Embed Size (px)
Citation preview

1
Sommaire
_______________________________________Introduction aux Types de Données Abstraits 4
1 _________________________________________________Généralités sur la modularité 4
1.1 ________________________________________________________But: Qualité du logiciel 4________________________________________________1.1.1 Coût de la non qualité : 4
________________1.1.2 Les qualités fondamentales de composants logiciels (modules) 5
1.2 _________________________________________________________Modularité : Principes 5__________________1.2.1 Modularité : Autour des données ou autour des traitements ? 6
_________________________________________1.2.2 Mise en œuvre de la modularité 7
2 ________________________________Introduction aux Type de Données Abstrait : TDA 7
2.1 ___________________________________________________________________Définition 7__________________________________________________2.1.1 Avantages des TDA 7
_______________________________________________2.1.2 Inconvénients des TDA 7
3 ______________________________________________Programmation à l'aide des TDA 7
3.1 ________________________________________________Concevoir correctement les TDA 7_________________________________________________3.1.1 Conception d'un TDA 7
3.2 ________________________________________________________________Exemple : Pile 7________________________________________________________3.2.1 Spécification 7
__________________________________________3.2.2 Représentation et implantation 7
4 ______________________________________________________________Types de base 7
4.1 ____________________________________________________________Les types scalaires 7____________________________________________________4.1.1 Les types discrets 7
______________________________________________________4.1.1.1 Les entiers 7_______________________________________________4.1.1.2 Les types énumérés 7
_____________________________4.1.1.3 Fonctions prédéfinies sur les types discrets 7________________________4.1.1.4 Représentation du type booléen comme un TDA 7
__________________________4.1.1.5 Représentation du type entier comme un TDA 7___________________________________________________________4.1.2 Les réels 7
___________________________________4.1.2.1 Représentation en virgule flottante 7_______________________________________4.1.2.2 Représentation en virgule fixe 7
_________________________4.1.2.3 Représentation du type réel sous forme de TDA 7___________________________________________________4.1.3 Conversion de type 7
4.2 ___________________________________________________________Les types composés 7________________________________________________4.2.1 Les structures statiques 7
______________________________________4.2.1.1 Structures cartésiennes simples 7_________________________4.2.1.2 Représentation statique du type Ensemble en C 7
_________________________________________________________4.2.1.3 Résumé 7_____________________________________________4.2.2 Les structures dynamiques 7
_______________________________________________________4.2.3 Les pointeurs 7_________________________________________________4.2.3.1 Ramasse miettes 7
________________________________________________4.2.3.2 Chaînage des trous 7
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

2
5 ________________________________________________Définition d'un nouveau TDA 7
5.1 ______________________________________________________Vue interne et vue externe 7__________________________________________5.1.1 Spécification de la vue externe 7
_________________________________________________5.1.2 Opérations primitives 7
5.2 _________________________________________Exemple : Spécification du type Fraction 7___________________________________5.2.1 Définition structurelle du type Fraction 7
_____________________________5.2.2 Définition logique (abstraite) du type Fraction 7______________________________________5.2.3 Quelle sorte de définition utiliser ? 7
________________________________5.2.4 Implantations alternatives du type Fraction 7____________________________________________5.2.5 Opérations du type Fraction 7
6 __________________________________________________Programmation par contrat 7
6.1 _______________Application de la programmation par contrat à l'exemple des Fractions 7
_____________________________________________Types de Données Abstraits Classiques 7
7 ___________________________________________________________TDA Pile (Stack) 7
7.1 ______________________________________________________Spécification du TDA Pile 7______________________________________________________________7.1.1 LIFO 7
7.2 ______________________________________________Implantation statique du TDA Pile 7____________________________________________7.2.1 Pile bornée (bounded Stack) 7
_________________________________7.2.2 Pile : Représentation par tableau en ADA 7___________________________7.2.2.1 Spécification 1 : sans abstraction de données 7___________________________7.2.2.2 Spécification 2 : avec abstraction de données 7
__________________7.2.2.3 Spécification 3 : Possibilité de définir la taille de la Pile 7__________________7.2.3 Code du TDA PileEntiers en C avec abstraction des données 7
______________________7.2.4 TDA Pile défini comme une machine abstraite en ADA 7___________________7.2.5 TDA PileEntiers défini comme une machine abstraite en C 7
__________________________________________7.2.6 Code de Pile statique en JAVA 7
7.3 ____________________________________________Implantation dynamique du TDA Pile 7_______________________________________7.3.1 Implantation dynamique en ADA 7
__________________________________________7.3.2 Implantation dynamique en C 7_______________________________________7.3.3 Implantation dynamique en JAVA 7
7.4 ________________________________________________________Utilisation du TDA Pile 7____________________________________7.4.1 Exemple - vérificateur de parenthèses 7
_________________________7.4.2 Evaluation des expressions arithmétiques postfixées 7__________7.4.3 Exemple d'algorithme utilisant des piles : le Quick Sort ( non récursif ) 7
8 ________________________________________________________TDA Files (Queues) 7
8.1 _____________________________________________________Spécification du TDA Files 7______________________________________________________________8.1.1 FIFO 7
8.2 ______________________________________________Implantation statique du TDA File 7______________________________8.2.1 Représentation statique du TDA File en ADA 7
____________________________________________8.2.1.1 Représentation linéaire 7___________________________________________8.2.1.2 Représentation circulaire 7
_________________________________8.2.2 Représentation statique du TDA File en C 7_____________________________8.2.3 Représentation statique du TDA File en JAVA 7
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

3
______________________________8.2.4 Représentation statique du TDA File en C++ 7
8.3 ____________________________________________Implantation dynamique du TDA File 7_____________________8.3.1 Représentation dynamique du TDA File en ADA et en C 7
____________________________8.3.2 Représentation dynamique du TDA File en Java 7
8.4 ________________________________________________________Utilisation du TDA File 7
9 _______________________________________________________________Listes (List) 7
9.1 _______________________________________________________________Listes linéaires 7
9.2 _________________________________________________________________Listes Triées 7
9.3 ________________________________________Implantation semi-dynamique (Curseurs) 7___________________________________9.3.1 Implantation semi-dynamique en ADA 7
9.4 _______________________________________________________Implantation dynamique 7__________________________________________9.4.1 Implantation dynamique en C 7
9.5 ___________________________________________________Sentinelle et double chaînage 7
9.6 ____________________________________________Implantation récursive du TDA Liste 7
10 ________________________________________________________Graphes (Graphs) 7
10.1 ________________________________________________________Graphes non orientés 7
10.2 _____________________________________________________Graphes orientés simples 7________________________________________________________10.2.1 Définitions 7
10.3 ____________________________________Spécification du TDA GrapheOrienté simple 7
10.4 ______________________________________________________Utilisation des Graphes 7
10.5 ______________________________________Représentation d'un graphe simple orienté 7______________________10.5.1 Matrice booléenne associée (ou matrice d'adjacence) 7
__________________________________________10.5.2 Matrice d'incidence aux arcs 7_______________________________10.5.2.1 Première solution : Liste de successeurs 7
__________________10.5.2.2 Deuxième solution : Liste de sommets et de successeurs 7____________________________10.5.2.3 Troisième solution : Structures homogènes 7
10.6 ________________________________________________________Parcours de Graphes 7______________________________________________10.6.1 Parcours en profondeur 7
_________________________________________________10.6.2 Parcours en largeur 7_______________________________________________10.6.3 Détection d'un circuit 7
____________________________________________________10.6.4 Tri topologique 7
11 __________________________________________________________________Arbres 7
11.1 _______________________________________________________________Terminologie 7
11.2 ______________________Spécification du TDA ArbreBin (Type Arbre Binaire (2-aire)) 7
11.3 ________________________________________________________Utilisation des Arbres 7
11.4 ___________________________________________________________Parcours d'Arbre 7_______________________________________11.4.1 Parcours en profondeur d'abord 7
11.5 ____________________________________________________Représentation des Arbres 7__________________________________11.5.1 Arbre Binaire : Représentation chaînée 7
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

4
___________________________11.5.1.1 Implantation dynamique d'ArbreBin en ADA 7___________________________11.5.1.2 Implémentation dynamique d'ArbreBin en C 7
___________________________________11.5.2 Arbre n-aire : Représentation chaînée 7__________________________11.5.3 Arbre Binaire : Représentation semi-dynamique 7
____________________11.5.4 ArbreBinaire en largeur : représentation dans un tableau 7___________________________________________11.5.5 Arbre Binaire de recherche 7
_________________11.5.5.1 Implantation dynamique d'un arbre de recherche en ADA 7___________11.5.5.2 Utilisation d'un Arbre Binaire de Recherche pour trier un tableau 7
____________________________________________________11.5.6 Arbre équilibré 7
11.6 ____________________________________________________Isomorphisme liste-arbre 7
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

5
Introduction aux Types de Données Abstraits
1 Généralités sur la modularité
1.1 But: Qualité du logiciel
Qualités fondamentales : Réutilisabilité, fiabilité…
Difficultés : Mettre en œuvre une vraie réutilisabilité. Gestion correcte des erreurs. 30 % du coût d'un logiciel passé en développement
• 60% en réflexion initiale, • 15% codage et • 25% en test et mise au point,
70 % en maintenance• 41% modifications demandées par les utilisateurs• 21% correction de bugs (urgents et routine)• 17,5% prise en compte de changements de formats dans les données• 9% correction de routine• 6% prise en compte de changements matériels• 5,5% documentation• 4% amélioration de l'efficacité• 3,5% divers
1.1.1 Coût de la non qualité :
Logiciel de commande et de contrôle de l'US air force :• Prévision initiale : 1,5 million de $• Coût total : 3,7 millions de $
Système de réservation United Airlines• Abandon après 56 millions de $ dépensés
Problèmes rencontrés dans des logiciels de gestion :• Envoi de 20 000 journaux à la même adresse (sélecteur d'adresse bloqué),• Cartes de crédits systématiquement avalées (désaccord entre 2 calculateurs sur les
années bissextiles)• Crack à la bourse de Londres (surcharge du système)
Problèmes rencontrés dans des logiciels temps réels embarqués :• Avion F16 Déclaré sur le dos après le passage de l'équateur,• Mission Vénus : passage à 500 000 km au lieu de 5000 km (remplacement d'une
virgule par un point),• Sonde sur Mars : perdu après le passage derrière Mars (altitude calculée en miles par
une partie des développeurs et en km par une autre),• Exocet répertorié comme missile ennemi dans la guerre des Malouines
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

6
• Fusée Russe pointant Hambourg au lieu du pôle nord (erreur de signe et donc de 180° du système de navigation),
Problèmes rencontrés dans des logiciels temps réels sols :• Déclenchement d'un système de détection de missiles Américains (lune à l'horizon
considérée comme OVNI),• Inondation de la ville de Colorado River (erreur de temps d'ouverture du barrage),
1.1.2 Les qualités fondamentales de composants logiciels (modules)
Validité Aptitude d'un produit logiciel à remplir exactement ses fonctions, définies par le cahier des charges et la spécification.
Fiabilité Aptitude à fonctionner dans des conditions éventuellement anormales. Reprise d’erreurs et fonctionnement dégradé.
Encapsulation (intégrité)
Aptitude d'un composant logiciel à protéger ses données contre des accès extérieurs non autorisés.
Extensibilité Facilité avec laquelle un composant logiciel se prête à une modification ou à une extension des fonctions qui lui sont demandées.
Réutilisabilité Aptitude à être réutilisé, en tout ou partie, dans de nouvelles applications.Eviter dans le développement d'une application la re-conception et la ré-écriture d'algorithmes classiques de tri, recherche, lecture-écriture, comparaisons, parcours … qui reviennent sans cesse sous des formes légèrement différentes : en factorisant, une bonne fois pour toute, tout ce qui peut l'être.
Compatibilité Facilité avec laquelle un composant logiciel peut être associé à d'autres pour construire une application.
Portabilité Facilité avec laquelle un produit peut être transféré sur différents environnements matériels et logiciels.
Facilité d'emploi Facilité d'apprentissage, d'utilisation, de préparation des données, de correction des erreurs, d'interprétation et d'utilisation des résultats.
Vérifiabilité Facilité de préparation de la recette et de la validation (jeux d'essais).Efficacité Utilisation optimale des ressources matérielles (processeurs, mémoire interne
et externe, dispositifs d'entrée/sortie, etc.).
1.2 Modularité : Principes
Principes à respecter :
Le problème doit être décomposé en modules indépendants : division du travail et simplification du problème au niveau de chaque module.Les modules produits doivent pouvoir être facilement combinés les uns avec les autres pour construire de nouvelles applications éventuellement dans des environnements très variés.Les modules développés dans la cadre d'une application doivent être compréhensibles séparément (indépendamment les uns des autres) (commentaires explicites, spécification bien pensée, lisibilité du code, sous-programmes bien ciblés et courts, etc.). L'application doit être conçue de telle façon qu'un changement mineur de spécification aura pour résultat des changements très limités et bien contrôlés au niveau des modules.
• Principe N°1 : ne pas utiliser de constantes “en dur” dans le code.
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

7
Chaque module qui effectue un traitement susceptible de produire une erreur doit le plus possible en assurer le traitement.
• L'opération qui effectue une saisie clavier doit assurer que l'entrée tapée par l'utilisateur est correcte avant de la transmettre à l'appelant.
Chaque module doit correspondre avec aussi peu de modules que possible :
Deux modules qui communiquent s'échangent aussi peu d'informations que possible, juste le nécessaire.Si deux modules communiquent, ceci doit être évident au coup d'œil (paramètres explicites, commentaires, documentation…).Encapsulation : masquage de l'information. Tout accès à une donnée d'un module doit être protégé. Une modification d'une donnée doit être effectuée uniquement par le module dans lequel est défini cette donnée (pas de modification d’une variable d’un module dans du code extérieur au module.
Exemple de définition d'un module utilisé par un autre module :
1.2.1 Modularité : Autour des données ou autour des traitements ?
Un programme effectue des actions sur des données. La structure du programme peut donc être fondée sur les actions ou sur les données.
Décomposition classique par les actions (traitements) (décomposition fonctionnelle en sous-programmes).
OU Décomposition par les données (modules, classes).
NON à la décomposition fonctionnelle descendante :
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

8
La décomposition descendante exige qu'on commence par définir précisément et rigoureusement le but à atteindre (c.à.d. le sommet de la décomposition arborescente).
Exemple : Pour trier les personnes dans la commune, le maire définit un critère :
Tri d'un les personnes selon leur âge puis selon le nom :
fonction trierPersonnesSelonAge (t : TableauDePersonnes) i, j, deb, fin : integer;début pour i := t'first; i < t'last; i++ faire pour j := t'succ(i); j <= t'last; j++ faire si t(i).age > t(j).age alors permuter (t(i), t(j)); fsi fpour fpour deb := t'first; tq deb <= t'last faire // rechercher l'indice de la première personne d'une tranche d'age fin := deb; tq t(fin).age = t(deb).age faire j++; ftq fin--; pour i := deb; i < fin; i++ faire pour j := i; j<= fin; j++ faire si t(i).nom > t(j).nom alors permuter (t(i), t(j)); fsi fpour fpour deb := fin+1; ftqfin
Ce sous-programme sera difficilement utilisable ailleurs. Il faudrait avoir le même type de tableau de personnes et le même besoin de trier selon l'âge puis le nom dans une tranche d'âge.
• Les choix initiaux conditionnent a priori les suivants.• Le système obtenu est fait sur mesure à l'usage exclusif de LA fonction qu'il fallait
réaliser.• Chaque fonction est faite sur mesure pour répondre aux besoins spécifiques de celle
du dessus (généralité ? réutilisabilité ??).• Si les spécifications de la fonction requise (sommet de l'arbre) viennent à changer,
toute l'arborescence s'écroule, sciée à la racine !• La notion de décomposition procédurale descendante est par principe contraire à la
notion de réutilisabilité.Les vrais systèmes logiciels n'ont pas de sommets.
OUI à la composition ascendante de composants logiciels :
• Au lieu de partir de LA fonction à réaliser, partir des objets du système (avions, employés, piles, capteurs, comptes bancaires, tableaux, moteurs, souris, arbres, …)
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

9
en créant un module par type d'objets qui gère la structure de chaque type d'objets et les services qu'il est capable d'offrir.
• Un type d'objet ainsi modélisé est stable dans le temps et peut être utilisé pour développer une application donnée.
• Compatibilité : L'utilisation d'opérations développées dans un module gérant un type d'objets assure que ces opérations sont compatibles entre elles.
♦ Exemple : les opérations stocker (x : X, index : integer, table T) et rechercher (index : integer, table : T) return X agiront bien sur la même donnée stockée dans un type de table donné.
• Réutilisabilité : Il faut pouvoir réutiliser des structures de données entières et non pas seulement les opérations.
Les systèmes logiciels sont caractérisés au premier abord par les données qu'ils manipulent et non par LA fonction (généralement instable) qu'ils assurent pour un temps.
Ne pas demander ce que fait le système : Demander SUR QUOI il agit !
Pour décrire les données, ne pas considérer une seule donnée mais une classe de données équivalentes : un Type de Données.Un Type de Données doit être décrit par le comportement des données (leurs propriétés externes) c'est-à-dire les services que le Type offre à l'extérieur :
Types de Données Abstraits
1.2.2 Mise en œuvre de la modularité
Chaque module est connu de l'extérieur au travers d'une interface publique. Cette interface propose à un client extérieur tous les services offerts par le module (opérations publiques). Le reste des données et opérations du module constitue l'ensemble de ses "secrets" et doit être inaccessible de l'extérieur.
Un module correspond à une unité de compilation :
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

10
En C un module est construit à partir :•d'un fichier nomModule.h qui contient la spécification des données et la
signature des opérations (sous-programmes) visibles depuis l'extérieur => INTERFACE,
•d'un fichier nomModule.c qui contient le code des opérations (sous-programmes) déclarées dans nomModule.h et le code des opérations (sous-programmes) non visibles depuis l'extérieur => CORPS.
En ADA un module est construit à partir d'un paquetage (package) comprenant les deux parties suivantes :
•la spécification du package qui contient les données et signatures des opérations (sous-programmes) visibles depuis l'extérieur => INTERFACE,
•le corps du package (body) qui contient le code des opérations (sous-programmes) déclarées dans la partie spécification du package et le code des opérations (sous-programmes) non visibles depuis l'extérieur => CORPS.
En JAVA un module est implanté par une classe qui décrit les attributs (données) et les méthodes (sous-programmes) accessibles ou non accessibles depuis l'extérieur.
Exemple : Module Point2D
En ADA :package Point2D_P is-- Attention type non protégétype Point2D is array (1..2) of float;
-- Le Point est créé en (0,0)PROCEDURE creerPoint (p : out Point2D);
-- Le point est déplacé de (x,y)PROCEDURE changerValeur ( p : in out Point2D; x, y : float);FUNCTION abscisse(p : Point2D) return float;FUNCTION ordonnee(p : Point2D) return float;END Point2D_P;
package body Point2D_P is
-- Le Point est créé en (0,0)PROCEDURE creerPoint (p : out Point2D) isbegin p(p'first) := 0.0; p(p'last) := 0.0;end creerPoint;
-- Le point est déplacé de (x,y)PROCEDURE changerValeur ( p : in out Point2D; x, y : float) isbegin p(p'first) := p(p'first) + x;
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

11
p(p'last) := p(p'last) + y;end changerValeur;FUNCTION abscisse(p : Point2D) return float isbegin return p(p'first);end abscisse;FUNCTION ordonnee(p : Point2D) return float isbegin return p(p'last);end ordonnee;
END Point2D_P;
--en ADA:with Point2D_P, float_io;
procedure essai1 isp : Point2D_P.Point2D;
beginPoint2D_P.creerPoint(p);Point2D_P.changerValeur(p, 10.0, 20.0);Point2D_P.changerValeur(p, 11.0, 22.0);float_io.put(Point2D_P.abscisse(p)); -- affiche 11.0
end essai1;
En C Point2D.h/* Définition des données *//* le module exporte le type Point2D */ /* ATTENTION, déclaré ainsi le type n'est pas protégé */typedef struct { float coord[2];} Point2D; /* Spécification des opérations (sous-programmes) */ /* Le Point est créé en (0,0) */extern void creerPoint(Point2D *); /* Point en IN OUT */ /* Le Point est déplacé de (x,y) */extern void changerValeur ( Point2D *,/* Point2D en IN OUT */ float, /* coord en x */ float); /* coord en y */Point2D.c#include "Point2D.h"/* Corps des sous-programmes */ /* Le Point est créé en (0,0) */void creerPoint(Point2D *p) /* Point2D en IN OUT */ { (*p).coord[0] = 0.0f; (*p).coord[1] = 0.0f;}/* Le Point est déplacé de (x,y) */void changerValeur ( Point2D * p,/* Point2D en IN OUT */ float x, /* coord en x */ float y) /* coord en y */{ (*p).coord[0] = (*p).coord[0] + x; (*p).coord[1] = (*p).coord[0] + y;}
En JAVA :// la classe met en oeuvre le type Point2D
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

12
class Point2D{ // attributs = données qui définissent un Point2D protected double coord[]; // l'accès de la donnée est protégé
// opérations, méthodes /* Le Point est créé en (0,0) */ public void Point2D() // méthode de création d'un // nouveau Point2D { coord = new double[2]; coord[0] = 0.0; coord[1] = 0.0; } /* Le Point est déplacé de (x,y) */ public void changerValeur ( float x, /* coord en x */ float y)/* coord en y */ { coord[0] = coord[0] + x; coord[1] = coord[0] + y; }}
2 Introduction aux Type de Données Abstrait : TDA
Un type abstrait est une structure qui n'est pas définie en terme d'implantation en mémoire ou par la simple définition de ses composantes, mais plutôt en termes d'opérations et des propriétés d'application de ces opérations sur les données.
2.1 Définition
Un TDA est un ensemble de données et d'opérations sur ces données.
Un TDA est une vue logique (abstraite) d'un ensemble de données, associée à la spécification des opérations nécessaires à la création, à l'accès et à la modification de ces données.
Un TDA est un ensemble de données, organisé pour que les spécifications des données et des opérations sur ces données soient séparées de la représentation interne des données et de la mise en œuvre des opérations.
Un TDA est caractérisé par :° Son identité (nom, adresse en mémoire). ° Le type des données qu'il manipule (ce qui définit son état ou caractéristiques). ° Les opérations sur les données (sous-programmes définis dans le TDA). ° Les propriétés de ces opérations (axiomes permettant de définir le TDA).
Encapsuler : c'est associer données et opérations qui manipulent ces données en un seul endroit.Seuls le type et les opérations exportées sont visibles de l'extérieur. Les données du TDA ne doivent être manipulables que par des opérations du TDA.
L'abstraction de données (Information Hiding) : isole l'utilisateur des détails d'implantation de la structure employée.
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

13
La spécification du type abstrait est indépendante de toute représentation de la (ou des) structure(s) en machine et de l'implantation des opérations associées. Les détails sont connus seulement par les fonctions qui mettent en œuvre les opérations sur la structure de données. Ces détails sont cachés au code utilisateur.Ceci a pour intérêt d'empêcher l'utilisateur d'une telle structure de modifier directement la structure avec le risque de la rendre éventuellement incohérente. Une autre conséquence intéressante est l'amélioration de la portabilité qui découle de l'indépendance entre la spécification des opérations sur de la structure et la méthode d'implantation choisie.
Les TDA sont nés de préoccupations de génie logiciel telles que l'abstraction, l'encapsulation et la vérification de type. Les TDA généralisent ainsi les types prédéfinis (ou types simples) : integer, float, boolean, array… Des concepteurs peuvent ainsi définir un nouveau type et les opérations agissant sur ce type.Le but est de gérer un ensemble fini d'éléments dont le nombre n'est pas fixé a priori. Les éléments de cet ensemble peuvent être de différentes sortes : nombres entiers ou réels, chaîne de caractères, ou des données plus complexes.
L'Application : partie qui utilise un TDA.L'Implantation : partie qui met en œuvre le TDA.
L'application et l'implantation sont deux entités totalement distinctes. Une implantation donnée peut être utilisée par des applications très différentes sans lui apporter aucun changement.
2.1.1 Avantages des TDA
Les TDA permettent une conception ascendante d'un problème à résoudre. On réutilise des briques de base (TDA offrant des types élémentaires tels que ListeChaînée, Pile, File, …).D'autres TDA sont ensuite généralement définis au-dessus des TDA de base pour construire des briques plus complexes.
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

14
Au plus haut niveau, un programme principal permet de faire démarrer l'application qui déclenchera l'utilisation de services offerts par tous les TDA utilisés par l'application.Exemple de conception :
Des TDA correctement conçus doivent être faciles à comprendre et à utiliser.
Les TDA permettent de séparer complètement la spécification des données et services offerts de la mise en œuvre des services.Exemple : Spécification et Body d'un package ADA qui peuvent être dans des fichiers séparés.
Les TDA permettent de cacher à l'utilisateur la façon dont les données sont mises en œuvre et donc d'empêcher l'utilisateur des TDA de modifier lui-même les données. Il faut l'obliger à utiliser des opérations du TDA pour modifier les données.Exemple : En ADA, le type déclaré dans la partie Spécification doit être déclaré PRIVATE (voire LIMITED PRIVATE) pour empêcher toute modification depuis l'extérieur du package.
La spécification des types abstraits est indépendante du langage, de l'implémentation.Par contre la mise en œuvre doit être réalisée avec un langage permettant l'abstraction et l'encapsulation des données.
Les TDA permettent la prise en compte de types complexes (bâtis à partir des types de base).
En finale, les TDA sont les briques d'une conception modulaire rigoureuse.
2.1.2 Inconvénients des TDA
L'utilisateur d'un TDA connaît les services mais ne connaît pas leur coût d'utilisation (car il ne sait pas comment le TDA a été implanté : structure statique ou dynamique ; efficacité de l'implantation selon la plateforme sur laquelle l'application doit tourner).
Le concepteur du TDA connaît le coût des services mais ne connaît pas leurs conditions d'utilisation. Il doit donc offrir des services très étudiés de façon à convenir à de nombreuses applications. Le choix des primitives est quelquefois difficile à faire.
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

