Embed Size (px)
Citation preview

Karamatou LIADY DESS SITN [email protected]
Damien LAHMI DESS SITN [email protected]
WebFountain
Mars 2005
Recherche d’information sur le Web

Mars 2005 WebFountain 2
Plan• Le projet WebFountain
• WebFountain : fonctionnement et sémantique
• Procédures de recherche
• Architecture du moteur
• Algorithme utilisé : HITS
• Les concurrents de WebFountain
• Les enjeux économiques du nouveau moteur
• Vers l’Internet payant ?

Mars 2005 WebFountain 3
Rappel du contexte
Moteurs de recherche : outils standards pour traiter la surabondance d’information But : conduire l’utilisateur vers un plus petit choix des documents qui contiennent
simplement les mots recherchés
Règne suprême de Google 2/3 des utilisateurs du Web utilisent Google pour trouver des informations sur les questions
qu'ils se posent.
La consultation des premières pages fournies en réponse par le moteur de recherche ne suffisent pas à cerner le sujet de l'interrogation.
Démarche actuelle pousser l'investigation au delà des premières réponses de la première page de Google sauter de liens en liens pour obtenir une quantité et qualité d'information satisfaisante
Ex : un marketer cherchant en ligne des informations des consommateurs par rapport à Pink, la chanteuse de Rock devra trier dans les pages trouvées les informations sur la personne et sur la couleur…

Mars 2005 WebFountain 4
Buts du projet WebFountain
Il ne s’agit pas de reproduire un nouveau moteur de recherche à la Google
Plate-forme associant fonctions de moteur de recherche et de texte mining
Mise en place d’un moteur d'analyse qui peut : « renifler » ses propres indices à propos du sens global d'un document fournir de la perspicacité le sens global des résultats de la recherche
Permettre une automatisation des recherches sur le Web
WebFountain idée d'un Web Sémantique, reposant les technologies nouvelles dérivées de XML
Défi majeur Aller delà de la difficulté d'indexer convenablement les données du Web Rendre les données du Web « signifiantes » pour un robot
IBM vs Google Google : premier moteur à indexer pertinemment les pages du Web IBM avec WebFountain : premier à avoir transcodé le Web en Web Sémantique.

Mars 2005 WebFountain 5
Quoi et pour qui ?
Objectifs à atteindre Créer un système convertit l'anarchie des données sur le Web (page Web en ligne, E-mail,
chat, forums, blogs...) en un format qui peut être analysé pour identifier l'information ayant une valeur commerciale
Offrir des solutions permettant aux ordinateurs des entreprises D'entrer dans le contenu des informations en ligne
De restituer tous les documents susceptibles de concerner une recherche donnée :
– Analystes économiques et financiers,
– Observateurs politiques
– Vendeurs de données
– Services de renseignement et de police
Service payant => réservé aux entreprises ou administartions riches
Avantages Accroître les vastes réserves d'information inexploitée en ligne Facilité de prises de décisions économiques

Mars 2005 WebFountain 6
Moyens mis en oeuvre
IBM Almaden Research Center de San Jose en Californie
Moyens humains : 120 personnes (divisées en équipes)
Moyens matériels : énorme complexe de processeurs, routeurs, disques et logiciels, occupant la
superficie d'un demi-terrain de football Durée : 4 ans
Moyens financiers : plus 100 millions de dollars en frais de développement
Mise en service avec Factiva dont le métier est de vendre des informations économiques

Mars 2005 WebFountain 7
Premier test

Mars 2005 WebFountain 8
Analyse des données
Majorité des documents sur le web contiennent des données non structurées Démarche WebFountain :
Convertir l'information reçue en un format permettant son analyse automatique
Les programmes « Crawler » ou « Spider »
– Parcourent le web en 1 semaine
– Archivent les pages rencontrées dans de bases de données (de 160 terabits d'espace disque)
Transfert des données dans le cluster des processeurs centraux de données
Analyse des données avec 40 programmes appelés « annotators »
– Les annotateurs sont spécialisés par type de recherche
– Chaque annotateur recherche dans le document analysé les mots ou phrases qu'il peut reconnaître, qu'il identifie en cas de succès par un tag XML
Stockage des documents labellisés dans des bases de données
Soumission en fonction des informations recherchées à procédures de data-mining ou procédures utilisant l’intelligence artificielle

