . . . . . . . . . . . . . . . . . . . . . 458.2 Détermination du statut d’éligibilité en milieu urbain . . . . . 468.3 La distinction entre "grandes" et "petites" communes urbaines 518.4 Construction d’une cartographie de la pauvreté par quartier
pour les grandes communes urbaines . . . . . . . . . . . . . . 538.4.1 Un contrefactuel inter-communal ? . . . . . . . . . . . . 548.4.2 Un contrefactuel basé sur les quartiers . . . . . . . . . 54
2

9 Calculs de puissance 569.1 Les calculs de base : L’Impact Minimal Détectable (IMD) . . . 569.2 L’IMD dans le cas de covariés et d’un échantillonnage stratifié 589.3 Sélection sur observables et estimations par variables instru-
mentales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 599.4 Coûts des enquêtes . . . . . . . . . . . . . . . . . . . . . . . . 61
10 Autres aspects méthodologiques relevant de la source de biaisNo. 1 6210.1 Vérification ex ante de l’hypothèse des tendances parallèles . . 6210.2 Doubles-différences et les enquêtes de 2010 . . . . . . . . . . . 6310.3 Impact des projets INDH complétés . . . . . . . . . . . . . . . 64
10.3.1 Estimation par les variables instrumentales de l’effetdes projets complétés . . . . . . . . . . . . . . . . . . . 65
10.3.2 Variables instrumentales possibles . . . . . . . . . . . . 6510.4 L’importance d’identifier des variables Z absentes de X . . . . 66
11 Hétérogénéité essentielle : Les sources de biais No.2 et No.3 6711.1 L’élément de base : Le MTE . . . . . . . . . . . . . . . . . . . 6811.2 Les différents effets traitement . . . . . . . . . . . . . . . . . . 69
11.2.1 Average treatment effect : ATE . . . . . . . . . . . . . 6911.2.2 Effect of treatment on the treated : TT . . . . . . . . . 7011.2.3 Effets locaux : LATE et LIV . . . . . . . . . . . . . . . 70
11.3 Comment estimer le MTE . . . . . . . . . . . . . . . . . . . . 71
12 Hétérogénéité de l’effet traitement le long de la distributionde Y 7312.1 La fonction de quantile . . . . . . . . . . . . . . . . . . . . . . 7312.2 Régression par quantile . . . . . . . . . . . . . . . . . . . . . . 74
13 Chronogramme et estimations des coûts 7613.1 Mise en œuvre des enquêtes rurales par un bureau d’étude . . 76
13.1.1 Termes de references pour l’enquete rurale . . . . . . . 7713.1.2 Profil de l’équipe du consultant . . . . . . . . . . . . . 81
13.2 Construction de l’échantillon urbain . . . . . . . . . . . . . . . 8113.3 T + 1 mois . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8113.4 T + 2 mois . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8113.5 T + 3 mois . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
3

13.6 T + 5 mois . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8213.7 T + 6 mois . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8213.8 T + 7 mois . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
A Liste des 124 communes rurales de l’échantillon proposé à lasection 7 83
Table des figures
1 Densité kernel des taux de pauvreté (en %) en 2004 dansl’échantillon rural : 1298 communes rurales, dont 403 INDH ;bande passante (bandwidth) = 2.447. . . . . . . . . . . . . . . 36
2 Densités kernel du taux de pauvreté en 2004 pour les deuxsous-échantillons : 403 communes rurales traitées par l’INDHà partir de 2005 (en noir), et 895 non-traitées (en rouge poin-tillé). Bande passante = 1.752. . . . . . . . . . . . . . . . . . . 37
3 Histogramme du score de propension pour l’échantillon dansson ensemble. . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
4 Histogrammes des scores de propension, par statut de traite-ment : en rouge les communes non-traitées par l’INDH, en noircelles qui sont traitées. . . . . . . . . . . . . . . . . . . . . . . 40
5 Estimation semi-paramétrique de l’effet du taux de pauvretéen 2004 sur la probabilité pour une commune d’être traitée àpartir de 2005. Résultat en niveau. Le graphique représente
f (p) avec l’intervale de confiance à 95%. . . . . . . . . . . . . 416 Estimation semi-paramétrique de l’effet du taux de pauvreté
en 2004 sur la probabilité pour une commune d’être traitée àpartir de 2005. Résultat pour la dérivée première. Le gra-
phique représente ∂f (p) /∂p avec l’intervale de confiance à 95%. 427 Estimation semi-paramétrique de l’effet du taux de pauvreté
en 2004 sur la probabilité pour une commune d’être traitée àpartir de 2005. Résultat pour la dérivée seconde. Le graphique
représente ∂2f (p) /∂p2 avec l’intervale de confiance à 95%. . . 438 Densité kernel des taux de pauvreté (en %) en 2004 dans
l’échantillon urbain : 402 communes urbaines, dont 93 incluantau moins un quartier traité par l’INDH; bande passante (band-width) = 1.617. . . . . . . . . . . . . . . . . . . . . . . . . . . 47
4

9 Densités kernel du taux de pauvreté en 2004 pour les deuxsous-échantillons urbains : 93 communes urbaines avec au moinsun quartier traité par l’INDH à partir de 2005 (en noir), et 302non-traitées (en rouge pointillé). Bande passante = 1.341. . . . 48
10 Densités kernel des scores de propension, par statut de trai-tement : en rouge les communes urbaines non-traitées parl’INDH, en noir celles qui sont traitées. . . . . . . . . . . . . . 50
11 Estimation non-paramétrique de l’effet du logarithme de lapopulation de la commune sur son taux de pauvreté, en 2004.Résultat en niveau, avec l’intervale de confiance à 95%. . . . . 52
12 Estimation non-paramétrique de l’effet du logarithme de lapopulation de la commune sur son taux de pauvreté, en 2004.Résultat pour la dérivée première, avec l’intervale de confianceà 95%. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
Liste des tableaux
1 Le problème fondamental de l’évaluation : les contrefactuelsinexistants. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2 Liste préliminaire des indicateurs de résultats potentiels, parsecteur et par niveau d’agrégation. . . . . . . . . . . . . . . . 30
3 Le taux de pauvreté en 2004 : statistiques descriptives. 1298communes rurales, dont 403 traitées par l’INDH à partir de2005. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4 Estimation en probit de la probabilité de traitement par l’INDH.La variable expliquée est égale à 1 si la commune est traitéepar l’INDH à partir de 2005, et 0 autrement. 1298 communesrurales, dont 403 traitées par l’INDH à partir de 2005. Ecarts-types entre parenthèses. . . . . . . . . . . . . . . . . . . . . . 38
5 Le taux de pauvreté en 2004 : statistiques descriptives. 402communes urbaines, dont 93 avec au moins un quartier traitépar l’INDH à partir de 2005. . . . . . . . . . . . . . . . . . . . 46
6 Estimation en probit de la probabilité de traitement par l’INDH.La variable expliquée est égale à 1 si la commune est traitéepar l’INDH à partir de 2005, et 0 autrement. 402 communesurbaines, dont 93 traitées par l’INDH à partir de 2005. Ecarts-types entre parenthèses. . . . . . . . . . . . . . . . . . . . . . 49
5

7 Calcul de l’IMD pour différentes combinaisons du nombre decommunes et du nombre de ménages enquêtées. . . . . . . . . 59
6

1 Résumé
1.1 Faisabilité
Le présent rapport détaille les méthodologies potentiellement applicablesà l’évaluation d’impact de l’INDH. Sur la base de la cartographie de lapauvreté du Maroc et des données disponibles au niveau des communes, ilapparaît que l’évaluation d’impact de l’INDH est faisable, bien quecertaines questions techniques devront être résolues. En particulier,il apparaît que la construction des contrefactuels, sine qua non de touteévaluation d’impact rigoureuse, est plus ardue pour le milieu urbain quepour le milieu rural, en particulier à cause de l’inexistence de la notion dequartier dans l’appareil statistique du Royaume.
1.1.1 Les données existantes
Les données existantes, bien que riches, ne permettent pas defaire l’évaluation d’impact de l’INDH, et ceci pour deux raisons. Pre-mièrement, aucune base de données existante (que ce soient les recensements,les enquêtes consommation, ou les enquêtes démographie/santé) ne regroupela panoplie d’indicateurs de résultats souhaitée pour l’évaluation d’impact del’INDH (voir le Tableau 2). A titre d’exemple, l’enquête démographie/santéfournit des informations sur la santé des ménages, mais ne fournit rien surles dépenses. Deuxièmement, les différentes enquêtes ne correspondent pas àl’échantillonnage de communes nécessaire pour procéder à l’évaluation d’im-pact (détaillé et justifié dans le rapport aux sections 7 et 8), à savoir unsous-ensemble de communes traitées et un sous-ensemble de communes non-traitées, mais avec des caractéristiques semblables.
En outre, utiliser ces enquêtes, ou même un sous-ensemble des observa-tions issues de ces enquêtes, comme situation de référence pour l’évaluationd’impact de l’INDH impliquerait une duplication inacceptable du travail : ilfaudrait en effet identifier le sous-ensemble de ménages correspondant auxcommunes des échantillons proposés aux sections 7 et 8 de ce rapport (cequi n’est d’ailleurs pas possible, dans la mesure où les échantillons ne sechevauchent qu’en partie), retrouver ces ménages sur le terrain, et procé-der à la collecte d’information pour ces mêmes ménages au printemps 2008.Cette approche impliquerait donc essentiellement de refaire les enquêtes dé-mographie/santé et les enquêtes consommation, sur des sous-échantillons de
7

ménages différents. Finalement, aucune de ces enquêtes ne fournit de l’infor-mation sur la participation par les populations dans les activités de l’INDH.
1.1.2 Rural
Pour les communes rurales, je montre dans ce rapport qu’il est possiblede construire un contrefactuel rigoureux en grande partie sur la base de laméthode du regression discontinuity design, étant donné qu’un seuil du tauxde pauvreté est un facteur déterminant dans le traitement des communes parl’INDH. Spécifiquement, je propose que la construction de l’échantillon rural,pour les besoins de l’évaluation, soit constitué de 124 communes rurales dontles taux de pauvreté sont situés dans entre 27 et 31%. La taille de l’échantillonest justifiée à la section 9 à l’aide de calculs de puissance. Pour le milieurural, le timing développé à la section 13 du rapport implique qu’il devraitêtre possible de démarrer les enquêtes en milieu rural en février 2008.
Notons qu’un grand nombre de variables affectant la probabilité de trai-tement par l’INDH pourront être introduites dans l’analyse statistique aprèsla construction du contrefactuel. Ceci est particulièrement vrai pour des ca-ractéristiques des communes qui affectent la probabilité de traitement, maisqui n’affectent pas les résultats. L’importance de la collecte de ces variables,denotées par Z dans le rapport, est soulignée à maintes reprises.
1.1.3 Urbain
En milieu urbain, contrairement au milieu rural, le traitement par l’INDHopère au niveau de "quartiers", unité statistique inexistante, rappellons-le,du point de vue formel. Ce choix du niveau d’agrégation pour le traitementpar l’INDH complique énormément l’évaluation d’impact, et mène à deuxoptions méthologiques, dont la première devrait en toute probabilité êtreécartée.
Option 1 En se basant sur le score de propension (la probabilité de trai-tement par l’INDH prédite par un modèle statistique) il est faisable deconstruire un contrefactuel de communes urbaines dont aucun quartier n’aété traité, et ayant une probabilité de traitement semblable aux communesdont au moins un quartier a été traité par l’INDH. Toutefois, et c’est surtoutun problème pour les grandes communes urbaines qui représentent la frac-tion la plus importante de l’échantillon urbain, ces interventions au titre de
8

l’INDH risquent d’être relativement insignifiantes au regard de la taille descommunes, rendant ainsi difficile la mise en exergue d’un effet significatif, sicelui-ci existe. Sur la base des informations disponibles, je propose de ne paspoursuivre cette option méthodologique.
Option 2 La deuxième option pour les communes urbaines, plus satisfai-sante du point de vue méthodologique, nécessite une mobilisation de res-sources financières et humaines additionnelles. Il s’agirait, pour 7 grandesvilles du Royaume, de construire une cartographie partielle de la pau-vreté par quartier. Dans chaque ville une dizaine de quartiers traitéspar l’INDH seraient identifiés. En association avec les Walis, un quartiernon-traité par l’INDH serait alors apparié à chaque quartier traité. Les in-formations concernant les districts de recensement qui constituent chacun deces quartiers devraient également être fournies par leWali. Pour les quartiersinclus dans cet échantillon, il s’agirait ensuite de construire une cartographiede la pauvreté, comme celle déjà construite par le HCP au niveau des com-munes. Les détails de cette procédure, et donc de la commande qui devraêtre adressée au HCP, sont reportés à la section 8.4 du rapport. Le calcul,par des méthodes statistiques détaillées dans le rapport, de la probabilité detraitement, permettra ensuite d’affiner l’estimation de l’impact de l’INDH enmilieu urbain, en particulier en éliminant au moins une partie de la subjec-tivité qui aurait éventuellement pu être introduite par les choix initiaux decontrefactuels.
1.2 Timing et coûts
Sur la base de ce qui précède, les enquêtes de référence (le premier pas-sage) en milieu rural pourront démarrer en février 2008. Un second passage,permettant de mettre en oeuvre les méthodologies de double différence dé-crites à la section 10 du rapport, devrait avoir lieu en 2010/11.
Pour le milieu urbain, en supposant que l’option 2 soit retenue et queles ressources nécessaires à la construction de la cartographie partielle de lapauvreté par quartier pour 7 grandes villes du Royaume soient disponibles,les enquêtes pourraient avoir lieu au même moment, bien qu’un glissementsoit possible.
La taille des échantillons requis dépend bien sûr des ressources allouées.
9

Toutefois, les calculs de puissance détaillées à la section 9, ainsi que les es-timations de la section 7 suggèrent qu’un échantillon rural constitué de 124communes (62 traitées et 62 non-traitées), avec 15 ménages par commune,serait suffisant pour détecter des impacts de l’INDH pour la plupart des va-riables de résultats envisageables. Pour le milieu urbain, une structure destratification similaire devrait être mise en oeuvre. Avec un coût estimé de300 Dirhams par ménage enquêté, tout compris, le coût des enquêtes en mi-lieu rural s’élèverait donc à un total de 124×15×300 = 558 000 Dirhams. Uncoût semblable devrait s’appliquer pour l’échantillon urbain, majoré par lecoût de la construction de la cartographie partielle de pauvreté par quartieren milieu urbain.
1.3 Structure de ce rapport
La structure de ce rapport est comme suit. Dans la section 2, je présentede façon non-technique le principe de base de toute évaluation d’impact :la construction d’un contrefactuel, à savoir un échantillon d’individus (com-munes ou quartiers) non-traités par le programme que l’on souhaite évaluer,mais qui ont les mêmes caractéristiques que les individus traités par le pro-gramme. Dans la section 3, cette intuition est formalisée sous la forme d’unmodèle de traitement. Dans la section 4, je détaille les sources de biais pos-sibles dans une évaluation d’impact, avec une emphase toute particulière surles facteurs qui peuvent invalider un contrefactuel. A la section 5, je résumeles préoccupations spécifiques des principaux partenaires associés à l’évalua-tion d’impact de l’INDH. A la section 6, je détaille les deux méthodologiesapplicables à l’évaluation d’impact de l’INDH, le regression discontinuity de-sign et l’appariement par score de propension. A la section 7, je considèreen détail le cas des communes rurales, et je spécifie la stratégie d’identifica-tion qui devrait être adoptée en termes de la construction du contrefactuel.A la section 8, je fais la même chose pour les communes urbaines avec, enparticulier, le détail de la construction d’un identifiant "quartier". Les cal-culs de puissance nécessaires pour l’établissement de la taille des échantillonsrequis sont détaillés à la section 9. D’autres questions méthodologiques,dont l’importance d’une deuxième série d’enquêtes en 2010/11, sont traitéesà la section 10. Dans la section 11, je montre comment d’autres sources debiais –en particulier ce que l’on appelle techniquement l’hétérogénéité essen-tielle– pourront affecter les résultats de l’évaluation d’impact, et je montreconcrètement comment les traiter du point de vue technique. La section 12
10

reporte les solutions statistiques permettant de détecter de l’hétérogénéité del’effet traitement le long de la distribution de la variable d’impact, condui-sant entre autres, à une évaluation de l’INDH sous ses aspects pro-pauvres.Finalement, à la section 13, ces propositions méthodologiques sont traduitessous la forme d’une chronogramme pour la mise en oeuvre des enquêtes quiinclue une estimation des coûts qui seront encourus.
11

2 Introduction
2.1 Qu’est-ce qu’une évaluation d’impact ?
Le problème de base de l’évaluation d’impact est simple à comprendre,et relève de la construction par l’économètre de contrefactuels inobservés.
Considérons un programme social comme l’INDH. Supposons que lesindividus dans la population cible puissent être divisés en deux catégories :les individus traités par le programme et les individus non-traités. Afinde décrire économétriquement cette situation, nous spécifierons une variablemuette D qui prendra la valeur 1 lorsqu’un individu est traité, et 0 lorsquel’individu n’est pas traité. Le résultat d’un individu (son revenu, son poids,son niveau de scolarité, etc.) sera décrit par une variable que nous dénote-rons généralement par Y . Lorsqu’un individu est traité, nous dénoterons lavariable de résultat par Y = Y1, tandis que lorsque l’individu n’est pas traité,nous écrirons Y = Y0.
Par "évaluation d’impact du traitement par le programme sur un indi-vidu", nous entendons évaluer la différence Y1 − Y0 pour un individu donné.La difficulté de l’exercice réside dans le fait que nous n’observons Y1 quepour les individus traités, c’est-à-dire ceux pour lesquels D = 1, tandis quenous n’observons Y0 que pour les individus non-traités, c’est-à-dire ceux pourlesquels D = 0 : jamais nous ne pourrons observer Y1 et Y0 pour un mêmeindividu au même moment. Ce problème est illustré au Tableau 1.
Les cases supérieure de gauche et inférieure de droite sont observées, tan-dis que les cases inférieure de gauche et supérieure de droite ne le sont pas.Dans tout ce qui suit dans ce rapport, le but sera de construire des estima-tions, basées sur les données disponibles, de ces deux "cases manquantes".Il s’agira donc de mettre en oeuvre les procédures permettant de construireles contrefactuels manquants.
Y1 Y0D = 1 Y1|D = 1 observé Y0|D = 1 inobservéD = 0 Y1|D = 0 inobservé Y0|D = 0 observé
T��. 1 — Le problème fondamental de l’évaluation : les contrefactuels inexis-tants.
12

2.2 Qu’est-ce qui n’est pas une évaluation d’impact ?
Le terme "évaluation d’impact" est très précis en économie. Tout commele terme "bien public" a un sens différent pour un journaliste d’une part, etpour un économiste de l’autre, le terme "évaluation d’impact" porte souventà confusion. En effet, il est fréquent que l’on appelle "évaluation d’impact"un exercice qui ne l’est pas du tout. Prenons un exemple concret.
Supposons que vous êtes chargé(e) d’évaluer l’impact attribuable à unprogramme de nutrition infantile en zône rurale. Dans chaque école où leprogramme est mis en oeuvre, votre équipe d’enquêteurs pèse et mesure lataille de chaque enfant. Supposons que vous procédez à cette exercice avantla mise en oeuvre du programme, et que vous répétez le même exercice à lafin du programme. Vous comparez ensuite le poids-pour-age (un indicateuranthropométrique communément utilisé pour mesurer la sous-alimentation)moyen des enfants avant le programme et après le programme. Supposonségalement que vous trouvez que le poids-pour-age des enfants après traite-ment par le programme est, en moyenne, inférieur à celui avant le programme.Pouvez-vous conclure que le programme est en train d’empirer le statut nutri-tionnel des enfants ? Pouvez conclure sur la base de ces résultats statistiquesqu’il faudrait donc interrompre le programme parce qu’il influence de façonnégative la santé des enfants traités ? La réponse, bien évidemment, est"non" ! Pourquoi ?
Parce que vous n’avez pas de contrefactuel. En particulier, il se peut quele statut nutritionnel des enfants se soit détérioré pour des raisons qui n’ontstrictement rien à voir avec le programme que vous êtes chargé(e) d’évaluer.Plus précisément, si les conditions en milieu rural se sont détériorées (unesérie de mauvaises récoltes, par exemple), il se peut que la cause derrière laréduction dans le poids-pour-age moyen des enfants ne reflète pas du toutl’intervention dont vous tentez de mesurer l’impact. Ce qu’il vous manque estun étalon de comparaison, qui serait constitué par un échantillon d’enfantssemblables à ceux traités par le programme, mais qui ne le sont pas. Ce quimanque à votre analyse, c’est un bon contrefactuel.
Dans le cas précis de cette exemple, supposez que vous avez également eula bonne idée de collecter les mêmes statistiques sur un échantillon d’enfantsdans des villages de la même région, mais où le programme nutritionneln’intervient pas. Dans ce cas, vous pourrez étudier la même évolution dans le
13

statut nutritionnel des enfants, mais pour le sous-échantillon des non-traités.Sous un certain nombre d’hypothèse, la différence entre les évolutions desdeux groupes (appellé techniquement, pour des raisons évidentes, la "doubledifférence") vous fournira une estimation de l’effet net sur la santé des enfantsattribuable au programme.
Ce qui devrait être évident de cet exemple c’est qu’en l’absence d’uncontrefactuel, vos conclusions concernant la continuation du programme se-raient complètement erronées. Malheureusement, un grand nombre de soit-disantes "évaluations d’impact" ne le sont aucunement, et se cantonnent àmesurer l’évoluation du groupe traité. L’absence de contrefactuel dans cesexercices réduit considérablement leur intérêt, et implique qu’ils ne peuventpas être utilisés pour décider de l’impact net attribuable à un programme.
Ce que cet exemple met en exergue également est que ce qui nous intéresseen tant qu’économistes, et encore plus en tant qu’économistes au service desdécideurs, relève de la seule chose que les économistes font bien : raisonner enceteris paribus. Une bonne évaluation d’impact, conduite selon les règles del’art, doit permettre conceptuellement de chiffrer la dérivée partielle, touteschoses étant par ailleurs égales, du programme d’intérêt sur la variable derésultat choisie.
3 Une approche unifiée au problème : Le mo-
dèle de traitement
Il sera utile dans les pages qui suivent d’adopter une notation unifiée quipermettra de traiter de façon séquentielle les problèmes économétriques quise présenteront, ainsi que les solutions proposées. La notation utilisée iciest celle introduite par Heckman dans ses nombreux travaux sur l’évaluationd’impact (voir, par exemple, Heckman et Vytlacil (2005)).
Les ingrédients de base seront toujours les mêmes : (i) une équation quidéfinit le statut traitement, exprimée généralement sous la forme d’un modèled’indexe linéaire, (ii) une paire d’équations de résultats qui correspondent auxdeux statuts possibles.
14