15
Un TDA doit également être très stable pour que l'application qui l'utilise ne soit pas amenée à changer son code parce que le TDA a modifié la spécification ou le service offert par une opération du TDA.
3 Programmation à l'aide des TDA
3.1 Concevoir correctement les TDA
Les programmeurs ont deux casquettes :
Concepteur UtilisateurLe concepteur du TDA qui met en œuvre les primitives et doit connaître la représentation interne adoptée.
L'utilisateur du TDA qui ne connaît que les services (les opérations exportées) et n'accède jamais à la représentation interne.
L'application qui utilise un TDA est client du TDA :
Le type est connu à l'extérieur du TDA. Dans la signature des opérations se trouve le Point2D passé en paramètre.
• creerPoint2D(pt : out Point2D, x : integer, y : integer);• changerValeur (pt : in out Point2D, x : integer, y : integer);• abscisse (pt : Point2D) return integer;• ordonnee (pt : Point2D) return integer;• …
Le client de Point2D applique les opérations à un Point2D particulier qu'il a déclaré.• en ADA
with Point2D_P, integer_io; -- import des packages utilisésprocedure essai is
p1, p2 : Point2D_P.Point2D begin
Point2D_P.creerPoint2D(p1,10, 20);Point2D_P.creerPoint2D(p2,10, 20);Point2D_P.changerValeur(p1, 1, 2);Point2D_P.changerValeur(p1, 2, 3);integer_io.put(Point2D_P.abscisse(p1)); -- affiche 11integer_io.put(Point2D_P.ordonnee(p1)); -- affiche 22
end essai;
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat
16
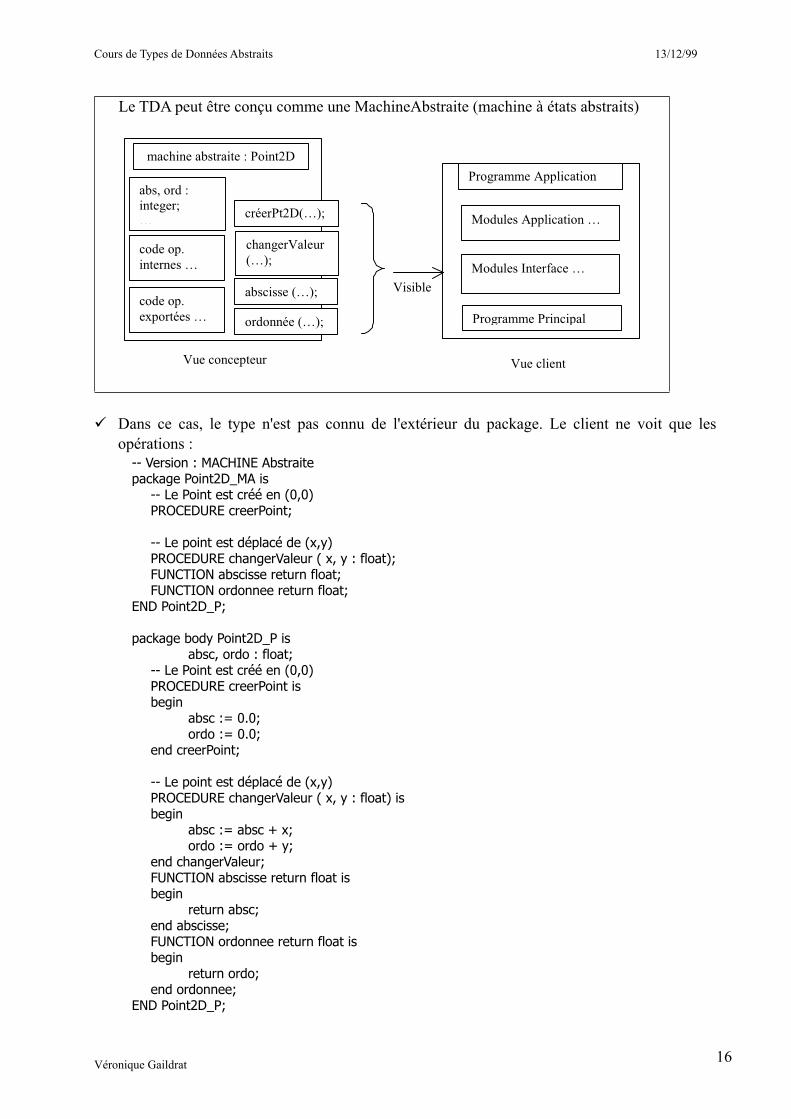
Le TDA peut être conçu comme une MachineAbstraite (machine à états abstraits)
Dans ce cas, le type n'est pas connu de l'extérieur du package. Le client ne voit que les opérations :
-- Version : MACHINE Abstraitepackage Point2D_MA is
-- Le Point est créé en (0,0)PROCEDURE creerPoint;
-- Le point est déplacé de (x,y)PROCEDURE changerValeur ( x, y : float);FUNCTION abscisse return float;FUNCTION ordonnee return float;
END Point2D_P;
package body Point2D_P isabsc, ordo : float;
-- Le Point est créé en (0,0)PROCEDURE creerPoint isbegin absc := 0.0; ordo := 0.0;end creerPoint;
-- Le point est déplacé de (x,y)PROCEDURE changerValeur ( x, y : float) isbegin absc := absc + x; ordo := ordo + y;end changerValeur;FUNCTION abscisse return float isbegin return absc;end abscisse;FUNCTION ordonnee return float isbegin return ordo;end ordonnee;
END Point2D_P;
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat
17
Si le client veut utiliser un Point2D il faut faire référence à la machine abstraite Point2D_P :• en ADA:
with Point2D_P, float_io;procedure essai1 isbegin
Point2D_P.creerPoint;Point2D_P.changerValeur(10.0, 20.0);Point2D_P.changerValeur(11.0, 22.0);float_io.put(Point2D_P.abscisse); -- affiche 11.0
end essai1;
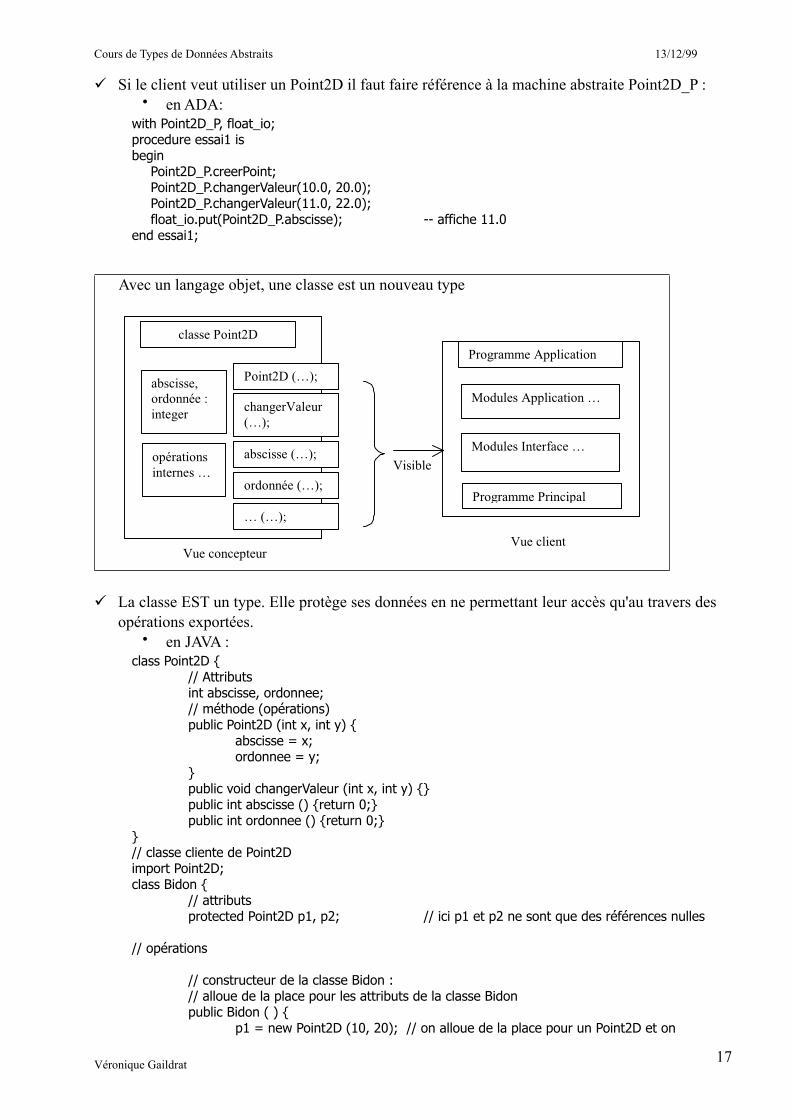
Avec un langage objet, une classe est un nouveau type
La classe EST un type. Elle protège ses données en ne permettant leur accès qu'au travers des opérations exportées.
• en JAVA :class Point2D {
// Attributs int abscisse, ordonnee; // méthode (opérations) public Point2D (int x, int y) { abscisse = x; ordonnee = y; } public void changerValeur (int x, int y) {} public int abscisse () {return 0;} public int ordonnee () {return 0;}
}// classe cliente de Point2Dimport Point2D;class Bidon { // attributs protected Point2D p1, p2; // ici p1 et p2 ne sont que des références nulles // opérations
// constructeur de la classe Bidon : // alloue de la place pour les attributs de la classe Bidon public Bidon ( ) { p1 = new Point2D (10, 20); // on alloue de la place pour un Point2D et on
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

18
// stocke sa référence (son adresse mémoire) dans p1 p2 = new Point2D (11, 22); // on alloue de la place pour un Point2D et on // stocke sa référence (son adresse mémoire) dans p2 } void operation1 () { p1.changerValeur (1, 2); p2.changerValeur (2, 3); System.out.print(p1.abscisse()); // affiche 11 System.out.print(p2.abscisse()); // affiche 13 }}
Idée générale : voir les TDA comme une 'black box' (où l'information d'implantation est
cachée)• entrées-sorties sont connues• la manière dont cela a été implanté ne l'est pas
Règle générale : garder les calculs internes privés• avantage : meilleure modularité• meilleure répartition du travail• localisation non unique (la spécification et le code peuvent être dans des fichiers
séparés)
3.1.1 Conception d'un TDA
Fournir une "interface" pour l'accès aux données et services les données doivent être protégées (private ou protected selon le langage et le niveau de
protection souhaité)• souvent nécessité de fonctions protected ou private également (fonctions utilitaires)
définition de fonctions publiques (public) pour permettre l'accès aux services
la spécification (l'interface) doit être stable est bien conçue spécification (interface) : ensemble d'opérations vues en dehors du TDA
• c'est la partie publique de la définition• les méthodes publiques peuvent être appelées par des fonctions extérieures
l'interface doit être extrêmement stable et ne changer qu'en cas d'absolu nécessité (il fallait réfléchir avant !!)
Les TDA sont égocentriques :• ils agissent sur leurs propres données• ils N'AGISSENT PAS sur des données d'autres TDA
Exemple de ce qu'il ne faut pas faire POUR UNE CONCEPTION ORIENTEE OBJET :TDA changeant des données d'autres TDA
TDA Transaction // pseudo langage{// interface publique :
int getTransactions (Trans, int);
// partie privée :int acct, amt;
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

19
// change les données de la Transaction passé en paramètre !int getTransactions (Transaction data[ ], int max){
int count; for (count := 0; count < max; count++) data[count].acct := lectureClavier ( );
data[count].amt := lectureClavier ( ); return count;
}}
void main () { Transaction data[max], tmp; int numXActions = 0; numXActions = tmp.getTransactions (data, max); }
Conception correcteChaque TDA est responsable de ses propres données :
TDA Transaction{interface publique :
void getTransactions ();partie privée : // attributs, données du TDA
int acct, amt;};
void getTransactions (){ acct := lectureClavier ( );
amt := lectureClavier ( );}// pour modifier plusieurs TDA boucle à l'extérieur du TDAvoid main ()
{ Transaction data[max], tmp; int numXActions = 0; for (numXActions = 0; numXActions < max; numXActions++) data[numXActions].getTransactions (); }
3.2 Exemple : Pile
Intéressons nous à la façon de spécifier un TDA en prenant l'exemple de la Pile qui est basé sur l'observation de piles de la vie réelle : Pile de livres, d'assiettes …
Les Piles sont très utilisées en informatique, non seulement dans des application utilisateurs mais également lors de l'exécution de programmes où elles sont utilisées pour stocker les contextes d'exécution des sous-programmes.
• On accède au 1° élément : le sommet.• On enlève le 1° élément : on dépile.• On ajoute un élément sur la pile : on empile.
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

20
On décrira des opérations manipulant une pile avec les termes : sommet , empiler , dépiler…Avantages : c'est une formulation universelle qui est indépendante du langage cible (C, ADA, JAVA, etc.).
Contrainte : il faudra construire avec le langage cible une structure de données représentant ce type abstrait de données, à l'aide de tableaux, structures, pointeurs, etc. et les fonctions ou procédures implantant les opérations sur le type.
L'application qui utilise un TDA est client du TDA :
Le type est connu à l'extérieur de la Pile. Dans la signature des opérations se trouve la Pile passée en paramètre.
• empiler (p : in out Pile, e : Element);• sommet (p : Pile) return Element;• …
Le client de la Pile applique les opérations à une Pile particulière qu'il a déclarée.• en ADA
with Pile_P, integer_io;procedure … is
p1, p2 : Pile_P.Pile -- on considère que ce sont des Piles d'entierbegin
Pile_P.empiler(p1, 10);Pile_P.empiler(p2, 20);integer_io.put(Pile_P.sommet(p1)); -- affiche 10integer_io.put(Pile_P.sommet(p2)); -- affiche 20…
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

21
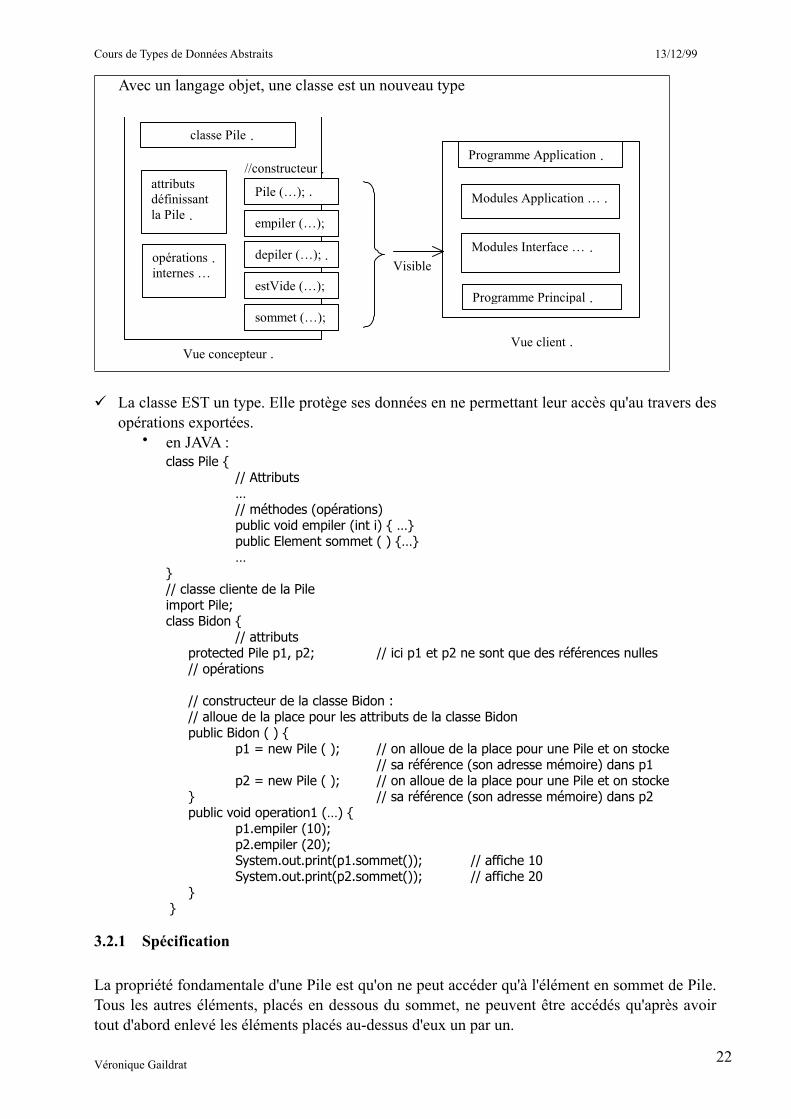
Le TDA peut être conçu comme une MachineAbstraite (machine à états abstraits)
Dans ce cas, le type n'est pas connu de l'extérieur de la Pile (pas exporté). Le client de la Pile ne voit que les opérations :
• empiler (e : Element);• sommet return Element;• …
Si le client veut utiliser une Pile il faut créer une ou plusieurs références à la machine abstraite Pile :
• en ADA:with Pile_MA;package Saisie_p is procedure entreeDonnees; …end Saisie;package body Saisie is procedure entreeDonnees is begin Pile_MA.empiler(20); -- empile dans LA Pile_MA Pile_MA.empiler(10); end entreeDonnees;end Saisie_p;
with Pile_MA, integer_io, Saisie_p;procedure essai isbegin
Saisie.entreeDonnees;integer_io.put(Pile_MA.sommet); -- affiche 10Pile_MA.depiler; -- depile dans LA Pile_MAinteger_io.put (Pile_MA.sommet); -- affiche 20Pile_MA.depiler;
end essai;
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat
22
Avec un langage objet, une classe est un nouveau type
La classe EST un type. Elle protège ses données en ne permettant leur accès qu'au travers des opérations exportées.
• en JAVA :class Pile { // Attributs … // méthodes (opérations) public void empiler (int i) { …} public Element sommet ( ) {…} …}// classe cliente de la Pileimport Pile;class Bidon { // attributs
protected Pile p1, p2; // ici p1 et p2 ne sont que des références nulles // opérations
// constructeur de la classe Bidon : // alloue de la place pour les attributs de la classe Bidon
public Bidon ( ) { p1 = new Pile ( ); // on alloue de la place pour une Pile et on stocke
// sa référence (son adresse mémoire) dans p1 p2 = new Pile ( ); // on alloue de la place pour une Pile et on stocke
} // sa référence (son adresse mémoire) dans p2 public void operation1 (…) { p1.empiler (10); p2.empiler (20); System.out.print(p1.sommet()); // affiche 10 System.out.print(p2.sommet()); // affiche 20 }
}
3.2.1 Spécification
La propriété fondamentale d'une Pile est qu'on ne peut accéder qu'à l'élément en sommet de Pile. Tous les autres éléments, placés en dessous du sommet, ne peuvent être accédés qu'après avoir tout d'abord enlevé les éléments placés au-dessus d'eux un par un.
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

23
Comment définir ou spécifier le concept abstrait de Pile ?Il est nécessaire de spécifier tout ce qu'il faut connaître pour utiliser correctement et aisément une Pile, sans pour autant avoir à connaître l'implantation sous-jacente.
3.2.2 Représentation et implantation
Il y a plusieurs manières de représenter les piles. Statique : Tableaux => nombre max d'éléments fixés a priori.
Gestion simple mais taille statique.Dynamique : Chaînages mis en œuvre à l'aide de pointeurs => nombre d'éléments
uniquement limité par la place mémoire disponible.Gestion plus complexe mais taille dynamique.
4 Types de base
Définition : Le typage est le fait d'associer à une variable (un objet), un ensemble de valeurs possibles ainsi que d'un ensemble d'opérations admissibles sur ces valeurs. Type = {ensemble de valeurs, opérations possibles}
Le langage de programmation doit vérifier (autant que possible) que les valeurs que l'on place dans une variable, ainsi que le résultat d'une opération sont compatibles avec le(s) type(s) correspondant à l'affectation et à l'opération utilisée.
4.1 Les types scalaires
Les types scalaires sont les types de données (généralement prédéfinis dans le langage de programmation) pour lesquels une variable ne contient qu'une seule information élémentaire. Ils se partagent en deux groupes : les types discrets et les réels.
Les types scalaires• discrets : • réels:
4.1.1 Les types discrets Ils représentent des objets dont les valeurs possibles sont énumérables, en y ajoutant la contrainte d'un nombre fini de valeurs.
• discrets : ° entiers ° énumérés ° intervalles
4.1.1.1 Les entiers Ils représentent des valeurs numériques signées ne comportant pas de partie fractionnaire. Le nombre de valeurs représentables sur un ordinateur étant fini, les entiers sont généralement limités à un intervalle de valeurs possibles.
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

24
En ADA integer'last qui est donc le plus grand nombre entier représentable. Les valeurs de integer'first et integer'last dépendent de l'implantation : sur un micro-ordinateur, leur valeur sera plus petite que sur de plus gros systèmes. En C, les valeurs représentables dépendent de la taille du mot machine.
4.1.1.2 Les types énumérés
4.1.1.2.1 Les booléens Les objets de type booléen ne peuvent prendre que deux valeurs possibles : true et false. Les expressions comportant des valeurs booléens sont appelées des expressions logiques. Les opérations possibles sont : and, or, not et la comparaison ( =, /= ). Il est à noter que les opérateurs de comparaison donnent un résultat booléen, même si les opérandes sont d'un autre type.
4.1.1.2.2 Les caractères Le jeu de caractères d'une machine est l'énumération, dans un certain ordre, des lettres et signes affichables sur un écran ou imprimables sur papier. Les opérations possibles sont principalement les comparaisons : =, <>, >, <, <=, >=..
4.1.1.2.3 Les énumérations définies par l'utilisateur Il est possible de déclarer une suite ordonnée de labels qui ont un sens particulier pour l'utilisateur. Par exemple, on peut déclarer un
type Semaine = (dimanche, lundi, mardi, mercredi, jeudi, vendredi, samedi);Toute variable du type Semaine pourra prendre une de ces sept valeurs (et aucune autre valeur ne sera légale). Les opérations possibles sont les comparaisons ( =, <>, <, >, <=, >= ).
4.1.1.2.4 Les intervalles Les intervalles ne forment pas, à proprement parler, un type de base. Il s'agit plutôt de types, générés à partir de types de base ou définis par l'utilisateur, restreignant l'ensemble des valeurs possibles du type parent. Exemple : subtype JourOuvrable is Semaine range lundi .. vendredi;
subtype natural is integer range 0..integer'last;subtype positive is integer range 1..integer'last;
Toutes les opérations applicables au type de base sont applicables au type qui en est dérivé. L'intérêt de l'utilisation des intervalles réside dans l'amélioration de la lisibilité des programmes (on voit plus clairement quelles sont les valeurs possibles) et l'augmentation de la sécurité de programmation (des valeurs illégales peuvent être automatiquement détectées à la compilation et à l'exécution).
4.1.1.3 Fonctions prédéfinies sur les types discrets En ADA, un certain nombre d'attributs peuvent s'appliquer aux types discrets :
° first : donne la première valeur de l'ensemble de valeurs,° last : donne la dernière,° succ : donne la valeur suivante° pred : donne la précédente° image : donne un équivalent de la valeur sous forme de chaîne de caractères,° value : donne la valeur correspondante à une chaîne de caractères,
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

25
° pos : donne la position de la valeur en considérant que la valeur first est en position 0
° val : donne la valeur qui est à une position donnée° …
Exemple Semaine'pred(lundi) = dimanche Semaine'pred(dimanche) !!! n'existe pas character'pred('b') = 'a' integer'pred(i) = i-1 Exemple Semaine'succ(dimanche) = lundi Semaine'succ(samedi) !!! n'existe pas character'succ('a') = 'b' integer'succ(i) = i+1
4.1.1.4 Représentation du type booléen comme un TDA
Spécification du type Boolean : Autre type utilisé :
• aucun
Ensemble de valeurs ° Vrai, faux
Opérations :° not : booléen booléen // fournit non b
♦ en entrée : b : booléen♦ en sortie : b' : booléen♦ pré-conditions : aucun♦ post-conditions : b' == vrai si b == faux, b' == faux sinon
° ou : booléen x booléen booléen // ou de deux booléens♦ en entrée : a, b : booléen♦ en sortie : b': booléen , a et b non modifiés♦ pré-conditions : aucun♦ post-conditions : b' == vrai si a == vrai ou si b == vrai, b' == faux sinon
° et : booléen x booléen booléen // et de deux booléens♦ en entrée : a, b : booléen♦ en sortie : b': booléen , a et b non modifiés♦ pré-conditions : aucun♦ post-conditions : b' == vrai si a == vrai et si b == vrai, b' == faux sinon
Axiomes : a, b, c : booléen° (1) not vrai == faux // relation entre constantes° (2) not (not a) == a // négation involutive° (3) a et vrai == a // vrai est l'élément neutre de et° (4) a et faux == faux // faux est l'élément absorbant de et° (5) (a et b) et c == a et (b et c) // associativité de et° (6) a et b == b et a // commutativité de et° (7) a ou b = not (not a et not b)
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

26
// définition de ou (not (a ou b) == (not a et not b))° …
4.1.1.5 Représentation du type entier comme un TDA
Spécification du type integer : Autre type utilisé :
• booléen
Ensemble de valeurs ° integer'first .. integerl'last intervalle dans IN
Opérations : ° - * / mod % power° != > ° := pred
(on ne détaillera que les suivantes)° succ : integer integer // fournit l'entier suivant
♦ en entrée : i : integer♦ en sortie : i' : integer (i non modifié)♦ pré-conditions : i < integer'last♦ post-conditions : i' = i+1
° + : integer x integer integer // addition de deux entiers ♦ en entrée : i, j : integer♦ en sortie : i' : integer (i et j non modifiés)♦ pré-conditions : i + j <= integer'last♦ post-conditions : i' = i+j
° - : integer integer // moins unaire♦ en entrée : i: integer♦ en sortie : i' : integer♦ pré-conditions : aucun♦ post-conditions : i' = -i
° == : integer x integer booléen // égalité d'entiers ♦ en entrée : i, j : integer♦ en sortie : b : booléen (i et j non modifiés)♦ pré-conditions : aucune♦ post-conditions : b = vrai si i ==j, faux sinon
° < : Natural x Natural booléen // comparaison d'entiers Natural♦ en entrée : i, j : Natural♦ en sortie : b : booléen (i et j non modifiés)♦ pré-conditions : aucune♦ post-conditions : b = vrai si i < j, faux sinon
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

27
Axiomes : m, n, p : integer° (1) 0 + n = n // élément neutre à gauche° (1') n + 0 = n // élément neutre à droite° (2) succ(m) + n = succ(m+n) // définition de +° (3) (m + n) + p = m + (n + p) // associativité de +° (4) m + n = n + m // commutativité de +° (5) 0 == 0 est vrai // définition de ==° (6) succ(m) == 0 est faux // ""° (7) 0 == succ(n) est faux° (8) succ(m) == succ(n) n == m° (9) 0 < 0 est faux // définition de <° (10) succ(m) < 0 est faux° (11) 0 < succ(n) est vrai° (12) succ(m) < succ(n) m < n° (13) m < n et n < p m < p° (14) –0 == 0 // définition du moins unaire° (15) –(-n) == n // moins unaire involutive° (16) succ(n) + (-succ(m)) == n + (-m) // n+1 + (-(m+1))° (17) -n + (-m) = -(n + m)
Axiome concernant les opérations arithmétiques : ° m = ((m / n) * n) + (m mod n) // 3 = ((3 / 2) * 2) + (3 mod 2) = (2) + (1) = 3
// 2 = ((2 / 3) * 3) + (2 mod 3) = (0) + (2) = 2
4.1.2 Les réels • réels:
° virgule flottante ° virgule fixe
De tous les types de base, ce sont les nombres réels qui posent le plus de problèmes de représentation. L'ensemble des nombres réels étant, par définition, infini et indénombrable, il est impossible de le représenter avec une totale exactitude dans un ordinateur. La représentation qui en est faite ne peut donc constituer qu'une approximation. Il existe d'ailleurs plusieurs techniques de représentation, chacune ayant ses avantages et ses inconvénients.
4.1.2.1 Représentation en virgule flottante La représentation en virgule flottante consiste à représenter un nombre réel à l'aide de 3 composantes : le signe (S), l'exposant (E) et la mantisse (M).
4.1.2.2 Représentation en virgule fixe La représentation en virgule fixe consiste à utiliser une représentation similaire aux nombres entiers en attribuant un nombre de "bits" fixes à la partie fractionnaire et un autre nombre de "bits" à la partie entière. L'avantage principal de cette représentation étant de pouvoir utiliser les opérations arithmétiques des nombres entiers, auxquelles s'ajoute l'opération de décalage. Ces opérations sont très efficaces et accélèrent d'autant le calcul. Les principaux inconvénients sont que la répartition de la "gamme" de nombres représentables est beaucoup plus étroite que pour la virgule flottante et que les erreurs d'arrondis sont aussi inévitables et s'accumulent beaucoup plus vite.
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

28
4.1.2.3 Représentation du type réel sous forme de TDA Autre type utilisé :
° booléen Ensemble de valeurs
° sous ensemble (fini) de IR Opérations :
° + : IR x IR IR♦ entrée : e, f : réel♦ sortie : e' : réel (e et f inchangés)♦ pré-conditions : e+f représentable en machine♦ post-conditions : e' == e + f
° cos : IR IR♦ entrée : e : réel♦ sortie : e' : réel (e inchangé)♦ pré-conditions : e exprime un angle en radians♦ post-conditions : e' == cos(e)
° < : IR x IR booléen♦ entrée : e, f : réel♦ sortie : b : booléen (e et f inchangés)♦ pré-conditions : aucun♦ post-conditions : b == vrai si e < f, faux sinon
° power : IR x IR IR ♦ entrée : e, f : réel♦ sortie : e' : réel (e et f inchangés)♦ pré-conditions : e^f représentable en machine♦ post-conditions : e' == e^f
° - * / = > …° sin log sqrt …° …
Axiomes° x* (y + z) = x * y + x * z ...
4.1.3 Conversion de type
Le langage ADA impose, des contraintes lors de la conversion de types. Il fait la distinction entre types dérivés et sous-types. Un sous-type, de même qu'un type dérivé, consiste en une restriction apportée à un type de base. Un sous-type reste compatible avec son type de base alors qu'un type dérivé est incompatible avec son type de base.
Exemples : subtype OneDigit is integer range 0..9; subtype JourOuvrable is Semaine range Lundi..Vendredi; type Entier is new integer; type MilieuDeSemaine is new Semaine range Mardi..Jeudi;
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