Mars 2005 WebFountain 9
Les annotateurs
Processus d’annotation => création de données structurée à analyser
Deux types d’annotateurs Simples : identifient les liens aux autres documents ou le language et
l’ensemble de caractères utilisé Complexes
– Infèrent le sens et la signification des documents analysés– Mettent les documents analysés dans les bases de connaissances
Les bases de connaissances Mises ou non à la disposition du public ou des clients payants Ex : base de US Securities and Exchange Commission (publique)
Propriété de IBM et de ses partenaires privilégiés – Description de l’information dans des domaines de connaissances particuliers – Ex : pétrochimie , industrie pharmaceutique

Mars 2005 WebFountain 10
La structuration des données (1)
WebFountain utilise une approche plus souple de structuration de données que leur stockage dans une base de données.
Utilisation de méthode d'ajout des étiquettes textes aux documents Étiquettes indiquant à un ordinateur les divers éléments du contenu en
utilisant XML Ex : les numéros d'identification de produit ou les prix sont identifiés en les
encadrant avec des étiquettes, comme dans < nom-produit> Grille pain de luxe < /nom-produit>, < prix > €19.95 </prix>.
Avantage par rapport à l'approche de base de données : Les documents sont plus facilement partagés. Ex : Une entreprise peut mettre son catalogue XML sur son site Web, et les
clients potentiels peuvent alors balayer le catalogue avec le logiciel qui compare automatiquement les prix et d'autres détails à des catalogues similaires d'autres entreprises.
Mars 2005 WebFountain 11
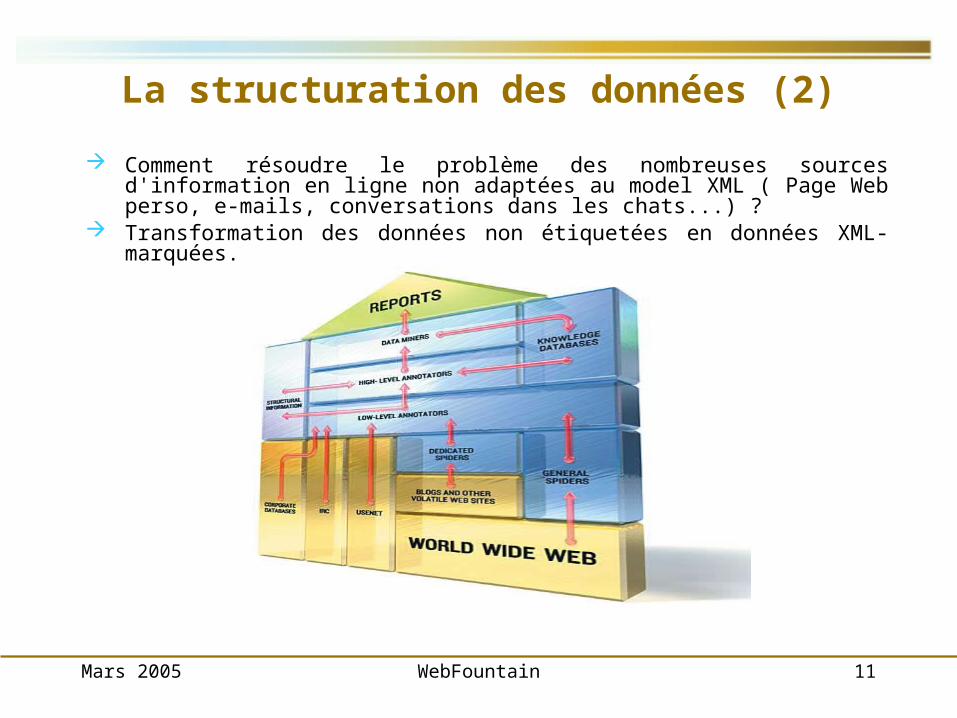
La structuration des données (2)
Comment résoudre le problème des nombreuses sources d'information en ligne non adaptées au model XML ( Page Web perso, e-mails, conversations dans les chats...) ?
Transformation des données non étiquetées en données XML-marquées.