3.1 Ecriture en termes d’une régression linéaire : Y =α+Dβ + ε
Considérez la spécification élémentaire suivante. Le statut traitement estdéfini par une variable muette D :
D =
{1 si la commune est traitée par l’INDH0 autrement
(1)
La structure de base est donnée par un modèle pour le résultat Yj , j = 0, 1comme fonction de facteurs observables X et de facteurs inobservables Uj :
Y0 = µ0(X) + U0, (2a)
Y1 = µ1(X) + U1. (2b)
L’indice 1 correspond aux individus traités, tandis que l’indice 0 correspondaux individus non-traités. Dans le cas de l’évaluation d’impact de l’INDH, lemot "individu" correspond à une commune, car c’est à ce niveau d’agrégationqu’est défini le statut traitement.
Dans cette notation, µj(X) représente la valeur moyenne de Yj, condi-tionnelle sur les observables X, tandis que Uj représente des déviations parrapport à cette moyenne conditionnelle. Entre autres, la matriceX inclue desmuettes indiquant la présence d’autres programmes dans les communes enquestion –voir la section 5 sur les réunions sectorielles pour de plus amplesdétails. On peut réécrire le modèle de façon plus succincte, en termes durésultat observé, comme :
Y = DY1 + (1−D)Y0. (3)
Cette écriture est utile car elle nous permettra de spécifier notre modèlesous la forme d’une régression linéaire :
Y = DY1 + (1−D)Y0 (4a)
= Y0 +D (Y1 − Y0) (4b)
= µ0(X) + U0︸ ︷︷ ︸=Y0
+D[(µ1(X) + U1)︸ ︷︷ ︸=Y1
− (µ0(X) + U0)︸ ︷︷ ︸=Y0
] (4c)
et donc :
Y = µ0(X) +D [µ1(X)− µ0(X) + U1 − U0] + U0. (5)
15

Nous pouvons ensuite réécrire (5) sous une forme qui devrait vous être fami-lière :
Y = α+Dβ + ε, (6)
où :
α = µ0(X), (7a)
β = µ1(X)− µ0(X) + U1 − U0, (7b)
ε = U0. (7c)
3.2 Détermination du statut de traitement : le modèled’indexe
Pour estimer le modèle décrit par (6), et tenter d’identifier β, nous devonsspécifier le mécanisme par lequel le statut de traitement est déterminé. Lafaçon la plus simple de spécifier le modèle de choix qui détermine la partici-pation au programme est d’écrire un modèle d’indexe linéaire (linear indexmodel) :
D∗ = µD (Z)− UD. (8)
avec :
D =
{1 si D∗ � 00 autrement
. (9)
Ici, le vecteur Z représente les caractéristiques observables des communes,et qui peut inclure les éléments de X (X ⊆ Z), qui affectent la décision departicipation. La variable UD représente, pour sa part, toutes les caractéris-tiques inobservables qui affectent la décision de participation. On résumerasouvent l’expression donnée en (9) sous la forme plus compacte d’une fonctionindicatrice 1 [.] :
D = 1 [D∗� 0] . (10)
4 Les trois sources de biais dans une évalua-
tion d’impact
Cette spécification générale, où le "coefficient" β = µ1(X)−µ0(X)+U1−U0 que l’on cherche à estimer est en fait spécifique à chaque individu, est
16

indicative des complications qui suivront. Vous aurez sans doutes remarquéqu’il y a potentiellement trois sources de biais dans l’estimation représentéepar (5) ou (6).
4.1 Source de biais No. 1 : D est corrélé avec ε
Une première source de biais peut provenir du fait que D soit corrélé avecε = U0. C’est le type de violation des conditions Gauss-Markov auquel vousêtes probablement le plus habitué(e), et vous le reconnaîtrez comme de l’en-dogénéité "classique". On le retrouve par exemple sous la forme d’habiletéinobservée dans une équation mincérienne de salaire, d’effets individuels cor-rélés dans une spécification standard en panel, ou dans les modèles d’erreurde mesure. Les sections 6, 7, 8 et 10 de ce rapport se penchent essentielle-ment sur ce problème, pour ce qui concerne la construction d’un contrefactuelapproprié et l’identification de restrictions d’exclusion admissibles.
4.2 Source de biais No. 2 : β est corrélé avec D
Une deuxième source de biais provient du fait qu’il se peut que β =µ1(X) − µ0(X) + U1 − U0 soit corrélé avec D (ou, plus précisément, queU1 − U0 soit corrélé avec D). Cette source de biais apparaît dès lors que lesagents économiques basent, au moins en partie, leur décisions de participationau programme sur les gains U1 − U0 qu’ils espèrent en tirer. A priori, vousn’êtes pas habitué(e) à ce type de biais, sauf si vous avez vu les modèles àcoefficients aléatoires (random coefficients model). Nous traiterons de cettequestion à la section 11 de ce rapport.
4.3 Source de biais No. 3 : β est corrélé avec ε
Une troisième source de biais provient d’une corrélation potentielle entreβ = µ1(X)− µ0(X) + U1 − U0 et ε = U0. Cette forme de corrélation appa-raît, par exemple, lorsque les gains issus de la participation au programmedépendent de la situation de référence de l’individu (sans le programme).Pour un programme de formation, bien que U1 soit le même pour tout lemonde, il se peut que seulement les individus avec un U0 faible en tirerontprofit. Comme pour la Source de biais No. 2, nous traiterons de cette ques-tion à la section 11 de ce rapport.
17

4.4 Organisation de l’évaluation d’impact autour deces trois sources de biais
Dans l’évaluation d’impact de l’INDH, il sera utile d’organiser notre pen-sée autour de différentes hypothèses, progressivement moins restrictives, quipermettront d’estimer des versions de plus en plus riches du modèle de trai-tement.
Dans un premier temps, nous supposerons qu’aucune des trois sources debiais n’est présente. Dans un deuxième temps nous permettrons à la sourcede biais No. 1 de faire surface, tandis que dans un troisième temps nouspermettrons aux trois types de biais potentiels d’exister. L’avant-dernièresection du rapport (la section 12) poussera cette analyse plus loins, en per-mettant à l’effet du programme de varier sur l’ensemble de la distribution deY , le but étant de voir si l’INDH est potentiellement pro-pauvre.
Dans un premier temps, nous supposerons donc (i) que les inobservablesdans les équations de résultats, U1 et U0, suivent la même distribution :
U1 = U0 = U, (11)
que l’individu soit traité ou non, et (ii) que le statut de traitement est déter-miné par les facteurs observables X. La première hypothèse implique que leterme en U1 − U0 s’annule dans l’expression pour β dans (7b), et donc queles sources No. 2 et No. 3 de biais disparaissent. La deuxième hypothèse,que le statut de traitement est déterminé par les observables inclus dans (5),implique que Z = X. Le modèle d’indexe se réduira donc à
D∗ = µD (X)− UD, D = 1 [D∗� 0] , (12)
où nous supposerons que :U ⊥ UD. (13)
Il suit que la source de biais No. 1 disparaît, elle aussi. Nous montreronsà la section 6 que ces deux hypothèses ne sont certainement pas satisfaitesdans le cas de l’INDH, et que nous serons donc nécessairement confrontés àla source de biais No. 1.
Dans un deuxième temps, nous continuerons à supposer que U1 = U0 = U ,mais nous permettrons à D et ε = U0 = U d’être corrélés. La source de biaisNo. 1 sera donc le point focal, et nous la traiterons par deux méthodes.
18

La première méthode, basée sur l’existence d’au moins deux observationspar individu, dont une où tous les individus sont non-traités, supposera quele statut de traitement est déterminé par des facteurs observables et inobser-vables, mais que ces derniers sont invariants dans le temps. En rajoutantun indice temporel t, le terme d’erreur des équations de résultats s’écrira :
Ut + λ, (14)
où λ est la partie du terme d’erreur spécifique à chaque individu et invariantepar rapport au temps, tandis que le modèle d’indexe deviendra :
D∗t = µD (Xt)− UDt,D = 1 [D∗
� 0] , (15)
et où l’on supposera :
Cov [Ut, UDt] = 0, (16a)
Cov [λ, UDt] �= 0. (16b)
La méthode de la double différence ou, plus généralement, de panel, permet-tra alors de purger la biais induit par (16b), et qui correspond à la source debiais No. 1 énoncée ci-dessus. Cette approche nécessite un deuxième passaged’enquête (en 2010), et sera considérée en détail à la section 10.2.
La deuxième méthode relachera encore plus la forme prise par la corré-lation entre les inobservables dans la fonction d’indexe de l’équation (8), etl’erreur idiosyncratique U dans la fonction de résultats. Nous supposeronsque :
Cov [U,UD] �= 0, (17)
mais qu’il existe au moins une variable dans Z qui n’est pas dansX (X ⊂ Z),avec deux propriétés fondamentales. D’abord, nous supposerons que cettevariable qui apparaît dans Z est bel et bien absent de X et, plus précisément,que Z, conditionnellement sur X, est orthogonal par rapport à U . C’est ceque l’on appelle une "restriction d’exclusion" et elle constitue la clef de voûtede l’approche par les variables instrumentales, ainsi que par les fonctions decontrôle. Nous supposerons également que la décision de participation auprogramme, D, est une fonction non-dégénérée de Z, une fois que nous avonscontrôlé pour X. Intuitivement, ceci veut dire que la variable dans Z quin’est pas dans X est un déterminant significatif du choix de participation auprogramme, une fois que nous avons pris en compte les effets de X sur la
19

participation. L’identification de variables Z potentielles sera un leitmotivde ce rapport.
Finalement, dans un troisième temps, nous ne supposerons plus un termed’erreur commun dans les équations de résultats (U1 �= U0) et nous porteronsnotre attention sur les différents "effets traitement" qui peuvent être estimésà partir de l’équation (5) lorsque l’hétérogénéité entre individus est présente.Ces questions seront traitées à la section 11.
5 Partenaires sectoriels
Les réunions sectorielles avec les différents partenaires producteurs d’in-formation pendant les deux premières missions (de septembre et d’octobre),ainsi que la réunion le 23 octobre au siège de l’ONDH, avaient pour but :
— (i) de les sensibiliser à la méthodologie d’une étude d’impact, baséenécessairement sur la construction d’un contrefactuel ;
— (ii) de recueillir des suggestions concernant les sources de données ;
— (iii) d’identifier différents indicateurs de résultats (la variable de gaucheY dans l’équation (6)), tant au niveau de la commune, qu’au niveaudes ménages ou des individus ;
— (iv) d’identifier les différents éléments qui affectent les résultats (leséléments de la matrice X), ainsi que les différents facteurs qui déter-minent le statut de traitement (les éléments de la matrice Z), avec uneemphase particulière sur les variables instrumentales possibles ;
— (v) de comprendre les avantages en termes de suivi-évaluation d’en-quêtes de terrain régulières (surtout pour ce qui concerne le sous-échantillon de bénéficiaires)
Pour chaque interlocuteur, je fais donc état des indicateurs de résultatspotentiels Y qui ont été suggérés, ainsi que les éléments de X et de Z iden-tifiés. Un problème qui a été souvent soulevé concerne l’hétérogénéité desidentifiants géographiques utilisés par différents services, et il sera importantpar la suite de bien veiller à leur harmonisation.
20

Un certain nombres de points sont communs à presque tous les parte-naires, dont :
— l’interaction du traitement par l’INDH avec l’effet d’autres programmes,et les méthodes statistiques pouvant être utilisées pour saisir ces sy-nergies potentielles ; l’importance d’un relevé exhaustif de la présenced’autres programmes sur le terrain pendant les enquêtes a été souli-gnée ;
— l’extrapolation des résultats de l’évaluation d’impact à d’autres com-munes ne faisant pas partie de l’échantillon retenu ;
— le problème de l’évaluation de la composante de l’INDH qui n’est pasciblée d’un point de vue territorial ;
— les champs devant être abordés par l’évaluation (ainsi que les indica-teurs de résultats devant être retenus), dont les indicateurs directs, lesindicateurs administratifs et les indicateurs sociaux ;
— l’aspect qualitatif de l’évaluation d’impact, et la nécessité d’inclure desindicateurs qualitatifs (ainsi que de perception subjective de la partdes bénéficiaires) dans l’analyse ; ces deux derniers points impliqueronsune collaboration étroite entre l’ONDH et les différents partenaires afind’assurer l’inclusion dans les enquêtes de références d’autant d’indica-teurs que possible souhaités par les partenaires ;
— le problème technique principal identifié est la notion de «quartier»au niveau urbain ; tous les participants sont d’ailleurs de l’avis que ceproblème compliquera la construction du contrefactuel pour le milieuurbain (voir la section 8.4 pour une proposition de solution à ce pro-blème) ;
— l’utilisation de l’évaluation d’impact comme outil d’aide à la décision,pour les responsables du programme ainsi que pour différents parte-naires ; l’importance d’une étroite collaboration entre l’ONDH et lacellule nationale de coordination de l’INDH a été soulignée ;
— le rôle catalyseur pouvant être joué par l’évaluation d’impact dans lamise en place d’un dispositif statistique au niveau local.
21

5.1 Ministère de la santé, Division de la population
Le problème principal identifié grace à la réunion au ministère de la santéest qu’il est improbable qu’une méthodologie d’enquête classique (c.à.d., avecpar exemple, un échantillon aléatoire de 8 ou 20 ménages par commune)puisse permettre d’obtenir des résultats représentatifs, au niveau de la com-mune, concernant la mortalité infantile ou la mortalité maternelle. D’unpoint de vue formel, l’équation (6) est estimée au niveau du ménage, Y re-présente un indicateur de mortalité maternelle ou infantile pour un ménagedonné, et X est une matrice de variables de contrôle reflétant les caractéris-tiques du ménage ainsi que celles de la commune. Plus précisément, Y seraégal à 1 si un enfant du ménage est décédé et zéro autrement.
L’estimation de cette équation, par un probit par exemple, permettraitalors de calculer l’impact du traitement par l’INDH sur la probabilité demort d’un enfant du ménage. Le problème statistique est qu’il est très peuprobable que l’on ait un nombre suffisamment important de ménages enquêtésdans chaque commune pour lesquels Y = 1 : en statistique, on appelle ceciun problème "d’évènement rare."
La discussion avec nos interlocuteurs de la santé a donc porté en partiesur la possibilité d’utiliser des techniques d’enquêtes novatrices permettantd’opérer un recensement indirect des caractéristiques de la population danschaque commune. Ces techniques, souvent basées sur l’utilisation d’infor-mateurs ayant préalablement réunis tous les habitants de la localité dans unmême lieu (la mosquée ?), sont communément utilisées en anthropologie et ensociologie, mais presque jamais en économie. Une autre possibilité serait debaser la collecte d’information sur la mortalité maternelle sur les méthodesadoptées lors d’un projet pilote à Marrakesh, où l’input des sages-femmes(qui enregistrent la mort des mères au niveau hospitalier) s’est avéré essen-tiel. Obtenir une copie des rapports concernant cette étude pilote seraitd’ailleurs souhaitable.
Une réflexion sur ce sujet me semble essentielle, mais une décision surl’adoption éventuelle de ces méthodologies non-conventionnelles pour les en-quêtes du printemps 2008 dépend entièrement des variables de résultats (lesY ) qui seront retenues. Ma proposition à ce stade est donc d’ouvrir un"dossier" complémentaire à l’ONDH "enquêtes et informations au niveau
22

communautaire", où nous réunirons toutes les informations pouvant être re-groupées sous cette rubrique (ceci incluera probablement les volets éducationet vie associative –voir ci-dessous).
Un résultat important de nos entretiens est que la direction est disposée àfournir les informations pertinentes concernant la localisation par communedes différents programmes d’intervention en santé (ce qui sera important afinde controller pour la présence d’autres programmes, pour ne pas attribuerde façon erronée des effets à l’INDH qui proviennent d’autres sources), gracenotamment à un système GIS de positionnement géographique des centresde santé. Ceci permettra de compléter les éléments de la matrice X. Il seraimportant de veiller à la collecte de ces informations à partir des fichiers duministère, en parallèle avec les enquêtes sur le terrain au printemps 2008.
Finalement, il semblerait souhaitable d’inclure des mesures d’anthropo-métrie infantile (les z−scores de la taille pour age et du poids pour age)parmi les indicateurs de résultats Y . Les indicateurs suggérés sont reportésau Tableau 2 (et le seront pour toutes les parties de la section 5 qui suivent).
5.2 Education nationale, Direction de la stratégie etde la planification
Nos interlocuteurs à l’éducation nationale ont mis l’accent sur trois fac-teurs susceptibles de rendre problématique l’évaluation d’impact de l’INDH.Premièrement, il y a énormément d’intervenants dans le secteur éducatif(voir par exemple la section 5.3 ci-dessous) qui ne sont pas forcément recen-sés dans les systèmes d’information de l’éducation nationale. Deuxièmement,et ce point rejoint le premier, l’information concernant le secteur éducatif esttrès dispersé. Troisièmement, un choix judicieux devra être opéré en termesdes indicateurs de résultats (Y ) retenus.
Le clou de la réunion à l’éducation nationale a été la présentation parnos interlocuteurs de la base de données SISE de l’éducation nationale, quidevrait d’ailleurs être bientôt accessible par interface internet. Cette base dedonnées, dont la conception et la mise en oeuvre sont tout à fait remarquables,permet entre autres d’identifier, au niveau de chaque école et de chaque classe,les "mouvements" (entrées, sorties, redoublements). Si l’abandon scolaireétait retenu comme un indicateur Y au niveau des communes, disposer des
23

informations pour toutes les écoles de toutes les communes de l’échantillonserait un atout considérable.
Un problème existe du fait que les recoupements par district de recense-ment ne correpondent pas avec ceux des "quartiers" urbains (problème quin’existe pas dans le contexte rural). Les discussions ont indiqué qu’il estpossible que l’utilisation des codes postaux soit une solution à ce problèmed’identification géographique de la localisation des écoles par rapport à l’unité"commune" qui sera probablement utilisé pour définir le statut traitementINDH, au moins en milieu rural. D’autres problèmes d’attribution d’impact(qui existent d’ailleurs pour le volet santé) concernent les spillovers d’unezone géographique donnée sur les zones environnantes. Il serait ainsi utile deconsidérer, comme variables de contrôle devant être incluses dans la matriceX, les caractéristiques éducatives des communes voisines, lorsque la variablede résultats Y sera d’ordre éducatif (et ceci particulièrement pour les zonesurbaines –voir aussi les sections 7 et 8 de ce rapport).
Tout commes pour le ministère de la santé, il sera important de collecterles informations disponibles dans les fichiers du ministère au moment desenquêtes de référence de 2008.
Finalement, deux indicateurs intéressants concernant la qualité des écolesont été proposés : le fait que l’école soit branchée sur le réseau électrique, etla présence de structures d’assainissement au sein de l’école.
5.3 Direction de l’éducation non-formelle
Nos entretiens avec l’éducation non-formelle ont porté essentiellement surla décentralisation et la société civile. L’information sur les projets financéspar l’ENF est disponible auprès de la division "partenariat", permettant ainside compléter la matrice X des facteurs qui pourraient affecter les indicateursde résultats éducatifs retenus.
Notre interlocuteur a surtout mis l’accent sur l’importance du degré departicipation des populations en termes de mobilisation et de responsabilisa-tion. L’évolution de ces attributs pourra être appréhendée par des indicateursde la capacités des populations à formuler explicitement leurs besoin et à seprendre en charge.
24

Les indicateurs suggérés, mis à part le cas évident de l’alphabétisation(au niveau ménage et individuel), incluent la densité des ONG et des asso-ciations (ainsi que la participation des ménages dans leurs activités), et laparticipation féminine dans ces associations. Un autre indicateur originalqui a été suggéré serait une mesure du degré d’encadrement et de suivi dela part des administrations, rejoignant ainsi certaines suggestions du HautCommissariat au Plan (voir la section 5.4 qui suit).
5.4 Haut Commissariat au Plan
Notre première réunion au HCP a débuté avec un rappel important dutime line de l’évaluation d’impact de l’INDH : Est-ce que suffisamment detemps s’écoulera entre les enquêtes de référence de 2008 et les follow up de2010 pour que l’on puisse espérer identifier un impact quelconque ? Cetteremarque nous rappelle qu’un choix judicieux des indicateurs de résultatsY est nécessaire : bien que nous voulions à tout prix mesurer l’impact del’INDH sur une panoplie d’indicateurs potentiels, il est probable qu’un certainnombre d’entre eux ne seront modifiés par le programme qu’à plus long-terme,nécessitant ainsi la mise en place d’enquêtes de panel sur une durée longue(et au-delà de l’horizon 2010). Des indicateurs plus qualitatifs, susceptiblesd’être affectés par le programme sur le court-terme, devraient ainsi être prisen compte.
Un exemple concret d’un tel indicateur, qui pourrait aisément être re-cueilli lors des enquêtes de 2008, est un indice de satisfaction des populationsavec l’administration locale (rejoignant ainsi la suggestion de l’ENF).
La discussion a ensuite porté sur la carte de pauvreté de 2004, sur lesdonnées microéconomiques disponibles dans les enquêtes du HCP, ainsi quesur la possibilité de recueillir des informations sur la matrice Z des détermi-nants du statut de traitement par l’INDH, incluant différentes mesures dupoids politique des communes. Ces mesures de pouvoir politique au niveaucommunal pourraient se révéler primordiales pour les stratégies d’identifica-tion qui sont esquissées dans ce rapport, mais sont également potentiellementimportantes pour l’estimation de (8) et (9).
Notre deuxième réunion au HCP a porté essentiellement sur les problèmede construction d’un contrefactuel pour le milieu urbain (voir la section 8ci-dessous).
25

5.5 Lutte contre l’analphabétisme
Notre entretien avec les responsables de la lutte contre l’analphabétismea permis de dégager l’importance du lien analphabétisme/pauvreté, et decomprendre la logique des interventions existantes, divisées en trois parties :
— l’apprentissage de la lecture et de l’écriture ;— la formation professionnelle (par l’entremise des ONG et de l’entraidenationale) ;
— les programmes de post-alphabétisation.
Selon notre interlocuteur, la lutte contre l’analphabétisme n’est pas suf-fisamment présente dans les actions de l’INDH, et la transmission de l’infor-mation du niveau local au niveau provincial concernant cette composante duprogramme est mal structurée. En outre, le processus et le mode de gestionde l’INDH, ainsi que le choix des projets retenus pour financement (du moinsconcernant la composante lutte contre l’analphabétisme), sont à revoir.
Du point de vue des données accessibles, une carte de l’analphabétismeau niveau national est disponible (ou plutôt pourrait être construite très fa-cilement), permettant entre autres d’évaluer la validité de tout contrefactuelen termes de taux d’analphabétisme. La direction est disposée à fournirces données à l’ONDH. De même, une liste des interventions en matière delutte contre l’analphabétisme est disponible, permettant ainsi de contrôlerpour des interventions qui pourraient affecter plusieurs parmi les indicateursde résultats Y potentiels. Les profils d’analphabètes construits par la di-rection dans le contexte d’une étude au niveau national impliquent que lestatut d’alphabétisation sera une variable de contrôle clef (dans la matriceX) pour toute évaluation de l’impact de l’INDH sur la pauvreté au niveaudes ménages.
5.6 Coordination nationale de l’INDH
Les deux entretiens avec la coordination nationale de l’INDH ont permisde constater l’existence d’un système informatisé de suivi tout à fait remar-quable.
Les informations recueillies systématiquement par la cellule sur les carac-téristiques des projets proposés (et non pas seulement sur les projets rete-nus pour financement) permettrait de mettre en oeuvre différentes stratégies
26

d’identification de l’impact des projets financés (et non seulement de l’éli-gibilité des communes pour l’INDH) que je développe en détail à la section10.3.
Les discussions avec la coordination nationale ont en outre porté sur l’uti-lisation potentielle des données recueillies dans le cadre des enquêtes commeoutils d’aide à la décision pour l’INDH. Il sera très important, dans cequi suit, d’être attentifs aux besoins de la coordination en cette matière, etde veiller à bien incorporer leurs indicateurs souhaités dans les instrumentsd’enquête.
5.7 Développement social, de la famille et de la soli-darité
L’entretien avec les responsables du ministère du développement social, dela famille, et de la solidarité s’est révélée particulièrement fructueuse, de parla compréhension ex ante de nos interlocuteurs concernant les méthodologiesd’évaluation d’impact basées sur le principe du contrefactuel.
L’entretien a permis de mieux saisir le rôle joué par l’INDH dans le pro-cessus de démocratisation au niveau local, et l’importance revêtue par lerenforcement des capacités des ONG et du tissus associatif en général. Nosinterlocuteurs nous ont d’ailleurs informés de l’existence d’une base de don-nées concernant la dynamique des mouvements associatifs locaux, hébergéeau secrétariat général du gouvernement, et qu’il serait intéressant de pouvoirconsulter. Les résultats de l’enquête nationale du secteur associatif, ainsi quedes contacts avec les responsables de sa réalisation, permettrait de raffinerles indicateurs potentiels de l’impact de l’INDH sur ce milieu. Des contacts àcet égard devraient également être pris par l’ONDH avec le Conseil nationalde la vie associative, et la Division de l’observatoire social.
En général, l’entretien a renforcé l’a priori concernant le rôle de coordina-tion de ce ministère, rôle qui pourrait faciliter l’identification des nombreusesinterventions sociales sur le terrain, et qu’il faudra inclure dans la matrice devariables de contrôle X.
27

