Embed Size (px)
Citation preview

Mathématiques(MPSI)
1 Nombres Complexes et trigonométrie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
1 L’ensemble des nombres complexes 131.1 Définitions et généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141.2 Interprétation géométrique des nombres complexes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2 Module et argument 172.1 Module . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172.2 Ensemble des nombres complexes de module 1 et argument . . . . . . . . . . . . . . . . . . . . . . . . . . . 192.3 Exponentielle complexe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3 Applications à la trigonométrie 233.1 Quelques rappels de trigonométrie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 233.2 Formules trigonométriques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 253.3 Linéarisation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 273.4 Transformation de cos(nx) et sin(nx) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 273.5 Transformation de Fresnel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 283.6 Sommes de cosinus et de sinus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
4 Résolution d’équations dans C 284.1 Equation du second degré . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 284.2 Racines n-ième d’un nombre complexe (n ∈ N?) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
5 Géométrie plane 325.1 Applications géométriques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 325.2 Transformation du plan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
2 Fonctions usuelles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
1 Rappels 361.1 Relation d’ordre et inégalités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 371.2 Composition, monotonie et majoration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 391.3 Dérivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 401.4 Bijections et fonctions réciproques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
2 Fonctions logarithmes, exponentielles et puissances 422.1 La fonction logarithme népérien . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 422.2 La fonction exponentielle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 432.3 Les fonctions exponentielle et logarithme de base a . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 442.4 Fonctions puissances . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
1

3 Étude d’une fonction réelle 473.1 Périodicité, parité et symétrie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 483.2 Limites et croissances comparées . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 493.3 Branches infinies . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
4 Fonctions circulaires réciproques 534.1 La fonction arcosinus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 534.2 La fonction arcsinus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 544.3 La fonction arctangente . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
5 Fonctions hyperboliques 565.1 Fonctions hyperboliques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
6 Fonctions à valeurs complexes 586.1 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
6.2 La fonction t 7→ eϕ(t) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
3 Ensembles, applications, relations d’équivalence et relations d’ordre 60
1 Logique 611.1 Assertions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 611.2 Ensemble, appartenance et inclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 631.3 Prédicats et quantificateurs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 641.4 Méthodes de démonstration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 651.5 Principe de récurrence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
2 Les ensembles 682.1 Sous-ensembles d’un ensemble . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 682.2 Opérations dans P(E) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 692.3 Produit cartésien . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
3 Applications 713.1 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 713.2 Image directe et image réciproque . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 743.3 Applications injectives, surjectives et bijectives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 753.4 Application réciproque . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 773.5 Familles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
4 Relations binaires 794.1 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 794.2 Relation d’équivalence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 794.3 Relation d’ordre . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
4 Primitives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
1 Généralités 821.1 Définition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 821.2 Primitives usuelles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
2 Méthodes de calculs 842.1 Intégration par partie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 842.2 Changement de variables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 852.3 Calculs classiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
5 Équations différentielles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
1 Généralités 901.1 Définition et exemples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
1.2 Équations différentielles linéaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
2 Équation différentielle linéaire d’ordre 1 932.1 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 932.2 Résolution des équations différentielles linéaires homogènes d’ordre 1 . . . . . . . . . . . . . . . . . . . . . 93
2.3 Équation différentielle linéaire d’ordre 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 942.4 Equation avec condition initiale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 962.5 Raccordement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
2

2.6 Méthode d’Euler . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
3 Équation différentielle linéaire d’ordre 2 à coefficients constants 973.1 Équation homogène . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
3.2 Équations avec second membre . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1003.3 Equation avec des conditions initiales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
6 Nombres entiers, sommes et produits . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
1 Les ensembles N et Z 1031.1 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1031.2 Division euclidienne dans N . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1041.3 Principe de récurrence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
2 Suites classiques 1052.1 Suites arithmétiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1052.2 Suites géométriques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1062.3 Suites artithmético-géométriques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1062.4 Suites récurrentes linéaires d’ordre 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
3 Calculs de sommes et produits 1083.1 Les signes ∑ et ∏ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1083.2 Sommes classiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
7 Systèmes linéaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114
1 L’ensemble Kp 1141.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1141.2 Opérations sur Kp . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114
2 Systèmes linéaires 1162.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1162.2 Structure de l’ensemble des solutions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
2.3 Écriture matricielle des systèmes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1182.4 Systèmes diagonaux, triangulaires et echelonnés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118
3 Méthode du pivot de Gauss 1213.1 Systèmes équivalents et opérations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1223.2 Méthode du pivot de Gauss . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1223.3 Retour sur le résolution des systèmes échelonnés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124
8 Ensemble des nombres réels . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 125
1 Le corps des nombres réels 1251.1 Introduction et définition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1251.2 Borne inférieure et borne supérieure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 125
2 Propriétés des réels 1272.1 Inégalités et valeur absolue . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1272.2 Droite numérique achevée . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1272.3 Intervalles de R . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1282.4 Partie entière et nombres décimaux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1282.5 Densité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130
9 Suites numériques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
1 Généralités sur les suites réelles 1311.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1311.2 Opérations sur les suites . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
2 Convergence 1342.1 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1342.2 Convergence et suite extraite . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1362.3 Inégalités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1372.4 Construction de suite à limite donnée . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 139
3

2.5 Opérations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1402.6 Convergence monotone . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1412.7 Suites adjacentes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142
3 Relations de comparaison 1433.1 Définition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1433.2 Propriétés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1443.3 Croissances comparées et équivalents classiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 145
4 Extension au cas des suites complexes 1464.1 Définition et généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1464.2 Convergence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1474.3 Popriétés des suites convergentes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1474.4 Opérations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 147
10 Structures algébriques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 149
1 Groupes 1491.1 Lois de composition interne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1491.2 Itérés d’un élément . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1511.3 Groupes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152
2 Anneaux 1552.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1552.2 Règles de calculs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1562.3 Corps . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 157
11 Arithmétique de Z . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 159
1 Divisibilité dans Z 1591.1 Diviseurs et multiples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1591.2 Division euclidienne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1601.3 Congruences dans Z . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161
2 Plus grand commun diviseur (PGCD) 1612.1 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1612.2 Algorithme d’Euclide . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1622.3 Relation de Bézout . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1632.4 Algorithme d’Euclide augmenté . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1642.5 Nombres premiers entre eux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1652.6 Résolution de l’équation au + bv = c. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1672.7 PGCD de plusieurs entiers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 167
3 Le plus petit commun multiple (PPCM) 1683.1 Définition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1683.2 Lien avec le PGCD et nombres premiers entre eux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 169
4 Nombres premiers 1694.1 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1704.2 Décomposition en produit de facteurs premiers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 170
12 Limites . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 173
1 Limites 1741.1 Limite . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1741.2 Voisinage et propriétés locales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1761.3 Limite à droite et à gauche . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1771.4 Continuité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1781.5 Caractérisation séquentielle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1791.6 Opérations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1801.7 Inégalités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1811.8 Fonctions monotones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 182
4

2 Relations de comparaisons 1832.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1842.2 Propriétés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 185
2.3 Équivalents classiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1862.4 Opérations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 188
13 Continuité sur un intervalle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 190
1 Fonctions continues 1901.1 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1901.2 Théorèmes des valeurs intermédiaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1921.3 Cas des fonctions monotones - théorème de la bijection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1941.4 Bornes d’une fonction continue . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1951.5 Exemple de résolution d’équations fonctionnelles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 195
2 Très brève extension aux fonctions à valeurs complexes 1962.1 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1962.2 Le théorème des valeurs intermédiaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 197
14 Polynômes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 198
1 Ensembles de polynômes à coefficients dans K 1991.1 Construction et propriétés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1991.2 Degré et valuation d’un polynôme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2021.3 Fonctions polynomiales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 204
2 Dérivation 2042.1 Définition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2042.2 Dérivées successives et formule de Taylor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 205
3 Divisibilité et racines d’un polynôme 2073.1 Divisibilité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2073.2 Division euclidienne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2083.3 Racines . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2093.4 Ordre de multiplicité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2113.5 Fonctions symétriques des racines . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2133.6 Interpolation de Lagrange . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 214
4 Arithmétique dans K[X] 2154.1 Plus grand commun diviseur (PGCD) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2154.2 Polynômes premiers entre eux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2164.3 Généralisation à une famille de polynômes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2174.4 Le plus grand commun multiple (PPCM) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2184.5 Propriétés du PGCD et du PPCM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 218
5 Factorisation 2195.1 Polynômes irréductibles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2195.2 Décomposition en produit de facteurs irréductibles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2205.3 Factorisation sur C . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2215.4 Quelques applications de la factorisation sur C . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2215.5 Factorisation sur R . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 221
15 Dérivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 224
1 Définitions 2241.1 Nombre dérivé . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2241.2 Interprétation graphique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2271.3 Fonction dérivée . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2271.4 Opérations algébriques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2271.5 Dérivées des fonctions usuelles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 230
2 Dérivées d’ordre supérieure 2312.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2312.2 Opérations algébriques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 231
5

3 Accroissements finis 2333.1 Extremums . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2333.2 Théorème des accroissements finis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2343.3 Inégalités des accroissements finis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2353.4 Application à la monotonie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2363.5 Application aux prolongements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 237
16 Suites récurrentes : un+1 = f (un) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 239
1 Généralités 2391.1 Représentation graphique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2391.2 Existence de la suite . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 240
2 Méthodes d’étude 2402.1 Caractérisation de la limite . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2402.2 Utilisation des accroissements finis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2412.3 Cas où f est croissante . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2412.4 Cas où f est décroissante . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 242
3 Méthode de Newton 244
17 Corps des fractions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 245
1 Généralités 2451.1 Corps des fractions d’un anneau intègre . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2451.2 Le corps K(X) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2471.3 Degré . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2481.4 Pôles et zéros . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2491.5 Fonction rationnelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2501.6 Dérivation (HP?) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2501.7 Composition par un polynôme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 250
2 Décomposition en éléments simples 2512.1 Partie entière d’une fraction rationnelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2512.2 Partie polaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2522.3 Décomposition en éléments simples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2532.4 Méthodes de calcul . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2542.5 Décomposition en éléments simple dans R(X) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 256
18 Développements limités et analyse asymptotique . . . . . . . . . . . . . . . . . . 257
1 Introduction 2571.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2571.2 Rappel sur les notation de Landau . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 258
2 Développements limités 2582.1 Définition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2582.2 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2592.3 Calculs de développements limités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2602.4 Opérations sur les développements limités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 262
3 Applications des développements limités 2653.1 Développements limités et équivalents . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2653.2 Détermination de limites . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 266
3.3 Étude locale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2663.4 Développements asymptotiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 267
19 Espaces vectoriels . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 272
1 Espaces vectoriels 2721.1 Défintion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2721.2 Combinaisons linéaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 274
6

2 Sous-espaces vectoriels 2752.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2752.2 Sous-espace vectoriel engendré par une partie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 276
3 Familles de vecteurs 2773.1 Exemple introductif . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2773.2 Familles génératrices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2773.3 Familles libres . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2783.4 Bases . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 279
4 Somme de sous-espaces vectoriels 2804.1 Défintions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2804.2 Somme directe et supplémentaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2814.3 Somme directe d’un nombre fini de sous-espaces vectoriels . . . . . . . . . . . . . . . . . . . . . . . . . . . 282
5 Sous-espaces affines 2835.1 Définition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2835.2 Sous-espaces affines . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2845.3 Intersection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 285
20 Espaces vectoriels de dimension finie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 286
1 Espaces vectoriels de dimension finie 2861.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2861.2 Existence d’une base . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2871.3 Dimension . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2881.4 Dimension et famille . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 289
2 Sous-espaces vectoriels 2902.1 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2912.2 Somme et supplémentaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2922.3 Rang d’une famille de vecteurs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2942.4 Première approche des calculs matriciels . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2942.5 Détermination du rang d’une famille . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2952.6 Extraction d’une base . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 295
3 Retour aux sous-espaces affines 2953.1 Dimension d’un sous-espace affine . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2953.2 Quelques exemples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 295
21 Dénombrements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 296
1 Ensembles finis et cardinal 2961.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2961.2 Propriété du cardinal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2981.3 Opérations et cardinal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 299
2 Dénombrements classiques 3012.1 Applications de E dans F . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3012.2 Applications injectives de E dans F . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3022.3 Parties à p éléments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 303
22 Applications linéaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 306
1 Applications linéaires 3061.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3061.2 Applications linéaires et sous-espaces vectoriels . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3081.3 Composition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 309
2 L’ensemble des applications linéaires 3092.1 Structure de L (E, F) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3102.2 Structure de L (E) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3102.3 Ensemble GL(E) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 312
3 Elements remarquables de L (E) 3133.1 Sous-espaces stables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3133.2 Projecteurs et symétries . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 313
7

4 Applications linéaires données dans une base 3164.1 Caractérisation d’une application linéaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3164.2 Caractérisation des isomorphismes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3174.3 Dimension de L (E, F) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3184.4 Théorème du rang . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3194.5 Formes linéaires et hyperplans . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 322
23 Intégration et formules de Taylor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 324
1 Continuité uniforme 3251.1 Definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3251.2 Fonction lipshitzienne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3251.3 Théorème de Heine . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 326
2 Fonctions en escalier et fonctions continues par morceaux 3262.1 Subdivisions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3262.2 Fonctions en escalier . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3272.3 Fonctions continues par morceaux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 328
3 Construction de l’intégrale 3293.1 Intégrale des fonctions en escalier . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3293.2 Propriétés de l’intégrale des fonctions en escalier . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3303.3 Intégrales des fonctions continues par morceaux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 331
4 Propriétés de l’intégrale des fonctions continues par morceaux 3324.1 Linéarité et relation de Chasles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3324.2 Positivité et corrollaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3334.3 Cas des fonctions continues . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3354.4 Invariance par translation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 335
5 Sommes de Riemann et méthodes des trapèzes 3365.1 Somme de Riemann . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3365.2 Méthode des trapèzes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 338
6 Primitives 3386.1 Généralisation de l’intégrale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3386.2 Cas des fonctions continues par morceaux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3396.3 Cas des fonctions continues . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 340
7 Calculs 3407.1 Primitives de fonctions rationnelles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3407.2 Primitives se ramenant à une primitive de fraction rationnelle . . . . . . . . . . . . . . . . . . . . . . . . . . . 342
8 Formules de Taylor 3448.1 Formule de Taylor avec reste intégral . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3448.2 Inégalité de Taylor-Lagrange . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3458.3 Formule de Taylor-Young . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 346
9 Extension au fonctions à valeurs complexes 3479.1 Definitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3479.2 Propriétés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 347
24 Probabilités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 348
1 Espace probabilisé 3481.1 Univers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3481.2 Probabilités et espace probabilisé . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 350
2 Probabilités conditionnelles 3522.1 Exemple introductif . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3522.2 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3532.3 Formules sur les probabilités conditionnelles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 353
3 Indépendance 3553.1 Indépendance de deux événements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3553.2 Indépendance mutuelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 356
8

25 Séries . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 358
1 Généralités 3591.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3591.2 Propriétés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 360
2 Séries de références 3612.1 Séries géométriques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3612.2 Séries de Riemann . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3612.3 Comparaison séries - intégrales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 362
3 Séries à termes positifs 3633.1 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3643.2 Théorème de comparaison pour les séries à termes positifs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 365
4 Séries absolument convergentes 3664.1 Définition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3664.2 Applications aux séries dont le terme général n’a pas un signe constant . . . . . . . . . . . . . . . . . . . 366
5 Représentation décimale des réels 367
26 Matrices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 369
1 Définitions 3691.1 Motiviation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3691.2 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3701.3 L’espace vectoriel Mn,p(K) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3711.4 Produit de matrices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3721.5 Produit dans Mn(K) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3731.6 Transposition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3751.7 Quelques matrices particulières . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3751.8 Calculs par blocs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 378
2 Matrices et applications linéaires 3792.1 Matrice d’une famille de vecteurs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3792.2 Application linéaire canoniquement associée à une matrice . . . . . . . . . . . . . . . . . . . . . . . . . . . 3802.3 Matrice d’une application linéaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3822.4 Propriétés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3832.5 Cas des endomorphismes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 384
3 Changements de bases 3853.1 Matrices de changement de bases . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3853.2 Changement de base des applications linéaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3873.3 Trace d’un endomorphisme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 390
4 Rang d’une matrice 3904.1 Définition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3904.2 Calcul du rang - Opérations élémentaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 393
5 Applications aux systèmes linéaires 3945.1 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3945.2 Determination de l’inverse d’une matrice . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 395
27 Variables aléatoires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 397
1 Variables aléatoires réelles 3971.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3971.2 Loi d’une variable aléatoire réelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3981.3 Fonctions de répartitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3991.4 Fonction d’une variable aléatoire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 400
2 Moments d’une variable aléatoire réelle 4002.1 Espérance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4002.2 Variance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4032.3 Les moments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 405
9

3 Lois usuelles 4053.1 Loi uniforme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4053.2 Loi de Bernoulli . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4063.3 Loi binomiale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4063.4 Retour sur l’inégalité de Bienaymé-Tchebychev . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 407
28 Groupe symétrique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 408
1 Généralités sur les groupes 4081.1 Rappels sur les groupes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4081.2 Morphismes de groupes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4091.3 Image directe et réciproque . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 410
2 Sous-groupes engendré et ordre 4112.1 Sous-groupe engendré par une partie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4112.2 Ordre d’un élément . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 412
3 Groupe symétrique 4123.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4123.2 Transpositions et cycles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 413
4 Signature 4154.1 Défintion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4154.2 Complément sur la signature . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4164.3 Permutations paires et impaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 417
29 Déterminant . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 418
1 Introduction 418
2 Applications multilinéaires 4192.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4192.2 Expression d’une application p-linéaire sur un espace vectoriel de dimension finie . . . . . . . . . . . . 4202.3 Applications symétriques, antisymétriques et alternées . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 421
3 Déterminant 4223.1 Formes n-linéaires sur un espace vectoriel de dimension n . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4223.2 Déterminant d’une famille de vecteurs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4233.3 Volume dans R3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4243.4 Orientation d’un R-espace vectoriel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4253.5 Déterminant d’un endomorphisme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4263.6 Déterminant d’une matrice . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4273.7 Propriétés et calculs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4293.8 Développements suivant une ligne ou une colonne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4313.9 Déterminants classiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 432
4 Utilisation des déterminants 4354.1 Commatrice . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4354.2 Formule de Cramer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 435
30 Couples de variables aléatoires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 437
1 Couples de variables aléatoires 4371.1 Loi conjointe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4371.2 Variables aléatoires indépendantes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4391.3 Lois conditionnelles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4391.4 Lois marginales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4401.5 Fonction d’un couple de variables aléatoires réelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 441
2 Moments 4422.1 Espérance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4422.2 Variance et covariance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 442
3 Généralisation à n variables 4453.1 Variables aléatoires mutuellement indépendantes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4453.2 Somme de n variables aléatoires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 446
10

31 Espaces préhilbertiens réels . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 447
1 Produit scalaire 4471.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4471.2 Norme euclidienne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 449
2 Orthogonalité 4512.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 451
3 Bases orthogonales 4533.1 Généralité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4533.2 Produit mixte et produit vectoriel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4553.3 Sous-espaces vectoriels orthogonaux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4563.4 Projecteurs orthogonaux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4583.5 Hyperplans . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 459
4 Endomorphismes orthogonaux 4614.1 Endomorphismes orthogonaux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4614.2 Matrices orthogonales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4634.3 Endomorphismes orthogonaux du plan euclidien . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4654.4 Automorphismes orthogonaux de l’espace . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 468
32 Fonctions de deux variables - Bonus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 471
1 Généralités 4711.1 Fonctions à deux variables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4711.2 Rudiments de topologie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 472
2 Fonctions continues 4732.1 Limites . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4732.2 Continuité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4742.3 Fonctions à valeurs dans R2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4752.4 Composition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 476
3 Calcul différentiel 4763.1 Première dérivées partielles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4773.2 Fonctions de classe C 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4783.3 Composées . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4803.4 Différentielle et gradient . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4823.5 Extremums . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4833.6 Dérivées partielles d’ordre 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4843.7 Quelques équations aux dérivées partielles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 485
11

Présentation
Voici les notes de cours de MPSI (programme de 2013). Ce sont des notes préliminaires. Il y a probablementde nombreux oublis et coquilles. Je remercie Felix Faisant (MP 2016-2017) pour m’avoir signalé quelques erreurs.
12

1Nombres Complexes
et trigonométrie1 L’ensemble des nombres complexes 131.1 Définitions et généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141.2 Interprétation géométrique des nombres complexes . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2 Module et argument 172.1 Module . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172.2 Ensemble des nombres complexes de module 1 et argument . . . . . . . . . . . . . . . . . . . 192.3 Exponentielle complexe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3 Applications à la trigonométrie 233.1 Quelques rappels de trigonométrie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 233.2 Formules trigonométriques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 253.3 Linéarisation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 273.4 Transformation de cos(nx) et sin(nx) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 273.5 Transformation de Fresnel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 283.6 Sommes de cosinus et de sinus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
4 Résolution d’équations dans C 284.1 Equation du second degré . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 284.2 Racines n-ième d’un nombre complexe (n ∈ N?) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
5 Géométrie plane 325.1 Applications géométriques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 325.2 Transformation du plan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
Vous avez déjà étudié les nombres complexes en terminale. Nous allons revoir cette année. Il n’y aura pasbeaucoup de nouveautés dans ce chapitre.
1 L’ensemble des nombres complexes
Avant de donner la définition des nombres complexes, quelques petits rappels d’ordre historique. Il est bienconnu que le carré de tout nombre réel est un réel positif. De ce fait l’équation x2 = −a d’inconnue réelle x où aest un réel strictement positif n’a pas de solutions. Dès le XVIe siècle les mathématiciens (Cardan, Tartaglia,Ferrari) se sont rendus compte qu’il pouvait être utile d’utiliser les solutions de telles équations afin de résoudre
13

des équations de degré 3, de degré 4. On voit alors apparaitre des notations comme√−a. Ces nombres sont
alors qualifiés d’impossibles ou d’imaginaires. Ce n’est que plus tard, au XIXe siècle que les nombres complexescomme nous les connaissons aujourd’hui sont formalisés. On découvre alors l’utilité de ces nombres pour traiterdes problèmes de géométrie plane.
1.1 Définitions et généralités
Il existe un ensemble des nombres complexes noté C qui contient R. Il vérifie les propriétés suivantes :
1. Il est muni d’une addition (notée +) et d’une multiplication (notée ×) qui prolongent celles deR et qui suivent les mêmes règles de calculs.
2. Il existe un élément noté i qui vérifie i2 = −1.
3. Tout élément de C s’écrit de manière unique de la forme z = a + ib où a et b sont des réels.Cela s’appelle la forme algébrique de z.
Théorème 1.1.1.1
Remarques :
1. On est resté volontairement flou sur les « règles de calculs ». Nous détaillerons cela plus précisément plustard dans l’année. On demande :
— L’addition et le produit sont associatifs : A écrire
— L’addition et le produit sont commutatifs : A écrire
— La multiplication est distributive par rapport à l’addition : A écrire
— L’addition admet un élément neutre, noté 0, qui vérifie que z + 0 = z. De plus, tout élément z à unopposé z′ qui vérifie z + z′ = 0.
— La multiplication admet un élément neutre, noté 1, qui vérifie que z× 1 = z. De plus, tout élémentnon nul z à un inverse z′ qui vérifie z× z′ = 1.
On dit alors que (C,+,×) est un corps .
2. On déduit des règles précédentes que si z = a + ib et z′ = a′ + ib′ sont deux nombres complexes où a, b, a′
et b′ sont des réels alors,
z + z′ = (a + ib) + (a′ + ib′) = (a + a′) + i(b + b′)
et
z× z′ = (a + ib)× (a′ + ib) = aa′ + iab + ia′b + a′b′i2 = (aa′ − bb′) + i(ab′ + a′b).
Démonstration : On considère l’ensemble R2 des couples de réels (a, b). On le munit des opérations suivantes :
(a, b) + (a′, b′) = (a + a′, b + b′) et (a, b)× (a′, b′) = (aa′ − bb′, ab′ + a′b).
Il suffit alors de vérifier que cet ensemble vérifie bien les axiomes voulus.Pour commencer, il prolonge R en associe à tout réel l’élément (a, 0). On voit que dans ce cas les opérations
ci-dessus sont celles de R.On pose ensuite i = (0, 1). Il vérifie que i2 = (−1, 0). C’est ce que l’on voulait.L’élément (0, 0) est un élément neutre pour l’addition dans le sens où pour tout (a, b), (0, 0) + (a, b) = (a, b).
De même l’élément (1, 0) est un élément neutre pour la multiplication car (1, 0)× (a, b) = (a, b).Tout élément (a, b) admet un opposé qui est (−a,−b) et qui vérifie que (a, b) + (−a,−b) = (0, 0) Tout
élément (a, b) non nul admet un inverse (a′, b′) et qui vérifie que (a, b)× (a′, b′) = (1, 0). Il suffit de remarquerque
(a, b)×(
aa2 + b2 ,
−ba2 + b2
)= (1, 0).
14

Soit z un élément de C. On note z = a + ib où a et b sont des réels. On appelle partie réelle de z et on noteRe(z) le nombre a et on appelle partie imaginaire de z et on note Im(z) le nombre b.On appelle imaginaire pur un nombre complexe dont la partie réelle est nulle. L’ensemble des imaginaires pursse note iR.
Définition 1.1.1.2
Les parties réelles et imaginaires sont compatibles à l’addition et à la multiplication par un réel.Précisément si z et z′ sont deux nombres complexes et que λ est un réel.
Re(z + z′) = Re(z) +Re(z′), Im(z + z′) = Im(z) + Im(z′),Re(λz) = λRe(z) et Im(λz) = λIm(z).
Proposition 1.1.1.3
Soit z et z′ deux nombres complexes,
(z = z′)⇔ (Re(z) = Re(z′) et Imz = Imz′).
Proposition 1.1.1.4 (Unicité de la forme algébrique)
Démonstration : Cela découle de l’unicité de l’écriture d’un nombre complexe sous la forme z = a + ib où a etb sont des réels.
Soit z un élément de C. On note z = a + ib où a et b sont des réels. On appelle conjugué de z et on note z lenombre complexe z = a− ib.
Définition 1.1.1.5
Soit z et z′ deux nombres complexes :
1. la conjugaison est involutive : z = z.
2. la conjugaison est compatible à l’addition : z + z′ = z + z′.
3. la conjugaison est compatible à la multiplication et au quotient : z× z′ = z× z′ et( z
z′)=
zz′
.
4. la conjugaison est compatible aux puissances : zn = zn pour tout entier n.
Proposition 1.1.1.6 (Propriétés de la conjugaison complexe)
Démonstration :
1. Évident
2. On note z = a + ib et z′ = a′ − ib′. On a donc z + z′ = (a + a′) + i(b + b′) = (a + a′)− i(b + b′). De plusz + z′ = (a− ib) + (a′ − ib′) = (a + a′)− i(b + b′).
3. Comme ci-dessus pour le produit. Pour le quotient, on remarque que z′ × zz′
= z. On conjugue et on
obtient z′ ×( z
z′)= z et donc
( zz′)=
zz′
.
4. Par récurrence.
15

Soit z un nombre complexe.
1. on a 2Re(z) = z + z et 2Im(z) = z− z.
2. le nombre z est réel si et seulement si z = z.
3. le nombre z est imaginaire pur si et seulement si z = −z.
Proposition 1.1.1.7
Démonstration : Évident. À faire en exercice.
1.2 Interprétation géométrique des nombres complexes
On peut se donner une représentation géométrique des nombres complexes. Cela peut être utilisé dans lesdeux sens c’est-à-dire que l’on peut résoudre des problèmes de géométrie avec des nombres complexes maison peut aussi, se servir de la géométrie pour prouver (ou au moins avoir une intuition) des résultats sur lesnombres complexes.
On suppose le plan muni d’un repère orthonormé direct (O,−→i ,−→j )
On a les définitions suivantes :
1. L’affixe (complexe) du point M de coordonnées (x, y) est le nombre complexe zM = x + iy.
2. L’affixe (complexe) du vecteur −→u de coordonnées (x, y) est le nombre complexe z−→u = x + iy.
3. L’image du nombre complexe z = x + iy est le point M(z) de coordonnées (x, y).
Définition 1.1.2.8
Remarque : Avec ces notations, si A et B sont deux points d’affixe complexe zA et zB alors z−→AB
= zB − zA.
Soit M un point du plan d’affixe complexe z.
1. Le point M′ image du nombre complexe z est le symétrique de M par rapport à l’axe (Ox).
2. Soit z0 un nombre complexe. Le point M′ image du nombre complexe z + z0 est l’image du
point M par la translation de vecteur−−−−→OM(z0).
Proposition 1.1.2.9
Démonstration :
1. On note z = x + iy avec x et y deux réels. On a donc z = x − iy. D’où M′(x,−y) est bien l’image deM(x, y) par la symétrie d’axe (Ox).
2. On note de plus z0 = x0 + iy0 avec x0 et y0 deux réels. On obtient
z−−−→MM′
= zM′ − zM = z + z0 − z = z0.
Donc−−→MM′ =
−−−−→OM(z0) et M′ est bien l’image de M par la translation de vecteur
−−−−→OM(z0).
16

2 Module et argument
2.1 Module
Soit z un nombre complexe. On appelle module de z et on note |z| le réel défini par
|z| =√
zz.
En particulier si z = a + ib avec a et b réels, |z| =√
a2 + b2.
Définition 1.2.1.10
Remarques :1. Cette définition a un sens, en effet, avec les notations précédentes, zz = (a + ib)(a− ib) = a2 + b2. C’est
donc on réel positif et on peut prendre sa racine carrée.2. Il faut savoir écrire et utiliser la définition sous toutes ses formes. En particulier, on a
zz = |z|2 et z =|z|2
zsi z 6= 0.
3. Cette notation est compatible avec la notation de la valeur absolue. En effet, si z est un réel, z = z et on a|z| =
√z2 = |z|.
Soit z et z′ deux nombres complexes.
1. On a z = 0⇔ |z| = 0.
2. Le module est compatible au produit et quotient : |zz′| = |z||z′| et∣∣∣ zz′∣∣∣ = |z||z′| si z′ 6= 0.
3. Le module est compatible aux puissances, pour tout entier naturel n, |zn| = |z|n.
4. On a |z| = |z|.5. On a Re(z) 6 |z| et Im(z) 6 |z|.
Proposition 1.2.1.11 (Propriétés du module)
Démonstration :1. Il suffit de voir que |z| = 0⇔ z = 0 ou z = 0⇔ z = 0.2. Evident.3. Par récurrence en utilisant ce qui précède.4. Evident.5. itou
Remarque : Dans les dernières formules on a égalité si et seulement si z est un réel positif (resp. de la forme iαpour α ∈ R+).
FMéthode : Cela permet de calculer simplement la forme algébrique de l’inverse d’un nombre complexe (donnésous forme algébrique). Par exemple
12− 3i
=2 + 3i
(2− 3i)(2 + 3i)=
2 + 3i13
.
Exercice : Calculer la forme algébrique de3− i1 + 4i
.
Soit z et z′ deux nombres complexes
1. |z + z′|2 = |z|2 + |z′|2 + 2Re(zz′)
2. |z− z′|2 = |z|2 + |z′|2 − 2Re(zz′)
Proposition 1.2.1.12 (Identités remarquables)
17

Soit z et z′ des nombres complexes, le module |z− z′| est la norme euclidienne du vecteur−−−−−−−→M(z′)M(z)
où M(z) (resp. M(z′)) est le point image de z (resp z′). C’est donc la distance euclidienne entre M(z′)et M(z).
Proposition 1.2.1.13
Démonstration : Par définition en utilisant que |z| =√(x− x′)2 + (y− y′)2 avec M(z) (resp. M(z′)) le point
de coordonnées (x, y) (resp. (x′, y′)).
Soit z0 un nombre complexe, M(z0) son point image et r un réel positif.
1. L’ensemble C des points M dont l’affixe zM vérifie |zM − z0| = r est le cercle de centre M(z0)et de rayon r. C’est-à-dire l’ensemble des points M dont la distance à M(z0) est r.
2. L’ensemble C des points M dont l’affixe zM vérifie |zM − z0| < r est le disque ouvert decentre M(z0) et de rayon r. C’est-à-dire l’ensemble des points M dont la distance à M(z0) eststrictement inférieure r.
3. L’ensemble C des points M dont l’affixe zM vérifie |zM − z0| 6 r est le disque fermé de centreM(z0) et de rayon r. C’est-à-dire l’ensemble des points M dont la distance à M(z0) inférieureou égale à r.
Proposition 1.2.1.14
Soit z et z′ deux nombres complexes.
1. On a|z + z′| 6 |z|+ |z′| Première inégalité triangulaire
2. On a||z| − |z′|| 6 |z + z′| Deuxième inégalité triangulaire
Cela peut aussi s’écrire :−|z + z′| 6 |z| − |z′| 6 |z + z′|.
Proposition 1.2.1.15 (Inégalités triangulaire)
Démonstration :— Démontrons la première. On remarque que
|z + z′|2 = (z + z′)(z + z′)= zz + z′z′ + 2Re(zz′)6 |z|2 + |z′|2 + 2|z||z′|6 |z|2 + |z′|2 + 2|z||z′|6 (|z|+ |z′|)2
On peut alors conclure en utilisant que X 7→√
X est croissante.
— Il suffit d’appliquer l’inégalité précédente à z + z′ et −z′. On obtient
|z| = |z + z′ − z′| 6 |z + z′|+ | − z′| = |z + z′|+ |z′|.
On obtient donc|z| − |z′| 6 |z + z′|.
Si on recommence avec z + z′ et −z′ on obtient alors
|z′| − |z| 6 |z + z′|.
Cela revient à−|z + z′| 6 |z| − |z′|.
18

Remarques :1. Si on considère les trois points O, M d’affixe z et N d’affixe z + z′. On a OM = |z|, ON = |z + z′| et
MN = |z′|. On a donc l’inégalité triangulaire classique
ON 6 OM + MN.
2. On a vu que les partie réelles et imaginaires sont commodes pour calculer avec des sommes car Re(z + z′) =Rez +Rez′ et pareil pour les parties imaginaires. Par contre, les calculs avec des produits étaient pluscompliqués. A l’inverse, calculer des modules pour les produits (et les puissances) est simple mais c’estplus compliqué avec les additions.
Dans la première inégalité triangulaire on a égalité si et seulement si |zz′| = Re(zz′) c’est à direquand zz′ est un réel positif.
Proposition 1.2.1.16
2.2 Ensemble des nombres complexes de module 1 et argument
On note U l’ensemble des nombres complexes de module 1.
U = z ∈ C | |z| = 1.
Définition 1.2.2.17
Remarque : L’ensemble U est l’ensemble des nombres complexes dont le point image est sur le cercle de centreO et de rayon 1 qui s’appelle le cercle trigonométrique.
L’ensemble U vérifie les propriétés suivantes :
1. Le nombre complexe 1 qui est l’élément neutre de la multiplication est un élément de U.
2. L’ensemble U est stable par produit. En effet si z et z′ sont deux éléments de U alors zz′
appartient à U.
3. Tout élément z de U admet un inverse das U c’est-à-dire un élément1z
qui vérifie que z× 1z= 1.
Proposition 1.2.2.18
Remarque : Pour ce qui est de l’inverse, on remarque que si z est un élément de U,1z= z.
Soit z un élément de U, il existe un unique θ dans ]− π, π] tel que
z = cos(θ) + i sin(θ).
Proposition 1.2.2.19
Démonstration : Soit z un élément de U. On note z = x+ iy où x et y sont des réels. On a alors lx| = |Re(z)| 6 1et de même pour |y|. Or, si on considère la restriction de la fonction cosinus à l’intervalle [0, π]. Elle est continueet strictement décroissante. De plus, cos(0) = 1 et cos(π) = −1. On en déduit que pour tout réel x dans[−1, 1], il existe un unique ϕ dans [0, π] tel que cos ϕ = x. Dès lors, sin2 ϕ = 1− cos2 ϕ = 1− x2 = y2 carx2 + y2 = |z| = 1. On en déduit que sin ϕ = ±y. Or on sait que sin ϕ > 0 car ϕ est compris entre 0 et π. Onsépare donc les cas selon le signe de y.
— si y > 0 : on pose θ = ϕ et on a bien l’égalité voulue.
19

— si y < 0 : on pose θ = −ϕ. Dans ce cas, θ est strictement compris entre −π et 0. On a là encore l’égalitévoulue.
Remarque : Le réel θ a été construit dans ]− π, π]. On aurait tout aussi bien le construire dans l’intervalle[0, 2π[ ou dans tout intervalle de longueur 2π. Dans la pratique, on se contentera souvent d’une déterminationà 2π-près de θ.Notation : Soit θ un réel on note
eiθ = cos θ + i sin θ.
Remarque : Cette notation peut-être justifiée de nombreuses manières. En voici une. Si on considère f définiede R dans C par
f (θ) = cos θ + i sin θ.
On peut la dériver et on trouve
f ′(θ) = − sin θ + i cos θ = i(cos θ + i sin θ) = i f (θ).
On voit donc que f vérifie l’équation différentielle y′ = iy avec la condition f (0) = 1.Exemple : On a donc ei0 = cos(0) + i sin(0) = 1, eiπ/2 = cos(π/2) + i sin(π/2) = i et eiπ = −1.
Soit θ un réel,
cos(θ) =eiθ + e−iθ
2et sin(θ) =
eiθ − e−iθ
2i.
Proposition 1.2.2.20 (Formules d’Euler)
Soit θ et θ′ deux réels,ei(θ+θ′) = eiθ × eiθ′ .
En particulier,1
eiθ = e−iθ = eiθ .
Proposition 1.2.2.21
Démonstration : Cela découle des formules d’addition des cosinus et des sinus (et cela permet donc de leretrouver si on les a oubliées).
eiθ × eiθ′ = (cos(θ) + i sin(θ))× ((cos(θ′) + i sin(θ′))= (cos(θ) cos(θ′)− sin(θ) sin(θ′)) + i(cos(θ) sin(θ′) + cos(θ′) sin(θ))= cos(θ + θ′) + i sin(θ + θ′)
= ei(θ+θ′).
La deuxième partie est évidente.
Soit θ un réel un réel et n un entier naturel, (eiθ)n = einθ . En particulier
(cos θ + i sin θ)n = cos(nθ) + i sin(nθ).
Corollaire 1.2.2.22 (Formules de (De) Moivre)
Démonstration : Par recurrence
20

Soit z un nombre réel non nul. Il existe des réels θ tels que
z = |z|eiθ .
Tout réel vérifiant cette relation est appelé un argument de z.
Proposition-Définition 1.2.2.23
Démonstration : Il suffit de remarquer que z/|z| est un nombre complexe de module 1.
Soit z un nombre complexe non nul et θ0 un argument de z. L’ensemble des arguments de z est
θ0 + 2kπ | k ∈ Z.
Proposition 1.2.2.24
Démonstration : Soit θ ∈ R. Le réel θ est un argument si et seulement si cos(θ) = cos(θ0) et sin(θ) = sin(θ0).On en déduit donc que θ − θ0 est un multiple de 2π.
Soit A un réel non nul. Soit x et y deux réels, on dit que x et y sont congrus modulo A et on note x ≡ y[A] six− y est un multiple entier du réel A.
Définition 1.2.2.25 (Congruence)
Exemple : Les réels congrus à 1/2 modulo 1 sont . . . ;−2, 5;−1, 5;−0, 5; 0, 5; 1, 5; 2, 5; . . .Remarque : D’après ce qui précède, l’argument d’un nombre complexe n’est donc défini qu’à 2π-près (oumodulo 2π).Notation : Si z est un nombre complexe non nul et θ un argument de z, on note
arg (z) ≡ θ[2π].
Par convention on appelle argument principal l’unique argument dans l’intervalle ]− π, π]. Il est parfois notéArg.
Soit z un nombre complexe non nul. Si M(z) est son point image. Les arguments de z sont les mesures
de l’angle orienté
(−→i ,−−−−→OM(z)).
Proposition 1.2.2.26 (Interprétation géométrique)
Démonstration : Par définition.
Soit z un nombre complexe non nul. Il existe r dans R?+ (le module de z) et θ dans R (un argument de z) tel
quez = r(cos(θ) + i sin(θ)) = reiθ(forme trigonométrique).
Définition 1.2.2.27
Remarque : On pourrait inclure le cas du complexe nul z = 0 en posant r = 0 mais dans ce cas θ seraitquelconque et non pas défini à 2π-près. De ce fait, quand on voudra travailler avec des formes trigonométriques,il faudra TOUJOURS traiter à part le cas de z = 0.Exemples :
21

1. Soit z1 = 3 + 3i. On a |z1| =√
9 + 9 = 3√
2 d’où z1 = 3√
2(
1√2+ i
1√2
)= 3√
2eiπ/4.
2. Soit z2 = −2. On a z2 = 2eiπ .
Soit z un nombre complexe non nul et r1, r2 deux réels strictement positifs et θ1, θ2 deux réels. On az = r1eiθ1 = r2eiθ2 si et seulement si
r1 = r2 et θ1 ≡ θ2[2π].
Proposition 1.2.2.28 ("Unicité" de la forme trigonométrique)
Soit z1 et z2 deux nombres complexes non nuls de forme trigonométrique
z1 = r1eiθ1 et z2 = r2eiθ2 .
On a alors
z1.z2 = (r1r2)ei(θ1+θ2) etz1
z2=
(r1
r2
)ei(θ1−θ2).
Proposition 1.2.2.29
Démonstration : Evident en utilisant ce qui précède.
FMéthode : Angle moitié : On remarque donc que les formes trigonométriques sont adaptées aux produits etau quotients mais beaucoup moins aux sommes. Il n’y a pas de moyen simple, dans le cas général de trouver laforme trigonométrique de z1 + z2 à partir des formes trigonométriques de z1 et z2 sauf si z1 et z2 sont de mêmemodule. En effet pour θ et θ′ deux réels,
eiθ + eiθ′ = ei(
θ+θ′2
) (ei(
θ−θ′2
)+ e−i
(θ+θ′
2
))
= 2 cos(
θ − θ′
2
)ei(
θ+θ′2
)
Pour déterminer la forme trigonométrique il convient ensuite d’étudier le signe de cos( θ−θ′2 ). Ce calcul est à
connaître, il est souvent utile pour simplifier des expressions du type 1 + eiθ ou 1− eiθ .Exercice : Soit θ ∈]− π, π] calculer le module et l’argument de 1 + eiθ , de 1− eiθ et de e−iθ − 1.
Soit z1 et z2 deux nombres complexes non nuls,
1. arg (z1z2) ≡ arg (z1) + arg (z2)[2π]
2. arg(
z1
z2
)≡ arg (z1)− arg (z2)[2π]
3. Pour tout entier relatif n, arg (zn) ≡ narg z[2π].
Proposition 1.2.2.30
Remarque : Ces égalités ne sont vraies qu’à 2π-près. Par exemple si z = −1− i =√
2e5iπ/4 alors arg (z) =5π/4. On a alors z2 = 2i. On voit que arg (z2) = π
2 ≡ 10π4 [2π].
2.3 Exponentielle complexe
On peut généraliser la notion d’exponentielle d’un réel (ex pour un réel x) et la notation eiθ pour un réel θ endéfinissant l’exponentielle d’un nombre complexe.
22

Soit z = x + iy un nombre complexe où x et y sont des réels. On appelle exponentielle de z et on note ez lenombre complexe
ez = exeiy.
Définition 1.2.3.31
Avec les notations précédentes, on voit que le module de ez est ex et que y est un argument de ez. Enparticulier, ez n’est jamais nul. On définit ainsi une application
exp : C → C?
z 7→ ez.
Proposition 1.2.3.32
Soit z et z′ deux nombres complexes. On a
ez+z′ = ezez′ .
En particulier, l’inverse de ez est e−z.
Proposition 1.2.3.33
Démonstration : On note z = x + iy et z′ = x′ + iy′ où x, y, x′ et y′ sont des réels. Dès lors,
ez+z′ = ex+x′ ei(y+y′) = exex′ eiyeiy′ = ezez′ .
Remarque : On voit donc que l’application exponentielle transforme les additions en multiplications.
Soit ω un nombre complexe non nul. Il existe z0 tel que ez0 = ω. On dit que l’application exponentielleest surjective de C dans C?. De plus, si z0 vérifie ez0 = ω alors les nombres complexes z vérifiantez = ω sont les nombres de la forme z0 + 2kπi où k est un entier relatif.
Proposition 1.2.3.34
Démonstration : Notons ω = reiθ où r = |ω| et θ un argument de ω. On pose z0 = ln r + iθ. Maintenant, soit zdans C tel que ez = ω, on a donc
ez = ez0 ⇔ ez−z0 = 1.
On en déduit donc que z− z0 est de la forme 2ikπ où k est un entier relatif.
Remarque : On ne peut donc par définir proprement le logarithme d’un nombre complexe. On pourrait choisirde prendre la seule solution de ez = ω dont la partie entière appartient à −]π, π] (comme pour l’argumentprincipal) mais dans ce cas, la relation ln(zz′) = ln(z) + ln(z′) ne serait plus toujours vraie.Exercice : Résoudre l’équation ez = 2 + 2i.
3 Applications à la trigonométrie
3.1 Quelques rappels de trigonométrie
Revoyons rapidement quelques points sur les fonctions trigonométriques.
23

— Les fonctions sinus et cosinus sont définies sur R.
— Elles sont périodiques de période 2π. La fonction cosinus est paire et la fonction sinus estimpaire.
— Elles sont dérivables : pour tout x dans R, sin′(x) = cos(x) et cos′(x) = − sin(x).
— Il faut connaître certaines valeurs :
θ 0 π/6 π/4 π/3 π/2sin(θ) 0 1/2
√2/2
√3/2 1
cos(θ) 1√
3/2√
2/2 1/2 0
-4 -3 -2 -1 0 1 2 3 4 5 6 7
-1
-0,5
0,5
1
Proposition 1.3.1.35
Soit x ∈ R \ π/2 + kπ | k ∈ Z on pose :
tan x =sin xcos x
.
La fonction tangente est alors la fonction définie sur R \ π/2 + kπ | k ∈ Z qui associe à x le nombre tan x.
Définition 1.3.1.36
On notera, dans ce paragraphe seulement, D = R \ π/2 + kπ | k ∈ Z.
Voici les propriétés de la fonction tangente.
1. La fonction tan est π-périodique et impaire.
2. Elle est dérivable : Pour tout x dans D f , tan′(x) =1
cos2(x)= 1 + tan2(x).
3. Il faut connaître certaines valeurs :
θ 0 π/6 π/4 π/3 π/2tan(θ) 0
√3/3 1
√3 X
Proposition 1.3.1.37
24

-Π Π 2 Π
-6
-4
-2
2
4
6
Soit a ∈ R.Les solutions de l’équation cos x = cos a sont :
— S = a + 2kπ | k ∈ Z ∪ −a + 2kπ | k ∈ Z si a n’est pas un multiple entier de π.
— S = a + 2kπ | k ∈ Z si a est un multiple entier de π.
Les solutions de l’équation sin x = sin a sont :
— S = a + 2kπ | k ∈ Z ∪ π − a + 2kπ | k ∈ Z si a n’est pas de la forme a =π
2+ kπ avec k
entier.
— S = a + 2kπ | k ∈ Z si a est de la forme a =π
2+ kπ avec k entier.
Proposition 1.3.1.38
Démonstration : Démontrons juste le premier point, les autres se démontrent de manière similaire. On saitque la fonction cos est 2π-périodique, de ce fait il existe α ∈]− π, π[ tel que cos a = cos α. Il suffit de prendreα = a + 2nπ où n est l’unique entier relatif tel que α soit dans ]− π, π[. Séparons deux cas.
— Si α est compris entre −π et 0. Alors on sait que α est l’unique solution de l’équation dans l’intervalle]− π, 0[. En effet sur cette intervalle la fonction cosinus est strictement croissante et continue donc d’aprèsle théorème de la bijection notre équation n’a qu’une unique solution. Maintenant, la fonction est pairedonc −α est l’unique solution de l’équation dans l’intervalle ]0, π[. On conclut alors en utilisant que cosest 2π-périodique.
— Si α est compris entre 0 et π. On procède de même.
3.2 Formules trigonométriques
On a déjà vu que la relation ei(θ+θ′) = eiθeiθ′ était une conséquence directe des formules d’addition pourles cosinus et les sinus. Nous allons voir que l’usage des nombres complexes (en particulier sous formetrigonométrique) permet de retrouver la plupart des relations trigonométriques.
Soit a et b deux réels
cos(a + b) = cos(a) cos(b)− sin(a) sin(b) et sin(a + b) = sin(a) cos(b) + sin(b) cos(a).
Proposition 1.3.2.39
Remarque : Il faut ABSOLUMENT connaitre ces formules. En cas d’oubli, on peut les retrouver à l’aide de larelation ei(a+b) = eiaeib.
25

Soit a et b deux réels.
1. cos(a− b) = cos(a) cos(b) + sin(a) sin(b) et sin(a− b) = sin(a) cos(b)− sin(b) cos(a).
2. si tan(a), tan(b) et tan(a + b) sont définis, tan(a + b) =tan(a) + tan(b)
1− tan(a) tan(b).
3. cos(2a) = cos2(a)− sin2(a) = 2 cos2(a)− 1 = 1− 2 sin2(a) et sin(2a) = 2 cos(a) sin(a).
4. cos2(a) =1 + cos(2a)
2et sin2(a) =
1− cos(2a)2
.
5. si tan(a) et tan(2a) sont définis, tan(2a) =2 tan(a)
1− tan2(a).
Corollaire 1.3.2.40
Démonstration : Toutes ces formules découlent des formules d’addition.
Soit a un réel,cos(π/2− a) = sin a et sin(π/2− a) = cos(a).
Corollaire 1.3.2.41
Remarque : Ces formules sont importantes. Elles se retrouvent facilement sur un dessin.
x
y
sin(π/2− a)
cos(a)
Remarque : Cela permet de « transformer » des cosinus en sinus (et réciproquement). En fonction des cas, onutilisera cette méthode ou cos2 a + sin2 a = 1.
Soit a et b deux réels,
1. cos a cos b =12(cos(a + b) + cos(a− b))
2. sin a cos b =12(sin(a + b) + sin(a− b))
3. sin a sin b =12(− cos(a + b) + cos(a− b)).
Proposition 1.3.2.42
Remarque : Ce sont juste les formules d’addition lues à l’envers. On peut aussi les retrouver en développantles formules d’Euler.
26

Soit p et q deux réels :
1. sin p + sin q = 2 sin(
p + q2
)cos
(p− q
2
).
2. cos p + cos q = 2 cos(
p + q2
)cos
(p− q
2
).
3. cos p− cos q = −2 sin(
p + q2
)sin(
p− q2
).
Proposition 1.3.2.43
Remarques :
1. Pourquoi ne donne-t-on de formules pour sin p− sin q ?
2. Ces formules proviennent des formules précédentes en les lisant à l’envers et en remarquant que
a + b = pa− b = q est équivalent à
a =p + q
2b =
p− q2
3. On peut aussi les retrouver en utilisant la méthode de l’angle moitié.
Exercice : Trouver une formule pour sin p + cos q.
3.3 Linéarisation
FMéthode : On voit ci-dessus que l’on peut exprimer cos2(x) et sin2(x) comme combinaison linéaire (c’est-à-diresans puissances) de terme de la forme cos(kx) et sin(kx) où k est un entier naturel. Cela est vrai pour toutterme de la forme cosm x sinn x où n et m sont des entiers. C’est la linéarisation. Voici comme on procède sur unexemple :
cos4(x) =18(cos(4x) + 4 cos(2x) + 3) .
En récapitulant
— On écrit les cosinus et les sinus à l’aide des formules d’Euler.
— On développe avec le binôme de Newton. (voir plus loin)
— On regroupe avec les formules d’Euler
Exercice : Linéariser cos2(x) sin3(x).
3.4 Transformation de cos(nx) et sin(nx)
FMéthode : A l’inverse on voit que l’on peut aussi écrire les terme cos(nx) et sin(nx) comme des polynômes encos(x) et sin(x). Là encore procédons sur un exemple
cos(3x) = Re(e3ix) = Re((cos x + i sin x)3) = cos3(x)− 3 cos(x) sin2(x) = 4 cos3(x)− 3 cos(x).
En récapitulant
— On écrit que cos(nx) = Re((cos x + i sin x)n ou sin(nx) = Im((cos x + i sin x)n(en utilisant la formule de(De) Moivre).
— On développe le terme de droite avec la formule du binôme de Newton. (voir plus loin)
— On ne garde que les termes réels pour un cosinus et que les termes imaginaires pour un sinus.
— On utilise éventuellement la formule cos2(x) + sin2(x) = 1 pour simplifier.
Exercice : Exprimer sin(4x) sous la forme cos(x)P(sin x) où P est une fonction polynomiale.Remarque : On peut appliquer cette méthode pour exprimer tan(nx) en tant que fraction rationnelle en tan x. Il
suffit d’écrire tan(nx) =sin(nx)cos(nx)
, d’utiliser la méthode précédente pour de diviser numérateur et dénominateur
par cosn x.
27

3.5 Transformation de Fresnel
Soit a et b deux réels non tous nuls. Il existe A et ϕ tels que pour tout réel t,
a cos(t) + b sin(t) = A cos(t + ϕ).
Proposition 1.3.5.44 (Transformation de Fresnel)
Remarque : Cette formule est très utile en physique.Démonstration : L’idée est d’essayer d’écrire une formule d’addition de la forme
cos(t + ϕ) = cos(t) cos(ϕ)− sin(t) sin(ϕ).
On factorise donc par A =√
a2 + b2 et on obtient,
a cos(t) + b sin(t) =√
a2 + b2
a√a2 + b2
︸ ︷︷ ︸a′
cos(t)− b√a2 + b2
︸ ︷︷ ︸b′
sin(t)
.
Maintenant, comme (a′)2 + (−b′)2 = 1 il existe ϕ tel que cos(ϕ) = (a′) et sin(ϕ) = −b′ (ϕ est un argumentde a′ + ib′).
Exercice : Appliquer cette transformation à cos(t)− sin(t) et à cos(t) +√
3 sin(t).
3.6 Sommes de cosinus et de sinus
On peut ramener le calcul des sommes
Cn =n
∑k=0
cos(kt) = cos(0) + · · ·+ cos(nt) et Sn =n
∑k=0
sin(kt) = sin(0) + · · ·+ sin(nt)
à des sommes des termes d’une suite géométrique. On suppose que t 6= 0[2π].En effet,
Cn =n
∑k=0
Re(eikt) = Re
(n
∑k=0
(eit)k
).
En utilisant la somme des termes d’une suite géométrique (qui sera revue au chapitre VI) on a donc
n
∑k=0
(eit)k =1− ei(n+1)t
1− eit =−2i sin((n + 1)t/2)e(n+1)it/2
−2i sin(t/2)eit/2 =sin((n + 1)t/2)enit/2
sin(t/2)
Il ne reste plus qu’à prendre les parties réelles et imaginaires :
Cn =sin((n + 1)t/2) cos(nt/2)
sin(t/2)et Sn =
sin((n + 1)t/2) sin(nt/2)sin(t/2)
4 Résolution d’équations dans C
4.1 Equation du second degré
Commençons par résoudre l’équation z2 = ω d’inconnue complexe z où ω est un nombre complexe.
Soit ω un nombre complexe. On considère l’équation
z2 = ω (E)
— si ω est nul (E) a pour unique solution z = 0.
— si ω est non nul, (E) a deux solutions opposés.
Proposition 1.4.1.45
28

Démonstration :
— Si ω = 0 on a z2 = 0 implique z = 0 car, dans C, un produit n’est nul que si l’un des deux termes est nul.
— Si ω 6= 0, on peut poser ω = αeiϕ avec α ∈ R∗+. Si on cherche z (qui n’est pas nul) sous la forme ρeiθ on a
z2 = ω ⇐⇒
ρ2 = α2θ = ϕ[2π]
⇐⇒
ρ =√
αθ = ϕ/2[π]
Donc S = √αeiϕ/2;−√αeiϕ/2.
Soit ω un nombre complexe non nul. Les deux solutions opposées de l’équation z2 = ω s’appellent les racinescarrées de ω.
Définition 1.4.1.46
ne jamais utiliser la notation√
ω quand ω n’est pas un réel positif. En effet, dans ce cas, les racinescarrées sont des nombres complexes non réels. Il n’y a aucune manière intelligente (c’est-à-direcompatible au produit) de choisir l’une plutôt que l’autre.
ATTENTION
Exemple : Si ω est un réel positif, ses racines carrées sont√
ω et −√ω. Si ω est un réel négatifs, ses racinescarrées sont i
√|ω| et −i
√|ω|.
FMéthode : On a vu que la manière la plus simple de déterminer les racines carrées d’un nombre complexe estde passer par sa forme trigonométrique. Cependant, il arrive que l’on veuille travailler avec des nombres donton ne connait pas de forme trigonométrique simple. On passe alors par la forme algébrique.
Traitons un exemple. On prend ω = 3 + 4i. On pose z = a + ib où a et b sont des réels. Dès lors
a2 + b2 = |z|2 = |ω| =√
9 + 16 = 5 et a2 − b2 = Re(ω) = 3.
On remarque de plus que 2ab = Im(z2) = Im(ω) et donc ab > 0.Il ne reste plus qu’à résoudre le système
a2 + b2 = 5a2 − b2 = 3
ab > 0
On trouve a2 = 4, b2 = 1 d’où z ∈ 2 + i,−2− i.
Soit a, b et c trois nombres complexes avec a différent de 0. On considère l’équation
ax2 + bx + c = 0 (E)
d’inconnue complexe x.On note ∆ = b2 − 4ac le discriminant de l’équation (E).
— Si ∆ est nul, l’équation (E) admet une racine double x = − b2a
.
— Si ∆ est non nul, on note δ une racine carrée de ∆. L’équation (E) admet alors deux solutions
x1 =−b + δ
2aet x2 =
−b− δ
2a.
Théorème 1.4.1.47 (Equation du second degré)
29

Démonstration : Par mise sous forme canonique
Exemple : Résolvons l’équationx2 − 2ix− 2− i = 0.
On retrouve alors le cas classique de l’équation du second degré à coefficients réels :
Soit a, b et c trois nombres réels avec a différent de 0. On considère l’équation
ax2 + bx + c = 0 (E)
d’inconnue complexe x.On note ∆ = b2 − 4ac le discriminant de l’équation (E).
— Si ∆ est nul, l’équation (E) admet une racine double x = − b2a
.
— Si ∆ > 0. L’équation (E) admet alors deux solutions réelles
x1 =−b +
√∆
2aet x2 =
−b−√
∆2a
.
— Si ∆ < 0. L’équation (E) admet alors deux solutions complexes conjuguées
x1 =−b + i
√|∆|
2aet x2 =
−b− i√|∆|
2a.
Théorème 1.4.1.48 (Equation du second degré à coefficients réels)
Exemple : On chercher a = tan(π/8). On sait que
1 = tan(π/4) = cos(2× (π/8)) =2a
1− a2 .
On en déduit que a vérifie l’équation a2 + 2a− 1 = 0 dont les solutions sont a1 = −1 +√
2 et a2 = −1−√
2. Ora > 0 donc tan(π/8) = −1 +
√2.
Exercice : Résoudre αx2 + 2αx− α2 − α− 1 = 0.
Soit a, b et c trois nombres complexes avec a différent de 0. On considère l’équation
ax2 + bx + c = 0 (E)
d’inconnue complexe x.Soit z1 et z2 deux nombres complexes (éventuellement confondus). Les nombres z1 et z2 sont lesracines de l’équation (E) si et seulement si
z1z2 =ca
et z1 + z2 = − ba
.
Proposition 1.4.1.49 (Relation coefficients-racines)
Démonstration :
— ⇒ : Evident en utilisant les formules.
— ⇐ : Il suffit de remarquer que pour tout nombre complexe z,
a(z− z1)(z− z2) = a(z2 − (z1 + z2)z + z1z2) = az2 + bz + c.
Exemples :
30

1. Si on se donne deux nombres S et P. On considère le système
z1 + z2 = Sz1z2 = P
Ses solutions sont les couples (α, β) où α et β sont les solutions de l’équation X2 − SX + P = 0.Si on cherche les couples (z1, z2) vérifiant le système
z1 + z2 = 1z1z2 = 1
on résout X2 − X + 1 dont les solutions sont1±√
32
.
2. Soit θ un réel. On considère l’équation X2 − 2 cos(θ)X + 1 = 0. On peut voir que eiθ + e−iθ = 2 cos(θ)(formule d’Euler) et eiθe−iθ = 1 donc les solutions sont eiθ , e−iθ. On peut aussi le faire avec la méthodeclassique. Il faut cependant faire attention à la rédaction.
4.2 Racines n-ième d’un nombre complexe (n ∈ N?)
Dans cette section n désigne un nombre entier naturel non nul.
Soit ω un nombre complexe. On appelle racines n-ième de ω les solutions de l’équation zn = ω.Les racines n-ième de 1 s’appellent les racines n-ième de l’unité. On note Un leur ensemble.
Définition 1.4.2.50
L’ensemble Un est stable par produit et par passage à l’inverse.
Proposition 1.4.2.51
Démonstration
Il existe exactement n racines de l’unités qui sont
ζk = e2ikπ/n où k ∈ [[ 0 ; n− 1 ]] .
On a donc pour tout k dans [[ 0 ; n− 1 ]], ζk = ζk1.
Proposition 1.4.2.52
Démonstration : On remarque déjà que le nombre z = 0 n’est pas une racine n-ième de l’unité. Dès lors onpose z = ρeiθ la forme trigonométrique de z.
zn = 1 ⇔ (ρeiθ)n = 1
⇔ ρneinθ = 1ei0
⇔
ρn = 1nθ = 0 [2π]
⇔
ρ = 1θ = 0 [2π/n]
On en déduit que l’ensemble des solutions de zn = 1 est ζk | k ∈ Z. Il suffit de voir que l’on peutrestreindre les valeurs de k. Par division euclidienne, on voit que pour tout entier k, il existe des entiersq et r tels que k = qn + r avec r compris entre 0 et n − 1. Comme de plus, ζqn+r = ζr , on en déduit queUn = ζk | k ∈ [[ 0 ; n− 1 ]]. Il ne reste plus qu’à montrer que ces nombres sont deux à deux distincts.Procédons par l’absurde. S’il existe k1 et k2 dans [[ 0 ; n− 1 ]] tels que ζk1 = ζk2 alors il existe un entier m tels que
2k1π
n=
2k2π
n+ 2mπ
31

d’oùk1 − k2 = nm.
or −(n− 1) 6 k1 − k2 6 n− 1. On en déduit que k1 − k2 = 0 et donc que k1 = k2.
Si n est au moins égal à 2, la somme des racines de l’unité est nulle : 1 + ζ1 + · · ·+ ζn−11 = 0.
Proposition 1.4.2.53
Démonstration : Il suffit de faire le calcul et utilisant la somme des termes d’une suite géométrique.
Exercice : Calculer le produit des racines n-ième de l’unité.
Soit ω un nombre complexe non nul.
1. Si u est une racine n-ième de ω, l’ensemble des racines n-ième de ω est uζ | ζ ∈ Un. Lasomme des racines n-ième de ω est donc nulle.
2. Si ω = ρeiθ (forme trigonométrique) alors l’ensemble des racines n-ième de ω est
n√
ρei( θn +
2kπn ) | k ∈ [[ 0 ; n− 1 ]].
Proposition 1.4.2.54
Démonstration
x
y
u
uζ
uζ2
uζ3
uζ4
racine de z5 = eiπ/4
Exercice : Calculer le produit des racines n-ième de −2.
5 Géométrie plane
Nous avons déjà vu que les calculs de nombres complexes peuvent s’interpréter géométriquement. On peutles utiliser en particulier pour les transformations du plan.
5.1 Applications géométriques
1. Soit z un nombre complexe non nul et M le point image de z. Le module de z est la distance
OM et les arguments de z sont les mesures de l’angle (−→i ,−−→OM).
2. Soit z et z′ deux complexes distincts et M, M′ leur point image. Le module de z′ − z est la
distance MM′ et les arguments de z′ − z sont les mesures de l’angle
(−→i ,−−→MM′).
Proposition 1.5.1.55
32

Démonstration :1. Par définition.
2. Le premier point a déjà été vu. Pour le deuxième, on translate de vecteur−−→OM.
−→j
−→i
M
M′
arg(z′ − z)
Soit A et B deux points du plan d’affixe complexe a et b. Soit M un point du plan distinct de B
d’affixe z. On note u =z− az− b
.
Le module de u est égal au rapportAMBM
alors que les arguments de u sont les mesures de l’angle
(−−→AM,
−→BM).
Corollaire 1.5.1.56
Démonstration : On a |u| = |z− a||z− b| =
AMBM
. De même, arg (u) = arg (z − a) − arg (z − b) = (−→i ,−−→AM) −
(−→i ,−→BM) = (
−−→AM,
−→BM). Ces égalités étant définies uniquement à 2π-près.
Avec les notations précédentes
— Les points A, B et M sont alignés si et seulement si u est réel.
— Les vecteurs−−→AM et
−→BM sont orthogonaux (ce qui revient à dire que le point M appartient au
cercle de diamètre [AB]) si et seulement si u est un imaginaire pur.
Corollaire 1.5.1.57
5.2 Transformation du plan
Une transformation f du plan est un moyen qui permet d’associer à tout point M du plan un unique pointM′ = f (M) du plan qui soit réversible. C’est une application bijective du plan dans lui même. On lui associeune application que l’on notera g de C dans lui même en associant à tout nombre complexe z l’affixe du pointf (M(z)). On dira que la transformation f est représentée par g.
Soit −→u un vecteur du plan. La translation de vecteur −→u est la transformation du plan qui associe à tout point
M l’unique point M′ qui vérifie−−→MM′ = −→u .
Si on note b l’affixe du vecteur −→u . La translation de vecteur −→u est représentée par g : z 7→ z + b.
Définition 1.5.2.58 (Translation)
Remarque : Cette transformation est bien réversible. Son inverse est la translation de vecteur −−→u .
33

Soit λ un réel non nul et Ω un point du plan. L’homothétie de centre Ω et de rapport λ est la transformation
plan qui associe à tout point M l’unique point M′ tel que−−→ΩM′ = λ
−−→ΩM.
Si on note z0 l’affixe du point M′. L’homothétie de centre Ω et de rapport λ est représentée par g : z 7→z0 + λ(z− z0).
Définition 1.5.2.59 (Homothétie)
Démonstration : Si on note z l’affixe de M et z′ l’affixe de M′. On a donc, par définition, z′ − z0 = λ(z− z0).On en déduit que g : z 7→ z0 + λ(z− z0).
Remarque : Cette transformation est bien réversible. Son inverse est l’homothétie de centre Ω et de rapport1/λ.
Soit θ un réel et Ω un point du plan. La rotation de centre Ω et d’angle θ est la transformation plan qui associe
à tout point M l’unique point M′ tel que ||−−→ΩM′|| = ||−−→ΩM|| et
(−−→ΩM,
−−→ΩM′) = θ[2π] .
Si on note z0 l’affixe du point Ω. L’homothétie de centre Ω et d’angle θ est représentée par g : z 7→z0 + eiθ(z− z0).
Définition 1.5.2.60 (Rotation)
Exercice : Justifier la formule donnée par g. Trouver l’inverse de la rotation de centre Ω et d’angle θ.
On appelle similitude directe toute transformation du plan qui est représenté par une application de la formeg : z 7→ az + b où a et b sont des complexes avec a non nul.
Définition 1.5.2.61 (Similitudes directes)
Remarque : Que se passe-t-il si a = 0?
Une similitude directe conserve les angles et les rapports de distances.
Proposition 1.5.2.62
Démonstration : Soit M1, M2, M3 et M4 des points deux à deux distincts. On note z1, z2, z3 et z4 leur affixe res-pective. On considère une similitude directe représentée par l’application z 7→ az + b. On note alors M′1, M′2, M′3et M′4 les images de M1, M2, M3 et M4 par la similitude et z′1, z′2, z′3 et z′4 leur affixe respective.
On en déduit donc que z′2 − z′1 = a(z2 − z1) et z′4 − z′3 = a(z4 − z3) d’où
z′2 − z′1z′4 − z′3
=z2 − z1
z4 − z3.
On en déduit que l’angle
(−−−→M′1M′2,
−−−→M′3M′4) est égal à
(−−−→M1M2,
−−−→M3M4). De même
M′1M′2M′3M′4
=M1M2
M3M4.
Remarque : On notera par contre qu’une similitude directe ne conserve les distance que si |a| = 1.
Soit f la similitude directe représentée par z 7→ az + b où a est un complexe non nul et b un complexe.
— Si a = 1 l’application est la translation de vecteur b.
— Si a 6= 1, on pose ω =b
1− a. La représentation complexe de la similitude s’écrit alors z 7→
ω + a(z−ω).
Proposition 1.5.2.63
34

Remarque : Le nombre ω est trouvé en résolvant l’équation g(z) = z.Exemple : Soit z 7→ (1 + i)z− (2 + i). Dans toute la suite on suppose a 6= 1.
Avec les notations précédentes. Le point Ω image de ω s’appelle le centre de la similitude. Il est stable (vérifief (Ω) = Ω). Le réel |a| s’appelle le rapport de la similitude et si θ est un argument de a, c’est une mesure del’angle de la similitude.
Définition 1.5.2.64
Avec les notations précédentes, si on note r la rotation de centre Ω et de rapport |a| et h l’homothétiede centre Ω et d’angle θ alors f = h r = r h. En particulier, si |a| = 1, f est une rotation et si a estréel c’est une homothétie.
Proposition 1.5.2.65
Soit M1, M2,deux points distincts et M′1, M′2 deux autre points distincts. Il existe une unique simili-tude directe transformant M1 en M′1 et M2 en M′2.
Théorème 1.5.2.66
Démonstration : On cherche a et b deux nombres complexes dont le premier n’est pas nul vérifiant
z′1 = az1 + bz′2 = az2 + b ⇐⇒
a(z1 − z2) = z′1 − z′2b(z2 − z1) = z2z′1 − z1z′2
Exercice : Soit M1, M2, M′1 et M′2 les points d’affixes respectives 1, i,−1 − 2i et 5 − 2i. Trouver l’uniquesimilitude qui transforme M1 en M′1 et M2 en M′2. On précisera son rapport et son angle.Remarque : On a vu que la conjugaison complexe correspondait à la symétrie d’axe (Ox). Ce n’est pas unesimilitude directe car elle change l’orientation des angles.
35

2Fonctions usuelles
1 Rappels 361.1 Relation d’ordre et inégalités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 371.2 Composition, monotonie et majoration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 391.3 Dérivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 401.4 Bijections et fonctions réciproques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
2 Fonctions logarithmes, exponentielles et puissances 422.1 La fonction logarithme népérien . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 422.2 La fonction exponentielle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 432.3 Les fonctions exponentielle et logarithme de base a . . . . . . . . . . . . . . . . . . . . . . . . . . 442.4 Fonctions puissances . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
3 Étude d’une fonction réelle 473.1 Périodicité, parité et symétrie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 483.2 Limites et croissances comparées . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 493.3 Branches infinies . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
4 Fonctions circulaires réciproques 534.1 La fonction arcosinus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 534.2 La fonction arcsinus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 544.3 La fonction arctangente . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
5 Fonctions hyperboliques 565.1 Fonctions hyperboliques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
6 Fonctions à valeurs complexes 586.1 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
6.2 La fonction t 7→ eϕ(t) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
Nous allons faire le point sur les fonctions usuelles déjà vues au lycée. Par la suite nous définirons lesfonctions circulaires réciproques. Dans tout ce chapitre I désignera un intervalle de R et les fonctions étudiéesseront à valeurs dans R sauf exprimés précisément.
1 Rappels
Voici quelques rapides rappels de la terminale qui nous seront utiles dans ce chapitre. Nous y reviendronsdans l’année.
36

1.1 Relation d’ordre et inégalités
L’ensemble R des nombres réels est muni d’une relation d’ordre noté 6 définie par x 6 y si etseulement si y− x est positif. Cette relation est compatible avec les opérations de R à savoir :
1. Si x, y et z sont trois réels tels que x 6 y alors x + z 6 y + z.
2. Si x et y sont deux réels positifs (c’est-à-dire x > 0 et y > 0) alors xy est positif.
Théorème 2.1.1.67
Nous reviendrons plus en détails sur ce point dans la suite du cours. Notons déjà quelques corollaires
1. Si x et y sont deux nombres réels tels que x 6 y alors −y 6 −x. En particulier, si x > 0 alors−x 6 0.
2. (Règles des signes). Si x et y sont deux réels.
— Si x et y sont de même signe alors xy > 0.
— Si x est positif et y négatif (ou l’inverse) alors xy 6 0.
3. Si x, y et z sont trois réels. Si x 6 y et z > 0 alors xy 6 yz.
4. Si x, y sont deux réels strictement positifs. Si 0 < x 6 y alors 0 61y6
1x
.
Corollaire 2.1.1.68
Démonstration :
1. Il suffit d’ajouter −x− y des deux cotés.
2. — Il suffit de voir que si xy = (−x)(−y).
— Il suffit de voir que si x > 0 et y 6 0 alors xy = −x(−y).
3. En exercice.
4. En exercice.
Soit x un réel.
1. On appelle partie positive (resp. partie négative) de x le plus grand des deux réels x et 0 (resp. −x et 0).On la note x+ (resp. x−). On a donc
x+ =
x si x > 00 sinon et x− =
−x si x > 0x sinon .
En particulier, x+ et x− sont positifs.
2. On appelle valeur absolue de x le plus grand des deux réels x et −x. On la note |x|. On a donc
|x| =
x si x > 0−x sinon .
Définition 2.1.1.69
Exemple : Pour x = 3, 14 on a x+ = |x| = 3, 14 et x− = 0. De même pour x = −2, on a x+ = 2, x− = 2 et|x| = 2. Exercices :
1. Montrer en procédant à une disjonction que x = x+ − x− et |x| = x+ + x−.
2. Montrer en procédant à une disjonction que x+ =x + |x|
2. Trouver une formule analogue pour x−.
37

Soit x, y deux réels|x + y| 6 |x|+ |y|.
Proposition 2.1.1.70 (Inégalité triangulaire)
Démonstration : Il suffit d’élever au carré et d’utiliser que xy 6 |xy|.
Remarque : Cette propriété est TRES importante.
On appelle intervalle de R une partie de R qui est soit R en entier soit est de la forme :
[a, b] = x ∈ R | a 6 x 6 b [a, b[= x ∈ R | a 6 x < b]a, b] = x ∈ R | a < x 6 b ]a, b[= x ∈ R | a < x < b]−∞, b] = x ∈ R | x 6 b ]−∞, b[= x ∈ R | x < b[a,+∞[ = x ∈ R | a 6 x ]a,+∞[ = x ∈ R | a < x
où a et b sont deux réels.
Définition 2.1.1.71
Remarque : En particulier, l’ensemble vide est un intervalle (il suffit de prendre a > b). De même les singletonssont des intervalles.Terminologie : Un intervalle de la forme [a, b] (avec a 6 b) est appelé intervalle fermé. Un intervalle de la forme]a, b[ (avec a 6 b) est appelé intervalle ouvert. Un intervalle de la forme ]a, b] ou [a, b[ est appelé semi-ouvert ousemi-fermé.
Soit a et b deux réels. L’ensemble des réels x tels que |x − a| 6 b est un intervalle. Si b > 0 c’est[a− b, a + b].
Proposition 2.1.1.72
Remarque : A l’inverse soit I = [a, b]. Le milieu de l’intervalle est c =a + b
2. Sa longueur est l = b− a. On a
alors[a, b] = x ∈ R | |x− c| 6 l/2..
a c = (a + b)/2 b
(b− a)/2
b− a
Il est important de savoir résoudre efficacement quelques inéquations simples :
1. Résoudre dans R, x2 + 3x− 1 6 2x + 5.
x2 + 3x− 1 6 2x + 5 ⇐⇒ x2 + x− 6 6 0⇐⇒ (x− 2)(x + 3) 6 0
Via un tableau de signe on trouve alors S = [−3, 2].
2. Résoudre1
x− 46
2x + 1x2 − 3x + 2
On travaille sur R \ 1, 2, 4.
1x− 4
6x + 1
x2 − 3x + 2⇐⇒ x2 − 3x + 2− (x− 4)(2x + 1)
(x− 4)(x− 1)(x− 2)6 0
−x2 + 4x + 6(x− 4)(x− 1)(x− 2)
6 0
−(x− x1)(x− x2)
(x− 4)(x− 1)(x− 2)6 0
où x1 = 2 + 2√
3 et x2 = 2− 2√
3.
38

3. Résoudre x +√
x2 − 3x + 2 > 0. On travaille sur R\]1, 2[.
x +√
x2 − 3x + 2 > 0 ⇐⇒√
x2 − 3x + 2 > x
On voit en particulier que si x est négatif, l’inéquation est vérifié. Ensuite, si x est positif on est ramené (enpassant au carré) à x2 − 3x + 2 > x2 ⇐⇒ x 6 2/3. On a donc S =]−∞, 2/3].
1.2 Composition, monotonie et majoration
Soit f une fonction définie sur I et g une fonction définie sur une partie K. On suppose que pour tout x de I,f (x) appartienne à K. On appelle alors composée de g et f et on note g f la fonction définie sur I par
g f : I → Rx 7→ g( f (x))
Définition 2.1.2.73
Exemples :
1. Si on note f : x 7→ cos(x) et g : x 7→ x2. On a f g : x 7→ cos(x2) et g f : x 7→ (cos x)2 = cos2 x. Onutilise souvent cette dernière notation qui se confond moins avec la première.
2. Si f est une fonction qui ne s’annule pas sur I et g définie sur R? par X 7→ 1X
, la fonction g f est la
fonction1f
.
Commençons par rappeler la définition d’une fonction croissante.
Soit f une fonction définie sur I.
1. On dit que f est croissante (resp. décroissante) si et seulement si, pour tout x, y dans I, si x 6 y alorsf (x) 6 f (y) (resp. f (x) > f (y))
2. On dit que f est strictement croissante (resp. décroissante) si et seulement si, pour tout x, y dans I, six < y alors f (x) < f (y) (resp. f (x) > f (y))
3. On dit que f est monotone (resp. strictement monotone) si elle est croissante ou décroissante (resp.strictement croissante ou strictement décroissante).
Définition 2.1.2.74 (Monotonie)
Remarques :
1. Cela signifie que quand f est croissante alors « les images sont dans le même sens que les éléments ».
2. Si f et g sont feux fonctions croissantes sur I alors f + g est croissante. Est-ce vrai pour f × g ?
Exemples :
1. La fonction x 7→ x2 est croissante sur R+ (mais pas sur R).
2. La fonction x 7→ 1/x est croissante sur R?∗ (mais pas sur R).
Exercice : Justifier que la composée de deux fonctions croissantes est croissante.
Soit f une fonction définie sur une partie K de R.
1. On dit que f est majorée (resp. minorée) s’il existe un réel M (resp. m) tel que pour tout x dans K,f (x) 6 M (resp. f (x) > m).
2. On dit que f est bornée si elle est majorée et minorée
Définition 2.1.2.75
39

Il est essentiel que le M (ou m) soit indépendant de x. Par exemple, on a que pour tout x de R,x− 1 6 x mais cela ne signifie par que x 7→ x− 1 soit majorée. Par contre, on sait que pour tout réelx, x2 − 1 > −4 donc x 7→ x2 − 1 est minorée.
ATTENTION
Remarque : Pour montrer que f est bornée, il suffit de montrer que | f | est majorée.
1.3 Dérivation
Dans ce paragraphe, nous n’allons pas rentrer dans la théorie de la dérivation des fonctions (cela sera l’objetd’un chapitre plus tard dans l’année). Nous allons nous conter de rappels les principes de calculs des fonctionsdérivées et l’utilisation pour étudier la monotonie et les tangentes.
Soit f une fonction dérivable sur un intervalle I. Elle est croissante (resp. décroissante) si et seulementsi f ′ est positive (resp. négative) De plus si f ′ est strictement positive (resp. négative) alors f eststrictement croissante (resp. décroissante).
Théorème 2.1.3.76
Soit f et g deux fonctions dérivables.
1. La fonction f + g est dérivable et ( f + g)′ = f ′ + g′.
2. Soit λ un réel, la fonction λ f est dérivable et (λ f )′ = λ f ′.
3. La fonction f × g est dérivable et ( f × g)′ = f ′ × g + f × g′.
Théorème 2.1.3.77 (Opérations usuelles)
Remarque : Tous ces résultats seront prouvés dans le chapitre sur la dérivation.Exemple : La fonction x 7→ x2 cos(x) + sin(x) est dérivable et sa dérivée est x 7→ 2x cos(x)− x2 sin(x) + cos(x).
Soit f une fonction définie sur I et g une fonction définie sur une partie K. On suppose que pour toutx de I, f (x) appartienne à K. Si f et g sont dérivables alors g f aussi et
(g f )′ = f ′ × g′ f
ce qui signifie que pour tout x de I,
(g f )′(x) = f ′(x)× g′( f (x)).
Théorème 2.1.3.78 (Dérivée d’une composée)
Cette formule est importante. Une erreur standard est d’oublier le terme en f ′(x).
ATTENTION
Exemples :
1. La dérivée de x 7→ cos(x2) est −2x sin(x2).
2. La dérivée de x 7→ f (2x) est x 7→ 2 f ′(2x).
40

1. Soit f une fonction dérivable sur I qui ne s’annule pas. La fonction1f
est dérivable et(
1f
)′=
− f ′
f 2 .
2. Soit f et g deux fonctions dérivables sur I qui ne s’annulent pas. La fonctionfg
est dérivable et(
fg
)′=
f ′g− g′ fg2 .
Corollaire 2.1.3.79
Démonstration : Il suffit d’utiliser la composition.
Exemple : La dérivée de x 7→ sin xx
définie sur R?+ est x 7→ x cos x− sin x
x2 .
1.4 Bijections et fonctions réciproques
Soit I et J deux intervalles de R et f une application de I dans J. On dit que f est une bijection (ou que f estune application bijective) si tout élément de J a un unique antécédent par f .
Définition 2.1.4.80
Exemples :
1. La fonction carrée de R+ dans lui même est bijective.
2. La fonction carrée de R dans R ne l’est pas.
Remarque : Pour définir une bijection il est important de préciser non seulement l’ensemble de départ maisaussi l’ensemble d’arrivée... Nous y reviendrons plus en détails dans le chapitre suivant.
Soit f une bijection de I dans J. On appelle bijection réciproque de f l’application que J dans I qui associe àtout élément de J son antécédent par f . Elle se note f−1.
Définition 2.1.4.81
Avec les notations précédentes, pour tout x de I, f−1( f (x)) = x. De ce fait ( f−1)−1 = f .
Proposition 2.1.4.82
Remarque : La première propriétés signifie que f f−1 est l’application identité de I qui associe à x dans I,l’élément x lui-même.
41

Avec les notations précédentes.
1. La courbe représentative de f−1 est le symétrique de la courbe représentative de celle de f parla symétrie d’axe la première bissectrice.
2. si f est continue, f−1 aussi.
3. si f est dérivable et que f ′ ne s’annule pas alors f−1 est dérivable et
( f−1)′ =1
f ′ f−1 .
Proposition 2.1.4.83
Nous utiliserons le théorème suivant vu en terminale (nous le démontrerons plus loin).
Soit f une fonction définie sur un intervalle I. Si f est continue et strictement monotone elle réaliseune bijection de I sur son intervalle image J.
Théorème 2.1.4.84 (Théorème de la bijection)
Remarque : Nous restons pour le moment un peu flou sur l’intervalle J. Dans les exemples il sera aisé de ledéterminer.Exemple : La fonction f : x 7→ x2 est continue et strictement croissante sur R+. De plus f (0) = 0 et lim
x→+∞x2 =
+∞. On en déduit que f est une bijection de R+ dans R+. Sa bijection réciproque est la fonction racine carrée.
2 Fonctions logarithmes, exponentielles et puissances
2.1 La fonction logarithme népérien
La fonction logarithme népérien notée ln est l’unique primitive sur R?+ de la fonction x 7→ 1/x qui s’annule
en 1. On a donc pour tout réel strictement positif x :
ln(x) =∫ x
1
dtt
.
Définition 2.2.1.85
42

Remarque : La fonction existe du fait que la fonction x 7→ 1/x est continue sur R?+.
Soit x et y deux élément de R?+,
ln(xy) = ln x + ln y.
Proposition 2.2.1.86
Démonstration : Il suffit de fixer y est de considérer la fonction x 7→ ln(xy)− ln(x)− ln(y).
1. Soit x et y deux élément de R?+, ln(x/y) = ln(x)− ln(y).
2. Soit x un élément de R?+ et n un entier relatif, ln(xn) = n ln(x).
Corollaire 2.2.1.87
La fonction ln est continue sur R?+, lim
x→0ln(x) = −∞ et lim
x→+∞ln(x) = +∞. On en déduit que ln
réalise une bijection de R?+ sur R.
Proposition 2.2.1.88
Démonstration : La fonction ln est strictement croissante car sa dérivée 1/x est positive. Il suffit donc demontrer qu’elle n’est pas majorée. Or pour tout entier naturel n, ln(2n) = n ln(2) et ln(2) > ln(1) = 0. On endéduit que lim
x→+∞ln(x) = +∞. Maintenant, en utilisant que ln(1/x) = − ln(x) on trouve la limite en 0. On peut
conclure avec le théorème de la bijection.
x
y
0 1 2 3 4 5 6 7
2.2 La fonction exponentielle
La fonction exponentielle, noté exp est la fonction réciproque de la fonction logarithme népérien. Elle est définiede R dans R?
+.
Définition 2.2.2.89
Soit x un réel et y un réel strictement positif. On a x = ln(y) si et seulement si y = exp(x).
Proposition 2.2.2.90
43
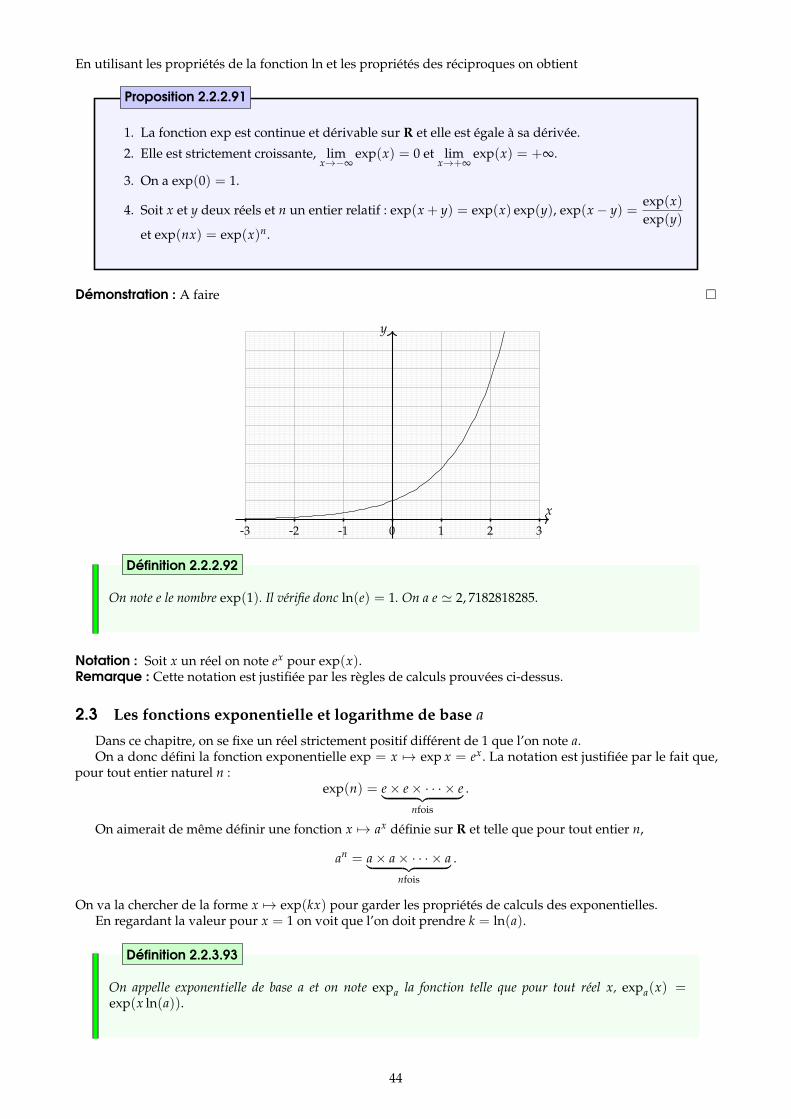
En utilisant les propriétés de la fonction ln et les propriétés des réciproques on obtient
1. La fonction exp est continue et dérivable sur R et elle est égale à sa dérivée.
2. Elle est strictement croissante, limx→−∞
exp(x) = 0 et limx→+∞
exp(x) = +∞.
3. On a exp(0) = 1.
4. Soit x et y deux réels et n un entier relatif : exp(x + y) = exp(x) exp(y), exp(x− y) =exp(x)exp(y)
et exp(nx) = exp(x)n.
Proposition 2.2.2.91
Démonstration : A faire
x
y
-3 -2 -1 0 1 2 3
On note e le nombre exp(1). Il vérifie donc ln(e) = 1. On a e ' 2, 7182818285.
Définition 2.2.2.92
Notation : Soit x un réel on note ex pour exp(x).Remarque : Cette notation est justifiée par les règles de calculs prouvées ci-dessus.
2.3 Les fonctions exponentielle et logarithme de base a
Dans ce chapitre, on se fixe un réel strictement positif différent de 1 que l’on note a.On a donc défini la fonction exponentielle exp = x 7→ exp x = ex. La notation est justifiée par le fait que,
pour tout entier naturel n :exp(n) = e× e× · · · × e︸ ︷︷ ︸
nfois
.
On aimerait de même définir une fonction x 7→ ax définie sur R et telle que pour tout entier n,
an = a× a× · · · × a︸ ︷︷ ︸nfois
.
On va la chercher de la forme x 7→ exp(kx) pour garder les propriétés de calculs des exponentielles.En regardant la valeur pour x = 1 on voit que l’on doit prendre k = ln(a).
On appelle exponentielle de base a et on note expa la fonction telle que pour tout réel x, expa(x) =exp(x ln(a)).
Définition 2.2.3.93
44
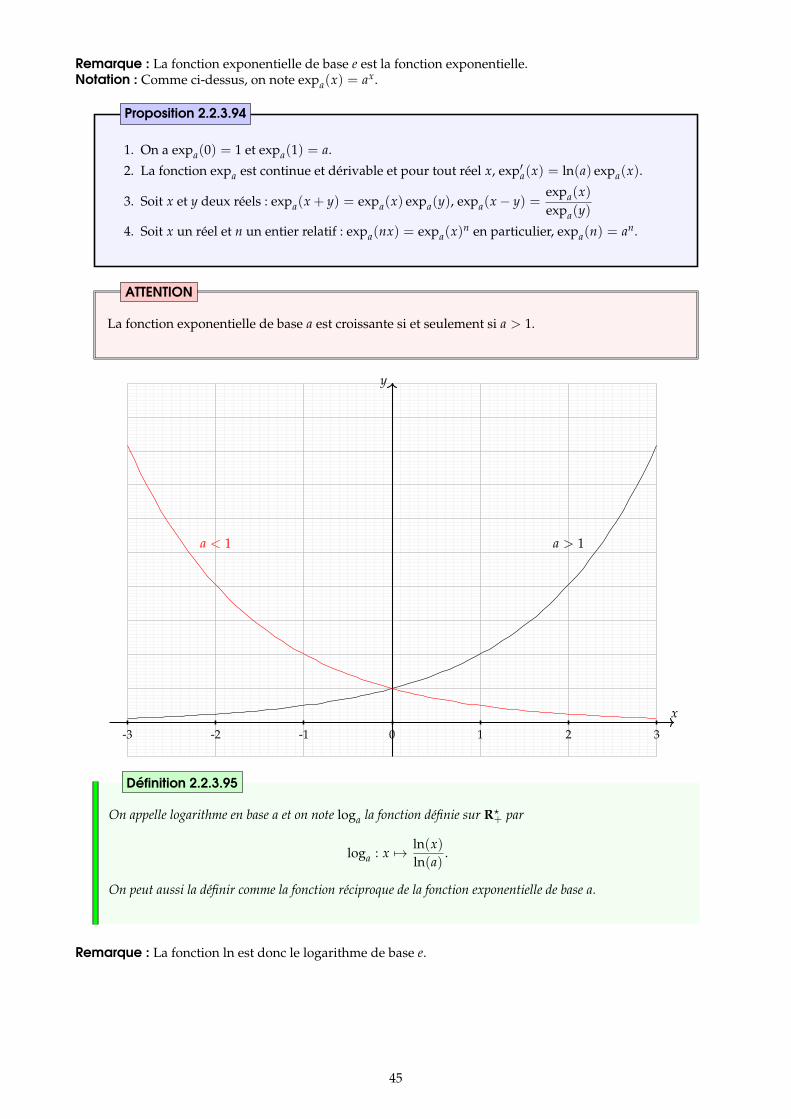
Remarque : La fonction exponentielle de base e est la fonction exponentielle.Notation : Comme ci-dessus, on note expa(x) = ax.
1. On a expa(0) = 1 et expa(1) = a.
2. La fonction expa est continue et dérivable et pour tout réel x, exp′a(x) = ln(a) expa(x).
3. Soit x et y deux réels : expa(x + y) = expa(x) expa(y), expa(x− y) =expa(x)expa(y)
4. Soit x un réel et n un entier relatif : expa(nx) = expa(x)n en particulier, expa(n) = an.
Proposition 2.2.3.94
La fonction exponentielle de base a est croissante si et seulement si a > 1.
ATTENTION
x
y
-3 -2 -1 0 1 2 3
a < 1 a > 1
On appelle logarithme en base a et on note loga la fonction définie sur R?+ par
loga : x 7→ ln(x)ln(a)
.
On peut aussi la définir comme la fonction réciproque de la fonction exponentielle de base a.
Définition 2.2.3.95
Remarque : La fonction ln est donc le logarithme de base e.
45

1. On a loga(1) = 0 et loga(a) = 1.
2. La fonction loga est continue et dérivable et pour tout réel strictement positif x, log′a(x) =1
x ln(a).
3. Soit x et y deux réels et n un entier relatif, loga(x + y) = loga(x) + loga(y), loga(x/y) =loga(x)− loga(y) et loga(an) = n.
Proposition 2.2.3.96
Exemples :
1. Le logarithme de base 10 est appelé logarithme décimal. Il se note log Il est utile car log(10n) = n. Il permetdonc de mesurer l’ordre de grandeur d’un nombre (dans une écriture décimale). On l’utilise par exemplepour les échelles logarithmiques comme le pH où pH = − log[H+] avec [H+] est la concentration en ionshydrogènes exprimées en moles par litre.De fait, si N est un nombre entier et si p est le nombre de chiffres de son écriture décimale alors 10p−1 6N < 10p. De ce fait, p− 1 6 log(N) < p. On en déduit que p est blog(N)c − 1
2. En informatique, on travaille souvent avec des puissances de 2. On utilise alors le logarithme de base 2 ditlogarithme binaire.
Exercice : Soit a > 0. Résoudre l’équation loga x = logx a.
2.4 Fonctions puissances
Soit α un réel, on définit la fonction puissance de R?+ dans lui même par :
x 7→ xα = exp(α ln(x)).
Définition 2.2.4.97
Remarque : Il ne faut pas confondre cette fonction puissance avec l’exponentielle de base a : x 7→ ax =exp(x ln(a)).Exemples :
1. Dans le cas ou α est un réel strictement positif on retrouve les classiques fonctions puissances : x 7→x2, x 7→ x3, . . .. De fait c’est la restriction à R?
+ que l’on retrouve.
2. Dans le cas où α est réel strictement négatif, là encore on retrouve les fonctions classiques : x 7→ x−1 =1x
, x 7→ x−2 =1x2 , . . .
3. Si α est nulle la fonction est constante.
Remarque : Par définition (à cause du ln) les fonctions puissances sont définies sur R?+. Cependant, si α > 0,
quand on fait tendre x vers 0, xα tend vers 0 (ou 1 si α = 0). De ce fait, on peut « prolonger »la fonction à R+. De,plus si α ∈ N, on peut réexprimer cette fonction comme xα = x× · · · × x (α fois) et de ce fait, on peut prolongercette définition à R en entier.
1. La fonction x 7→ xα est continue et dérivable et sa dérivée est x 7→ α.xα−1.
2. Soit α et β deux réels et x et y deux réels strictement positifs. On a
xα.xβ = xα+β, xα.yα = (xy)α (xα)β = xαβ.
3. ln(xα) = α ln(x).
Proposition 2.2.4.98
Démonstration : A faire en exercice.
46

Soit I un intervalle et u et v deux fonction définies et dérivables sur I. On suppose que u prend sesvaleurs dans R?
+. La fonction f : x 7→ u(x)v(x) est dérivable et sa dérivée est :
f ′ : x 7→(
v′(x) ln(u(x)) + v(x)u′(x)u(x)
)f (x).
Proposition 2.2.4.99
Le comportement des fonctions puissances dépend de la valeur de a.
ATTENTION
x
y
0 1 2 3 4
α = −1 α = 2
α = 1/2
En particulier si α > 0, la fonction puissance tend vers 0 en 0 et peut être prolongée par continuité. Ceprolongement sera dérivable en 0 si α > 1, sinon il y a une tangente verticale.Notation : Soit n un entier naturel non nul, pour tout réel strictement positif, (x1/n)n = x. De ce fait la fonctionx 7→ x1/n est la réciproque de la restriction à R?
+ de x 7→ xn. On l’appelle la racine n-ième et elle se note x 7→ n√
x.On remarquera que, si n est impair, la fonction réciproque peut-être définie de R dans R.Exercice : Résoudre l’équation x
√x =√
xx.
3 Étude d’une fonction réelle
Nous allons repasser en revue le plan d’étude d’une fonction réelle.
47

3.1 Périodicité, parité et symétrie
Soit f une fonction numérique.
— Elle est paire si ∀x ∈ D f , (−x ∈ D f et f (−x) = f (x)).
— Elle est impaire si ∀x ∈ D f , (−x ∈ D f et f (−x) = − f (x)).
Définition 2.3.1.100
Exemple : Soit n ∈ N, la fonction f (x) = xn est paire si n est pair et impaire si n est impair.
Soit f une fonction numérique et Γ f son graphe.
La fonction f est paire⇔ le graphe Γ f est symétrique par rapport à (Oy).La fonction f est impaire⇔ le graphe Γ f est symétrique par rapport à O.
Proposition 2.3.1.101
Soit f une fonction numérique.
— Soit α ∈ R. La courbe de f admet la droite d’équation x = α poux axe de symétrie si :
∀x ∈ R, α + x ∈ D f ⇔ 2α− x ∈ D f et ∀x ∈ D f , f (x) = f (2α− x).
— Soit (α, β) ∈ R2. La courbe de f admet le point (α, β) pour centre de symétrie si :
∀x ∈ R, α + x ∈ D f ⇔ 2α− x ∈ D f et ∀x ∈ D f , f (x) = 2β− f (2α− x).
Proposition 2.3.1.102
x
y
αα− h α + h
x
y
α
β
α− h α + h
Remarque : Il n’est pas simple de retenir que si la courbe de f admet la droite d’équation x = α poux axe desymétrie alors f (α + h) = f (α− h) et que si la courbe de f admet le point (α, β) pour centre de symétrie alorsf (α + h) + f (α− h) = 2β.
Soit f une fonction numérique et T un réel non nul. On dit que x est périodique de période T si :
— ∀x ∈ D f , x + T ∈ D f et x− T ∈ D f
— ∀x ∈ D f , f (x + T) = f (x).
On dit alors que T est une période de f .
Définition 2.3.1.103
Exemples :
48

1. La fonction x 7→ sin(x) est périodique de période 2π. Elle est aussi périodique de période 4π.
2. La fonction tangente est périodique de période π.
3. La fonction x 7→ x− bxc est périodique de période 1.
Soit f une fonction périodique de période T. La courbe C de f est invariante par translation devecteur (T, 0).
Proposition 2.3.1.104
Soit f une fonction numérique. On dit que f est périodique s’il existe une réel T non nul tel que f soitpériodique de période T.
Définition 2.3.1.105
Remarque : si f est une fonction périodique, alors elle admet une infinité de période. En effet si T est unepériode alors 2T aussi et par extension tous les nombres de la forme nT pour n ∈ Z− 0. On parlera - par abus- de la période d’une fonction pour la plus petite période positive.
3.2 Limites et croissances comparées
Soit a et b deux réels strictement positifs on a les limites suivantes :
limx→0
xa| ln(x)|b = 0, limx→+∞
ln(x)b
xa = 0, limx→−∞
|x|a exp(bx) = 0 et limx→+∞
exp(bx)xa = +∞.
Proposition 2.3.2.106
Remarques :
1. Les cas où a ou b sont négatifs peuvent se ramener ceux-ci en passant à l’inverse. D’autre part, on n’a
indiquer que les limites qui sont des formes indéterminées. Par exemple, limx→0
ln xx
= −∞ est évidente.
2. On peut dire pour raccourcir que l’exponentielle « l’emporte » sur les puissances et que ces dernières« l’emportent » sur les logarithmes.
Démonstration :
— Commençons par montrer limx→+∞
exp(bx)xa = +∞.
D’abord on voit que pour tout réel x,exp(bx)
xa =
(exp(x)
xa/b
)b. On est donc ramené à prouver que
limx→+∞
exp(x)xα
= +∞ où α = a/b est un réel positif. Si on note f : x 7→ exp(x)xα
. C’est une fonction
dérivable. En calculant la dérivée, on voit qu’elle est croissante au voisinage de +∞. Il suffit donc demontrer que la suite (un) définie par un = f (n) tend vers +∞.Or pour tout entier naturel n,
un+1
un=
en+1nα
en(n + 1)α= e
(n
n + 1
)α
→ e.
Dès lors il existe N tel que pour n > N, un+1 > 2un. Par récurrence on montre alors que pour n > N,un > 2n−NuN .
— Maintenant étudions limx→−∞
|x|a exp(bx) = 0. Il suffit de voir que
|xa exp(bx)| =∣∣∣∣
xa
exp(b(−x))
∣∣∣∣ =∣∣∣∣
(−x)a
exp(b(−x))
∣∣∣∣ .
49

— Il suffit de faire le changement de variables x = et (ou t = ln x). En effet on sait que limt→−∞
(et)a|t|b = 0 et
que limx→0
ln x = −∞ donc, par composition de limites,
limx→0
(eln x)| ln(x)|b = 0.
FMéthode :— Pour étudier la limite d’un polynôme ou d’un quotient de polynôme en en ±∞ on factorise par le terme
de plus haut degré (nous verrons plus tard une autre manière de rédiger).
Par exemple, limx→∞
3x2 + x− 1x2 + 2x + 7
. On écrit
3x2 + x− 1x2 + 2x + 7
=x2(
3 + 1x − 1
x2
)
x2(
1 + 2x + 7
x2
) =3 + 1
x − 1x2
1 + 2x + 7
x2
.
Sous cette forme on voit que la limite est 3.— Pour déterminer la limite d’un quotient de polynôme en a quand les deux polynômes s’annulent, on peut,
au choix, faire une factorisation ou poser x = a + h. Déterminons par exemple
limx→3
x3 − 2x2 − x− 6x2 − x− 6
.
On a
limx→0
sin xx
= 1 limx→0
cos x− 1x2 = −1/2 lim
x→0
ln(1 + x)x
= 1
limx→0
exp(x)− 1x
= 1 limx→0
(1 + x)α − 1x
= α.
Proposition 2.3.2.107 (Limites usuelles)
Démonstration : A part celle sur les cosinus, elles se démontrent en utilisant le limite du taux d’accroissementà l’origine. Pour ce qui est de cosinus, on remarque que pour x non nul,
cos x− 1x2 =
−2 cos2(x/2)x2 = −1
2
(sin(x/2)
x/2
)2
.
3.3 Branches infinies
Le but de l’étude des branches infinies et de préciser le comportement des fonctions quand la courbe de lafonction « part à l’infini ».• Asymptote verticale : Soit a ∈ R. Si lim
x→af (x) = ±∞, on dit que la courbe de f admet une asymptote verticale
d’équation x = a. Par exemple, la fonction f : x → 1x + 2
admet une asymptote verticale d’équation x = −2 car
limx→−2
= ±∞.
x
y
50
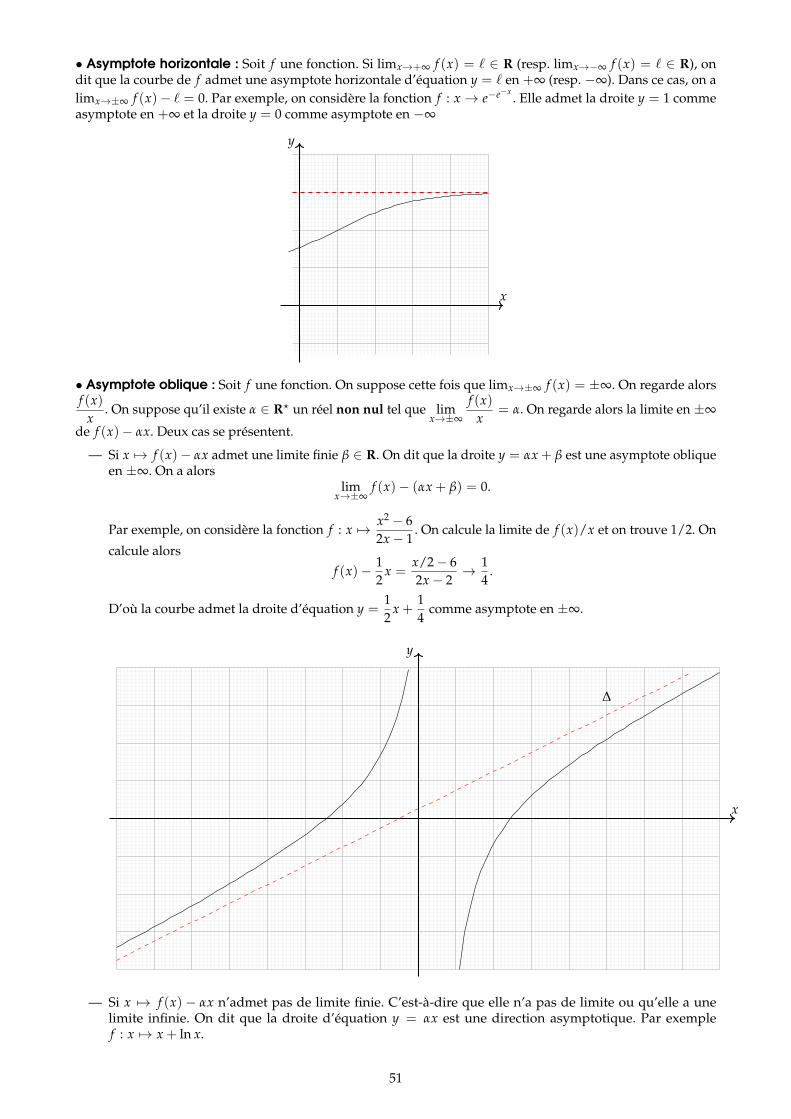
• Asymptote horizontale : Soit f une fonction. Si limx→+∞ f (x) = ` ∈ R (resp. limx→−∞ f (x) = ` ∈ R), ondit que la courbe de f admet une asymptote horizontale d’équation y = ` en +∞ (resp. −∞). Dans ce cas, on alimx→±∞ f (x)− ` = 0. Par exemple, on considère la fonction f : x → e−e−x
. Elle admet la droite y = 1 commeasymptote en +∞ et la droite y = 0 comme asymptote en −∞
x
y
• Asymptote oblique : Soit f une fonction. On suppose cette fois que limx→±∞ f (x) = ±∞. On regarde alorsf (x)
x. On suppose qu’il existe α ∈ R? un réel non nul tel que lim
x→±∞
f (x)x
= α. On regarde alors la limite en ±∞
de f (x)− αx. Deux cas se présentent.
— Si x 7→ f (x)− αx admet une limite finie β ∈ R. On dit que la droite y = αx + β est une asymptote obliqueen ±∞. On a alors
limx→±∞
f (x)− (αx + β) = 0.
Par exemple, on considère la fonction f : x 7→ x2 − 62x− 1
. On calcule la limite de f (x)/x et on trouve 1/2. On
calcule alorsf (x)− 1
2x =
x/2− 62x− 2
→ 14
.
D’où la courbe admet la droite d’équation y =12
x +14
comme asymptote en ±∞.
x
y
∆
— Si x 7→ f (x)− αx n’admet pas de limite finie. C’est-à-dire que elle n’a pas de limite ou qu’elle a unelimite infinie. On dit que la droite d’équation y = αx est une direction asymptotique. Par exemplef : x 7→ x + ln x.
51
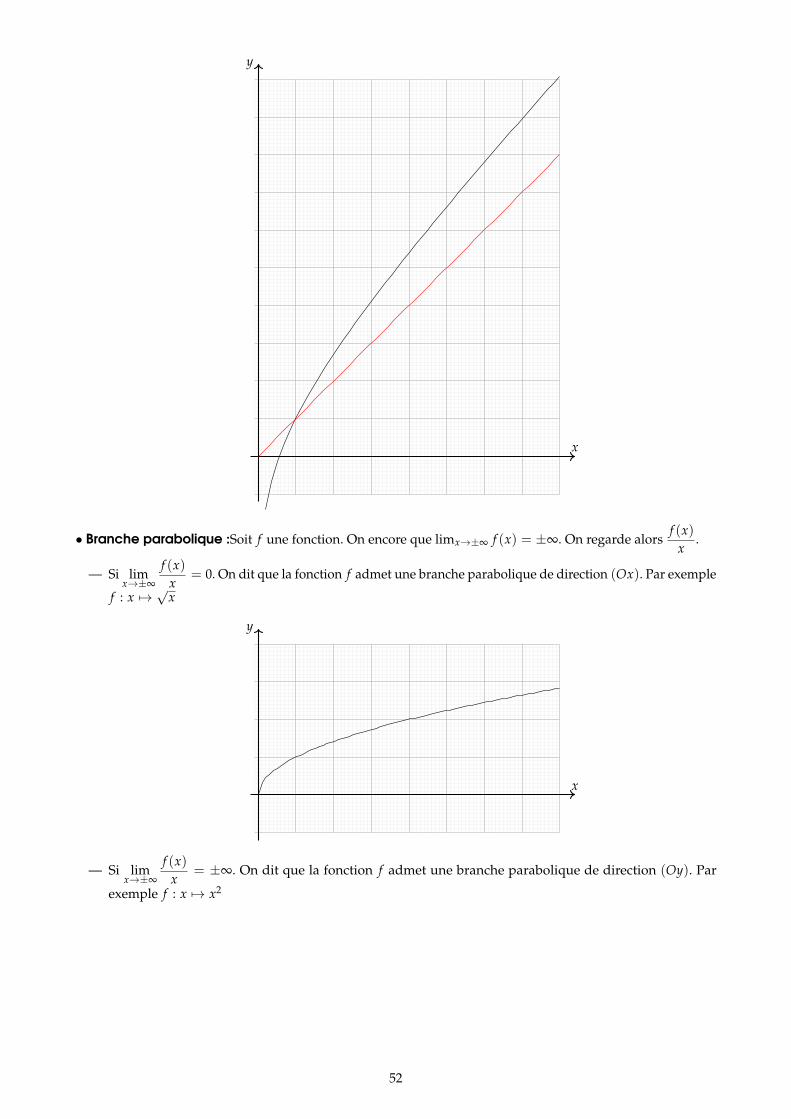
x
y
• Branche parabolique :Soit f une fonction. On encore que limx→±∞ f (x) = ±∞. On regarde alorsf (x)
x.
— Si limx→±∞
f (x)x
= 0. On dit que la fonction f admet une branche parabolique de direction (Ox). Par exemple
f : x 7→ √x
x
y
— Si limx→±∞
f (x)x
= ±∞. On dit que la fonction f admet une branche parabolique de direction (Oy). Par
exemple f : x 7→ x2
52

x
y
4 Fonctions circulaires réciproques
4.1 La fonction arcosinus
La fonction cosinus de R dans R n’est pas bijective. Si on la restreint de [0, π] dans [−1, 1] elle semblebijective.
De fait, la fonction x 7→ cos x est continue, elle est strictement décroissante sur [0, π], cos(0) = 1 etcos(π) = −1. C’est donc bien une bijection de [0, π] dans [−1, 1]. Sa fonction réciproque s’appelle Arccosinus :
Arccos : [−1, 1]→ [0, π].
Remarque : On notera Arccos x et non pas cos−1(x) pour ne pas le confondre avec1
cos x.
Terminologie : La dénomination vient du fait que l’arccosinus est la longeur de l’arc dont le cosinus est connu.
53

1. La fonction Arccosinus est continue et décroissante.
2. La fonction Arccosinus est dérivable sur ]− 1, 1[ et Arccos′(x) =−1√
1− x2.
3. Pour tout x ∈ [−1, 1], Arccos(−x) = π −Arccos(x).
4. On a Arccos(0) = π/2, Arccos(1) = 0 et Arccos(−1) = π.
5. Pour tout x dans [−1, 1], cos(Arccosx) = x.
6. Pour tout x dans [0, π], Arccos(cos x) = x.
7. Le graphe de la fonction Arcosinus est
Proposition 2.4.1.108 (Propriétés de la fonction Arccosinus)
Démonstration : Montrons que pour tout x ∈ [−1, 1], Arccos(−x) = π−Arccos(x). On sait que cos(Arccos(−x)) =−x. De plus cos(π−Arccos(x)) = − cos(Arccos(x)) = −x. Ils ont le même cosinus et sont tous les deux dans[0, π] donc ils sont égaux.
si x ∈ [−1, 1], Arccos(x) est un antécédent de x par cos. Plus précisément c’est le seul antécédentde x par cos qui est dans l’intervalle [0, π]. Par exemple Arccos(cos(9)) 6= 9 mais 9− 2π. En effet,si on note a = Arccos(cos(9)). Par définition, a ∈ [0, π] et cos(a) = cos(9). On peut alors trouverfacilement que a = 9− 2π car cos(9− 2π) = cos(9) par 2π-périodicité de cos et 2π 6 9 6 3π donc9− 2πß[0, π].
ATTENTION
Exercice : Calculer Arccos(cos(10)). On pourra commencer par un dessin.
4.2 La fonction arcsinus
La fonction sinus de R dans R n’est ni injective, ni surjective. Si on la considère de R dans [−1, 1] elle estsurjective mais toujours pas injective. Si on la restreint à [−π/2, π/2] elle semble bijective.
54

De fait, la fonction x 7→ sin x est continue, elle est strictement croissante sur [−π/2, π/2], sin(−π/2) = −1et sin(π/2) = 1. C’est donc bien une bijection de [−π/2, π/2] dans [−1, 1]. Sa fonction réciproque s’appelleArcsinus :
Arcsin : [−1, 1]→ [−π/2, π/2].
1. La fonction Arcsinus est continue et croissante. Elle est impaire.
2. La fonction Arcsinus est dérivable sur ]− 1, 1[ et Arcsin′(x) =1√
1− x2.
3. On a Arcsin(0) = 0, Arcsin(1) = π/2 et Arcsin(−1) = −π/2.
4. Pour tout x dans [−1, 1], sin(Arcsinx) = x.
5. Pour tout x dans [−π/2, π/2], Arcsin(sin x) = x.
6. Le graphe de la fonction Arcsinus est
Proposition 2.4.2.109 (Propriétés de la fonction Arcsinus)
Exercices :
1. Soit x ∈ [−1, 1] calculer cos(Arcsinx).
2. Calculer Arcsin(cos 7).
4.3 La fonction arctangente
La fonction tangente est bijective de ]− π/2, π/2[ dans R. En effet elle est continue, strictement croissante et
limx→−π/2+
tan x = −∞ et limx→π/2−
tan x = +∞.
Sa fonction réciproque est Arctan.
55
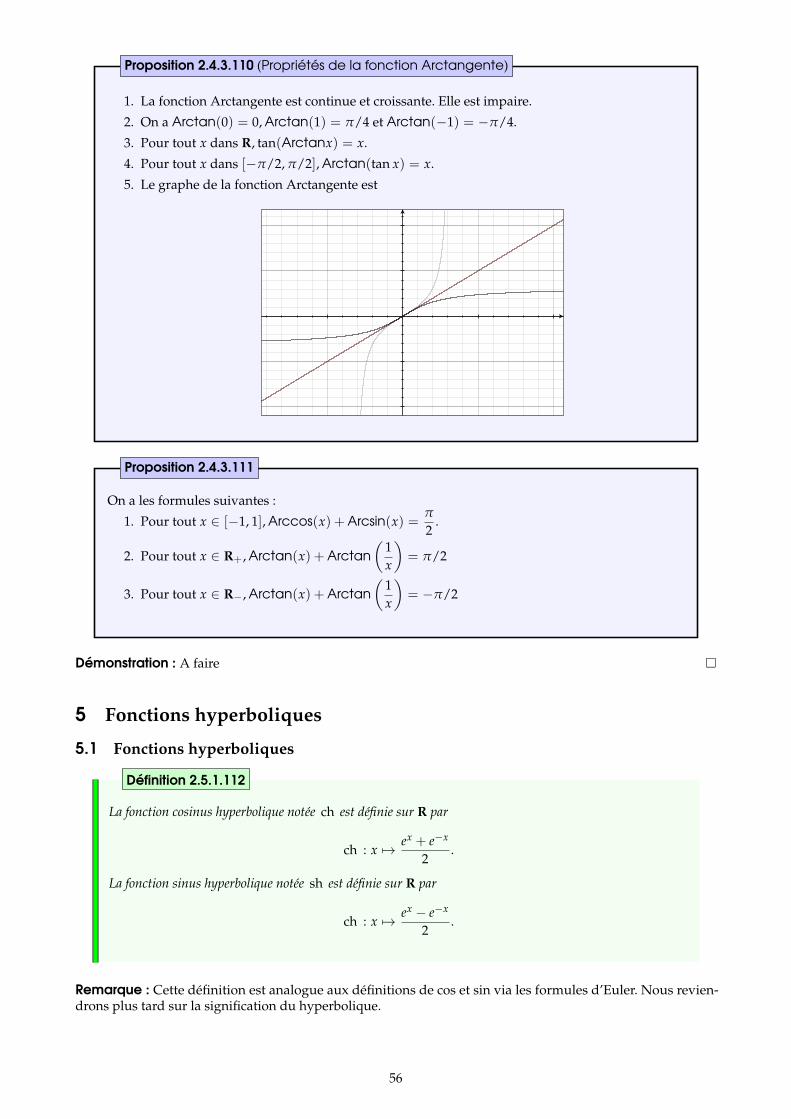
1. La fonction Arctangente est continue et croissante. Elle est impaire.
2. On a Arctan(0) = 0, Arctan(1) = π/4 et Arctan(−1) = −π/4.
3. Pour tout x dans R, tan(Arctanx) = x.
4. Pour tout x dans [−π/2, π/2], Arctan(tan x) = x.
5. Le graphe de la fonction Arctangente est
Proposition 2.4.3.110 (Propriétés de la fonction Arctangente)
On a les formules suivantes :
1. Pour tout x ∈ [−1, 1], Arccos(x) + Arcsin(x) =π
2.
2. Pour tout x ∈ R+, Arctan(x) + Arctan(
1x
)= π/2
3. Pour tout x ∈ R−, Arctan(x) + Arctan(
1x
)= −π/2
Proposition 2.4.3.111
Démonstration : A faire
5 Fonctions hyperboliques
5.1 Fonctions hyperboliques
La fonction cosinus hyperbolique notée ch est définie sur R par
ch : x 7→ ex + e−x
2.
La fonction sinus hyperbolique notée sh est définie sur R par
ch : x 7→ ex − e−x
2.
Définition 2.5.1.112
Remarque : Cette définition est analogue aux définitions de cos et sin via les formules d’Euler. Nous revien-drons plus tard sur la signification du hyperbolique.
56

1. Les fonctions ch et sh sont continues et dérivables et pour tout réel x,
ch ′(x) = sh (x) et sh ′(x) = ch (x).
2. La fonction ch est paire, la fonction sh est impaire.
3. On a ch (0) = 1 et sh (0) = 0. De plus limx→+∞
ch (x) = +∞ et limx→+∞
sh (x) = +∞.
4. Les courbes des fonctions ch et sh sont
-2 -1 1 2
-3
-2
-1
1
2
3
Proposition 2.5.1.113
Démonstration : A faire
Soit x un réel,ch 2(x)− sh 2(x) = 1.
Proposition 2.5.1.114
Démonstration : A faire.
Soit a et b deux réels,
ch (a + b) = ch (a) ch (b) + sh (a) sh (b) et sh (a + b) = ch (a) sh (b) + ch (b) sh (a).
Proposition 2.5.1.115
La fonction tangente hyperbolique notée th est définie sur R par
th : x 7→ sh (x)ch (x)
=e2x − 1e2x + 1
.
Définition 2.5.1.116
57

1. La fonction tangente hyperbolique est définie continue et dérivable sur R.
2. Pour tout réel x, th ′(x) =1
ch 2(x)= 1− th 2(x).
3. La fonction th est impaire.
4. Sa courbe représentative est
-3 -2 -1 1 2 3
-1.0
-0.5
0.5
1.0
5. On a th (0) = 0, limx→−∞
th (x) = −1 et limx→+∞
th (x) = 1.
Proposition 2.5.1.117
6 Fonctions à valeurs complexes
6.1 Généralités
Dans tout ce paragraphe on se fixe un intervalle I de R et f une fonction de I dans C. L’exemple principalsera t 7→ eωt où ω est un complexe.
Avec les notations précédentes, on appelle partie réelle (resp. partie imaginaire) de f la fonction notée Re( f )(resp. Im( f )) définie de I dans R par
Re( f ) : t 7→ Re( f (t))(resp. Im( f ) : t 7→ Im( f (t))).
Définition 2.6.1.118
Remarque : On associe comme cela à f deux fonctions à valeurs réelles.
1. La fonction f est dite continue si et seulement si Re( f ) et Im( f ) le sont.
2. La fonction f est dite dérivable si et seulement si Re( f ) et Im( f ) le sont. Dans ce cas, on notef ′ = (Re( f ))′ + i(Im( f ))′.
3. Si la fonction f est continue et que a et b sont deux éléments de I, on note
∫ b
af (t) dt =
∫ b
aRe( f )(t) dt + i
∫ b
aIm( f )(t) dt.
Définition 2.6.1.119
Les propriétés classiques de la dérivation et de l’intégration s’étendent à ce cas.
Proposition 2.6.1.120
58

6.2 La fonction t 7→ eϕ(t)
Soit ϕ une fonction dérivable sur I et à valeurs dans C. La fonction f : t 7→ exp(ϕ(t)) est dérivableet pour tout t de I,
f ′(t) = ϕ′(t) exp(ϕ(t)).
Proposition 2.6.2.121
Démonstration
Soit ω un nombre complexe. On pose f : t 7→ eωt. Cette fonction est dérivable et vérifie :
∀t ∈ R, f ′(t) = ω f (t) et f (0) = 1.
Corollaire 2.6.2.122
Démonstration : On applique ce qui précède à ϕ(t) = ωt.
Remarque : Cela prouve que la fonction f vérifie l’équation différentielle y′ = ωy et y(0) = 1.
59

3Ensembles,
applications,relations
d’équivalence etrelations d’ordre
1 Logique 611.1 Assertions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 611.2 Ensemble, appartenance et inclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 631.3 Prédicats et quantificateurs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 641.4 Méthodes de démonstration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 651.5 Principe de récurrence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
2 Les ensembles 682.1 Sous-ensembles d’un ensemble . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 682.2 Opérations dans P(E) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 692.3 Produit cartésien . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
3 Applications 713.1 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 713.2 Image directe et image réciproque . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 743.3 Applications injectives, surjectives et bijectives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 753.4 Application réciproque . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 773.5 Familles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
4 Relations binaires 794.1 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 794.2 Relation d’équivalence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 794.3 Relation d’ordre . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
60

1 Logique
1.1 Assertions
On appelle assertion une phrase mathématique qui est soit vraie soit fausse.
Définition 3.1.1.123
Exemple : La phrase « 3 > 1 » est une assertion (qui est vraie) et « 2 = 0 »est une assertion (qui est fausse)Quand on se donne une ou plusieurs assertions, on peut construire de nouvelles assertions avec des
opérateurs logiques. La valeur logique (à savoir si elles sont vraies ou fausses) de ces dernières dépendent desvaleurs logiques des assertions dont on est parti.
Soit P une assertion, l’assertion non P est l’assertion qui est vraie si P est fausse et fausse si P est vraie.
Définition 3.1.1.124 (Négation)
Exemple : Si P est l’assertion « 3 > 1 », non P est « 3 < 1 ».On représente souvent cela sous la forme d’un tableau de vérité.
P V Fnon P F V
Soit P et Q deux assertions. On définit deux nouvelles assertions :
1. L’assertion P ou Q qui est vraie si P ou Q est vraie (et fausse sinon). C’est la disjonction.
2. L’assertion P et Q qui est vraie si P et Q est vraie (et fausse sinon). C’est la conjonction.
Définition 3.1.1.125 (Disjonction et conjonction)
Exemple : « 3 > 1 » ou « 2 = 0 » est vraie. « 3 > 1 » et « 2 = 0 » est fausse.Là encore, le plus simple est de donner les tables de vérités
P V V F FQ V F V F
P ou Q V V V F
P V V F FQ V F V F
P et Q V F F F
Remarques :
1. En mathématiques le ou est inclusif.
2. On note aussi ∧ pour et et ∨ pour ou.
Voici une proposition qui précise les liens entre les opérateurs et la négation.
Soit P et Q deux assertions.
1. L’assertion non (non P) est équivalente à P.
2. L’assertion non (P ou Q) est équivalente à (non P) et (non Q).
3. L’assertion non (P et Q) est équivalente à (non P) ou (non Q).
Proposition 3.1.1.126 (Lois de (De) Morgan)
Remarque : Les deux dernières assertions sont connues sous le nom de Lois de Morgan.Démonstration : Le dire en français pour le comprendre et les tableaux de vérités pour le démontrer. Parexemple pour la deuxième.
61

P V V F FQ V F V F
(P ou Q) V V V Fnon P F F V Vnon Q F V F V
non (P ou Q) F F F V(non P) et (non Q) F F F V
On remarque bien que les deux dernières lignes sont similaires.
Exemple : On choisit un nombre soit P l’assertion « le nombre est pair » et Q l’assertion « le nombre est divisiblepar 3 ». Dès lors P et Q est « le nombre est divisible par 6 ». Le contraire est « le nombre n’est pas divisible par6 », ce qui revient à « il n’est pas divisible par 2 » OU « il n’est pas divisible par 3 ».
Soit P, Q et R trois assertions.
1. L’assertion P ou (Q et R) est équivalente à (P ou Q ) et (P ou R).
2. L’assertion P et (Q ou R) est équivalente à (P et Q ) ou (P et R).
Proposition 3.1.1.127 (Distributivité)
Soit P et Q deux assertions. On définit deux nouvelles assertions :
1. P implique Q. C’est l’implication que l’on note P⇒ Q.
2. P est équivalent à Q. C’est l’équivalence que l’on note P⇔ Q
Elles sont données par les tables de vérité suivantes :
P V V F FQ V F V F
P⇒ Q V F V V
P V V F FQ V F V F
P⇔ Q V F F V
Définition 3.1.1.128 (Implication et équivalence)
Remarque : Cela correspond au sens "classique" en français de l’implication et de l’équivalence. Précisément :
— si P⇒ Q est vraie alors, si P est vraie Q aussi. Par contre si P est faux on ne peut rien dire.
— si P⇔ Q est vraie alors P et Q ont la même valeur logique (que ce soit vrai ou faux).
On notera que l’implication ne signifie pas la causalité. Par exemple « 3 > 1⇒ 0 = 0 » est vraie.Terminologie : L’implication est le connecteur principal en mathématique 1. On a donc beaucoup de manièrepour le dire en français. Pour signifier P⇒ Q, on dira indifféremment,
— P implique Q,
— si P alors Q,
— P est une condition suffisante pour avoir Q,
— Q est une condition nécessaire pour avoir P.
Pour signifier P⇔ Q on dira indifféremment,
— P est équivalent à Q,
— P si et seulement si Q. (On notera d’ailleurs ssi pour si et seulement si).
— P est une condition nécessaire et suffisante pour avoir Q.
Bien évidemment, tout ce qui concerne l’équivalence est symétrique en P et Q.
Le contraire de l’implication P⇒ Q n’est pas une implication. C’est P et (non Q).
ATTENTION
1. En effet pour montrer qu’une assertion Q est vraie, on montrera qu’une assertion P0 est vraie ainsi que P0 ⇒ P1, P1 ⇒ P2, . . . ,Pn−1 ⇒ Pn et Pn ⇒ Q.
62

Exercices :1. (Cours) Montrer que P⇒ Q est équivalente à Q ou (non P).2. Établir la table de vérité de ((P⇒ Q) et (Q⇒ R))⇒ (P⇒ R)3. Établir la table de vérité de A ou (nonA).
Soit P et Q deux assertions. La réciproque de P⇒ Q est Q⇒ P.
Définition 3.1.1.129 (Réciproque)
Exemples :1. Le théorème de Pythagore dit que si un triangle ABC est rectangle en A alors BC2 = AB2 + AC2. C’est
une implication. Sa réciproque - qui est aussi vraie - dit que si BC2 = AB2 + AC2 alors le triangle ABCest rectangle en A.
2. Soit n un nombre entier, on sait que si 6 divise n alors 2 divise n. Par contre la réciproque est fausse.
Soit P et Q deux assertions. L’assertion P⇔ Q est la même que (P⇒ Q) et (Q⇒ P).
Proposition 3.1.1.130 (Equivalence)
Démonstration : Il suffit de faire les tables de vérités.
Remarque : Pour démontrer une équivalence on démontrera souvent les deux implications. Cela s’appelle ladémonstration par double implication.Exemple : Soit (un)n∈N une suite réelle croissante. On a
(un) est bornée ⇔ (un) est convergente.
A-t-on pour (un)n∈N une suite réelle bornée
(un) est croissante ⇔ (un) est convergente?
Soit P et Q deux assertions. La contraposée de l’implication P⇒ Q est l’implication non P⇒ non Q.
Définition 3.1.1.131 (Contraposée)
Soit P et Q deux assertions. Les implications P⇒ Q et non P⇒ non Q sont équivalentes.
Proposition 3.1.1.132
Exemple : Nous voulons montrer que « pour toute fonction continue f de [0, 1] dans R, si f ne s’annule pasalors f garde un signe constant ». Pour montrer cela on se fixe une fonction f continue de [0, 1] dans R arbitraire.La contraposée de notre proposition est « si f change de signe alors f s’annule ». Or cette dernière propositionest une conséquence directe du théorème des valeurs intermédiaires.
1.2 Ensemble, appartenance et inclusion
Un ensemble E est une collection d’éléments. On note x ∈ E (et on lit x appartient à E) pour dire que l’élémentx est un élément de l’ensemble E. On note x /∈ E dans le cas contraire.
Définition 3.1.2.133
63

Exemple : On a 0 ∈ N et −1 /∈ N.
Soit E et F deux ensembles on dit que E est inclus dans F et on note E ⊂ F si et seulement si tous les élémentsde E sont aussi des éléments de F. On dit alors que E est un sous-ensemble (ou une partie) de F.
Définition 3.1.2.134
Soit E et F deux ensembles. Ils sont égaux s’ils ont les mêmes éléments c’est-à-dire si E est inclusdans F et si F est inclus dans E.
Proposition 3.1.2.135 (Double inclusion)
On admettra qu’il existe un ensemble vide qui se note ∅. Il ne contient aucun élément et, de ce fait, est inclusdans tous les ensembles.
1.3 Prédicats et quantificateurs
On doit souvent utiliser des phrases mathématiques qui font intervenir des variables. Par exemple « n estpair » ou « x > 3 ». Ce ne sont pas des assertions car la valeurs logiques de telle phrase dépend de la (ou les)valeur prise par la (ou les) variable. On parle alors de prédicats. En théorie il faut stipuler les ensembles danslesquels on peut choisir les variables. Si on spécialise le prédicats en affectant des valeurs à toutes les variableson obtient une assertion.Exemples :
1. la phrase « n est pair » est un prédicat sur N mais pas sur R car la parité n’a pas de sens dans R.2. la phrase « x + y > 0 » est un prédicat à deux variables (x et y) sur R.
FQuantificateur existentiel
Soit P(x) un prédicat dépendant d’une variable x définie dans un ensemble E. L’assertion
∃x ∈ E, P(x)
est vraie si P(x) est vraie pour au moins une valeur que peut prendre la variable x.
Définition 3.1.3.136
Terminologie : La phrase ∃x ∈ E, P(x) se lit « il existe x dans E tel que P(x) ».Exemples :
1. L’assertion ∃x ∈ R, x > 3 est vrai car il existe au moins un nombre qui soit supérieur à 3, par exemple 4.2. L’assertion ∃x ∈ R, x > 3 et x < −1 est fausse.3. L’assertion ∃x ∈ I, f (x) = 0 signifie que la fonction f s’annule sur l’intervalle I.
Remarques :1. Il faut noter que « x > 3 » n’est pas une assertion car cela dépend de x mais « ∃x ∈ R, x > 3 » en est une.2. La phrase « f (x) = 0 » dépend de x et de f . De ce fait « ∃x ∈ I, f (x) = 0 » ne dépend plus de x mais
encore de f . Par contre « ∃ f ∈ RI , ∃x, f (x) = 0 » est une assertion - qui est vraie.3. Il est souvent utile de préciser dans quel ensemble si situe la variable. Est-ce un nombre? un réel? un
entier? une fonction? Dans ce cas on écrira par exemple
∃x ∈ R, x2 + 1 = 0.
On voit alors l’importance de préciser l’ensemble car, bien évidemment, l’assertion ci-dessus est faussealors que
∃x ∈ C, x2 + 1 = 0 est vraie.
4. L’assertion ∃x ∈ E, P(x) ne dit rien sur le nombre d’éléments x de E tels que P(x) soit vrai. Par commodité,on utilisera la notation
∃!x, P(x)pour signifier qu’il existe un unique x tel que P(x) soit vérifié 2.
2. cela n’est pas un quantificateur car il peut s’exprimer à l’aide des deux autres. Essayez de le faire...
64

Quantificateur universel
Soit P(x) un prédicat dépendant d’une variable x définie sur un ensemble E. L’assertion
∀x ∈ E, P(x)
est vraie si, P(x) est vraie pour toutes les valeurs que peut prendre la variable x.
Définition 3.1.3.137
Terminologie : La phrase ∀x ∈ E, P(x) se lit « pour tout x de E, P(x) » ou « quelque soit x dans E, P(x) ».Exemples :
1. L’assertion ∀x ∈ R, x > 3 est fausse car il existe des nombre qui sont inférieurs à 3.
2. L’assertion ∀x ∈ R, x > 3 ou x < 7 est vraie.
3. L’assertion ∀x ∈ R, f (x) = 0 signifie que la fonction f est la fonction nulle.
4. L’assertion ∀x ∈ I, ∀y ∈ I, (x > y)⇒ f (x) > f (y) signifie que l’application est croissante.
Remarque : Il faut noter que,là encore ∀x ∈ R, P(x) ne dépend pas de x contrairement à P(x).Exercice : Quelle est la valeur logique des assertions suivantes :
∃ f , ∃x, f (x) = 0 ∃x, ∃ f , f (x) = 0∀ f , ∃x, f (x) = 0 ∀x, ∃ f , f (x) = 0∃ f , ∀x, f (x) = 0 ∃x, ∃ f , f (x) = 0∀ f , ∃x, f (x) = 0 ∀x, ∃ f , f (x) = 0
Négation de quantificateur
Commençons par un exemple.Exemple : On dispose des boules dans une urne. Le contraire de « toutes les boules sont rouges » est « il y a aumoins une boule rouge » et non pas « toutes les boules ne sont pas rouges ». De même le contraire de « il y a(au moins) une boule rouge » est « aucune boule n’est rouge » ce qui revient à « toutes les boules ne sont pasrouges ».
Soit P(x) un prédicat dépendant de x.
1. L’assertion non (∀x, P(x)) est équivalente à ∃x,non P(x).
2. L’assertion non (∃x, P(x)) est équivalente à ∀x,non P(x).
Proposition 3.1.3.138
Exemples :
1. Dire qu’une fonction f ne s’annule pas revient à non (∃x, f (x) = 0) ce qui est équivalent à ∀x, f (x) 6= 0.Ecrire de même de deux manière que f n’est pas la fonction nulle.
2. Soit E un ensemble et A, B deux parties de E. Que signifie ∀x ∈ E, x ∈ A⇒ x ∈ B ? Quel est le contraire ?
3. Le contraire de « f est croissante » n’est pas « f est décroissante ». Cela se quantifie par : ∃x ∈ I, ∃y ∈I, (x > y) et f (x) < f (y).
1.4 Méthodes de démonstration
Nous allons essayer de faire un catalogue des principales méthodes de démonstration.
Le raisonnement par implication
C’est le raisonnement le plus classique. Cela consiste à essayer de montrer que P implique Q (c’est-à-direque P⇒ Q est vrai). Pour cela on part de P, puis par implications on arrive à Q.Exemple : Montrons par exemple que pour tout entier naturel, si n est impair alors n2 est impair. Soit n unentier naturel Si n est impair, alors il existe un entier k tel que n = 2k + 1. Alors, n2 = (2k + 1)2 = 4k2 + 4k + 1 =2(2k2 + 2k) + 1. Donc n2 est impair.
65

On peut l’écrire avec des implications
n est impair ⇒ ∃k ∈ N, n = 2k + 1
⇒ ∃k ∈ N, n2 = (2k + 1)2
⇒ ∃k ∈ N, n2 = 2(2k2 + 2k) + 1⇒ ∃K ∈ N, n2 = 2K + 1⇒ n2 est impair.
Le raisonnement par équivalence
On cherche cette fois à montrer que P est équivalent à Q (c’est-à-dire que P ⇔ Q est vrai). Pour cela onprocède comme précédemment mais en n’utilisant que des équivalences. C’est typiquement le raisonnementque l’on réalise lors de la résolution d’équations ou d’inéquations.
Le raisonnement par double implication
Cela consiste encore à montrer que P est équivalent à Q (c’est-à-dire que P⇔ Q est vrai) en montrant que Pimplique Q et que, réciproquement Q implique P. Très souvent dans ce genre de raisonnement, l’un des sensest plus simple que l’autre. On commence par celui-ci.Exemple : On se place dans le plan. On veut montrer que deux droites sont parallèles si et seulement si ellessont orthogonales à une même troisième.
Le raisonnement par contraposé
On veut démontrer l’implication P⇒ Q. Pour cela on montre sa contraposé (qui lui est équivalente) nonP⇒ non Q.Exemple : Montrons que si p2 est pair alors p est pair.
Le raisonnement par l’absurde
On veut démontrer une assertion P. Pour cela on montre que non P est fausse. On suppose que non P estvraie et on aboutit à une absurdité.Exemple : Montrons que
√2 est irrationnel.
La disjonction de cas
On veut démontrer l’implication P⇒ Q. Pour cela on montre [(P et A)⇒ Q] et [(P et nonA)⇒ Q]
Exemple : Soit n un entier naturel. Montrer quen(n + 1)
2est un entier.
Analyse-Synthèse
On suppose que le problème que l’on veut démontrer. On essaye alors de trouver des informations sur lerésultat. On suppose alors ces informations pro montrer le problème initial. Il est important de bien séparer laphase d’analyse de la phase de synthèse.Exemple : Montrer que toute fonction de R dans R est somme d’une fonction paire et d’une fonction impaire.
1.5 Principe de récurrence
Revoyons maintenant les raisonnements par récurrences. Nous y reviendrons un peu plus tard en justifiantplus proprement pourquoi cela est vrai.
Soit P(n) un prédicat défini sur N. Si :
1. P(0) est vraie.
2. ∀n ∈ N, (P(n)⇒ P(n + 1))
alors pour tout entier naturel n, P(n) est vraie.
Théorème 3.1.5.139 (Principe de récurrence)
Remarques :
66