29
Dans les exemples qui précèdent :OneDigit est compatible avec integer,JourOuvrable est compatible avec Semaine,mais Entier n'est pas compatible avec integer : c'est un nouveau type !et MilieuDeSemaine n'est pas compatible avec Semaine : c'est également un nouveau type...
Il est toutefois possible de faire une conversion explicite d'un type dérivé vers son type de base (ou vice-versa) en préfixant l'objet du type à convertir par le type du résultat. Par exemple, si Jour est une variable de type Semaine, MilieuDeSemaine(Jour) est de type MilieuDeSemaine (il y aura erreur si la valeur associée à la variable Jour n'est pas comprise dans l'ensemble des valeurs possibles pour le type MilieuDeSemaine ).
L'intérêt de cette distinction entre types dérivés et sous-types est une fois encore au niveau de la sécurité de programmation. Par exemple, si une variable est sensée représenter une superficie et une autre variable sensée représenter une longueur, cela n'aurait pas beaucoup de sens de vouloir les additionner, même si elles sont toutes les deux des valeurs numériques entières.
4.2 Les types composés
Les types structurés (composés) • structures statiques • structures dynamiques
4.2.1 Les structures statiques
4.2.1.1 Structures cartésiennes simples Les structures cartésiennes simples sont des structures regroupant plusieurs composantes de type de base. Nous verrons ici 4 types de structures cartésiennes simples :
• structures statiques ° tableaux ° enregistrements ° chaînes de caractères ° ensembles
4.2.1.1.1 Les tableaux Les tableaux sont constitués d'un regroupement de données de même type. Les données individuelles sont repérées par un sélecteur que l'on nomme indice du tableau. L'indice d'un tableau doit être de type énuméré. Cela pourra donc être un type énuméré défini par l'utilisateur, un intervalle d'entiers ou de booléens.
Des variables de type tableau ne changent que de valeurs, jamais de structure ou d'ensemble de valeurs de base. Conséquence : l'espace qu'elles occupent en mémoire reste constant.
Exemple procedure essai is
subtype Index is integer range 0..9; type Semaine is (Dimanche, Lundi, Mardi, Mercredi, Jeudi, Vendredi, Samedi);
type T1 is array [Index] of integer; type T2 is array [0..9] of integer;
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

30
type T3 is array [boolean] of character; type T4 is array [false..true] of character; type T5 is array [Semaine] of integer;
heuresDeTravail : T5;
begin ... heuresDeTravail[Lundi] := 8; ...
end essai;
La spécification de la structure de tableau peut se faire de la manière suivante : leur déclaration spécifie un intervalle d'indices et un type de base. Ceci détermine
indirectement la taille du tableau. le rôle du tableau est de conserver pour chaque valeur d'indice une valeur de type de base
associée. une seule valeur du type de base peut être associée à chaque valeur d'indice.
Les primitives de manipulations sont : associer une valeur du type de base à une certaine valeur d'indice, fournir la valeur de type de base associée à une certaine valeur d'indice. en fonction de la déclaration, diagnostiquer la validité de l'indice fourni.
On peut envisager de pouvoir associer, lors de la déclaration d'un tableau, une valeur initiale à quelques (ou toutes les) valeurs d'indices. C'est le cas en Ada, par exemple.
Deux valeurs se suivent dans le tableau si les valeurs des indices auxquels elles sont associées se suivent dans la séquence des indices. Cela ne signifie pas pour autant que ces valeurs seront effectivement stockées dans des zones contiguës de la mémoire (même si c'est presque toujours le cas en réalité, pour des raisons d'efficacité).
4.2.1.1.2 Les enregistrements (structures)Les enregistrements sont constitués d'un regroupement de données de types différents. Les données individuelles sont repérées par un sélecteur que l'on nomme champ de l'enregistrement. L'identificateur de champ doit être un identificateur conforme aux règles lexicales du langage.
Exemple procedure essai is
type Individu is record nom, prénom: string(1..20); age: integer;
end record; --Individu lui: Individu;
begin . . . lui.age := 15; . . .
end essai ;
La spécification d'un enregistrement peut être la suivante :• La déclaration d'un enregistrement spécifie le nombre et le type d'éléments qu'il doit
contenir.• La taille nécessaire pour un enregistrement est ainsi fixée.• Chaque champ doit contenir une valeur correspondante à son type.
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

31
Les opérations possibles sur les enregistrements dans leur globalité sont : • l'affectation• la comparaison ( =, <> ). • Les opérations possibles sur les différents champs d'un enregistrement sont celles
associées au type du champ.
4.2.1.1.3 Les chaînes de caractèresLe type chaîne de caractère : String, existe dans des langages comme ADA ou JAVA.Il existe donc des opérateurs permettant de manipuler les chaînes de caractères : concaténation par exemple. Toutefois, les chaînes de caractères sont représentées par des tableaux de caractères et peuvent être vues comme tel.En C, les chaînes de caractères sont stockées dans des tableaux de caractères et doivent obligatoirement être terminées par un caractère spécial qui indique la fin de la chaîne dans le tableau : '\0'. Ainsi, une chaîne de n caractères doit être contenue dans un tableau d'au moins n+1 caractères.La spécification des chaînes de caractères s'apparente à celle des tableaux, avec des opérations supplémentaires, différentes selon les langages.
Question : ne pourrait-on pas définir un type ChaîneDeCaractères, offrant un ensemble de services couvrant tous les besoins des utilisateurs, indépendant du langage et pouvant donc être mis en œuvre dans différents langages et sur différentes plateformes ???
Les primitives de manipulations sont : • constituer une chaîne de caractères à partir d'une séquence de zéro, un ou plusieurs
caractères,• l'affectation d'une chaîne à une variable de type compatible, • fournir la longueur d'une chaîne, • fournir le caractère se trouvant à une certaine position, • redéfinir le caractère se trouvant à une certaine position, • insérer une chaîne dans une autre à partir d'une certaine position,• détruire une portion d'une chaîne, à une certaine position et sur une certaine longueur, • concaténer deux chaînes, • extraire une sous-chaîne d'une chaîne, • trouver la position de la première occurrence d'une sous-chaîne,• …
4.2.1.1.4 Les ensembles Les ensembles sont des structures que l'on ne retrouve quasiment qu'en Pascal. Ada ne les offre pas de manière prédéfinie. Les ensembles se rapprochent beaucoup de la notion mathématique d'ensembles. Ils sont construits à partir de types de bases énumérés et permettent d'indiquer, pour chacune des valeurs du type de base, si cette valeur est présente ou absente de l'ensemble en question. Il n'y a pas de sélecteur possible.
Exemple : var S, Voyelles, Consonnes: set of char; . . . S := []; { ensemble vide } Voyelles := ['a','e','i','o','u','y']; Consonnes := ['b'..'d','f'..'h','j'..'n', 'p'..'t','v'..'x' ,'z']; S := [ 'b'..c ]; { noter le fait que c est une variable character }
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

32
La spécification d'un ensemble peut être la suivante :Se définit à partir de la définition mathématique des ensembles : Autres types utilisés (sortes) :
• Elément, Booléen, Natural Opérations :
• créer : -> Ensemble♦ entrée : aucun♦ sortie : e : Ensemble♦ pré-conditions : ♦ post-conditions : e == {} ensemble vide, card(e) == 0
• ajout : Elément x Ensemble -> Ensemble♦ entrée : i : Elément, e : Ensemble ♦ sortie : e' : Ensemble♦ pré-conditions : !present(i, e)♦ post-conditions : e' == e ∪ {i}
• suppression : Elément x Ensemble -> Ensemble♦ entrée : i : Elément, e : Ensemble ♦ sortie : e' : Ensemble♦ pré-conditions : present(i, e)♦ post-conditions : e' == e - {i}
• présent : Elément x Ensemble -> Booléen• cardinal : Ensemble : Natural• ∪ : Ensemble x Ensemble Ensemble
♦ entrée : e, f : Ensemble ♦ sortie : e' : Ensemble (e et f inchangés)♦ pré-conditions : aucun♦ post-conditions : e' == e ∪ éléments de f non présents dans e ♦
• ∩ : Ensemble x Ensemble Ensemble♦ entrée : e, f : Ensemble ♦ sortie : e' : Ensemble (e et f inchangés)♦ pré-conditions : aucun♦ post-conditions : e' == éléments de e présents aussi dans f
Axiomes (équations) : e : Ensemble, x : Elément• présent (x, créer ()) = faux• présent (x, ajout (x, e)) = vrai• présent (x, ajout (y, e)) = présent (x, e)• ajout( y, ajout(x, e)) == ajout( x, ajout(y, e))• card (créer()) == 0• card (ajout (x, e)) == card(e) + 1• suppression(y, ajout(x, e)) ==
° si x == y alors e sinon ajout(x, suppression(y, e))• …
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

33
D'autres opérations sur les ensembles peuvent être les suivants :. • création d'un ensemble singleton (initialisé avec un élément à la création),• la différence de deux ensembles (permet de supprimer un ou plusieurs éléments), • la comparaison de deux ensembles, • le test d'inclusion d'un ensemble dans un autre.
N.B. L'expression a ∉ S sera notée : not (a in S).
Cardinalité Définition : La cardinalité est le nombre de valeurs distinctes appartenant à un type T. Un objet de ce type T ne pourra bien entendu avoir qu'une seule de ces valeurs à un instant donné Exemple
type Forme = (Carré, Rectangle, Cercle, Ellipse); type Monnaie = (Franc, Livre, Dollar, Lire, Yen, Mark); type Genre = (Féminin, Masculin);
card(Forme) = 4card(Monnaie) = 6card(Genre) = 2
type SmallInteger = 1..100; type Vecteur=array[1..3] of SmallInteger;
card (SmallInteger) = 100card (Vecteur) = 1003
card (boolean) = 2card (integer) = 2*(MaxInt+1) { pour le langage Pascal }
4.2.1.2 Représentation statique du type Ensemble en CEnsemble.h
// Attention le type Ensemble n'est pas protégé#define maxE 100typedef void * Element;typedef struct {Element v[maxE]; int n;} Ensemble;
extern Ensemble creerEnsemble ();extern int ajout (Element, Ensemble *);…
Ensemble.c#include Ensemble.h
Ensemble creerEnsemble () { Ensemble e; e.n = 0; return e;}
int ajout (Element i, Ensemble * e) { if ((*e).n == maxE) return 0; /* code d'erreur pour traiter les erreurs en C */ (*e).n = (*e).n+1; (*e).v[(*e).n] = i; return 1; /* code correct */}
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

34
…
4.2.1.3 RésuméOn peut résumer les principales caractéristiques des structures cartésiennes simples dans le tableau suivant :
Structure : Tableau Enregistrement EnsembleDéclaration a : array[I] of To r : record
S1 : T1; S2 : T2; Sn : Tn; end;
set of To
Sélecteur : a[i] (i∈I) r.s (S∈S1,...Sn ) aucunAccès aux composantes:
par le sélecteur et le calcul de l'indice
par le sélecteur avec le n o m d é c l a r é d ' u n élément
Test d'appartenance avec l'opérateur de relation présent
Type des composantes:
Toutes de même typeTo
Peuvent être de type différent
Toutes de même type scalaire To
Cardinalité :Card(To)Card(I)
n∏ card (Ti)i=1prod. cartésien
2Card(TO)
Ces structures simples peuvent être combinées pour former des structures plus complexes .
4.2.2 Les structures dynamiques • structures dynamiques
° structures non récursives : les fichiers séquentiels ° structures récursives
♦ structures récursives linéaires : (listes chaînées, listes chaînées bidirectionnelles, anneaux, anneaux bidirectionnels)
♦ structures récursives non-linéaires : (les listes quelconques (matrices creuses, etc.), les arbres, les graphes, les réseaux)
Dans un langage donné, certains de ces types sont prédéfinis et certains autres doivent être construits par le programmeur. Par exemple, les ensembles sont prédéfinis en Pascal, les listes sont prédéfinies en Lisp ou en CAML alors qu'ils doivent être construites en ADA ou en C.
Les structures statiques sont toutes caractérisées par une cardinalité fixe. Cependant, des structures plus élaborées sont caractérisées par une cardinalité qui évolue. Ce sont les structures de données dynamiques telles que : les listes, les piles, les files, les arbres, les graphes, etc.
L'objectif principal des structures de données est de permettre à l'utilisateur de développer une solution informatique à un problème qui soit conceptuellement aussi proche du problème que possible. Prenons par exemple, un système de réservation pour une compagnie aérienne. On peut distinguer trois niveaux de traitement :
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

35
domaine du problème• horaires • vols • dates • destinations • réservations
implantation du système• fichiers • tableaux • enregistrements • chaînes de caractères • structures de données plus complexe
niveau mémoire• octets • suites de mots mémoires • pages
Nous nous intéresserons à la mise en œuvre des concepts généraux des structures de données et au développement des algorithmes permettant de gérer ces structures efficacement, indépendamment du problème pour lequel on souhaite les utiliser.
Définition : une structure dynamique est une structure dont la taille (le nombre de composantes) peut varier en cours d'exécution.
On distingue généralement deux sortes de structures dynamiques : les fichiers et les structures récursives. Les structures dynamiques peuvent être subdivisées en deux catégories : les structures linéaires et les structures non-linéaires
structures dynamiques linéaires fichier
• structures non-récursives listes chaînées, piles, files
• structures récursives structures dynamiques non-linéaires
listes quelconques arbres graphes
Une structure récursive est une structure (basée en général sur un enregistrement) dont la définition comporte une référence à elle-même. S'il n'y a qu'une seule référence, cette structure est linéaire; s'il y en a plusieurs, cette structure est non-linéaire. Pour beaucoup de langages impératifs, ces références se font à l'aide du type pointeur.
Prenons comme exemple la liste chaînée : On peut décrire les listes chaînées en terme de type abstrait de la manière suivante :
• le rôle d'une chaîne est de stocker un nombre indéterminé d'éléments de même type dans un certain ordre. Cet ordre pourra dépendre de la chronologie d'insertion des
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

36
éléments, de la valeur des éléments insérés ou d'un quelconque autre critère fixé par l'utilisateur.
• la déclaration d'une chaîne doit spécifier le type de base des éléments qu'elle pourra contenir.
primitives de manipulation : • initialiser une chaîne à vide. • insérer un élément en début de chaîne. • insérer un élément en fin de chaîne. • fournir la valeur contenue dans l'élément en début de chaîne. • fournir la valeur contenue dans l'élément en fin de chaîne. • détruire l'élément en début de chaîne. • détruire l'élément en fin de chaîne. • détruire le ième élément de la chaîne. • insérer un élément avant le ième élément de la chaîne. • insérer un élément après le ième élément de la chaîne. • fournir la valeur contenue dans le ième élément. • indiquer si le ième élément possède un successeur. • indiquer si la chaîne est vide. • fournir la longueur de la chaîne
Il faut également spécifier les axiomes qui décrivent le comportement des opérations sur la liste chaînée :
• vide (créer(listeChaînée))• non vide (insérer (élément, créer(listeChaînée)))• fournirElementEnTête (insérerEnTête(élément, listeChaînée)) = élément• …
On pourrait encore énumérer d'autres primitives de manipulation de chaînages basées sur une position courante dans la chaîne. Par exemple, positionner le courant sur le premier ou le dernier élément de la chaîne, insérer un élément après ou avant le courant, détruire le courant, trouver la position du premier élément contenant une valeur donnée (si un tel élément existe), supprimer les multiples occurrences d'un objet dans la chaîne ...
4.2.3 Les pointeurs
Une variable de type pointeur est une variable dont le contenu (qui est une adresse en mémoire) peut indiquer l'emplacement en mémoire d'un objet (contenant une donnée), créé dynamiquement lors de l'exécution.
Dans ce qui suit, nous allons voir la manière dont les pointeurs sont implantés.
Déclaration ADA type TypeDonnée is ….; type PtTypeDonnée is acces TypeDonnée; pt : PtTypeDonnée; -- initialisé de base à null par ADA
Déclaration C typedef …. TypeDonnée; typedef TypeDonnée * PtTypeDonnée; PtTypeDonnée pt; /* pas d'initialisation par défaut */ pt = NULL;
/* ou = 0 si NULL pas défini : initialisation conseillée */
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

37
Lorsqu'une variable de type pointeur est déclarée dans un programme ou une procédure, le contenu (adresse) peut être indéterminé à la déclaration (pas forcément NULL). Pour définir le contenu d'une variable de type pointeur, on a trois possibilités :
lui affecter la valeur NULL ( pt := NULL; ) (ou NIL ou 0 selon le langage)
lui affecter le contenu d'une autre variable du même type ( pt2 := pt2; )
utiliser les méthode d'allocation de mémoire : new ou malloc ° pt := new TypeDonnée; ° pt = (PtTypeDonnée) malloc (sizeof(TypeDonnée));
La fonction new (malloc) a pour tâche de trouver un emplacement libre en mémoire suffisamment grand pour contenir un objet de type TypeDonnée, de réserver la place nécessaire et de retourner l'adresse de cet emplacement. Après l'appel, on aura donc deux objets accessibles pt (le pointeur), qui contient une adresse mémoire, et l'objet pointé (ne possédant pas d'identificateur propre et accessible par pt.all en ADA ou *pt en C), qui contient une information de type TypeDonnée.
On peut décrire les pointeurs en terme de type abstrait de la manière suivante : le rôle d'un pointeur est de permettre l'accès à un objet créée lors de l'exécution. la déclaration doit spécifier le type de base de l'objet qui pourra être accessible à l'aide du
pointeur. Primitives de manipulation :
réserver un nouvel emplacement mémoire (servent à stocker un objet) et placer l'adresse de cet emplacement dans un pointeur (ceci ne définit pas la valeur de l'objet mais juste un emplacement mémoire et l'adresse de cet emplacement),
détruire l'objet accessible à partie du pointeur (libérer l'emplacement mémoire), indiquer l'absence d'objet à accéder (quand pt == null), permettre à un pointeur d'accéder au même emplacement mémoire et donc au même objet
qu'un autre pointeur,
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

38
associer une valeur à l'objet accessible par un pointeur, fournir la valeur associée à l'objet accessible par un pointeur (attention au cas où il n'y a
pas d'objet à accéder), comparer deux pointeurs sur le même type pour savoir s'ils permettent d'accéder au
même objet.
Ce modèle ne précise pas ce qu'il advient d'un éventuel objet précédemment pointé par un pointeur lorsque l'on alloue un nouvel objet accessible à l'aide du même pointeur sans avoir détruit, au préalable, l'objet précédemment pointé. Il ne spécifie pas non plus ce qui se passe si l'on essaye d'accéder à l'objet pointé par un pointeur si l'on n'a jamais associé d'objet à ce pointeur, ni indiqué l'absence d'objet accessible (pas d'initialisation du pointeur).
La fonction free (inexistante en ADA où l'on se contente de mettre pt à NULL) a pour tâche de libérer la place occupée par l'objet pointé (*pt). En C il faudra en plus indiquer que pt ne pointe plus d'objet en le mettant à NULL ou à 0.
Si l'on utilise l'affectation pour faire pointer une variable pt2 de type pointeur sur un emplacement mémoire déjà pointé par un pointeur pt1, il faut bien faire attention au cas où pt2 pointait déjà sur un objet en mémoire. Cet objet pourrait bien ne plus être accessible par le programme tout en continuant à occuper de la place en mémoire. En C il est indispensable à libérer tout emplacement mémoire avant de le rendre inaccessible par modification du pointeur qui pointait sur lui. On utilisera préalablement la fonction free qui libérera la place. Ce n'est qu'après qu'on modifiera le pointeur.
Ceci peut être illustré de la manière suivante :
Dans le même ordre d'idées, si un pointeur est déclaré dans un sous-programme, et qu'il pointe vers un objet créé dynamiquement, il faut s'assurer, avant de sortir du sous-programme, soit que cet objet est accessible autrement que par la variable locale, soit que l'on libère la place occupée par l'objet pointé.
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

39
La libération automatique de la place mémoire occupée par les variables locales quand on quitte un sous-programme n'implique en effet pas la destruction des objets alloués dynamiquement lors de l'exécution du sous-programme.
L'affectation permet à deux pointeurs de pointer vers le même objet en mémoire . Si l'on désire qu'un de ces deux pointeurs ne pointe plus vers rien (par exemple pt1), on le mettra à NULL mais on n'utilisera pas la fonction free, car il faut que td1 continue d'exister puisqu'un autre pointeur pt2 pointe aussi vers lui.
Lorsqu'un pointeur est passé en paramètre à une procédure, son passage par valeur empêche toute modification du pointeur mais pas de l'objet pointé. L'objet pointé peut donc être modifié, ce qui entraîne des vérifications supplémentaires.
4.2.3.1 Ramasse miettes La première solution, appelée "ramassage miettes" (Garbage Collector), ne peut se faire que si le système gère l'ensemble des objets alloués dynamiquement à l'aide d'informations supplémentaires associées à chaque objet, permettant ainsi de savoir qui leur fait référence.
Chaque nouvelle allocation dynamique est effectuée en utilisant une place mémoire jusque là inoccupée. Ce n'est que lorsque cette place fera défaut qu'une réorganisation globale de l'espace mémoire sera entreprise pour regrouper en une seule zone contiguë l'ensemble des places libérées en cours d'exécution. Cette procédure est assez difficile à implanter et, qui plus est, assez longue à exécuter.
4.2.3.2 Chaînage des trous La deuxième solution est plus facile à mettre en œuvre mais ne résout pas tous les problèmes pour autant. Elle consiste à chaîner les trous entre eux avec, pour chaque trou, l'indication de sa taille et de l'emplacement du trou suivant.
Si tous les objets créés dynamiquement ont la même taille, on peut chaîner les zones libres entre elles dans n'importe quel ordre. La procédure d'allocation dynamique n'aura qu'à utiliser le premier de cette chaîne pour allouer de la place à un nouvel objet. Si les objets créés dynamiquement ont des tailles différentes, on risque d'arriver à une situation où la totalité de l'espace libre permettrait de créer un nouvel objet, mais où aucun trou n'est assez grand pour le contenir. Pour minimiser cet effet, il est donc important de pouvoir regrouper, en un seul bloc, des trous contigus. Pour ce faire, il est nécessaire de chaîner les trous dans l'ordre d'apparition en mémoire. Chaque fois qu'un objet dynamique est détruit, la "chaîne libre" est parcourue pour voir où ranger ce nouveau trou. S'il se trouve juste à côté d'un autre trou, ou entre deux trous, les deux ou trois trous sont alors regroupés pour ne plus en former qu'un.
Deux principales possibilités d'utilisation des trous peuvent être envisagées. La méthode dite de la première convenance (first fit) et celle de la meilleure convenance (best fit). La première consistant à parcourir la chaîne libre depuis son début et à utiliser le premier trou suffisamment grand pour contenir le nouvel objet; la deuxième méthode consiste, elle aussi, à parcourir la chaîne libre, mais cette fois jusqu'à la fin de la chaîne pour déterminer quel est le plus petit trou suffisamment grand pour contenir le nouvel objet. La méthode du "best fit" semble de prime abord plus intéressante. Elle a toutefois l'inconvénient d'impliquer une plus longue recherche et de générer des trous de plus en plus petits qui seront difficilement réutilisables. C'est donc la méthode de la première convenance (first fit) qui est généralement choisie.
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

40
Les avantages principaux du chaînage de trous sont la simplicité d'implantation et la rapidité d'exécution. L'inconvénient principal est que l'on ne peut pas garantir la création d'un nouvel objet, même s'il y a assez de place en mémoire. La fragmentation de l'espace libre peut en effet être telle qu'aucun morceau n'est assez grand pour contenir l'objet à créer. Certains systèmes combinent les deux solutions (ramassage des miettes et chaînage des trous) pour avoir les avantages de chacune. Le chaînage des trous est utilisé jusqu'à ce que l'on arrive à une situation où aucun trou n'est assez grand pour le nouvel objet à créer. Ce n'est qu'alors que le processus de ramasse miettes est amorcé.
5 Définition d'un nouveau TDA
La définition d'un nouveau TDA, c’est-à-dire d'une nouvelle abstraction, consiste à définir l'ensemble des valeurs possibles pour les objets de ce type et l'ensemble des opérations agissant sur ces valeurs.
Pour accueillir les valeurs du type il est nécessaire de définir une structure interne de données construite à partir des types de base du langage et/ou des types déjà définis. Les opérations seront définies par des sous-programmes du langage de programmation.
5.1 Vue interne et vue externe
D'un point de vue pratique il est extrêmement utile de séparer, dans la définition d'un type, ce qu'il faut connaître pour utiliser ce nouveau type de ce qui constitue les détails internes de sa réalisation. Ces deux parties constitueront respectivement la vue externe (définition logique) et la vue interne du type (définition structurelle).
5.1.1 Spécification de la vue externe
Dans les langages de programmation permettant la modularité, la vue externe d'un type se compose en général :
du nom du type de la signature de chaque opération (nom, type retourné, type des paramètres)
Une telle spécification ne se suffit pas car le comportement des opérations n'est pas défini. C'est pourquoi la vue externe doit être complétée par une description précise du comportement de chaque opération. Il existe pour cela différentes méthodes plus ou moins formelles telles que:
le texte en langue française les pré et post-conditions (voir programmation par contrat § 6) les spécifications algébriques (axiomes)
5.1.2 Opérations primitives
Dans la définition d'un TDA, on prévoit des opérations primitives, c'est-à-dire des opérations qui ne sont pas réalisables en dehors de la connaissance de la structure interne du TDA et donc en dehors du TDA.
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

41
Parmi les primitives on distingue en général les opérations de constructions, d'accès, de modification d'un nouvel objet de ce TDA.Une opération de construction (création) a pour fonction de créer un nouvel objet du type alors qu'une opération de sélection permet d'accéder aux composantes d'un objet déjà créé.
A partir des opérations primitives, ont peut par la suite créer de nouveaux TDA par ajout d'opérations non primitives.
5.2 Exemple : Spécification du type Fraction
L'objectif de cet exercice est de définir un TDA qui met en œuvre des opérations simples sur les nombres rationnels (nous appellerons ce type Fraction). L'importance de ce TDA est illustrée par l'exemple suivant :
Si on calcule l'expression réelle "(1.0 / 3.0)*3.0", on s'attend à obtenir 1.0 comme résultat.Toutefois, à cause du mode de représentation des nombres réels, certains compilateurs sont susceptibles de retourner une valeur arrondie, 0.999999, et non 1.0.
Si on pouvait utiliser les Fractions, on pourrait calculer "(1/3)*3" et obtenir la réponse exacte sous forme de Fraction, c'est à dire 1/1. En effet, il n'y a pas d'arrondis pour les nombres rationnels : on peut les représenter par deux nombres entiers, le numérateur et le dénominateur.
Les fractions sont donc des nombres.Comment spécifier le domaine de valeurs et l'ensemble d'opérations applicables sur le type Fraction ?
Les opérations applicables sont les opérations arithmétiques habituellement appliquées sur les nombres :
• addition, • multiplication, • comparaison, • etc.
On peut envisager des opérations spécifiques telles que : normaliser une fraction : 6/9 devient 2/3. De plus, les opérations arithmétiques "classiques" peuvent retourner une fraction normalisée.
Un type de données consiste en :• un domaine (= un ensemble de valeurs) • un ensemble d'opérations.
5.2.1 Définition structurelle du type Fraction
Une définition structurelle définit le domaine de valeurs d'un type en donnant la structure interne de ses composants.
Les composants du type Fraction sont ainsi définis => 3 composants de type fixé.
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

42
• le signe : un caractère • le numérateur et le dénominateur : deux entiers
Le domaine de valeur de chaque composant est lui-même parfaitement défini.• le signe : + ou –• le numérateur qui est un entier naturel (>= 0)• le dénominateur qui est un entier positif (> 0)
Les composants peuvent être également contraints :• Représentation normalisée : Numérateur et dénominateur ne doivent pas avoir de
commun diviseur.
Avec cette définition, 6/9 ne peut être considéré comme une Fraction.
5.2.2 Définition logique (abstraite) du type Fraction
Une définition logique du type Fraction nécessite une opération qui crée une Fraction à partir de données passées en paramètres.
Autres types utilisés : integer, character booléen
Opérations : Création d'une Fraction à partir d'un entier numérateur et d'un entier non nul
dénominateur.creerFraction : integer x integer Fraction
♦ en entrée : i, j : integer♦ en sortie : f : Fraction♦ pré-conditions : j /= 0♦ post-conditions : f = i/j
Réduction d'une Fraction afin que numérateur et dénominateur n'aient pas de commun diviseurs.reduire : Fraction Fraction
♦ en entrée : f : Fraction♦ en sortie : f' : Fraction = (f.num/e, f.den/e) avec e = pgcd(f.num, f.den)♦ pré-conditions : aucune♦ post-conditions : f : Fraction / !∃ commun diviseur à f.den et f.num
Signe de la Fractionsigne : Fraction character
♦ en entrée : f : Fraction♦ en sortie : c : character♦ pré-conditions : aucune♦ post-conditions : c== '-' si f.num <0, + sinon
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