Mars 2005 WebFountain 12
Architecture du moteur
La plate-forme Infrastructure incorporant le tiers contenu et technologies des partenaires associés
pour fournir les solutions clientes complètes Intègre des miners, des crawlers et les applications liées à des tâches spécifiques ou
globales Adhère aux normes ouvertes et scalables
Les données Stocks de plusieurs Terabytes de données non structurées et semi-structurées. Concernent des données d'Internet, des blogs, des tableaux d'affichage, des données
d'entreprise, de contenu autorisé, des journaux, des magazines et des journaux commerciaux
Les analyseurs de texte multi-domaines WebFountain fournit une plateforme intégrée pour des approches analytiques des
textes multidisciplinaires Ceci inclut le traitement de langage naturel, les statistiques, les probabilités, l'étude
de machine, l'identification de modèle et l'intelligence artificielle

Mars 2005 WebFountain 13
Solution commerciale
Partenariat technologique de IBM avec Factiva (sur WebFountain)
Greffe du Module Insight for Reputation de Factiva sur l’nfrastructure WebFountain
Fourniture de service par Factiva (New-York) par abonnement
Coût annuel du service : entre 150 000 et 300 000 $

Mars 2005 WebFountain 14
WebFountain & Insight for Reputation
Exemple : Un industriel dénommé Dupont fabrique une série de produits défectueux.
le couple Dupont/panne apparaît dans les blogs et les groupes de discussion.
les associations de consommateurs commencent, elles aussi, à y prêter attention.
Alerté à ce stade, l'industriel a encore le temps d'organiser sa défense avant que la presse ne se saisisse de l'information...
Au-delà de la surveillance, le logiciel peut établir également des corrélations insoupçonnées (ex : défaillance technique).
Factiva lance une requête (saisie en langage naturel par l'utilisateur), récupère le flux d'IBM et présente les données dans son propre format
Les outils de textmining d'IBM englobent - les sources propriétaires de Factiva- tous les contenus produits sur le web. Une fois extraites, ces différentes sources sont stockées, indexées et analysées. Les résultats sont ensuite présentés sous forme graphique.

Mars 2005 WebFountain 15
Algorithme utilisé : HITS (1)(Hyperlinked Induced Topic Search)
Contexte historique Inventeur : Jon Kleinberg Origines de cet algorithme de classement
La méthode de Pinski-Narin Les méthodes dites « bibliométriques »
Les principes de l’algorithme Les sites de référence appelés « authorities » Les sites contenant des liens vers les «authorities» appelés «hubs» L’hypothèse est : «Un document qui pointe vers beaucoup de bonnes
Authorities est un bon Hub, et un document pointé par beaucoup de bon Hubs est une bonne Authority» [Kleinberg99]
Mars 2005 WebFountain 16
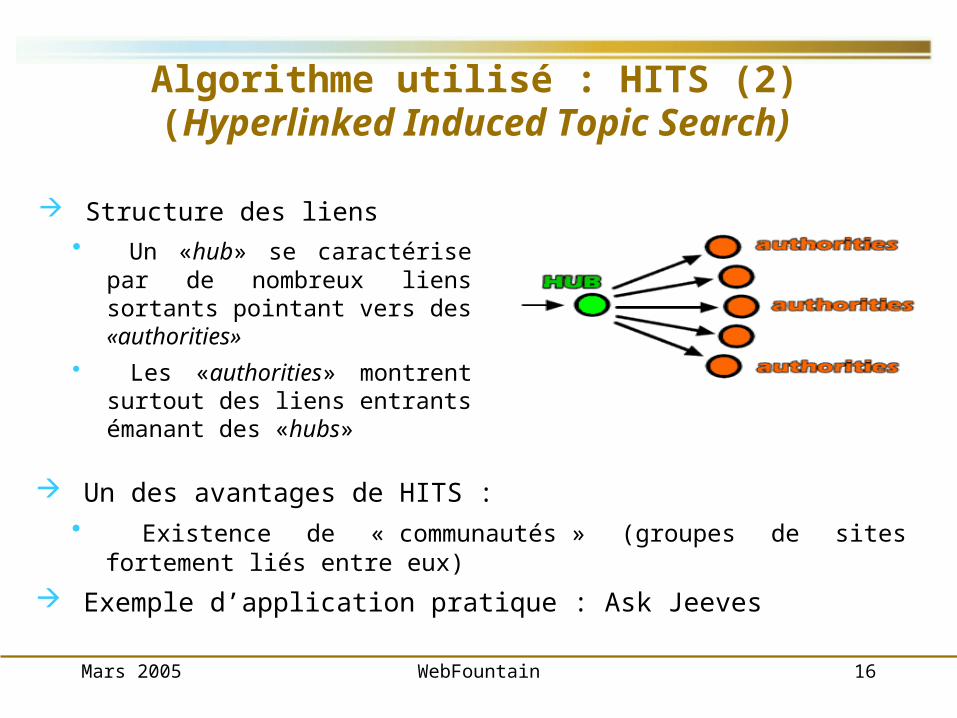
Algorithme utilisé : HITS (2)(Hyperlinked Induced Topic Search)
Structure des liens Un «hub» se caractérise par de
nombreux liens sortants pointant vers des «authorities»
Les «authorities» montrent surtout des liens entrants émanant des «hubs»
Un des avantages de HITS : Existence de « communautés » (groupes de sites fortement liés entre eux)
Exemple d’application pratique : Ask Jeeves