1. Le principe de récurrence est intuitif. On suppose en effet que P(0) est vraie et que P(0) implique P(1).De ce fait P(1) est vraie. Maintenant on suppose que P(1) implique P(2). De ce fait P(2) est vraie. Etainsi de suite. De fait, quand dans une rédaction on a envie d’écrire « et ainsi de suite » c’est que la bonnerédaction est une récurrence.
2. Il est important de bien savoir rédiger une récurrence, en particulier la deuxième propriétés (qui s’appellehérédité). Il faut bien comprendre le sens des parenthèses. En effet
(∀n ∈ N, P(n))⇒ P(n + 1)
est stupide. En pratique, on fixe UN entier noté n et on suppose P(n) juste pour CET entier. Il reste alors àmontrer que P(n + 1) est vraie.
3. Il faut faire attention aux fausses récurrences où vous n’utilisez pas P(n) pour montrer P(n + 1). Ce n’estlogiquement pas faux mais cela montre que vous n’avez pas beaucoup de recul.
Exemples :
1. Montrons par récurrence que ∀n ∈ N, 2n > n + 1.
— Initialisation Pour n = 0, 1 = 20 > 0 + 1 est vrai.
— Hérédité Soit n une entier quelconque fixé. On suppose que 2n > n + 1. Dès lors
2n+1 = 2.2n > 2(n + 1) = 2n + 2.
Or 2n + 2 > n + 2 car n est positif. On en déduit que 2n+1 > (n + 1) + 1.
Par le principe de récurrence, ∀n ∈ N, 2n > n + 1.
2. Montrons par récurrence que ∀n ∈ N, 3n > n2. Avant de se lancer dans la récurrence, essayons de fairel’hérédité. On suppose que 3n > n2. Dès lors
3n+1 = 3.3n > 3n2.
On voudrait donc avoir 3n2 > (n + 1)2 ⇔ 2n2 − 2n− 1 > 0. Une rapide étude de signe nous montre quece n’est vrai que pour n supérieur ou égal à 2. Il faut donc découper le problème en deux. On le montre àla main pour n = 0 et n = 1 puis on fait la récurrence pour n > 2.
Il existe quelques variantes de la récurrence.
Soit n0 un entier relatif et P(n) un prédicat sur [[ n0 ; +∞ [[. Si :
1. P(n0) est vraie.
2. ∀n ∈ [[ n0 ; +∞ [[ , (P(n)⇒ P(n + 1))
alors pour tout entier n supérieur à n0, P(n) est vraie.
Proposition 3.1.5.140
Soit n0 un entier relatif et P(n) un prédicat sur [[ n0 ; +∞ [[. Si :
1. P(n0) et P(n0 + 1) est vraie.
2. ∀n ∈ [[ n0 ; +∞ [[ , (P(n) et P(n + 1)⇒ P(n + 2))
alors pour tout entier n supérieur à n0, P(n) est vraie.
Proposition 3.1.5.141 (Récurrence à deux pas)
Exemple : Soit (un) la suite définie par u0 = 2, u1 = 1 et pour tout entier naturel un+2 = un+1 + 2un. Montronspar récurrence que pour tout entier n, un = (−1)n + 2n.
A faire
Pour finir,
67

Soit n0 un entier relatif et P(n) un prédicat sur [[ n0 ; +∞ [[. Si :
1. P(n0) est vraie.
2. ∀n ∈ [[ n0 ; +∞ [[ , (P(n0) et P(n0 + 1) · · · et P(n)⇒ P(n + 1))
alors pour tout entier n supérieur à n0, P(n) est vraie.
Proposition 3.1.5.142 (Récurrence « forte »)
Remarque : La différence est que là, pour montrer P(n + 1), on suppose que P est vraie pour tous les entiersinférieurs ou égaux à n et non plus que pour n.Démonstration : Il suffit d’appliquer le principe de récurrence au prédicat : Q(n) : ∀k ∈ [[ n0 ; n ]] P(k).
Exemple : Montrons que tout entier naturel n supérieur ou égal à 2 peut s’écrire comme un produit de nombrepremier. On rappelle qu’un entier naturel est premier s’il n’est divisible que par lui-même et par 1.
— Initialisation Pour n = 2, C’est un nombre premier— Hérédité Soit n une entier quelconque fixé. On suppose que tout entier compris entre 2 et n s’écrit comme
un produit de nombres premiers. On considère n + 1. S’il est premier c’est fini. S’il n’est pas premier,il existe un diviseur d compris entre 2 et n. De même n/d est un entier compris entre 2 et n. Il suffitd’appliquer l’hypothèse de récurrence à d et à n/d.
Par le principe de récurrence, tout entier naturel n supérieur ou égal à 2 peut s’écrire comme un produit denombre premier.
2 Les ensembles
Nous allons regarder les opérations que l’on peut faire avec les ensembles. Pour des problèmes de logiquesnous considérerons la plupart des temps des parties d’un grand ensemble qui sert d’univers.
2.1 Sous-ensembles d’un ensemble
Dans toute cette section, on se fixe un ensemble E.
Soit P(x) un prédicat défini sur E. On définit l’ensemble
F = x ∈ E | P(x).
C’est la partie de E contenant les éléments x de E tels que P(x) soit vrai.
Définition 3.2.1.143
Remarque : C’est l’une des méthodes de décrire un ensemble. Il y en a essentiellement deux autres.— Description « en extension » : cela consiste à donner la liste de tous les éléments de l’ensemble entre
accolades.— Description paramètres : nous y reviendrons un peu plus loin, mais essentiellement cela consiste à donner
les éléments en fonction de paramètres. Par exemple :
(2k, k + 1) | k ∈ N ⊂ N2.
On définit l’ensemble P(E) qui est l’ensemble dont les éléments sont les parties de E.
Définition 3.2.1.144
Exemples :1. Si E = 0, 1 alors P(E) = ∅, 0, 1, 0, 1. Il faut bien faire attention à distinguer 0 qui est un
élément de E du singleton 0 qui est une partie de E.2. Que vaut P(∅) ? et P(P(∅)) ?
68

2.2 Opérations dans P(E)
Soit E un ensemble et A et B deux parties de E.
1. La réunion de A et B : A ∪ B = x ∈ E | x ∈ A ou x ∈ B.2. L’intersection de A et B : A ∩ B = x ∈ E | x ∈ A et x ∈ B.3. Le complémentaire de A dans E : E A = A = x ∈ E | x /∈ A.4. La différence : A− B = x ∈ E | x ∈ A et x /∈ B.5. La différence symétrique : A∆B = (A ∪ B) \ (A ∩ B).
Définition 3.2.2.145
A B
A ∪ B
A B
A ∩ B
A
A B
A− B
Remarque : La notation E A est plus précise que A car elle indique dans quel "univers" on se situe.Exercice : On pose E = R, A = [0, 3] et B =]− 1, 2[. Déterminer A ∪ B, A ∩ B, A, A− B et B− A.Exercice : On pose E = R, F = N et A = 0, 1. Déterminer E A et F A.
Soit E un ensemble et A et B deux parties de E on a :
1. A ∪ B = B ∪ A
2. A ∪ (B ∪ C) = (A ∪ B) ∪ C
3. A ∩ B = B ∩ A
4. A ∩ (B ∩ C) = (A ∩ B) ∩ C
Proposition 3.2.2.146 (Commutativité et associativité de la réunion et de l’intersection)
Avec les mêmes notations.(A ∩ B) ⊂ A et A ⊂ (A ∪ B).
Proposition 3.2.2.147
Exercice : Soit E un ensemble. Soit A, B et C trois parties de E. Montrer que
(A ∪ B) ⊂ (A ∪ C)(A ∩ B) ⊂ (A ∩ C)
⇒ B ⊂ C.
69

Soit E un ensemble. Soit A et B deux parties de E.
1. A ∩ B = A⇔ A ⊂ B
2. A ∪ B = A⇔ B ⊂ A
Proposition 3.2.2.148
Soit E un ensemble et A, B et C trois parties de E on a :
1. L’intersection est distributive sur la réunion : A ∩ (B ∪ C) = (A ∪ B) ∩ (A ∪ C)
2. La réunion est distributive sur l’union : A ∪ (B ∩ C) = (A ∩ B) ∪ (A ∩ B)
Proposition 3.2.2.149 (Distributivité)
Notation : On généralise cela à un ensemble de parties. Si (Ai)i∈I sont des parties de E on note⋃
i∈IAi = x ∈ E | ∃i ∈ I, x ∈ Ai et
⋂
i∈IAi = x ∈ E | ∀i ∈ I, x ∈ Ai.
Nous allons maintenant regarder le complémentaire d’une partie. Intuitivement cela correspond aux élé-ments qui ne sont pas dans la partie que l’on regarde. Précisément on a :
Soit E un ensemble et A, B deux parties de E. On a :
1. A = EB si et seulement si B = E A.
2. E(E A) = A.
3. A ⊂ B⇔ EB ⊂ E A.
Proposition 3.2.2.150
De plus, les liens entre le complémentaire et les réunions et intersections sont donnés par la proposition suivante.
Soit E un ensemble et A, B deux parties de E. On a :
1. Le complémentaire d’une réunion est l’intersection des complémentaires :
E(A ∪ B) = E A ∩ EB.
2. Le complémentaire d’une intersection est la réunion des complémentaires :
E(A ∩ B) = E A ∪ EB.
Proposition 3.2.2.151
Remarque : C’est juste les lois de Morgan.
2.3 Produit cartésien
Soit E et F deux ensembles. On appelle produit cartésien de E et F, et on note E× F, l’ensemble dont leséléments sont les couples (x, y) où x est un élément de E et y un élément de F. On a donc :
E× F = (x, y) | x ∈ E, y ∈ F.
Définition 3.2.3.152
70

Notation : On notera E2 pour E× E.Remarques :
1. On prendra garde que l’ordre compte dans un couple. L’élément (1, 2) ∈ R× R est différent de l’élément(2, 1).
2. Il ne faut pas confondre le couple (1, 2) avec l’ensemble 1, 2.Exemple : On considère l’ensemble R × R. Ses éléments sont les couples de nombres réels. On peut doncreprésenter cet ensemble de la manière suivante. On considère le plan P et on le muni d’un repère (O,
−→i ,−→j ).
On associe alors à un point du plan son couple de coordonnées et réciproquement.Voici une représentation de [0, 2]× [−1, 3].
DessinOn peut aussi généraliser le produit cartésien à plus de deux ensembles.
Soit n un entier naturel supérieur ou égal à 2 et E1, E2, . . . , En des ensembles. Le produit cartésien E1 × E2 ×· · · × En est défini par :
n
∏i=1
Ei = E1 × E2 × · · · × En = (x1, x2, . . . , xn) | x1 ∈ E1, x2 ∈ E2, . . . , xn ∈ En.
La liste ordonnée (x1, x2, . . . , xn) est appelée un n-uplet.
Définition 3.2.3.153
Notation : De même que ci dessus, on notera En pour E× E× · · · × E (n fois).
3 Applications
3.1 Généralités
Soit E et F deux ensembles. Une application de E dans F est la donnée d’une partie Γ de E× F telle que pourtout x dans E il existe un unique y dans F tel que (x, y) ∈ Γ. La partie Γ s’appelle le graphe de l’application.
Définition 3.3.1.154
Remarques :
1. Cette définition correspond bien à la notion d’application vue en terminale. En effet, à tout élément x de Eon associe l’unique élément y de F tel que (x, y) ∈ Γ.
2. Il faut retenir que l’on associe, par définition, à tout élément de l’ensemble de départ, un unique élémentde l’ensemble d’arrivé. Il faut aussi noter que l’ensemble de départ et d’arrivé font partie intégrante de ladéfinition.
Exemples :
1. L’application "carré" de R dans R qui associe à un nombre x son carrée. Son graphe est la paraboled’équation y = x2.
2. L’application de N dans [0; 1] qui associe à un entier n le nombre sin(n) si n est pair et cos(n) s’il estimpair.
3. Pour des ensembles finis on peut la représenter par des diagrammes :
71

E F
×
×
×
×
×
×
×
×
×
Terminologie :
— On note f : E→ F une application de E dans F.
— Soit f : E→ F, l’ensemble E s’appelle ensemble de départ et F s’appelle ensemble d’arrivé.
— Soit f : E → F. Si x est un élément de E, l’élément de F que l’on lui associe est noté f (x) et s’appellel’image de x par f .
— Si y est un élément de F, les éléments x de E tels que y = f (x) s’appellent les antécédents de y par f . Ilfaut noter qu’un élément peut avoir zéro, un ou plusieurs antécédents.
— Soit f et g deux fonctions de E dans F. Elles sont égales si :
∀x ∈ E, f (x) = g(x).
— On notef : E → F
x 7→ f (x)
— L’ensemble des application de E dans F se note FE ou F (E, F) (le F est pour fonction).
Exemples :
1. Soit E un ensemble, on appelle application identité et on note IdE l’application :
IdE : E → Ex 7→ x.
2. Soit E et F deux ensembles et y0 ∈ F un élément fixé. On appelle application constante de valeur y0l’application qui associe à tout élément x de E, l’élément y0.
3. Soit E et F deux ensembles. On appelle première projection (resp. deuxième projection) l’application
p1 : E× F → E(x, y) 7→ x
(resp. p2 : E× F → F
(x, y) 7→ y
).
4. La fonction partie entière de R dans R associe à tout réel x, l’unique entier p tel que p > x < p + 1. Songraphe est :
-4 -3 -2 -1 0 1 2 3 4
-3
-2
-1
1
2
3
72

Soit E un ensemble et A une partie de E. On appelle fonction indicatrice de A (ou fonction caractéristique deA) et on note 1A (on trouve aussi χA) la fonction de E dans 0, 1 définie par
1A : E → 0, 1x 7→
1 si x ∈ A0 si x /∈ A
.
Définition 3.3.1.155
Les fonctions indicatrices permettent de transformer les problèmes sur les ensembles en problèmes sur lesfonctions (et cetla peut-être utile).
Soit E un ensemble et A, B deux parties de E. On a
1A∩B = 1A × 1B
Proposition 3.3.1.156
Exercice : Trouver les formules pour 1A, 1A∪B et 1A\B.Comme on a vu les ensembles de départ et d’arrivé font partie intégrante de la définition d’une application.
Nous aurons donc recours à des prolongements et des restrictions.
Soit E et F deux ensembles.
— Soit f : E→ F et A ∈P(E). On appelle restriction de f à E et on note f|A l’application :
f|A : A → Fx 7→ f (x).
— Soit A ∈P(E) et f : A→ F. Un prolongement de f à E est une application f : E→ F telle que
∀x ∈ A, f (x) = f (x).
Définition 3.3.1.157 (Restriction et prolongement)
Exemples :
1. Soit [.] la fonction partie entière de R dans R. Sa restriction à l’intervalle [0; 1[ est la fonction constanteégale à zéro. Sa restriction à N est la fonction IdN.
2. Soitf : ]0;+∞[ → R
x 7→ x ln x.
On veut prolonger f en 0. On sait quelim
x→0+x ln x = 0.
On prolongera f par continuité en posant f définie par :
f : [0;+∞[ → R
x 7→
x ln x si x > 00 si x = 0.
Dessin
73

Soit E, F et G trois ensembles. Soit f : E → F et g : F → G. L’application composée, qui se note g f estdéfinie par :
g f : E → Gx 7→ g( f (x)).
Définition 3.3.1.158
Exemples :
1. Soit f : R → R l’application définie par f (x) = cos(x) et g : R → R l’application définie par g(x) = x2.Alors f g est x 7→ cos(x2) et g f est x 7→ cos2 x. On voit que la composition n’est pas commutative.
2. Dessin avec des patates.
Soit E, F, G et H quatre ensembles. Soit f : E→ F, g : F → G et h : G → H. On a
h (g f ) = (h g) f .
Proposition 3.3.1.159 (Associativité de la composition)
3.2 Image directe et image réciproque
Soit E et F deux ensembles ainsi que f : E→ F.
— Soit A ∈P(E). L’image directe de A par f est :
f (A) = y ∈ F | ∃x ∈ A, y = f (x) = f (x) | x ∈ A.
— Soit B ∈P(F). L’image réciproque de B par f est :
f #(B) = x ∈ E | f (x) ∈ B.
— On appelle image de f et on note Im ( f ) l’image de l’ensemble de départ : Im ( f ) = f (E).
Définition 3.3.2.160
Remarques :
1. L’image directe d’une partie A par une application f : E→ F est l’ensemble des images par f des élémentsde A. C’est une partie de F.
2. L’image réciproque d’une partie B par une application f est l’ensemble des antécédents par f des élémentsde B. C’est une partie de E.
Exemples :
1. Soit f : R→ R définie par ∀x ∈ R, f (x) = x2 + x. Soit A = [−3; 4] et B =]2, 6].On cherche f (A) et f #(B).Dans ce cadre, nous pourrons plus tard utiliser des théorèmes du type du TVI. Essayons de la faire pourle moment « à la main ». On peut remarquer que graphiquement on voit la solution à savoir :
f (A) = [−1/4, 20] et f #(B) = [−3,−2[∪]1, 2].
Cela se prouve par le calcul.Pour f (A). On cherche
f (A) = y ∈ R | ∃x ∈ A, f (x) = y.On cherche donc les éléments y tels que l’équation x2 + x = y a des solutions dans A.Pour f #(B). On cherche
f #(B) = x ∈ R | f (x) ∈ B.On résout donc l’inéquation 2 < x2 + x 6 6.
74

Dessin
2. Un exemple avec des patates.
Soit f ∈ F (E, F). Soit A et B des parties de E
1. f (A ∪ B) = f (A) ∪ f (B)
2. f (A ∩ B) ⊂ f (A) ∩ f (B)
Proposition 3.3.2.161
Démonstration
Remarque : Soit f : E → F et A et B deux parties de E. Alors f (A ∩ B) ⊂ f (A) ∩ f (B) mais ce n’est pasobligatoirement une égalité. En effet, si y est dans f (A ∩ B), il existe x dans A ∩ B tel que y = f (x). Dès lors yest dans f (A) car x est dans A et de même y est dans f (B) car x est dans B. Par contre si f n’est pas injective, iln’y a pas obligatoirement égalité par exemple si A et B sont disjoints et que F est un singleton.Exercice : Trouver et démontrer les relations analogues avec f #(A ∩ B) et f #(A ∪ B). (ici tout marche bien)
3.3 Applications injectives, surjectives et bijectives
On a vu que si f : E→ F était une application alors tous les éléments x de E on une unique image dans F. Àl’inverse, si y est un élément de F il peut avoir 0, 1 ou plusieurs antécédents.
Soit E et F deux ensembles ainsi que f : E→ F.
— L’application f est dite injective si tous les éléments de F ont au plus un antécédent.
— L’application f est dite surjective si tous les éléments de F ont au moins un antécédent.
— L’application f est dite bijective si tous les éléments de F ont exactement un antécédent.
Définition 3.3.3.162
Terminologie : Une application injective s’appelle une injection ; une application surjective s’appelle unesurjection ; une application bijective s’appelle une bijection.Exemples :
1. Illustrons ces définitions avec des patates.
2. Illustrons maintenant cela avec des application de R dans R
— Une application est injective si son graphe coupe au plus une fois les droites horizontales. Parexemple x 7→ ex.
— Une application est surjective si son graphe coupe toutes les droites horizontales. Par exemplex 7→ x3 − x. On prendra garde à l’ensemble d’arrivée. Par exemple x 7→ x2 n’est pas surjective si elleest considérée de R dans R mais elle le devient si on regarde de R dans R+.
— L’application de R dans R qui associe x3 à x est bijective.
Faire un exercice avec des papates
Avec les notations précédentes.
f est bijective⇔ ( f est injective et surjective).
Proposition 3.3.3.163
Nous allons maintenant réécrire ces définitions avec des quantificateurs :
— f surjective⇔ ∀y ∈ F, ∃x ∈ E, y = f (x).
75

— f bijective⇔ ∀y ∈ F, ∃!x ∈ E, y = f (x).
La quantification de l’injctivité est moins immédiate. On a
Avec les mêmes notations
f injective⇔ (∀(x, x′) ∈ E× E, f (x) = f (x′)⇒ x = x′).
Proposition 3.3.3.164
Remarque : C’est cela que nous prendrons comme définition.Démonstration :
— ⇒ : On suppose que f est injective. Soit x et x′ deux éléments de E ayant même image y. Ils sont tous lesdeux dans f #(y). Or cet ensemble a au plus un élément d’où x = x′.
— ⇐ : On suppose l’assertion de gauche. Par l’absurde, supposons qu’il existe un élément y de F telque f #(y) a plus de deux éléments. On choisit alors x et x′ distincts dans f #(y). Dès lors, commef (x) = f (x′) = y on a x = x′ ce qui est impossible car on les a pris distincts.
Remarque : En pratique on se servira aussi de la contraposée. On a
f injective⇔ (∀(x, x′) ∈ E× E, x 6= x′ ⇒ f (x) 6= f (x′)).
Exercice : Écrire la quantification de non injective, non surjective.Exemple : Montrons à l’aide de la quantification que l’application x 7→ x3 est injective sur R.
Soit x et x′ deux éléments de R. On suppose que x3 = x′3 et on veut montrer que x = x′. On a
x3 = x′3 ⇔ x3 − x′3 = 0⇔ (x− x′)(x2 + xx′ + x′2).
On suppose que x′ est fixé et on étudie le trinôme x 7→ x2 + xx′ + x′2. Son discriminant est ∆ = −3x′2.
— si x′ 6= 0 alors ∆ < 0 et ∀x ∈ R, x2 + xx′ + x′2 6= 0.
— si x′ = 0 alors ∆ = 0 et la racine double de x2 = 0 est x = 0.
On a bienx3 = x′3 ⇒ x = x′.
Soit E, F et G trois ensembles ainsi que f : E→ F et g : F → G.
1. Si f et g sont injective alors g f aussi.
2. Si f et g sont surjective alors g f aussi.
3. Si g f est bijective alors g aussi.
Proposition 3.3.3.165
Démonstration :
1. On suppose que f et g sont injectives et on veut montrer que g f l’est aussi. Soit x et x′ tels queg f (x) = g f (x′). On a g( f (x)) = g( f (x′)) donc f (x) = f (x′) car g est injective. De plus f étant aussiinjective f (x) = f (x′) implique que x = x′.
Exercice : Montrer que Soit E, F et G trois ensembles ainsi que f : E→ F et g : F → G.
1. Si g f est injective alors f aussi.
2. Si g f est surjective alors g aussi.
76

3.4 Application réciproque
Soit E et F deux ensembles et f une bijection de E dans F. La bijection réciproque de f est l’application de Fdans E qui associe à tout élément de E son unique antécédent. On la note f−1.
Définition 3.3.4.166 (Application réciproque)
Remarques :
1. Il est nécessaire que f soit bijective. En effet si f n’est pas injective on peut "avoir le choix" entre plusieursantécédents et si f n’est pas surjective on peut trouver des éléments de F qui n’ont pas d’antécédents.
2. Pour tout x de E on a f−1( f (x)) = x. Cela signifie que f−1 f = IdE. De même f f−1 = IdF.
Exemples :
1. La fonction ln : R?+ → R est l’application réciproque de exp : R→ R?
+.
2. La fonction√
:R+ → R+ est l’application réciproque de la restriction de x 7→ x2 à R+.
Remarque : dans la plupart des cas, on ne sait exprimer l’application réciproque. C’est de ce fait une "nouvelle"application.Exercice : Soit f la fonction définie par :
f : R− 3 → R− 2x 7→ 2x + 3
x− 3.
Montrer que f est bijective et trouver sa bijection réciproque.Quelques propriétés des applications réciproques maintenant.
Soit f : E→ F une application on a :
f est bijective⇔
il existe une application g telle quef g = IdF et g f = IdE.
Proposition 3.3.4.167
— ⇒ : par définition de l’application réciproque.
— ⇐ : Soit y dans F. On note x = g(y). Dés lors f (x) = f (g(y)) = y car f g = IdF. Donc x estun antécédent de y et f est surjective. Supposons maintenant qu’il existe x′ tel que f (x′) = y. On ax = g(y) = g( f (x′)) = x′. Cela prouve l’injectivité de f .
Remarque : Dans certain cas, pour montrer qu’une application f est bijective on se contentera d’exhiber unefonction g telle que f g = IdF et g f = IdE.Exemple : Pour montrer que
Φ : P(E) → P(E)A 7→ A
est une bijection il suffit de voir que Φ Φ = IdP(E)
Soit f : E→ F une bijection on a :( f−1)−1 = f .
Corollaire 3.3.4.168
On fera attention au comportement des applications composées. Précisément on a
77

Si f : E→ F et g : F → G sont deux bijections, alors g f est bijective et
(g f )−1 = f−1 g−1.
Proposition 3.3.4.169
Démonstration : On remarque d’abord que g f est bijective car elle est injective et surjective. De plus on a :
g f f−1 g−1 = g IdF g−1 = g g−1 = IdE.
De même dans l’autre sens...
Remarque : La notation des applications réciproques est compatibles avec celle des image réciproque. En effet,si f est une bijection de E dans F alors on a
∀y ∈ F, f #(y) = f−1(y).
Plus généralement, si A est une partie de F on a :
f #(A) = f−1(A).
C’est à dire que l’image réciproque de A par f est aussi l’image directe de A par f−1.
3.5 Familles
Soit E et I deux ensembles. Une famille d’éléments de E indexées par I est une application de I dans E.C’est-à-dire que pour tout élément i de I on se donne un élément xi de E. On note (xi)i∈I la famille.
Définition 3.3.5.170
Remarques :1. Une famille indexée par N s’appelle une suite.
2. La donnée d’une famille (xi)i∈I d’éléments de E indexée par I permet de se donner une partie de E notée :
xi | i ∈ I.
On peut généraliser les intersections et les réunions à plus de deux ensembles.
Soit E et I des ensembles et (Ai)i∈I une famille de parties de E.
1. La réunion des ensembles Ai que l’on note⋃
i∈IAi est l’ensemble des éléments de E qui sont dans au
moins un des ensembles Ai.⋃
i∈IAi = x ∈ E | ∃i ∈ I, x ∈ Ai.
2. L’intersection des ensembles Ai que l’on note⋂
i∈IAi est l’ensemble des éléments de E qui sont dans tous
les ensembles Ai. ⋃
i∈IAi = x ∈ E | ∀i ∈ I, x ∈ Ai.
Définition 3.3.5.171
Exemple : Soit E = R, A1 = [0, 2], A2 = [−1, 1] et A3 = [3, 6]. On a alors
A1 ∪ A2 ∪ A3 =3⋃
i=1
Ai = [−1, 3] ∪ [3, 6] et A1 ∩ A2 ∩ A3 =3⋂
i=1
Ai = ∅.
78

Soit E un ensemble, on appelle partition de E la donnée d’une famille (Ai)i∈I de parties de E telles que :
1. elles "recouvrent" l’ensemble E : ⋃
i∈IAi = E
2. elles sont deux à deux disjointes : soit i et j deux éléments disjoints de I alors Ai ∩ Aj = ∅.
Définition 3.3.5.172
Remarques :1. La définition précédente signifie pour pour chaque x dans E il existe un unique i dans I tel que x ∈ Ai.
2. Dans certains ouvrages on demande de plus à une partition que les ensembles Ai soient distincts del’ensemble vide. Cela n’est qu’un point de détail.
Exercices :1. Écrire la deuxième condition à l’aide de quantificateurs
2. Donner toutes les partitions en ensembles non vides de 0, 1 puis de 0, 1, 2.
4 Relations binaires
4.1 Généralités
Soit E un ensemble. On appelle relation binaire R sur E la donnée d’une partie Γ de E× E.
Définition 3.4.1.173
Terminologie :— L’ensemble Γ s’appelle le graphe de la relation
— Soit x et y deux éléments de E. On note xRy si (x, y) ∈ Γ. On dit alors que x et y sont en relation.
Exemples :1. On peut définir une relation en prenant Γ = ∅. Dans ce cas aucun élément n’est en relation avec un autre
(ce n’est pas passionnant).
2. On peut définir une relation en prenant Γ = E× E. Dans ce cas tout élément est en relation avec tout autreélément (ce n’est pas passionnant non plus).
3. Sur R. On peut définir la relation binaire définie par xRy si et seulement si x et y sont de même signe.Quel est son graphe?
4.2 Relation d’équivalence
Soit E un ensemble. Une relation d’équivalence sur E est une relation binaire qui vérifie les condition suivante :
1. Elle est réflexive c’est-à-dire : ∀x ∈ E, xRx.
2. Elle est symétrique c’est-à-dire : ∀(x, y) ∈ E2, xRy⇒ yRx.
3. Elle est transitive c’est-à-dire : ∀(x, y, z) ∈ E3, xRy et yRz⇒ xRz.
Définition 3.4.2.174
Remarque : Pourquoi demander la symétrie alors que cela semble découler de la réflexivité et de la transitivité ?Notation : Les relations d’équivalences se notent ∼,',∼=,≈,≡. Dans la suite nous les noterons '.Exemples :
1. Soit E un ensemble. La relation d’égalité définie par xRy⇔ x = y est une relation d’équivalence.
2. Dans R. La relation de congruence modulo un réel A vu au chapitre des nombres complexes est unerelation d’équivalence.
79

3. Soit Z l’ensemble des entiers relatifs et N un entier non nul. On définit la relation xRy ⇔ x − y estdivisible par N. Vérifions que c’est une relation d’équivalence. On note alors x ≡ y[N].
Soit E un ensemble et ' une relation d’équivalence.
1. Soit x un élément de E. On appelle classe d’équivalence de x pour la relation ' l’ensemble :
Cx = y ∈ E | y ' x.
2. On appelle classe d’équivalence de E pour la relation ', toute partie A de E telle qu’il existe un élémentx de E dont c’est la classe d’équivalence. Les éléments x dont c’est la classe d’équivalence s’appellent lesreprésentants de A.
Définition 3.4.2.175
Exemples :
1. Si on reprend l’égalité sur E. Les classes d’équivalences sont les singletons.
2. Si on reprend la congruence modulo N. Les classes d’équivalence sont de la forme n + kN | k ∈ Z.
Soit E un ensemble muni d’une relation d’équivalence '.
1. Les classes d’équivalences sont des ensembles non vides.
2. Soit x et y deux éléments de E,Cx = Cy ⇔ x ' y.
3. Tout élément de x est dans une classe d’équivalence et une seule.
Proposition 3.4.2.176
Démonstration
Remarque : La dernière assertion signifie que les classes d’équivalence définissent une partition de E.
4.3 Relation d’ordre
Soit E un ensemble. Une relation d’ordre sur E est une relation binaire qui vérifie les condition suivante :
1. Elle est réflexive c’est-à-dire : ∀x ∈ E, xRx.
2. Elle est antisymétrique c’est-à-dire : ∀(x, y) ∈ E2, xRy et yRx ⇒ x = y.
3. Elle est transitive c’est-à-dire : ∀(x, y, z) ∈ E3, xRy et yRz⇒ xRz.
La donnée de E et de la relation d’ordre s’appelle un ensemble ordonnée.
Définition 3.4.3.177
Notation : Nous noterons les relations d’ordre >, 6.Exemples :
1. La relation d’ordre classique dans R (ou Q, Z, N).
2. La relation < n’est pas une relation d’ordre car elle n’est pas antisymétrique.
3. Soit E un ensemble, la relation d’inclusion dans P(E) est une relation d’ordre.
4. Soit E1 et E2 deux ensembles munis chacun d’une relation d’ordre. On peut ordonner E1 × E2 par l’ordrelexicographique défini par
(x1, y1) 6 (x2, y2)⇔ (x1 < y1) ou [(x1 = y1) et (x2 6 y2)].
Où on a noté x1 < y1 pour x1 6 y1 et x1 6= y1.
80

Soit (E,6) un ensemble ordonné. On dit que l’ordre est total ou que E est totalement ordonnée si pour toutcouple (x, y) de E× E, x 6 y ou y 6 x.Si l’ordre n’est pas total on dit qu’il est partiel.
Définition 3.4.3.178
Exemples :
1. L’ordre classique dans R est un ordre total.
2. L’inclusion dans P(E) est un ordre partiel dès que E a au moins deux éléments.
Soit (E,6) un ensemble ordonné et A une partie non vide de E. Soit x un élément de E
— On dit que x est un majorant de A s’il est plus grand que tout les éléments de A. C’est-à-dire :
∀a ∈ A, a 6 x.
En particulier, il est comparable à tous les éléments de A
— On dit que x est un minorant de A s’il est plus petit que tout les éléments de A C’est-à-dire :
∀x ∈ A, x 6 a.
En particulier, il est comparable à tous les éléments de A
— On dit que x est un plus grand élément de A s’il est dans A et que c’est un majorant.
— On dit que x est un plus petit élément de A s’il est dans A et que c’est un minorant.
De manière générale :
— la partie A est dite majorée s’il existe un majorant.
— la partie A est dite minorée s’il existe un minorant.
— la partie A est dite bornée s’il existe un majorant et un minorant.
Définition 3.4.3.179
Exemples :
1. L’ensemble [0, 1] est bornée. Il admet 1 comme majorant mais aussi π. Son plus grand élément est 1.
2. L’ensemble ]− e,+∞[ est minoré mais n’est pas majoré. −e est un minorant, −50 aussi. Par contre il n’y ani plus grand élément, ni plus petit élément.
3. L’ensemble Q n’est pas borné.
Avec les notations précédentes.
1. Si A admet un plus grand élément alors il est unique. On le note Max(A).
2. Si A admet un plus petit élément alors il est unique. On le note Min(A).
Proposition 3.4.3.180
Remarque : Cela n’est pas vrai pour les majorants/minorants.
81

4Primitives
1 Généralités 821.1 Définition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 821.2 Primitives usuelles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
2 Méthodes de calculs 842.1 Intégration par partie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 842.2 Changement de variables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 852.3 Calculs classiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
Nous allons revoir les notions principales déjà vues en terminale sur les primitives. Nous verrons aussi laméthode du changement de variables pour calculer les primitives.
Dans tout ce paragraphe I désigne un intervalle de R.
1 Généralités
1.1 Définition
Soit f une fonction définie sur I. On dit qu’une fonction F est une primitive de f sur I si et seulement si F etdérivable et F′ = f .
Définition 4.1.1.181
Si f est une fonction continue sur I. Elle admet des primitives.
Théorème 4.1.1.182
Démonstration : Ce théorème est admis pour le moment. Sa démonstration sera obtenue dans le chapitre surl’intégration.
Remarque : On peut trouver des fonctions non continues qui admettent des primitives. Si on prend parexemple
F : x 7→
x2 sin(
1x
)si x 6= 0
0 sinon
82

On vérifie que cette fonction est dérivable mais sa dérivée
f : x 7→
2x sin(
1x
)− cos
(1x
)si x 6= 0
0 sinon
n’est pas continue.
Soit f une fonction définie sur I admettant une primitive F sur I. L’ensemble des primitives de f surI sont les fonctions de la forme
x 7→ F(x) + C.
Proposition 4.1.1.183
Démonstration : On voit de manière évidente que ces fonctions sont bien des primitives de f . Réciproquement,si G est une primitive de f alors la fonction F− G est de dérivée nulle. Or I est un intervalle donc F− G estconstante.
Remarques :
1. Le fait qu’une fonction de dérivée nulle sur un intervalle set constante sera démontré par la suite.
2. Il est essentielle d’être sur un intervalle. Par exemple, si on considère f : x 7→ 1/x sur R?. On a x 7→ ln |x|comme primitive mais aussi
x 7→
ln x + 1 si x > 0ln(−x) + 2 si x < 0
Notation : Avec les mêmes notations, si a est un élément de I. On notera l’unique primitive de f qui s’annule
en a : x 7→∫ x
af (t) dt.
De même, pour désigner une primitive de f , on notera∫ x
f (t) dt.
Ce n’est qu’une notation. On a par exemple :
∀x ∈ R+,∫ x dt
t= ln x
mais aussi,
∀x ∈ R+,∫ x dt
t= 3 + ln x.
1.2 Primitives usuelles
Voici le tableaux des primitives usuelles
83

Fonction Primitive Intervalle
xn (n ∈ N)xn+1
n + 1R
xn (n ∈ Z, n < −1)xn+1
n + 1R?+ ou R?
−
xα (α ∈ R \ −1) xα+1
α + 1sur R?
+
1/x ln |x| R?+ ou R?
−ln |x| x ln |x| − x R?
+ ou R?−
ex ex Rcos x sin x Rsin x − cos x Rch x sh x Rsh x ch x R
tan x − ln | cos x| ]− π/2 + kπ, π/2 + kπ[cotanx ln | sin x| ]kπ, (k + 1)π[
th x ln | ch x| R1/(cos2 x) tan x ]− π/2 + kπ, π/2 + kπ[1/(sin2 x) −cotantx ]kπ, (k + 1)π[1/( ch 2x) th x R1/( sh 2x) −1/ th x R?
+ ou R?−
1/(1 + x2) arctan x R
1/(1− x2)12
ln∣∣∣∣1 + x1− x
∣∣∣∣ ]−∞,−1[ ou ]− 1, 1[ ou ]1,+∞[
1/√
1− x2 arcsin x ]− 1, 1[1√
h + x2(h ∈ R?) ln |x +
√x2 + h| R si h > 0; ]−∞,−
√−h[ et ]
√−h,+∞[ sinon
OPÉRATIONS SUR LES PRIMITIVES
Fonction Primitive Paramètreu′ + v′ u + v
k.u′ k.u k ∈ R− u′
u21u
u′.eu eu
u′u ln |u|
n.un−1.u′ un n ∈ N?
Remarques :1. La primitive de ln se retrouve à l’aide d’une intégration par parties.
2. Ne pas confondre ax avec xa.
Exemple : On a ∀x ∈ R?+, ∫ x 1
t ln(t)dt =
12
ln2(x).
2 Méthodes de calculs
Les méthodes de calculs de primitives sont les mêmes que les méthodes pour calculer les intégrales. La seuledifférence est dans la gestion des constantes. Nous alternerons donc entre les deux visions.
2.1 Intégration par partie
On sait que la dérivée d’un produit de deux fonctions dérivables f et g est donné par la formule ( f g)′ =f ′g + g′ f . En intégrant, on trouve la propriété suivante.
84

Soit u et v deux fonctions dérivables sur I = [a, b] dont les dérivées sont continues. On a
∫ b
au′v = [uv]ba −
∫ b
auv′.
Cela donne (en primitives) :
∀x ∈ I,∫ x
u′v = u(x)v(x)−∫ x
uv′.
Proposition 4.2.1.184
Remarque : Les hypothèses sont nécessaires car u′ et v′ doivent être continues.
Soit f une fonction définie sur un intervalle I. On dit qu’elle est de classe C 1 si elle est dérivable et que sadérivée est continue.
Définition 4.2.1.185
Exemple : On a
∀x ∈ R,∫ x
tet dt = xex −∫ x
et dt = xex − ex.
2.2 Changement de variables
Autant l’intégration par partie est juste une écriture pour les intégrale de la formule ( f g)′ = f ′g + g′ f autantle changement de variables sera une écriture de la formule ( f g)′ = g′ × f ′ g. Commençons par un exemple.Exemple : Soit f (t) = sin t et g(t) = ln t. On pose F(t) = ( f g)(t) = sin(ln t). Elle est dérivable et F′(t) =1t
cos(ln t). On en déduit que∫ 2
1
cos(ln t) dtt
= [sin(ln t)]21 = sin(ln 2).
Le problème est que la primitive ne saute pas aux yeux. Essayons de voir comment retrouver ce résultat. On
part donc avec∫ 2
1
cos(ln t) dtt
. Le cos(ln t) posant problème on pose u = ln t ce qui correspond à t = eu. On
doit alors
— Remplacer les t par des eu (ou les ln t par des u).
— Remplacer le dt par un du. La méthode est pour cela d’utiliser la « recette » suivante. On sait que u = ln tdonc en physique vous écririez :
dudt
=1t
.
Cette notation n’est pas correcte en mathématiques mais on écrira - sans savoir exactement la signification-
du =1t
dt ou dt = t du = eu du.
Cela est juste : du = u′(t) dt.
— Remplacer les bornes. Quand t = 1 on a u = ln t = 0 et quand t = 2 on a u = ln t = ln 2.
On trouve donc : ∫ ln 2
0cos(u) du = [sin u]ln 2
0 = sin(ln 2).
Exercice : Appliquer la recette pour calculer∫ 4
1
e√
t−1 dt2√
t. On posera u =
√t.
85

Soit ϕ de classe C 1 sur un intervalle I et f de classe C 0 sur ϕ(I) on a :
∫ b
a( f ϕ)(t)× ϕ′(t)dt =
∫ ϕ(b)
ϕ(a)f (u)du.
Théorème 4.2.2.186
Démonstration : Soit F une primitive de f sur ϕ([a, b]).
— On a∫ ϕ(b)
ϕ(a)f (u)du = [F]ϕ(b)
ϕ(a) = F(ϕ(b))− F(ϕ(a)).
— De même F ϕ est de classe C 1 sur [a, b] et (F ϕ)′ = ϕ′ × f ϕ d’où∫ b
a( f ϕ)(t)× ϕ′(t)dt = [F ϕ]ba = F(ϕ(b))− F(ϕ(a)).
Remarques :1. Cette formule peut se lire dans les deux sens nous allons le voir sur deux exemples.2. Il n’est pas nécessaire que ϕ soit bijective.
Exemples :
1. Calculons∫ 7
3−2 cos7 t sin t dt. On pose u = cos t. C’est le sens de l’exemple précédent. Cela consiste
à lire la formule ci-dessus de gauche à droite. La fonction t 7→ cos t est de classe C 1 sur [3, 7] et on adu = − sin t dt. D’où
∫ 7
3−2 cos7 t sin t dt =
∫ cos(7)
cos(3)2u7 du =
cos8(7)− cos8(3)4
.
2. Calculons∫ 1
−1
√1− u2 du. On pose u = cos t. Cette fois-ci on va lire l’égalité de la proposition de la droite
vers la gauche. Là encore t 7→ cos t est de classe C 1 sur R. De plus du = − sin t dt. Le changement desbornes est un peu plus subtil. En effet on doit « inverser »le changement de variables. Ici on doit trouvera et b tel que cos(a) = −1 et cos(b) = 1. De fait on choisit les antécédents que l’on veut. Je vais prendrea = π et b = 0. On a alors
∫ 1
−1
√1− u2 du =
∫ 0
π
√1− cos2 t(− sin t) dt
=∫ π
0sin t sin t dt
=∫ π
0
1− cos(2t) dt2
=π
2−[
sin(2t)4
]π
0
=π
2.
Remarque : On peut aussi se servir du changement de variables pour trouver des primitives. Il faudra alorsfaire attention aux bornes. Essayons par exemple, en reprenant l’exemple ci-dessus de déterminer la primitive F
de u 7→√
1− u2 sur [−1, 1] qui s’annule en 0. On a F(x) =∫ x
0
√1− u2 du. On pose là encore le changement
de variables u = cos t On trouve alors
F(x) = −∫ arccos(x)
π/2sin t sin t dt =
(π
2− arccos x
)+
sin(2 arccos x)4
=π
2− arccos x +
x√
1− x2
2.
Notons d’ailleurs que cette fonction est, par construction, de classe C 1 sur [−1, 1] comme primitive defonction continue contrairement à ce que l’arccosinus pourrait faire croire.Exercices :
1. Refaire le calcul du deuxième exemple en prenant −π pour antécédent de −1.
2. Déterminer une primitive de t 7→ ln tt
.
86

Utilisation de changements de variables affines
1. Parité : Si f est une fonction paire définie sur un intervalle I. On peut utiliser le changement de variableu = −t. On trouve alors que pour tout x dans I,
∫ x
0f (t) dt = −
∫ −x
0f (−u) du =
∫ 0
−xf (u) du.
On en déduit que∫ x
−xf (u) du = 2
∫ x
0f (u) du.
De même si f est impaire,
∫ x
0f (t) dt = −
∫ −x
0f (−u) du = −
∫ 0
−xf (u) du.
On en déduit que∫ x
−xf (u) du = 0.
2. Fonctions périodiques : Soit f une fonction périodique de période T. En posant u = t + T on trouve quepour tout (a, b), ∫ b
af (t) dt =
∫ b+T
a+Tf (u− T) du =
∫ b+T
a+Tf (u) du.
On en déduit que pour tout a,
∫ a+T
af −
∫ T
0f =
∫ 0
af +
∫ T
0f +
∫ a+T
Tf −
∫ T
0f = 0.
3. Transformation en une intégrale sur [0, 1] : Soit f une fonction continue. Si on pose t = a + (b− a)u. Onobtient ∫ b
af (t) dt = (b− a)
∫ 1
0f (a + (b− a)u) du.
2.3 Calculs classiques
Passons en revue quelques classiques classiques qu’il faut connaitre.
Primitive d’une fonction de la forme t 7→ P(t)et
On fait des intégrations par parties en dérivant le polynôme jusqu’à ce qu’il « disparaisse ».
Primitive d’une fonction de la forme t 7→ P(t) ln(t)
On fait des intégrations par parties en intégrant le polynôme et en dérivant le ln.
Intégrale des fonctions de la forme t 7→ cosp t. sinq t
Dans tous les cas on peut linéariser ces expressions. On peut cependant faire plus rapide dans un casparticulier.
Si p ou q est impair : on peut alors intégrer à vue, sans linéariser. Par exemple :
∀x ∈ R,∫ x
sin5 t. cos2 t dt =∫ x
sin t.(1− cos2 t)2 cos2 t dt
=∫ x
sin t.(cos2 t− 2 cos4 t + cos6 t) dt
= −13
cos3 x +25
cos5 x− 17
cos7 x.
Si p et q sont pairs : la méthode précédente ne fonctionne plus. On va linéariser.
87

Calculs des primitives des fonctions de la forme t 7→ 1at2 + bt + c
Soit (a, b, c) trois réels (avec a 6= 0 sinon on sait faire). On veut calculer une primitive (ou une intégrale) de
t 7→ 1at2 + bt + c
en se plaçant sur un intervalle I où at2 + bt + c ne s’annule pas.
Il y a trois cas :— Si at2 + bt + c a deux racines réels distinctes (discriminant strictement positif) que l’on note α et β. On
peut le factoriserat2 + bt + c = a(t− α)(t− β).
Par la suite, on chercher A, B tels que
∀t ∈ I,1
a(t− α)(t− β)=
At− α
+B
t− β
On peut les déterminer en mettant tout au même dénominateur ou en multipliant par (t − α) pourdéterminer A et par (t− β) pour déterminer B. Cette méthode sera justifiée un peu plus tard dans lechapitre sur les fractions rationnelles.Par exemple, calculons sur I = [0, 1] ∫ x dt
2t2 − 2t− 4.
On factorise et on obtient∀t ∈ I,
12t2 − 2t− 4
=1
2(t + 1)(t− 2).
On cherche alors A, B tels que
∀t ∈ I,1
2(t + 1)(t− 2)=
At + 1
+B
t− 2.
On trouve A = −1/6 et B = 1/6. On a donc∫ x dt
2t2 − 2t− 4=
16
(∫ x dtt− 2
−∫ x dt
t + 1
)=
16
ln∣∣∣∣x− 2x + 1
∣∣∣∣ .
— Si at2 + bt + c a une racine double notée α. Là encore on factorise,
at2 + bt + c = a(t− α)2.
Il ne reste qu’à intégrer classiquementPar exemple sur I = [0, 1]
∫ x dt2t2 − 8t + 8
=12
∫ x dt(t− 2)2 =
12(x− 2)
.
— Si at2 + bt + c a deux racines complexes conjuguées (discriminant strictement négatif). On fait la mise
sous forme canonique et on se ramène à∫ du
1 + u2 par un changement de variables.
Calculons par exemple∫ x dt
t2 − 4t + 6. On a
∫ x dtt2 − 4t + 6
=∫ x dt
(t− 2)2 + 2
=12
∫ x dt(
t− 2√2
)2+ 1
On pose alors u =t− 2√
2et on obtient :
∫ x dtt2 − 4t + 6
=12
∫ (x−2)/√
2√
2 duu2 + 1
=
√2
2arctan
(x− 2√
2
).
Exercice : Calculer∫ 1
0
dtt2 + t + 1
Remarques :
88

1. Cette méthode est très importante. Elle permet de calculer toutes les primitives des fractions ration-nelles (voir plus loin).
2. On peut gérer le dernier cas comme le premier en passant dans C. En effet, on peut aussi se ramenerà des primitives du type ∫ x dt
t− α
avec α ∈ C. Il suffit alors d’utiliser (ou de redemonter) le lemme suivant
Soit α = u + iv ∈ C avec v 6= 0. La fonction t 7→ 1(t− α)n est continue sur R et admet donc des
primitives sur R. De plus
∫ x dt(t− α)n =
1−n + 1
1(x− α)n−1 si n 6= 1
12
ln((x− u)2 + v2) + i arctan(
x− uv
)si n = 1
Lemme 4.2.3.187
Démonstration : La partie n 6= 1 est juste la formule classique de la primitive de (x− α)k en prenantgarde qu’ici, k = −n. Pour démontrer la partie pour n = 1 on peut juste dériver le terme de droite,nous allons le faire autrement ce qui permet de retrouver la formule si on l’a oubliée.On a pour tout t dans R,
1t− α
=t− α
|t− α|2
=t− α
(t− u)2 + v2
=t− u
(t− u)2 + v2 + iv
(t− u)2 + v2
=t− u
(t− u)2 + v2 + i1v
1((t− u)/v)2 + 1
Il ne reste qu’à intégrer.
89

5Équations
différentielles1 Généralités 901.1 Définition et exemples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
1.2 Équations différentielles linéaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
2 Équation différentielle linéaire d’ordre 1 932.1 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 932.2 Résolution des équations différentielles linéaires homogènes d’ordre 1 . . . . . . . . . . . . . 93
2.3 Équation différentielle linéaire d’ordre 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 942.4 Equation avec condition initiale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 962.5 Raccordement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 962.6 Méthode d’Euler . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
3 Équation différentielle linéaire d’ordre 2 à coefficients constants 97
3.1 Équation homogène . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
3.2 Équations avec second membre . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1003.3 Equation avec des conditions initiales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
Une équation différentielle est une équation reliant les valeurs d’une fonction aux valeurs de ses déri-vées. Les équations différentielles sont très utilisées en physique (principe fondamental de la dynamique,électromagnétisme, radioactivité...).
Dans tout ce chapitre, nous nous intéresserons à des fonctions définies sur un intervalle I (non réduit à unpoint) et à valeurs dans K = R ou C.
1 Généralités
1.1 Définition et exemples
Nous allons donner une définition générale de ce que nous entendrons par équation différentielles. Dans lapratique nous nous intéresserons seulement à des cas très particuliers.
90

Soit n un entier non nul. On appelle équation différentielle d’ordre n, la donnée d’une application F définie surune partie de R×Kn. On note alors l’équation :
y(n) = F(t, y, y′, . . . , y(n−1)).
Définition 5.1.1.188
Remarque : Dans la pratique on travaille uniquement avec n = 1 (équation différentielle du premier ordre :y′ = F(t, y)) et n = 2 (équation différentielle du second ordre : y′′ = F(t, y, y′)).
Soit I un intervalle de R et y(n) = F(t, y, y′, . . . , y(n−1)) une équation différentielle. On appelle solution del’équation différentielle sur I toute fonction f définie et suffisamment dérivable sur I telle que pour tout t dansI,
y(n)(t) = F(t, y′(t), . . . , y(n−1)(t)).
Définition 5.1.1.189
Remarques :
1. Il est important de noter que résoudre une équation différentielle n’a de sens que sur un intervalle fixé. Sion considère par exemple l’équation
y′ =1x
.
On sait que sur R?+ les solutions sont x 7→ ln x + K où K ∈ R. Alors que sur R?
− les solutions sontx 7→ ln(−x) + K où K ∈ R. De plus il est essentiel d’être sur un intervalle et non sur une partie de Rquelconque car les équations différentielles correspondent à la « propagation » d’un phénomène. Si ontravaille par exemple sur R? ce que l’on va trouver pour les nombre négatifs ne sera pas lié à ce que l’onva obtenir pour les nombres positifs.
2. Il faut avoir conscience, que l’on ne sait résoudre de manière exacte qu’un très petit nombre d’équationsdifférentielles. Nous n’étudierons que deux cas très particuliers. Dans la pratique, on a recours à deméthode approchée via des simulations numériques sur ordinateurs.
Exemples :
1. y′ = 0
2. yy′ = 2
3. y′′′ + sin(y) = 0.
4. La désintégration radioactive : Si on considère un échantillon d’un élément radioactif. Si on note N(t) lenombre d’atomes présent dans l’échantillon à l’instant t, alors :
N(t) = −λN(t).
Où λ est la constante radioactive de l’élément.
5. Chute libre. On se donne un mobile de masse m et on note z son altitude. Dans le cas d’une chute libre :
mz′′ = −mg.
6. Oscillateur. Si on se donne un ressort linéaire de raideur k sa position x vérifie
mx′′ = −kx.
Si on rajoute une force de frottement (oscillateur amorti) on trouve
mx′′ = −kx− λx′.
Pour finir, on peut entretenir les oscillations (oscillateur forcé) on trouve :
mx′′ + λx′ + kx = A sin(ωt).
91

1.2 Équations différentielles linéaires
Soit n un entier non nul et I un intervalle. Un équation différentielle linéaire d’ordre n est une équation de laforme :
an(t)y(n) + · · ·+ a1(t)y′ + a0(t)y = b(t),
où les a0, a1, . . . , an et b sont des fonctions définies sur I. Les fonctions a0, . . . , an s’appellent les coefficientsde l’équation différentielle et la fonction b s’appelle le second membre.
Définition 5.1.2.190 (Équations différentielles linéaires)
Exemples :1. Une équation différentielle linéaire d’ordre 1 s’écrit donc
a1(t)y′ + a0(t)y = b(t).
2. Une équation différentielle linéaire d’ordre 2 s’écrit donc
a2(t)y′′ + a1(t)y′ + a0(t)y = b(t).
Remarque : On ne demande pas aux fonctions ai d’être linéaire... L’équation y′′ + cos(t)y′ − ety = sin t estlinéaire mais sin(y′) = 2y ne l’est pas.
Soit (E) une équation différentielle linéaire :
an(t)y(n) + · · ·+ a1(t)y′ + a0(t)y = b(t) (E)
Elle est dite homogène si b est la fonction nulle. De manière générale, l’équation différentielle linéaire homogèneobtenue en prenant b = 0 pour second membre (et en conservant les mêmes coefficients) s’appelle équationdifférentielle linéaire homogène associée.
Définition 5.1.2.191
Soit (E) une équation différentielle linéaire d’ordre n définie sur un intervalle I et (H) l’équationhomogène associée.
1. L’ensemble SH des solutions de (H) est un sous-espace vectoriel de F (I, K).
2. S’il existe une solution f0 de (E) on a SE = f + f0 | f ∈ SH. On dit alors que SE est unespace affine de direction SH . C’est-à-dire
f ∈ SE ⇐⇒ ( f − f0) ∈ SH .
Théorème 5.1.2.192 (Structure de l’ensemble des solutions)
Démonstration
On considère deux équations différentielles linéaires ayant les mêmes coefficients :
an(t)y(n) + · · ·+ a1(t)y′ + a0(t)y = b1(t) (E1)
et
an(t)y(n) + · · ·+ a1(t)y′ + a0(t)y = b− 2(t). (E2)
Soit f1 une solution de (E1) et f2 une solution de (E2). Alors f1 + f2 est solution de l’équation :
an(t)y(n) + · · ·+ a1(t)y′ + a0(t)y = b1(t) + b2(t).
Proposition 5.1.2.193 (Principe de superposition)
92

2 Équation différentielle linéaire d’ordre 1
2.1 Généralités
Une équation différentielle linéaire d’ordre 1 s’écrit :
a1(t)y′ + a0(t)y = b(t).
où a1, a0 et b sont des fonctions définies sur un intervalle I.Si la fonction b est la fonction nulle, l’équation est dite homogène (ou sans second membre).
Définition 5.2.1.194
Remarque : On se ramènera toujours à une équation du type
y′ + a(t)y = b(t).
Pour cela, il suffit de diviser par a1(t) en ayant pris soin de découper l’intervalle de définition aux éventuellesracines de a1.
2.2 Résolution des équations différentielles linéaires homogènes d’ordre 1
On sait résoudre les équations différentielles linéaires homogènes d’ordre 1. On a
Soit I un intervalle et a : I → R une fonction continue sur I. Les solutions de l’équation différentielley′ + a(t)y = 0 sont les fonctions f définies sur I par :
∀x ∈ I, f (t) = λ.e−A(t),
où λ ∈ R et x 7→ A(t) est une primitive de a.
Théorème 5.2.2.195
Remarques :1. Le fait que a soit continue assure l’existence des primitives A.2. Modifier une primitive A par une autre primitive de la forme B(t) = A(t) + C revient à modifier la
constante λ.3. On peut retrouver la formule par le calcul suivant.
y′ = ay → y′ = −ay
→ y′
y= −a
→∫ x y′
y= −
∫ xa
→ ln(y) = −A(x) + K
→ y = λ.e−A(t).
Attention, le calcul précédent n’est pas rigoureux et ne constitue pas une preuve du théorème.
Démonstration : On commence par vérifier que les fonctions x 7→ λ.e−A(t) sont bien des solutions.Maintenant, soit f une solution de l’équation différentielle. On considère la fonction g définie par :
∀t ∈ I, g(t) = f (t)eA(t).
La fonction g est dérivable et
∀t ∈ I, g′(t) = f ′(t)eA(t) + a(t) f (t)eA(t) = 0.
On en déduit qu’il existe λ ∈ R tel que ∀t ∈ I, g(t) = λ.
Exemples :
93

1. Considérons l’équation y′ = 0. Les solutions sont les fonctions définies sur R par t 7→ λ avec λ ∈ R.
2. Considérons l’équation y′ = y. Les solutions sont les fonctions définies sur R par t 7→ λet avec λ ∈ R.
3. Considérons l’équation y′ = ty. Les solutions sont les fonctions définies sur R par t 7→ λet2/2 avec λ ∈ R.
4. Considérons l’équation y′ =yt
. Les solutions sont les fonctions définies sur R?− ou R?
+ par t 7→ λx avecλ ∈ R.
5. Considérons l’équation y′ =2yt
. Les solutions sont les fonctions définies sur R?− ou R?
+ par t 7→ λt2 avecλ ∈ R.
2.3 Équation différentielle linéaire d’ordre 1
On se propose de résoudre l’équation différentielle
y′ + a(t)y = b(t) (E)
où a et b sont des fonctions continues sur un intervalle I.On commence par considérer l’équation homogène sans second membre associée.
y′ + a(t)y = 0. (H)
Voici alors la méthode à appliquer pour résoudre l’équation (E).
1. On exprime l’équation homogène associée (H).
2. On résout (H).
3. On trouve une solution particulière de (E) - voir plus bas.
4. On exprime la forme générale des solutions.
Exemple : On veut résoudre
y′ + ty = t (E)
L’équation homogène associée est
y′ + ty = 0. (H)
Les solutions de l’équation homogène sont
SH = t 7→ λe−t2/2 | λ ∈ R.
De plus on remarque que la fonction constante égale à 1 est solution de (E). On en déduit que :
SE = t 7→ 1 + λe−t2/2 | λ ∈ R.
La plupart du temps, il ne sera pas aussi simple de trouver une solution particulière. On a alors recours à laméthode dite de la variation de la constante.
Le principe est de chercher une solution particulière de la forme :
f : t 7→ λ(t)e−A(t)
où λ est un fonction. On a donc
∀t ∈ I, f ′(t) = λ′(t)e−A(t) − λ(t)a(t)e−A(t).
D’où
f solution de E ⇐⇒ ∀t ∈ I, f ′(t) + a(t) f (t) = b(t)
⇐⇒ ∀t ∈ I, λ′(t)e−A(t) − λ(t)a(t)e−A(t) + a(t)λ(t)e−A(t) = b(t)
⇐⇒ ∀t ∈ I, λ′(t) = b(t)eA(t).
On en déduit donc
94

Les solutions de l’équation différentielle sur I
y′ + a(t)y = b(t)
où a et b sont des fonctions continues sur I sont de la forme
t 7→(∫ t
b(u)eA(u) du)
e−A(t) + Ke−A(t).
Proposition 5.2.3.196
Remarque : On peut supprimer la constante si on fait varier la borne « en bas »de l’intégrale.Exemples :
1. On veut résoudre
y′ + y = cos x (E)
L’équation homogène associée est
y′ + y = 0. (H)
Les solutions de l’équation homogène sont
SH = x 7→ λe−x | λ ∈ R.
On va chercher la solution particulière sous la forme :
f : x 7→ λ(x)e−x où λ : R→ R,
est une fonction dérivable.Dés lors on a
f vérifie (E) ⇔ ∀x ∈ R, f ′(x) + f (x) = cos x⇔ ∀x ∈ R, λ′(x)e−x − λ(x)e−x + λ(x)e−x = cos x⇔ ∀x ∈ R, λ′(x)e−x = cos x la simplification aura toujours lieu⇔ ∀x ∈ R, λ′(x) = ex cos x
Il ne reste plus qu’a trouver une primitive de ex cos x. Pour cela on remarque que
∀x ∈ R, ex cos x = Re(
e(1+i)x)
.
On en déduit qu’une primitive de ex cos x est donnée par
Re
(e(1+i)x
1 + i
)= Re
((1− i)ex(cos x + i sin x)
2
)=
12(cos x + sin x).
On en déduit que la fonction x 7→ 12 (cos x + sin x)e−x est une solution particulière et que
SE =
x 7→ 1
2(cos x + sin x + λ)e−x | λ ∈ R
.
2. On peut penser au principe de superposition.Si on veut résoudre l’équation
y′ + y = 1 + cos x (E)
L’équation homogène associée est
y′ + y = 0. (H)
95

On voit que la fonction constante égale à 1 est solution de y′ + y = 1. On sait de plus que x 7→ 12 (cos x +
sin x)e−x est solution de y′ + y = cos x. On en déduit que
x 7→ 1 +12(cos x + sin x)e−x
est une solution particulière de (E). Donc on a
SE =
x 7→ 1 +
12(cos x + sin x + λ)e−x | λ ∈ R
.
Exercice : Résoudre l’équation différentielle :
xy′ + y = x cos x.
2.4 Equation avec condition initiale
On considère une équation différentielle du premier ordre
y′ + a(x)y = b(x)
avec a et b des fonctions continues sur un intervalle I. Soit t0 dans I et y0 dans K. Résoudre l’équation avecla condition initiale y(t0) = y0 revient à trouver toutes les fonctions f dérivables sur I, solution de l’équationdifférentielle et vérifiant que f (t0) = y0.Remarque : On dira alors que l’on cherche à résoudre le problème de Cauchy :
y′ + a(x)y = b(x)y(t0) = y0.
Le problème de Cauchy y′ + a(x)y = b(x)y(t0) = y0.
a une unique solution donnée par
t 7→(∫ t
t0
b(u)eA(u) du)
e−A(t) + y0eA(t0)−A(t).
Théorème 5.2.4.197
Remarque : Le problème de Cauchy y′ + a(x)y = 0y(t0) = 0.
a pour unique solution la fonction nulle.
2.5 Raccordement
On peut se poser la question de la résolution d’une équation différentielle
a0y′ + a1y = b
sur un intervalle I où a0 s’annule. Le principe est alors de résoudre l’équation sur chaque sous-intervalle de Ioù a0 ne s’annule pas et d’essayer ensuite de recoller les solutions. Il n’y a plus de résultats généraux. Traitonsun exemple.Exemples :
1. Résolvons l’équation (E)ty′ − 2y = 0
sur R. On pose I+ =]0,+∞[ et I− =]−∞, 0[. On va résoudre l’équation sur chacun de ses intervalles. Onpose (E’) l’équation
y′ − 2t
y = 0.
96

Un primitive de t 7→ −2t
sur I+ ou I− est A : t 7→ −2 ln |t|. On en déduit que les solutions sont
S± = t 7→ λt2.
Soit f une éventuelle solution de (E) sur R, sa restriction à R+ et à R− vérifie l’équation. On en déduitqu’il existe λ+ et λ− tels que
∀t ∈ R?, f (t) =
λ+t2 si t > 0λ−t2 si t < 0
Comme de plus, f doit être dérivable donc continue, on a f (0) = 0.Réciproquement toutes ces fonctions sont solutions de l’équation sur R.
2. Résolvons maintenant l’équation (E)ty′ − y = t2
(· · · )On en déduit que les solutions sont
S± = t 7→ λt + t2.Soit f une éventuelle solution de (E) sur R, sa restriction à R+ et à R− vérifie l’équation. On en déduitqu’il existe λ+ et λ− tels que
∀t ∈ R?, f (t) =
λ+t + t2 si t > 0λ−t + t2 si t < 0
Là encore, on doit avoir f (0) = 0. Mais cette fois, la fonction n’est dérivable que si λ− = λ+.
Exercice : Résoudre sur ]0,+∞[ l’équation, t ln(t)y′ + y = 0.
2.6 Méthode d’Euler
Vous avez du voir ( ?) au lycée la méthode d’Euler pour résoudre de manière approchée les équationsdifférentielles. Je renvoie au cours d’informatique de deuxième période.
3 Équation différentielle linéaire d’ordre 2 à coefficients constants
On va essayer de résoudre l’équation différentielle
ay′′ + by′ + cy = f (t) (E)
où a, b et c sont des constantes complexes avec a 6= 0 et f une fonction définie sur un intervalle I. L’équationhomogène associée est alors
ay′′ + by′ + cy = 0. (H)
Remarque : Nous allons chercher les solutions dans F (I, C). Cependant, nous verrons comment « revenir » àR quand les constantes sont réelles.
3.1 Équation homogène
On considère l’équation
ay′′ + by′ + cy = 0. (H)
Soit f : t 7→ eαt. La fonction f vérifie (H) si et seulement si aα2 + bα + c = 0.
Lemme 5.3.1.198
Démonstration
97

On appelle équation caractéristique de (H) l’équation du second degré :
X2 + aX + b = 0.
Définition 5.3.1.199
Avec les notations précédentes, on note ∆ = b2 − 4ac le discriminant de l’équation caractéristique.On a alors
— Si ∆ 6= 0 : on note α1 et α2 les deux racines de l’équation caractéristique. On a
SH = t 7→ λeα1t + µeα2t | (λ, µ) ∈ R2.
— Si ∆ = 0 : on note α la racine double de l’équation caractéristique. On a
SH = t 7→ (λt + µ)eαt | (λ, µ) ∈ R2.
En particulier, c’est un C-espace vectoriel de dimension 2.
Théorème 5.3.1.200 (Cas Complexe)
Démonstration : On peut commencer par remarquer que ce sont des solutions de manière évidente. Reste àmontrer que ce sont les seules. On va se ramener au cas d’une équation d’ordre 1. On considère α une solutionde l’équation (que ∆ soit nul ou non).
Soit f ∈ F (R, C) on considère g : t 7→ f (t)e−αt et donc f : t 7→ g(t)eαt. On caclule alors les dérivées de f enfonction de celles de g et on trouve que pour tout t dans R :
f (t) = g(t)eαt, f ′(t) = [αg(t) + g′(t)]eαt, f ′′(t) = [α2g(t) + 2αg′(t) + g′′(t)]eαt.
On a alors
f solution de E ⇐⇒ ∀t ∈ R, (2aα + b)g′(t) + ag′′(t) = 0⇐⇒ g′ solution de F
où (F) est l’équationay′ + (2aα + b)y = 0
ou
y′ +(
2α +ba
)y = 0.
On sépare alors les deux cas.
— Si ∆ = 0 alors 2α = − ba
donc l’équation (F) est juste y′ = 0. On en déduit que g′ est de la forme t 7→ λ,puis, par intégration, g : t 7→ λt + µ. On obtient bien alors
SH = t 7→ (λt + µ)eαt | (λ, µ) ∈ R2.
— Si ∆ 6= 0. Dans ce cas 2aα + b = ± δ
a6= 0 où δ vérifie que δ2 = ∆. Les solutions de (F) sont de la forme
t 7→ λe−δt/a.
On en déduit que g est de la formet 7→ λ′e−δt/a + µ.
Il ne reste plus qu’à multiplier par eαt. On a bien
SH = t 7→ λeα1t + µeα2t | (λ, µ) ∈ R2.
98

Exemple : Résolvons l’équation y′′+ iy′− y = 0. L’équation caractéristique est X2 + iX− 1 = 0. Le discriminantvaut ∆ = 3 d’ou
α1 =−i +
√3
2et α2 =
−i +√
32
.
Les solutions sont donc de la forme
t 7→ λeα1t + µeα2t = (λe√
3t/2 + µe−√
3t/2)e−it/2.
Très souvent (en physique par exemple) on s’intéresse au cas où a, b et c sont des réels et on cherche lessolutions réelles de l’équation différentielle.
Avec les notations précédentes, suppose que a, b et c sont des réels. On note ∆ = b2 − 4ac lediscriminant de l’équation caractéristique. On a alors
— Si ∆ > 0 : on note α1 et α2 le deux racines réelles de l’équation caractéristique. On a
SH = t 7→ λeα1t + µeα2t | (λ, µ) ∈ R2.
— Si ∆ = 0 : on note α la racine double réelle de l’équation caractéristique. On a
SH = t 7→ (λt + µ)eαt | (λ, µ) ∈ R2.
— Si ∆ < 0 : on note α + iβ et α − iβ le deux racines complexes conjuguées de l’équationcaractéristique. On a
SH = t 7→ eαt(λ cos(βt) + µ sin(βt)) | (λ, µ) ∈ R2.
Là encore l’ensemble des solutions est un R-espace vectoriel de dimension 2.
Théorème 5.3.1.201 (Cas réel)
Démonstration :
— Les deux premiers cas sont les mêmes que dans C.— Pour le troisième, on cherche d’abord les fonctions à valeurs complexes qui vérifient (H). Si on note α± iβ
les deux racines conjuguées. Les solutions sont alors de la forme
t 7→ λe(α+iβ)t + µe(α−iβ)t où (λ, µ) ∈ C2.
En particulier les fonctions
t 7→ eαt cos(βt) =12
(e(α+iβ)t + e(α−iβ)t
)et t 7→ eαt sin(βt) =
12i
(e(α+iβ)t − e(α−iβ)t
)
appartiennent à SH .Réciproquement, une solution réelle est de la forme
t 7→ λe(α+iβ)t + µe(α−iβ)t où (λ, µ) ∈ C2.
Or elle est réelle, elle est donc égale à sa partie réelle qui est
t 7→ eαt (Re(λ) cos(βt)− Im(λ) sin(βt) +Re(µ) cos(βt) + Im(µ) sin(βt)) .
C’est de la forme cherchée.
Exemples :1. On considère l’équation y′′ = 0. Son équation caractéristique est X2 = 0. On voit que 0 est racine double.
Les solutions sont de la forme :x 7→ λx + µ avec (λ, µ) ∈ R2.
2. On considère l’équation y′′ − y = 0. Son équation caractéristique est X2 − 1 = 0. On voit que −1 et 1 sontracines simples. Les solutions sont de la forme :
x 7→ λex + µe−x avec (λ, µ) ∈ R2.
99

3. On considère l’équation y′′ − 2y′ + 2y = 0. Son équation caractéristique est X2 − 2X + 2 = 0. On voit que1− i et 1 + i sont racines simples. Les solutions sont de la forme :
x 7→ ex(λ cos x + µ sin x) avec (λ, µ) ∈ R2.
4. Ce genre d’équations apparaissent en physique. Prenons par exemple un mobile attaché à un ressort.On note f (t) la position relative du mobile par rapport au point d’équilibre (c’est-à-dire l’allongementdu ressort). On note k > 0 la constante de raideur du ressort et m la masse du mobile. On suppose quel’on étire le ressort à la situation initiale (c’est-à-dire f (0) = 1) et que l’on le lâche sans vitesse initiale(c’est-à-dire f ′(0) = 0).
— La cas sans frottements : Dans ce cas, le principe fondamental de la dynamique (ou deuxième loide Newton) affirme que
m f ′′(t) = −k f (t).
Autrement dit, la fonction f vérifie l’équation différentielle :
y′′ +km
y = 0
où k/m > 0. L’équation caractéristique est X2 + k/m = 0. Ses racines sont ω = i√
k/m et ω =−i√
k/m. On en déduit qu’il existe des constantes λ et µ telles que pour tout t ∈ R,
f (t) = λ cos(√
k/mt)+ µ sin
(√k/mt
).
En utilisant alors que f (0) = 1 et f ′(0) = 0 on en déduit que f (t) = cos(√
k/mt)
.
— La cas avec frottements : Dans ce cas, on suppose de plus que le mobile est soumis à une force defrottement qui est inversement proportionnelle à la vitesse. Il existe une constante C > 0 telle que laforce soit −C f ′(t). Dès lors, le principe fondamental de la dynamique (ou deuxième loi de Newton)affirme que
m f ′′(t) = −C f ′(t)− k f (t).
Autrement dit, la fonction f vérifie l’équation différentielle :
y′′ + Cy′ +km
y = 0.
L’équation caractéristique est X2 + CX + k/m = 0. Le discriminant est ∆ = C2 − 4α2. On a donc
— Si ∆ > 0, (c’est-à-dire pour C > 2α) : L’équation a deux racines réelles distinctes. Notons les u etv. La fonction f est de la forme : f : t 7→ λeut + µevt. On peut déterminer λ et µ en utilisant lesconditions initiales.
— Si ∆ < 0, (c’est-à-dire pour C < 2α) :
Les racines complexes conjuguées sont ω = −C/2 + i√(∆)/2 et ω = −C/2− i
√(∆)/2.
On en déduit qu’il existe des constantes λ et µ telles que pour tout t ∈ R,
f (t) = e−Ct/2(
λ cos(√
(∆)t/2)+ µ sin
(√(∆)t/2
)).
Exercice : Résoudre l’équation y′′ + y′ + y = 0.
3.2 Équations avec second membre
On va maintenant résoudre l’équation
ay′′ + by′ + cy = d (E)
où a, b et c sont des constantes complexes et d une fonction définie sur un intervalle I. On est, par le théorème destructure ramené à chercher des solutions particulières. On sait trouver des solutions particulières dans certaincas.
100

Soit
ay′′ + by′ + cy = Aeλx (E)
où A et λ sont des constantes complexes.Il existe une solution particulière de (E) de la forme x 7→ Bxαeλx où
— α = 0 si λ n’est pas une racine de l’équation caractéristique,
— α = 1 si λ est une racine simple de l’équation caractéristique,
— α = 2 si λ est une racine double de l’équation caractéristique.
Théorème 5.3.2.202
Remarque : le théorème précédent englobe les cas suivants
x 7→ c(x) λUne constante 0
cos x iex cos x 1 + i
Exemples :
1. On considère l’équation
y′′ − 3y′ + 2y = ex (E)
L’équation caractéristique est X2 − 3X + 2 = (X− 1)(X− 2). On voit que 1 est racine. On peut chercherune solution de la forme f : x 7→ axex.On trouve
S = x 7→ (−x + λ)ex + µe2x | (λ, µ) ∈ R2.En fait, il n’est pas nécessaire de mettre le b car il s’annule dans les calculs.
2. On considère l’équation
y′′ − 4y′ + 3y = ex cos(2x) (E)
On a ex cos(2x) = Re(e(1+2i)x). On regarde alors
y′′ − 4y′ + 3y = e(1+2i)x (E’)
L’équation caractéristique est X2 − 4X + 3 = (X − 1)(X − 3). On a (1 + 2i) n’est pas une racine del’équation caractéristique. On cherche une solution sous la forme x 7→ Be(1+2i)x. On trouve que B ∈ Cvérifie :
B((1 + 2i)2 − 4(1 + 2i) + 3) = 1
D’oùB = − 1
4(1 + i)= −1− i
8.
On en déduit que (E’) admet pour solution particulière
x 7→ −1− i8
ex(cos(2x) + i sin(2x)).
En prenant la partie réelle, on obtient que :
x 7→ −18(cos(2x)−+2 sin(2x))ex
est une solution particulière de (E).
S = x 7→ −18(cos(2x)−+2 sin(2x))ex + λex + µe3x | (λ, µ) ∈ R2.
3. Résoudre y′′ + y′ + y = cos2 x
101

3.3 Equation avec des conditions initiales
On se donne (E) une équation différentielle linéaire du second ordre à coefficients constants :
ay′′ + by′ + cy = d(t)
où d est une fonction définie sur un intervalle IOn suppose que l’on connait une solution particulière f0.
Soit t0 ∈ I et y0, y′0 dans K. Il existe une unique solution f de (E) qui vérifie que f (t0) = y0 etf ′(t0) = y′0.
Proposition 5.3.3.203
Démonstration : Ce théorème est admis. Donnons quand même une idée de la preuve. On se place dans le casoù K = C et où les deux racines de l’équations caractéristiques sont distinctes. Commençons déjà par justifierqu’il existe une solution f0 de l’équation (E). Afin de simplifier les notations, on voit que quitter à diviserpar a qui n’est pas nul on peut supposer que a = 1. Ensuite, on note α et β les racines dans C de l’équationcaractéristique. On remarque alors que pour toute fonction y,
[(y′ − αy)′ − β(y′ − αy)
]=(y′′ − (α + β)y′ + αβy
)= y′′ + by′ + cy.
De ce fait, pour toute fonction y, on a
y vérifie (E) ⇐⇒ z = y′ − αy vérifie z′ − βz = d(t).
Or on sait qu’il existe des solutions z0 de l’équation z′ − βz = d(t). De plus l’équation y′ − αy = z0 a elle aussides solutions. On en déduit qu’il existe bien (au moins une) fonction f0 vérifiant (E).
On peut alors dire queSE = f0 + h | h ∈ SH
où (H) est l’équation homogène associée. On en déduit qu’il suffit alors de montrer que pour tout t0 ∈ I et toutz0, z′0 dans C, il existe une unique solution h de (H) vérifiant
h(t0) = z0 et h′(t0) = z′0.
Le résultat voulut en découle en prenant z0 = y0 − f0(t0) et ′ = y′0 − f ′0(t0).Il suffit de montrer qu’il existe un unique couple (λ, µ) ∈ C2 tel que g : t 7→ λeαt + µeβt vérifie les conditions
initiales voulues. Cela signifie λeαt0 + µeβt0 = z0
λαeαt0 + µβeβt0 = z′0
Or ce système a une unique solution car son déterminant (β− α)e(α+β)t0 6= 0.
102

6Nombres entiers,
sommes et produits1 Les ensembles N et Z 1031.1 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1031.2 Division euclidienne dans N . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1041.3 Principe de récurrence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
2 Suites classiques 1052.1 Suites arithmétiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1052.2 Suites géométriques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1062.3 Suites artithmético-géométriques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1062.4 Suites récurrentes linéaires d’ordre 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
3 Calculs de sommes et produits 1083.1 Les signes ∑ et ∏ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1083.2 Sommes classiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
1 Les ensembles N et Z
1.1 Généralités
On appelle ensemble des entiers naturels (resp. relatifs) et on note N (resp. Z) l’ensemble :
N = 0, 1, 2, 3, . . . (resp. Z = 0, 1,−1, 2,−2, . . .).
On les considère avec les opérations usuelles + et ×.
Définition 6.1.1.204
103

L’ensemble N muni de son ordre naturel qui est total vérifie les propriétés suivantes :
1. Toute partie non vide de N admet un plus petit élément.
2. L’ensemble N n’est pas majoré.
3. Toute partie non vide majorée admet un plus grand élément.
Théorème 6.1.1.205 (Admis)
Remarque : Toutes ces propriétés correspondent à l’intuition que l’on a sur les entiers naturels. De fait celapermet de définir l’ensemble N car on peut prouver qu’il n’existe qu’un seul ensemble qui vérifie cela.
L’ensemble Z des entiers relatifs vérifie les propriétés suivantes :
1. L’ensemble Z n’est ni majoré ni minoré.
2. Toute partie non vide et minorée de Z admet un plus petit élément.
3. Toute partie non vide majorée de Z admet un plus grand élément.
Corollaire 6.1.1.206
Démonstration : Cela découle du théorème précédent. Démontrons par exemple que toute partie non vide etminorée de Z admet un plus petit élément. Soit A une partie minorée de Z et m un minorant de A. On considèreA = n−m | n ∈ A.
Par construction c’est une partie non vide de N. Notons d son plus petit élément et posons a = m + d. Onvoit d’abord que a est un minorant de A. En effet pour tout n de A,
n−m > d⇔ n > d + m = a.
De plus a est un élément de A car d est un élément de A. On en déduit que a est le plus petit élément de A.Le reste est identique.
Remarques :1. Une propriété essentielle des entiers est que si on considère un entier n naturel, il y a un entier (appelé
le successeur) qui est « juste après ». Pour cela il suffit de considérer l’ensemble A = m ∈ N | m > n.Cet ensemble n’est pas vide car N n’est pas majoré. Il admet donc un plus petit élément. C’est n + 1. Enparticulier, on a :
x > n⇔ x > n + 1.
On a une propriété identique dans Z.
2. De même si on considère un entier naturel n non nul, il existe un entier (appelé prédécesseur) qui est« juste avant » et de même dans Z sans l’hypothèse différent de 0.
Notation : Soit a et b deux entiers relatifs on note
[[ a ; b ]] = n ∈ Z | a 6 n 6 b.
1.2 Division euclidienne dans N
Commençons par un lemme
Soit a et b deux entier naturels avec b 6= 0. Il existe n dans N tel que a < nb.
Lemme 6.1.2.207 (Propriété d’Archimède)
Démonstration : On considère l’ensemble A = nb | n ∈ N. On veut montrer que cet ensemble n’est pasmajoré par a. Supposons par l’absurde que A est majorée. Dans ce cas il admet un plus grand élément que l’onpeut noter Nb pour N ∈ N. Alors (N + 1)b est dans A et (N + 1)b > Nb ce qui contredit que Nb est le plusgrand élément de A.
On en déduit donc que A n’est pas majoré. De ce fait il existe n dans N tel que nb > a.
104

Soit a et b deux entiers naturels avec b non nul. Il existe un unique couple (q, r) dans N2 qui vérifie :
a = qb + r et 0 6 r < b.
Le nombre q est le quotient et r le reste de la division euclidienne de a par b.
Théorème 6.1.2.208 (Division euclidienne)
Démonstration : On considère A = nb | n ∈ N ∩ [[ 0 ; a ]] . Cet ensemble n’est pas vide car il contient 0. Deplus il est majoré par a. On en déduit qu’il existe un plus grand élément. On le note qb. On pose aussi r = a− qbde telle sorte que a = qb + r.
Maintenant, a majore A, de ce fait, qb 6 a d’où r > 0. D’autre part, (q + 1)b n’est pas dans A (car il eststrictement supérieur à qb). On en déduit que
(q + 1)b > a⇔ a− qb < b.
Exemples :
1. La division de 17 par 5 est 17 = 3× 5 + 2.
2. On voit que a est divisible par b si et seulement si r est nul.
Remarque : Voir le cours d’informatique pour l’implémentation de ce calcul.
1.3 Principe de récurrence
On a déjà revu le principe de récurrence. Voyons pourquoi cela découle de notre axiomatisation de N.
Soit P(n) un prédicat défini sur N. Si :
1. P(0) est vraie.
2. ∀n ∈ N, (P(n)⇒ P(n + 1))
alors pour tout entier naturel n, P(n) est vraie.
Théorème 6.1.3.209 (Principe de récurrence)
Démonstration : On considère l’ensemble A = n ∈ N | P(n) est fausse. Supposons par l’absurde que cetensemble ne soit pas vide. Dans ce cas il admet un plus petit élément N qui ne peut pas être 0 car 0 /∈ A. On aalors que N − 1 /∈ A et de ce fait P(N − 1) est vraie. D’après la deuxième hypothèses, P(N) est alors aussi vraiece qui est absurde. On peut donc conclure que A est vide et c’est ce que l’on voulait.
2 Suites classiques
2.1 Suites arithmétiques
Une suite (un) à valeur complexe est une suite arithmétique s’il existe un complexe r tel que
∀n ∈ N, un+1 − un = r.
Le nombre r s’appelle la raison de la suite (un).
Définition 6.2.1.210
Remarque : Pour montrer qu’une suite est une suite arithmétique, on pourra calculer un+1 − un.
105

Soit (un) une suite arithmétique de raison r. Soit n, p deux entier,
un = up + (n− p)r.
En particulier si (un) est définie en 0 on a
un = u0 + nr.
Proposition 6.2.1.211
2.2 Suites géométriques
Une suite (un) à valeur complexe est une suite géométrique s’il existe un complexe r tel que
∀n ∈ N, un+1 = run.
Le nombre r s’appelle la raison de la suite (un).
Définition 6.2.2.212
Remarque : Pour montrer qu’une suite est une suite géométrique, on pourra calculerun+1
unaprès avoir montré
que la suite ne s’annule pas...
Soit (un) une suite géométrique de raison r. Soit n, p deux entier,
un = rn−pup.
En particulier si (un) est définie en 0 on a
un = u0rn.
Proposition 6.2.2.213
2.3 Suites artithmético-géométriques
Une suite (un) à valeur complexe est une suite arithmético-géométrique s’il existe des nombres complexes a etb tels que
∀n ∈ N, un+1 = aun + b.
Définition 6.2.3.214
Remarque : Si a = 1 on retrouve une suite arithmétique. Si b = 0 on retrouve une suite géométrique.FMéthode : Pour trouver le terme général d’une suite arithmético-géométrique (un), où a 6= 1, on cherche un
« point fixe » qui est un nombre α qui vérifié α = aα + b. Par la suite, on montre que (un − α) est une suitegéométrique.Exemple : Trouvons le terme général de la suite (un) définie par
u0 = 7 et ∀n ∈ N, un+1 = −2un + 3.
106

2.4 Suites récurrentes linéaires d’ordre 2
Une suite (un) à valeur complexe est une suite récurrente linéaire d’ordre 2 (homogène) s’il existe des nombrescomplexes a, b et c tels que
∀n ∈ N, aun+2 + bun+1 + cun = 0.
Définition 6.2.4.215
Remarque : Si a = 0, la suite est alors arithmético-géométrique. Dans toute la suite on supposera donc a 6= 0.
Soit (un) une suite récurrente linéaire d’ordre 2 vérifiant la relation
∀n ∈ N, aun+2 + bun+1 + cun = 0.
On appelle polynôme caractéristique le polynôme P = aX2 + bX + c. C’est un polynôme de degré 2.
Définition 6.2.4.216
Nous allons déterminer la terme général de ces suites. L’idée est la même que pour les équations différen-tielles d’ordre 2 à coefficients constants. On va d’abord chercher des suites géométriques qui vérifient la mêmerelation de récurrence.
Dans toute la suite on se fixe a, b et c trois complexes. On note P = aX2 + bX + c et on note (F) la relation :
∀n ∈ N, aun+2 + bun+1 + cun = 0.
Soit α ∈ C.
1. On a P(α) = 0 ⇐⇒ la suite (αn) vérifie la relation (F).
2. Si α 6= 0. On a P(α) = P′(α) = 0 ⇐⇒ les suites (αn) et (nαn) vérifient la relation (F).
Proposition 6.2.4.217
Démonstration :1. On a
la suite (αn) vérifie la relation (F) ⇐⇒ ∀n ∈ N, aun+2 + bun+1 + cun = 0
⇐⇒ ∀n ∈ N, aαn+2 + bαn+1 + cαn = 0⇐⇒ ∀n ∈ N, αnP(α) = 0⇐⇒ P(α) = 0
Pour la dernière équivalence, le sens⇒ s’obtient en prenant n = 0.2. Il suffit de procéder par double implication. Le fait que α 6= 0 sert pour le sens⇐.
On en déduit le théorème suivant
On note ∆ le discriminant de l’équation aX2 + bX + c = 0 où (b, c) 6= (0, 0).
1. Si ∆ 6= 0. On note α et β les deux racines. Alors ((αn), (βn)) vérifient (F) et pour toute suite(un) vérifiant cette relation est de la forme, il existe (λ, µ) ∈ C2 tels que
∀n ∈ N, un = λαn + µβn.
2. Si ∆ = 0. On note α la racine double qui est non nulle. Alors ((αn), (nαn)) vérifient (F) et pourtoute suite (un) vérifiant cette relation est de la forme, il existe (λ, µ) ∈ C2 tels que
∀n ∈ N, un = (λ + nµ)αn.
Théorème 6.2.4.218 (Cas complexe)
107

Exemple : Si on considère la suite de Fibonnacci ( fn). On trouve que les solutions de X2 − X − 1 = 0 sont
ϕ =1 +√
52
et ϕ′ =1−√
52
. Donc il existe λ et µ tels que ∀n ∈ N, fn = λϕn + µϕ′n. En résolvant le systèmepour n = 0 et n = 1 on obtient
λ + µ = 0
λϕ + µϕ′ = 1 ⇐⇒
λ + µ = 0µ(ϕ′ − ϕ) = 1 ⇐⇒
λ =
√5
5
µ =1
(ϕ′ − ϕ)= −√
55
.
Donc
∀n ∈ N, fn =
√5
5
((1 +√
52
)n
−(
1−√
52
)n).
Démonstration : La démonstration se base sur le lemme suivant :
Soit (un) et (vn) deux suites qui vérifient (F). Si u0 = v0 et u1 = v1 alors (un) = (vn).
Lemme 6.2.4.219
Démonstration du lemme : Par récurrence double
Revenons à la démonstration du théorème.
1. Il est aisé de vérifier que les suites de la forme (λαn + µβn) vérifient (F) quand P(α) = P(β) = 0. Il suffitdonc de chercher des solutions au système
λ + µ = u0
λα + µβ = u1
Or ce système a toujours des solutions car α 6= β.
2. On procède pareil et on se ramène au système
λ = u0(λ + µ)α = u1
Ce dernier a des solutions car α 6= 0.
3 Calculs de sommes et produits
3.1 Les signes ∑ et ∏Nous allons (re)voir les notations et certains calculs afférents aux sommes et produits. Le but n’est pas de
traiter la théorie des séries qui relève de la la fin de l’année.On utilisera les signes ∑ et ∏ pour désigner des sommes et des produits :
n
∑i=1
i = 1 + 2 + · · ·+ n =n(n + 1)
2n
∏i=1
i = 1× 2× · · · × n = n!.
Remarque : Dans ces deux cas le i est une variable muette. On a
n
∑i=0
i =n
∑j=0
j
108

si (ai)i∈I est une famille de nombres indexée par un ensemble fini I on note ∑i∈I
ai la somme des nombres et
∏i∈I
ai leur produit. Dans le cas où I = [[ 1 ; n ]] on a donc
n
∑i=1
ai = a1 + a2 + · · ·+ an etn
∏i=1
ai = a1 × a2 × · · · × an.
Définition 6.3.1.220
Soit n un entier, (ai)i∈I , (bi)i∈I deux familles indexées par un ensemble fini I et λ un nombre. On a
∑i∈I
(ai + bi) = ∑i∈I
ai + ∑i∈I
bi et ∑i∈I
(λ× ai) = λ×∑i∈I
ai.
Proposition 6.3.1.221 (Linéarité des sommes)
Soit n un entier, (ai)16i6n une famille indexée par [[ 1 ; n ]].
n
∑i=1
ai =n+1
∑i=2
ai−1 =n−1
∑i=0
ai+1 =n−1
∑i=0
an−i.
Proposition 6.3.1.222 (Décalage d’indices)
Remarque : Il ne faut pas hésiter (au moins au brouillon) à revenir à l’écriture en extension avec des points desuspensions pour vérifier ces formules.
Soit I et J deux ensembles finis. Soit (ai)i∈I et (bj)j∈J deux familles de nombres complexes.
(∑i∈I
ai
)×(
∑j∈J
bj
)= ∑
(i,j)∈I×Jaibj.
En particulier (n
∑i=1
ai
)2
= ∑(i,j)∈[[ 1 ; n ]]2
aiaj =n
∑i=1
a2i + ∑
(i,j)∈[[ 1 ; n ]]2
i 6=j
aiaj.
Proposition 6.3.1.223
Exercice : Le démontrer par récurrence.
3.2 Sommes classiques
Somme des termes d’une suite arithmétique
Soit (u) une suite arithmétique. Pour tous entiers a et b on a :
b
∑i=a
ui = (b− a + 1)× ua + ub2
.
Proposition 6.3.2.224
109

Remarques :
1. Cette formule peut se retenir en disant que la somme vaut
(nombre de termes) × (terme moyen)
En faisant attention que le nombre de termes entre a et b est b− a + 1 et non b− a.
2. On retiendra en particulier le cas r = 1, u0 = 0 qui donne :
n
∑i=0
i =n(n + 1)
2.
Démonstration : Par récurrence.
Somme des termes d’une suite géométrique
Soit (u) une suite géométrique de raison r. Pour tous entiers a et b on a :
b
∑i=a
ui =
ua.1− rb−a+1
1− rsi r 6= 1
(b− a + 1)ua si r = 1.
Proposition 6.3.2.225
Démonstration : Par récurrence
Remarques :
1. Penser à séparer le cas où la raison est 1 quand on utilise cette formule.
2. Cette formule se retient sous la forme
n
∑i=a
ui = (premier terme)× 1− (raison)(nb de termes)
1− (raison).
Formule du binôme et identité remarquables
Commençons par rappeler rapidement la définition des coefficients binomiaux.
Soit n et p deux entiers on note
(np
)=
n!p!(n− p)!
si p 6 n
0 sinon.
Définition 6.3.2.226
Remarque : Nous reverrons plus loin la signification combinatoire de cette formule.
1. Pour tout entier n,(
n0
)= 1,
(n1
)= n et
(n2
)=
n(n + 1)2
.
2. Pour tout couple d’entiers (n, p),(
n + 1p + 1
)=
(np
)+
(n
p + 1
)(Formule de Pascal).
Proposition 6.3.2.227 (Propriétés des coefficients binomiaux)
110

Démonstration
Remarque : On en déduit la construction du triangle de Pascal.
Soit (a, b) ∈ C2. On a
∀n ∈ N, (a + b)n =n
∑i=0
(ni
)akbn−k.
Proposition 6.3.2.228 (Formule du binôme de Newton)
Démonstration
Remarque : Cette formule généralise les identité remarquables
(a + b)2 = .., (a− b)2 = .., (a + b)3 = ..
On a les égalités suivantes pour n ∈ N :
n
∑i=0
(ni
)= 2n et
n
∑i=0
(−1)i(
ni
)= 0.
Corollaire 6.3.2.229
Démonstration : On applique la formule du binôme avec a = b = 1 pour la première égalité puis avec a = −1et b = 1 pour la seconde.
On peut aussi généraliser l’identité remarquable a2 − b2 = ...
Soit a et b deux nombres complexes et n un entier
an+1 − bn+1 = (a− b)n
∑k=0
akbn−k.
Proposition 6.3.2.230
Démonstration
Somme téléscopique
Commençons par un exemple :Exemple : si (un)n∈N est une suite alors
5
∑k=1
(uk+1 − uk) = (u6 − u5) + (u5 − u4) + (u4 − u3) + (u3 − u2) + (u2 − u1) = u6 − u1.
si (un)n∈N est une suite alors pour tout entier n,
n
∑k=0
(uk+1 − uk) = un+1 − u0.
Proposition 6.3.2.231
111

Démonstration : Par les décalages d’indices.
Exemple : On va calculer la somme des carrés (la somme des cubes se traite de manière identique). On remarqueque pour tout entier i,
(i + 1)3 − i3 = 3i2 + 3i + 1.
On en déduit quen
∑i=0
(i + 1)3 − i3 = 3n
∑i=0
i2 + 3n
∑i=0
i+n
∑i=0
1.
Or cela se calcule par un télescopage. On en déduit :
3n
∑i=0
i2 = (n + 1)3 − 0− 3n(n + 1)
2− (n + 1).
D’oùn
∑i=0
i2 =n(n + 1)(2n + 1)
6.
Exercice :
1. Rappeler la formule de Pascal pour les coefficients binomiaux.
2. En déduiren
∑i=p
(ip
).
Produit téléscopique
De manière identique on a
si (un)n∈N est une suite de nombres non nuls, alors pour tout entier n,
n
∏k=0
uk+1uk
=un+1
u0.
Proposition 6.3.2.232
Sommes des carrés et des cubes
On a vu précédemment comment calculer la somme des n premiers entiers. On va maintenant calculer lasomme des n premiers carrés puis des n premiers cubes.
Pour tout entier n on a :
n
∑i=0
i2 =n(n + 1)(2n + 1)
6et
n
∑i=0
i3 =n2(n + 1)2
4.
Proposition 6.3.2.233
Remarque : il est simple de se souvenir de la formule de la somme des cubes car on trouve le carré de lasomme des n premiers entiers.Démonstration : Cela se démontre par récurrence. On peut les retrouver de proches en proche en utilisant lecalculs fait ci-dessus avec un télescopage.
Terme général d’une suite de la forme un+1 = un + αn
On considère une suite définie par
u0 ∈ C et ∀n ∈ N, un+1 = un + αn
112

. Dans certains cas, si (αn) n’est pas trop compliquée on peut retrouver le terme général. En effet, par télescopage :
∀n ∈ N?, un − u0 =n−1
∑k=0
uk+1 − uk =n−1
∑k=0
αk.
Par exemple, siu0 = 3 et ∀n ∈ N, un+1 = un + n + 2n
. On a
∀n ∈ N?, un − 3 =n−1
∑k=0
n + 2n =n(n− 1)
2+
1− 2n
1− 2=
n(n− 1)2
+ 2n − 1.
On a donc
∀n ∈ N, un =n(n− 1)
2+ 2n + 2.
On voit que la formule est encore vérifiée pour n = 0.
Sommes doubles
On peut travailler avec des sommes « sur des tableaux à deux dimensions ».
Soit n, m deux entiers naturels non nuls. Soit (aij) une famille de nombres indexés par [[ 1 ; n ]]×[[ 1 ; m ]].On a
∑(i,j)∈[[ 1 ; n ]]×[[ 1 ; m ]]
aij =n
∑i=1
m
∑j=1
aij =m
∑j=1
n
∑i=1
aij.
Proposition 6.3.2.234 (Somme « carrées »)
Exemple : Calculons ∑(i,j)∈[[ 1 ; n ]]×[[ 1 ; m ]]
2i + 3j.
Soit n un entier naturel non nul. Soit (aij) une famille de nombres indexés par [[ 1 ; n ]]2.On a
∑16i6j6n
aij =n
∑i=1
m
∑j=i
aij =n
∑j=1
j
∑i=1
aij.
Proposition 6.3.2.235 (Somme « triangulaires »)
Exemple : Calculons ∑16i6j6n
2i + 3j.
113

7Systèmes linéaires
Dans tout ce chapitre nous désignerons par K les ensembles de nombres R et C. Notre but est de résoudredes systèmes d’équations linéaires. Les solutions d’un système à p inconnue sera une partie de Kp. C’est pourcette raison que nous allons commencer par étudier (rapidement) l’ensemble Kp ainsi que sa structure.
1 L’ensemble Kp
1.1 Définitions
Soit p ∈ N?, on rappelle que Kp est le produit cartésien K × · · · × K (p fois). C’est-à-dire que Kp estl’ensemble des p-uplets d’éléments de K. On appellera les éléments de Kp des vecteurs.
Définition 7.1.1.236
Remarques :
1. On pourrait à la limite définir aussi K0. La meilleure méthode consiste alors à le définir comme étant unl’ensemble ne contenant que 0. Cependant, nous essayerons d’éviter de traiter ce cas.
2. Nous expliquerons plus tard en détails la terminologie vecteur. Mais nous pouvons déjà remarquer que,via un système de coordonnées, l’ensemble des vecteurs du plan est en correspondance avec R2 et quel’ensemble des vecteurs de l’espace est en correspondance avec R3.
3. On peut penser au plan et à l’espace pour se représenter R2 et R3. Malheureusement il n’y a plus de telles"images" pour Rn avec n > 4. Cependant, on peut continuer à avoir une intuition "géométrique".
Exemples :
1. Le vecteur (1,−1, π) est un vecteur de R3 mais aussi de C3. Le vecteur (i, 0) est un vecteur de C2.
2. Soit n un entier fixé et i ∈ [[ 1 ; n ]] on notera souvent ei le vecteur dont la i-ème coordonnée est 1 est lesautres 0. Par exemple pour n = 3 on a :
e1 = (1, 0, 0), e2 = (0, 1, 0) et e3 = (0, 0, 1).
3. On notera 0 (ou 0 ou 0Kp ) le vecteur dont toutes les coordonnées sont nulles. Il s’appelle le vecteur nul.
1.2 Opérations sur Kp
Que savons-nous faire sur des vecteurs du plan ou de l’espace? On sait en faire la somme et on sait aussifaire la multiplication par un réel. Ce sont ses deux opérations que nous allons généraliser à l’ensemble Kp.
114

Remarquons que l’on sait aussi faire le produit scalaire de deux vecteurs mais dans ce cas nous n’obtenons pasun vecteur : cette opération ne sera donc pas prise en compte.• Somme :
Soit u et v deux vecteurs de Kp. On note
u = (x1, . . . , xp) et (y1, . . . , yp).
On appelle somme de u et de v et on note u + v le vecteur :
u + v = (x1 + y1, . . . , xp + yp).
C’est la somme terme à terme.
Définition 7.1.2.237
Remarques :
1. Cela correspond à la somme de deux vecteurs du plan ou de l’espace.
2. On ne peut pas additionner des vecteurs de taille différente. Par exemple un vecteur du plan et un vecteurde l’espace.
•Multiplication externe :
Soit u un vecteur de Kp et λ un élément de K (un scalaire). On note
u = (x1, . . . , xp)
On appelle multiplication de u par λ et on note λ.u le vecteur :
λ.u = (λ.x1, . . . , λ.xp);
C’est le produit terme à terme.
Définition 7.1.2.238
Remarques :
1. Cela correspond à la multiplication des vecteurs du plan ou de l’espace.
2. On ne multiplie pas un vecteur par un autre vecteur mais un vecteur par un scalaire.
• Propriétés :
Les opérations vérifient les propriétés suivantes :
1. L’addition est associative : ∀(u, v, w) ∈ (Kp)3, (u + v) + w = u + (v + w).
2. L’addition est commutative : ∀(u, v) ∈ (Kp)2, u + v = v + u.
3. Distributivité à droite : ∀λ ∈ K, ∀(u, v) ∈ (Kp)2, λ.(u + v) = λ.u + λ.v.
4. Distributivité à gauche : ∀(λ, µ) ∈ K2, ∀u ∈ (Kp), (λ + µ).u = λ.u + µ.u.
5. Compatibilité de la multiplication : ∀(λ, µ) ∈ K2, ∀u ∈ (Kp), λ.(µ.u) = (λ× µ).u.
6. Propriétés du vecteur nul : ∀λ ∈ K, ∀u ∈ (Kp), λ.0Kp = 0Kp , 0.u = 0Kp et u + 0Kp = u.
Proposition 7.1.2.239
Remarque : Les propriétés ci-dessus expriment le fait que Kp est un espace vectoriel.
115

Soit (u1, . . . , un) ∈ (Kp)n. Une combinaison linéaire des (u1, . . . , un) est un vecteur v ∈ Kp qui peut s’écrire
v =n
∑i=1
λi.ui où les λi sont des scalaires. L’ensemble des combinaisons linéaires des vecteurs (u1, . . . , un) se
note Vect(u1, . . . , un). C’est une partie de Kp.
Définition 7.1.2.240
Remarque : Soit (u1, . . . , up) ∈ (Kp)p alors 0Kp ∈ Vect(u1, . . . , up).Exemples :
1. Dans R. On considère u = 7. On a Vect(u) = R.2. Dans R2, on considère u = (1, 2). L’ensemble Vect(u) est l’ensemble des vecteurs de la forme (λ, 2λ).
C’est une droite.3. Dans R2 on considère u = (1, 2) et v = (−1, 1). On veut alors montrer que Vect(u, v) = R2. Il faut
montrer que tous les vecteurs de R2 sont des combinaisons linéaires de u et de v, c’est à dire que pour toutcouple w = (x, y) ∈ R2, il existe (λ, µ) ∈ R2 tels que
λ.u + µ.v = w.
Or λ.u + µ.v = (λ− µ, 2λ + µ). Il faut donc résoudre le système :
λ− µ = x2λ + µ = y ⇔
λ =x + y
3µ =
y− 2x3
4. Dans R3, on considère u = (1, 2,−1). L’ensemble Vect(u) est l’ensemble des vecteurs de la forme(λ, 2λ,−λ). C’est une droite.
5. Dans R3 on considère u = (1, 2,−1) et v = (−1, 1, 0). On veut alors déterminer Vect(u, v). Soit w =(x, y, z) ∈ R3, on cherche s’il existe (λ, µ, ) ∈ R tels que
λ.u + µ.v = w.
Or λ.u + µ.v = (λ− µ, 2λ + µ,−λ = z). Il faut donc résoudre le système :
λ− µ = x2λ + µ = y−λ = z
⇔
λ =x + y
3µ =
y− 2x3
0 = z +x + y
3
On trouve qu’un vecteur w = (x, y, z) ∈ R3 est dans Vect(u, v) si et seulement si x + y + 3z = 0. C’est àdire s’il est dans le plan d’équation x + y + 3z = 0.
6. Dans R3, si u = (1, 2,−1), v = (−1, 1, 0) et w = (1, 0, 0) alors Vect(u, v, w) = R3.
2 Systèmes linéaires
2.1 Définitions
On appelle système linéaire de n équations à p inconnues un système du type
(S)
a11x1+ · · · +a1pxp = b1 (L1)a21x1+ · · · +a2pxp = b2 (L2)
...... =
...an1x1+ · · · +anpxp = bn (Ln)
— Les aij pour (i, j) ∈ [[ 1 ; n ]]× [[ 1 ; p ]] s’appellent les coefficients du système.
— Les xj pour j ∈ [[ 1 ; p ]] s’appellent les inconnues du système.
— Les bi pour i ∈ [[ 1 ; n ]] forment le second membre du système.
Définition 7.2.1.241
116

Notations :1. Les solutions du système (S) sont les vecteurs (x1, . . . , xp) ∈ Kp dont les coordonnées vérifient le système.2. Si tous les termes du second membre sont nuls, le système est dit homogène.3. Le système obtenu en conservant les coefficients mais en prenant un second membre nul s’appelle le
système homogène associé.4. Les systèmes ayant autant de lignes que de colonnes s’appellent des systèmes carrés. C’est ceux que nous
étudierons le plus souvent.Exemples :
1. Soit (S) le système
2x + 3y = 2x − y = 7
2. Soit (S) le système
2x + 3y − z + t = 0y + t = 0
x + t = 0
3. Soit (S) le système x1 − x2 + · · ·+ (−1)n+1xn = 7.
2.2 Structure de l’ensemble des solutions
• Cas sans solution : Commençons par noter qu’un système peut ne pas avoir de solutions. Par exemple le
système
x − y = 2x − y = 4 n’a pas de solutions.
• Réduction au cas homogène : Si on suppose que le système a une solution, on peut se ramener à l’étudedu système linéaire associé. Si on considère le système
(S)
a11x1+ · · · +a1pxp = b1 (L1)a21x1+ · · · +a2pxp = b2 (L2)
...... =
...an1x1+ · · · +anpxp = bn (Ln)
Si on suppose disposer d’une solutions (α1, . . . , αp) ∈ Kp. On peut alors se ramener au système homogène
(H)
a11(x1 − α1)+ · · · +a1p(xp − αp) = 0 (L1)a21(x1 − α1)+ · · · +a2p(xp − αp) = 0 (L2)
...... =
...an1(x1 − α1)+ · · · +anp(xp = αp) = 0 (Ln)
• Étude du cas homogène : On considère un système homogène (H). On peut remarquer qu’il a toujoursdes solutions en particulier 0Kp=(0,...,0) est une solution de (H). De plus, si u et v sont deux solutions de (H)alors toute combinaison linéaire de u et de v est encore une solution.
1. Soit (H) un système linéaire homogène.
— Le vecteur nul est solution.
— Toute combinaison linéaire de solutions est encore une solution.
— S’il y a une solution alors il y en a une infinité.
2. Soit (S) un système linéaire et (H) le système linéaire homogène associé.
— Le système peut ne pas avoir de solutions.
— Si (S) a une solution u0 ∈ Kp alors
∀u ∈ Kp, (u est solution de (S))⇔ ((u− u0) est solution de (H)).
Théorème 7.2.2.242 (Structure des solutions)
Un système n’ayant pas de solution est dit incompatible. Au contraire un système ayant des solution est ditcompatible. Un système carré n’ayant qu’une unique solution est dit de Cramer ou inversible.
Définition 7.2.2.243
117

Remarque : le fait d’être compatible ou non dépend en grande partie du second membre. En effet, un systèmehomogène est toujours compatible.Exemples :
1. Les solutions d’un système homogène à trois inconnues est une partie de K3 stable par combinaisonslinéaires. Cela ne peut être que : l’ensemble réduit à 0, une droite passant par l’origine, un plan passantpar l’origine ou tout K3.
— Le système
2x + 3y + z = 0y − z = 0y + z = 0
est inversible. Son unique solution est (0, 0, 0).
— Le système
2x − y − z = 0y − z = 0
x − z = 0n’est pas inversible. Le vecteur u = (1, 1, 1) est une solu-
tion. De fait ses solutions sont la droite Vect(u).
— Le système
x + y + z = 02x + 2y + 2z = 03x + 3y + 3z = 0
n’est pas inversible. Les vecteurs u = (1,−1, 0) et v =
(1, 0,−1). sont des solutions. De fait ses solutions sont le plan Vect(u, v).
2. Si on considère des systèmes qui ne sont plus homogènes.
— Le système
2x + 3y + z = −2y − z = 0y + z = 1
a pour solution le vecteur (−2, 1, 1). Comme le système
homogène associé n’a que 0 comme solution c’est la seule.
— Le système
2x − y − z = 1y − z = 1
x − z = 1a pour solution u = (1, 1, 0). On en déduit que l’ensemble
des solutions est la droite affine
S = (1, 1, 0) + λ.(1, 1, 1) | λ ∈ R = (1 + λ, 1 + λ, λ) ∈ R3 | λ ∈ R.
— Le système
2x − y − z = 2y − z = 1
x − z = 1est incompatible.
2.3 Écriture matricielle des systèmes
Le plus long dans la résolution d’un système est de l’écrire. Nous adopterons une notation « matricielle » (leterme sera justifié au chapitre suivant) pour alléger l’écriture. Pour le moment il faut voir cela comme unesimple notation. On se rend compte que lors de la résolution du système le noms des variables n’importe pason ne va donc noter que les coefficients.
Le système
a11x1+ · · · +a1pxp = b1 (L1)a21x1+ · · · +a2pxp = b2 (L2)
...... =
...an1x1+ · · · +anpxp = bn (Ln)
sera noté
a11 · · · a1p b1p...
......
an1 · · · anp bnp
.
De plus, quand nous considérerons un système homogène nous ne noterons pas le second membre car il n’ya que des zéros.
Le système
2x − y − z = 0y − z = 0
x − z = 0sera noté
2 −1 −10 1 −11 0 −1
.
2.4 Systèmes diagonaux, triangulaires et echelonnés
Nous allons voir certains cas particuliers de systèmes qui sont plus faciles à résoudre.
— Systèmes diagonaux : Soit n ∈ N?. Un système carré de n équations à n inconnues est dit diagonal sitous ses coefficients hors de la diagonal sont nuls. C’est-à-dire :
∀(i, j) ∈ [[ 1 ; n ]]2 , i 6= j⇒ aij = 0.
118

Il est donc de la forme
a11 0 · · · 0 b10 a22 0 b2...
. . ....
...0 · · · · · · ann bn
.
Ces systèmes sont particulièrement simples à résoudre. En effet, ils peuvent être vus comme n équationsdistinctes. Exemples :
1. On considère le système
2 0 0 40 −1 0 30 0 1 0
. Sa solution est (2,−3, 0).
2. On considère le système
2 0 0 20 0 0 30 0 1 −1
. Il est incompatible.
3. On considère le système
2 0 0 20 0 0 00 0 1 −1
. Ses solutions sont (1, y,−1) ∈ R3 | y ∈ R.
Soit (S) un système diagonal
a11 0 · · · 0 b10 a22 0 b2...
. . ....
...0 · · · · · · ann bn
.
1. Si tous les aii sont non nuls, le système est inversible et son unique solution est(
b1
a11, . . . ,
bn
ann
).
2. S’il existe un i tel que aii = 0, le système n’est pas inversible. On note I l’ensemble des i tel queaii = 0 et J son complémentaire.
— si pour tous les i dans I on a bi = 0 le système a une infinité de donnée. Le systèmehomogène ayant pour solution Vect((ei)i∈I).
— s’il existe un i de I tel que bi 6= 0 le système est incompatible.
Proposition 7.2.4.244
— Systèmes triangulaires : Soit n ∈ N?. Un système carré de n équations à n inconnues est dit triangulairesupérieur (resp. inférieur) si tous ses coefficients sous la diagonale (resp. sur la diagonale) sont nuls.C’est-à-dire :
∀(i, j) ∈ [[ 1 ; n ]]2 , i > j⇒ aij = 0 (resp. ∀(i, j) ∈ [[ 1 ; n ]]2 , i > j⇒ aij = 0).
Il est donc de la forme
a11 a12 · · · a1n b10 a22 a2n b2...
. . ....
...0 · · · · · · ann bn
resp.
a11 0 · · · 0 b1a21 a22 0 b2...
. . ....
...an1 · · · · · · ann bn
.
La résolution d’un système triangulaire supérieur se fait « en remontant ».Exemples :
1. On considère le système
2 1 3 50 −1 1 30 0 1 0
. Si on note (x, y, z) une solution, on voit que z = 0.
On en déduit alors que y = −3 puis en remplaçant y par sa valeur que x = 4. La solution est donc(4,−3, 0).
2. On considère le système
2 1 2 20 0 4 30 0 1 −1
. Là encore on peut tenter une remontée. On a z = −1
mais ensuite ou est bloqué... Le système est incompatible.
119

3. On considère le système
2 1 2 20 0 4 −40 0 1 −1
. La remontée, nous donne z = −1, y quelconque et
x = 2− y/2. L’ensemble des solution est alors : (2− y, 2y,−1) | y ∈ R.Les système triangulaires inférieurs se résolvent de la même manière mais en descendant. Cependantnous n’en rencontrerons peu.
Soit (S) un système triangulaire supérieur,
a11 a12 · · · a1n b10 a22 a2n b2...
. . ....
...0 · · · · · · ann bn
.
1. Si tous les coefficients diagonaux sont non nuls, le système est inversible.
2. S’il y a au moins un coefficient nul, le système est soit incompatible, soit il a une infinité desolutions.
Proposition 7.2.4.245
Remarques :
1. On a les même propriétés pour les systèmes triangulaires inférieurs.
2. On comprend bien, d’où arrive cette proposition. On commence par le bas et on remonte. Si on veutêtre précis, cela se démontre par récurrence sur la taille n du système.
— Systèmes échelonnés : les systèmes échelonnés sont un peu plus généraux. Ils sont très importants carnous allons voir par la suite que l’on peut toujours se ramener à un système échelonné. On peut voir unsystème triangulaire supérieur comme un système on l’on ajoute à chaque ligne un zéro en plus à gauche.Un système échelonné sera un système on on ajoutera au moins un zéro à chaque ligne.
Soit (S) un système de n équations à p inconnues on pose
d : [[ 1 ; n ]] → N
i 7→
n + 1 si ∀j ∈ [[ 1 ; p ]] aij = 0Minj | aij 6= 0 sinon
Définition 7.2.4.246
L’application d associe à un nombre i la colonne la plus à gauche qui contient un coefficient non nul à laligne i.
Exemple : On considère le système
2 1 3 50 −1 1 3−1 0 1 0
. On a d(1) = 0, d(2) = 2 et d(3) = 1.
Soit (S) un système de n équations à p inconnues. On dit que le système est échelonné si l’application d eststrictement croissante.
Définition 7.2.4.247
Remarque : contrairement aux systèmes diagonaux et triangulaires, les systèmes échelonnés ne sont pasobligatoirement carrés (mais ils peuvent l’être).Exemples :
1. Le système
2 1 3 5 30 -1 1 0 30 0 1 0 0
est échelonné.
120

2. Le système
2 1 3 5 30 0 1 0 30 0 0 1 1
est échelonné.
3. Le système
2 1 3 5 30 -1 1 0 30 0 0 1 10 0 0 0 00 0 0 0 5
est échelonné.
Notations :
1. Soit i ∈ [[ 1 ; n ]], si d(i) < n+ 1, l’équation de la ligne i s’appelle une équation principale. Le coefficientnon nul le plus à gauche aid(i) s’appelle le pivot de la ligne i.
2. Soit i ∈ [[ 1 ; n ]], si d(i) = n + 1, l’équation de la ligne i s’appelle une équation de compatibilités. Elleest de la forme 0 = bi.
3. Les inconnues dont la colonne contient un pivot s’appellent les inconnues principales.
4. Les inconnues dont la colonne ne contient pas de pivot s’appellent les inconnues auxiliaires ouvariables libres.
Soit (S) un système échelonné.
1. Si les équations de compatibilités sont vérifiées, le système a des solutions.
2. Dans ce cas, le système a une unique solution, si et seulement s’il n’y a pas d’inconnuesauxiliaires.
Proposition 7.2.4.248
Démonstration : Comme précédemment, la démonstration rigoureuse doit être faite par récurrence sur p.Nous nous contenterons de donner les grandes lignes de la méthode de résolution.
— On regarde les équations de compatibilités. Si dans ces équations le second membre est nul, on a0 = 0 et on peut l’ôter. Si le second membre n’est pas nul, le système est incompatibles.
— On suppose donc que les éventuelles équations de compatibilités sont vérifiées. On procède alors àune remontée. On passe les inconnues auxiliaires dans le second membre.
— On est ramené à un système triangulaire supérieur.
Exemple : On veut résoudre le système
1 −1 1 −1 20 1 −1 −1 10 0 0 -1 4
. On peut noter x, y, z, t les inconnues.
On voit que z est une inconnue auxiliaire. On la passe dans le second membre et on obtient le système
x − y − t = 2− zy − t = 1 + z− t = 4
Ses solutions sont alors de la forme (−5,−3+ z, z,−4) | z ∈ R = (−5,−3, 0,−4)+ z(0, 1, 1, 0) | z ∈ R.Exercice : Résoudre les systèmes suivants
2 1 −2 3 10 7 4 −5 50 0 0 0 −8
2 1 −2 3 10 7 4 −5 50 0 2 1 30 0 0 1 1
2 1 −2 3 10 7 4 −5 50 0 2 1 3
.
3 Méthode du pivot de Gauss
La méthode du pivot de Gauss, consiste à associer de manière systématique et algorithmique à un système(S) un système (S′) échelonné qui a les mêmes solutions que (S). Pour cela nous allons faire des opérations surles lignes du système.
121

3.1 Systèmes équivalents et opérations
Soit (S) et (S′) deux systèmes. On dit que (S) et (S′) sont équivalents et on note (S) ∼ (S′) s’ils ont lesmêmes solutions.
Définition 7.3.1.249
Soit (S) un système de n équations à p inconnues. On note L1, . . . Ln les n lignes/équations. Lesopérations suivantes conduisent à un système (S′) équivalent à (S)
1. Echanger deux lignes. Cela se note (Li ↔ Lj) pour (i, j) ∈ [[ 1 ; n ]]2 .
2. Multiplier une ligne par un réel non nul. Cela se note (Li ← λLi) pour i ∈ [[ 1 ; n ]] et λ ∈K \ 0.
3. Ajouter une ligne à une autre. Cela se note (Li ← Li + Lj) pour (i, j) ∈ [[ 1 ; n ]]2 .
Proposition 7.3.1.250 (Opérations sur les lignes)
Démonstration : Les deux premiers points sont évidents. Le troisième découle du fait que si on considère deuxnombres A et B alors
(A = 0 et B = 0)⇔ (A = 0 et A + B = 0).
Avec les mêmes notations, on obtient un système équivalent en remplaçant une ligne Li par unecombinaison linéaires des lignes (Li ← λ1L1 + · · ·+ λnLn) a condition que le coefficient λi soit nonnul.
Corollaire 7.3.1.251
Démonstration : il suffit d’appliquer les points 2 et 3 de la proposition précédente.
Exemple : L’opération (L2 ← 2L1− L2 + 7L3) est obtenu ...Remarque : il est TOUJOURS nécessaire de vérifier que le coefficient de la ligne que l’on remplace est non nul.Dans les exercices, il y aura souvent des paramètres et il faudra distinguer des cas.
3.2 Méthode du pivot de Gauss
Tout système est équivalent à un système échelonné.
Théorème 7.3.2.252 (Pivot de Gauss)
Nous allons d’abord le faire sur deux exemples avant de passer au cas général.Exemples :
1. On considère le système (S)
1 2 −1 32 1 −1 23 0 1 0
. Le coefficient en haut à gauche est pris comme pivot.
On remplace alors les lignes L2 et L3 par des combinaisons linéaires Li ← Li + λiL1 afin de ne mettre quedes zéros dans le première colonne (sous le pivot).
(S) ∼
1 2 −1 30 -3 1 −40 −6 4 −9
.
122

On recommence en descendant d’une ligne. On fait (L3 ← L3 − 2L2). On obtient
(S) ∼
1 2 −1 30 -3 1 −40 0 2 1
.
On voit alors que le système obtenu est échelonné (il est même triangulaire). Ses coefficients diagonauxsont non nuls (il y a autant de pivots que de lignes/colonnes) il est donc inversible. Son unique solutionest (1/2, 3/2, 1/2)
2. On considère le système (S)
1 2 −1 1 12 4 1 0 2−1 −1 1 0 2
. On fait les opérations (L2 ← L2 − 2L1) et (L3 ←
L3 + L1) et on obtient
(S) ∼
1 2 −1 1 10 0 3 −2 10 1 0 1 3
.
On ne peut pas faire comme précédemment car le coefficient a22 est nul. On inverse donc les lignes(L2 ↔ L3) et on continue
(S) ∼
1 2 −1 1 10 1 0 1 30 0 3 −2 1
.
Le système est échelonné.
3. On considère le système (S)
1 2 −1 1 12 4 1 0 2−1 −2 2 0 2
. On fait les opérations (L2 ← L2 − 2L1) et (L3 ←
L3 + L1) et on obtient
(S) ∼
1 2 −1 1 10 0 3 −2 10 0 1 1 3
.
Là aucun coefficient de la deuxième colonne (sans compter le première ligne) n’est non nul donc, on sedécale et on passe à la troisième colonne. On peut faire l’opération (L3 ← L3 − 1
3 L2). Afin d’éviter lesrationnels on va faire (L3 ← 3L3 − L2). On obtient
(S) ∼
1 2 −1 1 10 0 3 −2 10 0 0 5 8
.
Le système est échelonné.
Démonstration : On considère un système à n équations et p inconnues. Les coefficients sont notés aij pour(i, j) ∈ [[ 1 ; n ]]× [[ 1 ; p ]] . On regarde le coefficient en haut à gauche, c’est à dire a11. Il se présente plusieurs cas
— Si a11 6= 0. C’est notre pivot on va alors « mettre » des zéros sous ligne dans la colonne. Pour cela on faitles opérations (Li ← a11Li − ai1L1). Cela donne un système équivalent car a11 6= 0.
— Si a11 = 0 on va chercher un pivot dans la première colonne.
— Si tous les coefficients de la première colonne sont nuls (∀i ∈ [[ 1 ; n ]] ai1 = 0), on se décale et onpasse à la colonne suivante.
— S’il y a un coefficient non nul dans le première colonne (∃i ∈ [[ 1 ; n ]] ai1 6= 0), on le prend et onéchange les lignes 1 et i : (L1 ↔ Li). On peut alors procéder comme ci-dessus avec a11 6= 0
À la fin de cette première étape, si la première colonne ne comportait que des zéros, on passe à la deuxièmecolonne et on recommence en partant avec a12. Si on a trouvé un pivot, on a mis des zéros en dessous. On peutalors continuer en « ôtant » la première ligne et la première colonne. On considère donc a22.
Remarques :
1. Là encore, la méthode rigoureuse consiste à faire une récurrence sur le nombre p d’inconnues.
2. On peut remarquer que la résolution ci-dessus, ne dépend que des coefficients du système et pas dusecond membre.
123

Le nombre de pivots dans le système échelonné obtenu ne dépend ni du second membre, ni de larésolution. On l’appelle le rang du système. Il se note rg (S).
Proposition-Définition 7.3.2.253
Remarque : le nombre d’inconnues est égal au rang plus le nombre d’inconnue auxiliaires. De même, le nombrede lignes, est égal au rang plus le nombre d’équations de compatibilitées.
Si (S) est un système carré de taille n. Les propositions suivantes sont équivalentes
1. Le système est inversible
2. Le rang de (S) est n
3. Il n’y a pas d’inconnues auxiliaires
4. Il n’y a pas d’inconnues de compatibilités.
5. À chaque étape on trouve un pivot.
Proposition 7.3.2.254
3.3 Retour sur le résolution des systèmes échelonnés
Les opérations sur les lignes permettent de résoudre entièrement les système échelonnés en gardant laprésentation matricielle. Pour cela on « remonte » le système en utilisant les pivots trouvés pour mettre deszéros « au-dessus » des pivots. On ne touche pas aux colonnes sans pivots (inconnues auxiliaires).Exemples :
1. Résolution de
(S) ∼
1 4 −2 3 22 3 0 5 α0 1 0 1 1−1 0 1 0 0
.
2. Résolution de
(S) ∼
1 + m 0 −10 m 0−1 0 1 + m
.
124

8Ensemble desnombres réels
1 Le corps des nombres réels 1251.1 Introduction et définition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1251.2 Borne inférieure et borne supérieure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 125
2 Propriétés des réels 1272.1 Inégalités et valeur absolue . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1272.2 Droite numérique achevée . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1272.3 Intervalles de R . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1282.4 Partie entière et nombres décimaux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1282.5 Densité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130
1 Le corps des nombres réels
1.1 Introduction et définition
Revenons rapidement sur la construction historique des nombres. Au début on a construit l’ensemble N desentiers naturels. Par la suite, on a voulu disposer de nombres nombres négatifs on a donc construit l’ensembleZ des entiers relatifs. Cependant dans Z on ne pouvait pas faire de division. On a donc introduit la notion denombres rationnels. Leur ensemble est Q.
Là c’est un peu plus compliqué. On s’est rendu compte qu’il manquait encore des nombres (par exemple√
2qui est un nombre qui apparait naturellement comme la longueur de la diagonale d’un carré de coté 1). Il fallaittrouver un moyen de caractériser l’ensemble de tous les nombres réels (que nous noterons R) par rapport àl’ensemble Q. Il y a plusieurs constructions. Nous utiliserons celle de la borne supérieure.
1.2 Borne inférieure et borne supérieure
On considère un ensemble E muni d’un ordre total.On a vu que les plus grands et plus petits éléments sont plus utiles que les simples majorants et minorants -
en particulier du fait de leur unicité. Cependant on a aussi vu qu’il n’y en avait pas toujours. On voudrait trouverune définition qui remplace le plus grand élément (resp. le plus petit élément) et qui, pour ]0, 1[ donnerait1 (resp. 0). En effet dans le cas ci-dessus cela est simple de voir que c’est 0 et 1 qui vont nous servir mais sil’ensemble est donné sous la forme A = y ∈ R|∃x ∈ R, y = e−x2 cela semble plus complexe.
Commençons sur un exemple. On considère A = [0, 1]. L’ensemble de tous les majorants de A est [1,+∞[.Cet ensemble a un plus petit élément qui est 1. Maintenant si on part avec A = [0, 1[. L’ensemble de tous lesmajorants de A est encore [1,+∞[ et son plus petit élément qui est encore 1.
125

Soit A une partie non vide de R.
— On appelle borne supérieure, et on note sup A, (s’il existe) le plus petit des majorants. C’est-à-dire leplus petit élément de l’ensemble des majorants.
— On appelle borne inférieur, et on note inf A, (s’il existe) le plus grand des minorants. C’est-à-dire le plusgrand élément de l’ensemble des minorants.
Définition 8.1.2.255
Remarque : Les bornes supérieures et inférieures étant définies comme étant des plus grands/petits élémentsd’un ensemble ils sont uniques s’ils existent.
Commençons par remarquer qu’il existe dans Q des ensembles majorés qui n’ont pas de borne supérieure.En effet si on pose X = x ∈ Q+ | x2 < 2. Cet ensemble est clairement majoré par 2 par exemple. Supposonsqu’il admette une borne supérieure (dans Q) que nous noterons α.
— Commençons par montrer que α2 > 2. En effet, par l’absurde, si α2 < 2 on peut trouver un entiern tel que (α + 1/n)2 < 2. En effet (α + 1/n)2 = α + 2α/n + 1/n2. Il suffit donc de prendre n tel que(2α/n + 1/n2) < 2− α2.
— Comme on sait de plus que α2 6= 2 car α ∈ Q, alors α2 > 2. Maintenant un raisonnement similaire auprécédent montre alors que l’on peut trouver n tel que (α− 1/n) soit encore un majorant ce qui contreditla définition de la borne supérieure.
L’ensemble de nombres réels est le seul corps commutatif contenant Q totalement ordonné dont toute partiemajorée admet une borne supérieure.
Définition 8.1.2.256
Remarques :
1. On dit qu’il vérifie la propriété de la borne supérieure (contrairement à Q).
2. Nous verrons plus loin la définition d’un corps. En gros il s’agit d’un ensemble muni de deux opérations :une addition (+) et un produit (x), qui vérifie les règles classiques de calculs : commutativité, associativité,distributivé et dont tout élément x a un opposé (noté −x) et, s’il est non nul, un inverse noté 1/x.
3. On demande que la relation d’ordre soit totale et compatible avec les opérations à savoir que pour toutx, y et z dans R3,
x 6 y⇒ x + z 6 y + z et (x 6 y et z > 0)⇒ xz 6 yz.
4. L’ensemble Q est un sous-ensemble de R. Les éléments de R \Q s’appellent les nombres irrationnels.
Tout partie non vide minorée de R admet une borne inférieure.
Proposition 8.1.2.257
Démonstration : Soit X une partie non vide de R. On considère X′ = x ∈ R | − x ∈ X. La partie X′ estmajorée et non vide. Elle admet donc une borne supérieure que nous notons m. Alors−m est une borne inférieurde X.
Soit A une partie non vide de R et m ∈ R on a :
sup A = m⇔ ∀x ∈ A, x 6 m∀ε > 0, ∃x ∈ A, x > m− ε.
Proposition 8.1.2.258 (Caractérisation de la borne supérieure)
Démonstration :
126

— ⇒ Si m est la borne supérieure alors c’est un majorant A donc ∀x ∈ A, x 6 m. De plus, pour tout ε > 0,le nombre m− ε est strictement inférieur à m ce n’est donc pas un majorant de A (car m est le plus petitdes majorants de A). On en déduit qu’il existe x dans A tel que x > m− ε.
— ⇐ La première partie dit que m est un majorant de A. Supposons par l’absurde que ce ne soit pas le pluspetit. Il existe alors m′ un majorant de A strictement inférieur à m. On note ε = m−m′ > 0. D’après ladeuxième assertion il existe x dans A tel que x > m− ε = m′ ce qui contredit que m′ soit un majorant deA.
Remarque : la double expression de droite signifie que m est un majorant et que tout nombre plus petit n’enn’est plus un. C’est donc le plus petit des majorants.
Exercice : Soit A =
(−1)n +
1n| n ∈ N?
. Déterminer les éventuels plus grand élément, plus petit élément,
borne supérieur, borne inférieure.On a aussi :
Soit A une partie non vide de R et m ∈ R on a :
inf A = m⇔ ∀x ∈ A, m 6 x∀ε > 0, ∃x ∈ A, x < m + ε.
Proposition 8.1.2.259 (Caractérisation de la borne inférieure)
2 Propriétés des réels
2.1 Inégalités et valeur absolue
Revoir le chapitre 2
2.2 Droite numérique achevée
On appelle droite numérique achevée et on note R l’ensemble :
R = R ∪ ±∞.
Définition 8.2.2.260
On peut prolonger l’ordre usuel sur R en un ordre total sur R en posant :
∀x ∈ R, x 6 +∞, ∀x ∈ R,−∞ 6 x et −∞ 6 +∞.
On obtient ainsi une relation d’ordre sur R.
Proposition 8.2.2.261
Soit X une partie de R.
— Si elle n’est pas majorée dans R, on note sup X = +∞.
— Si elle n’est pas minorée dans R, on note inf X = −∞.
Proposition 8.2.2.262
Remarque : cela correspond bien aux bornes supérieures et inférieures dans (R,6).
127

Notation : De même si I est un intervalle de R on note I l’ensemble obtenu en ajoutant les bornes. Par exemple
[0, 1[ = [0, 1] et ]−∞, 0] = −∞∪]−∞, 0].
Remarques :
1. On évitera de noter [−∞, 0].
2. Cette notation a un sens plus précis en mathématiques (adhérence) que vous verrez l’année prochaine.
2.3 Intervalles de R
Les intervalles de R sont les parties convexes de R, c’est-à-dire les parties I qui vérifient :
∀x ∈ I, ∀y ∈ I, [x, y] ⊂ I.
Proposition 8.2.3.263
Démonstration : Pour commencer, les intervalles sont des parties convexes.Réciproquement, si I est une partie convexe de R montrons que c’est un intervalle. Si I est l’ensemble vide
c’est bon. Supposons maintenant que I est non vide.
— Supposons que I n’est ni majoré, ni minoré et montrons alors que I = R. Soit x un élément quelconque deR. Il existe a dans I qui est inférieur à x (car I n’est pas minoré par x). De même il existe b dans I qui estsupérieur à x (car I n’est pas majoré par x). Dès lors
x ∈ [a, b] ⊂ I
donc x ∈ I. On en déduit que I = R.
— Supposons que I n’est pas majoré mais qu’il est minoré. Notons a = inf I.
— Si a est un élément de I, on va montrer que I = [a,+∞[. Il est évident que I ⊂ [a,+∞[. Reciproque-ment, pour tout réel x supérieur à a, il existe b dans I tel que x 6 b (car sinon x serait un majorant) etdonc x ∈ [a, b] ⊂ I. D’où x ∈ I. On en déduit donc que I = [a,+∞[.
— Si a n’est pas un élément de I. On va montrer que I =]a,+∞[. Là encore l’inclusion I ⊂]a,+∞[est évidente. Réciproquement si x est un élément de ]a,+∞[ on peut trouver α et β dans I tels quea < α < x < β. On en déduit que x ∈ I.
Les autres cas se traitent de manière identique.
2.4 Partie entière et nombres décimaux
Le corps des nombres réels est archimédien, c’est-à-dire :
∀x ∈ R?+, ∀y ∈ R, ∃n ∈ N, nx > y.
Proposition 8.2.4.264
Démonstration : Supposons par l’absurde qu’il existe x dans R?+ et y dans R tel que ∀n ∈ N, nx < y. Cela
signifie queA = nx | n ∈ N
set majoré. De ce fait il admet une borne supérieure α. Comme α est la borne supérieure de A, α− x n’est pas unmajorant de A. Il existe donc N dans N tel que
Nx > α− x ⇔ (N + 1)x > α.
Ceci est absurde car α est un majorant de A.
Remarque : On a utilisé la propriété de la borne supérieure pour démontrer cette propriété mais ce n’est pasune condition nécessaire puisque Q est aussi archimédien.
128

Soit x un réel strictement supérieur à 1 et y un réel, il existe un entier naturel n tel que xn > y.
Corollaire 8.2.4.265
Démonstration : Il suffit de remarquer que xn = (1 + (x− 1))n > 1 + n(x− 1) > n(x− 1). Il ne reste plus qu’àutiliser que R est archimédien.
Soit x un nombre réel. Il existe un unique entier p tel que
p 6 x < p + 1.
On appelle cet entier la partie entière de x et on le note bxc.
Définition 8.2.4.266
Remarque : On peut généraliser cette propriété en « faisant des pas de longueur a ». C’est-à-dire que pour pourtout réel strictement positif a et tout réel x, il existe un unique entier p tel que pa 6 x < (p + 1)a.Démonstration : On considère l’ensemble A = n ∈ Z | n 6 x. Le fait que R soit archimédien permetd’affirmer que A est non vide. En effet il existe n tel que −x 6 n et donc −n 6 x. De plus, A est aussi majorée(toujours çar R est archimédien). La partie A admet donc un plus grand élément que nous noterons p. Il vérifiep 6 x. De plus, p + 1 n’appartient pas à A donc x < p + 1.
Remarques :1. On définit ainsi une application de R dans R (ou dans Z car son image est égale à Z). Son graphe est
-5 0 5
2. Soit x un réel, le nombre x− bxc s’appelle la partie décimale (ou fractionnaire) de x.
On appelle ensemble des nombres décimaux et on note D l’ensemble
D =⋃
n∈N10−nZ.
C’est l’ensemble des nombres qui s’écriventp
10n avec p un entier relatif et n un entier naturel.
Définition 8.2.4.267
Remarques :1. C’est la définition classique des nombres décimaux qui s’écrivent avec un nombre de chiffres fini après la
virgule dans l’écriture décimale.
2. Par construction, D ⊂ Q.
129

Soit x un nombre réel.
1. Pour tout entier naturel, on appelle approximation décimale de x à 10−n près par défaut le nombreb10nxc
10n .
2. Pour tout entier naturel, on appelle approximation décimale de x à 10−n près par défaut le nombreb10nxc+ 1
10n .
Définition 8.2.4.268
Remarque : Les approximations décimales d’un réel x sont des nombres décimaux par construction. De plus,
b10nxc 6 10nx < b10nxc+ 1⇒ b10nxc10n 6 x <
b10nxc10n + 10−n.
Si on note αn =b10nxc
10n . On a donc
|x− αn| 6 10−n et αn 6 x.
De la même manière, si on note βn =b10nxc+ 1
10n on obtient
|x− βn| 6 10−n et βn > x.
2.5 Densité
Soit A une partie R. On dit que A est dense si pour tout couple de réels x, y tels que x < y, A∩]x, y[ 6= ∅.
Définition 8.2.5.269
Les ensembles D, Q et R \Q sont denses dans R.
Proposition 8.2.5.270
Démonstration : Soit n tel que 10n >1
y− x. On a alors 10−n 6 y− x. De ce fait l’approximation décimale par
défaut de y à 10−n près appartient à ]x, y[. De plus c’est un nombre décimal donc rationnel.Si on applique ce raisonnement à x +
√2 et y +
√2 on trouve un rationnel r tel que
x +√
2 < r < y−√
2⇒ x < r−√
2 < y.
Or r étant rationnel, r−√
2 est irrationnel.
Tout réel est limite d’une suite de nombres rationnels.
Proposition 8.2.5.271
Démonstration : Il suffit de prendre la suite des approximation de x par défaut à 10−n près.
130