43
Produit de deux fractionsprod : Fraction x Fraction Fraction
♦ en entrée : f , g: Fraction♦ en sortie : f' : Fraction, f et g non modifiées♦ pré-conditions : aucune♦ post-conditions : f'.num = f.num*g.num, f'.den = f.den*g.den
Teste l’équivalence entre deux Fractionséquivalent : Fraction, Fraction Boolean
♦ en entrée : f, g : Fraction♦ en sortie : b : booléen♦ pré-conditions : aucune♦ post-conditions : b == vrai si reduire(f) == reduire(g)
Retourne l’inverse d’une Fractioninverse : Fraction Fraction
♦ en entrée : f : Fraction♦ en sortie : f' : Fraction ♦ pré-conditions : f.num /= 0♦ post-conditions : f'.num = f.den et f'.den = f.num
etc.
Axiomes : f1, f2 : Fraction, n est un entier quelconque et d un entier non nul,♦ (1) reduire (prod(f1, f2)) = 1/1 , // avec f1 = n/d et f2 = d/n
// (reduire ((n/d) * (d/n)) = 1/1♦ (2) reduire (prod(creerFraction (n, d), creerFraction (d, n))) = creerFraction
(1,1),♦ (3) getNumerateur (creerFraction(x, y)) = x♦ (4) getDénominateur (creerFraction(x, y)) = y♦ (5) equivalent (creerFraction (x, x), creerFraction (1, 1)) = vrai♦ (6) equivalent (a, b) = equivalent(prod(a, inverse(b)), creerFraction (1, 1))
// a/b * 2b/2a ==1/1♦ (7) equivalent( prod( inverse(a), a), creerFraction (1, 1)) == vrai♦ etc.
Cette manière de définir un type est basé sur une vue logique de ce type. Elle utilise des axiomes et des contraintes pour décrire le comportement des opérations sur les éléments de ce type.Cette approche pour définir un type n'impose aucune structure interne pour les composants du type.Le domaine de valeurs d’un composant est fixé par l’ensemble des valeurs possibles au vu des axiomes et contraintes.
Les noms des opérations définies doivent être suffisamment explicites pour indiquer leur rôle :creerFraction : integer x integer Fraction
Ici il est facile de comprendre qu'une Fraction est créée à partir de deux valeurs entières.
Comment expliciter le comportement de l'opération de création d'une Fonction ?
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

44
En utilisant des axiomes en mettant en relation l'opération de création avec les autres opérations, par exemple :
reduire (prod(creerFraction (n, d), creerFraction (d, n))) = creerFraction (1,1),creerFraction (n*t, d*t) = creerFraction (n, d)
signe (creerFraction (-1, 1)) = signe (creerFraction (1, -1)) = '-' signe (creerFraction (1, 1)) = signe (creerFraction (-1, -1)) = '+'
Pour expliciter le produit de deux Fractions : prod(creerFraction (n1, d1), creerFraction (n2, d2))
= réduire (creerFraction (n1*n2, d1*d2))
5.2.3 Quelle sorte de définition utiliser ?
La spécification d’un nouveau TDA se fera principalement par la définition logique des opérations.Le niveau d’abstraction est plus grand et aucune contrainte arbitraire n’est à donner a priori lors de la spécification du TDA.Ceci correspond donc bien mieux à l’idée centrale concernant les TDA où la spécification est définie de façon complètement indépendante de l’implantation dans un langage donné.On peut utiliser occasionnellement la définition structurelle pour compléter la définition logique. Ou pour réaliser la transition depuis la définition logique jusqu’à l’implantation. Car cette définition donne une idée plus précise de la façon dont doivent être définies les données.
5.2.4 Implantations alternatives du type Fraction
Pour définir structurellement un TDA, il faut utiliser les types de base. Le type Fraction ne correspond à aucun des types de base existant. Il faut donc définir à l’aide des types de base un nouveau type.Nous allons voir 2 façons de définir le type Fraction en C :
Implantation 1 typedef struct { int numerator, denominator;
} Fraction;Fraction creerFraction(int, int) ;
#define numerator 0#define denominator 1typedef int Fraction[2];Fraction creerFraction(int, int) ;
Implantation 2 Fraction creerFraction (int n, int d){
Fraction f; f.numerator = 1; f.denominator = 2; return f ;
}main(){
Fraction f;f = creerFraction(1, 2);…
}
Fraction creerFraction (int n, int d){
Fraction f; f[numerator] = 1; f[denominator] = 2; return f ;
}main(){
Fraction f;f = creerFraction(1, 2);…
}
Ce sont deux possibilités parmi beaucoup d’autres qui n’interfèrent pas avec les domaines de valeurs ou la signification des opérations définies sur le type Fraction.
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

45
Notons bien qu'il n'est pas nécessaire pour pouvoir utiliser le type Fraction de connaître sa définition structurelle interne, en effet, la fonction creerFraction( ) permet de construire une Fraction à partir de deux entiers, sans se soucier du mode de représentation utilisé. Vu de l'extérieur le type Fraction n'est déterminé que par les opérations qui lui sont associées.
5.2.5 Opérations du type Fraction
Fraction creerFraction(int, int) ;// crée une Fraction à partir de deux entiers
int getNumerator(Fraction);// retourne le numérateur d’une Fraction
int getDenominator(Fraction) // retourne le dénominateur d’une Fraction
int setNumerator(Fraction *, int);// modifie le numérateur d’une Fraction
int setDenominator(Fraction *, int) // modifie le dénominateur d’une Fraction
A partir de la définition de ces fonctions, on peut définir des opérations supplémentaires :
Fraction addition (Fraction f1, Fraction f2) { // additionne les deux Fractions
int n1 = getNumerator(f1); int n2 = getNumerator(f2); int d1 = getDenominator(f1); int d2 = getDenominator(f2); return creerFraction( n1*d2+n2*d1 , d1*d2 ); }
boolean equivalent (Fraction a, Fraction) { // teste l'équivalence de deux Fractions
return (a.n * b.d == a.d * b.n) ;}
La définition de l’opération de réduction peut être faire ainsi :• A partir des formules d’Euclide on calcule le PGCD puis on divise le numérateur et le
dénominateur par le PGCD :V e r s i o n itérative
int pgcd (int a, int b) {
while (a != b)if (a > b) a = a-b;else b = b-a;
return a;}
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat
46
V e r s i o n récursive
int pgcd (int a, int b) { if (a == b) return a ; else if (a < b) return pgcd (a, b-a) ; else return pgcd (a-b, b) ;}
Fraction reduction (Fraction f){ int p = pgcd (getNumerateur (f), getDenominateur (f)) ; Fraction tmp ;
setDenominateur(tmp, getDenominateur (f)); setNumerateur (tmp, getNumerateur(f)); return tmp ;
}
6 Programmation par contrat
La programmation par contrat permet de rendre fiable l'utilisation de composants logiciels.Un client (appelant) appelle un sous-traitant (appelé) et un contrat explicite spécifie les limites que doivent respecter les deux parties :
• Pour l'appelant, il s'agit de fixer le minimum que doit assurer l'appelé.• Pour l'appelé il s'agit de fixer les règles que doit respecter l'appelant.
Exemple :Obligations Garanties
Client (appelant) Fournir un terrain d'au moins 2000 m²
Obtenir une maison d'au moins 120 m² habitables pour au plus 100 000 Euros
Sous-traitant (appelé) Construire uns maison d'au moins 120 m² habitables pour au plus 100 000 Euros
Ne rien faire si le terrain n'est pas fourni ou s'il fait moins de 2000 m²
La programmation par contrat applique le même genre de contrat pour les appels de sous-programmes (opérations définies dans les modules, appelées par les clients du module).Exemple :
Obligations GarantiesClient (appelant) Appeler insert(x)
seulement si la table n'est pas pleine
Obtenir une table modifiée dans laquelle l'élément x a été inséré
Sous-traitant (appelé) Insère la valeur x dans la table Aucune action à entreprendre si la table est pleine avant l'insertion(!!aucune gestion des erreurs)
Le sous-traitant n'a pas à prévoir une gestion des erreurs dans le cas où c'est le client qui ne respecte pas le contrat.En contre partie, le client doit être "honnête" et doit absolument respecter le contrat et donc prévoir les cas où l'appel du sous-traitant est impossible.
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

47
La programmation par contrat peut être mise en œuvre par différents moyens selon le langage utilisé :S a n s g e s t i o n d'exceptions (C)
Tests à effectuer sur les paramètres en entrée et convention d'un code d'erreur à renvoyer à l'appelant en cas de problème.Charge à l'appelant de tester le retour de l'opération pour vérifier si les résultats sont valides.
A v e c g e s t i o n d'exceptions (ADA, JAVA)
Tests à effectuer sur les paramètres en entrée et déclenchement d'une exception en cas de problème.
• raise nomException;Charge à l'appelant de récupérer l'exception et d'agir en fonction de l'erreur produite.
• exceptionwhen nomException => -- traitement de l'exception
Avec gestion des e x c e p t i o n s + require et ensure (EIFFEL)
Chaque opération définit les prérequis sur les paramètres d'appel (sous forme d'axiomes) et déclenche une exception s'ils ne sont pas vérifiés.De la même façon, des prérequis sur les résultats sont établis et s'ils ne sont pas vérifiés c'est normalement à l'appelé de traiter l'erreur.
6.1 Application de la programmation par contrat à l'exemple des Fractions
En C : Pour l'ensemble du TDA Fraction : le code d'erreur est fixé à une fraction (0/0).
// L'inverse d'une Fraction peut ne pas exister dans le cas où le numérateur est nul. Fraction inverse (Fraction a) { // inverse d'un rationnel
Fraction tmp ;tmp = creerFraction (0, 0); // Si tmp n'est pas modifié => erreurif (getNumerateur(*a) <> 0) {
setDenominateur(tmp, getNumerateur(*a)); setNumerateur (tmp, getDenominateur (*a)); return tmp;
}else return tmp ; // gestion d’erreur : la Fraction (0, 0) est retournée
}
En ADA : Pour l'ensemble de TDA, l'exception suivante est déclarée :
• erreurFractionDenominateurNul : exception;
function inverse (Fraction a) return Fraction is tmp : Fraction;begin if (getNumerateur(a) = 0) then raise erreurFractionDenominateurNul; else tmp := creerFraction (getDenominateur(a), getNumerateur(a)); end if;end inverse;
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

48
Types de Données Abstraits Classiques
7 TDA Pile (Stack)
Un des plus simples TDA est la pile.
1. Définition: Une Pile est un ensemble d'éléments dont seul le dernier ajouté peut être accédé ou enlevé. Le dernier élément ajouté est au sommet (top) de la Pile.
2. Une Pile est une structure de données ordonnée qui ne permet l'accès qu'à un seul élément : celui qui est au sommet.
3. Une pile est une collection muni d'un objet particulier appelé sommet. Lorsqu'on ajoute un élément à la pile celui-ci devient le nouveau sommet et l'ancien sommet est "repoussé en dessous de lui" . Lorsqu'on enlève l'élément du sommet c'est celui qui était "en dessous" de lui qui devient le sommet. On peut remarquer que le premier élément mis dans la pile sera le dernier à en sortir.
Le rôle d'une pile est de permettre la mise en attente d'informations dans le but de les récupérer plus tard. La déclaration d'une pile doit spécifier le type des Eléments qu'elle pourra contenir. Le type des Eléments peut être quelconque, mais tous les éléments doivent être de même type.
7.1 Spécification du TDA Pile
Une Pile est un conteneur d'objets que l'on peut manipuler avec 3 opérations fondamentales : Placer un objet sur une Pile (ou empiler), accéder à l'objet qui est au sommet d'une Pile, et retirer cet objet (ou dépiler).
Pour définir la spécification de la Pile on va donner :
Entrées Données en entrée, paramètres de l'opération.Sorties Données en sortie, résultat de l'opération.
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

49
Pré-Conditions Propriétés que doivent assurer les données en entrée de l'opération.Si elles sont satisfaites, l'opération doit fonctionner correctement.Dans le cas contraire, l'opération doit refuser de s'exécuter ou sinon elle peut provoquer une erreur d'exécution ou des résultats erronés.
Post-Conditions Précise les effets de l'opérations sur les données manipulées.C'est la seule certitude que l'appelant ait à propos du déroulement de l'opération. Les post-conditions ne sont garanties que si les pré conditions sont satisfaites.
Spécification de la Pile : Autre type utilisé :
• Elément // Type des éléments contenus dans la Pile
Opérations :
° créerPile : Pile // Crée une nouvelle Pile vide♦ en entrée : aucun♦ en sortie : p : Pile♦ pré-conditions : aucune♦ post-conditions : p définie et vide
° empiler : Pile x Elément Pile // empilement d'un élément♦ en entrée : p : Pile; e : Elément♦ en sortie : p : Pile ♦ pré-conditions : e est du type des Eléments de p♦ post-conditions : en sortie, la Pile p avec un élément de plus au sommet
° dépiler : Pile Pile // dépilement du sommet♦ en entrée : p : Pile♦ en sortie : p : Pile♦ pré-conditions : p est non vide♦ post-conditions : en sortie, on obtient la Pile p privée de son sommet
° remplacer : Pile x Elément Pile // remplacement du sommet♦ en entrée : p : Pile; e : Elément♦ en sortie : p : Pile ♦ pré-conditions : p non vide♦ post-conditions : la valeur de l'élément placé au sommet de p a été changée,
maintenant la valeur du sommet est celle de e.
° sommet : Pile Elément // retourne l'élément au sommet♦ en entrée : p : Pile♦ en sortie : e : Elément♦ pré-conditions : p non vide♦ post-conditions : e est l'élément placé au sommet de p (p est inchangée).
° estVide : Pile booléen // teste si la Pile est vide♦ en entrée : Pile
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

50
♦ en sortie : booléen♦ pré-conditions : aucune♦ post-conditions : renvoie vrai ssi la Pile ne contient aucun élément
° hauteur : Pile int // nombre d'éléments♦ en entrée : p : Pile♦ en sortie : h : int♦ pré-conditions : aucune♦ post-conditions : h est le nombre d'éléments placés dans p
Axiomes : p : Pile; e : Elément° (1) estVide (créerPile()) == vrai° (2) hauteur (créerPile ()) == 0° (3) estVide (empiler (p, e)) == faux° (4) hauteur (empiler (p, e)) == hauteur (p) + 1° (5) sommet (empiler (p, x)) == x° (6) dépiler (empiler (p, x)) == p° (7) remplacer (p, x) == empiler (dépiler (p), x)
Application des règles obtenues :sommet (dépiler (empiler (c, empiler (b, empiler (a, créerPile ())))))
= sommet (empiler (b, empiler (a, créerPile ()))) (règle 6)= b (règle 5)
estVide (dépiler (dépiler (empiler (c, empiler (b, dépiler (empiler (a, créerPile ())))))))= estVide (dépiler (empiler (b, dépiler (empiler (a, créerPile ()))))) (règle 6)= estVide(retirer(ajouter(b, créerPile ()))) (règle 6)= estVide(créerPile ()) (règle 6)= vrai (règle 1)
A partir de là on peut définir l'égalité entre deux Piles, définir une fonction dépiler qui retourne la valeur au sommet de Pile (si la Pile est non vide), etc.
En anglais les fonctions principales sont les suivantes : ° créer : new,° empiler : push,° dépiler : pop,° sommet : top,° estVide : isEmpty.
Une Piles peut être soit vide, soit considérée comme constituée de deux parties :• un sommet,• une Pile (contenant le reste des éléments).
Attention : La définition du TDA Pile ne fait pas mention de la capacité maximum d'une Pile. Dans les faits, il y a une limite supérieure qui dépend du choix de l'implantation du TDA Pile. Cette limite peut être ajoutée en pré-condition sur les opérations qui ajoutent un élément à une Pile.
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

51
Le cas de la copieThéoriquement on peut copier une pile uniquement à l'aide des opérations sommet, retirer, ajouter et estVide. Il faut commencer par vider la pile de départ pour construire une pile intermédiaire où les éléments sont dans l'ordre inverse. Puis on vide cette pile dans l'originale et la copie.Cette manière de faire étant peu efficace il peut être nécessaire de définir l'opération copier comme une primitive pour pouvoir effectuer la copie directement au niveau de la structure de données utilisée.
7.1.1 LIFO
Définition: Acronyme pour "last-in, first-out".
7.2 Implantation statique du TDA Pile
La réalisation des opérations sur les piles peut s'effectuer en utilisant une structure de données statique (par exemple un tableau) qui contient les éléments et un index qui indiquera la position du sommet de la pile. Ce type d'implantation implique forcément que le nombre d'éléments que peut contenir la Pile est limité à un maximum.
7.2.1 Pile bornée (bounded Stack)
Définition : Une Pile bornée est une Pile dont le nombre maximum d'éléments est fixé à une limite donnée.Une Pile statique est donc une Pile bornée car la structure de données qui stocke les données est de taille statique.
7.2.2 Pile : Représentation par tableau en ADA
7.2.2.1 Spécification 1 : sans abstraction de donnéespackage PileEntiers_P is -- déclarations des attributs (données) exportés par le TDA
maxP : constant integer := 100; -- hauteur max de la Piletype Donnees is array (1.. maxP) of integer;type PileEntiers is record hauteur : integer range 0..maxP; data : Donnees;end record;PILE_VIDE, PILE_PLEINE : exception;
-- déclarations des opérations exportées par le TDAprocedure creerPile (p: out PileEntiers);procedure empiler (p : in out PileEntiers; i : integer);procedure depiler (p : in out PileEntiers);procedure remplacer (p : in out PileEntiers; i : integer);function sommet (p : in PileEntiers) return integer;function estVide (p : in PileEntiers) return boolean;function estPleine (p : in PileEntiers) return boolean;function hauteur (p : in PileEntiers) return integer;
end PileEntiers_P;
Mise en œuvre des opérations :
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

52
package body PileEntiers_P isprocedure creerPile (p: out PileEntiers) is-- dans le cas d'une implantation statique, l'opération de création est en fait -- une opération d'initialisation à vide. begin p.hauteur := 0; end creerPile; procedure empiler (p : in out PileEntiers; i : integer) is begin -- précondition p non pleine if estPleine(p) then raise PILE_PLEINE; end if; -- p non pleine, on empile p.hauteur := p.hauteur + 1; p.data(p.hauteur) := i; end empiler; procedure depiler (p : in out PileEntiers) is begin -- précondition p non vide if estVide(p) then raise PILE_VIDE; end if; -- p non vide, on dépile p.hauteur := p.hauteur - 1; end depiler; procedure remplacer (p : in out PileEntiers; i : integer) is begin null; end remplacer; function sommet (p : in PileEntiers) return integer is begin return 0; end sommet; function estVide (p : in PileEntiers) return boolean is begin return true; end estVide; function estPleine (p : in PileEntiers) return boolean is begin return true; end estPleine;
function hauteur (p : in PileEntiers) return integer is begin return 0; end hauteur;
end PileEntiers_P;
Avec cette spécification, les données sont connues et manipulables depuis l'extérieur du TDA. Il n'y a pas abstraction de données.
7.2.2.2 Spécification 2 : avec abstraction de données
package PileEntiers_P is -- déclarations des attributs (données) exportés par le TDA
maxP : constant integer := 100; -- hauteur max de la Piletype PileEntiers is private; -- les données de la Pile ne sont plus accessiblesPILE_VIDE, PILE_PLEINE : exception;
-- déclarations des opérations exportées par le TDAprocedure creerPile (p: out PileEntiers);
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

53
procedure empiler (p : in out PileEntiers; i : integer);procedure depiler (p : in out PileEntiers);procedure remplacer (p : in out PileEntiers; i : integer);function sommet (p : in PileEntiers) return integer;function estVide (p : in PileEntiers) return boolean;function estPleine (p : in PileEntiers) return boolean;function hauteur (p : in PileEntiers) return integer;
private-- concept de propriété privée : on peut y jeter un œil mais on ne peut pas y mettre les pieds. -- voir le mot clé private comme une grille autour d'une propriété
type Donnees is array (1.. maxP) of integer;type PileEntiers is recordhauteur : integer range 0..maxP;data : Donnees;end record;
end PileEntiers_P;
Utilisation du type PileEntiers abstrait with PileEntiers_P; procedure principale is pile1 : PileEntiers_P.PileEntiers; pile2 : PileEntiers_P.PileEntiers; begin PileEntiers_P.empiler (pile1, 2); exception when PileEntiers_P.PILE_PLEINE => …; when … end principale;
7.2.2.3 Spécification 3 : Possibilité de définir la taille de la Pile
package PileEntiers_P is -- déclarations des attributs (données) exportés par le TDA
-- les données de la Pile ne sont plus accessibles et la taille de la Pile est donnée-- lors de la création de la Piletype PileEntiers (maxP : positive) is private; PILE_VIDE, PILE_PLEINE : exception;
-- déclarations des opérations exportées par le TDAprocedure creerPile (p: out PileEntiers);procedure empiler (p : in out PileEntiers; i : integer);procedure depiler (p : in out PileEntiers);procedure remplacer (p : in out PileEntiers; i : integer);function sommet (p : in PileEntiers) return integer;function estVide (p : in PileEntiers) return boolean;function estPleine (p : in PileEntiers) return boolean;function hauteur (p : in PileEntiers) return integer;
private -- type tableau non contraint, ainsi la Pile déclarera le nombre de données nécessaire
type Donnees is array (positive range <>) of integer; type PileEntiers (maxP : positive) is record hauteur : natural; data : Donnees (1..maxP);end record;
end PileEntiers_P;
Dans ce cas, la taille de la PileEntiers est fixée à la déclaration : with PileEntiers_P; procedure principale is
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

54
pileMoyenne : PileEntiers_P.PileEntiers (25); grandePile : PileEntiers_P.PileEntiers (200); begin PileEntiers_P.empiler (grandePile, 2); …
7.2.3 Code du TDA PileEntiers en C avec abstraction des données
Spécification : fichier PileEntiers.h// Le TDA PileEntiers est un pointeur vers une structure de données dont on ne connaît pas la // composition => encapsulation des données dont la structure est définie // dans le fichier PileEntiers.c// Le TDA PileEntiers est un pointeur vers une structure de données dont on ne connaît pas la // composition => encapsulation des données dont la structure est définie // dans le fichier PileEntiers.c#ifndef _PileEntiers_ /* Le fichier PileEntiers.h ne doit être inclus */#define _PileEntiers_ /* qu'une seule fois */
#ifndef _typePileEntiers_ /* Vue du type PileEntiers de l’'exterieur */ typedef void * PileEntiers; #endif
extern PileEntiers creerPileEntiers( int /* maxP */);/* on précise le nombre d'éléments à la création *//* construit une nouvelle PileEntiers Pre-condition : (maxP > 0) Post-condition: retourne une PileEntiers vide*/
extern int estVide (PileEntiers /* p */) ;/* Renvoie 1 (=true) si la PileEntiers est vide, 0 (=false) sinon */
extern int estPleine (PileEntiers /* p */) ;/* Renvoie 1 si la PileEntiers est pleine, 0 sinon */
extern int empiler( PileEntiers /* p */, int /* item */ ); /* PileEntiers étant un pointeur vers une structure, cette structure est modifiable dans la méthode dépiler *//* empile un integer au sommet d'une PileEntiers Pre-condition : (p est une PileEntiers créée par l'appel à créerPileEntiers) && (le nombre d'éléments de p < maxP) Post-condition: item a été ajouté au sommet de p*/
extern int depiler( PileEntiers /* p */); /* PileEntiers étant un pointeur vers une structure, cette structure est modifiable dans la méthode dépiler *//* dépile un int de la PileEntiersPre-condition : (p est une PileEntiers créée par l'appel à créerPileEntiers) && (le nombre d'éléments de p < maxP) Post-condition: le sommet a été enlevé*/
#endif
Mise en œuvre : fichier PileEntiers.c// Définition des données manipulées par le TDA
#include <malloc.h> // inclusion des bibliothèques utilisées
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

55
#include <stdio.h>
#include <malloc.h> /* inclusion des bibliothèques utilisées */#include <stdio.h>#define _typePileEntiers_ /* Vue du type PileEntiers interne au module */ typedef struct { int hauteur; int * data; int maxPile;} Donnees;typedef Donnees * PileEntiers;
#include "PileEntiers.h" /* ici la vue externe n’est pas définie */
PileEntiers creerPileEntiers( int maxP) { /* on précise le nombre d'éléments à la création */ PileEntiers p; p = (Donnees *) malloc (sizeof (Donnees)); (*p).maxPile = maxP; (*p).data = (int *) malloc (maxP * sizeof (int)); (*p).hauteur = -1; return p;}int estVide (PileEntiers p) { return ((*p).hauteur == -1);}int estPleine (PileEntiers p) { return ((*p).hauteur == (*p).maxPile);}int empiler( PileEntiers p, int item ){ if (estPleine(p)) return 0; /* code d'erreur, 0 quand impossible */ (*p).hauteur++; (*p).data[(*p).hauteur] = item; return 1; /* code d'erreur : OK */}int depiler( PileEntiers p){ if (estVide(p)) return 0; /* code d'erreur, 0 quand impossible */ (*p).hauteur--; return 1;}…
7.2.4 TDA Pile défini comme une machine abstraite en ADA
Seules les opérations sont données dans la spécification, le type et les données ne sont déclarés et utilisables que dans le corps.
En ADA :package PileEntiers_P is
PILE_VIDE, PILE_PLEINE : exception;
-- déclarations des opérations exportées par le TDA, pas de type visibleprocedure creerPile ;procedure empiler (i : integer);procedure depiler ;procedure remplacer (i : integer);
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

56
function sommet return integer;function estVide return boolean;function estPleine return boolean;function hauteur return integer;
end PileEntiers_P;
package body PileEntiers_P is -- déclarations des attributs (données) internes au corps
maxP : constant integer := 100; -- hauteur max de la Piletype Donnees is array (1.. maxP) of integer;type PileEntiers is recordhauteur : integer range 0..maxP;data : Donnees;end record;-- Déclaration de LA PILE manipulée par la machine abstraite dont la portée -- ne sort pas du packagep : PileEntiers;
-- corps des opérations procedure creerPile is
-- dans le cas d'une implantation statique, l'opération de création est en fait -- une opération d'initialisation à vide.
begin p.hauteur := 0; end creerPile; procedure empiler (i : integer) is begin -- précondition p non pleine if estPleine then raise PILE_PLEINE; end if; -- p non pleine, on empile p.hauteur := p.hauteur + 1; p.data(p.hauteur) := i; end empiler; procedure depiler is begin -- précondition p non vide if estVide then raise PILE_VIDE; end if; -- p non vide, on dépile p.hauteur := p.hauteur - 1; end depiler; procedure remplacer (i : integer) is begin null; -- à coder end remplacer; function sommet return integer is begin return 0; -- à coder end sommet; function estVide return boolean is begin return true; -- à coder end estVide; function estPleine return boolean is begin return true; -- à coder end estPleine;
function hauteur return integer is begin return 0; -- à coder
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

57
end hauteur;
end PileEntiers_P;
L'utilisation d'un tel package est différent de la version avec type exporté : with PileEntiers_P; procedure principale is i : integer; begin PileEntiers_P.empiler (2); i := PileEntiers_P.sommet; exception when PILE_PLEINE => …; when … end principale;
7.2.5 TDA PileEntiers défini comme une machine abstraite en C
Dans le fichier PileEntiers.h on ne trouve que les signatures des opérations exportées et les constantes qui doivent être connus à l'extérieur :
PileEntiers.h#define dim_pile 100#define composante int
// signature des operationsextern void creerPileEntiers (); /* pas de paramètres là non plus */extern int empiler(composante);extern int depiler(composante *);
Dans le fichier PileEntiers.c on trouve les données manipulées par le TDA PileEntiers dont la portée est limitée au fichier .c.
#include PileEntiers.h
/* static pour empêcher l'accès direct extérieur*/static composante pile[dim_pile]; static int sommet;
void creerPileEntiers () // pas de paramètres là non plus{ sommet=0;}
int estVide(void){ return(sommet=0);}
int empiler(composante x)/* retourne 1 si pas d'erreur (donc il restait de la place dans la pile) */{
if(sommet<dim_pile) { pile[sommet]=x; sommet++; return(1); // ok}else return(0); // erreur
}
composante depiler(){
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