Mars 2005 WebFountain 17
Les concurrents de WebFountain (1)
Inktomi Search Engine
Société américaine
Moteur de recherche «indirect»
La technologie d’Inktomi est considérée comme l’une des plus valables
Produit adopté par MSN

Mars 2005 WebFountain 18
Les concurrents de WebFountain (2)
Google in a box Société américaine Solution de recherche Intranet Détecte de 28 langues Indexe les principaux types de fichiers rencontrés en
entreprises (Office, HTML, PDF, etc.) Un «package» logiciel + 2 ans de support à partir de 32
000 US$.

Mars 2005 WebFountain 19
Les concurrents de WebFountain (3)
Fast Search & Transfer Société norvégienne Un puissant moteur de recherche : alltheweb.com
– 2,1 milliards de pages indexées (très près de Google)
– Technologie du moteur caractérisée par sa rapidité de recherche
– Haute qualité de navigation
– Détecte 46 langues
– Client le plus important de FAST : Lycos
– 30 millions de requêtes en moyenne par jour

Mars 2005 WebFountain 20
Les concurrents de WebFountain (4)
ClearForest Société Israélo-américaine Logicielle de fouille textuelle => capable de lire 250 000 pages à
l’heure Adapté pour analyser les données non structurées, les mails ... Analyse les textes en plusieurs langues Système utilisé par des agences gouvernementales américaines, des
institutions privées, des universités– Exemple : le FBI utilise cet outil pour contrecarrer des attaques
terroristes

Mars 2005 WebFountain 21
Les enjeux économiques (1)
Un investissement important d’IBM
Des moyens financiers et humains importants 100 millions de dollars en frais de développement
Plusieurs équipes du laboratoire Almaden ont participé au projet
Diminution de l’infrastructure nécessaire
– Un cluster de 1000 PC travaillant en parallèle pour alimenter une base d’un ordre de grandeur de plusieurs petaoctets
(1 petaoctets=1 000 teraoctets=100 000 gigaoctets).
– A titre indicatif : Google travaille avec 15 000 PC de base.

Mars 2005 WebFountain 22
Les enjeux économiques (2)
Les cibles touchées par WebFountain Un outil développé selon 3 directions
– Un partenariat économique avec des sociétés spécialisées dans le Knowledge Management ou l’intelligence économique
Exemple : accord avec la société FACTIVA en septembre 2003
– Service de type «business on demand» pour des sociétés souhaitant faire des recherches ponctuelles ou régulières en utilisant les ressources d’IBM
– Mise en place de solutions d’infrastructure complètes au profit d’entreprises désireuses de se doter de leur propre moteur de recherche
Pas de concurrence à court de terme par rapport Google
IBM possède les moyens technologiques de lancer à tout moment un moteur de recherche «grand public» très performant

Mars 2005 WebFountain 23
Les enjeux économiques (3)
Fournir en temps réel l’évolution de l’image d’une société sur le web
Suivre les désirs des consommateurs à la trace à des fins économiques
Première utilisation de WebFountain : surveiller la toile pour savoir à l’avance quel allait être le succès d’un album lancé par une grande maison de disques
WebFountain pourrait devenir un outil incontournable dans le monde économique
Un coût important variant entre 150 000 et 300 000 dollars par an.Avantage pour les firmes déjà riches et dominantes

Mars 2005 WebFountain 24
Vers l’internet payant
Des moteurs de recherche payants En quelques années, la plupart des moteurs de recherche sont devenus
payants
Après allopass, le e-commerce, la vente de news, articles, cours, voici le référencement payant
– Une recherche va devenir un service payant en fonction du nombre de requêtes ou en fonction d’une durée d’utilisation
Problème
Les critères de positionnement en pages de résultats d’un moteur de recherche doivent porter uniquement sur le contenu du site. Mais avec le référencement payant, nous pouvons craindre d’avoir des résultats faussés

Mars 2005 WebFountain 25
??





