9Suites numériques
1 Généralités sur les suites réelles 1311.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1311.2 Opérations sur les suites . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
2 Convergence 1342.1 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1342.2 Convergence et suite extraite . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1362.3 Inégalités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1372.4 Construction de suite à limite donnée . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1392.5 Opérations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1402.6 Convergence monotone . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1412.7 Suites adjacentes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142
3 Relations de comparaison 1433.1 Définition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1433.2 Propriétés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1443.3 Croissances comparées et équivalents classiques . . . . . . . . . . . . . . . . . . . . . . . . . . . 145
4 Extension au cas des suites complexes 1464.1 Définition et généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1464.2 Convergence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1474.3 Popriétés des suites convergentes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1474.4 Opérations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 147
1 Généralités sur les suites réelles
1.1 Définitions
Une suite réelle est une application de N dans R. On note alors pour tout entier n, un l’image de n parl’application et non pas u(n) comme d’habitude. La suite elle même sera notée un∈N.
Définition 9.1.1.272
Remarques :1. On peut en théorie faire des suites à valeurs dans autre choses que R comme des suites de complexes, de
fonctions ou des suites de polynômes. Cependant, on omettra de spécifier « réelles » la plupart du temps.
131

2. On désignera encore par suite une application de N? dans R. C’est une suite qui commence à 1. On noteraalors un∈N? .
3. Faire attention à le pas confondre un qui est un nombre - le n-ième terme de la suite - et un∈N qui estl’intégralité de la suite. C’est la même distinction qu’entre la fonction f et f (x) qui est la valeur de lafonction en x.
Notations :1. par abus, nous noterons aussi u pour un∈N. La plupart du temps nous noterons une suite juste u.
2. L’ensemble des suites réelles se note RN.
Exemples :1. On peut définir une suite par son terme général : soit u la suite telle que ∀n ∈ N, un = (−12)n.
2. On peut définir une suite par une formule de récurrence : soit u la suite définie par u0 = 1, u1 = 1 et∀n ∈ N, un+2 = un+1 + un.
3. Il y a d’autres manières de définir les suites : soit u la suite définie par
u1 = 1, ∀n ∈ N, u2n = 0 et u2n+1 =
u2n−1 si n est pairla n-ieme décimale de π sinon
Remarque : de manière générale, il faut vérifier que la définition définissent bien une et une seule image pourtous les entiers. Par exemple on ne peut définir une suite par ∀n ∈ N, un =
√sin(n) car pour n = 4, sin(4) < 0.
Soit u une suite réelle.
— Soit M ∈ R, la suite u est majorée par M si : ∀n ∈ N, un 6 M.
— Soit m ∈ R, la suite u est minorée par m si : ∀n ∈ N, m 6 un.
— La suite u est majorée s’il existe un réel M tel quelle soit majorée par M.
— La suite u est minorée s’il existe un réel m tel quelle soit minorée par m.
— La suite u est bornée si elle est majorée et minorée.
Définition 9.1.1.273
Remarque : Le fait d’être majorée (resp. minorée, bornée) est une propriété globale sur la suite en entier. Enparticulier, cela n’a aucun sens d’écrire « ∀n ∈ N, un est majorée ».Exemples :
1. La suite u définie par ∀n ∈ N, un = n n’est pas majorée mais elle est minorée.
2. La suite u définie par ∀n ∈ N?, un = 1/n est bornée.
Soit u une suite réelle.
— La suite u est croissante si ∀n ∈ N, un+1 > un.
— La suite u est décroissante si ∀n ∈ N, un > un+1.
— La suite u est strictement croissante si ∀n ∈ N, un+1 > un.
— La suite u est strictement décroissante si ∀n ∈ N, un > un+1.
— La suite u est monotone (resp. strictement monotone) si elle est croissante ou décroissante (resp.strictement croissante ou strictement décroissante).
Définition 9.1.1.274
Remarques :1. On pourrait plus simplement dire que la suite u est croissante si elle est croissante comme application. En
effet (∀n ∈ N, un+1 > un)⇔ (∀(n, n′) ∈ N2, n > n′ ⇒ un > un′)
2. Là encore le contraire de croissante n’est pas décroissante.
3. Là encore c’est une notion globale et (∀n ∈ N, un est croissante) n’a pas de sens
4. Dire que la suite u est monotone ne s’écrit pas ∀n ∈ N, un+1 > un ou un+1 6 un.
132

F Méthode : pour étudier la monotonie d’une suite u la méthode standard est de considérer les quantitésun+1 − un. Si, par exemple, pour tout entier n, un+1 − un > 0 la suite u est croissante. Dans le cas d’une suite
strictement positive, on peut aussi considérer les quotientsun+1
un. On a alors :
(∀n ∈ N,
un+1
un> 0
)⇔ la suite u est croissante.
Exercice : Quantifier « u n’est pas majorée » et « u n’est pas bornée ».
Exemple : Étudions les variations de la suite un =n!
n + 2.
On peut munir l’ensemble RN d’une relation d’ordre 6 en posant
∀(u, v) ∈ (RN)2, u 6 v⇔ ∀n ∈ N, un 6 vn.
Définition 9.1.1.275
Remarques :
1. Ce n’est clairement pas un ordre total.
2. Une suite u est majorée s’il existe une suite constante égale à M notée M par abus tel que u 6 M.
Soit u ∈ RN. On appelle suite extraite de u toute suite v telle qu’il existe une application strictement croissanteϕ de N dans lui-même vérifiant que :
∀n ∈ N, vn = uϕ(n).
Définition 9.1.1.276
Terminologie : Une suite extraite s’appelle aussi une sous-suite.Exemples :
1. Soit u on peut considérer (u2n) et (u2n+1), les suites extraites des termes d’indices pairs et celle des termesd’indices impairs.
2. Soit u une suite et N un entier. La suite (un+N)n∈N dont le premier terme est uN est une suite extraite de(u).
Soit P une proposition dépendant d’une suite. On dit qu’une suite u vérifie la propriété P à partir d’un certainrang s’il existe un entier N tel que la suite extraite (un + N)n>N vérifie P.
Définition 9.1.1.277
Exemple : La suite un = n− 7 est positive à partir d’un certain rang.
Une suite u est dite stationnaire si elle est constante à partir d’un certain rang.
Définition 9.1.1.278
1.2 Opérations sur les suites
Nous allons définir des opérations sur les suites. On ne rentrera pas dans les détails car c’est assez similaireaux opérations sur les polynômes et les fonctions.
133

Soit u et v deux suites. La somme est la suite u + v dont le terme de rang n est un + vn.
Définition 9.1.2.279 (Somme)
Soit λ un réel et uune suite. La suite λ.u est la suite dont le terme de rang n est λ.un.
Définition 9.1.2.280 (Multiplication externe)
Soit u et v deux suites. Le produit est la suite u.v dont le terme de rang n est un.vn. De plus si, pour toutentier n, vn 6= 0, on peut définir la suite quotient
uv
comme étant la suite dont le terme de rang n estun
vn.
Définition 9.1.2.281 (Produit et quotient)
Notation : on notera aussi (un + vn)n∈N la suite somme, (λ.un)n∈N la multiplication externe, (un.vn)n∈N la
suite produit ainsi que(
un
vn
)
n∈Nla suite quotient.
Ces opérations vérifient les propriétés classiques (associativité, commutativité, distributivité,...)
Proposition 9.1.2.282
Remarque : en particulier l’ensemble des suites est un espace vectoriel.
2 Convergence
2.1 Généralités
Soit u une suite et ` un réel on dit que la suite u tend vers ` ou que ` est la limite de la suite u si les termes unde la suite sont très proches de ` quand n tend vers l’infini.C’est-à-dire que « tout intervalle ouvert contenant ` contient tous les termes de la suite à partir d’un certainrang ». Cela peut s’exprimer par la phrase, pour tout réel positif ε, tous les termes assez grands de la suite sontà distance de ` inférieur à ε.
∀ε > 0, ∃N ∈ N, ∀n ∈ N, (n > N)⇒ |un − `| 6 ε.
On note alors un → `.
Définition 9.2.1.283
Remarques :1. Dire que |un − `| 6 ε revient à dire que un ∈ [`− ε, `+ ε].2. Il suffit de tester que tout intervalle de la forme [`− ε, `+ ε] contient tous les termes de la suite à partir
d’un certain rang. En effet, tout intervalle ouvert contenant ` contient un tel intervalle.Exercice : Nier les phrases précédentes.
Soit u une suite. On dira qu’elle est convergente s’il existe un réel ` tel que la suite u tend vers `. Dans le cascontraire elle est divergente.
Définition 9.2.1.284
134

Soit u une suite convergente. Sa limite est unique.
Théorème 9.2.1.285
Idée de la preuve : Par l’absurde on suppose que la suite tend vers ` et vers `′. Si on prend ε très petit, lestermes de la suites doivent être dans [`− ε, `+ ε] et dans [`′ − ε, `′ + ε]. Or si on prend ε assez petit ces deuxintervalles sont disjoints.
`− ε `+ ε `′ − ε `′ + ε
Notation : Pour dire qu’une suite u tend vers ` on note
limn→+∞
un = ` ou lim u = ` ou un → `.
Exercice : les assertions suivantes sont elles vraies ou fausses :
— Une suite croissante est convergente
— Une suite convergente est monotone
— Une suite positive tendant vers 0 est décroissante
— Une suite convergente est bornée.
— Une suite tendant vers 1 est positive.
Exemples :
1. On considère la suite définie par ∀n ∈ N, un = 1/n. Elle tend vers 0. Soit ε > 0, il existe un entier N > 1/ε.Pour n ∈ N, si n > N, n > N > 1/ε > 0 d’où
0 <1n< ε.
On a bien limn→+∞
1n= 0.
2. On considère la suite définie par ∀n ∈ N, un = (−1)n. Montrons qu’elle est divergente. Supposons parl’absurde qu’elle converge vers un réel `. En particulier pour ε = 1/3, tous les termes assez grands dela suite sont dans l’intervalle ]`− 1/3, `+ 1/3[. C’est impossible car si 1 est dedans, −1 ne l’est pas etréciproquement.
Soit u une suite réelle. On dit que u tend vers +∞ et on note limn→+∞
un = +∞ si
∀M ∈ R, ∃N ∈ N, ∀n ∈ N, (n > N)⇒ un > M.
De même, on dit que u tend vers −∞ et on note limn→+∞
un = −∞ si
∀M ∈ R, ∃N ∈ N, ∀n ∈ N, (n > N)⇒ un 6 M.
Définition 9.2.1.286
Remarque : une suite qui tend vers +∞ est une suite divergente. Cependant la réciproque n’est pas vraie.Exercice : Trouver une suite tendant vers +∞ qui n’est pas croissante.Exemple : (Fondamental) Soit ρ ∈ R. On considère la suite géométrique (ρn)n∈N? .
— si |ρ| < 1 la suite converge vers 0.
— si ρ = 1 la suite est constante égale à 1 et donc tend vers 1.
— si ρ 6 −1 la suite est divergente.
— si ρ > 1 la suite est divergente et tend vers +∞.
135

Soit u une suite et ` un réel.
( limn→+∞
u = `)⇔ La suite (un − `)n∈N tend vers 0.
Proposition 9.2.1.287
Cette proposition est utile car elle permet de ramener la convergence de toute suite à l’étude d’une conver-gence vers 0. On peut en particulier l’utiliser avec la proposition suivante pour se ramener à l’étude d’une suitepositive.
Soit u une suite.lim
n→+∞un = 0⇔ lim
n→+∞|un| = 0.
Proposition 9.2.1.288
Exercices :
1. Montrer que la suite un =2n + sin n
n + 1tend vers 2
2. La propriété précédente reste vrai pour une limite non nulle?
Soit u une suite. Si u est convergente elle est bornée.
Proposition 9.2.1.289
Démonstration
Remarque : La contraposée peut-être utile. Si u n’est pas bornée elle diverge. Attention cela n’implique paspour autant qu’elle tende vers ±∞.
Soit A une partie non vide de R.
1. Si A est majorée, il existe une suite de AN qui tend vers sup A.
2. Si A n’est pas majorée, il existe une suite de AN qui tend vers +∞.
Proposition 9.2.1.290
2.2 Convergence et suite extraite
Soit u une suite.
1. Si u converge vers une limite ` alors toute suite extraite converge aussi vers `.
2. Si lim u = +∞ (resp. −∞) alors toute suite extraite v vérifie que lim v = +∞ (resp. −∞).
Proposition 9.2.2.291
Démonstration
Remarque : Cette proposition est assez souvent utilisée pour montrer qu’une suite ne converge pas. En effetpar contraposée, pour montrer qu’une suite diverge il suffit de trouver deux suites extraites qui ne convergentpas vers la même valeur.Exemples :
1. La suite un = (−1)n.
136

2. La suite sin(n) ne converge pas. En effet si on pose ϕ(n) =
⌊2π
3+ 2nπ
⌋, alors sin(ϕ(n)) ∈ [α, 1] où
α = Min(sin(2π/3), sin(2π/3− 1)). De même on pose ψ(n) =⌊−π
3+ 2nπ
⌋.
On va chercher une bribe de réciproque.
Soit u une suite. On considère la suite des termes pairs (u2n)n∈N et la suite des termes impairs(u2n+1)n∈N. Les suites (u2n)n∈N et (u2n+1)n∈N converge vers la même limite ` si et seulement si lasuite u converge vers `.
Proposition 9.2.2.292
Démonstration :— ⇐ On suppose que u converge vers ` et on veut montrer que (u2n)n∈N et (u2n+1)n∈N convergent aussi
vers `. On va le faire pour (u2n)n∈N. Soit ε > 0. On sait qu’il existe N ∈ N tel que, pour tout entier n, sin > N alors |un − `| 6 ε. On en déduit que pour tout entier n, si n > N alors 2n > N et donc |u2n − `| 6 ε.
— ⇒ On suppose que (u2n)n∈N et (u2n+1)n∈N convergent aussi vers la même limite `. Dès lors si on sedonne un réel positif ε. On sait qu’il existe des entiers N1 et N2 tels que pour tout entier n, si n > N1 on a|u2n − `| 6 ε et si n > N2 on a |u2n+1 − `| 6 ε. On pose alors N = 2.Max(N1, N2) + 1. Soit n un entier, on
suppose que n > N. Si n est pair alors n = 2p et
p =n2>
N2> N1.
On en déduit que |un − `| = |u2p − `| 6 ε.De même si n est impair, on a n = 2p + 1 et
p =n− 1
2> N2.
On en déduit encore que |un − `| = |u2p+1 − `| 6 ε.
2.3 Inégalités
Soit u et v deux suites. On suppose que pour tout n ∈ N, un 6 vn. S’il existe ` et `′ dans R tels que utend vers ` et v tend vers `′ alors ` 6 `′.
Théorème 9.2.3.293
Remarques :1. Les inégalités x > y s’étendent aux cas où x et y sont des éléments de R de manière naturelle. Par exemple,
pour tout x ∈ R, −∞ 6 x 6 +∞.
2. Dans le cas où l’une des deux suites est constante. Cela exprime alors que, pour un réel a, si pour toutn, un > a alors ` > a. En particulier si a = 0, on obtient qu’une suite positive convergente a une limitepositive.
3. Ce théorème reste vrai si l’inégalité un 6 vn est vérifiée pour tous les entiers n à partir d’un certain rang.
B Ce résultat n’est pas vrai avec des inégalités strictes. Par exemple si u est la suite définie par un = 1/n.Tous les termes sont strictement positifs mais pas la limite.Exercice : La réciproque est-elle vraie ? C’est-à-dire, si u et v sont des suites convergentes telles que lim u 6 lim va-t-on que un 6 vn à partir d’un certain rang? Et si l’on suppose lim u < lim v ?
Soit u une suite convergente de limite ` > 0. La suite est positive à partir d’un certain rang.
Proposition 9.2.3.294
137

Démonstration
Soit u, v et (wn) trois suites. On suppose que
1. Les suites u et (wn) convergent vers la même limite.
2. Pour tout entier n, un 6 vn 6 wn.
Alors la suite v converge et lim u = lim v = lim(wn).
Théorème 9.2.3.295 (Théorème d’encadrement)
Remarques :
1. ce théorème est beaucoup plus puissant que le précédent. En effet, on n’a pas besoin de savoir, à priori,que la suite v converge. C’est l’un des quatre théorèmes (avec les opérations, la convergence monotone etles suites adjacentes) qui permet de montrer qu’une suite converge.
2. Il est nécessaire que u et (wn) aient la même limite comme le montre l’exemple :
∀n ∈ N, un = −1, vn = (−1)n, wn = 1.
3. Là encore ce théorème peut s’appliquer même si la propriété 2. n’est vrai qu’à partir d’un certain rang.
4. La terminologie « théorème d’encadrement » est plus convenable que « théorème des gendarmes ».
FMéthode : Pour montrer qu’une suite u converge vers `, on peut montrer que |un − `| tend vers 0. Pour cela ilsuffit de trouver une suite v tendant vers 0 telle que |un − `| 6 vn.Exemple : Soit u définie par u0 = 5 et ∀n ∈ N, un+1 =
√2 + un. On montre que
∀n ∈ N, |un+1 − 2| 6 |un − 2|2
en utilisant la quantité conjuguée.Dès lors, par récurrence,
∀n ∈ N, |un − 2| 6 32n .
Soit u et v deux suites. On suppose que u est bornée et que v tend vers 0. On a uv→ 0
Corollaire 9.2.3.296
Démonstration : Comme u est bornée, il existe M ∈ R tel que ∀n ∈ N, |u| 6 M. Dès lors
∀n ∈ N, |unvn| 6 M|vn|.
Maintenant comme M|vn| → 0 alors |unvn| → 0 et la suite uv tend vers 0.
On voit que l’on se ramène souvent à montrer qu’une suite tend vers 0. Voici un critère utile.
Soit u une suite strictement positive telle qu’il existe k ∈]0, 1[ vérifiant que pour un entier n0,
∀n > n0,un+1
un6 k.
La suite u converge vers 0.
Proposition 9.2.3.297
B Il faut qu’il existe k tel quean+1
an6 k < 1. La condition,
an+1
an< 1 n’est pas suffisante.
138

Soit u et v deux suites. On suppose que
1. La suite u tend vers +∞
2. Pour tout entier n, un 6 vn.
Alors la suite v tend vers +∞.
Théorème 9.2.3.298 (Variante à l’infini)
Remarques :
1. là encore l’inégalité n’a besoin d’être vérifiée qu’à partir d’un certain rang.
2. il y a un variante de la variante en −∞.
Exercice : On considère la suite (H) définie par
∀n ∈ N?, Hn =n
∑k=1
1k
.
1. Montrer que pour tout k ∈ N?,1
k + 16∫ k+1
k
dtt6
1k
.
2. En déduire que pour tout n ∈ N?, Hn > ln(n + 1). Que peut-on en déduire sur la limite de (H) ?
2.4 Construction de suite à limite donnée
Il arrive que, pour utiliser des arguments de passage à la limite on veuille construire des suites d’élémentsune partie A de R dont la limite ` est donnée. Voici deux cas.
Soit A une partie de R. Les assertions suivantes sont équivalentes :
i) La partie A est dense dans R
ii) Tout élément de R est limite d’une suite d’éléments de A
Proposition 9.2.4.299 (Caractérisation Séquentielle de la densité)
Démonstration :
— i)⇒ ii) : On suppose que A est dense dans R. Soit ` dans R on veut construire une suite u d’éléments deA convergeant vers `. Il suffit de voir que pour tout n ∈ N, A∩]`− 10−n, `+ 10−n[ 6= ∅ par définition dela densité. On définit un comme un élément de cette intersection. De ce fait, u ∈ AN et, ∀n ∈ N, |un − `| 610−n. On en déduit alors que u→ `.
— ii)⇒ i) : On suppose ii). Soit x, y deux réels tels que x < y. On recherche a ∈ A∩]x, y[. On pose ` =x + y
2(le milieu de ]x, y[). Il suffit de considérer une suite u ∈ AN tendant vers `. En s’approchant de `, les
termes de la suite (qui sont dans A) vont être dans ]x, y[. Précisément, si on pose ε =|y− x|
3on a
x < `− ε < ` < `+ ε < y.
Or, il existe un rang N tel que uN ∈ [`− ε, `+ ε] car u tend vers `. On a donc uN ∈ A∩]x, y[.
Soit A une partie non vide et majorée de R (resp. non majorée) il existe une suite u d’éléments de Aqui tend vers sup(A) (resp. +∞).
Proposition 9.2.4.300 (Suite et borne supérieure)
139

2.5 Opérations
• Addition Soit u et v deux suites. Le tableau suivant donne la limite de la suite u + v.PPPPPPPPlim v
lim u` −∞ +∞
`′ `+ `′ −∞ +∞−∞ −∞ −∞ ?+∞ +∞ ? +∞
Les? sont les « formes indéterminées ». On ne peut rien dire de manière systématique. Nous verrons plus loincomment traiter ces cas.Démonstration : Faisons le cas où ` = +∞ et `′ ∈ R. On veut montrer que u + v tend vers +∞. On considèreε = 1. Il existe alors N tel que pour tout n de N, si n est supérieur à N alors `′ − 1 6 v 6 `′ + 1. Maintenantpour tout M ∈ R, il existe N′ tel que
n > N′ ⇒ vn > M− (`′ − 1).
De ce fait, si n est supérieur à N et N′ (c’est-à-dire n > Max(N, N′)),
un + vn > M.
Exemples :
1. La suite un = 1− 1/n tend vers 1 et vn = 2/n tend vers 0. La somme u + v tend vers 1.
2. Les suites wn = n et w′n = n2 tendent vers +∞. On voit que uw tend vers +∞, vw tend vers 2 et vw′ tendvers +∞.
•Multiplication externeSoit u une suite et λ un réel. On considère la suite λ.u. La limite de la suite λ.u est donnée par le tableau
suivant :PPPPPPPPλ
lim u` −∞ +∞
λ > 0 λ.` −∞ +∞λ = 0 0 0 0λ < 0 λ.` +∞ −∞
Notons que si λ = 0 et que la suite u tend vers ±∞ ce n’est pas une forme indéterminée. En effet la suite λ.u estla suite nulle.• Produit
Soit u et v deux suites. On considère la suite u.v. La limite de la suite est donnée par le tableau suivant :
PPPPPPPPlim vlim u
` < 0 ` = 0 ` > 0 −∞ +∞
`′ < 0 `.`′ 0 `.`′ +∞ −∞`′ = 0 0 0 0 ? ?`′ > 0 `.`′ 0 `.`′ −∞ +∞−∞ +∞ ? −∞ +∞ −∞+∞ −∞ ? +∞ −∞ +∞
Noter en particulier que la forme (+∞)× (−∞) n’est pas une forme indéterminée.• Quotient
Soit u et v deux suites et on suppose que pour tout n ∈ N, vn 6= 0. On considère la suiteuv
. La limite de lasuite est donnée par le tableau suivant :
PPPPPPPPlim vlim u
` < 0 ` = 0 ` > 0 −∞ +∞
`′ < 0 `/`′ 0 `/`′ +∞ −∞`′ = 0− +∞ ? +∞ +∞ -∞`′ = 0+ −∞ ? +∞ −∞ +∞`′ > 0 `/`′ 0 `/`′ −∞ +∞−∞ 0 0 0 ? ?+∞ 0 0 0 ? ?
140

Remarques :1. On dit que u tend vers 0+ (resp. 0−) si u tend vers 0 et que u est positive (resp. négative) à partir d’un
certain rang.
2. Les opérations sont la deuxième méthode qui permet de montrer qu’une suite est convergente. Dans cecas on détermine sa limite.
2.6 Convergence monotone
Soit u une suite croissante.
1. Si u est majorée alors elle converge et lim u = sup un | n ∈ N.2. Si u n’est pas majorée alors elle diverge et lim u = +∞.
Théorème 9.2.6.301
Démonstration : Soit u une suite croissante et majorée, montrons qu’elle est convergente (le cas décroissante etminorée s’en déduit en considérant (−un)). Le problème est que pour montrer qu’un suite est convergente viala quantification on doit connaître sa limite. Soit U = un | n ∈ N. La suite u étant majorée, l’ensemble U estune partie non vide et majorée de R. On en déduit donc qu’il admet une borne supérieure. Notons α = sup U.Le nombre α va être notre limite. Montrons donc que
∀ε > 0, ∃N ∈ N, ∀n ∈ N, (n > N ⇒ |un − α| < ε).
dessin
Soit ε > 0. On sait que α étant la borne supérieure de U, α− ε n’est pas un majorant de U. Il existe donc unentier N tel que uN > α− ε. Dès lors, la suite étant croissante, pour tout entier n, si n > N alors un > uN > α− ε.De plus, α est un majorant de U donc un 6 α 6 α + ε. On a bien montré que |un − α| < ε.
Remarques :1. C’est le sens ⇐ qui est utile - l’autre est vrai sans hypothèse de monotonie. Cela peut aussi s’écrire :
« toute suite croissante et majorée converge » ou »toute suite décroissante et minorée converge ».
2. En particulier une suite croissante n’a que deux comportements asymptotiques possibles : converger versune limite finie ou tendre vers +∞. De même pour une suite décroissante.
3. C’est le deuxième théorème qui permet de montrer qu’une suite converge.
B Prendre garde que le majorant (ou minorant) utilisé n’est pas toujours la limite de la suite. Voir l’exerciceci-dessous.Exercice : Soit u définie par
∀n > 2, un =n
∑k=2
1k2 .
1. Étudier la monotonie de u.
2. Prouver que pour tout n > 2, un 6n
∑k=2
1k(k− 1)
.
3. Calculer la somme de droite en utilisant un téléscopage.
4. En déduire que u est convergente.
Regardons maintenant un corollaire du théorème de convergence monotone qui va nous servir plus loin.
1. Soit u une suite croissante. Soit la suite est majorée et elle converge, soit la suite tend vers +∞.
2. Soit u une suite décroissante. Soit la suite est minorée et elle converge, soit la suite tend vers−∞.
Proposition 9.2.6.302
Remarque : L’énoncé précédent n’est vrai que dans le cas d’une suite monotone. une suite quelconque peuttrès bien diverger sans tendre vers +∞ ou −∞.
141

2.7 Suites adjacentes
Soit u et v deux suites. On dit que ce sont des suites adjacentes si
1. La suite u est croissante et la suite v est décroissante.
2. La suite u− v tend vers 0.
Définition 9.2.7.303
Soit u et v deux suites adjacentes. Elles convergent vers la même limite.
Théorème 9.2.7.304
Démonstration : Commençons par montrer que si (un) et (vn) son adjacente avec (un) croissante alors pourtout entier naturel n, un 6 vn. On remarque que la suite (un − vn) est croissante or comme elle tend vers 0, on a0 = supun − vn | n ∈ N. De ce fait, pour tout entier naturel un − vn 6 0 ⇐⇒ un 6 vn.
On a donc pour tout entier naturel n ,
u0 6 un 6 vn 6 v0.
On en déduit que (un) est majorée (par v0), comme elle est croissante, elle converge. Notons ` sa limite. Demême (vn) converge. Notons `′ sa limite. Par les opérations, (un − vn) converge vers `− `′ donc ` = `′.
Remarques :
1. C’est le troisième théorème qui montre la convergence d’une suite.
2. Le fait que les termes de la suite u sont inférieurs à ceux de la suite v est une conséquence de la définition.Si on note ` la limite commune :
u0 6 u1 6 · · · 6 un 6 ` 6 vn 6 · · · 6 v1 6 u0.
Exemple : On considère les suites u et v définies par
∀n ∈ N?, un =n
∑k=0
1k!
et vn = un +1
n.n!.
Ce sont des suites adjacentes. Leur limite commune est e.Exercice : On veut montrer que e est un irrationnel.
1. Montrer que la suite u est strictement croissante et que v est strictement décroissante.
2. Montrer que pour tout n ∈ N?, il existe un entier pn tel que
un =pn
n.n!et vn =
1 + pn
n.n!.
3. En déduire que e est un irrationnel.
Exercice : On reprend la suite (H) définie par
∀n ∈ N?, Hn =n
∑k=1
1k
.
1. Montrer que pour tout x compris entre −1 et 1, ln(1 + x) 6 x.
2. On pose un = Hn − ln(n) et vn = un − 1/n. Montrer que u et v sont adjacentes.
Soit ([an, bn]) une suite décroissante de segments non vide (d’où des segments emboités) dont lalongueur tend vers 0. L’ensemble
⋂n∈N[an, bn] est réduit à un point.
Théorème 9.2.7.305 (Théorème des segments emboités)
142

Démonstration
Soit u une suite bornée. On peut en extraire une sous suite convergente.
Théorème 9.2.7.306 (Theorème de Bolzano-Weierstrass)
Démonstration
Remarque : Ce théorème permet d’affirmer que l’on peut construire une suite extraite de sin(n) qui converge.Mais ce n’est pas constructif...
3 Relations de comparaison
3.1 Définition
Avant de donner la définition précise, regardons un exemple. On considère la suite u définie par ∀n ∈N?, un = n2/(1 + n). C’est une forme indéterminée (+∞)/(+∞). Cependant, quand n devient très grand, onest tenté de considérer que 1 + n est "équivalent" à n et de ce fait que un va être proche de n2/n = n et donctendre vers l’infini. Pour donner plus de sérieux à ce qui précède on peut écrire
∀n ∈ N?, un =n2
1 + n=
n2
n(1 + 1/n)=
n1 + 1/n
.
Soit u et v deux suites.
1. On dit que u est dominée par v s’il existe une suite (wn) bornée telle que u = (vnwn). On note alorsu = O(v).
2. On dit que u est négligeable devant v s’il existe une suite (wn) tendant vers 0 telle que u = (vnwn).On note alors u = o (v) .
3. On dit que u et v sont équivalentes s’il existe une suite (wn) tendant vers 1 telle que u = (vnwn). Onnote alors u ∼ v.
Définition 9.3.1.307
Quand les suites ne s’annulent pas (au moins à partir d’un certain rang) on a une caractérisation plus simple :
Soit u et v deux suites ne s’annulant pas.
1. La suite u est dominée par v si la suiteuv
est bornée.
2. La suite u est négligeable devant v si la suiteuv
tend vers 0.
3. La suite u est equivalente à v si la suiteuv
tend vers 1.
Proposition 9.3.1.308
Remarque : Seule la limite compte pour l’équivalence de deux suites. On peut de ce fait « modifier » un nombrefini de termes sans changer les équivalents, domination ou négligeabilité.B Une suite u est équivalente à 0 si et seulement si elle est stationnaire à 0.Terminologie : Ce sont des notions qui portent sur l’ensemble de la suite, cependant, nous écrirons pour alléger,n2 + n + 1 ∼ n2 ou n = o
(n2) .
Exemples :
1. On considère la suite u définie par ∀n ∈ N, un = n + 1. Alors un ∼ n.
2. On considère la suite u définie par ∀n ∈ N, un = n +√
n. Alors un ∼ n.
143

3. On considère la suite u définie par ∀n ∈ N, un = 5n + 6. Alors un = O(n) et un = o(n2) .
On peut lier les notions d’équivalence et de négligeabilité de la manière suivante.
Soit u et v deux suites. Si un = o (vn) alors un + vn ∼ vn.
Proposition 9.3.1.309
Exemple : On considère la suite (n + cos n). Le terme cos n est borné et n tend vers +∞. On en déduit quecos(n) = o(n) et donc n + cos n ∼ n.
3.2 Propriétés
1. Ces trois notions sont transitives.
2. La notion d’équivalence est symétrique et réflexive : c’est donc une relation d’équivalence.
3. La notion de domination est reflexive.
Proposition 9.3.2.310
Remarque : On note aussi « à la physicienne » un << vn pour un = o (vn). Cette notation à l’avantage de bien
montrer la transitivité.
Soit u, v, (wn) et (x) quatre suites.
1. Multiplication par un réel non nul : soit λ un réel non nul, si un ∼ vn alors λun ∼ λvn.
2. Inverse : si un ∼ vn alors1
un∼ 1
vn.
3. Puissance : si α est un réel et si un ∼ vn alors uα ∼ vα. (on suppose que les suites sont à valeursstrictement positives).
4. Valeur absolue : si un ∼ vn alors |un| ∼ |vn|.5. Produit et quotient : si un ∼ vn et si wn ∼ xn alors un.wn ∼ vn.xn et
un
wn∼ vn
xn.
Théorème 9.3.2.311 (Opérations sur les équivalents)
B Dans les formules suivantes on n’a pas la somme! Par exemple n2 +√
n ∼ n2 et −n2 ∼ −n2 + n, mais√n n. C’est souvent en utilisant ce genre de résultat que l’on obtient un équivalent à 0.
B On ne peut pas composer les équivalents. Par exemple, n + n2 ∼ n2 mais en+n2 en2car le rapport
en+n2
en2 = en tend vers +∞.
Remarques :
1. La formule des puissances du théorème est vraie pour les suites changeant de signe si on prend α ∈ N.
2. Toujours sur la formule des puissance, il faut que α soit constant. Par exemple 1 + 1/n ∼ 1 mais (1 +1/n)n 1n.
Exemple : On pose un =
√n3 + n
√n + 1
n2 + 4. On cherche un équivalent à un. On sait que n3 + n
√n + 1 ∼ n3 et
que n2 + 4 ∼ n2. Doncn3 + n
√n + 1
n2 + 4∼ n et un ∼
√n.
B Prendre une puissance est une composition, mais c’est à cas particulier on la composition conservel’équivalence.
Les suites équivalentes sont utiles pour calculer les limites.
144

Soit u et v deux suites équivalentes on a :
1. La suite u converge si et seulement si la suite v converge. Dans ce cas, on a en plus lim u = lim v.
2. La suite u tend vers +∞ (resp. −∞) si et seulement si la suite v tend vers +∞ (resp. −∞).
Proposition 9.3.2.312
Remarque : cela signifie que pour trouver la limite d’une suite, on la remplace par une suite équivalente plussimple.
3.3 Croissances comparées et équivalents classiques
Via des équivalents, on peut souvent se ramener à des suites qui sont, des puissances, des logarithmes oudes exponentielles. Il faut alors savoir les comparer.
1. Soit α et β deux réels. Si α < β alors nα = o(nβ)
.
2. Soit (a0, . . . , ak) ∈ Rk+1. On suppose que ak 6= 0. Alors
a0 + a1n + · · ·+ aknk ∼ aknk.
Proposition 9.3.3.313 (Equivalent d’un polynôme)
Démonstration : Pour tout n 6= 0 on a :
a0 + a1n + · · ·+ aknk = ak.nk(a0
akn−k + · · ·+ 1).
Or limn→+∞
a0
akn−k + · · ·+ 1 = 1 donc a0 + a1n + · · ·+ aknk ∼ aknk.
1. Soit α ∈ R et β > 0, (ln(n))α = o(nβ)
.
2. Soit α et β deux réels. Si α < β alors nα = o(nβ)
.
3. Soit α ∈ R et β > 0, nα = o (exp(βn)). En particulier si k > 1, nα = o (kn) .
4. Soit k > 1, kn = o (n!) .
Proposition 9.3.3.314 (Croissances comparées)
Exemple : Plutôt que de faire la démonstration en général, étudions juste un exemple. Montrons que n = o(en).
Pour cela on étudie la suite wn =nen et on veut prouver qu’elle tend vers 0.
On remarque que pour tout n ∈ N?,
wn+1
wn=
n + 1en+1 .
en
n=
n + 1ne
.
On en déduit que wn+1/wn tend vers 1/e. On peut donc trouver N tel que pour n > N, wn+1/wn 6 1/2 et donc
∀n > N, wn+1 612
wn.
On en déduit classiquement que (wn) tend vers 0.Remarques :
1. En utilisant la notation << la proposition ci-dessus s’écrit :
(ln n)α << nβ << kn << n!
où β > 0 et k > 1.
145

2. On a indiqué que les cas qui ne sont pas triviaux. C’est-à-dire que tous les termes tendent vers +∞. Maison peut aussi remarquer que n−1 = 1
n = o(en) est vrai de manière évidente car 1/n tend vers 0 et en tendvers +∞.
Soit u une suite tendant vers 0. On a
(1 + un)α − 1 ∼ αun, eun − 1 ∼ un, ln(1 + un) ∼ un,
sin(un) ∼ un, tan(un) ∼ un, cos(un)− 1 ∼ −u2n
2.
Proposition 9.3.3.315 (Equivalents classiques)
Démonstration : Ce sont juste les limites vues dans le chapitre sur les fonctions usuelles composées avec des
suites. Par exemple, on sait que limx→0
sin xx
= 1. De ce fait, si lim(un) = 0 alors limn
sin(un)
un= 1 ce qui signifie
que sin(un) ∼ un.
B Si on cherche un équivalent de ln(1 + sin(un)) avec (un) tend vers 0. On peut rédiger de deux manières
— On sait que sin(un) ∼ un. De ce fait ln(1 + sin(un)) ∼ ln(1 + un) ∼ un.
— On sait que u tend vers 0 donc (sin(un)) aussi. De ce fait, ln(1 + sin(un)) ∼ sin(un) ∼ un.
Laquelle de ces deux rédaction n’est pas correcte?
4 Extension au cas des suites complexes
Nous allons (rapidement) étendre certaines notion au cas des suites de nombres complexes.
4.1 Définition et généralités
On appelle suite de nombres complexes toute application de N dans C.
Définition 9.4.1.316
Remarque : on reprend les notation des suites réelles.Exemples :
1. Soit u la suite définie par ∀n ∈ N, un = (2− i)n + 3 + 2i.
2. Soit v la suite définie par u0 = 0 et ∀n ∈ N, un = u2n + (1 + i).
Soit u une suite à valeurs complexes.
1. On appelle partie réelle de la suite u et on note Reu la suite définie par ∀n ∈ N, (Reu)n = Re(un).
2. On appelle partie imaginaire de la suite u et on note Imu la suite définie par ∀n ∈ N, (Imu)n =Im(un).
3. On appelle suite conjuguée de la suite u et on note u la suite définie par ∀n ∈ N, un = un.
4. On appelle suite des modules de la suite u et on note |u| la suite définie par ∀n ∈ N, |u|n = |un|.
Définition 9.4.1.317
Soit u une suite complexe. On dit que u est bornée si |u| l’est.
Définition 9.4.1.318
146

4.2 Convergence
1. Soit u une suite complexe et ` un nombre complexe. On dit que u converge vers ` (ou que la limite de uest `) si et seulement si la suite |u− `| tend vers 0.
2. Soit u une suite. S’il existe un nombre complexe ` tel que u converge vers `, on dit que la suite u estconvergente. Dans le cas contraire on dit qu’elle est divergente.
Définition 9.4.2.319
Exemple : Soit α un nombre complexe de module strictement inférieur à 1. La suite (αn) tend vers 0.
Soit u une suite complexe. La suite u est convergente si et seulement si Reu et Imu le sont. Dans cecas,
lim u = limReu + i lim Imu.
Proposition 9.4.2.320
Démonstration
Remarque : De même si (αn) et (βn) sont deux suites réelles, la suite (αneiβn) converge. Par contre la réciproqueest fausse. Il suffit de prendre βn = 2nπ.
4.3 Popriétés des suites convergentes
Soit u une suite convergeant vers `.
1. La suite |u| converge vers |`|. En particulier, elle est bornée.
2. La suite u converge vers `.
3. Si v est une suite extraite de u, elle converge vers `.
Proposition 9.4.3.321
Remarque : Les assertions 1. et 3. ne sont pas des équivalences alors 2. l’est par involution.
Soit u une suite complexe. Si u est bornée, il existe une suite extraite convergente.
Théorème 9.4.3.322 (Théorème de Bolzanno-Weierstrass)
Démonstration : Considérons la suite Reu.Elle est bornée car pour tout entier n, |Reun| 6 |un|. De ce fait ilexiste une application strictement croissante ϕ de N dans lui même telle que (Reuϕ(n)) converge. On considèrealors la suite (Imuϕ(n)). Elle est aussi bornée. On peut donc en extraire une sous suite convergente (Imuϕ(ψ(n))).Maintenant comme (Imuϕ(ψ(n))) et (Reuϕ(ψ(n))) convergent alors (uϕ(ψ(n))) converge aussi.
4.4 Opérations
Les limites de suites complexes sont compatibles aux opérations habituelles.
147

Soit u et v deux suites complexes convergentes.
1. Pour tout (λ, µ) ∈ C2, λu + µv converge et lim λu + µv = λ lim u + µ lim v.
2. La suite uv est convergente et lim uv = lim u× lim v.
3. Si la limite de v est non nulle alors les termes de la suite sont non nuls à partir d’un certainrang n0 et la suite (un/vn)n>n0 converge vers lim u/ lim v.
Proposition 9.4.4.323
148

10Structures
algébriques1 Groupes 1491.1 Lois de composition interne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1491.2 Itérés d’un élément . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1511.3 Groupes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152
2 Anneaux 1552.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1552.2 Règles de calculs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1562.3 Corps . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 157
1 Groupes
1.1 Lois de composition interne
Soit E un ensemble. On appelle loi de composition interne sur E tout application de E× E dans E. On note
E× E → E(x, y) 7→ x>y .
Définition 10.1.1.324
Exemples :
1. Soit E = N. L’addition et la multiplication sont des lois de composition interne.
2. Soit E = Z. La loi qui a tout couple (x, y) associe 0 est une loi de composition interne.
3. Soit E = RR. La composée qui a ( f , g) associe f g est une loi de composition interne.
4. Le produit scalaire n’est pas une loi de composition interne.
149

Soit E un ensemble et > une loi de composition interne sur E.
1. On dit que > est associative si et seulement si :
∀(x, y, z) ∈ E3, x>(y>z) = (x>y)>z.
2. On dit que > est commutative si et seulement si :
∀(x, y) ∈ E2, x>y = y>x.
Définition 10.1.1.325
Exemples :
1. Dans N l’addition et la multiplication sont associatives et commutatives.
2. Dans N la puissance n’est ni associative, ni commutative.
3. Dans EE la composition est associative mais pas commutative.
4. Dans Q la loi x>y =x + y
2est commutative mais pas associative.
Remarques :
1. On note souvent les lois de composition interne : +,×, ?,⊥,>. La convention veut que l’on réserve lesymbole + pour les lois commutatives.
2. L’intérêt de l’associativité est de pouvoir se passer des parenthèses. En effet si ? est associative on ax ? (y ? z) = (x ? y) ? z. On peut donc noter x ? y ? z sans que cela soit ambiguë.
Soit E un ensemble muni de deux lois de composition interne notée > et ?. On dit que ? estdistributive par rapport à > si et seulement si :
∀(x, y, z) ∈ E3, x ? (y>z) = (x ? y)>(x ? z) et (x>y) ? z = (x ? z)>(y ? z).
Proposition 10.1.1.326 (Distributivité)
Exemples :
1. Dans Z, la multiplication est distributive par rapport à l’addition.
2. Dans P(E), ∩ est distributive par rapport à ∪ (et réciproquement)
Soit E un ensemble muni d’une loi de composition interne >. On dit qu’un élément e de E est un élémentneutre si
∀x ∈ E, x>e = e>x = x.
Définition 10.1.1.327
Exemples :
1. Dans Z, 0 est un élément neutre pour + et 1 est un élément neutre pour ×.
2. L’application identité IdE est un élément neutre pour dans EE.
3. Il n’y a pas d’élément neutre pour l’addition dans N?.
Remarque : On peut plus généralement parler de neutre à droite (si ∀x ∈ E, x>e = x) et de neutre à gauche (si∀x ∈ E, e>x = x).
Soit E un ensemble muni d’une loi de composition interne >. S’il existe, l’élément neutre est unique.
Proposition 10.1.1.328
150

Démonstration : Soit e1 et e2 deux éléments neutres de E. On a e1 = e1>e2 = e2.
Soit (E,>) un ensemble muni d’une loi de composition interne admettant un élément neutre e. Un élément xde E est dit symétrisable ou inversible s’il existe y dans E tel que
x>y = y>x = e.
Définition 10.1.1.329 (Inversibilité)
Remarques :
1. Quand la loi est commutative on peut ne vérifier qu’une des deux conditions.
2. Là encore, quand la loi n’est pas commutative on peut parler d’inverse à droite et à gauche. Par exempledans E = RR si f est la fonction tan prolongée en posant tan(π/2 + kπ) = 0. La fonction g = arctan estun inverse à gauche car g f = IdR.
3. La notion d’inverse est utile pour simplifier une équation. En effet si on veut résoudre l’équation a>x = bd’inconnue x. Si a est inversible d’inverse a′ on a
a>x = b⇒ a′>(a>x) = a′>b⇒ (a′>a)>x = a′>b⇒ x = a′>b.
Soit (E,>) un ensemble muni d’une loi de composition interne admettant un élément neutre e. Onsuppose de plus la loi associative.
1. Si x est inversible alors l’élément y vérifiant x>y = y>x = e est unique. On l’appelle l’inversede x et il se note souvent x−1.
2. Si x est inversible alors x−1 aussi et (x−1)−1 = x.
3. Si x et y sont inversibles alors x>y aussi et (x>y)−1 = y−1>x−1.
Proposition 10.1.1.330 (Propriété de l’inverse)
Démonstration :
1. Soit y1 et y2 deux inverses de x,y1 = y1>x>y2 = y2.
2. Il suffit de voir que x>x−1 = x−1>x = e.
3. Là encore, il suffit de faire le calcul
(x>y)>(y−1>x−1) = x>(y>y−1)>x−1 = e.
B Quand la loi n’est pas commutative, (x>y)−1 peut être différent de x−1>y−1. Nous le verrons avec lesmatrices.
Soit (E,>) un ensemble muni d’une loi de composition interne. Soit A une partie de E. Elle est dite stablepour > si
∀(x, y) ∈ A2, x>y ∈ A.
Définition 10.1.1.331 (Partie stable)
1.2 Itérés d’un élément
Notation multiplicative
Dans tout ce chapitre on considère un ensemble E muni d’une loi de composition interne associative noté ?.On suppose qu’il existe un élément neutre noté e.
151

Soit x un élément de E et n un entier naturel on définit xn par récurrence en posant :
x0 = e et ∀n ∈ N, xn+1 = x ? xn.
Définition 10.1.2.332
Remarques :
1. Cela correspond à la classique : xn est égale à x ? · · · ? x︸ ︷︷ ︸n fois
.
2. Il faut noter que même si ? n’est pas commutative, cela n’est pas important si on pose x ? xn ou xn ? x.
Avec les notations précédentes on a
xn ? xp = xn+p et (xn)p = xnp.
Proposition 10.1.2.333
B Faire attention que la relation xn ? yn = (x ? y)n n’est vraie que si ? est commutative.
Quand x est inversible et n ∈ N, on note x−n pour (x−1)n = (xn)−1.
Définition 10.1.2.334
Notation additive
Dans tout ce chapitre on considère un ensemble E muni d’une loi de composition interne associative noté +(et donc supposée commutative). On suppose qu’il existe un élément neutre noté 0.
Soit x un élément de E et n un entier naturel on définit n.x par récurrence en posant :
0.x = 0 et ∀n ∈ N, (n + 1).x = x + n.x.
Définition 10.1.2.335
Avec les notations précédentes on a
n.x + p.x = (n + p).x et n.(p.x) = (np).x.
Proposition 10.1.2.336
Soit x un élément inversible. On note −x (au lieu de x−1) son inverse que l’on appelle opposé.Dans ce cas pour n ∈ N, on note (−n).x pour n.(−x) = −(n.x).
Définition 10.1.2.337
1.3 Groupes
On a vu que pour résoudre des équations du type a>x = b on avait besoin d’un élément neutre et d’inverse.
152

Soit G un ensemble muni d’une loi de composition interne ?. On dit que (G, ?) est un groupe si :
1. La loi ? est associative ;
2. il existe un élément neutre e de G qui vérifie : ∀g ∈ G, e ? g = g ? e = g.
3. Tout g dans G est inversible.C’est-à-dire qu’il existe g′ dans G tel que g ? g′ = g′ ? g = e.
Définition 10.1.3.338
Remarque : Quand la loi de composition interne est évidente on ne la rajoute pas dans la notation.Exemples :
1. L’ensemble (N,+) n’est pas un groupe car 1, par exemple, n’a pas de symétrique.
2. Les ensembles (Z,+), (Q,+), (R,+) et (C,+) sont des groupes.
3. L’ensemble (Z,×) n’est pas un groupe car 2 n’a pas de symétrique.
4. L’ensemble (Q,×) n’est pas un groupe car 0 n’a pas d’inverse.
5. Les ensembles (Q?,×), (R?,×) et (C?,×) sont des groupes.
6. Soit U = z ∈ C | |z| = 1 et Un = z ∈ C | zn = 1. Ce sont des groupes mutliplicatifs.
7. Soit E un ensemble. L’ensemble des bijections de E forme un groupe que l’on note SE.
8. On peut aussi donner des groupes en donnant tous les éléments et les tables de la loi de compositioninterne.Par exemple G1 = 0, 1 avec
+ 0 10 0 11 1 0
Dans ce cas, 1 est le symétrique de 1.
9. On peut aussi construire un groupe à 4 éléments. On pose G2 = 0, 1, 2, 3 avec la loi
+ 0 1 2 30 0 1 2 31 1 2 3 02 2 3 0 13 3 0 1 2
L’idée est de dire que x + y est le reste de la division par 4 de x + y.Ici on voit que −1 = 3 et −2 = 2.
Quand on essaye de déterminer la loi d’un groupe, on peut remarquer que chaque colonne et chaqueligne contient tous les éléments du groupe. En effet a>x = b ⇐⇒ x = (a−1)>b ce qui signifie quetout élément b apparait une (et une seule) fois dans la ligne des éléments de la forme a>x. On peutfaire pareil pour les colonnes
ATTENTION
10. On s’intéresse à un triangle équilatéral ABC. On note G son centre de gravité. On cherche les transforma-tions géométriques qui le laisse stable.
— Il y a bien évidement l’identité que l’on note e.
— Il y a les rotations de centre G et d’angle 2π/3 et −2π/3 que nous noterons r+ et r−.
— Il y a les symétries par rapport aux hauteurs que nous noterons sA, sB et sC.
On peut alors considérer D3 = e, r+, r−, sA, sB, sC. C’est un sous-groupe du groupe des bijections duplan.Ecrire sa table.
11. Si E est un ensemble. On note SE l’ensemble des bijections de E dans E. On a alors (SE, ) est un groupe.
Exercice : On pose G =]− 1, 1[ et la loi > est définie par x>y =x + y
1 + xy. Montrer que (G,>) est un groupe.
153

Soit (G,>) un groupe. Si la loi > est commutative, on dit que G est un groupe commutatif ou abélien.
Définition 10.1.3.339
Exemples :
1. Il est clair que (Z,+), (Q,+), (R,+) et (C,+) sont abéliens.
2. Soit E un ensemble avec au moins trois éléments et (SE, ) n’est pas abélien.
Soit (G,>) un groupe et H une partie de G. On dit que H est un sous-groupe de G si et seulement si :
1. L’ensemble H est stable par >.
2. L’ensemble H est stable par passage au symétrique.
3. L’ensemble H contient l’élément neutre.
Définition 10.1.3.340
Remarque : Cela signifie que H est une partie de G telle que la loi de G induit une loi de composition internesur H et que pour cette loi, H est un groupe.
Soit (G,>) un groupe et H un sous-groupe de G. L’ensemble (H,>) est un groupe.
Proposition 10.1.3.341
Démonstration : La loi > est bien une loi de compostion interne de H car H est stable par >. De plus elle estassociative car elle l’est dans G. L’élément neutre de G est un élément neutre dans H. Tout élément h de H abien un inverse dans H.
Exemples :
1. Pour tout groupe (G,>) les ensembles e et G en entier sont des sous-groupes (dits triviaux). Les autres
2. (Z,+) est un sous groupe de (R,+).
3. (U,×) est un sous-groupe de (C?,×).
Soit (G,×) un groupe et H une partie de G. L’ensemble H est un sous-groupe de G si et seulement si
— H est non vide.
— ∀(x, y) ∈ H2, xy−1 ∈ H.
Proposition 10.1.3.342 (Caractérisation d’un sous groupe)
Remarque : Il est évident que pour tout groupe G, les parties e et G sont des sous-groupes dits triviaux. Lesautres sous-groupes sont dits propres.Exercice : Soit ω ∈ C. On pose H = a + ωb ∈ C | (a, b) ∈ Z2. Montrer que H est un sous-groupe de C.Exemples :
1. Déterminons les sous groupes (propre) de (U5,×). On sait que U5 = 1, ω, ω2, ω3, ω4 où ω = e2iπ/5.De ce fait, si on se donne un sous groupe H contenant un élément α différent de 1 dans U5. En considérantses puissances (qui sont dans U5 par stabilité) on en déduit que H = U5.
2. On recommence pour U6.
154

2 Anneaux
2.1 Définitions
Soit A un ensemble muni de deux lois de compositions internes notée + et ×. On dit que (A,+,×) est unanneau si
1. (A,+) est un groupe commutatif (d’où la notation +)
2. la loi × est associative
3. il existe un élément neutre pour ×4. la loi × est distributive par rapport à +
Si la loi × est aussi commutative, on dit que A est un anneau commutatif.
Définition 10.2.1.343
Remarques :
1. Cette définition correspondent aux règles de calculs classiques dans Z, Q, R.
2. L’ensemble (A,×) n’est pas forcement un groupe car des éléments peuvent pas avoir de symétrique.
3. On peut voir que A = 0 est un anneau que l’on appelle l’anneau nul. Ce n’est pas le plus intéressant eton essaye souvent d’exclure ce cas.
Notations :
1. On note 0 ou 0A l’élément neutre pour +.
2. On note 1 ou 1A l’élément neutre pour ×.
3. On abrège x× y en xy.
Exemples :
1. Les ensembles Z, Q, R et C sont des anneaux pour les opérations usuelles.
2. L’ensemble des applications de R dans R muni des opérations + et × est un anneau.
3. On peut reprendre G1 = 0, 1 avec+ 0 10 0 11 1 0
On ajoute une multiplication
× 0 10 0 11 0 1
Cela nous fait bien un anneau (à vérifier).
4. On peut aussi construire un anneau à 4 éléments. On pose G2 = 0, 1, 2, 3 avec la loi
+ 0 1 2 30 0 1 2 31 1 2 3 02 2 3 0 13 3 0 1 2
Là aussi on ajoute une multiplication où a = 1.
× 0 1 2 30 0 0 0 01 0 1 2 32 0 2 0 2c 0 3 2 1
On peut vérifier que cela fait un anneau.
155

Soit (A,+,×) un anneau. Un élément x de A est dit inversible s’il est inversible pour la multiplication.C’est-à-dire s’il existe y dans A tel que xy = yx = 1. Dans ce cas y est unique et on le note y−1. On dit aussique x est une unité
Définition 10.2.1.344
Remarques :
1. La notion d’inversible réfère à la loi × et pas la loi +. Tous les éléments sont « inversible » par +.
2. A priori, il y a des éléments qui ne sont pas inversibles dans un anneau.
3. On ne note pas1x
l’inverse pour éviter d’écrire par la suitey′
yqui pourrait être y′ × 1
you
1y× y′ qui sont à
priori différents.
4. On nota la plupart du temps A× l’ensemble des éléments inversibles d’un anneau.
5. Quand un élément x est inversible, on étend les notations xn au cas où n est négatif.
Soit (A,+,×) un anneau. L’ensemble des éléments inversibles forme un groupe multiplicatif noté(A×,×).
Proposition 10.2.1.345
Démonstration
Exemples :
1. Dans Z, 1 et −1 sont les seuls inversibles. On a donc Z× = ±1. Cette notation est en conflit avec Z \ 0c’est pour cela qu’il vaut mieux ne pas utiliser les deux ou alors préciser ce dont on parle.
2. Les éléments inversibles de R sont tous les réels non nuls.
3. Les éléments inversibles de RR sont les fonctions qui ne s’annulent pas.
Soit (A,+,×) un anneau. On appelle, sous-anneau de A tout sous groupe de (A,+) contenant 1 et qui eststable par multiplication.
Définition 10.2.1.346 (Sous-anneau)
Exemples :
1. On voit Z est un sous-anneau de R.
2. 0 n’est pas un sous-anneau de R car il ne contient par 1.
Exercice : Soit d ∈ N. Montrer que Z[√
5] = a + b√
5 | (a, b) ∈ Z2 est un sous-anneau de R. L’élément1 +√
5 est-il inversible? Et 2 +√
5?
2.2 Règles de calculs
Les axiomes des anneaux sont fait pour pouvoir faire les calculs « comme d’habitude ».
Soit A un anneau.
1. Soit x dans A, 0.x = x.0 = 0. On dit que 0 est absorbant.
2. Si A n’est pas l’anneau nul alors 1 6= 0.
3. Soit x et y dans A : (−x).y = x.(−y) = −(x.y).
Proposition 10.2.2.347
156

Démonstration :
1. On a 0.x + 0.x = (0 + 0).x = 0.x. En ajoutant le symétrique de 0.x de part et d’autre on a 0.x = 0. Demême dans l’autre sens.
2. Si on suppose que 1 = 0 alors, pour α un élément de A. On a
α = 1.α = 0.α = 0.
L’anneau est obligatoirement l’anneau nul.
3. On a (−x).y + xy = (−x + x).y = 0.y = 0 donc (−x).y est le symétrique de xy c’est-à-dire : (−x).y =−(x.y).
On appelle anneau intègre, un anneau commutatif vérifiant que
∀(x, y) ∈ A2, xy = 0⇒ x = 0 ou y = 0.
Définition 10.2.2.348
Exemple : Les anneaux Z, R, C sont intègres. Nous verrons plus tard des exemples d’anneau qui ne sont pasintègres.
Soit (A,+,×) un anneau.
1. Soit n ∈ N. Si xy = yx alors (x + y)n =n
∑k=0
(kn
)xkyn−k.
2. Soit n ∈ N. Si xy = yx alors (xn+1 − yn+1) = (x− y)n
∑k=0
xkyn−k.
3. Soit n ∈ N et x ∈ A, (1− x)n
∑k=0
kk = 1− xn+1.
Proposition 10.2.2.349
Cela ne « marche » que si xy = yx. Par exemple (x + y)2 = x2 + xy + yx + y2 dans le cas général.
ATTENTION
2.3 Corps
Un ensemble (K,+,×) est un corps si c’est un anneau commutatif dont tous les éléments non nuls sontinversibles.
Définition 10.2.3.350
Exemples :
1. Les ensembles Q, R, C sont des corps.
2. L’ensemble Z n’est pas un corps.
3. L’ensemble G1 est un corps mais pas G2.
Remarque : Un corps est intègre.
Notation : Soit K un corps. Pour (a, b) dans K avec b 6= 0 on noteab
pour ab−1 = b−1a.
157

Soit a un élément non nuln
∑k=0
ak =1− an+1
1− a.
Proposition 10.2.3.351
Soit K un corps et L un sous-anneau de K. On dit que L est un sous-corps de K ou que K est un sur corps deL.
Définition 10.2.3.352
Exemple : Q, R et C.
158

11Arithmétique de Z
1 Divisibilité dans Z 1591.1 Diviseurs et multiples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1591.2 Division euclidienne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1601.3 Congruences dans Z . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161
2 Plus grand commun diviseur (PGCD) 1612.1 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1612.2 Algorithme d’Euclide . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1622.3 Relation de Bézout . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1632.4 Algorithme d’Euclide augmenté . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1642.5 Nombres premiers entre eux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1652.6 Résolution de l’équation au + bv = c. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1672.7 PGCD de plusieurs entiers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 167
3 Le plus petit commun multiple (PPCM) 1683.1 Définition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1683.2 Lien avec le PGCD et nombres premiers entre eux . . . . . . . . . . . . . . . . . . . . . . . . . . . 169
4 Nombres premiers 1694.1 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1704.2 Décomposition en produit de facteurs premiers . . . . . . . . . . . . . . . . . . . . . . . . . . . . 170
1 Divisibilité dans Z
1.1 Diviseurs et multiples
Soit a et b deux entiers relatifs, on dit que a est un diviseur de b ou que b est un multiple de a s’il existe unentier k tel que b = ak.
Définition 11.1.1.353
Notations :
1. On note a|b pour a divise b.
2. On note D(a) l’ensemble des diviseurs de a.
3. On note aZ l’ensemble des multiples de a. On a aZ = ak | k ∈ Z.
159

Exemples :
1. Le nombre 2 divise 6. De même −2 divise 6.
2. Les entiers 1 et −1 divisent tous les entiers mais D(1) = D(−1) = ±1.3. Tout entier divise 0 ou 0 est un multiple de tous les entiers. Par contre 0Z = 0.
Soit a et b deux entiers(a|b et b|a) ⇐⇒ |a| = |b|.
Proposition 11.1.1.354
Remarques :
1. On dit alors que les entiers a et b sont associés.
2. C’est une méthode pour montrer que deux nombres sont égaux. Il faut faire attention que, dans Z ilspeuvent être opposés.
3. La relation de divisibilité est transitive, réflexive mais elle n’est pas anti-symétrique.
Démonstration : Démontrons le sens qui n’est pas trivial. On suppose donc qu’il existe k et k′ des entiers telsque a = kb et b = k′a d’où a = kk′a c’est-à-dire a(1− kk′) = 0.
— Si a = 0, comme a|b on a b = 0.
— Si a 6= 0, kk′ = 1 car le produit de deux entiers est nul si et seulement si l’un des deux est nul. En particulierk et k′ divise 1 d’où |k| = |k′| = 1. On en déduit |a| = |b|.
1. Soit a, b et c trois entiers. On suppose que a|b et a|c alors pour tout (u, v) ∈ Z2, a|(ub + vc).
2. Soit a, b et c trois entiers avec c 6= 0 :
a|b ⇐⇒ ac|bc.
Proposition 11.1.1.355
Démonstration : En exercice.
1.2 Division euclidienne
Soit a un entier relatif et b un entier naturel non nul. Il existe un unique couple (q, r) où q est unentier relatif et r ∈ [[ 0 ; b− 1 ]] tel que
a = bq + r.
Le nombre q s’appelle le quotient et le nombre r s’appelle le reste.
Théorème 11.1.2.356 (Division euclidienne)
Démonstration : On a déjà démontré le cas où a ∈ N dans le chapitre 6. Le cas général se traite en remarquantque a + |a|b est un entier naturel auquel on peut appliquer la division euclidienne.
Remarques :
1. On peut voir que q = E(a/b) même si cette caractérisation est rarement utile car « on sort des entiers ».
2. De manière évidente, a|b ⇐⇒ r = 0.
160

1.3 Congruences dans Z
Soit m un entier naturel non nul. On définit la relation binaire sur Z
∀(a, b) ∈ Z2, a ≡ b[m] ⇐⇒ m|(a− b).
On dit alors que a et b sont congrus modulo m.
Définition 11.1.3.357
Remarque : On peut aussi définir la relation en disant que a et b ont le même reste dans la division euclidiennepar m.
La relation binaire de congruence est une relation d’équivalence.
Proposition 11.1.3.358
Soit m ∈ N?. La relation de congruence modulo m est compatible à l’addition et à la multiplication.C’est-à-dire :
1. ∀(a, b, a′, b′) ∈ Z4, a ≡ b[m] et a′ ≡ b′[m]⇒ (a + a′) ≡ (b + b′)[m].
2. ∀(a, b, a′, b′) ∈ Z4, a ≡ b[m] et a′ ≡ b′[m]⇒ (aa′) ≡ (bb′)[m].
3. ∀(a, b) ∈ Z2, ∀k ∈ N, a ≡ b[m]⇒ ak ≡ bk[m].
Théorème 11.1.3.359
Démonstration : Pour le point 2. il suffit de remarquer que aa′ − bb′ = a(a′ − b′) + b′(a− b).
Exemples :1. Calculons le reste de la division euclidienne de 1003 par 7. On a 100 ≡ 2[7] Donc 1003 ≡ 8[7] d’où
1003 ≡ 1[7].2. Critères de divisibilité par 3 et 9 : Soit N un nombre. On note a0, . . . ap ses chiffres dans l’écriture
décimale. On a
N =p
∑k=0
ak10k.
Or, si on remarque que 10 est congru à 1 modulo 3 (ou 9) on en déduit que
N ≡p
∑k=0
ak[3] ou [9].
On en déduit qu’un nombre entier est divisible par 3 (ou 9) si et seulement si la somme de ses chiffres l’est.3. On veut montrer que si p2 est pair alors p2 est divisible par 4. On regarde les congruences modulo 4 de p.
C’est 0, 1, 2 ou 3. De ce fait la congruence de p2 est 0, 1, 0 ou 1. Donc si ce n’est pas 1 (car p2 est pair) celane peut être que 0 (et pas 2).
Exercice : Déterminer des critères de divisibilité par 11 et 37.
2 Plus grand commun diviseur (PGCD)
2.1 Généralités
Soit a et b deux entiers naturels. Si (a, b) 6= (0, 0), l’ensemble D(a) ∩D(b) des diviseurs communs àa et b est un ensemble non-vide et majoré de Z. En particulier il admet un plus grand élément.
Proposition 11.2.1.360
161

Démonstration : L’ensemble D(a) ∩D(b) est non vide car il contient 1. Si a est non nul il est majorée par a. Si aest nul (et donc b non nul), il est majorée par b.
Soit a et b deux entiers relatifs. Le PGCD de a et de b que l’on note a ∧ b est :
— le plus grand élément de D(|a|) ∩D(|b|) si (a, b) 6= (0, 0).
— 0 si a = b = 0 par convention.
Définition 11.2.1.361
Remarque : On voit que l’on travaille avec les valeurs absolues de a et de b. De ce fait, on se ramènera souventau cas des entiers naturels.Exemples :
1. On a 13∧ 6 = 1
2. On a 15∧ 6 = 3.
3. Si a 6= 0, a ∧ 0 = |a|. En effet D(0) ∩D(|a|) = D(|a|). Le plus grand élément de D(|a|) est |a|.
2.2 Algorithme d’Euclide
La méthode la plus simple pour calculer le PGCD de deux nombres est d’utiliser l’algorithme d’Euclide. Cedernier se base sur le lemme suivant.
Soit a et b deux entiers naturels avec b 6= 0. Si r est le reste de la division euclidienne de a par b alors
D(a) ∩D(b) = D(b) ∩D(r).
De ce fait a ∧ b = b ∧ r.
Lemme 11.2.2.362
Démonstration : Par définition on a a = bq + r où q est le quotient de la division euclidienne. Soit n ∈ Z. Ona que si n|a et n|b alors n|r = a− bq. Réciproquement si n|b et n|r alors n|a = qb + r. En conclusion on a bienD(a) ∩D(b) = D(b) ∩D(r) et donc a ∧ b = b ∧ r.
On cherche le PGCD de a et de b. Le principe est que tant que b n’est pas nul on remplace a par b et b par lereste de la division euclidienne de a par b. On recommence jusqu’à ce que b vaille 0. Le PGCD est alors la valeurde a. On dit que c’est le dernier reste non nul. Cela nous donne en python
def euclide(a,b) :while b <> 0 :
r = a%ba = bb =r
return a
Le programme termine car la variable b décrit une suite strictement décroissante d’entiers naturels. Pourl’invariant de boucle il suffit de choisir D(a) ∩D(b).
Mathématiquement on peut voir cela comme la construction de deux suites (ak) et (bk) définies par a0 = aet b0 = b. Les formules de récurrence étant
∀k ∈ N,
ak+1 = bkbk+1 = ak mod bk
La suite (bk) décroit strictement. Il existe n tel que bn = 0 et on a an = a ∧ b.Remarques :
1. Historiquement Euclide l’a fait en utilisant que D(a) ∩D(b) = D(a− b) ∩D(b).
2. Cela fonctionne aussi si a < b, a = 0 ou b = 0.
Exemples :
162

1. On prend a = 53 et b = 17
53 = 1× 37 + 1637 = 2× 16 + 516 = 3× 5 + 1
5 = 5× 1 + 0
Donc 53∧ 37 = 1.2. On prend a = 156 et b = 42
156 = 3× 42 + 2442 = 1× 24 + 1824 = 1× 18 + 618 = 3× 6 + 0
Donc 156∧ 42 = 6.Remarque : Bien évidemment, si a ou b est négatif, on peut appliquer cet algorithme à |a| et |b|.
2.3 Relation de Bézout
Soit a et b deux entiers. Il existe des couples (u, v) ∈ Z2 tels que
au + bv = a ∧ b.
De tels couples s’appellent des coefficients de Bézout.
Théorème 11.2.3.363 (IMPORTANT - Relation de Bézout)
Démonstration : Quitte à remplacer a et b par |a| et |b|, on peut supposer que ce sont des entiers naturels.On va procéder par récurrence forte sur b. Précisément, pour b ∈ N on pose
Hb = ”∀a ∈ N, ∃(u, v) ∈ Z2, au + bv = a ∧ b”.
— Initialisation : Pour b = 0 c’est vrai car a ∧ 0 = a = a× 1 + 0× 0.— Hérédité : Soit b ∈ N?, on suppose que pour tout entier k < b, Hk est vraie. Si on écrit la division
euclidienne de a par b on a a = bq + r et a ∧ b = b ∧ r. On peut donc utiliser Hr pour justifier l’existencede u′ et v′ dans Z tels que
bu′ + rv′ = b ∧ r = a ∧ b.
Il ne reste plus qu’à remplacer r par r = a− bq. Cela donne
a ∧ b = bu′ + (a− bq)v′ = av′ + b(u′ − qv′).
On pose u = v′ et v = u′ − qv′.
Remarques :1. Nous verrons plus loin comment les calculer à partir de l’algorithme d’Euclide. Ce calcul pourra donner
une preuve algorithmique de l’existence.2. Si on note aZ + bZ l’ensemble des nombres de la forme au + bv où u et v sont des entiers relatifs, le
théorème prouve que a ∧ b appartient à aZ + bZ. On en déduit immédiatement que c’est aussi le cas pourles multiples de a ∧ b. C’est-à-dire (a ∧ b)Z ⊂ aZ + bZ. Réciproquement, un élément de la forme au + bvest divisible par a ∧ b car ce dernier divise a et b. En conclusion
(a ∧ b)Z = aZ + bZ.
Soit a et b deux entiers relatifs. Pour tout entier n,
(n|a et n|b)⇔ n|a ∧ b.
Cela signifie que les diviseurs communs à a et b sont les diviseurs de a ∧ b.
Corollaire 11.2.3.364 (IMPORTANT)
163

Démonstration :
— ⇐ Par transitivité de la division car (a ∧ b) divise a et b.
— ⇒ Soit n un entier qui divise a et b. On sait qu’il existe d’après le théorème de Bezout, des entiers u et vtels que a ∧ b = au + bv. On en déduit que n|au et n|bv et donc n|a ∧ b.
Remarque : Le sens ⇒ signifie que a ∧ b est le plus grand diviseur commun de a et b au sens de la division.
2.4 Algorithme d’Euclide augmenté
On a vu que l’algorithme d’Euclide permet de déterminer le PGCD de deux nombres que nous supposeronspositifs (en effet on peut prendre la valeur absolue sans changer le PGCD).
On peut maintenant modifier l’algorithme d’Euclide afin de déterminer de plus un couple (u, v) tel queau + bv = a ∧ b.
Reprenons les suites définies dans l’algorithme d’Euclide. On veut construire une des suites (uk) et (vk)telles que
auk + bvk = ak.
Comme on sait que ak+1 = bk, on a aussi besoin de suite u′k et v′k vérifiant
au′k + bv′k = bk.
On peut alors aisément calculer les relations de récurrences de ces suites
∀k ∈ N,
uk+1 = u′kvk+1 = v′ku′k+1 = uk − qu′kv′k+1 = vk − qv′k
Dans les relations de récurrence, q désigne le quotient de ak par bk. Cela vient du fait que bk+1 = ak mod bk =ak − qbk.
Par exemple pour a = 156 et b = 42.
ak bk q r uk vk u′k v′k156 42 3 30 1 0 0 142 30 1 12 0 1 1 −330 12 2 6 1 −3 −1 412 6 2 0 −1 4 3 −116 0 3 −11
On trouve donc que6 = 3× 156− 11× 42.
En python cela donne
def euclideplus(a,b) :u = 1v = 0uu = 0vv = 1# On initialise les variables u, v, uu (pour u’) et vv (pour v’)while b <> 0 :
r = a % bq = a / buuu = u - q*uuvvv = v - q*vvu = uuv = vvuu = uuuvv = vvv# on calcule les nouvelles valeurs de u, v, uu et vv#(on utilise uuu et vvv comme variables temporaires)a = bb = r
return (u,v,a)
164

Là encore l’algorithme termine car la variable b est un entier naturel qui décroit strictement à chaque itération.Pour prouver que l’algorithme renvoie les valeurs voulue il suffit de voir que A ∗ u + B ∗ v = a où A et B sontles valeurs initiales des paramètres.
2.5 Nombres premiers entre eux
Soit a et b deux entiers relatifs. On dit que a et b sont premiers entre eux si et seulement si a ∧ b = 1. Celasignifie que les seuls diviseurs communs de a et b sont 1 et −1.
Définition 11.2.5.365
Exemple : Les nombres 12 et 35 sont premiers entre eux.Remarque : Les nombres 1 et −1 sont premiers avec tous les nombres. Par contre 0 n’est premier qu’avec 1 et−1.
Soit a et b deux entiers relatifs :
(a et b sont premiers entre eux ) ⇐⇒ (∃(u, v) ∈ Z2, au + bv = 1).
Proposition 11.2.5.366
Démonstration :
— ⇒ : C’est la relation de Bézout
— ⇐ : On suppose qu’il existe u et v tels que au + bv = 1. Cela implique que aZ + bZ = Z. En utilisant laremarque après le théorème de Bézout on obtient a ∧ b = 1.
Exemple : On peut ainsi montrer que pour tout entier n non nul, 2n + 1 et 9n + 4 sont premiers entre eux. Eneffet 9.(2n + 1)− 2(9n + 4) = 1.
Soit a et b deux entiers premiers entre eux et a′ et b′ des diviseurs de a et b respectivement. Lesnombres a′ et b′ sont premiers entre eux.
Corollaire 11.2.5.367
Soit a et b deux entiers naturels. On note d = a ∧ b. Il existe deux entier a′ et b′ premiers entre euxtels que
a = da′ et b = db′.
Proposition 11.2.5.368
Démonstration :
— Si a = b = 0 on peut prendre a′ = b′ = 1.
— Sinon, d 6= 0. Il existe par définition, a′ et b′ tels que a = a′d et b = b′d. D’après ce qui précède il existe u etv tels que au + bv = d ce qui s’écrit
a′du + b′dv = d.
En divisant par d on obtienta′u + b′v = 1
On en déduit que a′ et b′ sont premiers entre eux.
Remarques :
165

1. Si on exclut le cas où a = b = 0 ce résultat peut s’écrire sous la forme plus simple suivant. Si a et b sont
deux entiers alorsa
a ∧ bet
ba ∧ b
sont premiers entre eux.
2. On utilisera cela dans les les exercices pour ramener un problème au cas des nombres premiers entre euxLa propriété principale des nombres premiers entre eux est le lemme de Gauss.
Soit a, b et c trois entiers relatifs.(a ∧ b = 1 et a|bc)⇒ a|c.
Théorème 11.2.5.369 (Lemme de Gauss)
Remarque : Commençons par remarquer que cela n’est pas vrai si a et b ne sont pas premiers entre eux. Prenonspar exemple a = 2, b = 2 et c = 3 on a bien a|bc mais a ne divise pas c.Démonstration : On utilise le théorème de Bézout. Soit (u, v) tels que au + bv = 1 on en déduit que
auc + bvc = c.
Or a|auc et a|bvc donc a|c.
Exemple : Cela permet de redémontrer que si p est un entier alors p2 pair implique p est pair. En effet sisupposons par l’absurde que p ne soit pas pair. Donc p est premier avec 2. On en déduit, comme 2|p× p que2|p. C’est absurde.
Soit r un nombre rationnel. On appelle écriture irréductible de r une écriture de la formeab
où a ∈ Z et b ∈ N?
avec a et b premiers entre eux.
Définition 11.2.5.370
Tout nombre rationnel a une unique écriture irréductible.
Corollaire 11.2.5.371
Démonstration : C’est vrai pour r = 0 car 1 est le seul nombre positif premier avec 0.Si r 6= 0, on prouve l’existence en prenant une écriture et en divisant par le pgcd du numérateur et du
dénominateur (après avoir éventuellement changé le signe du numérateur). Pour l’unicité, on se donne deuxécritures qui vérifient l’énoncé. On a
r =ab=
a′
b′.
On en déduit que ab′ = a′b. En particulier b|(ab′) mais comme a et b sont premiers entre eux, b|b′. En refaisantle raisonnement dans l’autre sens, on trouve que b et b′ sont associés, comme ils sont positifs, ils sont égaux. Ona donc b = b′ et a = a′ en découle.
Soit a, b et c trois entiers relatifs.
(a ∧ b = 1 et a ∧ c = 1)⇒ a ∧ (bc) = 1.
En particulier, si a et b sont premier entre eux alors an et bm aussi pour tout n, m non nuls.
Corollaire 11.2.5.372
Démonstration : On suppose que a ∧ b = 1 et a ∧ c = 1. Il existe donc (u, v) et (u′, v′) tels que au + bv = 1 etau′ + cv′ = 1. En faisant le produit on trouve
a(auu′ + cv′u + bvu′) + bcvv′ = 1.
On en déduit que a et bc sont premiers entre eux.
166

2.6 Résolution de l’équation au + bv = c.
On se donne trois entiers relatifs a, b et c et on suppose que a et b sont non nuls et on veut résoudre l’équationau + bv = c d’inconnues (u, v). On notera d = a ∧ b.
1. On a vu que aZ + bZ = dZ. De ce fait, si d ne divise pas c, S = ∅. Dans la suite on suppose que d|c de cefait on sait qu’il y a des solutions.
2. D’après ce qui précède on sait trouver (u0, v0) vérifiant au0 + bv0 = d. Il ne reste plus qu’à multiplier park tel que c = kd pour trouver une solution de l’équation. Nous noterons (α0, β0) cette solution.
3. Supposons donc que l’on connaisse une solution (α0, β0) de l’équation. On a alors pour tout (u, v) dansZ2 :
au + bv = c ⇐⇒ au + bv = au0 + bv0 ⇐⇒ a(u− β0) + b(v− β0) = 0.
Il ne nous reste donc qu’à résoudre l’équation aU + bV = 0.
4. On peut noter a′ et b′ tels que a = da′ et b = db′ avec a′ et b′ premiers entre eux. On a alors
aU + bV = 0 ⇐⇒ d(a′U + b′V) = 0 ⇐⇒ a′U + b′V = 0.
5. Pour finir, soit (U, V) une solution de a′U + b′V = 0 on a donc a′U = −b′V d’où a′|b′V et donc a′|V car a′
et b′ sont premiers entre eux. On en déduit que les solutions de cette équation sont (kb′,−ka′) | k ∈ Z.L’ensemble des solutions est donc :
S =
(α0 + kb′, β0 − ka′) | k ∈ Z si d |c∅ sinon
2.7 PGCD de plusieurs entiers
Nous allons généraliser ce que l’on vient de faire pour deux entiers à plusieurs entiers. On se fixe p > 2.La plupart des démonstrations ne seront qu’esquissées car semblables au cas de deux entiers.
Soit a1, . . . , ap des entiers naturels non tous nuls. L’ensemble⋂p
i=1 D(ai) est non vide et majorée.
Proposition 11.2.7.373
Soit (ai)16i6p une famille d’entiers.
— Si a1 = · · · = ap = 0 on appelle PGCD de la famille (ai)16i6p et on note a1 ∧ · · · ∧ ap = 0
— Si un des ai n’est pas nul on appelle PGCD de la famille (ai)16i6p et on note a1 ∧ · · · ∧ ap le plusgrand élément de
⋂pi=1 D(|ai|)
Définition 11.2.7.374
Exemples :
1. On a 3∧ 9∧ 12 = 3
2. On a 3∧ 6∧ 10 = 1.
Soit (ai)16i6p une famille d’entiers. Il existe une famille (ui)16i6n d’entiers tels que
a1u1 + · · ·+ apup = a1 ∧ · · · ∧ ap.
Proposition 11.2.7.375 (Relation de Bézout)
Démonstration : On procède par récurrence sur p > 2. On note Hp le prédicat« pour toute famille (ai)16i6p il existe une famille (ui)16i6p d’entiers tels que a1u1 + · · ·+ apup = a1 ∧ · · · ∧
ap. »
— Initialisation Si p = 2 c’est le cas connu
167

— Hérédité On suppose la propriété vraie pour p et on la démontre pour p + 1. On procède par récurrencesur ap+1. On note Gn le prédicat « pour toute famille (ai)16i6p il existe une famille (ui)16i6(p+1) d’entierstels que a1u1 + · · ·+ apup + ap+1n = a1 ∧ · · · ∧ ap ∧ n. »(Ici la variable est n et pas p).
— Initialisation Si n = 0 on est ramené à Hp
— Hérédité Si n > 0, on procède comme dans la démonstration de la relation de Bézout en effectuant adivision euclidienne de ap par n.
Remarque : Comme dans le cas de deux nombres, on peut en déduire que
a1Z + · · ·+ apZ = (a1 ∧ · · · ∧ ap)Z.
Avec les mêmes notations
∀n ∈ Z, (n|a1 et · · · et n|ap) ⇐⇒ n|a1 ∧ · · · ∧ ap.
Corollaire 11.2.7.376
Soit (ai)16i6p une famille d’entiers.
1. On dit qu’ils sont premiers entre eux dans leur ensemble si a1 ∧ · · · ∧ ap = 1
2. On dit qu’ils sont deux à deux premiers entre eux si : ∀(i, j) ∈ [[ 1 ; p ]]2 , i 6= j⇒ ai ∧ aj = 1
Définition 11.2.7.377
Remarque : Il est clair que si les nombres sont deux à deux premiers entre eux ils sont premiers entre eux dansleur ensemble. En effet un diviseur commun aux p entiers est aussi un diviseur commun à deux d’entre eux. Laréciproque est fausse. Par exemples si on prend a = 6, b = 15 et c = 10. Alors a ∧ b = 3, a ∧ c = 2 et b ∧ c = 5par contre a ∧ b ∧ c = 1.
3 Le plus petit commun multiple (PPCM)
3.1 Définition
Soit a et b deux entiers. On appelle plus petit commun multiple (PPCM) de a et de b et on note a ∨ b l’élémentdéfini de la manière suivante :
— Si a = 0 ou b = 0 on pose a ∨ b = 0.
— Si a 6= 0 et b 6= 0, a ∨ b est le plus petit élément strictement positif de aZ ∩ bZ.
Définition 11.3.1.378
Remarque : L’ensemble aZ ∩ bZ est l’ensemble des nombres qui sont des multiples de a et de b. Si ab 6= 0, ilcontient |ab| donc aZ ∩ bZ admet un plus petit élément strictement positif.Remarques :
1. On a aussi a ∨ b = |a| ∨ |b|.2. On a a ∨ b = 0 si a ou b est nul.
Soit a et b deux entiers relatifs et D = a ∨ b. On a
∀n ∈ Z, (a|n et b|n)⇔ D|n.
Proposition 11.3.1.379 (IMPORTANT)
168

Démonstration : Si a = 0 ou b = 0 c’est évident. La partie ⇐ est évidente car a|D et b|D. On finira ladémonstration dans le paragraphe suivant.
Remarque : On en déduit bien que D = a ∨ b est un multiple commun à a et b. De plus c’est le plus petit ausens de la division et de ce fait aussi au sens de l’ordre de Z.
3.2 Lien avec le PGCD et nombres premiers entre eux
Soit a et b deux entiers, si a et b sont premiers entre eux a ∨ b = |ab|.
Proposition 11.3.2.380
Démonstration : On peut se ramener à a et b strictement positif. On voit déjà que ab est un multiple commun dea et de b. De plus, si d est un multiple commun de a et b strictement positif. Il existe k tel que d = ak. Maintenant,b|d donc b|(ak). Par le lemme de Gauss b|k. Donc d = abk′ d’où d > ab. On en déduit que ab est bien le pluspetit multiple commun de a et b qui soit strictement positif.
On a bien a ∨ b = |ab|.
Soit a et b deux entiers,
1. Pour tout entier k, ka ∧ kb = k(a ∧ b) et ka ∨ kb = k(a ∨ b).
2. On a |ab| = (a ∧ b)(a ∨ b).
Corollaire 11.3.2.381
Démonstration :1. En exercice
2. On se ramène comme d’habitude au cas des entiers strictement positifs. Il suffit ensuite d’utiliser a′ et b′
premiers entre eux qui vérifient a = da′ et b = db′ ou d = a ∧ b. On a alors d’après 1.
a ∨ b = (da′) ∨ (db′) = d(a′ ∨ b′) = da′b′.
En multipliant par d = a ∧ b on a(a ∧ b)(a ∨ b) = d2a′b′ = ab.
Remarque : On en déduit une méthode simple pour déterminer le PPCM. On calcule le PGCD et on a
a ∨ b =|ab|a ∧ b
. Par exemple si a = 152 et b = 68. On a a ∧ b = 4 donc a ∨ b = 152× 17 = 2584.On peut maintenant démontrer notre théorème ci-dessus.
Démonstration : Comme d’habitude on se ramène au cas où a et b sont strictement positifs. On veut montrerque
∀n ∈ Z, (a|n et b|n)⇒ D| n où D = a ∧ b.
Comme ci-dessus, on pose d = a ∧ b et a = da′, b = db′. De ce fait D = da′b′. Maintenant, si a|n, on peut écriren = ka = kda′. De plus b|n d’où db′|dka′. Cela implique b′|ka′ et donc b′|k car a′ et b′ sont premiers entre eux.Finalement, en notant k = b′u on obtient n = dub′a′ = uD. On a bien D|n.
Si a et b sont premiers entre eux. Pour tout entier n, a|n et b|n implique ab|n.
Corollaire 11.3.2.382
4 Nombres premiers
Nous travaillons dans N dans ce paragraphe.
169

4.1 Généralités
On appelle nombre premier un entier naturel différent de 1 n’admettant pour diviseurs que 1 et lui même. Onnote P l’ensemble des nombres premiers.
Définition 11.4.1.383
Exemple : Les premiers nombres premiers sont : 2, 3, 5, 7, 11, 13.
Soit p un nombre premier et n un entier. Les entiers p et n sont premiers entre eux ou p divise n. Enparticulier si n ∈ [[ 1 ; p− 1 ]] alors p et n sont premiers entre eux.
Proposition 11.4.1.384
Exemple : Soit k ∈ [[ 1 ; p− 1 ]] alors (pk) est divisible par p. En effet on sait que k(p
k) = p(p−1k−1). Donc p divise
k(pk) mais comme k et p sont premiers entre eux, p divise (p
k).
1. Soit p un nombre premier et a, b deux entiers. On a p|ab⇒ (p|a ou p|b).2. Tout entier naturel strictement supérieur à 1 admet un diviseur premier.
3. Il y a une infinité de nombres premiers.
Proposition 11.4.1.385
Démonstration :1. Évident
2. Par récurrence forte.
3. Supposons par l’absurde qu’il existe un nombre fini de nombre premiers. Notons les (p1, . . . , pn). On
considère m =n
∏k=1
pk + 1. Ce nombre n’est divisible par aucun pi or il admet un diviseur premier. C’est
absurde.
Remarque : Le dernier point est du à Euclide.Exercice : Montrer qu’il existe une infinité de nombres premiers congru à −1 modulo 4. On pourra considérer4 ∏ pk − 1.
4.2 Décomposition en produit de facteurs premiers
Soit n un entier naturel supérieur ou égal à 2.Le nombre n admet une décomposition en produit de nombres premiers
n = q1q2 · · · qr = pα11 × · · · p
αkk
(la deuxième écriture est obtenue en regroupant les différentes occurrences d’un même nombrepremier on a donc que les pi sont deux à deux disjoints).De plus cette décomposition est unique à l’ordre des facteurs près.
Théorème 11.4.2.386 (Décomposition en produit de facteurs premiers)
Remarque : Il arrive que l’on doivent ajouter des nombres premiers qui n’apparaissent pas dans la décomposi-tion. Dans ce cas on les affecte de l’exposant αi = 0.Démonstration : Commençons par l’existence. Cela se fait par récurrence forte sur n. On note Hn l’hypothèse« n peut se décomposer en produit de nombres premiers.
170

— Initialisation : Pour n = 2 c’est vrai.
— Hérédité Soit n un entier au moins égal à 3 on suppose que Hk est vrai pour tout k ∈ [[ 2 ; n− 1 ]] . Onsait que n admet un diviseur premier. Soit p ce diviseur. On a donc n = p.n′ Si n′ = 1, on a fini. Sinon, onutilise Hn′ .
Par récurrence (forte) on a que tout entier supérieur à 2 admet une décomposition en facteurs premiers.Montrons maintenant l’unicité. On suppose se donner deux décompositions
n = pα11 × · · · × pαr
r = pβ11 × · · · × pβr
r .
On peut supposer que les deux décompositions sont sur les mêmes nombres premiers en utilisant la remarqueci-dessus. Supposons par l’absurde que ces deux décompositions diffèrent. Il existe alors i ∈ [[ 1 ; r ]] tel queαi 6= βi. Par symétrie on suppose que αi < βi. On obtient alors, après « simplification » par pαi
i que
∏j 6=i
pαjj = pβi−αi
i ∏i 6=j
pβ jj .
On voit alors que pi divise le terme de droite mais pas celui de gauche par pi est premier avec tous les pj(j 6= i).
On a donc bien unicité de la décomposition.
Exemple : Soit n = 893172. On a n = 22.3.74.31.Remarque : Le problème de calculer la décomposition d’un nombre entier est un sujet de recherche important.Actuellement on ne sait pas trouver une telle décomposition en temps polynomial. Si on y arrivait cela mettraità mal toutes les techniques de chiffrages à clé publique type RSA.
Soit a et b deux entiers. On note
a = pα11 × · · · × pαr
r et b = pβ11 × · · · × pβr
r
les décompositions en facteurs premiers. On a alors
1. Le nombre a divise b si et seulement si ∀i ∈ [[ 1 ; r ]] , αi 6 βi.
2. On a
a ∧ b =r
∏i=1
pMin(αi ,βi)
i et a ∨ b =r
∏i=1
pMax(αi ,βi)
i .
Proposition 11.4.2.387
Soit p un nombre premier. On définit la valuation p-adique d’un nombre entier n comme étant l’exposant quep dans sa décomposition. On la note vp(n).
Définition 11.4.2.388
Remarque : On a donc p|n ⇐⇒ vp(n) > 1.Exemple : On a v2(12) = 2, v3(12) = 1 et v5(12) = 0.
1. Soit a et b deux entiers naturels :
a|b ⇐⇒ ∀p ∈P , vp(a) 6 vp(b).
2. Pour tout nombre premier p,
vp(a ∧ b) = Min(vp(a), vp(b)) et vp(a ∨ b) = Max(vp(a), vp(b)).
Proposition 11.4.2.389
171

Soit p un nombre premier et a un entier non divisible par p. On a
ap−1 ≡ 1[p].
Théorème 11.4.2.390 (Petit théorème de Fermat)
Remarque : On peut le généraliser en enlevant la condition que p ne divise pas a. On obtient alors ap ≡ a[p].Démonstration : Soit a un entier. On a
(a + 1)p = (a + 1)p =p
∑k=0
(pk
)ak1p−k ≡ ap + 1p [p]
Le résultat de congruence vient du fait que si k ∈ [[ 1 ; p− 1 ]],(
pk
)≡ 0 [p]
On en déduit alors par une récurrence immédiate que ap ≡ a [p] pour tout entier a.Maintenant si p ne divise pas a alors a et p sont premiers entre eux et d’après la relation de Bézout il existe
des entiers u et v tels queau + pv = 1
Cela revient à au ≡ 1 [p]. On en déduit que
uap ≡ au [p] ⇐⇒ uaap−1 ≡ 1 [p] ≡ ap−1 ≡ 1 [p]
172

12Limites
1 Limites 1741.1 Limite . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1741.2 Voisinage et propriétés locales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1761.3 Limite à droite et à gauche . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1771.4 Continuité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1781.5 Caractérisation séquentielle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1791.6 Opérations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1801.7 Inégalités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1811.8 Fonctions monotones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 182
2 Relations de comparaisons 1832.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1842.2 Propriétés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 185
2.3 Équivalents classiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1862.4 Opérations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 188
Notation : Dans ce chapitre I désignera toujours un intervalle de R non vide et non réduit à un point.Nous allons dans un premier temps définir la notion de limite en un point (ou en ±∞) puis nous étudierons
ses propriétés.Exemples :
1. Soit f la fonction inverse définie sur R? par f : x 7→ 1x
.
— si on prend pour x des valeurs proches de 2, f (x) sera proche de 0, 5 :
x f (x)2, 1 0, 4762, 01 0, 4961, 99 0, 503
— si x est très grand (ou proche de +∞) alors f (x) va être très petit.
x f (x)1000 0, 001
10000 0, 0001100000 0, 00001
173
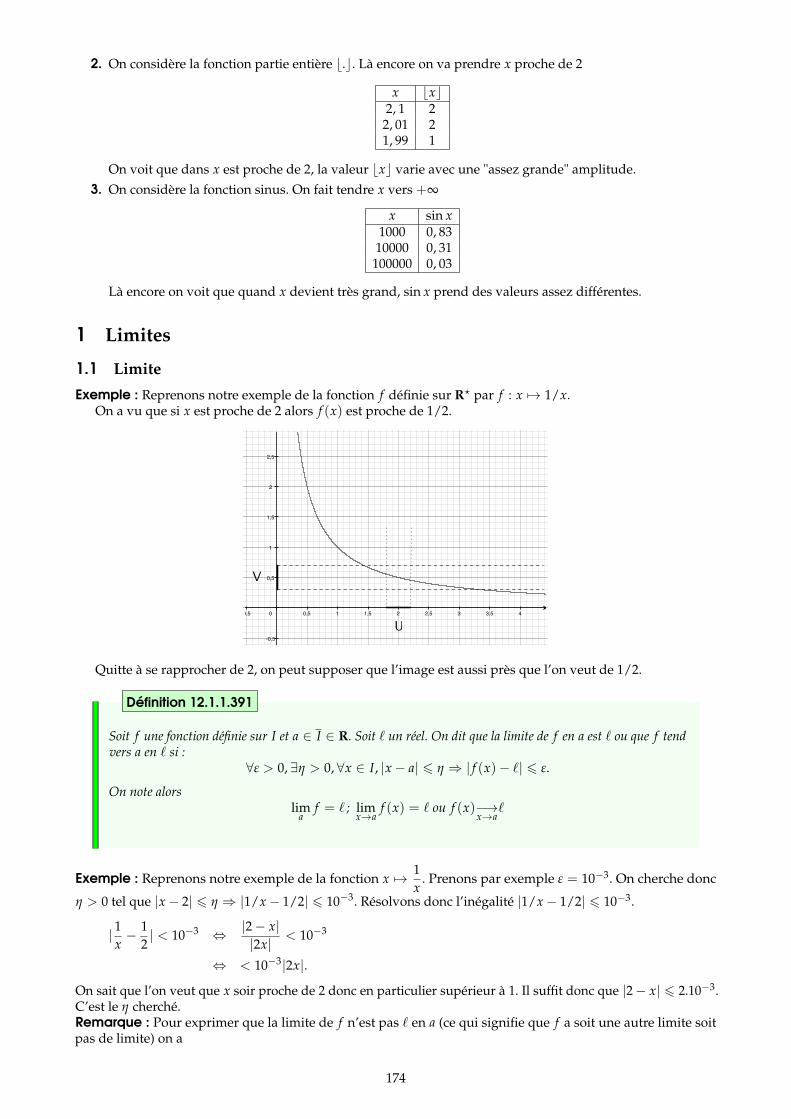
2. On considère la fonction partie entière b.c. Là encore on va prendre x proche de 2
x bxc2, 1 2
2, 01 21, 99 1
On voit que dans x est proche de 2, la valeur bxc varie avec une "assez grande" amplitude.3. On considère la fonction sinus. On fait tendre x vers +∞
x sin x1000 0, 8310000 0, 31
100000 0, 03
Là encore on voit que quand x devient très grand, sin x prend des valeurs assez différentes.
1 Limites
1.1 Limite
Exemple : Reprenons notre exemple de la fonction f définie sur R? par f : x 7→ 1/x.On a vu que si x est proche de 2 alors f (x) est proche de 1/2.
-0,5 0 0,5 1 1,5 2 2,5 3 3,5 4
-0,5
0,5
1
1,5
2
2,5
3
3,5
4
4,5
U
V
Quitte à se rapprocher de 2, on peut supposer que l’image est aussi près que l’on veut de 1/2.
Soit f une fonction définie sur I et a ∈ I ∈ R. Soit ` un réel. On dit que la limite de f en a est ` ou que f tendvers a en ` si :
∀ε > 0, ∃η > 0, ∀x ∈ I, |x− a| 6 η ⇒ | f (x)− `| 6 ε.
On note alorslim
af = ` ; lim
x→af (x) = ` ou f (x)−→
x→a`
Définition 12.1.1.391
Exemple : Reprenons notre exemple de la fonction x 7→ 1x
. Prenons par exemple ε = 10−3. On cherche donc
η > 0 tel que |x− 2| 6 η ⇒ |1/x− 1/2| 6 10−3. Résolvons donc l’inégalité |1/x− 1/2| 6 10−3.
| 1x− 1
2| < 10−3 ⇔ |2− x|
|2x| < 10−3
⇔ < 10−3|2x|.On sait que l’on veut que x soir proche de 2 donc en particulier supérieur à 1. Il suffit donc que |2− x| 6 2.10−3.C’est le η cherché.Remarque : Pour exprimer que la limite de f n’est pas ` en a (ce qui signifie que f a soit une autre limite soitpas de limite) on a
174

∃ε > 0, ∀η > 0, ∃x ∈ I, |x− a| < η et | f (x)− `| > ε.
On peut généraliser cette définition au cas où a est un réel ou +∞ ou −∞ et où ` est un réel ou +∞ ou −∞,cela donne toutes les définitions suivantes :
Soit f une fonction définie sur I et a ∈ I. Soit ` ∈ R. On dit que la limite de f en a est ` ou que f tend vers aen ` si :
Si a ∈ R et ` ∈ R : ∀ε > 0, ∃η > 0, ∀x ∈ I, |x− a| 6 η ⇒ | f (x)− `| 6 εSi a ∈ R et ` = +∞ : ∀M ∈ R, ∃η > 0, ∀x ∈ I, |x− a| 6 η ⇒ f (x) > MSi a ∈ R et ` = −∞ : ∀M ∈ R, ∃η > 0, ∀x ∈ I, |x− a| 6 η ⇒ f (x) 6 MSi a = +∞ et ` ∈ R : ∀ε > 0, ∃A ∈ R, ∀x ∈ I, x > A⇒ | f (x)− `| 6 εSi a = +∞ et ` = +∞ : ∀M ∈ R, ∃A ∈ R, ∀x ∈ I, x > A⇒ f (x) > MSi a = +∞ et ` = −∞ : ∀M ∈ R, ∃A ∈ R, ∀x ∈ I, x > A⇒ f (x) 6 MSi a = −∞ et ` ∈ R : ∀ε > 0, ∃A ∈ R, ∀x ∈ I, x 6 A⇒ | f (x)− `| 6 εSi a = −∞ et ` = +∞ : ∀M ∈ R, ∃A ∈ R, ∀x ∈ I, x 6 A⇒ f (x) > MSi a = −∞ et ` = −∞ : ∀M ∈ R, ∃A ∈ R, ∀x ∈ I, x 6 A⇒ f (x) 6 M
On note alorslim
af = ` ; lim
x→af (x) = ` ou f (x)−→
x→a`
Définition 12.1.1.392
Exemple : Montrons par exemple que la fonction x 7→ x2 + 1 tend vers +∞ en −∞. Pour n’importe quelnombre M, on cherche A tel que x 6 A⇒ x2 + 1 > M. Or
x2 + 1 > M⇔ x2 > M− 1.
Donc si M 6 1 ceci est toujours vrai, on peut prendre A = −23. Si M > 1, on prend A = −√
M− 1.
Avec les notations précédentes, si la limite de f en a existe alors elle est unique.
Proposition 12.1.1.393
Démonstration : Montrons par exemple qu’une fonction f ne peut pas tendre en a ∈ R vers ` ∈ R et +∞. Eneffet cela signifierait que pour ε = 1 on puisse trouver η tel que pour tout x dans ]a− η, a+ η[, f (x) ∈]`− 1, `+ 1[.De même, on peut trouver pour M = `+ 2 > `+ 1, η′ tel que pour tout x dans ]a− η′, a + η′[, f (x) ∈> `+ 2.
Soit f une fonction définie sur I et a ∈ I (en particulier f est définie en a). Si f admet une limite ` ena alors ` = f (a).
Proposition 12.1.1.394
Démonstration : Supposons par l’absurde que ` 6= f (a). Soit ε tel que f (a) /∈ [` − ε, ` + ε]. On sait qu’ilexiste alors η tel que pour tout x de I si x appartient à [a − η, a + η] alors f (x) ∈ [` − ε, ` + ε]. Cependant,a ∈ [a− η, a + η] et f (a) /∈ [`− ε, `+ ε]. C’est absurde.
On procède de même pour montrer que ` 6= ±∞.
On essaye souvent de se ramener au cas de 0 (aussi bien pour ` si elle est réelle que pour a).
175

Soit f une fonction définie sur I.
1. Soit a dans I et ` ∈ R. On a
(lima
f = `)⇐⇒ (lima( f − `) = 0).
2. Soit a un réel dans I et ` ∈ R. On a
limx→a
f (x) = `⇐⇒ limh→0
f (a + h) = `.
Proposition 12.1.1.395
1.2 Voisinage et propriétés locales
Si on reprend la définition de lima f = ` quand a ∈ R et ` ∈ R, on peut voir apparaitre des "blocs". On a
∀ ε > 0 , ∃ η > 0 , ∀x ∈ I, |x− a| 6 η ⇒ | f (x)− `| 6 ε .
On voit que toutes les autres se construisent à partir de celle là en changeant ces blocs. On peut préciser celagrâce à la notion de voisinage.
1. Soit a ∈ R on appelle voisinage de a tout intervalle de la forme [a− ε, a + ε] où ε > 0.
2. On appelle voisinage de +∞ (resp. −∞) tout intervalle de la forme [M,+∞[ (resp. ]−∞, M]).
Définition 12.1.2.396
De cette manière on peut redéfinir lima f = ` pour a et ` dans R par
« Pour tout voisinage V` de `, il existe un voisinage Va de a tel que, pour x dans I, alors si x est dans Va alorsf (x) est dans V`. »
Soit f une fonction définie sur I et a un élément de I. Soit P une propriété. On dit que P est vraie auvoisinage de a s’il existe un voisinage V de a tel que P est vraie pour tout élément x de V ∩ I.
Définition 12.1.2.397
Remarque : Dans la définition de voisinage on a choisit de prendre des intervalles fermés mais on peut toutautant prendre des intervalles ouverts. Il suffit de remarque par exemple que, au voisinage de a :
[a− ε/2, a + ε/2] ⊂]a− ε, a + ε[⊂ [a− ε, a + ε].
De même en +∞]M,+∞[⊂ [M,+∞[⊂]M− 1,+∞[.
Exemples :
1. Soit P la propriété « f est strictement positive ». Dire que f est strictement positive au voisinage de a ∈ Rsignifie que
∃ε > 0, ∀x ∈ I ∩ [a− ε, a + ε], f (x) > 0
Par exemple x 7→ cos(x) est strictement positive au voisinage de 0.
2. Soit f et g deux fonctions. On dira que f 6 g au voisinage de a s’il existe Va un voisinage de a tel que
∀x ∈ Va, f (x) 6 g(x).
3. Soit P la propriété « f est bornée ». La fonction x 7→ ex est bornée au voisinage de tout a dans R. Elle estbornée au voisinage de −∞ mais pas au voisinage de +∞.
176

Exercice : soit P1 et P2 deux propositions. Montrer que si P1 et P2 sont vraies aux voisinage de a alors (P1 et P2)l’est. Peut-on généraliser à une infinité de propositions?Remarque : Dans le cas des suites, le a où l’on évalue la limite est toujours +∞. Dans ce cas dire « au voisinagede +∞ » revient à dire « à partir d’un certain rang ».
Soit f une fonction définie sur I et a ∈ I.
1. Si f admet une limite finie ` en a alors elle est bornée au voisinage de a.
2. Si f admet une limite ` > 0 en a alors f est strictement positive au voisinage de a.
3. Si f admet une limite ` > 0 en a alors il existe A > 0 tel que f soit supérieure à A au voisinagede a.
Proposition 12.1.2.398
Remarque : Noter que la deuxième partie n’est pas vraie si on remplace > 0 par > 0.
Démonstration
1.3 Limite à droite et à gauche
Exemple : On s’intéresse toujours à f : x 7→ 1/x définie sur R?. On cherche à déterminer la limite en 0. On serend compte que quand x tend vers 0, f (x) peut prendre des valeurs très grandes ou très petites (grandes ennégatives). De ce fait, il n’y a pas de limite - on verra plus loin une méthode pour écrire proprement ce fait.Cependant on se rend compte que si on reste pour des x positifs (« à droite de 0 ») alors f (x) semble tendre vers+∞.
Soit f une fonction définie sur un intervalle I, a un réel de I et ` ∈ R. On dit que f admet ` pour limite àdroite (resp. à gauche) en a si f I∩]a,+∞[ (resp. f I∩]−∞,a[) admet ` comme limite en a.On note alors lim
x→a+f (x) = ` (resp. lim
x→a−f (x) = `).
Définition 12.1.3.399
Remarque : Par exemple si ` ∈ R cela peut s’écrire :
∀ε > 0, ∃η > 0, ∀x ∈ I, 0 < x− a 6 η ⇒ | f (x)− `| 6 ε (resp.∀ε > 0, ∃η > 0, ∀x ∈ I,−η 6 x− a < 0⇒ | f (x)− `| 6 ε).
B Dans le cas des limites à gauche et à droite en a on exclut a même si f est définie en a. De ce fait, unefonction peut avoir une limite à droite (ou à gauche) en a qui soit différente de f (a). Par exemple, la fonctionf : x 7→ E(x) admet 0 pour limite à gauche en 1 alors que f (1) = 1.
Soit f une fonction définie sur I et a un réel de I qui n’est pas une borne. La fonction f admet unelimite en a si et seulement si f admet des limites à droite et à gauche en a qui sont identiques et quisont égales à f (a). C’est-à-dire :
lima
f = lima+
f = lima−
f = f (a).
Proposition 12.1.3.400
Remarque : cela peut s’utiliser pour montrer qu’une fonction n’est pas continue en un point. Par exemple, onconsidère f la fonction partie entière de R dans R. Soit a un réel.
— si a n’est pas un entier. Il existe ε > 0 tel que V =]a − ε, a + ε[⊂]n, n + 1[ ne contient pas d’entier. Larestriction de f à V est la fonction constante égale à n. On en déduit que
lima
f = lima+
f = lima−
f = n = E(a).
177

— si a est un entier. En raisonnant comme ci-dessus, on voit que
lima−
f = a− 1 et lima+
f = a.
La fonction f n’a pas de limite en a car les limites à droite et à gauche ne sont pas égales.Remarque : On peut étendre les définitions des limites au cas des fonctions définies sur I \ a où a est unélément de I qui n’est pas une borne.B Il faut bien différencier deux cas distincts
— Si f est définie sur I et si a est un élément de I (en particulier f définie en a). On a
lima
f = ` ⇐⇒ lima+
f = lima−
f = f (a)
— Si f est définie sur I \ a où a est un élément de I (en particulier f n’est pas définie en a). On a
lima
f = ` ⇐⇒ lima+
f = lima−
f
Remarque : il se peut aussi qu’il n’ait pas de limite à droite et gauche. Nous verrons des exemples plus loin.
1.4 Continuité
Soit f une fonction définie sur un intervalle I et a un élément de I. Si la limite de f en a existe, on dit que fest continue en a. Dans ce cas
limx→a
f (x) = f (a).
Définition 12.1.4.401
Remarques :1. Pour qu’une fonction soit continue en a, il faut déjà qu’elle y soit définie.2. La définition classique est lim
x→af (x) = f (a). De fait, f est définie en a et admet une limite en a alors la
limite est automatiquement égale à f (a).
Exemple : La fonction x 7→
1 si x 6= 00 sinon n’est pas continue en 0.
Soit f une fonction définie sur I et a ∈ I.
1. On dit que f est continue à droite en a si la restriction de f à I ∩ [a,+∞[ est continue en a c’est-à-dire :lima+
f = f (a).
2. On dit que f est continue à gauche en a si la restriction de f à I∩]−∞, a] est continue en a c’est-à-dire :lima−
f = f (a).
Définition 12.1.4.402
Exemple : Toujours la fonction partie entière. Elle est continue à droite en tout point. Par contre elle n’est pascontinue à gauche aux entiers.
Soit f une fonction définie sur I et a une bornée réelle de I qui n’est pas dans I (en particulier f (a) n’est pasdéfini). Si f admet une limite finie quand x tend vers a. On dit que f est prolongeable par continuité et onappelle prolongement par continuité la fonction
f : I ∪ a → R
x 7→
f (x) si x ∈ Ilim
af si x = a
.
Définition 12.1.4.403
178

Exemple : Regardons la fonction f définie sur R?+ par f (x) =
sin xx
. Elle peut se prolonger par continuité en 0
en posant f (0) = limx→0
sin xx
= 1.
Remarque : Par extension, on peut aussi prolonger par continuité une fonction f définie sur I \ a où a est unélément de I qui n’est pas une borne. Dans ce cas, on peut la prolonger si lima f existe ce qui revient à lima− f et
lima+ f existent et sont égales. Par exemple pour x 7→ sin xx
définie sur R?.
1.5 Caractérisation séquentielle
Nous allons relier les limites de fonctions et les limites de suites.
Soit f une fonction définie sur un intervalle I. Soit a ∈ I et ` ∈ R.La limite de f en a est ` si et seulement si pour toute suite (un) à valeur dans I de limite a, la suitef (un) tend vers `.
Théorème 12.1.5.404
Remarques :
1. La partie ⇐ est utile pour moi. Cela permet de déduire des théorèmes sur les limites des fonctions en sebasant sur les résultats similaires sur les limites des suites.
2. La partie ⇒ est utile pour vous.
— Si lim un = a et limx→a
f (x) = ` alors lim f (un) = `. Par exemple limn→∞
[n2 + 1
2n2 + n
]= 0.
— C’est aussi le résultat que l’on utilise pour montrer que la limite d’une suite un+1 = f (un) avec f unefonction continue est un point fixe de f .
— On peut démontrer qu’une fonction n’a pas de limite. En effet si on trouve deux suites (un) et (vn)convergeant vers a telles que f (un) et f (vn) ne convergent pas ou pas vers la même limite alors f n’apas de limite. Montrons pas exemple de la fonction f définie sur R? par f (x) = sin(1/x) n’a pas de
limite en 0. On considère les suites un =1
2nπet vn =
12nπ + π/2
. On a lim(un) = lim(vn) = 0 mais
lim( f (un)) = 0 et lim( f (vn)) = 1. En particulier elle n’a pas de limite en 0 (pas plus en 0+).
-1,25 -1 -0,75 -0,5 -0,25 0 0,25 0,5 0,75 1 1,25
-1
-0,5
0,5
1
Exercice : Montrer que la fonction x 7→ cos(x) n’a pas de limite en +∞.Démonstration :
— ⇒ On suppose que lima
f = `. Soit u une suite tendant vers a on veut montrer que ( f (un)) tend vers
`. Faisons le avec des voisinage pour traiter tous les cas à la fois. On veut donc montrer que pour toutvoisinage V de ` il existe N tel que si n > N alors f (un) appartient à V . On se fixe donc un voisinage Vquelconque. Maintenant on sait que lim
af = `. De ce fait il existe un voisinage U de a tel que si x ∈ I ∩U
alors f (x) ∈ V . Pour finir, il suffit de voir que, comme lim u = a. Pour ce voisinage U il existe N tel quesi n > N alors un ∈ U . Si on récapitule on a donc que dès que n est supérieur à N, un appartient à U etdonc f (un) appartient à V .
— ⇐ On procède par l’absurde. On suppose que la limite de f en a n’est pas ` (ce qui signifie que cettelimite n’existe pas ou qu’elle existe mais qu’elle ne vaut pas `). On va alors prouver qu’il existe une suite utendant vers a telle que ( f (un)) ne tende pas vers `. Pour simplifier on fait le cas où ` ∈ R et a ∈ R.
179

Le fait que la limite de f en a n’est pas ` s’écrit :
∃ε > 0, ∀η > 0, ∃x ∈ I, |x− a| 6 η et | f (x)− `| > ε.
Soit un ε fixé par le résultat ci dessus, pour tout entier n, on pose η = 1/n et ce qui précède nous dit qu’ilexiste xn ∈ I tel que
|xn − a| 6 η =1n
et | f (xn)− `| > ε.
Cela signifie bien que (xn) tend vers a et que f (xn) ne tend pas vers `.
Soit f une fonction définie sur I et a ∈ I. La fonction f est continue en a si et seulement si pour toutesuite (un) tendant vers a, ( f (un)) tend vers f (a).
Corollaire 12.1.5.405
1.6 Opérations
Soit I un intervalle et a ∈ I. Soit f et g deux fonctions définies sur I. Soit (`, `′) ∈ R2. On suppose quelimx→a
f (x) = ` et limx→a
g(x) = `′. On a les même formules que pour les suites.
• SommeLa limite de la fonction f + g en a est donnée par :
PPPPPPPPlim glim f
` −∞ +∞
`′ `+ `′ −∞ +∞−∞ −∞ −∞ ?+∞ +∞ ? +∞
Démonstration : Montrons, en utilisant la caractérisation séquentielle, par exemple que si limx→a
f (x) = ` ∈ R
et limx→a
g(x) = `′ ∈ R alors limx→a
( f + g)(x) = ` + `′. En effet, pour tout suite (un) tendant vers a en +∞, la
suite f (un) tend vers ` et la suite g(un) tend vers `′. En utilisant le théorème sur les limites de suites, onobtient que lim
n→+∞( f + g)(un) = ` + `′. Ceci étant vrai pour toute suite tendant vers a, on en déduit que
limx→a
( f + g)(x) = `+ `′.
Exercice : Faire la démonstration de manière « directe » en utilisant la quantification.Remarque : Si on fixe un intervalle I et un élément a dans I. L’ensemble (RI ,+,×) des fonctions de I dans Rest un anneau et donc (RI ,+) est un groupe abélien. Le résultat précédent permet de dire que l’ensemble desfonctions tendant vers 0 forment un sous-groupe de (RI ,+).•Multiplication externe
Soit λ un réel. La limite de la fonction λ. f est donnée par :
PPPPPPPPλlim f
` −∞ +∞
λ > 0 λ.` −∞ +∞λ = 0 0 0 0λ < 0 λ.` +∞ −∞
Notons que si λ = 0 et que f tend vers ±∞ ce n’est pas une forme indéterminée. En effet la fonction λ. f est lafonction nulle.• Produit
La limite de la fonction f .g est donnée par le tableau suivant :
PPPPPPPPlim glim f
` < 0 ` = 0 ` > 0 −∞ +∞
`′ < 0 `.`′ 0 `.`′ +∞ −∞`′ = 0 0 0 0 ? ?`′ > 0 `.`′ 0 `.`′ −∞ +∞−∞ +∞ ? −∞ +∞ −∞+∞ −∞ ? +∞ −∞ +∞
180

Noter en particulier que la forme (+∞)× (−∞) n’est pas une forme indéterminée.• Quotient
La limite de la fonction f /g est donnée par le tableau suivant :
PPPPPPPPlim glim f
` < 0 ` = 0 ` > 0 −∞ +∞
`′ < 0 `/`′ 0 `/`′ +∞ −∞`′ = 0− +∞ ? +∞ +∞ -∞`′ = 0+ −∞ ? +∞ −∞ +∞`′ > 0 `/`′ 0 `/`′ −∞ +∞−∞ 0 0 0 ? ?+∞ 0 0 0 ? ?
• CompositionOn a aussi un théorème sur la limite d’une composée de fonctions.
Soit f une fonction définie sur un intervalle I et g une fonction définie sur un intervalle J contenantf (I).
1. Soit a ∈ I, b ∈ R. Si limx→a
f (x) = b alors b ∈ J.
2. Si de plus il existe ` ∈ R tel que limx→b
f (x) = ` alors lima(g f )(x) = `.
Théorème 12.1.6.406
Démonstration : Cela découle de la caractérisation séquentielle.Exemples :
1. On veut étudier la limite de x 7→ e1/x2en +∞. On a lim
x→+∞
1x2 = 0 et lim
x→0ex = 1 donc lim
x→+∞e1/x2
= 1.
2. On veut étudier la limite en 0 de x 7→ 42 + 1
1−ex
.
1.7 Inégalités
Là encore, on a des théorèmes similaires à ceux sur les limites des suites et les inégalités.
Soit I un intervalle et f , g deux fonctions définies sur I. Soit a ∈ I, on suppose que :
— la fonction f est supérieure à la fonction g au voisinage de a
— Il existe ` et `′ des éléments de R tels que limx→a
f (x) = ` et limx→a
g(x) = `′.
Dans ce cas ` > `′.
Théorème 12.1.7.407
Remarques :
1. Pour ce théorème, les inégalités dans R sont définis en supposant que pour tout x dans R, −∞ 6 x 6 +∞.
2. Comme d’habitude, même si on a de plus, que pour tout x de I, f (x) > g(x), on ne peut pas conclure à` > `′. Il suffit de considérer par exemple les fonctions x 7→ |x| et x 7→ 0 en 0.
Exercice : (En classe) Faire la démonstration pour a, ` et `′ réels. On procédera par l’absurde.Il y a aussi un analogue des théorèmes des gendarmes.
181

Soit I un intervalle, f , g et h trois fonctions définies sur I et a ∈ I
1. S’il existe ` ∈ R tel que limx→a
f (x) = limx→a
g(x) = ` et si, pour tout x dans I, f (x) 6 h(x) 6 g(x)alors h tend vers ` en a.
2. Si limx→a
f (x) = +∞ et si, pour tout x dans I, f (x) 6 h(x) alors h tend vers +∞ en a.
3. Si limx→a
f (x) = −∞ et si, pour tout x dans I, f (x) > h(x) alors h tend vers −∞ en a.
Théorème 12.1.7.408 (Théorèmes d’encadrements)
Remarque : Là encore il suffit que les majorations ne soient vraies que sur un voisinage de a.
Soit I un intervalle, f et g deux fonctions définies sur I et a ∈ I.
1. Si lima
g = 0 et que | f | 6 g au voisinage de a alors lima
f = 0.
2. Si lima
g = 0 et que f est bornée au voisinage de a alors lima
f g = 0.
Corollaire 12.1.7.409
Démonstration
Exemple : La fonction x 7→ x sin(1/x) est prolongeable par continuité en 0.
-0.3 -0.2 -0.1 0.1 0.2 0.3
-0.20
-0.15
-0.10
-0.05
0.05
0.10
1.8 Fonctions monotones
Nous allons établir des résultats analogues aux théorèmes de convergence monotone des suites. Cependant,dans le cas des fonctions ils sont moins utiles.
Soit I un intervalle ouvert c’est-à-dire de la forme I =]a, b[ où (a, b) ∈ R2. Soit f une fonctioncroissante sur I.
1. Si f est majorée alors f admet une limite en b qui est supx∈I
f (x).
2. Si f n’est pas majorée alors limb
f = +∞.
3. Si f est minorée alors f admet une limite en a qui est infx∈I
f (x).
4. Si f n’est pas minorée alors lima
f = −∞.
Proposition 12.1.8.410
Démonstration
Remarques :
182
1. Si l’intervalle n’est pas ouvert, ce résultat n’est plus vrai. On peut prendre par exemple la fonction partieentière sur [0, 1]. Elle n’a pas de limite en 1. Mais elle a une limite à gauche en 1.
2. On a des résultats analogues pour f décroissante, il suffit de remplacer f par − f .
3. Il faut bien voir que l’hypothèse croissante est essentielle comme le prouver par exemple sin(1/x) sur]0, 1[.
Soit f une fonction monotone définie sur un intervalle I. Elle admet des limites à droite et à gaucheen tout point a de I qui n’est pas une extrémité de I.
Corollaire 12.1.8.411
Remarques :
1. Si les extrémités sont dans I, il n’y a qu’une limite à droite ou à gauche.
2. De part la démonstration, si f est croissante, soit a un élément de I qui n’est pas une extrémité,
lima−
f 6 f (a) 6 lima+
f .
2 Relations de comparaisons
Si on regarde les courbes des fonctions x 7→ x et x 7→ sin x on voit que ce sont deux fonctions très différentes.Cependant, au voisinage de 0 elles sont similaires.
-2 -1 1 2
-2
-1
1
2
Le but de ce chapitre est de donner des définitions précises de « les fonctions x 7→ sin x et x 7→ x sontéquivalentes en 0 » ou « la fonction x2 est négligeable devant x 7→ ex en +∞ ».
On va avoir besoin d’une hypothèse technique qui va nous permettre de simplifier nos définitions.Notation : Soit a ∈ R on va dire que f vérifieFa si elle est définie au voisinage de a et qu’elle ne s’annule passur un voisinage de a sauf peut-être en a. cela s’écrit
— ∃ε > 0, ∀x ∈]a− ε, a[∩]a, a + ε[, f (x) 6= 0 si a ∈ R
— ∃M ∈ R, ∀x > M, f (x) 6= 0 si a = +∞.
— ∃M ∈ R, ∀x 6 M, f (x) 6= 0 si a = −∞.
183

2.1 Définitions
Soit a ∈ R et f , g deux fonctions vérifiantFa. Les fonctions f et g sont équivalentes au voisinage de a et onnote f ∼
ag si
limx→a
f (x)g(x)
= 1.
Définition 12.2.1.412
De part la définition deFa on ne peut pas considérer la fonction nulle. Nous n’aurons jamais f ∼a
0.
ATTENTION
Exemples :1. On le reverra plus bas. Si on considère le polynôme P(x) = −3x4 − 3x2 + x− 1. On a
−3x4 − 3x2 + x− 1 ∼∞−3x4.
Attention par contre que P(x) n’est pas équivalent à x4. De plus, cet équivalent n’est plus vrai du tout auvoisinage de 0 ou de a = 3 par exemple.
2. On a limx→0
sin xx
= 1 donc sin x ∼0
x. En pratique, on pourra donc remplacer dans les calculs de limite en 0,
les sin x par x. Si on veut déterminer limx→0
sin3 xx2 qui est une forme indéterminée, on écrira que sin3 x ∼
0x3
d’oùsin3 x
x2 ∼0
x3
x2 = x. Donc
limx→0
sin3 xx2 = 0.
Remarques :1. On pourra omettre le a dans la notation f ∼
ag s’il est évident.
2. Faire attention que cette notion est locale. Par exemple sin x est équivalente à x au voisinage de a = 0ncependant, ce n’est plus du tout vrai si on se place au voisinage de a = 7 par exemple...
3. On peut définir la notion d’équivalence en a pour des fonctions qui ne vérifient parFa. On dit que f estéquivalente à g s’il existe un voisinage V de a, une fonction ε définie sur V telle que
— pour tout x dans V , f (x) = g(x)ε(x).— lim
aε = 1.
On voit que f ∼a
0 signifie qu’il existe un voisinage V de a telle que f soit la fonction nulle sur V .
4. Le but de cette notion est de remplacer des fonctions f à priori compliquée par des fonctions g plussimples qui sont équivalentes au voisinage de l’endroit qui nous intéresse. Dans la plupart des cas lafonction g sera de la forme (x− a)n pour a ∈ R et xα pour a = ±∞.
5. Il n’est réellement intéressant de faire des équivalents que pour lever des formes indéterminées. De ce faitcela ne concerne que des fonctions qui tendent vers 0 ou vers ±∞. C’est pour cela que l’équivalent en 1 desin n’est pas très intéressant car c’est juste sa valeur.
Soit a ∈ R et f , g deux fonctions vérifiantFa.
1. On dit que f est négligeable devant g en a (ou au voisinage de a) et on notera f = oa(g) si lim
x→a
f (x)g(x)
= 0.
2. On dit que f est dominée devant g en a (ou au voisinage de a) et on notera f = Oa(g) si f /g est bornée
au voisinage de a.
Définition 12.2.1.413
184

Remarques :
1. On pourra omettre le a dans les notations f = o (g) et f = O (g)s’il est évident.
2. Faire attention que ces notions sont locales.
3. On peut aussi définir ces notions en a pour des fonctions qui ne vérifient parFa de la même manière queci-dessus.
Exemples :
1. On a x = o+∞
(x2). En effet, lim
x→+∞
xx2 = 0.
2. On a aussi x = o0(1).
3. On a 2x2 = O+∞
(x2) .
Soit f une fonction définie au voisinage de a. On suppose que f est dérivable en a et que f ′(a) 6= 0.On a
f (x) ∼a
f ′(a)(x− a).
Proposition 12.2.1.414
Démonstration : Par définition.
Remarque : Cette proposition illustre le fait que la recherche d’équivalent peut-être visualisée comme larecherche d’une tangente à une courbe (dans le cas où la fonction est dérivable).
2.2 Propriétés
Le lien entre les fonctions équivalentes et les fonctions négligeables sont donnés par la proposition suivante.
Soit a ∈ R et f et g deux fonctions vérifiantFa.
f = g + oa(g)⇔ f ∼
ag.
Proposition 12.2.2.415
Démonstration : On raisonne par équivalence :
f = g + oa(g) ⇔ f − g = o
a(g)
⇔ lima
f − gg
= 0.
Or, pour tout x, on af − g
g(x) =
fg(x)− 1 donc
lima
f − gg
= 0 ⇔ lima
fg= 1
⇔ f ∼a
g.
Soit a ∈ R et f , g et h trois fonctions qui vérifientFa.
f = oa(g) et g = o
a(h)⇒ f = o
a(h) (Transitivité).
Proposition 12.2.2.416
185

Soit a ∈ R et f , g et h trois fonctions qui vérifientFa.
1. on a f ∼a
f (Réfléxivité).
2. si f ∼a
g alors g ∼a
f . (Symétrique)
3. si f ∼a
g et g ∼a
h alors f ∼a
h. (Transitivité)
Proposition 12.2.2.417
Remarque : La relation d’équivalence est une relation d’équivalence ! ! ! !
Soit a ∈ R et f , g deux fonctions qui vérifientFa. Soit ` ∈ R. Si f ∼a
g alors
(lim
af = `
)⇔(
lima
g = `)
.
Proposition 12.2.2.418
Remarque : Bien comprendre le sens de ce qui précède. Cela signifie que si f a une limite alors g aussi et quece sont les mêmes limites. En particulier cela signifie que pour déterminer l’existence et faire le calcul d’unelimite on peut remplacer une fonction par une fonction qui lui est équivalente.
A l’inverse, il est faut en général de penser que deux fonctions f et g qui ont la même limite ` en asont équivalentes. Si ` est fini et non nul c’est vrai mais pas pour ` = 0 ou ` = ±∞. Par exemple x etx2 en 0.
ATTENTION
On peut donc voir la relation d’équivalence en a comme « plus fine »que la relation avoir la même limite en a.
Soit f et g deux fonctions vérifiantFa. Si f ∼a
g alors f et g ont le même signe au voisinage de a.
Proposition 12.2.2.419
Démonstration : Il suffit de voir que comme f /g tend vers 1 en a, elle est strictement positive au voisinage dea.
2.3 Équivalents classiques
Au voisinage de +∞ on les mêmes croissances comparées que pour les suites. Précisément :
1. Soit α ∈ R et β > 0, (ln(x))α = o+∞
(xβ)
.
2. Soit α et β deux réels. Si α < β alors xα = o+∞
(xβ)
.
3. Soit α ∈ R et β > 0, xα = o+∞
(exp(βx)). En particulier si k > 1, xα = o+∞
(kx) .
Proposition 12.2.3.420 (Croissances comparées en +∞)
Démonstration :
186

— Le point 1 se ramène au 3 par un changement de variable t = ln x.
— Le point 2 est évident.
— On étudie la fonction f : x 7→ eβx
xα. Elle est dérivable de dérivée :
f ′ : x 7→ eβxxα−1
x2α(βx− α) .
On en déduit donc que pour x > α/β la fonction f est croissante. L’étude de sa limite se ramène alors àl’étude de f (n) qui a déjà été faite.
1. Soit α ∈ R et β > 0, (ln(x))α = o0+
((1x
)β)
.
2. Soit α et β deux réels. Si α < β alors xβ = o0(xα) .
Proposition 12.2.3.421 (Croissances comparées en 0)
Ce ne sont pas les mêmes qu’en +∞.
ATTENTION
Remarques :
1. Pour le premier, il faut faire attention que l’on compare ln(x) qui tend vers ∞ avec(
1x
)β
qui tend aussi
vers ∞ pour β > 0.
2. Pour le deuxième c’est le sens inverse de la comparaison en +∞.
Un polynôme non nul est quivalent à son terme de plus haut degré en ±∞ et à son terme de plusbas degré en 0.
Proposition 12.2.3.422 (Equivalent d’un polynôme)
Voici les équivalents à connaître :
Voici les équivalents des fonctions usuelles en 0
? sin x ∼0
x ? cos x ∼0
1 et cos x− 1 ∼0− x2
2? tan x ∼
0x ? (1 + x)α ∼
01 et (1 + x)α − 1 ∼
0αx
? ln(1 + x) ∼0
x ? ex ∼0
1 et ex − 1 ∼0
x
? sh x ∼0
x ? th x ∼0
x
? ch x ∼0
1 et ch x− 1 ∼0
x2
2? arcsin x ∼
0x et arctan x ∼
0x
Théorème 12.2.3.423
Démonstration : Il se démontre tous en calculant des dérivées. La seule qui est différente est celle du cosinus etdu cosinus hyperbolique. Nous les démontrerons plus loin.
Remarque : Il y a des cas particuliers à connaitre.
187

— La formule (1 + x)α − 1 ∼0
αx permet d’obtenir :
11 + x
− 1 ∼0−x
√1 + x− 1 ∼
0
12
x.
— La formule ln(1 + x) ∼0
x peut aussi s’écrire ln X ∼1
X− 1.
2.4 Opérations
Soit a ∈ R et f , g et h trois fonctions qui vérifientFa. Si f = oa(g) alors f h = o
a(hg).
Proposition 12.2.4.424
Exemple : Si f (x) = o0
(x2) alors x3 f (x) = o
0
(x5) .
Soit a ∈ R et f1, f2, g1 et g2 quatre fonctions qui vérifientFa. On suppose que f1 ∼a f2 et que g1 ∼a g2.Alors
1. f1g1 ∼a f2g2 etf1
g1∼a
f2
g2.
2. Pour α ∈ R? FIXÉ, f α1 ∼a f α
2 .
Proposition 12.2.4.425
Remarque : Dans la deuxième partie, si α /∈ N, on doit supposer que f1 et f2 sont strictement positives auvoisinage de a sauf éventuellement en a.
Exemple : Cette proposition justifie le calcul desin3 x
x2 ∼0
x fait plus haut.
Il y a des opérations qui ne sont pas compatibles avec les équivalents.
1. La somme ou différence : par exemple, x + x2 ∼0
x et x + x3 ∼0
x mais x2 − x3 0.
C’est une erreur très très classique. Elle conduit souvent à une équivalence à 0 ce qui n’est JAMAIS possible .
2. La composition : par exemple x + x2 ∼+∞
x2 mais ex+x2 ex2. Autre exemple 1 + x ∼
01 mais
(1 + x)1/x 11/x = 1. Comparer ceci avec la propriété 2. de la proposition ci-dessus.
ATTENTION
Étudions quelques calculs de calculs de somme d’équivalents Exemples :
1. Soit f : x 7→ sin x + sh x. On ne peut pas faire la somme, on va essayer de se ramener à des limites endisant que
sin x + sh x = x(
sin xx
+sh x
x
).
Maintenant comme sin x ∼0
x et sh x ∼0
x la parenthèse tend vers 2 et donc f ∼0
2x. Dans ce cas, la somme
« marchait ».
2. Soit g : x 7→ sin x− sh x. Cette fois on ne peut plus procéder comme ci-dessus car
sin x− sh x = x(
sin xx− sh x
x
).
Là, la parenthèse tend vers 0. On en tire g = o0(x) . On verra plus tard dans l’année que faire dans ce cas...
188

3. Soit h : x 7→ sin x + (cos x− 1). Dans ce cas, on utilise que cos x− 1 = o0(() sin x) car cos x− 1 ∼
0−x2/2
et sin x ∼0
x donc h ∼0
sin x ∼0
x.
Soit a ∈ R et f , g deux fonctions qui vérifientFa. Soit b ∈ R et h une fonction qui vérifieFb telleque limb h = a.Si f ∼
ag alors f h ∼
bg h.
Proposition 12.2.4.426 (Changement de variable)
Exemple : On sait que sin x ∼0
x donc sin x2 ∼0
x2 ou sin(
12 +√
x
)∼+∞
12 +√
x.
Remarque : ne pas confondre avec la composition « à gauche ». Par exemple on veut montrer que ln(1+ sin x) ∼0
x en utilisant que sin x ∼0
x et ln(1 + x) ∼0
x. Voici deux rédactions :
— On a sin x ∼0
x donc ln(1 + sin x) ∼0
ln(1 + x). Or ln(1 + x) ∼0
x donc ln(1 + sin x) ∼0
x.
— On sait que limx→0 sin x = 0 et ln(1 + x) ∼0
x donc ln(1 + sin x) ∼0
sin x. De plus sin x ∼0
x donc
ln(1 + sin x) ∼0
x.
La première rédaction n’est pas correcte - même si le résultat final est bon - car elle repose sur la compositionpar x 7→ ln(1 + x) de l’équivalent sin x ∼
0x. Par contre la deuxième est correcte. En effet, on fait un changement
de variable X = sin x.Exemple : On peut maintenant démontrer la formule pour l’équivalent de cos et de ch . Le cosinus se traitede la manière suivante. Au voisinage de 0, cos x =
√cos2 x =
√1− sin2 x. D’où cos x− 1 =
√1− sin2 x− 1.
Comme limx→0− sin2 x = 0 et que
√1 + X ∼
012 X. On a en utilisant la substitution que nous verrons plus loin.
cos x− 1 ∼0− sin2 x
2∼0− x2
2.
189

13Continuité sur un
intervalle1 Fonctions continues 1901.1 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1901.2 Théorèmes des valeurs intermédiaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1921.3 Cas des fonctions monotones - théorème de la bijection . . . . . . . . . . . . . . . . . . . . . . 1941.4 Bornes d’une fonction continue . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1951.5 Exemple de résolution d’équations fonctionnelles . . . . . . . . . . . . . . . . . . . . . . . . . . . 195
2 Très brève extension aux fonctions à valeurs complexes 1962.1 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1962.2 Le théorème des valeurs intermédiaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 197
Nous allons nous intéresser aux fonctions qui sont continues partout où elles sont définies. Le but estd’obtenir alors des propriétés « globales » et non plus « locales ».
1 Fonctions continues
1.1 Généralités
Soit f une fonction définie sur un intervalle I. On dit que f est continue si elle est continue en tout point de I.L’ensemble des fonctions continues sur un intervalle I sera notée C 0(I).
Définition 13.1.1.427
Exemples :1. Les polynômes sont des fonctions continues.
2. Les fonction circulaires, cos, sin et tan sont continues.
3. Les fonctions exponentielles, trigonométriques hyperboliques et logarithmes sont continues
4. Les fonctions puissances sont continues. En particulier x 7→ √x et x 7→ 1/xRemarque : on peut définir des fonctions continues sur des parties de R qui ne sont pas des intervalles (parexemple (x 7→ 1/x) est continue sur R?), cependant, la plupart des théorèmes de ce chapitre nécessiteront de sesituer sur un intervalle.
190

Soit f et g deux fonctions continues et λ ∈ R
1. la somme f + g est continue.
2. le produit externe λ. f est continue.
3. le produit f × g est continue.
4. le quotient f /g est continue (sur son ensemble de définition).
5. la composition f g est continue (sur son ensemble de définition).
Théorème 13.1.1.428
Remarque : dans les deux derniers cas, on a précisé, sur son ensemble de définition pour bien signifier qu’ilfaut justifier dans ce cas la définition de la fonction. Quand on veut montrer que f = f1/ f2 est continue sur unintervalle I on montre que f1 et f2 le sont et que f2 ne s’annule pas sur I.Exemples :
1. Soit f la fonction définie par
f (x) =1√
sin(x3 + 2x) + 2.
La fonction f est définie sur R car, pour tout x dans R, sin(x3 + 2x) > −1 d’où√
sin(x3 + 2x) + 2 estdéfini et non nul. De plus x 7→ x3 + 2x , x 7→
√x + 2, x 7→ 1/x sont des fonctions continues donc f est
continue.2. On considère la fonction partie entière notée [.] Elle n’est pas continue car elle n’est pas continue en 1.
Cela correspond bien à l’intuition qui dit que le graphe d’une fonction continue se trace « sans lever lecrayon ».
Soit I un intervalle et f et g deux fonctions continues sur I.
1. La fonction | f | est continue.
2. Les fonctions sup( f , g) : x 7→ Max( f (x), g(x)) et inf( f , g) : x 7→ Min( f (x), g(x)) sont conti-nues.
Proposition 13.1.1.429
Démonstration :1. Par composition avec X 7→ |X|.
2. On remarque que sup( f , g) =f + g + | f − g|
2et
f + g− | f − g|2
.
Soit I un intervalle de f une fonction continue sur I. Si J est un intervalle inclus dans I alors larestriction f|J de f à J est continue.
Proposition 13.1.1.430
191