58
if (sommet>0) {sommet--;composante* = pile[sommet];return 1; // ok
else return(0); // erreur}…
7.2.6 Code de Pile statique en JAVA
La classe EST un type. Elle protège ses données en ne permettant leur accès qu'au travers des opérations exportées.
class PileEntiers {
// Attributs final static int maxP = 100; // constante : taille de la Pile fixée dans la classe
protected int hauteur ; protected int contenu[]; // tableau d'Eléments
// Méthodes public PileEntiers () { // constructeur d'une nouvelle Pile hauteur = 0; contenu = new int[maxP]; // allocation de la place pour maxP Eléments }
public void faireLeVide () { hauteur = 0; }
public boolean estVide () { return hauteur == 0; }
public boolean estPleine () { return hauteur == maxP; }
public void empiler (int x) throws ExceptionPile { if (this.estPleine ()) throw new ExceptionPile("pleine"); this.contenu[this.hauteur] = x; hauteur++; }
public int sommet () throws ExceptionPile { if (this.estVide ()) throw new ExceptionPile("vide"); return this.contenu [this.hauteur - 1]; }
public void depiler () throws ExceptionPile { if (this.estVide ()) throw new ExceptionPile ("vide"); this.hauteur--; }}
où on suppose qu'une nouvelle classe définit les exceptions ExceptionPile :
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

59
class ExceptionPile extends Exception { String nom; public ExceptionPile (String x) { nom = x; }
}
// classe cliente de la Pileimport Pile;class Bidon { // attributs protected PileEntiers p1, p2; // ici p1 et p2 ne sont que des références nulles
// opérations // constructeur de la classe Bidon :
// alloue de la place pour les attributs de la classe Bidon public Bidon ( ) { p1 = new PileEntiers (); // on alloue de la place pour une Pile et on // stocke sa référence (son adresse mémoire) dans p1 p2 = new PileEntiers (); // on alloue de la place pour une Pile et on // stocke sa référence (son adresse mémoire) dans p2 } void operation1 () { p1.empiler (10); p2.empiler (10); System.out.print(p1.sommet()); // affiche 10 System.out.print(p2.sommet()); // affiche 20 }}
7.3 Implantation dynamique du TDA Pile
Si l'on désire un dimensionnement totalement dynamique de la pile, on utilisera une structure chaînée :Instructions : Implantation chaînée : Pile construite :Pile_P.creerPile(p);
Pile_P.empiler(p, 10);
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat
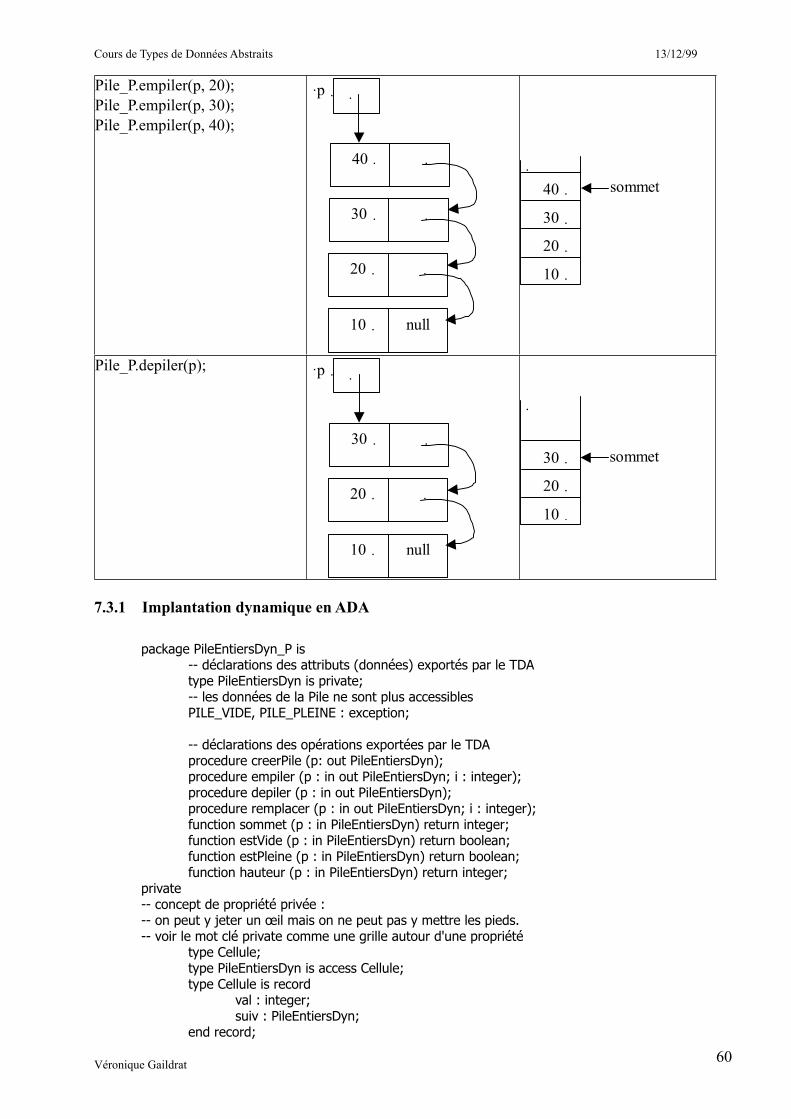
60
Pile_P.empiler(p, 20);Pile_P.empiler(p, 30);Pile_P.empiler(p, 40);
Pile_P.depiler(p);
7.3.1 Implantation dynamique en ADA
package PileEntiersDyn_P is -- déclarations des attributs (données) exportés par le TDA
type PileEntiersDyn is private; -- les données de la Pile ne sont plus accessiblesPILE_VIDE, PILE_PLEINE : exception;
-- déclarations des opérations exportées par le TDAprocedure creerPile (p: out PileEntiersDyn);procedure empiler (p : in out PileEntiersDyn; i : integer);procedure depiler (p : in out PileEntiersDyn);procedure remplacer (p : in out PileEntiersDyn; i : integer);function sommet (p : in PileEntiersDyn) return integer;function estVide (p : in PileEntiersDyn) return boolean;function estPleine (p : in PileEntiersDyn) return boolean;function hauteur (p : in PileEntiersDyn) return integer;
private-- concept de propriété privée : -- on peut y jeter un œil mais on ne peut pas y mettre les pieds. -- voir le mot clé private comme une grille autour d'une propriété type Cellule; type PileEntiersDyn is access Cellule; type Cellule is record val : integer; suiv : PileEntiersDyn; end record;
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

61
end PileEntiersDyn_P;
package body PileEntiersDyn_P is procedure creerPile (p: out PileEntiersDyn) is begin p := null; end creerPile; procedure empiler (p : in out PileEntiersDyn; i : integer) is tmp : PileEntiersDyn; begin -- précondition p non pleine, -- arrive seulement s'il n'y a plus de place en mémoire if estPleine(p) then raise PILE_PLEINE; end if; -- p non pleine, on crée une nouvelle cellule chaînée avec p tmp := new Cellule'(i, p); p := tmp; -- tête de Pile modifiée end empiler; procedure depiler (p : in out PileEntiersDyn) is begin -- précondition p non vide if estVide(p) then raise PILE_VIDE; end if; -- p non vide, on dépile p := p.suiv; end depiler; function estVide (p : in PileEntiersDyn) return boolean is begin
return p = null; end estVide; function estPleine (p : in PileEntiersDyn) return boolean is tmp : PileEntiersDyn; begin tmp := new Cellule; return false;
-- tout est OK, la place allouée pour tmp sera libérée par le garbage collector exception
-- erreur lors du new, quelquesoit l'origine de l'erreur on revoie true when others => return true; end estPleine; procedure remplacer (p : in out PileEntiersDyn; i : integer) is begin null; -- à coder end remplacer; function sommet (p : in PileEntiersDyn) return integer is begin return 0; -- à coder end sommet; function hauteur (p : in PileEntiersDyn) return integer is begin return 0; -- à coder end hauteur; end PileEntiersDyn_P;
7.3.2 Implantation dynamique en C//Spécification : fichier PileEntiers.h// Le TDA PileEntiers est un pointeur vers une structure de données dont on ne connaît pas la // composition => encapsulation des données dont la structure est définie // dans le fichier PileEntiers.c#ifndef _PileEntiersDyn_ /* Le fichier PileEntiers.h ne doit être inclus */#define _PileEntiersDyn_ /* qu'une seule fois */
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

62
#ifndef _typePileEntiers_ /* Vue du type PileEntiers de l’'exterieur */ typedef void * PileEntiersDyn; #endif
extern void creerPileEntiers(PileEntiersDyn *);extern int estVide(PileEntiersDyn) ;extern int empiler(PileEntiersDyn *, int ); extern int depiler(PileEntiersDyn *);
#endif
PileEntier.c
#include <malloc.h>#include <stdio.h>
#define _typePileEntiers_
typedef struct cellule_ { int val; struct cellule_ *suiv;} Cellule;
typedef Cellule * PileEntiersDyn;
// corps du TDA Pile d'entiers avec implantation dynamique#include "PileEntier.h"
void creerPileEntiers(PileEntiersDyn *p){ (*p) = NULL; }
int estVide (PileEntiersDyn p) { return (p == NULL);}
int empiler(PileEntiersDyn *p, int x)/* retourne 1 si pas d'erreur (donc il restait de la place dans la pile)*/{ PileEntiersDyn tmp; if((tmp=( PileEntiersDyn)malloc(sizeof(Cellule)))!=NULL) { (*tmp).val=x; (*tmp).suiv=(*p); (*p)=tmp; return(1); } else { return(0); }}
int depiler(PileEntiersDyn *p){ PileEntiersDyn tmp; if ((*p) == NULL) return 0; // Pile non vide on peut depiler tmp = (*p); (*p) = (*tmp).suiv; free(tmp); // surtout ne pas oublier de désallouer sinon mémoire grignotée !! return 1;}…
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

63
7.3.3 Implantation dynamique en JAVA
En JAVA, l'implantation dynamique va être extrêmement facile à mettre en œuvre grâce à l'utilisation d'une classe faisant partie de l'API de JAVA : java.util.Vector qui offre à la fois les facilités d'utilisation d'une structure de données statique et les avantages d'une structure de données dynamique.
import java.util.*;class PileEntiersDyn {
// Attributs
Vector contenu; // Vector d'Eléments
// Méthodes public PileEntiersDyn () { // constructeur d'une nouvelle Pile
this.contenu = new Vector(); // allocation de la place pour 0 entiers }
public void faireLeVide () { this.contenu = new Vector(); // met le Vector à vide, mémoire récupérée par le garbage collector
}
public boolean estVide () { return this.contenu.size() == 0;
}
public void empiler (int x) throws ExceptionPile { // dans une SDD telle que Vector on ne peut stocker que // des instances de classes : int --> Integer Integer i = new Integer(x); // transformer en Integer this.contenu.add(0,i); // Gérer l'exception renvoyée par addElementAt en cas de Pile pleine }
public int sommet () throws ExceptionPile { int x; if (this.estVide ()) throw new ExceptionPile("vide"); // A partir de Integer on retourne un int attendu x = ((Integer)this.contenu.elementAt(0)).intValue(); return x;
}
public void depiler () throws ExceptionPile { if (this.estVide ()) throw new ExceptionPile ("vide"); this.contenu.removeElementAt(0);
}}
7.4 Utilisation du TDA Pile
L'utilisation des structures de piles est fortement liée aux structures emboîtées ou récursives.
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

64
7.4.1 Exemple - vérificateur de parenthèsesDans une expression mathématique peuvent apparaître des parenthèses de différentes formes: `( )`, `{ }` et `[ ]'. Pour que l'expression soit correcte il faut que les parenthèses soient bien équilibrées, c'est à dire qu'une parenthèse ouverte par `[` doit être fermée par `]' et pas par `)' ou `}'. Par exemple 3*(2-[4 / (2 +x)] * y) est correcte du point de vue des parenthèses.
Un algorithme de vérification utilisant une pile peut s'écrire schématiquement ainsi:
p : PileCharacter;s : String(1..taille);i : integer;
créerPile(p);saisir(s);i := 1TQ i <= taille FRE si (s(i)= `(`) ou (s(i)=`{`) ou (s(i)=`[`) alors
empiler(p, s(i)); sinon
si (s(i)=`)`) ou s(i)=`}`) ou s(i)=`]`) alors si s(i) = sommet(p) alors
dépiler(p); sinon ERREUR -- les types de parenthèses ne correspondent pas fsi
fsi fsi
i := i + 1FTQ
7.4.2 Evaluation des expressions arithmétiques postfixées
Dans ce qui suit, pour simplifier, nous nous limiterons aux opérations binaires + et * et aux nombres entier naturels. Sur certaines machines à calculer (HP), les calculs s'effectuent en mettant le symbole d'opération après les nombres sur lesquels on effectue l'opération. On a alors une notation dite postfixée. Dans certains langages de programmation, c'est par exemple le cas de Lisp ou de Scheme, on écrit les expressions de façon préfixée c'est-à-dire que le symbole d'opération précède cette fois les deux opérandes.On définit ces expressions récursivement. Les expressions postfixées comprennent :
• des symboles parmi les 4 suivants: + * ( )• des entiers naturels
Une expression postfixée est ou bien un nombre entier naturel ou bien est de l'une des deux formes:
• (e1 e2 +) • (e1 e2 *)
où e1 et e2 sont des expressions préfixées.
Exemples d’expressions préfixées : 47(2 3 *)
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

65
(12 8 +)((2 3 *) (12 8 +) +)(((35 36 +) (5 6 +) *) ((7 8 +) (9 9 *) *) +)Les parenthèses sont facultatives ce qui fait que la dernière expression est équivalente à 35 36 + 5 6 + * 7 8 + 9 9 * * +L’évaluation de ces expressions donne respectivement 47, 6, 20, 26 et 1996.
Pour représenter une expression postfixée en Java, on utilise ici une structure de données dont chaque élément représente une entité de l'expression : [entier, *, +, (, )]. Ainsi les expressions ci-dessus seront représentées par des structures de données contenant respectivement 1, 5, 5, 13 et 29 éléments. Les éléments de la structure sont des objets à trois champs, le premier indique la nature de l'entité: (symbole ou nombre), le second champ est rempli par la valeur de l'entité dans le cas où celle ci est un nombre, enfin le dernier champ est un caractère rempli dans les cas où l'entité est un symbole.
class Element { protected boolean estOperateur; protected int valInt; protected char valSymb; // constructeurs Element (char c) { estOperateur = true; valSymb = c; } Element (int val) { estOperateur = false; valInt = val; } // methodes d'acces public boolean estOperateur() {return estOperateur;} public static boolean operateurAutorise (char c) { if ((c =='+') || (c =='*')) return true; else return false; } public static boolean separateurAutorise (char c) { if ((c =='(') || (c ==')') || (c ==' ')) return true; else return false; } public int valeur () {return valInt;} public char symbole () {return valSymb;} public int appliquerA (int a, int b) throws ErreurOperation{ if (!this.estOperateur) { ErreurOperation epf = new ErreurOperation ("operateur errone") ; throw epf ; } if (this.valSymb == '+') return a+b; else if (this.valSymb == '*') return a*b; else { ErreurOperation epf = new ErreurOperation ("operateur errone") ; throw epf ;
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

66
} } public String toString () { if (estOperateur) return (""+valSymb); else return (""+valInt); }}
// Classes exceptions nécessairesclass ErreurElement extends Throwable{ public ErreurElement (String s) { super (s); }}
class ErreurOperation extends Throwable{ public ErreurOperation (String s) { super (s); }}
On va créer une classe ExpPostfixée qui est cliente du TDA Pile et de la classe Elément et qui possède les méthodes suivantes :
un constructeur une méthode servant à évaluer la valeur de l’expressionExpPostfixée (String s) ; int évaluer ( );
Algorithme de la méthode évaluer :p : PileEntier;i : integer;e : ExpPostfixée
créerPile(p);index := 0TQ i < e.taille FRE si (e(index)= `+`) ou (e(index)=`*`) alors
int i = p.sommet;p.dépiler();int j = p.sommet ();p.dépiler ();p.empiler (appliquer(i , e(i), j) ;
sinon p.empiler (e(i));
fsi i := i + 1FTQ
96 8 9 81
36 5 5 11 7 7 15 15 15 121535 35 71 71 71 71 781 781 781 781 781 781 781 1996
Pile d'évaluation de l'expression postfixée dont le résultat est 1996
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

67
Code de la classe ExpPostFixée :
import java.util.*;import PileEntiers;public class ExpPostFixee { // attribut structure de données permettant de stocker l'expression Vector sdd;
// un constructeur ExpPostFixee (String s) throws ErreurElement{ sdd = new Vector (); int i = 0; System.out.println("longueur s = "+s.length()); while (i < s.length()) { // si s(i) est un entier alors appliquer le schéma de Horner pour déterminer // la valeur du nombre et placer i sur le caractère suivant ce nombre if (('0' < s.charAt(i)) && (s.charAt(i) < '9')) { int valeur = 0 ; while ((i < s.length()) && ('0' < s.charAt(i)) && (s.charAt(i) < '9')) { System.out.println("s(i..i) = "+s.substring(i,i+1)); valeur=valeur*10+Integer.parseInt(s.substring(i,i+1)) ; i++ ; } Element e = new Element (valeur); sdd.add(e) ; } else if (Element.operateurAutorise(s.charAt(i))) { // c'est un operateur Element e = new Element (s.charAt(i)); sdd.add(e); i++ ; } else if (Element.separateurAutorise(s.charAt(i))) i++; else {// caractère inconnu ErreurElement ee = new ErreurElement("caractère erroné"); throw ee ; } } System.out.println("sdd = " + sdd.toString()); } // une méthode servant à évaluer la valeur de l'expression int evaluer( ) throws ErreurPostFixee { PileEntiers p = new PileEntiers(); int index, resultat ; System.out.println("taille sdd : " + sdd.size()); try { for (index = 0 ; index < sdd.size () ; index++) { if ( !(((Element)sdd.elementAt(index)).estOperateur())) { p.empiler (((Element)sdd.elementAt(index)).valeur()) ; } else { int i = p.sommet () ; p.depiler () ; int j = p.sommet () ; p.depiler () ; p.empiler (((Element) sdd.elementAt(index)).appliquerA (i, j)) ; } }
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

68
resultat = p.sommet(); p.depiler () ; } catch (ExceptionPile ep) { ErreurPostFixee epf = new ErreurPostFixee ("pile vide") ; throw epf ; } catch (ErreurOperation eo) { ErreurPostFixee epf = new ErreurPostFixee ("Expression erronee") ; throw epf ; } if ( !(p.estVide ())) { ErreurPostFixee epf = new ErreurPostFixee ("pile non vide à la fin") ; throw epf ; } // pas d'erreur dans la pile, on retourne le resultat return resultat;
}}class ErreurPostFixee extends Throwable{ public ErreurPostFixee (String s) { super (s); }}
// Classe principale utilisant ExpPostFixee
public class Main {
public static void main (String [] args) { // args[0] est la chaine ce caracteres contenant l'expression // postfixee a evaluer ExpPostFixee epf; try { System.out.println (args[0]); epf = new ExpPostFixee(args[0]); System.out.println("Resultat de l'evaluation : " + epf.evaluer()); } catch (java.lang.ArrayIndexOutOfBoundsException e) { System.out.println("Entrez l'expression a evaluer en ligne de commande"); } catch (ErreurPostFixee errpf) { System.out.println (errpf.getMessage()); } catch (ErreurElement ee) { System.out.println (ee.getMessage()); } }}
Si une exception se produit, c’est que l’expression postfixée est mal construite (caractères erronés) ou bien il n’y a pas toujours 2 valeurs dans la pile quand on rencontre un opérateur.Le résultat de l’évaluation est la valeur unique restant dans la pile à le fin.Par contre, s’il reste plus d'une valeur, c'est également parce que l'expression est mal construite.
7.4.3 Exemple d'algorithme utilisant des piles : le Quick Sort ( non récursif )
procédure trirapide (t : IN OUT tableau ; first, last : IN indices ) couple d'indices [debut, fin] <- [first, last]
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

69
P : pile de couple d'indices;m : indice;
débutempiler (p, [ first, last ]) ;tant que (non estVide(p)) m <- chercher pivot(t[debut, fin]) partitionner t / t[début..m[ < t[m] <= t]m..fin]
[début , fin] <- sommet (p);dépiler (p);si fin > début alors
empiler (p, [ début , m - 1 ]);empiler (p, [ m + 1 , fin ]);
fsi ftqfin
8 TDA Files (Queues)
Définition : Une File est un ensemble d'éléments dont seul le premier élément inséré (le plus ancien dans la liste) peut être accédé ou enlevé. La valeur d'une file est par convention celle de l'élément de tête. Dans une file les éléments sont systématiquement ajoutés en queue et supprimés en tête.Ce sont des structures de données ordonnées, mais qui ne permettent l'accès qu'à une seule donnée.Dans une file d'attente l'ordre d'arrivée des éléments est préservé.
Les files correspondent aux files d'attente : on sert toujours le premier élément, donc le plus ancien (on ne tolère pas ici les resquilleurs). Les files sont très souvent utiles : elles servent à mémoriser des choses en attente de traitement. Elles permettront une clarification des algorithmes quand effectivement on n'a pas besoin d'accéder directement à tous les éléments. Il n'y a généralement pas de structures spécifiques prévues dans les langages, il faut donc les créer de toutes pièces. Les files sont utilisées en programmation pour gérer des objets qui sont en attente d'un traitement ultérieur, par exemple :
• des processus en attente d'une ressource du système, • des sommets d'un graphe, • transformation d'une expression arithmétique infixée et parenthésée et expression
postfixée, • etc ...
Une file d'attente est caractérisée par le fait que les insertions se font à un bout de la suite et les extractions à l'autre.
tète queue
enlèvement insertion
8.1 Spécification du TDA Files
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

70
Spécification de la File : Autre type utilisé :
• Elément // Type des éléments contenus dans la File
Opérations :
° créerFile : File // Crée une nouvelle Pile vide♦ en entrée : aucun♦ en sortie : f : File♦ pré-conditions : aucune♦ post-conditions : f définie et vide
° insérer : File x Elément File // insertion d'un élément♦ en entrée : f : File; e : Elément♦ en sortie : f : File ♦ pré-conditions : e est du type des Eléments de f♦ post-conditions : en sortie, la File f avec un élément de plus en queue
° enlever : File File // enlèvement de l'élément en tète♦ en entrée : f : File♦ en sortie : f : File♦ pré-conditions : f est non vide♦ post-conditions : en sortie, on obtient la File f privée de son élément de tète
° premier : File Elément // retourne l'élément en tète♦ en entrée : f : File♦ en sortie : e : Elément♦ pré-conditions : f non vide♦ post-conditions : e est l'élément placé en tète de f (f est inchangée).
° estVide : File booléen // teste si la File est vide♦ en entrée : f : File♦ en sortie : booléen♦ pré-conditions : aucune♦ post-conditions : renvoie vrai ssi la File ne contient aucun élément
° longueur: File int // longueur ou nombre d'éléments♦ en entrée : f : File♦ en sortie : l : int♦ pré-conditions : aucune♦ post-conditions : l est le nombre d'éléments placés dans f
Axiomes : f : File; e : Elément° (1) estVide (créerFile()) == vrai° (2) longueur (créerFile ()) == 0° (3) estVide (insérer (f, e)) == faux° (4) longueur (insérer (f, e)) == longueur (f) + 1° (5) premier (insérer (créerFile(), x)) == x
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

71
° (6) premier (insérer (f, x)) == premier (f) // non estVide (f)° (7) enlever (insérer (créerFile(), x)) == créerFile()° (8) enlever (insérer (f, x)) == insérer (enlever (f)) // non estVide (f)° (9) longueur (enlever (f)) == longueur (f) – 1 // non estVide (f)
Application des règles obtenues :
En anglais les fonctions principales sont les suivantes : ° créer : new,° insérer : enqueue, insert,° enlever : dequeue, remove, ° longueur : length,° premier : head,° estVide : isEmpty.
8.1.1 FIFO
Définition: Acronyme pour "first-in, first-out".
8.2 Implantation statique du TDA File
Une première idée de réalisation sous forme de programmes des opérations sur les files est empruntée à une technique mise en œuvre dans des lieux où des clients font la queue pour être servis, il s'agit par exemple de certains guichets de réservation dans les gares, de bureaux de certaines administrations, ou des étals de certains supermarchés. Chaque client qui se présente obtient un numéro et les clients sont ensuite appelés par les serveurs du guichet en fonction croissante de leur numéro d'arrivée. Pour gérer ce système deux nombres doivent être connus par les gestionnaires : le numéro obtenu par le dernier client arrivé et le numéro du dernier client servi. On note ces deux nombres par fin et début respectivement et on gère le système de la façon suivante
• la file d'attente est vide si et seulement si début = fin,• lorsqu'un nouveau client arrive on incrémente fin et on donne ce numéro au client,• lorsque le serveur est libre et peut servir un autre client, si la file n'est pas vide, il
incrémente début et appelle le possesseur de ce numéro.
8.2.1 Représentation statique du TDA File en ADA
L'organisation la plus simple d'une file d'attente à l'intérieur d'un tableau est la plus simple mais n'est pas très efficace. C'est pourquoi une solution de file circulaire sera aussi proposée.
8.2.1.1 Représentation linéairepackage FileEntiers_P is type FileEntiers (max : positive) is private;
procedure creerFileEntiers ( f : out FileEntiers);procedure inserer (f : in out FileEntiers; i : integer);procedure enlever (f : in out FileEntiers);function longueur (f : in FileEntiers) return natural;function premier (f : in FileEntiers) return integer;function estVide (f : in FileEntiers) return boolean;function estPleine (f : in FileEntiers) return boolean;
fileVide, filePleine : exception;
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

72
private type Elements is array (positive range <>) of integer; type FileEntiers (max : positive) is record element: Elements (1..max); nbElements: natural; end record ; -- FileEntiersend FileEntiers_P;
package body FileEntiers_P is procedure creerFileEntiers ( f : out FileEntiers) isbegin f.nbElements := 0;end creerFileEntiers;
procedure inserer (f : in out FileEntiers; i : integer) isbegin if estPleine(f) then raise filePleine; end if; f.nbElements := f.nbElements + 1; f.element(f.nbElements) := i;end inserer;
procedure enlever (f : in out FileEntiers) isbegin if estVide(f) then raise FileVide; end if; f.element (1.. f.nbElements-1) := f.element (2..f.nbElements); f.nbElements := f.nbElements - 1;end enlever;
function longueur (f : in FileEntiers) return natural isbegin return f.nbElements;end longueur;
function premier (f : in FileEntiers) return integer isbegin if estVide(f) then raise fileVide; end if; return f.element(1);end premier;
function estVide (f : in FileEntiers) return boolean isbegin return f.nbElements=0;end estVide; function estPleine (f : in FileEntiers) return boolean isbegin return f.nbElements=f.max;end estPleine; end FileEntiers_P;
8.2.1.2 Représentation circulaire
Pour les files, l'utilisation d'un tableau circulaire nécessite deux variables : la position du premier et celle du dernier. La suppression du premier élément ne se fait pas par décalage des suivants mais en incrémentant la variable indiquant le premier. La gestion est alors un peu plus complexe que pour les piles, puisque le suivant de la fin du tableau est le début du tableau (en fait, l'indice du suivant est l'indice plus 1, modulo la taille du tableau.
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

73
0 1 2 3 …. …. MAX-1e5 e6 e1 e2 e3 e4
dernier premier
° succ(i) = i + 1 mod MAX° La File est vide quand tête = queue et que vide == true.° La File est pleine quand tête = queue et que vide == false.° Insertion d'un élément dans la cellule indiquée par dernier, puis dernier++ mod
max.° Enlèvement de l'élément en premier, puis premier++ mod max.
package FileEntiers_P is type FileEntiers (max : positive) is private;procedure creerFileEntiers ( f : out FileEntiers);procedure inserer (f : in out FileEntiers; i : integer);procedure enlever (f : in out FileEntiers);function longueur (f : in FileEntiers) return natural;function premier (f : in FileEntiers) return integer;function estVide (f : in FileEntiers) return boolean;function estPleine (f : in FileEntiers) return boolean;fileVide, filePleine : exception;
private type Elements is array (natural range <>) of integer; type FileEntiers (max : positive) is record element: Elements (0..max); -- attention max est l'indice max -- le compilateur refuse max -1 !!!! vide : boolean; prem, der : natural ; end record ; -- FileEntiersend FileEntiers_P;
package body FileEntiers_P is procedure creerFileEntiers ( f : out FileEntiers) isbegin f.vide := true; f.prem := 0; f.der := 0;end creerFileEntiers;
procedure inserer (f : in out FileEntiers; i : integer) isbegin if estPleine(f) then raise FilePleine; end if; f.vide := false; f.element(f.der) := i; f.der := (f.der + 1) mod f.max;end inserer;
procedure enlever (f : in out FileEntiers) isbegin if estVide(f) then raise FileVide; end if;
f.prem := (f.prem + 1) mod f.max; if f.prem = f.der then f.vide := true; end if;end enlever;
function longueur (f : in FileEntiers) return natural isbegin
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