5.8 Agence de développement social
L’entretien avec les responsables de l’agence de développement social arévélé l’existence d’un système de suivi-évaluation qui permettra de cernerun nombre important d’interventions sur le terrain qui devront être pris encompte dans la matrice X de variables de contrôle. L’entretien a égalementpermi de mieux cerner les interractions entres les différents palliers de l’ad-ministration dans le processus, parfois difficile, de décentralisation.
Une activité importante de l’ADS étant de renforcer la capacité des ONGet des associations à monter des projets, il sera essentiel de contrôller poursa présence sur le terrain dans toute évaluation d’impact de l’INDH. Enoutre, il est tout à fait possible qu’il existe des synergies entre les actions del’ADS et celles de l’INDH, qu’il faudra tenter de saisir, possiblement à traversdes effets multiplicatifs dans la spécification de l’équation (6) (par exemple,il est possible que l’impact de l’éligibilité d’une commune pour l’INDH soitplus grande pour des communes où intervient l’ADS que pour des communes,également éligibles, où l’ADS n’intervient pas, ce qui implique l’inclusion devariables de la forme X ×D dans l’équation).1
Nos interlocuteurs de l’ADS ont également mis l’accent sur la mesure desperceptions subjectives des populations, rejoignant ainsi l’une des suggestionsdu HCP. L’accent mis sur les indicateurs de résultats Y de mobilisation etde participation des populations dans le mileu associatif est semblable auxsuggestions de la direction de l’ENF.
5.9 Inspection générale de l’administration territoriale
Notre dernier entretien, avec l’inspection générale de l’administration ter-ritoriale, a relevé un nombre de problèmes pouvant affecter le bon déroule-ment de l’évaluation d’impact de l’INDH.
Premièrement, il sera essentiel de prendre en considération la grande hé-térogénéité des communes de l’échantillon (à travers l’inclusion d’une matrice
1Des synergies potentielles existent bien sûr pour beaucoup d’autres interventions : ilsuffit de penser, par exemple, aux effets multiplicateurs sur la performance scolaire deprogrammes de nutrition mis en oeuvre dans les cantines scolaires.
28

appropriée des variables de contrôle X), et de veiller à une distinction claireentre les communes rurales et les communes urbaines, dont les dynamiquessont profondément différentes.
Deuxièment, la mise en oeuvre de l’INDH manque d’une perspective delong-terme, rendant peut-être problématique l’identification d’effets traite-ment du programme durant une période aussi courte que les deux annéesséparant les enquêtes de référence de 2008 et celles de 2010. Les indicateursde performance retenus devront prendre cette limitation en compte (ce quirejoint l’un des point du HCP).
Troisièmement, notre interlocuteur a mis l’emphase sur un aspect jus-qu’alors absent de nos discussions concernant l’impact de l’INDH, à savoirson effet sur les activités culturelles qui, selon lui, peuvent jouer un rôle pri-mordial dans la lutte contre la pauvreté et la précarité, surtout en milieuurbain.
La discussion a également porté sur l’identification des déterminants dustatut de traitement (les éléments de la matrice Z) où une compréhensionfine de l’influence de la localisation géographique des différentes communes(surtout pour les communes urbaines) pourrait être un moyen subtil de "me-surer" leur poids politique relatif, et de construire ainsi un contrefactuelapproprié. La définition des indicateurs d’impact de l’INDH sur le voletculturel demande une réflexion approfondie avec la collaboration d’opéra-teurs expérimentés sur le sujet.
5.10 Utilisation des données administratives
Pour tous les partenaires sectoriels impliqués dans l’évaluation d’impactde l’INDH, il sera important, au moment des enquêtes de référence de 2008,de saisir les données sectorielles pertinentes, avec un soucis particulier concer-nant la présence d’autres programmes sur le terrain. Ces données des dif-férents ministères compétents ne seront pas, bien évidemment, à la base del’évaluation d’impact en tant que telle. Par contre, elle permettront de com-pléter la matrice X des facteurs pouvant directement affecter l’impact del’INDH. Les mêmes informations devront bien sûr être collectêes lors dudeuxième passage d’enquête en 2010.
29

Indicateurs potentiels Y au niveau :
Commune Ménage/Individuel
Pauvreté taux (et autres indicateurs) dépenses des ménages
de pauvreté revenus des ménages
Santé taux de mortalité infantile anthropométrie infantile
taux de mortalité maternelle
Education taux d’alphabétisation alphabétisation
taux d’abandon scolaire niveau scolaire atteint
"mouvements" scolaires
branchement électrique
présence d’assainissement
Société civile densité des associations/ONG appartenance à des
et culture taux de participation des femmes associations ou à des ONG
densité des associations appartenance à des
culturelles associations culturelles
Administration satisfaction des ménages
avec l’administration locale
T��. 2 — Liste préliminaire des indicateurs de résultats potentiels, par secteuret par niveau d’agrégation.
30

6 Construire un contrefactuel afin de purger
la source de biais No. 1
Prenons, à titre d’exemple, le taux de pauvreté de la commune commeindicateur d’impact Y , où chaque observation correspondra à une commune.Supposons que les enquêtes du printemps 2008 soient complétées, et que nousayions une estimation du taux de pauvreté par commune. Pour le moment,je présenterai les enjeux dans le cas où nous disposerions d’information auniveau de la commune, mais il est très probable que l’information soit en faitau niveau d’un échantillon aléatoire de ménages dans chaque commune. Ilse peut alors que les mêmes méthodes utilisées dans la construction de lacarte de pauvreté de 2004 nous permettront d’extrapoler et d’obtenir unemesure agrégée de pauvreté au niveau communal. Si cela n’était pas le cas,le niveau d’observation devra être compris dans ce qui suit comme se référantau niveau ménage.
6.1 La source de biais No. 1 est forcément présente
Dans un premier temps, et de façon tout à fait naïve (l’importance d’undeuxième passage sera esquissée dans la section 10.2), considérons l’estima-tion de l’impact de l’INDH en utilisant uniquement ces données. L’équationque nous estimerions par les moindres carrés ordinaires (MCO) serait donnéepar (5) ou, de façon équivalente, (6). Pour ce faire, nous serions en train desupposer qu’aucune des trois sources de biais identifiées à la section 4 ne soitprésente.
A priori, on pourrait penser que le coefficient β dans l’équation (6) re-présente une estimation de l’impact du traitement par l’INDH sur le taux depauvreté Y . Il n’en est rien, pour une raison très simple : le traitement parl’INDH est déterminé, en partie ou en totalité, par le taux de pauvreté de lacommune en 2004. Et si le taux de pauvreté en 2008 est fonction du tauxde pauvreté en 2004 (ce qui est très probable, car les taux de pauvreté onttendance à être fortement autocorrélés dans le temps), il en découle queD estfonction de Y . Formellement, nous faisons face à la source biais No.1, sou-levée à la section 4.1, induite par la corrélation entre D et ε dans l’équation(6).
31

Quelle serait alors l’estimation de "l’impact" de l’INDH, donné par le co-efficient β, qui découlerait de l’équation (6) ? A priori, "l’impact" β estiméserait positif (l’éligibilité pour l’INDH augmenterait le taux de pauvreté)pour une raison très simple : ce sont les communes les plus pauvres qui sontéligibles. On voit alors clairement que le coefficient β ne reflète aucune-ment l’effet du traitement par l’INDH, et correspondrait tout simplementau mécanisme de sélection par lequel les communes éligibles ont été choisies.En termes statistiques, le problème est que la variable D est endogène, estdonc corrélée avec le terme d’erreur ε, et que l’estimation par les MCO del’équation donne des résultats complètement biaisés. En termes intuitifs,c’est un problème de "poule et d’oeuf" : les communes éligibles pour l’INDHsont-elles plus pauvres à cause de l’INDH, ou sont-elles éligibles pour l’INDHparce qu’elles sont plus pauvres ?
A priori, et en supposant que le programme agit positivement en réduisantle taux de pauvreté, c’est la deuxième réponse qui est la bonne, et tout letravail de montage de l’évaluation d’impact doit assurer que nous puissionsbien distinguer l’impact du programme sur la pauvreté, de l’impact de lapauvreté sur l’éligibilité pour le programme. En termes techniques, noussommes donc nécessairement confrontés à la source de biais No. 1 énoncée àla section 4.
6.2 Stratégies d’identification
Quelles sont les solutions à ce problème (la source de biais No. 1), etcomment les mettre en oeuvre ? La solution de base au problème est donnéepar la construction d’un contrefactuel, en termes d’éligibilité, qui nous per-mette de séparer l’effet de la pauvreté sur l’éligibilité pour l’INDH, de l’effetde l’INDH sur la pauvreté. Reste à choisir la méthodologie qui sera utiliséepour construire le contrefactuel. Dans ce qui suit, je fais état des deux solu-tions les plus probables : (i) une approche par regression discontinuity designet (ii) une approche par appariement par score de propension (en Anglais–propensity score matching).
6.2.1 Regression discontinuity design
Supposons, comme il a été suggéré par nombre de nos interlocuteurs, quel’éligibilité pour l’INDH a été entièrement déterminée par le taux de pauvreté
32

de la commune en 2004. Formellement, ceci équivaut à remplacer (8) et (9)par :
D =
{1 si Y 2004 > Y0 autrement
, (18)
où Y 2004 est le taux de la pauvreté de la commune selon la carte de pauvretéde 2004 et Y est le seuil du taux de pauvreté choisi par les initiateurs duprogramme. Si c’est effectivement le cas, et la réponse ne peut venir qued’une estimation de (8) et (9), la construction du contrefactuel devra se faireà partir de la méthode du regression discontinuity design. Intuitivement,on utilise le fait qu’il existe une discontinuité dans le statut de traitementdes communes, discontinuité qui apparaît exactement au niveau seuil Y , afind’identifier l’impact du programme.
Les détails techniques de cette approche sont très bien résumés dans Im-bens et Lemieux (2007), et que j’ai fait parvenir à l’ONDH en fichier attachéle 13 octobre.
6.2.2 Appariement par score de propension
Il est probable que la détermination du statut d’éligibilité d’une communepour l’INDH ne soit pas entièrement fonction du niveau seuil de pauvreté Y ,mais aussi d’autres facteurs, représentés dans l’équation (8) par la matriceZ. Si c’est le cas, une approche par appariement par score de propensionpour la construction du contrefactuel sera également possible. En passant,le score de propension est tout simplement un terme technique qui se réfèreà la probabilité de traitement par l’INDH. Plus précisément, le score depropension est donné par la probabilité prédite de traitement d’une commune,issue de l’estimation de (8) et (9).
Les variables Z peuvent prendre deux formes. D’une part, il y a lesvariables qui affectent le résultat Y , et qui sont donc partie intégrante de X.D’autres part il y a les éléments de Z qui n’apparaissent pas dans X, et quiconstitueront ce que l’on appelle, en économétrie, des restrictions d’exclusion.L’identification de ces deux types de variables est l’un des principaux objectifsdes discussions avec les différents partenaires : D’une part, ne pas contrôllerpour X dans l’équation de résultats (6) pourrait mener à l’identification d’unimpact associé avec l’INDH qui serait en fait dü à d’autres interventions.
33

D’autre part, l’absence de restrictions d’exclusion rendrait la constructiondu contrefactuel par appariement par score de propension peu crédible.
Concrètement, il s’agit donc d’estimer (8) et (9), en rajoutant progres-sivement les éléments de Z au fur et à mesure que ces informations serontdisponibles. Des résultats préliminaires de cet exercice sont présentés dans leTableau 4 pour les communes rurales (voir la section 7), et dans le Tableau6 pour les communes urbaines (voir la section 8). Pour le moment, nousn’avons que des variables X. Il sera essentiel dans les semaines à venir quel’ONDH se penchent sur la collecte d’information de variables Z (absentesde X) afin d’affiner la stratégie d’identification.
La méthodologie du score de propension, ainsi que les assises théoriquessous-jacentes, sont parfaitement bien résumées dans Caliendo et Kopeinig(2005), que j’ai fait parvenir à l’ONDH en fichier attaché le 13 octobre.
7 Les communes rurales
7.1 Statistiques descriptives
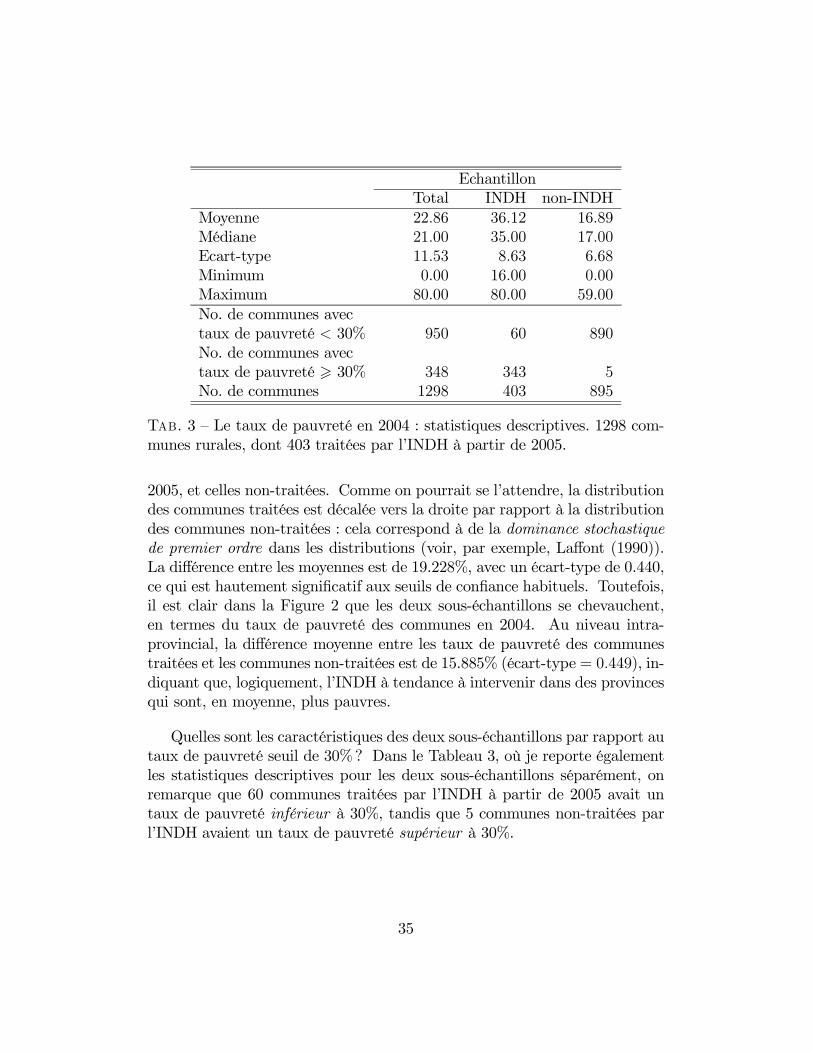
La Figure 1 illustre la distribution des taux de pauvreté pour l’échantillontotal composé de 1298 communes rurales. Tel que montré par la premièrecolonne du Tableau 3, le taux moyen de pauvreté est de 22.86% (médianede 21), avec une grande hétérogénéité, indiquée par un écart-type de 11.53.Notons que cette hétérogénéité est en partie déterminée par des différencesinter-provinciales. Lorsque je purge le taux de pauvreté de chaque communede son élément provincial (en estimant une régression linéaire du taux depauvreté sur des muettes provinciales et en récupérant le résidu), l’écart-type tombe à 8.80. Ainsi, une fraction importante de la variation dans lestaux de pauvreté au niveau des communes rurales au Maroc est attribuableà des différences inter-provinciales : en termes de variance, 41% de la va-riance communale dans les taux de pauvreté au niveau national découle dedifférences inter-provinciales, et 59% de différences intra-provinciales. Il seraimportant de garder cela en tête lorsque l’on arrivera à la stratification del’échantillon pour l’évaluation d’impact de l’INDH.
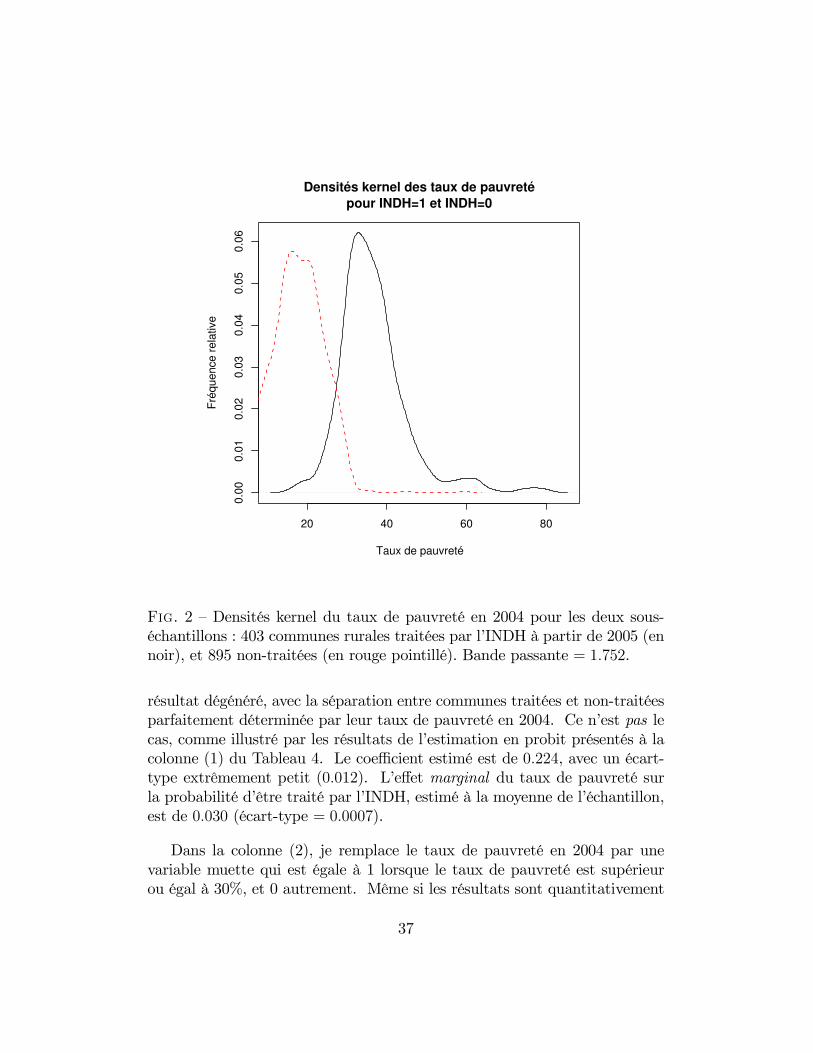
La Figure 2 compare les distributions des taux de pauvreté pour les deuxsous-échantillons : celui des communes rurales traitées par l’INDH à partir de
34
EchantillonTotal INDH non-INDH
Moyenne 22.86 36.12 16.89Médiane 21.00 35.00 17.00Ecart-type 11.53 8.63 6.68Minimum 0.00 16.00 0.00Maximum 80.00 80.00 59.00No. de communes avectaux de pauvreté < 30% 950 60 890No. de communes avectaux de pauvreté � 30% 348 343 5No. de communes 1298 403 895
T��. 3 — Le taux de pauvreté en 2004 : statistiques descriptives. 1298 com-munes rurales, dont 403 traitées par l’INDH à partir de 2005.
2005, et celles non-traitées. Comme on pourrait se l’attendre, la distributiondes communes traitées est décalée vers la droite par rapport à la distributiondes communes non-traitées : cela correspond à de la dominance stochastiquede premier ordre dans les distributions (voir, par exemple, Laffont (1990)).La différence entre les moyennes est de 19.228%, avec un écart-type de 0.440,ce qui est hautement significatif aux seuils de confiance habituels. Toutefois,il est clair dans la Figure 2 que les deux sous-échantillons se chevauchent,en termes du taux de pauvreté des communes en 2004. Au niveau intra-provincial, la différence moyenne entre les taux de pauvreté des communestraitées et les communes non-traitées est de 15.885% (écart-type = 0.449), in-diquant que, logiquement, l’INDH à tendance à intervenir dans des provincesqui sont, en moyenne, plus pauvres.
Quelles sont les caractéristiques des deux sous-échantillons par rapport autaux de pauvreté seuil de 30%? Dans le Tableau 3, où je reporte égalementles statistiques descriptives pour les deux sous-échantillons séparément, onremarque que 60 communes traitées par l’INDH à partir de 2005 avait untaux de pauvreté inférieur à 30%, tandis que 5 communes non-traitées parl’INDH avaient un taux de pauvreté supérieur à 30%.
35
0 20 40 60 80
0.0
00
.01
0.0
20
.03
0.0
4
Densité kernel des taux de pauvreté
Taux de pauvreté
Fré
qu
en
ce
re
lative
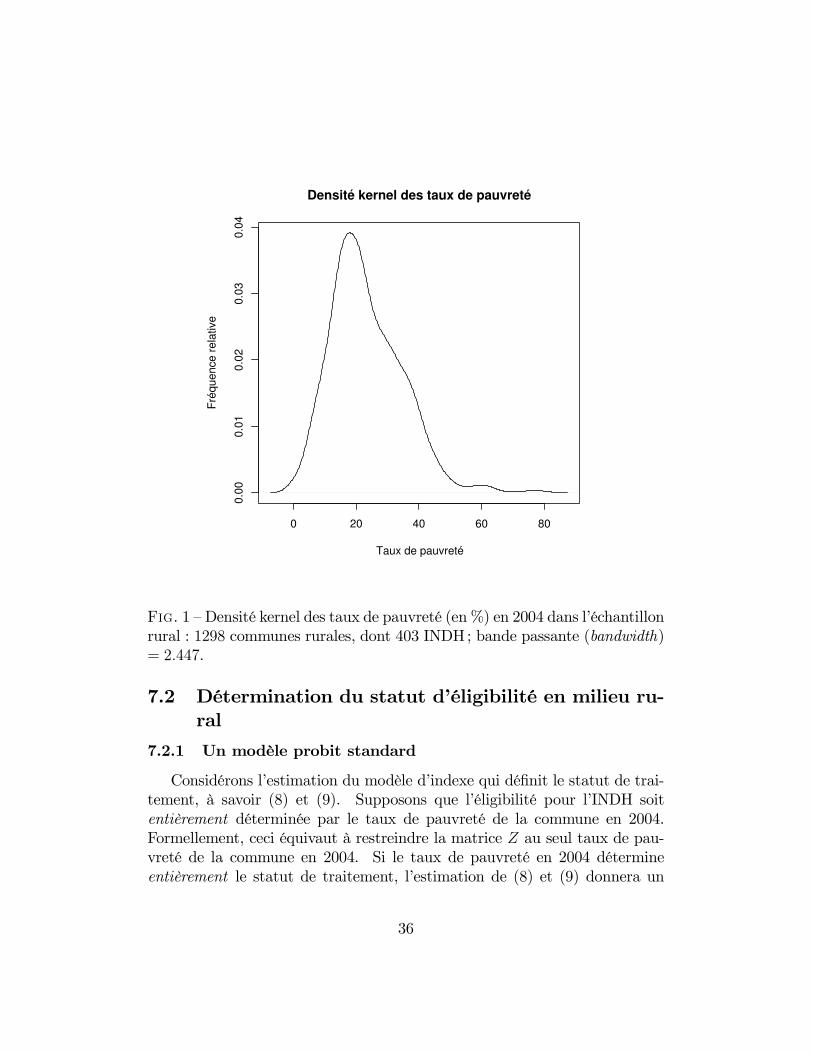
F��. 1 — Densité kernel des taux de pauvreté (en %) en 2004 dans l’échantillonrural : 1298 communes rurales, dont 403 INDH; bande passante (bandwidth)= 2.447.
7.2 Détermination du statut d’éligibilité en milieu ru-ral
7.2.1 Un modèle probit standard
Considérons l’estimation du modèle d’indexe qui définit le statut de trai-tement, à savoir (8) et (9). Supposons que l’éligibilité pour l’INDH soitentièrement déterminée par le taux de pauvreté de la commune en 2004.Formellement, ceci équivaut à restreindre la matrice Z au seul taux de pau-vreté de la commune en 2004. Si le taux de pauvreté en 2004 détermineentièrement le statut de traitement, l’estimation de (8) et (9) donnera un
36
20 40 60 80
0.0
00
.01
0.0
20
.03
0.0
40
.05
0.0
6
Densités kernel des taux de pauvreté
pour INDH=1 et INDH=0
Taux de pauvreté
Fré
qu
en
ce
re
lative
F��. 2 — Densités kernel du taux de pauvreté en 2004 pour les deux sous-échantillons : 403 communes rurales traitées par l’INDH à partir de 2005 (ennoir), et 895 non-traitées (en rouge pointillé). Bande passante = 1.752.
résultat dégénéré, avec la séparation entre communes traitées et non-traitéesparfaitement déterminée par leur taux de pauvreté en 2004. Ce n’est pas lecas, comme illustré par les résultats de l’estimation en probit présentés à lacolonne (1) du Tableau 4. Le coefficient estimé est de 0.224, avec un écart-type extrêmement petit (0.012). L’effet marginal du taux de pauvreté surla probabilité d’être traité par l’INDH, estimé à la moyenne de l’échantillon,est de 0.030 (écart-type = 0.0007).
Dans la colonne (2), je remplace le taux de pauvreté en 2004 par unevariable muette qui est égale à 1 lorsque le taux de pauvreté est supérieurou égal à 30%, et 0 autrement. Même si les résultats sont quantitativement
37