Soit I in intervalle et a ∈ I. On note I− = I∩]−∞, a] et I+ = I ∩ [a,+∞[. Soit f une fonction définiesur I. Si les restrictions de f à I+ et I− sont continues alors f est continue.
Proposition 13.1.1.431
Remarque : Ce n’est pas évident. Par exemple, le même énoncé avec dérivable est faux.Démonstration : Pour tout x dans I \ a alors il existe un voisinage de x contenu dans I+ ou dans I−. De cefait, la continuité de f en x découle de la continuité des restrictions.
Pour x = a. Comme la restriction de f à I− (resp. à I+) est continue alors f est continue à gauche (resp. àdroite). Donc f est continue.
1.2 Théorèmes des valeurs intermédiaires
Soit f une fonction continue sur un intervalle I. Soit (a, b) ∈ I2. On suppose que f (a) f (b) 6 0 alorsil existe c compris entre a et b tel que f (c) = 0. Si de plus f (a) f (b) < 0 on peut supposer que c eststrictement compris entre a et b.
Théorème 13.1.2.432
Remarque : Par contraposé on en déduit qu’une fonction continue qui ne s’annule pas garde un signe constant.Démonstration : La démonstration du théorème se fait par dichotomie. Cela consiste à construire deux suites(an) et (bn) puis à montrer qu’elles sont adjacentes. De ce fait elles convergent et le c cherché sera la limite.
On suppose que a < b par convention et on suppose aussi que f (a) 6 0 6 f (b) (sinon on peut faire demême avec − f ). Dès lors on pose a0 = a et b0 = b. On va construire des suites adjacentes (an) et (bn) telles que
pour tout entier n, f (an) 6 0 6 f (bn). On coupe l’intervalle [a0, b0] en deux en posant u0 =a0 + b0
2: le milieu.
On sépare les cas selon le signe de f (u0)
— si f (u0) 6 0 on pose a1 = u0 et b1 = b0.
— si f (u0) < 0 on pose a1 = a0 et b1 = u0.
Et on recommence. On construit ainsi des suites (an) et (bn) et on remarque que
a = a0 6 a1 6 a2 6 · · · 6 an 6 · · · 6 bn 6 · · · 6 b2 6 b1 6 b0 = b.
De plus, ∀n ∈ N f (an) est négatif et f (bn) positif. Pour finir, on a
∀n ∈ N, bn+1 − an+1 =bn − an
2d’où bn − an =
b0 − a0
2n .
On en déduit que les suites sont adjacentes et on note c la limite commune.Il reste à montrer que c répond bien à la question. Comme f est continue, les suites ( f (an)) et ( f (bn))
convergent vers f (c). On en déduit que f (c) est positif et négatif donc il est nul.
Soit I un intervalle, f une fonction continue sur I et (a, b) ∈ I2. Pour tout ` compris entre f (a) etf (b), il existe un c compris entre a et b tel que f (c) = `.
Théorème 13.1.2.433 (Théorème des valeurs intermédiaires)
Remarques :
1. C’est un théorème fondamental. Il faut l’utiliser dès que l’on veut montrer l’existence, d’un nombre xvérifiant f (x) = c (ou si on prend c = 0 l’existence d’une racine de f ).
2. Sous cette forme, ce théorème ne donne que l’existence, si l’on a besoin en plus de l’unicité il faut setourner vers le théorème de la bijection - voir plus loin. Par exemple pour x 7→ x3 − x si on prend a = −2( f (a) = −6) et b = 2 ( f (b) = 6) et ` = 0, il y a plusieurs solutions pour c : −1, 0 et 1.
192
3. Si la fonction f n’est pas continue ce n’est plus vrai. Considérons par exemple la fonction partie entièreavec a = 0, b = 1 et ` = 1/2.
4. Si l’on n’est pas sur un intervalle ce n’est plus vrai. Par exemple x 7→ 1/x, a = −1, b = 1 et ` = 0.
5. L’abréviation TVI n’est pas à mettre sur une copie.
Remarque : Nous verrons en IPT l’implémentation de cette démonstration.
Soit f une fonction continue sur I. Si f ne s’annule pas elle garde un signe constant.
Corollaire 13.1.2.434
Démonstration : Par contraposée
Soit a ∈ R et f une fonction continue sur [a,+∞[. Soit ` un nombre strictement compris entre f (a) etlim+∞
f . Il existe c > a tel que f (c) = `.
Proposition 13.1.2.435 (Variante à l’infini)
Démonstration : Il suffit de voir que, comme lim+∞
f = +∞ il existe b > a tel que f (b) > `. On applique alors le
TVI.Remarques :
1. On peut de même remplacer a par −∞. On peut aussi le faire en supposant que f est continue sur ]a, b] oùa ∈ R. Là encore, il faut alors supposer que ` est strictement compris entre f (a) et f (b).
2. On est obligé de prendre des inégalités strictes. Par exemple pour x 7→ 1/x, a = 1 et ` = 0.
Soit I un intervalle et f une fonction continue sur I alors f (I) est un intervalle.
Corollaire 13.1.2.436
Démonstration : c’est juste une reformulation du théorème des valeurs intermédiaires. En effet, soit x et y deuxéléments de f (I). Il existe donc a et b dans I tels que f (a) = x et f (b) = y. Maintenant pour tout ` compris entrex et y, il existe bien c dans I (car I est un intervalle) tel que f (c) = ` donc ` ∈ f (I).
Exercice : Soit f la fonction définie sur [0, π/2] par
f (x) =1
x + 1cos x− x2 + 1
Montrer qu’il existe une solution de l’équation f (x) = 0 et donner une méthode pour en localiser une avec uneprécision de 0, 1.
193

1.3 Cas des fonctions monotones - théorème de la bijection
Soit I un intervalle et f une fonction continue et strictement monotone sur I. La fonction f réaliseune bijection de I sur f (I).
Théorème 13.1.3.437 (Théorème de la bijection)
Remarque : Si f est croissante, f (I) est un intervalle de la forme suivante
I [a, b] [a, b[ ]a, b] ]a, b[f (I) [ f (a), f (b)] [ f (a), limb f [ ] lima f , f (b)] ] lima f , limb f [
Si f est decroissante, f (I) est un intervalle de la forme suivante
I [a, b] [a, b[ ]a, b] ]a, b[f (I) [ f (b), f (a)] ] limb f , f (a)] [ f (b), lima f [ ] limb f , lima f [
Exemples :
1. Soit f la fonction définie sur [−2, 4] par f (x) = x3 + 2x. Elle est continue et strictement croissante. De plusf (−2) = −12 et f (4) = 72. C’est donc une bijection de [−2, 4] sur [−12, 72].
2. La fonction exponentielle est définie sur R. Elle est continue et strictement croissante. De plus limx→−∞
ex = 0
et limx→+∞
ex = +∞. Elle réalise donc une bijection de R sur ]0,+∞[.
Démonstration : Nous allons faire la démonstration dans le cas où I est de la forme [a, b]. Nous supposeronsque f est strictement croissante (le cas décroissant est similaire).
Par définition, f est surjective si on prend f (I) comme ensemble d’arrivé.Il reste à montrer l’injectivité. C’est-à-dire, que pour tout couple (x, x′) d’éléments de I tels que x 6= x′ alors
f (x) 6= f (x′). Comme x 6= x′, l’un est strictement plus grand que l’autre. Posons par exemple x′ > x. Dans cecas, f (x′) > f (x) et donc f (x′) 6= f (x). L’application est bien injective.
Elle est injective et surjective, c’est donc une bijection.
Avec les hypothèses précédentes, la fonction f−1 de f (I) dans I est continue.
Proposition 13.1.3.438
Démonstration : On a donc g = f−1 qui réalise une bijection strictement monotone de J = f (I) dans I. Quitteà échanger g en −g on peut supposer que g est strictement croissante. On va montrer par l’absurde que g estcontinue. Supposons donc que g n’est pas continue. Il existe y ∈ J tel que g ne soit pas continue en y.
— Supposons que y n’est ps une borne de J. On sait que, g étant strictement monotone elle admet des limitesà droite et à gauche en y et de plus
limy−
g 6 g(y) 6 limy+
g.
La fonction n’étant pas continue, l’une des deux inégalités est stricte. Supposons par symétrie queg(y) < lim
y+g. Un élément α strictement compris entre g(y) et lim
y+g ne peut pas être dans l’image de g. En
effet pour tout x de J, si x 6 y alors g(x) 6 g(y) < α et si x > y alors g(x) > limy+ g. Donc α /∈ g(J) = I.Cela contredit le fait que I est un intervalle.
— La démonstration est similaire si y est une borne.
Il y a un énoncé qui ressemble à une réciproque
Soit f une fonction injective et continue sur un intervalle. Elle est strictement monotone.
Proposition 13.1.3.439
194

Idée de démonstration : Supposons que f n’est pas strictement monotone par l’absurde. Il existe alors x < ytels que f (x) 6 f (y) (et même f (x) < f (y) par injectivité) car f n’est pas strictement décroissante. De même ilexiste a < b tels que f (a) > f (b).
Il suffit (c’est facile à dire) d’étudier les différent cas pour conclure. Si on suppose par exemple que x < y 6a < b.
— si f (a) < f (y) : en appliquant le TVI entre x et y puis entre y et a on peut trouver deux antécédents àf (a) + f (y)
2ou à
f (x) + f (y)2
selon que f (a) soit supérieur ou inférieur à f (x).
— si f (a) > f (y) : en appliquant le TVI entre x et a puis entre a et b on peut trouver deux antécédents àf (a) + f (b)
2ou à
f (x) + f (a)2
selon que f (b) soit supérieur ou inférieur à f (x).
Les autres cas sont similaires.
1.4 Bornes d’une fonction continue
On appelle segment ou intervalle fermé et borné tout intervalle I de la forme [a, b] où a et b sont des réels.
Définition 13.1.4.440
Soit I un segment et f une fonction continue sur I. La fonction est bornée et atteint ses bornes.
Théorème 13.1.4.441
Démonstration : On note I = [a, b]. Remarquons tout de suite que si f est constante c’est vrai. On exclut par lasuite ce cas.
— Commençons par montrer que f est majorée. Par l’absurde, supposons que ce n’est pas le cas. Pour toutentier naturel n il existe alors un élément xn de I tel que f (xn) > n. La suite (xn) étant une suite d’élémentde I elle est bornée (∀n ∈ N, a 6 xn 6 b). Il existe donc une sous suite (xϕ(n)) convergente. Soit ` salimite. Comme f est continue, f (xϕ(n)) tend vers f (`). Cependant, pour tout entier n, f (xϕ(n)) > ϕ(n) parconstruction. C’est donc absurde.
— Montrons maintenant que α = supx∈[a,b] f (x) = sup f (I) est atteint par f . Comme f (I) n’est pas réduit à
un point. Il existe un entier N tel que α− 1N∈ f (I). Dès lors, par définition de la borne supérieure, pour
tout entier n > N , α− 1/n appartient à f (I) donc il existe un dans I tel que
α− 1n= f (un)
. Là encore, on peut extraire une sous-suite convergente de (un) car elle est bornée. Cette sous suiteconverge vers c dans I et, par continuité f (c) = α.
On fait de même pour l’inf.
Exemple : Soit f une fonction strictement positive sur un segment. Il existe α > 0 tel que ∀x ∈ I, f (x) > α.
Soit I un segment et f ∈ C 0(I). On pose m = Min[a,b]
f et M = Max[a,b]
f alors f (I) = [m, M].
Corollaire 13.1.4.442
1.5 Exemple de résolution d’équations fonctionnelles
La résolution d’une équation fonctionnelle consiste à trouver toutes les fonctions f vérifiant une certainecondition.
195

Déterminer toutes les fonctions f de R dans R telles que
∀(x, y) ∈ R2, f (x + y) = f (x) + f (y).
On commence souvent par chercher des cas particuliers. Ici pour x = 0 on trouve f (0 + y) = f (0) + f (y)donc f (0) = 0.
De plus, on peut voir que f (2) = f (1 + 1) = f (1) + f (1) = 2 f (1). Par récurrence on prouve alors que pourtout entier naturel n, f (n) = n f (1). On peut ensuite l’étendre au cas de n dans Z.
On remarque alors que tout entier naturel n non nul
n f (1/n) = f (1/n) + · · ·+ f (1/n) = f (1/n + · · ·+ 1/n) = f (1).
Il en découle que pour tout x dans Q, f (x) = x f (1).Sans autres hypothèses, on ne peut pas aller plus loin. Si on suppose de plus que f est continue alors
f : x 7→ x f (1) en approchant un réel x par une suite de rationnels.Exercices :
1. Déterminer toutes les applications continues f de I =]0,+∞[ dans R telles que ∀(x, y) ∈ I2, f (xy) =f (x) + f (y).
2. Déterminer toutes les applications continues f de R dans R telles que ∀(x, y) ∈ R2, f (x + y) = f (xy).
2 Très brève extension aux fonctions à valeurs complexes
2.1 Généralités
Dans tout ce paragraphe on se fixe un intervalle I de R et f une fonction de I dans C.
Avec les notations précédentes, on appelle partie réelle (resp. partie imaginaire) de f la fonction notée Re( f )(resp. Im( f )) définie de I dans R par
Re( f ) : t 7→ Re( f (t))(resp. Im( f ) : t 7→ Im( f (t))).
Définition 13.2.1.443
Avec les notations précédentes on note | f | et f les fonctions définies sur I par
∀x ∈ I, | f |(x) = | f (x)| et f (x) = f (x).
Définition 13.2.1.444
On dit que f de I dans C est bornée si | f | l’est.
Définition 13.2.1.445
On peut alors définir la limite en a ∈ I dans le cas où cette limite est finie : ` ∈ C.
Soit f une fonction définie de I sur C, a ∈ I et ` ∈ C. On dit que f tend vers ` en a si | f − `| tend vers 0 en a.
Définition 13.2.1.446
Remarques :
1. Dans la définition ci dessus, | f − `| est une fonction à valeurs réelles.
2. Cela revient à réécrire la définition avec cette fois des modules et non plus des valeurs absolues.
196

Avec les notations précédentes :
lima
f = ` ⇐⇒ lima
Re( f ) = Re(`) et lima
Im f = Im`.
Proposition 13.2.1.447
Soit I un intervalle de R et f une fonction définie de I sur C. On dit que f est continue si pour tout a de I ,lim
af = f (a). On note C 0(I, C) l’ensemble des fonctions complexes continues sur I.
Définition 13.2.1.448
La fonction f est continue si et seulement si Re( f ) et Im( f ) le sont.En particulier, les sommes, produits et multiplication externe de fonctions continues sont continues
Proposition 13.2.1.449
2.2 Le théorème des valeurs intermédiaires
B Le théorème des valeurs intermédiaires n’est plus vrai dans C. On peut « contourner » une valeur. Parexemple, la fonction f : t 7→ eiπt. On a f (−1) = −1 et f (0) = 1 mais il n’existe pas t0 entre 0 et 1 tel quef (t0) = 0.
197

14Polynômes
1 Ensembles de polynômes à coefficients dans K 1991.1 Construction et propriétés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1991.2 Degré et valuation d’un polynôme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2021.3 Fonctions polynomiales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 204
2 Dérivation 2042.1 Définition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2042.2 Dérivées successives et formule de Taylor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 205
3 Divisibilité et racines d’un polynôme 2073.1 Divisibilité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2073.2 Division euclidienne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2083.3 Racines . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2093.4 Ordre de multiplicité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2113.5 Fonctions symétriques des racines . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2133.6 Interpolation de Lagrange . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 214
4 Arithmétique dans K[X] 2154.1 Plus grand commun diviseur (PGCD) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2154.2 Polynômes premiers entre eux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2164.3 Généralisation à une famille de polynômes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2174.4 Le plus grand commun multiple (PPCM) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2184.5 Propriétés du PGCD et du PPCM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 218
5 Factorisation 2195.1 Polynômes irréductibles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2195.2 Décomposition en produit de facteurs irréductibles . . . . . . . . . . . . . . . . . . . . . . . . . . 2205.3 Factorisation sur C . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2215.4 Quelques applications de la factorisation sur C . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2215.5 Factorisation sur R . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 221
Dans tout ce chapitre K désigne le corps des réels R ou le corps des nombres réels C. La très grande majoritédes résultats s’applique au cas où K est un corps en général. On pourra aussi à l’occasion utiliser le corps Q.
198

1 Ensembles de polynômes à coefficients dans K
1.1 Construction et propriétés
On va vouloir construire des polynômes. Ce sont des « fonctions »de la forme x 7→ a0 + · · ·+ anxn pourun entier n fixé et (a0, . . . , an) ∈ Kn+1. En pratique on veut définir un vrai objet algébrique dont la fonctionprésentée ci-dessus ne sera qu’une réalisation.
On appelle polynôme à coefficients dans K une suite d’éléments de K stationnaire à 0.
Définition 14.1.1.450
Remarque : Un polynôme est donc une suite (an) ∈ KN tel qu’il existe un entier naturel N tel que
∀n > N, an = 0.
Terminologie :
1. On appelle coefficient du polynôme (an) les nombres a0, a1, . . . , aN .
2. On appelle polynôme nul et on notera 0 si cela ne porte pas à confusion le polynôme dont tous lescoefficients sont nuls.
1. L’ensemble des polynômes à coefficients dans K est stable par l’addition de KN.
2. Soit λ un élément de K. La multiplication (externe) par λ stabilise l’ensemble des polynômes àcoefficients dans K.
On définit donc ainsi une addition noté + et une multiplication externe par un élément de K surl’ensemble des polynômes.
Proposition 14.1.1.451
Démonstration
Exemple : Soit p = (1, 6, 2,−1, 0, 0, . . .) et q = (2, 7,−1, 3, 1, 0, 0, . . .) deux polynômes. Alors p+ q = (3, 13, 1, 2, 1, 0, 0, . . .).De même 5.p = (5, 30, 10,−5, 0, 0, . . .).Remarques :
1. Nous verrons dans un prochain chapitre que cela signifie que l’ensemble des polynômes sur K est unsous-espace vectoriel de RN.
2. Cette somme correspond bien à ce que nous voulons sur nos fonctions
On va aussi vouloir définir un produit. Ce ne sera pas le produit terme à terme. Regardons sur un exemplece que cela donne sur un exemple :
(a0 + a1x + a2x2)× (b0 + b1x + b2x2) = · · · = c0 + c1x + c2x2 + c3x3 + c4x4.
oùc0 = a0b0; c1 = a1b0 + a0b1; c2 = a2b0 + a1b1 + a0b2; . . .
On peut donc généraliser
Soit p = (an) et q = (bn) deux polynômes à coefficients dans K. On pose pour tout entier n,
cn =n
∑k=0
akbn−k = ∑i+j=n
aibj.
La suite (cn) est un polynôme.
Proposition 14.1.1.452
199

Remarque : Dans la deuxième somme, on fait la somme sur tous les couples (i, j) de N2 tels que i + j = n.Démonstration : Posons N1 et N2 tels que ∀k > N1, ak = 0 et ∀k > N2, bk = 0. Soit n > N1 + N2 on a
cn =n
∑k=0
akbn−k =N1
∑k=0
akbn−k +n
∑k=N1+1
akbn−k.
Dans la deuxième somme tous les termes sont nuls car ak = 0 pour k > N1. Dans la première somme, k 6 N1donc n− k > n− N1 > N2 donc bn−k = 0.
On a bien cn = 0.
Soit p et q deux polynômes à coefficients dans K, on appelle produit de p et de q et on note p× q le polynômedéfini par la proposition ci-dessus.
Définition 14.1.1.453
Exemple : Soit p = (1, 6,−1, 0, 0, . . .) et q = (2, 7, 0, 0, . . .). Le polynôme p× q est (2, 19, 40, 0, . . .).Remarque : Ce n’est pas la multiplication « classique »dans RN.
L’ensemble des polynômes à coefficients dans K muni de l’addition et de multiplication définiesci-dessus est un anneau commutatif.
Théorème 14.1.1.454
Remarques :
1. Ce n’est pas un sous-anneau de KN car le produit n’est pas le même.
2. C’est aussi un anneau intègre mais on repousse cette partie à plus tard
Démonstration :
— L’ensemble des polynômes n’est pas vide car il contient le polynôme nul.
— L’addition est associative et commutative car elle l’est dans KN.
— Le polynôme nul est un élément neutre pour l’addition.
— Pour tout polynôme p = (an), le polynôme q = (−an) vérifie que p + q = 0. C’est le symétrique de p pour+
On a prouvé que l’ensemble des polynômes à coefficients dans K est un groupe abélien.
— Soit p = (an), q = (bn) et r = (cn). On a alors (p.q).r = (dn) et p.(q.r) = en où
dn = ∑i+j=n
(∑
k+l=iakbl
)cj = ∑
i+k+l=nakblcj
et
en = ∑i+j=n
ai
(∑
k+l=jbkcl
)= ∑
i+k+l=naibkcl .
On a bien (en) = (dn). Le produit est donc associatif.
— On peut montrer de même que la multiplication est distributive sur l’addition.
— Le polynôme 1 = (1, 0, 0, . . .) est un élément neutre pour la multiplication.
— De par la symétrie de la formule la multiplication est commutative.
Notation : On convient de noter X le polynôme (0, 1, 0, 0, . . .). On montre par récurrence que pour tout entier kle polynôme Xk est défini par (an) où
∀n ∈ N, an = δkn =
1 si k = n0 sinon.
200

Dès lors le polynôme p = (a0, a1, a2, . . . , aN , 0, 0, 0, . . .) peut s’écrire a0X0 + a1X1 + · · ·+ aN XN =N
∑k=0
akXk.
On notera souvent un polynômeN
∑k=0
akXk. Il faut noter que rien n’implique a priori que aN est non nul. De
fait, si on considère deux polynômes (et même un nombre fini de polynômes)N1
∑k=0
akXk etN2
∑k=0
bkXk on peut les
écrireN
∑k=0
akXk etN
∑k=0
bkXk en prenant N = Max(N1, N2). Comme on sait que plus que tous les termes de la
suite sont nuls à partir d’un certain rang on notera aussi+∞
∑k=0
akXk mais en comprenant bien que c’est une somme
finie.
On remarque que l’on peut faire les calculs de produit comme d’habitude. En effet si P =N
∑k=0
akXk et
Q =N
∑k=0
bkXk
La formule P×Q =
(N
∑k=0
akXk
)×(
N
∑k=0
bkXk
)=
2N
∑k=0
ckXk où ck = ∑i+j=k
aibj est obtenu par distributivité.
Terminologie :
1. On notera K[X] l’ensemble des polynômes à coefficients dans K.
2. Les polynômes de la formes λXk où λ ∈ K et k ∈ N s’appellent des monômes.
3. On appelle polynôme constant tout monôme de la forme λX0.
En tant qu’anneau commutatif, on peut calculer les puissances d’une somme de polynômes avec la formuledu binôme de Newton :
Soit (P, Q) ∈ K[X]2 et n ∈ N,
(P + Q)n =n
∑k=0
(nk
)PkQn−k.
Proposition 14.1.1.455 (Binôme de Newton)
La mutliplication
Soit (P, Q) ∈ K[X]2 et (λ, µ) ∈ K2 on a :
?λ.(µ.P) = (λ× µ).P ?(λ + µ).P = λ.P + λ.µ?λ.(P + Q) = λ.P + λ.Q ?0.P = 0?(λ.P)× (µ.Q) = (λ.µ).(P×Q) ?(λ.P)k = λk.Pk.
Proposition 14.1.1.456 (Propriétés de multiplication externe)
Soit P et Q deux polynômes de K[X]. On note P =N
∑k=0
ak. On appelle compostion de P et de Q et on
note P Q ou P(Q) le polynôme
P Q =N
∑k=0
akPk
où Pk désigne la puissance k-ième de P.
Proposition 14.1.1.457 (Composition)
201

Remarque : Si le polynôme Q est le polynôme X on trouve P X = P. C’est pour cela que l’on trouve lanotation P(X) pour le polynôme P.Exemple : Soit P = −X2 + 3X + 2 et Q = 2X− 1 On trouve
P(Q) = −2Q2 + 3Q + 2Q0 = −(2X− 1)2 + 3(2X− 1) + 2 = −4X2 + 10X− 3.
Soit P, Q et R trois éléments de K[X].
(P×Q)(R) = P(R)×Q(R).
Proposition 14.1.1.458
Démonstration : C’est la classique formule du produit obtenue par distributivité.
1.2 Degré et valuation d’un polynôme
Soit P un polynôme de K[X] non nul. L’ensemble k ∈ N | ak 6= 0 est une partie non vide (car P 6= 0) etmajorée (par définition) de N. Elle admet donc un plus grand élément.
Soit P un polynôme de K[X] non nul. Le degré du polynôme P, que l’on note deg P est le plus grand élémentde k ∈ N | ak 6= 0. Par convention, on dira que le polynôme nul est de degré −∞.
Définition 14.1.2.459
Exemples :1. Un polynôme de degré zéro est un polynôme constant non nul.2. Un polynôme de degré un est de la forme a0 + a1X où a1 6= 0.
Remarques :1. Les exemples ci-dessus montrent que, si n est un entier, il est souvent plus agréable de considérer les
polynômes de degré inférieur ou égal à n que les polynômes de degré exactement n. On dit alors que c’estun polynôme de degré au plus n.
2. Comme on le voit sur la définition, le cas du polynôme nul est souvent à part. Il faut penser, dès que l’ontravaille avec le degré à réfléchir au cas du polynôme nul.
Notation : Soit n un entier, l’ensemble des polynômes de degré inférieur à n se note
Kn[X].
Soit P un polynôme non nul.
— le coefficient du monôme Xdeg P s’appelle le coefficient dominant de P. Le monôme de degré deg Ps’appelle le terme dominant.
— si le coefficient dominant est égal à 1, le polynôme est dit unitaire ou normalisé.
Définition 14.1.2.460
Remarque : Soit P un polynôme non nul. Si λ est son coefficient dominant, le polynôme1λ
P est normalisé. Ils’appelle le normalisé de P.
Soit P et Q deux polynômes non nuls.
deg(P + Q) 6 Maxdeg P, deg Q.
De plus si deg P 6= deg Q l’inégalité ci-dessus est une égalité.
Proposition 14.1.2.461
202

Démonstration : Il suffit de l’écrire pour prouver l’inégalité. De plus si deg P 6= deg Q, le coefficient dominantdu polynôme de plus haut degré ne peut pas être compensé par un terme de l’autre polynôme. On a bienl’égalité.
B Il se peut que le degré de P + Q soit strictement inférieur au degré de P et de Q. Par exemple si P = 2 + Xet Q = −1− X. De ce fait Kn[X] est stable par addition et pas l’ensemble de polynômes de degré exactement n.
1. Soit P et Q deux polynômes non nuls
deg(P.Q) = deg P + deg Q.
2. Soit P un polynôme non nul et Q un polynôme non constant,
deg(P Q) = deg P. deg Q.
Proposition 14.1.2.462
Remarque : Que se passe-t-il dans le cas 2. si le polynôme Q est constant?Exercice : Soit (Pn) la suite de polynôme définie par
P0 = 1, P1 = 1 + 3X et ∀n ∈ N?, Pn+1 = 2XPn + (X2 − 2X + 3)Pn−1.
Déterminer le degré de Pn. (on trouve Pn = αnXn + · · · où αn = 2n + 1)
Soit P et Q deux éléments de K[X].
P×Q = 0⇒ P = 0 ou Q = 0.
L’anneau K[X] est donc intègre.
Proposition 14.1.2.463
Démonstration : Par contraposée, si P 6= 0 et Q 6= 0 alors deg(PQ) > 0 donc PQ 6= 0.
Les éléments inversibles de K[X] sont les polynômes de degré 0 c’est-à-dire les polynômes constantsnon nuls.
Proposition 14.1.2.464
Démonstration :
— Soit P = λ un polynôme constant avec λ 6= 0. On pose Q =1λ
. On a alors
P×Q = 1.
Donc P est inversible.— Réciproquement, si P est un polynôme inversible, il n’est pas nul (car le polynôme nul est absorbant).
Soit Q son inverse, deg(P) + deg(Q) = deg(P×Q) = deg(1) = 0. On en déduit que deg(P) 6 0 et doncdeg(P) = 0.
Remarque : Quand nous aborderons l’arithmétique des polynômes ils faudra faire attention aux polynômesinversibles qui jouent le rôle des éléments inversibles de Z qui sont ±1.
Soit P un polynôme non nul. On appelle valuation de P et on note val(P) le plus petit élément de k |ak 6= 0qui existe car c’est un ensemble non vide de N. Par convention la valuation du polynôme nul est +∞.
Définition 14.1.2.465
203

On a alors des propriétés analogues à celles sur le degré :
Soit P et Q deux polynômes non nuls.
1. val(P + Q) > Min(val(P), val(Q)).
2. val(PQ) = val(P) + val(Q).
Proposition 14.1.2.466
1.3 Fonctions polynomiales
Soit P un élément de K[X] et α un élément de K. Si P =N
∑k=0
akXk pour N ∈ N. On note P(α) =N
∑k=0
akαk.
La fonction de K dans lui même définie par α 7→ P(α) s’appelle la fonction polynomiale associée à P. On lanotera P.
Définition 14.1.3.467
Terminologie : On dit que l’on remplace ou substitue X par α.Remarque : On verra plus loin que l’application définie de K[X] dans l’ensemble des fonctions de K dans Kqui associe à un polynôme sa fonction polynomiale est injective.
La substitution est compatibles aux opérations. Précisément :
1. La fonction polynomiale associée à une somme de deux polynômes et la somme des fonctionspolynomiales. Il en est de même pour la multiplication par λ dans K.
2. La fonction polynomiale associée à un produit de deux polynômes et le produit des fonctionspolynomiales.
Proposition 14.1.3.468
Remarque : Pour calculer la valeur d’un polynôme en α on utilise l’algorithme de Hörner (voir cours d’algo-rithmique). De même pour calculer un monôme, on utilise l’algorithme d’exponentiation rapide.
2 Dérivation
2.1 Définition
On peut dériver "formellement" un polynôme sans avoir recours à la notion "analytique" de dérivée vue enclasse de première.
Soit P un polynôme on note P =N
∑k=0
akXk. Le polynôme dérivée, que l’on note P′ est le polynôme :
P′ =N
∑k=1
kakXk−1 =N−1
∑k=0
(k + 1)ak+1Xk.
Définition 14.2.1.469
204

Avec les notations précédentes, si P est un polynôme à coefficients réels, alors P est un fonction de Rdans R dérivable et la fonction polynomiale associée au polynôme dérivé de P est la fonction dérivéede la fonction polynomiale associée à P. C’est-à-dire
(P)′ = P′.
Proposition 14.2.1.470
Exemples :1. La dérivée du polynôme nul est le polynôme nul.2. La dérivée du polynôme 7X3 + 4X− 1 est le polynôme 21X2 + 4.
Soit P et Q deux polynômes et soit (λ, µ) deux scalaires, on a
(λP + µQ)′ = λP′ + µQ′.
Proposition 14.2.1.471 (Linéarité de la dérivation)
Démonstration : Evident
Soit P un polynôme.
1. Si P est non constant,deg(P′) = deg(P)− 1.
2. Le polynôme P est constant si et seulement si P′ = 0.
Proposition 14.2.1.472
Démonstration
Soit P et Q deux polynômes, on a
(P×Q)′ = P′ ×Q + P×Q′.
Proposition 14.2.1.473
Demo à faire en prenant pour formule de la dérivéeN
∑k=0
(k + 1)ak+1Xk.
Exemple : Soit Pk = (X− α)k. Démontrons par récurrence que P′k = k(X− α)k−1. Il suffit de voir qu’en dérivantPk+1 = (X− α)Pk on obtient,
P′k+1 = Pk + k(X− α).P′k.
2.2 Dérivées successives et formule de Taylor
Soit P un polynôme. On définit les dérivées successives par récurrence. Précisément, soit n un entier la dérivéen-ième, notée P(n), est donnée par :
P(0) = PP(1) = P′
∀n ∈ N, P(n+1) = (P(n))′
Définition 14.2.2.474
205

Exemple : Soit P = X4 − 3X3 + 5X − 1. On a P′ = 4X3 − 9X2 + 5, P(2) = 12X2 − 18X, P(3) = 24X − 18,P(4) = 24 et pour tout entier supérieur à 5 on a P(n) = 0.
Soit i, k deux entiers on a
(Xk)(i) =
0 si i > kk!
(k− i)!Xk−i sinon
Proposition 14.2.2.475
Soit P un polynôme et n un entier non nul on a :
1. Si deg P > n alors deg P(n) = deg P− n.
2. (deg P 6 n− 1)⇔(
P(n) = 0)
.
Proposition 14.2.2.476
Soit P et Q deux polynômes et n un entier on a :
(P.Q)(n)(X) =n
∑k=0
(kn
)P(k)(X)Q(n−k)(X).
Proposition 14.2.2.477 (Formule de Leibniz)
Remarques :1. Pour le cas n = 1 on retrouve la classique formule de la dérivée d’un produit.2. Cela sera encore vrai pour toute fonctions suffisamment dérivables de R dans R.
Démonstration : Par une récurrence similaire à celle du binôme de Newton.
Soit P un polynôme. On note P = ∑Nk=0 akXk. On peut retrouver les coefficients ak en regardant les
dérivées successives en 0. On a
a0 = P(0), a1 = P′(a1), a2 =P′′(0)
2, . . . , ak =
P(k)(0)k!
, . . . , an =P(n)(0)
k!.
Proposition 14.2.2.478
Exemple : Soit P = a0 + a1X + a2X2 + a3X3 + . . .. On a
P′ = a1 + 2a2X + 3a3X2 + . . .P′′ = 2a2 + 6a3X + . . .
P(3) = 6a3 + . . .
Démonstration : De manière générale, on écrit que P = R +N
∑k=p
akXk avec deg(R) < p. D’où
P(p) = R(p) +N
∑k=p
ak
(Xk)(p)
=N
∑k=p
k!(k− p)!
akXk−p.
On a doncP(p)(0) =
p!(p− p)!
ap = p!ap.
On voit que l’on sait calculer les coefficients d’un polynôme à partir de ses dérivées en 0. On peut généralisercela.
206

Soit P un polynôme à coefficients dans K et α un élément de K. Pour tout entier n supérieur au degréde P on a :
P = P(α) + P′(α)(X− α) +P′′(α)
2!(X− α)2 + · · ·+ P(n)(α)
n!(X− α)n
=n
∑k=0
P(k)(α)
k!(X− α)k.
Théorème 14.2.2.479 (Formule de Taylor)
Remarques :1. Si on prend α = 0 dans la formule de Taylor, on retrouve la proposition précédente.
2. La plupart du temps on prendre pour N le degré de P, cependant, si on ne sait exactement déterminer cedegré on utilisera un nombre N plus grand. C’est sans influence sur la formule car si k > deg(P) alorsP(k)(α) = 0.
3. Cette formule est importante, on la reverra dans le cas des fonctions.
4. Il faut essayer de penser à cette formule dès que l’on a dans un énoncé la valeur d’un polynôme et de sesdérivées en un même point.
Démonstration : On va se ramener au cas α = 0. On pose Q = P (X + α) on a donc P = Q (X − α) car(X− α) (X + α) = X.
D’après la proposition précédentes, on a
Q =N
∑k=0
Q(k)(0)k!
Xk.
On en déduit que
P = Q (X− α) =N
∑k=0
Q(k)(0)k!
(X− α)k.
Il ne reste plus qu’à montrer que pour tout entier k entre 0 et N, Q(k)(0) = P(k)(α).
On voit déjà que Q(0) = P(α). De plus, on remarque que si P = ∑Nk=0 akXk alors Q =
N
∑k=0
ak(X + α)k. En
dérivant on obtient par linéarité
Q′ =N
∑k=1
kak(X + α)k−1 en effet on montre par récurrence que ((X + α)k)′ = k(X + α)k−1.
On a donc Q′(0) = P′(α). Il ne reste plus qu’a réitérer le procédé.
Exemple : On veut déterminer les polynômes P de degré inférieur à 2 tels que P(1) = 1 et P′(1) = 3. On peutposer P = a + bX + cX2 et essayer de trouver des équations sur a, b et c. Il est plus rapide de dire que si Pvérifient les équations alors :
P = 1 + 3(X− 1) + γ(X− 1)2 = (1 + γ) + (3− 2γ)X + γX2.
3 Divisibilité et racines d’un polynôme
3.1 Divisibilité
Soit P et Q deux polynômes. On dit que P divise Q ou que Q est multiple de P et on note P|Q s’il existe unpolynôme R tel que Q = P.R. Le polynôme R est alors le quotient de Q par P.
Définition 14.3.1.480
Remarque : Cette définition est l’analogue de la notion de divisibilité des entiers.Exemples :
207

1. Le polynôme X divise le polynôme X + 3X2 car X + 3X2 = X.(1 + 3X).2. Le polynôme 1 + X + X2 divise le polynôme 1− X3 car 1− X3 = (1− X).(1 + X + X2)
3. Le polynôme 1 + X ne divise pas le polynôme 2 + 3X− X2.4. Soit a ∈ K?. Tout polynôme non nul est divisible par le polynôme constant de valeur a.5. Seul le polynôme nul est divisible par le polynôme nul.
Soit P et Q deux polynômes.
1. Si P|Q et Q est non nul alors deg P 6 deg Q.
2. Si P|Q et Q|P alors il existe a ∈ K? tel que P = αQ.
Proposition 14.3.1.481
Démonstration
B Il faut faire attention à la deuxième partie de la proposition. On a en fait P = UQ où U est un élémentinversible de K[X]. D’ailleurs dans Z on a l’analogue avec ±1.
Soit P et Q deux polynômes. On dit que P et Q sont associés s’il existe λ ∈ K∗ tel que P = λ.Q.
Définition 14.3.1.482
Remarque : Le fait d’être associé est une relation d’équivalence.
3.2 Division euclidienne
Comme dans Z on a une division euclidienne en utilisant le degré car on ne peut pas dire que R < Q.
Soit P1 et P2 deux polynômes de K[X] avec P2 6= 0. Il existe un unique couple (Q, R) de polynômesvérifiant
P1 = Q.P2 + R et deg Q < deg R.
Le polynôme Q s’appelle le quotient et le polynôme R s’appelle le reste de la division euclidienne deP1 par P2.
Théorème 14.3.2.483
Démonstration :— (Unicité) Supposons qu’il existe deux couples (Q1, R1) et (Q2, R2) qui satisfont au résultat du théorème.
On a donc(Q1 −Q2)P2 = R2 − R1.
Donc P2 divise (R2 − R1). Mais le degré de R2 − R1 est strictement inférieur de celui de P2 cela impliqueque R2 − R1 = 0 et donc R1 = R2.Par la suite (Q1 −Q2)P2 = 0 et on conclut en utilisant que K[X] est intègre.
— (Existence) On procède par récurrence sur le degré de P1. Précisément on pose
Hn = ”∀P1 ∈ K[X], deg(P1) < n⇒ ∃(Q, R) ∈ (K[X])2, P1 = Q.P2 + R et deg Q < deg R”.
— I Pour n 6 deg P2. Dans ce cas le couple (0, P2) convient.
— H Soit n un entier supérieur ou égal à deg P2. On suppose Hn et on veut montrer Hn+1. Soit P2un polynôme de degré strictement inférieur à n + 1. Si son degré est inférieur strictement à n + 1 ilsuffit d’utiliser Hn. Sinon, on pose an+1 6= 0 le coefficient dominant de P1 et on note bmXm le termedominant de P2. On considère le polynôme obtenu en "tuant" le terme de plus haut degré de P1. Onpose
P = P1 −an+1
bmXn+1−mP2.
208

Par construction, P a un degré inférieur strictement à n. On peut donc appliquer Hn. Il existe (Q, R)tels que P = QP2 + R donc
P1 =
(Q +
an+1
bmXn+1−m
)P2 + R.
Remarque : La preuve ci-dessus donne une méthode algorithmique de faire cette division euclidienne. Onremarquera au passage que c’est beaucoup plus simple quand P2 est unitaire car dans ce cas il n’y a pas dedivisions.Exemple : Calculer la division euclidienne de X5 + 3X4− 7X3 +X+ 2 par X3 + 3X− 2 donne Q = X2− 3X− 10et R = 11X2 + 25X + 22.
Soit P1 et P2 deux polynômes avec P2 6= 0. Le polynôme P2 divise P1 si et seulement si le reste dedivision euclidienne de P1 par P2 est nul.
Proposition 14.3.2.484
Démonstration
Remarques :
1. En particulier si P1 et P2 sont deux polynômes de R[X]. On peut aussi les considérer comme polynômesde C[X]. Par l’unicité on voit que les quotient et les reste de la division euclidienne de P1 par P2 sont lesmêmes dans R[X] et dans C[X]. En particulier P2 divise P1 dans R[X] si et seulement P2 divise P1 dansC[X].
2. On voit donc que l’anneau K[X] a à peu près les mêmes propriétés que Z. Nous pourrons développer lesnotions de PGCD, PPCM, etc. Cela est en fait un cas particulier des anneaux euclidiens.
3.3 Racines
Soit P un polynôme et α ∈ K. On dit que α est une racine de P si P(α) = 0.
Définition 14.3.3.485
Exemples :
1. Soit P = −3− 2X + X2, ses racines sont 3 et −1.
2. Le polynôme X2 + 1 n’ a pas de racines dans R. Dans C ses racines sont i et −i.
3. Tout nombre est racine du polynôme nul.
Soit Q un polynôme non nul et α ∈ K. Le nombre α est racine de Q si et seulement si X− α divise Q.C’est à dire :
P(α) = 0⇔ (X− α)|Q.
Théorème 14.3.3.486
Démonstration :
— ⇐ : C’est la proposition précédente.
— ⇒ : On utilise la formule de Taylor en α. On peut aussi le faire avec la division euclidienne.
209

Soit Q un polynôme non nul et (α1, . . . , αp) ∈ Kp des nombres distincts. Tous les αi sont racines de
Q si et seulement sip
∏i=1
(X− αi) divise Q. C’est à dire :
(∀i ∈ [[ 1 ; p ]] , Q(αi) = 0)⇔(
p
∏i=1
(X− αi)
)|Q.
Corollaire 14.3.3.487
Démonstration :— ⇐ : C’est encore la proposition précédente.— ⇒ : On a Q(α1) = 0 d’où il existe un polynôme Q1 tel que Q = (X− α1).Q1. De plus pour tout i compris
entre 2 et p on a Q1(αi) = 0 car (αi − α1) = 0. On peut recommencer.
Remarque : Nous verrons plus loin une meilleure preuve de ce corollaire. Il suffira d’utiliser que les (X− αi)sont premier entre eux.Exemples :
1. Considérons le polynôme P = X4 − X3 − 5X2 − X − 6. On remarque que P(3) = P(−2) = 0. Onen déduit que P est divisible par (X − 3)(X + 2) = X2 − X − 6. Vérifions par le calcul. On a P =(X− 3)(X3 + 2X2 + X + 2) = (X− 3)(X + 2)(X2 + 1).
2. Soit n un entier et Pn = Xn − 1. On sait que pour tout k ∈ [[ 0 ; n− 1 ]] le nombre ωk = e2ikπ/n est uneracine de Pn. D’où
n−1
∏k=0
(X−ωk)|Pn.
De plus, deg
(n−1
∏k=0
(X−ωk)
)= deg Pn = n. Le quotient est donc de degré 0 : c’est un polynôme constant.
En regardant le terme de plus haut degré on en déduit que
Pn =n−1
∏k=0
(X−ωk).
Soit P un polynôme non nul. Le nombre de racine de P est inférieur au degré de P.
Corollaire 14.3.3.488
Démonstration : Il suffit de regarder le degré dans la proposition précédente.
Remarques :1. On en déduit que si deg P = n et si P a plus de n + 1 racines alors c’est le polynôme nul.2. Le seul polynôme avec une infinité de racine est le polynôme nul.On peut maintenant prouver la propriété énoncée plus haut.
L’application de K[X] dans KK qui associe à un polynôme P sa fonction polynomiale associée estinjective.
Proposition 14.3.3.489
Démonstration : Soit P et Q. On suppose que P = Q et on veut montrer que P = Q.Si on pose H = P− Q. On a H = 0. Le polynôme H a donc une infinité de racines. Il est donc nul d’où
P = Q.
Remarque : C’est la méthode la plus classique pour montrer que deux polynômes sont égaux. On montre queleur fonctions polynomiales associées coïncident sur une infinité de valeurs.
210

3.4 Ordre de multiplicité
Nous verrons un peu plus loin qu’au moins dans C[X] les polynômes (X− α) vont jouer le rôle des nombrespremiers. On va maintenant définir l’analogue de la validation p-adique. A savoir caractériser qu’un polynômesoit divisible par une puissance de (X− α).
Soit P un polynôme et α ∈ K. Soit r ∈ N.
1. on dit que α est une racine de multiplicité au moins r si et seulement si (X− α)r|P2. on dit que α est une racine de multiplicité r si et seulement si elle racine d’ordre au moins r mais pas
d’ordre au moins r + 1. C’est-à-dire
(X− α)r|P et (X− α)r+1 - P.
On dit alors que r est l’ordre de multiplicité de α.
Définition 14.3.4.490
Remarques :
1. De fait, on va compter une racine de multiplicité r comme r racines confondues.
2. Une racine de multiplicité 0 est juste un α qui n’est pas racine.
3. Une racine de multiplicité supérieure à 1 est juste un α qui est racine.
4. Soit P un polynôme non nul et α ∈ K. On peut définir l’ordre de multiplicité de α en tant que racine de Pcomme le plus grand entier p tel que (X− α)p divise P. Il existe car p ∈ N | (X− α)p|P est majoré parle degré de P.
5. La multiplicité de 0 est la valuation.
Exemples :
1. Dans le cas du trinôme P = aX2 + bX + c avec a 6= 0. On retrouve les cas connus. Si ∆ = 0 on a une racinedouble α et (X− α)2|P.
2. On considère P = X3 − 7X2 + 15X− 9. On a P = (X− 1)(X− 3)2 donc 1 est racine de multiplicité 1 et 3est racine de multiplicité 2.
Terminologie : Une racine de multiplicité 1 est dite racine simple. Une racine de multiplicité strictementsupérieure à 1 est dite racine multiple. En particulier une racine de multiplicité 2 est dite racine double.
Soit P un polynôme et α une racine d’ordre au moins r. Il existe Q tel que P = (X− α)rQ. De plus
Q(α) 6= 0 ⇐⇒ l’ordre de multiplicité de α est r
Proposition 14.3.4.491
Démonstration :
— ⇒ Par contraposée, si l’ordre de multiplicité n’est pas r il est au moins r + 1. On a alors (X − α)rQ =
(X− α)r+1R donc, comme K[X] est intègre, Q = (X− α)R et donc Q(α) = 0.
— ⇐ Encore par contraposée. Si Q(α) = 0, alors Q = (X− α)R et la multiplicité est strictement supérieureà r.
Nous allons voir comment la notion de multiplicité d’une racine peut se voir avec le polynôme dérivé. Nousallons commencer par un lemme.
Soit P un polynôme et r un entier naturel non nul. Si α est une racine d’ordre r de P alors c’est uneracine d’ordre r− 1 de P′. En particulier, si α est une racine simple de P alors P′(α) 6= 0.
Lemme 14.3.4.492
211

Démonstration du lemme : D’après les hypothèses, il existe un polynôme Q tel que P = (X− α)r.Q(X) etQ(α) 6= 0. On dérive et on obtient :
P′ = r(X− α)r−1Q + (X− α)r.Q′ = (X− α)r−1(rQ + (X− α).Q′).
Or en α, le polynôme rQ + (X − α).Q′ vaut rQ(α) et donc ne s’annule pas. On en déduit que α est bien uneracine d’ordre r− 1 de P′.
Soit P un polynôme, α ∈ K et r ∈ N?.
1. Le nombre α est une racine de multiplicité supérieure à r si et seulement si P(α) = 0, P′(α) =0, · · · , P(r−1)(α) = 0.
2. Le nombre α est une racine de multiplicité r si et seulement si P(α) = 0, P′(α) =
0, · · · , P(r−1)(α) = 0 et P(r)(α) 6= 0.
Théorème 14.3.4.493
Remarque : pour se souvenir des exposants, il suffit de se souvenir des petites valeurs.— Le nombre α est une racine simple (de multiplicité 1) si et seulement si P(α) = 0 et P′(α) 6= 0.— Le nombre α est une racine au moins double (de multiplicité supérieure ou égale à 2) si et seulement si
P(α) = 0 et P′(α) = 0.Démonstration : Il suffit de démontrer le 1.
— ⇒ On suppose que α est racine d’ordre r. En appliquant le lemme, α est racine d’ordre r− 1 de P′ puisd’ordre r − 2 de P′′. Et ainsi de suite. On en déduit que pour tout i ∈ [[ 0 ; r− 1 ]], α est racine d’ordrer− i > 0 de P(i). En particulier pour tout i ∈ [[ 0 ; r− 1 ]], P(i)(α) = 0.
— ⇐ C’est juste la formule de Taylor en α :
P(X) = 0 + 0 + · · ·+ 0 + (X− α)r P(r)(α)
r!+ · · ·
Remarque : C’est, en pratique, comme cela que l’on détermine la multiplicité d’une racine.Exemple : Déterminer la multiplicité de −1 dans P(X) = X5 + 3X4 + 5X3 + 7X2 + 6X + 2.
Soit P un polynôme non nul. Les éléments (α1, . . . , αn) ∈ Kn sont des racines de multiplicité
respective r1, . . . , rn si et seulement si P est divisible parn
∏i=1
(X− αi)ri .
Corollaire 14.3.4.494
Démonstration :— ⇐ C’est évident.— ⇒ Attention ce n’est pas évident. En effet si (X − α1)
r1 |P et (X − α2)r2 |P, rien ne dit à priori que
(X− α1)r1 .(X− α2)
r2 divise P. Cela découlera plus tard du fait que (X− αi)ri et (X− αj)
rj sont premiersentre eux.
Soit P un polynôme non nul. On suppose que les éléments (α1, . . . , αn) ∈ Kn sont des racines demultiplicité respective r1, . . . , rn. On a alors
r1 + r2 + · · ·+ rn 6 deg(P).
En particulier, si P est un polynôme de degré inférieur ou égal à n et que les éléments (α1, . . . , αn) ∈Kn sont des racines de multiplicité respective r1, . . . , rn. Si r1 + r2 + · · · + rn > n alors P est lepolynôme nul.
Corollaire 14.3.4.495
212

Démonstration : C’est la proposition précédente en utilisant que si Q|P alors deg Q 6 deg P.
Remarque : Cela justifie bien que l’on compte autant de fois une racine que sa multiplicité.
3.5 Fonctions symétriques des racines
Un polynôme P de K[X] est dit scindé s’il existe λ, x1, . . . , xn des éléments de K tels que
P = λn
∏k=1
(X− xk).
Définition 14.3.5.496
Remarques :
1. Si un polynôme non nul de degré n a n racines distinctes, il est scindé.
2. Si un polynôme non nul de degré n a n racines comptées avec leur multiplicité, il est scindé.
3. Réciproquement, si P = λ ∏nk=1(X− xk), les racines de P sont les xk.
Exemples :
1. Soit n un entier naturel. Le polynôme Xn− 1 est scindé sur C. On a vu en effet que Xn− 1 = ∏(
X− e2ikπ/n)
.
Par contre, pour n = 3, X3 − 1 n’est pas scindé sur R car il n’a qu’une racine réelle qui est simple et qui est1.
2. Soit P = aX2 + bX + c. Il est scindé sur C. Il est scindé sur R si et seulement si ∆ > 0.
Nous voulons voir comment les coefficients d’un polynôme scindé s’expriment en fonction des racines de cepolynômes. Commençons par deux exemples.Exemples :
1. Si P est de degré 2, ce résultat est déjà connu. Si on note P = a0 + a1X + a2X2 = a2(X− x1)(X− x2). Endéveloppant on trouve :
x1x2 =a0
a2et x1 + x2 = − a1
a2.
2. Si P est de degré 3 et si on note P = a0 + a1X + a2X2 + a3X3 = a3(X − x1)(X − x2)(X − x3). Là encore,en développant on trouve :
x1x2x3 = − a0
a3, x1x2 + x1x3 + x2x3 =
a1
a3et x1 + x2 + x3 = − a2
a3.
Cela conduit à la définition suivante (nous nous plaçons dans le cas d’un polynôme unitaire pour simplifier) :
Soit P =n
∏k=1
(X− xk). Pour tout entier p dans [[ 1 ; n ]] on note
σp = ∑i1<i2<···<ip
x1x2 · · · xp.
Définition 14.3.5.497 (Fonctions symétriques des racines)
Remarques :
1. On a donc
σ1 =n
∑i=1
xi = x1 + · · · xn
σ2 = ∑i<j
xixj = x1x2 + x1x2 + · · · xn−1xn
σn =n
∏i=1
xi = x1 · · · xn
213

2. Cela s’appelle les fonctions symétriques car elles sont clairement symétriques. Elle ne dépendent pas del’ordre des racines. De fait on peut montrer que toute expression polynomiale symétrique des racines peuts’exprimer unique en fonctions des σi. Par exemple,
x21 + x2
2 + x23 = (x1 + x2 + x3)
2 − 2(x1x2 + x1x3 + x2x3) = σ21 − 2σ2.
Trouver en exercice l’expression de x31 + x3
2 + x33
Soit P un polynôme scindé unitaire. Si on note P = a0 + a1X + · · ·+ Xn =n
∏k=1
(X− xk). On a
a0 = (−1)nσn, a1 = (−1)n−1σn−1, . . . , ak = (−1)n−kσn−k , . . . , an−1 = −σ1.
Proposition 14.3.5.498
Remarque : Ces formules s’appellent les relations coefficients-racines et généralisent celles qui ont été vuespour le degré 2.Exemple : Soit P = X3− X2− X− 2. Nous allons voir qu’il est scindé sur C. Si on note a, b et c ses racines alors
a2 + b2 + c2 = σ21 − 2σ2 = (1)2 − 2(−1) = 3.
3.6 Interpolation de Lagrange
Soit n ∈ N∗. On se donne (xi) ∈ Kn et yi ∈ Kn. On cherche à trouver des polynômes L de degré minimaltel que ∀i ∈ [[ 1 ; n ]] L(xi) = yi. Cela revient à chercher une courbe représentant un polynôme passant par lespoints Ai(xi , yi) pour tout i dans [[ 1 ; n ]].Exemple : On sait bien que par deux points passe toujours une droite. On doit donc pour n = 2 trouver unpolynôme de degré 1. De même pour trois points, il ne passe plus toujours une droite (même si cela peut arriver)on va donc chercher un polynôme de degré 2 et faire passer une parabole par ces points et ainsi de suite
Avec les notations ci-dessus, il existe un unique polynôme L tel que ∀i ∈ [[ 1 ; n ]] L(xi) = yi de degréinférieur ou égal à n− 1
Théorème 14.3.6.499 (Polynôme interpolateur de Lagrange)
Le polynôme défini par le théorème ci-dessus s’appelle polynôme interpolateur de Lagrange.
Définition 14.3.6.500
Démonstration :— Unicité : Soit P et Q deux polynômes de Kn−1[X] tels que ∀i ∈ [[ 1 ; n ]] P(xi) = Q(xi) = yi. Si on considère
P−Q qui est encore de degré au plus n− 1, il vérifie que ∀i ∈ [[ 1 ; n ]] (P−Q)(xi) = 0. Il est donc nul etP = Q.
— Existence : Si on considère le polynôme
Ai =n
∏k=0k 6=i
(X− xk).
Ce dernier s’annule en x1, . . . , xi−1, xi+1, . . . , xn et Ai(xi) = ∏nk=0k 6=i
(xi − xk) 6= 0. On introduit donc
Li =
n
∏k=0k 6=i
(X− xk)
n
∏k=0k 6=i
(xi − xk)
.
214

Il vérifie que
∀j ∈ [[ 1 ; r ]] , Li(xj) = δij =
1 si i = j0 si i 6= j
Il suffit donc de prendre
L =r
∑i=1
yiLi.
4 Arithmétique dans K[X]
Nous allons voir que la grande partie des résultats vus en arithmétique s’étendent au cas des polynômes.
4.1 Plus grand commun diviseur (PGCD)
On a vu que dans l’anneau K[X], comme dans l’anneau Z on avait une notion de divisibilité ainsi que ladivision euclidienne. De ce fait, la plupart des définitions et résultats de l’arithmétique de Z s’étende à K[X].La plus grande différence est que dans Z si n|n′ et n′|n alors n = n′ ou n = −n′ car les inversibles de Z sontjustes +1 et −1. Dans K[X] si P|Q et Q|P, il existe un polynôme constant non nul α tel que P = αQ. Pour celaon remplacera le « positif » par « unitaire ».
Soit P et Q deux polynômes non tous nuls. L’ensemble D(P) ∩D(Q) est non vide. De plus il existeun entier d tel que D(P) ∩D(Q) ⊂ Kd[X]
Proposition 14.4.1.501
Démonstration : L’ensemble D(P) ∩ D(Q) n’est pas vide car il contient 1. De plus, par symétrie on peutsupposer que P 6= 0. De ce fait, tout polynôme R de D(P) ∩D(Q) vérifie que deg(R) 6 deg(P).
Soit P et Q deux polynômes non tous nuls. On appelle un PGCD de P et Q tout polynôme R de D(P)∩D(Q)de degré maximal.
Définition 14.4.1.502
Exemple : Soit P = X2− 2X + 1 et Q = X2− 3X + 2. On voit que (X− 1) divise P et Q mais que tout polynômede degré 2 ne peut pas diviser P et Q.
Soit P et Q deux polynômes avec Q 6= 0. On pose P = AQ + R, alors les diviseurs communs à P etQ sont les même que ceux à Q et R. En particulier, si P = SQ + R est la division euclidienne de Ppar Q, on a
D(P) ∩D(Q) = D(Q) ∩D(R).
Proposition 14.4.1.503
Remarque : C’est la même chose que dans ZFMéthode : Comme dans le cas de Z, l’algorithme d’Euclide permet de calculer un PGCD.
Soit P = X4 + 3X3 − X2 + 3X− 6 et Q = X2 + 4X− 5.On a P = (X2 − X + 8)Q + (−34X + 34) puis Q = R(−34X + 34) + 0. Donc −34X + 34 est un PGCD de P
et Q.
Soit P et Q deux polynômes de K[X] non tous nuls et D un PGCD de P et Q. On a
∀R ∈ K[X], (R|P et R|Q) ⇐⇒ R|D.
Proposition 14.4.1.504
215

Remarque : Dans la proposition le sens ⇐ signifie en particulier que D est un diviseur commun car il sedivise lui même. Le sens ⇒ signifie que D est bien le plus grand diviseur commun au sens de la division.Démonstration :
— ⇐ : C’est juste la transitivité de la division car D|P et D|Q.— ⇒ : Comme dans le cas de Z, on fait une récurrence sur le degré de Q (ou de P si Q = 0). Le principe est
d’utiliser la division euclidienne.
Soit P et Q deux polynômes non tous nuls. Si D1 et D2 sont deux PGCD de P et Q alors D1 et D2sont associés.
Corollaire 14.4.1.505
Soit P et Q deux polynômes non tous nuls. On appelle le PGCD de P et Q l’unique PGCD unitaire de P etQ. On le note P ∧Q. Par extension, si P = Q = 0 on note P ∧Q = 0.
Définition 14.4.1.506
Soit P et Q deux polynômes non tous. Il existe des polynômes U et V tels que
PU + QV = P ∧Q.
Théorème 14.4.1.507 (Théorème de Bézout)
Démonstration : Il suffit d’utiliser l’algorithme mis en en place dans Z pour déterminer U et V.
Remarques :1. Cela signifie que PU + QV | (U, V) ∈ (K[X])2 = (P ∧Q).R | R ∈ K[X]. Relation que l’on peut écrire
PK[X] + QK[X] = (P ∧Q)K[X].
Là encore, cela serait une bonne manière de définir plus abstraitement le PGCD.2. En appliquant l’algorithme d’Euclide on obtient les coefficients de Bézout.
4.2 Polynômes premiers entre eux
Soit P et Q deux polynômes. On dit que P et Q sont premiers entre eux si et seulement si P ∧Q = 1.
Définition 14.4.2.508
Remarque : Cela signifie que les seuls polynômes divisant P et Q sont les polynômes constants.
Soit P et Q deux polynômes, ils sont premiers entre eux si et seulement s’il existe U, V dans K[X]tels que
PU + QV = 1.
Cela revient à dire que tout polynôme R de K[X] peut s’écrire sous la forme PU + QV.
Proposition 14.4.2.509
Exemple : Soit P = X− α et Q = X− β avec α 6= β. On a alors P−Q = β− α donc
1β− α
P− 1β− α
Q = 1.
On en déduit que P et Q sont premier entre eux.On a aussi une version du lemme de Gauss
216

Soit P et Q deux polynômes premiers entre eux alors pour tout polynôme R,
P|QR⇒ P|R.
Proposition 14.4.2.510 (Lemme de Gauss)
Démonstration : Même démonstration que sur Z en utilisant le théorème de Bézout.
Soit P et Q deux polynômes premiers entre eux alors Pr et Qs sont premiers entre eux.En particulier si α 6= β, (X− α)r ∧ (X− β)s = 1.
Corollaire 14.4.2.511
Soit P et Q deux polynômes. Il existe des polynômes P1 et Q1 premiers entre eux tels que
P = DP1 et Q = DQ1
où D = P ∧Q.
Proposition 14.4.2.512
Démonstration : Là encore la démonstration est analogue à celle dans Z.
4.3 Généralisation à une famille de polynômes
Comme dans le cas de Z, on peut généraliser ces définitions au cas d’une famille finie de polynômes
Soit r ∈ N \ 0, 1 et P1, . . . , Pr une famille de polynômes non tous nuls.
1. Il existe un unique polynôme unitaire D tel que
∀R ∈ K[X], (∀i ∈ [[ 1 ; r ]] , R|Pi)⇔ R|D
on le note D = P1 ∧ . . . ∧ Pr
2. Il existe (U1, . . . , Ur) ∈ K[X]r , P1U1 + · · ·+ PrUr = P1 ∧ . . . ∧ Pr.
Proposition-Définition 14.4.3.513
Remarque : On a par exemple P1 ∧ P2 ∧ P3 = (P1 ∧ P2) ∧ P3. Il suffit de voir que
P1K[X] + P2K[X] + P3K[X] = (P1 ∧ P2 ∧ P3)K[X].
Soit P1, . . . , Pr une famille de polynômes. On dit qu’il sont mutuellement premiers entre eux (ou premiersentre eux dans leur ensemble) si et seulement si P1 ∧ . . . ∧ Pr = 1.
Définition 14.4.3.514
Comme dans le cas de Z. La notion de premiers en leur ensemble est plus faible que 2 à 2 premiersentre eux.
ATTENTION
Exemple : Soit α1, . . . , αr des éléments de K deux à deux distincts. Les polynômes (X − αi)ni sont premiers
entre eux dans leur ensemble
217

4.4 Le plus grand commun multiple (PPCM)
Soit P et Q deux polynômes. Il existe un unique polynôme M unitaire ou nul dont les multiples sontles multiples communs à P et Q. On a
∀R ∈ K[X], P|R et Q|R⇒ M|R.
Proposition 14.4.4.515
Démonstration :
— Unicité : C’est le même argument que pour le PGCD.
— Existence : Remarquons d’abord que si A ou B est nul, on peut prendre M = 0. Par la suite, supposonsA et B non nuls. Il existe des multiples communs par exemple AB. Notons M l’ensemble des multiplescommuns non nuls et D = deg N | N ∈M . L’ensemble D est une partie non vide de N (car 0 /∈M ).Considérons un polynôme N de M de degré minimal.
— Tout multiple de N est bien un multiple commun de P et Q.
— Soit R un multiple commun de P et Q montrons que N divise R. On fait pour cela la divisioneuclidienne de R par N et on note S le reste. On a donc S = R− TN. Donc S est un multiple communde P et Q. Comme il est de degré strictement inférieur à celui de N on a S = 0 et N|R.
Soit P et Q deux polynômes. On appelle PPCM le polynôme défini ci-dessus. On le note P ∨Q.
Définition 14.4.4.516
Remarque : Là encore, M est un multiple commun et c’est le plus petit au sens de la division.Exemples :
1. Si P ou Q est nul, P ∨Q = 0.
2. Soit P = (X− α) et Q = (X− β). On a
P ∨Q =
(X− α)(X− β) si α 6= β
X− α si α = β
4.5 Propriétés du PGCD et du PPCM
Soit P et Q deux polynômes. Soit R un polynôme unitaire alors
PR ∧QR = (P ∧Q)R et PR ∨QR = (P ∨Q)R.
Proposition 14.4.5.517
Démonstration : Comme nous ne l’avions pas faite sur Z, nous allons la faire.
— Pour le PGCD : On note D = P ∧Q. On sait que D divise P et Q donc DR divise PR et QR. On en déduitque DR|(PR ∧QR).De plus, si on note T = (PR ∧QR). On veut montrer que T|DR. Remarquons d’abord que R|T car R estun diviseur commun de PR et QR. On peut donc écrire T = UR. Maintenant comme T divise PR on a Uqui divise P. De même U divise Q. On en déduit que U|D et donc T = UR|DR.On conclut en utilisant que PR ∧QR et (P ∧Q)R sont unitaires.
— Pour le PPCM : On note M = P ∨ Q. Alors P|M et Q|M donc PR|MR et QR|MR. On en déduit (PR ∨QR)|MR. Maintenant on sait que PR|(PR ∨ QR) donc R|(PR ∨ QR). On note PR ∨ QR = UR. CommePR|UR on en déduit que P|U. De même on trouve que Q|U et donc (P ∨Q)|U. En multipliant par R ona (P ∨Q)R|UR = PR ∨QR. On conclut comme précédemment en utilisant que ce sont des polynômesunitaires.
218

Soit P et Q deux polynômes premiers entre eux. Soit R un polynôme alors
P|R et Q|R⇒ PQ|R.
En particulier si PQ est unitaire alors P ∨Q = PQ.
Proposition 14.4.5.518
Démonstration : Puisque P et Q sont premiers entre eux il existe U et V tels que PU + QV = 1 et doncPRU + QRV = R. Maintenant, Q|R donc PQ|PRU. De même PQ|QRV. On a bien PQ|R.
Soit P et Q deux polynômes. Il existe λ ∈ K? tel que
(P ∧Q)(P ∨Q) = λPQ.
Corollaire 14.4.5.519
Démonstration : La proposition précédente est le cas où P et Q sont premiers entre eux. On démontre le casgénéral en écrivant P = DP1 et Q = DQ1 où D = P ∧Q et P1 ∧Q1 = 1.
5 Factorisation
C’est un résultat connu que si n est un entier, il peut s’écrire de manière unique comme un produit denombres premiers. Par exemple 12936 = 23 × 3× 72 × 11. Nous allons essayer de faire de même pour lespolynômes dans R[X] et C[X]. La première tache est alors de trouver un analogue aux nombres premiers.
5.1 Polynômes irréductibles
Un polynôme non constant P est dit irréductible s’il n’a pas de diviseurs triviaux, c’est-à-dire que P n’estdivisible que par les multiples de P et les polynômes constants. Cela s’écrit :
∀Q ∈ K[X], Q|P⇒ (∃λ ∈ K, Q = λ.P ou Q = λ).
Définition 14.5.1.520
Remarques :
1. C’est un analogue des nombres premiers. Un nombre entier est dit premier s’il n’est divisible que parlui-même et par 1. Avec toujours le fait que les inversibles de K[X] ne sont pas que 1 et −1 mais tous lespolynômes constants.
2. On considère qu’un polynôme constant n’est pas irréductible, de la même manière que 1 n’est pas unnombre premier.
Exemples :
1. Les polynômes de degré 1 sont irréductibles.
2. Étudions le cas des polynôme de degré 2 pour K = C. On sait qu’ils ont toujours une racine α. De ce faitils ne sont pas irréductibles car divisible par (X− α).
3. Étudions le cas des polynôme de degré 2 pour K = R. On regarde ∆ le discriminant.
— si ∆ > 0 le polynôme a des racines réelles. Il n’est donc pas irréductible.
— si ∆ < 0 le polynôme n’a pas de racines réelles. Supposons par l’absurde qu’il ne soit pas irréductible.Il serait alors divisible par un polynôme non constant de degré strictement inférieur. C’est à dire parun polynôme de degré 1. C’est absurde car il n’a pas de racines réelles. Dans ce cas, le polynôme estirréductible.
219

Remarque : Attention, contrairement à ce que pourrait faire croire ci qui précède, il n’y a pas équivalence entreêtre irréductible et ne pas avoir de racines. On a bien
(P est irréductible )⇒ P n’a pas de racines.
Cela se démontre bien par contraposée. Mais la réciproque est fausse. Par exemple le polynôme P = 2X4 +6X2 + 4 n’a pas de racines réelles de manière évidente. Cependant P = 2(X2 + 1)(X2 + 2). Donc P n’est pasirréductible.
5.2 Décomposition en produit de facteurs irréductibles
C’est l’analogue de la décomposition en facteurs premiers dans Z. Nous avons déjà énoncé le théorèmeprécédemment. Nous allons maintenant le démontrer. Nous aurons avant besoin d’un proposition.
Soit P un polynôme irréductible. Il est premier avec tous les polynômes qu’il ne divise pas.
Proposition 14.5.2.521
Démonstration : Soit Q un autre polynôme. On suppose que P et Q ne sont pas premiers. Dans ce cas il existe Rnon constant qui divise P et Q. Comme R est non constant et qu’il divise P qui est irréductible, il existe λ ∈ K?
tel que P = Rλ. On a donc P|Q.
Soit P un polynôme non constant. Il peut s’écrire sous la forme
P = λ.p
∏k=1
Qk ,
où λ ∈ K et les Qk sont des polynômes unitaires irréductibles sur K. De plus cette décomposition estunique à l’ordre des facteurs.
Théorème 14.5.2.522
Démonstration : L’existence se fait par récurrence sur le degré de P. L’unicité est la même démonstration quedans Z.
Remarques :1. C’est l’analogue de la décomposition en nombres premiers dans Z.2. Nous le démontrerons plus loin.3. Une telle décomposition s’appelle une factorisation de P.
Exemple : Dans l’exemple précédent, l’écriture P = 2(X2 + 1)(X2 + 2) est la factorisation sur R car lespolynômes X2 + 1 et X2 + 2 sont irréductibles sur R (les discriminants sont −4 et −8). Par contre sur C lafactorisation sera
P = 2(X + i)(X− i)(X + i√
2)(X− i√
2).
On a alors le même corollaire que dans Z :
Soit P et Q deux polynômes. On note
P = Rα11 × · · · × Rαr
r et Q = Rβ11 × · · · × Rβr
r
les décompositions en facteurs premiers. On a alors
1. Le nombre P divise Q si et seulement si ∀i ∈ [[ 1 ; r ]] , αi 6 βi.
2. On a
P ∧Q =r
∏i=1
RMin(αi ,βi)
i et P ∨Q =r
∏i=1
RMax(αi ,βi)
i .
Proposition 14.5.2.523
220

5.3 Factorisation sur C
Contrairement à ce que vous pourriez penser, il est plus simple de factoriser sur C. La raison est que ladescription des polynômes irréductibles est plus élémentaires. On a
Soit P un polynôme à coefficient complexe. Si deg P > 1 alors P a une racine dans C.
Théorème 14.5.3.524 (Théorème de Gauss-D’alembert)
Remarques :
1. Il faut comprendre le « P a une racine » dans le sens de l’existante d’une racine c’est-à-dire qu’il peut enavoir plusieurs.
2. Ce théorème est très important en mathématique et est assez difficile à démontrer.
3. Cela englobe en particulier le cas des polynômes réels.
Les polynômes irréductibles dans C[X] sont les polynômes de degré 1. En particulier, soit P unpolynôme à coefficient dans C, sa factorisation est de la forme
P(X) = λ.p
∏k=1
(X− αi)ri ,
où λ ∈ C est le coefficient dominant de P, αi les racines de P et ri leur multiplicité.
Corollaire 14.5.3.525
Remarque : Cela signifie que tout polynôme est scindé sur C.Exemple : On considère le polynôme P = 1− X4. On l’écrit P = −(X4 − 1). Ses racines sont 1, eiπ/2, eiπ ete3iπ/2. On a quatre racines distinctes, elles sont donc toutes simples. On a alors
P(X) = −3
∏k=0
(X− eikπ/2) = −(X− 1)(X− i)(X + 1)(X + i).
Exercice : Factoriser le polynôme X5 + X4 − X− 1.
5.4 Quelques applications de la factorisation sur C
Soit P un polynôme à coefficients dans C. Soit (α1, . . . , αp) ∈ Cp ses racines et (r1, . . . , rp) lesmultiplicités respectives. On a
r1 + · · ·+ rp = deg P.
Proposition 14.5.4.526
Soit P et Q deux polynômes non nuls à coefficients complexes. Le polynôme Q divise P si etseulement si toutes les racines de Q sont des racines de P avec des multiplicités supérieures.
Proposition 14.5.4.527
Exemple : Pour quels entiers n, X2 + X + 1 divise-t-il Pn = X2n+1 + Xn+2 + 1? A-t-on (X2 + X + 1)2|Pn ?
5.5 Factorisation sur R
Attention le théorème de d’Alembert-Gauss n’est plus vrai dans R. Par exemple le polynôme X2 + 1 n’a pasde racines et est irréductible.
221

Les polynômes irréductibles de R sont :
— Les polynômes de degré 1.
— Les polynômes de degré 2 de la forme aX2 + bX + c avec b2 − 4ac < 0.
Proposition 14.5.5.528
Soit P un polynôme à coefficients réels. Il existe λ ∈ R, (p, q) ∈ N2, (r1, · · · , rp) ∈ Np, (s1, . . . , sq) ∈Nq, (α1, · · · , αp) ∈ Rp, (β1, · · · , βq) ∈ Rq et (γ1, . . . , γq) ∈ Rq tels que
P = λ.p
∏i=1
(X− αi)ri .
q
∏i=1
(X2 − βi + γi)si .
Théorème 14.5.5.529 (Factorisation dans R[X])
Avant de le démontrer on va devoir un peu travailler sur la conjugaison complexe.
Soit P =N
∑k=0
akXk un polynôme de C[X]. On appelle conjugué de P et on note P le polynôme
P =N
∑k=0
akXk.
Définition 14.5.5.530
On a alors les propriétés suivantes :
Soit (P, Q) ∈ (C[X])2.
1. P + Q = P + Q.
2. ∀α ∈ C, P(α) = P(α).
3. P′ = P′ et donc ∀k ∈ N, P(k) = P(k).
4. P ∈ R[X] ⇐⇒ P = P.
Proposition 14.5.5.531
Soit P un polynôme à coefficients réels. Soit α une racine complexe, le conjugué α est aussi racine etde même multiplicité.
Corollaire 14.5.5.532
Démonstration
On peut maintenant démontrer le théorème. La démonstration est importante car c’est la méthode utiliséedans les calculs.Démonstration : On considère toutes les racines complexes de P. On met d’un coté les racines réelles. On
donne le termep
∏i=1
(X− αi)ri . On considère alors les racines complexes que l’on regroupe deux à deux avec les
conjugués puis on utilise que(X− α)(X− α) = (X2 − 2Re(α)X + |α|2).
222

Exemple : On considère le polynôme X4 + 1. Ses racines dans C sont eiπ/4, e3iπ/4, e5iπ/4 et e7iπ/4. On remarquealors que
e5iπ/4 = eiπ/4 et e7iπ/4 = e3iπ/4.
D’où(X4 + 1) = (X2 +
√2 + 1)(X2 −
√2 + 1).
Exercice : Soit P = 1+ 2X + 3X2 + 2X3 + X4. Montrer que j est racine et déterminer sa multiplicité. En déduiresa factorisation sur C puis sur R
223

15Dérivation
1 Définitions 2241.1 Nombre dérivé . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2241.2 Interprétation graphique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2271.3 Fonction dérivée . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2271.4 Opérations algébriques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2271.5 Dérivées des fonctions usuelles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 230
2 Dérivées d’ordre supérieure 2312.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2312.2 Opérations algébriques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 231
3 Accroissements finis 2333.1 Extremums . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2333.2 Théorème des accroissements finis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2343.3 Inégalités des accroissements finis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2353.4 Application à la monotonie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2363.5 Application aux prolongements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 237
Nous allons étudier la notion de dérivée. Pour cela nous commencerons pas regarder la dérivée en un pointpuis la notion de fonction dérivée.
1 Définitions
1.1 Nombre dérivé
Soit I un intervalle et I une fonction définie sur I. Soit a ∈ I, on dit que la fonction est dérivable en a si letaux d’accroissement en a à une limite finie. C’est à dire si la fonction ϕa définie sur I − a par
ϕa(x) =f (x)− f (a)
x− a
admet une limite quand x tend vers a.
Dans ce cas, cette limite s’appelle nombre dérivé de f en a et se note f ′(a) oud fdx
(a). On dit que f est dérivableen a.
Définition 15.1.1.533 (Nombre dérivé)
224

Remarque : Si on veut faire ce calcul, on se ramène la plupart du temps à une limite en 0 en posant x = a + h.Dès lors, sous réserve d’existence,
f ′(a) = limh→0
f (a + h)− f (a)h
.
Exemples :
1. Soit f : x 7→ 2x2 + 3. On cherche à savoir si elle est dérivable en a = 3. On calcule
ϕa(x) =f (x)− f (3)
x− 3=
2x2 + 3− 21x− 3
= 2.x2 − 9x− 3
= x + 3.
On en déduit que ϕa tend vers 6 quand x tend vers 3 donc f est dérivable en 3 et f ′(3) = 6..
2. Soit f : x 7→ √x. Soit a ∈ R+. On a donc
ϕa(x) =√
x−√ax− a
=1√
x +√
a.
On en déduit que si a 6= 0 alors f est dérivable et f ′(a) =1
2√
a. Par contre elle n’est pas dérivable en 0.
3. Soit f la fonction définie sur R? par f : x 7→ x sin(
1x
).
On remarque que ∀x ∈ R?, | f (x)| 6 |x|. En particulier on peut la prolonger par continuité en 0 en posantf (0) = 0 1.On peut alors se demander si le prolongement obtenu est dérivable en 0. Pour cela on regarde le tauxd’accroissement en 0 :
∀x ∈ R?, ϕ0(x) =x sin(1/x)− 0
x= sin(1/x).
On en déduit que le taux d’accroissement n’a pas de limite en 0 et, de ce fait, la fonction f n’est pasdérivable en 0.
Exercice : Le prolongement par continuité de x 7→ x2 sin(1/x) est-il dérivable en 0?
Si f est dérivable en a alors elle est continue en a. La réciproque est fausse.
Proposition 15.1.1.534
Démonstration
Avec les notations précédentes, on dit que f est dérivable à droite (resp. à gauche) en a si ϕa admet une limite àdroite (resp. à gauche) finie. On note alors
f ′d(a) = limx→a+
f (x)− f (a)x− a
,(
resp. f ′g(a) = limx→a−
f (x)− f (a)x− a
).
Définition 15.1.1.535 (Nombre dérivé à droite et à gauche)
Remarque : La fonction f est dérivable à droite en a si la restriction de f à I ∩ [a,+∞[ est dérivable. De mêmeà gauche avec la restriction à I∩]−∞, a].
On a alors comme pour les limites
Avec les notations précédentes :
( f dérivable en a)⇔ ( f dérivable à droite et à gauche en a et f ′d(a) = f ′g(a)).
Proposition 15.1.1.536
1. Par abus on note encore f le prolongement par continuité obtenu.
225

Démonstration : La fonction ϕa n’est pas définie en a. De ce fait, elle a une limite en a si et seulement elle a deslimites à gauche et à droite qui existent et sont égales.
Exemple : Soit f définie sur R par f : x 7→ |x|.Soit a ∈ R?
+, il existe un voisinage V de a dont tous les éléments sont strictement positif. Pour tout x dansV \ a, on a
ϕa(x) =|x| − |a|
x− a=
x− ax− a
= 1.
On en déduit que f est dérivable en a et que f ′(a) = 1.De même si a ∈ R?
−, on trouve f ′(a) = −1.Pour a = 0, les calculs précédents montrent que f ′d(0) = 1 et f ′g(0) = −1. On en déduit alors par la
proposition ci-dessus que f n’est pas dérivable en 0.
On dit que f admet un développement limité à l’ordre 1 au voisinage de a s’il existe (a0, a1) ∈ R2, pour toutx au voisinage de a
f (x) = a0 + a1(x− a) + oa(x− a) .
Définition 15.1.1.537
Remarque : Si on applique cela à x = a on trouve que nécessairement, a0 = f (a).
Une fonction f est dérivable en a si et seulement si elle admet un développement limité à l’ordre 1en a. Dans ce cas, a0 = f (a) et a1 = f ′(a).
Proposition 15.1.1.538
Démonstration :
— ⇒ On suppose que f est dérivable en a et on veut montrer que f (x)− f (a)− f ′(a)(x− a) est négligeabledevant x− a en a. Il suffit de calculer
∀x 6= a,f (x)− f (a)− f ′(a)(x− a)
x− a=
f (x)− f (a)x− a
− f ′(a).
Ceci tend bien vers 0 par définition de f ′.
— ⇐ Il suffit de faire le calcul dans l’autre sens.
Avec les notations précédentes, si f est dérivable en a et que f ′(a) 6= 0 alors
f (x)− f (a) ∼a(x− a) f ′(a).
Corollaire 15.1.1.539
Soit f et g deux fonctions qui coïncident au voisinage de a. On a alors f est dérivable en a si etseulement si g dérivable en a. De plus, dans ce cas, f ′(a) = g′(a).
Proposition 15.1.1.540
226

1.2 Interprétation graphique
Soit f une fonction définie sur I et a un élément de I. On appelle C la courbe de f . On pose A le point de
coordonnées(
af (a)
)et M le point de coordonnées
(x
f (x)
). On regarde alors la corde (AM). Sa pente est
donnée par le taux d’accroissement ϕa(x). En particulier, le vecteur (1, ϕa(x)) en est un vecteur directeur.Si on suppose que f est dérivable en a alors les vecteurs directeurs (1, ϕa(x)) tendent vers (1, f ′(a)) qui est
donc la « limite »des cordes (AM).La tangente à la courbe C en a est donc la droite passant par A et de vecteur directeur (1, ϕa(x)). Son
équation esty− f (a) = f ′(a)(x− a) ( ou y = f (a) + f ′(a)(x− a)).
Remarques :
1. Si un fonction admet une dérivée à droite (ou à gauche) en a alors sa courbe a une demi-tangente à cepoint. Par exemple la fonction x 7→ |x|.
2. Si f est continue en a et que le taux d’accroissement tend vers ±∞ alors les cordes « tendent »vers la droiteverticale passant par A. On dit que C a une tangente verticale. Par exemple x 7→ √x en 0.
1.3 Fonction dérivée
Soit I un intervalle et f une fonction définie sur I.On dit que f est dérivable sur I (ou juste dérivable) si f estdérivable en tout point de I. La fonction dérivée de f est alors la fonction, notée f ′ définie sur I qui associe à x
dans I le nombre dérivée f ′(x). On la note aussid fdx
.
Définition 15.1.3.541
Notation : On notera D1(I) l’ensemble des fonctions définies et dérivables sur un intervalle I.
Soit I un intervalle et f une fonction définie sur I. On dit que f est de classe C 1 si elle est dérivable sur I et sisa fonction dérivée est continue sur I. L’ensemble des fonctions de classe C 1 sur I se note C 1(I).
Définition 15.1.3.542
Remarque : De fait, la notion de fonction de classe C 1 est souvent plus utile que celle de fonction dérivable.On a
C 1(I) ⊂ D1(I) ⊂ C 0(I).
1.4 Opérations algébriques
On se fixe un intervalle I dans tout ce paragraphe.
Soit f , g deux fonctions définies sur I et (λ, µ) ∈ R2. Soit a ∈ I, si f et g sont dérivable en a alorsλ. f + µ.g est dérivable en a et (λ. f + µ.g)′(a) = λ. f ′(a) + µ.g′(a).On en déduit que si f et g appartiennent à D1(I), (λ. f + µ.g) aussi et (λ. f + µ.g)′ = λ. f ′ + µ.g′.
Proposition 15.1.4.543 (Linéarité)
Remarque : cette proposition remplace l’addition et la multiplication externe.Démonstration : En utilisant le développement limité.
227

Les ensembles C 1(I) et D1(I) sont des sous-espaces vectoriels de F (I, R). En particulier, unecombinaison linéaire de fonctions dérivables est dérivable. De plus l’application
D : D1(I) → F (I, R)f 7→ f ′
est linéaire
Corollaire 15.1.4.544
Soit f , g deux fonctions définies sur I. Soit a ∈ I, si f et g sont dérivables en a alors f .g est dérivableen a et ( f .g)′(a) = f ′(a).g(a) + f (a).g′(a).On en déduit que si f et g appartiennent à D1(I), ( f .g) aussi et ( f .g)′ = f ′.g + f .g′.
Proposition 15.1.4.545 (Produit)
Démonstration : En utilisant les développements limités.
f (x) = f (a) + (x− a) f ′(a) + oa(x− a) et g(x) = g(a) + (x− a)g′(a) + o
a(x− a) .
C’est à dire qu’il existe des fonctions ε1 et ε2 tendant vers 0 en a telle que
f (x) = f (a) + (x− a) f ′(a) + (x− a)ε1(x) et g(x) = g(a) + (x− a)g′(a) + (x− a)ε2(x).
On fait le produit et on trouve :
( f .g)(x) = ( f .g)(a) + (x− a)[ f (a)g′(a) + f ′(a)g(a)] + (x− a)2 f ′(a)g′(a) + (x− a)ε1(x)(g(a) + (x− a)g′(a) + (x− a)ε2(x)) + (x− a)ε2(x)( f (a) + (x− a) f ′(a))= ( f .g)(a) + (x− a)[ f (a)g′(a) + f ′(a)g(a)] + o
a((x− a)) .
Exemple : On trouve directement que la fonction x 7→ x2 est dérivable et que sa dérivée est x 7→ 2x. Parrécurrence, on prouve que la dérivée de x 7→ xn est x 7→ nxn−1. On peut ensuite généraliser aux polynômes parlinéarité
Soit f , g deux fonctions définies sur I. Soit a ∈ I, si f et g sont dérivable en a et g(a) 6= 0, alors f /gest dérivable en a et (
fg
)′(a) =
f ′(a)g(a)− f (a)g′(a)g2(a)
.
On en déduit que si f et g appartiennent à D1(I) et que g ne s’annule pas sur I, ( f /g) aussi et
( f /g)′ =f ′.g− f .g′
g2 .
Proposition 15.1.4.546 (Quotient)
Démonstration : Commençons par 1/g. On en déduira alors le cas général en utilisant le produit. Soit g unefonction dérivable en a et qui ne s’annule pas en a.
Alors pour x 6= a,
ϕa(x) =
1g(x)
− 1g(a)
x− a=
g(x)− g(a)x− a
.−1
g(x)g(a).
Quand x tend vers a cela tend vers−g′(a)g2(a)
.
Maintenant, on a donc
( f × 1/g)′(a) = f ′(a)× (1/g)(a) + f (a)× −g′(a)g2(a)
=f ′(a)g(a)− f (a)g′(a)
g2(a).
228

Soit f une fonction définie sur I et g une fonction définie sur J. On suppose que g(J) ⊂ I. Soit a unélément de J. Si g est dérivable en a et f est dérivable en g(a) alors f g est dérivable en a et
( f g)′(a) = g′(a).( f ′ g)(a).
On en déduit que si f appartient à D1(I) et g appartient à D1(J) alors f g est un élément de D1(J)et
( f g)′ = g′ × f ′ g.
Proposition 15.1.4.547 (Composée)
Démonstration :Soit x 6= a. On a
ϕa(x) =f (g(x))− f (g(a))
x− a.
On voudrait écrire que
f (g(x))− f (g(a))x− a
=f (g(x))− f (g(a))
g(x)− g(a)× g(x)− g(a)
x− a
mais on est embêté si jamais g(x) = g(a).Pour cela on pose
ψ : y 7→
f (y)− f (g(a))y− g(a)
si y 6= g(a)
f ′(g(a)) sinon
Ainsi définie, cette fonction est continue sur J (car on pris la bonne valeur quand y = g(a).).Maintenant, pour tout x 6= a,
ϕa(x) =f (g(x))− f (g(a))
x− a= ψ(g(x))× g(x)− g(a)
x− a.
En effet, c’est ce que l’on avait vu quand g(x) 6= g(a) et de plus quand g(x) = g(a) les deux termes sontnuls.
En faisant tendre x vers a on trouve le résultat cherché.
Soit f : I → J une bijection.
— Soit a un élément de I. Si f est dérivable en a et que f ′(a) 6= 0 alors f−1 est dérivable en f (a) et
( f−1)′( f (a)) =1
f ′(a)ou ( f−1)′(b) =
1f ′( f−1(b))
en posant b = f (a).
— Si f est dérivable sur I et si f ′ ne s’annule pas alors f−1 est dérivable sur J et
( f−1)′ =1
f ′ f−1 .
Proposition 15.1.4.548 (Réciproque)
Démonstration : On pose b = f (a) et on veut montrer que
limy→b
f−1(y)− f−1(b)y− b
=1
f ′(a).
Or
f ′(a) = limx→a
f (x)− f (a)x− a
.
229

Comme la fonction f−1 est continue, limy→b
f−1(y) = f−1(b) = a, par composition,
f ′(a) = limy→b
f ( f−1(y))− f (a)f−1(y)− a
= limy→b
y− bf−1(y)− f−1(b)
.
Comme f ′(a) n’est pas nul on peut passer à l’inverse.
Remarque : Si on veut juste la formule sans à redémontrer la dérivabilité, on peut ultiliser que ( f f−1) = Id.En dérivant, ( f−1)′ × f ′ f−1 = 1 et donc
( f−1)′ =1
f ′ f−1 .
Exemple : On prend f la restriction de cos à [0, π]. On sait que c’est une bijection de [0, π] sur [−1, 1] et qu’elleest dérivable. De plus f ′ s’annule en 0 et en π. Donc arccos est dérivable sur [−1, 1] \ f (0), f (π) =]− 1, 1[.De plus, sa dérivée en x ∈]− 1, 1[ est
arccos′(x) =1
− sin(arccos x).
Et on sait que que sin(arccos(x)) =√
1− x2. On a donc
arccos′(x) =−1√
1− x2.
Nous verrons plus loin que l’on peut dire qu’en 1 et −1 la courbe représentative de de arccos a une tangenteverticale.
1.5 Dérivées des fonctions usuelles
Fonction Dérivée Remarquesxn (n ∈ Z) nxn−1 sur R ou R? si n < 0xα (α /∈ Z) αxα−1 sur R?
+
†√
x1
2√
xR?+
eωx (ω ∈ C) ω.eωx sur Rax ln a× ax R
ln x 1/x sur R?+
loga x1
x ln asur R?
+
sin x cos x sur Rcos x − sin x sur R
tan x 1 + tan2 x =1
cos2 xsur ]− π/2 + kπ, π/2 + kπ[
† arcsin x1√
1− x2sur ]− 1, 1[
† arccos x−1√
1− x2sur ]− 1, 1[
arctan x1
1 + x2 sur R
th x ch x sur Rch x sh x sur R
th x 1− th 2x =1
ch 2xsur R
En utilisant la formule pour les dérivées de fonctions composées et les dérivées des fonctions usuelles ontrouve que :
Fonction Dérivéeuα αu′uα−1
√u
u′
2√
ueu u′.eαu
ln uu′
u
230

2 Dérivées d’ordre supérieure
2.1 Définitions
L’idée est que si f est dérivable sur un intervalle I. Si la fonction dérivée f ′ est encore dérivable on dira quela fonction est deux fois dérivable et que se dérivée seconde est f ′′ = ( f ′)′. Précisément :
Soit I un intervalle et f une fonction définie sur I. On définit les dérivées d’ordre 0, 1, · · · , n par récurrencequand elles existent par :
∀x ∈ I, f (n)(x) = ( f (n−1))′(x).
La fonction f (n) s’appelle la dérivée n-ième. Si elle existe, la fonction f est dite n fois dérivable.
Définition 15.2.1.549
Notation : L’ensemble des fonctions n fois dérivables sur un intervalle I se note Dn(I). On note aussi C n(I)l’ensemble des fonctions n fois dérivable et dont la dérivée n-ième est continue. 2
On a donc :· · · ⊂ Dn+1 ⊂ C n ⊂ Dn ⊂ · · · ⊂ D2 ⊂ C 1 ⊂ D1 ⊂ C 0
On notera aussi C ∞ les fonctions infiniment dérivables, c’est à dire que l’on peut dériver autant de fois quel’on veut.
1. Les polynômes sont des fonctions C ∞ sur R.
2. Les fonctions exponentielles et logarithmes sont C ∞ sur leur ensemble de définition.
3. Les fonctions puissances sont C ∞. On fera attention à l’intervalle de définition.
4. Les fonctions circulaires sont C ∞ sur leur ensemble de définition.
5. Les fonctions arcsin et arccos sont C ∞ sur ]− 1, 1[. La fonction arctan est C ∞ sur R.
6. Les fonctions ch , sh et th sont C ∞.
Proposition 15.2.1.550
Exemples :
1. Soit p ∈ N et n un entier inférieur à p alors (xp)(n) =p!
(p− n)!xp−n.
2. Soit α ∈ R et f : x 7→ xα. Pour tout réel strictement positif x et tout entier n,
f (n)(x) = α(α− 1) · · · (α− n + 1)xα−n.
3. Soit n ∈ N et α ∈ R, (eαx)(n) = αneαx.
4. Soit n ∈ N, cos(n)(x) = cos(x + nπ/2). En effet si on remarque que cos(x) = Re(eix). Alors
cos(n)(x) = Reineix = Re(eiπ/2)neix = Reei(x+nπ/2) = cos(n + nπ/2).
2.2 Opérations algébriques
On va voir que les relations sur les opérations algébriques sont aussi vraies pour les dérivées n-ièmes. Nousallons écrire tous les énoncés pour les ensembles C n mais ils sont aussi vrais pour C ∞ ou Dn.
Soit I un intervalle et f , g deux fonctions et (λ, µ) ∈ R2. Si f et g appartiennent à C n(I), (λ. f + µ.g)aussi et (λ. f + µ.g)(n) = λ. f (n) + µ.g(n).
Proposition 15.2.2.551 (Linéarité)
2. la condition ne porte que sur la dérivée n-ième car les autres étant dérivables elles sont obligatoirement continues.
231

On en déduit que C n(I), C ∞(I) et Dn(I) sont des sous-espaces vectoriels de F (I, R). Une combi-naison linéaire de fonctions n fois dérivables est n fois dérivable. Sa dérivée n-ième est la mêmecombinaison linéaire des dérivées n-ième. En effet l’application
Dn : Dn(I) → F (I, R)
f 7→ f (n)
est linéaire.
Corollaire 15.2.2.552
Soit I un intervalle et f et g deux fonctions définies sur I.Si f et g appartiennent à C n(I), ( f .g) aussi et
( f .g)(n) =n
∑k=0
(nk
)f (k).g(n−k).
Proposition 15.2.2.553 (Produit - Formule de Leibniz)
Démonstration : Montrons par récurrence sur n ∈ N? que pour tout entier non nul n, « Si f et g appartiennentà C n(I), ( f .g) aussi et ( f .g)(n) = ∑n
k=0 (nk) f (k).g(n−k). ».
— Initialisation : pour n = 1, c’est la propriété vue précédemment. On a bien
( f .g)′ = f ′g + g′ f =1
∑k=0
(1k
)f (k)g(1−k).
— Hérédité : On suppose que f et g sont n + 1 fois dérivables. Alors elles sont n fois dérivables et de ce fait( f g) aussi et
( f .g)(n) =n
∑k=0
(nk
)f (k).g(n−k).
La forme de droite est dérivable, on en déduit que celle de gauche aussi et
( f g)(n+1) =
(n
∑k=0
(nk
)f (k).g(n−k)
)′
=n
∑k=0
(nk
)(f (k).g(n−k)
)′
=n
∑k=0
(nk
)(f (k+1).g(n−k) + f (k)g(n+1−k)
)
=
(n
∑k=0
(nk
)f (k+1).g(n−k)
)+
(n
∑k=0
(nk
)f (k)g(n+1−k)
)
=
(n+1
∑k=1
(n
k− 1
)f (k).g(n+1−k)
)+
(n
∑k=0
(nk
)f (k)g(n+1−k)
)
=
(00
)f (0)g(n+1) +
n+1
∑k=1
((n
k− 1
)+
(nk
))f (k).g(n+1−k) +
(nn
)f (n+1)g(0)
=n+1
∑k=0
(n + 1
k
)f (k).g(n+1−k)
Soit I un intervalle et f , g deux fonctions. Si f et g appartiennent à C n(I) et que g ne s’annule passur I, ( f /g) est n fois dérivable.
Proposition 15.2.2.554 (Quotient)
232

Soit f une fonction définie sur I et g une fonction définie sur J. On suppose que g(J) ⊂ I. Si fappartient à C n(I) et g appartient à C n(J) alors f g est un élément de C n(J).
Proposition 15.2.2.555 (Composée)
Démonstration : Montrons par récurrence.
— I Pour n = 1 cela a été fait ci-dessus.
— H Soit n on suppose que si f et g sont de classe C n alors f g aussi. Montrons que la propriété est aussivraie pour n + 1. Supposons donc que f et g soient de classe C n+1. On sait alors que ( f g) est dérivableet ( f g)′ = g′ × f ′ g. Maintenant, g′ ∈ C n car g ∈ C n+1 et f ′ g ∈ C n donc, par produit, ( f g)′ est declasse C n d’où f g est de classe C n+1.
Donc, par récurrence . . .
La formule de la dérivée n-ieme d’une composé est TRES compliquée. C’est la formule de Faà diBruno :
( f g)(n)(x) = ∑n!
m1! · · ·mn!f (m1+···+mn)(g(x))×
n
∏j=1
(g(j)(x)
j!
)mj
.
La somme est prise sur tous les n-uplets (m1, . . . , mn) tels que m1 + 2m2 + · · ·+ nmn = n.
ATTENTION
Soit f : I → J une bijection. Si f est n fois dérivable sur I et si f ′ ne s’annule pas alors f−1 est n foisdérivable sur J.
Proposition 15.2.2.556 (Réciproque)
Exercice : faire la démonstration par récurrence.Exercice : Calculer les dérivées n-ièmes de x 7→ ln(1 + x) et x 7→ x2 ln(1 + x).
3 Accroissements finis
3.1 Extremums
Soit I un intervalle et f une fonction définie sur I. Soit a un élément de I.
1. On dit que a est un maximum global si : ∀x ∈ I, f (x) 6 f (a).
2. On dit que a est un minimum global si : ∀x ∈ I, f (x) > f (a).
3. On dit que a est un maximum local s’il existe un voisinage V de a tel que a soit un maximum global dela restriction de f à V. C’est-à-dire : ∃ε > 0, ∀x ∈ I∩]a− ε, a + ε[, f (a) > f (x).
4. On dit que a est un minimum local s’il existe un voisinage V de a tel que a soit un minimum global dela restriction de f à V. C’est-à-dire : ∃ε > 0, ∀x ∈ I∩]a− ε, a + ε[, f (a) 6 f (x).
5. On dit que a est un extremum global si c’est un maximum global ou un minimum global.
6. On dit que a est un extremum local si c’est un maximum local ou un minimum local.
Définition 15.3.1.557
Remarque : Un extremum global est aussi un extremum local le contraire est faux.
233

Soit I un intervalle et a ∈ I.
1. On dit que a est un point intérieur à I s’il appartient à I et que ce n’est pas une borne.
2. Soit f une fonction définie et dérivable sur I. On dit que a est un point critique de f si f ′(a) = 0.
Définition 15.3.1.558
Soit f une fonction dérivable sur un intervalle I et a un point intérieur de I. Si a est un extremumlocal pour f alors f ′(a) = 0. C’est un point critique.
Théorème 15.3.1.559
Remarques :1. Il faut faire attention que le point a peut-être un extremum sans que la dérivée ne s’annule si c’est une
borne. Par exemple x 7→ x sur [0, 1].2. La réciproque est bien sûre fausse. Par exemple, le point 0 pour la fonction f : x 7→ x3.
Démonstration : Soit a, on suppose que c’est un extremum local. Soit ε > 0 tel que a soit un maximum globalsur ]a− ε, a + ε[⊂ I. On a alors
f ′(a) = limh→0
f (a + h)− f (a)h
.
Pour tout h ∈]− ε, 0[ on af (a + h)− f (a)
h> 0 car le numérateur et le dénominateur sont négatifs. Par contre
Pour tout h ∈]0, ε[ on af (a + h)− f (a)
h6 0 car le numérateur est encore négatif mais le dénominateur est
positif. On en déduit que
limh→0−
f (a + h)− f (a)h
> 0 et limh→0+
f (a + h)− f (a)h
6 0.
On en déduit que f ′(a) = 0.
3.2 Théorème des accroissements finis
Soit f une fonction continue sur [a, b] et dérivable sur ]a, b[. Si f (a) = f (b) il existe c ∈]a, b[ tel quef ′(c) = 0.
Théorème 15.3.2.560 (Théorème de Rolle)
Démonstration : Si la fonction est constante, c’est évident. On élimine donc ce cas. La fonction f est alorscontinue sur un intervalle fermé et bornée, elle est donc bornée et atteint ses bornes. Elle a donc soit unmaximum, soit un minimum dans ]a, b[. On l’appelle c, il vérifie f ′(c) = 0.
Remarques :1. Cela se voit bien sur un dessin.2. Il faut faire attention aux hypothèses et il faut les connaître. Cela est vrai de manière plus générale avec
f dérivable sur [a, b] mais le petit raffinement permet de l’utiliser avec des fonctions définies à l’aide defonctions comme x 7→ √x ou x 7→ arcsin x.
Le théorème de Rolle sert à démontrer le suivant :
Soit f une fonction continue sur [a, b] et dérivable sur ]a, b[. Il existe c ∈]a, b[ tel que
f (b)− f (a)b− a
= f ′(c).
Théorème 15.3.2.561 (Théorème des accroissements finis)
234

Remarques :
1. Cela se voit aussi géométriquement, c’est une version « penchée » du théorème de Rolle. En effet, celasignifie qu’il y a une tangente parallèle à la droite (AB) où A = (a, f (a)) et B=(b, f (b)).
2. Ce théorème s’appelle aussi « égalité des accroissements finis ».
Démonstration : On veut se ramener au théorème de Rolle. On considère la fonction g définie sur [a, b] par
∀x ∈ [a, b], g(x) = f (x)− f (b)− f (a)b− a
x.
On a alors que g est encore continue sur [a, b] et dérivable sur ]a, b[. De plus g(a) = g(b). On applique le
théorème de Rolle. Il existe c ∈]a, b[ tel que g′(c) = 0 or g′(c) = f ′(c)− f (b)− f (a)b− a
. On en déduit que
f (b)− f (a)b− a
= f ′(c).
Exemple : Montrons que pour tout x > 0, il existe c ∈]0, x[ tel que ln(1 + x) =x
1 + c. On applique le théorème
des accroissements finis à f : x 7→ ln(1 + x) entre 0 et x. Il existe c ∈]0, x[ tel que
ln(1 + x)− 0x− 0
=1
1 + ccar f ′(x) =
11 + x
.
En particulier, ln(1 + x) 6 x.
3.3 Inégalités des accroissements finis
Soit f une fonction continue sur [a, b] et dérivable sur ]a, b[. On suppose que la dérivée f ′ est bornéesur ]a, b[. Soit (m, M) ∈ R2 tels que ∀x ∈]a, b[, m 6 f ′(x) 6 M alors
m(b− a) 6 f (b)− f (a) 6 M(b− a).
Corollaire 15.3.3.562 (Inégalités des accroissements finis)
Remarques :
1. Ce corollaire est très utile pour majorer la différence de deux valeurs prises par une fonction.
2. Si, et c’est le cas le plus courant, la fonction f est de classe C 1 sur [a, b] alors la dérivée est obligatoirementbornée sur [a, b] donc sur ]a, b[. C’est ce qui explique que l’on est fréquemment en situation d’utiliser cetteformule.
Soit f une fonction continue sur [a, b] et dérivable sur ]a, b[. On suppose que la dérivée f ′ est bornéesur ]a, b[. Soit M ∈ R tels que ∀x ∈]a, b[, | f ′(x)| 6 M alors
| f (b)− f (a)| 6 M|b− a|.
En particulier, la fonction f est lipschitzienne.
Corollaire 15.3.3.563 (Reformulation de l’inégalités des accroissements finis)
B La plupart des résultats donné dans le chapitre s’étend aux fonctions à valeurs dans C mais pas le théorèmede Rolle (et donc pas le théorème des accroissements finis) car on peut « tourner »autour de 0 dans C. Parexemple, la fonction f : t 7→ exp 2itπ. Elle vérifie, f (0) = f (2π) = 1. Sa dérivée ne s’annule pourtant pas.Cependant l’inégalité des accroissements finis reste vraie. On peut en effet la démontrer par d’autres moyenscomme l’intégration. Si on suppose que pour tout t dans I, | f ′(t)| 6 k alors
| f (x)− f (y)| =∣∣∣∣∫ y
xf ′(t) dt
∣∣∣∣ 6∫ y
x| f ′(t)| dt = k|x− y|.
235

Soit I un intervalle et k ∈ R+. Une fonction f définie sur I est dite k-lipschitzienne si
∀(x, y) ∈ I2, | f (x)− f (y)| 6 k|x− y|.
On dit qu’une fonction est lipschitzienne s’il existe k ∈ R+ tel qu’elle soit k-lipschitzienne.
Définition 15.3.3.564
Avec les notations précédentes :
1. Si f est lipschitzienne alors elle est continue.
2. Une fonction de classe C 1 sur un segment est lipschitzienne.
Proposition 15.3.3.565
Démonstration
Remarques :1. Il existe des fonctions continues qui ne sont pas lipschitziennes. Par exemple, x 7→ ex sur R ou x 7→ √x
sur [0, 1].2. Une fonction de classe C 1 (et même C ∞) peut ne pas être lipschitzienne sur un intervalle non borné. Par
exemple x 7→ exp(x).
3.4 Application à la monotonie
Soit I un intervalle et f une fonction dérivable sur I.
1. La fonction f est constante sur I ⇔ ∀x ∈ I, f ′(x) = 0.
2. La fonction f est croissante sur I ⇔ ∀x ∈ I, f ′(x) > 0.
3. La fonction f est décroissante sur I ⇔ ∀x ∈ I, f ′(x) 6 0.
Proposition 15.3.4.566
Remarque : Ce théorème est très classique et très utile. Il faut faire attention que le fait que I soit un intervalleest essentiel. Par exemple sur R? la dérivée de x 7→ 1/x est toujours négative mais la fonction n’est pasdécroissante sur R?.Démonstration : On va se contenter de démontrer le 2.
— ⇒ Soit a ∈ I. On sait que f ′(a) = limx→a
ϕa(x) ou ϕa(x) =f (x)− f (a)
x− a.
Or pour tout x > a, on a f (x) > f (a) d’où f (x)− f (a) > 0 et x− a > 0. On en déduit que ϕa(x) > 0.De même, pour tout x 6 a, on a f (x) 6 f (a) d’où f (x) − f (a) 6 0 et x − a 6 0. On en déduit queϕa(x) > 0.Par passage à la limite, f ′(a) > 0.
— ⇐ Soit x et y des éléments de I. On suppose que x 6 y. On peut appliquer le théorème des accroissementsfinis entre x et y. Il existe c ∈]x, y[ tels que f (y)− f (x) = f ′(c)(y− x) or f ′(c) > 0 par hypothèses doncf (y)− f (x) > 0.
Il y a une variante avec des inégalités strictes. Il faut cependant faire un peu plus attention.
Soit I un intervalle et f une fonction dérivable sur I.
1. ∀x ∈ I, f ′(x) > 0⇒ la fonction f est strictement croissante sur I.
2. ∀x ∈ I, f ′(x) < 0⇒ la fonction f est strictement décroissante sur I.
Proposition 15.3.4.567
236

Remarque : On n’a plus que l’implication dans ce sens, qui se démontre encore en utilisant le théorème desaccroissements finis. La démonstration de la réciproque n’est plus bonne car l’inégalité stricte ne survie pas aupassage à la limite. Et de fait le résultat est faux comme le prouve la fonction x 7→ x3.
On a quand même un énoncé plus précis
Soit I un intervalle et f une fonction dérivable sur I. La fonction f est strictement monotone si etseulement si f ′ est de signe constant et ne s’annule pas sur un sous intervalle de I non réduit à unpoint.
Proposition 15.3.4.568
Démonstration
On utilise la plupart du temps le corollaire suivant :
Soit f une fonction dérivable sur I. Si f ′ est de signe constant et ne s’annule qu’en un nombre fini depoints elle est strictement monotone.
Corollaire 15.3.4.569
3.5 Application aux prolongements
On a vu dans le chapitre sur la continuité que quand une fonction à une limite à une borne finie de sonintervalle de définition, on pouvait la prolonger par continuité. Il est alors naturel de se demander dans quellesconditions ce prolongement est dérivable. Nous allons commencer par regarder des exemples.Exemples :
1. Soit f la fonction définie sur R? par f : x 7→ x sin(
1x
). On a vu dans le chapitre sur la continuité que
limx→0 f (x) = 0. On la prolonge par continuité en posant f (0) = 0. La fonction obtenue est-elle dérivableen 0? On calcule la limite du taux d’accroissement :
ϕ0(x) =f (x)− f (0)
x− 0= sin
(1x
).
On en déduit que la fonction n’est pas dérivable en 0.
2. Soit f la fonction définie sur R? par f : x 7→ x2 sin(
1x
). On de même que limx→0 f (x) = 0. On la
prolonge par continuité en posant f (0) = 0. La fonction obtenue est-elle dérivable en 0? On calcule lalimite du taux d’accroissement :
ϕ0(x) =f (x)− f (0)
x− 0= x sin
(1x
).
Donc limx→0 ϕ0(x) = 0. La fonction est donc dérivable en 0. Cependant la dérivée n’est pas continue. Eneffet, pour tout x non nul
f ′(x) = 2x sin(
1x
)− cos
(1x
).
Exercice : Montrer que la fonction x 7→ x3 sin(
1x
)se prolonge par continuité et que le prolongement est de
classe C 1.
Soit f une fonction continue sur un intervalle I et a ∈ I. On suppose que f est dérivable sur I \ a.Soit ` ∈ R.
Si limx→a
f ′(x) = ` alors limx→a
f (x)− f (a)x− a
= `.
En particulier, si ` ∈ R, alors f est dérivable en a et f ′(a) = `. Par contre si ` ∈ ±∞ la fonction fn’est pas dérivable et sa courbe admet une tangente verticale.
Théorème 15.3.5.570
237

Démonstration : Avec le théorème des accroissements finis.
Soit f une fonction continue sur un intervalle I et a ∈ I. On suppose que f est de classe C 1 surI \ a. Si la dérivée f ′(x) a une limite finie quand x tend vers a alors la fonction f est de classe C 1
sur I.
Corollaire 15.3.5.571
Exemples :
1. On considère la fonction x 7→ arccos x. On sait qu’elle est continue sur [−1, 1] et dérivable sur ]− 1, 1[. De
plus, pour tout x de ]− 1, 1[, arccos′(x) =−1√
1− x2. On particulier
limx→−1
arccos′(x) = −∞ et limx→1
arccos′(x) = −∞.
On en déduit que arccos n’est pas dérivable en −1 et 1 et que la courbe admet des tangentes verticales.
2. On considère la fonction définie sur R? par
f (x) = exp(
x− 1x2
).
Étudions son prolongement en 0. On remarque d’abord que f est de classe C 1 sur R?. De plus limx→0
f (x) = 0.
On peut donc la prolonger par continuité.Maintenant, pour tout x de R?,
f ′(x) =−x + 2
x3 exp(
x− 1x2
)∼0
−1x2 exp
(x− 1
x2
).
Par croissance comparée, limx→0
f ′(x) = 0. Le prolongement est donc de classe C 1.
Il y a aussi un résultat analogue pour montrer qu’un prolongement est de classe C k.
Soit I un intervalle et a ∈ I. Soit f une fonction de classe C n sur I \ a. Si pour tout k ∈ [[ 0 ; n ]]
la dérivée k-ième f (k)(x) a une limite finie quand x tend vers a alors la fonction f se prolonge parcontinuité et ce prolongement est de classe C n sur I.
Corollaire 15.3.5.572
Exemple : Considérons f : x 7→ e−1/x2définie sur R∗.
Elle se prolonge naturellement par continuité en posant f (0) = 0.On peut montrer de plus que pour tout entier n et tout réel non nul x,
f (n)(x) =Pn(x)
x3n e−1/x2
où Pn est un polynôme donné par la relation de récurrence :
P0 = 1 et Pn+1 = X3P′n − (3nX2 + 2)Pn.
Par croissances comparées on en déduit alors que pour tout entier n, f (n)(x)−→x→0 0. D’après le théorèmeprécédent, on en déduit que le prolongement par continuité de f est de classe C ∞.
238

16Suites récurrentes :
un+1 = f (un)1 Généralités 2391.1 Représentation graphique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2391.2 Existence de la suite . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 240
2 Méthodes d’étude 2402.1 Caractérisation de la limite . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2402.2 Utilisation des accroissements finis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2412.3 Cas où f est croissante . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2412.4 Cas où f est décroissante . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 242
3 Méthode de Newton 244
1 Généralités
Nous allons nous intéresser à des suites définies par une relation du type un+1 = f (un) où f est une fonctiondéfinie sur un intervalle I. On se placera le plus souvent sur des intervalles fermés c’est à dire de la forme [a, b],[a,+∞[,]−∞, b] ou R.
1.1 Représentation graphique
On peut essayer de représenter ces suites à l’aide de la courbe de f et de la première bissectrice.
u0u1u2u3
u0 u1u2
239

1.2 Existence de la suite
La première chose à vérifier est que la suite est entièrement définie. C’est-à-dire que l’on puisse bien définirun pour tout entier n. Si la fonction f est définie sur R c’est évident. Dans un autre cas, cela ne l’est pas.
Soit X une partie de R. On dit qu’elle est stable par f si f (X) ⊂ X c’est-à-dire : ∀x ∈ X, f (x) ∈ X.
Définition 16.1.2.573
S’il existe N ∈ N tel que uN existe et appartienne à une partie stable par f alors la suite est définie etde plus : ∀n > N, un ∈ X.
Proposition 16.1.2.574
Démonstration : C’est une récurrence.
Exemples :1. Soit (u) définie par u0 = 0 et ∀n ∈ N, un+1 =
√1 + un. On voit que la partie X = R+ est une partie stable
pour f . Comme u0 ∈ R+, la suite est définie (et tous ses termes sont positifs).
2. Soit (u) une suite définie par u0 et ∀n ∈ N, un+1 =x
x + 1.
— Si u0 = −1, u1 n’est pas défini et donc la suite (u) non plus.
— Là encore X = R+ est stable pour f donc si u0 ∈ R+ alors la suite est définie.
— De même on voit que si u0 < −1 alors u1 > 0 et donc la suite (u) est définie.
— On voit que si u0 = −1/2 alors u1 = −1 et u2 n’existe pas. En fait on voit que f réalise une bijection
de R \ −1 sur R \ 1. La bijection réciproque est g : y 7→ y1− y
. On en déduit que les valeurs
prises par la suite (v) définies par v0 = −1 et vn+1 = g(vn) sont les valeurs interdites pour u0. Lasuite (v) est bien définie car X = [−1, 0] est stable par g.
2 Méthodes d’étude
2.1 Caractérisation de la limite
Un élément a de I est un point fixe de f si f (a) = a.
Définition 16.2.1.575
On suppose que f est continue. Si la suite (u) converge et que I est fermé alors la limite ` appartientà I et est un point fixe de f .
Proposition 16.2.1.576
Démonstration : L’intervalle I est défini avec des inégalités larges donc, en passant à la limite, ` ∈ I. On peutdonc utiliser la continuité de f en `. On a donc
lim( f (un)) = f (`)
Or la suite ( f (un)) est la suite (un+1) qui converge aussi vers `. Par unicité de la limite, on obtient f (`) = `.
Remarques :1. C’est un résultat important pour déterminer la limite d’une suite mais il faut démontrer au préalable que
la suite converge.
2. Ce n’est pas à proprement parlé un résultat du programme. Il faut donc le redémontrer à chaque fois.
240

2.2 Utilisation des accroissements finis
On veut étudier la suite définie par u0 > −2 et ∀n ∈ N, un+1 =√
2 + un.
— On commence par remarquer que [−2,+∞[ est stable par f : x 7→√
2 + x donc la suite est définie.
— La fonction f étant continue, si (un) converge ce sera vers une solution de√
2 + x = x ⇐⇒ x = 2. On vadonc essayer de montrer que |un − 2| tend vers 0 en la majorant par une suite géométrique.
— Pour cela il faut se restreindre à un intervalle où la dérivée de f est strictement inférieure à 1. On voit
que f ′(x) =1
2√
x + 2. En particulier si x > 0 alors | f ′(x)| 6 a =
12√
2< 1. Maintenant u1 > 0 et
∀n ∈ N, un > 0. On peut donc appliquer le théorème de l’inégalité des accroissements finis : pour toutentier n > 1,
|un+1 − 2| = | f (un)− f (2)| 6 a|un − 2|.On en déduit par une récurrence immédiate que
∀n > 1, |un − 2| 6 an−1|u1 − 2|.
Comme |a| 6 1, la suite de droite tend vers 0 donc celle de gauche aussi et (un) tend 2. On a même unemajoration de la vitesse de convergence. Si on veut que |u2 − 2| 6 10−N il suffit de prendre n tel que
an−1 × 1 6 10−N ⇐⇒ (n− 1) >−N ln(10)− ln(2)
ln aon a ln(a) < 0.
Remarque : L’argument clé est que la dérivée de f est strictement inférieure à 1 en valeur absolue au voisinagedu point fixe. Dans ce cas la fonction f est k-lipschitzienne avec |k| < 1. On dit alors que f est contractante.
2.3 Cas où f est croissante
Dans cet exemple, on va supposer que f est croissante sur la partie stable X considérée. L’argument clé (quiest redémontrer est le suivant).
Soit (un) une suite définie par u0 ∈ X et un+1 = f (un) où X est stable par f est f est croissante surX. La suite (un) est monotone. Pour connaitre son sens de variations il suffit de calculer u1 − u0.
Proposition 16.2.3.577
Démonstration : Par recurrence.
Remarques :
1. Ce résultat est à redémontrer.
2. Dans certains cas, il est aussi simple d’étudier le signe de f (x)− x sur un intervalle stable. Cela permetd’éviter la récurrence.
On considère la fonction f définie sur R+ par f : x 7→ 23+
x2
3. On se donne u0 ∈ R+ et ∀n ∈ N, un+1 =
f (un).On voit que R+ est stable par f et que f est croissante sur R+.Commençons par essayer de visualiser la suite sur des dessins.
u0u1u2u3
u0 u1u2
241

On cherche les points fixes de la fonction f . Soit x ∈ R+,
f (x) = x ⇔ 23+
x2
3= x
⇔ 2− 3x + x2 = 0⇔ x = 1 ou x = 2.
On distingue alors les cas suivant les valeurs de u0.On peut remarquer tout de suite que si u0 = 1 ou si u0 = 2 alors la suite est constante. Elle converge donc
vers sa valeur.
Si u0 ∈ [0, 1[
1. On localise les termes de la suite. L’intervalle [0, 1[ est stable, donc par récurrence, ∀n ∈ N, un ∈ [0, 1[.
2. On sait que (un) est monotone et u1 > u0 car u1 − u0 = f (u0) − u0 et f : x 7→ f (x) − x est positivesur [0, 1[. Donc (un) est croissante. On peut ici, éviter la récurrence en disant que pour tout entier,un+1 − un = f (un)− un > 0.
3. On étudie la convergence. On a vu que la suite (un) est croissante et majorée (car tous les termes de lasuite sont inférieurs à 1). La suite (un) est donc convergente. Notons ` sa limite. D’après la propositionci-dessus, ` est un point fixe de f . On en déduit que ` = 1 ou ` = 2. Or comme tous les termes de la suitesont inférieurs à 1, la limite ` aussi. On a donc
lim(un) = 1.
Si u0 ∈]1, 2[
On reprend une étude similaire.
1. On localise les termes de la suite en montrant par récurrence que pour tout n ∈ N un ∈]1, 2[.
2. On étudie les variations de la suite. Soit n ∈ N, un ∈]1, 2[ or on a vu que pour tout x dans ]1, 2[,f (x)− x 6 0. D’où, pour x = un, un+1 − un = f (un)− un 6 0. La suite (un) est donc décroissante.
3. On étudie la convergence. On a vu que la suite (un) est décroissante et minorée (car tous les termes de lasuite sont supérieurs à 1). La suite (un) est donc convergente. Notons ` sa limite. Pour déterminer ` onutilise la même propriété que ci-dessus.On en déduit que ` = 1 ou ` = 2.
Faire une fausse rédaction
La suite (un) est décroissante donc pour tout entier n, un 6 u0 < 2. On en déduit que ` 6 u0 < 2. Donc
lim(un) = 1.
Si u0 ∈]2,+∞[
On reprend une étude similaire.
1. On localise les termes de la suite en montrant par récurrence que pour tout n ∈ N un > 2.
2. On étudie les variations de la suite. Soit n ∈ N, un > 2 or on a vu que pour tout x dans ]2,+∞[,f (x)− x > 0. D’où, pour x = un, un+1 − un = f (un)− un > 0. La suite (un) est donc croissante.
3. On étudie la convergence. Sur le dessin, on voit que lim(un) = +∞. On va le prouver par l’absurde.Supposons qu’elle converge vers un réel `. D’après ce qui précède, ` = 1 ou ` = 2.Or, comme ci-dessus pour tout entier n, un > u0 > 2. On en déduit que ` > u0 > 2 ce qui est absurde. Lasuite (un) ne converge donc pas, comme elle est croissante on en déduit que
lim(un) = +∞.
2.4 Cas où f est décroissante
On a vu dans l’exemple précédent que le fait que f soit croissante (sur l’intervalle stable) était fondamentalcar cela implique que (un) est monotone. Nous allons voir ce qui se passe quand f est décroissante.
242

Premier exemple
On considère la suite définie par u0 = 0 et ∀n ∈ N, un+1 = cos(un). On pose f : x 7→ cos(x) et on remarqueque l’intervalle I = [0, 1] est stable par f . De ce fait la suite est bien définie et ∀n ∈ N, un ∈ [0, 1].
On peut appliquer le théorème de la bijection à g : x 7→ f (x)− x pour monter qu’il existe un unique pointfixe de f que nous noterons α et qui vérifie, α = cos(α). Si la suite (un) converge cela ne peut-être que vers α.
Maintenant, comme f est décroissante sur [0, 1], on en déduit que f f est croissante sur [0, 1]. De ce fait lessuites extraites (vn) = (u2n) et (wn) = (u2n+1) sont monotone car ∀n ∈ N, vn+1 = ( f f )(vn) et de même pour(wn). On en déduit que les (vn) et (wn) sont convergentes car monotone est bornée.
Cependant, on voit que α est un point fixe de f f mais il se pourrait qu’il y en ait d’autre (ce n’est pas lecas). Il n’est donc pas évident de montrer que (vn) et (wn) convergent vers α.
Le plus simple est d’alors de retourner aux accroissements finis. En effet sur [0, 1], la fonction f est dérivableet | f ′(x)| = | sin x| 6 sin 1 < 1.
0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.40.0
0.2
0.4
0.6
0.8
1.0
1.2
1.4
Deuxième exemple
On considère la suite définie par u0 = 3 et ∀n ∈ N, un+1 = f (un) où on pose f : x 7→ 31 + 2x2 . La fonction
est dérivable sur R de dérivée, f ′ : x 7→ − 12x(1 + 2x2)2 . En particulier, elle est strictement décroissante sur R+ et
comme f (0) = 3 on en déduit que I = [0, 3] est stable par f . La suite (un) est bien définie et ∀n ∈ N, un ∈ [0, 3].Là encore, la fonction f n’a qu’un point fixe dans I qui est 1. On remarque cette fois que, contrairement au cas
précédent, | f ′(1)| = 129
=43> 1. On ne peut donc par utiliser un argument de type accroissements finis.
Là encore, on peut introduire les suites extraites (vn) = (u2n) et (wn) = (u2n+1). Elles sont monotones. Si oncalcule les premiers termes on trouve.
u0 = 3 ; u1 =319' 0, 16 ; u2 =
1083379
' 2.86 < u0 ; u3 =430923
2489419' 0, 17 > u1.
En particulier, on en déduit que (vn) est décroissante et (wn) est croissante. On pourrait penser que les suites(vn) et (wn) sont adjacentes et que de ce fait (un) converge mais ce n’est pas le cas.
0.5 1.0 1.5 2.0 2.5 3.0
0.5
1.0
1.5
2.0
2.5
3.0
Si on étudie la fonction f f : x 7→ 3 + 12x2 + 12x4
19 + 4x2 + 4x4 . On peut voir (avec Mathematica) qu’elle admet
α =3−√
72
' 0, 177 et β3 +√
72
' 2, 823 comme point fixe en plus de 1. De ce fait, (vn) tend vers β et (un)
tend vers α et donc (un) diverge.
243

0.5 1.0 1.5 2.0 2.5 3.0 3.5
0.5
1.0
1.5
2.0
2.5
3.0
3.5
3 Méthode de Newton
La méthode de Newton est abordée dans le cours d’IPT La convergence est quadratique.
244

17Corps des fractions
1 Généralités 2451.1 Corps des fractions d’un anneau intègre . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2451.2 Le corps K(X) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2471.3 Degré . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2481.4 Pôles et zéros . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2491.5 Fonction rationnelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2501.6 Dérivation (HP?) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2501.7 Composition par un polynôme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 250
2 Décomposition en éléments simples 2512.1 Partie entière d’une fraction rationnelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2512.2 Partie polaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2522.3 Décomposition en éléments simples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2532.4 Méthodes de calcul . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2542.5 Décomposition en éléments simple dans R(X) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 256
Dans ce chapitre K désigne R ou C.
1 Généralités
On va vouloir définir les fractions rationnelles qui sont des quotientsPQ
où P et Q sont des polynômes avec
Q non nul à l’image de ce que l’on fait pour passer de Z à Q. Nous allons d’abord le faire dans un cas général.
1.1 Corps des fractions d’un anneau intègre
Rappelons la définition d’un anneau intègre :
On appelle anneau intègre un anneau commutatif qui vérifie :
∀(a, b) ∈ A2, ab = 0⇒ a = 0 ou b = 0.
Définition 17.1.1.578
245

Exemple : Les anneaux Z et K[X] sont intègres.Soit A un anneau intègre on considère l’ensemble C = A× (A \ 0) = (a, b) ∈ A2 | b 6= 0.L’ensemble C n’est pas celui que l’on veut car, si on revient sur l’exemple des rationnels, on veut que les
couples (1, 2) et (2, 4) soient « les mêmes » car c’est juste12=
24
.
Soient (a, b) et (c, d) deux éléments de C. On dit qu’ils sont équivalents et on note (a, b) ∼ (c, d) si ad = bc.
Définition 17.1.1.579
La relation ∼ est une relation d’équivalence.
Proposition 17.1.1.580
Démonstration : Montrons juste la transitivité. On suppose (a, b) ∼ (c, d) et (c, d) ∼ (e, f ). De ce fait, ad = bcet c f = ed. Donc par produit, adc f = bced ce qui revient à cd(a f − be) = 0. Comme A est intègre on en déduitque a f = be.
On note Frac(A) l’ensemble des classes d’équivalences de la relation ∼ sur C. Soit x un élément de Frac(A).On appelle représentant de x tout couple (a, b) de C qui appartient à x. La classe d’un élément (a, b) se noteab
.
Définition 17.1.1.581
Remarque : De fait l’ensemble Frac(A) est un ensemble de parties de C. Mais il ne faut surtout pas se l’imaginerainsi. Il faut voir ses éléments comme des couples (a, b) où a est dans A et b est non nul. Cependant, on identifiedeux couples (a, b) et (c, d) qui vérifient ad = cb car de fait « cela donne la même fractions ». Il faut quandmême faire la différence entre une fraction et son représentant.
On peut définir des additions et multiplications sur Frac(A) par
+ : Frac(A)× Frac(A) → Frac(A)(ab
,a′
b′
)7→ ab′ + a′b
bb′et× : Frac(A)× Frac(A) → Frac(A)(
ab
,a′
b′
)7→ aa′
bb′.
Proposition 17.1.1.582
Il faut comprendre qu’il y a quelque chose à démontrer. En effet, il faut vérifier que si on choisitdifférents représentants pour les fractions de départs on obtiendra un élément différent de C maisqui sera toujours un représentant de la même fraction à la fin.
ATTENTION
Démonstration : Par symétrie, il suffit de montrer que si (a, b) ∼ (α, β) alors (ab′ + a′b, bb′) ∼ (αb′ + a′β, b′β)ce qui ce vérifie par le calcul. De même, si (a, b) ∼ (α, β) alors (aa′, bb′) ∼ (αa′, b′β).
246

Avec les notations précédentes, (Frac(A),+,×) est un corps. En particulier, siab
est un élément non
nul de Frac(A) alors a 6= 0 et son inverse etba
.
De plus il existe une application injective de A dans Frac(A) compatible aux opérations (morphismed’anneaux)
ι : A → Frac(A)
a 7→ a1
.
Théorème 17.1.1.583
1.2 Le corps K(X)
Le corps des fractions de l’anneau K[X] s’appelle corps des fractions rationnelles sur K. Il se note K(X). Pour
toute fraction rationnelle F il existe un représentant (P, Q) ∈ (K[X])2 avec Q 6= 0 tel que F =PQ
.
Définition 17.1.2.584
Remarques :
1. Il suffit de remarquer que K[X] est un anneau intègre (donc commutatif).
2. Si (P, Q) est un représentant d’une fraction rationnelle, les couples (PR, QR) où R est un polynôme nonnul représente la même fraction rationnelle.
Exemples :
1. Le terme1 + 3X− X2
3− 2Xest une fraction rationnelle qui est égale à
X + 3X2 − X3
3X− 2X2
2. Tout polynôme P peut être vu comme la fraction rationnelleP1
via l’injection ι.
3. On appelle fraction rationnelle nulle la fraction rationnelle01
qui est égale à0Q
pour tout Q non nul.
4. On appelle fraction rationnelle unité la fraction rationnelle11
qui est égale àPP
pour tout P non nul.
Les addition et multiplication sur K(X) sont définies en posant :
1. SoitP1
Q1et
P2
Q2deux fractions rationnelles, on pose
P1
Q1+
P2
Q2=
P1Q2 + P2Q1
Q1Q2.
2. SoitP1
Q1et
P2
Q2deux fractions rationnelles, on pose
P1
Q1× P2
Q2=
P1P2
Q1Q2.
Définition 17.1.2.585
Remarque : C’est la construction précédente. Il faut juste remarquer que si on change le représentant d’unefraction rationnelle, on ne change pas le résultat (mais on trouve peut-être un autre représentant de la mêmefraction).
247

On appelle représentant irréductible d’une fraction rationnelle, tout représentant (P, Q) où P ∧Q = 1. Onappelle représentant irréductible unitaire d’une fraction rationnelle un représentant irréductible où Q estunitaire.
Définition 17.1.2.586
Remarque : C’est l’équivalent de la notion de fraction irréductible dans Q. Là on a de plus besoin de la notionde représentant unitaire car les éléments inversibles de K[X] sont les constantes et pas juste ±1.
Toute fraction rationnelle admet un unique représentant irréductible unitaire.
Proposition 17.1.2.587
Démonstration :
— Existence : NotonsPQ
un représentant de la fraction. On sait qu’il existe P1 et Q1 premiers entre eux telsque
P = (P ∧Q)P1 et Q = (P ∧Q)Q1.
De plus si on note a le coefficient dominant de Q1. On a alors
PQ
=P1
Q1=
P/aQ/a
et Q/a est unitaire.
— Unicité : SoitPQ
=P1
Q1deux représentants unitaires irréductibles d’une même fraction. On a donc
PQ1 = QP1. Or Q|QP1 dont Q|PQ1 mais comme Q est premier avec P alors Q|Q1. Par symétrie, Q1|Q.On en déduit qu’il existe λ dans K tel que Q1 = λQ comme ils sont unitaires, Q = Q1 et par suite, P = P1.
Exemples :
1. Soit F =X3 − 1
2X4 − 2. Son représentant irréductible unitaire est
12(X2 + X + 1)
X3 + X2 + X1 + 1.
2. Le représentant irréductible unitaire de la fraction nulle est01
.
1.3 Degré
Soit F une fraction rationnelle etP1
Q1et
P2
Q2deux représentants de F. On a
deg P1 − deg Q1 = deg P2 − deg Q2.
Proposition 17.1.3.588
Remarque : Les grandeurs deg P1 − deg Q1 et deg P2 − deg Q2 sont bien définies car Q1 et Q2 n’étant pas nulson n’a pas de « forme indeterminée ». Cette égalité est dans Z ∪ −∞.Démonstration : On a P1Q2 = P2Q1. De ce fait, deg P1 + deg Q2 = deg P2 + deg Q1 et donc deg P1 − deg Q1 =deg P2 − deg Q2.
Soit F un fraction rationnelle, on appelle degré de F et on note deg F le terme deg P− deg Q oùPQ
est un représentant de F. En particulier deg F ∈ Z ∪ −∞.
Proposition 17.1.3.589
248

Exemples :
1. Si P est un polynôme alors la fraction rationnelleP1
a pour degré le degré de P. En particulier, deg F =
−∞ ⇐⇒ F = 0.
2. Le degré de2X− 1X− 6
est 0.
Soit F1 et F2 deux fractions rationnelles.
1. deg(F1F2) = deg(F1) + deg(F2)
2. deg(F1 + F2) 6 Max(deg(F1), deg(F2))
Proposition 17.1.3.590
Démonstration :
1. Si on choisit des représentants, F1 =P1
Q1et F2 =
P2
Q2. On a alors
F1F2 =P1P2
Q1Q2.
D’où
deg(F1F2) = deg(P1P2)− deg(Q1Q2) = deg(P1) + deg(P2)− deg(Q1)− deg(Q2) = deg(F1) + deg(F2).
2. On a aussiF1 + F2 =
P1Q2 + P2Q1
Q1Q2.
D’où
deg(F1F2) = deg(P1Q2 + P2Q1)−deg(Q1)−deg(Q2) 6 Max(deg P1−deg Q1, deg P2−deg Q2) = Max(deg F1, deg F2).
1.4 Pôles et zéros
Soit F une fraction rationnelle etPQ
un représentant irréductible.
1. On appelle zéro (ou racine) de F toute racine de P.
2. On appelle pole de F toute racine de Q.
3. Si F 6= 0. On appelle ordre de multiplicité du zéro (ou du pole) a son ordre de multiplicité en tant queracine de P (ou de Q).
Définition 17.1.4.591
Remarques :1. Il est essentiel de prendre un représentant irréductible. En effet on a par exemple
F =X3 − 1X4 − 1
=X2 + X + 1
X3 + X2 + X + 1.
On voit que 1 est racine de X3 − 1 et de X4 − 1. Par contre les zéros de F sont j et j2. Ses pôles sont −1, i et−i.
2. Soit F une fraction rationnelle et a un élément de K, il ne peut pas être un zéro et un pole de F car sinon
X− a divise P et Q oùPQ
est un représentant irréductible de F.
3. Dans C, le degré de F est le nombre de zéros (comptés avec multiplicité) moins de nombre de pôles(comptés avec multiplicité).
249

1.5 Fonction rationnelle
De même que l’on peut associer une fonction polynomiale à un polynôme, on peut associer une fonctionrationnelle à un fraction rationnelle.
Soit F une fraction rationnelle etPQ
un représentant irréductible. Si on note Z l’ensemble des pôles de A. On
appelle fonction rationnelle associée à F la fonction
F : K \ Z → K
x 7→ P(x)Q(x)
.
Définition 17.1.5.592
Remarques :1. Là encore, il faut prendre un représentant irréductible pour ne pas avoir une forme indéterminée du type
00
.
2. L’application qui associe à une fraction rationnelle sa fonction rationnelle est compatible à la somme et auproduit en prolongeant éventuellement les fonctions par continuité sur les pôles qui ont disparus. Parexemple si
F1 =1
X2 − 1et F2 =
−XX2 − 1
La fraction F1 + F2 =1− XX2 − 1
= − 1X + 1
.
1.6 Dérivation (HP?)
Soit F une fraction rationnelle et F =PQ
un représentant. On appelle dérivée de F et on note F′ la fraction
rationnelle dont un représentant estP′Q− PQ′
Q2 .
Définition 17.1.6.593
Remarques :1. Là encore, il faut vérifier que si on change de représentant de F on obtient un représentant de la même
fraction.2. Cette dérivation est compatible avec la dérivation des fonctions rationnelles.3. L’ensemble des pôles de F′ est inclus dans l’ensemble des pôles de F.
Exemple : Si on prend F =X3 − 1X4 − 1
. Alors F′ =−X6 + 4X3 − 3X2
(X4 − 1)2 .
1.7 Composition par un polynôme
Soit F une fraction rationnelle et R polynôme non constant. On note F(R) la fraction dont un représentant estP RQ R
oùPQ
est un représentant de F.
Définition 17.1.7.594
Remarques :1. Pour justifier cette définition il faut vérifier que si on prend un autre représentant de F alors on obtient un
autre représentant de la même fraction.
250

2. Dans la pratique on ne l’utilise que pour R un polynôme de degré 1.
3. Cela justifie la notation F(X) pour F.
Soit F une fraction rationnelle, elle est dite paire (reps. impaire) si F(−X) = F(X) (resp. F(−X) = F(X)).
Définition 17.1.7.595
Exemple : La fractionX4 − 1X3 − X
est impaire alors que1
X2 est paire.
2 Décomposition en éléments simples
2.1 Partie entière d’une fraction rationnelle
Toute fraction rationnelle s’écrit de manière unique somme la forme
E + F
où E est un polynôme et F une fraction rationnelle de degré strictement négative.
Proposition 17.2.1.596
Démonstration :
— Unicité : Si E1 + F1 = E2 + F2 où E1 et E2 sont des polynômes et F1, F2 des fractions rationnelles de degréstrictement négatif.On a alors E1 − E2 = F2 − F1 où E1 − E2 est un polynôme et F2 − F1 est une fraction rationnelle de degréinférieur à Max(deg F1, deg F2) < 0. On en déduit que deg(E1 − E2) < 0 donc E1 = E2 et F1 = F2.
— Existence : Si on choisit un représentant F =PQ
. On peut faire la division euclidienne de P par Q. On a
P = QS + R. On a alors
F =QS + R
Q= S +
RQ
.
On a S qui est un polynôme et deg R < deg Q donc degRQ
< 0.
Avec les notations précédentes, le polynôme E s’appelle la partie entière de F.
Définition 17.2.1.597
Soit F une fraction rationnelle.
1. Si deg F < 0 alors la partie entière de F est nulle.
2. Si deg F > 0, la partie entière de F n’est pas nulle et son degré est le degré de F.
Proposition 17.2.1.598
Exemples :
1. Si P est un polynôme vu comme une fraction rationnelle. Il est égale à sa partie entière.
2. Si P est un polynôme non constant, la partie entière de1P
est nulle.
251

3. Si F =X4 − 1X3 − 1
. On voit que deg F = 1 donc la partie entière de F n’est pas nulle et elle est de degré 1. On
voit que X4 − 1 = X(X3 − 1) + (X− 1) donc
F = X +X− 1X3 − 1
= X +1
X2 + X + 1.
1. La partie entière d’une somme de deux fractions rationnelles est la somme des parties entières.
2. La partie entière d’une fraction paire (resp impaire) est paire (resp. impaire)
Proposition 17.2.1.599
Remarque : Cela n’est pas vrai pour le produit. Par exemple,
(1 +1X)(X +
1X) = (X + 1) +
X + 1X2 .
2.2 Partie polaire
Soit F une fraction rationnelle et a un pole de F d’ordre n > 1. Il existe un unique n-uplet d’élémentsde K (ak)16k6n tel que
F = F0 + ∑16k6n
ak
(X− a)k
où F0 est une fraction rationnelle n’ayant pas a pour pôle. L’expression ∑16k6n
ak
(X− a)k s’appelle la
partie polaire en a de F.
Proposition 17.2.2.600
Démonstration :
— Unicité : Si F0 + ∑16k6n
ak
(X− a)k = F1 + ∑16k6n
bk
(X− a)k où F0 et F1 n’ont pas de poles en a. On suppose
par l’absurde que (ak)16k6n 6= (bk)16k6n. On note p = Maxk ∈ [[ 1 ; n ]] | ak 6= bk on a donc
F0 − F1 =p
∑k=1
bk − ak
(X− a)k .
Si on multiplie par (X− a)p−1 on obtient,
(X− a)p−1(F0 − F1) +p−1
∑k=1
(ak − bk)(X− a)p−1−k =bp − ap
(X− a).
Le terme de droite admet un pole d’ordre 1 en a alors que le terme de gauche n’a pas de pole en a. C’estdonc absurde. On en déduit que (ak) = (bk) et donc F0 = F1.
— Existence : On considère un représentant irréductible F =PQ
et on note Q = (X− a)nR où R est premier
avec (X− a). D’après le théorème de Bézout, il existe U, V tels que 1 = U(X− a)n + VR. On en déduitque
F =PU(X− a)n + PVR
(X− a)nR=
PUR
+PV
(X− a)n .
Si utilise la formule de Taylor en a pour le polynome PV =n−1
∑k=0
ak(X − a)k + T où T est divisible par
(X− a)n. On en déduit que
F =PUR
+T
(X− a)n +n−1
∑k=0
ak
(X− a)n−k = F0 +n
∑k=1
a′k(X− a)k
en posant a′k = an−k.
252