74
return (f.der - f.prem) mod f.max;end longueur;
function premier (f : in FileEntiers) return integer isbegin if estVide(f) then raise FileVide; end if; return f.element(f.prem);end premier;
function estVide (f : in FileEntiers) return boolean isbegin return f.vide;end estVide;
function estPleine (f : in FileEntiers) return boolean isbegin return (f.prem = f.der) and not f.vide;end estPleine; end FileEntiers_P;
8.2.2 Représentation statique du TDA File en C
On utilise une gestion circulaire du tableau contenant les données.
Spécification : fichier FileEntiers.h// avec encapsulation des données dont la structure est définie dans le fichier FileEntiers.c#ifndef _FileEntiers_ // Le fichier FileEntiers.h ne doit être inclus #define _FileEntiers_ // qu'une seule fois
#ifndef _typeFileEntiers_ // Vue du type FileEntiers de l'extérieurtypedef void * FileEntiers;
#endif
extern FileEntiers creerFileEntiers( int);
extern int estVide (FileEntiers) ;/* Renvoie 1 (=true) si la FileEntiers est vide, 0 (=false) sinon */extern int estPleine (FileEntiers) ;/* Renvoie 1 si la FileEntiers est pleine, 0 sinon */extern int inserer( FileEntiers, int); extern int enlever( FileEntiers); extern int premier (FileEntiers, int *);
#endif
Mise en œuvre : fichier FileEntiers.c// Définition des données manipulées par le TDA
#include <malloc.h> // inclusion des bibliothèques utilisées#include <stdio.h>
#define _typeFileEntiers_ // Vue du type FileEntiers interne au module
typedef struct { int prem; int der; int vide; int max;
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

75
int * data;} Donnees;typedef Donnees * FileEntiers;
#include "FileEntiers.h" // ici la vue externe n’est pas définie
FileEntiers creerFileEntiers( int MAX_F) { // on précise le nombre d'éléments à la création FileEntiers f; f = (Donnees *) malloc (sizeof (Donnees)); (*f).data = (int *) malloc (MAX_F * sizeof (int)); (*f).prem = 0; (*f).der = 0; (*f).vide = 1; // true (*f).max = MAX_F; return f;}int estVide (FileEntiers f) { return ((*f).vide);}int estPleine (FileEntiers f) { return (((*f).prem == (*f).der) && (!(*f).vide));}int inserer( FileEntiers f, int item ) { if (estPleine(f)) return 0; // code d'erreur, 0 quand impossible (*f).data[(*f).der] = item; (*f).der = ((*f).der % (*f).max); (*f).vide = 0; // falsereturn 1; // code d'erreur : OK}int enlever( FileEntiers f) { if (estVide(f)) return 0; // code d'erreur, 0 quand impossible (*f).prem = ((*f).prem % (*f).max);; if ((*f).prem == (*f).der) (*f).vide = 1; // true return 1;}int premier (FileEntiers f, int * v) { if (estVide(f)) return 0; // code d'erreur, 0 quand impossible (*v) = (*f).data[(*f).prem]; return 1;}…
8.2.3 Représentation statique du TDA File en JAVA
On utilise une gestion circulaire du tableau contenant les données.
public class FileEntiers {
static int MAX_F = 100; protected int debut; protected int fin; protected boolean pleine, vide; protected int contenu[];
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

76
public FileEntiers() { debut = 0; fin = 0; pleine = false; vide = true; contenu = new int[MAX_F]; } public boolean estVide () { return vide; } public boolean estPleine() { return pleine; } public int premier() throws ExceptionFile { if (vide) throw new ExceptionFile("File vide dans 'premier'"); return contenu[debut]; } public void inserer(int x) throws ExceptionFile { if (pleine) throw new ExceptionFile("File pleine dans 'inserer'"); contenu[fin] = x; fin = fin+1; vide = false; if (fin == debut) pleine = true; } public void enlever() throws ExceptionFile { if (vide) throw new ExceptionFile("File vide dans 'enlever'"); debut = debut + 1; if (fin == debut) vide = true; pleine = false; }}
class ExceptionFile extends Throwable{ public ExceptionFile (String s) { super (s); }}
8.2.4 Représentation statique du TDA File en C++
//Queue.h #ifndef QUEUE_H#define QUEUE_H
typedef int queueElement; // change from int to suit your application
class Queue{ private: const int maxItems = 5; queueElement A[maxItems];
int head; int tail; int count; public: Queue(void); int enqueue( const queueElement & item ); int dequeue( queueElement & item ); int isEmpty(void);
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

77
int isFull(void); int length(void);};#endif
//Queue.cc #include "Queue.h"
Queue::Queue(void){ head = 0; tail = head; count = 0;}int Queue::enqueue( const queueElement & item ){ if ( isFull() ) return 0; else { A[tail] = item;
tail = (tail+1) % maxItems; count ++; return 1; } }int Queue::dequeue( queueElement & item ){ if ( isEmpty() ) return 0; else { head = (head+1) % maxItems; count --; return 1; }}int Queue::isEmpty(void){ return count==0;}int Queue::isFull(void){ return count==maxItems;}int Queue::length(void){ return count;}
//main.cc
#include "Queue.h"#include <iostream.h>
main()
{ Queue x; int i;
for( i=0; !x.isFull(); i++) x.enqueue(i); cout << endl <<"The queue length= "<< x.length() <<endl;
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

78
cout << "The queue contains :" << endl; while( !x.isEmpty() ) { x.dequeue(i); cout << i << endl; } cout << endl <<"The queue length= "<< x.length() <<endl; return 1;}
8.3 Implantation dynamique du TDA File
Chaque élément est contenu dans une cellule , celle-ci contient val qui est l'élément , et l'adresse de la cellule suivante , suiv , appelée aussi pointeur .
La tête est représentée par un couple de pointeurs , début et fin .
Si l'on désire un dimensionnement totalement dynamique de la pile, on utilisera une structure chaînée :Instructions : Implantation chaînée :File_P.creerFile(f);
File_P.inserer(f, 10);
File_P.inserer(f, 20);File_P.inserer(f, 30);File_P.inserer(f, 40);
File_P.enlever(f);
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

79
8.3.1 Représentation dynamique du TDA File en ADA et en C
En ce qui concerne la représentation dynamique du TDA File dans des langages ne possédant aucun mécanisme de gestion de structures de données dynamiques, il est plus efficace d’implanter le TDA dynamique de Liste est de considérer que :
inserer (f, e) insererEnQueue (f, e) enlever (f, e) enleverEnTete (f, e) creerFile(f) creerListe(f)
Toutes les autres opérations (estVide, premier, longueur) étant identiques à celles du TDA Liste.
8.3.2 Représentation dynamique du TDA File en Java
// Local class type used to construct the Queue class.class QueueNode { Object item; // Current item QueueNode link; // Link on the next item
public QueueNode () { // pas utile : constructeur par défaut item = null; link = null; } }
public class Queue { private QueueNode head; private QueueNode tail; private int itemCount; // Constructor. public Queue() { itemCount = 0; }//Returns whether the queue is empty. public boolean isEmpty() { return (itemCount == 0); }// Inserts an item into the queue.// param newItem, the new item to insert into the queue. public void insert(Object newItem) { QueueNode temp = new QueueNode();
temp.item = newItem; temp.link = null; if(tail == null) { head = temp; tail = temp; } else { tail.link = temp; tail = temp; } itemCount++; }
// Removes an item from the queue.
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

80
// return the item being removed from the queue or null if the queue is empty. public Object remove() { if(itemCount == 0) return null; Object temp = head.item; head = head.link; if(head == null) tail = null; itemCount--; return temp; }}
Une autre façon de gérer des File en JAVA consiste à utiliser une SDD de java.util:Vector pour lequel on connaît à la fois la référence du premier (indice 0) et du dernier (indice v.size() –1).élément. Vector est vue comme une structure statique (accès à un élément par son index) tout en ayant un comportement dynamique (possibilité d'insérer un élément à un index donné).Cela donne les opérations suivantes:
import java.util.Vector;class File { Vector elements;
public File () { elements = new Vector (); } public boolean estVide () { return elements.size() == 0; } public Object premier () { return elements.elementAt(0); } public void inserer (Object o) { elements.add(o); } public void enlever () throws ExceptionFile { if (this.estVide ( )) throw new ExceptionFile("File vide dans 'enlever'"); elements.removeElementAt(0); } public int longueur () { return elements.size(); }}
8.4 Utilisation du TDA File
Transformation d'une expression infixée totalement parenthésée en expression postfixée.
Expression initiale infixée, saisie au clavier et stockée dans une file :expression :infixée.premier infixée.dernier ( ( 1 0 + 2 ) * ( 5 - 3 ) * 2 ) + 1 2
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

81
Algorithme :
principal ( ) creerFileChar (infixée) ; creerFileChar (polonaise) ; transformer ( ) ; // l’infixée en polonaisefin
transformer ( )creerPileChar (pOperateurs) ;TQ non estVide(expression) FRE
analyser (premier (expression)) ; enlever (expression) ;
FTQTQ non estVide (pOperateurs) FRE
inserer (polonaise, sommet (pOperateurs)) ; depiler (pOperateurs) FTQfin
analyser (char c) si c == ‘)’ alors signaler la fin de l’expression ; sinonsi c == ‘(‘ alors // début d’une nouvelle expression : appel récursif de
transformer ( ) sinonsi operande (c) alors inserer (polonaise, c) ; sinon // c’est un opérateur TQ non estVide(pOperateurs) AND THEN
priorité(c) <= priorité(sommet(pOperateurs)) FREinserer (polonaise, sommet (pOperateur)) ;depiler (pOperateurs) ;
FTQ empiler (pOperateurs, c) ; fsifin
9 Listes (List)
Définitions :
Une liste est une suite finie (éventuellement vide) d'éléments. Une liste chaînée est une structure de données composée de blocs de même nature (appelés
éléments ou nœuds) chaînés de telle manière que chaque nœud, à l'exception du dernier, désigne son successeur.
Une liste est une abstraction qui représente une séquence d'éléments <e1, e2, ..., en> à laquelle on peut ajouter ou retirer un élément à n'importe quelle place. On peut considérer qu'un liste est une structure récursive composée d'une tête de liste et d'un reste qui est lui-même une liste. Il existe une liste particulière appelée "liste vide" qui ne contient aucun élément.On arrive alors à la définition suivante :Une liste d'objets est
• soit la liste vide,
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

82
• soit une paire (tète, reste) où tète est un objet contenant la valeur du premier élément et reste est une liste.
Dans ce cas la séquence d'éléments <a, b, c, d> sera représentée par la liste (a, (b, (c, (d, vide))))
9.1 Listes linéaires
Spécification de la Liste : Autre type utilisé :
• Elément // Type des éléments contenus dans la Liste
Opérations :
° créerListe : Liste // Crée une nouvelle Liste vide♦ en entrée : aucun♦ en sortie : l : Liste♦ pré-conditions : aucune♦ post-conditions : l définie et vide
° insérerEnTète : Liste x Elément Liste // insertion d'un élément en tète♦ en entrée : l : Liste; e : Elément♦ en sortie : l : Liste ♦ pré-conditions : e est du type des Eléments de l♦ post-conditions : en sortie, la Liste l avec un élément de plus en tète
° insérerEnQueue : Liste x Elément Liste // insertion d'un élément en queue♦ en entrée : l : Liste; e : Elément♦ en sortie : l : Liste ♦ pré-conditions : e est du type des Eléments de l♦ post-conditions : en sortie, la Liste l avec un élément de plus en queue
° insérerEléméntA : Liste x Elément x int Liste // insertion d'un élément en position i
♦ en entrée : l : Liste; e : Elément, i : int♦ en sortie : l : Liste ♦ pré-conditions : e est du type des Eléments de l, 0 <= i < longueur(l)♦ post-conditions : en sortie, la Liste l avec un élément de plus en position i
° changeEléméntA : Liste x Elément x int Liste // changement de la valeur de l'élément en position i
♦ en entrée : l : Liste; e : Elément, i : int♦ en sortie : l : Liste ♦ pré-conditions : e est du type des Eléments de l, 0 <= i < longueur(l)♦ post-conditions : en sortie, l'élément en position i de la Liste l a changé de
valeur
° enleverEnTète : Liste Liste // enlèvement de l'élément en tète♦ en entrée : l : Liste
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

83
♦ en sortie : l : Liste♦ pré-conditions : l est non vide♦ post-conditions : en sortie, on obtient la Liste l privée de son élément de tète
° enleverEnQueue : Liste Liste // enlèvement de l'élément en tète♦ en entrée : l : Liste♦ en sortie : l : Liste♦ pré-conditions : l est non vide♦ post-conditions : en sortie, on obtient la Liste l privée de son élément de queue
° enleverElémentA : Liste x int Liste // enlèvement de l'élément en tète♦ en entrée : l : Liste, i : int♦ en sortie : l : Liste♦ pré-conditions : l est non vide, 0 <= i < longueur(l)♦ post-conditions : en sortie, on obtient la Liste l privée du ième élément
° premier : Liste Elément // retourne l'élément en tète♦ en entrée : l : Liste♦ en sortie : e : Elément♦ pré-conditions : l non vide♦ post-conditions : e est l'élément placé en tète de l (l est inchangée).
° dernier : Liste Elément // retourne l'élément en queue♦ en entrée : l : Liste♦ en sortie : e : Elément♦ pré-conditions : l non vide♦ post-conditions : e est l'élément placé en queue de l (l est inchangée).
° élementA : Liste x int Elément // retourne le ième élément de la Liste♦ en entrée : l : Liste, i : int♦ en sortie : e : Elément♦ pré-conditions : l non vide, 0 <= i < longueur(l)♦ post-conditions : e est le ième élément de l (l est inchangée).
° estVide : Liste booléen // teste si la Liste est vide♦ en entrée : l : Liste♦ en sortie : booléen♦ pré-conditions : aucune♦ post-conditions : renvoie vrai ssi la Liste ne contient aucun élément
° présent : Liste x Elément booléen // teste si un élément est présent dans la Liste♦ en entrée : l : Liste, e : Elément♦ en sortie : booléen♦ pré-conditions : aucune♦ post-conditions : renvoie vrai ssi la Liste contient cet élément
° longueur: Liste int // longueur ou nombre d'éléments♦ en entrée : f : Liste
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

84
♦ en sortie : l : int♦ pré-conditions : aucune♦ post-conditions : l est le nombre d'éléments placés dans f
° concat: Liste x Liste Liste // concaténation de la 2eme Liste à la première♦ en entrée : l, l2 : Liste♦ en sortie : l : Liste♦ pré-conditions : aucune♦ post-conditions : l est formée des élément de l, suivis des éléments de l2
Axiomes : l : Liste; e : Elément° (1) estVide (créerListe ()) == vrai° (2) longueur (créerListe ()) == 0° (3) estVide (insérer (l, e)) == faux° (4) longueur (insérer (l, e)) == longueur (l) + 1° (5) premier (insérerEnTète (l, e)) == e° (6) dernier (insérerEnQueue (l, e)) == dernier (l) // non estVide (l)° (7) enleverEn[Tète|Queue] (insérerEn[Tète|Queue] (créerListe (), e)) ==
créerListe ()° (8) enleverEn[Tète|Queue] (insérerEn[Tète|Queue] (l, e)) ==
insérerEn[Tète|Queue] (enleverEn[Tète|Queue] (l, e)) // non estVide (l)° (9) concat (l, insérerEnTète (créerListe (), e)) == insérerEnQueue (l, e)° (10) premier (concat (créerListe (), l)) == premier (l) // non estVide (l)° (11) premier (concat (l1, l2)) == tète (l1) // non estVide (l1)° (12) eléméntAt(l, 0) == premier(l) // non estVide (l)° (13) elémentAt (longueur (l) –1) == dernier (l) // non estVide (l)° (14) présent (insérerEn[Tète|Queue] (l, e)) == True° …
9.2 Listes Triées
Le type Liste vu précédemment peut être étendu pour définir le type ListeTriée.Les éléments d'une ListeTriée doivent pouvoir être rangés de manière croissante ou décroissante.Les éléments de la ListeTriée doivent être "Comparable" c'est-à-dire munis d'un opérateur booléen < permettant d'ordonner les éléments.L'opérateur == doit lui aussi être défini sur les Eléments.
Spécification de la ListeTriée : Etend :
• Liste Autre type utilisé :
• Comparable // Contrainte sur les Eléments de la ListeTriée
Opérations ajoutées :
° créerListeTriée : ListeTriée // Création d'une nouvelle ListeTriée♦ en entrée : aucun♦ en sortie : l : ListeTriée
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

85
♦ pré-conditions : aucune♦ post-conditions : l est définie et vide
° triée : Liste boolean // test de tri d'une Liste quelconque♦ en entrée : l : Liste♦ en sortie : b : boolean♦ pré-conditions : aucune♦ post-conditions : retourne True si la Liste est triée, False sinon
° insérer : ListeTriée x Elément ListeTriée // Ajout d'un Elément à sa place♦ en entrée : l : ListeTriée, e : Comparable♦ en sortie : l : ListeTriée♦ pré-conditions : aucune♦ post-conditions : l'élément e est ajouté au rang i dans la ListeTriée :
l[0..i[ < l[i] <= l[i+1..longueur(l)[
Axiomes : l : ListeTriée; e : Elément° (1) estVide (créerListeTriée ()) == True° (2) triée (créerListe ()) == True° (3) triée (insérer (créerListe (), e)) == True
9.3 Implantation semi-dynamique (Curseurs)
Une implantation totalement statique, dans un tableau sera totalement inefficace car il faudra faire des décalages dans le tableau chaque fois qu’un élément qui ne se trouve ni en tète ni en queue est enlevé.
Pour palier ce problème, on propose une implantation semi-dynamique, stockée dans un tableau mais où chaque élément connaît l’indice de son suivant. La valeur (-1) signifiant qu'il n'y a pas de suivant (l'équivalent d'un pointeur suivant NULL et implantation dynamique).
Avantage Gestion directe de l'espace Inconvénient Choix de MAX ?
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

86
Il est très utile de chaîner les emplacements libres de façon à obtenir immédiatement l'indice d'un emplacement disponible et savoir instantanément (sans parcourir le tableau) si tout est occupé.
Initialement : la totalité des emplacements sont disponibles :
L'opération d'insertion demande l'allocation d'un emplacement, celui-ci sera le premier disponible, celui en tète de la liste des libres (ici celui d'indice 0). La valeur à insérer sera donc placée à l'indice 0.L'emplacement d'indice 0 est enlevé de la Liste des emplacements libres qui commencera donc ensuite au suivant de celui-ci (ici l'emplacement d'indice 1).
Quand un élément est retiré de la Liste, son emplacement devient disponible et il doit donc être inséré en tète de la Liste des emplacements libres.
Après un certain nombre de manipulations sur la Liste : insertions et enlèvement, on se retrouve dans la configuration suivante :
9.3.1 Implantation semi-dynamique en ADA
package ListeEntiers_P is -- déclarations des attributs (données) exportés par le TDA
-- les données de la Liste ne sont pas accessibles et la taille de la Liste est donnée
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

87
-- lors de la création de la Listetype ListeEntiers (maxP : positive) is private; LISTE_VIDE, LISTE_PLEINE, ERREUR_INDEX : exception;
-- déclarations des opérations exportées par le TDAprocedure creerListe (le: out ListeEntiers);procedure insererEnTete (le : in out ListeEntiers; i : integer);procedure insererEnQueue (le : in out ListeEntiers; i : integer);procedure insererElementA (le : in out ListeEntiers; i : integer; index : integer);procedure enleverEnTete (le : in out ListeEntiers);procedure enleverEnQueue (le : in out ListeEntiers);procedure enleverElementA (le : in out ListeEntiers; index : integer);procedure changeElementA (le : in out ListeEntiers; i : integer; index : integer);function premier (le : in ListeEntiers) return integer;function dernier (le : in ListeEntiers) return integer;function elementA (le : in ListeEntiers; index : integer) return integer;function estVide (le : in ListeEntiers) return boolean;function present (le : in ListeEntiers; i : integer) return boolean;function longueur (le : in ListeEntiers) return integer;
private -- type tableau non contraint, ainsi la Liste déclarera le nombre de données nécessaire type Element is record valeur : integer; suivant : integer; end record; type Donnees is array (natural range <>) of Element; type ListeEntiers (maxP : positive) is record premier : integer ; dernier : integer ; libre : integer;
-- le tableau commence en 0 pour être homogène avec d'autres représentations-- JAVA par exemple
data : Donnees (0..maxP);end record;
end ListeEntiers_P;
package body ListeEntiers_P is
-- procédures internes au body non vues de l'extérieur
-- permet d'obtenir l'indice d'un emplacement libreprocedure allouer(le : in out ListeEntiers; index : out integer) isbegin if (le.libre = -1) then index := -1; else index := le.libre; le.libre := le.data(le.libre).suivant; end if;end allouer;-- permet de remettre l'indice d'un emplacement dans la Liste des libresprocedure desallouer(le : in out ListeEntiers; index : integer) isbegin le.data(index).suivant := le.libre; le.libre := index;end desallouer;
-- recherche l'indice du index'ième élément ainsi que l'indice de son précédentprocedure rechercherIndice (le : ListeEntiers; index : integer;
indPred : out integer; indRech : out integer) is iStop : integer;
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

88
irech : integer;begin if (index = 0) then indPred := -1; iRech := le.premier; elsif (index = longueur(le))then indPred := le.dernier; iRech := -1; elsif (index < 0) or (longueur(le) < index) then indPred := -1; iRech := -1; else -- rechercher le ième élément de la Liste indPred := le.premier; iRech := le.data(le.premier).suivant; iStop := 1; while iStop < index loop indPred := iRech; iRech := le.data(iRech).suivant; iStop := iStop + 1; end loop; end if; indRech := iRech;end rechercherIndice;
-- corps des opérations exportées par le TDA
procedure creerListe (le: out ListeEntiers) isbegin le.premier := -1; le.dernier := -1; le.libre := 0; -- chaînage des libres dans tout le tableau for i in le.data'first .. le.data'last-1 loop le.data(i).suivant := i+1; end loop; le.data(le.data'last).suivant := -1;end creerListe;
procedure insererEnTete (le : in out ListeEntiers; i : integer) is index : integer;begin -- obtention d'un indice d'emplacement libre allouer(le, index); if (index = -1) then raise LISTE_PLEINE; end if; -- cet emplacement est placé en tète de le et devient le nouveau premier le.data(index).valeur := i; le.data(index).suivant := le.premier; le.premier := index;end insererEnTete;
procedure insererEnQueue (le : in out ListeEntiers; i : integer) is index : integer;begin -- obtention d'un indice d'emplacement libre allouer(le, index); if (index = -1) then raise LISTE_PLEINE; end if;
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

89
-- cet emplacement est placé après le dernier élément de le et -- devient le nouveau dernier le.data(index).valeur := i; le.data(le.dernier).suivant := index; le.dernier := index;end insererEnQueue;
-- insertion d'un élément avant le index'ième de leprocedure insererElementA (le : in out ListeEntiers; i : integer; index : integer) is indice, indRech, indPred : integer;begin -- obtention de l'indice du index'ième élément, ainsi que de l'indice du precédent rechercherIndice (le, index, indPred, indRech); -- réutilisation des méthodes déjà écrites if index = 0 then insererEnTete(le, i); elsif index = longueur(le) then insererEnQueue(le, i); -- cas d'erreur quand l'index est hors des limites de le elsif (index < 0) or (longueur(le) < index) then raise ERREUR_INDEX; else -- obtention d'un indice d'emplacement libre allouer(le, indice); if indice = -1 then raise LISTE_PLEINE; end if; -- cet élément est placé entre celui d'indice indPrec et celui d'indice indRech le.data(indice).valeur := i; le.data(indice).suivant := indRech; le.data(indPred).suivant := indice; end if;end insererElementA;
procedure enleverEnTete (le : in out ListeEntiers) is index : integer := le.premier;begin if estVide(le) then raise LISTE_VIDE; end if; -- l'élément suivant le premier devient le nouveau premier le.premier := le.data(le.premier).suivant; -- l'emplacement qui devient libre est inséré en tète de la Liste des libres desallouer(le, index);end enleverEnTete;
procedure enleverEnQueue (le : in out ListeEntiers) is indPred, indRech : integer;begin if estVide(le) then raise LISTE_VIDE; end if; -- recherche de l'indice du dernier et de l'avant dernier rechercherIndice (le, longueur(le)-1, indPred, indRech); -- l'avant dernier devient le nouveau dernier le.dernier := indPred; le.data(le.dernier).suivant := -1; -- l'emplacement qui devient libre est inséré en tète de la Liste des libres desallouer(le, indRech);end enleverEnQueue;
procedure enleverElementA (le : in out ListeEntiers; index : integer) is indPred, indRech : integer;begin if estVide(le) then raise LISTE_VIDE; end if; -- réutilisation des méthodes déjà écrites if index = 0 then
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

90
enleverEnTete(le); elsif index = longueur(le)-1 then enleverEnQueue(le); -- cas d'erreur quand l'index est hors des limites de le elsif (index < 0) or (longueur(le) <= index) then raise ERREUR_INDEX; else -- recherche de l'indice du index'ième élément et de son précédent rechercherIndice (le, index, indPred, indRech); -- le précédent est chaîné avec le suivant du index'ième le.data(indPred).suivant := le.data(indRech).suivant; -- l'emplacement qui devient libre est inséré en tète de la Liste des libres desallouer(le, indRech); end if;end enleverElementA;
procedure changeElementA (le : in out ListeEntiers; i : integer; index : integer) is indPred, indRech : integer;begin if estVide(le) then raise LISTE_VIDE; end if; -- la valeur du premier élément est modifiée if index = 0 then le.data(le.premier).valeur := i; -- la valeur du dernier élément est modifiée elsif index = longueur(le)-1 then le.data(le.dernier).valeur := i; -- cas d'erreur quand l'index est hors des limites de le elsif (index < 0) or (longueur(le) <= index) then raise ERREUR_INDEX; else -- recherche de l'indice du index'ième élément rechercherIndice (le, index, indPred, indRech); -- modification de sa valeur le.data(indRech).valeur := i; end if;end changeElementA;
function premier (le : in ListeEntiers) return integer isbegin if estVide(le) then raise LISTE_VIDE; end if; return (le.data(le.premier).valeur);end premier;
function dernier (le : in ListeEntiers) return integer isbegin if estVide(le) then raise LISTE_VIDE; end if; return (le.data(le.dernier).valeur);end dernier;
function elementA (le : in ListeEntiers; index : integer) return integer is indPred, indRech : integer;begin if estVide(le) then raise LISTE_VIDE; end if; if index = 0 then return(le.data(le.premier).valeur); elsif index = longueur(le)-1 then return(le.data(le.dernier).valeur); elsif (index < 0) or (longueur(le) <= index) then raise ERREUR_INDEX; else rechercherIndice (le, index, indPred, indRech); return(le.data(indRech).valeur); end if;
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

91
end elementA;
function estVide (le : in ListeEntiers) return Boolean isbegin return (le.premier = -1);end estVide;
function present (le : in ListeEntiers; i : integer) return Boolean is index : integer;begin index := le.premier; while (index < longueur(le)) loop if (le.data(index).valeur = i) then return true; end if; index := le.data(index).suivant; end loop; return false; -- pas trouvéend present;
-- retourne le nombre d'éléments dans la Listefunction longueur (le : in ListeEntiers) return integer is index, cpt : integer;begin if estVide(le) then return 0; end if; index := le.premier; cpt := 1; while (le.data(index).suivant /= 0) loop index := le.data(index).suivant; cpt := cpt + 1; end loop; return cpt;end longueur;end ListeEntiers_P;
9.4 Implantation dynamique
La tète de Liste contient l'adresse du premier élément. Ensuite, chaque élément contient un champ suivant qui donne l'adresse de l'élément suivant, et ainsi de suite jusqu'au dernier élément dont le suivant est à NULL.
Avantagesgestion dynamique de l'espace mémoirepossibilité d'insérer des éléments tant que l'allocation d'un nouvel espace mémoire est possible
Inconvénientpas d'accès direct, la liste doit être parcourue, élément par élément.
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