(1) (2) (3) (4)Constante −6.284
(0.342)−1.528(0.063)
−4.105(0.366)
−6.245(0.351)
Taux de pauvreté en 2004 0.224(0.012)
0.122(0.015)
0.224(0.012)
Taux de pauvreté en 2004 � 30% 3.715(0.186)
1.972(0.242)
Taux d’alphabétisation en 2004 −9.54× 10−5(2.04×10−4)
Critère d’information d’Akaike 476.2 503.9 401.3 477.9
T��. 4 — Estimation en probit de la probabilité de traitement par l’INDH.La variable expliquée est égale à 1 si la commune est traitée par l’INDH àpartir de 2005, et 0 autrement. 1298 communes rurales, dont 403 traitées parl’INDH à partir de 2005. Ecarts-types entre parenthèses.
différents, leur aspect qualitatif reste le même : bien que la muette soit haute-ment significative, et que l’effet marginal estimé à la moyenne de l’échantillonsoit très élevé et de l’ordre de 0.922 (écart-type = 0.013), nous n’obtenonspas une solution dégénérée. Des facteurs qui, pour le moment, se retrouventdans l’écart aléatoire vi, déterminent donc également le statut de traitement.En outre, comme démontré par les résultats présentés à la colonne (3), le tauxde pauvreté reste statistiquement significatif, même en incluant la muette.Ce n’est donc pas seulement le fait d’avoir un taux de pauvreté en 2004 su-périeur ou égal à 30% qui détermine le statut de traitement par l’INDH :le taux de pauvreté lui-même le détermine également. Ce résultat provientprobablement de négociations et/ou des pressions politiques à la marge duseuil de pauvreté de 30%, par lesquelles 60 communes (voir le Tableau 3) avecdes taux de pauvreté inférieurs à 30% ont été retenues pour un traitementpar l’INDH. Identifier les caractéristiques pertinentes de ces 60 communes"privilégiées" sera d’une grande importance.2
A quoi ressemblent les scores de propension (c.à.d. la probabilité esti-mée de traitement par l’INDH) qui découlent de ces estimations ? A titre
2Notons qu’aucune autre variable disponible dans la base correspondant à la carto-graphie de la pauvreté au Maroc ne ressort comme étant un déterminant statistiquementsignificatif de la probabilité de traitement. Ceci est illustré dans la colonne (4) du Tableau4 pour le cas du taux d’analphabétisation.
38

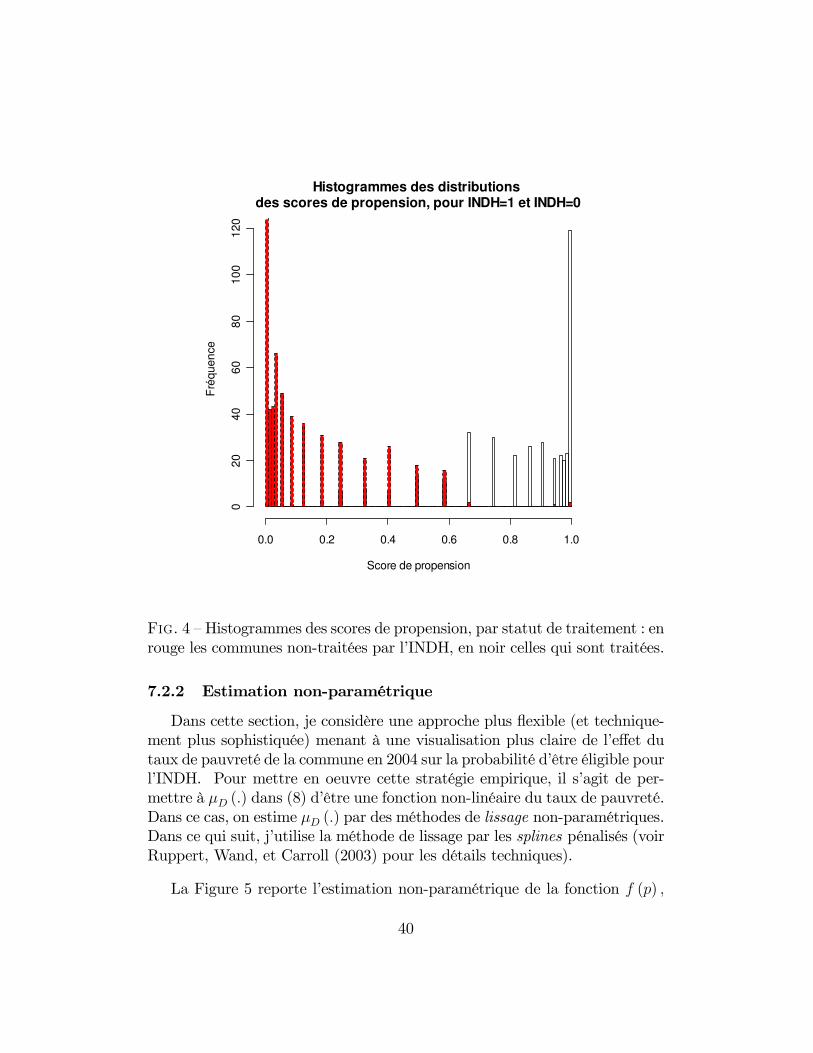
d’illustration, considérons les scores de propension issus des résultats de lacolonne (1) du Tableau 4. La Figure 3 présente le histogramme des scores depropension pour l’échantillon dans son ensemble. Dans la Figure 4, je sépareles scores de propension par statut traitement. Le score de propension pourles communes effectivement traitées par l’INDH (en blanc) se concentre au-tour de la valeur de 1, tandis que le score de propension pour les communesnon-traitées (en rouge) se concentre fortement autour de 0. Etant donné lepouvoir explicatif très important du taux de pauvreté en 2004, ceci n’est pasdu tout surprenant.
Histogramme de la distribution des scores de propension, échantillon total
Score de propension
Fré
quen
ce
0.0 0.2 0.4 0.6 0.8 1.0
010
020
03
00
40
05
00
F��. 3 — Histogramme du score de propension pour l’échantillon dans sonensemble.
39
Histogrammes des distributions des scores de propension, pour INDH=1 et INDH=0
Score de propension
Fré
quen
ce
0.0 0.2 0.4 0.6 0.8 1.0
02
040
60
80
10
01
20
F��. 4 — Histogrammes des scores de propension, par statut de traitement : enrouge les communes non-traitées par l’INDH, en noir celles qui sont traitées.
7.2.2 Estimation non-paramétrique
Dans cette section, je considère une approche plus flexible (et technique-ment plus sophistiquée) menant à une visualisation plus claire de l’effet dutaux de pauvreté de la commune en 2004 sur la probabilité d’être éligible pourl’INDH. Pour mettre en oeuvre cette stratégie empirique, il s’agit de per-mettre à µD (.) dans (8) d’être une fonction non-linéaire du taux de pauvreté.Dans ce cas, on estime µD (.) par des méthodes de lissage non-paramétriques.Dans ce qui suit, j’utilise la méthode de lissage par les splines pénalisés (voirRuppert, Wand, et Carroll (2003) pour les détails techniques).
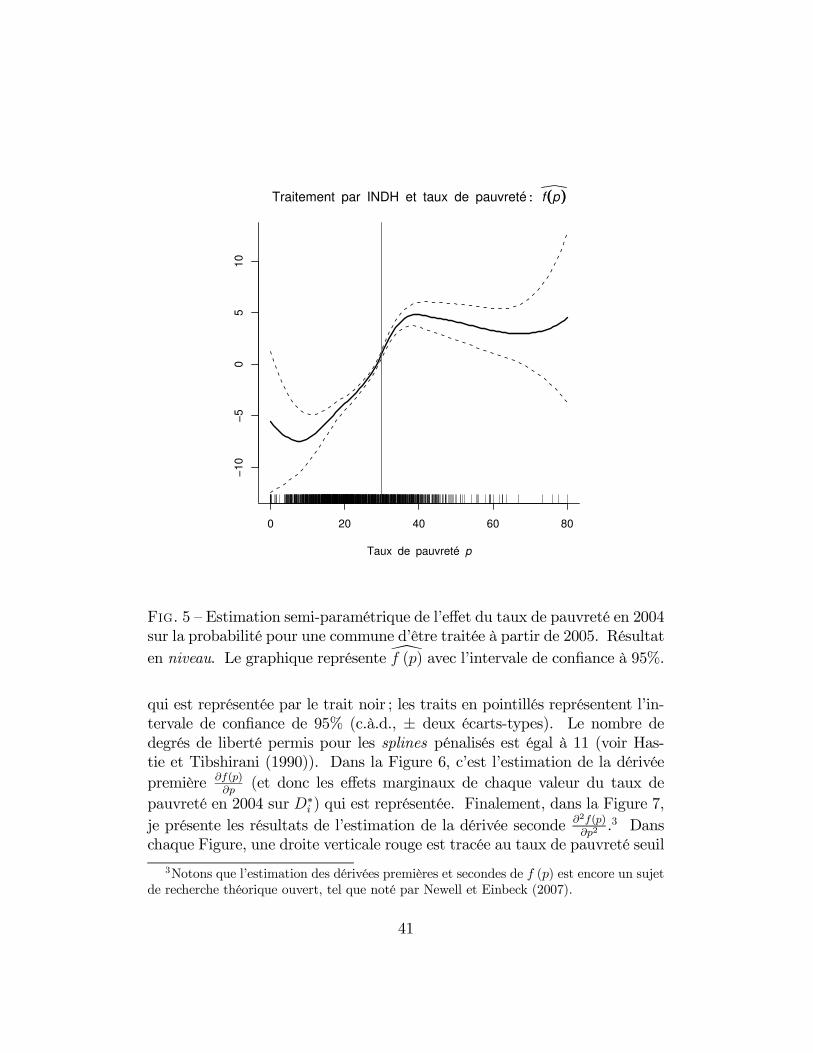
La Figure 5 reporte l’estimation non-paramétrique de la fonction f (p) ,
40
0 20 40 60 80
−1
0−
50
51
0
Traitement par INDH et taux de pauvreté :: f((p))
Taux de pauvreté p
F��. 5 — Estimation semi-paramétrique de l’effet du taux de pauvreté en 2004sur la probabilité pour une commune d’être traitée à partir de 2005. Résultat
en niveau. Le graphique représente f (p) avec l’intervale de confiance à 95%.
qui est représentée par le trait noir ; les traits en pointillés représentent l’in-tervale de confiance de 95% (c.à.d., ± deux écarts-types). Le nombre dedegrés de liberté permis pour les splines pénalisés est égal à 11 (voir Has-tie et Tibshirani (1990)). Dans la Figure 6, c’est l’estimation de la dérivée
première ∂f(p)∂p
(et donc les effets marginaux de chaque valeur du taux de
pauvreté en 2004 sur D∗i ) qui est représentée. Finalement, dans la Figure 7,
je présente les résultats de l’estimation de la dérivée seconde ∂2f(p)∂p2
.3 Danschaque Figure, une droite verticale rouge est tracée au taux de pauvreté seuil
3Notons que l’estimation des dérivées premières et secondes de f (p) est encore un sujetde recherche théorique ouvert, tel que noté par Newell et Einbeck (2007).
41

0 20 40 60 80
−0
.50
.00
.51
.0
Traitement par INDH et taux de pauvreté :: ∂∂f((p))
∂∂p
Taux de pauvreté p
F��. 6 — Estimation semi-paramétrique de l’effet du taux de pauvreté en2004 sur la probabilité pour une commune d’être traitée à partir de 2005.
Résultat pour la dérivée première. Le graphique représente ∂f (p) /∂p avecl’intervale de confiance à 95%.
42
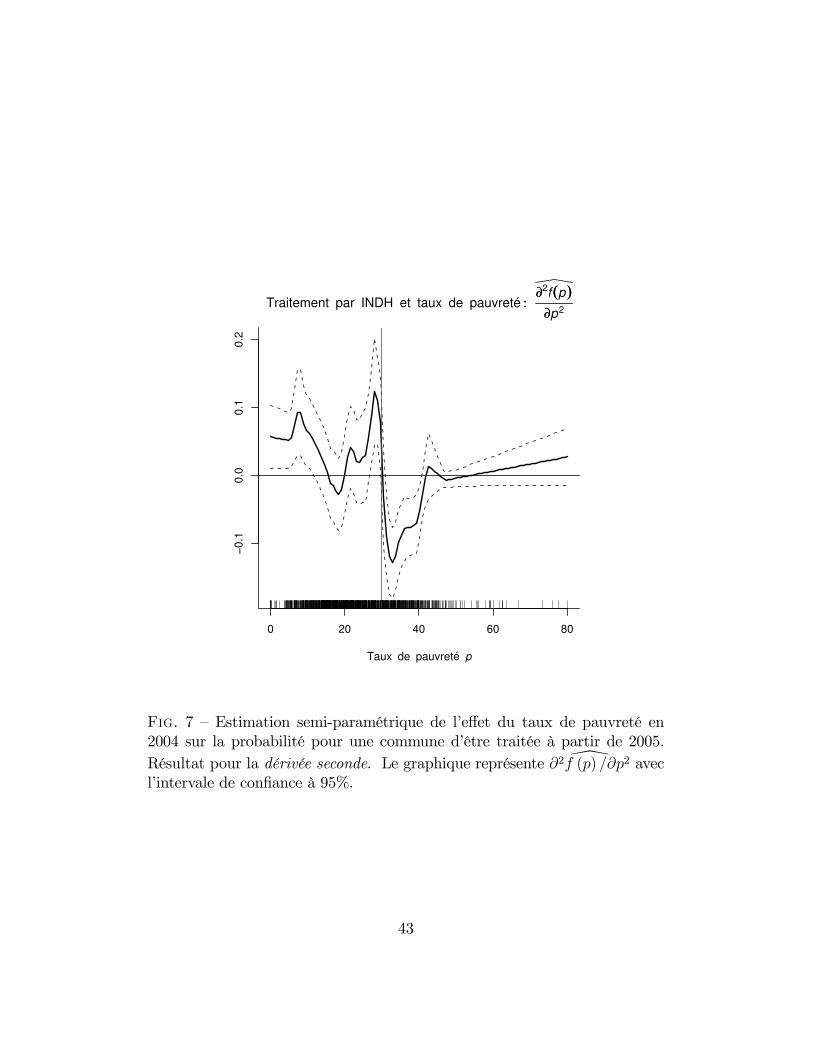
0 20 40 60 80
−0
.10
.00
.10
.2
Traitement par INDH et taux de pauvreté :: ∂∂2f((p))
∂∂p2
Taux de pauvreté p
F��. 7 — Estimation semi-paramétrique de l’effet du taux de pauvreté en2004 sur la probabilité pour une commune d’être traitée à partir de 2005.
Résultat pour la dérivée seconde. Le graphique représente ∂2f (p) /∂p2 avecl’intervale de confiance à 95%.
43

de 30%.
Dans la Figure 5, on remarque que la probabilité de traitement par l’INDHest croissante dans le taux de pauvreté pour la partie centrale de l’intervale.On remarque également que l’estimation devient moins précise aux extré-mités, à cause du faible nombre de communes rurales qui ont des taux depauvreté inférieurs à 10% ou supérieurs à 60%. Il apparaît en outre qu’ilexiste un point d’inflexion situé approximativement au seuil de 30%. L’exis-tence de ce point d’inflexion devient encore plus claire lorsque l’on passe àl’estimation de la dérivée première dans la Figure 6 : un important "pic"apparaît dans l’effet marginal du taux de pauvreté sur la probabilité de trai-tement par l’INDH, précisément à un taux de pauvreté de 30%. Je tiensà souligner que cette estimation n’est pas "forcée" : les données génèrentcette non-différenciabilité de l’effet marginal du taux de pauvreté sponta-nément. Le résultat de la Figure 6 est confirmé par la Figure 7 : le pointd’inflexion dans la Figure 5 et le pic de la dérivée première dans la Figure6 correspondent à un changement de signe de la dérivée seconde, car f (.)est localement convexe à gauche du taux de pauvreté de 30% et localementconcave à droite.
Ces résultats nous permettent de conclure qu’il existe effectivement uneimportante non-différenciabilité de l’effet du taux de pauvreté sur la proba-bilité de traitement par l’INDH à un taux de pauvreté de 30%, permettantainsi, à travers le choix judicieux d’un échantillon de communes rurales non-traitées juste à gauche du seuil, et traitées juste à droite, de mettre en oeuvreune stratégie d’identification par le Regression Discontinuity Design (RDD).
7.3 Construction du contrefactuel
De quoi aurait l’air l’échantillon pour les enquêtes du printemps 2008 dansl’éventualité d’une approche par RDD? Si l’on considére un échantillonconstitué de communes rurales dont (i) les taux de pauvreté en 2004 sontcompris entre 27 et 31% et (ii) qui ont un taux de pauvreté inférieur à30% pour les non-traitées et supérieur à 30% pour les traités, on obtient unensemble de 124 communes rurales dont le taux de pauvreté moyen est de29.19%, la médiane de 30.00% et l’écart-type de 1.48%. De celles-ci, 62 sonttraités par l’INDH et 62 ne le sont pas. La différence moyenne dans les tauxde pauvreté entre les deux groupes (traités et non-traités) est de 2.580 (écart-type = 0.131). Evidemment, cette échantillon n’est qu’une possibilité, que
44