Exemple : Nous verrons plus loin de nombreuses méthodes pour déterminer les parties polaires d’une fraction
rationnelle. Si F =X4 − 1X3 − 1
=X3 + X2 + X + 1
X2 + X + 1. On sait que les pôles (simples) de F sont j et j = j2. En
particulier, F = F0 +a
X− j. Pour déterminer a, il suffit de multiplier F par X− j et d’évaluer en j. On a en effet
X3 + X2 + X + 1X− j2
= F0(X− j) + a.
Donc
a =j3 + j2 + j + 1
j− j2=
j2
1− j.
Remarque : Avec les notations précédentes, F0 a les mêmes pôles (et de même ordre) que F si on enlève a.
2.3 Décomposition en éléments simples
Dans cette partie, on pose K = C.
Soit F une fraction rationnelle dans C(X). La fraction est la somme de sa partie entière et de toutesses parties polaires. C’est-à-dire que si on note x1, . . . , xn les pôles de F et que l’on note r1, . . . , rn lesordres alors F s’écrit de manière unique sous la forme
F = E +n
∑k=1
rk
∑i=1
aki
(X− xk)i
où E est un polynôme.
Théorème 17.2.3.601
Terminologie : Cette écriture s’appelle la décomposition en éléments simples de F.Démonstration :
— Unicité : Si on considère une écriture
F = E +n
∑k=1
rk
∑i=1
aki
(X− xk)i .
On voit que E est la partie entière car degn
∑k=1
rk
∑i=1
aki
(X− xk)i < 0. De même, si on écrit Fj = E+ ∑k 6=j
rk
∑i=1
aki
(X− xk)i
de sorte que
F = Fj +
rj
∑i=1
aji
(X− xj)i .
Alors Fj n’admet pas de pôle en xj et de ce faitrj
∑i=1
aji
(X− xj)i est la partie polaire de F.
— Existence : Il suffit de procéder par récurrence sur le nombre de pôle et remarquant que, sur C, unefraction rationnelle sans pôle est un polynôme (ce qui est faut si K = R).
Exemple : Soit P un polynôme. On note P = λn
∏k=1
(X− ak)rk sa factorisation sur C. On a alors
P′ = λn
∑j=1
rj(X− aj)rj−1 ∏
k 6=j(X− ak)
rk .
Dès lorsP′
P=
n
∑j=1
rj
X− aj.
Exercice :
253

1. Soit P un polynôme scindé sur R. Montrer que les racines de P′ sont des barycentres à coefficients positifsdes racines de P. On pourra montrer que les racines de P′ sont toutes entre deux racines de P en utilisantle théorème de Rolle.
2. Soit P un polynôme sur C (donc scindé). Montrer que les racines de P′ sont des barycentres à coefficientspositifs des racines de P. Interprétation géométrique.
2.4 Méthodes de calcul
Dans la plupart des cas, pour déterminer la décomposition en éléments simples d’une fraction rationnelle,on commence par déterminer la partie entière (via une division euclidienne du numérateur). Il reste alors àdéterminer les parties polaires.
Substitution
On peut toujours substituer autant de valeurs que le nombre de coefficients inconnus dans la décompositionen éléments simples. Cela donne un système linéaire. Cette méthode est à n’utiliser que s’il n’y a qu’un ou deuxcoefficients à déterminer.
Détermination d’un pole simple
Soit F une fraction rationnelle. On suppose que a ∈ K est un pole simple. On note F =PQ
=P
(X− a)R. Si
on note F = F0 +λ
X− aoù
λ
X− aest la partie polaire en a. On a alors
PR
= (X− a)F = (X− a)F0 + λ.
On a donc
λ =P(a)R(a)
.
De plus, on peut remarquer que R(a) = Q′(a).
Exemple : Si F =3X2 − X + 2X2 − 3X + 2
. remarque d’abord que la partie principale est 3 car c’est le quotient de la
division euclidienne de 3X2 − X + 2 par X2 − 3X + 2. De plus, X2 − 3X + 2 a pour factorisation (X− 2)(X− 1).Les deux pôles sont donc 1 et 2 et ils sont simples.
— Pole 1 : On a (X− 1)F =3X2 − X + 2
(X− 2). On évalue en 1, et on trouve λ1 = −4.
— Pole 2 : On a (X− 2)F =3X2 − X + 2
(X− 1). On évalue en 2, et on trouve λ2 = 12.
En conclusion,
F = 3 +−4
X− 1+
12X− 2
.
Remarque : Cette méthode fonctionne aussi pour déterminer la partie de « plus bas degré » de la partie polaire
d’un pole d’ordre supérieure. On trouve alors λn =n!P(a)Q(n)(a)
. Ensuite, de proche en proche, on peut en déduire
toute la décomposition en éléments simples. Cela fonctionne mais ce n’est pas forcément la méthode la plusefficace.Exercice : Calculer les décomposition en éléments simples de
1X3 − 1
et1
Xn − 1.
Pole double (HP?)
Soit F une fraction rationnelle. On suppose que a ∈ K est un pole double. On note F =PQ
= G(X− a)2 où
G est une fraction rationnelle sans pôle en a.
Si on note F = F0 +λ1
X− a+
λ2
(X− a)2 . On a alors
(X− a)2F = G = (X− a)2F0 + (X− a)λ1 + λ2.
254

On a doncλ2 = G(a).
De plus si on dérive on obtient :G′ = 2(X− a)F0 + (X− a)2F′0 + λ1
et doncλ1 = G′(a).
Exemple : Soit F =X3 + 2X2 − X + 6(X− 1)2(X− 2)
. La encore, on trouve que la partie principale est 1. On déterminer les
parties polaires en 1 et en 2 avec les méthodes précédentes et on trouve :
F = 1 +−14
X− 1+
−8(X− 1)2 +
20X− 2
.
Parité
Si F est une fraction rationnelle paire ou impaire et si a est un pole d’ordre n alors −a est aussi un poled’ordre n. Cela permet de simplifier certain calculs. Par exemple si
F =1
(X2 − 1)2 =a
X− 1+
b(X− 1)2 +
cX + 1
+d
(X + 1)2 .
Comme F est paire, F(−X) = F(X) d’où par unicité de la décomposition,
a = −c et b = d
En multipliant par (X− 1)2 on trouve que b = 1/4 = d. Si on prend aussi X = 0 on a
1 = −a + b + c + d
D’où 2c = 1− 1/2 = 1/2.
1(X2 − 1)2 =
−1/4X− 1
+1/4
(X− 1)2 +1/4
X + 1+
1/4(X + 1)2 .
Fraction réelle
Si F est une fraction rationnelle réelle et si a est un pôle d’ordre n alors a est aussi un pôle d’ordre n et deplus sa partie polaire est obtenue en conjuguant les coefficients de la partie polaire de a. Il suffit de conjuguer larelation
F = F0 +n
∑k=1
λk
(X− a)k
et d’utiliser l’unicité de cette décomposition.
Utilisation d’une limite à l’infini
Si F est une fraction rationnelle de degré négatif (ou si on a déjà retiré la partie principale). On peutdéterminer la partie de plus haut degré en multipliant par X et en faisant tendre x vers ∞.
Par exemple si F =3X3 − 2X2 + X + 1
(X− 1)3 . La partie principale est 3. On a donc
F = 3 +7X2 − 8X + 4
(X− 1)3 = 3 +a1
X− 1+
a2
(X− 1)2 +a3
(X− 1)3 .
AlorsX(7X2 − 8X + 4)
(X− 1)3 =a1X
X− 1+
a2X(X− 1)2 +
a3X(X− 1)3 . En faisant tendre x vers +∞ on récupère, 7 = a1.
De plus, en multipliant par (X − 1)3 on a a3 = 3. Pour finir en prenant X = 0 on a −4 = −a1 + a2 − a3 etdonc a2 = 6. Finalement,
F = 3 +7X2 − 8X + 4
(X− 1)3 = 3 +7
X− 1+
6(X− 1)2 +
3(X− 1)3 .
255

2.5 Décomposition en éléments simple dans R(X)
Pour certains calculs, il se peut que l’on ne veuille que travailler dans R(X). On a, là encore un théorème dedécomposition en éléments simples. La difficultés est que le dénominateur n’est pas toujours scindé
Soit F une fraction rationnelle dans R(X). Si on note Q le dénominateur du représentant irréductibleunitaire et s’il se factorise sous la forme
Q =n
∏k=1
(X− ak)rk
m
∏j=1
(X2 − αjX + β j)sj
alors
F = E +n
∑k=1
rk
∑i=1
λkj
(X− ak)j +
m
∑i=1
sk
∑i=1
µijX + γij
(X2 − αiX + βi)j .
où E est un polynôme.
Théorème 17.2.5.602
Démonstration : Il « suffit » de faire la décomposition dans C(X) puis de regroupe même si cela n’est pas sisimple que cela.
Pour déterminer la décomposition le plus simple n’est pas toujours (et même rarement) de revenir sur C. Onessaye plutôt d’appliquer les méthodes directement. Voyons sur des des exemplesExemples :
1. SoitF =
X + 1X4 + X2 + 1
=X + 1
(X2 + X + 1)(X2 − X + 1)=
aX + bX2 + X + 1
+cX + d
X2 − X + 1.
Si on multiplie par X2 + X + 1 on obtient
X + 1X2 − X + 1
= aX + b +(cX + d)(X2 + X + 1)
X2 − X + 1.
On évalue en j et on trouvej + 1
j2 − j + 1= aj + b. Or
j + 1j2 − j + 1
=−j2
−2j=
j2
.
On a donc a = 1/2 et b = 0. On fait de même pour l’autre Si on multiplie par X2 − X + 1 on obtient
X + 1X2 + X + 1
= cX + d +(aX + b)(X2 − X + 1)
X2 + X + 1.
On évalue en α = eiπ/3 et on trouveα + 1
α2 + α + 1= cα + d.
Or α2 + α + 1 = 2α et α + 1 = −α2 + 2α. On en déduit que cα + d = (−1/2)α + 1. En conclusion
F =X + 1
X4 + X2 + 1=
X + 1(X2 + X + 1)(X2 − X + 1)
=(1/2)X
X2 + X + 1+
(−1/2)X + 1X2 − X + 1
.
256

18Développements
limités et analyseasymptotique
1 Introduction 2571.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2571.2 Rappel sur les notation de Landau . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 258
2 Développements limités 2582.1 Définition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2582.2 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2592.3 Calculs de développements limités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2602.4 Opérations sur les développements limités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 262
3 Applications des développements limités 2653.1 Développements limités et équivalents . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2653.2 Détermination de limites . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 266
3.3 Étude locale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2663.4 Développements asymptotiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 267
1 Introduction
1.1 Introduction
Le but du développement limité est de donner une approximation d’une fonction au voisinage d’un point.Regardons la fonction exponentielle x 7→ ex au voisinage de x = 0.
— A l’ordre 0 : on a ex ' 1. On peut écrire
ex = 1 + ε(x) et limx→0
ε(x) = 0.
— A l’ordre 1 : on peut approcher la fonction par sa tangente on a ex ' 1+ x. On écrit alors ex = 1+ x + h(x).On voit que
h(x) = ex − 1− x = x(
ex − 1x− 1)
.
257

Or limx→0
ex − 1x
= 1 donc le terme entre parenthèses tend vers 0 d’où :
ex = 1 + x + x.ε(x) et limx→0
ε(x) = 0.
Le problème est que cette approximation pourra ne pas être suffisante car on ne sait rien sur ε(x) à part le faitqu’il tende vers 0. Si on veut calculer par exemple :
limx→0
ex − 1− xx2 .
Il faudra aller plus loin pour écrire, par exemple,
ex = 1 + x + αx2 + x2.ε(x) et limx→0
ε(x) = 0.
Remarque : On peut penser au développement limité comme à l’approximation décimale. En effet, on a pour π
valeurs précision3 1
3, 1 10−1
3, 14 10−2
3, 142 10−3
De même pour exp(x) au voisinage de 0 on aura
valeurs précision1 o (1)
1 + x o (x)
1 + x + x2/2 o(
x2)
1.2 Rappel sur les notation de Landau
Soit I un intervalle, f une fonction définie sur I et a ∈ I. Tout fonction de la forme (x 7→ f (x).ε(x)) où ε estune fonction tendant vers 0 quand x tend vers a sera noté o( f ).
Définition 18.1.2.603
Remarque : Dans la pratique la fonction f sera toujours de la forme (x− a)n pour n ∈ N.Exemples :
1. la notation o(1) désigne une fonction qui tend vers 0.2. on a x4 = o(x2) car x4 = x2.x2.3. on a o(x4) + o(x5) = o(x4).4. on a 7.o(x3) = o(x3).
2 Développements limités
2.1 Définition
Soit I in intervalle, a un point de I qui n’est pas une borne. Soit n ∈ N et f une fonction définie sur I. On ditque f admet un développement limité à l’ordre n en a et on note f ∈ DLn,a s’il existe (a0, a1, . . . , an) ∈ Rn+1
tel que∀x ∈ I, f (x) = a0 + a1.(x− a) + · · ·+ an(x− a)n + o((x− a)n).
En particulier pour a = 0, f admet un développement limité à l’ordre n en 0 s’il existe (a0, a1, . . . , an) ∈ Rn+1
tel que∀x ∈ I, f (x) = a0 + a1.x + · · ·+ anxn + o(xn).
Définition 18.2.1.604
258

Exemple : On a montré dans l’introduction que la fonction exponentielle admettait un développement limité àl’ordre 1 en 0 :
ex = 1 + x + o(x).
Remarques :
1. On peut reformuler cette définition en écrivant :
( f ∈ DL,n,a)⇔ (∃P ∈ Rn[X], ∀x ∈ I, f (x) = P(x− a) + o((x− a)n)).
2. On fera attention au fait que le développement limité ne donne que des informations locales.
3. On peut définir aussi la notion de développement asymptotique de la même manière en considérant desfonctions ( fi)i∈N telles que
∀i ∈ N, fi+1 = oa( fi) .
La suite ( fi) s’appelle une échelle de comparaison. Nous en donnerons quelques exemples.
Soit I in intervalle, a un point de I qui n’est pas une borne. Soit n ∈ N et f une fonction définie sur I admettantun développement limité à l’ordre n en a. On appelle, si elle existe, forme normalisée du développement limitél’écriture :
f (a + h) = hp(
α0 + α1h + · · ·+ αn−phn−p + oh→0
(hn−p)
)où α0 6= 0.
Définition 18.2.1.605 (Forme normalisée)
Avec les notations précédentes, on a f (x) ∼a
α0(x− a)p.
Proposition 18.2.1.606
2.2 Généralités
Avec les notations précédentes, si f admet un développement limité en a à l’ordre n il est unique.
Proposition 18.2.2.607 (Unicité)
Démonstration
Soit I un intervalle, a un point de I qui n’est pas une borne. Soit n ∈ N et f une fonction n foisdérivable sur I. Alors pour tout x dans I
f (x) = f (a) + f ′(a)(x− a) + · · ·+ f (n)(a)n!
(x− a)n + o((x− a)n).
Théorème 18.2.2.608 (Formule de Taylor-Young)
Remarques :
1. Cette formule ne donne des informations qu’au voisinage de a.
2. Ce théorème sera démontré plus tard comme conséquence de la formule de Taylor avec reste intégral (onsupposera que f est de classe C n+1).
Démonstration
259

Soit I un intervalle et f une fonction définie sur I.
1. Soit n ∈ N. Si f est de classe C n alors elle admet un développement limité à l’ordre n en toutpoint de I.
2. Une fonction de classe C ∞ admet des développements limités à tout ordre.
Corollaire 18.2.2.609
Étudions la réciproque :
Soit I un intervalle, f une fonction définie sur I et a un point de I qui n’est pas une borne.
— Si f ∈ DL0,a alors f est continue en a.
— Si f ∈ DL1,a alors f est dérivable en a.
— Une fonction peut admettre des développements limités d’ordre supérieur sans être deux foisdérivable.
Proposition 18.2.2.610
Démonstration :
— OK
— OK
— Le problème est que l’on ne peut pas dériver un développement limité car une fonction peut être "trèspetite" et avoir une dérivée "très grande". Par exemple
x 7→ x4 sin(
1x6
).
Soit I un intervalle, a un point de I, n un entier et f ∈ DLn,a. Pour tout p 6 n, on a f ∈ DLp,a et ledéveloppement à l’ordre p est obtenu en tronquant le développement à l’ordre n.
Proposition 18.2.2.611 (Troncature)
Démonstration : Faire la démonstration avec n = 4 et p = 2.
2.3 Calculs de développements limités
La formule de Taylor-Young permet de calculer les développements limités. Dans la pratique on se ramèneraaux développement des fonctions classiques en 0 par des opérations.
260

— La fonction x 7→ ex est de classe C ∞ elle admet des développement à tout ordre en 0 et, pourtout n ∈ N :
∀x ∈ R, ex = 1 + x +x2
2!+ · · ·+ xn
n!+ o(xn).
— Les fonctions x 7→ ch x et x 7→ sh x sont de classe C ∞ elles admettent des développement àtout ordre en 0 et, pour tout n ∈ N :
∀x ∈ R, ch x = 1 +x2
2!+ · · ·+ x2n
2n!+ o(x2n+1).
∀x ∈ R, sh x = x +x3
3!+ · · ·+ x2n+1
(2n + 1)!+ o(x2n+2).
— Les fonctions x 7→ cos x et x 7→ sin x sont de classe C ∞ elles admettent des développement àtout ordre en 0 et, pour tout n ∈ N :
∀x ∈ R, cos x = 1− x2
2!+ · · ·+ (−1)n x2n
2n!+ o(x2n+1).
∀x ∈ R, sin x = x− x3
3!+ · · ·+ (−1)n x2n+1
(2n + 1)!+ o(x2n+2).
— La fonction x 7→ ln(1 + x) est de classe C ∞ elle admet des développement à tout ordre en 0 et,pour tout n ∈ N :
∀x > −1, ln(1 + x) = x− x2
2+ · · ·+ (−1)n+1 xn
n+ o(xn).
— Soit α ∈ R, la fonction x 7→ (1 + x)α est de classe C ∞ elle admet des développement à toutordre en 0 et, pour tout n ∈ N :
∀x > −1, (1 + x)α = 1 + αx +α(α− 1)x2
2!+ · · ·+ α(α− 1) · · · (α− n + 1)xn
n!+ o(xn).
Théorème 18.2.3.612 (A SAVOIR)
Remarques :1. Les formules de cos et sin se retrouve à partir du développement de ex avec
sin x = Im(eix) et cos x = Re(eix).
2. Les DLs de cosinus et sinus n’ont que des termes paires ou impairs, c’est pour cela que l’on les donne àl’ordre 2n ou 2n + 1. Mais si on fait n = 5 dans la formule du DL de cosinus, on trouver le DL à l’ordre 10(et même 11). Si on veut le DL à l’ordre 5, on prend n = 2 et on trouve :
cos x = 1− x2
2+
x4
24+ o(x4).
3. Il n’y a pas de factorielles dans le développement de ln(1 + x)4. Cas particulier à savoir pour (1 + x)α
— α = −1 : on a
11 + x
= (1+ x)−1 = 1− x+ x2 + · · ·+(−1)nxn + o(xn) et1
1− x= (1− x)−1 = 1+ x+ x2 + · · ·+ xn + o(xn).
— α = 1/2 :√
1 + x = (1 + x)1/2 = 1 +12
x− x2
8+ o(x2)
— α = −1/2 :1√
1 + x= (1 + x)−1/2 = 1− 1
2x +
3x2
8+ o(x2)
261

5. Attention que l’on ne donne ci-dessus que des développements limités en 0. Essayons par exemple decalculer le développement limité de x 7→ ex en 2 à l’ordre 2. On pose x = 2 + h (ou h = x− 2). Dès lors ona :
ex = e2+h
= e2.eh
= e2(1 + h +h2
2+
h3
6) + o(h3)
= e2(1 + (x− 2) +(x− 2)2
2+
(x− 2)3
6+ o((x− 2)3).
2.4 Opérations sur les développements limités
L’avantage des développements limités - par rapport aux équivalents - c’est que l’on peut faire toutes lesopérations que l’on veut. Dans la pratique, on calculera toujours les développements limités par des suitesd’opérations en partant des développements limités standards donnés dans la section précédente.
Dans tout ce chapitre on se fixe un intervalle I et un point a intérieur à I.
Somme
Soit n un entier. Soit f et g deux éléments de DLn,a. Alors la fonction f + g est un élément de DLn,a.De plus, si les développements limités de f et g sont donnés par les polynômes P et Q alors :
∀x ∈ I, ( f + g)(x) = (P + Q)(x− a) + o((x− a)n).
Proposition 18.2.4.613
Remarque : la proposition ci-dessus dit que le développement limité d’une somme est la somme des dévelop-pements limités.Exemple : Regardons au voisinage de 0 la fonction définie sur ]− 1,+∞[ par x 7→ sin(x)− ln(1 + x). On nepeut pas utiliser des équivalents, en effet sin x ∼ x et ln(1 + x) ∼ x mais on n’a pas sin x− ln(1 + x) ∼ 0. Nousallons faire des développements à l’ordre 1 (ce qui revient à des équivalents). On a
sin x = x + o(x) et ln(1 + x) = x + o(x).
On en déduit quesin x− ln(1 + x) = o(x).
Maintenant, si on veut un équivalent de sin x− ln(1 + x) on fait des développements à l’ordre 2 :
sin x = x + o(x2) et ln(1 + x) = x− x2
2+ o(x2).
On en déduit que
sin x− ln(1 + x) =x2
2+ o(x2) d’où sin x− ln(1 + x) ∼ x2
2.
Exercice : Déterminer le développement limité à l’ordre 3 de sin x en π/4.
Produit
Exemple : Essayons de déterminer un développement limité à l’ordre 3 en 0 de la fonction x 7→ ex. sin x. On apour tout x réel :
ex = 1 + x +x+
x2
2+
x3
6+ o(x3) et sin x = x− x3
6+ o(x3).
Comme ce qui précède sont des vraies égalités ont peut faire le produit et on a :
ex. sin x =
(1 + x +
x2
2+
x3
6+ o(x3)
).(
sin x = x− x3
6+ o(x3)
)
= Faire le calcul explicite
= x− x2 +x3
3+ o(x3)
262

Soit n un entier. Soit f et g deux éléments de DLn,a. Alors la fonction f × g est un élément de DLn,a.De plus, si les développements limités de f et g sont donnés par les polynômes P et Q alors :
∀x ∈ I, ( f × g)(x) = Tn(P×Q)(x− a) + o((x− a)n),
où Tn(P×Q) est le polynôme obtenu en tronquant au degré n le polynôme P×Q.
Proposition 18.2.4.614
Remarque : la proposition signifie que pour obtenir le développement limité d’un produit de fonctions, on faitle produit des développements limités des fonctions considérées et on tronque à l’ordre désiré.Exercice : calculer le développement limité de x 7→ sin x. cos x à l’ordre 4 en 0.
Si on se donne deux développements limités normalisés :
f1(a + h) = hp1
(α0 + α1h + · · ·+ αn1−p1 hn1−p1 + o
h→0
(hn1−p1
))
et
f2(a + h) = hp2
(α0 + α1h + · · ·+ αn2−p2 hn2−p2 + o
h→0
(hn2−p2
))
Si on fait le produit f1(x) f2(x) on obtient un développement limité à l’ordre Min(n1 + h2, n2 + h1).
ATTENTION
Composition
Commençons par un lemme.
Soit α et β deux fonctions. On suppose que β(x) ∼a
C(x− a)p avec p strictement positif et α(x) =
o0(xq). On a alors
α β(x) = oa((x− a)pq) .
Lemme 18.2.4.615
Démonstration : Il suffit de montrer que
limx→a
α(β(x))(x− a)pq = 0.
Orα(β(x))(x− a)pq =
α(β(x))β(x)q .
(β(x)
(x− a)q
)p.
Le premier terme tend vers 0 car β tend vers 0 en a du fait que p > 0. Le deuxième tend vers la constante Cp.
On peut maintenant donner un exemple :Exemple : Calculer le développement limité de x 7→ esin x à l’ordre 4 en 0. On a sin x = x− x3/6 + o(x3). Donc,
esin x = ex−x3/6+o(x3).
Or sin 0 = 0, on peut donc utiliser un développement limité de x 7→ ex en 0. On a alors
esin x = 1 +(
x− x3
6+ o(x3)
)+
(x− x3
6 + o(x3))2
2+
(x− x3
6 + o(x3))3
6+ o(x3)
= 1 + x +x2
2− x3
6+ o(x3).
263

Soit n un entier. Soit f un élément de DLn,a et g un élément de DLn,b où b = f (a). Alors la fonctiong f est un élément de DLn,a. De plus, si les développements limités de f et g sont donnés par lespolynômes P et Q alors :
∀x ∈ I, (g f )(x) = Tn(Q P)(x− a) + o((x− a)n),
où Tn(Q P) est le polynôme obtenu en tronquant au degré n le polynôme Q P.
Proposition 18.2.4.616
Exercice : calculer le développement limité à l’ordre 4 de x 7→ ecos x.
Il est essentiel de bien faire le DL de g en b et non pas en a.
ATTENTION
Le développement limité d’une fonction paire (resp. impaire) en 0 n’a que des termes d’exposantspairs (resp. impairs).
Corollaire 18.2.4.617
Soit n un entier. Soit f un élément de DLn,a tel que f (a) 6= 0 alors1f∈ DLn,a.
Corollaire 18.2.4.618 (Quotient)
Démonstration : Plutôt que de faire la démonstration, on va traiter un exemple. Soit f : x 7→ 1 + ex. On saitque f admet un DL à l’ordre 3 en 0 et
1 + ex = 1 + 1 + x + x2/2 + x3/6 + o(x3).
D’oùf (x) =
12 + x + x2/2 + x3/6 + o(x3)
.
La méthode consiste à factoriser, de sorte à obtenir une fonction du type 1/(1 + X) avec X tendant vers 0. Ici onpose
f (x) =12
11 + x/2 + x2/4 + x3/12 + o(x3)
.
On fait alors le DL de 1/(1 + X) avec X = x/2 + x2/4 + x3/12 + o(x3).
Exemple : Calculons le DL de tan à l’ordre 3 en 0. On sait que tan x =sin xcos x
de ce fait
tan x =x− x3
6 + o(
x3)
1− x2
2+ o (x3)
=
(x− x3
6+ o
(x3))×(
1 +x2
2+ o
(x3))
= x +x3
3+ o
(x3)
Il faut connaitre ce DL jusqu’à l’ordre 3, nous verrons en exercice comment calculer les ordres suivant demanière plus efficace.
264

Intégration
Soit f un élément de DLn,a. La fonction f est continue elle admet une primitive que l’on note F. AlorsF ∈ DLn+1,a. De plus si
∀x ∈ I, f (x) = a0 + a1(x− a) + · · ·+ an(x− a)n + o((x− a)n)
alors
∀x ∈ I, F(x) = F(a) + a0(x− a) + a1(x− a)2
2+ · · ·+ an
(x− a)n+1
n + 1+ o((x− a)n+1).
Proposition 18.2.4.619
Exemples :1. On sait que
∀x ∈ R,1
1 + x2 = 1− x2 + x4 + o(x5).
Donc,
∀x ∈ R, arctan(x) = x− x3
3+
x5
5+ o(x6).
De manière générale
∀x ∈ R, arctan(x) = x− x3
3+
x5
5+ · · ·+ (−1)n x2n+1
(2n + 1)!+ o(x2n+2).
2. On sait que la dérivée d’arccos est x 7→ −1√1− x2
or,
∀x ∈]− 1, 1[,1√
1− x2= 1− 1
2x2 +
34
x4 + o(x5).
Donc,
∀x ∈]− 1, 1[, arccos(x) =π
2+ x− x3
6+
3x5
20+ o(x6).
Exercice : Calculer les DL de arccos à l’ordre 3 en 1/2.Remarque : il faut faire plus attention avec la dérivation des développements limités. En effet comme on l’a vuprécédemment, une fonction peut avoir un développement limité à l’ordre n sans que sa dérivée n’ait même delimite. Cependant, si on suppose qu’une fonction f est de classe C n+1 au voisinage d’un point a pour n ∈ N?.Alors f admet un développement limité à l’ordre n en a de plus la dérivée g = f ′ de f est de classe C n et admetde ce fait un développement limité à l’ordre n− 1. Maintenant, les développements limités de f et g sont donnéspar la formule de Taylor-Young or, pour tout entier 1 6 k 6 n, g(k−1) = f (k), on en déduit que si
f (x) = a0 + · · ·+ an(x− a)n + o((x− a)n)
alorsg(x) = a1 + · · ·+
an
n(x− a)n−1 + o((x− a)n−1).
3 Applications des développements limités
3.1 Développements limités et équivalents
De fait on trouve un équivalent simple d’une fonction en prenant le premier terme non nul du développementlimité.
Par exemple, on sait que
cos x = 1− x2
2+
x4
24+ o(x4).
On en déduit que cos x ∼ 1 puis que cos x− 1 ∼ − x2
2.
Cela permet de retrouver des résultats aperçus lors de l’étude des équivalents sur les sommes d’équivalents.Exemples :
265

1. On cherche un équivalent à f (x) = sin x + cos x− 1. On disait que sin x ∼ x et que cos x− 1 ∼ − x2
2donc
que la fonction devait être équivalente à x et on le démontrait. Là on peut le faire simplement.
f (x) = (x + o(x2)) +
(− x2
2+ o(x2)
)= x + o(x) ∼ x.
2. Par contre si on regarde g(x) = x sin x + cos x− 1, on pouvait essayer de faire de même. Les deux sontéquivalents à des termes en x2 qui ne se compensent pas. On obtient :
g(x) =x2
2+ o(x2) ∼ x2
2.
3. Pour finir si on regarde h(x) =x2
sin x + cos x− 1, on peut essayer de faire de même. Mais là, les deux
sont équivalents à des termes en x2 qui se compensent. On doit vraiment faire un développement limitéafin d’obtenir le terme en x3 ou en x4.
h(x) =x2
2+ o(x3)− x2
2+ o(x3) = o(x3).
Le terme en x3 est nul, on doit pousser plus loin de DL.
h(x) =x2
2− x4
12+ o(x4)− x2
2+
x4
24+ o(x4) = − x4
24+ o(x4) ∼ − x4
24.
Remarque : C’est vraiment dans ce dernier cas, que les DL sont essentiel. Si les termes principaux se com-pensent, on est obligé d’aller chercher des termes « plus loin dans le DL ».
3.2 Détermination de limites
Les développements limités sont utiles pour déterminer des limites. Le problème est que l’on ne sait pas, apriori, à quel ordre on doit faire le développement.Exemples :
1. Calculer limx→0
ln(1 + x2)
1− cos x. Ce premier exemple et très simple et peut même se traiter avec des équivalents.
2. Calculer limx→0
cos x + sin x√x
. Celui-là est un peu plus compliqué car, on utilise un développement limité ce
qui évite d’avoir un problème avec les sommes d’équivalents.
3. Calculer limx→0
x sin x− ln(1 + x2)
x4 . On voit ici que le dénominateur est équivalent à x4. Il faut donc faire un
développement limité à l’ordre 4 en haut.
4. Calculer limx→∞
x((
1 +1x
)x− e)
.
3.3 Étude locale
Les développements limités permettent de déterminer les tangentes et la position relative de la courbe parrapport à la tangente.
Soit a ∈ R et f ∈ DL2,a. On suppose que le développement limité à l’ordre 2 est :
f (x) = a0 + a1(x− a) + a2(x− a)2 + o((x− a)2).
Alors f admet pour tangente au point d’abscisse a la droite d’équation y = a0 + a1(x− a). De plus, sia2 > 0, la courbe est au-dessus de sa tangente au voisinage de a et si a2 < 0, la courbe est au-dessousde sa tangente au voisinage de a.
Proposition 18.3.3.620
Remarques :
266

1. La proposition précédente, ne donne pas d’informations dans le cas ou a2 = 0. Plus généralement si fadmet un développement limité de la forme :
f (x) = a0 + a1(x− a) + ap(x− a)p + o((x− a)p)
avec ap le plus petit terme non nul de degré strictement supérieur à 1.Si p est impair, la courbe traverse sa tangente au point d’abscisse p. On sait de plus dans quel sens enétudiant le signe de ap. Si p est pair, la courbe reste du même coté de la tangente et on a le même résultatque si p = 2.
2. Cette méthode est souvent plus rapide qu’un calcul direct de dérivé, en particulier si la fonction f estdéfinie via un quotient.
Exemple : Soit f la fonction définie par x 7→ ex ln(x). Trouver l’équation de la tangente au point x = 1 ainsique la position de la courbe par rapport à la tangente.
On obtient
f (x) = e((x− 1) +
(x− 1)2
2
)+ o((x− 1)2).
D’où la tangente au point d’abscisse 1 est y = e(x− 1). De plus la courbe est au-dessus de sa tangente.
3.4 Développements asymptotiques
Pour le moment on a utilisé les développements limités afin d’obtenir des informations au voisinage d’unpoint a dans R. Cependant, comme pour les limites, on peut aussi essayer d’obtenir des informations auvoisinage de ±∞. Cela va nous permettre d’obtenir des limites ou d’étudier les branches infinies.
De manière plus générale, on peut définir la notion de développement asymptotique en a ∈ R en considérantdes fonctions ( fi)i∈N telles que
∀i ∈ N, fi+1 = oa( fi) .
La suite ( fi) s’appelle alors une échelle de comparaison.
Un développement asymptotique en 0
On cherche à faire un développement de√
sin x en 0. On ne peut peut-être pas faire de développement limitécar on sait bien que cette fonction n’est pas dérivable en 0 (on a
√sin x ∼ √x). On va quand même pouvoir
faire un développement asymptotique. On a en effet sin x = x− x3/6 + o0
(x3). De ce fait
√sin x =
√x− x3/6 + o
0(x3)
=√
x√
1− x2/6 + o (x2)
=√
x(
1− x2
12+ o
0
(x2))
=√
x− x2√x12
+ o(
x2√x)
.
Ici on utilise l’échelle des xn√x.
Un développement asymptotique en ∞
Soit f une fonction définie au voisinage de ±∞. On cherche des réels (a0, . . . , an) ∈ Rn+1 tel que, pour toutx proche de +∞ (resp. −∞),
f (x) = a0 + a1
(1x
)+ · · ·+ an
(1x
)n+ o
((1x
)n).
Remarque : cela revient à faire un développement limité de la fonction g : t 7→ f (1/t) au voisinage de 0. Enparticulier, tous les théorèmes vus précédemment restent vrais.Exemple : On considère la fonction f : x 7→
√x2 + x−
√x2 − x. On a au voisinage de +∞
√x2 + x−
√x2 − x = x
(√1 + 1/x−
√1− 1/x
)
= x(
1 +1
2x− 1 +
12x
+ o(
1x
))
=12+ o(1).
267

On en déduit quelim
x→+∞f (x) = 1/2.
Il faut faire attention dans ce genre de calcul, qu’il y a une multiplication par x à la fin et que cela faitdescendre de 1 l’ordre du développement fait.
Exercice : Déterminer limx→+∞
x(√
x +√
x + 1−√
x +√
x− 1)
.
Recherche de branches infinies
Les développements asymptotiques à l’infini permettent aussi d’étudier les branches infinies. En particulier,les asymptotes obliques. On peut aussi, en poussant le développement à un ordre de plus déterminer lespositions relatives.
On va chercher a0, a1 tels que
f (x) = a0x + a1 + ε(x) avec limx→∞
ε(x) = 0.
En pratique on cherche a0, a1 et ap tels que
f (x) = a0x + a1 +ap
xp + o+∞
((1
xp+1
)).
On peut alors conclure à la position relative de la courbe de f et de l’asymptote en fonction du signe de ap(et de la parité de p si on est en −∞).
Cela revient donc à faire un développement en ∞ de x 7→ f (x)x
.
Exemple : Déterminons les branches infinies de f : x 7→ x3 + xx2 − x
en +∞.
On a f (x) =x3
x2 .1 + 1/x2
1− 1/x. Afin d’obtenir l’asymptote et la position relative, on veut calculer le développe-
ment asymptotique à l’infini à l’ordre 1. Il faut cependant faire attention que pour ce faire, comme nous allons,
multiplier par x à la fin, il faut commencer par calculer le développement de1 + 1/x3
1− 1/x2 à l’ordre 2 en +∞.
On a
1 + 1/x2
1− 1/x=
(1 +
1x2
)(1 +
1x+
1x2 + o
(1x2
))
= 1 +1x+
2x2 + o
(1x2
).
On en déduit que
f (x) = x + 1 +2x+ o
(1x
).
L’asymptote est donc y = x + 1 et la fonction est au-dessus de son asymptote.Exercice : Étude x 7→
√x2 + x + 1 en ±∞.
Étude d’une suite implicite
Soit n ∈ N∗, on pose fn : x 7→ x5 + nx− 1. Cette fonction est strictement croissante sur R+ et fn(0) = −1 < 0,fn(1) = n > 0. On en déduit qu’il existe une solution de l’équation fn(x) = 0 dans l’intervalle ]0, 1[. On la notexn.
— On remarque alors que fn+1(xn) = x5n + (n + 1)xn − 1 = nxn + fn(xn) = nxn > 0. De ce fait,
fn+1(xn) > 0 = fn+1(xn+1)⇒ xn > xn+1 car f−1n+1 est croissante
La suite (xn) est décroissante et minorée par 0 donc elle converge. Si on note ` sa limite. Montrons parl’absurde que ` = 0. On suppose que ` > 0. Dans ce cas, nxn ∼ n` et donc tend vers +∞, on nxn = 1− x5
n
qui est bornée.On en déduit que
(xn)→ 0
Remarque : On aurait aussi pu voir que fn(1/n) =1n5 + 1− 1 =
1n5 > 0 et donc 0 < xn < 1/n.
268

— On cherche maintenant la suite du développement asymptotique. On remarque que comme (xn) → 0alors x5
n = o (xn) de ce fait, x5n + nxn ∼ nxn. On a donc nxn ∼ 1 et donc
xn ∼1n
.
— On cherche maintenant la suite du développement asymptotique. On pose xn =1n+ αn où donc αn =
o (1/n) c’est-à-dire que nαn → 0. En remplaçant dans l’équation
(1n+ αn
)5+ n
(1n+ αn
)= 1 ⇐⇒ 1
n5 (1 + nαn)5 + nαn = 0
⇐⇒ 1n5 (1 + 5nαn + o (nαn)) + nαn = 0
⇐⇒ nαn + o (nαn) = −1n5
On en déduit que αn ∼ −1n6
En conclusionxn =
1n− 1
n6 + o(
1/n6)
Remarque : En recommençant on peut trouver que
xn =1n− 1
n6 +5
n11 + o(
1/n11)
Formule de Stirling
Notre but est de démontrer la formule de Stirling qui donne un équivalent de factoriel n :
On an! ∼ nne−n
√2πn ou nn+1/2e−n
√2π
Théorème 18.3.4.621 (Formule de Stirling)
Démonstration : Commençons par essayer de « justifier » d’où vient cette formule. On considère
ln(n!) =n
∑k=2
ln k.
Étant donné la croissance du logarithme, on peut se dire que cela ne doit pas être trop loin de n ln n. On posedonc vk = k ln k− (k− 1) ln(k− 1) et on a
n ln n =n
∑k=2
vk.
Maintenant, vk = ln k− (k− 1) ln(
k− 1k
). On en déduit que
n ln n = ln(n!)−n
∑k=2
(k− 1) ln(
1− 1k
). (A)
Maintenant, en utilisant le développement asymptotique de de (k− 1) ln(1− 1/k) pour k→ ∞ on a
(k− 1) ln(
1− 1k
)= k
(1− 1
k
)(−1
k− 1
2k2 −1
3k3 + o(
1/k3))
= −1 +12k
+1
6k2 + o(
1/k2)
= −1 +12k
+ αk
269

où αk ∼1
6k2 . En conclusion, ln(n!) = n ln n− n +n
∑k=2
12k
+ αk. Il ne reste plus qu’à voir quen
∑k=2
12k
=12
ln n +
γ + o (1) (série harmonique) et quen
∑k=2
αk converge vers une constante réelle (cela sera prouvé en fin d’année)
pour en conclure queln(n!)− (n + 1/2) ln n + n→ ` ∈ R.
En prenant l’exponentiellen!en
nn+1/2 tend vers une constante non nulle K et donc
n! ∼ Knn+1/2e−n.
On peut démontrer plus simplement ce fait (quand on connait le résultat). On considère en effet
un =n!en
nn√n.
C’est une suite strictement positive. Le but est alors de montrer que (un) converge vers une limitenon nulle. On considère alors
ln(
un+1
un
)= ln
[e(
nn + 1
)n+1/2]
= 1−(
n +12
)ln(1 + 1/n)
= − 112n2 + o
(1/n2
)
On en déduit que la série de terme général ln(
un+1
un
)est convergente. Or
∀N ∈ N,N
∑n=1
ln(
un+1
un
)= ln(uN+1)− ln(u1).
On en déduit que ln(un) tend vers une limite finie et donc (un) aussi.
ATTENTION
Pour conclure la démonstration il reste à calculer la valeur de K. On introduit pour cela l’intégrale de Wallis :
∀n ∈ N, In =∫ π/2
0sinn t dt.
— A l’aide d’une classique intégration par partie on obtient que
∀n > 2, nIn = (n− 1)In−2.
— En remarquant que I0 =π
2on en déduit que pour n = 2p,
I2p =2p− 1
2p× 2p− 3
2p− 2× · · · × 1
2I0 =
(2p)!22p(p!)2 ×
π
2.
— La suite (In) est décroissante d’oùIn 6 In−1 6 In−2
et doncn− 1
n=
In−2
In6
In−1
In6 1.
Par encadrement, on obtient que (In−1/In) tend vers 1 et donc que In ∼ In−1.
— Pour finir, on montrer que la suite Zn = (n + 1)In In+1 est constante et de ce fait est égale à Z0 =π
2. On a
Zn ∼ nI2n d’où
In ∼√
π
2n.
270

Maintenant en utilisant la formule trouvée ci dessus et l’équivalent précédent on obtient que
I2p ∼K(2p)2p+1/2e−2p
22pK2(p)2p+1e−2pπ
2∼√
2K√
pπ
2∼ π
K√
2p.
En comparant avec la formule précédente, on obtient :√
π
4p∼ π
K√
2p.
On en obtient K =√
2π.
271

19Espaces vectoriels
1 Espaces vectoriels 2721.1 Défintion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2721.2 Combinaisons linéaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 274
2 Sous-espaces vectoriels 2752.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2752.2 Sous-espace vectoriel engendré par une partie . . . . . . . . . . . . . . . . . . . . . . . . . . . . 276
3 Familles de vecteurs 2773.1 Exemple introductif . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2773.2 Familles génératrices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2773.3 Familles libres . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2783.4 Bases . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 279
4 Somme de sous-espaces vectoriels 2804.1 Défintions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2804.2 Somme directe et supplémentaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2814.3 Somme directe d’un nombre fini de sous-espaces vectoriels . . . . . . . . . . . . . . . . . . . 282
5 Sous-espaces affines 2835.1 Définition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2835.2 Sous-espaces affines . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2845.3 Intersection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 285
Dans ce chapitre K désignera R ou C (et éventuellement Q). Dans la pratique la grande majorité des résultatsrestent vrais dès que K est un corps.
1 Espaces vectoriels
1.1 Défintion
Si on considère l’ensemble des vecteurs de R2 et R3. C’est un ensemble sur lequel on a deux opérations : lasomme et la multiplication par un réel. Nous allons construire la structure d’espace vectoriel pour généraliserce concept.
272

On appelle K−espace vectoriel (ou espace vectoriel sur K) tout ensemble E muni d’une loi de compositioninterne (notée +) et d’une loi externe c’est-a-dire une application K× E→ E notée λ.x (où λ ∈ K et x ∈ E)vérifiant :
1. (E,+) est un groupe commutatif ;
2. ∀x ∈ E, ∀(λ, µ) ∈ K2, α.(β.x) = (αβ).x.
3. ∀(λ, µ) ∈ K2, ∀x ∈ E, (λ + µ).x = λ.x + µ.x
4. ∀x ∈ E, 1.x = x
5. ∀(x, y) ∈ E2, ∀λ ∈ K, λ.(x + y) = λ.x + λ.y.
Définition 19.1.1.622
Terminologie :
1. Les éléments de E s’appellent des vecteurs. Cependant, pour alléger on ne les désigne pas avec des flèches.
2. L’élément neutre de (E,+) s’appelle le vecteur nul. On le désigne par 0 ou 0E si on veut le différencier du0 de K.
3. Les éléments de K s’appellent des scalaires.
4. On note souvent λx pour λ.x s’il n’y a pas de confusion.
5. Le corps K s’appelle corps de la base de l’espace vectoriel. Il arrive de l’omettre dans la notation. On diraalors « soit E un espace vectoriel ».
Exemples :
1. L’ensemble R2 avec les opérations classiques est un espace vectoriel sur R. Rappelons la définition deslois sur R2. Soit u = (x, y), v = (x′, y′) et λ ∈ R on définit :
u + v = (x + x′, y + y′) et λ.u = (λ.x, λ.y).
Nous démontrons ci-dessous, dans un cas plus général, que c’est bien un espace vectoriel.
2. On munit l’ensemble Kn des opérations suivantes :
(x1, . . . xn) + (y1, . . . , yn) = (x1 + y1, . . . , xn + yn) et λ.(x1, . . . , xn) = (λ.x1, . . . , λ.xn).
L’ensemble Kn est alors un espace vectoriel sur K.
1. La loi + est associative car elle l’est sur K. De même elle est commutative.Le vecteur 0E = (0, . . . , 0) est un élément neutre pour l’addition.Pour tout u = (x1, . . . , xn), le vecteur −u = (−x1, . . . ,−xn) est son symétrique.Donc (E,+) est bien un groupe commutatif.
2. ∀u = (x1, . . . , xn) ∈ E, ∀(λ, µ) ∈ K2, α.(β.u) = α.(βx1, . . . , βxn) = (αβx1, . . . , αβxn) = (αβ).u.
3. ∀(λ, µ) ∈ K2, ∀u = (x1, . . . , xn) ∈ E(λ + µ).x = ((λ + µ)x1, . . . , (λ + µ)xn) = (λx1 + µx1, . . . , λxn +µxn) = λ.u + µ.u.
4. ∀u = (x1, . . . , xn) ∈ E, 1.u = u
5. ∀(u, v) ∈ E2, ∀λ ∈ K, λ.(u + v) = λ.(x1 + y1, . . . , xn + yn) = (λx1 + λy1, . . . , λxn + λyn) = λ.u +λ.v.
En particulier, R est un R-espace vectoriel (pareil pour C).
3. L’ensemble réduit à un élément 0 est un espace vectoriel sur K. On conviendra que c’est K0.
4. L’ensemble K[X] des polynômes est un espace vectoriel.
5. Soit X un ensemble et E un espace vectoriel, l’ensemble F = F (X, E) des applications de X dans E est unespace vectoriel avec les lois suivantes :
∀( f , g) ∈ F2, f + g : x 7→ f (x) + g(x) et ∀ f ∈ F, ∀λ ∈ K, λ. f : x 7→ λ. f (x).
Cela englobe en particulier
— les fonctions définies d’un intervalle I dans R ou dans C ;
— les suites (définies sur N) à valeurs dans R ou C.
273
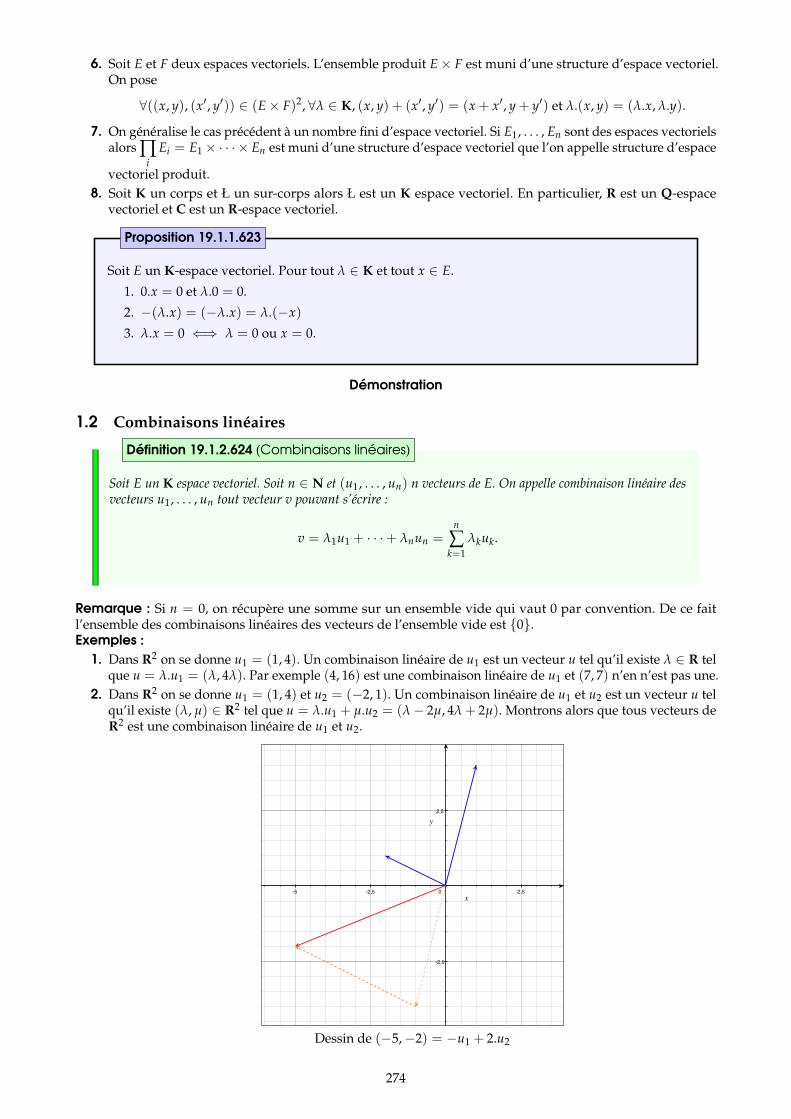
6. Soit E et F deux espaces vectoriels. L’ensemble produit E× F est muni d’une structure d’espace vectoriel.On pose
∀((x, y), (x′, y′)) ∈ (E× F)2, ∀λ ∈ K, (x, y) + (x′, y′) = (x + x′, y + y′) et λ.(x, y) = (λ.x, λ.y).
7. On généralise le cas précédent à un nombre fini d’espace vectoriel. Si E1, . . . , En sont des espaces vectorielsalors ∏
iEi = E1× · · · × En est muni d’une structure d’espace vectoriel que l’on appelle structure d’espace
vectoriel produit.8. Soit K un corps et Ł un sur-corps alors Ł est un K espace vectoriel. En particulier, R est un Q-espace
vectoriel et C est un R-espace vectoriel.
Soit E un K-espace vectoriel. Pour tout λ ∈ K et tout x ∈ E.
1. 0.x = 0 et λ.0 = 0.
2. −(λ.x) = (−λ.x) = λ.(−x)
3. λ.x = 0 ⇐⇒ λ = 0 ou x = 0.
Proposition 19.1.1.623
Démonstration
1.2 Combinaisons linéaires
Soit E un K espace vectoriel. Soit n ∈ N et (u1, . . . , un) n vecteurs de E. On appelle combinaison linéaire desvecteurs u1, . . . , un tout vecteur v pouvant s’écrire :
v = λ1u1 + · · ·+ λnun =n
∑k=1
λkuk.
Définition 19.1.2.624 (Combinaisons linéaires)
Remarque : Si n = 0, on récupère une somme sur un ensemble vide qui vaut 0 par convention. De ce faitl’ensemble des combinaisons linéaires des vecteurs de l’ensemble vide est 0.Exemples :
1. Dans R2 on se donne u1 = (1, 4). Un combinaison linéaire de u1 est un vecteur u tel qu’il existe λ ∈ R telque u = λ.u1 = (λ, 4λ). Par exemple (4, 16) est une combinaison linéaire de u1 et (7, 7) n’en n’est pas une.
2. Dans R2 on se donne u1 = (1, 4) et u2 = (−2, 1). Un combinaison linéaire de u1 et u2 est un vecteur u telqu’il existe (λ, µ) ∈ R2 tel que u = λ.u1 + µ.u2 = (λ− 2µ, 4λ + 2µ). Montrons alors que tous vecteurs deR2 est une combinaison linéaire de u1 et u2.
-5 -2,5 0 2,5
-2,5
2,5
Dessin de (−5,−2) = −u1 + 2.u2
274

3. Dans R3 on se donne les vecteurs u1 = (1, 1, 0) et u2 = (−1, 1,−2). L’ensemble des combinaisons linéairesde u1 et u2 est alors un plan vectoriel.
4. Dans K[X], les combinaisons linéaires des vecteurs 1, X et X2 sont les polynômes de degré inférieur à 2.
Remarques :
1. On voit en particulier que particulier que le vecteur nul est une combinaison linéaire de toute famille devecteurs (et même de la famille vide).
2. La notion de combinaison linéaire ne dépend pas de l’ordre des vecteurs u1, . . . , un. Cependant on garderale plus souvent un ordre pour préparer à la notion de base
On va étendre la notion de combinaison linéaire au cas d’une famille infinie de vecteurs. Il faut faire attentionque ’lin ne considérera alors que la somme d’un nombre fini de vecteur.
Soit E un K-espace vectoriel.
1. Soit A une partie de E (éventuellement infinie). On appelle combinaison linéaire des vecteurs de A toutecombinaison linéaire d’une partie finie de A.
2. Soit I un ensemble. On appelle famille presque nulle (ou à support fini) de K un famille (λi) ∈ KI telque l’ensemble J = i ∈ I | λi 6= 0 des indices i tels que λi ne soit pas nulle est fini.
3. Si on note A = (ui)i∈I une partie de E, toute combinaison linéaire v des vecteurs de A se note
v = ∑i∈I
λiui
où (λi)i∈I est une famille presque nulle.
Définition 19.1.2.625
Exemple : Dans F (R, R), on pose A = x 7→ xn | n ∈ N. L’ensemble des combinaisons linéaires des élémentsde A est l’ensemble des fonctions polynomiales.Remarque : Cette année nous travaillerons assez rarement avec des familles de vecteurs infinies.Notation : Avec les notation précédente, on note VectA l’ensemble des combinaisons linéaires des vecteurs deA (où A est un ensemble ou une famille).
2 Sous-espaces vectoriels
Dans tout ce paragraphe on se fixe E un K-espace vectoriel.
2.1 Définitions
On appelle sous-espace vectoriel de E tout sous-groupe F de (E,+) stable par la multiplication. L’ensemble Fest alors un espace vectoriel.
Définition 19.2.1.626
Remarque : On abrège souvent "sous-espace vectoriel" en "sev".
Soit F une partie de E. Les assertions suivantes sont équivalentes :
1. L’ensemble F est un sous-espace vectoriel de E.
2. 0 ∈ F et ∀(u, v) ∈ F2, ∀(λ, µ) ∈ K2, λ.u + µ.v ∈ F.
Proposition 19.2.1.627 (Caractérisation des sous-espaces vectoriels)
Démonstration
Remarques :
275

1. On peut alléger la deuxième condition en ne demandant que 0 ∈ F et ∀(u, v) ∈ F2, ∀λ ∈ K, λ.u + v ∈ F.Cependant, ce faisant on perd la symétrie de l’expression.
2. De même on peut remplacer 0 ∈ F par F 6= ∅ mais dans 99,9%, c’est le vecteur nul que nous chercheronscomme élément de F.
3. Comme pour les groupes/anneaux, quand on veut démontrer qu’un ensemble est un espace vectoriel onessaye très souvent de démontrer que c’est un sev d’un espace vectoriel connu.
Exemples :
1. L’ensemble C 0(R, R) des fonctions continues sur de R dans R est un sev de F (R, R).
2. L’ensemble Kn[X] est polynômes de degré inférieur à n.
3. Si on considère C comme un R espace vectoriel alors R = z ∈ C | Im(z) = 0 est un sev de C.
4. Dans R2, l’ensemble H = (x, y) | x− 2y = 0 est un sev. Par contre ni (x, y) | x = y2 ou (x, y) | x+ y =1 en est un.
5. Dans R3, l’ensemble (x, y, z) | x− 3y + 2z = 0 est un sev.
6. Dans tout espace vectoriel E, E en entier et 0 sont des sev.
Soit F un sous-espace vectoriel de E. Soit u1, . . . , un des vecteurs de F et λ1, . . . , λn des scalaires alorsλ1u1 + · · ·+ λnun appartient à F.
Proposition 19.2.1.628
Démonstration : On voit que par définition λ1u1 + λ2u2 appartient à F. Ensuite on en déduit que (λ1u1 +λ2u2) + λ3u3 aussi. Et ainsi de suite. De fait, on peut procéder par récurrence sur n.
Remarque : Cela signifie qu’un sev est stable par combinaisons linéaires.
2.2 Sous-espace vectoriel engendré par une partie
Soit F1 et F2 deux sous-espaces vectoriels de E. L’ensemble F1 ∩ F2 est un sous-espace vectoriel deE. De même si (Fi)i∈I est une famille de sous-espaces vectoriels de E alors
⋂
i∈IFi est un sous-espace
vectoriel.
Proposition 19.2.2.629
Démonstration
Exemple : Par exemple si on prend deux plans vectoriels non confondus dans R3. Leur intersection sera unedroite vectorielle qui sera un sev.Remarque : Cela n’est plus du tout vrai pour l’union. Par exemple si on considère les deux droites d’équationx = y et y = 2x dans R2. Nous verrons plus loin le « substitut » à l’union.
Soit A une partie de E. Il existe un plus petit espace vectoriel contenant A. On l’appelle espacevectoriel engendré par A et on le note Vect(A).
Proposition-Définition 19.2.2.630
Remarques :
1. On trouve aussi (mais plus rarement dans ce cadre) la notation < A > .
2. Si A = ∅, Vect(A) = 0.Démonstration : Il suffit de voir que l’ensemble I des sous-espaces vectoriels de E contenant A n’est pas vide(car il contient E lui même). L’ensemble
⋂
F∈IF est un sev et il contient A.
276

Soit A une partie de E. Le sous-espace vectoriel Vect(A) est l’ensemble des combinaisons linéairesde vecteurs de A.
Proposition 19.2.2.631
Démonstration : Notons F l’ensemble des combinaisons linéaires des vecteurs de A et montrons par doubleinclusion que F = Vect(A).
— F ⊂ Vect(A) Soit w un élément de F. Il existe u1, . . . , un des vecteurs de A et λ1, . . . , λn des scalaires
tels que w =n
∑i=1
λiui. Maintenant, par définition, tous les ui appartiennent à A donc à Vect(A). D’après
la proposition, ci-dessus, la combinaison linéaire w appartient aussi à Vect(A). On a bien F ⊂ Vect(A).
— Vect(A) ⊂ F Il suffit de remarquer que F est un sev de E car il est non vide et il est stable par combinaisonlinéaire. Comme, de plus il contient A, on a bien Vect(A) ⊂ F.
Exemples :1. Dans R2, soit u1 = (2, 1). L’espace vectoriel engendré par u1 est l’ensemble Vect(u1) = (2x, x)|x ∈
R = (x, y) ∈ R2 | x = 2y. Si on ajoute u2 = (2, 0). Alors Vect(u1, u2) = R2.
2. Dans K[X], on a Kn[X] = Vect(1, X, X2, . . . , Xn).
3. Dans RN. Si on note u la suite constante à 1 et v la suite définie par vn = n. On a Vect(A) = suites arithmétiques.C’est donc un sev de RN.
3 Familles de vecteurs
On se fixe un espace vectoriel E.
3.1 Exemple introductif
Reprenons l’exemple déjà vu ci-dessus. Dans R2 on se donne u1 = (1, 4). Un combinaison linéaire de u1 estun vecteur u tel qu’il existe λ ∈ R tel que u = λ.u1 = (λ, 4λ). Par exemple (4, 16) est une combinaison linéairede u1 et (7, 7) n’en n’est pas une. On en déduit que tous les vecteurs du plan ne peuvent pas s’écrire commecombinaison linéaire du vecteur u1. On a Vect(u1) est strictement inclus dans R2.
Si on se donne alors u2 = (−2, 1). Un combinaison linéaire de u1 et u2 est un vecteur u tel qu’il existe(λ, µ) ∈ R2 tel que u = λ.u1 + µ.u2 = (λ− 2µ, 4λ + 2µ). Comme on l’a vu, tous les vecteurs de R2 sont descombinaisons linéaires de u1 et u2. De plus, à un vecteur w donné il y a même une unique combinaison linéaire« qui marche ».
Si on rajoute alors u3 = (−2, 7). Bien évidemment, tout vecteur w est encore combinaison linéaire des troisvecteurs u1, u2 et u3. Il suffit d’ajouter un 0.u3 à celle trouvée au-dessus. Cependant, dans ce cas, il y a d’autrespossibilités. On n’a plus l’unicité.
En conclusion, on pourrait dire que dans le premier cas il n’y avait pas assez de vecteurs dans la famille etque dans le dernier cas, il y en avait trop.
3.2 Familles génératrices
Soit (ui)i∈I une famille de vecteurs de E. On dit que la famille est génératrice de E (ou qu’elle engendre E) siE = Vect(ui). C’est-à-dire que tout vecteur de E peut s’écrire comme une combinaison linéaire des vecteursde la famille.
Définition 19.3.2.632
Cette année, on s’en servira principalement pour des familles finies.
ATTENTION
277

Exemples :
1. Dans l’exemple précédent la famille (u1) n’engendre par R2. Par contre (u1, u2) et (u1, u2, u3) engendrentR2.
2. La famille (1, X, X2, Xn) n’engendre par K[X] mais elle engendre Kn[X].
B Le caractère générateur d’une famille dépend de l’espace vectoriel dans lequel on la considère comme onle voit à l’exemple ci-dessus.
Soit F une famille génératrice de E.
1. Toute famille obtenue en permutant les termes de F est encore génératrice de E.
2. Toute sur-famille de F (c’est-à-dire une famille G dont F est une sous-famille) est encoregénératrice de E.
Proposition 19.3.2.633
Remarques :
1. En gros, plus il y a de vecteurs dans une famille plus elle a de chances d’être génératrice.
2. La notion de famille génératrice ne dépend pas de l’ordre. On pourra donc parler de parties génératices
3.3 Familles libres
Soit (u1, . . . , un) une famille finie de vecteurs de E. On dit que la famille est libre ou que les vecteurs u1, . . . , unsont linéairement indépendants si
∀(λi) ∈ Kn,n
∑i=1
λiui = 0⇒ λ1 = λ2 = · · · = λn = 0.
Définition 19.3.3.634
Terminologie : Dans le cas contraire on dit que la famille est liée ou que les vecteurs sont linéairementdépendants. Dans ce cas il existe une relation du type λ1u1 + · · · λnun = 0 avec les λi non tous nuls (ce qui n’estpas la même chose que tous non nuls). Cette relation s’appelle relation de dépendance linéaire des vecteursu1, . . . , un.
On généralise cela au cas d’une famille éventuellement infinie
Soit (ui) une famille de vecteurs. Elle est dite libre si toute sous-famille finie est libre ce qui revient à dire quepour toute famille (λi) presque nulle telle que ∑
iλiui = 0 on a ∀i ∈ I, λi = 0.
Définition 19.3.3.635
Le fait d’être libre ne dépend de l’espace vectoriel dans lequel on regarde la famille.
ATTENTION
Exemples :
1. On reprend notre exemple de R2. Les familles (u1) et (u1, u2) sont libres mais pas la famille (u1, u2, u3)par exemple −4u1 − 5u2 + 3u3 = 0. C’est une relation de dépendance linéaire.
2. La famille (1, X, X2, Xn) est libre. En effet, un polynôme est nul si et seulement si tous ses coefficients sontnuls.
3. De même la famille (Xi)i∈N est libre dans K[X].
4. Dans le R-espace vectoriel C, les vecteurs 1 et j sont libres.
278

5. Un famille composée d’un seul vecteur non nul est libre.6. Un famille contenant le vecteur nul est liée.7. Soit u et v deux vecteurs. La famille (u, v) est liée, s’il existe des scalaires λ, µ tels que λu + µv = 0. On dit
que les deux vecteurs sont colinéaires. En particulier si u n’est pas nul, alors µ non plus et on a v = −λ
µu.
Ce dernier point n’est plus vrai pour 3 vecteurs. Par exemple si u = (1, 0, 0), v = (0, 1, 0) etw = (1, 1, 0) alors (u, v) ne sont pas colinéaires (comme (v, w) et (u, w)) mais la famille est liée carw = u + v.
ATTENTION
Soit (ui) une famille libre de vecteurs de E. Pour tout vecteur w de Vect(ui) il existe une uniquecombinaison linéaire de (ui) égale à w.
Proposition 19.3.3.636
Démonstration
Soit F une famille libre de E.
1. Toute famille obtenue en permutant les termes de F est encore libre.
2. Toute sous-famille de F est encore libre de E.
Proposition 19.3.3.637
Remarque : En gros, moins il y a de vecteurs dans une famille plus elle a de chances d’être libre.
3.4 Bases
Soit (ui) une famille de vecteurs. On dit que la famille est une base si elle est libre et génératrice.
Définition 19.3.4.638
Remarques :1. Comme dans le cas de la famille génératrice, cela dépend de l’espace vectoriel E.2. Là encore, l’ordre des vecteurs n’est pas important.
Exemples :1. Dans R2, la famille (u1, u2) est une base. De même pour la famille (1, 0), (0, 1).2. Dans Kn, on note ei = (0, . . . , 1
i, 0, . . .). La famille (e1, . . . , en) est une base de Kn. On l’appelle la base
canonique.3. La famille (1, X, . . . , Xn) est une base de Kn[X] (mais pas de K[X]). Elle s’appelle la base canonique. La
famille (1, X, . . .) est une base de K[X].4. La famille (X, X− 1, X− 2) est une base de K2[X].
Soit B = (u1, . . . , un) une base finie de E. Pour tout vecteur w de E il existe une unique (λ1, . . . , λn) ∈Kn tel que
w =n
∑i=1
λiui.
Les scalaires λi s’appellent les composantes ou les coordonnées de w dans la base B.
Théorème 19.3.4.639
279

Démonstration
Les coordonnées d’un vecteur dans une base DEPENDENT du vecteur, de la base (en particulier del’ordre des vecteurs dans la base)
ATTENTION
Notation : On note
λ1...
λn
les coordonnées d’un vecteur.
Soit B = (ui) une base de E. Pour tout vecteur w de E il existe une unique famille presque nulle (λi)tel que
w = ∑i
λiui.
Théorème 19.3.4.640
Exemples :
1. Dans R2. On considère notre base B = (u1, u2). Le vecteur w = (1,−1) a pour coordonnées( −1/9
5/9
).
Dans la base canonique ce même vecteur w a pour coordonnées(
1−1
). On prendra soin de ne pas
confondre le vecteur (1,−1) avec ses coordonnées dans la base canonique même si ce sont les mêmeschiffres.
2. Trouver une base de H = (x, y, z) ∈ R3 | x + y− z = 0.
3. Dans R2[X] le polynôme X2 − 3X + 5 a pour coordonnées
5−31
dans la base canonique. Il a pour
coordonnées
3−21
dans la base (1, X− 1, X(X− 1)).
Exercice : Calculer les coordonnées de i dans la base (1, j) du R-espace vectoriel C.
4 Somme de sous-espaces vectoriels
On se fixe un espace vectoriel E.
4.1 Défintions
On a vu que si on se donne deux sous-espaces vectoriels F et G de E, l’ensemble F ∪ G n’en n’est plus un.On va définir un sous-espace vectoriel contenant F et G.
Soit F et G deux sous-espaces vectoriels de E. L’ensemble des sous-espaces vectoriels contenant F etG admet un plus petit élément que l’on note F + G et qui s’appelle la somme de F et G. On a
F + G = u + v | u ∈ F, v ∈ G.
Proposition-Définition 19.4.1.641
Démonstration : Montrons que F + G = u + v | u ∈ F, v ∈ G est un sev de E.
— H 6= ∅ car 0 = 0 + 0.
— (a faire)
280

Donc F + G est un sev et il contient F et G.De plus, soit H un sev contentant F et G on veut montrer que F + G ⊂ H. Soit w = u + v un élément de
F + G. On sait que u et v appartiennent à H car ils appartiennent respectivement à F et à G donc, H étant unsev, u + v ∈ H.
Exemples :
1. Dans R3. On considère u1 = (−1, 2,−1) et u2 = (0, 1,−1) ainsi que F1 = Vect(u1) et F2 = Vect(u2).Alors F1 + F2 est un plan défini par x + y + z = 0.
2. Dans R3. On considère H1 = (x, y, z) | x + y + z = 0 et H2 = (x, y, z) | x = 0. On a H1 + H2 = R3.
De même si F1, . . . , Fn sont n sous-espaces vectoriels de E On note
n
∑i=1
Fi = F1 + F2 + · · ·+ Fn = u1 + · · ·+ un | ∀i ∈ [[ 1 ; n ]] , ui ∈ Fi.
C’est le plus petit sous-espace vectoriel contenant tous les Fi.
Définition 19.4.1.642
Soit (u1, . . . , up) et (v1, . . . , vq) deux familles de vecteurs,
Vect(u1, . . . , up) + Vect(v1, . . . , vq) = Vect(u1, . . . , up, v1, . . . , vq)
Proposition 19.4.1.643
Démonstration : En execice
4.2 Somme directe et supplémentaires
Soit F et G deux sous-espaces vectoriels de E. On dit que F et G sont en somme directe si pour tout w dansF + G il existe un unique couple (u, v) ∈ F× G tels que w = u + v. On note alors F⊕ G le sous-espacevectoriel somme.
Définition 19.4.2.644
Exemples :
1. On reprend les exemples précédents, F1 ⊕ F2 = H.
2. Les sev H1 et H2 ne sont pas en somme directe.
Soit F et G deux sous-espaces vectoriels. Ils sont en somme directe si et seulement si F ∩ G = 0.
Proposition 19.4.2.645
Démonstration :
— Montrons que si F ∩ G = 0 alors F et G sont en somme directe. Soit w ∈ F + G. On suppose quew = u1 + v1 = u2 + v2 avec (u1, u2) ∈ F2 et (v1, v2) ∈ G2. Dès lors u1 − u2 = v2 − v1 ∈ F ∩ G. On endéduit que u1 = u2 et v1 = v2
— Réciproquement on suppose que F et G sont en somme directe et on veut montrer que F ∩ G = 0. Soitu ∈ F ∩ G. On a alors
u = u + 0G = 0F + u.
Par unicité de la décomposition, u = 0
281

Soit F et G deux sous-espaces vectoriels de E. On dit qu’ils sont supplémentaires (ou que G est un supplé-mentaire de F ou réciproquement) si F⊕ G = E. C’est-à-dire que pour tout w de E il existe un unique couple(u, v) de F× G tel que w = u + v.
Définition 19.4.2.646
Remarque : Dans la pratique, pour montrer que deux sevs sont supplémentaires, on le fait en deux fois. Onmontre que F + G = E et que F ∩ G = 0.Exemples :
1. Dans R2, on pose F = (x, 0)|x ∈ R et G = (x, x) | x ∈ R. Ils sont supplémentaires.2. Dans K[X]. On pose F = K0[X] et G = P ∈ K[X] | P(0) = 0. Alors F⊕ G = K[X].3. Dans F (R, R). On pose P l’ensemble des fonctions paires et I l’ensemble des fonctions impaires. Ils
sont supplémentaires.En particulier, exp = ch + sh .
Exercice : Soit Q un polynôme non nul. On pose F = P ∈ K[X] | deg P < deg Q et G = PQ | P ∈ K[X].1. Montrer que F et G sont des sevs.2. Montrer qu’ils sont supplémentaires.
4.3 Somme directe d’un nombre fini de sous-espaces vectoriels
Soit F1, . . . , Fn des sous-espaces vectoriels de E. On dit que les Fi sont en somme directe si pour tout w
dansn
∑i=1
Fi il existe un unique (u1, . . . , un) ∈ F1 × · · · × Fn tels que w =n
∑i=1
ui. On note alors⊕n
i=1 Fi =
F1 ⊕ · · · ⊕ Fn le sous-espace vectoriel somme.
Définition 19.4.3.647
Il n’est plus vrai que si Fi ∩ Fj = 0 pour i 6= j alors les Fi sont en somme directe. Par exemple dansR2, si on pose F1 = Vect(1, 1), F2 = Vect(1, 2) et F3 = Vect(1, 3)
ATTENTION
Soit F1, . . . , Fn des sous-espaces vectoriels de E. Il sont en somme directe si et seulement s’il existe un
unique (u1, . . . , un) ∈ F1 × · · · × Fn tels quen
∑i=1
ui = 0. C’est-à-dire :
∀(u1, . . . , un) ∈ F1 × · · · × Fn,n
∑i=1
ui = 0⇒ u1 = · · · = un = 0.
Proposition 19.4.3.648
Démonstration :— ⇒ Évident.— ⇐ Soit w ∈ ∑n
i=1 Fi, (u1, . . . , un) et (v1, . . . , vn) tels que
w = u1 + · · ·+ un = v1 + · · ·+ vn.
On en déduit que
0 =n
∑i=1
(ui − vi)
et donc ∀i ∈ [[ 1 ; n ]] , ui = vi
Exemple : On a Kn[X] =⊕n
i=0 Vect(Xi).
282

5 Sous-espaces affines
5.1 Définition
On a vu dans les exemples précédents que les sous-espaces vectoriels de R2 et R3 pouvaient être visualiséscomme les droites et plans passant par 0. On voudrait maintenant pouvoir travailler avec les autres droites /plans.
Pour cela on va définir la structure affine d’un espace vectoriel. Nous n’allons pas trop entrer dans le détailcar nous ne l’utiliserons que dans des cas très simples.
Soit E un K-espace vectoriel, on le munit d’une structure affine en notant E l’ensemble des points et El’ensemble des vecteurs. Ces deux ensembles sont les mêmes objets mais vu différemment. Afin de biendifférencier les objets les éléments de E (les points) seront notés par les lettres majuscules A, B, C, M, N, . . . alorsque les éléments de E (les vecteurs) seront notés par des lettres minuscules avec des flèches −→u ,
−→i , . . .
On a alors une opération :+ : E × E → E
(A,−→u ) 7→ M = A +−→uDans le terme de droite la somme est juste la somme classique de l’espace vectoriel.
O
−→u
A
A +−→u
Notation : Dans toute quand on considérera la structure affine d’un espace vectoriel on notera avec une lettrescripte l’ensemble des points et une lettre droite l’ensemble des vecteur.Exemple : Pour E = R2. Si A = (3, 1) et −→u = (1,−3) alors A +−→u = (4,−2).
Il est important de comprendre (et d’utiliser des notations cohérentes) la différence entre les pointset les vecteurs même si, à la fin, ce sont les mêmes objets
ATTENTION
Soit E un espace vectoriel et −→u ∈ E. On appelle translation de vecteur −→u l’application :
t−→u : E → EA 7→ M = A +−→u
Définition 19.5.1.649
Avec les notations précédentes.
1. Soit (−→u ,−→v ) ∈ E2 on a t−→u t−→v = t−→v t−→u = t−→u +−→v2. Pour tout tout −→u ∈ E, t−→u est une bijection et t−1−→u = t−−→u .
Proposition 19.5.1.650
Remarque : La propriété ci-dessus peut s’exprimer en disant que l’ensemble T des translations est un sous-groupe des bijections de E .
Soit (A, B) ∈ E 2. Il existe un unique vecteur −→u tel que A +−→u = B. On le note−→AB ou B− A.
Proposition 19.5.1.651
283

Démonstration : Il suffit de voir que A +−→u = B ⇐⇒ −→u = B− A (en se rappelant que les points sont aussides éléments de E).
On peut faire des calculs du genre :
A + B + C− 2A = B + C− A = B +−→AC ∈ E
De fait
— Une somme de points dont la somme des coefficients est 0 est un vecteur.
— Une somme de points dont la somme des coefficients est 1 est un point.
— Tout autre somme n’a pas de sens. Par exemples A + B.
ATTENTION
5.2 Sous-espaces affines
On a maintenant tout ce qu’il faut pour définir nos sous-espaces affines.Notation : Soit E un espace vectoriel. Soit Ω ∈ E et F un sous-espace vectoriel de E on note
Ω + F = Ω +−→u | −→u ∈ F
Exemples :
1. Pour E = R2. Si on note Ω = (2, 1) et F = Vect−→u où −→u = (1, 1) alors
Ω + F = (2 + t, 1 + t) | t ∈ R
C’est une droite donnée sous forme paramétrique. On a aussi
Ω + F = (x, y) ∈ R2 | x− y = 1.
2. Quand on considère l’équation différentielle linéaire :
y′ + y = x (E)
On considère l’équation homogène associée
y′ + y = 0 (H)
On sait que SH est le sous-espace vectoriel de C 1(R, R) engendré par x 7→ e−x : SH = x 7→ λe−x | λ ∈R. De manière évidente on voit que f0 : x 7→ x− 1 est une solution évidente et donc
SE = f0 +SH .
Une partie F de E est un sous-espace affine s’il existe un point Ω et un sous-espace vectoriel F de E tels que
F = Ω + F.
Définition 19.5.2.652
Pour une même partie F la donnée du point Ω n’est pas unique (sauf si F = 0). En effet si −→u ∈ F,on a
Ω + F = (Ω +−→u ) + F.
Par contre, F est unique en effet F = B− A | (A, B) ∈ F 2 (démonstration en exercice)
ATTENTION
284

Avec les notations précédentes, F s’appelle la direction du sous-espace affine F . On dit que F est le sous-espaceaffine passant par Ω et de direction F.
Définition 19.5.2.653
Exemple : Soit F = (x, y, z) ∈ R3 | x + y− 4z = 2. Montrons que c’est un sous-espace affine. Considéronsun point de F . Par exemple Ω = (2, 0, 0). Soit a = (x, y, z) un élément de R3. On a alors
a ∈ F ⇐⇒ x + y− 4z = 2⇐⇒ (x− 2) + y− 4z = 0⇐⇒ a−Ω ∈ F où F = (X, Y, Z) | X + Y− 4Z = 0.
On en déduit que F = Ω + F.
5.3 Intersection
Commençons par traiter quelques exemplesExemples :
1. Dans R3 on considère les deux droites :
D1 : (1, 0, 0) + Vect(1, 1, 1) et D2 : (3, 1, 1) + Vect0, 1, 0
On voit alors que D1 ∩D2 = ∅ car on ne peut pas trouver (s, t) ∈ R2 tels que
(1 + s, s, s) = (3, 1 + t, 1)
2. Toujours dans R3 on considère les deux plans :
P1 = (x, y, z) ∈ R3 | x− y + z = 4 et P2 = (x, y, z) ∈ R3 | x + 3y = −1.
En résolvant le système :
(S) =
x− y + z = 4x + 3y = −1
on trouve queP1 ∩P2 = (11/4,−5/4, 0) + z(1/4, 1/4, 1) | z ∈ R
C’est donc l’espace affine Ω + F où Ω = (11/4,−5/4, 0) et F = Vect(1/4, 1/4, 1) = Vect(1, 1, 4). Onpeut remarquer que si l’on résout le système homogène associé à (S) alors on trouve que F est l’intersectiondes directions P1 = (x, y, z) ∈ R3 | x− y + z = 0 et P2 = (x, y, z) ∈ R3 | x + 3y = 0.
Soit F et G deux sous-espaces affines. Deux cas peuvent se produire :
— F ∩ G peut être vide
— Si F ∩ G n’est pas vide c’est un sous-espace affine de direction F ∩ G.
Proposition 19.5.3.654 (Intersection)
Démonstration : S’il est vide il n’y a rien à dire.Supposons que F ∩ G ne soit pas vide. On considère Ω ∈ F ∩ G . Maintenant pour tout x de E,
x ∈ F ∩ G ⇐⇒ x ∈ F et x ∈ G
⇐⇒ x−Ω ∈ F et x−ω ∈ G⇐⇒ x−Ω ∈ F ∩ G
On a donc bienF ∩ G = Ω + (F ∩ G).
285

20Espaces vectorielsde dimension finie
1 Espaces vectoriels de dimension finie 2861.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2861.2 Existence d’une base . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2871.3 Dimension . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2881.4 Dimension et famille . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 289
2 Sous-espaces vectoriels 2902.1 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2912.2 Somme et supplémentaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2922.3 Rang d’une famille de vecteurs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2942.4 Première approche des calculs matriciels . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2942.5 Détermination du rang d’une famille . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2952.6 Extraction d’une base . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 295
3 Retour aux sous-espaces affines 2953.1 Dimension d’un sous-espace affine . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2953.2 Quelques exemples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 295
On voudrait dire que R2 est de dimension 2, R3 est de dimension 3 et ainsi de suite. On peut remarquer quec’est le nombre de vecteurs de la base canonique et de toutes les bases que l’on a trouvé.
1 Espaces vectoriels de dimension finie
1.1 Définitions
Soit E un espace vectoriel on dit que E est de dimension finie s’il existe une famille génératrice de cardinal fini.
Définition 20.1.1.655
Remarques :
286

1. On va voir que ce qui va nous intéresser sera plutôt une base avec un nombre fini de vecteurs mais il estplus simple de demander une famille génératrice car cela nous évitera de vérifier qu’elle est libre.
2. Dans le cas contraire, on dit que E est de dimension infinie.
Exemples :
1. Soit n un entier, l’espace vectoriel Kn est de dimension finie car la base canonique est une famillegénératrice finie.
2. Soit n un entier, l’espace vectoriel Kn[X] est un espace vectoriel de dimension finie pour la même raison.
3. L’espace vectoriel K[X] n’est pas de dimension finie. Supposons en par l’absurde qu’il existe une famillegénératrice finie : (P1, . . . , Pn). Tout polynôme P s’écrit alors comme combinaison linéaire des (Pi) :P = ∑
iλiPi. On en déduit alors que deg(P) 6 Max
i(deg(Pi)). C’est absurde. Donc K[X] n’est pas de
dimension finie.
1.2 Existence d’une base
Nous allons montrer que tout espace vectoriel de dimension finie admet une base.
Soit E un espace vectoriel, G une famille génératrice finie et F un sous famille de G libre. On peutcompléter la famille F avec des vecteurs de G pour obtenir une base B. On a donc
F ⊂ B ⊂ G .
Lemme 20.1.2.656
Démonstration : Le principe est de rajouter des vecteurs pour rendre la famille génératrice mais pas trop pourqu’elle reste libre.
On note (u1, . . . , un) la famille G telle que, quitte à échanger l’ordre des vecteurs, F = (u1, . . . , ur). On vaprocéder de manière algorithmique. On note p = n− r :
— Si F est une famille génératrice alors, comme elle est libre, c’est une base : c’est gagné !
— Si F n’est pas une famille génératrice. Alors il existe un vecteur de G \F qui n’est pas une combinaisonlinéaire des vecteurs de F . En effet, si tous les vecteurs de G s’écrivaient comme combinaison linéaire desvecteurs de F , la famille F serait génératrice. Quitte à inverser l’ordre des vecteurs (ur+1, . . . , un) dansG , on peut supposer que ur+1 n’est pas une combinaison linéaire des vecteurs de F . On ajoute alors ur+1
à F . La famille obtenue reste libre. En effet soit (λi) tels quer+1
∑i=1
λiui = 0. On sépare les cas. On ne peut
pas avoir λr+1 différent de 0 car ur+1 n’est pas une combinaison linéaire des vecteurs de F et si λr+1 estnul alors λ1 = · · · = λr0 car (u1, . . . , ur) est libre.On peut alors recommencer avec la nouvelle famille F et p = p− 1.
L’algorithme s’arrête au plus tard quand p = 0.
Remarque : On peut aussi, de manière moins constructive, considérer les familles libres comprises entre F etG et prendre une famille de cardinal maximal.
Soit E un espace vectoriel de dimension finie. Il admet une base. De plus, on peut extraire une basede toute famille génératrice finie.
Théorème 20.1.2.657 (Théorème de la base extraite)
Exemple : Dans R3. On considère les vecteurs u1 = (1, 2, 3), u2 = (2,−2, 1), u3 = (4, 2, 7) et u4 = (1, 1, 1). Lafamille est liée car par exemple 2u1 + u2 − u3 = 0. On peut enlever u3 et voir que (u1, u2, u4) est une base de R3.Démonstration : On applique le lemme en prenant pour F la sous-famille vide qui est libre ou (si E 6= 0)une famille à un élément qui n’est pas le vecteur nul.
On a aussi le théorème suivant
287

Soit E un espace vectoriel de dimension finie et F une famille libre. On peut la compléter en unebase. C’est-à-dire qu’il existe une famille G qui soit une base et telle que F ⊂ G .
Théorème 20.1.2.658 (Théorème de la base incomplète)
Exemple : Toujours dans R3. Soit u1 = (1, 2, 3) et u2 = (2,−2, 1). La famille est libre mais elle n’engendre pasR3. On peut la compléter avec par exemple u3 = (1, 0, 0). La famille obtenue est une base.Démonstration : Il suffit de considérer une base de E que l’on note B. On a alors F ⊂ (F ∪B) et on appliquele lemme précédent.
Remarque : On a utilisé ci-dessus le fait que la famille F était finie (pour que F ∪B soit finie). On verra plusloin que c’est systématique.
1.3 Dimension
Notre but est de montrer que toutes les bases ont le même nombre de vecteurs. Par exemple dans R2 on abien vu que les famille avec strictement moins de deux vecteurs n’engendraient pas R2 et que les familles avecstrictement plus de deux vecteurs n’étaient pas libres. On veut généraliser ce fait.
Soit E un espace vectoriel et n un entier naturel. Soit F une famille de n vecteurs. Toute famille G den + 1 vecteurs de Vect(F ) est liée.
Proposition 20.1.3.659
Démonstration : On procède par récurrence sur n. On pose Hn = « Pour toute famille F de n vecteurs. Toutefamille G de n + 1 vecteurs de Vect(F ) est liée ».
— I : Pour n = 0, la famille F est vide et donc Vect(F ) = 0. La famille G ne contient qu’un vecteur quiest nécessairement le vecteur nul et donc la famille G est liée. Si cet argument ne vous convainc pas, onpeut aussi regarder pour n = 1. On a alors F = (u) et Vect(F ) = Vect(u). La famille G est composéede deux vecteurs colinéaires. Elle est liée.
— H : Soit n ∈ N?. On suppose Hn. On veut démontrer Hn+1. On note (u1, . . . , un+1) la famille F et(v1, . . . , vn+2) la famille G . On sait que tous les vecteurs (vi) s’écrivent comme combinaison linéaire des(ui). Notons pour tout i ∈ [[ 1 ; n + 2 ]], αi le coefficient de un+1 dans une décomposition de (vi).
— Si tous les αi sont nuls alors les vecteurs de G appartiennent à Vect(F \ un+1). On en déduitqu’une sous famille à n + 1 élément de G est liée et donc G est liée.
— S’il existe un αi qui n’est pas nul, qui à échanger l’ordre des vecteurs on peut supposer que c’est αn+2.On construit alors la famille
wi = vi −αi
αn+2vn+2 pour i ∈ [[ 1 ; n + 1 ]] .
Par construction ces vecteurs appartiennent à Vect(u1, . . . , un) car on a « tué » la composante enun+1. On en déduit que c’est une famille liée par récurrence. Un relation de dépendance linéaire nontriviale sur les (wi) permet d’obtenir une relation de dépendance linéaire non triviale sur les vi.
Soit E un espace vectoriel de dimension finie. Toutes les bases ont le même nombre d’éléments.
Corollaire 20.1.3.660
Démonstration : Supposons par l’absurde qu’il existe deux bases B et B′ qui n’ont pas le même nombred’éléments. Par symétrie, on peut supposer que Card(B) = n et Card(B′) = n′ > n. Dès lors on peut extraireune sous-famille libre de B′ contenant n + 1 éléments. Cela est absurde d’après la proposition précédente.
288

Soit E un espace vectoriel de dimension finie. On appelle dimension de E et on note dim E le nombre d’élémentsdans les bases de E.
Définition 20.1.3.661
Remarque : Pour déterminer la dimension d’un espace vectoriel on essayer d’en trouver une base.Exemples :
1. La dimension de l’espace vectoriel 0 est 0 car la famille vide est une base.
2. On a pour tout entier n, dim Kn = n. Il suffit de considérer la base canonique.
3. De même, l’espace vectoriel Kn[X] est de dimension (n + 1).
4. Soit H = (x, y, z) ∈ R3 | x + y− z = 0. On a vu que la famille ((1, 0, 1), (0, 1, 1)) est une base doncdim H = 2.
5. On a vu que C en tant que C espace vectoriel est de dimension 1. Par contre il est dimension 2 en tant queR espace vectoriel (une base est 1 et i).
6. Soit E une equation différentielle linéaire homogène d’ordre 1. On a vu que l’ensemble des solutions estun espace vectoriel de dimension 1.
7. Soit E une equation différentielle linéaire homogène d’ordre 2 à coefficients constants. On a vu quel’ensemble des solutions est un espace vectoriel de dimension 2.
1. Soit E et F deux espaces vectoriels de dimension finie. Si (u1, . . . , un) est une base de E et(v1, . . . , vp) est une base de F alors la famille ((u1, 0), . . . , (un, 0), (0, v1), . . . , (0, vp) est unebase de E× F. En particulier l’espace vectoriel E× F est de dimension finie et dim(E× F) =dim E + dim F.
2. Soit E1, E2, . . . , En des espaces vectoriels de dimension finie. Alorsn
∏i=1
Ei est de dimension finie
et
dim
(n
∏i=1
Ei
)=
n
∑i=1
dim(Ei).
Proposition 20.1.3.662
Démonstration
1.4 Dimension et famille
Dans tout ce paragraphe on fixe E un espace vectoriel de dimension n.
Soit F une famille de vecteurs de E
1. Si F est libre elle a au plus n vecteurs.
1’. Si elle a au moins n + 1 vecteurs, elle est liée.
2. Si F est génératrice elle a au moins n vecteurs.
2’. Si elle a au plus n− 1 vecteurs, elle n’est pas génératrice de E.
Proposition 20.1.4.663
Remarque : On voit que les assertions 1’ et 2’ sont les contraposées des assertions 1 et 2.Exemple : Si on considère quatre polynômes de degré au plus 2. Ils forment une famille liée car c’est unefamille de R2[X] qui est de dimension 3.Démonstration :
1. L’assertion 1’ est juste la proposition vue précédemment. En effet, on considère une base B contenant nvecteurs et si F est une famille de n + 1 vecteurs (ou plus) elle est liée.
289

2. L’assertion 2. découle aussi de cette proposition. En effet, supposons par l’absurde que F est une famillegénératrice de N < n vecteurs. Alors une base B de E est un famille de n > N + 1 de Vect(F ). Elle estdonc liée ce qui est absurde car c’est une base de E.
Soit E un espace vectoriel de dimension finie. Soit F une famille libre. On peut la compléter en unebase de E.
Théorème 20.1.4.664 (Théorème de la base incomplète)
Démonstration : Il suffit d’utiliser le lemme ci-dessus en remarquant que F est une sous-famille libre deF ∩B où B est une base de E.
Remarque : C’est l’analogue du fait que l’on peut extraire une base d’une famille génératrice.
Soit F une famille de n vecteurs. Les assertions suivantes sont équivalentes.
i.) La famille est une base.
ii.) La famille est génératrice.
iii.) La famille est libre.
Théorème 20.1.4.665
Remarque : Ce théorème est très utile. En particulier, pour prouver qu’une famille est une base d’un espacevectoriel dont on connait la dimension. Il suffit de vérifier qu’elle a le bon nombre de vecteurs (autant quedim E) et qu’elle est libre.Démonstration : De manière évidente i.) implique ii.) et iii.).
— Montrons que ii.) implique i.) : On sait que l’on peut extraire une base d’une famille génératrice. Or lafamille contenant déjà n vecteurs, la base extraite est égale à la famille entière.
— Montrons que iii.) implique i.) : On vient de voir que l’on peut compléter une famille libre en une base. Onconclut comme précédemment.
Exemples :1. Soit n ∈ N. On sait que Kn[X] est de dimension n + 1 (car on sait que la base canonique a n + 1 vecteurs).
Soit α. Considérons maintenant, la famille (X− α)i06i6n. La formule de Taylor nous dit que cette familleest génératrice. Comme elle comporte le bon nombre de vecteurs (n + 1) c’est une base (que l’on appellebase de Taylor). Les coordonnées d’un polynôme P dans cette base est donnée par P(k)/k!.
2. Dans Kn on considère la famille des n vecteurs ui = (1, 1, . . . , 1i, 0 . . . , 0). Vérifions que cette famille est
libre. Soit (λi) des scalaires tels que w = ∑i
λiui est nul. La dernière coordonnées de w est λn. On en
déduit que λn = 0 et ainsi de suite (si on veut le faire « bien »on suppose par l’absurde que la famille n’estpas nul et on considère n0 le plus grand indice tel que λn0 6= 0.) Cette famille étant libre et avec n vecteurs,c’est une base de Kn.
3. Soit A ⊂ CN l’ensemble des suites vérifiant une relation de récurrence linéaire
aun+2 + bun+1 + cun = 0 où a 6= 0.
On a vu que c’est un espace vectoriel. Une base est donnée par les suites (u, v) définies par u0 = 1, u1 = 0et v0 = 0, v1 = 1. On en déduit que A est de dimension 2. Si on suppose que aX2 + bX + c = 0 a deuxracines distinctes (∆ 6= 0) que l’on note α et β. On sait que (αn) et (βn) sont deux suites de A. Elles sontlibres car (1, α) et (1, β) est libre. On en déduit directement que c’est une base. Vous pouvez comparer à ladémonstration du cours au début de l’année.
Exercice : Montrer qu’une famille échelonnée en degré de Kn[X] est une base.
2 Sous-espaces vectoriels
On se fixe un espace vectoriel de dimension finie et on note n = dim E.
290

2.1 Généralités
Soit F un sous-espace vectoriel de E. L’espace vectoriel F est de dimension finie et dim F 6 dim E.
Proposition 20.2.1.666
Démonstration : On considère l’ensemble des familles libres de vecteurs de F. On sait que cet ensemble contientla famille vide. Il n’est donc pas vide. On sait de plus qu’une famille de F (et donc de E) avec plus de n + 1vecteurs ne peut pas être libre. Il existe donc une famille libre de vecteurs de F de cardinal maximal. Notons(u1, . . . , up) une telle famille. On va montrer que c’est une base de F. Déjà elle est libre. Maintenant pour tout vde F, la famille (u1, . . . , up, v) n’est pas libre car de cardinal p + 1. Or une relation de dépendance linéaire s’écrit
λ1u1 + · · ·+ λpup + α.v = 0
Comme α 6= 0 puisque la famille initiale est libre, on a
v = −λ1
αu1 − · · · −
λp
αup.
Comme ceci est possible avec tout vecteur v de F, on en déduit que la famille (u1, . . . , up) est génératrice de F.C’est donc une base et dim F = p 6 n = dim E.
Exemples :
1. Soit P = (x, y, z, t) ∈ R4 | x + y + z + t = 0 et x − y + z − t = 0. On peut supposer que cet espacevectoriel est de dimension 4-2 =2. Il faut donc trouver, pour le prouver, une base contenant deux vecteurs.On remarque que si les valeurs de x et de y sont fixées alors il n’y a plus de choix pour z et t qui vérifientle système
z + t = −x− yz− t = −x + y
L’unique solution de ce système est z =12(−x− y− x + y) = x et t =
12(−x− y + x− y) = −y. On pose
doncu1 = (1, 0, 1, 0) et u2 = (0, 1, 0,−1).
Cette famille est bien libre et génératrice donc c’est une base de H.
2. De manière générale dans R3 il y a des sous-espaces vectoriels de dimension 0 : 0 ; des sous-espacesvectoriels de dimensions 1 (des droites vectorielles) ; des sous-espaces vectoriels de dimension 2 (des plansvectoriels) et R3 en entier.
Terminologie : On appelle droite vectorielle tout sous-espace vectoriel de dimension 1, plan vectoriel toutsous-espace de dimension 2 et hyperplan vectoriel tout sous-espace vectoriel de dimension n− 1 dans un espacevectoriel de dimension n. On dit qu’il est codimension 1.
Soit F un sous-espace vectoriel de E. On a
dim F = dim E⇒ F = E.
Proposition 20.2.1.667
Remarques :
1. La réciproque est aussi vraie mais triviale.
2. C’est très utile pour montrer l’égalité de deux espaces vectoriels de dimension finie. On montre que l’unest inclus dans l’autre et qu’ils ont la même dimension.
Exemple : On se place dans R3. On considère les vecteurs u1 = (1, 0, 0), u2 = (0, 1, 0), v1 = (1, 1, 0) etv2 = (1,−1, 0). On veut montrer que F = Vect(u1, u2) est égal à G = Vect(v1, v2). Remarquons pourcommencer que les familles (u1, u2) et (v1, v2) sont des bases respectives de F et G. Donc dim F = dim G = 2.Maintenant, v1 = u1 + u2 et v2 = u1 − u2. On a donc G ⊂ F donc F = G.
291

2.2 Somme et supplémentaires
Commençons par remarquer que tout sous-espace vectoriel admet un supplémentaire.
Soit F un sous-espace vectoriel de E. Il admet un (et même une infinité) supplémentaire.
Proposition 20.2.2.668
Démonstration : On considère une base (u1, . . . , up) de F comme une famille libre de E. Elle peut être complétéen une base (u1, . . . up, v1, . . . , vr) de E. On pose F′ = Vect(v1, . . . , vr). Il ne reste plus qu’à vérifier queF⊕ F′ = E.
Exemples :1. On considère F = Vect(1, 1) dans R2. Un supplémentaire est donné par F′ = Vect(1,−1).2. Soit n ∈ N. On pose E = K2n[X]. On considère P = Vect(X2i)06i6n. C’est l’ensemble des polynôme
paires. On peut aisément voir que I = Vect(X2i+1)06i6n−1 est un supplémentaire.
Soit F et G deux sous-espaces vectoriels de E Soit (u1, . . . , un) une base de F et (v1, . . . , vp) une basede G.
1. La famille (u1, . . . , un, v1, . . . , vp) est une famille génératrice de F + G.
2. La famille (u1, . . . , un, v1, . . . , vp) est une base de F + G si et seulement si F et G sont en sommedirecte.
Proposition 20.2.2.669
Démonstration :1. Evident2. — ⇒ On suppose que (u1, . . . , un, v1, . . . , vp) est une base de F + G et on veut montrer que F et G sont
en somme directe. Supposons par l’absurde que F et G ne sont pas en somme directe. Il existe alorsun vecteur w ayant deux décompositions :
w = f + g = f ′ + g′
où ( f , g) 6= ( f ′, g′′). Par symétrie on peut suppose que f 6= f ′. En décomposant f , g, f ′ et g′
dans les bases (u1, . . . , un) et (v1, . . . , vp) on en déduit deux décompositions de w dans la base(u1, . . . , un, v1, . . . , vp) ce qui est absurde. On a donc bien que F et G sont en somme directe.
— ⇐ On suppose maintenant que F et G sont en somme directe et on veut montrer que (u1, . . . , un, v1, . . . , vp)est libre. Soit (λ1, . . . , λn, µ1, . . . , µp) ∈ Kn+p tels que
(λ1u1 + · · ·+ λnun) + (µ1v1 + · · ·+ µpvp) = 0
Comme la somme est directe on a que
(λ1u1 + · · ·+ λnun) = (µ1v1 + · · ·+ µpvp) = 0.
Maintenant, en utilisant que (u1, . . . , un) et (v1, . . . , vp) sont des bases on obtient que
λ1 = · · · = λn = µ1 = · · · = µp = 0.
La famille est donc libre.Remarque : On voit de manière directe que cette proposition se généralise au cas de plus de deux sous-espacesvectoriels.
Soit F1, · · · , Fp des sous-espaces vectoriels de E tels que E =p⊕
i=1
Fi. On appelle base adaptée à la décomposition
précédente toute base obtenue en juxtaposant des bases de chaque Fi.
Définition 20.2.2.670
292

Soit F et G deux sous-espaces vectoriels.
1. Si F et G sont en somme directe alors dim(F⊕ G) = dim F + dim G. En particulier si F et Gsont supplémentaires, dim F + dim G = n.
2. Dans le cas général dim(F + G) = dim F + dim G− dim(F ∩ G) 6 dim F + dim G. En particu-lier, on a que dim(F + G) = dim F + dim G ⇒ (F et G sont en somme directe).
3. Tous les supplémentaires d’un espace vectoriel F ont la même dimension : n− dim F.
Corollaire 20.2.2.671 (Formule de Grassmann)
Démonstration :1. Evident2. Notons H = F ∩ G. On considère une base (u1, . . . , up) de H. On peut la compléter en une base de
G : (u1, . . . , up, w1, . . . , wr). Ici, dim(H) = dim(F ∩ G) = p et dim G = p + r. Considérons aussi F′ =Vect(w1, . . . , wr) ⊂ G. On remarque que G = F′ ⊕ H.On va montrer que F⊕ F′ = F + G.
— Soit z un vecteur de F ⊕ F′. Il s’écrit z = z1 + z2 avec z1 ∈ F et z2 ∈ F′ ⊂ G. Donc z ∈ F + Get on a F ⊕ F′ ⊂ F + G. Réciproquement soit z′ un vecteur de F + G il s’écrit z = z1 + z2 avecz1 ∈ F et z2 ∈ G. Maintenant, z2 peut s’écrire z2 = z3 + z4 avec z3 ∈ F ∩ G et z4 ∈ F′. On a doncz = z1 + (z3 + z4) = (z1 + z3) + z4 ∈ F + F′.
— Montrons que F ∩ F′ = 0. Soit z ∈ F ∩ F′. L’élément z est dans F′ donc dans G. Or il est dans Fdonc dans F ∩ G = H. Il appartient donc à H ∩ F′ = 0 d’ou z = 0.
On conclut en disant que dim(F + G) = p+ q+ r = (p+ q) + (p+ r)− p = dim F +dim G−dim(F∩G).
Exemple : Intersection de deux plans dans l’espace.On peut généraliser cela à plus de deux sous-espaces vectoriels.
Soit F1, . . . , Fp des sous-espaces vectoriels :
dim
(p
∑i=1
Fi
)6
p
∑i=1
dim Fi.
De plus il y a égalité si et seulement si la somme est directe.
Proposition 20.2.2.672
Démonstration : La première partie se démontre directement par récurrence sur p. Étudions la deuxièmepartie.
— ⇒ On suppose que l’on a égalité des dimensions. On sait de plus qu’en « collant » les bases de chaquesous-espace vectoriels on obtient une famille génératrice qui a ∑
pi=1 dim Fi vecteurs qui est donc la
dimension de l’espace somme. On en déduit que c’est une base. De ce fait, la somme est directe.— ⇐ Si la somme est directe, on sait que l’on peut obtenir une base en « collant » les bases de chaque
sous-espace vectoriels. On a donc bien
dim
(p
∑i=1
Fi
)=
p
∑i=1
dim Fi.
Exemple : Dans Kn[X] on considère F0 = P | P(0) = 0, F1 = P | P(1) = 0. On veut montrer queF0 ⊕ F1 ⊕Kn−2[X] = Kn[X]. On remarque déjà que dim F0 + dim F1 + dim Kn−2[X] = 1 + 1 + n− 2 = n + 1 =
dim Kn[X]. De plus, F0 + F1 + Kn−2[X] = Kn[X]. En effet, si P =n
∑k=0
akXk alors
P = anXn︸ ︷︷ ︸∈F0
+ an−1(X− 1)n−1︸ ︷︷ ︸
∈F1
+n−2
∑k=0
akXk − an−1
n−1
∑k=0
(k
n− 1
)Xk
︸ ︷︷ ︸∈Kn−2[X]
.
293

On a donc biendim (F0 + F1 + Kn−2[X]) = dim F0 + dim F1 + dim Kn−2[X].
2.3 Rang d’une famille de vecteurs
Soit F = (u1, . . . , up) une famille de vecteurs. On appelle rang de F et on note rg (F ) la dimension del’espace vectoriel Vect(F ) engendré par F .
Définition 20.2.3.673
Soit E un espace de dimension n et F = (u1, . . . , up) une famille de vecteurs.
1. rg (F ) 6 dim E et rg (F ) 6 p.
2. On a rg (F ) = p si et seulement si la famille est libre.
3. Soit G une sous-famille de F , rg (G ) 6 rg (F ).
4. Le rang de F est le cardinal maximal d’une sous-famille libre de F .
Proposition 20.2.3.674
Exemple : On considère la famille de R[X] suivante : P1 = 1 + X + X2, P2 = 1− X − X2, P3 = 2X + 2X2. Oncherche le rang de la famille (P0, P1, P2). On essaye de voir si la famille est libre. Soit λ1, λ2 et λ3 trois scalaires.
λ1P1 + λ2P2 + λ3P3 = 0 ⇐⇒
λ1 + λ2 = 0λ1 − λ2 + 2λ3 = 0 .
On en déduit (pour λ2 = 1 par exemple) que −P1 + P2 + P3 = 0.La famille n’est pas libre donc son rang est strictement inférieur à 3. Comme de plus la sous-famille (P1, P2)
est libre elle est de rang 2 doncrg (P1, P2, P3) = 2.
2.4 Première approche des calculs matriciels
Si on dispose d’une base B = (u1, . . . , un) de E (par exemple si on travaille avec E = Kn ou E = Kn[X]) onpeut assez simplement savoir si une famille est libre et de même déterminer son rang.
Indépendance linéaire
On se donne une famille (v1, . . . , vp) que l’on peut décomposer dans la base B. De ce fait, pour (λ1, . . . , λp)des scalaires l’équation
λ1v1 + · · ·+ λpvp = 0
peut s’écrire (en projetant sur les coordonnées définies par la base B)
∀i ∈ [[ 1 ; n ]] λ1xi1 + · · ·+ λpxip = 0
où le vecteur vj a pour coordonnées (x1j, . . . , xnj) dans la base B. Ce qui donne en utilisant l’écriture matricielledes systèmes
x11 · · · x1p
......
xn1 · · · xnp
.
(le second membre n’est pas nécessaire car le système est homogène). Il ne reste plus qu’à échelonner ce système
— Si on obtient des inconnues auxiliaires (s’il reste des colonnes sans pivots) alors le système admet dessolutions non triviales (ce qui signifie que la famille n’est pas libre)
— A l’inverse la famille est libre.
294

2.5 Détermination du rang d’une famille
On utilise les mêmes notations et on procède de la même manière. Le nombre de pivots non nuls que l’onobtient correspond au nombre de vecteurs maximal d’une sous-famille libre. C’est donc le rang de la familleExercice : Déterminer le rang de la famille
u1 = (1, 2, 3, 4), u2 = (−1, 3, 0, 2), u3 = (4, 1, 6, 6), u4 = (1, 0, 1,−1), u5 = (4, 4, 7, 7)
.
2.6 Extraction d’une base
On fait pareil et on « supprime »les colonnes sans pivots.Exercice : compléter en une base de R4 la famille u1 = (1, 1,−1, 1), u2 = (4, 0,−2, 2).
3 Retour aux sous-espaces affines
3.1 Dimension d’un sous-espace affine
Soit E un espace vectoriel de dimension finie. On appelle dimension d’un sous-espace affine de E la dimensionde sa direction.
Définition 20.3.1.675
Notation :
1. Un sous-espace affine de dimension 1 s’appelle une droite (affine)
2. Un sous-espace affine de dimension 2 s’appelle un plan (affine)
3. Un sous-espace affine de dimension n− 1 s’appelle un hyperplan (affine)
3.2 Quelques exemples
Exemples :
1. Les sous espaces affines de R2 sont :
— Les points de dimension 0.
— Les droites de dimension 1
— le plan R2 en entier.
2. Les sous espaces affines de R3 sont :
— Les points de dimension 0.
— Les droites de dimension 1
— Les plans de dimension 2.
— L’espace R3 en entier.
Soit E un espace vectoriel de dimension finie. On appelle repère affine la donnée d’un point Ω qui est le centredu repère et d’une base B de E. De ce fait pour tout point M de E, on peut décomposer le vecteur
−−→ΩM dans la
base B. Ce sont les coordonnées du point M dans le repère (Ω, B).
Définition 20.3.2.676
295

21Dénombrements
1 Ensembles finis et cardinal 2961.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2961.2 Propriété du cardinal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2981.3 Opérations et cardinal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 299
2 Dénombrements classiques 3012.1 Applications de E dans F . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3012.2 Applications injectives de E dans F . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3022.3 Parties à p éléments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 303
1 Ensembles finis et cardinal
1.1 Définitions
Nous allons essayer de donner des expressions mathématiques pour les notions très intuitives d’ensemblefini et du nombre d’éléments d’un tel ensemble. Pour cela nous aurons besoin de « prototypes » d’ensembles à0, 1, 2, · · · , n éléments.Notation : Nous noterons F0 = ∅, F1 = 1 et pour tout n > 2, Fn = [[ 1 ; n ]]. De ce fait l’ensemble Fn est unensemble ayant n éléments.
Soit E et F deux ensembles. On dit que E et F sont equipotents s’il existe une bijection ϕ : E→ F. On noteE ' F.
Définition 21.1.1.677
La relation d’équipotence vérifie les axiomes des relations d’équivalence.
Proposition 21.1.1.678
Démonstration :i) Tout ensemble est équipotent à lui-même, il suffit de prendre l’application indentité.
ii) Si E est équipotent à F alors F est équipotent à E. Il suffit en effet de prendre ϕ−1 qui est encore unebijection.
iii) De même, la composée de deux bijections étant une bijection on en déduit que si E, F et G sont troisensembles et que E ' F et F ' G alors E ' G.
296

Cependant, on ne dira pas que c’est une relation d’équivalence car nous ne disposons pas d’ensemble de tousles ensembles.
Une bijection associe à un élément de l’ensemble de départ un et un seul élément de l’ensemble d’arrivée etréciproquement. On imagine donc que deux ensembles équipotents doivent avoir le même nombre d’éléments.
Soit m et n deux entiers.(Fn ' Fp)⇔ (n = p).
Proposition 21.1.1.679
Avant de démontrer cette proposition, nous allons avoir besoin d’un lemme.
Si on place quatre paires de chaussettes dans trois tiroirs, un tiroir contient au moins deux paires.
Lemme 21.1.1.680 (Lemme des tiroirs - version simple)
Soit n et p deux entiers et ϕ une application de Fn dans Fp. Si n > p alors ϕ n’est pas injective.
Lemme 21.1.1.681 (Lemme des tiroirs - version sophistiqué)
Le lemme des tiroirs peut aussi s’utiliser par contraposée. Soit n et p deux entiers et ϕ une applicationde Fn dans Fp. Si ϕ est injective alors n 6 p.
ATTENTION
Démonstration du lemme : Cela se fait par récurrence sur p. Précisément, si p ∈ N on pose
Hp = ∀n ∈ N, (n > p)⇒ toute application de Fn dans Fp n’est pas injective.
— Initialisation : Pour p = 0. Pour tout n > 0 il n’y a pas d’applications de Fn dans F0 car F0 est vide et pasFn.
— Hérédité : Soit p ∈ N. On suppose Hp. On veut montrer Hp+1. Pour cela on se donne n > p + 1 etϕ : Fn → Fp et on veut montrer que ϕ n’est pas injective. On considère p + 1 ∈ Fp.
— Si p + 1 a plusieurs antécédent c’est gagné.
— Si p + 1 n’a pas d’antécédents alors ϕ est une fonction de Fn dans Fp et on applique Hp.
— Si p + 1 a un unique antécédent α dans Fn. On a n > 1. On construit ϕ de Fn−1 dans Fp en enlevant αdans Fn et p + 1 dans Fp+1. Précisément on pose
ϕ(u) =
ϕ(u) si u < αϕ(u + 1) si u > α
D’après Hn, ϕ n’est pas injective donc ϕ non plus.
Soit n et p deux entiers et ϕ une application de Fn dans Fp.
1. Si n < p alors ϕ n’est pas surjective.
2. Si ϕ est surjective alors n > p
Corollaire 21.1.1.682
297

Démonstration : Remarquons que les deux assertions sont la contraposée l’une de l’autre. Montrons ladeuxième. S’il existe une surjection ϕ de Fn dans Fp alors on peut construire ψ : Fp → Fn telle que pourtout x de Fp, ϕ(ψ(x)) = x. En effet pour tout x de Fp on choisit pour ψ(x) un antécédent de x par ϕ. On voitalors que ψ est injective car pour (x, x′) ∈ F2
p :
ψ(x) = ψ(x′)⇒ ϕ(ψ(x)) = ϕ(ψ(x′))⇒ x = x′.
Le lemme des tiroirs permet alors de conclure que p 6 n.
Démonstration de la proposition :— ⇐ C’est évident, l’identité est une bijection de Fn dans Fn.
— ⇒ On suppose qu’il existe une bijection ϕ : Fn → Fp. En particulier elle est injective. Le lemme des tiroirsnous dit alors que n 6 p. Comme elle est aussi surjective alors n > p et donc n = p.
Soit E un ensemble. On dit que E est un ensemble fini s’il existe un entier n tel que E soit équipotent à Fn. Deplus, dans ce cas cet entier n est unique. On l’appelle le cardinal de E et on le note Card(E). On trouve aussiles notations |E| et #E.
Définition 21.1.1.683
Remarques :1. L’unicité découle du fait que s’il existait n et p des entiers distincts tels que E ' Fn et E ' Fp, alors Fn ' Fp
ce qui est impossible.
2. Le cardinal correspond au nombre d’éléments d’un ensemble.
3. En particulier une bijection ϕ entre Fn et E permet de numéroter les éléments de E en posant xi = ϕ(i).On a alors E = x1, . . . , xn
Exemple : Soit E = −2, π, 6, 100000. On a Card(E) = 4. Par exemple l’application ϕ : [[ 1 ; 4 ]]→ E définiepar ϕ(1) = π, ϕ(2) = −2, ϕ(3) = 100000 et ϕ(4) = 6 est une bijection.
1.2 Propriété du cardinal
Soit E et F deux ensembles finis.
1. Il existe une injection de E dans F si et seulement si Card(E) 6 Card(F).
2. Il existe une surjection de E dans F si et seulement si Card(E) > Card(F).
3. Il existe une bijection de E dans F si et seulement si Card(E) = Card(F).
Proposition 21.1.2.684
Démonstration :1. Procédons par double implication
— ⇒ :On veut montrer que si n = Card(E) 6 Card(F) = p alors il existe une injection de E dans F. Onsait par définition qu’il existe une bijection ϕE de E dans Fn et une bijection ϕF de F dans Fp. Onconstruit d’abord une injection i de Fn dans Fp. On peut prendre par exemple l’application qui associei à i. Il ne reste plus qu’à composer. L’application ϕ−1
F i ϕE est bien une injection (comme composéed’injections) de E dans F.
E
ϕE
// F
ϕF
Fn // Fp
— ⇐ : On suppose qu’il existe une injection de E dans F. On garde les même notations. On voit queϕE i ϕ−1
F est une injection de Fn dans Fp. Donc n 6 p d’après le lemme des tiroirs.
298

2. Comme ci-dessus mais en utilisant la propriété sur les surjections.3. Il suffit d’utiliser que la composition de deux bijections est une bijection.
Soit f une application de E dans F où E et F sont deux ensembles finis de même cardinal. Lesassertions suivantes sont équivalentes :
i.) L’application f est injective.
ii.) L’application f est surjective.
iii.) L’application f est bijective.
Corollaire 21.1.2.685
Remarques :1. Cela fait penser au cas des familles de n vecteurs dans un espace vectoriel de dimension n.2. Ce résultat est faux si E et F ne sont pas finis ou pas de même cardinal. Par exemple n 7→ n + 1.
Démonstration :— Montrons que i.) implique ii.) Par contraposée, on est ramené à montrer que si f n’est pas surjective
alors elle n’est pas injective. Soit α un élément de F qui n’a pas d’antécédent (il existe car f n’est passurjective). L’application f peut donc être vue comme une application de E dans F \ α. Maintenant,comme |E| > |F \ α| on en déduit que f n’est pas injective d’après le proposition précédente.
— Montrons que ii.) implique iii.) Le raisonnement est un peu similaire au précédent. On suppose que f estsurjective. Supposons par l’absurde que f n’est pas bijective (donc pas injective). Soit α un élément ayantau moins deux antécédents. On note x1 et x2 deux de ces antécédents. Alors f la restriction de f à E \ x1est encore surjective ce qui est absurde car Card(E \ x1) < Card(E).
Soit E un ensemble fini et A une partie de E (A ∈P(E)). Alors A est un ensemble fini et Card(A) 6Card(E). De plus, dans ce cas on a A = E⇔ Card(A) = Card(E).
Corollaire 21.1.2.686
Ne pas faire
Démonstration : Il suffit de remarquer qu’il y a une injection i de A dans E. Si ϕ est une bijection de E vers Fnoù n = Card(E). On note X ⊂ E l’image de ϕ i. Alors A est en bijection avec X. Maintenant X est un ensemblefini de cardinal inférieur à n. Il suffit de renuméroter ses éléments par ordre croissant. Dans la deuxième partie,le sens ⇒ est évident et le sens ⇐ découle de ce qui précède.
1.3 Opérations et cardinal
Soit E un ensemble fini et (A, B) ∈P(E)2.
1. Si A ∩ B = ∅, Card(A ∪ B) = Card(A) + Card(B).
2. Card(A) = Card(E)−Card(A).
3. Si B ⊂ A alors Card(A \ B) = Card(A)−Card(B).
4. Card(A ∪ B) = Card(A) + Card(B)−Card(A ∩ B).
Proposition 21.1.3.687
Exemple : Si A = 1, 2, 3, 4, 5, 6 et B = 1, 3, 5, 7, 9. Alors Card(A) = 6, Card(B) = 5, Card(A ∩ B) = 3 etCard(A ∪ B) = 8.Démonstration :
299

1. On suppose qu’il existe ϕA : A→ Fn et ϕB : B→ Fp des bijections. On construit alors
ψ : A ∪ B → Fn+p
x 7→
ψA(x) si x ∈ An + ψB(x) sinon
C’est une bijection (quelle est sa bijection réciproque?)
2. Il suffit de voir que A ∩ A = ∅ et que A ∪ A = E.
3. Comme ci-dessus
4. On pose X = A \ (A ∩ B). On a alors A ∪ B = X ∪ B et X ∩ B = ∅.
Soit E un ensemble fini et (Ai)i∈[[ 1 ; n ]] une partition. Card(E) =n
∑i=1
Card(Ai).
Corollaire 21.1.3.688
Dessin avec des patates pour faire deviner les formules pour Card(A ∪ B ∪ C) et Card(A ∪ B ∪ C ∪ D).
Soit E un ensemble et (Ai)i∈[[ 1 ; n ]] des parties de E.
Card
(n⋃
i=1
Ai
)=
n
∑k=1
(−1)k+1 ∑16i1<···<ik6n
Card(Ai1 ∩ · · · ∩ Aik ).
Proposition 21.1.3.689 (Formule du crible de Poincaré - HP)
Soit E et F des ensembles finis,
Card(E× F) = Card(E)×Card(F).
Proposition 21.1.3.690
Démonstration : On peut noter E = x1, . . . , xn où n = Card(E) et F = y1, . . . , yp où p = Card(F). Dèslors
E× F = (xi , yj) | i ∈ [[ 1 ; n ]] , j ∈ [[ 1 ; p ]].Il est donc en bijection avec Fn × Fp lui même en bijection avec Fnp.
Soit E un ensemble fini. Pour tout entier naturel p non nul, Card(Ep) = Card(E)p.
Corollaire 21.1.3.691
Démonstration : Cela se démontre par récurrence sur p.
Remarque : On rappelle que Ep est l’ensemble E × · · · × E des p-uplets (ou p-listes) d’éléments de E. Cerésultat se conçoit bien. En effet pour se donner une p-listes d’éléments de E il faut se donner (x1, . . . , xp) ou,pour chaque xi il y a Card(E) possibilités.
300

2 Dénombrements classiques
2.1 Applications de E dans F
Soit E et F des ensembles finis de cardinal respectif p et n. L’ensemble F (E, F) = FE des applicationsde E dans F est un ensemble fini et son cardinal est np.
Proposition 21.2.1.692
Démonstration : Il suffit de remarquer que si l’on note E = x1, . . . , xp (via une bijection de E dans Fp) alors
FE → Fp
f 7→ ( f (x1), . . . , f (xp))
est une bijection de FE dans Fp. On a donc Card(FE) = Card(Fp) = Card(F)p.
Exercice : Tracer avec des patates toutes les applications de F3 dans F2. Faire correspondre à chacune unélément de 0, 13.Exemples :
1. On fait 10 tirages à pile ou face et on note dans l’ordre les résultats obtenus. L’ensemble des résultatspossibles est donc P, F10. Son cardinal est 210 = 1024.
2. On dispose de 10 boules numérotés de 1 à 10 et on veut les repartir dans 4 boites distinctes (disons A, B,C et D). On cherche le nombre de répartitions possibles. Il suffit de voir qu’une répartition est juste uneapplication de l’ensemble de boules (de cardinal 10) dans l’ensemble des boites (de cardinal 4). Il y a donc410 répartitions possibles.
Par contre cela ne correspond pas à une application dans l’autre sens. On associe pas à une boite uneboule car il y a des boites avec plusieurs boules et à l’inverses des boites sans boules
ATTENTION
3. On dispose d’une urne avec 10 boules numérotées. On tire dedans 5 boules avec ordre et remise. Untirage peut alors être vu comme une application de [[ 1 ; 5 ]] dans l’ensemble B des boules. Il y a donc 105
tirages possibles. Ce sont des tirages avec ordre et avec repetitions.
Soit E un ensemble. On associe à toute partie A de E une application χA de E dans 0, 1 définie par
1A = χA : E → 0, 1x 7→
1 si x ∈ A0 sinon.
L’application χA s’appelle l’application caractéristique de A.
Définition 21.2.1.693 (Application caractéristique)
Soit E un ensemble. Les applications
Φ : P(E) → 0, 1E
A 7→ χAet Ψ : 0, 1E → P(E)
f 7→ f−1(1)
sont des bijections réciproques l’une de l’autre.En particulier si E est un ensemble fini, P(E) aussi et Card(P(E)) = Card(0, 1E = 2Card(E).
Proposition 21.2.1.694
301

Démonstration : Il suffit de vérifier que ∀A ∈P(E), (Ψ Φ)(A) = χ−1A (1) = A. On a bien Ψ Φ = IdP(E).
De même Φ Ψ = Id0,1E .
Exercice : Soit E = 0, 1, 2. Vérifier que P(E) a bien 8 éléments et exhiber les bijections ci-dessus entre P(E),0, 1E et 0, 13.
2.2 Applications injectives de E dans F
Soit E et F deux ensembles finis. On note p = Card(E) et n = Card(F). L’ensemble des applicationsinjectives de E dans F est une partie de FE. En particulier il est fini. De plus, il est en bijection avecl’ensembles des p-listes d’éléments de E deux à deux disjoints . Son cardinal est
Apn =
n!(n− p)!
= n(n− 1) · · · (n− p + 1) si p 6 n
0 sinon.
Proposition 21.2.2.695
Démonstration : Cela se démontre par récurrence sur p.
Remarques :
1. On appelle arrangement une p-liste s d’éléments deux à deux disjoints.
2. Cette formule est assez intuitive car il suffit de chosir le premier élément de la p-liste. Il y a n possibilités(tous les éléments de E) puis le deuxième où il n’y a plus que n− 1 possibilités car on ne peut pas reprendrele même et ainsi de suite.
Exemples :
1. On considère un tiercé avec 17 chevaux au départ. Un tiercé dans l’ordre est la donnée de 3 chevaux avecordre et sans repetitions. Cela peut-être modélisé par une application injective de [[ 1 ; 3 ]] dans l’ensembleC des chevaux. Il y a donc A3
17 = 17× 16× 15 = 4080 tiercés possibles.
2. On dispose d’une urne avec 10 boules numérotées. On tire dedans 5 boules avec ordre et sans remise. Untirage peut alors être vu comme une application injective de [[ 1 ; 5 ]] dans l’ensemble B des boules. Il y adonc A5
10 tirages possibles. Ce sont des tirages avec ordre et sans repetitions.
Soit E un ensemble fini. On appelle permutation de E une application bijective de E dans lui même. On noteSE l’ensemble des permutations de E.
Définition 21.2.2.696
Remarque : Cela correspond à la notion intuitive de permutation. En effet, si on note E = x1, . . . , xn (via unebijection de E dans Fn) on associe à tout permutation f de E le n-uplet ( f (x1), . . . , f (xn)) qui est une écrituredes éléments x1, . . . , xn dans un autre ordre.
Soit E un ensemble fini de cardinal n, Card(SE) = n!.
Proposition 21.2.2.697
Démonstration : ll suffit de remarquer que comme E à le même cardinal que E alors une application bijectivede E dans E est la même chose qu’une application injective. D’où Card(SE) = An
n = n!
302

2.3 Parties à p éléments
Soit E un ensemble fini de cardinal n et p un entier naturel on note Pp(E) l’ensemble des parties de E decardinal p. On a
Pp(E) = X ∈P(E) | Card(X) = p.
L’ensemble Pp(E) est fini et on note(
np
)son cardinal.
Définition 21.2.3.698
Notation : on trouve encore couramment la notation Cpn pour
(np
).
Avec les notations précédentes
(np
)=
n!p!(n− p)!
=n(n− 1)(n− 2) · · · (n− p + 1)
p!si n > p
0 sinon.
Proposition 21.2.3.699
Démonstration : On pourrait dire qu’une même combinaison donne lieu à p! arrangements (les p! permutationscorrespondent à toutes les manières d’ordonner les p éléments) et que de ce fait
(np
)=
Apn
p!.
Par exemple écrivons les pour p = 3 et n = 4. Cependant nous allons faire une démonstration rigoureuse. Pourcela nous allons avoir besoin d’un lemme
Pour tous entiers n et p on a (n + 1p + 1
)=
(n
p + 1
)+
(np
).
Lemme 21.2.3.700 (Formule de Pascal)
Démonstration du lemme : Rappelons au préalable que pour le moment(
np
)ne désigne que le cardinal de
Pp(E). On ne connaît pas encore la formule.Notons d’abord que si p > n alors tous les termes sont nuls. On suppose donc que p 6 n. On considère un
ensemble E à n + 1 éléments. Prenons par exemple E = [[ 1 ; n + 1 ]]. On cherche à dénombrer les partie de E decardinal p + 1. On sépare alors ses parties en deux.
— soit n + 1 est dedans, et il reste alors à choisir les p autres éléments parmi [[ 1 ; n ]] . Il y a donc(
np
)telles
parties.
— soit n + 1 n’est pas dedans, et il reste alors à choisir les p + 1 éléments parmi [[ 1 ; n ]] . Il y a donc(
np + 1
)
telles parties.
Cela forme une partition. On a donc(
n + 1p + 1
)=
(n
p + 1
)+
(np
).
Démonstration de la proposition : On va donc montrer par récurrence que ∀n ∈ N, « ∀p ∈ [[ 0 ; n ]] ,(
np
)=
n!p!(n− p)!
. ».
— Initialisation : pour n = 0 on a (00) = 1. Pour n = 1 on a (1
0) = (11) = 1.
303

— Hérédité : Soit n un entier fixé. On suppose que ∀p ∈ [[ 0 ; n ]] ,(
np
)=
n!p!(n− p)!
. Soit p ∈ [[ 0 ; n + 1 ]]. Si
p = 0,(
n + 10
)= 1 =
(n + 1)!(n + 1)!
.
Si p > 0, on utilise la formule de Pascal :(
n + 1p
)=
(np
)+
(n
p− 1
)
=n!
p!(n− p)!+
n!(p− 1)!(n− p + 1)!
=n!(n− p + 1)p!(n− p + 1)!
+n!p
p!(n− p + 1)!
=n!(n + 1)
p!(n− p + 1)!
=(n + 1)!
p!(n− p + 1)!
Donc, par récurrence, ∀n ∈ N, ∀p ∈ [[ 0 ; n ]] ,(
np
)=
n!p!(n− p)!
.
Remarques :1. La formule de Pascal permet de construire le triangle de Pascal qui permet de calculer simplement les
coefficients binomiaux.
!!!!!np 0 1 2 3 4 5 6
0 11 1 12 1 2 13 1 3 3 14 1 4 6 4 15 1 5 10 10 5 16 1 6 15 20 15 6 1
1
2. Pour calculer un coefficient binomial, on le simplifie. On a(
np
)=
n!p!(n− p)!
=n× (n− 1)× · · · × (n− p + 1)
p!.
En particulier (n2
)=
n(n− 1)2
et(
n3
)=
n(n− 1)(n− 2)6
.
Soit n et p deux entiers :
1. On a(
pn
)=
(n− p
n
).
2. Si n et p sont supérieurs à 1,(
pn
)=
np
(p− 1n− 1
).
Proposition 21.2.3.701
Démonstration : Cela peut se faire par le calcul ou de manière combinatoire.
Exemples :1. Tirage du loto. On a une urne avec 49 boules numérotées de 1 à 49 et on en prélève simultanément 6 (sans
ordre sans remise). L’ensemble des possibilité est A ⊂ [[ 1 ; 49 ]] | Card(A) = 6. Il y en a(
496
)=
49!6!(43)!
=49× 48× 47× 46× 45× 44
6!= 13983816.
304

2. On dispose d’une urne avec 10 boules numérotées. On tire dedans 5 boules sans ordre et sans remise. Untirage peut alors être vu comme une partie à 5 éléments de l’ensemble B des boules. Il y a donc (10
5 ) tiragespossibles. Ce sont des tirages sans ordre et sans repetitions.
3. Soit E un ensemble à n éléments. On note Pk = A ⊂ E | Card(A) = k. On a alors
P(E) =n⋃
k=0
Pk(E).
C’est une partition. On en déduit que
2n =n
∑k=0
(nk
).
4. Si on considère (a + b)n = (a + b)× (a + b)× · · · × (a + b). Pour déterminer un terme akbn−k du déve-loppement il suffit de choisir dans lesquels des n facteurs on prend les k termes a (les n− k autres serontdes b). Il y en aura donc (n
k). On en déduit que
(a + b)n =n
∑k=0
(nk
)akbn−k.
5. Soit (n, p) ∈ N2. On note SC(p, n) l’ensemble des applications strictement croissantes de [[ 1 ; p ]] dans[[ 1 ; n ]] . Se donner une application croissante revient à se donner les p éléments de [[ 1 ; n ]] qui sont les lesimages. On en déduit que
Card(SC(p, n)) =(
np
).
On note de même C(p,n) les applications croissantes de [[ 1 ; p ]] dans [[ 1 ; n ]] . On peut remarquer que
Φ : C(p,n) → C(p,n+p-1)f 7→ (Φ( f ) : x 7→ f (x) + x− 1)
On peut voir que Φ est une bijection. On en déduit que
Card(C(p, n)) = Card(C(p, n + p− 1)) =(
n + p− 1n
).
305

22Applications
linéaires1 Applications linéaires 3061.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3061.2 Applications linéaires et sous-espaces vectoriels . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3081.3 Composition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 309
2 L’ensemble des applications linéaires 3092.1 Structure de L (E, F) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3102.2 Structure de L (E) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3102.3 Ensemble GL(E) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 312
3 Elements remarquables de L (E) 3133.1 Sous-espaces stables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3133.2 Projecteurs et symétries . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 313
4 Applications linéaires données dans une base 3164.1 Caractérisation d’une application linéaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3164.2 Caractérisation des isomorphismes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3174.3 Dimension de L (E, F) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3184.4 Théorème du rang . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3194.5 Formes linéaires et hyperplans . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 322
Dans ce chapitre K désigne encore un corps le plus souvent égal à R ou C (voire Q).
1 Applications linéaires
1.1 Définitions
On va définir une application linéaire entre deux K-espace vectoriel comme une application qui « préservela structure ».
306

Soit E et F deux K-espaces vectoriels. On appelle application linéaire toute application f de E dans F telle que
∀(u, v) ∈ E2, ∀(λ, µ) ∈ K2, f (λu + µv) = λ f (u) + µ f (v).
Définition 22.1.1.702
Remarque : Le corps des scalaires K doit être le même pour les deux espaces vcetoriels.Terminologie :
1. On note L (E, F) l’ensemble des applications linéaires de E dans F.
2. Une application linéaire de E dans E est un endomorphisme de E et on note L (E) pour L (E, E).
3. Une application linéaire bijective de E dans F s’appelle un isomorphisme.
4. Une application linéaire bijective de E dans lui même s’appelle un automorphisme de E. On note GL(E)l’ensemble des automorphismes.
5. Une application linéaire de E dans K s’appelle une forme linéaire. L’ensemble des formes linéaires sur Ese note E? et s’appelle l’espace dual de E.
Remarque : On voit que si f est une application linéaire, f (0E) = f (0.0E + 0.0E) = 0 f (0E) + 0 f (0E) = 0F.Exemples :
1. Cherchons les applications linéaires de K dans lui même. Si on note α = f (1) alors pour tout x dans K,f (x) = f (x.1) = x. f (1) = αx. On voit donc que les applications linéaires de K dans K sont les applicationslinéaires....
2. Soit E et F des espaces vectoriels. L’application nulle de E dans F est linéaire.
3. Soit E un espace vectoriel. L’application identité de E dans lui même qui associe u à u est linéaire. Onl’appelle application identité. Elle se note IdE.
4. Soit E un espace vectoriel. Soit λ ∈ K. On appelle homothétie de rapport λ l’application linéaire λIdE :u 7→ λ.u.
5. Soit f : R2 → R3 définie par f (x, y) = (x + 2y, x− y, 3x). C’est une application linéaire.
6. La dérivation ∆ : K[X] → K[X] définie par ∆(P) = P′ est un endomorphisme de K[X]. On peut aussidéfinir ∆n de Kn[X] dans lui même ou de Kn[X] dans Kn−1[X].
7. Si on appelle C ∞ l’ensemble des fonctions indéfiniment dérivables. On peut définir ∆ sur C ∞.
8. Soit E = C 0(R, R). Pour tout (a, b) ∈ R2, l’application ϕ : f 7→∫ b
af est une application linéaire de E dans
R.
9. L’application pi de Kn dans K qui associe à (x1, . . . , xn) l’élément xi est une forme linéaire. On l’appelle lai-ème projection.
10. Soit (x1, . . . , xn) ∈ Kn deux à deux distincts. L’application
K[X] → Kn
P 7→ (P(x1), . . . , P(xn))
est linéaire.
Soit E et F des espaces vectoriels
1. Si f ∈ L (E, F) et si (u1, . . . , un) sont des vecteurs de E et λ1, . . . , λn des scalaires alors,
f
(n
∑k=1
λkuk
)=
n
∑k=1
λk f (uk).
2. Si ( f , g) ∈ (L (E, F))2. Soit F une famille génératrice de E. Si pour tout vecteur u de F ,f (u) = g(u) alors f = g.
Théorème 22.1.1.703
Démonstration :
307

1. Par récurrence sur n.
2. Soit w dans E. Il existe (u1, . . . , un) des vecteurs de F et λ1, . . . , λn des scalaires tels que
w =n
∑k=1
λkuk.
Dès lors
f (w) =n
∑k=1
λk f (uk) =n
∑k=1
λkg(uk) = g(w).
1.2 Applications linéaires et sous-espaces vectoriels
Soit E et F deux espaces vectoriels et f ∈ L (E, F).
1. Si G est un sous-espace vectoriel de E alors f (G) est un sous-espace vectoriel de F.
2. Si H est un sous-espace vectoriel de F alors f−1(H) est un sous-espace vectoriel de E.
Proposition 22.1.2.704
Démonstration
Soit E et F deux espaces vectoriels et f ∈ L (E, F).
1. On appelle noyau de f et on note Ker f le sous-espace vectoriel f−1(0F) de E. On a donc
Ker f = u ∈ E | f (u) = 0F.
2. On appelle image de f et on note Im f le sous-espace vectoriel f (E). On a donc
Im f = v ∈ F | ∃u ∈ E, v = f (u) = f (u) | u ∈ E.
Définition 22.1.2.705
Exemples :1. Si on considère l’application f : (x + 2y, x− y, 3x) de R2 dans R3. On peut déterminer Ker f en résolvant
le système
x + 2y = 0x− y = 0
3x = 0On trouve que Ker f = 0. Pour Im f . On voit que, par définition, Im f =
Vect(1, 1, 3), (2,−1, 0).
2. Pour ∆ : K[X]→ K[X], on a Ker ∆ = K0[X] et Im∆ = K[X]. Par contre, Im∆n = Kn−1[X].
Soit E et F deux espaces vectoriels et f ∈ L (E, F). On suppose que (ui)i∈I est une famille génératricede E. On a alors
Im f = Vect( f (ui)i∈I .
Proposition 22.1.2.706
Soit E et F deux espaces vectoriels et f ∈ L (E, F).
1. L’application f est injective si et seulement si Ker f = 0.2. L’application f est surjective si et seulement si Im f = F.
Proposition 22.1.2.707
308

Soit E et F deux espaces vectoriels et f ∈ L (E, F). On se donne v ∈ F et on veut résoudre l’équationf (u) = v d’inconnue u.
— Si v /∈ Im f , l’équation n’a pas de solution.
— Si v ∈ Im f . Soit u0 une solution, l’ensemble des solutions est le sous-espace affine : u0 +Ker f =u0 + u | u ∈ Ker f .
Proposition 22.1.2.708
Démonstration
Exemples :1. Si on considère E = C 2(R, C) et D : f 7→ ay′′+ by′+ cy. On trouve alors que D est linéaire et la proposition
précédente redonne la structure des solutions des équations différentielles linéaires du second ordre.2. Si on considère (x1, . . . , xn) ∈ Kn deux à deux distincts et Φ l’application
Φ : K[X] → Kn
P 7→ (P(x1), . . . , P(xn))
On voit alors que si on se donne Y = (y1, . . . , yn) ∈ Kn, on sait que le polynôme interpolateur de LagrangeL ∈ Kn−1[X] vérifie l’équation Φ(P) = Y. De ce fait, l’ensemble des solutions est L + Ker Φ. De plus,
Ker Φ est l’ensemble des polynômes s’annulant en tous les xi. C’est -à-dure les mulitples den
∏i=1
(X− xi).
1.3 Composition
Soit E, F et G trois espaces vectoriels et f ∈ L (E, F), g ∈ L (F, G) deux applications linéaires.L’application g f est une application linéaire de E dans G.
Proposition 22.1.3.709
Démonstration
Soit E et F deux espaces vectoriels et f un isomorphisme de E dans F. L’application f−1 de F dans Eest aussi linéaire.
Proposition 22.1.3.710
Démonstration : Soit v1 et v2 dans F et λ1, λ2 dans K. On veut montrer que f−1(λ1v1 + λ2v2) = λ1 f−1(v1) +λ2 f−1(v2) = λ1u1 + λ2u2 où l’on note u1 = f−1(v1) et u2 = f−1(v2). Cela revient à montrer que λ1u1 + λ2u2est un antécédent de λ1v1 + λ2v2 par f . Or c’est vrai car
f (λ1u1 + λ2u2) = λ1 f (u1) + λ2 f (u2) = λ1v1 + λ2v2.
Exemple : Calculer la bijection reciproque de f : (x, y) 7→ (2x + y, 3x− 7y).
La relation « être isomorphe » vérifie les axiomes d’une relation d’équivalence.
Corollaire 22.1.3.711
Démonstration
2 L’ensemble des applications linéaires
Nous allons nous intéresser à la structure des ensembles L (E, F) et L (E).
309