92
9.4.1 Implantation dynamique en C
Notations : (*pt).v ptv
Spécification : fichier ListeEntiers.h// avec encapsulation des données dont la structure est définie dans le fichier ListeEntiers.c
#ifndef _ListeEntiers_ // Le fichier ListeEntiers.h ne doit être inclus #define _ListeEntiers_ // qu'une seule fois
#ifndef _typeListeEntiers_ // Vue du type ListeEntiers de l’extérieur typedef void * ListeEntiers; #endif
static const int LISTE_VIDE = 1;static const int LISTE_PLEINE = 2;static const int ERREUR_INDEX = 3;static const int TRUE = 1;static const int FALSE = 0;
ListeEntiers creerListeEntiers( );extern int estVide (ListeEntiers) ;/* Renvoie 1 (=true) si la ListeEntiers est vide, 0 (=false) sinon */extern int estPleine (ListeEntiers);/* Renvoie 1 si la ListeEntiers est pleine, 0 sinon */extern int insererEnTete(ListeEntiers, int); extern int insererEnQueue(ListeEntiers, int); extern int insererElementA(ListeEntiers, int /* valeur */, int /* index */); extern int changerElementA(ListeEntiers, int /* valeur */, int /* index */); extern int enleverEnTete(ListeEntiers); extern int enleverEnQueue(ListeEntiers); extern int enleverElementA(ListeEntiers, int /* index */); extern int premier (ListeEntiers, int *);extern int dernier (ListeEntiers, int *);extern int present (ListeEntiers, int /* valeur */); // retourne 1 si la valeur est présente, 0 sinonextern int elementA (ListeEntiers, int /* index */, int *);extern int longueur (ListeEntiers);
#endif
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

93
Mise en œuvre : fichier ListeEntiers.c// Définition des données manipulées par le TDA
#include <malloc.h> // inclusion des bibliothèques utilisées#include <stdio.h>
#define _typeListeEntiers_ // Vue du type ListeEntiers interne au module
typedef struct cellule_{ struct cellule_ * suiv; int valeur;}Cellule;typedef Cellule * PtCellule;
typedef struct { PtCellule premier; PtCellule dernier;} CelluleListe;typedef CelluleListe * ListeEntiers;
#include "essai.h" // ici la vue externe n’est pas définie
PtCellule chercherPrec (ListeEntiers le, PtCellule pc) { PtCellule pt = le->premier;
while (pt != NULL) { if(pt->suiv == pc) return pt; else pt = pt->suiv; } return pt;}
ListeEntiers creerListeEntiers( ) { ListeEntiers le = (ListeEntiers) malloc (sizeof(CelluleListe)); le->premier = NULL; le->dernier = NULL; return le;}
/* Renvoie 1 (=true) si la ListeEntiers est vide, 0 (=false) sinon */int estVide (ListeEntiers le) { return (le->premier == NULL);}
/* Renvoie 1 si la ListeEntiers est pleine, 0 sinon */int estPleine (ListeEntiers le) { PtCellule c = (PtCellule) malloc (sizeof(Cellule)); if (c != NULL) {free (c); return FALSE; } // on peut encore allouer return TRUE;}int insererEnTete(ListeEntiers le, int i) { PtCellule pt = (PtCellule) malloc (sizeof(Cellule)); if (estPleine(le)) return LISTE_PLEINE; pt->suiv = le->premier; pt->valeur = i; le->premier = pt; if (le->dernier == NULL) le->dernier = pt;
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

94
return TRUE;}int insererEnQueue(ListeEntiers le, int i) { PtCellule pt = (PtCellule) malloc (sizeof(Cellule)); if (estPleine(le)) return LISTE_PLEINE; pt->suiv = NULL; pt->valeur = i; le->dernier = pt; if (le->premier == NULL) le->premier = pt; return TRUE;}int insererElementA(ListeEntiers le, int valeur, int index) { PtCellule pt = le->premier; PtCellule ptnew = (PtCellule) malloc (sizeof (Cellule)); int cpt = 0; if (estVide(le)) return LISTE_VIDE; if (index == 0) { insererEnTete(le, valeur); return TRUE; } while (pt != NULL) { if (cpt == index-1) { // trouvé l'élément juste avant !! ptnew->valeur = valeur; ptnew->suiv = pt->suiv; pt->suiv = ptnew; return TRUE; } // pas trouvé, on passe au suivant cpt++; pt = pt->suiv; } // pas trouvé du tout !! return ERREUR_INDEX;}int changerElementA(ListeEntiers le, int valeur, int index) { PtCellule pt = le->premier; int cpt = 0;
if (estVide(le)) return LISTE_VIDE; while (pt != NULL) { if (cpt == index) { // trouvé !! pt->valeur = valeur; return TRUE; } // pas trouvé, on passe au suivant cpt++; pt = pt->suiv; } // pas trouvé du tout !! return ERREUR_INDEX;}int enleverEnTete(ListeEntiers le) { if (estVide(le)) return LISTE_VIDE; le->premier = le->premier->suiv; if (estVide(le)) le->dernier = NULL; return TRUE;}int enleverEnQueue(ListeEntiers le) { PtCellule pt;
if (estVide(le)) return LISTE_VIDE; if (le->premier == le->dernier) {
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat
95
le->premier = NULL; le->dernier = NULL; return TRUE; // traitement fini } // sinon il reste au moins 2 éléments pt = chercherPrec(le, le->dernier); le->dernier = pt; free(pt->suiv); pt->suiv = NULL; return TRUE;}int enleverElementA(ListeEntiers le, int index) { PtCellule pt = le->premier; PtCellule prec; int cpt = 0;
if (estVide(le)) return LISTE_VIDE; while (pt != NULL) { if (cpt == index) { // trouvé !! // cas d'un seul élément if ((pt == le->premier) && (pt == le->dernier)) { le->dernier = NULL; le->premier = NULL; free(pt); return TRUE; } // cas où on enlève le premier élément (qui n'est pas seul) if (pt == le->premier) le->premier = pt->suiv; else { prec = chercherPrec (le, pt); // recherche du précédent // cas où on enlève le dernier élément (non seul) if (pt == le->dernier) { le->dernier = prec; le->dernier->suiv = NULL; } else // cas général // chaînage du précédent avec le suivant de pt prec->suiv = pt->suiv; } free(pt); return TRUE; } // pas trouvé, on passe au suivant cpt++; pt = pt->suiv; } // pas trouvé du tout !! return ERREUR_INDEX;}int premier (ListeEntiers le, int * i) { if (estVide(le)) return LISTE_VIDE; (*i) = le->premier->valeur; return TRUE;}int dernier (ListeEntiers le, int * i) { if (estVide(le)) return LISTE_VIDE; (*i) = le->dernier->valeur; return TRUE;}int present (ListeEntiers le, int valeur) { // retourne 1 si la valeur est présente, 0 sinon PtCellule pt = le->premier;
while (pt != NULL) {
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

96
if (pt->valeur == valeur) return TRUE; pt = pt->suiv; } return FALSE;}int elementA (ListeEntiers le, int index, int * i) { PtCellule pt = le->premier; int cpt = 0;
if (estVide(le)) return LISTE_VIDE; while (pt != NULL) { if (cpt == index) { (*i) = pt->valeur; return TRUE; } cpt++; pt = pt->suiv; } return ERREUR_INDEX;}int longueur (ListeEntiers le) { PtCellule pt = le->premier; int cpt = 0;
while (pt != NULL) { cpt++; pt = pt->suiv; } return cpt;}
9.5 Sentinelle et double chaînage
Une sentinelle est un pointeur qui se déplace d'élément en élément suivant pour permettre l'accès à un élément particulier de la liste.Cela permet entre autres un traitement séquentiel sur les éléments de la liste.
Tout traitement qui ne peut s'effectuer en un seul appel à une méthode peut avoir besoin de gérer un "curseur" sur la Liste afin de continuer le traitement là où il avait été arrêté.Par exemple un tri ou une partition de Liste dont la sentinelle sera positionnée après les éléments déjà triés.
La mise en place d'un double chaînage permet la gestion d'une Liste "par les deux bouts".Ceci est particulièrement utile lors de traitements qui nécessitent de parcourir la liste aussi fréquemment dans les deux sens.Cela évite notamment d'avoir à recommencer systématiquement le parcours depuis la tête de Liste pour trouver le prédécesseur d'un élément.
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

97
Généralement les Listes doublement chaînées possèdent également une sentinelle qui permet de gérer un "curseur" sur la Liste qui se déplace indifféremment dans les deux sens.Les Cellules d'une Liste doublement chaînée ont donc un champ supplémentaire : un pointeur vers l'élément précédent.
Il faut compléter la spécification de la Liste pour ajouter les opérations relatives à la gestion de la sentinelle. Le double chaînage n'entraîne pas de modifications visibles de l'extérieur du TDA, mais l'écriture des méthodes va être simplifiée et les temps de recherche d'un élément réduits.
Spécification de la Liste avec sentinelle :
ListeDB : // Liste Doublement Chaînée avec sentinelle Extends :
• Liste Autre type utilisé :
• Elément // Type des éléments contenus dans la Liste Opérations :
° sentinelleEnTete : Liste Liste // Place la sentinelle en début de Liste♦ en entrée : l : ListeDB♦ en sortie : l : ListeDB♦ pré-conditions : aucune♦ post-conditions : si l non vide : l.sentinelle = l.premier sinon l.sentinelle = null
° sentinelleEnQueue : ListeDB ListeDB // Place la sentinelle en fin de Liste♦ en entrée : l : ListeDB♦ en sortie : l : ListeDB♦ pré-conditions : aucune♦ post-conditions : si l non vide : l.sentinelle = l.dernier sinon l.sentinelle = null
° avancerSentinelle : ListeDB ListeDB // Place la sentinelle à l'élém suivant♦ en entrée : l : ListeDB♦ en sortie : l : Liste DB♦ pré-conditions : aucune♦ post-conditions : si possible : l.sentinelle = l.sentinelle.suivant
sinon l.sentinelle = null
° reculerSentinelle : ListeDB Liste // Place la sentinelle à l'élément préc♦ en entrée : l : ListeDB♦ en sortie : l : Liste DB♦ pré-conditions : aucune♦ post-conditions : si possible : l.sentinelle = l.sentinelle.précédent
sinon l.sentinelle = null
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

98
° elémentEnSentinelle : ListeDB Element // retourne l'élément courant♦ en entrée : l : ListeDB♦ en sortie : e : Element ♦ pré-conditions : sentinelle placée sur un élément de la ListeDB♦ post-conditions : e est l'élément pointé par la sentinelle
° modifElemSentinelle : ListeDB x Element ListeDB // modifie le courant♦ en entrée : l : ListeDB, e : Elément♦ en sortie : l : ListeDB ♦ pré-conditions : sentinelle placée sur un élément de la ListeDB♦ post-conditions : la valeur de l'élément pointé par la sentinelle a été modifiée
° enleverElemSentinelle : ListeDB ListeDB // supprime le courant♦ en entrée : l : ListeDB♦ en sortie : l : ListeDB ♦ pré-conditions : sentinelle placée sur un élément de la ListeDB♦ post-conditions : l'élément pointé par la sentinelle a été supprimé
° insérerAvantSentinelle : ListeDB x Elément ListeDB ♦ en entrée : l : ListeDB, e : Elément♦ en sortie : l : ListeDB ♦ pré-conditions : sentinelle placée sur un élément de la ListeDB♦ post-conditions : l'élément est inséré avant celui pointé par la sentinelle
° insérerAprèsSentinelle : ListeDB x Elément ListeDB ♦ en entrée : l : ListeDB, e : Elément♦ en sortie : l : ListeDB ♦ pré-conditions : sentinelle placée sur un élément de la ListeDB♦ post-conditions : l'élément est inséré après celui pointé par la sentinelle
Axiomes : l : Liste; e : Elément° (1) premier (sentinelleEnTète (le)) == premier (le)° (2) dernier (sentinelleEnQueue (le)) == dernier (le)° (3) premier (insérerAvantSentinelle(sentinelleEnTète(le), e)) == e° (4) dernier (insérerAprèsSentinelle(sentinelleEnQueue(le), e)) == e° (5) premier (insérerAprèsSentinelle(sentinelleEnQueue(le), e)) == premier(le)° (6) dernier (insérerAvantSentinelle(sentinelleEnTète(le), e)) == dernier(le)° (7) enleverElemSentinelle (sentinelleEnTète(le)) == enleverEnTète(le)° (8) enleverElemSentinelle (sentinelleEnQueue(le)) == enleverEnQueue(le)° …
9.6 Implantation récursive du TDA Liste
Ce type d'implantation équivaut à une vision récursive du type Liste : une Liste est composée d'une tète et d'une Liste (comme en LISP).
Avantages : Les fonctions de parcours sont plus faciles à écrire, l'expression est simple et lisible .
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

99
Exemple de méthodes implémentées récursivement en ADA :
generic type Element is private;package essai_p is
type Cellule;type ListeElements is access Cellule;type Cellule is record valeur : Element; suivant : ListeElements;end record;procedure insererEnQueue (tete : in out ListeElements; e : Element) ;function elementPresent (tete : ListeElements; e : Element) return boolean ;procedure supprimerTtOcc (tete : in out ListeElements; e : Element) ;procedure supprimerTtOccIT (tete : in out ListeElements; e : Element) ;function egalite (l1, l2 : ListeElements) return Boolean ;procedure clone (l1 : ListeElements; l2 : in out ListeElements) ;function estVide (tete : ListeElements) return boolean;end essai_p;
package body essai_p is
function estVide (tete : ListeElements) return boolean isbegin return tete = null;end estVide; function elementPresent (tete : ListeElements; e : Element) return boolean isbegin if estVide(tete) then return false; elsif tete.valeur = e then return true; else return elementPresent (tete.suivant, e); end if;end elementPresent;
procedure insererEnQueue (tete : in out ListeElements; e : Element) isbegin if estVide(tete) then tete := new Cellule'(e, null); else insererEnQueue (tete.suivant, e); end if;end insererEnQueue;
procedure supprimerTtOcc (tete : in out ListeElements; e : Element) isbegin if not estVide(tete) then if tete.valeur = e then tete := tete.suivant; supprimerTtOcc (tete, e); else supprimerTtOcc (tete.suivant, e); end if; end if;
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

100
end supprimerTtOcc;
----------------------------------------------------------------Le même en itératif :
procedure supprimerTtOccIT (tete : in out ListeElements; e : Element) is prec, pc : ListeElements; trouve : boolean;begin if (not estVide(tete)) then -- au moins 1 élément if tete.valeur = e then -- le supprimer tete := tete.suivant; else -- au moins 2 éléments pc := tete.suivant; prec := tete; -- rechercher l'élément à partir de pc while not estVide(pc) loop trouve := false; while (not estVide(pc)) and not trouve loop if pc.valeur = e then trouve := true; else prec := pc; pc := pc.suivant; end if; end loop; if trouve then prec.suivant := pc.suivant; end if; end loop; end if; end if;end supprimerTtOccIT;
function egalite (l1, l2 : ListeElements) return Boolean isbegin if estVide(l1) AND estVide(l2) then return true; elsif estVide(l1) or estVide(l2) then return false; else return (l1.valeur = l2.valeur) AND THEN egalite (l1.suivant, l2.suivant); end if;end egalite;
procedure clone (l1 : ListeElements; l2 : in out ListeElements) isbegin if estVide(l1) then l2 := null; else l2 := new Cellule'(l1.valeur, null); clone (l1.suivant, l2.suivant); end if;end clone;
end essai_p;
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

101
10 Graphes (Graphs)
Beaucoup de problèmes sont naturellement formulés en termes d'objets et de connexions, relations entre ces objets. Ces relations peuvent aussi bien être réelles (liaison ferroviaire entre deux villes) que virtuelles (relation d'ordonnancement dans une chaîne de montage). Par exemple, pour un réseau routier, on peut se demander :
Quel est le chemin le plus rapide pour aller de Genève à Nantes ? Quelle est la manière la plus économique d'aller de Genève à Nantes ?
Pour un circuit électrique : Tous les éléments sont-ils interconnectés ? Si un tel circuit est construit, fonctionnera-t-il ?
Pour l'ordonnancement de tâches d'un processus : Est-ce que toutes les tâches du processus de fabrication seront exécutables ? Dans quel ordre?
Un graphe est une structure qui modélise parfaitement de telles situations.
10.1 Graphes non orientés
Un Graphe non orienté est un couple G = (E, A) où E = {Sommets} et A = {(si, sj) / si A sj}. A est une relation symétrique dans E définissant les arêtes du Graphe : s1 A s2 l'arête non orienté (s1, s2) (ou (s2, s1)) est définie dans le Graphe.
10.2 Graphes orientés simples
10.2.1 Définitions
Terminologie :° sommet, nœud (vextex)° arc (arc)° arête (edge)° chemin (path)° orienté (directed)
Un Graphe est dit simple quand il n'existe pas plusieurs arcs de même origine et de même extrémité.
Un Graphe orienté est un couple G = (E, R) où E = {Sommets} et R = {(si, sj) / si R sj}. R est une relation binaire dans E définissant les arcs du Graphe : s1 R s2 l'arc (s1, s2) est défini dans le Graphe avec s1 prédécesseur de s2 et s2 successeur de s1, s1 origine de l'arc et s2 extrémité.
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

102
L'arc (s1, s2) est dit incident aux sommets s1, s2 et les sommets s1, s2 incidents à l'arc (s1, s2).
Exemple (1) de graphe simple orienté :
E = {1, 2, 3, 4, 5, 6, 7} R = {(1, 3), (1, 6), (4, 5), (5, 5), (6, 1), (6, 3), (6, 7), (3, 7), (3, 1)}
Le Graphe G = (E, R) est dit fini si E est fini. Alors R est aussi fini car card(R) <= card(E)².
Dans ce qui suit nous noterons R(si) l'ensemble des successeurs de si et R-1(si) l'ensemble des prédécesseurs de si.
Dans l'exemple : R(1) = {3, 6}, R(2) = ∅, R-1(3) = {1, 6} et R-1(4) = ∅.
Le demi-degré intérieur di et le demi-degré extérieur de du sommet si dans le graphe G sont définis par
• di(si) = card(R-1(si)) // nombre d'arcs entrants• de(si) = card(R(si)) // nombre d'arcs sortants
Le degré de si est défini par• d(si) = di(si) + de(si) // somme des arcs entrants et sortants
Un sommet sans prédécesseurs est appelé racine et un sommet sans successeurs feuille.Un sommet isolé est à la fois racine et feuille.
Dans l'exemple : di(6) = 1, de(3) = 2, d(3) = 4, 2 et 4 sont des racines, 2 et 7 sont des feuilles 2 est le seul sommet isolé.
Un chemin du sommet x au sommet y est une liste de sommets dans laquelle chaque sommet successif est relié au précédent par un arc. chemin c = (So,S1,...,Sk) / Si +1 adjacent à Si
Un graphe est connexe s'il existe un chemin de chaque sommet vers chaque autre sommet; sinon, il est formé de composantes connexes.
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

103
Un chemin simple est un chemin dans lequel aucun arc n'est répété.
Un cycle est un chemin simple ayant le même sommet aux deux extrémités. Cycle c = chemin (So,...Sk) avec So adjacent à Sk
Si un graphe, de S sommets, a moins de S-1 arcs il ne peut pas être connexe; s'il a plus de S-1 arcs, il doit avoir un cycle.
Un graphe est pondéré si, à chaque arc, on associe une valeur représentant par exemple une distance, un coût, un débit, etc. Les graphes orientés et pondérés sont appelés des réseaux.
10.3 Spécification du TDA GrapheOrienté simple
Autre type utilisé :• Sommet // Type sommet du graphe• Elément // Type des Eléments du GrapheO (stockés à un sommet)
Opérations:
° créerGrapheO : GrapheO // Création d'un nouveau GrapheO♦ en entrée : aucun♦ en sortie : g : GrapheO♦ pré-conditions : aucune♦ post-conditions : g est défini et vide
° ajoutSommet : GrapheO x Sommet GrapheO // Ajout d'un sommet♦ en entrée : s : Sommet, g : GrapheO♦ en sortie : g : GrapheO♦ pré-conditions : s n'est par déjà présent dans G♦ post-conditions : s a été ajouté à g
° ajoutArc : GrapheO x Sommet x Sommet GrapheO // Ajout d'un arc♦ en entrée : s1, s2 : Sommet, g : GrapheO♦ en sortie : g : GrapheO♦ pré-conditions : s1, s2 et g existent, mais l'arc (s1, s2) n'est pas déjà dans G♦ post-conditions : l'arc (s1, s2) a été ajouté à g
° supressionSommet : GrapheO x Sommet GrapheO //Sup d'un sommet♦ en entrée : s : Sommet, g : GrapheO♦ en sortie : g : GrapheO♦ pré-conditions : s et g existent, di(s) et de(s) == 0 (s sommet isolé)♦ post-conditions : s a été enlevé à g
° suppressionArc : GrapheO x Sommet x Sommet GrapheO // Sup d'un arc♦ en entrée : s1, s2 : Sommet, g : GrapheO♦ en sortie : g : GrapheO♦ pré-conditions : s1, s2 et g existent♦ post-conditions : l'arc (s1, s2) n'est pas dans g
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

104
° existeSommet : GrapheO x Sommet boolean // Sommet dans le GrapheO?♦ en entrée : s : Sommet, g : GrapheO♦ en sortie : b : boolean♦ pré-conditions : aucune♦ post-conditions : b = true si s est dans g, false sinon
° existeArc : GrapheO x Sommet x Sommet boolean // Arc dans GrapheO?♦ en entrée : s1, s2 : Sommet, g : GrapheO♦ en sortie : b : boolean♦ pré-conditions : aucune♦ post-conditions : b = true si l'arc (s1, s2) est dans g, false sinon
° degréIntérieur : GrapheO x Sommet integer // degré intérieur d'un Sommet♦ en entrée : s : Sommet, g : GrapheO♦ en sortie : i : integer♦ pré-conditions : s et g existent♦ post-conditions : i = nombre de sommets entrants en s
° degréExtérieur : GrapheO x Sommet integer // degré extérieur d'un Sommet♦ en entrée : s : Sommet, g : GrapheO♦ en sortie : i : integer♦ pré-conditions : s et g existent♦ post-conditions : i = nombre de sommets sortants de s
Axiomes : g : GrapheO; x, y, z, u : Sommet• (1) ajoutSommet (ajoutommet (g, x), y) ==
ajoutSommet (ajoutommet (g, y), x) // permutativité• (2) ajoutArc(ajoutArc(g, x, y), z, u) == ajoutArc(ajoutArc(g, , z, u) x, y) // permutat.• (3) ajoutArc(ajoutSommet(g, x), z, u) == ajoutSommet(ajoutArc(g, z, u) x) i• (4) existeSommet (créerGraphe( ), x) == false• (5) existeSommet (ajoutSommet(g, x), z) ==
° si (z == x) alors true sinon existeSommet(g, z) • (6) existeSommet(ajoutArc(g, x, y), z) == existeSommet(g, z)• (7) existeArc(créerGraphe( ), x, y) == false• (8) degréIntérieur(gréerGraphe( ), x) == 0• (9) degréIntérieur(ajoutSommet(g, x), z) ==
° si z == x alors 0 sinon degréIntérieur(g, z)• (10) degréIntérieur(ajoutArc(g, x, y), z) ==
° si z == y alors degréIntérieur(g, z) + 1 sinon degréIntérieur(g, z)• (8) degréExtérieur(gréerGraphe( ), x) == 0• (9) degréExtérieur(ajoutSommet(g, x), z) ==
° si z == x alors 0 sinon degréExtérieur(g, z)• (10) degréExtérieur(ajoutArc(g, x, y), z) ==
° si z == y alors degréExtérieur(g, z) + 1 sinon degréExtérieur(g, z)• (11) suppressionSommet (créerGraphe( ), x) == créerGraphe( )• (12) suppressionSommet(ajoutSommet(g, x), z) ==
° si x == z alors g sinon ajoutSommet(suppressionSommet(g, z), x)
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat
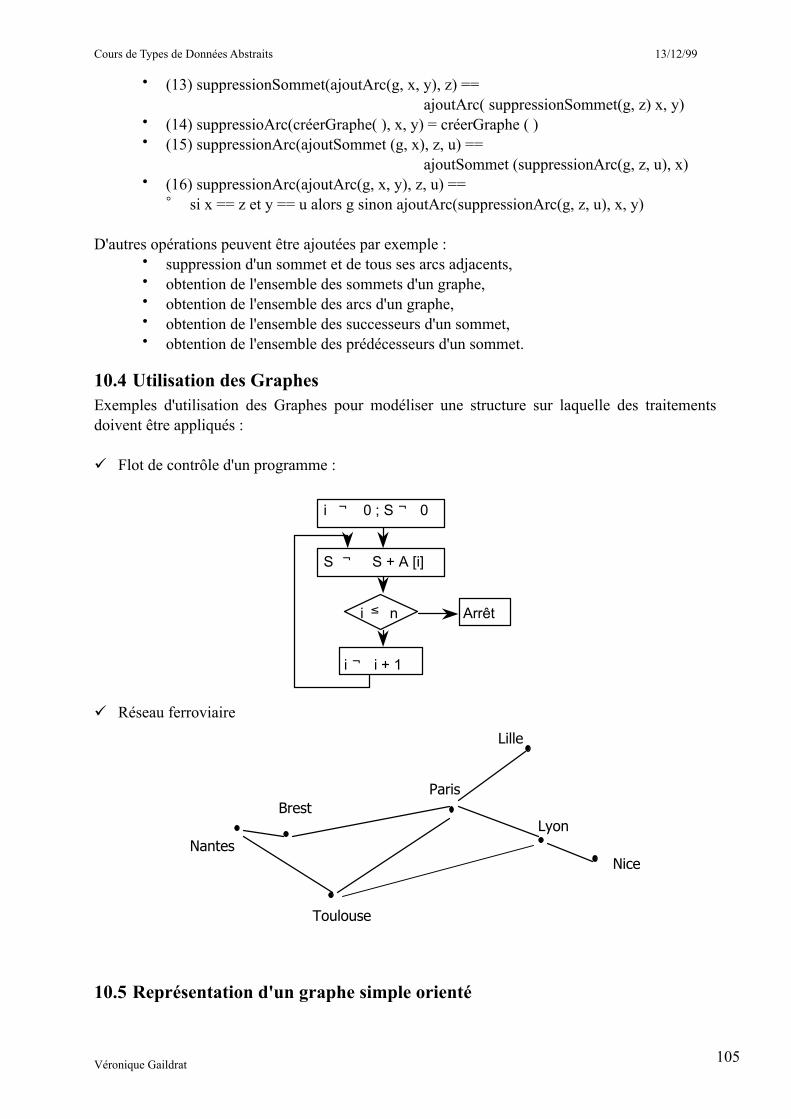
105
• (13) suppressionSommet(ajoutArc(g, x, y), z) == ajoutArc( suppressionSommet(g, z) x, y)
• (14) suppressioArc(créerGraphe( ), x, y) = créerGraphe ( )• (15) suppressionArc(ajoutSommet (g, x), z, u) ==
ajoutSommet (suppressionArc(g, z, u), x)• (16) suppressionArc(ajoutArc(g, x, y), z, u) ==
° si x == z et y == u alors g sinon ajoutArc(suppressionArc(g, z, u), x, y)
D'autres opérations peuvent être ajoutées par exemple : • suppression d'un sommet et de tous ses arcs adjacents,• obtention de l'ensemble des sommets d'un graphe,• obtention de l'ensemble des arcs d'un graphe,• obtention de l'ensemble des successeurs d'un sommet,• obtention de l'ensemble des prédécesseurs d'un sommet.
10.4 Utilisation des GraphesExemples d'utilisation des Graphes pour modéliser une structure sur laquelle des traitements doivent être appliqués :
Flot de contrôle d'un programme :
Réseau ferroviaire
10.5 Représentation d'un graphe simple orienté
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