l’on pourra évidemment modifier dans les semaines à venir. En particulier,des ajustements sont possibles, basés sur les scores de propension estimés àpartir de versions plus sophistiquées de (8) et (9), en particulier avec le rajoutde variables Z. La liste des communes incluses dans cet échantillonest reporté (avec les codes commune) en annexe.
Notons finalement que l’estimation de l’impact de l’INDH issu de cecontrefactuel devrait nous fournir une borne inférieure de l’effet traitement.Bien que le phénomène soit probablement plus fort en milieu urbain, il estprobable que nous ayions à faire à des effets de "spillover" de communesrurales traitées sur des communes rurales voisines non-traitées. Ces exter-nalités positives des communes rurales traitées sur leurs voisines non-traitéesauront tendance à améliorer la performance comparative des communes decontrôle, réduisant ainsi l’impact du traitement estimé. Différentes méthodesissues de l’économétrie spatiale pourront alors être mises en oeuvre afin detenter de corriger pour ce phénomène.
8 Les communes urbaines
8.1 Statistiques descriptives
La Figure 8 illustre la distribution des taux de pauvreté pour l’échantillonurbain composé de 402 communes. Tel que montré par la première colonnedu Tableau 5, le taux moyen de pauvreté est beaucoup plus bas en zoneurbaine qu’en zone rurale. En effet, en zone urbaine, le taux de pauvretéurbain moyen est de 11.59% (médiane de 10.81), avec une hétérogénéité,nettement plus petite qu’en milieu rural indiquée par un écart-type de 6.51 (lechiffre correspondant en milieu rural est de 11.53). Notons, tout comme pourl’échantillon rural, que cette hétérogénéité est en partie déterminée par desdifférences inter-provinciales : 45% de la variance communale dans les taux depauvreté urbains au niveau national découle de différences inter-provinciales,et 55% de différences intra-provinciales (les variations inter-provinciales sontdonc proportionnellement plus importantes en milieu urbain qu’en milieurural).
La Figure 9 compare les distributions des taux de pauvreté pour les deuxsous-échantillons : celui des communes urbaines traitées par l’INDH à partirde 2005, et celles non-traitées. Contrairement au cas des communes rurales,
45
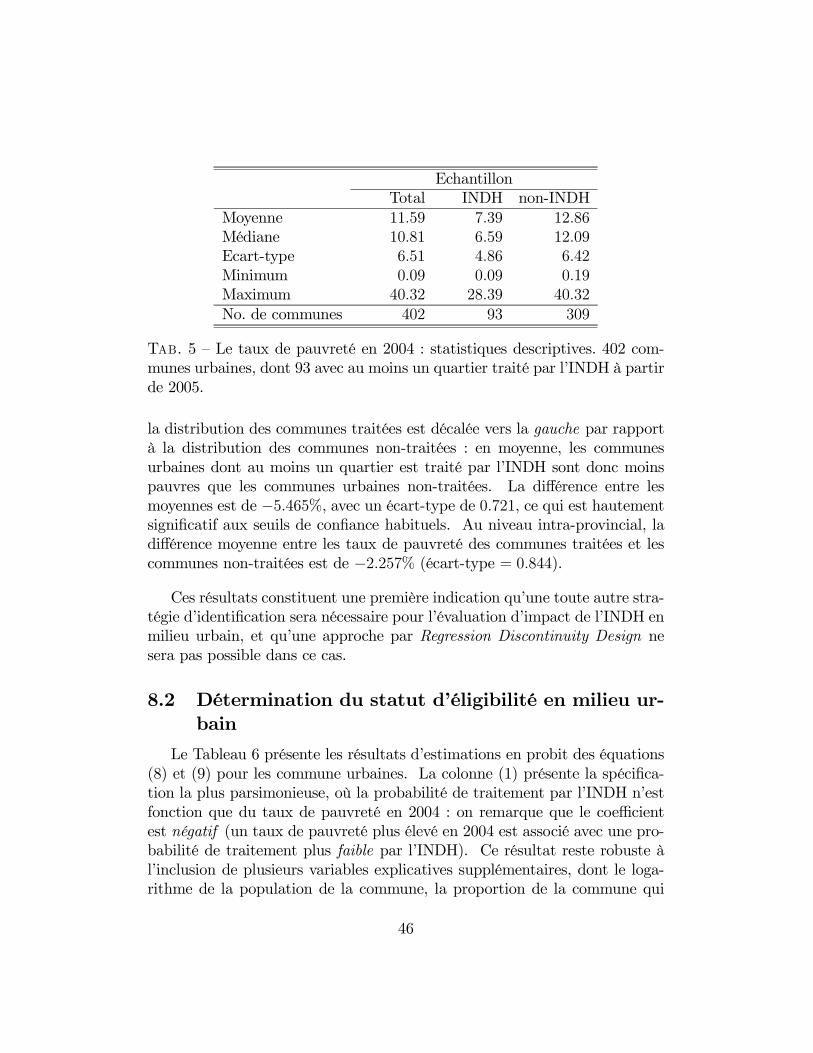
EchantillonTotal INDH non-INDH
Moyenne 11.59 7.39 12.86Médiane 10.81 6.59 12.09Ecart-type 6.51 4.86 6.42Minimum 0.09 0.09 0.19Maximum 40.32 28.39 40.32No. de communes 402 93 309
T��. 5 — Le taux de pauvreté en 2004 : statistiques descriptives. 402 com-munes urbaines, dont 93 avec au moins un quartier traité par l’INDH à partirde 2005.
la distribution des communes traitées est décalée vers la gauche par rapportà la distribution des communes non-traitées : en moyenne, les communesurbaines dont au moins un quartier est traité par l’INDH sont donc moinspauvres que les communes urbaines non-traitées. La différence entre lesmoyennes est de −5.465%, avec un écart-type de 0.721, ce qui est hautementsignificatif aux seuils de confiance habituels. Au niveau intra-provincial, ladifférence moyenne entre les taux de pauvreté des communes traitées et lescommunes non-traitées est de −2.257% (écart-type = 0.844).
Ces résultats constituent une première indication qu’une toute autre stra-tégie d’identification sera nécessaire pour l’évaluation d’impact de l’INDH enmilieu urbain, et qu’une approche par Regression Discontinuity Design nesera pas possible dans ce cas.
8.2 Détermination du statut d’éligibilité en milieu ur-bain
Le Tableau 6 présente les résultats d’estimations en probit des équations(8) et (9) pour les commune urbaines. La colonne (1) présente la spécifica-tion la plus parsimonieuse, où la probabilité de traitement par l’INDH n’estfonction que du taux de pauvreté en 2004 : on remarque que le coefficientest négatif (un taux de pauvreté plus élevé en 2004 est associé avec une pro-babilité de traitement plus faible par l’INDH). Ce résultat reste robuste àl’inclusion de plusieurs variables explicatives supplémentaires, dont le loga-rithme de la population de la commune, la proportion de la commune qui
46
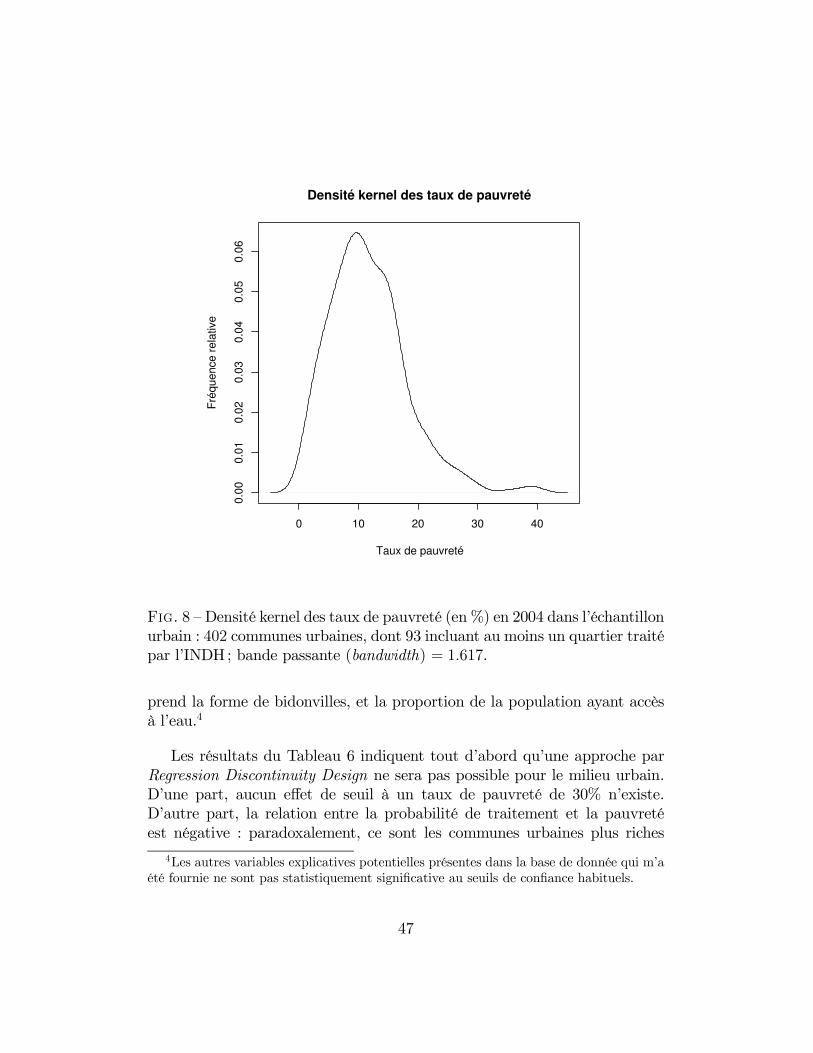
0 10 20 30 40
0.0
00
.01
0.0
20
.03
0.0
40
.05
0.0
6
Densité kernel des taux de pauvreté
Taux de pauvreté
Fré
qu
en
ce
re
lative
F��. 8 — Densité kernel des taux de pauvreté (en %) en 2004 dans l’échantillonurbain : 402 communes urbaines, dont 93 incluant au moins un quartier traitépar l’INDH; bande passante (bandwidth) = 1.617.
prend la forme de bidonvilles, et la proportion de la population ayant accèsà l’eau.4
Les résultats du Tableau 6 indiquent tout d’abord qu’une approche parRegression Discontinuity Design ne sera pas possible pour le milieu urbain.D’une part, aucun effet de seuil à un taux de pauvreté de 30% n’existe.D’autre part, la relation entre la probabilité de traitement et la pauvretéest négative : paradoxalement, ce sont les communes urbaines plus riches
4Les autres variables explicatives potentielles présentes dans la base de donnée qui m’aété fournie ne sont pas statistiquement significative au seuils de confiance habituels.
47
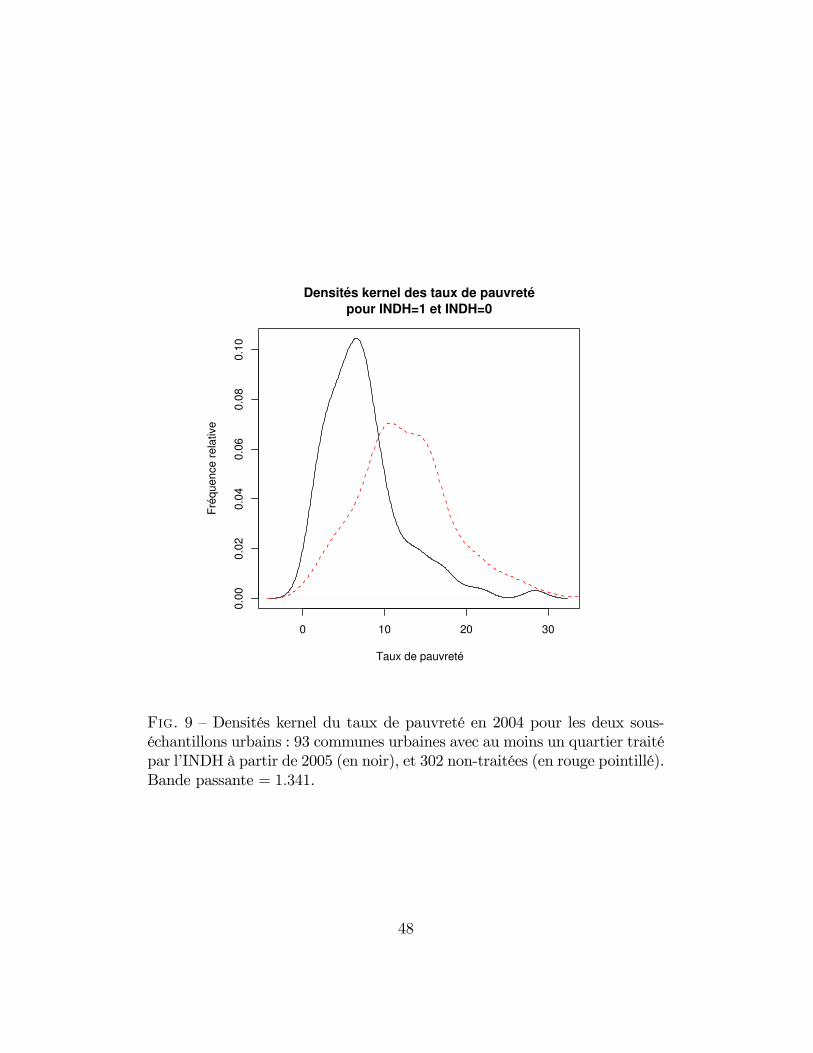
0 10 20 30
0.0
00
.02
0.0
40
.06
0.0
80
.10
Densités kernel des taux de pauvreté
pour INDH=1 et INDH=0
Taux de pauvreté
Fré
qu
en
ce
re
lative
F��. 9 — Densités kernel du taux de pauvreté en 2004 pour les deux sous-échantillons urbains : 93 communes urbaines avec au moins un quartier traitépar l’INDH à partir de 2005 (en noir), et 302 non-traitées (en rouge pointillé).Bande passante = 1.341.
48

(1) (2) (3) (4)Constante −0.321
(0.161)−5.550(0.730)
−5.958(0.765)
−5.377(0.801)
Taux de pauvreté en 2004 −0.104(0.015)
−0.071(0.017)
−0.072(0.017)
−0.079(0.018)
Log population de la commune 0.556(0.065)
0.577(0.067)
0.643(0.074)
Proportion commune bidonville 1.886(0.552)
1.735(0.561)
Proportion pop. ayant accès à l’eau −1.372(0.474)
Critère d’information d’Akaike 376.83 286.09 276.75 270.53
T��. 6 — Estimation en probit de la probabilité de traitement par l’INDH.La variable expliquée est égale à 1 si la commune est traitée par l’INDH àpartir de 2005, et 0 autrement. 402 communes urbaines, dont 93 traitées parl’INDH à partir de 2005. Ecarts-types entre parenthèses.
qui ont une probabilité plus élevé d’être traitées par l’INDH. En outre, lerésultat associé avec le logarithme de la population de la commune –queles communes plus peuplées ont, ceteris paribus, une probabilité plus élevéed’être traitées– suggère que le facteur critique concernant le traitement parl’INDH, pour les communes urbaines, est constitué par leur population.
La Figure 10 présente les densités kernel des scores de propension, sépa-rées selon le statut de traitement de la commune urbaine (en rouge pointilléles commmunes urbaines n’ayant aucun quartier traité, en noir les communestraitées), pour la spécification de la colonne (4) du Tableau 6. On remarqueraque les scores de propension pour les communes non-traitées sont fortementconcentrée autour de 0, tandis que relativement peu de communes traitéessont associées avec un score de propension proche de 1. En outre, la dis-tribution pour les communes non-traitées se raréfie à partir d’un score depropension de 0.8. Ainsi, la Figure 10 indique qu’il sera difficile d’entrevoirune stratégie d’identification par score de propension sur l’ensemble des com-munes urbaines, étant donné que l’hypothèse du support commun ne semblepas être vérifiée pour des scores de propension supérieurs à 0.8.
49
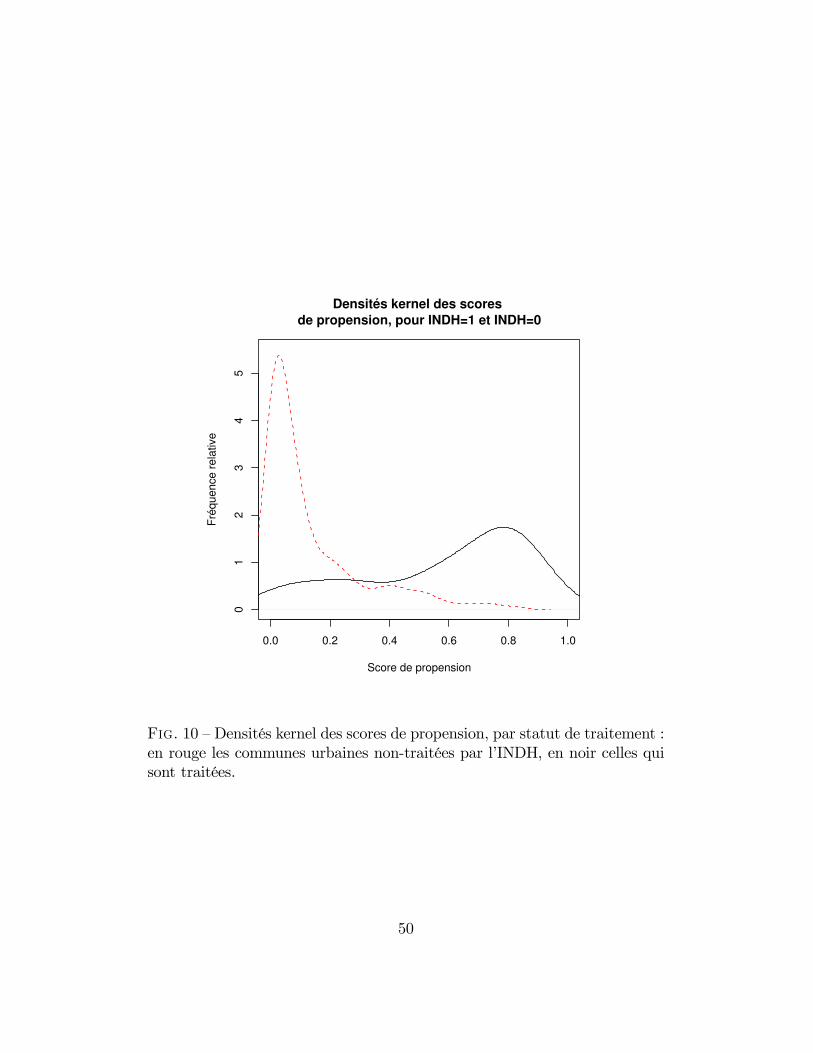
0.0 0.2 0.4 0.6 0.8 1.0
01
23
45
Densités kernel des scores
de propension, pour INDH=1 et INDH=0
Score de propension
Fré
qu
en
ce
re
lative
F��. 10 — Densités kernel des scores de propension, par statut de traitement :en rouge les communes urbaines non-traitées par l’INDH, en noir celles quisont traitées.
50

8.3 La distinction entre "grandes" et "petites" com-munes urbaines
Les résultats du Tableau 6 et les scores de propension qui en découlentsuggèrent donc qu’il sera important de prendre en considération certains élé-ments relevant de l’hétérogénéité de l’ensemble des communes urbaines. Unesource d’hétérogénéité évidente, mise en relief par les résultats des estima-tions en probit du statut de traitement, est fournie par la population de lacommune. Dans les Figures 11 et 12, je présente les résultats d’une estima-tion non-paramétrique de la relation liant le taux de pauvreté des communesurbaines et leur population. La Figure 11 présente les résultats en niveau,tandis que la Figure 12 correspond à la dérivée première.
On remarquerea dans la Figure 12 que la dérivée première devient signifi-cativement négative à partir d’une population dont le logarithme est environégal à 9.9, ce qui correspond à un niveau de population de 19930 habitants.Ce niveau seuil de population correspond à la valeur du logarithme de lapopulation pour lequel la borne supérieure de l’intervale de confiance à 95%(donnée par le trait en pointillés supérieur) croise l’axe horizontal. En des-sous de 19930 habitants, la relation entre la population et le taux de pauvretéest donc croissant ou statistiquement nul, tandis que pour une population su-périeure à 19930 habitants, la relation est significativement négative.
Cette différence structurelle dans la relation entre population et taux depauvreté suggère qu’il sera essentiel, dans l’évaluation d’impact de l’INDH, dedistinguer entre "grandes" et "petites" communes urbaines, où le qualificatif"grandes" correspondra à une population communale supérieure à environ19930 habitants. En opérant cette division de l’échantillon en deux groupessur la base d’un seuil de population de 19930 habitants, le sous-échantillon des"petites" communes urbaines est constitué de 247 communes, mais dont laprobabilité de traitement par l’INDH n’est que de 0.076. Pour les "grandes"communes urbaines, le sous-échantillon est constitué de 155 communes, maisdont la probabilité de traitement par l’INDH est de 0.477.
En termes de l’évaluation d’impact de l’INDH, il devient alors évidentque le traitement a surtout été opéré au niveau des "grandes" communesurbaines. Notons également que la plupart des petits centres traités parl’INDH sont situés à la périphérie des grandes villes. Cette concentrationpar l’INDH sur les grandes communes urbaines est problématique, dans la
51
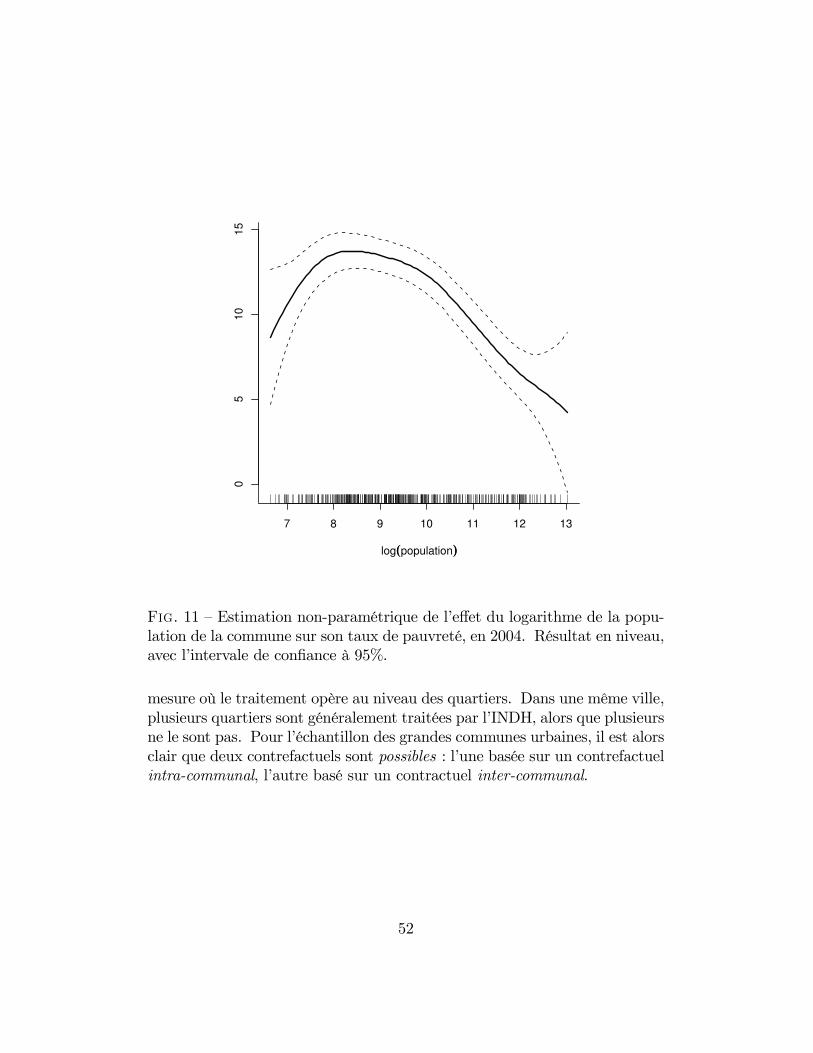
7 8 9 10 11 12 13
05
10
15
log((population))
F��. 11 — Estimation non-paramétrique de l’effet du logarithme de la popu-lation de la commune sur son taux de pauvreté, en 2004. Résultat en niveau,avec l’intervale de confiance à 95%.
mesure où le traitement opère au niveau des quartiers. Dans une même ville,plusieurs quartiers sont généralement traitées par l’INDH, alors que plusieursne le sont pas. Pour l’échantillon des grandes communes urbaines, il est alorsclair que deux contrefactuels sont possibles : l’une basée sur un contrefactuelintra-communal, l’autre basé sur un contractuel inter-communal.
52
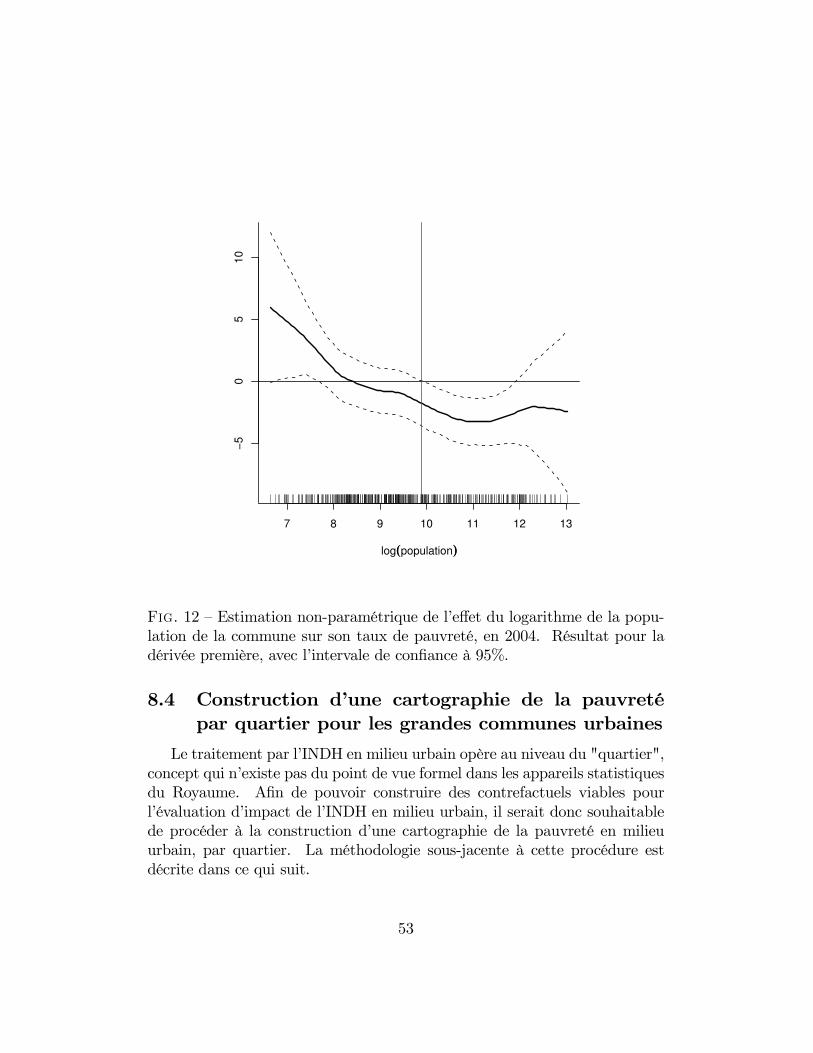
7 8 9 10 11 12 13
−5
05
10
log((population))
F��. 12 — Estimation non-paramétrique de l’effet du logarithme de la popu-lation de la commune sur son taux de pauvreté, en 2004. Résultat pour ladérivée première, avec l’intervale de confiance à 95%.
8.4 Construction d’une cartographie de la pauvretépar quartier pour les grandes communes urbaines
Le traitement par l’INDH en milieu urbain opère au niveau du "quartier",concept qui n’existe pas du point de vue formel dans les appareils statistiquesdu Royaume. Afin de pouvoir construire des contrefactuels viables pourl’évaluation d’impact de l’INDH en milieu urbain, il serait donc souhaitablede procéder à la construction d’une cartographie de la pauvreté en milieuurbain, par quartier. La méthodologie sous-jacente à cette procédure estdécrite dans ce qui suit.
53