2.1 Structure de L (E, F)
Dans ce paragraphe on se fixe E et F deux sous-espaces vectoriels
1. Soit f et g deux éléments de L (E, F). L’application f + g de E dans F est linéaire.
2. Soit f un élément de L (E, F) et λ ∈ K. L’application λ. f est linéaire.
Proposition 22.2.1.712
Démonstration
L’ensemble L (E, F) est un sous-espace vectoriel de F (E, F). En particulier, pour F = K, l’espacedual E? de E est un espace vectoriel.
Corollaire 22.2.1.713
Exercice : Soit u ∈ E. Montrer queθu : L (E, F) → F
f 7→ f (u)
est une application linéaire. C’est donc un élément de L (L (E, F), F).
Soit E, F et G des espaces vectoriels.
1. Pour tout ϕ ∈ L (F, G) l’application de L (E, F) dans L (E, G) définie par f 7→ ϕ f estlinéaire.
2. Pour tout ϕ ∈ L (E, F) l’application de L (F, G) dans L (E, G) définie par f 7→ f ϕ estlinéaire.
Proposition 22.2.1.714
Démonstration
Remarque : L’application : : L (E, F)×L (F, G) → L (E, G)
( f , g) 7→ g f
est linéaire à droite (en f ) et à gauche (en g). On dit qu’elle est bilinéaire.
2.2 Structure de L (E)
Le cas de L (E) est un cas particulier de L (E, F). C’est donc aussi un espace vectoriel. Cependant L (E) aune autre opération interne : la composition.
Soit E un espace vectoriel. L’ensemble (L (E),+, ) est un anneau.
Proposition 22.2.2.715
Démonstration :— On sait que L (E) est un espace vectoriel c’est donc, en particulier un groupe abélien pour +.— La loi est une loi de composition interne de L (E) et elle est associative.— L’application IdE est un élément neutre pour .— Soit ( f , g, h) ∈ L (E)3,
( f + g) h = f h + g h (par définition)
etf (g + h) = f g + f h (par linéarité).
310

A priori, L (E) n’est pas un anneau commutatif. Par exemple si f : (x, y) 7→ (2x + 3y, x − y) etg : (x, y) 7→ (x + y, y). En fait L (E) n’est commutatif que si E est de dimension 1.
ATTENTION
Comme dans tout anneau on peut définir les puissances. Pour tout f dans L (E) et k ∈ N, on pose f k =f f · · · f . C’est-à-dire :
f 0 = IdEf p = f f p−1 si p > 0
Définition 22.2.2.716 (Puissances)
Exemple : Soit ∆ : R[X]→ R[X]. On a pour tout polynôme P, ∆p(P) = P(p) la dérivée p-ième.
Soit ( f , g) ∈ L (E)2 et n ∈ N. Si f et g commutent c’est-à-dire f g = g f alors
( f + g)n =n
∑k=0
(kn
)f k gn−k.
Proposition 22.2.2.717 (Binôme de Newton)
Soit K un corps. On appelle K-algèbre, un ensemble E muni de deux lois de compositions internes (notées +et ×) et d’une loi de composition externe (noté .) telles que
— On a (E,+, .) est un K-espace vectoriel.
— On a (E,+,×) est un anneau.
— Les deux multiplications sont compatibles : ∀(λ, µ) ∈ K2, ∀(x, y) ∈ E2, (λ.x)× (µ.y) = (λµ).(x×y).
Définition 22.2.2.718
Remarque : Nous demandons ici plus que la définition classique d’algèbre qui ne nécessite par que la multi-plication soit associative ni qu’il existe un élément neutre pour la multiplication. Cependant c’est ce cadre quinous sera utile ici.Remarque : On voit que K[X] est une K-algèbre.
Soit E un K-espace vectoriel. L’ensemble L (E) est muni d’une structure de K-algèbre.
Proposition 22.2.2.719
Démonstration : Il suffit juste de vérifier la compatibilité des multiplications. Soit λ, µ des scalaires et f , g desendomorphismes de E.
(λ f ) (µg) = (λµ)( f g) par linéarité.
311

Soit P un polynôme de K[X] et f ∈ L (E). On note P =n
∑k=0
akXk. On note alors
P( f ) =n
∑k=0
ak f k.
Définition 22.2.2.720
Remarque : Cette définition peut se faire dans n’importe quelle algèbre.Exemples :
1. Soit ∆ la dérivation sur E = C ∞(R, C). Soit P = aX2 + bX + c un polynôme de degré 2 dans C. Alors,P(∆) est l’application linéaire sur E qui associe à toute fonction f la fonction a f ′′ + b f ′ + c f . En particulier,Ker (P(∆)) est l’ensemble des solutions de l’équation différentielle :
ay′′ + by′ + cy = 0.
2. Soit f ∈ L (E) et P = a un polynôme constant. L’endomorphisme P( f ) est l’homothétie a.IdE.
Soit (P, Q) ∈ K[X]2, f ∈ L (E) et λ ∈ K. On a
(P + Q)( f ) = P( f ) + Q( f ), (P×Q)( f ) = P( f ) Q( f ) et (λ.P)( f ) = λ.(P( f )).
On dit alors que l’applicationK[X] → L (E)
P 7→ P( f )
est un morphisme d’algèbre car il est compatible aux structures d’algèbre de K[X] et de L (E).
Proposition 22.2.2.721
Démonstration : Faisons le cas de (P×Q)( f ) = P( f ) Q( f ). Si on note P =n
∑k=0
akXk. On a donc
(P×Q) =n
∑k=0
ak(XkQ).
D’où
(P×Q)( f ) =n
∑k=0
ak( f k Q( f )) = P( f ) Q( f ).
2.3 Ensemble GL(E)
Soit f un endomorphisme de E.
f est inversible (dans l’anneau L (E)) ⇐⇒ f est bijective.
Proposition 22.2.3.722
Démonstration : Par définition. En effet
— ⇐ Si f est inversible dans L (E), il existe g dans L (E) tel que f g = g f = IdE C’est-à-dire que f estbijective et g = f−1.
— ⇒ Si f est bijective. On a vu que sa réciproque g = f−1 était aussi un endomorphisme (et même unautomorphisme). De plus ils vérifient que f g = g f = IdE.
312

L’ensemble (GL(E), ) est un groupe. Son élément neutre est IdE.
Proposition 22.2.3.723
Soit f et g deux éléments de GL(E). On a ( f g)−1 = g−1 f−1.
Proposition 22.2.3.724
3 Elements remarquables de L (E)
Dans tout ce chapitre on se fixe un espace vectoriel E.
3.1 Sous-espaces stables
Soit f ∈ L (E) et F un sous-espace vectoriel de E. On dit que F est stable par f si f (F) ⊂ F c’est-à-dire :
∀u ∈ F, f (u) ∈ F.
Définition 22.3.1.725
Exemple : Soit ∆ : K[X]→ K[X] l’endomorphisme de dérivation. Soit F = Kn[X]. Il est stable par ∆. Par contre,G = P ∈ K[X] | P(0) = 0 n’est pas stable par ∆.
Soit f ∈ L (E) et F un sous-espace vectoriel de E stable par f . On appelle endomorphisme induit par f sur Fet on note f|F l’endomorphisme de F défini par u 7→ f (u).
Définition 22.3.1.726
Exemple : Dans l’exemple précédent, on a vu que l’on pouvait définir ∆ sur Kn[X].Exercice : Montrer que si f g = g f alors Ker f est stable par g.
3.2 Projecteurs et symétries
Soit F et G deux sous-espaces vectoriels de E tels que F ⊕ G = E. On appelle projection sur Fparallèlement à G l’unique endomorphisme p de E qui associe à un vecteur u l’unique vecteur v deF tel que u = v + w avec w ∈ G.
Proposition-Définition 22.3.2.727
Démonstration : Notons p l’application de E dans E définie comme ci-dessus. Montrons que c’est un endomor-phisme de E. Soit λ1, λ2 deux scalaires et u1, u2 deux vecteurs de E. On sait que u1 et u2 s’écrivent uniquementsous la forme
u1 = v1 + w1 et u2 = v2 + w2
où v1, v2 sont dans F et w1, w2 dans G. Par définition, v1 = p(u1) et v2 = p(u2). On a alors
λ1u1 + λ2u2 = (λ1v1 + λ2v2) + (λ1w1 + λ2w2).
Par unicité de la décomposition, on en déduit que
p(λ1u1 + λ2u2) = λ1v1 + λ2v2 = λ1 p(u1) + λ2 p(u2).
313

Exemples :
1. Soit E = R3. On pose F = (x, y, z) ∈ R3 | x + y− z = 0 et G = Vect(1, 2, 1). On trouve alors
p(x, y, z) = (x, y, z) +12(−x− y + z)(1, 2, 1) =
12(x− y + z,−2x + 2z,−x− y + 3z).
2. Soit E = C 0(R, K). Si on considère P et I l’ensemble des fonctions paires et impaires. On sait queP ⊕ I = E. De plus, pour tout fonction f , la projection sur P parallèlement à I est p( f ) : x 7→f (x) + f (−x)
2.
3. Soit E = Kn. On note Hi = (x1, . . . , xn) | xi = 0 et ∆i = Vectei. La projection sur ∆i parallèlement à Hiest u 7→ pi(u)ei où pi est la i-ème projection.
Soit p la projection sur F parallèlement à G.
1. On a Ker p = G.
2. On a Im p = F
3. Pour tout vecteur u de E, p(u) = u ⇐⇒ u ∈ F. En particulier, F = Ker (p− IdE).
Proposition 22.3.2.728
Démonstration
Remarque : On a donc que F et G sont stables par p et pF = IdF et pG = 0L (G).
On appelle projecteur de E toute projection sur un espace vectoriel F de E parallèlement à un supplémentairede F.
Définition 22.3.2.729
Soit p ∈ L (E). L’endomorphisme p est un projecteur si et seulement si p2 = p p = p.
Proposition 22.3.2.730
Remarques :
1. On trouve cette caractérisation comme définition d’un projecteur.
2. On dit que p est un idempotent de L (E).
3. On en déduit par une récurrence immédiate que pour tout entier k non nul, pk = p.
Démonstration :
— ⇒ Soit p une projection sur un sous-espace vectoriel F. Pour tout vecteur u de E, p(u) ∈ F. On en déduitque p2(u) = p(p(u)) = p(u) car on a vu qu’un projection sur F laissait invariant les éléments de F.
— ⇐ Soit p un endomorphisme vérifiant p2 = p. C’est plus délicat car il faut « trouver » les sous-espacesvectoriels F et G. On pose F = Imp et G = Ker p. Montrons que F et G sont supplémentaires.
— Soit u ∈ F ∩ G. On sait que u ∈ Im p. Il existe donc v tel que u = p(v). D’où p(u) = p(p(v)) =p(v) = u. Or u ∈ Ker p donc p(u) = 0 et u = 0.
— Soit u ∈ E. On remarque que u = p(u) + (u− p(u)). Or p(u) ∈ F et u− p(u) ∈ G car p(u− p(u)) =p(u)− p2(u) = 0.
Maintenant, Tout vecteur u de E s’écrit v + w avec v ∈ F et w ∈ G. On a alors
p(u) = p(v + w) = p(v) + p(w) = v.
314

Soit F et G deux sous-espaces vectoriels de E tels que F⊕ G = E. On appelle symétrie par rapport Fparallèlement à G l’unique endomorphisme s de E qui associe à un vecteur u le vecteur u− w oùu = v + w avec v ∈ F et w ∈ G. En particulier s = 2p− IdE où p est la projection sur F parallèlementà G.
Proposition-Définition 22.3.2.731
Démonstration : Soit u un vecteur de E. On note u = v + w avec v ∈ F et w ∈ G. On a alors p(u) = v et(2p− IdE)(u) = 2v− (u + w) = u− w. On a donc bien s = 2p− IdE. C’est donc une application linéaire.
Remarque : On a aussi comme relation p =12(s + IdE).
Exemples :
1. Soit E = R3. On pose F = (x, y, z) ∈ R3 | x + y− z = 0 et G = Vect(1, 2, 1). On trouve alors
s(x, y, z) = (x, y, z) + (−x− y + z)(1, 2, 1) = (−y + z,−x− y + 3z,−x− y + 2z).
2. Soit E = C 0(R, K). Si on considère P et I l’ensemble des fonctions paires et impaires. On sait queP ⊕I = E. De plus, pour tout fonction f , la symétrie par rapport à P parallèlement à I est s( f ) : x 7→f (−x).
Soit s la symétrie parallèlement à F parallèlement à G.
1. On a Ker s = 0 et Im s = E. En particulier s est un automorphisme.
2. On a Ker (s− IdE) = F.
3. On a Ker (s + IdE) = G
4. Pour tout vecteur u de E, s(u) = u ⇐⇒ u ∈ F. De même, s(u) = −u ⇐⇒ u ∈ G.
Proposition 22.3.2.732
Démonstration
Remarque : On voit alors que F et G sont stables par s et que s|F = IdF et s|G = −IdG.
On appelle symétrie de E toute symétrie par rapport à un espace vectoriel F de E parallèlement à un supplé-mentaire de F.
Définition 22.3.2.733
Soit s ∈ L (E). L’endomorphisme s est une symétrie si et seulement si s2 = s s = IdE. En particulier,s−1 = s.
Proposition 22.3.2.734
Remarques :
1. On trouve cette caractérisation comme définition d’une symétrie.
2. On dit que s est un élément involutif de L (E).
Démonstration :
— ⇒ Soit s une symétrie par rapport à sous-espace vectoriel F. Pour tout vecteur u de E, on pose u = v + wavec v ∈ F et w ∈ G. On a alors :
s(s(u)) = s(s(v + w)) = s(v− w) = v + w = u.
315

— ⇐ Il suffit de poser p =12(s + IdE). On a alors
p2 =14(s2 + 2s + IdE) =
12(s + IdE) = p.
On en déduit que p est un projecteur sur F (avec F = Ker (p− IdE) = Ker (s− IdE)) parallèlement à G(avec G = Ker p = Ker (s + IdE)).Comme maintenant on a s = 2p− IdE on en déduit bien que s est lasymétrie par rapport à F et parallèlement à G.
4 Applications linéaires données dans une base
On se fixe E un espace vectoriel. Nous allons commencer par quelques résultats généraux puis étudier le casparticulier des espaces vectoriels de dimension finie.
4.1 Caractérisation d’une application linéaire
On a déjà vu que deux applications linéaires qui coïncidaient sur une famille génératrice étaient égales.On va donc pouvoir restreindre la définition d’une application linéaire f aux images par f des vecteurs d’unefamille génératrice. Cependant, si cette famille n’est pas libre, on ne peut pas définir n’importe comment lesimages. En effet supposons que les vecteurs de la famille génératrice satisfont une relation de dépendancelinéaire (∑ λiui = 0) alors, par linéarité leurs images aussi (∑ λi f (ui) = 0). On va donc avoir recours à desbases.
Soit (ui)i∈I une base de E. Soit (vi)i∈I une famille d’un espace vectoriel F. Il existe une uniqueapplication linéaire f de E dans F telle que
∀i ∈ I, f (ui) = vi.
Proposition 22.4.1.735
Remarque : On ne fait aucunes hypothèses sur la famille (vi).Démonstration :
— L’unicité à déjà été traitée.— Via un raisonnement analyse-synthèse, on voit que nécessairement, si u = ∑
i∈Iλiui où (λi)i∈I est une
famille presque nulle alors f (u) = ∑i∈I
λi f (ui) = ∑i∈I
λivi.
On pose donc f de E dans F définie de la sorte. Il est alors évident que pour tout i, f (ui) = vi. Il reste àvérifier qu’elle est linéaire. Soit (u, u′) deux vecteurs de E et α, β deux scalaires. Si on note
u = ∑i∈I
λiui et u′ = ∑i∈I
λ′iui
alorsαu + βu′ = ∑
i∈I(αλi + βλ′i)ui.
On en déduit
f (αu + βu′) = f
(∑i∈I
(αλi + βλ′i)ui
)
= ∑i∈I
(αλi + βλ′i)vi
= α
(∑i∈I
λivi
)+ β
(n
∑i=1
λ′ivi
)
= α f (u) + β f (u′).
Exemples :
316

1. On peut définir une application linéaire de R3 dans R2 en demandant que f (1, 0, 0) = (2, 8), f (0, 1, 0) =(−4, 0) et f (0, 0, 1) = (−1, 1). Dans ce cas,
f : (x, y, z) 7→ x(2, 8) + y(−4, 0) + z(−1, 1) = (2x− 4y− z, 8x + z).
2. Il existe une unique application linéaire de R2 dans R2 telle que f (1, 1) = (−4, 1) et f (1,−1) = (2, 0).
Soit n et p deux entiers. Un application linéaire f de Kn dans Kp est de la forme :
f : (x1, . . . , xn) 7→ (a11x1 + · · ·+ a1nxn, . . . , ap1x1 + · · ·+ anpxn)
oùf (e1) = f (1, 0, . . . , 0) = (a11, . . . , ap1), . . . , f (en) = f (0, 0, . . . , 0, 1) = (a1n, . . . , anp).
Corollaire 22.4.1.736
Remarque : On reverra cela dans le chapitre sur les matrices.
On se donne E1, . . . Ep des sous-espaces vectoriels de E tels que E =⊕p
i∈1 Ei ainsi que pour touti ∈ [[ 1 ; p ]] une application ui ∈ L (Ei , F). Il existe une unique application linéaire u de E dans Ftelle que
∀i ∈ [[ 1 ; p ]] , u|Ei= ui.
Proposition 22.4.1.737
Remarque : C’est une généralisation du cas précédent. Ce dernier étant obtenu en prenant Ei = Vectui. Ladémonstration est analogue.
4.2 Caractérisation des isomorphismes
Afin de ne pas avoir de problèmes sur les existences de bases ou de supplémentaires, on se placedésormais dans le cadre des espaces vectoriels de dimension finie.
ATTENTION
Soit f ∈ L (E, F) on a équivalence entre les assertions suivantes.
i.) l’image d’une base est une famille libre.
ii.) l’image de toute base est une famille libre.
iii.) l’application f est injective.
Proposition 22.4.2.738
Démonstration :
— ii.)⇒ i.) est evident.
— i.)⇒ iii.). Soit (ui) une base de f telle que ( f (ui)) est une famille libre. On veut montrer que f est injective.On calcule donc Ker f . Soit w = ∑
iλiui. On suppose que f (w) = 0 ce qui donne ∑ λi f (ui) = 0. Or la
famille est libre d’où ∀i ∈ [[ 1 ; n ]] , λi = 0. On a bien w = 0.
— iii.) ⇒ ii.) On suppose que f est injective et que (ui) est une base de E. On veut montrer que ( f (ui))
est libre. Soit λi tels que ∑i
λi f (ui) = 0. On a donc, par linéarité, f
(∑
iλiui
)= 0. L’application étant
injective, ∑i
λiui = 0. On conclut en utilisant que la famille (ui) est libre car c’est une base de E.
317

On a les propriétés analogues
Soit f ∈ L (E, F) on a équivalence entre les assertions suivantes.
i.) l’image d’une base est une famille génératrice.
ii.) l’image de toute base est une famille génératrice.
iii.) l’application f est surjective.
Proposition 22.4.2.739
Démonstration : En exercice
Soit f ∈ L (E, F) on a équivalence entre les assertions suivantes.
i.) l’image d’une base est une base.
ii.) l’image de toute base est une base.
iii.) l’application f est un isomorphisme.
Proposition 22.4.2.740
Soit E et F deux espaces vectoriels de dimension finie. Ils sont isomorphes si et seulement s’ils ont lamême dimension. En particulier, tout K espace vectoriel de dimension n est isomorphe à Kn.
Corollaire 22.4.2.741
Exemple : L’espace vectoriel Kn[X] est isomorphe à Kn+1. Un isomorphisme est donné par
ϕ : Xk 7→ ek+1.
4.3 Dimension de L (E, F)
On a vu que L (E, F) était un espace vectoriel. On va montrer que si E et F sont de dimension finie alorsL (E, F) aussi. On va commencer par le cas ou F = K c’est-à-dire, le cas de l’espace dual E? de E.
Soit E un espace vectoriel de dimension finie et (ui)16i6n une base de E. On définit des formes linéaires fi par
∀(i, j) ∈ [[ 1 ; n ]]2 , fi(ej) = δij.
On les appelle les formes coordonnées relativement à la base (ui)16i6n.
Définition 22.4.3.742
Notation : On note aussi u∗i la forme linéaire fi
Avec les notations précédentes, pour tout vecteur w =n
∑i=1
λiui, on a
∀i ∈ [[ 1 ; n ]] , u∗i (w) = λi
Proposition 22.4.3.743
318

Remarque : La forme linéaire u∗i donne donc la coordonnées selon le vecteur ui de la décomposition d’unvecteur dans la base.Exemples :
1. Soit E = Kn. On considère la base canonique (e1, . . . , en). On a
e?i : (x1, . . . , xn) 7→ xi.
C’est la i-ème projection.
2. Soit E = Kn[X]. On considère la base canonique (1, X, . . . , Xn). On a alors fi : P 7→ 1i!
P(i)(0).
Avec les notations précédentes les (u∗i )16i6n forment une base de E?. En particulier, dim E? = dim E.
Proposition 22.4.3.744
Démonstration
Avec les notations précédentes, la base (u∗i ) s’appelle la base duale de la base (ui).
Définition 22.4.3.745
Soit E un espace vectoriel de dimension n et F un espace vectoriel de dimension p.
1. Si (ui) et (vj) sont des bases de E et F. On définit les applications linéaires fij par
∀k ∈ [[ 1 ; n ]] fij(uk) = δikvj.
La famille ( fij est une base de L (E, F).
2. La dimension de E× F est dim(E)× dim(F).
Proposition 22.4.3.746
Démonstration
4.4 Théorème du rang
Soit f une application linéaire de E dans F. On appelle rang de f et on note rg ( f ) la dimension de Im f .
Définition 22.4.4.747
Remarque : On voit donc que si (u1, . . . , un) est une base de E (ou une famille génératrice),
rg ( f ) = dim(Vect( f (u1), . . . , f (un))) = rg ( f (u1), . . . , f (un)).
Soit f une application linéaire de E dans F.
1. On a rg ( f ) 6 dim F. Il y a égalité si et seulement si f est surjective.
2. On a rg ( f ) 6 dim E. Il y a égalité si et seulement si f est injective.
Proposition 22.4.4.748
Démonstration :
1. On sait que Im f est un sev de F. D’où rg ( f ) = dim Im f 6 dim F. De plus,
319

f surjective ⇐⇒ Im f = F ⇐⇒ rg ( f ) = dim Im f | = dim F.
2. On sait que si (u1, . . . , un) est une base de E alors Im f = Vect( f (u1), . . . , f (un)). On en déduit que Im f aune famille génératrice avec n vecteurs donc sa dimension, qui est le rang de f , est inférieure à n = dim E.De plus
f injective ⇐⇒ ( f (u1), . . . , f (un)) est libre ⇐⇒ rg ( f ) = dim Im f = n = dim E.
Soit f une application linéaire de E dans F. Soit S un supplémentaire de Ker f , l’application f induitun isomorphisme de S sur Im f . En particulier,
rg ( f ) = dim E− dimKer f .
Théorème 22.4.4.749 (Théorème du rang)
Remarques :1. Il faut savoir écrire et reconnaitre la formule sous toutes ses formes. Par exemple, dimKer f + dim Im f =
dim E.
2. La première partie du théorème se généralise au cas où les espaces vectoriels ne sont pas de dimensionfinie.
Même dans le cas d’un endomorphisme, on n’a pas toujours que Ker f ⊕ Im f = E car, à priori,Ker f ∩ Im f n’est pas réduit à 0.
ATTENTION
Démonstration : Soit S un supplémentaire de Ker f et f l’application induite par f sur S à valeurs dans Im f .
— Soit u ∈ Ker f . On a donc u ∈ S et de plus f (u) = f (u) = 0. Donc u ∈ Ker f . D’où u = 0 carS ∩Ker f = 0. L’application f est injective.
— Soit v ∈ Im f . Il existe, par définition u dans E tel que f (u) = v. On décompose u = u1 + u2 avec u1 ∈ Ker fet u2 ∈ S. On a alors f (u2) = v et donc v ∈ Im f . Donc f est surjective.
On a bien f qui est bijective. De ce fait, rg f = dim Im f = dim S = dim E− dimKer f .
Exemples :1. Soit ∆ : Kn[X] → Kn[X] la dérivation. On sait que Ker ∆ = K0[X] et S = P ∈ Kn[X] | P(1) = 0 est un
supplémentaire. De plus Im f = Kn−1[X] d’où
∆ : S→ Kn1 [X]
est un isomorphisme. Sa réciproque et l’unique primitive qui s’annule en 1 définie par Xk 7→ Xk+1 − 1(k + 1)!
.
2. On a vu quand on a résolu l’équation différentielle linéaire
ay′′ + by′ + cy = emt
quelle forme on pouvait prendre prendre pour la solution particulière. On peut justifier ce résultat ici. Onsuppose que m est racine simple de aX2 + bX + c. On pose
En = t 7→ P(t)emt | P ∈ Cn[X].
Ce sont des sevs de F (R, C).On considère alors
δn : En → Enf 7→ a f ′′ + b f ′ + c f .
C’est clairement une application linéaire de En dans lui même. On pose fk : t 7→ tkemt de telle sorte queEn = Vect( fk)06k6n.
320

On a f ′k = k fk−1 + m fk et f ′′k = k(k− 1) fk−2 + 2mk fk−1 + m2 fk. On en déduit que
δ( fk) = (am2 + bm + c) fk + k(2am + b) fk−1 + k(k− 1)a fk−2 = k(2am + b) fk−1 + k(k− 1)a fk−2
On sait que Ker δ = E0 ce que l’on retrouve car δ( f0) = 0. Donc rg δn = (n + 1)− 1 = n.On voit alors que δn(En) ⊂ En−1 donc Im δn = En−1 par les dimensions.On voit donc que l’on peut trouver ici une solution dans E1.
Soit f une application linéaire de E dans F avec dim E = dim F. Les assertions suivantes sontéquivalentes.
i.) L’application f est injective.
ii.) L’application f est surjective.
iii.) L’application f est bijective.
Corollaire 22.4.4.750
Remarques :
1. Cela s’applique en particulier au cas des endomorphismes.
2. Dans la pratique pour montrer qu’une application linéaire est bijective on montre souvent qu’elle estinjective quand on sait que dim E = dim F.
Soit f un endormorphisme de E. S’il existe g tel que f g = IdE (ou g f = IdE) alors f est unautomorphisme.
Corollaire 22.4.4.751
Démonstration : Il suffit de voir que
(∃g ∈ L (E), f g = IdE)⇒ f est surjective
et que(∃g ∈ L (E), g f = IdE)⇒ f est injective
Soit f et g des applications linéaires de L (E, F) et L (F, G).
1. Si f est un isomorphisme, rg g f = rg g.
2. Si g est un isomorphisme, rg g f = rg f .
Proposition 22.4.4.752
Remarque : Cela signifie que l’on ne modifie pas le rang d’une application linéaire en composant à droite ou àgauche par un isomorphisme.Démonstration : Étudions Im (g f ).
Im (g f ) = g( f (u)) | u ∈ E = g(Im f ).
1. Si f est un isomorphisme (seul surjectif sert) Im f = F et donc Im (g f ) = g(F) = Im g.
2. Si g est un isomorphisme (seul injectif sert). La restriction de g à Im f et à valeurs dans g(Im f ) est unisomorphisme (car injectif et surjectif) donc
rg f = dim Im f = dim g(Im f ) = rg (g f ).
321

4.5 Formes linéaires et hyperplans
On se donne E un espace vectoriel.
Un hyperplan de E est le noyau d’une forme linéaire non nulle.
Définition 22.4.5.753
Si E est de dimension finie avec dim E = n. Les hyperplans sont les espaces vectoriels de dimensionn− 1.
Proposition 22.4.5.754
Démonstration :
— Si H est un hyperplan et f une forme linéaire telle que H = ker f , le théorème du rang nous dit quedim H = n− 1 car rg ( f ) = 1.
— Soit H un sous-espace vectoriel de dimension n− 1. On considère une base (u1, . . . , un−1) de H. On peutla compléter en une base (u1, . . . , un−1, un) de E. Il suffit de prendre f = u∗n la forme coordonnée.
Soit H un hyperplan et D une droite qui n’est pas contenue dans H. On a H ⊕ D = E.
Proposition 22.4.5.755
Démonstration : Soit a un vecteur non nul de D. On a D = Vect(a). Comme D n’est pas contenue dans Halors H ∩ D = 0. On en déduit que H et D sont en somme directe. Soit f maintenant une forme linéaire quidéfinie H. On a f (a) 6= 0 et, quitte à diviser par f (a) on peut supposer que f (a) = 1. Dès lors, pour tout vecteurx de E
x = f (x)a + x− f (x)a
où f (x)a ∈ D et x− f (x)a ∈ H.
Soit f et g deux formes linéaires.
Ker f = Ker g ⇐⇒ ∃λ ∈ K, f = λg.
Proposition 22.4.5.756
Démonstration :
— ⇐ Evident.
— ⇒ Soit D = Vect(u) un supplémentaire de H. On a f (u) et g(u) qui sont non nuls donc il existe λ telque f (u) = λg(u). Maintenant tout vecteur w s’écrit w1 + αu où w1 ∈ H. Il suffit alors de faire le calcul.
Remarque : Cela revient à dire que deux équation d’un même hyperplan sont les mêmes à une constantemultiplicative près.
On se place maintenant dans le cadre où E est de dimension finie égale à n.
ATTENTION
322

Soit B = (u1, . . . , un) une base de E et H un hyperplan de E. Il existe des scalaires (λ1, . . . , λn)tels que pour tout vecteur u de coordonnées (x1, . . . , xn) dans B, le vecteur u appartient à H si etseulement si ∑
iλixi = 0.
Corollaire 22.4.5.757
Démonstration : Il suffit de prendre une forme linéaire f admettant H pour hyperplan et de poser λi = f (ui).
Exemple : Soit E = Kn[X] et H = P ∈ E | P(0) = P(2). On voit que H est un hyperplan de E car c’est lenoyau de la forme linéaire f : P 7→ P(2)− P(0). Dans la base canonique, on a f (Xk) = 2k. D’où
H = ∑k
akXk | ∑k
2kak = 0.
1. Soit H1, . . . , Hm des hyperplans, dim(H1 ∩ · · · ∩ Hm) > n−m.
2. Pour tout m ∈ [[ 0 ; n ]] et tout sous-espace vectoriel F de dimension n−m il existe des hyper-plans H1, . . . , Hm tels que
F =m⋂
i=1
Hi.
Proposition 22.4.5.758
Remarque : cela signifie qu’un sous-espace vectoriel de dimension n − m (c’est-à-dire de codimension m)peut-être défini par m équations.Démonstration :
1. Il suffit d’utiliser la formule de Grassmann. En effet si F est un espace vectoriel et H un hyperplan on adim(F + H) = dim F + dim H − dim(F ∩ H). On en déduit que
dim F + dim H − dim(F ∩ H) 6 n ⇐⇒ dim F + (n− 1)− dim(F ∩ H) 6 n⇐⇒ dim F− 1 6 dim(F ∩ H)
Il suffit donc de réitérer cela :
dim H1 > n− 1⇒ dim(H1 ∩ H2) > n− 2⇒ · · · ⇒ dim(H1 ∩ · · · ∩ Hm) > n−m.
2. On pose p = n−m et on considère une base (u1, . . . , up) une base de F. On sait que cette base se complèteen une base de E et on note (u1, . . . , up, up+1, . . . , un) la base obtenue. Si on considère les m formes linéairesu∗p+1, . . . , u∗n on peut alors définir F dans E par
F = w ∈ E | ∀i ∈ [[ p + 1 ; n ]] u∗i (w) = 0
De sorte que si on note Hi = Ker u∗i on a
F =n⋂
i=p+1
Hi.
Remarque : On peut aussi faire une récurrence sur m.
323

23Intégration et
formules de Taylor1 Continuité uniforme 3251.1 Definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3251.2 Fonction lipshitzienne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3251.3 Théorème de Heine . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 326
2 Fonctions en escalier et fonctions continues par morceaux 3262.1 Subdivisions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3262.2 Fonctions en escalier . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3272.3 Fonctions continues par morceaux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 328
3 Construction de l’intégrale 3293.1 Intégrale des fonctions en escalier . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3293.2 Propriétés de l’intégrale des fonctions en escalier . . . . . . . . . . . . . . . . . . . . . . . . . . . 3303.3 Intégrales des fonctions continues par morceaux . . . . . . . . . . . . . . . . . . . . . . . . . . . . 331
4 Propriétés de l’intégrale des fonctions continues par morceaux 3324.1 Linéarité et relation de Chasles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3324.2 Positivité et corrollaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3334.3 Cas des fonctions continues . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3354.4 Invariance par translation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 335
5 Sommes de Riemann et méthodes des trapèzes 3365.1 Somme de Riemann . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3365.2 Méthode des trapèzes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 338
6 Primitives 3386.1 Généralisation de l’intégrale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3386.2 Cas des fonctions continues par morceaux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3396.3 Cas des fonctions continues . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 340
7 Calculs 3407.1 Primitives de fonctions rationnelles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3407.2 Primitives se ramenant à une primitive de fraction rationnelle . . . . . . . . . . . . . . . . . . . 342
8 Formules de Taylor 3448.1 Formule de Taylor avec reste intégral . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3448.2 Inégalité de Taylor-Lagrange . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 345
324

8.3 Formule de Taylor-Young . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 346
9 Extension au fonctions à valeurs complexes 3479.1 Definitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3479.2 Propriétés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 347
Nous allons définir l’intégrale des fonctions. L’intuition principale est de dire que si f est une fonctioncontinue positive sur [a, b] alors
∫ ba f sera l’aire du domaine défini par (x, y) ∈ R2 | x ∈ [a, b], 0 6 y 6 f (x).
Nous allons commencer par étudier le cas en escaliers qui sont constantes par morceaux et dont l’intégrale seradonc « une somme d’aire de rectangles ».
1 Continuité uniforme
1.1 Definition
Soit I un intervalle et f une fonction définie sur I. On dit que f est uniformément continue si
∀ε > 0, ∃η > 0, ∀(x, y) ∈ I2, |x− y| 6 η ⇒ | f (x)− f (y)| 6 ε.
Définition 23.1.1.759
Une fonction uniformément continue est continue.
Proposition 23.1.1.760
Démonstration : Soit x dans I. On veut montrer que f est continue en x. C’est vrai car pour tout ε > 0 on peutprendre le η de la définition de l’uniforme continuité.
Remarque : On voit que l’uniforme continuité est « plus forte ». En effet, dans ce cas le η ne dépend que de ε etplus de x.Exemples :
1. Soit f : x 7→ x2 définie sur I = [0, 1]. Elle est uniformément continue. En effet ∀(x, y) ∈ I2, |x2 − y2| =|x− y||x + y| 6 2|x− y|. Donc pour tout ε > 0 il suffit de choisir η = ε/2.
2. Soit g : x 7→ x2 définie sur R. Elle n’est plus uniformément continue. Montrons le. Il faut montrer que
∃ε > 0, ∀η > 0, ∃(x, y) ∈ I2, |x− y| 6 η et | f (x)− f (y)| > ε.
On peut prendre ε = 1. Ensuite pour tout η on cherche x et y tels que |x− y| 6 η et |x− y||x + y| > 1. Ilsuffit de prendre x > 1/η et y = x + η.
1.2 Fonction lipshitzienne
Soit f une fonction définie sur un intervalle I. On dit que f est lipschitzienne s’il existe un réel strictementpositif k tel que
∀(x, y) ∈ I2, | f (x)− f (y)| 6 k|x− y|.On dit alors que f est k-lipschitzienne.
Définition 23.1.2.761
Exemples :
1. On a vu que la fonction x 7→ x2 sur [0, 1] était lipschitzienne. Par contre ce n’est plus vrai sur R.
325

2. La fonction sin est 1-lipschitzienne. En effet pour tout x, y dans R2
| sin(x)− sin(y)| = 2∣∣∣∣sin
(x− y
2
)cos
(x + y
2
)∣∣∣∣ 6 2∣∣∣∣sin
(x− y
2
)∣∣∣∣ 6 |x− y|.
Une application lipschitzienne est uniformément continue (et donc continue)
Proposition 23.1.2.762
Remarque : Il existe des fonctions uniformément continue mais qui ne sont pas lipschitzienne. Par exemplex 7→ √x. Elle n’est pas lispchtzienne car
√x−√yx− y
=1√
x +√
y
Donc si x et y sont très proches de 0, ce rapport est aussi grand que l’on veut.Cependant elle est uniformément continue en effet si on remarque que pour tout x > y,
√x−√y 6
√y− x.
Cela se prouve en étudiant sur [y,+∞[ la fonction x 7→ √y− x +√
y−√x. On a donc Dès lors pour tout ε > 0on peut prendre η = ε2.
En conclusion
Lipschitzienne ⊂ Uniformément continue ⊂ Continueet toutes les inclusions sont strictes.
1.3 Théorème de Heine
Soit f une fonction continue sur un segment. Elle est uniformément continue.
Proposition 23.1.3.763
Démonstration : On procède par l’absurde. Soit f une fonction continue sur un segment I. On suppose qu’ellen’est pas uniformément continue :
∃ε > 0, ∀η > 0, ∃(x, y) ∈ I2, |x− y| 6 η et | f (x)− f (y)| > ε.
On choisit donc un ε qui convient. Pour cet ε, pour tout entier n non nul, en posant η = 1/n, on trouve xn et yndans I tels que
|xn − yn| 61n
et | f (xn)− f (yn)| > ε.
Maintenant la suite (xn) est une suite bornée (car composée d’éléments de I). On peut extraire une sous-suiteconvergente (xϕ(n)). Dès lors comme pour tout entier n
xϕ(n) −1n6 yϕ(n) 6 xϕ(n) +
1n
.
La suite (yϕ(n)) converge vers la même limite c. Par continuité de f , les suites ( f (xϕ(n))) et ( f (yϕ(n))) convergenttoutes les deux vars f (c) ce qui contredit que pour tout entier n, | f (xn)− f (yn)| > ε.
2 Fonctions en escalier et fonctions continues par morceaux
2.1 Subdivisions
On appelle subdivision σ de [a, b] la donnée d’une famille de réels σ = (ti)06i6n où :
a = t0 < t1 < · · · < tn−1 < tn = b.
Définition 23.2.1.764
326

Exemple : Pour tout intervalle [a, b] non réduit à un point et n ∈ N?. Il existe une subdivision régulière obtenueen « coupant »l’intervalle [a, b] en n sous-intervalles de même longueur. Elle est obtenue en posant
∀i ∈ [[ 0 ; n ]] , ti = a + i× b− an
.
Soit σ = (ti)16i6n une subdivision de [a, b]. On appelle pas de σ le plus grand écart entre deux élémentsconsécutifs de σ, c’est-à-dire Max
i∈[[ 0 ; n−1 ]](ti+1 − ti).
Définition 23.2.1.765
Soit σ et σ′ deux subdivisions de [a, b]. La subdivision σ est dite plus fine que σ′ si tous les éléments de σ′
sont des éléments de σ. On note alors σ ≺ σ′.
Définition 23.2.1.766
Remarque : C’est en fait la relation d’ordre d’inclusion sur les parties finies de [a, b].
Soit σ et σ′ deux subdivisions de [a, b]. Il existe une subdivision σ′′ qui soit plus fine que les deuxsubdivisions.
Lemme 23.2.1.767
2.2 Fonctions en escalier
Une fonction ϕ définie sur [a, b] est dite en escalier, s’il existe une subdivision σ = (ti)06i6n telle que ϕ soitconstante sur tous les intervalles ]ti , ti+1[ pour 0 6 i 6 n− 1. Toute subdivision vérifiant la propriété est diteadaptée à ϕ. On notera E ([a, b]) l’ensemble des fonctions en escaliers sur [a, b].
Définition 23.2.2.768
Remarque : On n’impose rien sur les valeurs de ϕ aux points de la subdivision.Exemples :
1. Sur [0, 1] la fonction définie par
ϕ : x 7→
1 si x = 03 si 0 < x 6 1/3−1 si 1/3 < x < 2/31 si 2/3 6 x
C’est une fonction en escalier et la subdivision (0, 1/3, 2/3, 1) est adaptée à ϕ.
2. Soit [a, b] un segment, la fonction partie entière est une fonction en escalier sur [a, b].
1. Soit ϕ une fonction en escalier sur [a, b] et σ une subdivision adaptée à ϕ. Toute subdivisionplus fine que σ est adaptée à ϕ.
2. Soit ϕ et ϕ′ deux fonctions en escalier. Il existe une subdivision qui soit adaptée aux deuxfonctions.
Lemme 23.2.2.769
327

L’ensemble E ([a, b]) est un sous-espace vectoriel de F ([a, b], R).
Théorème 23.2.2.770
Démonstration :— La fonction nulle est en escalier.— Soit ϕ et ϕ′ deux fonctions en escalier. On considère une subdivision adaptée au deux pour prouver que
λϕ + µϕ′ est en escalier.
2.3 Fonctions continues par morceaux
Pour définir l’intégrale, on peut se restreindre au cas de fonctions continues mais, il n’est pas beaucoup plusdifficile de travailler avec une classe de fonctions un peu plus grande : l’ensemble des fonctions continues parmorceaux.
Soit f une fonction définie sur [a, b]. On dit que f est continue par morceaux s’il existe une subdivisionσ = (ti)06i6n telle que la restriction de f a ]ti , ti+1[ soit continue et admette des limites finies en ti et ti+1.Toute subdivision vérifiant la propriété est dite adaptée à f . On notera C M ([a, b]) l’ensemble des fonctions enescaliers sur [a, b].
Définition 23.2.3.771
Remarque : Là encore, les valeurs aux points de la subdivision sont arbitraires.Exemples :
1. Faire un exemple2. La fonction définie sur [−1, 1] par
x 7→
1/x si x 6= 00 si x = 0.
Elle n’est pas continue par morceaux car elle n’a pas de limite finie en 0+ et 0−.3. La fonction χQ n’est pas continue par morceaux.4. les fonctions en escalier sont continues par morceaux5. Les fonctions continues sont continues par morceaux.
1. Soit f une fonction continue par morceau sur [a, b] et σ une subdivision adaptée à f . Toutesubdivision plus fin que σ est adaptée à f .
2. Soit f et g deux fonctions en escalier. Il existe une subdivision qui soit adaptée aux deuxfonctions.
Lemme 23.2.3.772
Démonstration : Comme ci-dessus.
L’ensemble C M ([a, b]) est un sous-espace vectoriel de F ([a, b], R). Il est stable par produit.
Théorème 23.2.3.773
Toute fonction continue par morceau est bornée.
Proposition 23.2.3.774
328

Démonstration : Soit f une fonction continue par morceaux et σ = (ti)16i6n une subdivision adaptée à f .Alors la restriction fi de f à ]ti , ti+1[ est prolongeante en une fonction continue fi sur [xi , xi+1]. Comme c’est unsegment, la fonction | fi| est bornée par Mi. On a donc
supt∈]ti ,ti+1[
| f (t)| 6 supt∈[ti ,ti+1]
| f (t)| = Mi.
On en déduit que | f (t)| est majorée sur [a, b] par Max(M0, . . . , Mn−1, | f (t0)|, . . . , | f (xn)|).
On peut « approcher »une fonction continue par morceaux par une fonction en escalier.
Soit f une fonction continue par morceaux sur [a, b]. Pour tout réel strictement positif ε, il existe desfonctions en escaliers ϕ et ψ telles que
ϕ 6 f 6 ψ et 0 6 ψ− ϕ 6 ε.
En particulier | f − ϕ| 6 ε et | f − ψ| 6 ε.
Théorème 23.2.3.775
Commençons par un lemme.
Soit f une fonction continue sur un segment et ε un réel strictement positif, il existe des fonctions enescaliers ϕ et ψ telles que
ϕ 6 f 6 ψ et 0 6 ψ− ϕ 6 ε.
Lemme 23.2.3.776
Démonstration du lemme : La fonction f est continue sur un segment. Elle est donc uniformément continued’après le théorème de Heine. De ce fait, il existe η tel que
∀(x, y) ∈ [a, b], |x− y| 6 η ⇒ | f (x)− f (y)| 6 ε.
On considère donc une subdivision σ = (ti) dont le pas est inférieur à η. On peut prendre la subdivision
régulière en prenant n tel que|b− a|
n6 η. Dès lors, pour tout i dans [[ 0 ; n ]], on pose
∀t ∈]ti , ti+1[, ϕ(t) = Minx∈[xi ,xi+1]
f (x) = f (αi) et ψ(t) = Maxx∈[xi ,xi+1]
f (x) = f (βi).
On a alors, pour tout t dans ]ti , ti+1[, ϕ(t) 6 f (t)ψ(t) et ψ(t) − ϕ(t) = f (βi) − f (αi) 6 ε car |βi − αi| 6|ti+1 − ti| 6 η. Il ne reste plus qu’à poser, ∀i ∈ [[ 0 ; n ]] , ϕ(ti) = ψ(ti) = f (ti).
Démonstration du théorème : On considère σ = (ti)06i6n une subdivision adaptée à f . On va construireϕ et ψ en se basant sur cette subdivision. En suite, comme précédemment, pour tout i < n, on prolonge parcontinuité la restriction de f à ]ti , ti+1[ et on fi le prolongement. On peut appliquer le lemme à fi. On obtientdonc des fonctions en escaliers ϕi et ψi telles que
ϕi 6 fi 6 ψi et 0 6 ψi − ϕi 6 ε.
On construit alors ϕ et ψ en « mettant bout à bout »les subdivisions et les fonctions en escaliers ϕi et ψi. On poseaussi
∀i ∈ [[ 0 ; n ]] , ϕ(ti) = ψ(ti) = f (ti).
3 Construction de l’intégrale
3.1 Intégrale des fonctions en escalier
Si ϕ est une fonction en escalier et si σ = (ti) est une subdivision adaptée. On veut définir l’intégrale∫ ba ϕ(t) dt comme I(ϕ, σ) = ∑n
i=1 ci(ti − ti−1) où ci est la valeur de ϕ sur ]ti−1, ti[. Cela correspond à l’interpré-tation classique en terme d’aire. Cependant il faut d’abord prouver que cette quantité ne dépend pas de lasubdivision choisie.
329

Soit ϕ une fonction en escalier définie sur [a, b]. Soit σ et σ′ deux subdivisons adaptées à ϕ. Laquantité considérée ci-dessus est la même pour les deux subdivision.
Proposition 23.3.1.777
Démonstration : On peut considérer τ une subdivision plus fine de σ et σ′. Par transitivité, il suffit donc demontrer que I(ϕ, σ) = I(ϕ, τ) = I(ϕ, σ′). La subdivision τ est obtenue à partir de σ en ajoutant p élémentsà la subdivision. Montrons donc qu’en rajoutant un élément on ne change pas la valeur de I. On note doncσ = (ti)06i6n et τ = (t0 < · · · < ti0−1 < y < ti0 < · · · < tn). On a alors
I(ϕ, σ) =n
∑i=1
ci(ti − ti−1) =n
∑i=1i 6=i0
ci(ti − ti−1) + ci0(ti0 − ti0−1).
De même
I(ϕ, τ) =n
∑i=1i 6=i0
ci(ti − ti−1) + c(y− ti0−1) + c′(ti0 − y).
Maintenant comme σ est adaptée à ϕ, c = c′ = ci0 . On a donc bien I(ϕ, σ) = I(ϕ, τ) = I(ϕ, σ′).
Soit ϕ une fonction en escalier sur [a, b]. On appelle intégrale de ϕ sur [a, b] et on note∫ b
aϕ(t) dt ou
∫
[a,b]ϕ
le réel ∫ b
aϕ(t) dt =
n
∑i=1
ci(ti − ti−1)
où σ = (ti) est une subdivision adaptée à ϕ et ci est la valeur de ϕ sur l’intervalle ]ti−1, ti[.
Définition 23.3.1.778
Exemples :
1. On a∫ π
0E(t) dt = 0 + 1 + 2 + 3 ∗ (π − 2) = 3(π − 1).
2. Si ϕ est constante égale à C alors∫
[a,b]ϕ = C(b− a).
Remarque : La valeur de l’intégrale ne dépend pas de la valeur de la fonction aux points de la subdivision. Dece fait, si on modifie une fonction en escalier en un nombre fini de point, on ne modifie pas son intégrale.
3.2 Propriétés de l’intégrale des fonctions en escalier
Nous allons montrer que l’intégrale des fonctions en escalier vérifie les propriétés attendues de l’intégrale(linéarité, positivité, relation de Chasles).
L’intégrale est une forme linéaire sur E ([a, b]).
Proposition 23.3.2.779 (Linéarité)
Démonstration
Une fonction en escalier positive a une intégrale positive. De plus, si ϕ et ψ sont deux fonctions en
escaliers vérifiant ϕ 6 ψ alors∫
[a,b]ϕ 6
∫
[a,b]ψ.
Proposition 23.3.2.780 (Positivité)
330

Démonstration
Remarque : Notons que la positivité s’étend au cas des fonctions positive sauf en un nombre fini de points.
Soit ϕ une fonction en escalier sur [a, b] et c un réel compris strictement entre a et b. Les restrictionsϕ1 et ϕ2 de ϕ à [a, c] et [c, b] sont des fonctions en escalier et :
∫
[a,c]ϕ +
∫
[c,b]ϕ =
∫
[a,b]ϕ.
Proposition 23.3.2.781 (Relation de Chasles)
Démonstration
3.3 Intégrales des fonctions continues par morceaux
On a vu que les fonctions continues par morceaux peuvent être approchées par des fonctions en escalier parvaleurs inférieures et par valeurs supérieures. Nous allons en déduire l’intégrale d’une fonction continue parmorceaux à partir de celle des fonctions en escalier.Notation : Soit f une fonction continue par morceaux sur [a, b]. On note E +( f ) = ψ ∈ E ([a, b] | f 6 ψ etE +( f ) = ϕ ∈ E ([a, b] | ϕ 6 f .
Avec les notations précédentes :
1. l’ensemble A( f ) =
∫
[a,b]ϕ | ϕ ∈ E −( f )
admet une borne supérieure et B( f ) =
∫
[a,b]ψ | ψ ∈ E +( f )
admet une borne inférieure.
2. On a sup A( f ) = inf B( f ).
Théorème 23.3.3.782
Démonstration :
1. Comme f est une fonction continue par morceaux elle est bornée. Notons m et M tels que m 6 f 6 M.Les fonctions constantes egales à m et M sont des fonctions en escalier. De plus, pour tout ϕ dans E −( f )
alors ϕ 6 M. D’où, d’après ce qui précède,∫
[a,b]ϕ 6
∫
[a,b]M = M(b− a). On en déduit que A( f ) est une
partie non vide et majorée de R donc elle admet une borne supérieure. De même B( f ) est minorée parm(b− a) et admet donc une borne inférieure.
2. Notons S = inf B( f ) et I = sup A( f ). Si on fixe ϕ dans E −( f ) alors pour tout ψ dans E +( f ), ϕ 6 ψ etdonc ∫
[a,b]ϕ 6
∫
[a,b]ψ.
En particulier,∫
[a,b]ϕ est un minorant de B( f ) et, de ce fait, est inférieur à S. Ceci étant vrai pour tout ϕ de
E −( f ) on en déduit que S est un majorant de A( f ) et donc I 6 S.Maintenant, on sait que si on se donne ε, il existe des fonctions en escalier, ϕ et ψ telles que ϕ 6 f 6 ψ et0 6 ψ− ϕ 6 ε. On a donc ϕ 6 ψ 6 ϕ + ε. En prenant l’intégrale on obtient :
∫
[a,b]ϕ 6
∫
[a,b]ψ 6
∫
[a,b](ϕ + ε) =
(∫
[a,b]ϕ
)+ ε(b− a).
On en déduit que
S 6∫
[a,b]ψ 6
(∫
[a,b]ϕ
)+ ε(b− a) 6 I + ε(b− a).
Ceci étant vrai pour tout ε, S 6 I et donc S = I.
331

Remarque : On voit que la propriété essentielle que l’on utilise est que si f est une fonction continue parmorceaux et que ε est un réel strictement positif, il existe des fonctions en escalier ϕ et ψ telles que ϕ 6 f 6 ψ
et∫
[a,b](ψ− ϕ) 6 ε. De telles fonctions d’appellent les fonctions Riemann-intégrables. Un cas particulier des
fonctions Riemann-intégrables sont les fonctions réglées qui vérifient qu’il existe des fonctions en escalier ϕ et ψtelles que ϕ 6 f 6 ψ et (ψ− ϕ) 6 ε. .Exercice : (Difficile) :Les fonctions continues par morceaux sont réglées et les fonctions réglées sont Riemann-intégrables. Montrer que ces deux inclusions sont strictes.
Soit f une fonction continue par morceaux que [a, b] on appelle intégrale d e f sur [a, b] et on note∫
[a,b]f ou
∫ b
af (t) dt le réel
∫
[a,b]f = sup A( f ) = inf B( f ).
Définition 23.3.3.783 (Intégrale d’une fonction continue par morceaux)
Remarque : Si f est une fonction en escalier alors elle appartient à E +( f ) et à E −( f ). On trouve donc que lesdeux définitions d’intégrales coïncident. En particulier on retrouve que l’intégrale d’une constante C sur [a, b]est C(b− a).
Avec les notations précédentes, l’intégrale de f sur [a, b] est l’unique réel tel que, pour tout ϕ ∈ E −( f )et tout ψ ∈ E +( f ) alors, ∫
[a,b]ϕ 6
∫
[a,b]f 6
∫
[a,b]ψ.
Proposition 23.3.3.784
Démonstration
4 Propriétés de l’intégrale des fonctions continues par morceaux
4.1 Linéarité et relation de Chasles
L’intégrale est une forme linéaire sur C M ([a, b]).
Proposition 23.4.1.785 (Linéarité)
Nous aurons d’abord besoin d’un lemme (qui sera généralisé par la suite)
Soit f une fonction continue par morceaux sur [a, b] et ϕ une fonction en escalier telle que | f − ϕ| 6 εalors ∣∣∣∣
∫
[a,b]f −
∫
[a,b]ϕ
∣∣∣∣ 6 ε(b− a).
Lemme 23.4.1.786
Démonstration du lemme : On a ϕ− ε 6 f 6 ϕ + ε donc∫
[a,b]ϕ− ε(b− a) 6
∫
[a,b]f 6
∫
[a,b]ϕ + ε(b− a). D’où
∣∣∣∣∫
[a,b]f −
∫
[a,b]ϕ
∣∣∣∣ 6 ε(b− a).
332

Démonstration de la proposition : Soit f1 et f2 deux fonctions continues par morceaux et λ1, λ2 deux scalaires.
On pose f = λ1 f1 + λ2 f2 et on veut montrer que∫
[a,b]f = λ1
∫
[a,b]f1 + λ2
∫
[a,b]f2.
Soit ε un réel strictement positif, il existe ϕ1 et ϕ2 des fonctions en escalier qui vérifient que | f − 1− ϕ1| 6 εet | f2 − ϕ2| 6 ε.
On en déduit que | f − (λ1 ϕ1 + λ2 ϕ2)| 6 (|λ1|+ |λ2|)ε.
D’après le lemme,∣∣∣∣∫
[a,b]f −
(λ1
∫
[a,b]ϕ1 + λ2
∫
[a,b]ϕ2
)∣∣∣∣ =∣∣∣∣∫
[a,b]f −
∫
[a,b]λ1 ϕ1 + λ2 ϕ2
∣∣∣∣ 6 (|λ1|+ |λ2|)(b−a)ε.
Maintenant∣∣∣∣λ1
∫
[a,b]f1 − λ1
∫
[a,b]ϕ1
∣∣∣∣ 6 |λ1|(b− a)ε et∣∣∣∣λ2
∫
[a,b]f2 − λ2
∫
[a,b]ϕ2
∣∣∣∣ 6 |λ2|(b− a)ε.
On en déduit que∣∣∣∣∫
[a,b]f −
(λ1
∫
[a,b]f1 + λ2
∫
[a,b]f2
)∣∣∣∣ =
∣∣∣∣∫
[a,b]f −
(λ1
∫
[a,b]ϕ1 + λ2
∫
[a,b]ϕ2
)− λ1
∫
[a,b]f1 + λ1
∫
[a,b]ϕ1 − λ2
∫
[a,b]f2 + λ2
∫
[a,b]ϕ2
∣∣∣∣
6
∣∣∣∣∫
[a,b]f −
(λ1
∫
[a,b]ϕ1 + λ2
∫
[a,b]ϕ2
)∣∣∣∣+∣∣∣∣λ1
∫
[a,b]f1 − λ1
∫
[a,b]ϕ1
∣∣∣∣+∣∣∣∣λ2
∫
[a,b]f2 − λ2
∫
[a,b]ϕ2
∣∣∣∣6 2(|λ1|+ |λ2|)(b− a)ε.
Ceci étant vrai pour tout ε on a bien∫
[a,b]f = λ1
∫
[a,b]f1 + λ2
∫
[a,b]f2.
Remarque : Si f et g sont deux fonctions continues par morceaux qui ne différent qu’en un nombre fini de
points alors∫
[a,b]f =
∫
[a,b]g car
∫
[a,b]( f − g) = 0.
On appelle valeur moyenne d’une fonction continue par morceaux sur [a, b] la valeur
1b− a
∫
[a,b]f .
Définition 23.4.1.787
Remarque : La fonction constante égale à la valeur moyenne à la même intégrale que f sur [a, b].
Soit f une fonction définie sur [a, b] et c ∈]a, b[. La fonction est continue par morceaux si et seulementsi ses restrictions f1 et f2 à [a, c] et à [c, b] le sont. De plus
∫
[a,b]f =
∫
[a,c]f1 +
∫
[c,b]f2.
Proposition 23.4.1.788 (Relation de Chasles)
Démonstration : On procède comme ci-dessus.
Remarque : On peut donc ramener le calcul d’une intégrale d’une fonction continue par morceaux au calculd’intégrales de fonctions continues en « découpant »l’intégrale sur les intervalles où la fonction est continue.
4.2 Positivité et corrollaires
Une fonction continue par morceaux positive a une intégrale positive. De plus, si f et g sont deux
fonctions continues par morceaux vérifiant f 6 g alors∫
[a,b]f 6
∫
[a,b]g.
Proposition 23.4.2.789 (Positivité)
333

Démonstration : Pour la première partie, il suffit de voir que si f est une fonction continue par morceauxpositive la fonction nulle est un une fonction en escalier inférieure à f . La deuxième partie découle de la premièreen utilisant la linéarité.
Soit f une fonction continue par morceaux sur [a, b] :∣∣∣∣∫
[a,b]f∣∣∣∣ 6
∫
[a,b]| f |.
Corollaire 23.4.2.790
Remarques :1. Ce corollaire est TRES utile. C’est une version pour les les intégrales de l’inégalité triangulaire qui dit que
∣∣∣∣∣n
∑i=1
ai
∣∣∣∣∣ 6n
∑i=1|ai|.
2. On a déjà dit que l’on peut imaginer l’intégrale de f comme l’aire sous sa courbe en comptant positivement
ce qui est « au dessus »de l’axe des abscisses et négativement ce qui est « en dessous ». Le terme∫
[a,b]| f |
revient à considérer toutes les aires positivement.Démonstration : Il suffit de constater que −| f | 6 f 6 | f | donc
−∫
[a,b]| f | 6
∫
[a,b]f 6
∫
[a,b]| f |
Ceci implique ce que l’on veut.
Soit f et g deux fonctions continues par morceaux sur [a, b],∣∣∣∣∫
[a,b]f g∣∣∣∣ 6 (sup
[a,b]| f |)
∫
[a,b]|g|.
En particulier, pour g = 1,∣∣∣∣∫
[a,b]f∣∣∣∣ 6 (sup
[a,b]| f |)(b− a).
Proposition 23.4.2.791 (Inégalité de la moyenne)
Démonstration : On voit que | f g| 6 (sup[a,b] | f |)|g|. On conclut en utilisant ce qui précède et la linéarité.
Soit f et g deux fonctions continues par morceaux sur [a, b],
(∫
[a,b]f g)26∫
[a,b]f 2∫
[a,b]g2.
Proposition 23.4.2.792 (Inégalité de Cauchy-Schwarz)
Remarque : Cette inégalité sera revue par la suite de manière plus générale.
Démonstration : On considère P(λ) =∫
[a,b]( f + λg)2 =
(∫
[a,b]g2)
λ2 + 2λ∫
[a,b]f g+
∫
[a,b]f 2. Or c’est l’intégrale
d’une fonction positive donc P(λ) est toujours positif. De ce fait le discriminant est négatif.
∆ = 4(∫
[a,b]f g)2− 4
∫
[a,b]f 2∫
[a,b]g2 6 0.
334

4.3 Cas des fonctions continues
Les fonctions continues sont des cas particuliers de fonctions continues par morceaux. Elles vérifient quelquespropriétés intéressantes.
Soit f une fonction continue sur [a, b] et positive. Si∫
[a,b]f = 0 alors f est la fonction nulle.
Théorème 23.4.3.793
Remarques :
1. C’est un théorème qui nous sera utile. Il faut savoir le démontrer.
2. L’hypothèse continue est essentielle. Par exemple la fonction définie sur [0, 1], nulle sur ]0, 1] et valant 1 en0 est continue par morceaux, positive, d’intégrale nulle mais ce n’est pas la fonction nulle.
Démonstration : Supposons par l’absurde que f n’est pas nulle. Il existe t0 ∈ [a, b] tel que f (t0) 6= 0. Parcontinuité, il existe η tel que
∀t ∈ [t0 − η, t0 + η], f (t) >f (x0)
2.
Supposons (pour simplifier) que a 6 t0 − η 6 t0 + η 6 b. On en déduit que
∫
[a,b]f =
∫ t0−η
af +
∫ t0+η
t0−ηf +
∫ b
t0+ηf
Les deux intégrales de droite et de gauche sont positives et∫ t0+η
t0−ηf > 2η
f (x0)
2> 0. C’est absurde.
Remarque : On redémontrera ce résultat quand nous aurons défini les primitives.
Soit f et g deux fonctions continues sur [a, b],
(∫
[a,b]f g)26∫
[a,b]f 2∫
[a,b]g2.
De plus, il y a égalité si et seulement si f et g sont proportionnelles.
Proposition 23.4.3.794 (Inégalité de Cauchy-Schwarz)
Démonstration : Il suffit de reprendre la démonstration. S’il y a égalité alors ∆ = 0. De ce fait il existe λ tel que
0 = P(λ) =∫
[a,b]( f + λg)2. On en déduit que f + λg = 0.
4.4 Invariance par translation
Soit f une fonction continue par morceaux sur [a, b] et α un réel. On pose fα la fonction définie sur[a + α, b + β] par fα : x 7→ f (x− α). La fonction fα est continue par morceaux et
∫
[a,b]f =
∫
[a+α,b+α]fα.
Proposition 23.4.4.795
Remarque : Ce résultat est intuitif car il résulte juste de la « translation » de la courbe de f .
Exemple : Si f est une fonction continue par morceaux de période T alors pour tout α,∫
[0,T]f =
∫
[α,α+T]f . En
effet, si α est un multiple de T il suffit d’appliquer ce qui précède en remarquant alors que fα = f . Sinon il existen ∈ Z tel que α < nT < α + T. On utilise alors la relation de Chasles.
335

5 Sommes de Riemann et méthodes des trapèzes
Nous allons voir deux méthodes pour calculer une valeur approchée d’une intégrale, la méthode desrectangles (ou des sommes de Riemman) et la méthode des trapèzes.
Dans tout ce paragraphe, on se fixe un segment [a, b] et f une fonction continue sur [a, b].
5.1 Somme de Riemann
Dans tout ce paragraphe, f est une fonction continue sur un segment [a, b].
Soit σ = (ti)06i6n une subdivision et X = (xi)i∈[[ 1 ; n ]] une famille de réels tels que pour tout i ∈ [[ 1 ; n ]],xi ∈ [ti−1, ti]. On appelle somme de Riemann associée à f pour la subdivision σ et la famille X et on noteR( f , σ, X) le réel :
R( f , σ, X) =n
∑i=1
(ti − ti−1) f (xi).
Définition 23.5.1.796 (Somme de Riemann)
Exemples :
1. Le cas le plus utilisé est le suivant :Pour tout entier naturel non nul n on considère la subdivision régulière de [a, b] en n sous-intervalles. Onnote donc
∀i ∈ [[ 0 ; n ]] , ti = a + ib− a
n.
On prend de plus ∀i ∈ [[ 1 ; n ]] , xi = ti. On note alors
Rn( f ) = R( f , σ, X) =b− a
n
n
∑i=1
f (ti) =b− a
n
n
∑i=1
f(
a + ib− a
n
).
2. On utilise aussi les sommes de Riemann en utilisant la subdivision régulière mais en prenant xi = ti−1 ouxi = (ti + ti−1)/2.
Remarque : Si on regarde la somme de Riemann Rn( f ). Pour tout i ∈ [[ 1 ; n ]] on considère le rectangle plein
[ti−1, ti]× [0, f (ti)] (ou [ti−1, ti]× [ f (ti), 0] ) dont l’aire estb− a
nf (ti). On se dit alors que l’intégrale de f sur
[a, b] doit être proche de la somme des aires si n tend vers +∞.
Soit f une fonction continue sur [a, b]. Pour tout réel ε > 0 il existe un réel η > 0 tel que pour toutsubdivision σ dont le pas est inférieur à η et toute famille X,
∣∣∣∣∫
[a,b]f − R( f , σ, X)
∣∣∣∣ 6 ε.
Théorème 23.5.1.797
Démonstration : On sait que f est continue sur un segment donc, d’après le théorème de Heine elle estuniformément continue. De ce fait pour ε1 > 0, il existe η > 0 tel que
∀(x, y) ∈ [a, b]2, |x− y| < η ⇒ | f (x)− f (y)| < ε1.
Maintenant si on se donne une subdivision dont le pas est inférieur à η et X une famille de réels,∣∣∣∣∫
[a,b]f − R( f , σ, X)
∣∣∣∣ =
∣∣∣∣∣n
∑i=1
∫ ti
ti−1
f (t)− f (xi) dt
∣∣∣∣∣
6n
∑i=1
∫ ti
ti−1
| f (t)− f (xi)| dt
336

Maintenant quand t ∈ [ti−1, ti], |t− xi| 6 η et donc | f (t)− f (xi)| 6 ε1. On en déduit que∣∣∣∣∫
[a,b]f − R( f , σ, X)
∣∣∣∣ 6n
∑i=1
(ti − ti−1)ε1 = ε1.(b− a).
Il suffit d’appliquer cela à ε1 =ε
b− a.
Soit f une fonction continue sur [a, b]. La suite (Rn( f )) des sommes de Riemann tend vers∫
[a,b]f .
Corollaire 23.5.1.798
Remarques :1. C’est aussi vrai pour les « variantes ».2. En ne supposant que f continue on ne peut pas évaluer la vitesse de convergence.
On suppose que f est K-lipschitzienne on a une majoration de la vitesse de convergence.
1. Pour tout réel η > 0 et toute subdivision σ dont le pas est inférieur à η et toute famille X,∣∣∣∣∫
[a,b]f − R( f , σ, X)
∣∣∣∣ 6 K(b− a).η.
2. Dans le cas de la suite classique on obtient
∀n ∈ N?,∣∣∣∣∫
[a,b]f − Rn( f )
∣∣∣∣ 6 K(b− a)2
n.
Théorème 23.5.1.799
Démonstration : Il suffit de reprendre la démonstration précédente en voyant que l’on a alors ε1 = kη.
Remarques :1. La convergence n’est pas très rapide.2. Le cas des fonctions K-lipschitzienne est important en effet si f est de classe C 1 elle est K-lipschitzienne
en posant K = Max[a,b]| f ′(t)|.
Exemple : Nous allons bientôt voir que∫ 1
0
dt1 + t
=∫ 2
1
dtt
= ln 2. On peut donc essayer d’avoir des valeurs
approchées.
On a alors Rn =1n
n
∑k=1
11 + k/n
=n
∑k=1
1k + n
.
Ici, comme la dérivée de t 7→ 1/t est t 7→ −1/t2 on peut prendre K = 1. On a donc
|Rn − ln 2| 6 1n
Mathematica nous donne
N[Log[2],20]
0.69314718055994530942
Si on pose
riemann[n_] := (s = 0.; Do[s = s + 1/(k + n), k, 1, n]; s)
On récupère
riemann[10] = 0.668 riemann[100] = 0.6907 riemann[1000] = 0.692897 riemann[10000] = 0.693122
337

5.2 Méthode des trapèzes
L’idée est la même que ci-dessus mais en approchant le domaine par des trapèzes.
Soit f une fonction continue sur [a, b] et n ∈ N?. On pose
Tn( f ) =b− a
n
n
∑k=1
f (tk) + f (tk−1)
2.
Définition 23.5.2.800
Si f est continue Tn( f ) tend vers∫
[a,b]f . De plus si f est de classe C 2 alors
∣∣∣∣Tn( f )−∫
[a,b]f∣∣∣∣ =
O(1/n2) .
Proposition 23.5.2.801
Remarque : On trouve que∣∣∣∣Tn( f )−
∫
[a,b]f∣∣∣∣ 6
M(b− a)3
12n2 . Si M = Max[a,b]| f ′′(t)|.
Idée de la démonstration : Comme précédemment on découpe l’intégrale par la relation de Chasles et on seramène à travailler sur l’intervalle [tk−1, tk]. On veut comparer l’intégrale de f et l’intégrale de g la fonction
affine qui prend les mêmes valeurs en tk−1 et tk à savoir g : t 7→ f (tk−1) +f (tk)− f (tk−1)
tk − tk−1(t− tk−1). L’idée est
de voir, sachant que | f ′′| est bornée les cas où la différence va être le plus grande.
faire un dessin
Les cas extrêmes sont quand f ′′ est constante égale à M ou à −M. C’est à dire
h− : t 7→ g(t)− M2(t− tk−1)(tk − t) et h+ : t 7→ g(t) +
M2(t− tk−1)(tk − t)
On montre alors que pour tout t dans l’intervalle
h−(t)− g(t) 6 f (t)− g(t) 6 h+(t)− g(t).
Pour cela il suffit de remarquer que la fonction f − h+ est convexe, elle est donc negative car elle s’annule entk−1 et en tk. A l’inverse f − h− est concave et donc positive.
On en déduit que
| f (t)− g(t)| 6 M2(t− tk−1)(tk − t).
Il ne reste plus qu’a intégrer.
6 Primitives
Nous allons (enfin) voir le lien entre l’intégrale que nous avons construit et les primitives.On considère un intervalle [a, b] et f une fonction continue par morceaux sur [a, b]. A tout élément c compris
entre a et b on considèreF : x 7→
∫ x
cf (t) dt.
Cette fonction est définie sur [a, b].
6.1 Généralisation de l’intégrale
Jusqu’alors on prenait une fonction continue par morceaux sur un segment et on calculait son intégrale surtout le segment. On va maintenant définir l’intégrale d’une fonction entre deux bornes.
338

Soit I un intervalle. Un fonction f est dite continue par morceaux si sa restriction à tout segment de I estcontinue par morceaux.
Définition 23.6.1.802
Remarque : Une fonction continue par morceaux sur I peut ne pas être bornée si I n’est pas borné.Exemples :
1. La fonction partie entière est continue par morceaux sur R.2. La fonction χQ n’est pas continue par morceaux.
Soit f une fonction continue par morceaux sur I et soit a et b deux éléments de I on pose
∫ b
af (t) dt =
∫
[a,b]f si a < b
−∫
[b,a]f si a > b
0 si a = b
Définition 23.6.1.803
Remarque : Le signe moins est nécessaire si l’on veut garder la relation de Chasles.
Avec ces notations, la relation de Chasles est encore vérifiée.
Proposition 23.6.1.804
B Toutes les propositions avec des inégalités ne s’étendent à ce cas UNIQUEMENT si a < b. Sinon, il fautinverser les inégalités.
Soit f une fonction continue par morceaux
∀(a, b) ∈ I2,∣∣∣∣∫ b
af g∣∣∣∣ 6 |b− a| sup [a, b]| f |.
Proposition 23.6.1.805
6.2 Cas des fonctions continues par morceaux
Avec les notations précédentes, F est lipschitzienne donc continue sur [a, b].
Proposition 23.6.2.806
Démonstration : Soit x et y dans [a, b],
F(x)− F(y) =∫ x
cf (t) dt−
∫ y
cf (t) dt =
∫ x
cf (t) dt +
∫ c
yf (t) dt =
∫ x
yf (t) dt.
Maintenant f est bornée car continue par morceaux. Si M est un majorant de | f | on a
|F(x)− F(y)| 6 M|x− y|.
Remarques :
339

1. Dans ce cas la fonction peut très bien ne pas être dérivable. Si f : t 7→
1 si t > 0−1 sinon On voit que
F : x 7→∫ x
0f (t) dt = |x| − 1. Elle n’est pas dérivable en 0.
2. Si on n’est plus sur un segment ce n’est plus vrai car dans ce cas, f peut ne pas être bornée.
6.3 Cas des fonctions continues
Avec les notations précédentes, si f est continue sur I alors F est dérivable et sa dérivée est f .
Proposition 23.6.3.807
Remarques :1. Elle est même de classe C 1 car sa dérivée f est continue.
Démonstration
Soit f une fonction définie sur I, on appelle primitive de f sur I, toute fonction F dérivable sur I telle queF′ = f .
Définition 23.6.3.808
Soit f une fonction continue sur I.
1. Elle admet des primitives sur I.
2. La fonction x 7→∫ x
x0
f (t) dt est l’unique primitive qui s’annule en x0.
3. Soit F et G deux primitives de f sur I, il existe C ∈ R tel que F = G + C.
4. Soit (x, y) ∈ I2,∫ y
xf (t) dt = [F(t)]yx = F(y)− F(x) où F est une primitive de f .
Théorème 23.6.3.809
Démonstration
B Quand on veut dériver x 7→ F(x)− F(a) avec F un primitive de f on trouve f (x) et pas f (x)− f (a).
Exercice : On pose H : x 7→∫ 2x
x
12t− 1
dt.
1. Calculer l’ensemble de définition de H.
2. Montrer que H est dérivable et calculer H′.
7 Calculs
Nous allons montrer quelques méthodes de calculs classiques.
7.1 Primitives de fonctions rationnelles
On sait exprimer à l’aide des fonctions usuelles les primitives de toutes les fonctions rationnelles.
Théorème 23.7.1.810
Soit f une fonction rationnelle sur R et I un intervalle ne contenant aucun pôle de f . Le principe est de réaliserla décomposition en éléments simple de la fraction puis d’intégrer chaque terme. Il y a deux méthodes selonque l’on procède à une décomposition sur R ou sur C
340

— (Sans utiliser les nombres complexes) :Via la décomposition en éléments simples sur R et la linéarité, on est ramené à déterminer les primitivesdes fonctions de la forme :
1. un polynôme
2. une fonction t 7→ 1(t− a)n où a ∈ R.
3. une fonction t 7→ at + b(t2 + ct + d)n où t2 + ct + d ne s’annule pas.
Le cas 1. a été vu précédemment.Le point 2. aussi en séparant le cas où n = 1 du cas n > 1.Pour le point 3. Via une mise sous forme canonique et un changement de variables affine, on peut se
ramener à t 7→ at + b(t2 + d2)n avec d > 0. Maintenant, on peut « tuer » le t au numérateur en utilisant la
dérivée de t 7→ t2 + d2. Précisément on a
at + b(t2 + d2)n =
a2
2t(t2 + d2)n +
b(t2 + d2)n .
— La première partie est de la formeu′
un et on sait déterminer sa primitive.
— Pour la deuxième partie, si n = 1, on reconnait la dérivée debd
arctan(t/d).
— Pour la deuxième partie, si n 6= 1 on se ramène au cas n = 1 par intégration par parties. En effet,∫ x dt
(t2 + d2)n =
[t
(t2 + d2)n
]x−∫ x 2nt2
(t2 + d2)n+1 dt
=x
(x2 + d2)n − 2n(∫ x t2 + d2
(t2 + d2)n+1 dt−∫ x d2
(t2 + d2)n+1 dt)
On en déduit que
(2n + 1)∫ x dt
(t2 + d2)n =x
(x2 + d2)n + 2nd2∫ x dt
(t2 + d2)n+1 .
On a donc, par exemple∫ x dt
(t2 + d2)2 =1
2d2
(2∫ x dt
(t2 + d2)− x
(x2 + d2)
).
Exemple : On cherche une primitive de t 7→ tt3 − 1
sur I =]−∞, 1[ ou I =]1,+∞[. On sait que X3 − 1 =
(X− 1)(X2 + X + 1). On en déduit qu’il existe (a, b, c) tels que
∀t ∈ I,1
t3 − 1=
at− 1
+bt + c
t2 + t + 1.
Par les méthodes du chapitre précédent on trouve, a = 1/3 et on en déduit que
∀t ∈ I,1
t3 − 1=
13
1t− 1
+13−t + 2
t2 + t + 1=
13
1t− 1
− 16
2t + 1t2 + t + 1
− 12
1t2 + t + 1
.
Maintenant,∫ x 1
31
t− 1dt =
13
ln |x− 1| et∫ x−1
62t + 1
t2 + t + 1dt = −1
6ln(x2 + x + 1).
De plus
∫ x−1
21
t2 + t + 1dt = −1
2
∫ x 1(t + 1/2)2 + 3/4
dt
= − 1√3
arctan(
x + 1/2√3/2
)
En conclusion,∫ x dt
t3 − 1=
13
ln |x− 1| − 16
ln(x2 + x + 1)− 1√3
arctan(
x + 1/2√3/2
).
341

— (Utilisation des complexes) : Via la décomposition en éléments simples sur C et la linéarité, on estramené à déterminer les primitives des fonctions de la forme :
1. un polynôme
2. une fonction t 7→ 1(t− α)n où α ∈ C.
Soit α = u + iv ∈ C avec v 6= 0. La fonction t 7→ 1(t− α)n est continue sur R et admet donc des
primitives sur R. De plus
∫ x dt(t− α)n =
1−n + 1
1(x− α)n−1 si n 6= 1
12
ln((x− u)2 + v2) + i arctan(
x− uv
)si n = 1
Proposition 23.7.1.811
Démonstration : La partie n 6= 1 est juste la formule classique de la primitive de (x − α)k en prenantgarde qu’ici, k = −n. Pour démontrer la partie pour n = 1 on peut juste dériver le terme de droite, nousallons le faire autrement ce qui permet de retrouver la formule si on l’a oubliée.On a pour tout t dans R,
1t− α
=t− α
|t− α|2
=t− α
(t− u)2 + v2
=t− u
(t− u)2 + v2 + iv
(t− u)2 + v2
=t− u
(t− u)2 + v2 + i1v
1((t− u)/v)2 + 1
Il ne reste qu’à intégrer.
Exercice : Calculer une primitive de t 7→ tt3 − 1
par cette méthode.
Remarque : Dans la très grande majorité des cas, la méthode réelle est la plus simple. Il ne faut utiliser laméthode complexe qu’en présence de pôles complexes multiples.
7.2 Primitives se ramenant à une primitive de fraction rationnelle
Nous allons étudier des primitives qui se ramène à des primitives de fraction rationnelle. Tout ce qui est iciest « pour la culture ». Les changements de variables seront proposés.
Fractions rationnelles en cos t et sin t
On se donne une fonction de la forme f : t 7→ P(sin t, cos t)Q(sin t, cos t)
où P et Q sont des polynômes. Par exemple,
t 7→ cos t + sin tcos2 t sin t
.
— On peut toujours se ramener au cas de la primitive d’une fonction rationnelle en effectuant le changement
de variable u = tan(t/2). On a alors du =1 + tan(t/2)
2dt et donc dt =
21 + u2 du. De plus
cos t = cos(2.(t/2)) = 2 cos2(t/2)− 1 = 21
1 + tan2(t/2)− 1 =
1− u2
1 + u2
etsin t = 2 sin(t/2) cos(t/2) = 2 tan(t/2). cos2(t/2) =
2u1 + u2 .
342

Par exemple,
∫ x 2 + sin2 t3− cos t
dt =∫ tan(x/2) 2 +
4u2
(1 + u2)2
3− 1− u2
1 + u2
21 + u2 du
= 2∫ tan(x/2) 1 + 4u2 + u4 du
(1 + u2)2(1 + 2u2)
= 2∫ tan(x/2) 2
(1 + u2)2 +2
1 + u2 −3
1 + 2u2 du.
Remarques :
1. On voit que le degré augmente beaucoup
2. Il faut faire attention à l’ensemble de définition. En effet on peut poser u = tan(t/2) si on travaillepour x dans Ik =]− π + 2kπ, π + 2kπ[. En pratique on travaille sur un tel intervalle puis on recolle.
Si par exemple on veut étudier∫ x dt
2 + cos tqui est définie sur R. On se place sur un Ik et on pose
u = tan(t/2). On obtient
2∫ tan(x/2) du
3 + u2 =2√3
arctan(
tan(x/2)√3
)+ C.
Si on veut par exemple la primitive F sur [0, 2π] qui s’annule en 0 alors
— ∀x ∈ [0, π[, F(x) =2√3
arctan(
tan(x/2)√3
). La constante est nulle ar F(0) = 0.
— ∀x ∈]π, 2π], F(x) =2√3
arctan(
tan(x/2)√3
)+ C
En étudiant limπ−
F = 3√
3π et limπ+
F = −3√
3π + C on voit que C = 6√
3π.
— (Règles de Bioche) Dans certains cas, on peut se ramener au cas d’une fraction rationnelle avec leschangements de variables u = cos t, u = sin t et u = tan t. Si on pose ω(t) = f (t) dt, alors
— si ω(−t) = ω(t) on peut poser u = cos t
— si ω(π − t) = ω(t) on peut poser u = sin t
— si ω(π + t) = ω(t) on peut poser u = tan t
Remarques :
1. Dans les formules ci-dessus, il ne faut pas oublier le dt. Par exemple si f est impaire, on poserau = cos t.
2. Pour se souvenir de ces formules, il suffit de voir que ce sont les mêmes formules. Par exemplesin(π − t) = sin t.
Exemple : Calculons la primitive de t 7→ 2 + sin2(t)cos t
sur ] − π/2, π/2[. On peut poser u = sin t etdu = cos t dt. On a en effet
dtcos2 t
=du
cos2 t=
du1− u2 .
∫ x 2 + sin2(t)cos t
dt =∫ sin x 2 + u2
1− u2 du
=∫ sin x
−1 +32
(1
1− u+
11 + u
)du
= − sin x +32
ln(
1 + sin x1− sin x
)
343

Fonctions rationnelles en et, sh (t) et ch (t)
On cherche la primitive d’une fonction de la forme f = t 7→ F(et) où F est une fraction rationnelle ou
f : t 7→ P( sh t, ch t)Q( sh t, ch t)
ce qui revient au même.
Dans tous les cas, un changement de variables u = et permet de se ramener à une primitive de fractionrationnelle. On peut cependant là encore appliquer les règles de Bioche. Si on pose ω(t) = f (t) dt où f est lafonction obtenue en remplaçant ch t par cos t et sh t par sin t alors
— si ω(−t) = ω(t) on peut poser u = ch t— si ω(π − t) = ω(t) on peut poser u = sh t— si ω(π + t) = ω(t) on peut poser u = th t
Exemple : Calculons une primitive de t 7→ 1ch t
. D’après les règles de Bioche on peut poser u = sh t. Dès lors
∫ x dtch t
=∫ sh x du
1 + u2
= arctan( sh x).
Sans utiliser les règles de Bioche on peut aussi poser u = et et on trouve alors 2 arctan(ex) ce qui est là mêmechose.
Primitive de fraction rationnelle en√
at2 + bt + c
— Si a = 0. On se retrouve avec une fraction rationnelle en√
at + b. On pose u =√
at + b.
— Si a 6= 0. Quitte à diviser par√|a|, à faire une mise sous forme canonique et un changement de variable
affine, on se retrouve à traiter trois cas :—√
t2 + a2 : on pose t = a sh (u).
—√
t2 − a2 : on pose t = a ch (u).
—√
a2 − t2 : on pose t = a sin(u).Exemples :
1. Calculons∫ x √
t− t2 dt.
2. Calculons∫ x t√
t2 + t + 1dt.
Primitive de fraction rationnelle en√
at + bct + d
On fait le changement de variables u =
√at + bct + d
.
8 Formules de Taylor
On a déjà vu la formule de Taylor pour les polynômes qui affirme que si P est un polynôme de degréinférieur à n, pour tout α et tout x dans R,
P(x) =n
∑k=0
P(k)(α)
k!(X− α)k.
Nous allons généraliser ceci pour des fonctions quelconques (mais suffisamment dérivables).
8.1 Formule de Taylor avec reste intégral
Soit f une fonction de classe C n+1 sur [a, b] alors
f (b) =n
∑k=0
(b− a)k f (k)(a)k!
+∫ b
a
(b− t)n
n!f (n+1)(t) dt.
Théorème 23.8.1.812 (Formule de Taylor avec reste intégral)
344

Remarques :
1. Si f est une fonction polynomiale de degré inférieur à n on retrouve la formule de Taylor car f (n+1) = 0.
2. Le cas n = 0 est juste f (b) = f (a) +∫ b
af ′(t) dt.
3. La partien
∑k=0
(b− a)k f (k)(a)k!
se note Tn(b) est s’appelle le development de Taylor à l’ordre n. Le terme
∫ b
a
(b− t)n
n!f (n+1)(t) dt est le reste de Taylor. On le note Rn(b).
Démonstration : On procède par récurrence sur n.
— Initialisation : Pour n = 0 c’est vrai (voir remarque).
— Hérédité : Soit n un entier. Supposons la formule de Taylor vrai à l’ordre n. Soit f une fonction de classeC n+2. La fonction f est en particulier de classe C n+1. On en déduit que
f (b) =n
∑k=0
(b− a)k f (k)(a)k!
+∫ b
a
(b− t)n
n!f (n+1)(t) dt.
Maintenant, par intégration par parties
∫ b
a
(b− t)n
n!f (n+1)(t) dt =
[− (b− t)n+1
(n + 1)!f (n+1)(t)
]b
a+∫ b
a
(b− t)n+1
(n + 1)!f (n+2)(t) dt.
Il ne reste plus qu’à regrouper les deux deux équations.
Exemples :
1. Si on prend pour f la fonction cosinus et pour a = 0.On trouve
cos x = 1− x2
2+∫ x
0
(x− t)2
2sin t dt.
On remarque alors que sur [−π, π],∫ x
0
(x− t)2
2sin t dt > 0. De ce fait , cos x 6 1− x2
2.
2. Si on prend pour f la fonction exp et x = 0 on trouve
ex =n
∑k=0
xk
k!+∫ x
0
(x− t)n
n!et dt.
8.2 Inégalité de Taylor-Lagrange
Soit f une fonction de classe C n+1 sur [a, b] alors∣∣∣∣∣ f (b)−
n
∑k=0
(b− a)k f (k)(a)k!
∣∣∣∣∣ 6|b− a|n+1
(n + 1)!M
où M = Max[a,b]| f (n+1)|.
Théorème 23.8.2.813 (Formule de Taylor avec reste intégral)
Démonstration
Remarque : C’est une généralisation de l’inégalité des accroissements finis (qui est le cas n = 0). De fait ilexiste aussi une égalité de Taylor-Lagrange qui stipule que si f est de n fois dérivable, le reste de Taylor d’ordre
n peut s’écrire(b− a)n+1
(n + 1)!f (n+1)(c) avec c strictement compris entre a et b. Le cas n = 1 a été démontré en DL et
la démonstration générale est du même genre (exercice).
345

Exemple : Si on reprend l’exemple du paragraphe précédent. On trouve pour la fonction exponentielle que∣∣∣∣∣e
x −n
∑k=0
xk
k!
∣∣∣∣∣ 6xn+1
(n + 1)!ex.
Maintenant, quand x est fixé, la suite un =xn+1
(n + 1)!tend vers 0 par croissances comparées et de ce fait,
limn→∞
n
∑k=0
xk
k!= ex.
8.3 Formule de Taylor-Young
Soit f une fonction de classe C n sur I et a ∈ I. Il existe une fonction ε définie sur I et tendant vers 0en a telle que
∀x ∈ I, f (x) =n
∑k=0
f (k)(a)k!
(x− a)k + (x− a)nε(x).
C’est-à-dire,
∀x ∈ I, f (x) = f (a) + f ′(a)(x− a) + · · ·+ f (n)(a)n!
(x− a)n + oa((x− a)n) .
Théorème 23.8.3.814 (Formule de Taylor-Young)
Remarque : Ce résultats est un corollaire immédiat de l’inégalité de Taylor-Lagrange si on suppose f de classeC n+1. En effet on a ∣∣∣∣∣ f (x)−
n
∑k=0
f (k)(a)k!
(x− a)k
∣∣∣∣∣ 6 (x− a)n (x− a)n!
M
où M est le maximum de | f (n+1)| dans un voisinage du point a.Démonstration : Cela se fait par récurrence sur n. Les cas n = 0 et n = 1 ont déjà été vus. Faisons l’hérédité.Supposons que la formule de Taylor-Young soit vraie pour les fonctions de classe C n et considérons une fonctionf de classe C n+1. On sait que f ′ est alors de classe C n. D’où il existe ε1 telle que
∀t ∈ I, f ′(t) =n
∑k=0
( f ′)(k)(a)k!
(t− a)k + (t− a)nε1(t).
Or f (x) = f (a) +∫ x
af ′(t) dt. On obtient donc
f (x) = f (a) +∫ x
a
(n
∑k=0
( f ′)(k)(a)k!
(t− a)k + (t− a)nε1(t)
)dt
= f (a) +
(n
∑k=0
f (k+1)(a)∫ x
a
(t− a)k
k!dt
)+∫ x
a(t− a)nε1(t) dt
=n+1
∑k=0
f (k)(a)k!
(x− a)k +∫ x
a(t− a)nε1(t) dt
Il ne reste plus qu’à montrer que ε : x 7→
∫ x
a(t− a)nε1(t)
(x− a)n+1 tend vers 0.
B Cette formule ne donne que des informations locales.Exemples :
1. On a sin x = x− x3
6+ o
(x4) .
2. On a ex =n
∑k=0
xk
k!+ o (xn) .
346

9 Extension au fonctions à valeurs complexes
9.1 Definitions
Soit f une fonction continue (ou continue par morceaux) définie sur un intervalle I et à valeurs dans C. Onpose ∫ b
af =
∫ b
aRe( f ) + i
∫ b
aIm f .
Définition 23.9.1.815
Exemple :
∫ 1
0eiπt dt =
∫ 1
0cos(πt) dt + i
∫ 1
0sin(πt) dt =
2iπ
=
[eiπt − 1
iπ
]1
0.
9.2 Propriétés
L’integrale des fonctions à valeurs complexe est linéaire et elle vérifie la relation de Chasles.
Proposition 23.9.2.816
Soit f une fonction continue à valeurs dans C, et a < b,∣∣∣∣∫ b
af∣∣∣∣ 6
∫ b
a| f |.
Proposition 23.9.2.817
Démonstration :
— Si∫ b
a f est un réel positif et est donc égal à∫ b
a Re f alors cela découle de |Re f | 6 | f |.— Dans le cas général on considère Z un nombre complexe de module 1 tel que Z
∫ ba f soit un réel positif.
On a donc ∣∣∣∣∫ b
af∣∣∣∣ =
∫
[a,b]g
où g : t 7→ Z f (t). Or∫
[a,b]g ∈ R+ donc
∫
[a,b]g 6
∫
[a,b]|g| =
∫
[a,b]| f |.
347

24Probabilités
1 Espace probabilisé 3481.1 Univers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3481.2 Probabilités et espace probabilisé . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 350
2 Probabilités conditionnelles 3522.1 Exemple introductif . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3522.2 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3532.3 Formules sur les probabilités conditionnelles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 353
3 Indépendance 3553.1 Indépendance de deux événements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3553.2 Indépendance mutuelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 356
1 Espace probabilisé
La première chose à faire est de définir les objets mathématiques que nous allons étudier. Ils doiventreprésenter la réalité que l’on observe.
1.1 Univers
On appelle expérience aléatoire (ou épreuve) une expérience pouvant amener un ou plus résultats. On appelleunivers l’ensemble de tous les résultats possibles. Ces derniers s’appellent des éventualités.
Définition 24.1.1.818
Exemples :
1. On joue à pile ou face. On note P si la face fait pile et F si elle fait face. On a Ω = P, F.2. On lance un dé et on regarde le score obtenu. On a Ω = 1, . . . , 6.3. On lance deux dés et on regarde les deux scores obtenus. L’univers n’est pas le même si on distingue les
deux dés ou pas. Si on note Ωd (resp. Ωi) l’univers obtenu avec des dés différents (resp. non différentiés).on a :
Ωd = [[ 1 ; 6 ]]2 et Ωi = (1, 1), (1, 2), (1, 3), (1, 4), (1, 5), (1, 6), (2, 2), (2, 3), . . . , (6, 6).
4. On lance une pièce une infinité de fois pour attendre le premier pile : Ω = P, FN.
5. On mesure le temps qu’il reste à vivre à une bactérie. On a Ω = R+.
348

6. On mesure (en heure) le temps qu’il vous faudra faire la queue au self. Ω = [0, 2]
7. On lance une fléchette sur une cible. Ω = (x, y) ∈ R2 | x2 + y2 6 1.Remarque : cette année on se limitera au cas des expériences amenant un univers fini de résultats. L’annéeprochaine vous étudierez le cas d’un ensemble discret (dénombrable).Exercice : On considère une urne contenant 4 boules vertes et 1 boules rouges. On tire deux boules dans l’urne.Décrire l’univers selon que :
— On ne distingue pas les boules vertes et on tire successivement et sans remises.
— On ne distingue pas les boules vertes et on tire simultanément et sans remises.
— On ne distingue pas les boules vertes et on tire successivement et avec remises.
— Les trois cas précédents mais en distinguant les boules vertes entre elles.
On appelle événement un sous-ensemble de Ω dont on peut dire, au vu de l’expérience s’il est réalisé ou pas.
Définition 24.1.1.819
Exemples :
1. La pièce fait pile A = P ⊂ Ω.
2. On fait plus de 3, A = 3, 4, 5, 6 ⊂ Ω.
3. On fait un double A = (1, 1), (2, 2), (3, 3), . . . , (6, 6) ⊂ Ω.
4. Le premier pile est obtenu au quatrième lancer A = (ui) ∈ Ω | u1 = u2 = u3 = F et u4 = P ⊂ Ω
5. La bactérie vit plus de 2 heures A = [2,+∞[
6. Vous attendez moins d’un quart d’heure : A = [0, 1/4]
Terminologie : On a un dictionnaire entre les termes classiques de la théorie des ensembles et leurs pendant enprobabilités.
Ensembles ProbabilitésEnsemble Univers
élément de Ω éventualitépartie de Ω événement
Ω événement certain∅ événement impossible
Maintenant on se donne un univers Ω et A et B deux parties/événements.
Ensembles ProbabilitésA événement contraire de A
A ∩ B événement A et BA ∪ B événement A ou BA ⊂ B Si A alors BA \ B événement A et pas B
A ∩ B = ∅ événements incompatibles
Exemple : On lance un dé et Ω = [[ 1 ; 6 ]]. Soit P = « le résultat est pair », I = « le résultat est impair »et A =« le résultat est inférieur à 3 ».
Soit Ω un univers, on appelle système complet d’événements, la donnée d’un nombre fini d’événementsA1, . . . , An tels que toute éventualité soit dans un et un seul des événements Ai. C’est à dire que l’on veut :
1. Ω =n⋃
i=1
Ai ,
2. ∀(i, j) ∈ [[ 1 ; n ]]2 , (i 6= j)⇒ Ai ∩ Aj = ∅.
Définition 24.1.1.820
Exemples :
349

1. Pour Ω = [[ 1 ; 10 ]], on peut prendre, A1 = 1, 3, 5, 7, 9, A2 = 2, 10, A3 = 4 et A4 = 6, 8.2. Soit E un ensemble à n éléments et Ω = P(E). C’est à dire que que l’on tire des nombres (entre 0 et n)
compris entre 1 et n. On pose Ak = X ⊂ E | Card(X) = k pour k = 0, · · · , n. Les Ak forment unepartition de Ω.
Remarques :
1. Cela correspond à la notion ensembliste de partition.
2. Les systèmes complets sont très utiles, ils permettent de "découper" l’univers.
1.2 Probabilités et espace probabilisé
Maintenant que l’on sait ce qui peut arriver, on doit définir la probabilité d’un événement d’advenir. Pourcela il faut définir une application qui associe à un événement A ∈P(Ω) sa probabilité.
Avant de regarder précisément cela on va essayer de voir ce qu’il faut. Imaginons que l’on dispose d’uneexpérience aléatoire (par exemple lancer d’une pièce) avec son univers (Ω = P, F). On considère un événementA (par exemple A = P). Si on réalise l’expérience n fois et que l’on note nA le nombre de fois que l’expérience
est réalisé, on notera fn =nAn
la fréquence empirique de réalisation. Notre idée serait de dire que quand n tendvers l’infini, la probabilité de A est
P(A) = limn→∞
fn(A).
En regardant les propriété de fn, on peut se demander quelles propriétés on doit imposer à P : P(Ω)→ R.
— ∀A ∈P(Ω), P(A) ∈ [0, 1]
— P(Ω) = 1 et P(∅) = 0
— ∀A ∈P(Ω), P(A) = 1−P(A)
— Si A et B sont deux événements incompatibles P(A ∪ B) = P(A) + P(B)
— Si A ⊂ B, P(A) 6 P(B)
On va voir que certaines de ces conditions sont redondantes.
Soit Ω un univers, une probabilité sur (Ω, P(Ω)) est une application P : P(Ω)→ [0, 1] telle que
1. P(Ω) = 1
2. Si A et B sont deux événements incompatibles, P(A ∪ B) = P(A) + P(B).
Soit A un événement de Ω, le nombre P(A) s’appelle la probabilité de A. Le triplet (Ω, P(Ω), P) s’appelleun espace probabilisé.
Définition 24.1.2.821
Remarques :
1. Il peut sembler étrange de noter P(Ω). Cela n’a aucune utilité cette année mais vous verrez l’an prochainque dans le cas continue, il existe des partie de l’univers dont on ne pas calculer la probabilité. Pour cetteannée, on utilisera le terme de « probabilité sur Ω », par abus.
2. Cette définition peut sembler très minimaliste mais nous allons voir que toutes les propriétés classiquesque l’on attend en découle.
3. On ne pourra JAMAIS voir des probabilités négatives ou strictement supérieures à 1.
Soit Ω = x1, . . . , xn un ensemble fini et P une probabilité sur Ω alors pour tout A ∈P(Ω) on a :
P(A) =⋃
i∈[[ 1 ; n ]]xi∈A
pi.
Proposition 24.1.2.822
Démonstration
350

Soit Ω = x1, . . . , xn un ensemble fini de cardinal n. Se donner une probabilité sur Ω revient à sedonner n nombres p1, . . . , pn compris entre 0 et 1 tels que :
p1 + · · ·+ pn.
La correspondance est donnée par
∀i ∈ [[ 1 ; n ]] , P(xi) = pi.
Proposition 24.1.2.823
Démonstration
Remarque : ces deux propositions illustrent le fait que pour cette année, on peut penser à l’application deprobabilité comme l’application qui associe à chaque élément de Ω sa probabilité. Cela détermine de manièreunique la probabilité sur tout P(Ω). Là encore, cela est différent pour les probabilités sur des univers infinis.Exemples :
1. On considère une pièce équilibrée et on joue à pile ou face. On a Ω = P, F et la probabilité est donnéepar :
P(∅) = 0 ; P(P) = 1/2 ; P(F) = 1/2 ; P(Ω) = 1.
2. Equiprobabilté : sur tout univers fini Ω on peut définir la probabilité uniforme. Pour cela on considèreque la probabilité de tous les éventualités est la même. Elle est obligatoirement égale à 1/Card(Ω).On a alors,
∀A ∈P(Ω), P(A) =Card(A)
Card(Ω).
Vérifions que c’est une probabilité.
— on a P(Ω) =Card(Ω)
Card(Ω)= 1.
— si A et B sont deux ensembles disjoints Card(A ∪ B) = Card(A) + Card(B). D’où,
P(A ∪ B) = P(A) + P(B).
3. On lance deux dès à 6 faces et on regarde la somme des deux dés. On pourrait considérer comme universΩ = 2, . . . , 12. Le problème est que rien ne nous dit que tous les résultats sont équiprobables et de cefait on ne sait définir la probabilité. On considérera plutôt l’univers Ω′ = [[ 1 ; 6 ]]2 obtenu en regardant undé puis l’autre - on les distingue intellectuellement même s’ils ne sont pas physiquement distincts. A cemoment la probabilité est uniforme. Soit A l’événement « la somme fait 7 » et B l’événement « la sommefait 11 ». On a
P(A) =6
36=
16
et P(B) =2
36=
118
.
4. On considère un dé pipé qui a autant de chances de faire 1, 2 ou 3 et deux fois plus de chances de faire 4, 5ou 6. On a Ω = 1, . . . , 6. On note, pour i ∈ [[ 1 ; 6 ]] , pi = P(i). On a
p1 + p2 + p3 + p4 + p5 + p6 = 1 et p6 = p5 = p4 = 2p3 = 2p2 = 2p1.
D’où p1 = 1/9 et p5 = 2/9. Soit A l’événement « on obtient un résultat pair ». On a
P(A) = 2/9 + 2/9 + 1/9 = 5/9.
5. On considère une urne avec a boules blanches et b boules noires (a > 4). On suppose que toutes les boulessont semblables. On tire deux boules successivement dans l’urne et on note A l’événement « les deuxboules sont blanches ». Calculons P(A).
— Si on remet la boule dans l’urne après tirage :
On a Ω = [[ 1 ; a + b ]]2 et A = [[ 1 ; a ]]2. On en déduit P(A) =
(a
a + b
)2.
— Si on ne remet pas la boule dans l’urne après tirage :On a Ω = B ⊂ [[ 1 ; a + b ]] | CardB = 2. et A = B ⊂ [[ 1 ; a ]] | CardB = 2. On en déduit :
P(A) =(a
2)
(a+b2 )
=a(a− 1)
(a + b)(a + b− 1).
351

Soit (Ω, P(Ω), P) un espace probabilisé fini. On a les propriétés suivantes :
1. Pour tout événement A, P(A) = 1−P(A). En particulier P(∅) = 0.
2. Pour tous événements A et B, P(A \ B) = P(A)−P(A ∩ B).
3. Pour tous événements A et B, P(A ∪ B) = P(A) + P(B)−P(A ∩ B).
4. Pour tous événements A et B, A ⊂ B⇒ P(A) 6 P(B).
Proposition 24.1.2.824
Démonstration
Soit (Ω, P(Ω), P) un espace probabilisé fini et (Ai)16i6n une famille finie d’événements. On a
p
(n⋃
i=1
Ai
)=
n
∑k=1
(−1)k+1 ∑16i1<···<ik6n
P(Ai1 ∪ · · · ∪ aik ).
Proposition 24.1.2.825 (Formule du crible de Poincaré - Hors programme)
Remarques :
1. Cette formule est utile car elle permet de calculer la probabilité d’une union uniquement avec desprobabilité de produit.
2. C’est l’analogue de la formule de Poincaré pour les cardinaux. Notons cependant que cette formule estvraie en tout généralité et pas que pour une probabilité uniforme.
3. Il faut retenir les cas particuliers :
— pour n = 2 : P(A ∪ B) = P(A) + P(B)−P(A ∩ B).
— pour n = 3 : P(A ∪ B ∪ C) = P(A) + P(B) + P(C)− P(A ∩ B)− P(A ∩ C)− P(B ∩ C) + P(A ∩B ∩ C).
— pour n = 4 : en exercice...
2 Probabilités conditionnelles
La notion de probabilités conditionnelles sert à calculer la probabilité d’un événement en sachant q’un autreévénement est réalisé. En effet, nous allons voir que le fait de savoir qu’un événement est réalisé (ou non) influesur la probabilité de l’univers.
2.1 Exemple introductif
On lance deux dés . On regarde la somme des deux dés. On a Ω = [[ 1 ; 6 ]]2 . Soit A l’événement « la sommeest supérieure à 10 ». On a
A = (4, 6); (5, 5); (5, 6); (6, 4); (6, 5); (6, 6).D’où P(A) = 1/6. On suppose maintenant que l’on lance le premier dé et que l’on obtient 5. Quelle est laprobabilité d’obtenir plus de 10 en lançant le deuxième ? On considère l’événement B qui est « le premier dé fait5 ». C’est à dire B = (5, 1); (5, 2); (5, 3); (5, 4); (5, 5); (5, 6). On voit alors que la probabilité de A sachant que Best réalisé est :
CardA ∩ BCardB
=P(A ∩ B)
P(B).
C’est ce que l’on appellera la probabilité conditionnelle.
352

2.2 Définitions
Soit (Ω, P(Ω), P) un espace probabilisé et B un événement tel que P(B) 6= 0. Pour tout événementA ∈P(Ω) on appelle probabilité de A sachant B et on note PB(A) ou P(A|B) le nombre
P(A ∩ B)P(B)
.
Définition 24.2.2.826
Remarques :
1. Cela correspond réellement à l’intution que l’on a, c’est à dire que PB(A) est la probabilité A se réalise ensachant que B est réalisé.
2. On peut étendre la notion au cas où P(B) = 0 en posant alors PB(A) = 0.
3. On utilisera souvent la probabilité conditionnelle sous la forme :
P(A ∩ B) = P(B).PB(A).
Exemple : On reprend un exemple précédent. On considère une urne avec a boules blanches et b boules noires(a > 4). On suppose que toutes les boules sont semblables. On tire deux boules successivement dans l’urne et onnote A l’événement « les deux boules sont blanches ». Calculons P(A). On note, pour i ∈ 1, 2, Bi l’événement« la ième boule tirée est blanche ». On a A = B1 ∩ B2 d’où
P(A) = P(B1).P(B2|B1).
On a P(B1) = a/(a + b). On sépare alors les cas.
— Si on remet la boule dans l’urne après tirage :au moment du deuxième tirage on est dans une situation identique au premier tirage (la boule tirée a étéremise dans l’urne) d’où P(B2|B1) = a/(a + b) et
P(A) =
(a
a + b
)2.
— Si on ne remet pas la boule dans l’urne après tirage :au moment du deuxième tirage, on suppose que l’on a tiré une boule blanche dans l’urne au premier. Ilreste donc a− 1 boules blanches et toujours b boules noires. D’où P(B2|B1) = (a− 1)/(a + b− 1) et
P(A) =a(a− 1)
(a + b)(a + b− 1).
Avec les notations précédentes, l’application PB : P(Ω)→ R est une probabilité sur P(Ω).
Proposition 24.2.2.827
Remarque : En particulier, tout ce que l’on va dire sur les probabilités s’applique aux probabilités condition-nelles.
2.3 Formules sur les probabilités conditionnelles
Soit (Ω, P(Ω), P) un espace probabilisé et A1, . . . An des événements tels que P(A1 ∩ · · · ∩ An−1) 6=0. On a
P(A1 ∩ · · · ∩ An) = P(A1)×P(A2|A1)×P(A3|A1 ∩ A2)× · · · ×P(An|A1 ∩ · · · ∩ An−1).
Proposition 24.2.3.828 (Formule des probabilités composées)
353

Remarques :1. Le fait que P(A1 ∩ · · · ∩ An−1) soit non nul nous assure que toutes les probabilités conditionnelles sont
bien définies. Remarquons que la convention définie ci-dessus permet d’étendre l’égalité au cas oùP(A1 ∩ · · · ∩ An−1) = 0.
2. Là encore c’est cohérent avec l’intuition : le fait que A1, . . . , An soit réalisé revient à ce que A1 soit réalisé,A2 soit réalisé sachant que A1 l’est, A3 soit réalisé sachant que A1 et A2 le sont, · · · , An soit réalisé sachantque A1, . . . , An−1 le sont.
Démonstration
Exemple : Toujours le même exemple. On considère une urne avec a boules blanches et b boules noires (a > 4).On suppose que toutes les boules sont semblables. On tire trois boules successivement et sans remise dansl’urne et on note A′ l’événement « les trois boules sont blanches ». On note, pour i ∈ 1, 2, Bi l’événement « laième boule tirée est blanche ». On a donc A′ = B1 ∩ B2 ∩ B3 et
P(A′) = P(B1).P(B2|B1).P(B3|B1 ∩ B2).
D’où
P(A′) =a(a− 1)(a− 2)
(a + b)(a + b− 1)(a + b− 2).
Soit (Ω, P(Ω), P) un espace probabilisé et A1, . . . An un système complet d’événements. Pour toutévénement B on a
P(B) =n
∑i=1
P(B ∩ Ai) =n
∑i=1
P(Ai).P(B|Ai).
Proposition 24.2.3.829 (Formule des probabilités totales)
Remarques :1. En théorie, on ne peut appliquer la partie à droite de la formule que si les événements Ai ont des
probabilités non nulles afin de pouvoir déterminer P(B|Ai). Cependant, on voit dans la formule que sipour un (ou plusieurs) i on a P(Ai) = 0, certes le terme P(B|Ai) n’est pas défini, mais il est multiplié par0. On a en effet P(Ai ∩ B) = 0 = 0.P(B|Ai).
2. Cette formule est utile quand on a un système complet d’événements qui permet de "découper" l’univers.Pour connaître la probabilités d’un événement il s’agit de connaître les probabilités de l’événement ensupposant être dans l’un cas.
3. On peut étendre cette formule en acceptant des événements de probabilité nulle dans le système complet.
Exemple : Toujours le même exemple. On considère une urne avec a boules blanches et b boules noires (a > 4).On suppose que toutes les boules sont semblables. On tire trois boules successivement et sans remise dansl’urne. On note, pour i ∈ 1, 2, Bi l’événement « la ième boule tirée est blanche ». On cherche à calculer P(B2).On considère le système complet d’événement (B1, B1). On a
P(B2) = P(B1 ∩ B2) + P(B1 ∩ B2)
= P(B1).P(B2|B1) + P(B1).P(B2|B1)
=a
a + b.
a− 1a + b− 1
+b
a + b.
aa + b− 1
=a
a + b
On peut présenter cela sous forme d’un arbre.
Exercice : Avec les notations de l’exemple précédent, calculer la probabilité que la troisième boule soit blanche.
354

Soit (Ω, P(Ω), P) un espace probabilisé et A1, . . . An un système complet d’événements. Soit B unévénement, pour tout i ∈ 1, . . . , n, on a
pB(Ai) =P(Ai ∩ B)
P(B)=
P(Ai).P(B|Ai)
∑ni=1 P(Ai).P(B|Ai)
.
Proposition 24.2.3.830 (Formule de Bayes)
Remarques :
1. Cette formule est, dans un sens, la formule des probabilités totales "à l’envers". En effet, si on suppose quel’on sait calculer P(Ai) et P(B|Ai), elle permet de savoir avec quelle probabilité on est dans l’événementAi en sachant que B est réalisé.
2. On utilise souvent le terme le plus à droite, mais il est plus simple de "retrouver" la formule que d’essayerde s’en souvenir.
Exemple : Toujours le même exemple. On considère une urne avec a boules blanches et b boules noires (a > 4).On suppose que toutes les boules sont semblables. On tire trois boules successivement et sans remise dansl’urne. On note pour i ∈ 1, 2, Bi l’événement « la ième boule tirée est blanche ». On suppose que la deuxièmeboule tirée est blanche et on veut savoir quelle est la probabilité que la première le fut. C’est à dire on veutcalculer P(B1|B2). La formule de Bayes donne alors :
P(B1|B2) =P(B1).P(B2|B1)
P(B1).P(B2|B1) + P(B1).P(B2|B1)=
a(a− 1)a(a− 1) + a.b
=a− 1
a + b− 1.
3 Indépendance
3.1 Indépendance de deux événements
Nous dirons que deux événements sont indépendants quand le fait de savoir que l’un est réalisé (ou non)n’influe pas sur la probabilité que l’autre le soit.
Soit (Ω, P(Ω), P) un espace probabilisé et A et B deux événements. On dit que A et B sont indépendants si
P(A ∩ B) = P(A).P(B).
Définition 24.3.1.831
Remarque : Cela correspond à l’intuition. En effet si P(B) 6= 0 alors A et B sont indépendants si et seulement
si pB(A) =P(A ∩ B)
P(B)= P(A).
Exemples :
1. Toujours le même exemple. On considère une urne avec a boules blanches et b boules noires (a > 4). Onsuppose que toutes les boules sont semblables. On tire deux boules successivement dans l’urne. On notepour i ∈ 1, 2, Bi l’événement « la ième boule tirée est blanche ».
— on suppose que l’on procède à un tirage avec remise. Les événements B1 et B2 sont indépendants.
— on suppose que l’on procède à un tirage sans remise. Les événements B1 et B2 ne sont pas indépen-dants.
2. On lance un dé à 6 face. On a donc Ω = [[ 1 ; 6 ]]. On considère les événements A = 4, 5 et B = 5, 6 d’oùA ∩ B = 5. On munit alors Ω de deux probabilités. La probabilité uniforme notée p1 et la probabilité p2définie par
p2(6) = 1/3; p2(5) = p2(4) = 1/6; p1(1) = p2(2) = p2(3) = 1/9.
Les événements A et B ne sont pas indépendants pour p1 mais ils le sont pour p2.
Remarque : Contrairement à l’intuition que l’on a, la notion d’indépendance dépend de la probabilité. Nous levoyons à l’exemple 2. En général, nous ne démontrerons pas l’indépendance des événements par le calcul. Defait l’indépendance découlera souvent de la modélisation.
355

Deux épreuves sont indépendantes si leurs résultats sont indépendants. C’est à dire que si A est un événementportant sur la première épreuve et B un événement portant sur la deuxième alors :
P(A ∩ B) = P(A)×P(B).
Définition 24.3.1.832
Exemple : On lance deux fois un dé à 6 faces. On suppose que les deux lancers sont indépendants. Soit Al’événement « faire un nombre pair au premier lancer »et B l’événement « ne pas faire 6 au deuxième lancer ».Comme les épreuve sont indépendantes, les deux événements sont indépendants et
P(A ∩ B) = P(A)×P(B) =5
12.
Remarque : dans la définition précédente nous avons volontairement été flou sur les univers. Essayons d’êtreun peu sérieux. Soit E1 et E2 deux épreuves que l’on suppose indépendantes. Soit Ω1 et Ω2 les univers décrivantdeux épreuves. Alors l’ensemble des deux épreuves peut être décrit par l’univers Ω1 ×Ω2 l’univers décrivantl’ensemble des deux épreuves. Soit A ⊂ Ω1 un événement portant sur la première épreuve, on considèrealors l’événement A′ = A×Ω2 ⊂ Ω1 ×Ω2. De même on regarde B′ = Ω1 × B ⊂ Ω1 ×Ω2 où B ⊂ Ω2 est unévénement portant sur la deuxième épreuve. On en déduit que
P(A′ ∩ B′) = P(A′)×P(B′) = P(A)×P(B).
Dans l’exemple précédent, Ω1 = Ω2 = [[ 1 ; 6 ]] . L’événement A (resp. B) est 2, 4, 6 (resp. 1, 2, 3, 4, 5) etA′ = 2, 4, 6 × [[ 1 ; 6 ]] (resp. [[ 1 ; 6 ]]× 1, 2, 3, 4, 5). On a alors A′ ∩ B′ = 2, 4, 6 × 1, 2, 3, 4, 5.
il arrive de penser que des événements sont indépendants quand ils ne le sont pas. On considèredeux pièces. La pièce A est équilibrée et la pièce B fait pile avec un probabilité 1/3. On tire une pièceau hasard et on la lance deux fois de suite. Les deux lancers sont-ils indépendants ? On note P1 (resp.P2) l’événement « on a fait pile au lancer 1 (resp. au lancer 2) ». On a alors que P1 et P2 ne sont pasindépendants pour la probabilité de l’expérience totale P. Par contre, ils sont indépendants pour laprobabilité PA et PB
ATTENTION
3.2 Indépendance mutuelle
On se fixe un espace probabilisé (Ω, P(Ω), P). La question est alors comment définir la notion d’indépen-dance de trois événements. On pense naturellement à deux définitions.
— Définition 1. Trois événements A, B et C sont indépendants si
P(A ∩ B ∩ C) = P(A)×P(B)×P(C).
— Définition 2. Trois événements A, B et C sont indépendants si
P(A ∩ B) = P(A)×P(B), P(A ∩ C) = P(A)×P(C) et P(B ∩ C) = P(B)×P(C).
Malheureusement comme nous allons le voir ci-dessous aucune des deux n’implique l’autre.Exercices :
1. On considère un dé à 6 face équilibré ainsi que les événements suivants :
A = 1, 2, 3, B = 2, 3, 4 et C = 1, 2, 4, 5.
Les événements A, B et C vérifient-ils les conditions des définitions 1 et 2.
2. On considère deux dés à 6 face équilibrés ainsi que les événements suivants :
— A = « on obtient 6 au premier lancer »
— B = « on obtient 6 au deuxième lancer »
— C = « on obtient le même chiffre aux deux lancers »
356

Les événements A, B et C vérifient-ils les conditions des définitions 1 et 2.
Pour pallier à ce problème, nous dirons que trois événements sont équivalents s’ils vérifient les deuxpropriétés.
Soit (Ω, P(Ω), P) un espace probabilisé.
— Trois événement A, B et C sont dits mutuellement indépendants si,
P(A∩B∩C) = P(A)×P(B)×P(C), P(A∩B) = P(A)×P(B), P(A∩C) = P(A)×P(C) et P(B∩C) = P(B)×P(C).
— Plus généralement des événements (Ai)i∈[[ 1 ; n ]] sont mutuellement indépendants si, pour tout J ⊂[[ 1 ; n ]], on a
p
⋂
j∈JAj
= ∏
j∈JP(Aj).
Définition 24.3.2.833
Comme ci-dessus on peut étendre cette définition au cas d’épreuves mutuellement indépendantes.
Des épreuves sont indépendantes si leurs résultats sont indépendants.
Définition 24.3.2.834
Exemple : On a une pièce qui faire pile avec la probabilité p ∈]0, 1[. On lance 5 fois cette pièce, on suppose queles lancers sont indépendants et on veut calculer la probabilité des événements suivants
A = « on a fait que des piles » et B = « on a fait un face et un seul ».
On va soigner la rédaction...L’univers est Ω = P, F5. Pour i ∈ [[ 1 ; 5 ]] , on note Pi l’événement « on obtient pile au lancer i » et Fi = Pi.
Dès lors A = P1 ∩ P2 ∩ P3 ∩ P4 ∩ P5. On a donc
P(A) = P(P1)×P(P2|P1)× · · · ×P(P5|P1 ∩ P2 ∩ P3 ∩ P4).
Les lancers étant indépendants, on obtient, P(A) = p5.Maintenant on veut déterminer B. Il faut distinguer selon le numéro du lancer qui amène le face. Précisément
on a :B = (F1 ∩ P2 ∩ P3 ∩ P4 ∩ P5) ∪ (P1 ∩ F2 ∩ P3 ∩ P4 ∩ P5) ∪ · · · ∪ (P1 ∩ P2 ∩ P3 ∩ P4 ∩ F5).
Maintenant ces événements sont disjoints. De plus ils ont tous pour probabilité (1− p)p4 d’après le raisonnementprécédent. On a donc
P(B) = 5p4(1− p).
Exercice : Avec les notations de l’exemple précédent, calculer la probabilité d’obtenir exactement 3 faces.
357

25Séries
1 Généralités 3591.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3591.2 Propriétés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 360
2 Séries de références 3612.1 Séries géométriques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3612.2 Séries de Riemann . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3612.3 Comparaison séries - intégrales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 362
3 Séries à termes positifs 3633.1 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3643.2 Théorème de comparaison pour les séries à termes positifs . . . . . . . . . . . . . . . . . . . . . 365
4 Séries absolument convergentes 3664.1 Définition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3664.2 Applications aux séries dont le terme général n’a pas un signe constant . . . . . . . . . . . 366
5 Représentation décimale des réels 367
Une série est une somme infinie de nombres. La question qui nous occupera sera de savoir si ces sommesinfinies convergent ou non. Dans ce chapitre, K désigne R ou C.Exemples :
1. On a1 + 1 + · · ·+ 1 + · · · → ∞ (∼ n)
2. On a1 +
12+
13+ · · ·+ 1
n+ · · · → ∞ (∼ ln n)
3. On a1 +
12+
14+ · · ·+ 1
2n + · · · → 2.
358

1 Généralités
1.1 Définitions
Soit (un)n∈N une suite à valeurs dans K. On appelle suite des sommes partielles la suite (Sn)n∈N par
∀n ∈ N, Sn =n
∑k=0
uk.
On appelle série de terme général un et on note ∑ un le couple ((un), (Sn)).
Définition 25.1.1.835
Remarque : Il arrive que l’on ne veut pas commencer à 0 mais à un entier n0 (la plupart de temps 1). On note
alors ∑n>n0
un la série dont les sommes partielles sont, pour n > n0,n
∑k=n0
uk. Dans la suite, on ne traitera que le
cas des séries qui commencent à 0.Exemples :
1. Pour la série ∑ 1. On a donc pour n > 0, Sn =n
∑k=0
1 = n + 1.
2. Pour la série ∑12n . On a donc pour n > 0, Sn =
n
∑k=0
12k =
1− (1/2)n+1
1− (1/2)= 2−
(12
)n.
Soit ∑ un une série.
1. Si la suite des sommes partielles converge, on dit que la série est dite convergente. On note alors
S =+∞
∑k=0
uk la limite des sommes partielles. On l’appelle la somme de la série.
2. Si la suite des sommes partielles diverge, on dit que la série est divergente.
Définition 25.1.1.836
Remarque : Le fait d’être convergente ou divergente est la nature de la série.Exemples :
1. Les séries ∑ 1 et ∑1n
divergent.
2. La série ∑12n converge. Sa somme vaut
∞
∑n=0
12n = 2.
Soit ∑ un une série convergente. Pour tout p > 0 on appelle reste d’ordre p,
Rp =∞
∑k=p
uk =∞
∑k=0
uk −p−1
∑k=0
uk = S− Sp−1.
Définition 25.1.1.837
Remarque : On ne peut pas parler de reste d’une série divergente.
Exemple : Si on reprend encore la série ∑12n on a
Rp =∞
∑k=p
12k = lim
n→∞
n
∑k=p
12k = lim
n→∞
12p
1− (1/2)n−p+1
1− (1/2)=
12p−1
359

1.2 Propriétés
Soit ∑ un et ∑ vn deux séries et λ, µ deux scalaires.
1. Si ∑ un et ∑ vn convergent alors ∑(λun + µvn) converge.
2. Dans ce cas,∞
∑k=0
(λuk + µvk) = λ∞
∑k=0
uk + µ∞
∑k=0
vk.
Proposition 25.1.2.838 (Linéarité de la somme)
Remarque : Cela signifie que l’ensemble des séries convergentes est un sous-espace vectoriel de l’ensemble desséries. De plus l’application définie sur ce sous-espace vectoriel qui associe à une série sa somme est linéaire.Démonstration : Soit n ∈ N on a
n
∑k=0
(λuk + µvk) = λn
∑k=0
uk + µn
∑k=0
vk.
Maintenant, par hypothèsesn
∑k=0
uk etn
∑k=0
vk convergent vers∞
∑k=0
uk et∞
∑k=0
vk respectivement. La conclusion en
découle d’après le théorème d’opération sur les limites de suites.
Remarque : Par contre la somme de deux séries divergentes n’est pas toujours divergente. Par exemple
∑ 1 +12n et ∑(−1).
Soit un une suite. Les propositions suivantes sont équivalentes
i) La suite (un) est convergente.
ii) La série de terme général uk+1 − uk est convergente.
De plus, si elles sont satisfaite on a
lim(un) = u0 +∞
∑k=0
uk+1 − uk.
Proposition 25.1.2.839 (Lien série suite)
Démonstration : Il suffit d’utiliser le télescopage :
∀n ∈ N,n
∑k=0
uk+1 − uk = un+1 − u0.
Exemple : Pour étudier la série ∑n>1
1n(n + 1)
, il suffit de remarquer que
∀n ∈ N?,1
n(n + 1)=
1n− 1
n + 1.
Or1n→ 0 donc la série étudié converge et
∞
∑n=1
1n(n + 1)
= 1.
Soit ∑ un une série. Si elle converge alors le terme général un tend vers 0.
Proposition 25.1.2.840
360

Ce n’est pas une équivalence. On a vu par exemple que ∑1n
diverge.
ATTENTION
Démonstration : Soit ∑ un une série convergente. Pour tout entier n non nul on a
un =n
∑k=0
uk −n−1
∑k=0
uk.
Maintenant si la série converge,n
∑k=0
uk etn−1
∑k=0
uk tendent toutes les deux vers la somme de la série. La différence
tend donc vers 0.
Remarque : On peut se servir de la contraposée pour montrer la divergence d’une série. Si le terme général netend pas vers 0 alors la série diverge. On dit qu’elle diverge grossièrement.
2 Séries de références
2.1 Séries géométriques
Les séries géométriques sont les plus simples. Elles servent assez souvent en probabilités.
Soit z ∈ C. La série de terme général zn est convergente si et seulement si |z| < 1. Dans ce cas lasomme de la série est
∞
∑k=0
zk =1
1− z.
Théorème 25.2.1.841 (Séries géométriques)
Démonstration : On commence par exclure le cas où z = 1. Dans ce cas, la série diverge. On remarque ensuiteque si |z| > 1 alors pour tout entier k, |z|k > 1. De ce fait la série diverge grossièrement. A l’inverse, si |z| < 1, ilsuffit de calculer les sommes partielles. Soit n ∈ N,
n
∑k=0
zk =1− zk
1− z=
11− z
+zk
1− z.
On a
∣∣∣∣∣zk
1− z
∣∣∣∣∣ = |z|k ×
∣∣∣∣1
1− z
∣∣∣∣ qui tend donc vers 0. La série converge bien vers1
1− z.
Exercice : Étudier la nature (et l’éventuelle somme) de la série ∑ nzn.
2.2 Séries de Riemann
On appelle séries de Riemann les séries de la forme ∑ ns où s ∈ R.On considère ici des séries qui commencent à n = 1.
Définition 25.2.2.842 (Séries de Riemann)
La série de Riemann ∑1ns est convergente si et seulement si s > 1.
Théorème 25.2.2.843 (TRES IMPORTANT)
361

Démonstration : Si s 6 0, la série diverge grossièrement. On suppose par la suite que s > 0. On sait que lafonction t 7→ ts est décroissante sur R?
+. De ce fait pour tout k > 1,
1(k + 1)s =
∫ k+1
k
dt(k + 1)s 6
∫ k+1
k
dtts 6
∫ k+1
k
dtks =
1ks .
On en déduit que, pour k > 2 : ∫ k+1
k
dtts 6
1ks 6
∫ k
k−1
dtts .
On somme et on utilise la relation de Chasles :
∀n > 2,∫ n+1
2
dtts =
n
∑k=2
∫ k+1
k
dtts 6
n
∑k=2
1ks 6
n
∑k=2
∫ k
k−1
dtts =
∫ n
1
dtts .
— Si s > 1 on a donc
n
∑k=2
1ks 6
∫ n
1
dtts =
11− s
[t1−s
]n
1=
1s− 1
(1− n1−s) 61
s− 1
On en déduit que la suite des sommes partielles est majorée. Comme elle est croissante, elle converge. Lasérie est bien convergente.
— Si s = 1 on a cette fois,
ln(n + 1)− ln(2) 6∫ n+1
2
dtt6
n
∑k=2
1k
.
On en déduit que la suite des sommes partielles tend vers +∞ et donc la série diverge.
— Si s < 1 on procède comme pour le cas s = 1.
Notons que on ne regarde les sommes partielles qu’à partir de k = 2 mais cela ne change rien à la convergence.
Remarque : La limite des sommes de Riemann est difficile à calculer dans la majorité des cas. On pose
∀s ∈]1,+∞[, ζ(s) =+∞
∑n=0
1ns .
On sait calculer la valeur de la fonction ζ aux entiers pairs :
ζ(2) =π2
6, ζ(4) =
π4
90.
De manière générale, ζ(2k) = Ckπ2k où Ck ∈ Q. On sait peut de choses que les ζ(2k + 1). On conjecture que cesont tous des irrationnels comme ζ(3) (Apéry : 1979).
2.3 Comparaison séries - intégrales
La méthode utilisé pour la preuve de la convergence (ou divergence) des séries de Riemann peut-êtregénéralisée.
Soit f une fonction continue monotone sur R+ et 0 6 p < n.
1. Si f est croissante on a
∫ n
pf (t) dt 6
n
∑k=p+1
f (k) 6∫ n+1
p+1f (t) dt.
2. Si f est décroissante on a
∫ n+1
p+1f (t) dt 6
n
∑k=p+1
f (k) 6∫ n
pf (t) dt.
Théorème 25.2.3.844
362

Démonstration
Remarques :
1. Si f est définie sur R en entier on peut même prendre p = 0.
2. La démonstration des séries de Riemann repose sur ces cas avec f : t 7→ 1ts qui est décroissante.
3. Ces calculs sont juste les inégalités que l’on obtient en cherchant une valeur approchée d’une intégrale parla méthode des rectangle (pour un pas h = 1.)
Exemples :
1. On peut montrer la convergence (ou la divergence) des séries de Riemann en prenant la bonne inégalités.
2. Si on cherche la nature de ∑n>2
1n ln n
. On procède de même. La suite des sommes partielles est croissante
on cherche donc juste à majorer ou minorer. Comme t 7→ 1t ln t
est décroissante on est dans le deuxièmecas : ∫ n+1
3
dtt ln t
6n
∑k=3
1k ln k
6∫ n
2
dtt ln t
.
Or∫ x dt
t ln t= ln(ln x). En prenant la minoration, on montre que la série diverge.
3. Si on reprend la série précédente, on a montré la divergence mais on peut même trouver un équivalent dela suite des sommes partielles. En effet
ln(ln(n)) ∼ ln(ln(n+ 1))− ln(ln(3)) =∫ n+1
3
dtt ln t
6n
∑k=3
1k ln k
6∫ n
2
dtt ln t
= ln(ln n)− ln(ln 2) ∼ ln(ln n).
On en déduit quen
∑k=3
1k ln k
∼ ln(ln).
4. Dans le cas d’une série convergente, ce genre de méthode permet aussi de trouver un équivalent du reste(qui tend vers 0). Si on reprend la série de Riemann pour s > 1. On a pour tout n > p > 1
1s− 1
((1
p + 1
)s−1−(
1n + 1
)s−1)
=∫ n+1
p+1
dtts 6
n
∑k=p+1
1ks 6
∫ n
p
dtts =
1s− 1
((1p
)s−1−(
1n
)s−1)
.
On sait que le terme central tend vers le reste Rp quand n tend vers +∞. De plus, la limite
1s− 1
(1
p + 1
)s−16 Rp 6
1s− 1
(1p
)s−1.
On en déduit donc que
Rp ∼1
s− 1
(1p
)s−1.
Exercices :
1. Déterminer un équivalent den
∑k=1
1ks pour 0 < s < 1.
2. Montrer que la série de terme général ∑1
k ln2 kconverge et déterminer un équivalent du reste Rp.
3 Séries à termes positifs
Dans tout ce paragraphe nous supposeront que les termes de la série (les uk) sont des réels positifs. Tous lesrésultats se généralise (en adaptant) aux séries à termes négatifs en multipliant par −1.
363

3.1 Généralités
Soit ∑ un une série à termes positifs. La suite des sommes partielles est croissante.
Proposition 25.3.1.845
Démonstration : Evident.
On peut appliquer le théorème de convergence monotone.
Soit ∑ un une série à termes positif. Elle est convergente si et seulement si la suite des sommespartielles est majorée.
Proposition 25.3.1.846
En pratique on majore (ou minore) souvent par une autre série.
Soit ∑ un et ∑ vn deux séries à termes positifs. On suppose que pour tout entier n, un 6 vn.
1. Si ∑ vn converge alors ∑ un aussi et+∞
∑n=0
un 6+∞
∑n=0
vn.
2. Si ∑ un diverge alors ∑ vn aussi.
Théorème 25.3.1.847
Par contre, avec les hypothèses ci-dessus, le fait que ∑ vn diverge ne donne aucune information surla nature de la série ∑ un. De même le fait que ∑ un converge ne donne pas d’information sur lanature ∑ vn.
ATTENTION
Remarque : Comme dans le cas classique pour les suites, on peut supposer que l’inégalité un 6 vn ne soit vraiequ’à partir d’un certain rang. Cependant, on n’a plus l’information sur les sommes dans ce cas.Démonstration : Si on note Un et Vn les sommes partielles. On a donc
∀n ∈ N, Un 6 Vn.
1. Si on suppose que ∑ vn converge et si on note V = limn→+∞
Vn on en déduit que pour tout entier n,
Un 6 Vn 6 V.
De ce fait (Un) est majorée par V (et pas par Vn ce qui ne voudrait rien dire...). Comme elle est croissanteelle converge et
limn→∞
Un 6 V.
2. Si on suppose que ∑ un diverge alors nécessairement lim(Un) = +∞ car la suite des sommes partiellesest croissante. par comparaison lim(Vn) = +∞ et donc ∑ vn diverge.
Exemples :
1. Cherchons la nature ∑1
n(n + 1). On a déjà vu que l’on peut montrer que cette série est convergente (et
on peut même calculer sa somme) par un télescopage. On peut aussi dire directement,
∀n ∈ N?, 0 61
n(n + 1)6
1n2
364

or ∑1n2 est une série de Riemann convergente donc ∑
1n(n + 1)
converge (par contre ainsi on n’obtient
qu’une majoration de la somme par ζ(2)).
2. Cherchons la nature ∑n>2
1ln n
. On a pour tout entier n > 2,
0 61n6
1ln n
.
On sait que la série harmonique diverge donc ∑n>2
1ln n
diverge aussi.
Cela n’est bien évidemment plus vrai si la série n’est pas à termes positifs.
ATTENTION
3.2 Théorème de comparaison pour les séries à termes positifs
Dans le cas précédent on a vu que l’on pouvait déduire la nature de ∑ un si ∑ vn convergeait mais que l’onavait aucune information si cette dernière divergeait. On va résoudre ce problème grace à des équivalents.
Soit ∑ un et ∑ vn deux séries à termes positifs. On suppose que un ∼ vn alors ∑ un et ∑ vn sont demême nature.
Théorème 25.3.2.848 (Théorème de comparaison pour les séries à termes positifs)
Remarques :
1. Ce théorème est TRES utile. Dans la très grande majorité des cas pour étudier la nature d’une série àtermes positifs on cherche un équivalent simple (via un DL par exemple) et on en déduit ainsi sa nature.
2. On utilisera dans ce cours l’abbreviation TCPSP.
3. Il suffit que les deux séries soient positives à partir d’un certain rang.
Cela n’est plus vrai si la série n’est pas à termes positifs (ou à termes de signe constant). Par exemple
la série de terme général un =(−1)n
nconverge (voir DM? ou le faire avec les séries alternées ou la
formule de Taylor pour ln) mais la série de terme générale vn =(−1)n
n+
1n ln n
diverge (sommed’une série convergente et d’une série divergente) par contre on a bien un ∼ vn.
ATTENTION
Démonstration : Par définitionun
vn→ 1. De ce fait il existe N ∈ N tel que
∀n ∈ N, n > N ⇒ 126
un
vn6
32
(définition de la limite en prenant ε = 1/2). C’est-à-dire que
∀n ∈ N, n > N ⇒ 12
vn 6 un 632
vn
On en déduit (grace à l’inégalité de droite) que si ∑ vn converge alors ∑ un aussi. De plus, l’inégalité de gauchenous permet de dire que ∑ vn diverge alors ∑ un aussi.
On en déduit que ∑ un a la même nature que ∑ vn.
365

Remarque : On voit dans la preuve que ce qui compte est qu’il existe (m, M) ∈ R∗+ tels que, à partir d’uncertain rang,
∀n ∈ N, n > N ⇒ m 6un
vn6 M
C’est en particulier vrai siun
vna une limite finie non nulle (et pas nécessairement 1).
Exemples :
1. La série de terme général ∑3n + 2
n3 + ln nconverge car
3n + 2n3 + ln n
∼ 3n2 et que ∑
1n2 est une série de Riemann
convergente.
2. La série de terme général ∑3 + n ln nn2 + n + 1
converge car3 + n ln nn2 + n + 1
∼ ln nn
et que ∑ln n
ndiverge car
ln nn>
1n
et que cette dernière est une série de Riemann divergente.
4 Séries absolument convergentes
On a vu les critères de convergences pour les séries à termes de signe constant. Voyons un peu ce que l’onpeut faire pour des séries dont le terme général ne garde pas un signe constant (ou même des séries à termescomplexes).
4.1 Définition
Soit ∑ un une série éventuellement complexe. On dit qu’elle est absolument convergente si la série (à termesréels positifs) ∑ |un| est convergente.
Définition 25.4.1.849
Remarque : L’intérêt est que pour savoir si une série est absolument convergente, on est ramené à étudier unesérie à termes (réels) positifs.Exemples :
1. La série ∑(−1)n
nn’est pas absolument convergente car
∣∣∣∣(−1)n
n
∣∣∣∣ =1n
et que ∑1n
n’est pas convergente.
2. La série ∑cos(n)
n2 est absolument convergente car ∑∣∣∣∣cos(n)
n2
∣∣∣∣ est une série à termes positifs et que∣∣∣∣cos(n)
n2
∣∣∣∣ 61n2 cette dernière étant une série de Riemann convergente.
4.2 Applications aux séries dont le terme général n’a pas un signe constant
Le résultat principal est qu’une série complexe (ou réelle) absolument convergente est convergente.Rappels : Si x est un réel on note x+ (resp. x−) la partie positive (resp. négative) de x. C’est-à-dire que
x+ =
x si x > 00 sinon et x− =
0 si x > 0−x sinon
De ce fait on a x = x+ − x− et |x| = x+ + x−.
Soit ∑ un une série éventuellement complexe. Si elle est absolument convergente alors elle estconvergente.
Théorème 25.4.2.850
Ce n’est pas une équivalence. Par exemple ∑(−1)n
nn’est pas absolument convergente mais elle est
convergente. On dit que c’est une série semi-convergente.
ATTENTION
366

Remarque : Les séries semi-convergentes sont des objets dangereux à manipuler. En effet on peut montrerqu’en réordonnant les termes de la série on modifie la somme. Plus précisément on peut la faire tendre vers lavaleur voulue.Démonstration :
— Commençons par étudier le cas où ∑ un une série à termes réels absolument convergente. On considèreles séries à termes positifs ∑ u+
n et ∑ u−n . Comme on sait que pour tout entier n, u+n 6 |un| et u−n 6 |un|
et que ∑ |un| est une série convergente, on en déduit que ∑ u+n et ∑ u−n sont des séries convergentes. Par
linéarité on obtient alors que ∑ un est une série convergente.
— On suppose que ∑ un une série à termes complexes absolument convergente. On considère les sériesà termes réels ∑Re(un) et ∑ Im(un). Là encore on sait que |Re(un)| 6 |unl et |Im(un)| 6 |unl. Lesséries ∑Re(un) et ∑ Im(un) sont donc des séries à termes réels absolument convergentes. D’après cequi précède, elles convergent. On en déduit que ∑ un converge par linéarité.
Soit ∑ un une série à termes (éventuellement) complexes et ∑ vn une série à termes réels positifs.On suppose que
— on a un = O(vn)
— la série ∑ vn converge
Alors la série ∑ un est absolument convergente (donc convergente).
Corollaire 25.4.2.851
Démonstration : Ce sont les même arguments que précédemment. Remarques :1. Si on a un = o(vn) cela marche encore car cela implique que un = O(vn).2. On utilise souvent ce critère avec les séries de Riemann. En particulier si la série ∑ un vérifie qu’il existe
α STRICTEMENT supérieur à 1 tel que nαun est bornée (ce qui est vrai si elle a une limite finie) alors
un = O(
1nα
)et donc ∑ un converge.
Remarque : C’est la méthode la plus classique pour démontrer la convergence d’une série qui n’est pas àtermes positifs.
5 Représentation décimale des réels
On veut définir la représentation décimale des réels. Précisément, on va montrer que l’on peut écrire tous lesréels positifs sous une forme d’une suite infinie de la forme
x = α0 ++∞
∑n=1
αn
10n où α0 ∈ N et ∀n > 1, αn ∈ [[ 0 ; 9 ]] .
Par exemple
π = 3 +110
+4
100+
11000
+ · · ·Remarque : On va restreindre les chiffres. En effet si on prend ∀n ∈ N∗, αn = 9 on obtient le nombre 1 :
0, 999999 · · · = 1.
Pour s’en convaincre il suffit de calculer la limite des sommes partielles (séries géométriques) où de voir que10x− x = 9.
On appelle développement décimal la donnée d’une suite (αn) telle que
α0 ∈ N et ∀n > 1, αn ∈ [[ 0 ; 9 ]] .
Si de plus, la suite n’est pas stationnaire à 9 on dit que le développement décimal est propre.
Définition 25.5.0.852
367