8.4.1 Un contrefactuel inter-communal ?
En utilisant des méthodes d’appariement par score de propension, il seraitpossible de construire deux sous-échantillons de «grandes communes» : (i)des communes où au moins un quartier a été traité par l’INDH, (ii) des com-munes (avec approximativement le même score de propension de traitement)où aucun quartier n’a été traité par l’INDH. Le premier sous-échantillon ser-vira à la construction d’un contrefactuel intra-communal, le deuxième à laconstruction d’un contrefactuel inter-communal.
Le contrefactuel inter-communal pourrait aisément être construit à par-tir des estimations du Tableau 6 avec, bien évidemment, les améliorationsque l’ONDH pourrait apporter à ces résultats dans les semaines à venir enfonction des données supplémentaires qu’il sera capable de collecter. Unepremière approximation de ce sous-échantillon de communes urbaines, baséesur les scores de propension présentés à la Figure 10, serait de considérer lescommunes urbaines dont le score de propension est approximativement situéentre 0.3 et 0.6. Comme pour le cas des communes rurales, il serait importantd’identifier des variables Z potentielles qui pourront être introduites dans laspécification portant sur la détermination du statut traitement.
Bien que cette option soit attractive du point de vue méthodologique,la réalité sur le terrain suggère qu’elle n’est pas satisfaisante. En effet, letraitement de l’INDH opérant au niveau du quartier, et les quartiers traitésne représentant qu’une partie infime de la population dans certaines grandesvilles, il est probable que l’effet traitement mesurable soit extrêmement pe-tit. Dans cette optique, et afin de construire un contrefactuel urbain plussatisfaisant, il nous semble important de proposer une méthodologie alterna-tive, visant à construire des identifiant "quartier", permettant ainsi d’opérerdes comparaisons intra-communales entre quartiers traités et quartiers non-traités.
8.4.2 Un contrefactuel basé sur les quartiers
Etape 1 : choix de grandes villes
Il s’agit de choisir un ensemble de villes (Casablanca, Rabat, Tanger,Fès, Marrakech, Agadir, Beni Mellal), représentative de la diversité urbainedu Maroc. Pour chaque ville, il s’agit de choisir une dizaine de quartiers
54

traités par l’INDH. Dans un deuxième temps, on demandera au Wali res-ponsable, d’apparier à chaque quartier traité un quartier non-traité qu’il jugesemblable. Il sera également nécessaire que le Wali fournisse, pour chaquequartier, la liste des identifiants des districts de recensement qui le compose.
Etape 2 : Construction d’un identifiant « quartier »
Il s’agit de construire un identifiant correspondant aux quartiers, en agré-geant par identifiant des districts de recensement. Ce travail nécessiterait lacoopération de la Division de la cartographie de la statistique.
Etape 3 : Construction de la base de données ménage
Il s’agit d’obtenir tous les ménages correspondant aux identifiants quartierconstruits à l’étape 2, pour les 2 sous-échantillons spécifiés à l’étape 1. Il seraimportant d’obtenir toutes les variables utilisées dans les modèles associés àla carte de pauvreté de 2004.
Etape 4 : Construction d’une carte de pauvreté urbaine partielleau niveau des quartiers
Il s’agit de générer, à partir des données de l’étape 3 (les identifiantsquartier, les ménages, les variables clefs, et les modèles associés), une cartede pauvreté urbaine partielle, ainsi que d’autres mesures de bien-être.
Etape 5 : Construction des contrefactuels
A partir de l’étape 4, on retombe sur une méthodologie pour la construc-tion du contrefactuel basée sur la méthode de l’appariement par score depropension, mais où l’estimation du modèle qui détermine le statut de trai-tement se fait au niveau des quartiers.
Notons que la comparaison entre des quartiers dans la même commune,et donc géographiquement très proches, fera en sorte que les quartiers non-traités seront en toute probabilité les bénéficiaires d’externalités positivesissues des quartiers traités voisins –ceci fournira donc une borne inférieuresur l’impact de l’INDH. D’autre part, la comparaison entre des quartierssitués dans des communes différentes, relativement éloignées du point de vuegéographique, nous donnera ce qui devrait constituer une borne supérieuresur l’effet traitement, dans la mesure où les quartiers de contrôle ne devraient
55

pas bénéficier d’externalités positives significatives. La différence entre cesdeux effets nous fournira alors une estimation de l’ordre de grandeur deseffets externes du traitement par l’INDH.
L’échantillon urbain proposé ici implique une taille d’échantillon légère-ment supérieur à celui pour le rural. Au total, il s’agirait d’enquêter : 7villes×10 quartiers×2 (traités et non-traités)×15 ménages= 2100 ménages.Cette taille légèrement supérieure est proposée pour pallier à d’éventuelsimprévus dans la procédure de construction de la cartographie urbaine parquartier.
9 Calculs de puissance
Dans cette section, et en utilisant les approches habituelles en termes decalculs de puissance, je cherche à déterminer si les échantillons proposés auxsections 7 et 8 sont de taille suffisante pour détecter des impacts éventuelsde l’INDH.
9.1 Les calculs de base : L’Impact Minimal Détectable(IMD)
La puissance statistique est la probabilité qu’un échantillonnage trouveraun impact du programme statistiquement significatif, étant donné que l’im-pact effectif du programme est d’une certaine taille.
En faisant des calculs de puissance, le but est de déterminer :
— la probabilité que l’échantillonnage sera capable de détecter un impactde la taille que le programme devrait produire ;
— la taille de l’impact que devrait avoir le programme pour qu’il soitdétectable par l’échantillonnage proposé ; ceci est crystalisé dans leconcept de "l’impact minimal détectable" (IMD, voir Bloom (1995)).
Qui plus est, les calculs de puissance doivent permettre de répondre àdeux questions :
56

— étant donnée l’impact que le programme devrait générer, de quelle tailledevrait être l’échantillon afin de pouvoir le détecter ?
— quelle est la façon la plus efficace pour détecter l’impact du programme,étant donné le budget d’enquête disponible ?
La formule de base pour les calculs de puissance provient d’une compa-raison de moyennes entre le groupe traité et le groupe non-traité, et le seuilhabituel de puissance est fixé à 80%. Pour le cas d’une régression simplede la variable de résultats Y sur la muette traitement D (où les variables Xsont donc absentes), la formule est donnée par :
Puissance = Pr
Y 1 − Y 0
σY
√1n1+ 1
n0
� 1.645
∣∣∣∣∣∣β = IMD
= 0.80, (19)
où Y 1−Y 0 est la différence de moyennes entre le groupe traité et le groupe decontrôle, σY est l’écart-type de la variable de résultats Y dans l’échantillondans son ensemble, n1 et n0 sont les tailles respectives du sous-échantillontraité et du sous-échantillon non-traité, le chiffre 1.645 correspond à la valeurcritique de la statistique t de Student avec un niveau de confiance de 5%, etβ représente le coefficient associé avec la muette traitement dans l’équation(6).
Pour l’hypothèse nulle H0 : Y 1 = Y 0 (aucun effet du traitement), la ré-solution pour l’IMD de l’équation précédente (en supposant une distributiont de Student) implique que :
IMD = 2.487σY
√1
n1+1
n0. (20)
Cette expression nous permet de calculer la taille de l’echantillon nécessairepour atteindre un IMD donné, ou l’IMD possible pour une taille d’échantillondonnée. Dans ce cas très simple, la puissance sera maximisée lorsque l’échan-tillon sera divisée de façon symmétrique entre groupe de traitement et groupede contrôle. Il faut également noter que les rendements sont décroissants, entermes de l’IMD, pour toute augmentation de la taille de l’échantillon (dufait de la racine carrée du côté droit de la formule).
57

9.2 L’IMD dans le cas de covariés et d’un échantillon-nage stratifié
Dans le cas de l’évaluation d’impact de l’INDH, il ne sera pas souhaitablede se fier à l’équation (20), étant donné que la spécification de l’équation (6)implique l’inclusion de variables explicativesX additionnelles (rappellons quecelles-ci se retrouvent dans α). Si la muette traitement D était orthogonalepar rapport aux variables X (et si D était orthogonale par rapport à ε), laformule appropriée serait donnée par :
IMD = 2.487σY
√(1−R2
Y |X,D
)( 1
n1+1
n0
), (21)
où R2Y |X,D représente le R2 issu de l’estimation de l’équation (6). On voitdonc comment l’identification de la matrice X des variables qui affectentla variable de résultats constituera un aspect critique de la puissance del’évaluation d’impact de l’INDH.5
Dans le cas précis de l’INDH, et compte-tenu du fait que le traitementa lieu au niveau des communes, cette dernière expression devra encore êtremodifiée afin de prendre en considération la nature stratifiée de l’échantillon-nage. Considérons donc un échantillonnage à deux étapes où nous choisissonsd’abord les communes (strate 1), et ensuite les ménages (strate 2). L’expres-sion pour l’IMD est alors donnée par :
IMD = 2.487σY
√√√√(1−R2
Y |X,D
)[ (1− ρ)(
1Nn1
+ 1Nn0
)
+ρ(1N+ 1
N
)], (22)
où N représente le nombre de communes traitées (et de contrôle) enquêtéesau premier niveau de stratification, n1 (n0) représente le nombre de ménagesenquêtées au deuxième niveau de stratification, et ρ représente le "coefficientde corrélation intra-classe".
Intuitivement, ρ =σ2N−
σ2n
n−1
σ2Y
(pour le cas où l’on enquête des grappes de
ménages de taille identique dans les deux sous-échantillons) représente la
5Voir Bloom (2005) pour de plus amples détails.
58

Nombre de Taille de IMDCommunes Ménages l’échantillon ρ = 0.05 ρ = 0.10 ρ = 0.15
25 20 500 0.120 0.137 0.15225 40 1000 0.098 0.120 0.13825 60 1500 0.090 0.112 0.13350 10 500 0.110 0.118 0.12650 20 1000 0.085 0.097 0.10850 30 1500 0.075 0.089 0.101100 5 500 0.103 0.107 0.110100 10 1000 0.077 0.083 0.089100 15 1500 0.066 0.074 0.081
T��. 7 — Calcul de l’IMD pour différentes combinaisons du nombre de com-munes et du nombre de ménages enquêtées.
proportion de la variance dans la variable de résultats attribuable à des diffé-rences inter-communes. Il est clair de l’expression (22) que la puissance seraune fonction décroissante de la taille de ρ.
Dans le Tableau 7, j’illustre ces propos pour diverses combinaisons dunombre de communes et du nombre de ménages enquêtées par commune, pourσY = 0.5 et R
2Y |X,D = 0.2. Bien sûr, ces calculs devront être effectués pour
chaque variable Y identifiée par l’ONDH et ses partenaires pour l’évaluationd’impact, mais les résultats présentés ci-dessous indiquent :
— qu’il sera souhaitable, dans la mesure des ressources budgétaires dis-ponibles, d’opter pour un plus grand nombre de communes enquêtéesque pour un nombre important de ménages par communes ;
— qu’il sera possible, avec un échantillon d’environ 100 communes et de15 ménages par commune, de détecter des impacts qui sont de l’ordred’un dixième de l’écart-type de la variable de résultats Y de choix.
9.3 Sélection sur observables et estimations par va-riables instrumentales
Comme je l’ai montré dans les sections précédentes de ce rapport, lesvariables X qui affectent les résultats seront également des déterminantsimportant de la probabilité de traitement. Dans ce cas, nous ne pouvons
59

plus supposer, comme à la section précédente, que D est orthogonal à X.Dans ce cas, l’expression (22) devra être remplacée par :
IMD = 2.487σY
√√√√(1−R2
Y |X,D
1−R2D|X
)[(1− ρ)
(1
Nn1+ 1
Nn0
)
+ρ(1N+ 1
N
)], (23)
où R2D|X représente le R2 de la régression de la muette traitement sur la
matrice X, comme dans l’équation (12). On notera que l’IMD sera unefonction croissante du degré auquel les variables X expliquent le statut detraitement.
Tel qu’indiqué à la section 6.2, il est probable que l’évaluation de l’impactde l’INDH passe par une stratégie d’identification basée en partie sur lesvariables instrumentales (que ce soit dans la construction du contrefactuel,ou bien dans les stratégies d’estimation). Comme il très peu probable, dans lecontexte de l’estimation de (6), que la muette D soit orthogonale par rapportà ε (voir la section 6.1), l’expression (23) devra à nouveau être modifiée.
Si nous dénotons par R2D|Z le R2 de la forme réduite donnée par (8) et
(9), l’expression pour l’IMD devient :
IMD = 2.487σY
√√√√(1−R2
Y |X,D
R2D|Z −R2
D|X
)[(1− ρ)
(1
Nn1+ 1
Nn0
)
+ρ(1N+ 1
N
)]. (24)
L’expression (24) est une nouvelle indication de l’importance de l’identifica-tion de variables Z qui affectent la probabilité de traitement par l’INDH,mais qui n’affectent pas les variables de résultats Y . Un calcul approximatifindique que si la différence entre R2D|Z et R
2D|X est de l’ordre de 10% (ce
qui correspond à de très bonnes restrictions d’exclusion), l’IMD sera multi-plié par 3. Ceci implique que nous pourrons détecter des impact de l’INDHqui représenteront environ un tiers de l’écart-type de la variable de résultatsY choisie. Afin de pouvoir détecter des impact plus petits, il faudra aug-menter la taille de l’échantillon, probablement en rajoutant des communessupplémentaires.
60

9.4 Coûts des enquêtes
Tous ces calculs ne représentent, bien évidemment, qu’une première ap-proximation. Une fois les indicateurs d’impact Y arrêtés en collaborationavec les différents partenaires, il sera important pour l’ONDH de procéder àdes calculs supplémentaires afin d’établir la taille souhaitée de l’échantillon.
Dans ce contexte, une discussion avec le HCP sur le coût par ménageenquêté pourrait s’avérer utile dans l’optique de la préparation des enquêtesdu printemps 2008. Mes discussions à Rabat et à Casablanca avec mescollègues du monde académique me font pencher vers une estimation de 300Dirhams par ménage, tout compris.
La taille des échantillons requis dépend bien sûr des ressources dispo-nibles. Toutefois, les calculs de puissance détaillées ici suggèrent que l’échan-tillon rural constitué de 124 communes (62 traitées et 62 non-traitées), avec15 ménages par commune, et proposé à la section 7, serait suffisant pourdétecter des impacts de l’INDH pour la plupart des variables de résultatsenvisageables.6
Pour le milieu urbain, une structure de stratification similaire devrait êtremise en oeuvre. La taille d’échantillon de 2100 ménages proposée à la section8 devrait, sur la base des calculs de puissance, être elle-aussi suffisante pourdétecter des impacts éventuels de l’INDH.
Avec un coût estimé de 300 Dirhams par ménage enquêté, tout compris, lecoût des enquêtes en milieu rural s’élèverait donc à un total de 124×15×300 =558 000 Dirhams. Pour l’échantillon urbain, la collecte des données devraitcoûter 140×15×300 = 630000 Dirhams, majoré par le coût de la constructionde la cartographie partielle de pauvreté par quartier en milieu urbain.
6Un échantillon de 100 communes rurales serait probablement suffisant, mais mon ex-périence de terrain me fait pencher vers une majoration de 20% de la taille de l’échantillon,afin de faire face à des problèmes éventuels de non-réponse.
61

10 Autres aspects méthodologiques relevant
de la source de biais No. 1
10.1 Vérification ex ante de l’hypothèse des tendancesparallèles
Pour tout contrefactuel qui sera construit pour l’évaluation d’impact, quece soit à partir de la méthode du regression discontinuity design ou par ap-pariement par score de propension, il sera essentiel de procéder à toutes lesvérifications ex ante possibles. L’une de celles-ci est constituée par la va-lidité de l’hypothèse des tendances parallèles (en Anglais –parallel trendsassumption).7 L’existence de la carte de pauvreté de 1994, avec les ajus-tements nécessités par la non-compatibilité parfaite avec celle 2004, rendracette procédure possible.
L’intuition est très simple, et correspond non-seulement à la validité ponc-tuelle du contrefactuel juste avant la mise en oeuvre de l’INDH (que nouspourrons bien évidemment tester grace à la carte de pauvreté de 2004), maiségalement à sa validité en termes dynamiques.
Considérons à nouveau le taux de pauvreté dans une commune commeétant l’indicateur de résultats choisi. Bien sûr, aucune commune n’est traitéepar l’INDH en 1994. Ecrivons l’équation (6) pour 1994 ainsi que pour 2004 :
Y 1994 = α1994 +D1994β + ε1994, (25)
Y 2004 = α2004 +D2004β + ε2004, (26)
et faisons semblant que les communes traitées en réalité par l’INDH à partirde 2005 l’aient été en 2004. Ceci implique que : (i) pour toutes les communes,D1994 = 0, (ii) pour les communes non-éligibles en 2005 nous aurons D2004 =0, alors que (iii) nous fixerons D2004 = 1 pour toutes les communes éligiblesà partir de 2005. Prenons ensuite la différence entre les équations (26) et(25), obtenant ainsi :
(Y 2004 − Y 1994
)=(α2004 − α1994
)+(D2004 −D1994
)β+
(ε2004 − ε1994
). (27)
7Une discussion de l’importance de cette hypothèse est fournie dans Bertrand, Duflo,et Mullainathan (2004).
62

Un test de la validité dynamique de notre contrefactuel est alors fourni parle coefficient estimé β dans (27) : si l’évolution entre 1994 et 2004 de lapauvreté dans les communes traitées par l’INDH à partir de 2005 est la mêmeque celle dans les communes du groupe de contrôle, le coefficient estimé nesera pas statistiquement significatif. Si, par contre, nous trouvons un effetstatistiquement significatif de ce "traitement" placébo, alors la validité ducontrefactuel proposé pourra être mis en doute.8
Dans le but de mettre en oeuvre ce test pour tout contrefactuel quel’ONDH prendra en considération, il sera donc essentiel d’obtenir la carte depauvreté de 1994.
10.2 Doubles-différences et les enquêtes de 2010
Bien qu’il soit tôt pour parler des enquêtes de 2010, il me semble im-portant d’expliquer leur importance, qui découle de la présence de facteursinobservables qui pourraient fausser l’estimation de l’impact de l’INDH, auniveau de l’équation (6).
Réécrivons donc cette équation en rajoutant un indice temporel t (cor-respondant aux enquêtes de 2008 et à celles de 2010) et en décomposant leterme d’erreur en deux parties :
εt = λ+ ut. (28)
La composante λ du terme d’erreur représente des caractéristiques inobser-vables des communes que nous serions incapables de capter concrètementavec les indicateurs observables X. Cette décomposition du terme d’erreurnous permet alors de réécrire l’équation (6) sous la forme d’une spécificationen panel :
Yt = αt +Dtβ + λ+ ut, (29)
ou, plus explicitement pour chaque année d’enquête, comme :
Y 2010 = α2010 +D2010β + λ+ u2010, (30)
Y 2008 = α2008 +D2008β + λ+ u2008. (31)
8Un exemple de la mise en oeuvre pratique de ce test est fourni dans Arcand et Bassole(2007a).
63

Même en prenant toutes les précautions possibles concernant la constructiondes contrefactuels (tel qu’esquissé aux sections 7.3 et 8.4), il est possible quedes facteurs inobservables λ affectent le taux de pauvreté d’une communedonnée. L’estimation de (31) ou de (30) séparément pourrait alors nousdonner une estimation biaisée de l’impact de l’INDH, surtout si Dt et λ sontcorrélés, ce qui est fort probable.
Si ces facteurs inobservables λ sont constants dans le temps (tel qu’indiquépar la notation, où l’indice t n’apparaît pas), une approche par les doubles-différences permet de corriger l’estimation de l’impact du programme. Plusprécisément, il s’agit de prendre la différence entre (30) et (31) (tout commeà la section 10.1), obtenant ainsi :
(Y 2010 − Y 2008
)=(α2010 − α2008
)+(D2010 −D2008
)β+
(ε2010 − ε2008
). (32)
C’est ce qui est communément appelé en économétrie une spécification en"différences premières". Vous aurez sans doutes remarqué que le facteurλ n’apparaît pas dans l’équation (32) car il a été éliminé par le processusde différenciation. Cette méthode permet donc de corriger pour la présenced’hétérogénéité inobservable et invariante dans le temps, et il est très probablequ’elle sera un élément clef de l’évaluation de l’impact de l’INDH entre 2008et 2010. Un exemple de la mise en oeuvre pratique de cette approche estfournie dans Arcand et Bassole (2007a).
10.3 Impact des projets INDH complétés
Parmi les communes éligibles pour l’INDH, il est très probable, même en2010 au moment du deuxième passage d’enquêtes, que certaines communesaient des projets complétés et d’autres non. Comprendre pourquoi certainescommunes reçoivent des projets complétés et certaines non sera alors essentielpour toute évaluation de l’impact des projets INDH complétés, dont l’effetpourra être différent par rapport à celui de l’éligibilité. Afin de mettre enplace, dès les enquêtes de 2008, les éléments d’information nécessaires à cetteévaluation, il est important d’identifier dès maintenant les facteurs pouvantaffecter l’attribution de financements, ainsi que la stratégie d’estimation àmettre en oeuvre.
64

10.3.1 Estimation par les variables instrumentales de l’effet desprojets complétés
Dans ce contexte, et pour un sous-échantillon constitué par les communeséligibles pour l’INDH, le modèle de traitement sera semblable à celui esquisséaux équations (8) et (9), mais où nous construirons une variable muette P ,égale à 1 si la commune a reçu un projet INDH complété et 0 autrement,avec :
P ∗ = µD (Z)− UD. (33)
avec :
P =
{1 si P ∗ � 00 autrement
. (34)
et où Z représente maitenant une matrice de variables qui affectent la pro-babilité de recevoir un projet complété. L’équation structurelle qui permetd’identifier l’effet des projets INDH complétés est alors donnée par une simpleréécriture de l’équation (6) où nous remplaçons D par P . L’intuition de lastratégie d’identification reste la même qu’à la section 6.2, mais repose main-tenant entièrement sur l’identification de variables dans la matrice Z quiaffectent la probabilité de recevoir un projet complété mais qui n’affectentpas le résultat du traitement (et qui sont donc absentes de X).
Le principe de base de la méthode des variables instrumentales, qui seramise en oeuvre pour cette phase de l’évaluation d’impact, ainsi que les détailstechniques sont très bien résumés dans Angrist, Imbens, et Rubin (1996), quej’ai fait parvenir à l’ONDH en fichier attaché le 13 octobre.
10.3.2 Variables instrumentales possibles
Le canevas du Comité provincial de développement humain (CPDH) –que nous avons obtenu de la coordination nationale de l’INDH– donne desinformations sur la composition de cette structure qui pourraient servir devariables instrumentales dans l’estimation des équations (33) et (34). Lesdifférences dans la composition de ce comité (en termes des élus, des classesd’age, des niveaux d’éducation, etc.) entre différentes provinces pourraientaffecter la probabilité de financement de projets. S’il était possible d’obte-nir des informations sur les caractéristiques des membres individuels (commeleur origine géographique, par exemple), celles-ci pourraient s’avérer être des
65

variables instrumentales puissantes, dans la mesure où elle affecteraient pro-bablement la probabilité qu’un projet dans une commune donnée soit finan-cée.
Une deuxième source de variables instrumentales possibles est fourni parle canevas de la matrice des critères de sélection des projets, qui donne lesjustifications et les raisons pour les projets retenus et rejetés. L’utilisationde ces informations dans le contexte de l’estimation des équations (33) et(34) est bien sûr conditionnée par la possibilité de numériser les informationscontenues dans les canevas. Bien que la réflexion concernant la stratégied’identification de cet aspect de l’INDH ne soit qu’à ses premiers balbutie-ments, il sera important, lors des rencontres futures avec la coordinationnationale, de pouvoir procéder à une examination minutieuse des informa-tion disponibles sur support informatique, ou du moins "informatisables" àun coût relativement faible.
10.4 L’importance d’identifier des variables Z absentesde X
Il est utile à ce stade de revenir sur l’importance pour l’ONDH d’identifierdes variables Z absentes de la matrice X. Comme je l’ai montré tout au longde ce rapport, il y a 4 raisons sous-jacentes à cette nécessité :
1. les stratégies d’identification de l’effet de l’éligibilité pour l’INDH, telque décrites dans la section 6, seront en grande partie basées sur lesrestriction d’exclusion représentées par ces variables Z ; le problèmeest moins sévère pour les communes rurales, du fait de la possibilitéd’utiliser une stratégie d’identification par le Regression DiscontinuityDesign ; pour les communes urbaines, par contre, la collecte d’informa-tions sur les variables Z est cruciale ;
2. la construction du contrefactuel pour les communes rurales, ainsi quepour les communes urbaines, tel que décrite aux sections 7 et 8 reposeen partie sur l’identification de ces variables Z ;
3. les stratégies d’identification de l’effet de projets INDH complétées, telque décrit à la section 10.3, reposent entièrement sur l’existence devariables Z absentes de X ;
66

4. la puissance de l’évaluation d’impact de l’INDH, et donc la capacité desenquêtes de révéler des effets traitement statistiquement significatifs, telque décrit à la section 9, repose en partie sur l’identification de variablesZ exclues de X, qui seront des déterminants hautement significatifs dustatut traitement D, et qui diminueront ainsi l’IMD.
Il essentiel de noter que, même si les contrefactuels (et doncl’échantillonnage) sont construits entièrement sur la base des va-riables X, il sera extrêmement important de cerner des variablesZ (non-corrélées avec ε et donc différentes de X) permettant depurger les estimations de l’impact de l’INDH de toute corrélationrésiduelle entre D et ε. Ceci est particulièrement important pourle milieu urbain.
11 Hétérogénéité essentielle : Les sources de
biais No.2 et No.3
Une faiblesse des méthodes esquissées jusqu’à présent dans ce rapport estqu’elles limitent leur attention aux effets moyens du traitement. Bien queces méthodes nous fournirons une estimation de l’effet moyen de l’INDH surles variables de résultats retenues, il est facile d’entrevoir une importantehétérogénéité dans l’effet du traitement par l’INDH. Une autre façon d’ex-primer ceci est qu’il est difficile de croire que tous les individus, ménages, oucommunautés bénéficient de façon identique du traitement par l’INDH.
L’hétérogénéité dans l’effet traitement est intimement liée au problèmede sélection qui a été le point focal des sectiosn précédentes. Le problème desélection, comme nous l’avons vu, intervient lorsque le traitement des indivi-dus par le programme est basé en partie sur des caractéristiques (dont cellesinobservables) qui influencent également les résultats. Comme le disent sibien Heckman et Vytlacil (2001), si l’hétérogénéité est une partie intégrantede l’existence humaine, les questions de sélection sont une composante in-contournable des actions humaines.
Prendre en compte l’hétérogénéité des effets traitement a été le pointfocal d’une importante composante de la littérature sur l’identification d’un
67

effet causal.9 Dans la littérature microéconométrique portant sur l’évaluationd’impact de programmes, l’interraction entre l’hétérogénéité et la sélectiona récemment été dénotée par le terme "hétérogénéité essentielle" (essentialheterogeneity) par Heckman, Urzua, et Vytlacil (2006).10 Cette forme d’hé-térogénéité ne doit pas être confondue avec celle traitée par les méthodes dequantile, et qui sont esquissée à la section 12 de ce rapport.
L’origine de l’hétérogénéité essentielle réside dans les inobservables qui dé-terminent le gain idiosyncratique issu de la participation dans le programme.Dans ce contexte, et comme je l’ai déjà noté à la section 4.3, l’estimationdes effets traitement est relativement compliquée à cause de la corrélationentre les inobservables idiosyncratiques et le statut traitement. Alors que lesméthodes habituelles de variables instrumentales règlent les problèmes issusde la corrélation entre les inobservables et le statut traitement, ils ne sontplus valables lorsque les gains issus du traitement (en quelque sorte, le "para-mètre" que nous tentons d’estimer) sont corrélés avec les inobservables. Danscette situation, nous ne pouvons pas estimer "un" effet traitement. Bien aucontraire, nous devons estimer toute une distribution d’effets traitement, oùchaque effet traitement correspondra à une valeur donnée des inobservablesqui déterminent le statut traitement.11
11.1 L’élément de base : Le MTE
En utilisant la même notation qu’à la section 3, rappellons que l’effet dutraitement sur un individu est donné par :
∆ = Y1 − Y0. (35)
L’élément de base de l’approche de Heckman est "l’effet marginal de traite-ment" :
∆MTE (x, uD) (36)
9En économétrie, l’hétérogénéité dans les effets traitement a été introduit dans lecontexte des modèles de "switching regression" par Quandt (1972), Heckman (1978) etHeckman (1979), tandis que la littérature statistique, le modèle causal des résultats po-tentiels de Rubin (1974) permet également l’hétérogénéité des effets traitement.10Heckman, Smith, et Clements (1997) furent les premiers à analyser la question de
l’hétérogénéité essentielle en utilisant des données issues d’expérimentations sociales.11Une bonne introduction à ces méthodes est fournie par Heckman et Vytlacil (1999),
Florens, Heckman, Meghir, et Vytlacil (2004) et Heckman, Urzua, et Vytlacil (2006). Vousavez déjà un excellent résumé de ces méthodes sous la forme de l’article de Heckman etVytlacil (2005), que j’ai fait parvenir à l’ONDH par fichier attaché le 13 octobre.
68

(marginal treatment effect –MTE), défini par une espérance conditionnelle :
∆MTE (x, uD) = E (∆ |X = x, UD = uD ) . (37)
Un concept très proche, qui sera également utile par la suite, est celuidu ∆LIV (local instrumental variable –LIV) qui, nous le verrons plus tard,correspond au ∆MTE (x, uD), évalué à UD = P (Z) :
∆LIV (x, P (Z)) = E (∆ |X = x,UD = P (Z)) . (38)
Remarquez que, lorsque UD = P (Z), l’individu est juste indifférent entrechoisir et ne pas choisir le traitement, car, dans ce cas :
D∗(UD = P (Z)) = µD (Z)− P (Z) = P (Z)− P (Z) = 0. (39)
11.2 Les différents effets traitement
11.2.1 Average treatment effect : ATE
Nous définirons l’effet moyen du traitement (sur une personne tirée auhasard dans la population) par :
∆ATE (x) = E (∆ |X = x) . (40)
On doit donc éliminer la variable aléatoire UD (qui est inobservable) enintégrant l’espérance conditionnelle E (∆ |X = x, UD = uD ), par rapport àuD, sur l’ensemble de son support [0, 1] :
∆ATE (x) =
∫ 1
0
E (∆ |X = x, UD = uD )︸ ︷︷ ︸=∆MTE(x,uD)
fUD (uD)︸ ︷︷ ︸=1
duD (41a)
=
∫ 1
0
∆MTE (x, uD) duD. (41b)
On voit donc que le ATE pondère de façon identique le MTE pour chaqueobservation.12
12fUD (uD) = 1 par le Théorème de la fonction de transfert. Voir un bon livre deStatistiques mathématiques comme, par exemple, Roussas (1997), pp. 242-4.
69

11.2.2 Effect of treatment on the treated : TT
Nous dénoterons "l’effet du traitement sur les traités" par∆TT (x,D = 1) :
∆TT (x,D = 1) = E (∆ |X = x,D = 1) . (42)
La différence avec le ATE est que nous conditionnons sur le fait queD = 1. On doit donc éliminer la variable aléatoire inobservable UD enintégrant l’espérance conditionnelle E (∆ |X = x, UD = uD ), par rapport àuD, sur la partie de son support qui correspond aux personnes qui choisissentle traitement. En définissant la pondération :
hTT (x, uD) =1− FP (Z)|X=x (uD |X = x)∫ 1
0
[1− FP (Z)|X=x (t |X = x)
]dt, (43)
Heckman (2001) montre que :
∆TT (x,D = 1) =
∫ 1
0
∆MTE (x, uD) hTT (x, uD) duD. (44)
11.2.3 Effets locaux : LATE et LIV
Le LATE (local average treatment effect), introduit initiallement dans lalittérature par Imbens et Angrist (1994), est défini par :
∆LATE (x, P (z) , P (z′)) (45)
=E (Y |X = x, P (Z) = P (z))−E (Y |X = x, P (Z) = P (z′))
P (z)− P (z′).
Le LIV (local instrumental variables), lui, correspond à la limite de l’expres-sion pour le LATE, lorsque z → z′ :
∆LIV (x, P (z)) =∂E (Y |X = x, P (Z) = P (z))
∂P (z)(46)
= limz→z′
∆LATE (x, P (z) , P (z′)) .
Nous pouvons maintenant regrouper nos trois principaux résultats concer-nant le lien entre les effets traitements les plus communément utilisés –ATE,
70

TT et LATE– et le MTE :
∆LIV (x, P (z)) = ∆MTE (x, P (z)) , (47a)
∆ATE (x) =
∫ 1
0
∆MTE (x, uD) duD, (47b)
∆TT (x,D = 1) =
∫ 1
0
∆MTE (x, uD)hTT (x, uD) duD. (47c)
Lorsque le MTE est indépendant de uD, ∆MTE (x, uD) = ∆
MTE (x), les ex-pressions précédentes impliquent que :
∆MTE = ∆LIV = ∆ATE = ∆TT = ∆LATE. (48)
Intuitivement :
— ∆LIV (x, P (z)) évalue ∆MTE (x, uD) à UD = P (z) et représente l’effetmoyen de traitement pour les individus qui sont indifférents entre par-ticiper et ne pas participer au programme, pour une valeur donnée del’instrument P (z). Pour les individus pour lesquels P (z) est prochede 0, ∆LIV (x, P (z)) représente l’effet moyen de traitement pour quel-qu’un dont les caractéristiques inobservables UD sont telles qu’il esttrès probable qu’il choisira de participer au programme. Le contraireest vrai pour les individus pour lesquels P (z) est proche de 1.
— ∆ATE (x) intègre ∆MTE (x, uD) sur la totalité du support [0, 1] de UD,et correspond donc à l’effet moyen de traitement pour une personnetirée au hasard dans la population.
— ∆TT (x,D = 1) intègre ∆MTE (x, uD) sur l’ensemble du support [0, 1],avec un pondération qui est décroissante en uD, et qui met donc plus depoids sur les individus qui ont une plus forte probabilité de participerau programme (cet effet est également une moyenne pondérée de l’effetprécédent, où l’on intègre par rapport à la probabilité de participationP (z)).
11.3 Comment estimer le MTE
Du point de vue pratique, l’estimation duMTE pour le cas de l’INDH pas-sera par l’utilisation de méthodes semiparamétriques (celles-ci sont d’ailleursrelativement facile à mettre en oeuvre grace à l’utilisation du logiciel "R"dont vous disposez déjà depuis la mi-octobre).
71

L’approche de Heckman repose sur la construction d’une fonction decontrôle par des méthodes de lissage. En prenant l’espérance de l’équation(5), conditionnellement sur (X,P (Z)), on obtient :
E [Y |X = x, P (Z) = p ] = µ0(X) + p [µ1(X)− µ0(X)] +K (p) , (49)
où :K (p) = E [(U1 − U0)] p+ E [U0 |P (Z) = p ] . (50)
L’effet marginal de traitement, ou estimateur par les variables instrumentaleslocales (Heckman et Vytlacil 1999) est alors défini par :
∆MTE (x, uD) =∂E [Y |X = x, P (Z) = p ]
∂p
∣∣∣∣p=uD
= ∆LIV (x, uD) . (51)
Plus explicitement, en différenciant (49) par rapport à p :
∆MTE (x, uD) = µ1(X)− µ0(X) +∂K (p)
∂p
∣∣∣∣p=uD
. (52)
Afin de tester pour la présence d(hétérogénéité essentielles, il suffira d’estimerun modèle de choix discret (par la méthode du probit, par exemple), commenous l’avons déjà fait dans les sections 7.2 et 8.2 de ce rapport. Tester pourla présence d’hétérogénéité essentielle revient alors à un test de la linéaritédu score de propension dans l’équation (49). Pour ce faire, on inclut toutsimplement le score de propension sous la forme d’un polynôme du troisièmedegré, et l’on teste pour la significativité conjointe des termes au carré etau cube. Un test plus puissant rajoutera les interractions entre le score depropension et les variables explicatives X. Finalement, on peut égalementutiliser un test non-paramétrique de la linéarité de (49) en p.
Si la présence d’hétérogénéité essentielle est détectée par le test que jeviens de décrire, il s’agira d’appliquer les méthodes (de local linear regres-sion) introduites dans un premier temps par Heckman, Ichimura, Smith, etTodd (1998) and développées par Heckman, Urzua, et Vytlacil (2006).13 Lapremière étape est d’estimer l’équation (49) sous forme semiparamétrique
13Voir Carneiro, Heckman, et Vytlacil (2003) pour une application de ces méthodes àl’estimation des rendements de l’éducation universitaire, ainsi que Heckman et Navarro-Lozano (2004) pour une comparaison générale entre les méthodes de variables instrumen-tales, de matching, et de fonctions de contrôle.
72

(Ruppert, Wand, et Carroll 2003) en utilisant la procédure suggérée parHeckman, Urzua, et Vytlacil (2006). La deuxième étape est une estimation
semiparamétrique de ∂K(pivt)∂pivt
.14 Dans une troisième étape, on estime les effets
traitements définis à la section 11.2 comme des moyennes pondérées de (52),tel qu’indiqué par les formules données dans les équations (47b) et (47c). Unexemple de la mise en oeuvre pratique de toutes ces procédures est fourniepar Arcand et Bassole (2007b).
12 Hétérogénéité de l’effet traitement le long
de la distribution de Y
Un aspect important de toute intervention de développement décentralisétel que l’INDH est sa portée distributionnelle. Plus précisément, et du pointde vue des décideurs, il est important de savoir s’il existe des différences dansles gains issus du programme.
Prenons l’exemple concret des dépenses des ménages, et supposons quel’utilisation des méthodes esquissées jusqu’à présent dans ce rapport nousdévoile un effet positif et statistiquement significatif de l’INDH sur cette va-riable de résultats. Une question que tout décideur devrait se poser est lesuivant : qui gagne plus et qui gagne moins de cette intervention ? L’impactsur les pauvres (en termes de leurs dépenses) est-il plus important que l’im-pact sur les riches, ajoutant ainsi des bénéfices en termes d’une réduction del’inégalité ? Ou l’impact positif est-il plus important pour les riches que pourles pauvres, accentuant ainsi l’inégalité ?
Les méthodes de régression par quantile esquissées dans ce qui suit consti-tuent la charpente technique permettant de répondre à ces questions, et per-mettront ainsi de savoir si le traitement par l’INDH est pro-pauvre, neutre,ou pro-riche.
12.1 La fonction de quantile
Si les méthodes par les moindres carrés, qui ont fait l’objet de ce rapportjusqu’à présent, sont basées sur la moyenne d’une distribution condition-
14Tout comme à la section 7.2.2, voir Newell et Einbeck (2007) pour une discussion desproblèmes associés avec l’estimation des dérivées.
73

nelle de la variable de résultats y, les méthodes de quantile (Koenker etBassett 1978) se basent sur le fait qu’il est possible que l’effet marginal desvariables explicatives (X, ainsi que D) soit différent à différents points de ladistribution conditionnelle de y.
Le mot "quantile" est un synonyme des mots "percentile" ou "fraction".Supposons que le τ ieme quantile d’une population soit dénotée par mτ où0 < τ < 1 et FY est la distribution cumulative de y. On définit alors mτ par :
τ = P (Y ≤ mτ) = FY (mτ) (53)
La fonction de quantile mτ est alors définie comme :
mτ = F−1Y (τ ) = inf{y|FY (y) ≥ τ} (54)
Pour un échantillon aléatoire Y1, . . . , Yn avec distribution empirique FY (τ) =#(Yi≤τ)
n, nous pouvons définir la fonction de quantile empirique par :
mτ = F−1Y (τ ) = inf
{y
∣∣∣∣#(Yi ≤ τ)
n≥ τ
}(55)
Notons en passant que la médiane correspond à τ = 0.5.
12.2 Régression par quantile
Dans l’important papier par Koenker et Bassett (1978), les auteurs montrentque l’équation (55) correspond à la solution du problème de minimisation sui-vant :
mτ = argminb
{∑
i:y≥b
τ |Yi − b|+∑
i:y<b
(1− τ) |Yi − b|
},
= argminb
∑
i
ρτ (Yi − b) , (56)
où :
ρτ (z) =
{τ (z) si z ≥ 0
(τ − 1) z si z < 0= (τ − I (z < 0)) z (57)
74

et où I(.) est la fonction indicatrice habituelle. Considérons un échantillonde variables explicatives, xi, avec i, . . . , n. La régression par quantile linéaireprend alors la forme :
yi = x′iβτ + ετ i (58)
où l’on ne fait aucune hypothèse sur la distribution de l’écart aléaoire ετ i et :
mτ (ετ i |xi) = 0.
En combinant les expressions précédentes, le τ ieme quantile conditionnelde yi peut s’écrire :
mτ (yi|xi) = x′iβτ . (59)
Par analogie avec l’équation (56) la régression en quantile est alors la solutionen βτ du problème suivant :
βτ = argminβτ∈R
K
{ ∑
i:yi≥x′iβτ
τ |yi − x′iβτ |+∑
i:yi<x′iβτ
(1− τ ) |yi − x′iβτ |
}, (60)
= argminβτ∈R
K
∑
i
ρτ (yi − x′iβτ) . (61)
Intuitivement, les paramètres βτ sont les solutions à des problèmes deminimisation de sommes pondérées des valeurs absolues des résidus. Pourτ = 0.75, par exemple, plus de poids est attribué aux résidus se trouvantau-dessus de ce quantile qu’aux résidus se trouvant en-dessous. L’estima-teur Least absolute deviations (LAD), communément utilisé en économétrie,correspond au cas particulier où τ = 0.50 :
β0.5 = argminβ0.5∈R
K
∑
i
|yi − x′iβ0.5| (62)
Les régressions par quantile sont moins sensibles aux outliers que les ré-gressions basées sur les moindres carrés, et fournissent une estimation plus ro-buste lorsque les hypothèses de normalité ou d’homoskédasticité sont violées(Deaton (1997), Koenker (2005)). La solution numérique s’opère générale-ment par programmation linéaire (les méthodes d’optimisation par gradients
75

ne sont pas applicables du fait de la non-différenciabilité de la fonction ob-jectif), bien que des approches par moments généralisés soient égalementpossibles (Buchinsky (1998)).
Du point de vue de l’inférence statistique, deux méthodes sont généra-lement utilisées. La première méthode utilise l’écart-type asymptotique del’estimateur (Koenker et Bassett (1978)). La seconde méthode utilise l’ap-proche par le bootstrap (voir Buchinsky (1995), Buchinsky (1998), Koenkeret Hallock (2001)).15
Une complication qui sera soulevée par ces méthodes dans l’évaluationd’impact de l’INDH concerne l’endogénéité de la variable D. Peu de travauxont, jusqu’à présent, considéré ce problème dans le contexte des régressionspar quantile.16 Une approche simple, similaire à la procédure des doublesmoindres carrés, est proposée par Amemiya (1982) et Powell (1983)17.
13 Chronogramme et estimations des coûts
13.1 Mise en œuvre des enquêtes rurales par un bu-reau d’étude
La selection du bureau d’etude correspondra dans ce qui suit autemps T
NB : la méthodologie derrière la construction de l’échantillon rural estdécrite à la section 7 de ce rapport, et une liste de 124 communes rurales quipourrait faire l’objet des enquêtes du printemps 2008 est reportée en annexe.
15Voir Andrews et Buchinsky (2000) et Davidson et MacKinnon (2001) pour une dis-cussion du nombre approprié de réplications bootstrap.16Voir Ribeiro (2001) (ainsi que Amemiya (1982) et Powell (1983)). Une application, à
l’évaluation de l’impact de la taille des classes scolaires, et fourni par Levin (2001). Voirégalement Arias et al. (2001) pour une application aux rendements de l’éducation. Abadieet al. (2002) et Chernozhukov et Hansen (2005) développent des estimateurs de traitementpar quantile.17Voir Chen (1988) et Chen et Portnoy (1996) pour les méthodes de calcul de la matrice
de variance-covariance dans ce contexte, et Maitra et Vahid (2006) pour une approche parbootstrap.
76

13.1.1 Termes de references pour l’enquete rurale
Description des activités à mener Le questionnaire sur les ménagescontiendra des sections pour rassembler des données sur les points suivants :
1. Les caractéristiques socio-démographiques : une liste des personnes ré-sidant dans le ménage au cours des 12 derniers mois, leur âge et leursexe, de même que leur niveau d’instruction et leur type d’emploi (s’ily en a). La forme de codage devra mentionner les parents de tous lesenfants, s’ils sont présents–au cas contraire, mentionner si les parentssont toujours en vie. Une liste détaillée des avoirs sera élaborée pouservir d’indicateur sur le niveau socio-économique.
2. Les données anthropométriques : les poids seront enregistrés au dixièmeprès (0,1) d’un kilogramme pour tous les enfants de moins de six ansen utilisant des balances à affichage numérique qui seront fournies.
Le questionnaire de l’enquête comprendra alors huit (8) sections, classéespar thèmes :
Section A : Informations sur le questionnaire La section traite des in-formations nécessaires à l’identification des ménages à enquêter. Pour chaquegrappe de l’échantillon, le contrôleur de l’équipe disposera d’un dossier com-portant un plan ou une carte et une fiche définissant la composition de laditegrappe. En collaboration avec l’ensemble de l’équipe, il aura dressé la listecomplète de concessions et des ménages composant la grappe ainsi que leuradresse (région, département, arrondissement, village, quartier ou hameau).Cette liste qui donne l’identification de tous les ménages de la grappe sert debase de sondage pour le tirage des ménages de l’échantillon, c’est-à-dire ceuxqui seront sélectionnés pour faire partie de l’enquête. Le nombre de ménages-échantillons par grappe et le mode de tirage sont définis dans la manuel ducontrôleur. Pour le succès de l’enquête, il est important que les ménages in-terviewés soient ceux qui ont été initialement tirés ou sélectionnés commeménages de remplacement sur la base des critères définis par les responsablesde l’enquête.
Section B : Liste des membres du ménage Cette section porte surles caractéristiques individuelles de toutes les personnes du ménage. Cettesection permet :
77