Notation : On notera D l’ensemble des développements décimaux propres.
Tout nombre réel positif admet un unique développement décimal propre. C’est-à-dire que l’applica-tion
ϕ : D → R+
(αn) 7→+∞
∑n=0
αn
10n
est une bijection.
Théorème 25.5.0.853
Remarque : On peut commencer par voir que la série est clairement convergente car ∀n ∈ N∗, αn 6 10.Démonstration :
— Pour la surjectivité (ou l’existence) il suffit d’utiliser le développement décimal par défaut en remplaçantune éventuelle suite stationnaire à 9 par une suite stationnaire à 0 avec « une retenue ».
— Pour l’injectivité (ou l’unicité) on suppose se donner deux développements décimaux propres distincts(αn) et (βn) et on va montrer que
+∞
∑n=0
αn
10n 6=+∞
∑n=0
βn
10n .
Notons p le plus petit entier tel que αp 6= βp et, par symétrie on peut supposer que αp > βp. On va alorsmontrer que
A =+∞
∑n=p
αn
10n −+∞
∑n=p
βn
10n > 0.
On a A =αp − βp
10p ++∞
∑n=p+1
αn − βn
10n où, pour tout n > p + 1, −9 6 αn − βn 6 9. De plus, les développe-
ments étant propres, il existe q > p + 1 tel que |αq − βq| 6 8. On en déduit alors que∣∣∣∣∣
+∞
∑n=p+1
αn − βn
10n
∣∣∣∣∣ 6+∞
∑n=p+1
αn − βn
10n
=+∞
∑p+16n
n 6=q
910n +
810q
6+∞
∑n=p+1
910n −
1q
<+∞
∑n=p+1
910n =
110p
Or αp − βp > 1 donc A > 0.On en déduit que ϕ(αn) 6= ϕ(βn) et donc ϕ injective.
368

26Matrices
1 Définitions 3691.1 Motiviation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3691.2 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3701.3 L’espace vectoriel Mn,p(K) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3711.4 Produit de matrices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3721.5 Produit dans Mn(K) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3731.6 Transposition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3751.7 Quelques matrices particulières . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3751.8 Calculs par blocs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 378
2 Matrices et applications linéaires 3792.1 Matrice d’une famille de vecteurs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3792.2 Application linéaire canoniquement associée à une matrice . . . . . . . . . . . . . . . . . . . 3802.3 Matrice d’une application linéaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3822.4 Propriétés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3832.5 Cas des endomorphismes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 384
3 Changements de bases 3853.1 Matrices de changement de bases . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3853.2 Changement de base des applications linéaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3873.3 Trace d’un endomorphisme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 390
4 Rang d’une matrice 3904.1 Définition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3904.2 Calcul du rang - Opérations élémentaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 393
5 Applications aux systèmes linéaires 3945.1 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3945.2 Determination de l’inverse d’une matrice . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 395
Dans ce chapitre K désigne R ou C.
1 Définitions
1.1 Motiviation
On a vu dans le chapitre sur les applications linéaires que si E et F sont des espaces vectoriels de dimensionfinie (dim E = p, dim F = n) et si on se fixait des bases (e1, . . . , ep) et ( f1, . . . , fp) de E et F respectivement alors
369

une application linéaire de E dans F était uniquement déterminée par la donnée de scalaires (aij)16i6n16j6p
. On va
donc stocker ses scalaires dans un tableau à deux dimensions que nous appellerons matrice.
1.2 Définitions
Soit (n, p) ∈ (N?)2. On appelle matrice à n lignes et p colonnes et à coefficients dans K, la donnée d’uneapplication de [[ 1 ; n ]]× [[ 1 ; p ]] dans K. On dit que c’est une matrice de taille n, p.Cela revient à se donnerune famille (aij) d’éléments de K indexée par [[ 1 ; n ]]× [[ 1 ; p ]] en convenant que aij est l’image de (i, j) parl’application.
Définition 26.1.2.854
Notations :
1. On représente une matrice à n lignes et p colonnes, sous la forme d’un tableau à n lignes et p colonnes :
A =
a11 · · · a1p...
...an1 · · · anp
.
On note aussi A = (aij)16i6n16j6p
.
2. L’ensemble des matrices à n lignes et p colonnes à coefficient dans K se note Mn,p(K).
3. Si n = p, on dit que la matrice est carrée. L’ensemble des matrices carrées de taille n se note Mn(K).
4. Les nombres (aij) s’appellent les coefficients de la matrice.
5. On a coutume de désigner les matrices par des lettres majuscules : A, B, C, M, N, P, . . . .
6. On appelle j-ème colonne de la matrice A la matrice colonne Cj =
a1j...
anj
. On appelle i-ème ligne de la
matrice A la matrice la matrice ligne Li =(
ai1 · · · aip)
.
Exemples :
1. La matrice A =
(1 −1 02 3 7
)∈M2,3(R).
2. Si on prend n = 1, on a alors les matrices composées d’une seule ligne. On parle de matrice ligne. Parexemple A =
(1 −1 7 5
)∈M1,4(R).
3. Si on prend p = 1, on a alors les matrices composées d’une seule colonne. On parle de matrice colonne.
Par exemple A =
10−7
∈M3,1(R). On voit ainsi que l’on peut identifier Kn à Mn,1(K) et K à M1(K).
4. On note 0 (ou 0 ou 0Mn,p(K)) la matrice dont tous les coefficients sont nuls. On l’appelles la matrice nulle.
5. Soit (i, j) ∈ [[ 1 ; n ]]× [[ 1 ; p ]] . On note Eij la matrice dont tous les coefficients sont nuls sauf celui qui esten position (i, j). On a donc pour tout (α, β) ∈ [[ 1 ; n ]]× [[ 1 ; p ]] , aαβ = δα,iδβ,j.
6. Soit n ∈ N?. On appelle matrice identité et on note I (ou In) la matrice carrée dont tous les termes sontnuls sauf les termes diagonaux qui valent 1. On a
∀(i, j) ∈ [[ 1 ; n ]]2 , aij =
1 si i = j0 sinon.
On a
In =
1 0 · · · 0
0. . . . . .
......
. . . . . . 00 · · · 0 1
.
370

1.3 L’espace vectoriel Mn,p(K)
Soit n et p deux entiers non nuls.
Soit (A, B) ∈Mn,p(K)2. On note (aij) et (bij) leurs coefficients respectifs. On définit la somme C ∈Mnp(K)que l’on note A + B comme la matrice dont les coefficients (cij) vérifient :
∀(i, j) ∈ [[ 1 ; n ]]× [[ 1 ; p ]] , cij = aij + bij.
Définition 26.1.3.855 (Somme)
Remarques :
1. Cela correspond à la somme des applications.
2. Pour pouvoir faire la somme de deux matrices elles doivent avoir la même taille.
3. Cela consiste à faire la somme terme à terme. En particulier on retrouve la somme dans Kn pour lesmatrices Mn,1.
Exemple : On a (1 2 −10 2 9
)+
(4 0 2−2 0 −7
)=
(5 2 1−2 2 2
).
Soit A ∈Mn,p(K). On note (aij) ses coefficients. Soit λ ∈ K. On définit le produit λ.A comme la matricedont les coefficients (cij) vérifient :
∀(i, j) ∈ [[ 1 ; n ]]× [[ 1 ; p ]] , cij = λ.aij.
Définition 26.1.3.856 (Produit externe)
Remarques :
1. C’est encore la multiplication externe des applications.
2. Cela consiste à multiplier tous les termes de la matrice par λ. En particulier on retrouve le produit externedans Kn pour les matrices Mn,1.
Exemple : On a
(−2).(
1 2 −10 2 9
)=
( −2 −4 20 −4 −18
).
Les opérations ci-dessus munissent Mn,p(K) d’une structure d’espace vectoriel.
Théorème 26.1.3.857
Remarque : C’est juste une autre écriture de l’espace vectoriel F (X, K) où X = [[ 1 ; n ]]× [[ 1 ; p ]] .
Les matrices (Eij) pour (i, j) ∈ [[ 1 ; n ]]× [[ 1 ; p ]] forment une base de Mnp(K) que l’on appelle labase canonique. En particulier,
dim Mnp(K) = np.
Proposition 26.1.3.858
Démonstration : Cette famille engendre bien Mnp(K). En effet, pour toute matrice A. Si on note A = (aij)16i6n16j6p
.
AlorsA = ∑
16i6n16j6p
aijEij.
371

De plus, cette famille est aussi libre. Car si (λij)16i6n16j6p
est une famille de scalaire telle que ∑16i6n16j6p
λijEij = 0 alors
∀(i, j) ∈ [[ 1 ; n ]]× [[ 1 ; p ]] , λij = 0. C’est bien une base.
Exercice : Montrer que (1 11 1
),(
1 00 1
),(
1 00 −1
),(
0 20 0
)
est une base de M2(K).
1.4 Produit de matrices
Notre but est de définir le produit de deux matrices. On pourrait penser que le plus simple est de définir leproduit comme le le produit termes à termes ce qui correspondrait au produit classique pour les applicationsd’un ensemble X dans un corps K. Cependant, on va définir le produit autrement. La raison est que l’on veutqu’il corresponde à la composition des applications linéaires.
Soit (n, p, q) ∈ (N?)3, A ∈Mnp(K) et B ∈Mpq(K). Le produit AB est la matrice C ∈Mnq(K) dont lescoefficients (cij)16i6n
16j6psont donnés par :
∀(i, j) ∈ [[ 1 ; n ]]× [[ 1 ; q ]] , cij =p
∑k=1
aikbkj.
Définition 26.1.4.859
Pour pouvoir faire le produit AB, la matrice A doit avoir autant de colonne que B de lignes. Enparticulier, si A et B sont de même taille, on ne peut faire le produit AB que si A et B sont carrées.On en déduit que le produit n’est une loi de composition interne que dans Mn(K).
ATTENTION
Le produit matriciel vérifie les propriétés suivantes :
1. Il est associatif.
2. Il est distributif à droite et à gauche.
Proposition 26.1.4.860 (Propriétés du produit matriciel)
Démonstration : Nous le démontrerons plus tard.Exemples :
1. Calculer dans M3(K) les produits E11E12, E13E23 et E12E21.2. Soit (i, j, k, l) quatre entiers. On a
EijEkl = δjkEik
Remarque : Si on considèreϕ : Mn,p(K)×Mp,q(K) → Mn,q(K)
(A, B) 7→ AB
La distributivité à gauche (avec la compatibilité au produit externe) dit que pour toute matrice A, l’application
ϕ(A, •) : Mn(K) → Mn(K)B 7→ AB
est linéaire. De même, la distributivité à droite (avec la compatibilité au produit externe) dit que pour toutematrice B, l’application
ϕ(•, B) : Mn(K) → Mn(K)A 7→ AB
est aussi linéaire. On dit que ϕ est bilinéaire.
372

1.5 Produit dans Mn(K)
Soit A et B deux matrices de Mn(K). On dit que A et B commutent si AB = BA.
Définition 26.1.5.861
Exemples :1. On a (
2 1 00 1 −1
).
3 0 21 −1 24 1 2
=
(7 −1 6−3 −2 0
).
2. On appelle matrice scalaire toute matrice de la forme λIn pour λ ∈ K. Soit A ∈ Mn(K) on a alors(λIn)× A = A× (λIn). En particulier, les matrices scalaires commutent à toutes les matrices.
Exercices :1. Calculer AB et BA pour
A =
(2 1 01 −1 0
)et B =
4 10 02 −4
.
2. Factoriser A + AB et A + BA.3. Soit A ∈ Mn(K). Montrer que si A commutent à toutes les matrices de Mn(K) alors c’est une matrice
scalaire. On pourra calculer AEij et Eij A.
Les opérations définissent ci-dessus munissent (Mn(K),+,×) d’une structure d’anneau et(Mn(K),+,×, .) d’une structure de K-algèbre.
Proposition 26.1.5.862
Démonstration : On peut, là encore, tout démontrer « à la main ». Cependant, nous verrons un peu plus loinune méthode pour l’éviter. Nous repoussons donc la démonstration à plus tard.
Remarque : L’élément neutre de Mn(K) est la matrice identité In. On vérifie en effet que A× In = In × A = A.
Soit A ∈ Mnp(K) et pour tout i ∈ [[ 1 ; n ]] on note Xj =
0...10...0
∈ Mn1(K) où le 1 est à la j-ème
ligne. Le produit AXi est la matrice colonne qui est la j-ème colonne de la matrice A. En particuliersi A et B sont deux matrices de Mnp(K) telles que ∀j ∈ [[ 1 ; p ]] , AXj = BXj alors A = B.
Proposition 26.1.5.863
Démonstration
Exercice : Faire la même chose pour les lignes.
Soit A une matrice de Mn(K). Elle est dite inversible si elle l’est dans l’anneau Mn(K) c’est-à-dire, s’il existeune matrice B telle que
AB = BA = In.
Dans ce cas, l’inverse (qui est unique) est noté A−1. L’ensemble des matrices inversibles de Mn(K) se noteGLn(K).
Définition 26.1.5.864
373

Remarque : Nous verrons plus loin que AB = In ou BA = In est suffisant pour que A soit inversible (etB = A−1).
Exemple : La matrice(
1 10 −1
)est inversible alors que
(1 3−2 −6
)ne l’est pas.
Remarques :1. On voit qu’il existe des matrices non nulles qui ne sont pas inversibles donc Mn(K) n’est pas un corps
(sauf si n = 1).
2. Les matrices n’étant pas un anneau commutatif (sauf si n = 1) il ne faut pas noter1A
l’inverse de A.
3. Le fait qu’une matrice A soit inversible signifie que le système linéaire qu’elle représente est inversible (deCramer). Nous y reviendrons.
Soit A et B deux matrices inversibles. La matrice AB est inversible et (AB)−1 = B−1 A−1.
Proposition 26.1.5.865
Démonstration
L’ensemble des matrices inversibles est un groupe multiplicatif (GLn(K),×) dont l’élément neutreest In. Ce n’est pas un groupe abélien sauf si n = 1.
Corollaire 26.1.5.866
Soit (A, B) ∈Mn(K)2 et n un entier. Si A et B commutent,
(A + B)n =n
∑p=0
(np
)ApBn−p.
Proposition 26.1.5.867 (Formule de binôme de Newton)
Démonstration : On est dans un anneau.
Exemple : Soit A =
(2 10 2
). On veut calculer An. On remarque que A = 2I + N où N =
(0 10 0
). Or
N2 = 0 et donc ∀p > 2, Np = 0. On dit que N est nilpotente.Comme 2I et N commutent car 2I est une matrice scalaire. On a donc pour tout entier naturel n,
An =n
∑p=0
(np
)Np(2I)n−p = (2I)n + n(2I)n−1N =
(2n n2n−1
0 2n
).
On remarque que si on fait n = −1 dans la formule, on obtient(
1/2 −1/40 1/2
). On vérifie alors que A est
inversible et que A−1 =
(1/2 −1/4
0 1/2
).
Soit MMn(K) et P ∈ K[X]. On note P =d
∑k=0
akXk. On note
P(M) =d
∑k=0
ak Mk.
Définition 26.1.5.868
374

L’opération ci-dessus est compatible aux structures d’algèbre de K[X] et de Mn(K) c’est-à-dire.
1. ∀(P, Q) ∈ K[X], ∀M ∈Mn(K), (P + Q)(M) = P(M) + Q(M).
2. ∀(P, Q) ∈ K[X], ∀M ∈Mn(K), (P×Q)(M) = P(M)×Q(M).
3. ∀P ∈ K[X], ∀λ ∈ K, ∀M ∈Mn(K), (λP)(M) = λ(P(M)).
Proposition 26.1.5.869
Exemple : Soit
A =
0 1 −1−3 4 −3−1 1 0
.
En calculant les premières puissances de A on se rend compte que A2 − 3A + 2I = 0..On peut en déduire que A est inversible. En effet A(A − 3I) = −2I. D’où A est inversible et A−1 =
12(−A + 32I).
De plus on peut en déduire que pour tout entier n, il existe (an, bn) ∈ Rn tels que An = an A + bn I. Cela sefait par récurrence ou en utilisant une division euclidienne.
1.6 Transposition
Soit A ∈Mnp(K). On note (aij) les coefficients de A. On appelle transposée de A et on note tA la matrice deMpn(K) dont les coefficients (bij) sont données par :
∀(i, j) ∈ [[ 1 ; p ]]× [[ 1 ; n ]] , cij = aji.
Définition 26.1.6.870
Remarque : La transposée est donc obtenue par symétrie.
Exemple : Soit A =
(1 2 −10 2 9
). On a tA =
1 02 2−1 9
.
Voici les propriétés de la transposition.
1. La transposition est involutive : ∀A ∈Mnp(K), t(tA)= A.
2. La transposition est linéaire : ∀(A, B) ∈ (Mnp(K))2, ∀(λ, µ) ∈ K2, t(λ.A + µ.B) = λ.tA + µ.tB.
3. Soit n, p, q trois entiers. Soit A ∈Mpq(K) et B ∈Mnp(K) on a t(AB) = t(B)t(A).
Proposition 26.1.6.871
Démonstration
1.7 Quelques matrices particulières
Dans ce paragraphe on fixe un entier n et on s’intéresse à des matrices de E = Mn(K).
375

Matrices triangulaires
Soit A ∈Mn(K). La matrice est dite triangulaire supérieure (resp. inférieure) si les coefficients « sous »(resp.« au dessus de ») la diagonale sont nuls. C’est-à-dire :
∀(i, j) ∈ [[ 1 ; n ]]2 , (i > j)⇒ aij = 0 (resp. (i < j)⇒ aij = 0).
On note Tn(K) l’ensemble des matrices de E qui sont triangulaires supérieures.
Définition 26.1.7.872 (Matrices triangulaires)
Exemple : La matrice
1 2 30 5 00 0 −5
est triangulaire supérieure.
1. L’ensemble Tn(K) est un sous-espace vectoriel de E. Il est de dimensionn(n + 1)
2.
2. L’ensemble Tn(K) est stable par produit. C’est un sous-anneau de E.
Proposition 26.1.7.873
Remarque : On dit alors que Tn(K) est une sous-algèbre de Mn(K).
Démonstration
Matrices diagonales
Soit A ∈ Mn(K). La matrice est dite diagonale si les coefficients en dehors de la diagonale sont nuls.C’est-à-dire :
∀(i, j) ∈ [[ 1 ; n ]]2 , (i 6= j)⇒ aij = 0.
Il existe donc (λ1, · · · , λn) tels que
A =
λ1 0 · · · 0
0. . . . . .
......
. . . . . . 00 · · · 0 λn
.
Si de plus tous les λi sont égaux, la matrice est dite scalaire. Elle est alors de la forme λ.In pour λ ∈ K.On note Dn(K) l’ensemble des matrices diagonales de E.
Définition 26.1.7.874 (Matrices diagonales et matrices scalaires)
Remarque : Toutes la matrices scalaires sont diagonales mais il existe des matrices diagonales qui ne sont passcalaires.
L’ensemble Dn(K) est un sous-espace vectoriel de E de dimension n. Il est stable par produit, c’estune sous-algèbre de Mn(K).
Proposition 26.1.7.875
Démonstration
376

Matrices symétriques et anti-symétriques
Soit A ∈Mn(K). La matrice est dite symétrique (resp. antisymétrique) tA = A (resp. tA = −A). C’est-à-dire :
∀(i, j) ∈ [[ 1 ; n ]]2 , aij = aji (resp. aij = −aji).
En particulier, les termes diagonaux d’une matrice antisymétrique sont nuls. On note Sn(K) l’ensemble desmatrices symétriques de E et An(K) l’ensemble des matrices antisymétriques de E.
Définition 26.1.7.876 (Matrices symétriques et anti-symétriques)
Exemple : La matrice
1 2 32 5 03 0 −5
est symétrique. La matrice
0 2 −3−2 0 03 0 −5
est antisymétrique.
On considère f l’endomorphisme transposé de Mn(K) dans lui même.
1. On a Sn(K) = Ker ( f − Id) et An(K) = Ker ( f + Id).
2. L’endomorphisme f est la symétrie par rapport à Sn(K) parallèlement à An(K). En particulièreSn(K)⊕An(K) = E.
3. On a dim(Sn(K)) =n(n + 1)
2et dim An(K) =
n(n− 1)2
.
Proposition 26.1.7.877
Remarques :
1. La décomposition d’une matrice A en somme d’une matrice symétrique et d’une matrice antisymétriques’écrit :
A =12(
A + tA)+
12(
A− tA)
.
2. Pour toute matrice A, la matrice tAA est symétrique.
Trace d’une matrice
Soit A ∈Mn(K). On appelle trace de A et on note tr (A) le scalaire
tr (A) =n
∑k=1
akk.
C’est la somme des coefficients diagonaux.
Définition 26.1.7.878 (Trace)
L’applicationtr : Mn(K) → K
A 7→ tr (A)
est une forme linéaire sur Mn(K).
Proposition 26.1.7.879
Démonstration
Remarque : En particulier, comme l’application trace n’est pas l’application nulle car tr (In) = n, l’ensembledes matrices de trace nulle est un hyperplan de E.
377

Soit A et B deux matrices de Mn(K), tr (AB) = tr (BA).
Proposition 26.1.7.880
Démonstration : Fixons les notations. On note A = (aij) et B = (bij). Posons alors AB = (cij) et BA = (dij) desorte que
∀(i, j) ∈ [[ 1 ; n ]]2 , cij =n
∑k=1
aikbkj et dij =n
∑k=1
bikakj.
Dès lors
tr (AB) =n
∑i=1
cii =n
∑i=1
n
∑k=1
aikbki =n
∑k=1
n
∑i=1
bkiaik =n
∑k=1
dkk = tr (BA).
1.8 Calculs par blocs
Exemple : Commençons par un exemple. On considère les matrices suivantes :
M =
2 1 −10 −1 32 1 3
et M′ =
1 −12 −11 1
On peut poser les blocs suivants :
A =
(2 10 −1
), B =
( −13
), C =
(2 1
)et D =
(3)
et on écrit
M =
(A BC D
)
De même si on pose
A′ =(
12
), B′ =
( −1−1
), C′ =
(1)
et D′ =(
1)
et on écrit
M′ =(
A′ B′
C′ D′
)
Maintenant on peut voir que le produit MM′ peut se calculer par la formule :
MM′ =(
AA′ + BC′ AB′ + BD′
CA′ + DC′ CB′ + DD′
).
Soit (n, p) ∈ (N∗)2 et M ∈ Mnp(K) = (mij). Si on se donne n1 ∈ [[ 2 ; n− 1 ]] et p1 ∈ [[ 2 ; p− 1 ]]. Onpose
A = (mij)16i6n116j6p1
, B = (mi,j) 16i6n11+p16j6p
, C = (mij)1+n16i6n16j6p1
, D = (mi,j)n1+16i6n1+p16j6p
.
On note alors
M =
(A BC D
)
Définition 26.1.8.881
378

Soit M et M′ deux matrices appartenant respectivement à Mnp(K) et Mpq(K). Soit n1, p1, q1 permet-tant de définir des blocs :
M =
(A BC D
)et M′ =
(A′ B′
C′ D′
)
Le produit MM′ est alors donné par
MM′ =(
AA′ + BC′ AB′ + BD′
CA′ + DC′ CB′ + DD′
).
Théorème 26.1.8.882 (Produit par blocs)
Remarques :
1. Le terme p1 qui définit le nombre de colonnes de A est le même que celui qui définit le nombre de lignesde A′ afin que le produit AA′ existe.
2. Cela se généralise de manière naturelle à des découpages autres que ceux avec 4 blocs. Par exemples(
AB
)C =
(ACBC
).
3. Nous reviendrons sur la signification géométrique de ce calcul.
2 Matrices et applications linéaires
2.1 Matrice d’une famille de vecteurs
Soit B = (e1, . . . , ep) une base d’un espace vectoriel E et v un vecteur de E. On appelle matrice de v dans labase B et on note MatB(v) la matrice des coefficients du vecteur v exprimés dans la base B. C’est à dire quel’on pose
MatB(v) = (ai) où v = a11e1 + · · · apep.
Définition 26.2.1.883 (Matrice d’un vecteur dans une base)
Remarques :
1. La matrice dépend de la base choisie.
2. La matrice d’un vecteur est un vecteur colonne.
3. On construit ainsi une application :
E → Mn1(K)v 7→ MatE (v).
Cette application associe à un vecteur v la matrice de ses coordonnées dans la base E . On peut voir quec’est un isomorphisme. On peut même en déduire un isomorphisme E dans Kn en voyant la matricecolonne comme un élément de Kn.
4. Quand la base est évidente (en particulier pour la base canonique de Kn) on notera juste Mat(v).
Si on considère un vecteur u = (a1, . . . , ap) de Kp. Il ne faut pas confondre la notation (a1, . . . , ap)
qui est intrinsèque et qui définit le vecteur, de la notation
a1...
an
qui sont ses coordonnées dans la
base canonique. Si on change de base, ses coordonnées changeront aussi.
ATTENTION
379

Exemple : Dans R2. On considère w = (3,−1). On a
Matcan(w) =
(3−1
)et MatB(w) =
(12
)
où B = ((1, 1), (1,−1)).
Soit E = (e1, . . . , en) une base de E et (v1, . . . , vp) ∈ Ep une famille de vecteurs de E. On appelle matricede la famille (v1, . . . , vp) dans la base E et on note MatE (u1, . . . up) la matrice des coefficients des vecteursv1, . . . , vp exprimés dans la base E . C’est à dire que l’on pose
MatE (u1, . . . up) = (aij) où ∀j ∈ [[ 1 ; p ]] , vj = a1ju1 + · · · anjun.
Définition 26.2.1.884
Exemple : Dans R4 on considère les vecteurs v1 = (3, 0, 1, 1), u2 = (3,−1,−1, 0) et u3 = (5, 1, 1, 2). Alors
Mat(u1, u2, u3) =
3 3 50 −1 11 −1 11 0 0
.
Remarques :1. La matrice dépend de la base choisie.
2. Quand la base est évidente, on notera seulement Mat(u1, . . . up).
2.2 Application linéaire canoniquement associée à une matrice
Nous allons construire, pour chaque matrice, une application linéaire qui lui sera associée.
Soit (n, p) ∈ (N?)2 et A ∈Mnp(K). On note (aij)16i6n16j6p
. On note (ej)pj=1 la base canonique de Kp et ( fi)
ni=1
la base canonique de Kn. On appelle application linéaire canoniquement associée à A l’unique applicationlinéaire f de Kp dans Kn telle que
∀j ∈ [[ 1 ; p ]] , f (ej) =n
∑i=1
aij fi.
Définition 26.2.2.885
Exemple : Soit A =
(4 0 2−2 0 −7
). On lui associe l’application linéaire de K3 dans K2 définie par
f (1, 0, 0) = (4,−2), f (0, 1, 0) = (0, 0) et f (0, 0, 1) = (2,−7).
On a donc∀(x, y, z) ∈ K3, f (x, y, z) = (4x + 2z,−2x− 7z).
L’application F ainsi définie de Mnp(K) dans L (Kp, Kn) est un isomorphisme d’espace vectoriel.
Proposition 26.2.2.886
Démonstration : Montrons d’abord que c’est une application linéaire. Soit A et B deux matrices de Mnp(K) etλ, µ deux scalaires. Notons C = λA + µB. L’application F(C) est définie par
∀j ∈ [[ 1 ; p ]] , f (ej) =n
∑i=1
λaij + µbij fi.
380

L’application λF(A) + µF(B) aussi. De ce fait on a bien
F(λA + µB) = λF(A) + µF(B).
Montrons maintenant que c’est un isomorphisme. Pour cela nous allons exhiber une application réciproqueG de L (Kp, Kn) dans Mnp(K). Soit f dans L (Kp, Kn). Pour tout i ∈ [[ 1 ; p ]], le vecteurs f (ei) se décomposedans la base ( f j). On note, pour tout i dans [[ 1 ; p ]]
f (ei) =n
∑j=1
aij f j.
On pose alors G( f ) = (aij). On voit bien que F G est l’application identité de L (Kp, Kn).
Soit (n, p) ∈ (N∗)2 et A ∈Mnp(K). Pour tout x de Kp,
Mat(a(x)) = A.Mat(x)
Proposition 26.2.2.887
Démonstration : Le produit matriciel est fait pour...
Remarque : En identifiant Kn et Kp à Mn1(K) et Mp1(K) on voit que a est en fait l’application
X 7→ A.X
Soit (n, p, q) ∈ (N?)3 trois entiers, A ∈ Mnp(K) et B ∈ Mpq(K). On note a et b les applicationscanoniquement associées à A et B. L’application canoniquement associée à AB est a b.
Proposition 26.2.2.888
Remarques :1. Cette proposition est fondamentale. Elle explique la définition du produit matriciel.
2. D’après les définitions, a ∈ L (Kp, Kn) et b ∈ L (Kq, Kp) donc a b est bien définie et appartient àL (Kp, Kn).
Démonstration : Si on note c l’application canoniquement associée à AB. Pour tout vecteur x de Kp,
Mat(c(x)) = AB.Mat(x) = A.Mat(b(x)) = Mat(a(b(x)).
On a donc que pour tout vecteur x, c(x) = (a b)(x) et donc x = a b.
Cela permet d’en déduire que Mn(K) est bien un anneau.
Corollaire 26.2.2.889
Démonstration : Montrons par exemple que la multiplication est distributive à gauche à savoir :
∀(A, B, C) ∈Mnp(K)×Mpq(K)×Mpq(K), A× (B + C) = A× B + A× C.
On considère a, b et c les applications canoniques associées à A, B et C. D’après ce qui précède,
F(A× (B + C)) = a (b + c) = a b + a c (par linéarité)
De plusF(A× B + A× C) = a b + a c.
Comme F est injective, on a la propriété voulue.
381

Soit (n, p) ∈ (N?)2 et A ∈Mnp(K) on appelle noyau de A (resp. image de A) et on note Ker A (resp. Im A)le noyau (resp. l’image) de l’application linéaire canoniquement associée a. De plus, on considère souventKer A (resp. Im A) comme un sous-espace vectoriel de Mp1(K) (resp. de Mn1(K)) via l’identification de Kp
avec Mp1(K).
Définition 26.2.2.890
Remarque : On a donc que Ker A est l’ensemble des X ∈ Mp1(K) tels que AX = 0. A l’inverse Im A estl’ensemble de B ∈ Mn1(K) tel qu’il existe X ∈ Mp1(K) tels que AX = B. Cela revient à dire que Im A =Vect(C1, . . . , Cp) où C1, . . . , Cp sont les colonnes de A.
2.3 Matrice d’une application linéaire
On a vu que l’on pouvait associer à une matrice une application linéaire. On va montrer que réciproquement,on peut associer à toute application linéaire entre deux espaces vectoriels de dimension finie une matrice.
Soit E et F deux espaces vectoriels de dimension finie. Soit E = (e1, . . . , ep) et F = ( f1, . . . , fn) des bases deE et de F. A toute application linéaire u de E dans F on associe la matrice MatE ,F (u) = (aij) ∈Mnp(K)où les (aij) sont tels que
∀j ∈ [[ 1 ; p ]] , u(ej) =n
∑i=1
aij fi.
Définition 26.2.3.891 (Matrice associée à une application linéaire)
Remarques :
1. La matrice d’une application est donc les matrices des coordonnées dans la base F des images desvecteurs de la base E par u.
2. Cette construction est bien la réciproque de l’application linéaire canonique associée à une matrice. Lamatrice associée dans les bases canoniques à l’application linéaire canonique associée à une matrice est lamatrice dont on est parti.
3. En reprenant les notations du paragraphe précédent on a donc
MatE ,F (u) = MatF (u(e1), . . . , u(ep)).
B La matrice définie ci-dessus dépend des bases E et F comme nous allons le voir sur des exemples.Cependant, si les bases sont évidentes, nous les omettrons dans la notation.Exemples :
1. Soit u : (x, y) 7→ (2x + y, x− y, 3x). On cherche sa matrice dans les bases canoniques. On trouve
Matcan,can(u) =
2 11 −13 0
.
Maintenant on peut changer la base de R2 voulue. Si on considère B = (u, v) où u = (1, 1) et v = (1,−1)alors B est une base et
MatB,can(u) =
3 10 23 3
.
2. Soit v : (x, y, z) 7→ 12(x − y− z,−x + y− z, 2z). On cherche sa matrice dans les bases canoniques. On
trouve
Matcan,can(v) =12
1 −1 −1−1 1 −10 0 1
.
382

On peut déterminer non noyau et son image. On trouve Ker v = Vect(1, 1, 0) et Im v = (x, y, z) ∈R3 | x + y + z = 0 = Vect(1, 0,−1), (0, 1,−1). On remarque alors que Ker v et Im v sont supplé-mentaires et que v|Im v = Id. On en déduit que v est un projecteur et sa matrice dans la base B =
((1, 1, 0), (1, 0,−1), (0, 1,−1)) est
MatB,B(v) =
0 0 00 1 00 0 1
.
Ici on a encore pris B comme base « à l’arrivée ».3. Soit ∆ : R3[X]→ R3[X] définie par ∆(P) = P′. Sa matrice dans les bases canoniques est
Mat(∆) =
0 1 0 00 0 2 00 0 0 30 0 0 0
.
4. Soit E = Rn[X] et f la forme linéaire définie par
f (P) =∫ 1
0P(t) dt.
Sa matrice dans la base canonique est
( 1 1/2 · · · 1/(n + 1) ).
Exercice : Soit T : R3[X]→ R3[X] définie par T(P) = P(X + 1). Écrire sa matrice dans les bases canoniques.
2.4 Propriétés
La matrice d’une application linéaire permet de calculer « en coordonnées » l’image d’un vecteur parl’application linéaire.
Soit E et F deux espaces vectoriels de dimension finie. Soit E = (e1, . . . , ep) et F = ( f1, . . . , fn) desbases de E et de F. Soit u une application linéaire de E dans F et w un vecteur de E. On a
MatF (u(w)) = MatE ,F (u).MatE (w).
Théorème 26.2.4.892
Remarques :1. Il est important de prendre les bonnes bases pour E et pour F.2. De fait la connaissance de la matrice permet de faire les calculs.3. La formule de calcul de l’image d’une application linéaire par voie matricielle s’étend au cas d’une famille
de vecteurs. Précisément on a pour tout famille (w1, . . . , wk) de vecteurs de E,
MatF (u(w1), . . . , u(wk)) = MatE ,F (u)×MatE (w1, . . . , wk).
Démonstration : Il suffit de faire le calculExemples :
1. On reprend l’exemple 1. : u : (x, y) 7→ (2x + y, x− y, 3x). Sa matrice dans les bases canoniques est
Matcan,can(u) =
2 11 −13 0
.
Si on prend w = (3,−1) le calcul donne bien u(w) = (5, 4, 9).De même avec B = (u, v) où u = (1, 1) et v = (1,−1) alors B est une base et
MatB,can(u) =
3 10 23 3
.
Le calcul marche encore.
383

2. Calculons la dérivée de P = 2 + 3X− 4X3 avec sa matrice.... (à faire)
Soit E et F deux espaces vectoriels de dimension finie. Soit E = (e1, . . . , ep) et F = ( f1, . . . , fn) desbases de E et de F. L’application
MatE ,F : L (E, F) → Mnp(K)u 7→ MatE ,F (u).
est un isomorphisme.
Proposition 26.2.4.893
Démonstration :— Montrons d’abord qu’elle est linéaire (à faire). Il suffit de considérer les colonnes des matrices...— Montrons qu’elle est injective. Une application linéaire qui s’annule sur une base est nulle.— On utilise alors que dim L (E, F) = dim Mnp(K) = np pour conclure que c’est un isomorphisme.
Soit E, F et G trois espaces vectoriels munis de bases E , F et G . Soit v ∈ L (E, F) et u ∈ L (F, G) ona
MatE ,G (u v) = MatF ,G (u)×MatE ,F (v).
Proposition 26.2.4.894
Remarque : Il faut faire attention aux bases.Démonstration : Il suffit de remarquer que pour toute matrice colonne X. On note w le vecteur de E tel queX = MatE (w). On a alors
MatE ,G (u v).X = MatG ((u v)(w)).
De plus
MatE ,F (v).X = MatF (v(w)) et donc MatF ,G (u)×MatE ,F (v)× X = MatG ((u v)(w)).
On en déduit queMatE ,G (u v) = MatF ,G (u)×MatE ,F (v).
2.5 Cas des endomorphismes
Notation : Soit E un espace vectoriel de u ∈ L (E). Dans la plupart des cas, quand on étudiera une matrice deu on prendre la même base E au départ et à l’arrivée. On note alors MatE (u) pour MatE ,E (u).
Avec les notations précédentes si on note A = MatE (u).
1. Pour tout entier naturel n, An = MatE (un).
2. Soit P ∈ K[X], P(A) = MatE (P(u)).
Proposition 26.2.5.895
Exemples :1. On a vu précédemment que l’application linéaire v dont la matrice était
A =12
1 −1 −1−1 1 −10 0 1
était un projecteur. On peut le vérifier. On a bien A2 = A ce qui assure que v2 = v.
384

2. Si on reprend l’endomorphisme de dérivation ∆ dans R3[X] on a
Mat(∆) = A =
0 1 0 00 0 2 00 0 0 30 0 0 0
.
On en déduit
A2 =
0 0 2 00 0 60 0 0 00 0 0 0
, A3 =
0 0 0 60 0 0 00 0 0 30 0 0 0
et A4 = 0.
Soit u un endomorphisme. Les assertions suivantes sont équivalentes.
i.) L’application u est un isomorphisme.
ii.) Il existe une base E telle que MatE (u) soit inversible.
iii.) Pour toute base E , MatE (u) est inversible.
Théorème 26.2.5.896
Démonstration :
— i.)⇒ iii.) Il suffit de poser B = MatE (u−1) et de vérifier que AB = BA = MatE (Id) = I.
— iii.)⇒ ii.) Evident
— ii.)⇒ i.) Soit B = A−1 et v l’endomorphisme tel que MatE (v) = B. On a
MatE (u v) = MatE (v u) = I = MatE (Id).
Donc u v = v u = Id.
Remarque : Cela permet de montrer que s’il existe B telle que AB = I alors A est inversible. En effet on connaitce résultat sur les endomorphismes.
3 Changements de bases
3.1 Matrices de changement de bases
Soit E un espace vectoriel et (v1, . . . , vp) une famille de vecteurs de E. Les assertions suivantes sontéquivalentes.
i.) La famille est une base de E.
ii.) Il existe une base E telle que MatE (v1, . . . , vp) soit inversible.
iii.) Pour toute base E , MatE (v1, . . . , vp) est inversible.
Proposition 26.3.1.897
Démonstration :
— i.) ⇒ iii.) On suppose que la famille est une base de E. Soit E = (e1, . . . , ep) une base de E on noteA = MatE (v1, . . . , vp). On voit que A est la matrice de l’application linéaire f de E dans lui même définiepar f (ei) = vi. En particulier, l’image d’une base étant une base, f est bijective et donc A est inversible.
— iii.)⇒ ii.) Evident
— ii.)⇒ i.) On considère encore l’application f comme ci-dessus. Comme A est inversible alors f est bijectiveet donc l’image de la base E est une base de E.
385

Remarque : Pour tous ces calculs on peut remplacer E par Kp et la base E par la base canonique. Par exemple,la matrice
A =
1 1 11 2 31 −1 0
est inversible car les vecteurs (1, 1, 1), (1, 2,−1) et (1, 3, 0) forment une base de K3.
Soit E un espace vectoriel et B, B′ deux bases de E. On appelle matrice de passage de B dans B′ la matrice
PB′B = MatB(B′).
C’est la matrice des coordonnées des vecteurs de la nouvelle base dans l’ancienne base.
Définition 26.3.1.898
Exemples :
1. Dans R2 si B est la base canonique et B′ la base (u, v) où u = (1, 1) et v = (1,−1) donc la matrice depassage de B à B′ est
P =
(1 11 −1
).
Par contre la matrice de passage de B′ à B est
Q =12
(1 11 −1
).
En effet (1, 0) =12(u + v) et (0, 1) =
12(u− v).
2. Dans Kn[X]. On pose B la base canonique et T = ((X− a)k) la base de Taylor. La matrice de changementde base est alors
P =
1 −a (−a)2 · · · (−a)n
0 1 −2a · · · n(−a)n−1
.... . . . . . · · ·
.... . . . . . · · ·
0 · · · · · · 0 1
.
L’intérêt d’une matrice de changement de bases et qu’elle permet de calculer les coefficients d’un vecteurdans la nouvelle base.
Précisément, soit v un vecteur de E. On suppose que l’on connait ses coordonnées dans la base B. On pose
V = MatB(v) =
x1...
xn
.
On cherche alors ses coordonnées dans la base B′. Posons
V′ = MatB′(v) =
x′1...
x′n
.
Maintenant, on considère la matrice de passage P de B′ dans la base B. On pose
P = MatB(u′1, . . . , u′n) =
a11 · · · a1n...
...an1 · · · ann
.
On peut alors exprimer v.
386

v = x′1u′1 + · · ·+ x′nu′n= x′1(a11u1 + · · ·+ a1nun) + · · ·+ x′n(an1u1 + · · ·+ annun)
= (a11x′1 + · · ·+ an1x′n)u1 + · · ·+ (a1nx′1 + · · ·+ annx′n)un.
Par identification on obtient donc :
x1 = a11x′1 + · · ·+ an1x′n... =
...xn = a1nx′1 + · · ·+ annx′n
On en déduit que V = PV′.
Avec les notations précédentes. Si v est un vecteur de E. On note
V = MatB(v) et V′ = MatB′(v).
On a alorsX = PX′.
C’est-à-direX′ = P−1X.
Proposition 26.3.1.899
Remarque : On remarque en particulier que si P est la matrice de passage de B à B′ alors P−1 est la matricede B′ à B.Exemple : On se place dans R2. On considère B = ((1, 0), (0, 1)) la base canonique et B′ = ((1, 1), (1,−1)).La matrice de passage de B dans B′ est
P =
(1 11 −1
)d’où P−1 =
12
(1 11 −1
).
Prenons par exemple le vecteur v = (2, 1) dans la base canonique. On pose V =
(21
). Ses coordonnées
dans la base B′ sont données par
V′ = P−1V =12
(3−1
).
On vérifie bien que12(3(1, 1)− (−1, 1)) = (2, 1).
3.2 Changement de base des applications linéaires
On se fixe deux espaces vectoriels E et F de dimensions respectives p et n ainsi qu’une applicationlinéaire de E dans F. On se donne B1 et B2 deux bases de E ainsi que B′1 et B′2 deux bases de F. Onnote
A1 = MatB1 ,B′1( f ) et A2 = MatB2 ,B′2
( f ).
On note P = MatB1(B2) et P′ = MatB′1(B′2) les matrices de passage. On a donc :
A2 = (P′)−1 A1P.
Théorème 26.3.2.900
387

Démonstration : Il suffit de voir que pour tout j ∈ [[ 1 ; p ]], P′A2Xj = A1PXj où Xj =
0...10...0
∈Mn1(K) où le
1 est à la j-ème ligne. On a Xj = MatB2(ej) où B2 = (e1, . . . , ep).
Faire un diagramme commutatif
En effet, PXj = MatB1(ej) et donc A1PXj = MatB′1( f (ej)). Alors que A2Xj = MatB′2( f (ej) et P′A2Xj =
MatB′1( f (ej)).
Cette formule sera utile en particulier dans le cas des endomorphismes. Dans ce cas, on garde le plus souventla même base au départ et à l’arrivée. On a donc :
On se fixe un espace vectoriel E de dimension respective n ainsi qu’un endomorphisme de E. On sedonne B et B′ deux bases de E. On note
A = MatB( f ) et A′ = MatB′( f ).
On note P la matrice de passage de B à B′. On a donc :
A′ = P−1 AP.
Théorème 26.3.2.901 (Changement de bases de endomorphismes)
Remarques :
1. Cette formule est fondamentale et sera très utile.
2. Avec les notations de l’énoncé on trouve que pour tout entier naturel n, (A′)n = P−1 AnP. Cela se démontrepar le calcul ou le changement de base de l’endomorphisme f n.
Exemples :
1. Dans R3 on se donne l’application linéaire u dont la matrice dans la base canonique est
A =12
1 1 01 1 00 0 2
.
On peut remarquer que A2 = A. Donc u est un projecteur. On cherche son noyau et son image. Il est clairque Im v = Vect(1, 1, 0), (0, 0, 1). De plus, pour déterminer ker v on résout le système
x + y = 0
z = 0 .
On obtient Ker v = Vect(−1, 1, 0). On voit alors que B = ((1, 1, 0), (0, 0, 1), (−1, 1, 0)) est une base de E.La matrice de v dans E est alors
A′ =
1 0 00 1 00 0 0
.
Vérifions par le calcul. Si on pose
P =
1 0 −11 0 10 1 0
la matrice de passage de la base canonique à B. On cherche son inverse. Pour cela on considère l’applica-tion canonique associée à P
f : (x, y, z) 7→ (x− z, x + z, y)
388

On résout donc pour tout (a, b, c) le système
x− z = ax + z = b
y = c⇐⇒
x = (a + b)/2y = cz = (b− a)/2
D’où
P−1 =12
1 1 00 0 2−1 1 0
Et finalement A′ = P−1 AP.
2. Soit A =
0 0 1−2 1 2−2 −2 5
. On voudrait connaitre An. Pour ce la on considère l’endomorphisme f
canoniquement associé à A. On cherche alors des vecteurs v de R3 tels que f (v) = λv où λ ∈ R. Pour celaon cherche le noyau de f − λId. On sait que
Mat( f − λId) = A− λI =
− λ 0 1−2 1− λ 2−2 −2 5− λ
.
En résolvant le système on trouve que si λ /∈ 1, 2, 3, Ker ( f − λId) = 0. Par contre pour λ ∈ 1, 2, 3,Eλ = Ker ( f − λId) = Vect(ui) est de dimension 1 et
u1 = (1, 1, 1), u2 = (1, 2, 2) et u3 = (1, 2, 3).
Soit P la matrice de passage de la base canonique à la base u1, u2, u3. On a :
P =
1 1 11 2 21 2 3
et P−1 =
2 −1 0−1 2 −1−0 −1 1
On fait alors le changement de base. On a
P−1 AP = ∆ =
1 0 00 2 00 0 3
On en déduit que A = P∆P−1. et que, pour tout n ∈ N?, on a :
An = P∆P−1.P∆P−1. . . . .P∆P−1
= P.∆n.P−1.
Or ∆n =
1n 0 00 2n 00 0 3n
Donc
An =
2− 2n −1 + 2n+1 − 3n −2n + 3n
2− 2n+1 −1 + 2n+2 − 2.3n −2n+1 + 2.3n
2− 2n+1 −1 + 2n+2 − 3n+1 −2n+1 + 3n+1
Remarque : On aurait pu directement trouver ∆ en utilisant que f (v1) = v1, f (v2) = 2v2 et f (v3) = 3v3.
Soit A et B deux matrices de Mn(K). On dit que A et B sont semblables si elles représentent le mêmeendomorphisme dans des bases éventuellement différente. C’est équivalent au fait qu’il existe une matrice Pinversible telle que A = P−1BP.
Définition 26.3.2.902
La relation « être semblable » est une relation d’équivalence.
Proposition 26.3.2.903
Exemple : La matrice identité et la matrice nulle ne sont semblable qu’à elles même.
389

3.3 Trace d’un endomorphisme
Soit E un espace vectoriel et (A, B) ∈ (Mn(K))2. Si A et B sont semblables alors tr (A) = tr (B).
Proposition 26.3.3.904
Démonstration
Soit u ∈ L (E). On appelle trace de u et on note tr (u) la trace d’une de ses matrices dans une base de E .
Définition 26.3.3.905
Remarque : Il faut faire attention à bien prendre la même base au départ et à l’arrivée.Exemple : on a tr (0) = 0 et tr (Id) = dim E.
Soit p un projecteur. On a tr (p) = rg (p).
Proposition 26.3.3.906
Démonstration : Pour calculer la trace de p on va choisir une base adaptée. Précisément on sait qu’il Ker p etIm p sont en somme directe. Si on construit une base B de E en collant une base de Im p et une base de Ker p onobtient
MatB(p) =
1 0 . . . . . . . . . 0
0. . .
...... 1
...... 0
......
. . ....
0 . . . . . . . . . . . . 0
.
On en déduit que tr (p) est le nombre de vecteurs dans la base de Im p. C’est bien rg (p).
4 Rang d’une matrice
4.1 Définition
Soit A une matrice de Mnp(K). On appelle rang de A et on note rg (A) le rang des vecteurs colonnes de Avus comme des éléments de Kn. C’est aussi la dimension de Im A.
Définition 26.4.1.907
Exemple : Soit A =
1 1 11 2 21 2 3
. On avait vu que les vecteurs formaient une base donc rg (A) = 3. Si
B =
1 1 01 2 −11 3 −2
. On voit que C1 − C2 = C3. Donc rg (B) = 2.
390

Les différentes notions de rang sont compatibles.
1. Soit (v1, . . . , vp) une famille de vecteurs d’un espace vectoriel E et E une base de E. On a
rg (v1, . . . , vp) = rg (MatE (v1, . . . , vp)).
2. Soit u ∈ L (E, F) et E , F des bases de E et F. On a
rg (u) = rg (MatE ,F (u)).
Proposition 26.4.1.908
Démonstration :1. On considère
Φ : E → Mn1v 7→ MatE (v).
Cette application envoie le vecteur vj sur la j-ième colonne Cj de la matrice. Or on a vu que c’était unisomorphisme d’où
rg (MatE (v1, . . . , vp)) = dim(Vect(Φ(v1), . . . , Φ(vp))) = dim(Φ(Vect(v1, . . . , vp))) = dim((Vect(v1, . . . , vp))) = rg (v1, . . . , vp).
2. Il suffit de revenir à la définition de la matrice d’une application linéaire.
1. Si A ∈Mnp(K), rg (A) 6 n et rg (A) 6 p
2. Soit A ∈Mn(K), la matrice est inversible si et seulement si rg (A) = n.
3. Deux matrices semblables ont le même rang.
Corollaire 26.4.1.909
Soit A ∈Mnp(K). Soit P ∈ GLn(K) et Q ∈ GLp(K). On a
rg (PAQ) = rg (A).
Proposition 26.4.1.910
Démonstration : Il suffit d’utiliser que l’on ne modifie par le rang d’une application linéaire en composant àdroite ou à gauche par un isomorphisme.
Notation : Soit r 6 Min(n, p) on note Jr(n, p) la matrice
Jr(n, p) =
1 0 · · · · · · · · · 0
0. . . . . .
......
. . . 1 0 · · · ...... 0 0 · · · 0...
......
...0 · · · 0 0 · · · 0
.
Elle comporte des 1 sur les r première colonne. On a rg (A) = r.
Soit A ∈Mnp(K). Il existe P ∈ GLn(K) et Q ∈ GLp(K) tels que A = PJr(n, p)Q où r = rg (A).
Théorème 26.4.1.911
391

Démonstration : On considère l’application linéaire u de Kp dans Kn canoniquement associée à A. On saitque rg (u) = r et donc dimKer u = p− r. On considère un supplémentaire H de Ker u qui est de dimensionr. On note (α1, . . . , αr) et (αr+1, . . . , αp) des bases de H et de Ker u. La famille (α1, . . . , αp) est alors une basede Kp. On note T la matrice de passage de la base canonique à la base (α1, . . . , αp). Maintenant voit queIm u = Vect(u(α1), . . . , u(αr)) car u(αi) = 0 pour i > r. En particulier, la famille (u(α1), . . . , u(αr)) est libre crdim Im u = r. On peut donc la compléter en une base de Kn que l’on note (β1, . . . , βn). Si on note P la matricede passage de la base canonique à la base (βi). On voit alors que la matrice de u en prenant la base de (αi) audépart et (β j) à l’arrivée est Jr(n, p). On a donc
Jr(n, p) = P−1 AT ⇐⇒ A = PJr(n, p)T−1.
On pose alors Q = T−1.
Soit A et B deux matrices de Mnp(K), elles sont dites équivalentes si rg (A) = rg (B).
Définition 26.4.1.912
Remarque : C’est encore une relation d’équivalence.
B Ne pas confondre semblable et équivalente. Par exemple A =
(2 00 1
)est une matrice de rang 2 (car
inversible) elle est donc équivalente à I2 mais elle n’est pas semblable à I2 (car A 6= I2).
Soit A ∈ Mnp(K). On a rg (A) = rg (tA).
Proposition 26.4.1.913
Remarque : Cela signifie en pratique, pour déterminer le rang d’une matrice A on peut aussi calculer ladimension de l’espace vectoriel engendré par les lignes. Si
A =
1 2 52 4 103 6 15
.
On peut remarquer que rg (A) = 2 car L1 + L2 = L3.Démonstration : On note r le rang de A et on considère P ∈ GLn(K) et Q ∈ GLp(K) tels que A = PJr(n, p)Q.On obtient alors tA = tQtJr(n, p)tP. Or tP et tQ sont inversibles (d’inverse tP−1 et tQ−1) et tJr(n, p) = Jr(p, n).Donc tA = P′ Jr(p, n)Q′. Elle est de rang r.
Soit A une matrice de rang r. Toute sous-matrice extraite est de rang inférieur à r.
Proposition 26.4.1.914
Démonstration : Si une matrice extraite A′ est de rang strictement supérieure à r. On peut trouver r+ 1 colonnesqui sont libres. En les complétant pour obtenir des colonnes de A on obtient r + 1 colonnes de A libres ce qui estabsurde.
Soit A une matrice de Mnp(K). Le rang A est la plus grande taille d’une matrice carrée inversibleextraite de A. C’est -à-dire que A est de rang r si et seulement si
i) Il existe une matrice A′ extraite de A de taille r carrée et inversible.
ii) Tout matrice extraite A′′ de taille strictement supérieure à r n’est pas inversible.
Théorème 26.4.1.915
392

Démonstration : On procède par double implication.
— ⇒ On suppose que rg (A) = r. De ce fait on sait que toute sous-matrice de A est de rang inférieur à rdonc tout matrice extraite A′′ de taille strictement supérieure à r n’est pas inversible (ii). De plus, commeelle est de rang r il existe une famille de r colonnes qui sont libres. On considère B la matrice obtenue engardant ces r colonnes. La matrice B est encore de rang r. En particulier tB aussi on peut donc extraire detB r colonnes qui sont libres. En retransposant on obtient bien une sous-matrice de A qui est de rang r.
— ⇐ On suppose qu’il existe une matrice extraite inversible de taille r. En complétant les colonnes onobtient que le rang de A est supérieur à r car on trouve r colonnes libres. Maintenant si le rang de A étaitstrictement supérieur à r on pourrait trouver une sous-matrice carrée inversible de taille r + 1 d’après lesens⇒.
4.2 Calcul du rang - Opérations élémentaires
Nous allons voir dans ce paragraphe les opérations que l’on peut faire sur une matrice pour déterminer sonrang. On considère une matrice A ∈Mnp(K).
Avant cela regardons le résultat de la multiplication Eαβ A où Eαβ est la base canonique de Mn(K). Notons(aij) les coefficients de A, bij ceux de Eαβ et cij ceux du produit.
Pour tout (i, j) ∈ [[ 1 ; n ]]× [[ 1 ; p ]] ,
cij =n
∑k=1
bikakj.
On remarque déjà que si i 6= α alors cij = 0. Par contre
cαj = ∑k=1
δkβakj = aβj.
On en déduit que Eαβ A est la matrice obtenue en mettant la ligne Lβ de A comme α-ème ligne et en mettant deszéros autour.Remarque : On peut aussi le faire en utilisant les applications linéaires canoniquement associées. Dans ce cas,l’application u associée à Eαβ est définie par
∀i ∈ [[ 1 ; n ]] , u( fi) = δiβ fα.
Échange de deux lignes
On considère l’opération qui consiste à échanger deux lignes d’une matrice. On la note Li ↔ Lj. La nouvellematrice est obtenue en multipliant à gauche par P = In − Eii − Ejj + Eij + Eij. Cette matrice P est clairementinversible (c’est son propre inverse). On en déduit que la matrice PA obtenue après l’opération a le même rangque A.
Multiplication d’une ligne par un coefficient NON NUL
On considère l’opération qui consiste à multiplier une ligne par un coefficient λ non nul. On la note Li ← λLi.Elle est obtenue en multipliant à gauche par P = In − Eii + λEii. Là encore SI λ EST NON NUL, la matrice Pest inversible et la matrice obtenue a le même rang que A.B Si λ est nul, cela n’est pas vrai. On enlève une ligne de la matrice et le rang peut diminuer.
Ajout d’une ligne à une autre
On considère l’opération qui consiste à ajouter un multiple d’une ligne à une autre. On la note Li ← Li + µLj.Elle est obtenue en multipliant à gauche par P = In + µEij. La matrice P est inversible et la matrice obtenue a lemême rang que A.
De fait on utilise les deux dernières opérations ensemble et on obtient l’opération Li ← λLi + µLj avec λnon nul (alors que µ peut-être nul).
Opérations sur les colonnes
On considère les mêmes opérations sur les colonnes qui sont notées Ci ↔ Cj, . . .. Là encore on ne changepas le rang. En effet, cela revient à multiplier par des matrices similaires mais à droite (ou alors à transposer,faire l’opération sur les lignes et retransposer).
393

5 Applications aux systèmes linéaires
5.1 Généralités
On appelle système linéaire de n équations à p inconnues un système du type
(S)
a11x1+ · · · +a1pxp = b1 (L1)a21x1+ · · · +a2pxp = b2 (L2)
...... =
...an1x1+ · · · +anpxp = bn (Ln)
— Les aij pour (i, j) ∈ [[ 1 ; n ]]× [[ 1 ; p ]] s’appellent les coefficients du système.
— Les xj pour j ∈ [[ 1 ; p ]] s’appellent les inconnues du système.
— Les bi pour i ∈ [[ 1 ; n ]] forment le second membre du système.
Définition 26.5.1.916
Notations :
1. Les solutions du système (S) sont les vecteurs (x1, · · · , xp) ∈ Kp dont les coordonnées vérifient le système.
2. Si tous les termes du second membre sont nuls, le système est dit homogène.
3. Le système obtenu en conservant les coefficients mais en prenant un second membre nul s’appelle lesystème homogène associé.
4. Les systèmes ayant autant de lignes que de colonnes s’appellent des systèmes carrés. C’est ceux que nousétudierons le plus souvent.
Interprétation matricielle
Nous gardons les notations précédentes. On note alors A ∈Mnp(K) la matrice dont les coefficients sont les
coefficients du système et B ∈Mn1(K) la matrice colonne égale à
b1...
bn
. On pose alors X =
x1...
xn
. On a
alors(x1, . . . , xn) solution de (S) ⇐⇒ AX = B.
Interprétation vectorielle
On considère les vecteurs (vj)j∈[[ 1 ; p ]] de Kn définis par
∀j ∈ [[ 1 ; p ]] , vj = (a1j, . . . , anj).
C’est à dire que A = Mat(v1, . . . , vp). Dans ce cas, si on note aussi b = (b1, . . . , bn). La recherche d’une solution(x1, . . . , xp) revient alors à
p
∑j=1
xjvj = b.
Réciproquement si on ne donne un espace vectoriel E de dimension n et que l’on note E une base. Si on a
des vecteurs (vj)j∈[[ 1 ; p ]] et b de E. La recherche de scalaires (x1, . . . , xp) tels quep
∑j=1
xjvj = b revient à résoudre
le système AX = B oùA = MatE (v1, . . . , vp) et B = MatE (b).
Interprétation avec une application linéaire
Soit f l’application linéaire de Kp dans Kn canoniquement associée à la matrice A et b = (b1, . . . , bn) ∈ Kn.On a
u = (x1, . . . , xn) solution de (S) ⇐⇒ f (u) = b.
394

Réciproquement si f est une application linéaire de E dans F où E et F sont des espaces vectoriels dedimension respective p et n munis de base E et F . Soit b ∈ F résoudre l’équation f (u) = b revient à résoudre lesystème linéaire AX = B où
A = MatE ,F ( f ) et B = MatE (b).
Interprétation avec des formes linéaires
Soit f1, . . . fn les n applications linéaires de Kp qui correspondent aux n lignes de la matrices A. On a
u = (x1, . . . , xn) solution de (S) ⇐⇒ ∀i ∈ [[ 1 ; n ]] , fi(u) = bi.
Réciproquement si on considère f1, . . . , fn n formes linéaire sur E où Eest un espace vectories de dimensionp muni d’une base E . Soit b1, . . . , bn la donnée de n scalaires. Résoudre les équation fi(u) = bi revient à résoudreun système linéaire.Terminologie :
1. Un système est dit diagonal s’il est carré et que la matrice de ses coefficients est diagonale.
2. Un système est dit echelonné si la matrice de ses coefficients est échelonnée.
3. Un système est dit inversible (ou de Cramer) s’il est carré et la matrice de ses coefficients est inversible.
4. On appelle rang du système (S) le rang de la matrice de ses coefficients.
5.2 Determination de l’inverse d’une matrice
Soit (S) un système carré avec n lignes et n colonnes. Les assertions suivantes sont équivalentes.
i.) Il admet une unique solution
ii.) Le système homogène associé (H) n’admet que 0 comme solution.
iii.) La matrice du système est inversible.
iv.) Le système est de rang n.
Dans ce cas on dira que le système est inversible ou que c’est un système de Cramer.
Définition 26.5.2.917
Une matrice carrée triangulaire supérieure est inversible si et seulement si ses coefficients diagonauxsont non nuls.
Théorème 26.5.2.918
Si on considère une matrice A que l’on suppose carrée de taille n et inversible. Pour chercher A−1 on peutposer une matrice B carrée de taille n (avec donc n2 inconnues) et résoudre AB = In qui est un système de n2
inconnues à n2 équations. En fait il est beaucoup plus efficace de résoudre AX = B pour des seconds membresgénéraux. En effet AX = B ⇐⇒ X = A−1B. Si on sait donc résoudre ce système pour tous les secondsmembres C1, . . . Cn (matrice colonne représentant la base canonique) on obtiendra A−1 car la solution Xi deAX = Ci est A−1Ci c’est-à-dire la i-eme colonne de A−1.
En pratique on résout tous les systèmes en même temps en collant les seconds membres différents
Exemple : On pose A =
1 1 00 1 11 0 1
.
395

1 1 0 1 0 00 1 1 0 1 01 0 1 0 0 1
∼
1 1 0 1 0 00 1 1 0 1 00 −1 1 −1 0 1
∼
1 1 0 1 0 00 1 1 0 1 00 0 2 −1 1 1
∼
1 1 0 1 0 00 1 1 0 1 00 0 1 −1/2 1/2 1/2
∼
1 1 0 1 0 00 1 0 1/2 1/2 −1/20 0 1 −1/2 1/2 1/2
∼
1 0 0 1/2 −1/2 1/20 1 0 1/2 1/2 −1/20 0 1 −1/2 1/2 1/2
On en déduit que A−1 =12
1 −1 11 1 −1−1 1 1
.
Remarque : On peut expliquer ce calcul différemment. En effet on part avec deux matrices A et In. On appliquedes opérations sur les lignes ce qui revient à multiplier par des matrices inversibles à gauche. On trouve doncP1, . . . Pk inversibles telles que
P1 × · · · × Pk × A = In
On a alors A−1 = P1 × · · · × Pk et c’est exactement cette matrice qui est obtenue en appliquant les mêmesopérations à la matrice identité.
Soit (A, B) ∈M 2n (K) tels que AB = In alors A est inversible et B = A−1.
Théorème 26.5.2.919
Soit A =
(a bc d
). Elle est inversible si et seulement si ad− bc 6= 0. Dans ce cas
A−1 =1
ad− bc
(d −bcc a
).
Proposition 26.5.2.920
Démonstration :
396

27Variables aléatoires
1 Variables aléatoires réelles 3971.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3971.2 Loi d’une variable aléatoire réelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3981.3 Fonctions de répartitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3991.4 Fonction d’une variable aléatoire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 400
2 Moments d’une variable aléatoire réelle 4002.1 Espérance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4002.2 Variance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4032.3 Les moments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 405
3 Lois usuelles 4053.1 Loi uniforme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4053.2 Loi de Bernoulli . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4063.3 Loi binomiale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4063.4 Retour sur l’inégalité de Bienaymé-Tchebychev . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 407
En mathématiques, on travaille la plupart du temps avec des valeurs numériques qui nous permettent defaire des calculs. Le problème est que, dans le cadre des probabilités, la plupart des résultats sont des ensemblesnon nécessairement numérique (par exemple on tire 5 cartes sur un jeu de 32 cartes). On aura donc recours àla notion de variables aléatoires réelles. Le principe est que ce qui nous intéresse n’est pas nécessairement lerésultat exact de l’expérience mais ce que l’on veut regarder. Par exemple si on étudie les appels téléphoniquesà un standard d’appel. Les données exactes pour décrire tous les appels sont très compliquées. Alors que l’onrisque de ne s’intéresser qu’au nombre d’appel dans la première heure.
1 Variables aléatoires réelles
1.1 Définitions
Soit (Ω, P(Ω), P) un espace probabilisé. On appelle variable aléatoire réelle sur Ω toute application :
X : Ω→ R
Définition 27.1.1.921
Remarques :
397

1. On omettra souvent le mot « réelle », pour parler uniquement de variables aléatoires. De plus nousutiliserons l’abréviation v.a.
2. Vous verrez l’an prochain que ce qui précède n’est qu’un cas particulier de la "vraie" définition. En effet,lorsque l’on s’intéresse à des univers infinis, on ne considère, la plupart du temps, pas tout P(Ω) maisseulement une partie. Dans ce cas, il faudra ajouter une condition pour qu’une application X : Ω→ R soitune variable aléatoire.
3. On commencera souvent par regarder X(Ω) qui est l’ensemble des valeurs prises par X. C’est un ensemblefini car Ω est fini.
Notation : Soit (Ω, P(Ω), P) un espace probabilisé et X une v.a sur Ω. Pour toute partie A de R, l’ensembleX−1(A) = ω ∈ Ω | X(ω) ∈ A qui est l’ensemble des événements élémentaires ω tels que X(ω) appartienneà A sera noté
(X ∈ A) ou X ∈ ADe plus, si A = [a, b] on notera plutôt (a 6 X 6 b) ou a 6 X 6 b. De même si A =]a, b] on notera (a < X 6 b)ou a < X 6 b. Pour finir si A = a on notera (X = a) ou X = a.Exemples :
1. On lance une pièce équilibrée trois fois. On a donc Ω = P, F3 et on le munit de la probabilité uniforme.On gagne un point par pile obtenu et on en perd un par face obtenu. Soit X le nombre de points obtenu.C’est une variable aléatoire. Par exemple pour ω = (P, P, F) on a X(ω) = 1 + 1− 1 = 1. On a, a prioriX(Ω) ⊂ [[−3 ; 3 ]]. On a alors (X = 3) = (P, P, P) et (X = 1) = (P, P, F); (P, F, P); (F, P, P). Onremarque aussi que (X = 2) = (X = 0) = (X = −2) = ∅. De fait X(Ω) = −3,−1, 1, 3.
2. On lance deux dés et on considère la somme des deux résultats. Là encore on est en présence d’unevariable aléatoire. On a Ω = [[ 1 ; 6 ]]2 et S : Ω→ R. On a S(Ω) = [[ 2 ; 12 ]] .
3. Soit (Ω, P(Ω), P) un espace probabilisé. Soit A une partie de Ω. La fonction 1A est une variable aléatoire.Elle est définie par
1A(ω) =
1 si ω ∈ A0 sinon
Soit (Ω, P(Ω), P) un espace probabilisé et X une variable aléatoire réelle sur Ω. On note X(Ω) =x1, . . . , xr. La famille d’événements ((X = xi))16i6r est un système complet d’événements.
Proposition 27.1.1.922
1.2 Loi d’une variable aléatoire réelle
Soit (Ω, P(Ω), p) un espace probabilisé et X une variable aléatoire réelle sur Ω. L’application
PX : P(X(Ω)) → [0, 1]A 7→ P(X ∈ A)
est une probabilité sur X(Ω). On l’appelle la loi de X.
Proposition-Définition 27.1.2.923
Démonstration : On a bien PX à valeurs dans [0, 1]. De plus (X ∈ X(Ω)) = Ω donc PX(X(Ω)) = P(Ω) = 1.Pour finir si A et B sont deux parties disjointes de X(Ω) alors (X ∈ A) et (X ∈ B) sont deux parties disjointes
de Ω et (X ∈ A ∪ B) = (X ∈ A) ∪ (X ∈ B). On en déduit que PX(A ∪ B) = PX(A) + PX(B).
Notation : Dans la suite nous noterons p(X = xi) pour p([X = xi]). De même on note p(a 6 X 6 b) pourp([a 6 X 6 b]). Remarques :
1. Pour déterminer la loi d’une variable aléatoire X, on commence par déterminer X(Ω).2. Dans le cas des univers fini, comme X(Ω) est fini, on peut le noter X(Ω) = x1, . . . , xr. La loi de X revient
alors à se donner pour tout i ∈ [[ 1 ; r ]] , pi = PX(xi) = P(X = xi) ∈ [0, 1] tel que p1 + · · ·+ pr = 13. Avec les notations précédentes, la loi de X est déterminée par les pi. En effet pour tout A ⊂ X(ω) :
PX(A) = P(X ∈ A) = ∑16i6rxi∈A
P(X = xi).
398

Exemples :
1. On reprend l’exemple précédent. On a X(Ω) = −3,−1, 1, 3. De plus on a vu que [X = 3] = (P, P, P).D’où p(X = 3) = 1/8. De même p(X = −3) = 1/8 et p(X = −1) = p(X = 1) = 3/8.
2. On reprend l’exemple précédent. On a X(Ω) = [[ 2 ; 12 ]]. On a [X = 2] = (1, 1). D’où p(X = 2) = 1/36.On fait de même pour les autres.
1.3 Fonctions de répartitions
Soit (Ω, P(Ω), P) un espace probabilisé et X une variable aléatoire réelle sur Ω. La fonction de répartitionde la variable aléatoire réelle X est la fonction FX : R→ R. Définie par
∀x ∈ R, FX(x) = P(X 6 x) = PX(]−∞, x]).
Définition 27.1.3.924 (Fonction de répartition)
Exemple : Dans l’exemple précédent la fonction de répartition est
FX : R → R
x 7→
0 si x < −31/8 si − 3 6 x < −11/2 si − 1 6 x < 17/8 si 1 6 x < 31 si x > 3
Sa représentation graphique est :
-4 -3 -2 -1 0 1 2 3 4
0,5
1
Remarque : on voit bien sur l’exemple précédent, et ce sera toujours vrai, que la fonction FX est une fonctionen escalier croissante et que
lim−∞
FX = 0 et lim+∞
FX = 1.
On peut retrouver la loi quand on a la fonction de répartition. Les éléments de X(Ω) sont les "sauts". S’il y aun saut en x alors P(X = x) est la "hauteur du saut".
Avec les notations précédentes, on a
∀x ∈ R, P(X = x) = FX(x)− limt→x−
FX(t).
Proposition 27.1.3.925
Remarque : On étudiera souvent des variables aléatoires à valeurs entières. Dans ce cas la fonction de répartitionne présente des sauts qu’aux entiers (elle est continue sur R \ Z) et elle est continue à droite aux entiers :
FX(n) = limx→n+
FX(x).
En particulier, il suffit de connaitre la fonction de réparation aux entiers pour la connaitre en entier et on a
P(X = n) = P(X 6 n)−P(X 6 n− 1) = FX(n)− FX(n− 1).
399

On peut remarquer que P(X 6 n− 1) = P(X < n).Exemple : On lance deux dés équilibrés à 6 faces. On note X1 et X2 les variables aléatoires qui décrivent lerésultat du premier (resp. du deuxième dé) et on note M = Max(X1, X2) le plus grand des deux résultats. On
cherche la loi de M. Il est clair que pour tout i ∈ [1, 6], P(X1 = i) = P(X2 = i) =16
. D’où,
∀n ∈ [[ 0 ; 6 ]] , FX1(n) = FX2(n) =n6
.
Maintenant l’événement (M 6 n) = (X1 6 n) ∩ (X2 6 n). Les deux lancers étant indépendants,
P(X 6 n) = P(X1 6 n)×P(X2 6 n) =n2
36.
On en déduit que
∀i ∈ [[ 1 ; 6 ]] , P(M = i) =i2 − (i− 1)2
36=
2i− 136
.
1.4 Fonction d’une variable aléatoire
Soit (Ω, P(Ω), P) un espace probabilisé et X une variable aléatoire réelle sur Ω. Soit u une fonction réelledont l’ensemble de définition contient X(Ω), on note u(X) la variable aléatoire obtenue en composant u et X.
Définition 27.1.4.926
Remarque : Dans la plupart des cas la fonction u sera simple : y 7→ ay + b, y 7→ y2.
Soit (Ω, P(Ω), P) un espace probabilisé et X une variable aléatoire réelle sur Ω. Soit u une fonctionréelle dont l’ensemble de définition contient X(Ω). Pour tout y ∈ R on a
P(u(X) = y) = ∑x∈u−1(y)
P(X = x).
Proposition 27.1.4.927
Exemple : On lance un dé équilibré à 6 faces et on note X le résultat obtenu. Calculons la loi de Y = (X− 2)2.Pour commencer on cherche Y(Ω). On a X(Ω) = [[ 1 ; 6 ]] d’où Y(Ω) = 0, 1, 4, 9, 16. De plus on a
p(Y = 0) = p(X = 2) = 1/6; p(Y = 1) = p(X = 1) + p(X = −1) = 1/3, . . .
2 Moments d’une variable aléatoire réelle
2.1 Espérance
Soit (Ω, P(Ω), P) un espace probabilisé et X une variable aléatoire réelle sur Ω. On note X(Ω) =x1, . . . , xr. L’espérance (mathématique) de la variable aléatoire X est alors
E(X) =r
∑i=1
xi.P(X = xi).
Définition 27.2.1.928
Remarques :
1. L’espérance est donc une "moyenne" des valeurs prises coefficientée par la probabilité d’apparition. C’estle gain moyen.
400

2. Si on ne connait pas précisément X(Ω) mais que l’on sait juste que X(Ω) ⊂ T où T est un ensemble fini.On a encore
E(X) = ∑x∈T
x.p(X = x).
On reprend nos deux exemplesExemples :
1. E(X) = 0
2. E(X) = 7
3. Soit X une variable aléatoire et a ∈ R. On a alors E(1X=a) = P(X = a).
Avec les notation précédente, si E(X) = 0 la variable aléatoire est dite centrée.
Définition 27.2.1.929
On peut calculer l’espérance d’une variable aléatoire X sur (Ω, P(Ω), P) en faisant une somme surΩ et non pas X(Ω) :
E(X) = ∑ω∈Ω
X(ω)P(ω).
Proposition 27.2.1.930
Démonstration : Il suffit, dans la formule de l’espérance de X de remplacer P(X = x) par ∑ω∈Ω
X(ω)=x
P(ω).
Soit (Ω, P(Ω), P) un espace probabilisé et X une variable aléatoire réelle sur Ω. Pour tout (a, b) ∈ R2
on aE(aX + b) = aE(X) + b.
Proposition 27.2.1.931 (Linéarité de l’espérance - version 1)
Remarque : Nous verrons dans le chapitre sur les couples de variables aléatoires la vraie propriété de lalinéarité de l’espérance.Démonstration : Il suffit d’utiliser la deuxième formule :
E(aX + b) = ∑ω∈Ω
aX(ω) + bP(ω)
= a ∑ω∈Ω
X(ω)P(ω) + b ∑ω∈Ω
P(ω)
= aE(X) + b car ∑ω∈Ω
P(ω) = 1.
Soit X une variable aléatoire, E(X− E(X)) = 0.
Corollaire 27.2.1.932
Terminologie : La variable X− E(X) s’appelle la variable aléatoire centrée associée à X.Nous avons vu qu’il pouvait être difficile ou au moins technique de calculer u(X). On va voir que l’on peut
calculer E(u(X)) en utilisant la loi de X.
401

Soit (Ω, P(Ω), P) un espace probabilisé et X une variable aléatoire réelle sur Ω. On note X(Ω). Soitu une fonction dont l’ensemble de définition contient X(Ω). On a
E(u(X)) = ∑x∈X(Ω)
u(x).p(X = x).
Proposition 27.2.1.933 (Théorème de Transfert)
Remarque : Cette formule est importante. En effet elle permet de déterminer l’espérance de u(X) sans avoir àcalculer la loi de u(X).Démonstration : On a vu que
E(u(X)) = ∑ω∈Ω
u(X(ω))P(ω)
On peut regrouper les termes dans cette somme en fonction de la valeur de X(ω). On obtient alors
E(u(X)) = ∑x∈X(Ω)
∑ω∈Ω
X(ω)=x
u(X(ω))P(ω)
= ∑x∈X(Ω)
u(x) ∑ω∈Ω
X(ω)=x
u(X(ω))P(ω)
= ∑x∈X(Ω)
u(x)P(X = x)
Exemple : On lance un dé équilibré à 6 faces et on note X le résultat obtenu. Soit Y = (X− 2)2. On a
E(Y) =16
.(1 + 0 + 1 + 4 + 9 + 16) =316
.
1. (Positivité) : soit X une variable aléatoire positive. On a E(X) > 0.
2. (Croissance) : Soit X et Y deux variables aléatoires sur le même espace probabilisé. On supposeque X > Y. On a alors E(X) > E(Y).
Proposition 27.2.1.934 (Propriétés de l’espérance)
Démonstration : Évident
Remarque : On voit que l’espérance vérifie les propriétés des sommes et des intégrales.
Soit (Ω, P(Ω), P) un espace probabilisé et X une variable aléatoire réelle positive sur Ω. Soitα ∈ R?
+,
P(X > α) 6E(X)
α
Proposition 27.2.1.935 (Inégalité de Markov)
Démonstration : On note XΩ) = xii∈r avec 0 6 x1 < x2 < · · · < xr. Soit q le plus petit entier tel que xq > α(s’il n’y en a pas cela signifie que P(X > α) = 0 ce qui assure que l’inégalité est vraie). On a alors
p(X > α) =r
∑k=q
P(X = xk).
402

Donc
P(X > α) =r
∑k=q
P(X = xk)
6r
∑k=q
xkα
P(X = xk) car xk > α
61α
r
∑k=q
xkP(X = xk)
61α
r
∑k=0
xkP(X = xk) car X est à valeurs positives
6E(X)
α
Remarques :
1. On peut faire une preuve plus rapide en utilisant que 1(X>α) 6Xα
et en utilisant la croissance del’espérance.
2. Comme on peut le voir dans la preuve, cette inégalité n’est pas optimale.
Exemples :
1. Cette inégalité à de nombreuses applications comme nous le verrons au paragraphe suivant.
2. Si on tire 10 fois à pile ou face une pièce équilibrée et que l’on note X le nombre de pile obtenu. On verraque X suit la loi binomiale : X → B(10, 1/2). On en déduit que E(X) = 5. De ce fait, pour α = 8 onobtient :
P(X > 8) 658' 0, 625.
Ce n’est pas une très bonne inégalité. En effet
P(X > 8) =((
102
)+
(101
)+
(100
))×(
12
)10=
561024
' 0, 055.
2.2 Variance
On a vu que l’espérance donnait la valeur moyenne d’une variable aléatoire. Nous allons ici définir lavariance qui, pour sa part, exprime la dispersion autour de cette moyenne.
Soit (Ω, P(Ω), P) un espace probabilisé et X une variable aléatoire réelle sur Ω. On appelle variance de X eton note V(X) le nombre :
V(X) = E((X− E(X))2).
On appelle écart-type et on note σ(X) le nombre
σ(X) =√
V(X).
Définition 27.2.2.936
Remarques :
1. La variable aléatoire (X− E(X))2 est positive. Son espérance est donc aussi positive. Ce qui nous donneque la variance d’une variable aléatoire est toujours positive. Cela permet de montrer que l’écart-type estbien défini.
2. La variance mesure la dispersion. En effet si X est une variable aléatoire constante alors V(X) = 0.Réciproquement, si V(X) = 0 alors P(X 6= E(X)) = 0. On dit que X est constante presque surement.
On ne calculera rarement la variance en utilisant la définition. En effet pour ce faire, il faudrait d’aborddéterminer la loi de (X− E(X))2 puis son espérance. On passera plutôt par l’une des deux formules suivantes.
403

Avec les notations précédentes, on a :
V(X) = ∑ω∈Ω
(X(ω)− E(X))2P(ω)
ouV(X) = ∑
x∈X(Ω)
(x− E(X))2P(X = x)
Proposition 27.2.2.937
Démonstration : Cela découle du théorème de transfert.
Avec les notations précédentes on a :
V(X) = E(X2)− E(X)2.
Proposition 27.2.2.938 (Formule de Huygens)
Démonstration : On a
V(X) = E((X− E(X))2)
= E(X2 − 2XE(X) + E(X)2)
= E(X2)− 2E(X)2 + E(X)2
= E(X2)− E(X)2
Remarque : On a utilisé un vérsion un peu plus forte de la linéarité de l’espérance que nous démontreronsdans le chapitre sur les couples.Exemples :
1. E(X2) = V(X) = 3/2.
2. V(X) = 109/18.
Soit (Ω, P(Ω), P) un espace probabilisé et X une variable aléatoire réelle sur Ω. Pour tout (a, b) ∈ R2
on aV(aX + b) = a2V(X) et σ(aX + b) = |a|σ(X).
Proposition 27.2.2.939
Une variable aléatoire est dite réduite sur σ(X) = 1. En particulier si σ(X) > 0 alorsX− E(X)
σ(X)est centrée
et réduite.
Définition 27.2.2.940
Soit (Ω, P(Ω), P) un espace probabilisé et X une variable aléatoire réelle sur Ω. Pour tout réelstrictement positif α on a :
P(|X− E(X)| > α) 6V(X)
α2 .
Théorème 27.2.2.941 (Inégalité de Bienaymé-Tchebychev)
Remarques :
404

1. Cette inégalité montre bien que la variance mesure la dispersion autour de l’espérance. En effet, si lavariance est très petite alors la probabilité que X soit loin de E(X) va être aussi très petite.
2. Nous verrons des exemples plus loin après l’étude de la loi binomiale.Démonstration : Il suffit de voir que l’événement (|X− E(X)| > α) est égal à ((X− E(X))2 > α2). En suite ilsuffit d’utiliser l’inégalité de Markov.
Remarque : Comme pour l’inégalité de Markov, ce n’est pas une inégalité très fiable dans de nombreux cas.C’est intéressant si α est grand.
2.3 Les moments
Soit (Ω, P(Ω), P) un espace probabilisé et X une variable aléatoire réelle sur Ω. Soit p ∈ N? on appellemoment d’ordre p (resp. moment centré d’ordre p) le nombre E(Xp) (resp. E(|X− E(X)|p)).
Définition 27.2.3.942
Remarque : L’espérance est le moment d’ordre 1, la variance est le moment centré d’ordre 2.
3 Lois usuelles
Nous allons étudier dans ce paragraphe les lois classiques à connaître.
3.1 Loi uniforme
Soit N ∈ N? et x1, . . . , xN des réels distincts. Soit (Ω, P(Ω), P) un espace probabilisé et X une variablealéatoire réelle. On dit que X suit la loi uniforme sur x1, . . . , xN si :
1. X(Ω) = x1, . . . , xN
2. pour tout i compris entre 1 et N, P(X = xi) =1N
.
On note alors X → U (x1, . . . , xN).
Définition 27.3.1.943
Remarques :1. C’est la loi de l’équi-probabilité. En effet, savoir que toutes les instances sont équi-problables induit que la
loi de la variable aléatoire est la loi uniforme.2. La plupart du temps on regardera - ou en se ramènera à étudier - la loi uniforme sur [[ 1 ; N ]] .
Soit N ∈ N? et X → U ([[ 1 ; N ]]). On a
E(X) =N + 1
2et V(X) =
N2 − 112
.
Proposition 27.3.1.944
Démonstration
Remarque : La formule de l’espérance est au programme, celle de la variance doit être redémontrée.
Si X → U ([[ 0 ; N ]]) les formules ci-dessus ne sont plus bonnes. On a
E(X) =N2
et V(X) =(N + 1)2 − 1
12.
ATTENTION
405

3.2 Loi de Bernoulli
Soit p ∈ [0, 1]. Soit (Ω, P(Ω), P) un espace probabilisé et X une variable aléatoire réelle. On dit que X suitla loi de Bernoulli de paramètre p si :
1. X(Ω) = 0, 12. P(X = 1) = p et donc P(X = 0) = 1− p.
On note alors X → B(1, p).
Définition 27.3.2.945
Remarques :1. Avant toutes choses, remarquons que l’on écrit Bernoulli et non Bernouilli. La loi de Bernoulli est due à
Jacques Bernoulli qui vecut dans la deuxième moitié du XVII ème siècle.2. Cette loi est aussi appelée la loi succès-echec car cela décrit une expérience n’ayant que deux issues : le
succès (noté 1) ou l’echec (noté 0).3. On notera souvent q = 1− p = P(X = 0).
Soit p ∈ [0, 1] et X une variable aléatoire suivant la loi B(1, p). On a
E(X) = p et V(X) = p(1− p) = pq.
Proposition 27.3.2.946
Exemples :1. On procède à un tirage à pile ou face avec une pièce faisant pile avec la probabilité p. On considère X qui
vaut 1 si on a obtenu un pile et 0 sinon. On a X → B(1, p)2.3. On procède à deux tirages à pile ou face avec une pièce faisant pile avec la probabilité p. On considère X
qui vaut 1 si on a obtenu deux piles et 0 sinon. On a X → B(1, p2)
3.3 Loi binomiale
Soit p ∈ [0, 1] et n ∈ N?. Soit (Ω, P(Ω), P) un espace probabilisé et X une variable aléatoire réelle. On ditque X suit la loi binomiale de paramètres n, p si :
1. X(Ω) = 0, n
2. ∀k ∈ [[ 0 ; n ]] , P(X = k) =(
nk
)pk(1− p)n−k
On note alors X → B(n, p).
Définition 27.3.3.947
Remarques :1. Pour n = 1 on retrouve la loi de Bernoulli.2. On a bien
n
∑k=0
P(X = k) = 1.
C’est le binôme de Newton.3. C’est la loi qui modélise une succession d’épreuve de Bernoulli indépendantes et de même paramètre. La
loi est celle de la variable aléatoire « nombre de succès ». En effet si on considère n épreuves et que l’onnote A1
i l’événement « l’épreuve i amène un succès », A−1i l’événement contraire de A1
i et que X désignele nombre de succès. L’événement [X = k] est la réunion des événements
Aε11 ∩ Aε2
2 ∩ · · · ∩ Aεnn
406

où (ε1, . . . , εn) ∈ −1, 1n et tel que il y ait k fois le chiffre 1. Il y a(
nk
)tel n-uplets. De plus tous ces
événements ont la même probabilités qui, par indépendance est
n
∏i=1
P(Aεii ) = pk(1− p)n−k.
Exemples :
1. On considère une urne avec a boules blanches et b boules noires. On en tire n avec remise. Soit X le nombrede boules blanches tirées. La variable X suit la loi B(n, p) où p = a/(a + b).
2.
Soit p ∈ [0, 1], n ∈ N et X une variable aléatoire suivant la loi B(n, p). On a
E(X) = np et V(X) = np(1− p) = npq.
Proposition 27.3.3.948
Démonstration : Nous verrons au prochain chapitre que cela peut se déduire de l’espérance et la variance desvariables de Bernoulli. Pour le moment nous sommes obligés de faire le calcul.
Remarque : On peut aussi utiliser la fonction génératrice. En effet si on pose
GX(s) =n
∑k=0
P(X = k)sk.
C’est un polynôme.
On a GX(1) = 1 mais surtout G′X(s) =n
∑k=0
kP(X = k)sk−1 donc G′X(1) = E(X). Dans le cas de la loi
binomiale :GX(s) = (1− p + ps)n
et doncG′X(s) = np(1− p + sp)n−1 et donc E(X) = G′X(1) = np.
3.4 Retour sur l’inégalité de Bienaymé-Tchebychev
On considère une expérience aléatoire décrite par l’espace probabilisé (Ω, P(Ω), P) et A un événement. Onnote p = P(A). Si on effectue de nombreuses fois (N) l’expérience de manière indépendante et que l’on note
XN le nombre de fois que l’événement p se réalise et si on note FN =XNN
la fréquence à laquelle l’événement Ase réalise alors, il semble logique que FN va être proche de p.
On voit que XN → B(N, p). De ce fait, E(XN) = Np et V(XN) = Npq. On en déduit que
E(FN) = p et V(FN) =pqN
.
Dès lors, l’inégalité de Bienaymé-Tchebychev affirme que, pour ε > 0,
p(|FN − p| > ε) 6pq
Nε2 .
On voit donc que, quand N tend vers +∞, p(|FN − p| > ε) tend vers 0 et cela pour toute valeur de ε.Par exemple si on lance N fois un dé équilibré à 6 faces. Alors le dé fera 6 environ une fois sur 6 et de ce fait,
FN ne devrait pas être loin de 1/6. D’après l’inégalité de Bienaymé-Tchebychev affirme que, pour ε = 5% = 1/20
p(|FN − 1/6| > 1/20) 65/36
N × (1/20)2 =100018N
.
De ce fait, si on veut être sur à 90% que FN ne diffère de pas plus de 1/20 de 1/6, on doit prendre N tel que
100018N
6 1− 90/100 = 1/10 c’est-à-dire N >10000
18= 555, 5.
407

28Groupe symétrique
1 Généralités sur les groupes 4081.1 Rappels sur les groupes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4081.2 Morphismes de groupes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4091.3 Image directe et réciproque . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 410
2 Sous-groupes engendré et ordre 4112.1 Sous-groupe engendré par une partie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4112.2 Ordre d’un élément . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 412
3 Groupe symétrique 4123.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4123.2 Transpositions et cycles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 413
4 Signature 4154.1 Défintion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4154.2 Complément sur la signature . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4164.3 Permutations paires et impaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 417
1 Généralités sur les groupes
On va compléter ce que l’on a déjà vu sur les groupes et les anneaux.
1.1 Rappels sur les groupes
Soit G un ensemble muni d’une loi de composition interne ?. On dit que (G, ?) est un groupe si :
1. La loi ? est associative ;
2. il existe un élément neutre e de G qui vérifie : ∀g ∈ G, e ? g = g ? e = g.
3. Pour tout g dans G il existe g′ dans G tel que g ? g′ = g′ ? g = e.
Définition 28.1.1.949
408

Soit (G,>) un groupe et H une partie de G. On dit que H est un sous-groupe de G si et seulement si :
1. L’ensemble H est stable par >.
2. L’ensemble H est stable par passage au symétrique.
3. L’ensemble H contient l’élément neutre.
Définition 28.1.1.950
Soit (G,×) un groupe et H une partie de G. L’ensemble H est un sous-groupe de G si et seulement si
— H est non vide.
— ∀(x, y) ∈ H2, xy−1 ∈ H.
Proposition 28.1.1.951 (Caractérisation d’un sous groupe)
Soit G un groupe fini de cardinal n et H un sous-groupe de G. Alors le cardinal de H est fini et divisen.
Théorème 28.1.1.952 (Théorème de Lagrange)
Démonstration : Soit g dans G on pose gH = α ∈ G | ∃h ∈ H, α = gh. C’est-à-dire que pour α dans G,α ∈ gH ⇐⇒ g−1α ∈ H. Si on regarde ϕg : G → G qui associe à u l’élément g.u, c’est une bijection. On endéduit que Card gH = Card H. Maintenant si g1 et g2 sont deux éléments de G alors g1H et g2H sont disjointsou confondus. En effet s’ils ne sont pas confondus, il existe h ∈ H tel que g1 = g2h car g1 ∈ g1H. En fait on peutvoir les gH comme les classes d’équivalence pour la relation d’équivalence ∼ sur G suivante :
g ∼ g′ ⇐⇒ ∃h ∈ H, g = g′h ⇐⇒ g′−1g ∈ H.
A partir de là, on voit qu’il existe g1, . . . , gp tels que g1H, . . . , gp H forment une partition de G donc Card G =p×Card H.
1.2 Morphismes de groupes
Si on considère deux groupes (G,>) et (G′, ∗). Quand on considère une application f de G dans G′ onvoudra souvent que cette application conserve la structure. Précisément
Soit (G,>) et (G′, ∗) deux groupes. On appelle morphisme de groupe de (G,>) dans (G′, ∗) toute applicationf de G dans G′ telle que
∀(g1, g2) ∈ G2, f (g1>g2) = f (g1) ∗ f (g2).
Définition 28.1.2.953
Remarque : Dans la plupart des cas, si les structures sur G et G′ sont évidentes, on omettra le terme groupepour parler simplement de morphisme de G dans G′.Exemples :
1. Soit G un groupe. L’application identité IdG de G dans lui-même est un morphisme.
2. Soit G et G′ deux groupes dont les éléments neutres sont e et e′. L’application constante égale à e′ est unmorphisme (c’est la seul application constante qui vérifie cela car nous verrons plus loin que si f est unmorphisme alors f (e) = e′.)
3. De (Z,+) dans lui même, les applications n 7→ a.n sont des morphismes.
4. L’application ln est un morphisme de (R?+,×) dans (R,+) et inversement pour exp.
5. L’application θ 7→ eiθ de (R,+) dans (U ,×) où U = z ∈ C | |z| = 1 est un morphisme.
Terminologie :
409

1. Un morphisme de groupe bijectif s’appelle un isomorphisme.
2. Un morphisme de groupe dont l’ensemble de départ et d’arrivé sont les mêmes s’appelle un endomor-phisme.
3. Un morphisme de groupe bijectif dont l’ensemble de départ et d’arrivé sont les mêmes s’appelle unautomorphisme.
Soit (G,>) et (G′, ∗) deux groupes et f un morphisme de G dans G′. On note e et e′ les élémentsneutres respectifs.
1. On a f (e) = e′.
2. Pour tout g de G, f (g−1) = ( f (g))−1.
3. Pour tout g de G et tout n de Z, f (gn) = ( f (g))n.
Proposition 28.1.2.954
Démonstration :
1. On a f (e>e) = f (e). Or f (e>e) = f (e) ∗ f (e). En mutlipliant par ( f (e))−1 on obtient bien f (e) = e′.
2. Il suffit de vérifier que f (g−1) ∗ f (g) = f (g−1g) = f (e) = e′ et pareil pour f (g) ∗ f (g−1).
3. Par récurrence.
1.3 Image directe et réciproque
Soit (G,>) et (G′, ∗) deux groupes et f un morphisme de G dans G′.
1. Si H est un sous-groupe de G alors f (H) = g′ ∈ G′ | ∃h ∈ H, g′ = f (h) est un sous-groupede G′.
2. Si H′ est un sous-groupe de G′ alors f−1(H′) = g ∈ G | f (g) ∈ H′ est un sous-groupe de G.
Proposition 28.1.3.955
Démonstration
Exemples :
1. Soit f : θ 7→ eiθ le morpshime de groupe de (R,+) dans (U ,×). Soit Z ⊂ R le sous-groupe de R. Alors
f (Z) est un sous-groupe de U . De même si H′ = 1, j, j2 alors f−1(H′) =2π
3Z.
2. Soit f : n 7→ a.n de Z dans Z. Alors f (Z) est aZ.
Soit (G,>) et (G′, ∗) deux groupes et f un morphisme de G dans G′. On appelle noyau de f et on note Ker fle sous-groupe f−1(e′). On appelle image de f et on note Im f le sous-groupe f (G).
Définition 28.1.3.956
Avec les notations précédentes,
1. L’application f est injective si et seulement si Ker f = e.2. L’application f est surjective si et seulement si Im f = G′.
Proposition 28.1.3.957
Exemple : L’application f : θ 7→ eiθ est surjective mais pas injective. Son noyau est 2πZ.
410

2 Sous-groupes engendré et ordre
2.1 Sous-groupe engendré par une partie
Soit G un groupe.
1. Si H1 et H2 sont deux sous-groupes de G alors H1 ∩ H2 aussi.
2. Plus généralement si (Hi)i∈I est une famille de sous-groupes de G alors H =⋂
i∈IHi est un
sous-groupe de G.
Proposition 28.2.1.958
Démonstration : On ne traite que le deuxième cas, le premier s’en déduit. D’abord, H n’est pas vide car e ∈ H.De plus si g1 et g2 sont deux éléments de H alors pour tout i dans I, g1 et g2 appartiennent à Hi et donc g1g−1
2aussi. de ce fait, g1g−1
2 ∈ H.
Soit G un groupe et X une partie de G. On appelle sous-groupe engendré par X et on note < X > leplus petit sous-groupe de G contenant X.
Proposition-Définition 28.2.1.959
Démonstration : Il faut montrer qu’il existe un plus petit sous-groupe contenant les éléments de X. On poseH l’ensemble des sous-groupes contenant X et on considère
H =⋂
G′∈H
G′
Cela existe car H est non vide car il contient G. Il est évident que X ⊂ H et que H est inclus dans toutsous-groupe de G contenant X. De plus, c’est un sous-groupe d’après ce qui précède.
Remarque : En fait pour construire < X > il suffit de prendre toutes les combinaisons des « puissances » (posi-tives et négatives) des éléments de X si on utilise une notation multiplicative de G.
Soit G un groupe et g un élément de G. Le groupe engendré par g se note < g > et est égal à
< g >= gn | n ∈ Z.
Proposition 28.2.1.960
Soit G un groupe et g ∈ G. L’application
ϕg : Z → Gn 7→ gn
est un morphisme de groupe et Im ϕg =< g > .
Proposition 28.2.1.961
Démonstration
Exemples :1. Si G = Z, le sous-groupe engendré par a ∈ Z et aZ = ma | m ∈ Z. Attention ici on utilise une notation
additive.2. Si G = (U ,×). On a < 1 >= 1, < −1 >= −1, 1, < i >= i,−i, 1,−1. De manière générale, si
a = e2iπ/n, alors < a >= e2ikπ/n | k ∈ [[ 0 ; n− 1 ]] . Si a n’est pas une racine de l’unité, c’est-à-dire quepour tout n dans Z, an 6= 1 alors < a >= an |n ∈ Z. En effet dans ce cas ϕa est injectif.
411

2.2 Ordre d’un élément
Soit G un groupe et g un élément. Si < g > est un groupe de cardinal fini, on dit que g est d’ordre fini et queCard < g > est l’ordre de g.
Définition 28.2.2.962
Remarque : D’après ce qui précède, cela revient à dire que g est d’ordre p si p est le plus petit entier tel quegp = e. C’est-à-dire, Ker ϕg = pZ.Exemples :
1. Dans (Z,+), l’élément 0 est d’ordre 1, tous les autres ne sont pas d’ordre fini.2. Dans (U ,×), i est d’ordre 4 alors que ei est d’ordre infini.
Si G est un groupe fini, tout élément g de G est d’ordre fini et son ordre divise le cardinal de G.
Proposition 28.2.2.963
Démonstration : C’est juste le théorème de Lagrange.
Un groupe G est dit cyclique s’il existe g dans G tel que G =< g >.
Définition 28.2.2.964
Exemples :1. Le groupe (Z,+) est cyclique car engendré par 1 et −1.2. Le groupe (U ,×) n’est pas cyclique. En effet soit g = eiθ . On suppose que < g >= U . Cela revient à dire
que ∀x ∈ R, ∃(n, p) ∈ Z2, x = nθ + 2pπ ce qui est faux. Par contre z ∈ U | zn = 1 est cyclique. Il estengendré par ω = e2iπ/n et même par tous les wk pour k premier avec n.
3 Groupe symétrique
3.1 Définitions
Soit n un entier naturel non nul, on appelle groupe symétrique et on note (Sn, ) (ou Sn) le groupes despermutations de [[ 1 ; n ]] .
Définition 28.3.1.965
Remarque : On a vu que, pour tout ensemble E l’ensemble des bijections de E de E muni de la compositionétait un groupe.Notation : Si σ et τ sont deux éléments de Sn on notera στ pour σ τ.
Exemple : Dans S6 si σ est définie par σ =
(1 2 3 4 5 62 3 4 6 5 1
)et τ =
(1 2 3 4 5 61 4 2 5 6 3
). Alors
στ =
(1 2 3 4 5 62 6 3 5 1 4
)et τσ =
(1 2 3 4 5 64 2 5 3 6 1
).
En particulier στ 6= τσ. On voit que pour n > 3, Sn n’est pas abélien.
Le groupe Sn est fini et son cardinal est n!.
Proposition 28.3.1.966
412

Exemples :1. Pour n = 1, on a S1 = Id.2. Pour n = 2 le groupe S2 a deux éléments : l’identité Id qui est l’élément neutre et la permutation σ qui
échange 1 et 2 (nous la noterons (1, 2)). Elle vérifie que σ2 = Id. En particulier S2 est isomorphe au groupe(−1, 1,×) et il est cyclique et abélien.
Soit σ ∈ Sn et k ∈ [[ 1 ; n ]]. On appelle orbite de k sous l’action de σ l’ensemble σi(k) | i ∈ Z.
Définition 28.3.1.967
Remarque : Soit p > 0 le plus petit entier tel que σp(k) = k (qui existe car σ est d’ordre fini dans Sn) alors,l’orbite de k est σi(k) | i ∈ [[ 0 ; p− 1 ]].
3.2 Transpositions et cycles
1. Une permutation σ de Sn qui échange deux éléments i et j de [[ 1 ; n ]] s’appelle une transposition. Onla note σ = (i, j) et elle est définie par
∀k ∈ [[ 1 ; n ]] , σ(k) =
i si k = jj si k = ik sinon.
2. Soit n ∈ N? et X = (a1, . . . , ap) des éléments deux à deux disjoints de [[ 1 ; n ]]. La permutation σdéfinie par :
∀k ∈ [[ 1 ; n ]] , σ(k) =
k si k /∈ Xai+1 si k = ai pour 1 6 i 6 p− 1a1 si k = ap
Elle se note σ = (a1, . . . , ap). On dit que c’est un p-cycle ou un cycle d’ordre p. L’ensemble a1, . . . , ans’appelle le support du cycle.
Définition 28.3.2.968
Remarques :1. La transposition σ = (i, j) est égale à la transposition (j, i). On a σ−1 = σ car σ2 = Id.
2. Le cycle σ = (a1, . . . , ap) est aussi le cycle (a2, . . . , ap, a1). On a de plus σ−1 = (ap, ap−1, . . . , a2, a1).
Exemple : Pour n = 3, S3 a 6 éléments
— L’identité : Id
— Les transpositions : (1, 2), (1, 3) et (2, 3)
— Les 3-cycles : (1, 2, 3) et (1, 3, 2)
Un cycle d’ordre p est d’ordre p dans Sn. En particulier les transpositions sont involutives (ellesvérifient σ2 = Id).
Proposition 28.3.2.969
Toute permutation de Sn s’écrit comme un produit de transpositions.
Proposition 28.3.2.970
Démonstration : On procède par récurrence sur n.
— Initialisation : C’est évident pour n = 2.
413

— Hérédité : Soit n > 2. On suppose que l’hypothèse de récurrence est vraie pour n. Soit σ ∈ Sn+1. Onsépare deux cas :
— si σ(n + 1) = n + 1 alors σ peut être vu comme un élément de Sn. De ce fait c’est un produit detranspositions.
— si σ(n + 1) = u 6= n + 1, on pose τ = (n + 1, u) qui est une transposition. Dès lors, τσ est un élémentde Sn+1 qui laisse stable n + 1. C’est donc un produit de transpositions. On peut alors conclure enremarquant que
σ = τ(τσ)
car τ2 = Id.
On a bien montré que σ était un produit de transpositions.
Remarque : En reprenant la démonstration précédente, on peut même montrer qu’une permutation de Sn estle produit de au plus n− 1 transpositions.
Exemple : Dans S6 on considère σ =
(1 2 3 4 5 62 3 4 6 5 1
). On applique la méthode précédent :
σ = (1, 6)σ1 ou σ1 =
(1 2 3 4 5 62 3 4 1 5 6
).
Ensuite
σ1 = (1, 4)σ2 ou σ2 =
(1 2 3 4 5 62 3 1 4 5 6
).
Puis
σ2 = (1, 3)σ3 ou σ3 =
(1 2 3 4 5 62 1 3 4 5 6
)= (1, 2).
On a doncσ = (1, 6)(1, 4)(1, 3)(1, 2).
Attention au faut que l’ordre compte. En effet, (1, 2)(1, 3)(1, 4)(1, 6) = σ−1.
La méthode suggérée par la démonstration ci-dessus n’est pas la meilleure.
ATTENTION
Exercice : Soit σ l’élément de Sn défini par σ(i) = n + 1− i. Décomposer σ en produit de transposition. Onpourra séparer les cas où n est pair du cas où n est impair.
Soit σ = (a1, . . . , ap) un p-cycle, alors σ = (ap, ap−1) · · · (a3, a2)(a2, a1).
Proposition 28.3.2.971
Démonstration : Cela se fait par récurrence sur p en procédant comme ci-dessus.
Toute permutation σ peut s’écrire comme produit de cycles de supports disjoints.
Proposition 28.3.2.972
Démonstration : On procède de manière algorithmique. Soit σ ∈ Sn. On pose alors a1 = 1. On sépare les cas,
— Si σ(a1) = 1 on s’arrête.
— Si σ(a1) 6= 1, on pose a2 = σ(1) on on recommence, en considérant a2.
— Si σ(a2) = 1 on s’arrête.
— Si σ(a2) 6= 1 on pose a3 = σ(a2).
414

On fini par obtenir ap tel que σ(ap) = 1. On construit donc un cycle τ = (a1, a2, . . . , ap) de telle sorte que τ−1σfixe les éléments a1, . . . , ap. On recommence en considérant un élément de [[ 1 ; n ]] qui n’est pas dans le supportde τ. A la fin, on a construit des cycles τ1, . . . , τq de supports disjoints tels que
τ−1q · · · τ−1
1 σ = Id⇒ σ = τ1 · · · τq.
Remarques :
1. Ici le produit est commutatif car les supports des cycles sont disjoints.
2. On peut aussi procéder en considérant la relation d’équivalence ∼σ sur [[ 1 ; n ]] définie par
∀(i, j) ∈ [[ 1 ; n ]] , i ∼σ j ⇐⇒ ∃k ∈ Z, i = σk(j).
Dans ce cas, les classes d’équivalences sont les supports des cycles de la décomposition.
Exemple : On considère σ =
(1 2 3 4 5 63 4 6 2 5 1
). On a alors
σ = (1, 3, 6) (2, 4)
Soit σ = (a1, a2, . . . , ap) un p-cycle. On a
σ = (a1, a2) (a2, a3) · · · (ap−1, ap−2) (ap−1, ap)
Proposition 28.3.2.973
Remarque : On peut donc obtenir une décomposition en transpositions à l’aide de la décomposition en cycle.Par exemple
(1, 2, 3, 4, 6) = (1, 2) (2, 3) (3, 4) (4, 6)
Ne pas se tromper dans l’ordre.
ATTENTION
4 Signature
4.1 Défintion
On a vu que toute permutation pouvait se décomposer en produit de transpositions. Cette décompositionn’est pas unique (pas plus que le nombre de transposition qu’il y a dans la décomposition). Par contre la paritédu nombre de transposition l’est. Plus précisément :
Il existe un unique morphisme de groupe ε : Sn → ±1 tel que pour toute transposition τ,ε(τ) = −1.
Théorème 28.4.1.974
Remarque : Si on admet ce qui a été dit au-dessus, le théorème en découle. Cependant, nous allons démontrerle théorème de manière un peu différente (et « plus simple »)
Le morphisme ε s’appelle la signature et, pour tout permutation σ, ε(σ) s’appelle la signature de σ.
Définition 28.4.1.975
415

Si σ est un p-cycle alors ε(σ) = (−1)p−1.
Proposition 28.4.1.976
Démonstration :On sait qu’un p-cycle σ = (a1, . . . , ap) peut s’écrire comme le produit de p− 1 transpositions : (ap, ap−1) · · · (a3, a2)(a2, a1).
Donc ε(σ) = (−1)p−1.
Remarque : Pour calculer la signature, le plus simple est souvent de décomposer en produit de cycles àsupports disjoints et d’utiliser ce qui précède.
4.2 Complément sur la signature
Soit σ une permutation de Sn. Un couple (i, j) ∈ [[ 1 ; n ]]2 est dit une inversion de σ si i < j et σ(i) > σ(j).On note I(σ) le nombre d’inversion.
Définition 28.4.2.977
Remarque : Le nombre d’inversion est un entier compris entre 0 (pour σ = Id) etn(n− 1)
2(pour σ : i 7→
n + 1− i).
Exemple : Si σ =
(1 2 3 4 5 62 3 4 6 5 1
)les inversions de σ sont (1, 6), (2, 6), (3, 6), (4, 5), (4, 6), (5, 6). On a
I(σ) = 4.
Soit σ une permutation de Sn. On note α(σ) le nombre
α(σ) = ∏16i<j6n
σ(i)− σ(j)i− j
= (−1)I(σ) ∈ ±1.
Définition 28.4.2.978
Remarque : On peut voir que
∏16i<j6n
σ(i)− σ(j)i− j
=
∏16i<j6n
σ(i)− σ(j)
∏16i<j6n
i− j.
De ce fait on a les mêmes termes en haut et en bas sauf pour I(σ) termes qui sont inversés.
1. L’application α : Sn → ±1 est un morphisme de groupe.
2. Si τ est une transposition, α(τ) = −1.
Proposition 28.4.2.979
Démonstration :1. Soit (σ, τ) ∈ S2
n,
α(στ) =
∏16i<j6n
στ(i)− στ(j)
∏16i<j6n
i− j=
∏16i<j6n
στ(i)− στ(j)
∏16i<j6n
τ(i)− τ(j).
∏16i<j6n
τ(i)− τ(j)
∏16i<j6n
i− j.
416

La partie de droite est bien α(τ). Pour la partie de gauche, il suffit de voir queστ(i)− στ(j)
τ(i)− τ(j)=
στ(j)− στ(i)τ(j)− τ(i)
.
Si bien que l’on peut échanger si τ(i) > τ(j). On a donc :
∏16i<j6n
στ(i)− στ(j)τ(i)− τ(j)
= ∏16τ(i)<τ(j)6n
στ(i)− στ(j)τ(i)− τ(j)
= α(σ).
En conclusion, α(στ) = α(σ)α(τ).
2. Soit σ = (k, l) une transposition avec k < l. Les inversions de σ sont les couples de la forme :
— (k, j) pour k < j < l : il y en a l − k− 1
— (i, l) pour k < i < l : il y en a l − k− 1
— (k, l)
On en déduit que I(σ) = 2l − 2k− 1 qui est impair et donc α(σ) = −1.
L’application α : Sn → ±1 est un morphisme de groupe et pour toute transposition σ, α(σ) = −1.C’est donc la signature.
Théorème 28.4.2.980
4.3 Permutations paires et impaires
Terminologie :
1. Une permutation dont la signature est 1 est dite paire. On note An l’ensemble des permutations paires.
2. Une permutation dont la signature est −1 est dite impaire.
Remarque : On a donc An = Ker ε.
L’ensemble An des permutations paires est un sous-groupe de Sn.
Proposition 28.4.3.981
Démonstration : Par définition car An = Ker ε.
Exemple : On a A3 = Id, (1, 2, 3), (1, 3, 2).
Soit σ une permutation impaire fixée, l’ensemble des permutations impaires est Anσ = τσ | τ ∈An.
Proposition 28.4.3.982
Démonstration : De manière évidente, les éléments de Anσ sont des permutations impaires car ε(τσ) =ε(τ)ε(σ) = −1. Réciproquement, si µ est une permutation impaire, τ = µσ est alors paire et µ = τσ.
Soit σ une permutation impaire fixée, les ensembles An et Anσ forment une partition de Sn. Enparticulier,
Card An =n!2
.
Corollaire 28.4.3.983
417

29Déterminant
1 Introduction 418
2 Applications multilinéaires 4192.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4192.2 Expression d’une application p-linéaire sur un espace vectoriel de dimension finie . . . . 4202.3 Applications symétriques, antisymétriques et alternées . . . . . . . . . . . . . . . . . . . . . . . . . 421
3 Déterminant 4223.1 Formes n-linéaires sur un espace vectoriel de dimension n . . . . . . . . . . . . . . . . . . . . . 4223.2 Déterminant d’une famille de vecteurs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 423
3.3 Volume dans R3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4243.4 Orientation d’un R-espace vectoriel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4253.5 Déterminant d’un endomorphisme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4263.6 Déterminant d’une matrice . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4273.7 Propriétés et calculs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4293.8 Développements suivant une ligne ou une colonne . . . . . . . . . . . . . . . . . . . . . . . . . . . 4313.9 Déterminants classiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 432
4 Utilisation des déterminants 4354.1 Commatrice . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4354.2 Formule de Cramer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 435
Dans ce chapitre K désigne le corps R ou C.
1 Introduction
On a déjà rencontré le déterminant de deux vecteurs de R2. Soit −→u = (x, y) et −→u ′ = (x′, y′). On a noté
det(−→u ,−→u ′) =∣∣∣∣
x x′
y y′
∣∣∣∣ = xy′ − x′y.
On peut interpréter cela comme l’aire du parallélogramme basé sur les vecteurs −→u et −→u ′. En effet on saitque l’aire du parallélogramme est donnée par la formule
A = base× hauteur
Cela peut se voir sur le dessin :
418

A
A = b h
h
b
b
h
A ~u ~v~u0 = (y1, x1)
~u
|~v · ~u0| = h k~uk = hb = A
~vh
b
~u
~u0
A = |x1y2 y1x2|
a, b, c, d a cb d
:= ad bc
Maintenant si on considère le vecteur −→v = (y,−x) qui est directement orthogonal à −→u . Les relationsclassiques sur les produits scalaires nous permettent d’obtenir :
A = |−→u′ .−→v | = |x′y− xy′| = |det(−→u ,−→u ′)|.
L’application det de R2 dans R vérifie les propriétés suivantes :
1. Elle est bilinéaire.
2. On a det(−→u ,−→u ′) = −det(−→u ′,−→u )
3. On a det(−→u ,−→u ) = 0.
Proposition 29.1.0.984
Nous verrons aussi plus loin que cet exemple se généralise au volume d’un parallélépipède dans R3.
2 Applications multilinéaires
2.1 Définitions
Dans ce paragraphe E et F sont deux espaces vectoriels sur K.
Soit p ∈ N?. On appelle application p-linéaire de E dans F une application f de Ep dans F telle que pour tout(a1, . . . , ap) dans Ep et tout i dans [[ 1 ; p ]], l’application :
f (a1, . . . , ai−1, •, ai+1, . . . , ap) : E → Fx 7→ f (a1, . . . , ai−1, x, ai+1, . . . , ap)
est linéaire.
Définition 29.2.1.985
Remarques :
1. On dit que f est linéaire par rapport à toutes ses coordonnées.
2. On s’intéressera principalement au cas des formes p-linéaires qui sont des applications p-linéaires de Edans K. De même on s’intéressera principalement à p = 2 ou p = dim E.
Terminologie :
1. L’ensemple des applications p-linéaires de E dans F se note Lp(E, F).
2. Une application 1-linéaire est une application linéaire.
3. Une application 2-linéaire s’appelle une application bilinéaire.
4. Une application 3-linéaire s’appelle une application trilinéaire.
Exemples :
419

1. Les applications linéaires sont les applications 1-linéaires.
2. Si E = K[X] et f : E× E→ E défini par f (P, Q) = PQ. L’application f est bilinéaire.
3. Le cas précédent fonctionne encore pour toute algèbre E : L (E), Mn(K), C p(I, R).
4. De manière plus générale, soit E une algèbre :
Ep → E(x1, . . . , xp) 7→ x1 × · · · × xp
est p-lineaire.
5. Dans E = R2 (ou R3) le produit scalaire est une forme bilinéaire. On a dans R2
(x1, x2).(y1, y2) = x1y1 + x2y2.
6. Dans R2 le déterminant est une forme bilinéaire.
Det((x1, y1), (x2, y2)) =
∣∣∣∣x1 y1x2 y2
∣∣∣∣ = x1y2 − x2y1.
7. Pour E = C 0([0, 1], R), l’application ( f , g) 7→∫ 1
0f (t)g(t) dt est une forme bilinéaire.
2.2 Expression d’une application p-linéaire sur un espace vectoriel de dimension finie
On suppose que E est un espace vectoriel de dimension finie et on note (e1, . . . , en) une base de E. On vavoir que l’on peut décrire les formes multilinéaires comme les applications linéaires.
Commençons par étudier le cas des applications bilinéaires (qui est le plus courant).Soit f une application bilinéaire sur E. Pour tous vecteurs u et v, on note
u = ∑16i6n
xiei et v = ∑16j6n
yjej.
On a alors
f (u, v) = f
(∑
16i6nxiei , ∑
16j6nyjej
)
= ∑16i6n
xi f
(ei , ∑
16j6nyjej
)par linéarité à gauche
= ∑16i,j6n
xiyj f (ei , ej)
On voit donc que f est uniquement déterminée par son action sur la base. Il suffit de connaitre f (ei , ej) pour(i, j) ∈ [[ 1 ; n ]]2 pour connaitre f .
Réciproquement, si on se donne uij des scalaires (ou des vecteurs de F pour une application multilinéaire)l’application
f :
(∑
ixiei , ∑
jyjej
)7→∑
i,jxiyjuij
est bilineaire.Remarque : On retrouve par exemple le produit scalaire en posant (dans une base orthonormée) u11 = u22 = 1et u12 = u21 = 0
420

Avec les notations précédentes, si f est une forme p-linéaire de E dans F. Pour tous vecteurs
u1 = ∑i
xi1ei , . . . , up = ∑i
xipei ,
on af (u1, . . . , up) = ∑
16i1 ,...,ip6nxi11 · · · xip p f (ei1 , . . . , eip).
Réciproquement pour tout famille (uI)I∈[[ 1 ; n ]]p , l’application
f :
(∑
ixi1ei , · · · , ∑
ixipei
)7→ ∑
16i1 ,...,ip6nxi11 · · · xip pui1 ,...,ip
est une application p-linéaire.
Théorème 29.2.2.986
Démonstration : Cela se fait par récurrence sur p.
Exemple : Justifier que Lp(E, K) est un espace vectoriel et donner sa dimension. En faire de même pourLp(E, F).
2.3 Applications symétriques, antisymétriques et alternées
Soit f une forme p-linéaire de E dans F.
1. Elle est dite symétrique si pour tout (u1, . . . , up) de Ep et tout 1 6 i < j 6 p,
f (u1, . . . , up) = f (u1, . . . , ui−1, uj, ui+1, . . . , uj−1, ui , uj+1, . . . , up).
On ne change pas la valeur de f en inversant la place de deux vecteurs.
2. Elle est dite antisymétrique si si pour tout (u1, . . . , up) de Ep et tout 1 6 i < j 6 p,
f (u1, . . . , up) = − f (u1, . . . , ui−1, uj, ui+1, . . . , uj−1, ui , uj+1, . . . , up).
On obtient l’opposée de la valeur initiale en inversant la place de deux vecteurs.
Définition 29.2.3.987
Exemples :
1. Le produit scalaire de R2 (ou R3) est symétrique.
2. Le déterminant de R2 est antisymétrique.
3. La forme bilinéaire ((x1, y1), (x2, y2)) 7→ x1y2 n’est ni symétrique ni antisymétrique.
Soit f une forme p-linéaire et σ ∈ Sp. Pour tout (u1, . . . , up) ∈ Ep on a :
1. Si f est symétrique, f (uσ(1), . . . , uσ(p)) = f (u1, . . . , up).
2. Si f est antisymétrique, f (uσ(1), . . . , uσ(p)) = ε(σ) f (u1, . . . , up).
Proposition 29.2.3.988
Démonstration : Il suffit de décomposer σ en produit de transpositions.
421

Soit f une application p-linéaire de E dans F, elle est dite alternée si
∀(u1, . . . , up) ∈ Ep, (∃(i, j) ∈ [[ 1 ; p ]]2 , ui = uj)⇒ f (u1, . . . , up) = 0.
Définition 29.2.3.989
Exemple : Le produit scalaire n’est pas alterné alors que le déterminant l’est.
Toute application p-linéaire alternée est antisymétrique.
Théorème 29.2.3.990
Démonstration : Soit f une application p-linéaire alternée. Soit (u1, . . . , up) ∈ Ep et 1 6 i < j 6 p. On a
0 = f (u1, . . . , ui−1, ui + uj, ui+1, . . . , uj−1, ui + uj, uj+1, . . . , up)
= f (u1, . . . , ui−1, ui , ui+1, . . . , uj−1, ui , uj+1, . . . , up) + f (u1, . . . , ui−1, ui , ui+1, . . . , uj−1, uj, uj+1, . . . , up)
+ f (u1, . . . , ui−1, uj, ui+1, . . . , uj−1, ui , uj+1, . . . , up) + f (u1, . . . , ui−1, uj, ui+1, . . . , uj−1, uj, uj+1, . . . , up)
= f (u1, . . . , up) + f (u1, . . . , ui−1, uj, ui+1, . . . , uj−1, ui , uj+1, . . . , up)
Donc f est antisymétrique.
Remarque : La réciproque est encore vraie en effet, si f est alternée alors en échangeant les deux termes égauxon trouve :
f (u1, . . . , ui−1, a, ui+1, . . . , uj−1, a, uj+1, . . . , up) = − f (u1, . . . , ui−1, a, ui+1, . . . , uj−1, a, uj+1, . . . , up).
d’où2 f (u1, . . . , ui−1, a, ui+1, . . . , uj−1, a, uj+1, . . . , up) = 0.
Par contre il existe des corps (de caractéristique 2) où 2x = 0 n’implique pas que x = 0. Dans ce cas la réciproquen’est plus vraie.
Soit f une forme p linéaire alternée et (u1, . . . , up) une famille liée. On a f (u1, . . . , up) = 0.
Proposition 29.2.3.991
Démonstration : La famille est supposée liée, il existe donc un vecteur de la famille qui s’exprime en fonctiondes autres. Par antisymétrie, on peut supposer que c’est u1 (sinon, si c’est ui0 on échange u1 et ui0 ce qui multiplie
la valeur calculée par −1). On a alors u1 =p
∑k=2
λkuk et, par linéarité :
f (u1, . . . , up) =p
∑k=2
λk f (uk , u2, . . . , up) = 0.
3 Déterminant
On se fixe un espace vectoriel E de dimension n.
3.1 Formes n-linéaires sur un espace vectoriel de dimension n
L’ensemble des formes n-linéaires alternées de E est un espace vectoriel de dimension 1. On le noteΛ∗nE.
Théorème 29.3.1.992
422

Démonstration : Remarquons pour commencer que l’ensemble des formes n-linéaires alternées est inclus dansl’espace vectoriel L (Ep, K). Il est clairement stable par les opérations. On en déduit que c’est un un espacevectoriel. Il reste à montrer qu’il est de dimension 1.
— Commençons à le prouver dans le cas où n = 2. Considérons une base (e1, e2) de E. On sait que pourdéterminer f il suffit de connaitre u11 = f (e1, e1), u12 = f (e1, e2), u21 = f (e2, e1) et u22 = f (e2, e2). Commef est alternée, u11 = u22 = 0. De plus, elle est antisymétrique donc u21 = u12. On conclusion, si on pose f0la 2-forme linéaire alternée telle que u12 = 1 (et donc u21 = −1), alors pour toute 2-forme linéaire alternéef on a
f = f (e1, e2) f0.
D’où l’ensemble des formes 2-linéaires alternées de E est un espace vectoriel de dimension 1.Remarquons d’ailleurs que si E = R2 et (e1, e2) est la base canonique, f0 est juste le déterminant.
— Étudions maintenant le cas général. Soit f une forme n-linéaire alternée. On considère encore une base(e1, . . . , en) de E. Pour tout I = (i1, . . . , in) ∈ [[ 1 ; n ]]n on pose uI = f (ei1 , . . . , ein). Là encore, on a vu quef était uniquement déterminée par la famille (uI)I∈[[ 1 ; n ]]n .
On peut voir notre n-uplet I comme une application σ de [[ 1 ; n ]] dans lui même en posant σ(1) =i1, . . . , σ(n) = in et on notera uσ pour uI ;Maintenant, comme f est alternée, si σ n’est pas injective alors uσ = 0. A l’inverse, si σ est injective, c’estune permutation et on a donc
uσ = f (eσ(1), . . . , eσ(n)) = ε(σ) f (e1, . . . , en)
car f est antisymétrique.En conclusion, si on pose encore f0 l’unique application n-linéaire alternée vérifiant f0(e1, . . . , en) = 1alors f0 engendre l’ensemble des formes n-linéaires alternées de E qui est donc un espace vectoriel dedimension 1.
Soit B = (e1, . . . , en) une base de E et f0 l’unique forme n-linéaire telle que f0(e1, . . . , en) = 1. Soit(u1, . . . , un) dont les coordonnées dans B sont
∀j ∈ [[ 1 ; n ]] uj =n
∑i=1
xijei.
On af (u1, . . . , un) = ∑
σ∈Sn
ε(σ)xσ(1),1 · · · xσ(n),n.
Corollaire 29.3.1.993
Exercice : (Pas simple) Déterminer une base et la dimension des applications p-linéaires.
3.2 Déterminant d’une famille de vecteurs
Soit E = (e1, . . . , en) une base de E. Il existe une unique forme n-linéaire f0 telle que f0(e1, . . . , en) = 1. Onl’appelle le determinant relatif à la base E et on la note detE (ou det s’il n’y a pas de confusion)
Définition 29.3.2.994
Remarques :1. L’existence et l’unicité découle du fait que l’ensemble des formes n-linéaires sur E est un espace de
dimension 1.2. Si on change E , on change detE . Cela sera précisé par la proposition suivante.3. Si on prend E = R2 et E la base canonique, on retrouve le déterminant vu au début de l’année.
Exemple : Calculons le déterminant dans R3 par rapport à la base canonique :
Det((x, y, z), (x′, y′, z′), (x′′, y′′, z′′)) = xy′z′′ − xz′y′′ − yx′z′′ + yz′x′′ + zx′y′′ − zy′x′′.
423

Soit E et E ′ deux bases de E. On a
DetE = DetE (E ′)DetE ′ .
Proposition 29.3.2.995
Démonstration : On a vu que DetE et DetE ′ sont deux éléments non nuls de ∆∗nE qui est de dimension 1. Ilssont donc colinéaires et le coefficient de colinéarité n’est pas nul. Il suffit ensuite d’appliquer en E ′ pour trouverle coefficient.
Remarques :
1. On voit donc que DetE (E ′) =1
DetE (E ′).
2. En particulier, si on échange l’ordre des vecteurs d’une base on peut modifier le déterminant, si E =(ei)i∈[[ 1 ; n ]] et E ′ = (eσ(i))i∈[[ 1 ; n ]] alors
DetE ′ = ε(σ)DetE .
Exemple : Si on considère la famille E = (u, v) ou u = (1, 2) et v = (−3, 1). C’est une base de R2. On a
DetE = Det(E )Det où Det est le déterminant par rapport à la base canonique. Or Det(E ) =
∣∣∣∣1 −32 1
∣∣∣∣ = 7.
Donc DetE = 7.Det.
Soit B une base et (u1, . . . , un) ∈ En,
(u1, . . . , un) est une base de E ⇐⇒ DetB(u1, . . . , un) 6= 0.
Proposition 29.3.2.996
Démonstration :— ⇒ On suppose que (u1, . . . , un) est une base. Le scalaire DetB(u1, . . . , un) est celui qui est défini ci-
dessus, il est non nul.— ⇐ Procédons par contraposée. Si la famille (u1, . . . , un) n’est pas une base, elle est liée. Il existe donc
i ∈ [[ 1 ; n ]] tel que ui soit une combinaison linéaire des uj avec j 6= i. On note ui = ∑j 6=i
λjuj. On en déduit
que
DetB(u1, . . . , un) = ∑j 6=i
λjDetB(u1, . . . , ui−1, uj, ui+1, un)
= 0 car DetB est alternée
3.3 Volume dans R3
On a vu que le déterminant (ou plutôt sa valeur absolue) permettait de mesurer l’aire d’un parallélogramme.On va maintenant illustrer que le déterminant sert aussi à calculer le volume d’un parallélépipède.
Soit u1, u2 et u3 trois vecteurs de R3. On appelle parallélépipède engendré par (u1, u2, u3) l’ensemble
P(u1, u2, u3) = λ1u1 + λ2u2 + λ3u3 | (λ1, λ2, λ3) ∈ [0, 1]3
Définition 29.3.3.997
Remarque : On peut évidemment généraliser cela à Rn.Considérons alors une application ϕ qui associe à un parallélépipède son volume. Plus exactement on pose
ϕ : (R3)3 → R(u1, u2, u3) 7→ « volume » du parallélépipède P(u1, u2, u3)
424

L’application ϕ est une forme trilinéaire alternée.
Proposition 29.3.3.998
Démonstration :
— Montrons que ϕ est linéaire. Commençons par voir qu’elle est additive. Considérons par exemple
ϕ(u1 + u′1, u2, u3)
Un dessin permet de « voir » que
ϕ(u1 + u′1, u2, u3) = ϕ(u1, u2, u3) + ϕ(u′1, u2, u3)
Maintenant, il semble aussi clair que si on multiplie un vecteur par λ ∈ R+ alors le volume est multipliépar λ.Par contre si λ ∈ R− cela semble moins clair. En fait le volume au sens physique du terme est la valeurabsolue du « volume mathématique ». Cela dépend de l’orientation de l’espace comme on en parlera plustard.
— Il est clair que ϕ est alternée car si deux vecteurs sont identiques, le parallélépipède est aplati et de volumenul.
Remarque : On voit donc que notre volume est une forme trilinéaire alternée. Pour la définir, il suffit de fixerun volume étalon qui vaut 1. On prend bien évidemment la base canonique. Cela permet de définir proprementle volume d’un parallélépipède. On démontrera dans le chapitre 32 que l’on a la formule
volume = aire de la base × hauteur
3.4 Orientation d’un R-espace vectoriel
Si on considère un R-espace vectoriel E et deux bases B et B′ de E. Le determinant d’une base dans uneautre est un scalaire non nul. Il est donc strictement positif ou strictement négatif. On définit une relation binairesur l’ensemble des bases en notant B ∼ B′ si et seulement si DetB(B′) > 0.
La relation binaire ∼ est une relation d’équivalence
Proposition 29.3.4.999
Démonstration
La relation d’équivalence ∼ n’a que deux classes d’équivalences.
Proposition 29.3.4.1000
Démonstration : Soit B0 = (e1, . . . , en) une base de E. On considère B1 = (−e1, e2, . . . , en). On a alors
DetB0(B1) = −DetB0(B0) = −1.
De ce fait B0 et B1 ne sont pas en relation. Il y a donc au moins deux classes d’équivalence.Maintenant soit E une base de E. On a
DetB0(E ) = −DetB1(E )
De ce fait E est en relation avec B0 ou avec B1. Il n’y a que deux classes d’équivalence.
425

On appelle orientation de l’espace vectoriel le choix d’une des classes d’équivalence qui forme les bases qui sontdites directes. Les autres sont indirectes.
Définition 29.3.4.1001
Exemples :
1. si n = 1 et E = R. Alors u1 = 1 est une base de R. Si on note −u1 = −1. Comme dans la démonstrationci-dessus Detu1(−u1) = −1. Il faut choisir l’un ou l’autre pour orienter la droite.
2. Si n = 2 on procède de même avec les bases (u1, u2) et (−u1, u2) où u1 = (1, 0) et u2 = (0, 1). Laconvention veut que l’on prenne dans R2 la base canonique comme étant directe.
3.5 Déterminant d’un endomorphisme
Commençons par un exemple dans R2. Considérons l’application linéaire :
f : (x, y) 7→ (3x + 2y, x− y)
Si on considère le parallélépipède P1 = P(e1, e2) où e1 = (1, 0) et e2 = (0, 1). L’image de P1 par f est leparallélépipède P′1 = P( f (e1), f (e2)) où f (e1) = (3, 1) et f (e2) = (2,−1). On en déduit que le volume de P′1 est
Vol(P′1) =∣∣∣∣
3 21 −1
∣∣∣∣ = −5 (au signe près).
Considérons maintenant un autre parallélépipède P2 = P(u1, u2) où u1 = (1, 1) et u2 = (−1, 2). L’image estalors P′2 = P(u′1, u′2) où u′1 = f (u1) = (5, 0) et u′2 = f (u2) = (1,−3).
On en déduit que
Vol(P′2) =∣∣∣∣
5 10 −3
∣∣∣∣ = −15 (au signe près).
On remarque que dans les deux cas, Vol(P′i ) = 5Vol(Pi).Exercice : Montrer que pour tout parallélépipède on a Vol( f (P)) = 5Vol(P).
Soit f un endomorphisme de E. Il existe un unique scalaire λ tel que pour toute base B et toutefamille (u1, . . . , un) ∈ En,
DetB( f (u1), . . . , f (un)) = λDetB(u1, . . . , un).
Proposition 29.3.5.1002
Démonstration :
— Unicité : Soit λ1 et λ2 deux scalaires vérifiant la relation. Soit B = (e1, . . . , en) une base, alors
DetB( f (e1), . . . , f (en)) = λ1 et DetB( f (e1), . . . , f (en)) = λ2 car DetB(B) = 1.
Donc λ1 = λ2.
— Existence : On se fixe une base B. On considère l’application :
Φ : (u1, . . . , un) 7→ DetB( f (u1), . . . , f (un)).
C’est un élément de Λ∗nE. Il existe donc λ tel que Φ = λDetB.Maintenant si B′ est une autre base de E alors il existe α un scalaire non nul (qui est égal à DetB(B′)) telque DetB′ = αDetB.On en déduit que pour tout (u1, . . . , un) ∈ En,
DetB′( f (u1), . . . , f (un)) = αDetB( f (u1), . . . , f (un)) = αλDetB(u1, . . . , un) = λDetB′(u1, . . . , un).
426

Soit f un endomorphisme de E. On appelle déterminant de f et on note Det( f ) le scalaire défini à la propositionprécédente.
Définition 29.3.5.1003
Exemples :
1. Si f = Id, Det(Id) = 1. De plus, Det(λId) = λn.
2. Si s est la symétrie par rapport à G et parallèlement à F où F⊕ G = E. On prend une base adaptée c’est àdire une base B = (e1, . . . , en) telle que (e1, . . . , ep) est une base de F et (ep+1, . . . , en) une base de G. On aalors
DetB(s(e1), . . . , s(en)) = DetB(−e1, . . . ,−ep, ep+1, . . . , en) = (−1)pDetB(B).
Donc Det(s) = (−1)p.
Soit f ∈ L (E) :f ∈ GL(E) ⇐⇒ Det( f ) 6= 0.
Proposition 29.3.5.1004
Démonstration :
— ⇒ : On suppose que f est un automorphisme. On sait alors que l’image d’une base est une base. Soit Eune base et E ′ son image par f . On a
DetE (E ′) = Det( f )DetE (E ) = Det( f )
Or E ′ est une base donc DetE (E ′) 6= 0.
— ⇐ : Si Det( f ) 6= 0. On procède de même. On voit que l’image par f d’une base est une base donc f estun automorphisme.
Soit f et g deux endomorphisme, Det( f g) = Det( f )×Det(g)
Proposition 29.3.5.1005
Remarque : Cela se voit bien sur l’exemple des volumes de R2.
3.6 Déterminant d’une matrice
Soit A ∈ Mn(K) une matrice carrée. On appelle déterminant de A et on note Det(A) le déterminant desvecteurs colonnes de la matrice dans la base canonique de Kn.
Définition 29.3.6.1006
Notation : Si
A =
a11 · · · a1n...
...an1 · · · ann
on note Det(A) =
∣∣∣∣∣∣∣
a11 · · · a1n...
...an1 · · · ann
∣∣∣∣∣∣∣.
Exemple : Si A =
(a bc d
)alors
∣∣∣∣a bc d
∣∣∣∣ = ad− bc.
427

Soit A = (aij) une matrice de Mn(K). On a
Det(A) = ∑σ∈Sn
ε(σ)aσ(1),1 · · · aσ(n),n.
Proposition 29.3.6.1007
Démonstration : C’est la formule démontrée précédemment.
Exemple : Dans le cas n = 3 on trouve∣∣∣∣∣∣
a b cd e fg h i
∣∣∣∣∣∣= aei + dhc + gb f − gec− dbi− ah f .
Il suffit d’utiliser les trois permutations paires Id, (1, 2, 3) et (1, 3, 2) et les trois permutations impaires (1, 2), (1, 3), (2, 3).Cela s’appelle la règle de Sarrus.
Cela ne se généralise pas au cas du déterminant de taille 4 ou plus.
ATTENTION
La notion de déterminant d’une matrice est liée aux notions vues précédemment. Précisément,
1. Si B est une base de E et (u1, . . . , un) une famille de vecteurs. Si M = MatB(u1, . . . , un) alors
Det(M) = DetB(u1, . . . , un).
2. Si f ∈ L (E). Si B est une base de E et M = MatE ( f ) alors
Det( f ) = Det(M).
Proposition 29.3.6.1008
Démonstration :
1. La encore, il suffit d’utiliser la formule.
2. D’après ce qui précède on sait que M = MatB( f (e1), . . . , f (en)) si on note B = (e1, . . . , en). D’où
Det(M) = DetB( f (e1), . . . , f (en)) = Det( f )DetB(B) = Det( f ).
428

3.7 Propriétés et calculs
1) Soit f ∈ L (E), f est inversible si et seulement si Det( f ) 6= 0.
1.bis) Soit M ∈Mn(K), M est inversible si et seulement si Det(M) 6= 0.
1.ter) Soit (u1, . . . , un) ∈ En, c’est une base si et seulement si DetB(u1, . . . , un) 6= 0 où B est unebase de E.
2) Soit f ∈ L (E) et λ ∈ K, Det(λ f ) = λnDet( f )
2.bis) Soit M ∈Mn(K) et λ ∈ K, Det(λM) = λnDet(M).
3) Soit ( f , g) ∈ L (E)2, Det( f g) = Det( f )Det(g).
3.bis) Soit (M, N) ∈Mn(E)2, Det(MN) = Det(M)Det(N).
4) Si f ∈ GL(E), alors Det( f−1) =1
Det( f ).
4.bis) Si M ∈ GL(K), alors Det(M−1) =1
Det(M).
Théorème 29.3.7.1009 (Propriétés du déterminant)
Le déterminant n’est pas linéaire
ATTENTION
Démonstration : Les points 1 et 2 ont déjà été vus. Pour le point 3 il suffit de la faire pour les endomorphismes.On se donne une base B = (e1, . . . , en) de E. Alors
Det( f g) = DetB( f (g(e1), . . . , f (g(en))
= Det( f )DetB(g(e1), . . . , g(en))
= Det( f )Det(g)DetB(B)
= Det( f )Det(g).
Pour le 4, il suffit d’utiliser de plus que Det(Id) = 1.
Soit A une matrice,Det(A) = Det(tA).
Proposition 29.3.7.1010
Démonstration : On note A = (aij). On note B = (bij) la matrice tA et donc bij = aji. On sait alors que
Det(B) = ∑σ∈Sn
ε(σ)bσ(1),1 · · · bσ(n),n.
Orbσ(1),1 · · · bσ(n),n = a1,σ(1) · · · an,σ(n) = aσ−1(1),1 · · · aσ−1(n),n.
On en déduit que
Det(B) = ∑σ∈Sn
ε(σ)aσ−1(1),1 · · · aσ−1(n),n = ∑σ∈Sn
ε(σ−1)aσ−1(1),1 · · · aσ−1(n),n = Det(A).
En effet l’application σ 7→ σ−1 est une bijection.
Remarque : On en déduit que le déterminant est une forme n-linéaire alternée des lignes de la matrice.
429