— D’identifier tous les membres et de déterminer la composition du mé-nage ;
— D’obtenir les renseignements démographiques de base (sexe, lien deparenté ; âge, état matrimonial, situation de résidence, etc.) et écono-miques (contribution au revenu) indispensables à l’analyse des données ;
— De classer les ménages selon certains critères (taille du ménage, âge etsexe du chef de ménage, etc.).
La principale personne qui devra fournir les renseignements est le chefde ménage (CM) ou son représentant (le fils ou la fille aîné(e), le frère oul’épouse par exemple). Les autres membres peuvent participer à l’interviewen apportant des compléments d’informations ou des précisions aux réponses,surtout quand les questions posées les concernent personnellement
Section C : Education Concernant l’éducation, le taux de scolarisation etle taux d’abandon sont des principaux. D’autres indicateurs sur l’éducationsont observés, notamment, la classe la plus élevée que les enquêté(e)s ontachevée ainsi que le type d’école fréquenté, qu’il soit public, privé ou autre.
Section D : Santé L’accès aux soins médicaux, constitue un aspect im-portant du niveau de bien-être des ménages. L’enquête doit permettre decollecter des données sur les maladies et plus généralement les problèmes desanté auxquels les populations sont confrontées ainsi que sur les structuresou personnes auxquelles elles ont recours pour bénéficier de soins médicaux.Les données collectées portent également sur la fréquence d’utilisation desservices de santé et la satisfaction des populations pour les services fournisainsi que sur les raisons qui empêchent des personnes malades à recourir àun service/personnel de santé.
Section E : Emploi A travers cette section on cherche à appréhenderles aspects de l’emploi suivants : le statut dans l’emploi (pour distinguer lesemployés, les indépendants et les autres), le secteur (pour distinguer le public,le privé et les autres), la branche d’activité (pour distinguer l’agriculture, lesservices et les autres activités), et le statut d’occupation (pour distinguerles occupés, les chômeurs et les inactifs). Les questions doivent être posées àtoutes les personnes du ménage âgées de 5 ans ou plus. Cet âge relativementbas pour l’éligibilité aux questions de l’emploi relève d’un choix qui tientcompte du fait que dans de nombreuses sociétés, les enfants travaillent. Ils
78

peuvent garder le bétail, aller chercher de l’eau, vendre de la nourriture ouse consacrer à tout autre activité pour le compte de leur ménage.Au préalable, l’enquêteur devra entourer le numéro de personne de tous
les individus éligibles, numéro déjà attribué à la section B.
Section F : Avoirs du ménage La qualité du logement et la nature desbiens productifs tels que la terre et le bétail, sont des composantes impor-tantes du bien-être du ménage ; ils sont également des indicateurs pertinentsdu changement des conditions économiques et du niveau de vie. En périoded’ajustement économique, la capacité des ménages de se loger peut être affec-tée par les changements de revenus. Si les revenus diminuent par rapport aucoût des produits de base, les ménages peuvent se trouver dans l’obligationde vendre certains biens ou de renoncer à leur remplacement pour maintenirun niveau de vie minimum. En revanche, il est probable que de meilleuresconditions économiques se traduisent par l’acquisition de biens supplémen-taires. La section traite aussi bien des avoirs fixes (logement et terres) quedes biens moins fixes, comme le bétail. Le bétail constitue un moyen assezrépandu d’accumulation de richesses et fournit une mesure importante duniveau de bien-être économique.La section est assez délicate du fait qu’elle traite de questions très com-
plexes portant sur un domaine très sensible, notamment sur les avoirs duménage. Il est donc important que l’enquêteur puise identifier les personneshabilitées à répondre selon qu’il s’agisse du bétail, des terres ou de touteautre possession du ménage. La remarque est valable pour l’évaluation de lasituation économique du ménage et celle de la communauté ainsi que l’iden-tification de la personne qui contribue le plus au revenu du ménage. Si lechef de ménage est le principal répondant, il ne devra pas être le seul, enparticulier pour certains aspects dont la responsabilité relève de quelqu’und’autre.Les questions de cette section sont collectives en ce sens qu’elles s’adressent
au ménage en tant que entité. Elles seront posées une seule fois (contraire-ment aux questions individuelles posées à chaque personne concernée).
Section G : Caractéristiques du logement Cette section permet d’avoirdes informations sur les caractéristiques physiques du logement occupé par leménage (matériaux de construction, mode d’alimentation en eau, type d’ai-sance, type de combustible et mode d’éclairage) et l’accès à certains services
79

sociaux de base.Bien que les changements dans la mise en place, l’état, le fonctionnement
et l’utilisation des infrastructures puissent être lents, des enquêtes répétéespermettent de suivre l’évolution dans l’accès des ménages aux équipementsde base tels que l’eau, les toilettes, le combustible, les marchés et le transport.On considère généralement que l’état des infrastructures de base est par-
ticulièrement sensible aux conditions économiques. Or, les changements dansces conditions peuvent être spécifiques à certaines régions.
Section H : Enfants de moins de cinq ans (mesures anthropomé-triques) Les données sur la taille et le poids permettent d’évaluer l’étatnutritionnel des enfants de moins de 60 mois et d’identifier les groupes quicourent des risques importants d’avoir des problèmes de croissance et decontracter des maladies. Trois indices standards de croissance physique quirendent compte de l’état nutritionnel des enfants peuvent être calculés àpartir de ces données : la taille par âge, le poids par taille et le poids par âge.La taille par âge est une mesure de croissance selon laquelle un enfant qui
est petit pour son âge est considéré comme accusant un retard de croissance,une condition reflétant la malnutrition chronique. Le poids par taille rendcompte de la situation nutritionnelle actuelle d’un enfant. Un enfant quiest trop maigre pour sa taille est émacié, une condition reflétant un déficitalimentaire aigu ou récent. Le poids par âge est un indice global de l’état desanté nutritionnelle de l’enfant mais qui ne permet pas de faire la distinctionentre l’émaciation et le retard de croissance.Les enfants à bas âge sont particulièrement vulnérables quand, par exemple,
la nourriture disponible n’est pas suffisante pour satisfaire les besoins de tous.
Organisation du travail sur le terrain. Le Cabinet de consultation par-ticipera à l’ébauche des instruments de terrain avant l’enquête pilote et serale principal responsable de l’enquête pilote. Après ce test, le questionnairesera reformulé (en collaboration avec les responsables du projet). Le travailsur le terrain sera organisé en petites équipes constituées d’un superviseur,de deux ou trois intervieweurs responsables du questionnaire principal et desmesures anthropométriques.
80

13.1.2 Profil de l’équipe du consultant
Le personnel chargé de l’enquête devrait être constitué comme suit : (1)personnel d’enquête central : composé du directeur de l’enquête, du directeurde zone, du directeur de la gestion des données et du personnel de saisie dedonnées qui sera respectivement responsable de la supervision globale dela zone, de la coordination et du contrôle de la collecte des données , dela saisie des données et des activités de gestion des données. (2) personneld’enquête de zone : les enquêtes sur le terrain seront menées par des équipescomposées d’un superviseur, de deux (ou trois) intervieweurs responsablesdu questionnaire principal et des mesures anthropométriques et un chauffeur.(3) coordonnateur pour l’essai aléatoire du test : le coordonnateur aidera audéveloppement des instruments de collecte de données. Il ou elle superviserala saisie des données et la gestion de l’étude de l’ensemble des données, etparticipera à l’analyse principale à réaliser à la fin de l’étude.
13.2 Construction de l’échantillon urbain
NB : la description de la méthodologie pour l’échantillon urbain apparaîtà la section 8.4 de ce rapport ;
Coûts approximatifs de la construction de la carte de pauvretéau niveau des quartiers : 4 personnes/mois.
13.3 T + 1 mois
— Finalisation des instruments d’enquête ;— Validation des indicateurs de résultats retenus ;— Début de développement des manuels d’enquête et d’entretien.
Coûts approximatifs : inclus dans le contrat du cabinet.
13.4 T + 2 mois
— Enquêtes pilotes et validation des instruments d’enquête ;— Validation des manuels d’enquête et d’entretien ;— Sensibilisation et communication.
81

13.5 T + 3 mois
Début des enquêtes.
13.6 T + 5 mois
Fin des enquêtes.
Coûts approximatifs de la phase "enquêtes" (section 13.4 à lasection 13.6) : 300 Dirhams×(taille de l’échantillon rural + taille del’échantillon urbain).
13.7 T + 6 mois
Données traitées et premiers résultats descriptifs.
Coûts approximatifs : 2 personnes/mois.
13.8 T + 7 mois
Rapport sur les enquêtes référence.
Coûts approximatifs : 2 personnes/mois.
82

A Liste des 124 communes rurales de l’échan-
tillon proposé à la section 7
1 Agadir-Ida Ou Tanan Aqesri 10 5052 Agadir-Ida Ou Tanan Drargua 10 5093 Agadir-Ida Ou Tanan Imouzzer 10 5134 Agadir-Ida Ou Tanan Imsouane 10 5155 Agadir-Ida Ou Tanan Tiqqi 10 5296 Al Haouz Aghbar 410 7017 Al Haouz Ait Aadel 410 3038 Al Haouz Anougal 410 5059 Al Haouz Ijoukak 410 70710 Al Haouz Imgdal 410 70911 Al Haouz Lalla Takarkoust 410 51112 Al Haouz Oukaimden 410 90313 Azilal Tilougguite 810 92314 Benslimane Ziaida 1 110 31915 Boulemane Ait El Mane 1 310 30316 Boulemane El Mers 1 310 30717 Boulemane Fritissa 1 310 70518 Boulemane Guigou 1 310 31119 Boulemane Skoura M’Daz 1 310 31520 Boulemane Talzemt 1 310 31721 Boulemane Tissaf 1 310 70922 Chichaoua Afalla Issen 1 610 50123 Chichaoua Ahdil 1 610 30124 Chichaoua Ait Hadi 1 610 30325 Chichaoua Douirane 1 610 70526 Chichaoua Oued L’bour 1 610 51327 Chichaoua Oulad Moumna 1 610 30728 Chichaoua Sid L’Mokhtar 1 610 31129 Chichaoua Sidi Abdelmoumen 1 610 91130 Chichaoua Sidi M’Hamed Dalil 1 610 31531 Chichaoua Taouloukoult 1 610 91332 Chtouka- Ait Baha Ait Ouadrim 1 630 30733 Chtouka- Ait Baha Sidi Abdallah El Bouchoua 1 630 32534 El Kelaa Des Sraghn Ait Taleb 1 910 703
83

35 El Kelaa Des Sraghn Assahrij 1 910 50136 El Kelaa Des Sraghn Eddachra 1 910 30337 El Kelaa Des Sraghn Lamharra 1 910 90738 El Kelaa Des Sraghn Loued Lakhdar 1 910 51739 El Kelaa Des Sraghn Nzalat Laadam 1 910 90940 El Kelaa Des Sraghn Oulad El Garne 1 910 32341 El Kelaa Des Sraghn Oulad Msabbel 1 910 32742 El Kelaa Des Sraghn Sidi Ali Labrahla 1 910 71743 El Kelaa Des Sraghn Sidi Ghanem 1 910 71944 El Kelaa Des Sraghn Skhour Rhamna 1 910 72345 El-Jadida Metrane 1 810 72546 El-Jadida Oulad Amrane 1 810 72947 El-Jadida Tamda 1 810 73548 El-Jadida Zaouiat Saiss 1 810 92149 Errachidia En-nzala 2 010 90150 Errachidia M’Zizel 2 010 90951 Errachidia Sidi Aayad 2 010 91152 Essaouira Ait Said 2 110 30153 Essaouira Assais 2 110 50954 Essaouira Ezzaouite 2 110 51555 Essaouira Korimate 2 110 30956 Essaouira Meskala 2 110 31757 Essaouira Sidi Kaouki 2 110 53758 Essaouira Smimou 2 110 53959 Essaouira Tahelouante 2 110 54360 Figuig Bni Guil 2 510 50361 Guelmim Ait Boufoulen 2 610 30362 Guelmim Taghjijt 2 610 31163 Ifrane Timahdite 2 710 31164 Kenitra Ameur Seflia 2 810 30165 Khemisset Moulay Driss Aghbal 2 910 71566 Khenifra Ait Ben Yacoub 3 010 70767 Khenifra Lehri 3 010 51168 Khenifra Moha Ou Hammou Zayani 3 010 51369 Khouribga Braksa 3 110 70570 Khouribga Oulad Fennane 3 110 71771 Marrakech M’Nabha 3 510 30572 Meknès Ain Jemaa 610 301
84

73 Meknès Dkhissa 610 50174 Meknès M’haya 610 50575 Nador Bni Oukil Oulad M’Hand 3 810 70776 Ouarzazate Ait El Farsi 4 010 50177 Ouarzazate Ait Sedrate Jbel EL Soufl 4 010 50778 Ouarzazate Ait Youl 4 010 51379 Ouarzazate M’Semrir 4 010 52180 Ouarzazate Taghzoute N’Ait Atta 4 010 52781 Ouarzazate Tidli 4 010 31782 Ouarzazate Tilmi 4 010 52983 Ouarzazate Toudgha Essoufla 4 010 53384 Safi Esbiaat 4 310 50585 Safi Jdour 4 310 50986 Safi Jnane Bouih 4 310 51187 Safi Lakhoualqa 4 310 51388 Safi Lamrasla 4 310 30989 Sefrou Bir Tam Tam 4 510 30590 Settat Riah 4 610 82391 Sidi Kacem Bni Oual 4 810 30392 Sidi Kacem Chbanate 4 810 90593 Sidi Kacem Dar Laaslouji 4 810 50394 Sidi Kacem Selfat 4 810 90795 Sidi Kacem Sidi Ahmed Benaissa 4 810 31396 Sidi Kacem Tekna 4 810 90997 Tanger-Assilah Azzinate 5 110 30598 Taroudannt Amalou 5 410 30599 Taroudannt Azaghar N’Irs 5 410 307100 Taroudannt Eddir 5 410 509101 Taroudannt Ida Ou Moumen 5 410 919102 Taroudannt Ida Ougoummad 5 410 421103 Taroudannt Imaouen 5 410 309104 Taroudannt Imoulass 5 410 927105 Taroudannt Sidi Hsaine 5 410 715106 Taroudannt Sidi Mzal 5 410 319107 Taroudannt Tabia 5 410 321108 Taroudannt Zagmouzen 5 410 725109 Tata Ait Ouabelli 5 510 301110 Tata Tissint 5 510 509
85

111 Taza Mazguitam 5 610 509112 Tiznit Ait Erkha 5 810 701113 Tiznit Ait Issafen 5 810 301114 Tiznit Ait Ouafqa 5 810 903115 Tiznit Arbaa Ait Abdellah 5 810 501116 Tiznit Ida Ou Gougmar 5 810 307117 Tiznit Mirleft 5 810 507118 Tiznit Sidi Ahmed Ou Moussa 5 810 309119 Tiznit Sidi Bouabdelli 5 811 113120 Tiznit Sidi H’Saine Ou Ali 5 810 713121 Tiznit Tarsouat 5 810 909122 Zagora Ait Boudaoud 5 870 305123 Zagora Taftechna 5 870 929124 Zagora Tazarine 5 870 341
Références
A���� , A., J. A������, � G. I�� �� (2002) : “Instrumental VariablesEstimates of the Effect of Subsidized Training on the Quantiles of TraineeEarnings,” Econometrica, 70(1), 91—117.
A� ����, T. (1982) : “Two Stage Least Absolute Deviations Estimators,”Econometrica, 50(3), 689—711.
A��� ��, D. W. K., � M. B�������� (2000) : “A Three-Step Methodfor Choosing the Number of Bootstrap Repetitions,” Econometrica, 68(1),23—52.
A������, J. D., G. I�� ��, � D. B. R���� (1996) : “Identification ofCausal Effects Using Instrumental Variables,” Journal of the AmericanStatistical Association, 91(434), 444—455.
A�����, J.-L., � L. B���"# (2007a) : “Does Community Driven Deve-lopment Work ? Evidence from Senegal,” Etude et document CERDI, No.2006-6, CERDI-CNRS, Université d’Auvergne, juin.
(2007b) : “Essential Heterogeneity in the Impact of CommunityDriven Development,” processed, CERDI-CNRS, Université d’Auvergne,novembre.
86

A����, O., K. F. H�##"��, � W. S"��-E���� �" (2001) : “Indivi-dual Heterogeneity in the Returns to Schooling : Instrumental VariablesQuantile Regression Using Twins Data,” Empirical Economics, 26, 7—40.
B ������, M., E. D�(#", � S. M�##�������� (2004) : “How MuchShould We Trust Differences-in-Differences Estimates ?,” Quarterly Jour-nal of Economics, 119(1), 249—275.
B#""�, H. S. (1995) : “Minimum Detectable Effects : A Simple Way toReport the Statistical Power of Experimental Designs,” Evaluation Review,19, 547—556.
(2005) : Randomizing Groups to Evaluate Place-Based Programs.Russell Sage Foundation, New York, NY.
B��������, M. (1995) : “Estimating the Asymptotic Covariance Matrix forQuantile Regression Models a Monte Carlo Study,” Journal of Econome-trics, 68(2), 303—338.
(1998) : “Recent Advances in Quantile Regression Models : A Practi-cal Guideline for Empirical Research,” Journal of Human Resources, 33(1),88—126.
C�#� ��", M., � S. K"* ���� (2005) : “Some Practical Guidance for theImplementation of Propensity Score Matching,” IZA Discussion Paper No.1588.
C��� ��", P., J. J. H �����, � E. V��#���# (2003) : “UnderstandingWhat Instrumental Variables Estimate : Estimating Marginal and AverageReturns to Education,” processed, University of Chicago, The AmericanBar Foundation and Stanford University, July.
C� �, L. A. (1988) : “Regression Quantiles and Trimmed Least SquaresEstimators for Structural Equations and Non-Linear Regression Models.,”PhD Dissertation, University of Illinois at Urbana-Champaign.
C� �, L. A., � S. P"���"� (1996) : “Two-Stage Regression Quantilesand Two-Stage Trimmed Least Squares Estimators for Structural EquationModels,” Communications in statistics Theory and methods, 25(5), 1005—1032.
C� ��"-���"., V., � C. H��� � (2005) : “An IV Model of QuantileTreatment Effects,” Econometrica, 73, 245—261.
D�.���"�, R., � J. G. M��K���"� (2001) : “Bootstrap Tests : HowMany Bootstraps ?,” Queen’s University, Department of Economics Wor-king Paper No. 1036.
87

D ��"�, A. (1997) : The Analysis of Household Surveys. A MicroeconomicApproach to Development Policy. Johns Hopkins University Press, Balti-more, MD.
F#"� ��, J.-P., J. J. H �����, C. M ����, � E. V��#���# (2004) :“Instrumental Variables, Local Instrumental Variables and Control Func-tions,” Centre for Microdata Methods and Practice, Institute for FiscalStudies, CWP15/02.
H���� , T. J., � R. J. T��������� (1990) : Generalized Additive Models.Chapman and Hall, London, UK.
H �����, J. J. (1978) : “Dummy Endogenous Variables in a SimultaneousEquation System,” Econometrica, 46(4), 931—959.
(1979) : “Sample Selection Bias as a Specification Error,” Econo-metrica, 47(1), 153—161.
(2001) : “Micro Data, Heterogeneity and the Evaluation of PublicPolicy : Nobel Lecture,” Journal of Political Economy, 109(4), 673—748.
H �����, J. J., H. I�������, J. S����, � P. T"�� (1998) : “Charac-terizing Selection Bias Using Experimental Data,” Econometrica, 66(5),1017—1098.
H �����, J. J., � S. N�.���"-L"-��" (2004) : “Using Matching, Ins-trumental Variables and Control Functions to Estimate Economic ChoiceModels,” Review of Economics and Statistics, 86(1), 30—57.
H �����, J. J., J. S����, � N. C# � ��� (1997) : “Making the Mostof Programme Evaluations and Social Experiments : Accounting for He-terogeneity in Programme Impacts,” Review of Economic Studies, 64(4,Special Issue), 487—535.
H �����, J. J., S. U�-��, � E. V��#���# (2006) : “UnderstandingInstrumental Variables in Models with Essential Heterogeneity,” Reviewof Economics and Statistics, 88(3), 389—432.
H �����, J. J., � E. J. V��#���# (1999) : “Local Instrumental Variablesand Latent Variable Models for Identifying and Bounding Treatment Ef-fects,” Proceedings of the National Academy of Sciences, 96(8), 4730—4734.
(2001) : “Policy-Relevant Treatment Effects,” American EconomicReview, Papers and Proceedings, 91(2), 107—111.
(2005) : “Structural Equations, Treatment Effects and EconometricPolicy Evaluation,” Econometrica, 73(3), 669—738.
88

I�� ��, G., � J. A������ (1994) : “Identification and Estimation of LocalAverage Treatment Effects,” Econometrica, 62(2), 467—476.
I�� ��, G. W., � T. L �� �1 (2007) : “Regression Discontinuity Desi-gns : A Guide to Practice,” Journal of Econometrics, à paraître.
K" �� �, R. (2005) : Quantile Regression, Econometric Society Mono-graphs. Cambridge University Press, Cambridge, UK.
K" �� �, R., � G. J. B��� �� (1978) : “Regression Quantiles,” Econo-metrica, 46(1), 33—50.
K" �� �, R., � K. H�##"�� (2001) : “Quantile Regression,” Journal ofEconomic Perspectives, 15(4), 143—156.
L�(("��, J.-J. (1990) : The Economics of Uncertainty and Information.MIT Press, Cambridge, MA.
L .��, J. (2001) : “For Whom the Reductions Count : A Quantile Regres-sion Analysis of Class Size and Peer Effects on Scholastic Achievement,”Empirical Economics, 26, 221—246.
M�����, P., � F. V���� (2006) : “The Effect of Household Characteristicson Living Standards in South Africa 1993-1998 : A Quantile RegressionAnalysis with Sample Attrition,” Journal of Applied Econometrics, 21(7),999—1018.
N � ##, J., � J. E��� �� (2007) : “A Comparative Study of Nonpara-metric Derivative Estimators,” Proceedings of the 22th IWSM, Barcelona.
P"� ##, J. L. (1983) : “The Asymptotic Normality of Two-Stage LeastAbsolute Deviations Estimators,” Econometrica, 51(5), 1569—1575.
Q�����, R. (1972) : “A New Approach for Estimating Switching Regres-sions,” Journal of the American Statistical Association, 67(338), 306—310.
R�� ��", E. P. (2001) : “Asymmetric Labor Supply,” Empirical Economics,26, 183—197.
R"�����, G. (1997) : A Course in Mathematical Statistics. Academic Press,New York, NY, second edn.
R����, D. B. (1974) : “Estimating Causal Effects of Treatments in Rando-mized and Nonrandomized Studies,” Journal of Education Psychology, 66,688—701.
R�** ��, D., M. P. W���, � R. J. C���"## (2003) : SemiparametricRegression. Cambridge University Press, New York, NY.
89