Soit A = (aij) une matrice de la forme
A =
0
A′...0
∗ · · · ∗ α
.
On a Det(A) = αDet(A′).
Proposition 29.3.7.1011
Démonstration : Il suffit de revenir à la formule
Det(A) = ∑σ∈Sn
ε(σ)aσ(1),1 · · · aσ(n),n.
On voit que les termes de la somme sont nuls si σ(n) 6= n. On peut donc restreindre la somme aux permutationsde [[ 1 ; n− 1 ]] . On trouve alors
Det(A) = α ∑σ∈Sn−1
ε(σ)aσ(1),1 · · · aσ(n−1),n−1 = αDet(A′).
Si A est une matrice triangulaire inférieure
A =
α1 0 · · · 0
∗ α2. . .
......
. . . . . . 0∗ · · · ∗ αn
Alors Det(A) =n
∏i=1
αi. De même si A est triangulaire supérieure.
En particulier, A est inversible si et seulement si ∀i ∈ [[ 1 ; n ]] , αi 6= 0.
Corollaire 29.3.7.1012
Démonstration : C’est une récurrence en utilisant la propriété ci-dessus.Remarques :
1. On peut utiliser maintenant qu’une matrice triangulaire supérieure est inversible si et seulement si tousses coefficients diagonaux sont non nuls.
2. On peut aussi en déduire qu’une famille de polynôme échelonnée en degré (ou de manière générale unefamille échelonnée) est libre.
Exercice : Rédiger proprement ce deuxième point. On traitera le cas d’une famille de n + 1 polynômes deRn[X] et celle d’une famille de p < n + 1 polynômes.
On peut alors regarder, comme pour le pivot de Gauss, l’action des opérations élémentaires sur le déterminantd’une matrice.
Soit A une matrice et B la matrice obtenue par une opération élémentaire on a
— Pour Ci ↔ Cj, Det(B) = −Det(A).
— Pour Ci ← λCi, Det(B) = λDet(A).
— Pour Ci ← Ci + Cj, Det(B) = Det(A).
On en déduit que l’on peut ajouter à une colonne un combinaison linéaire des autres colonnes sansmodifier le déterminant. De plus, on peut faire les mêmes opérations sur les lignes.
Proposition 29.3.7.1013
430

Démonstration : Il suffit d’utiliser que les déterminant est une n-forme linéaire alternée.
Exemple : Si on veut calculer
∣∣∣∣∣∣
1 3 32 4 1−1 7 2
∣∣∣∣∣∣. On peut utiliser la règle de Sarrus et on trouve Det(A) = 40.
Sinon on peut aussi voir que∣∣∣∣∣∣
1 3 32 4 1−1 7 2
∣∣∣∣∣∣=
∣∣∣∣∣∣
1 3 30 −2 −50 10 5
∣∣∣∣∣∣=
∣∣∣∣−2 −510 5
∣∣∣∣
Exercice : Calculer
∣∣∣∣∣∣∣∣
a a a aa b b ba b c ca b c d
∣∣∣∣∣∣∣∣
3.8 Développements suivant une ligne ou une colonne
Il existe une autre méthode pour calculer un déterminant.
Soit A = (aij) une matrice et (i, j) ∈ [[ 1 ; n ]]2.
— On note Aij la sous-matrice de A obtenue en supprimant la ligne i et la colonne j.
— On appelle mineur associé à aij le déterminant ∆ij = Det(Aij).
— On appelle cofacteur associée à aij le terme (−1)i+j∆ij.
Définition 29.3.8.1014
Exemple : Soit A =
1 2 0 1−1 2 3 10 3 −2 10 −3 2 1
.
Le mineur en (1, 2) est
∣∣∣∣∣∣
−1 3 10 −2 10 2 1
∣∣∣∣∣∣= 4.
Soit A = (aij) une matrice.
1. Pour tout j ∈ [[ 1 ; n ]],
Det(A) =n
∑i=1
(−1)i+jaij∆ij (Développement par rapport à une colonne)
2. Pour tout i ∈ [[ 1 ; n ]],
Det(A) =n
∑j=1
(−1)i+jaij∆ij (Développement par rapport à une ligne)
Proposition 29.3.8.1015
Démonstration :
1. Notons C1, . . . , Cn les n colonnes de la matrices et Cj =
a1j...
anj
. On a donc
Det(A) = Det(C1, · · · , Cn) =n
∑i=1
aijDet(C1, . . . , Cj−1, Xi , Cj+1, . . . , Cn)
où Xi est la matrice colonne avec juste un 1 en position i.
431

Or
Det(C1, . . . , Cj−1, Xi , Cj+1, . . . , Cn) =
∣∣∣∣∣∣∣∣∣∣∣∣∣∣∣∣
a11 · · · a1,j−1 0 a1,j+1 · · · a1n...
......
......
ai−1,1 · · · ai−1,j−1 0 ai−1,j+1 · · · ai−1,nai,1 · · · ai,j−1 1 ai,j+1 · · · ai,n
ai+1,1 · · · ai+1,j−1 0 ai+1,j+1 · · · ai+1,n...
......
......
an,1 · · · an,j−1 0 an,j+1 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣∣∣∣∣
Maintenant en échangeant j− 1-fois de colonnes et i− 1 fois des lignes on peut amener le 1 en haut àgauche (ou en bas à droite avec n− j fois sur les colonnes et n− i fois sur les lignes). On en déduit que
Det(C1, . . . , Cj−1, Xi , Cj+1, . . . , Cn) = (−1)i+j−2∆ij = (−1)i+j∆ij.
2. Il suffit de transposer
Exemples :1. On retrouve ainsi la formule de Sarrus.
2. Soit a ∈]− 2, 2[ on pose
Dn(a) =
∣∣∣∣∣∣∣∣∣∣∣∣∣
a 1 0 · · · 0
1 a 1. . .
...
0 1. . . . . . 0
.... . . . . . a 1
0 · · · 0 1 a
∣∣∣∣∣∣∣∣∣∣∣∣∣
.
En développant par rapport à la première ligne on obtient
Dn(a) = aDn−1(a)−
∣∣∣∣∣∣∣∣∣∣∣∣∣
1 1 0 · · · 0
0 a 1. . .
...
0 1. . . . . . 0
.... . . . . . a 1
0 · · · 0 1 a
∣∣∣∣∣∣∣∣∣∣∣∣∣
.
En développant par rapport à la première colonne on récupère
Dn(a) = aDn−1(a)− Dn−2a.
De plus, D1(a) = a et D2(a) = a2 − 1. On étend en posant D0(a) = 1. On résout l’équation caractéristiqueX2 − 2aX + 1 = 0. Si on pose a = 2 cos(θ) avec θ = arccos(a/2) ∈]0, π[ on trouve e±iθ comme solutiond’où il existe (λ, µ) tels que
Dn(a) = λ cos(nθ) + µ sin(nθ).
On en déduit que λ = 1 et µ =cos θ
sin θ. Finalement
Dn(a) =sin(θ) cos(nθ) + cos(θ) sin(nθ)
sin θ=
sin(n + 1)θsin θ
.
3.9 Déterminants classiques
Déterminant de Vandermonde
Soit a0, . . . , an des scalaires on pose
V(a0, . . . , an) =
∣∣∣∣∣∣∣∣∣∣∣
1 1 · · · 1a0 a1 · · · ana2
0 a21 · · · a2
n...
......
an0 an
1 · · · ann
∣∣∣∣∣∣∣∣∣∣∣
.
Étudions les premières valeurs.
432

— Si n = 1, V(a0) = 1.
— Si n = 2, V(a0, a1) = a1 − a0.
— Si n = 3, il est plus simple de particulariser une valeur. On a V(a0, a1, x) =
∣∣∣∣∣∣
1 1 1a0 a1 xa2
0 a21 x2
∣∣∣∣∣∣. Si on
développe par rapport à la dernière colonne
V(a0, a1, x) = x2(a1− a0)− x(a21− a2
0)+ a0a21− a1a2
0 = (a1− a0)(x2− x(a1 + a0)+ a1a0) = (a1− a0)(x− a1)(x− a0).
On peut conjecturer queV(a0, . . . , an) = ∏
06i<j6n(aj − ai).
On le démontre par récurrenceOn suppose que l’on sait le démontrer pour n et on veut le démontrer pour n + 1. Soit x, une inconnue, on
considère V(a0, . . . , an, x). En le développant par rapport à la dernière colonne on voit que
V(a0, . . . , an, x) = V(a0, . . . , an)xn + · · ·
C’est donc un polynôme de degré au plus n. De plus le coefficient dominant vaut V(a0, . . . , an).
— S’il existe i et j distincts tels que ai = aj alors V(a0, . . . , an, x) = 0 = ∏06i<j6n(aj − ai)×∏nk=0(x− ak).
— Si ai 6= aj alors V(a0, . . . , an) 6= 0. Le polynôme n’est donc pas nul. De plus on sait qu’il s’annule ena0, . . . , an et que son coefficient dominant est V(a0, . . . , an) d’où
V(a0, . . . , , an, x) = ∏06i<j6n
(aj − ai)×n
∏k=0
(x− ak).
C’est ce que l’on voulait.Cela permet, par exemple de montrer que si on se donne deux n + 1 uplets (x0, . . . , xn) et (y0, . . . , yn)alors il existe un unique polynôme P de degré au plus n tel que
∀i [[ 0 ; n ]] , P(xi) = yi.
En effet si on pose P =n
∑k=0
ckXk. Alors P vérifie la condition si et seulement si
∀i ∈ [[ 0 ; n ]] , ∑k
ckxki = yi.
On note alors
A =
1 x0 · · · xn0
......
...1 xn · · · xn
n
, X =
c0...
cn
et Y =
y0...
yn
.
On a alors P vérifie les conditions si et seulement si Y = AX. Or DetA = DettA = V(x0, . . . , xn) 6= 0. Onen déduit qu’il existe une unique solution qui est X = A−1Y.
Déterminant triangulaire par blocs
Soit M une matrice de Mn(K) pouvant s’écrire par blocs
M =
(A B0 D
)
avec A ∈Mn′(K), B ∈Mn′ ,n−n′(K) et D ∈Mn−n′(K). On a
Det(M) = Det(A)Det(D)
Proposition 29.3.9.1016
Démonstration : Il y a plusieurs démonstration de cette proposition.
433

— La première consiste à reprendre la formule générale du déterminant :
Det(M) = ∑σ∈Sn
ε(σ)aσ(1),1 · · · aσ(n),n
Maintenant, pour tout p > n′ et q 6 n′, apq = 0. De ce fait, dans la somme ci-dessus on peut ne garder queles permutations σ qui laissent [[ n′ + 1 ; n ]] stable. De ce fait, [[ 1 ; n′ ]] est aussi stable. Une telle permutationest donc donnée par une permutation σ1 de [[ 1 ; n′ ]] et une permutation σ2 de [[ n′ + 1 ; n ]]. On en déduitdonc que
Det(M) =
∑
σ1∈Sn′aσ1(1),1 · · · aσ1(n′),n′
×
(∑
σ2∈Saσ2(n′+1),n′+1 · · · aσ2(n),n
)= Det(A)×Det(D),
où S est l’ensemble des permutations de [[ n′ + 1 ; n ]].— Une autre preuve (utile dans certains exercices) consiste à écrire la matrice M comme un produit. On a
M =
(A B0 I
)×(
I 00 D
).
Maintenant en développant on trouve que∣∣∣∣
A B0 I
∣∣∣∣ = Det(A) et∣∣∣∣
I 00 D
∣∣∣∣ = Det(D).
Donc Det(M) = Det(A)Det(D).
Exercices :1. Montrer que si
M =
(A BC D
)
avec A ∈Mn′(K), B ∈Mn′ ,n−n′(K), C ∈Mn−n′ ,n′(K) et D ∈Mn−n′(K) avec D inversible et qui commuteavec C alors
Det(M) = Det(AD− BC)
2. Trouver
M =
(A BC D
)
telle queDet(M) 6= Det(A)Det(D)−Det(B)Det(C)
Sol Ecrire (A BC D
)×(
D 0−C D−1
)=
(AD− BC 0
0 I
)
Pour la 2.
1 0 1 01 1 1 11 0 0 10 0 0 0
.
Soit M une matrice triangulaire supérieure par blocs. De la forme
M =
A1 ? · · · ?
0 A2. . . ?
0 0. . . ?
0 · · · 0 Ap
.
On a
det(M) =p
∏i=1
Det(Ai).
Corollaire 29.3.9.1017
434

4 Utilisation des déterminants
4.1 Commatrice
Soit A ∈Mn(K). On appelle commatrice de A et on note Com(A) la matrices des cofacteurs.
Définition 29.4.1.1018
Exemple : Si A =
1 0 2−2 3 −13 2 2
. On a Com(A) =
8 1 −134 −4 −1−6 −3 3
. Calculons tCom(A).A. On
trouve −18I. Or Det(A) = −18. On trouve donc tCom(A).A = Det(A)I.
Soit A ∈ Mn(K). On a tCom(A).A = Det(A)I et AtCom(A) = Det(A)I. En particulier, si A estinversible
A−1 =1
Det(A)tCom(A).
Proposition 29.4.1.1019
Démonstration : Notons comme précédemment A = (aij) et ∆ij le mineur associé à aij. On note bij = (−1)i+j∆jiles coefficients de tCom(A).
— Pour la diagonale : Soit i ∈ [[ 1 ; n ]] on a
n
∑j=1
aijbji =n
∑j=1
aij(−1)i+j∆ij = Det(A)(Formule de developpement par rapport à la ligne i)
— Or de la diagonale : Soit (i, j) ∈ [[ 1 ; n ]]2 avec i 6= j. On a
S =n
∑k=1
aikbkj = ∑k=1
aik(−1)i+k∆jk
On remarque alors que
S = ∑k=1
aik(−1)i+k∆jk = (−1)i+j ∑k=1
aik(−1)j+k∆jk.
De plus, si on considère la matrice A′ = (a′ij) obtenue en remplaçant la ligne j de A par la ligne i de tellesorte que aik = a′ik = a′jk on obtient
S = (−1)i+j ∑k=1
a′jk(−1)i+k∆jk.
C’est donc Det(A′) qui est nul.
Remarque : Cette méthode n’est à priori pas la bonne pour déterminer l’inverse d’une matrice.
4.2 Formule de Cramer
On appelle système de Cramer un système linéaire carré inversible. Il s’écrit matriciellement,
A.X = B
où A ∈ GLn(K) est la matrice des coefficients qui est inversible, X ∈M1,n(K) est la matrice des inconnueset B ∈M1,n(K) est le second membre.
Définition 29.4.2.1020 (Rappel)
435

On sait qu’un système de Cramer a une unique solution qui est donné par X =
x1...
xn
où
∀k ∈ [[ 1 ; n ]] , xk =Det(Ak)
Det(A)
où Ak est la matrice obtenue en remplaçant là k-ième colonne de A par B.
Proposition 29.4.2.1021 (Formules de Cramer)
Démonstration :On note C1, . . . , Cn les vecteurs colonnes de A de telle sorte que Det(A) = Det(C1, . . . , Cn).
Maintenant, si X =
x1...
xn
est la solution du système alors ∑
p=1xpCp = B. De ce fait,
Det(Ak) = Det(C1, . . . , Ck−1, ∑p=1
xpCp, Ck+1, . . . , Cn) =n
∑p=1
xpDet(C1, . . . , Ck−1, Cp, Ck+1, . . . , Cn).
Comme Det(C1, . . . , Ck−1, Cp, Ck+1, . . . , Cn) = 0 si p 6= k on obtient,
Det(Ak) = xkDet(C1, . . . , Cn)
On en déduit la formule voulue.
Remarque : Ces formules ne sont pas très utiles pour calculer explicitement les solutions d’un système (saufpour n = 2 voir n = 3).
436

30Couples de variables
aléatoires1 Couples de variables aléatoires 4371.1 Loi conjointe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4371.2 Variables aléatoires indépendantes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4391.3 Lois conditionnelles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4391.4 Lois marginales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4401.5 Fonction d’un couple de variables aléatoires réelle . . . . . . . . . . . . . . . . . . . . . . . . . . . 441
2 Moments 4422.1 Espérance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4422.2 Variance et covariance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 442
3 Généralisation à n variables 4453.1 Variables aléatoires mutuellement indépendantes . . . . . . . . . . . . . . . . . . . . . . . . . . . 4453.2 Somme de n variables aléatoires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 446
Dans ce chapitre nous allons étudier les relations qui peuvent exister entre plusieurs variables aléatoiresdéfinies sur un même espace probabilisé. Nous commencerons par étudier le cas de deux variables aléatoiresavant de généraliser au cas de n (n ∈ N?).
1 Couples de variables aléatoires
1.1 Loi conjointe
Soit X et Y deux variables aléatoires réelles définies sur un même espace probabilisé (Ω, P(Ω), P). La loi ducouple (X, Y) ou loi conjointe est la donnée :
— l’ensemble des valeurs prises par le couple : X(Ω)×Y(Ω)
— pour chaque (x, y) ∈ X(Ω)×Y(Ω), la valeur P((X = x) ∩ (Y = y)).
Définition 30.1.1.1022
Notation : On notera la probabilité de l’événement (X = x) ∩ (Y = y) par P((X = x) ∩ (Y = y)). On trouveaussi la notation P(X = x, Y = y). Par contre P(X = x ∩Y = y) est à proscrire.
437

Ne pas confondre P(X = x, Y = y) avec P(X = x|Y = y) !
ATTENTION
Exemples :
1. On lance deux fois un dé équilibré. On note X le nombre de chiffres pairs obtenus et Y le nombrede chiffres supérieurs à 4 obtenus. On sait que X → B(2, 1/2) et Y → B(2, 1/2). On en déduit queX(Ω)×Y(Ω) = [[ 0 ; 2 ]]2Cependant le fait d’obtenir un nombre plus grand que 4 n’est pas indépendantdu fait de faire un nombre pair. On va donc calculer "à la main" les nombres
pi,j = P(X = i, Y = j) pour (i, j) ∈ [[ 0 ; 2 ]]2 .
On a Ω = [[ 1 ; 6 ]]2. On le munit de la loi uniforme. On a
— [X = 0] ∩ [Y = 0] = 1, 32. De cela on en déduit p0,0 = 1/9.
— [X = 0] ∩ [Y = 1] = (1, 5), (3, 5), (5, 1), (5, 3)2. De cela on en déduit p0,1 = 1/9.
— [X = 0] ∩ [Y = 2] = (5, 5)2. De cela on en déduit p0,2 = 1/36.
— [X = 1] ∩ [Y = 0] = (1, 2), (2, 1), (1, 3), (3, 1)2. De cela on en déduit p1,0 = 1/9.
En continuant ainsi on trouve finalement :
HHHHHX
Y 0 1 2
0 1/9 1/9 1/361 1/9 5/18 1/92 1/36 1/9 1/9
Si on considère maintenant la variable aléatoire Y′ égale au nombre de chiffres impairs. Là encoreY′ → B(2, 1/2). On trouve aisément en utilisant que X + Y′ = 2 le tableau :
HHHHHX
Y′ 0 1 2
0 0 0 1/41 0 1/2 02 1/4 0 0
On remarque donc que connaître la loi de X et de Y n’est pas suffisant pour connaître la loi du couple(X, Y).
2. On dispose d’une pièce équilibrée. On la lance une première fois. On note X la variable aléatoire qui vaut1 si la pièce fait pile et 0 sinon. On fait alors un deuxième étape qui consiste à lancer deux fois la pièce sion a fait pile à la première étape et une fois si on a fait face. On note Y le nombre de pile obtenu lors decette deuxième étape.Ici, il est plus difficile de déterminer la loi de Y. On va juste chercher la loi conjointe de (X, Y).
Avec les notations précédentes, les événements (X = x) ∩ (Y = y) où (x, y) décrit X(Ω)× Y(Ω)forme un système complet d’événements. En particulier si X(Ω) = x1, . . . , xr et Y(Ω) =y1, . . . , ys et que l’on note pour tout (i, j) ∈ [[ 1 ; r ]]× [[ 1 ; s ]], pij = P(X = xi , Y = yj) alors
∑(i,j)∈[[ 1 ; r ]]×[[ 1 ; s ]]
pij = 1.
Proposition 30.1.1.1023
Remarque : on le vérifie bien sur les deux exemples précédents.
438

1.2 Variables aléatoires indépendantes
Soit X et Y deux variables aléatoires réelles définies sur un même espace probabilisé (Ω, P(Ω), P). Les deuxvariables sont dits indépendantes si ∀(x, y) ∈ X(Ω)× Y(Ω) les événements (X = x) et (Y = y) sontindépendants. C’est-à-dire si :
∀(x, y) ∈ X(Ω)×Y(Ω), P(X = x, X = y) = P(X = x)× P(Y = y).
Définition 30.1.2.1024
Remarque : Comme dans le cas des événements indépendants, l’indépendance sera la plupart du temps unehypothèse qui découlera de la modélisation. Attention au fait que l’examen de la modélisation ne permet pasde conclure au fait que des variables ne sont pas indépendantes.Exemples :
1. Deux personnes tirent successivement et avec remise une boule dans une urne qui contient N boulesnumérotées de 1 à N. On note Xi le nombre tiré par la i-ème personne (i ∈ 1, 2). Les variables sontindépendantes et
∀(k, k′) ∈ [[ 1 ; N ]] , P(X1 = k, X2 = k′) =1
N2 .
2. On reprend le même exercice mais cette fois ci, sans remise. Les variables ne sont plus indépendantes.Remarque : On voit que si X et Y sont indépendantes, la connaissance des lois de X et Y permet de déterminerla loi de (X, Y).
Avec les notations précédentes. Soit I et J deux sous-ensembles de R. On a :
P((X ∈ I) ∩ (Y ∈ J)) = P(X ∈ I)× P(Y ∈ J).
Proposition 30.1.2.1025
Démonstration
Soit X et Y deux variables aléatoires réelles définies sur un même espace probabilisé (Ω, P(Ω), P).On suppose que X et Y sont indépendantes. Soit f (resp. g) une fonction dont l’ensemble de définitioncontient X(Ω) (resp. Y(Ω)). Les variables aléatoires f (X) et g(Y) sont indépendantes.
Corollaire 30.1.2.1026
1.3 Lois conditionnelles
Soit X une variable aléatoire réelle définie sur l’espace probabilisé (Ω, P(Ω), P). Soit A ∈ P(Ω) unévénement tel que P(A) 6= 0. On définit la loi conditionnelle de X par A (ou loi de X conditionnée par A ouencore loi de X sachant A) de la manière suivante.
— L’ensemble des valeurs est inclus dans X(Ω).
— Pour tout x ∈ X(Ω), la probabilité est la probabilité de (X = x) sachant A que l’on note PA(X = x).
Définition 30.1.3.1027
Remarques :1. C’est une loi de probabilité en particulier :
∑x∈X(Ω)
PA(X = x) = 1.
2. L’ensemble des valeurs n’est pas toujours X(Ω) en entier (voir exemple 2).
439

3. La condition sera souvent définie comme la valeur d’une variable aléatoire.Exemples :
1. On reprend l’exemple 1. La loi de X sachant (Y = 0) est donnée par :
x 0 1 2P(Y=0)(X = x) 4/9 4/9 1/9
La loi de X sachant (Y = 1) est donnée par :
x 0 1 2P(Y=1)(X = x) 2/9 5/9 2/9
2. On reprend l’exemple 2. Soit i ∈ [[ 1 ; N ]]. Pour tout k ∈ [[ 1 ; N ]] on a
P(X=i)(Y = k) = δik ,
où δik est le symbole de Kronecker qui vaut 1 si i = k et 0 sinon.3. On considère une urne avec 4 boules noires. On en retire un nombre au hasard entre 0 et 4 (selon la loi
uniforme) que l’on remplace par des boules blanches. On tire par la suite 3 boules dans l’urne. On note Y lenombre de boules blanches avant le tirage et X le nombre de boules blanches tirées. Pour tout k ∈ [[ 0 ; 4 ]],la loi de X sachant [(Y = k) est alors H (4, 3, k/4). Pour faire les calculs il est plus simple de regarder lacouleur de la boule qui reste dans l’urne.
Remarque : si X et Y sont deux variables indépendantes, la loi conditionnelle de X sachant (Y = y) est la loide X.
1.4 Lois marginales
Soit (X, Y) un couple de variables aléatoires réelles définies sur un espace probabilisé (Ω, P(Ω), P). Les loisde X et de Y s’appellent les lois marginales du couple (X, Y).
Définition 30.1.4.1028
On peut facilement calculer les lois marginales si on connaît la loi conjointe.
Soit (X, Y) un couple de variables aléatoires réelles définies sur un espace probabilisé (Ω, P(Ω), P).On a :
?∀x ∈ X(Ω), P(X = x) = ∑y∈Y(Ω)
P(X = x, Y = y)
?∀y ∈ Y(Ω), P(Y = y) = ∑x∈X(Ω)
P(X = x, Y = y)
Proposition 30.1.4.1029
Démonstration : Il suffit d’utiliser que les événements (X = x) (resp. (Y = y)) forment un système completd’événements.
Remarque : Dans la pratique, pour déterminer les lois marginales, il suffit de faire la somme des lignes (resp.des colonnes) du tableau de la loi conjointe. Dans la pratique, cela peut permettre de vérifier les calculs d’uneloi conjointe.Exemples :
1. On reprend l’exemple 1 précédent. On a
HHHHHX
Y 0 1 2 X
0 1/9 1/9 1/36 1/41 1/9 5/18 1/9 1/22 1/36 1/9 1/9 1/4Y 1/4 1/2 1/4 1
440

2. On reprend l’exemple de l’urne avec 4 boules noires. On veut calculer la loi du couple (X, Y). On aX(Ω) = [[ 0 ; 3 ]] et Y(Ω) = [[ 0 ; 4 ]] et, pour (i, j) ∈ [[ 0 ; 3 ]]× [[ 0 ; 4 ]], on a :
P(X = i, Y = j) = P(Y = j)× P(X = i|Y = j) =P(X = i|Y = j)
5.
On en déduit donc la loi de (X, Y) ainsi que les lois marginales :
HHHHHYX 0 1 2 3 Y
0 1/5 0 0 0 1/51 1/20 3/20 0 0 1/52 0 1/10 1/10 0 1/53 0 0 3/20 1/20 1/54 0 0 0 1/5 1/5X 1/4 1/4 1/4 1/4 1
1.5 Fonction d’un couple de variables aléatoires réelle
Soit (X, Y) un couple de variables aléatoires réelles définies sur un même espace probabilisé (Ω, P(Ω), P).Soit u une fonction de R2 dans R. On suppose que X(Ω)×Y(Ω) est inclus dans l’ensemble de définition deu. On définit une nouvelle variable aléatoire Z = u(X, Y) en composant la fonction u avec les fonctions X etY. C’est-à-dire :
Z : Ω → Rω → u(X(ω), Y(ω)).
Définition 30.1.5.1030
Exemple : On lance deux dés à 6 faces. On note X (resp. Y) le résultat du premier (resp. second) dé. Si on poseu(x, y) = x + y alors S = u(X, Y) = X +Y est la somme obtenue. Si on pose v(x, y) = Min(x, y) et Z = v(X, Y),la variable Z est le plus petit des deux.
Il est souvent difficile de calculer loi d’une variable aléatoire définie par une fonction de deux variablesaléatoire. En effet soit z ∈ Z(Ω) alors l’événement (Z = z) est l’union des événements (X = x) ∩ (Y = y) où(x, y) sont tels que u(x, y) = z. On a
Soit (X, Y) un couple de variables aléatoires réelles définies sur un même espace probabilisé(Ω, P(Ω), P). Soit u une fonction de R2 dans R. On suppose que X(Ω) × Y(Ω) est inclus dansl’ensemble de définition de u. On pose Z = u(X, Y). On a :
∀z ∈ R, P(Z = z) = ∑(x,y)∈X(Ω)×Y(Ω)
u(x+y)=z
P(X = x, Y = y).
Proposition 30.1.5.1031
Remarque : En particulier, si z n’est pas dans l’image de u alors P(Z = z) = 0.Cas particulier : loi de la somme de deux variables aléatoiresSoit X (resp. Y) une variable aléatoire réelle telle que X(Ω) = [[ 0 ; N ]] (resp. Y(Ω) = [[ 0 ; N′ ]]). On poseZ = X + Y. Dès lors Z(Ω) ⊂ [[ 0 ; N + N′ ]]. De plus, pour tout k ∈ [[ 0 ; N + N′ ]] on a :
P(Z = k) = ∑(i,j)∈[[ 0 ; N ]]×[[ 0 ; N′ ]]
i+j=k
P(X = i, Y = j)
=k
∑i=0
P(X = i, Y = k− i)
=k
∑i=0
P(X = i).PX=i(Y = k− i).
Il faut prendre garde au fait que PX=i(Y = k− i) est nul si i < k− N′.
441

Supposons par exemple que X et Y soient indépendantes et suivent la loi U ([[ 0 ; N ]]). On a Z(Ω) ⊂ [[ 0 ; 2N ]]et pour tout n ∈ [[ 0 ; 2N ]],
P(Z = n) =n
∑i=0
P(X = i)P(Y = n− i).
Dans la somme tous les termes valent 1/(N + 1)2. On veut juste savoir combien il y a de termes. Cela revientà trouver le nombre d’entiers i tels que 0 6 i 6 N et n− N 6 i 6 n. Cela revient à 0 6 i 6 n si n 6 N etn− N 6 i 6 N si n > N. On en déduit que
P(Z = n) =
n + 1(N + 1)2 si n 6 N
2N + 1− n(N + 1)2 si n > N.
2 Moments
2.1 Espérance
Nous allons étudier les moments des couples de variables aléatoires.
Soit X et Y deux variables aléatoires définies sur un même espace probabilisé (Ω, P(Ω), P). Soit uune fonction de deux variables dont l’ensemble de définition contient X(Ω)×Y(Ω). On a
E(u(X, Y)) = ∑(x,y)∈(Ω)×Y(Ω)
u(x, y)P(X = x, Y = y).
Proposition 30.2.1.1032 (Théorème de Transfert)
Remarque : Cela peut-être très utile car il est souvent difficile voir impossible de déterminer la loi de u(X, Y)
L’espérance est linéaire. Avec les notations précédentes, on a pour tout (a, b) ∈ R2,
E(aX + bY) = aE(X) + bE(Y).
Corollaire 30.2.1.1033
Remarque : Ce corollaire s’utilise souvent pour calculer l’espérance d’une somme.Exemple : On lance deux dés à 6 faces équilibrés et on note S la somme. Soit X1 (resp. X2)le résultat du premierdé (resp. du second dé). Les variables X1 et X2 suivent la loi U (6). D’où
E(X1) = E(X2) =72
.
On en déduit queE(S) = E(X1) + E(X2) = 7.
2.2 Variance et covariance
Nous allons maintenant nous intéresser au cas de la variance. Soit X et Y deux variables aléatoires définiessur le même espace probabilisé (Ω, P(Ω), P). On veut calculer V(X + Y). On a
V(X + Y) = E((X + Y)2)− E(X + Y)2
= E(X2 + 2XY + Y2)− (E(X) + E(Y))2
= E(X2)− E(X)2 + E(Y2) + E(Y)2 + 2E(XY)− 2E(X).E(Y)= V(X) + V(Y) + 2(E(XY)− E(X)E(Y)).
442

Soit X et Y deux variables aléatoires définies sur le même espace probabilisé (Ω, P(Ω), P). La covariance ducouple (X, Y) est :
Cov(X, Y) = E(XY)− E(X)E(Y).
Définition 30.2.2.1034
Avec les notations précédentes on a
Cov(X, Y) = E((X− E(X))(Y− E(Y))).
Proposition 30.2.2.1035
Démonstration
Remarque : La "vraie" définition de la covariance est Cov(X, Y) = E((X − E(X))(Y − E(Y))). L’égalitéCov(X, Y) = E(XY)− E(X)E(Y) est la formule de Huygens pour la covariance.
Avec les notations précédentes, Cov(X, Y) = Cov(Y, X). De plus Cov(X, X) = V(X).
Proposition 30.2.2.1036
Avec les notations précédentes, on a, pour tout (a, b) ∈ R2,
V(aX + bY) = a2V(X) + b2V(Y) + 2abCov(X, Y).
En particulier pour a = b = 1 on a
V(X + Y) = V(X) + V(Y) + 2Cov(Y, Y).
Proposition 30.2.2.1037
Remarque : Ces formules nous disent que l’on peut imaginer la covariance comme un produit scalaire et que lavariance est alors le carré de la norme associée (la norme étant l’écart type). Il faut quand même faire attentionque c’est pas réellement exact car la covariance n’est pas définie. On peut avoir V(X) sans que X soit nulle.
Avec les notations précédentes, si X et Y sont indépendantes,
E(XY) = E(X)E(Y).
D’oùCov(X, Y) = 0 et V(X + Y) = V(X) + V(Y).
Théorème 30.2.2.1038
Démonstration : On a
E(X).E(Y) =
∑
x∈X(Ω)
x.P(X = x)
×
∑
y∈Y(Ω)
y.P(Y = y)
= ∑(x,y)∈X(Ω)×Y(Ω)
xy.P(X = x).P(Y = y)
= ∑(x,y)∈X(Ω)×Y(Ω)
xy.P(X = x, Y = y) car X et Y sont indépendantes
= E(XY).
443

Exemples :
1. On reprend l’exemple de la somme de deux dés. Les deux lancers sont indépendants d’où
V(S) = V(X1) + V(X2) = 2.3512
=356
.
2. On considère une urne avec les nombres de 1 à N. On tire deux boules, on note X le premier numéro tiréet Y le deuxième. Calculer Cov(X, Y) selon que le tirage se fasse avec ou sans remise.
3. Soit (X, Y) le couple de variables aléatoires de loi conjointe ;
HHHHHX
Y 0 1 2
0 1/30 11/30 1/301 6/30 5/30 6/30
1. Montrer que X et Y ne sont pas indépendantes
2. Calculer Cov(X, Y).
Remarque : Comme on l’a vu dans les exemples précédentes, le lien entre l’indépendance de X et Y et lacovariance n’est qu’une implication :
— On a : (X et Y indépendantes)⇒ Cov(X, Y) = 0 et, par contraposée, Cov(X, Y) 6= 0⇒ (X et Y ne sontpas indépendantes).
— On n’a pas Cov(X, Y) = 0⇒ (X et Y sont indépendantes).
Avec les notations précédentes, on suppose que X et Y ne sont pas constantes. On appelle coefficient decorrélation linéaire la grandeur :
ρ(X, Y) =Cov(X, Y)σ(X).σ(Y)
.
Définition 30.2.2.1039
Remarque : Cette grandeur a l’avantage par rapport à la covariance que sa valeur absolue ne varie soushomothétie. On a pour (a, b) ∈ (R?)2,
ρ(aX, aY) =Cov(aX, bY)σ(aX)σ(bY)
=ab.Cov(X, Y)|ab|σ(X)σ(Y)
.
Avec les notations précédentes on a|ρ(X, Y)| 6 1.
Proposition 30.2.2.1040
Démonstration : Soit λ ∈ R, on considère P(λ) = V(X + λ.Y). On a
P(λ) = V(X) + λ2V(Y) + 2λ.Cov(X, Y).
On voit donc que P(λ) est un trinôme du second degré en λ. De plus, comme une variance est toujours positive,il est toujours positif. On en déduit que son discriminant est négatif ou nul. D’où
∆ = 4Cov(X, Y)2 − 4V(X)V(Y) 6 0 et donc Cov(X, Y)2 6 V(X)V(Y).
On en déduit|Cov(X, Y)| 6 σ(X)σ(Y) et |ρ(X, Y)| 6 1.
444

Avec les notations précédentes on a :
1. si X et Y sont indépendantes alors ρ(X, Y) = 0.
2. on a |ρ(X, Y)| = 1 si et seulement s’il existe (a, b) ∈ R? × b tels que Y = aX + b.
Proposition 30.2.2.1041
Remarque : on voit que le coefficient de corrélation linéaire mesure bien la "dépendance" des deux variables.Plus il est grand plus elles dépendent l’une de l’autre. En particulier dans le cas extrême où |ρ| = 1.Démonstration :
1. Déjà vu.
2. — Commençons par montrer que : (il existe (a, b) ∈ R? × b tels que Y = aX + b)⇔ |ρ(X, Y)| = 1. Onpose donc Y = aX + b. Alors
Cov(X, aX + b) = E(aX2 + bX)− E(X).(aE(X) + b)= aE(X2) + bE(X)− aE(X)2 − bE(X)
= V(X).D’autre part, σ(aX + b) = |a|σ(X) d’où
σ(X).σ(aX + b) = |a|σ(X)2 = |a|V(X).
On a bien |ρ(X, Y)| = 1.
— Montrons maintenant que : |ρ(X, Y)| = 1⇔ (il existe (a, b) ∈ R?× b tels que Y = aX + b). Reprenonsles notations de la démonstration précédente. On pose P(λ) = V(X) + λ2V(Y) + 2λ.Cov(X, Y).Comme |ρ(X, Y)| = 1 on a ∆ = 0. De ce fait, il existe une valeur α ∈ R tel que P(α) = V(X + α.Y) = 0.On en déduit que la variable aléatoire X + α.Y est constante égale à β. On en déduit que X = −α.Y+ βOr α 6= 0 car X n’est pas constante. Donc
Y =1α
X +β
α.
3 Généralisation à n variables
Nous allons essayer de généraliser certaines notions au cas non plus de deux variables aléatoires mais de nvariables aléatoires.
3.1 Variables aléatoires mutuellement indépendantes
Soit (Ω, P(Ω), P) un espace probabilisé et X1, . . . , Xn des variables aléatoires réelles. On dit qu’elles sontmutuellement indépendantes si, pour tout (x1, . . . , xn) ∈ X1(Ω)× · · · × Xn(Ω), les événements (X1 =x1), . . . , (Xn = xn) sont mutuellement indépendants.
Définition 30.3.1.1042
Remarque : Là encore, on ne démontrera que rarement que l’on considère des variables aléatoires mutuellementindépendantes. Ce sera, la plupart du temps, une hypothèse qui découlera de l’expérience.
Avec les notations précédentes. Soit I1, . . . , In des parties de R. On a
P
(n⋂
i=1
(Xi ∈ Ii)
)=
n
∏i=1
P(Xi ∈ Ii).
Proposition 30.3.1.1043
445

Exemple : On lance n fois un dé à 6 faces équilibré. On note Xi le résultat obtenu au i-ème lancer. Les variablesainsi obtenues sont indépendantes. On a par exemple
P
(n⋂
i=1
(Xi > 5)
)=
13n .
Avec les notations précédentes, si X1, . . . , Xn sont des variables aléatoires mutuellement indépen-dantes alors toute sous-famille l’est aussi.
Proposition 30.3.1.1044
Démonstration : Par restriction des quantificateurs.
Avec les notations précédentes, on suppose que X1, . . . , Xn sont des variables aléatoires mutuellementindépendantes.
1. Soit p ∈ [[ 1 ; n− 1 ]], f une fonction Rp dans R et g une fonction de Rn−p dans R, alorsf (X1, . . . , Xp) et g(Xp+1, . . . , Xn) sont des variables aléatoires indépendantes.
2. Soit f1, . . . , fn des fonctions de R dans R. Les variables aléatoires f1(X1), . . . , fn(Xn) sontmutuellement indépendantes.
Proposition 30.3.1.1045
3.2 Somme de n variables aléatoires
Dans toute ce paragraphe, on se fixe (Ω, P(Ω), P) un espace probabilisé et X1, . . . , Xn des variables aléa-toires réelles. On note alors S = X1 + · · ·+ Xn. Il est en général difficile de déterminer S nous allons voir quecela peut se faire dans certains cas.
On a
E(S) =n
∑i=1
E(Xi).
De même on a
V(S) =n
∑i=1
V(Xi) + ∑i 6=j
Cov(Xi , Xj) =n
∑i=1
V(Xi) + 2 ∑i>j
Cov(Xi , Xj).
Proposition 30.3.2.1046
Démonstration : Par une récurrence immédiate sur n.
Si on suppose de plus que les variables aléatoires sont mutuellement indépendantes on a
V(S) =n
∑i=1
V(Xi).
Proposition 30.3.2.1047
Démonstration : Par une récurrence immédiate sur n.
On suppose maintenant que les variables Xi sont des variables aléatoires indépendantes de Bernoulliet de même paramètre p. On a alors S → B(n, P).
Proposition 30.3.2.1048
446

31Espaces
préhilbertiens réels1 Produit scalaire 4471.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4471.2 Norme euclidienne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 449
2 Orthogonalité 4512.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 451
3 Bases orthogonales 4533.1 Généralité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4533.2 Produit mixte et produit vectoriel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4553.3 Sous-espaces vectoriels orthogonaux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4563.4 Projecteurs orthogonaux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4583.5 Hyperplans . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 459
4 Endomorphismes orthogonaux 4614.1 Endomorphismes orthogonaux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4614.2 Matrices orthogonales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4634.3 Endomorphismes orthogonaux du plan euclidien . . . . . . . . . . . . . . . . . . . . . . . . . . . 4654.4 Automorphismes orthogonaux de l’espace . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 468
Dans ce chapitre nous allons voir comment on peut généraliser la notion de produit scalaire pour les espacesvectoriels sur R.
1 Produit scalaire
1.1 Définitions
On se fixe un espace vectoriel E.
447

Une forme bilinéaire symétrique est une application bilinéaire f de E× E dans R telle que
∀(u, v) ∈ E2, f (u, v) = f (v, u).
Définition 31.1.1.1049 (Rappel)
Soit f une forme bilinéaire symétrique.
1. On dit que f est positive si ∀u ∈ E, f (u, u) > 0.
2. On dit que f est définie si ∀u ∈ E, f (u, u) = 0⇒ u = 0.
Définition 31.1.1.1050
Remarques :
1. On ne peut définir positive que si le corps de base est R.
2. Il se peut que f (u, v) < 0 si u 6= v.
On appelle produit scalaire sur E la donnée d’une forme bilinéaire symétrique définie positive.
Définition 31.1.1.1051
Notation : On note souvent < u, v >, u.v ou (u|v) pour f (u, v)Exemples :
1. Dans E = Rn. On appelle produit scalaire canonique le produit scalaire définie par
(u|v) =n
∑i=1
xiyi
où u = (x1, . . . , xn) et v = (y1, . . . , yn). On vérifie que c’est bien un produit scalaire
2. Dans E = C 0([a, b], R) (ou E = R[X]) la forme bilinéaire ( f |g) =∫ b
af (t)g(t) dt est un produit scalaire.
3. Dans P l’ensemble des fonctions 2π-périodiques continues, ( f |g) = 12π
∫ 2π
0f (t)g(t) dt est un produit
scalaire.
4. Dans E = Mn(R) la forme linéaire (A|B) = tr (tAB) est un produit scalaire.
Remarque : La covariance d’un couple de variables aléatoires n’est pas un produit scalaire. En effet c’estbien une forme bilinéaire positive mais elle n’est pas définie car si X est une variable aléatoire constante,V(X) = Cov(X, X) = 0.Exercice : Montrer que (u|v) = xx′ − 2xy′ − 2yx′ + 5yy′ où u = (x, y) et v = (x′, y′) est un produit scalaire surR2
1. On appelle espace préhilbertien un espace vectoriel sur R muni d’un produit scalaire.
2. On appelle espace euclidien un espace préhilbertien de dimension finie.
Définition 31.1.1.1052
Remarque : On appelle espace hilbertien (ou espace de Hilbert) un espace vectoriel E sur R muni d’un produitscalaire qui est complet ce qui est une condition sur la convergence des suites d’élément de E. La conditiondemandée est en particulier vérifiée sur E est de dimension finie.
448

Soit (|) un produit scalaire.
1. Si u et v sont dans E,(u|v)2 6 (u|u).(v|v)
2. Dans l’inégalité précédente, on a égalité si et seulement u et v sont proportionnels.
Proposition 31.1.1.1053 (Inégalité de Cauchy-Schwarz)
Démonstration : Il suffit de considérer λ 7→ (u + λv|u + λv). Voir le cours sur les intégrales.
Exemple : On retrouve ce qui a été vu sur les intégrales
∫ b
af (t)g(t) dt 6
(∫ b
af 2(t) dt
).(∫ b
ag2(t) dt
).
1.2 Norme euclidienne
On considère un espace préhilbertien E.
On appelle norme (euclidienne) l’application de E dans R+ définie par
N(u) =√(u|u).
Définition 31.1.2.1054
Notation : On note aussi ||u|| pour N(u).Exemples :
1. Si on considère R3 muni du produit scalaire usuel, la norme euclidienne est la norme usuelle ||u|| =√x2 + y2 + z2.
2. Si on regarde E = C 0([a, b]) et que l’on pose ( f , g) =∫ b
af (t)g(t) dt, on a
N( f ) =
√∫ b
af 2(t) dt.
Soit u et v dans E,(u, v) 6 ||u||||v||.
De plus il y a égalité si et seulement si u et v sont colinéaire et le coefficient de colinéarité est positif.
Proposition 31.1.2.1055 (Inégalité de Cauchy-Schwarz)
La norme euclidienne vérifie les propriétés suivantes :
1. Pour tout u dans E, N(u) = 0 ⇐⇒ u = 0
2. Pour tout u dans E et λ dans R, N(λu) = |λ|N(u).
3. Pour tout u et v dans E, N(u + v) 6 N(u) + N(v) (c’est l’inégalité triangulaire). De plus on aN(u + v) = N(u) + N(v) si et seulement s’il existe k ∈ R+ tel que u = kv ou v = 0.
Proposition 31.1.2.1056 (Propriétés de la norme)
Démonstration :
1. OK
449

2. OK
3. Soit u et v deux vecteurs il suffit de montrer que ||u + v||2 6 ||u||2 + ||v||2 + 2||u||||v||. Or on sait que
||u + v||2 = (u + v, u + v)= ||u||2 + ||v||2 + 2(u, v) (Linéarité et symétrie)
6 ||u||2 + ||v||2 + 2||u||||v|| (Cauchy-Schwarz)
Le cas d’égalité découle de celui qui précède.
Soit u et v deux vecteurs. On appelle distance de u à v et on note d(u, v) la valeur :
d(u, v) = ||u− v||.
On définit ainsi une applicationd : E2 → R+
(u, v) 7→ d(u, v)
Définition 31.1.2.1057 (Distance)
On peut utiliser les propriétés de la norme pour définir les propriétés de la distance.
La distance d vérifie :
1. Pour tout (u, v) dans E2, d(u, v) = 0 ⇐⇒ u = v
2. Pour tout (u, v, w) dans E3, d(u, w) 6 d(u, v) + d(v, w).
Proposition 31.1.2.1058 (Propriétés de la distance)
Démonstration :
1. Évident
2. L’inégalité triangulaire affirme que
d(u, w) = ||u− w|| 6 ||u− v||+ ||v− w|| = d(u, v) + d(v, w).
Un vecteur u est dit unitaire (ou normé) si ||u|| = 1.
Définition 31.1.2.1059
Remarque : De manière plus générale on peut définir une distance sur un espace E comme une application
d : E2 → R+
qui vérifie que
1. d(u, v) = 0 ⇐⇒ u = v
2. Pour tout (u, v, w) dans E3, d(u, w) 6 d(u, v) + d(v, w)
On voit ainsi qu’il existe des distance plus générale que celles que l’on considère ici. On peut par exemple,regarder la distance triviale définie par
∀(u, v) ∈ E2, d(u, v) =
1 si u 6= v0 si u = v
450

Soit u et v deux vecteurs :
1. ||u + v||2 = ||u||2 + ||v||2 + 2(u, v)
2. ||u− v||2 = ||u||2 + ||v||2 − 2(u, v)
3. ||u + v||2 − ||u− v||2 = 4(u, v)
Proposition 31.1.2.1060 (Identités de polarisation)
Remarque : C’est égalité permettent de retrouver (u, v) en ne connaissant que les normes.
Soit u et v deux vecteurs,
||u + v||2 + ||u− v||2 = 2(||u||2 + ||v||2).
Proposition 31.1.2.1061 (Egalité du parallélogramme)
Remarque : Cette égalité a déjà été vue dans le cadre des complexes.
2 Orthogonalité
2.1 Définitions
Soit u et v deux vecteurs de E. Ils sont donc orthogonaux si (u|v) = 0. On note alors u ⊥ v.
Définition 31.2.1.1062
Remarque : La définition est symétrique car (u, v) = 0 ⇐⇒ (v, u) = 0.Exemples :
1. Cela généralise l’orthogonalité dans R2 ou R3. Par exemple u = (1,−1, 2, 0) et v = (1,−1,−1, 1) sontorthogonaux.
2. Dans R[X] muni du produit scalaire∫ 1
0P(t)Q(t) dt. Les polynômes X et X− 2
3sont orthogonaux.
Soit u et v deux vecteurs de E,
u ⊥ v ⇐⇒ ||u + v||2 = ||u||2 + ||v||2.
Proposition 31.2.1.1063 (Théorème de Pythagore)
Démonstration
Soit A et B deux parties de E. On dit que A et B sont orthogonales si tout vecteur de A est orthogonal à toutvecteur de B c’est-à-dire,
∀u ∈ A, ∀v ∈ B, (u|v) = 0.
Définition 31.2.1.1064
Exemples :
1. Dans R3 les droites ∆1 = Vect(1, 1, 1) et ∆2 = Vect(1,−1, 0) sont orthogonales.
2. Dans R[X] muni du produit scalaire précédent, les espaces F = R1[X] et G = Vect(−6X2 + 6X− 1) sontorthogonaux.
451

Soit A une partie de E, on appelle orthogonal de A et on note A⊥ l’ensemble des vecteurs qui sont orthogonauxà tous les vecteurs de A. On a
A⊥ = u ∈ E | ∀v ∈ A, (u|v) = 0.
Définition 31.2.1.1065
Remarque : On a donc que A et B sont orthogonaux si et seulement si A ⊂ B⊥ (ce qui est aussi équivalent àB ⊂ A⊥).
Avec les notations précédentes, A⊥ est un sous-espace vectoriel.
Proposition 31.2.1.1066
Démonstration
Exemples :
1. On a 0⊥ = E et E⊥ = 0.
2. Dans E = M2(R). Avec le produit scalaire tr (tAB), si on note E =
(a b0 a
)| (a, b) ∈ R2
. Un matrice
B =
(α βγ δ
)est dans l’orthogonal de E si et seulement si pour tout a et b, a(α− δ) + bβ = 0. C’est à
dire α = −δ et β = 0. On a donc
E⊥ =
(α 0γ −α
)| (α, γ) ∈ R2
.
Exercices :
1. Montrer que si F est un sous-espace vectoriel de E, F ∩ F⊥ = 0.
2. Dans R2[X] muni du produit scalaire (P|Q) =∫ 1
0P(t)Q(t) dt. Déterminer Vect(X)⊥.
Soit F et G deux sous-espaces vectoriels orthogonaux. Ils sont alors en somme directe. On note alors
F⊥⊕ G la somme
Proposition 31.2.1.1067
Démonstration
Soit (u1, . . . , up) une famille de vecteurs de E.
1. Elle est dite orthogonale si pour tout (i, j) dans [[ 1 ; p ]]2 avec i 6= j alors ui ⊥ uj.
2. Elle est dite orthonormale si elle est orthogonale et que tous les vecteurs sont unitaires. On a donc
∀(i, j) ∈ [[ 1 ; p ]]2 , (ui|uj) = δij.
Définition 31.2.1.1068
Exemples :
1. La base canonique est orthonormée pour le produit scalaire usuel.
2. Dans P , on pose fk : x 7→ cos(kx). La famille ( f0, . . . , fp) est orthonormée pour le produit scalaire
( f , g) =1
2π
∫ 2π
0f (t)g(t) dt.
452

Dans E = R2 la base canonique n’est plus orthogonale pour le produit scalaire :
(u|v) = xx′ + 2(xy′ + x′y) + 5yy′
ATTENTION
Soit (u1, . . . , up) une famille orthogonale de vecteurs non nuls. Elle est libre.
Proposition 31.2.1.1069
Démonstration
Remarque : En particulier une famille orthonormée est libre.
3 Bases orthogonales
On va vouloir travailler avec des bases, on va donc souvent se placer dans le cadre de la dimension finie(c’est-à-dire la cas des espaces euclidiens).
3.1 Généralité
Dans toute la suite de ce paragraphe, on note E un espace euclidien.
Soit E un espace euclidien. On appelle base othonormale (ou orthonormée) une base de E qui est une familleorthonormale.
Définition 31.3.1.1070
Remarque : Il suffit qu’une famille orthonormale ait le bon nombre de vecteurs (égal à la dimension de E) pourêtre une base orthonormale.
Soit (e1, . . . , ep) une famille libre de vecteurs de E. Il existe une famille orthonormale ( f1, . . . , fp)telle que, pour tout k ∈ [[ 1 ; p ]] , Vect(e1, . . . , ek) = Vect( f1, . . . , fk).
Théorème 31.3.1.1071 (Procédé d’orthonormalisation de Gram-Schmidt)
1. Un espace euclidien admet des bases orthonormales.
2. On peut compléter toute famille orthonormale en une base orthonormale.
Corollaire 31.3.1.1072
Exemple : Dans E = R3 muni du produit scalaire usuel. On pose e1 = (1, 1, 1), e2 = (0,−4, 1) et e3 = (2,−1, 1).Cette famille est libre. On va commencer par orthogonaliser cette famille.
— On prend donc v1 = e1 = (1, 1, 1).
— On cherche v2. Il doit être orthogonal à v1 et appartenir à Vect(e1, e2) = Vect(v1, e2). On pose doncv2 = e2 + av1 ∈ Vect(v1, e2). On a alors (v2|v1) = (e2|v1) + a(v1|v1). Si on veut que v2 soit orthogonal à
v1 il faut prendre a = − (e2, v1)
(v1|v1)= −−3
3= 1. On pose donc v2 = e2 + v1 = (1,−3, 2).
453

— On cherche v3. Il doit être orthogonal à v1 et à v2 et appartenir à Vect(e1, e2, e3) = Vect(v1, v2, e3). Onpose donc v3 = e3 + a1v1 + a2v2 ∈ Vect(v1, v2, e3). On a alors
(v3, v1) = (e3, v1) + a1(v1, v1) + a2(v2|v1) = (e3, v1) + a1(v1, v1)
et(v3, v2) = (e3|v2) + a1(v1|v2) + a2(v2, v2) = (e3|v2) + a2(v2, v2).
Si on veut que v3 soit orthogonal à v1et à v2 il faut prendre
a1 = − (e3, v1)
(v1|v1)= −2
3et a2 = − (e3, v2)
(v2|v2)= − 8
14= −4
7.
On en déduit que
v3 =121
(26, 1,−5)
Ensuite il ne reste plus qu’à normer v1, v2 et v3. On trouve alors
f1 =1√2(1, 1, 1), f2 =
1√14
(1,−3, 2) et f3 =1√702
(26, 1,−5).
Démonstration : La démonstration suit le même principe que l’exemple à la différence prêt que l’on norme
les vecteurs au fur et à mesure. On pose f1 =e1
||e1||. On suppose alors avoir construit ( f1, . . . , fk) vérifiant les
conditions. On pose alors vk+1 = ek+1 +k
∑i=1
ai fi où ai = −(ek+1, fi). C’est ici que l’on simplifie les formules en
normands au fur et à mesure.Ce vecteur n’est pas nul car ek+1 6∈ Vect( f1, . . . , fk). On pose donc fk+1 =
vk+1||vk+1||
qui est un vecteur
unitaire. De plus, par construction, pour tout i ∈ [[ 1 ; k ]], ( fk+1, fi) = (vk+1, fi) = 0. La famille ( f1, . . . , fk+1)est orthonormale. Elle est donc libre et de rang k + 1. Comme Vect( f1, . . . , fk+1) ⊂ Vect(e1, . . . , ek+1) parconstruction on a bien Vect( f1, . . . , fk+1) = Vect(e1, . . . , ek+1)
Remarques :
1. Il n’y a pas unicité de choix dans ce procédé, car à chaque fois on peut prendre ou fi ou − fi. Mais c’est leseul degré de liberté.
2. En reprenant la démonstration du théorème on voit que si B est une base, il existe une base orthonormaleE telle que la matrice de passage de B à E soit triangulaire supérieure.
Exercice : Soit E = Rn[X] muni du produit scalaire (P, Q) =∫ 1
−1P(t)Q(t) dt. Si on considère la base canonique
(1, X, . . . , Xn). Si on applique le procédé d’orthonormalisation de Gram-Schmidt on obtient une famille depolynôme Pn vérifiant
∀(i, j) ∈ [[ 0 ; n ]]2 , (Pi , Pj) = δij.
Déterminer P0, P1 et P2. Précisément on a P0 =12
. De même P1 =32
X et P2 =85(3X2 − 1).
Ces polynômes sont colinéaires aux polynômes de Legendre. C’est un cas particulier des polynômesorthogonaux.
Soit E un espace vectoriel euclidien, (e1, . . . , en) une base orthonormale. Pour tout vecteur u de E,
u = ∑i(u, ei)ei.
Proposition 31.3.1.1073
Remarque : Cela signifie que pour connaitre les coordonnées d’un vecteur dans une base orthonormale ilsuffit de faire le produit scalaire avec le vecteur de la base.
454

Avec les mêmes notations, si on note U = MatE (u) =
x1...
xn
la matrice des coordonnées d’un
vecteur u et V = MatE (v) =
y1...
yn
la matrice des coordonnées d’un vecteur v.
1. Le produit scalaire se calcule par (u, v) = ∑i
xiyi =tUV.
2. La norme norme se calcule par ||u|| =√
∑i
x2i
√tUU.
Proposition 31.3.1.1074
Démonstration : On a u = ∑i
xiei et v = ∑j
yjej. On en déduit par bilinéarité que
(u, v) = ∑i,j
xiej(ei , ej) = ∑i
xiyi.
Remarque : Cette propriété n’est vraie que dans une base orthonormale. Sinon on a (u, v) = tUAV oùA = ((ei , ej)).
3.2 Produit mixte et produit vectoriel
On considère E un espace euclidien que l’on suppose orienté. On a vu que si B était une base on pouvaitdéfinir detB comme étant l’unique forme n linéaire alternée valant 1 sur la base B. De plus, si B′ est une autrebase on a alors :
detB′
= detB′
(B)detB
.
Si B et B′ sont deux bases orthonormées directes, detB′(B) = 1. De ce fait
detB′
= detB
.
Théorème 31.3.2.1075
Démonstration : On a vu que detB′(B) est le déterminant de la matrice de passage P de B′ à B. Fixons lesnotations, on pose
B = (e1, . . . , en) et B′ = (e′1, . . . , e′n).
On a alorsP = ((ei|e′j))
On remarque alors queP−1 = ((e′i |ej)) =
tP
On en déduit que
det(P) = det(tP) = det(P−1) =1
det P.
Donc det(P) = ±1.Maintenant detB′(B) > 0 car ce sont deux bases directes donc detB′(B) = 1
Soit E un espace euclidien orienté, on appelle produit mixte le déterminant prenant comme base de référenceune base orthonormée directe. On le note
[u1, . . . , un]
Définition 31.3.2.1076
455

Exemples :
1. Si E est un espace vectoriel orienté de dimension 2, et u et v deux vecteurs, [u, v] est l’aire orientée duparallélogramme.
2. Si E est un espace vectoriel orienté de dimension 3, et u, v et w trois vecteurs, [u, v, w] est le volume orienté.
3. Si E est un espace vectoriel orienté et f un endomorphisme, det f mesure la dilatation que procure f .
Vous avez vu en physique le produit vectoriel de deux vecteurs. Si E est un espace vectoriel de dimension
3 et B une BOND. On se donne deux vecteurs u et v de coordonnées respectives
xyz
et
x′
y′
z′
. Alors le
produit vectoriel u ∧ v a pour coordonnées
∣∣∣∣y y′
z z′
∣∣∣∣
−∣∣∣∣
y y′
z z′
∣∣∣∣∣∣∣∣y y′
z z′
∣∣∣∣
=
yz′ − y′z−(xz′ − x′z)
xy′ − x′y
On remarque que pour tout vecteur w de coordonnées
αβγ
, le produit mixte [u, v, w] vaut
[u, v, w] =
∣∣∣∣∣∣
x x′ αy y′ βz z′ γ
∣∣∣∣∣∣= α
∣∣∣∣y y′
z z′
∣∣∣∣− β
∣∣∣∣y y′
z z′
∣∣∣∣+ γ
∣∣∣∣y y′
z z′
∣∣∣∣ = (u ∧ v|w).
On peut montrer que le produit vectoriel u ∧ v est l’unique vecteur ayant cette propriété ce qui permet d’enavoir une définition intrinsèque.
1. L’applicationE× E → E(u, v) 7→ u ∧ v
est bilinéaire et antisymétrique.
2. Le vecteur u ∧ v est orthogonal à u et v.
3. On a u ∧ v = 0 si et seulement si les vecteurs u et v sont liés.
4. Si u et v sont deux vecteurs unitaires et orthogonaux alors (u, v, u∧ v) est une base orthonornéedirecte.
Proposition 31.3.2.1077 (Propriétés du produit vectoriel)
3.3 Sous-espaces vectoriels orthogonaux
Soit E un espace euclidien et F un sous-espace vectoriel de E.
1. Le sous-espace F⊥ est un supplémentaire de F dans E.
2. On a dim F + dim F⊥ = dim E.
3. On a (F⊥)⊥ = F.
4. Si (e1, . . . , ep) est une base de F et u un vecteur de E. On a
u ∈ F⊥ ⇐⇒ ∀i ∈ [[ 1 ; p ]] (u, ei) = 0.
Proposition 31.3.3.1078
Démonstration :
456

1. Soit u ∈ F ∩ F⊥, on a u ⊥ u et donc u = 0. Il reste à montrer que F + F⊥ = E. Soit (e1, . . . , ep) unebase orthonormée de F (que l’on peut obtenir en appliquant le procédé d’orthonormalisation de Gram-Schmidt à une base de F). On peut la compléter en une base (e1, . . . , en) orthonormée de E. Si on poseH = Vect(ep+1, . . . , en) on a H ⊂ F⊥ et F + H = E. On en déduit que F + F⊥ = E.
2. Cela découle de 1.
3. On peut montrer que F ⊂ (F⊥)⊥. En effet soit u ∈ F. Pour tout v ∈ F⊥ on a (u, v) = 0 donc u ∈ (F⊥)⊥. Sion note n = dim E et p = dim F on a
dim(F⊥)⊥ = n− (n− p) = p = dim F
On a donc F = (F⊥)⊥.
Si F est un sous-espace vectoriel, on sait qu’il existe de nombreux sous-espaces supplémentaires. Parcontre il existe un unique supplémentaire qui soit orthogonal : c’est F⊥.
ATTENTION
Exemples :1. Dans R3. On considère le plan vectoriel F = (x, y, z) ∈ R3 | 2x + 3y− z = 0. On sait alors que le vecteur
n = (2, 3,−1) est orthogonal à F et on a
F⊥ = Vect(n).
2. Dans Mn(R) avec le produit scalaire défini ci-dessus. Si F = Vect(In), F⊥ = A ∈Mn(R) | tr (A) = 0.Une partie de la proposition précédente se généralise aux sous-espaces vectoriels de dimension finie d’un
espace préhilbertien.
Soit E un espace préhilbertien et F un sous-espace vectoriel de dimension finie. Les espaces F et F⊥
sont supplémentaires.
Proposition 31.3.3.1079
Démonstration : La démonstration précédente ne s’étend pas au cas où E n’est plus de dimension finie. Ona toujours F ∩ F⊥ = 0. Montrons de plus que F + F⊥ = E. On procède par analyse synthèse. On considèreB = (e1, . . . , ep) une base orthonormée de F.
— Analyse : Soit w ∈ E et u ∈ F, v ∈ F⊥ tels que u + v = w. Si on décompose u dans la base B :u = λ1e1 + · · · λpep. On a alors
∀i ∈ [[ 1 ; p ]] , (w|ei) = (u|ei) + (v|ei) = λi.
On en tire que u =p
∑i=1
(w|ei)ei et v = w− u
— Synthèse : Soi w ∈ E. On pose u =p
∑i=1
(w|ei)ei et v = w− u. On a bien u ∈ F, u + v = w, de plus pour tout
i ∈ [[ 1 ; p ]], (v|ei) = (w|ei)− (u|ei) = 0. Donc v ∈ F⊥.
Exemple : Dans R[X]. On pose F = R0[X] et (P|Q) =∫ 1
0P(t)Q(t)dt.
On a F⊥ =
Q ∈ R[X] |
∫ 1
0Q(t)dt = 0
= Vect(X− 1/2, X2 − 1/3, X3 − 1/4, . . .) et R[X] = F⊕ F⊥.
Remarque : Le fait que (F⊥)⊥ = F n’est plus vrai comme on va le voir dans l’exercice ci-dessous.Exercice : On pose E = C 0([0, 1]) muni du produit scalaire ( f |g) =
∫ 10 f (t)g(t)dt. On pose F = f ∈ E | f (0) =
0.1. Soit f une fonction non nulle de E.
457

(a) Montrer qu’il existe α 6= 0 tel que f (α) 6= 0.(b) Montrer qu’il existe ε > 0 tel que
[α− ε, α + ε] ⊂]0, 1[ et ∀x ∈ [α− ε, α + ε], | f (x)| > | f (α)|/2.
(c) Construire une fonction g de F telle que ( f |g) > 0.2. En déduire F⊥.3. Montrer que (F⊥)⊥ 6= F
3.4 Projecteurs orthogonaux
Soit F un sous-espace vectoriel de E de dimension finie. On appelle projection orthogonale sur F la projection psur F parallèlement à F⊥. Pour tout vecteur u de E, p(u) est l’unique vecteur de F vérifiant u− p(u) ∈ F⊥.
Définition 31.3.4.1080
Soit F un sous-espace vectoriel de dimension finie et (e1, . . . , ep) une base orthonormée de F. Soit uun vecteur de E le projeté orthogonal de u sur F est
p
∑i=1
(u|ei)ei.
Proposition 31.3.4.1081
Démonstration : On voit pour commencer que v =p
∑i=1
(u, ei)ei appartient à F. Il reste à montrer que u− v est
dans F⊥ c’est-à-dire qu’il doit être orthogonal à tous les vecteurs de F (il suffit de vérifier qu’il est orthogonalaux vecteurs de la base de F). Pour tout k ∈ [[ 1 ; p ]] ,
(u− v, ek) =
(u−
p
∑i=1
(u, ei)ei , ek
)= (u, ek)− (u, ek) = 0.
Donc v est bien le projeté orthogonal de u sur F.
Exemple : On considère F = R1[X] dans E = R[X] munit du produit scalaire
(P|Q) =∫ 1
−1P(t)Q(t)dt.
On veut déterminer la projection orthogonale d’un polynôme P sur F. Pour cela on détermine une baseorthonormée (Q0, Q1) de F par le procédé d’orthonormalisation de Gramm-Schmidt. On obtient
Q0 =1√2
et Q1 =
√3√2
X
On en déduit quepF(P) = (P|Q0)Q0 + (P|Q1)Q1.
En particulier
pF(Xn) =1
n + 1+
32(n + 2)
(1− (−1)n+2)X.
Remarque : On voit dans l’exemple précédent que l’on a commencé par déterminer une base orthonorméede F ce qui peut être assez pénible. On peut avoir recours à une autre méthode. Soit F = Vect(e1, . . . , ep) où(e1, . . . , ep) n’est pas nécessairement orthonormée. Pour tout u de E le projeté orthogonal pF(u) de u sur Fvérifie que
∀i ∈ [[ 1 ; p ]] , (u− pF(u)|ei) = 0
De ce fait si on notepF(u) = x1e1 + · · ·+ xpep
on a p inconnues que l’on peut déterminer avec les p équations.Exercice : Dans E = R4 avec le produit scalaire usuelle. On considère e1 = (1, 1, 0,−1) et e2 = (2, 0, 1, 1). Onpose F = Vect(e1, e2). Déterminer le projeté orthogonal de e4 sur F.
458

Soit u un vecteur et F un sous-espace vectoriel de E. On appelle distance de u à F et on note d(u, F) pour
d(u, F) = Minv∈F||u− v||.
Définition 31.3.4.1082
Remarque : Cela existe bien car ||u− v|| | v ∈ F est une partie non vide de R+ qui est donc minorée (par 0).
Avec les notations précédentes, d(u, F) = ||u− p(u)||.
Proposition 31.3.4.1083
Démonstration : Soit v ∈ F on a
||u− v||2 = ||(u− p(u)) + (p(u)− v)||2
= ||u− p(u)||2 + ||p(u)− v||2 d’après le théorème de Pythagore car u− p(u) ⊥ p(u)− v
> ||u− p(u)||2
Exemple : Calculons d(X3, R1[X]) dans R3[X] muni du produit scalaire (P, Q) =∫ 1
0P(t)Q(t) dt.
On cherche p(X3) le projeté orthogonal de X3 sur R1[X].
— Première méthode : On cherche aX + b tel que X3 − aX− b ∈ R1[X]⊥. On a donc le système
(X3 − aX− b, 1) = 0(X3 − aX− b, X) = 0
⇐⇒
14− a
2− b = 0
15− a
3− b
2= 0
⇐⇒ a = 9/10 et b = −1/5.
On trouve donc X3 − P(X3) = X3 − 910
X +15
et d(X3, R1[X]) = ...
— Deuxième méthode : On cherche une base orthonormé de R1[X]. On pose e0 = 1 et e2 =√
3(2X− 1)que l’on obtient par le procédé de Gram-Schmidt.
On en déduit que X3 − p(X3) = X3 − (X3, e1)e1 − (X3, e0)e0 = X3 − 910
X +15
.
3.5 Hyperplans
Dans ce paragraphe, E désigne un espace euclidien de dimension n (on le supposera la plupart du tempsorienté). On rappelle qu’un hyperplan (vectoriel) H est un sous-espace vectoriel de dimension n− 1. De mêmeun hyperplan affine H est la donnée d’un élément Ω de E (vu comme un point) et d’un hyperplan vectoriel H(la direction) et on a
H = Ω + h | h ∈ H = M ∈ E | −−→ΩM ∈ HCela généralise ce que l’on sait faire avec les droites de R2 et les plans de R3.
Soit H un hyperplan affine de direction H, on appelle vecteur normal tout vecteur non nul de H⊥.
Définition 31.3.5.1084
Remarque : Par définition, dim(H) = n− 1 donc dim(H⊥) = 1. Un vecteur normal est donc une base de H⊥
et tous les vecteurs normaux sont colinéaires entre eux.Exemples :
1. Dans E = R2 on considère D = (x, y) ∈ R2 | x + 2y = 2. C’est un hyperplan affine (ici une droite). Ladirection H = (x, y) ∈ R2 | x + 2y = 0 = Vect(2,−1). Un vecteur normal est donc n = (1, 2).
459

2. Dans E = R3, on considère P = (x, y, z) ∈ R3 | x + 2y− z = 1. C’est un hyperplan affine, ici un plan.La direction H = (x, y, z) ∈ R3 | x + 2y− z = 0 = Vect(u, v) où u = (1, 0, 1) et v = (−2, 1, 0). Pour sedonner un vecteur normal, n, il faut trouver un vecteur orthogonal à u et à v. On peut le faire avec unsystème ou utiliser le produit vectoriel vu en physique :
n = u ∧ v = (−1,−2, 1).
Soit H un hyperplan affine. Le choix d’un vecteur normal n définit une orientation de la direction Hen disant qu’une base (e1, . . . , en−1) de H est directe si et seulement si (e1, . . . , en−1, n) est une basedirecte de E.
Proposition 31.3.5.1085
Exemples :1. Cas de R2
2. Cas de R3 Faire des dessins
Soit A un point de E et n un vecteur de E. On considère
ϕ : E → RM 7→ −−→
AM.n
Pour tout λ ∈ R, la ligne de niveau Fλ = ϕ−1(λ) = M ∈ E | ϕ(M) = λ est un hyperplan affinede vecteur normal −→n .
Proposition 31.3.5.1086
Démonstration : Notons H = (Vect−→n )⊥. Déterminons un point de Fλ. On voit que
ϕ(A + x−→n ) = x−→n .−→n = x||−→n ||2.
Il suffit donc de poser x =λ
||−→n ||2 . Maintenant que l’on a trouvé M0 appartenant à Fλ. Pour tout M ∈ E
ϕ(M) =−−→AM.−→n =
−−→AM0.−→n +
−−−→M0M.−→n = λ +
−−−→M0M.−→n .
On en déduit que
M ∈ Fλ ⇐⇒−−−→M0M.−→n = 0 ⇐⇒ −−−→
M0M ∈ H ⇐⇒ M ∈ M0 + H.
Remarque : Réciproquement, tout hyperplan plan affine est une ligne de niveau de ce genre. Il suffit de prendrepour −→n un vecteur normal à H et pour λ la valeur de ϕ(B) où B est un point de H .
On considère un repère orthonormé (Ω, B). Soit H un hyperplan affine, il existe des scalairesλ1, . . . , λn, µ tels que pour tout point M de coordonnées (x1, . . . , xn),
M ∈H ⇐⇒ λ1x1 + · · ·+ λnxn = µ
On l’appelle l’équation cartésienne de H .
Corollaire 31.3.5.1087
Démonstration : Il suffit de voir que H est une ligne de niveau. Ensuite
−−→ΩM.−→n = µ ⇐⇒ λ1x1 + · · ·+ λnxn = µ.
Exemples :
460

1. Cas de R2
2. Cas de R3
Soit H un hyperplan affine de E défini par A ∈H et −→n un vecteur normal. Pour tout point M deE ,
d(M, H ) =|−−→AM.−→n |||−→n || .
Proposition 31.3.5.1088
Démonstration : On sait que d(M, H ) = ||−−→HM|| où H est le projeté orthogonal de M sur H . On a alors
|−−→AM.−→n | = |−→AH.−→n +−−→HM.−→n | = ||−−→HM||.||−→n ||
Exemples :
1. Cas de R2
2. Cas de R3
Exercice : Déterminer l’équation des bissectrices des droites D1 : 2x + y = 3 et D2 : 3x− y = 1.
4 Endomorphismes orthogonaux
Dans ce paragraphe, E désigne un espace euclidien.
4.1 Endomorphismes orthogonaux
On appelle isométrie vectorielle ou automorphisme orthogonal un endomorphisme f de E qui conserve la norme(c’est-à-dire, ∀u ∈ E, || f (u)|| = ||u||).
Définition 31.4.1.1089
Tout endomorphisme orthogonal est un automorphisme.
Proposition 31.4.1.1090
Démonstration : Comme E est de dimension finie, il suffit de montrer qu’il est injectif. Or si f (u) = 0 alors|| f (u)|| = 0 ce qui implique que ||u|| = 0 puis u = 0.
1. Soit f une application de E dans lui-même qui conserve le produit scalaire :
∀(u, v) ∈ E2, ( f (u), f (v)) = (u, v).
L’application f est linéaire et c’est un automorphisme orthogonal.
2. Réciproquement, tout automorphisme orthogonal préserve le produit scalaire.
Théorème 31.4.1.1091
Démonstration :
461

1. On montre d’abord que f préserve la norme. En effet, pour tout vecteur u,
|| f (u)||2 = ( f (u)| f (u)) = (u|u) = ||u||2.
Montrons qu’elle est linéaire. Si (e1, . . . , en) est une base orthonormée alors ( f (e1), . . . , f (en)) l’est aussi.De ce fait pour tout vecteur u :
f (u) = ∑( f (u)| f (ei))ei = ∑(u|ei)ei.
Maintenant, il suffit de voir que u 7→ (u|ei) est linéaire.2. On suppose que f préserve la norme. Pour tout (u, v) ∈ E2,
( f (u)| f (v)) =14
(|| f (u) + f (v)||2 + || f (u)− f (v)||2
)
=14
(|| f (u + v)||2 + || f (u− v)||2
)
=14
(||u + v||2 + ||u− v||2
)
= (u|v)
On appelle symétrie orthogonale par rapport à F la symétrie par rapport à F et parallèlement à F⊥. Si F est unhyperplan on dit que c’est une réflexion.
Définition 31.4.1.1092
Exemple : Les symétries orthogonales sont des endomorphismes orthogonaux. En effet soit s la symétrieorthogonale par rapport à un sous-espace vectoriel F. Soit u un vecteur de E, il se décompose uniquement sousla forme u = α + β avec α ∈ F et β ∈ F⊥. On a alors s(u) = α− β et
||s(u)||2 = ||α− β||2 = ||α||2 + ||β||2 = ||u||2.
En particulier l’identité et −Id sont des endomorphismes orthogonaux.B Les projections orthogonales ne sont pas des endomorphismes orthogonaux car ce ne sont pas desautomorphismes (sauf si F = E).
Soit f un endomorphisme de E. Les trois assertions suivantes sont équivalentes :
i.) L’endomorphisme f est orthogonal.
ii.) L’image de toute base orthogonale par f est une base orthogonale.
iii.) L’image d’une base orthogonale par f est une base orthogonale.
Proposition 31.4.1.1093
Démonstration :— i.)⇒ ii.) On suppose que f est orthogonal. Soit (e1, . . . , en) une base orthonormale. Alors pour tout
(i, j) ∈ [[ 1 ; n ]]2
( f (ei), f (ej)) = (ei , ej) = δij.
Donc ( f (ei)) est bien une base orthonormale.
— ii.)⇒ iii.) Evident.
— iii.)⇒ i.) Soit (ei) une base orthonormale dont l’image ( f (ei)) est encore orthonormale. Soit u = ∑i
xiei
un vecteur de E on a f (u) = ∑i
xi f (ei). Or, comme ( f (ei)) est une base orthonormale,
|| f (u)||2 = ∑i
x2i = ||u||2.
Donc f est orthogonale.
462

L’ensemble des endomorphismes orthogonaux est un groupe pour la composition que l’on ap-pelle groupe orthogonal et qui se note O(E). Cela signifie que si f et g sont des endomorphismesorthogonaux alors f−1 et f g aussi.
Proposition 31.4.1.1094
Démonstration : Il suffit de voir que c’est un sous-groupe de GL(E) car tous les endomorphismes orthogonauxsont des automorphismes. Pour cela il faut montrer que si f et g sont orthogonaux alors f−1 et f g aussi. Eneffet soit u dans E, on sait que pour v = f−1(u) on a
|| f (v)||2 = ||v||2 ⇐⇒ ||v||2 = || f−1(v)||2.
On en déduit que f−1 est orthogonal. De même soit u dans E,
|| f (g(u))||2 = ||g(u)||2 = ||u||2.
D’où f g est orthogonal.
Soit f un automorphisme orthogonal et F un sous-espace stable par f (c’est-à-dire que f (F) ⊂ F)alors F⊥ est aussi stable par f .
Proposition 31.4.1.1095
Démonstration : Soit u ∈ F⊥. On veut montrer que f (u) ∈ F⊥ c’est-à-dire que pour tout vecteur v de F alors( f (u), v) = 0. Commençons par remarquer que, comme f est un automorphisme, f (F) = F car le premier estinclus dans le deuxième et ils ont la même dimension. De ce fait si v appartient à F il existe v′ dans F tel quev = f (v′). On a alors
( f (u), v) = ( f (u), f (v′)) = (u, v′) = 0.
4.2 Matrices orthogonales
Nous allons définir des matrices particulières qui seront les matrices des endomorphismes orthogonaux dansune base orthonormée. Commençons par un petit calcul pour expliquer le phénomène. Soit f un endomorphismede E et B une base orthonormée de E. On note M = MatB( f ). Maintenant on se donne deux vecteurs x et y deE et on note X = MatBx et Y = MatBy. On a alors
(x, y) = tX.Y et ( f (x), f (y)) = t(MX).(MY) = tXtMMY.
Cela laisse imaginer que f sera orthogonal si et seulement si tMM = In.
Soit M ∈Mn(R). Les conditions suivantes sont équivalentes :
i.) La matrice M est inversible et M−1 = tM.
ii.) Les colonnes de M forment une base orthonormée.
iii.) Les lignes de M forment une base orthonormée.
Définition 31.4.2.1096
Remarques :1. Pour la condition i.) il suffit de vérifier que MtM = In ou que tMM = In.
2. Dans les conditions ii.) et iii.) on a identifié les colonnes ou les lignes de la matrice à Rn avec son produitscalaire usuel.
463

Démonstration : Si on note M = (aij), Ci les colonnes de M et que l’on note (bij) les coefficients de tMM. On a
∀(i, j) ∈ [[ 1 ; n ]]2 , bij =tCiCj =
n
∑k=1
akiakj = (Ci , Cj).
On a donc que les colonnes de M forment un base orthonormée si et seulement si tMM = In.De même les lignes de M forment une base orthonormée si et seulement si MtM = In.On conclut en utilisant que
tMM = In ⇐⇒ MtM = In ⇐⇒ M−1 = tM.
Un matrice vérifiant les conditions ci-dessus s’appelle une matrice orthogonale. On note O(n) ou On(R)l’ensemble des matrices orthogonales de Mn(K).
Définition 31.4.2.1097
Remarque : On voit que M ∈ O(n) ⇐⇒ tM ∈ O(n).Exemples :
1. Une matrice diagonale avec des éléments de ±1 sur la diagonale est orthogonale.
2. Les matrices A =
(cos θ − sin θsin θ cos θ
)sont orthogonales.
Soit B une base orthonormée. Soit f ∈ L (E) on a
f ∈ O(E) ⇐⇒ MatB( f ) ∈ O(n).
Théorème 31.4.2.1098
Démonstration : Si on note B = (e1, . . . , en).
f ∈ O(E) ⇐⇒ l’image de B par f est une base orthogonale⇐⇒ la famille ( f (ei)) est une famille orthonormale⇐⇒ La famille Ci est orthonormale⇐⇒ MatB( f ) ∈ O(n)
On a que O(n) est un sous-groupe de GLn(R) et pour toute base orthonormale,
O(E) → O(n)f 7→ MatB( f )
est un isomorphisme de groupe.
Corollaire 31.4.2.1099
Soit M une matrice orthogonale. Son déterminant appartient à ±1.
Proposition 31.4.2.1100
Démonstration : Il suffit de voir que tMM = In implique det(M)2 = 1.
Remarque : Ce n’est pas une équivalence. Par exemple, la matrice(
2 51 3
). Son déterminant vaut 1 mais elle
n’est pas orthogonale.
464

On appelle groupe spécial orthogonal (ou groupe des rotations) et on note SO(n) le sous-groupe de O(n)constitué des matrices orthogonales de déterminant 1.
Définition 31.4.2.1101
Remarque : On définit de même SO(E). Un élément de SO(E) est un automorphisme orthogonal direct (ouune rotation) alors q’un élément de O(E) qui n’est pas dans SO(E) est un automorphisme orthogonal indirect.
Soit B une base orthonormée et B′ une autre base. La base B′ est orthonormée si et seulement si lamatrice de passage de B à B′ est orthogonale.
Proposition 31.4.2.1102
4.3 Endomorphismes orthogonaux du plan euclidien
Dans tout ce paragraphe, E désigne un plan euclidien orienté c’est-à-dire un espace euclidien de dimension2 orienté.
Notation : Soit θ ∈ R on note R(θ) =(
cos θ − sin θsin θ cos θ
)et S(θ) =
(cos θ sin θsin θ − cos θ
).
Remarque : On voit que R(θ) et S(θ) sont des éléments de O(2). De plus DetR(θ) = 1 et donc R(θ) ∈ SO(2)alors que DetS(θ) = −1.
Soit M une matrice de O(2). Il existe θ dans R tel que M = R(θ) ou M = S(θ).
Théorème 31.4.3.1103
Démonstration : On note M =
(a bc d
). Comme M est orthogonale, on a a2 + c2 = 1 (car « la colonne est
normée ») et de ce fait il existe θ tel que a = cos θ et c = sin θ. De même, il existe ϕ tel que b = cos ϕ et d = sin ϕ.Maintenant, en utilisant les deux colonnes sont orthogonales on obtient :
cos θ cos ϕ + sin θ sin ϕ = 0 ⇐⇒ cos(θ − ϕ) = 0
⇐⇒ θ − ϕ =π
2[π]
⇐⇒ ϕ = θ +π
2[π].
— Si ϕ = θ +π
2on a donc c = cos ϕ = − sin θ et d = sin ϕ = cos θ. On a donc M = R(θ).
— Si ϕ = θ − π
2on a donc c = cos ϕ = sin θ et d = sin ϕ = − cos θ. On a donc M = S(θ).
1. On a SO(2) = R(θ) | θ ∈ R.2. L’application de (R,+) dans (SO(2),×) qui associe à θ la matrice R(θ) est un morphisme
surjectif de groupe dont le noyau est 2πZ. En particulier, SO(2) est un groupe abélien.
Corollaire 31.4.3.1104
Remarque : On peut aussi construire un isomorphisme de (U ,×) dans (SO(2),×) en associant à z la matriceR(arg z).
465

Soit f un endomorphisme de SO(E). Il existe un unique réel θ à 2π-près tel que dans toute baseorthonormée directe sa matrice soit R(θ).
Proposition 31.4.3.1105
Démonstration : On sait que la matrice de f dans une base orthonormée directe B appartient à SO(2). Elle estdonc de la forme R(θ). Maintenant si B′ est une autre base orthonormée directe alors la matrice de passage Pde B à B′ est aussi un élément de SO(2). Comme SO(2) est abélien,
MatB′( f ) = P−1R(θ)P = R(θ)P−1P = R(θ).
Avec les notations précédentes, on dit que f est une rotation d’angle θ ou que θ est une mesure de f .
Définition 31.4.3.1106
Soit u et v deux vecteurs unitaires. Il existe une unique rotation r telle que r(u) = v.
Proposition 31.4.3.1107
Démonstration : Il suffit de travailler dans la base (u, u′) où u′ est choisit tel que cette base soit orthonorméedirecte (il en existe un unique). Dès lors, dans cette base, comme v est un vecteur unitaire, il existe un unique θ à2π-près tel que v = (cos θ)u + (sin θ)u′. Dans cette base, un endomorphisme vérifiant f (u) = v s’écrit donc
(cos θ ∗sin θ ∗
).
La proposition en découle.
Si u et v sont deux vecteurs non nuls. On appelle mesure de l’angle orienté ˆ(u, v) une mesure θ de l’uniquerotation r telle que
r(u/||u||) = v/||v||.On note ˆ(u, v) = θ[2π].
Définition 31.4.3.1108
1. Soit u, v et w trois vecteurs non nuls,
ˆ(u, v) + ˆ(v, w) = ˆ(u, w)[2π] (Relation de Chasles)
2. Si u et v sont deux vecteurs non nuls et θ est une mesure de ˆ(u, v) alors
(u, v) = ||u||||v|| cos θ et Det(u, v) = ||u||||v|| sin θ.
Proposition 31.4.3.1109
Démonstration :
1. On peut supposer que les trois vecteurs sont unitaires. Ensuite si on note r1et r2 les rotations telles quer1(u) = v et r2(v) = w. On a (r2 r1)(u) = w. Or si θ1 est une mesure de r1 et θ2 une mesure de r2 alorsθ1 + θ2 est une mesure de r2 r1.
466

2. Là encore, on peut, par linéarité se ramener au cas où u et v sont unitaires. Dans la base (u, u′) utilisée
précédemment qui est orthonormée directe, les coordonnées de u sont(
10
)et celles de v sont
(cos θsin θ
).
Il suffit alors de faire le calcul.
Exemple : Tout ceci s’applique au cas E = R2 mais aussi à tout plan euclidien. Par exemple, si on se donne
E = R1[X] avec (P, Q) =∫ 1
0P(t)Q(t) dt. Il faut de plus orienté E en choisissant une base orthonormée
directe. On voit que u = 1 est unitaire. De plus u = X − 1/2 est orthogonal à u. On prend la base (u, u′) oùu′ = 2
√3(X− 1/2) = 2
√3X−
√3.
On peut alors chercher l’angle ˆ(1, X). On a vu u = 1 est unitaire. Par contre si v1 = X on a ||v1||2 = 1/3.
On pose donc v =√
3X qui est unitaire. Maintenant les coordonnées de v dans (u, u′) sont( √
3/21/2
). On en
déduit que l’angle cherché vaut π/6.
Soit f un automorphisme orthogonal indirect. C’est une réflexion.
Proposition 31.4.3.1110
Démonstration : On choisit une base orthogonale. On voit que la matrice de f est de la forme S(θ). On endéduit par le calcul que f 2 = Id car S(θ)2 = I2.
Donc f est une symétrie orthogonale. On regarde le noyau de f − Id. Comme f n’est pas Id ni -Id (qui sontdes rotations) on en déduit que le noyau de f − Id est de dimension 1. C’est bien une réflexion.
Remarque : En reprenant les notations ci-dessus. On se place dans une base orthonormée directe (i,j) et onnote S(θ) sa matrice. Si on cherche une équation de Ker ( f − Id) il suffit de résoudre :
((cos θ)− 1)x + (sin θ)y = 0
(sin θ)x + (−(cos θ)− 1)y = 0 ⇐⇒
sin(θ/2) (− sin(θ/2)x + cos(θ/2)y) = 0cos(θ/2) (sin(θ/2)x− cos(θ/2)y) = 0
Le vecteur u = cosθ
2i + sin
θ
2j est une solution. On en déduit que f est une symétrie par rapport à Vect(u).
Soit deux vecteurs non nuls u et v et r, s les réflexions par rapport Vect(u) et Vect(v). La composées r est une rotation d’angle 2 ˆ(u, v).
Proposition 31.4.3.1111
Démonstration : Il est clair que la composée de deux réflexions est une rotation. Pour déterminer l’angle decette rotation il suffit de calculer l’image d’un vecteur. Calculons (s r)(u).
D’abord on peut supposer que u et v sont unitaires. On a de plus r(u) = u. Il suffit donc de calculer s(u).Maintenant, considérons les bases orthonormées directes B = (u, u′) et B′ = (v, v′). On sait que la matrice de sdans B′ est S(0). On note θ une mesure de ˆ(u, v). De plus la matrice de passage de B à B′ est R(θ). Celle de B′ àB est donc R(−θ) On en déduit que la matrice de s dans B est R(−θ)−1S(0)R(−θ) = R(θ)S(0)R(−θ) = S(2θ).Les coordonnées de l’image de u dans (u, u′) sont donc (cos(2θ), sin(2θ)). On en déduit bien que s r estrotation d’angle 2θ.
Remarque : On peut faire les calculs dans O(2) en identifiant un vecteur (x, y) avec le nombre complexe x + iy.La matrice R(θ) correspond alors à la multiplication par eiθ . La matrice S(θ) à z 7→ eiθz.
Toute rotation peut s’écrire comme composée de deux réflexions.
Corollaire 31.4.3.1112
467

4.4 Automorphismes orthogonaux de l’espace
Dans ce paragraphe E désigne un espace euclidien orienté de dimension 3. Là encore on va essayer declassifier tous les éléments de SO(E) et de O(E) et donc de SO(3) et de O(3).
Commençons par une proposition sur les orientations.
Soit w un vecteur unitaire de E. Il existe une unique orientation du plan H = Vect(w)⊥ tel que pourtoute base orthonormée directe (u, v) de H, la base (u, v, w) soit directe dans E.
Proposition 31.4.4.1113
Remarques :
1. On dit alors que H est orienté par le vecteur w. On peut d’ailleurs procéder dans l’autre sens. Si on sedonne un plan H, pour l’orienter, il suffit de choisir un des deux vecteur unitaires de H⊥.
2. Dans la pratique si w est un vecteur unitaire, pour construire une base orthonormée directe, on prend unvecteur u dans H. On sait alors que uVectw est aussi dans H et orthogonal à u. D’où (u, w, u ∧ w) est uneBOND. On note plutôt (u,−(u ∧ w), w) = (u, w ∧ u, w).
Soit f ∈ SO(E). Il existe une base orthonormée directe B = (u, v, w) telle que
MatB( f ) =
cos θ − sin θ 0sin θ cos θ 0
0 0 1
où θ est un réel.
Théorème 31.4.4.1114
Avant de nous lancer dans la démonstration, commençons par un lemme
Soit f dans SO(E) tel que f 6= Id. Le sous-espace vectoriel F = Ker ( f − Id) est une droite vectorielle.
Lemme 31.4.4.1115
Démonstration du lemme : Commençons par montrer que F n’est pas réduit à 0.On étudie l’endomorphisme f − λId. Notons χ(λ) son déterminant. On a donc
χ(λ) =
∣∣∣∣∣∣
a11 − λ a12 a13a21 a22 − λ a23a31 a32 a33 − λ
∣∣∣∣∣∣.
En particulier, en développant avec la règle de Sarrus on voit que χ est un polynôme de degré 3 dont le degrédominant est −λ3. De plus, comme χ(0) = Det f = 1
On en déduit qu’il existe λ0 > 0 tel que χ(λ0) = 0. Cela revient à dire que f − λ0Id n’est pas injectif donc ilexiste u0 6= 0 tel que ( f − λ0Id)(u0) = 0 ⇐⇒ f (u0) = λ0u0.
Cependant, comme f est un automorphisme orthogonal, || f (u0)|| = |λ0|||u0|| = ||u0|| d’où |λ0| = 1 et doncλ0 = 1.
On a bien montré que F n’était pas réduit à 0. Montrons maintenant que dim F = 1. On voit déjà quedim F = 3 est impossible car f 6= Id. De plus si dim F = 2 alors f est la réflexion par rapport à F (il suffit devoir que F⊥ est stable mais pas invariante).
Démonstration du théorème : Soit w un vecteur unitaire qui engendre F = Ker f − Id. On a vu f laissaitstable H = F⊥. Par le même raisonnement que ci-dessus, on voit que fH est alors un élément de SO(H). C’estdonc une rotation.
468

Soit w une vecteur non nul de E et θ un réel. On appelle rotation d’axe autour de w et d’angle θ, l’auto-morphisme orthogonal laissant stable F = Vect(w) et tel que fH soit la rotation d’angle θ où H = F⊥. SiB = (u, v, w′) est une base orthonormée directe avec w′ = w/||w||, la matrice de f dans la base B est
MatB( f ) =
cos θ − sin θ 0sin θ cos θ 0
0 0 1
Définition 31.4.4.1116
Remarques :
1. La droite vectorielle F s’appelle l’axe de f . Remarque : Si l’angle vaut π et donc la matrice est
−1 0 00 −1 00 0 1
,
on dit que c’est un demi-tour.2. Il faut faire attention que si on change w en −w la rotation change car le plan H est alors orienté dans
l’autre sens.3. La plupart du temps on prendra w unitaire.4. On voit donc que dans les automorphismes orthogonaux de l’espace il y a les rotations (qui sont les
éléments de SO(E)). Il y a aussi les réflexions. Mais, contrairement au cas du plan, il y en a d’autre. Parexemple l’application u = −IdE est un élément de O(E) mais pas de SO(E) car det(u) = (−1)3 = −1.Mais ce n’est pas une réflexion car aucun vecteur n’est invariant. De fait, c’est la composée du demi-tour
de matrice
−1 0 00 −1 00 0 1
et de la réflexion de matrice =
1 0 00 1 00 0 −1
.
Soit w un vecteur unitaire, θ un réel et f la rotation d’angle θ autour de w. Pour tout vecteur uorthogonal à w, on a
f (u) = (cos θ)u + (sin θ)(w ∧ u).
Proposition 31.4.4.1117
Démonstration : Il suffit de voir que, comme (u, w, u ∧ w) est une base orthonormée directe alors (u, w ∧ u, w)De ce fait, la matrice de f dans cette base est
MatB( f ) =
cos θ − sin θ 0sin θ cos θ 0
0 0 1
Le résultat en découle en regardant la première colonne.
Exemples :1. Soit w le vecteur w = (1, 2, 0). On cherche la matrice dans la base canonique de R3 de la rotation autour
de w et d’angle θ. Pour tout vecteur u = (x, y, z) on peut le décomposer comme somme d’un vecteurcolinéaire à w et d’un vecteur qui lui est orthogonal (car F et F⊥ sont en somme directe si F = Vect(w)).On a
u =x + 2y
5w +
15(4x− 2y,−2x− 3y, 5z).
Maintenant w ∧ 15(4x− 2y,−2x− 3y, 5z) =
15(10z,−5z,−10x + y). On a donc
f (u) =x + 2y
5(1, 2, 0) +
cos θ
5(4x− 2y,−2x− 3y, 5z) +
sin θ
5(10z,−5z,−10x + y).
On peut alors en déduire la matrice ...
2. A l’inverse soit M =19
8 1 4−4 4 −71 8 4
. On vérifie que M est bien un matrice orthogonale et que son
déterminant vaut 1. L’endomorphisme f canoniquement associé est donc une rotation de R3.
469

Pour déterminer l’axe il suffit de chercher les invariant c’est-à-dire le noyau de f − Id. On trouve w =1√11
(3,−1,−1) en le prenant normé.
Maintenant on prend un vecteur orthogonal à w et normé. On prend u =1√10
(1, 3, 0). On a
cos θ = (u, f (u)) =7
18et sin θ = ( f (u), w ∧ u) = Det(w, u, f (u)) =
5√
1118
.
On peut aussi remarquer que tr ( f ) = 1 + 2 cos θ. On retrouve bien cos θ =tr ( f )− 1
2=
718
.
Une rotation de E peut s’écrire comme composé de deux réflexions.
Proposition 31.4.4.1118
Remarque : Dans l’espace on ne peut pas parler de l’angle orienté de deux vecteurs car cela dépend « dequel coté on regarde ». Cependant on peut définir un angle géométrique. Soit u et v deux vecteurs de E. Onsait d’après l’inégalité de Cauchy-Schwarz que |(u|v)| 6 ||u||||v|| donc il existe un unique θ ∈ [0, π] tel que(u|v) = ||u||||v|| cos θ. A partir de là, on peut voir que
||u ∧ v||2 = ||u||2||v||2 − (u|v)2
Il suffit en effet de faire les calculs dans une BOND où u = (a, 0, 0) et v = (b, c, 0). On en déduit que
u ∧ v|| = ||u||||v|| sin θ.
Maintenant si on se donne trois vecteurs u, v et w et que l’on considère le parallélépipède porté par ces troisvecteurs. On notera u =
−→AB, v =
−→AC et w =
−→AD. On sait que le volume est (base)× hauteur.
Or l’aire de la base est AB× AC× sin(−→AB,−→AC) = ||u ∧ v||. De plus le vecteur u ∧ v est colinéaire au vecteur
normal du plan (ABC). On en déduit que si −→n est un vecteur normal à (ABC), la hauteur vaut |−→AD.−→n |. On endéduit que le volume est
|(u ∧ v).w| = det(u, v, w).
470

32Fonctions de deuxvariables - Bonus
Ceci est un bonus, ce qui est ici n’est pas au programme de MPSI - c’est essentiellementune mise en jambe pour la deuxième année
Dans ce chapitre R2 est muni de la structure euclidienne usuelle. Pour u = (x, y) on note donc ||u|| =√x2 + y2. On notera (e1, e2) la base canonique de R2.
1 Généralités
1.1 Fonctions à deux variables
On appelle fonction à deux variables, toute application d’une partie A de R2 dans R.
Définition 32.1.1.1119
L’ensemble F (A, R) est muni d’une structure d’espace vectoriel hérité de celle de R.
Proposition 32.1.1.1120
Exemple : La fonction f : (x, y) 7→ ln(xy) est définie sur A = (R?+)
2 ∪ (R?−)
2
Soit f une fonction à deux variables définie sur A. Soit a = (x0, y0) un élément de A. On note
Ax = y ∈ R, (x0, y) ∈ A et Ay = x ∈ R, (x, y0) ∈ A.
On appelle application partielle en a les applications
f (•, y0) = f1 : Ax → Rx 7→ f (x, y0)
et f (x0, •) = f2 : Ay → Ry 7→ f (x0, y)
Définition 32.1.1.1121
471

Remarques :
1. Il faut faire attention que même si a n’apparait pas dans les notations Ax , Ay, f1 et f2, ces notions endépendent.
2. Les applications f1 et f2 sont des applications à une variable.
Exemples :
1. Si on reprend f : (x, y) 7→ ln(xy) définie sur A = (R?+)
2 ∪ (R?−)
2. Pour m = (2, 1) on a Ax = Ay = R?+ et
f1 : t 7→ ln t et f2 : t 7→ ln(2t).
2. Si f : (x, y) 7→√
1− x2 − y2. Elle est définie sur A = D(O, 1) = (x, y) ∈ R2, x2 + y2 6 1. Pourm = (1/3, 1/2) on a
Ax = [−√
3/2,√
3/2] et Ay = [−2√
2/3, 2√
2/3].
On a
f1 : t 7→ (
t, 1/2) =
√34− t2 et f2 : t 7→
√89− t2.
1.2 Rudiments de topologie
Afin de définir les notions de limites pour les fonctions à deux variables, nous allons avoir besoin de définirce qui va remplacer les intervalles et les voisinages.
Soit a un élément de R2 et r un réel positif. On appelle boule ouverte (resp. boule fermée, resp. sphère) de centrea et de rayon r et on note B(a, r) (resp. B(a, r) resp. S(a, r)) les ensembles
B(a, r) = u ∈ R2 | ||u− a|| < r, B(a, r) = u ∈ R2 | ||u− a|| 6 r et S(a, r) = u ∈ R2 | ||u− a|| = r.
Définition 32.1.2.1122
Remarque : La terminologie vient de l’espace euclidien R3 mais ces notions sont utiles pour tout espaceeuclidien, en particulier dans notre cas.
Soit A une partie de R2. On dit que A est une partie ouverte de R2 (ou que A est un ouvert de R2) si pourtout point a de A il existe un réel strictement positif a tel que B(a, r) ⊂ A.
Définition 32.1.2.1123
Remarques :
1. Cette notion est fondamentale. Elle consiste à dire que, si A est un ouvert on peut toujours se « dépla-cer » autour de tout élément de A mais en restant dans A.
2. Le r de la définition va bien évidemment dépendre de a.
Exemples :
1. L’ensemble vide et R2 en entier sont des ouverts.
2. Une boule ouverte B(a, r) est un ouvert. En effet soit u ∈ B(a, r). Si on note p = ||u− a|| < r. Il existeε ∈ R?
+ tel que p + ε < r. De ce fait B(u, ε) ⊂ B(a, r) car, d’après l’inégalité triangulaire, pour tout élémentv de R2,
||v− a|| = ||(v− u) + (u− a)|| 6 ||v− u||+ ||u− a||.3. A l’inverse une boule fermé n’est pas un ouvert. En effet, si on prend u tel que ||u− a|| = r alors pour
tout ε il existe des éléments de B(u, ε) qui ne soient pas dans B(a, r) par exemple u +ε
2u− a
r.
4. Le complémentaire d’une boule fermé est un ouvert.
Exercice : Montrer qu’une intersection ou une union de deux ouverts est encore un ouvert.
472

Soit A une partie de R2 et a un élément de R2. On dit que a est un point adhérent à A si pour tout ε > 0, lesensembles A et B(a, ε) ne sont pas d’intersection vide.On notera A l’ensemble des points adhérents à A.
Définition 32.1.2.1124
Remarques :
1. De manière évidente, tous les points de A sont des points adhérents à A.
2. Cela va permettre de définir la limite d’une fonction définie sur A. Si on reprend le cas des fonctions à unevariable. Si f était définie sur I =]a, b[ on pouvait définir lim
af car a est « juste à coté » de A. La notion de
point adhérent est l’analogue.
3. Avec les notations de la définition, le point a est adhérent à A si tout ouvert contenant a rencontre A.
Exemples :
1. Si A = R2 \ (0, 0) alors A = R2.
2. Si A =]− 1, 1[×R alors A = R2.
3. Si A = Q2 alors A = R2.
2 Fonctions continues
2.1 Limites
Soit f une fonction de deux variables définies sur une partie A et a ∈ A. Soit ` ∈ R. On dit que f tend vers `en a ou que la limite de f en a est ` et on note lim
af = ` si
∀ε > 0, ∃η > 0, ∀u ∈ A, u ∈ B(a, η)⇒ | f (u)− `| < ε.
Définition 32.2.1.1125
Remarque : Cette définition est l’analogue de celle pour les fonctions à une variables en remplaçant ]a− η, a+ η[par B(a, η).
Avec les notations précédentes on a
lima
f = ` ⇐⇒ lima( f − `) = 0.
Proposition 32.2.1.1126
Remarque : Comme avec une variable, on se ramènera souvent à montrer qu’une limite est nulle ce qui peutse faire avec des majorations.
Soit f une fonction de deux variables définies sur une partie A et a ∈ A. On dit que f tend vers +∞ (resp.−∞) en a ou que la limite de f en a est +∞ (resp. −∞) et on note lim
af = +∞ (resp. lim
af = −∞) si
∀M ∈ R, ∃η > 0, ∀u ∈ A, u ∈ B(a, η)⇒ f (u) > M (resp. ∀m ∈ R, ∃η > 0, ∀u ∈ A, u ∈ B(a, η)⇒ f (u) >< m).
Définition 32.2.1.1127
Exemples :
473

1. Soit f = (x, y) 7→ x2 + y. Elle est définie sur R2. Calculons sa limite en (3, 2). On voit que f (3, 2) = 11. Oron remarque que si η > 0,
(x, y) ∈ B((3, 2), η) ⇐⇒√(x− 3)2 + (y− 2)2 < η.
En particulier |x− 3| 6 η et |y− 2| 6 η. Maintenant f (x, y)− 11 = x2 − 32 + y− 2. Si on se donne ε > 0on sait qu’il existe ηx et ηy tels que
∀x ∈ R, |x− 3| < ηx ⇒ |x2 − 32| < ε/2 et ∀y ∈ R, |y− 2| < ηy ⇒ |y− 2| < ε/2.
Il suffit alors de poser η = Min(ηx , ηy).
2. Soit f la fonction définie sur R2 \ (0, 0 par f : (x, y) 7→ x + yx2 + y2 . Cette fonction n’a pas de limite en
(0, 0). En effet, pour tout ε < 1 dans la boule de centre (0, 0) et de rayon ε il y a u = (ε/2, ε/2) qui vérifie
f (u) =2ε> 2. Mais, dans cette même boule, il y a aussi v = (ε/2,−ε/2) qui vérifie f (v) = 0.
Soit f une fonction définie sur A. Soit a = (x0, y0) ∈ A. On suppose que lima
f = ` où ` ∈ R. Si
la première (resp. la deuxième) application partielle en a que l’on note f1 (resp. f2) est définie auvoisinage de x0 (resp. y0) alors lim
x0f1 = ` (resp. lim
y0f2 = `.).
Proposition 32.2.1.1128
Démonstration : Traitons le cas ` ∈ R. Pour tout ε > 0 il existe η > 0 tel que
∀u ∈ A, ||u− a|| < η ⇒ | f (u)− `| < ε.
Maintenant soit x tel que |x− x0| < η on pose u = (x, y0) et ||u− a|| =√(x− x0)2 + (y0 − y0)2 = |x− x0|. De
ce fait, | f (u)− `| < ε. Comme f (u) = f (x, y0) = f1(x) on a la propriété voulue. On peut faire de même pour f2.
Remarque : Les fonctions partielles peuvent ne pas exister. Par exemple si f : (x, y) 7→ ln(x2 − y2). Elle estdéfinie sur A = (x, y) ∈ R2 | |x| > |y|. Il n’y a donc pas de deuxième application partielle en (0, 0).
B Ce n’est pas une équivalence. Par exemple si f : (x, y) 7→ xyx2 + y2 . On a que les deux applications partielles
en (0, 0) sont nulles. Cependant, on a pour tout x dans R?, f (x, x) =12
. De ce fait la limite de f en (0, 0) ne peutpas être nulle.
Soit f une fonction définie sur A. Soit a ∈ A. On suppose que f a une limite finie en a. La fonction fest bornée au voisinage de a ce qui signifie qu’il existe ε > 0 et M ∈ R tels que
∀u ∈ A ∩ B(a, ε), | f (u) 6 M.
Proposition 32.2.1.1129
Démonstration : On se donne α = 1. D’après la définition de la limite, il existe ε tel que
∀u ∈ A, u ∈ B(a, ε)⇒ | f (u)− `| < 1.
Cela implique la propriété voulue en posant M = |l|+ 1.
2.2 Continuité
Soit f une fonction définie sur A.
1. Soit a ∈ A. Si f admet une limite ` en a alors ` = f (a) et on dit que f est continue en a.
2. Si f est continue en tout point a de A, on dit que f est continue. On note C (A, R) l’ensemble desfonctions continues sur A.
Définition 32.2.2.1130
474

Exemple : La fonction f : (x, y) 7→ x2 + y est continue sur R2.Remarque : Les théorèmes sur les opérations (somme, produit) sont encore vrais et se démontrent commeprécédemment.
L’ensemble C (A, R) est un sous-espace vectoriel de F (A, R). Il est de plus stable par produit c’estdonc une sous-algèbre.
Proposition 32.2.2.1131
Remarque : On a aussi des propriétés sur le quotient. Si f et g sont continues et si g ne s’annule pas alors f /gest continue.Exemple : Les fonctions p1 : (x, y) 7→ x et p2 : (x, y) 7→ y sont continues. En effet soit a = (α, β). On va montrerque lim
ap1 = α en montrant que lim
ap1 − α = 0. Pour tout ε > 0, on pose η = ε. Dès lors soit u = (x, y), si
u ∈ B(a, ε) alors ||u− a|| < ε et on a
|p1(u)− α| = |x− α| 6√(x− α)2 + (y− β)2 = ||u− a|| < ε.
On procède de même pour p2. On en déduit que tous les polynômes sont continus.
2.3 Fonctions à valeurs dans R2
On va étendre les notions précédentes au cas où f est définie d’une partie A de R2 dans R2. Il suffit deremplacer la valeur absolue dans la définition par la norme. Précisément on a
Soit f une fonction de deux variables définies sur une partie A et à valeurs dans R2.
1. Soit a ∈ A et ` ∈ R2. On dit que f tend vers ` en a ou que la limite de f en a est ` et on note lima
f = `
si∀ε > 0, ∃η > 0, ∀u ∈ A, u ∈ B(a, η)⇒ || f (u)− `|| < ε.
2. Si f est définie en a et que f a une limite en a (nécessairement égale à f (a)) alors on dit que f estcontinue en a.
3. Si f est continue en tout point a de A on dit que f est continue. On note C (A, R2) l’ensemble desfonctions continues.
Définition 32.2.3.1132
Soit f une fonction définie sur A et à valeurs dans R2. Pour tout u de A on note f (u) = (α(u), β(u)).On a alors
1. Soit a ∈ A. La fonction f est continue en a si et seulement si α et β le sont
2. On af ∈ C (A, R2) ⇐⇒ (α ∈ C (A, R) et β ∈ C (A, R)).
Proposition 32.2.3.1133
Remarque : Cela signifie que l’on peut justifier la continuité en regardant composantes par composantes.B Dans le cas d’une fonction de R2 dans R2, il ne faut pas confondre les applications partielles qui sontdéfinie d’une partie de R dans R2 avec les applications composantes qui sont définies d’une partie de R2 dansR.Démonstration : On traite la première.
— ⇒ Il suffit de voir que pour tout u dans A,
|| f (u)− f (a)|| =√(α(u)− α(a))2 + (β(u)− β(a))2.
D’où |α(u) − α(a)| 6 || f (u) − f (a)|| et |β(u) − β(a)| 6 || f (u) − f (a)||. Si f est continue en a alors|| f (u)− f (a)|| tend vers 0 et |α(u)− α(a)| et |β(u)− β(a)| aussi donc α et β sont continues en a.
475

— ⇐ Il suffit de voir là encore que pour tout u dans A,
|| f (u)− f (a)|| =√(α(u)− α(a))2 + (β(u)− β(a))2.
Donc si |α(u)− α(a)| et |β(u)− β(a)| tendent vers 0 alors || f (u)− f (a)|| aussi.
Exemple : La fonction (x, y) 7→ (2x + 2y, xy− x2) est continue.
1. L’ensemble C (A, R2) est un sous-espace vectoriel de F (A, R2).
2. Si f est une fonction de A dans R2 et a ∈ A. Si f est continue en a alors elle est bornée auvoisinage de a.
Corollaire 32.2.3.1134
Démonstration : Il suffit de travailler composantes par composantes.
2.4 Composition
On va montrer que la composée de deux fonctions continues est continues
Soit (p, q, r) trois entiers égaux à 1 ou 2. Soit A une partie de Rp et f ∈ C (A, Rq). Soit B une partiede Rp et g ∈ C (B, Rr). On suppose que f (A) ⊂ B afin de définir g f . Alors la fonction g f estcontinue de A dans Rr.
Théorème 32.2.4.1135
Démonstration : Afin de traiter tous les cas nous noterons encore ||.|| pour |.|Soit ε > 0. On sait que g est continue en f (a) donc pour cet ε il existe η1 tel que
∀u ∈ B, u ∈ B( f (a), η1)⇒ ||g(u)− g( f (a))|| < ε.
De plus, f est continue en a donc pour cet η1, il existe η2 tel que
∀v ∈ A, v ∈ B(a, η2)⇒ || f (v)− f (a)|| < η1 ⇒ f (v) ∈ B( f (a), η1).
On en déduit donc en posant u = f (v) que si v est dans B(a, η2) alors ||g( f (v))− g( f (a))|| < ε.C’est-à-dire que g f est continue en a par définition.
Exemples :
1. La fonction f : (x, y) 7→ sin(x + y)− cos(x2 + y2) est continue.
2. La fonction g : (u, t) 7→ (cos(ut), sin(ut)) est continue.
3 Calcul différentiel
Dans tout ce paragraphe on notera U un ouvert de R2 et on ne considérera que des fonctions définies sur Uet à valeurs dans R. C’est-à-dire des éléments de F (U, R).
476

3.1 Première dérivées partielles
Soit f dans F (U, R) et a = (α, β) ∈ U.
1. Si la première application partielle f1 en a est dérivable en α, on appelle première dérivée partielle en aou dérivée partielle en a par rapport à x le nombre f ′1(α). On le note
∂ f∂x
(a) = D1 f (a) = f ′x(a) = limh→0
f (α + h, β)− f (α, β)
h.
2. Si la deuxième application partielle f2 en a est dérivable en β, on appelle deuxième dérivée partielle en aou dérivée partielle en a par rapport à y le nombre f ′2(β). On le note
∂ f∂y
(a) = D2 f (a) = f ′y(a) = limh→0
f (α, β + h)− f (α, β)
h.
Définition 32.3.1.1136
Remarques :
1. On peut bien donner un sens à la dérivabilité de f1 (resp. f2) car U est un ouvert et donc f1 (resp. f2) estdéfinie sur un intervalle contenant ]α− ε, α + ε[ (resp. ]β− ε, β + ε[).
2. On dit dans ce cas que f admet des dérivées partielles en a et pas que f est dérivable.
3. Pour déterminer si f admet des dérivées partielles et les calculer il faut regarder les fonctions partielles.Cela revient à considérer l’une des deux variables comme une variable et l’autre comme une constante.
Exemples :
1. Soit f : (x, y) 7→ ln(xy) sur (R?+)
2. Elle admet des dérivées partielles et
∂ f∂x
(α, β) =1α
et∂ f∂y
(α, β) =1β
.
2. Soit f une fonction définie de R+ sur R et g : (x, y) 7→ f (y/x) pour (x, y) ∈ (R?+)
2. On a
∂g∂x
(α, β) = − yx2 f ′(y/x) et
∂g∂y
(α, β) =1x
f ′(y/x).
3. Soit f la fonction définie sur R2 par
(x, y) 7→
xyx2 + y2 si (x, y) 6= (0, 0)
0 si (x, y) = (0, 0)
La fonction f admet des dérivées partielles qui sont nulles en 0 car les applications partielles sont nulles.
Par contre elle n’est pas continue. En effet, pour tout x, f (x, x) =12
d’où lim(0,0)
f n’existe pas.
B Comme on vient de le voir, l’existence des dérivées partielles en un point n’implique pas que la fonctionsoit dérivable. Cela provient du fait que les dérivées partielles ne s’intéressent qu’à une direction privilégiée.
Avec les notations précédentes, si f admet des dérivées partielles par rapport à x (resp. à y) en tout point a de
U on note∂ f∂x
(resp.∂ f∂y
) la fonction définie de U dans R qui associe à a,∂ f∂x
(a)(resp.∂ f∂y
(a)).
Définition 32.3.1.1137
On voit que dans la définition des dérivées partielles on a privilégié les « axes coordonnées ». On peut defait essayer de calculer la dérivée selon toutes les directions.
477

Soit f dans F (u, R) et v un vecteur non nul. Pour a dans U on pose ϕv : t 7→ f (a + tv) qui est définie surun voisinage de 0. On dit que f admet une dérivée partielle selon v en a si ϕv est dérivable en 0 et on note
Dv f (a) = ϕ′v(0) = limh→0
f (a + hv)− f (a)h
.
Définition 32.3.1.1138
Remarques :
1. On trouve aussi la notation∂ f∂v
(a) pour Dv f (a).
2. Les dérivées partielles∂ f∂x
(a) et∂ f∂y
(a) sont juste De1 f (a) et De2 f (a) où (e1, e2) sont les vecteurs de la bases
canoniques.3. Soit λ un réel non nul. On suppose que Dv f (a) existe alors D(λv) f (a) existe aussi et vaut λ.Dv f (a). En
effet,
D(λv) f (a) = limh→0
f (a + hλv)− f (a)h
= limh→0
λf (a + hλv)− f (a)
λ.h= λ lim
h′→0λ
f (a + h′v)− f (a)h′
= λDv f (a).
Exemples :1. Soit f : (x, y) 7→ ln(xy) sur (R?
+)2. Soit v = (1, 2). On a alors en a = (α, β),
ϕa : t 7→ ln((α + t)(β + 2t)) = ln(αβ + tβ + 2tα + 2t2).
D’oùDv f (a) = ϕ′v(0) =
2α + β
αβ=
1α+
1β
.
On peut remarquer dans ce cas que
Dv f (a) = De1 f (a) + 2De2 f (a) car v = e1 + 2e2.
Nous reverrons ce point plus tard.2. Soit f la fonction définie sur R2 par
(x, y) 7→
x2
ysi y 6= 0
x si y = 0
Étudions les dérivées en a = (0, 0)— Si v ∈ Vect((1, 0) on a ϕv : t 7→ 0. D’où Dv f (0, 0) = 0.— Si v = (α, β) /∈ Vect(1, 0) on a
ϕv : t 7→ f (tα, tβ) = tα2
β.
On a donc Dv f (0, 0) =α2
β. Cependant la fonction n’est pas continue en 0 en effet si on tend vers
(0, 0) par x = t et y = t2 on a f (x, y) = 1.
3.2 Fonctions de classe C 1
On a vu que l’existence des dérivées partielles n’était pas une bonne condition de régularité car celan’implique même pas a continuité. On va définir la condition C 1 qui consiste à rajouter la continuité auxdérivées partielles.
Soit f une fonction de F (U, R). On dit que f est de classe C 1 si elle admet des dérivées partielles en tout
point a de U et que les fonctions∂ f∂x
et∂ f∂y
sont continues sur U. On note C 1(U, R) l’ensemble des fonctions
de classe C 1.
Définition 32.3.2.1139
478

Exemples :1. Soit f : (x, y) 7→ ln(xy). C’est une fonction de classe C 1. En effet, les dérivées partielles existent et elles
sont continues.
2. Soit f : (x, y) 7→
x2
ysi y 6= 0
x si y = 0Elle est de classe C 1 sur R× R?. Par contre elle n’est pas de classe C 1
sur R2. En effet,
∂ f∂x
: (x, y) 7→
2xy
si y 6= 0
1 si y = 0
Elle n’est pas continue.
L’ensemble C 1(U, R) est un sous-espace vectoriel de F (U, R).
Proposition 32.3.2.1140
Démonstration : Il suffit de vérifier la stabilité ce qui découle de ce qui a déjà été fait.
Soit f une fonction de classe C 1 sur un ouvert U. Pour tout a = (α, β) ∈ U, il existe une fonction εqui tend vers 0 en a telle que
∀u = (x, y) ∈ U, f (u) = f (a) + (x− α)∂ f∂x
(a) + (y− β)∂ f∂y
(a) + ||u− a||ε(u).
Théorème 32.3.2.1141
Remarques :1. C’est un équivalent du théorème de Taylor-Young. A noter que l’hypothèses est que f est de classe C 1 et
pas juste dérivable comme dans le cas d’une variable.
2. On peut aussi écrire
∀h = (h1, h2), f (a + h) = f (a) + h1∂ f∂x
(a) + h2∂ f∂y
(a) + ||h||ε(h)
où limh→0
ε(h) = 0.
3. Cela a une interprétation géométrique. Si on considère la surface S = (x, y, z) ∈ R3 | (x, y) ∈ U et z =f (x, y). On voit que le théorème permet de trouver l’équation du plan tangent. Son équation est
z = f (a) + h1∂ f∂x
(a) + h2∂ f∂y
(a).
Dit autrement, les vecteurs(
1, 0∂ f∂x
(a))
et(
0, 1∂ f∂y
(a))
sont des vecteurs directeurs du plan tangent.
4. L’expression s’appelle développement limité de f à l’ordre 1 en a.
Démonstration : La fonction f étant définie sur un ouvert U. Il existe η1 tel que B(a, η1) ⊂ U. On peut doncdéfinir sur B(0, η1) \ (0, 0) la fonction
ε : h 7→f (a + h)− f (a)− h1
∂ f∂x
(a)− h2∂ f∂y
(a)
||h|| .
Le but est de montrer que cela tend vers 0.On écrit
ε(h) =f (a′)− f (a)− h1
∂ f∂x
(a)
||h|| +
f (a + h)− f (a′)− h2∂ f∂y
(a)
||h|| où a′ = a + h1e1.
479

Maintenant, f (a′)− f (a)− h1∂ f∂x
(a) = f1(α + h1)− f1(α)− f ′1(α), c’est donc, d’après la formule de Taylor-
Young à l’ordre 1 négligeable devant h1 mais comme |h1| 6 ||h|| on a bien quef (a′)− f (a)− h1
∂ f∂x
(a)
||h|| tend
vers 0.On veut procéder de même pour l’autre mais il faut faire attention qu’il faut travailler avec la deuxième
application partielle en a′ et pas en a. On en déduit quef (a + h)− f (a′)− h2
∂ f∂y
(a′)
||h|| tend vers 0. On peut alors
conclure en vérifiant que
h2∂ f∂y
(a′)− h2∂ f∂y
(a)
||h||
tend vers 0 car∂ f∂y
est continue.
Une fonction de classe C 1 est continue.
Corollaire 32.3.2.1142
Remarque : Cela permet de montrer qu’une fonction est continue mais ce n’est pas très utile car dans lapratique, pour montrer que f est de classe C 1 il faut montrer que les deux dérivées partielles sont continues.
3.3 Composées
Nous allons voir comment on peut calculer les dérivées partielles d’une fonction composée.Nous commençons par composer une fonction de R dans R2 avec une fonction de R2 dans R.
Soit f une fonction de classe C 1 définie sur un ouvert U. Soit ϕ une fonction dérivable d’un intervalleI dans U. La fonction réelle F = f ϕ est dérivable et
∀t ∈ I, F′(t) =∂ f∂x
(ϕ(t))ϕ′1(t) +∂ f∂y
(ϕ(t))ϕ′2(t)
où ϕ1 et ϕ2 sont les composantes de ϕ.
Proposition 32.3.3.1143
Démonstration : On va essayer de calculer limh→0
F(t + h)− F(t)h
= limh→0
f (ϕ(t + h))− f (ϕ(t))h
.
On sait qu’il existe un développement limité de f en ϕ(t) à l’ordre 1. C’est-à-dire qu’il existe une fonction εtendant vers 0 quand u tend vers ϕ(t) telle que
f (u)− f (ϕ(t)) =∂ f∂x
(ϕ(t))(u1 − ϕ1(t)) +∂ f∂y
(ϕ(t))(u2 − ϕ′2(t)) + ||u− ϕ(t)||ε(u).
Cela donne :
f (ϕ(t + h))− f (ϕ(t))h
=
∂ f∂x
(ϕ(t))(ϕ1(t + h)− ϕ1(t))
h+
∂ f∂y
(ϕ(t))(ϕ2(t + h)− ϕ′2(t))
h+||ϕ(t + h)− ϕ(t)||
hε(ϕ(t+ h)).
Maintenant le premier terme tend vers∂ f∂x
(ϕ(t))ϕ′1(t) alors que le deuxième tend vers∂ f∂y
(ϕ(t))ϕ′2(t). Pour
finir, le troisième tend vers 0 car||ϕ(t + h)− ϕ(t)||
hest borné car cela tend vers ||ϕ′(t)|| et le terme en ε tend
vers 0 car ϕ est continue.
480

Remarque : On peut retenir cette formule en posant x(t) pour ϕ1(t) et y(t) pour ϕ2(t). On a alors
F : t 7→ f (x(t), y(t))
etdFdt
=∂ f∂x
dxdt
+∂ f∂y
dydt
.
Exemples :1. On reprend f : (x, y) 7→ ln(xy). On pose ϕ : t 7→ (λt, µt). Dans ce cas, F : t 7→ ln(λt× µt) = ln(λµt2)
d’oùF′(t) =
2t
.
Par la formule,
F′(t) =1λt
.λ +1µt
.µ =2t
.
2. Soit f de classe C 1. Si Ft 7→ f (cos t, sin t). On a
F′(t) = − sin t∂ f∂x
(cos t, sin t) + cos t∂ f∂y
(cos t, sin t).
Soit f une fonction de classe C 1 sur U et ϕ : (a, b) 7→ (x, y) une fonction d’un ouvert V de R2 dansU. On suppose que les composantes ϕ1 et ϕ2 admettent des dérivées partielles. Si on note F = f ϕ.Elle admet des dérivées partielles et pour tout u = (a, b) ∈ V,
∂F∂a
(u) =∂ f∂x
(ϕ(u))∂ϕ1
∂a(u) +
∂ f∂y
(ϕ(u))∂ϕ2
∂a(u)
et∂F∂b
(u) =∂ f∂x
(ϕ(u))∂ϕ1
∂b(u) +
∂ f∂y
(ϕ(u))∂ϕ2
∂b(u)
Corollaire 32.3.3.1144
Remarques :1. Il suffit d’appliquer ce qui précède aux applications partielles.
2. On utilise la notation suivante qui permet de bien retenir la formule. On pose ϕ(a, b) = (x(a, b), y(a, b)).On alors :
∂F∂a
=∂ f∂x
∂x∂a
+∂ f∂y
∂y∂a
et∂F∂b
=∂ f∂x
∂x∂b
+∂ f∂y
∂y∂b
.
Exemple : Un cas classique est celui du changement de variables en polaires. Si on prend encore f de classe C 1
sur (R?+)
2. On pose x = r cos θ et y = r sin θ pour (r, θ) ∈ R?+×]0, π/2[. Ce qui revient à poser
ϕ : (r, θ) 7→ (r cos θ, r sin θ)
On obtient en posant F = f ϕ (on écrit parfois F(r, θ) = f (x, y)). On a
∂F∂r
=∂ f∂x
cos θ +∂ f∂y
sin θ
et∂F∂θ
= −r∂ f∂x
sin θ + r∂ f∂y
cos θ
En particulier, si f : (x, y) 7→ ln(xy) on obtient
∂F∂r
=2r
et∂F∂θ
= − tan θ +1
tan θ.
481

3.4 Différentielle et gradient
Soit f une fonction de classe C 1 sur U. Soit a ∈ U.
1. Soit v = (v1, v2) un vecteur non nul. La fonction f admet une dérivées selon le vecteur v et
Dv f (a) =∂ f∂x
(a)v1 +∂ f∂y
(a)v2.
2. Avec les notations précédentes, la fonction notée d fa
d fa : v 7→ Dv f (a)
est une forme linéaire que l’on appelle différentielle de f en a.
Proposition 32.3.4.1145
Démonstration : Il suffit de voir que f (a + tv)− f (a) = tv1∂ f∂x
(a) + tv2∂ f∂x
(a) + |t|||v||ε(tv) d’où
limt→0
f (a + tv)− f (a)t
= v1∂ f∂x
(a) + v2∂ f∂x
(a).
Remarques :1. C’est ce que nous avions remarquer plus tôt. Pour calculer les dérivées d’une fonction selon un vecteur on
calcule la plupart du temps sa différentielle.
2. On a donc Dv f (a) = d fa(v). Ne pas se mélanger les pinceaux...
Exemple : Soit f : (x, y) 7→ cos(x2 − y2). On veut calculer D(1,2) f (2,−1). On calcule les dérivées partielles :
∂ f∂x
(x, y) = −2x sin(x2 − y2) et∂ f∂x
(x, y) = 2y sin(x2 − y2)
D’oùD(1,2) f (2,−1) = 1 ∗ (−2 sin(−3)) + 2 ∗ (2 sin(−3)) = 2 sin(−3).
Soit f une fonction de classe C 1 sur U. Soit a ∈ U. Il existe un unique vecteur noté−−→grad f (a) tel que
∀v ∈ R2, Dv f (a) = d fa(v) = (−−→grad f (a), v).
Proposition 32.3.4.1146
Démonstration : C’est juste la proposition qui dit que dans un espace euclidien toutes les formes linéaires sontde la forme v 7→ (b, v) pour un unique vecteur v.
Avec les notations précédentes, le vecteur−−→grad f (a) s’appelle le gradient de f en a. Il se note aussi ∇ f (a).
On a−−→grad f (a) =
(∂ f∂x
(a),∂ f∂y
(a))
.
Définition 32.3.4.1147
Exemple : Si f : 7→ ln(xy). On a−−→grad f (α, β) =
(1α
,1β
).
Interprétation géométrique : On considère une fonction f de classe C 1. Pour tout λ dans R, on appelle lignede niveau la courbe
Eλ(x, y) ∈ U | f (x, y) = λ.
482

On considère une courbe paramétrée Γ tracée dans Eλ. Si on note ϕ : t 7→ ϕ(t) = (x(t), y(t)) la fonctiond’un intervalle I dans U un paramétrage de Γ. On a donc, pour tout t dans I, F(t) = f ϕ(t) = λ. Dès lors si ondérive :
0 = F′(t) =∂ f∂x
(ϕ(t))x′(t) +∂ f∂y
(ϕ(t))y′(t) = D fϕ′(t)ϕ(t) = (−−→grad f (ϕ(t))|ϕ′(t)).
En particulier, on voit que le gradient est orthogonal à la tangente. On dit que le gradient dirige la ligne de plusgrande pente.
3.5 Extremums
On peut définir les extremums comme dans le cas des fonctions à une variables.
Soit f une fonction définie sur une partie A de R2 et à valeurs dans R. Soit a ∈ A.
1. On dit que a est un maximum (resp. minimum) (global) si : ∀u ∈ A, f (u) 6 f (a) (resp. f (u) > f (a)).Dans ce cas on dit que a est un extremum (global).
2. On dit que a est un maximum (resp. minimum) local si :
∃ε > 0, ∀u ∈ A, (u ∈ B(a, ε)⇒ f (u) 6 f (a)) (resp. ∃ε > 0, ∀u ∈ A, (u ∈ B(a, ε)⇒ f (u) > f (a)))
Dans ce cas on dit que a est un extremum local
Définition 32.3.5.1148
On a alors comme pour les fonctions définies sur R.
Soit f une fonction de classe C 1 définie sur un ouvert U. Soit a ∈ U. Si f est un extremum local alorsles dérivées partielles sont nulles en a.
Proposition 32.3.5.1149
Remarques :
1. Cela implique que la différentielle est nulle et que, de ce fait, les dérivées par rapport à tous les vecteursest nulle.
2. Comme dans le cas des fonctions définies sur R, il ne faut pas que a soit une borne. Cette hypothèse estremplacée par le fait que U soit un ouvert.
3. Comme dans le cas des fonctions définies sur R, ce n’est pas une équivalence. Par exemple la fonctionf : (x, y) 7→ x2 − y2 en (0, 0).
4. Pour déterminer des extremums, on cherche l’annulation des deux dérivées partielles, puis on regarde siles solutions sont ou ne sont pas des extremums.
Démonstration : Il suffit de voir qu’un extremum est aussi un extremum des applications partielles.
Exemple : Soit f : (x, y) 7→ x2 + y2 − 2x− 4y. On voit que
∂ f∂x
= 2x− 2 et∂ f∂y
= 2y− 4.
On étudie en a = (1, 2). On pose f (1 + h1, 2 + h2) = −5 + h21 + h2
2. On en déduit que a est un minimim global.Exercice : Étudier les extremums de f : (x, y) 7→ x3 + y2 − 6(x2 − y2).
483

3.6 Dérivées partielles d’ordre 2
Soit f une fonction de classe C 1 sur un ouvert U.
1. Si la fonction∂ f∂x
admet des dérivées partielles on note
∂2 f∂x2 =
∂
∂x
(∂ f∂x
)et
∂2 f∂y∂x
=∂
∂y
(∂ f∂x
).
2. Si la fonction∂ f∂y
admet des dérivées partielles on note
∂2 f∂x∂y
=∂
∂x
(∂ f∂y
)et
∂2 f∂y2 =
∂
∂y
(∂ f∂y
).
3. Si les quatre dérivées partielles existent et sont continues on dit que f est de classe C 2.
Définition 32.3.6.1150
Remarques :1. On peut évidemment définir de même des fonctions de classe C 3, etc mais il y a toujours plus de dérivées
partielles.
2. On note C 2(U, R) l’ensemble des fonctions de classe C 2.
3. L’ensemble C 2(U, R) est un sous-espace vectoriel de F (U, R).
Exemples :
1. Si f : (x, y) 7→ ln(xy). On a déjà vu que∂ f∂x
=1x
on a donc
∂2 f∂x2 = − 1
x2 et∂2 f
∂y∂x= 0.
De même∂ f∂y
=1y
on a donc
∂2 f∂y2 = − 1
y2 et∂2 f
∂x∂y= 0.
2. Si f : (x, y) 7→ x3 + 2x2y2 − 3y2. On a que∂ f∂x
= 3x2 + 4xy2 on a donc
∂2 f∂x2 = 6x + 4y2 et
∂2 f∂y∂x
= 8xy.
De même∂ f∂y
= 4x2y− 6y on a donc
∂2 f∂y2 = 8xy et
∂2 f∂x∂y
= 4x2 − 6.
On remarque que dans les deux cas précédents,∂2 f
∂x∂y=
∂2 f∂y∂x
.
Soit f une fonction de classe C 2 sur un ouvert. On a
∂2 f∂x∂y
=∂2 f
∂y∂x.
Théorème 32.3.6.1151 (Théorème de Schwarz)
484

Démonstration : Ce théorème est admis. Un des démonstration consiste à montrer que
∂2 f∂x∂y
= limh→0
f (α + h, β + h)− f (α, β + h)− f (α + h, β) + f (α, β)
h2 =∂2 f
∂y∂x.
3.7 Quelques équations aux dérivées partielles
Une équation aux dérivées partielles et juste une relation entre les dérivées partielles d’une fonction. Larésoudre consiste à trouver toutes les fonctions définies sur un ouvert U vérifiant cette relation. Nous nouscontenterons de quelque exemples pour la plupart issus de la physique.
F Commençons par l’équation sur R2 :∂ f∂x
= 0. On cherche une fonction de classe C 1 sur R. Pour tout y ∈ R,
l’application partielle f1 est constante car de dérivée nulle. On en déduit que pour tout y il existe ϕ(y) tel que∀x ∈ R, f (x, y) = ϕ(y). De plus, ϕ est de classe C 1 car f l’est. Réciproquement toutes les fonctions de la forme
(x, y) 7→ ϕ(y)
pour ϕ de classe C 1 vérifient l’équation.
F On pose maintenant
∂ f∂x− 5
∂ f∂y
= x. (E)
On peut remarquer (x, y) 7→ x2
2est une solution. Comme c’est une équation linéaire, on est ramené à
résoudre
∂ f∂x− 5
∂ f∂y
= 0. (H)
On va faire un changement de variables en posant x = u + αv et y = u + βv pour α 6= β.On voit que
ϕ : R2 → R2
(u, v) 7→ (x, y)
est une bijection de R2 dans lui même (la bijection réciproque est (x, y) 7→ (u, v) =(
βx− αyβ− α
,y− xβ− α
)). De plus
elle est de classe C 1 car polynomiale. Maintenant si f est une fonction de classe C 1 on pose F = f ϕ. On saitalors que
∂F∂u
=∂ f∂x
∂x∂u
+∂ f∂y
∂y∂u
=∂ f∂x
+∂ f∂y
et
∂F∂v
=∂ f∂x
∂x∂v
+∂ f∂y
∂y∂v
= α∂ f∂x
+ β∂ f∂y
.
On voit donc qu’en prenant α = 1 et β = −5, l’équation (H) se ramène à∂F∂v
. On a donc qu’il existe une
fonction ϕ de classe C 1 telle que
∀(u, v) ∈ R2F(u, v) = ϕ(u) et donc ∀(x, y) ∈ R2, f (x, y) = ϕ
(5x + y
6
).
485

Donc les solutions de E sont de la forme :
(x, y) 7→ x2
2+ ϕ
(5x + y
6
).
F Equation des ondes :On appelle équation des ondes en dimension 1 l’équation
∂2 f∂x2 −
1c2
∂2 f∂t2 = 0. (E)
C’est en particulier l’équation qui est vérifiée par une corde vibrante. Par exemple si on considère une cordede longueur `. On note f (x, t) la hauteur du point de la corde à l’abscisse x et à l’instant t. La grandeur c qui esthomogène à une vitesse.
On pose le changement de variables u = x + ct et v = x− ctOn voit que
ψ : R2 → R2
(x, t) 7→ (u, v)
est une bijection de R2 dans lui même. La bijection réciproque est ϕ : (u, v) 7→ (x, y) =(
u + v2
,u− v
2c
). De
plus elle est de classe C 1 car polynomiale. On pose encore F = f ϕ et donc f = F ψ.On obtient alors
∂2 f∂x2 =
∂2F∂u2 + 2
∂2F∂u∂v
+∂2F∂v2 et
∂2 f∂t2 = c2
(∂2F∂u2 − 2
∂2F∂u∂v
+∂2F∂v2
).
On en déduit que si f est une solution alors F vérifie∂2F
∂u∂v= 0.
On en déduit qu’il existe h de classe C1 sur R telle que∂F∂v
= h(v) puis F : (u, v) 7→ H(v) + G(u) où H estune primitive de h.
Finalement,f : (x, y) 7→ H(x− ct) + G(x + ct).
Réciproquement les fonctions de ce type vérifient l’équation.Après on peut essayer de déterminer H et G en fonction des conditions initiales. Si par exemple on suppose
que les deux extrémités de la corde ne bouge pas. On a
∀t ∈ R, f (0, t) = f (`, t) = 0.
On en déduit que pour tout t, H(−ct) = −G(ct). Donc f : (x, t) 7→ H(x − ct)− H(−x − ct). De plus H est2`-périodique.
486

















![[ MPSI – MECANIQUE ] 1 1 – SYSTEMES DE … · ˇ ˆ˙˝˛ Sommaire [ MPSI – MECANIQUE](https://img.pdfslide.fr/doc/110x75/5b96915609d3f27e758bc286/-mpsi-mecanique-1-1-systemes-de-sommaire-mpsi-mecanique.jpg)