106
10.5.1 Matrice booléenne associée (ou matrice d'adjacence)
La relation binaire R entre les sommets d'un graphe peut être représentée par une matrice carrée de booléens m = [mij] de n x n si n sommets sont dans le graphe. mij = existeArc(g, xi, xj) = xi R xj
Exemple : la matrice booléenne suivante correspond à l'exemple de graphe (1) :
1 2 3 4 5 6 71 0 0 1 0 0 1 0 2 0 0 0 0 0 0 0 3 1 0 0 0 0 0 1 4 0 0 0 0 1 0 0 5 0 0 0 0 1 0 0 6 1 0 1 0 0 0 1 7 0 0 0 0 0 0 0
Une telle matrice peut être stockée statiquement dans un tableau de (1..n, 1..n) booléens, mais si elle comporte beaucoup de valeurs à 0 (false) il est préférable de la stocker sous forme de matrice creuse.
Dans le cas ou les arcs sont pondérés l'élément m(i,j) contiendra la valeur associée à l'arc et une valeur particulière (null, 0 ou false) s'il n'existe pas d'arc entre i et j. Pour le graphe ci-dessous la matrice est la suivante:
Paris Lille Lyon Nice Toulouse Brest NantesParis null 200 300 null 600 350 nullLille 200 null null null null null nullLyon 300 null null 200 450 null nullNice null null 200 null null null nullToulouse 600 null 450 null null null 550Brest 350 null null null null null 300Nantes null null null null 550 300 null
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

107
10.5.2 Matrice d'incidence aux arcs
On suppose maintenant que les sommets sont numérotés de 1 à n mais aussi les arcs de 1 à p. La relation R peut être ainsi représentée par une matrice a = [aij] de taille n x p : aij = si le sommet xi est origine de l'arc aj alors –1
sinon si xi est l'extrémité de l'arc aj alors 1 sinon 0
Exemple : la matrice d'incidence suivante correspond à l'exemple (1) :
sommet \ arcs a b c d e f g h i1 -1 -1 0 0 1 0 0 0 1 2 0 0 0 0 0 0 0 0 0 3 1 0 0 0 0 1 0 -1 -1 4 0 0 -1 0 0 0 0 0 0 5 0 0 1 -1 0 0 0 0 0 6 0 1 0 0 -1 -1 -1 0 0 7 0 0 0 0 0 0 1 1 0
Cette matrice peut être stockée dans un tableau mais la place perdu est vraiment très importante car à chaque arc ne correspond qu'un et unique sommet origine et un ou zéro sommet extrémité (0 dans le cas d'un arc réflexif).
10.5.2.1 Première solution : Liste de successeurs
Exemple de stockage avec Liste de successeurs correspondant à l'exemple précédent :
Les opérations sur les graphes sont implantées en utilisant les opérations sur les Listes vues précédemment.Avec cette solution, le nombre d'arcs peut être étendu simplement en insérant une cellule à partir d'un sommet ou réduit en enlevant une cellule, mais il n'est pas possible d'étendre le nombre de sommets, ce qui est en contradiction avec la spécification du TDA GrapheO qui permet l'ajout de sommets.
10.5.2.2 Deuxième solution : Liste de sommets et de successeurs
Exemple de stockage avec Liste de sommets et de successeurs correspondant à l'exemple précédent :
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat
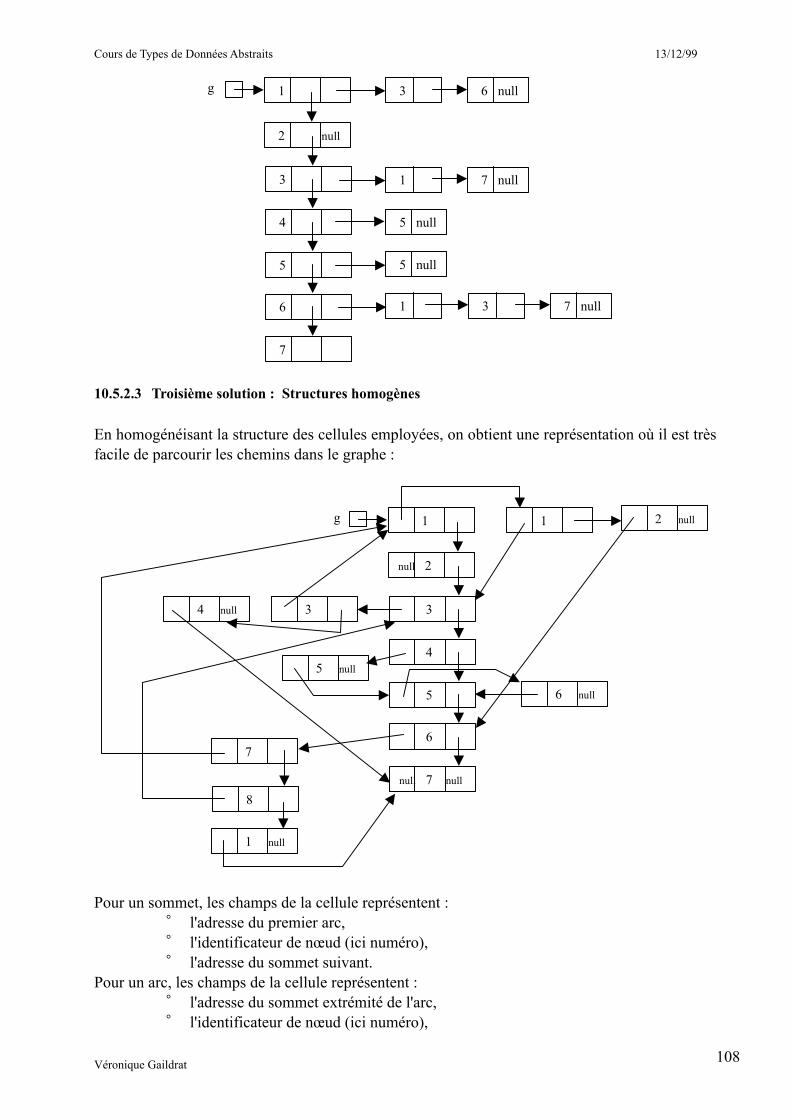
108
10.5.2.3 Troisième solution : Structures homogènes
En homogénéisant la structure des cellules employées, on obtient une représentation où il est très facile de parcourir les chemins dans le graphe :
Pour un sommet, les champs de la cellule représentent :° l'adresse du premier arc,° l'identificateur de nœud (ici numéro),° l'adresse du sommet suivant.
Pour un arc, les champs de la cellule représentent :° l'adresse du sommet extrémité de l'arc,° l'identificateur de nœud (ici numéro),
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

109
° l'adresse de l'arc suivant (dont le sommet origine est toujours donné par la tète de la liste d'arcs courante.
Avec cette représentation, on s'aperçoit qu'il est facile de suivre des chemins de sommet en sommet en passant par les arcs qui relient ces sommets :
Exemple : y a-t-il un chemin entre le sommet 1 et le sommet 7 : On suit le chaînage
° du sommet 1 à l'arc 1 au sommet 3,° du sommet 3 à l'arc 3 à l'arc 4 au sommet 7.
Bien entendu, ce chemin n'est pas trouvé directement et il faudra mettre en place un algorithme de parcours dans un graphe pour déterminer s'il existe ou non un chemin d'un nœud à un autre.
10.6 Parcours de Graphes
10.6.1 Parcours en profondeur
Version récursive :
procédure parcours (g : Graphe, ls : out ListeSommets) visité : boolean[g.nbSommets];début pour chaque sommet de s de G faire visité[s] := faux ; pour chaque sommet s de G faire si non visité [s] alors parcoursProf (g, s, ls) ;fin
procédure parcoursProf (g : Graphe, s : Sommet, ls : out ListeSommets, visité : in out Sommet[]) début
visité[s] := vrai ;insérer(ls, s);
pour chaque t adjacent à s faire si non visité[t] alors parcoursProf(t) ;fin
Version itérative :
procédure parcoursProf (g : Graphe, s : Sommet, ls : out ListeSommets, visité : in out Sommet[]) pile : PileSommets;début créerPile(pile); empiler (pile, s) ;
tant que (non estVide(pile)) faire { s' := sommet (pile) ;
dépiler (pile) ; si (non visité [s']) alors{ visité [s'] := vrai;
insérer(ls, s);pour t := dernier au premier sommet adjacent à s' faire
si (non visité [t]) alorspile:= empiler(pile, t) ;
} } fin
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

110
Cet algorithme appliqué au graphe ferroviaire entre villes donne la liste suivante : (Paris, Lille, Lyon, Nice, Toulouse, Nantes, Brest)
10.6.2 Parcours en largeur
Le parcours en largeur permet de savoir le nombre d'arcs parcourus pour atteindre un sommet à partir du nœud initial.Pour ceci, il faut stocker avec le nœud sa profondeur qui est celle du nœud dont il est issu incrémentée de 1.On définit donc une structure SommetProf qui permet d'insérer dans une Liste un Sommet et sa profondeur lors du parcours.
procédure parcours (g : Graphe, ls : out ListeSommets) type SommetProf {s : Sommet, prof : integer}; visité : boolean[g.nbSommets];début pour chaque Sommet de s de G faire visité[s] := faux ; pour chaque Sommet s de G faire si non visité [s] alors parcoursLarg (g, {s, 0}, ls) ;fin
procédure parcoursLarg (g : Graphe, sProf : SommetProf, ls : out ListeSommets, visité : Sommet[]) sProf' : SommeProf; file : FileSommets;début créerFile(file); file := insérer (file, sProf) ; tant que (non estVide(file)) faire { sProf' := premier(file) ;
file := enlever (file); si (non visité[sProf'.s]) alors { visité [sProf'.s] := vrai ; insérer(ls, sProf'); pour t := premier au dernier Sommet adjacent à s' faire si (non visité[t]) alors
file := insérer(file, {t, sProf'.prof+1}) ; } {fin
Cet algorithme appliqué au graphe ferroviaire entre villes donne la liste suivante : ({Paris, 0}, {Lille, 1}, {Lyon, 1}, {Toulouse, 1}, {Brest, 1}, {Nice, 2}, {Nantes, 2})
10.6.3 Détection d'un circuit
Un circuit est détecté lors d'un parcours en profondeur, quand à partir d'un sommet en cours d'exploration on atteint un autre sommet qui est également en cours d'exploration.
Définitions : G possède un circuit ssi il existe une arête arrière dans un parcours en profondeur de G
° d(s) : date de début d'appel de parcoursProf (s)° f(s) : date de fin d'appel de parcoursProf (s)
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

111
(s,t) arc de G est un° arc d'arbre ou arc avant ssi d(s) < d(t) < f(t) < f(s)° arc arrière ssi d(t) < d(s) < f(s) < f(t)° arc de traverse ssi f(t) < d(s)
Ce qui se ramène à trois états au cours d'une exploration :° état [s] = non visité° état [s] = en cours de visite° état [s] = déjà visité
Version récursive :
procédure parcours (g : Graphe, ls : out ListeSommets) état : Etat[g.nbSommets];début pour chaque sommet de s de G faire état[s] := non visité ; pour chaque sommet s de G faire si non visité [s] alors
parcoursProf (g, s, ls) ;fin
procédure parcoursProf (g : Graphe, s : Sommet, état : in out Sommet[]) début
état[s] := visite en cours ; pour chaque t adjacent à s faire si (état[t] = non visité) alors parcoursProf(t) ; sinon si ((état[t] = visite en cours) alors circuit !!!! état[s] := visité;fin
Version itérative :
procédure parcours (g : Graphe, ls : out ListeSommets)état : Etat[g.nbSommets];
début pour chaque sommet de s de G faire état[s] := non visité ; pour chaque sommet s de G faire si (non état[s] /= visité) alors parcoursProf (g, s, ls) ;fin
procédure parcoursProf (g : Graphe, s : Sommet, état : in out Sommet[]) pile : PileSommets;début créerPile(pile);
empiler (pile, s) ; tant que (non estVide(pile) faire { s' := sommet (Pile); si (état [s'] =non visité) alors { état [s'] := visite en cours ; pour t := dernier au premier Sommet adjacent de s' faire si (état [t] = non visité) alors pile := empiler (pile, t) ;
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat
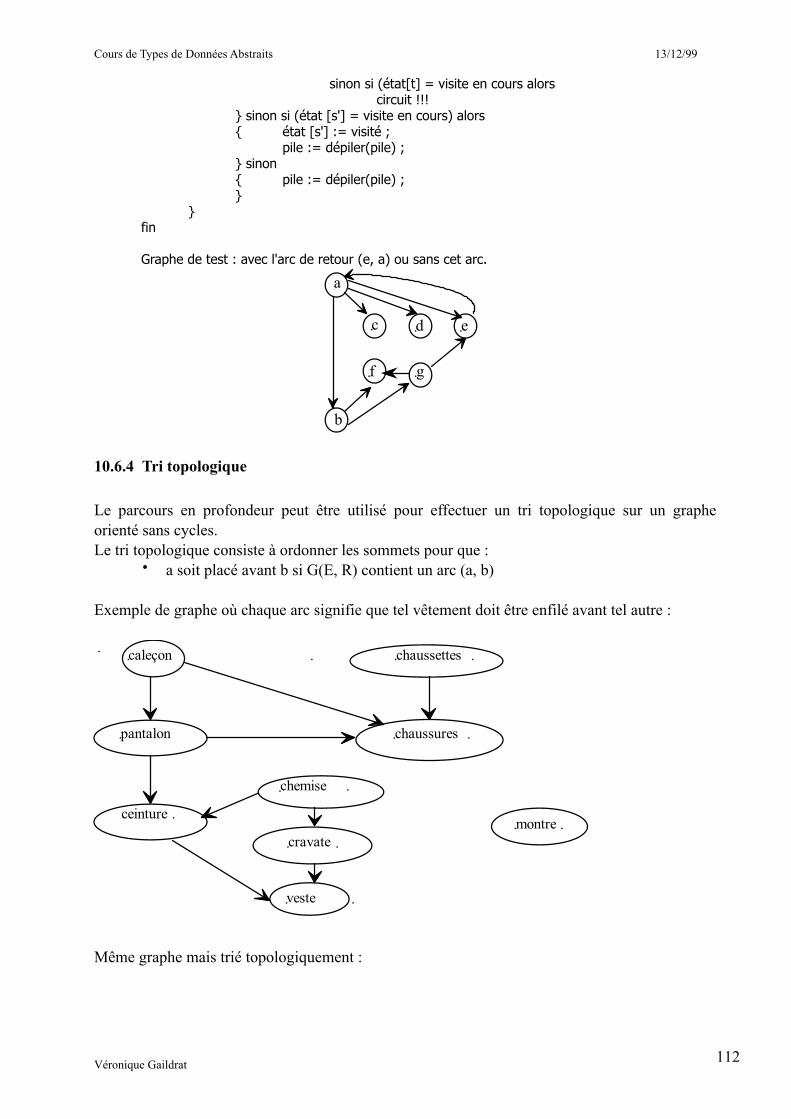
112
sinon si (état[t] = visite en cours alors circuit !!!
} sinon si (état [s'] = visite en cours) alors { état [s'] := visité ; pile := dépiler(pile) ;
} sinon { pile := dépiler(pile) ;
} } fin
Graphe de test : avec l'arc de retour (e, a) ou sans cet arc.
10.6.4 Tri topologique
Le parcours en profondeur peut être utilisé pour effectuer un tri topologique sur un graphe orienté sans cycles.Le tri topologique consiste à ordonner les sommets pour que :
• a soit placé avant b si G(E, R) contient un arc (a, b)
Exemple de graphe où chaque arc signifie que tel vêtement doit être enfilé avant tel autre :
Même graphe mais trié topologiquement :
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

113
Version itérative : fonction triTopologique (g : Graphe) return FileSommets file : FileSommets;début créerFile(file); tant que g non vide faire si tous les sommets ont un prédécesseur alors "G contient un circuit" sinon { s := sommet sans prédécesseur ; supprimerSommetsEtArcsAdjacents(g, s); insérer(file, s) ; } return (file) ;fin
Version récursive :
fonction triTopologique (g : Graphe ) return ListeSommets ; ls : ListeSommets; visité : Boolean[g.nbSommetq];début pour chaque sommet s de g faire visité [s] := faux ; créerListe(ls);
pour chaque sommet s de g faire si non visité [s] alors
topo (s, ls, visité) ; return (ls) ;fin
procédure topo (s sommet de g, ls : in out ListeSommets, visite : Boolean[]) début visité [s] := vrai ; pour chaque t adjacent à s faire si non visité [t] alors topo (t, ls, visite) ; insérerEnTête(ls, s);fin
11 Arbres
Un Arbre est un graphe sans circuit et avec une seule racine. Un ensemble d'arbres est appelé une forêt.Les Arbres et Forêts sont parmi les TDA les plus utilisés en informatique.
11.1 Terminologie
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

114
Un arbre peut être défini comme un Graphe tel que pour tout si, R-1(si) contient au plus un élément :
• chaque sommet ou nœud a 0 ou un prédécesseur,• le nœud particulier appelé racine a 0 prédécesseurs,• une feuille est un nœud sans successeur / R(s) = ∅,• un nœud interne est un sommet qui n'est pas une feuille,• un nœud interne est la racine d'un sous arbre, • le degré de branchement d'un nœud est le nombre de ses successeurs,• un arbre n-aire est un arbre dont le degré de branchement de tout nœud est au
maximum n,• un fils de si est un élément de R(si),• le père de si est l'élément unique de R-1(si) s'il existe,• deux nœuds de même père sont dits frères,• le nœud x est dit ascendant du nœud y si x est père de y ou ascendant du père de y,• le nœud y est dit descendant de x s'il est fils de x ou s'il est descendant d'un fils de x,• une branche d'un arbre est un chemin allant de la racine à une feuille• la taille d'un arbre est le nombre de ses nœuds,• la hauteur d'un nœud est la longueur du chemin entre la racine et ce nœud, elle est
aussi appelée profondeur, • la hauteur d'un arbre est la hauteur maximum des feuilles de cet arbre.
Exemple de 3 arbres dont un n'est constitué que d'une racine, le 2eme est 4-naire et le 3eme binaire :
On peut étiqueter les sommets et les arcs d'un Arbre comme dans les graphes. L'étiquette est placée à coté d'un nœud.
La définition la plus simple d'un arbre n-aire est récursive : on appelle Arbre n-aire une structure formée d'un Elément (donnée située à la racine de l'arbre) et d'un ensemble fini de 0 à n Arbres (appelés sous-arbres de l'Arbre racine).
11.2 Spécification du TDA ArbreBin (Type Arbre Binaire (2-aire))
Un Arbre Binaire est un graphe orienté tel que chaque noeud a au plus 2 fils appelés fils gauche et fils droit.Un nœud est composé de (fg : ArbreBin, e : Elément, fd : ArbreBin)
Autre type utilisé :• Elément // Type des Eléments de l'ArbreBin
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

115
Opérations:
° créerArbreBin : ArbreBin // Création d'un nouveau ArbreBin♦ en entrée : aucun♦ en sortie : a : ArbreBin♦ pré-conditions : aucune♦ post-conditions : a est défini et vide
° estVide : ArbreBin booléen // teste si l'ArbreBin est vide♦ en entrée : a : ArbreBin♦ en sortie : booléen♦ pré-conditions : aucune♦ post-conditions : renvoie vrai ssi l'arbre ne contient aucun élément
° créerNoeud : ArbreBin x Elément x ArbreBin ArbreBin// les deux arbres deviennent les fils gauches et droit de l'arbre créé
♦ en entrée : fg : ArbreBin, e : Elément, fd : ArbreBin♦ en sortie : a : ArbreBin♦ pré-conditions : aucune♦ post-conditions : a est défini, son fils gauche est fg, son fils droit est fd,
l'élément stocké à la racine de a est e
° filsGauche : ArbreBin ArbreBin // fournit le sous arbre gauche♦ en entrée : a : ArbreBin♦ en sortie : a' : ArbreBin♦ pré-conditions : a non vide♦ post-conditions : retourne le sous arbre gauche de a
° filsDroit : ArbreBin ArbreBin // fournit le sous arbre droit♦ en entrée : a : ArbreBin♦ en sortie : a' : ArbreBin♦ pré-conditions : a non vide♦ post-conditions : retourne le sous arbre droit de a
° racine : ArbreBin Elément // fournit l'Elément à la racine♦ en entrée : a : ArbreBin♦ en sortie : e : Elément♦ pré-conditions : a non vide♦ post-conditions : l'élément situé à la racine de a est retourné
° père : ArbreBin x ArbreBin ArbreBin // fournit le nœud père♦ en entrée : a : ArbreBin, n : ArbreBin dont on cherche le père dans a♦ en sortie : a' : Arbrebin♦ pré-conditions : aucune♦ post-conditions : a' est le nœud père de n s'il existe, null sinon
° taille : ArbreBin entier // fournit le nombre de nœuds de l'arbre
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

116
♦ en entrée : a : ArbreBin♦ en sortie : e : entier♦ pré-conditions : a non vide♦ post-conditions : e est le nombre de nœuds stockés dans l'arbre
° hauteur : ArbreBin entier // fournit la profondeur d'un nœud de l'arbre♦ en entrée : n : ArbreBin♦ en sortie : e : entier♦ pré-conditions : n nœud d'un arbre a non vide♦ post-conditions : e est le nombre de nœuds entre la racine(a) et n
Axiomes : a, fg, fd : ArbreBin; e : Elément° (1) estVide (créerArbreBin ()) == True° (2) estVide (créerNoeud (fg, e, fd)) == False° (3) filsGauche (créerNoeud (fg, e, fd)) == fg° (4) filsDroit (créerNoeud (fg, e, fd)) == fd° (5) racine (créerNoeud (fg, e, fd)) == e° (6) créerNoeud (filsGauche(a), racine(a), filsDroit(a)) == a° (7) père(créerArbre( )) == null° (8) a := créerNoeud(fg, e, fd) => père(fg) == a, père(fd) == a° (9) taille(créerArbreBin( )) == 0° (10) taille (créerNoeud(fg, e, fd)) = 1+taille(fg)+taille(fd)° (11) hauteur(créerArbre( )) == 0° (12) hauteur (n) == 1 + hauteur(père(n))
Ainsi un ArbreBin peut être construit de manière successive par création de nouveaux nœuds à partir de l'arbre vide.Exemple : créerNoeud ( créerNoeud ( créerNoeud ( créerArbreBin (),
5, créerArbreBin ()),
3, créerNoeud ( créerNoeud ( créerArbreBin (), 5, créerArbreBin ()), 7, créerArbreBin ()),
5, créerNoeud ( créerArbreBin (),
2, créerArbreBin ()).
Ce qui donne l'arbre suivant :
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

117
11.3 Utilisation des Arbres
Les répertoires (catalogues de fichiers) sont organisés de manière arborescente (Unix) :
Les Arbres sont également beaucoup utilisés en analyse syntaxique, ainsi à l'aide d'une grammaire, une phrase en langage naturel ou une instruction dans un langage de programmation peut être mise sous forme arborescente :
En math, les expressions arithmétiques sont arborescentes. Elles peuvent être représentées de façon concrète (les parenthèses sont utilisées pour modifier les priorités) ou bien de façon plus abstraite (sans parenthèses) :
Expression arithmétique : (a + b / c) * (d – 3 * b)
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

118
11.4 Parcours d'Arbre
Les parcours de Graphe peuvent s'appliquer aux Arbres, notamment les parcours en largeur qui ne sont pas différents pour les Arbres.
11.4.1 Parcours en profondeur d'abord
Nous allons ici voir 3 types de parcours particulièrement employés sur les Arbres qui sont très utilisés lors des traitements sur les Arbres.
Pour les arbres binaires : Pré-ordre ou parcours préfixé : la racine est d'abord traitée, puis récursivement le sous-arbre
gauche puis le sous-arbre droit. In-ordre ou parcours infixé : le sous-arbre gauche est d'abord traité, puis la racine, puis le
sous-arbre droit. Post-ordre ou parcours post-fixé : les sous-arbres gauches puis droit sont traités avant la
racine.
Préfixé Infixé Postfixé
procedure parcoursPréfixé ( a : ArbreBin) is begin
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

119
if (a /= null) then traiter (a.valeur);
parcoursPréfixé(a.fg); parcoursPréfixé(a.fd); end if; end parcoursPréfixé;
procedure parcoursInfixé ( a : ArbreBin) is begin if (a /= null) then parcoursInfixé(a.fg); traiter (a.valeur); parcoursInfixé(a.fd); end if; end parcoursInfixé;
procedure parcoursPostfixé ( a : ArbreBin) is begin if (a /= null) then parcoursPostfixé(a.fg); parcoursPostfixé(a.fd); traiter (a.valeur); end if; end parcoursPostfixé;
Pour les arbres n-aires : Parcours préfixé
P (a) = r.P(a1 ) . ... . P (ak ) Parcours suffixé
S (a) = S (a1 ) . ... . S (ak ). r Parcours symétrique (ou interne)
I (a) = I (a1 ). r.I (a2 ). ....I (ak )
Parcours Préfixé : première rencontre 1 2 5 6 3 7 9 10 4 8Parcours Suffixé : dernière rencontre 5 6 2 9 10 7 3 8 4 1 Parcours infixé : deuxième rencontre 5 2 6 1 9 7 10 3 8 4
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

120
11.5 Représentation des Arbres
Comme les Arbres sont des Graphes, les représentations données pour ceux-ci peuvent être utilisées, mais la spécificité des Arbres permet d'adopter des représentations plus efficaces.
11.5.1 Arbre Binaire : Représentation chaînée
Dans cette représentation très classique, un Arbre Binaire est un pointeur sur un nœud représenté par une cellule à trois champs : filsGauche, valeur, filsDroit.
Exemple : représentation de l'expression : (1 + a / (-b)) * ((c – 3) * d)
11.5.1.1 Implantation dynamique d'ArbreBin en ADA
generic type Element is private;package ArbreBin_P is
type ArbreBin is private;arbreVide, arbrePlein : exception;procedure creerArbreBin (a : out ArbreBin);function estVide (a : ArbreBin) return boolean;function feuille (a : ArbreBin) return Boolean;procedure creerNoeud (fg : in out ArbreBin; e : Element; fd : in out ArbreBin;
a : out ArbreBin);function filsGauche (a : ArbreBin) return ArbreBin;function filsDroit (a : ArbreBin) return ArbreBin;function racine(a : ArbreBin) return Element;function pere(n : ArbreBin) return ArbreBin;function taille (a : ArbreBin) return integer;function hauteur (n : ArbreBin) return integer;ARBRE_VIDE : constant ArbreBin;
private type Noeud; type ArbreBin is access Noeud; type Noeud is record fg : ArbreBin;
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

121
valeur : Element; fd : ArbreBin; -- ajout d'un champ père pour faciliter la remontée dans l'arbre pere : ArbreBin; end record; ARBRE_VIDE : constant ArbreBin := null;end ArbreBin_P;
package body ArbreBin_P isprocedure creerArbreBin (a : out ArbreBin) isbegin a := ARBRE_VIDE;end creerArbreBin;function estVide (a : ArbreBin) return Boolean isbegin return a = null;end estVide;function feuille (a : ArbreBin) return Boolean isbegin if estVide(a) then raise ArbreVide; end if; return (estVide(a.fd) and estVide(a.fg));end feuille;procedure creerNoeud (fg : in out ArbreBin; e : Element; fd : in out ArbreBin;
a : out ArbreBin) is aa : ArbreBin := new Noeud'(fg, e, fd, ARBRE_VIDE);begin fg.pere := aa; fd.pere := aa; a := aa;end creerNoeud;function filsGauche (a : ArbreBin) return ArbreBin isbegin if estVide(a) then raise arbreVide; end if; return a.fg;end filsGauche;function filsDroit (a : ArbreBin) return ArbreBin isbegin if estVide(a) then raise arbreVide; end if; return a.fd;end filsDroit;function racine(a : ArbreBin) return Element isbegin if estVide(a) then raise arbreVide; end if; return a.valeur;end racine;function pere(n : ArbreBin) return ArbreBin isbegin if estVide(n) then return null; end if; return (n.pere);end pere;function taille (a : ArbreBin) return integer is cpt : integer := 0;begin if estVide(a) then return 0; end if; return (1+taille(a.fg) + taille(a.fd));end taille;
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

122
function hauteur (n : Arbrebin) return integer isbegin return (1 + hauteur(n.pere));end hauteur;end ArbreBin_P;
11.5.1.2 Implémentation dynamique d'ArbreBin en C
//ArbreBin.h#ifndef _ArbreBin_ // Le fichier PileEntiers.h ne doit être inclus #define _ArbreBin_ // qu'une seule fois
#ifndef _typeArbreBin_ // Vue du type PileEntiers de l'extérieur typedef void * ArbreBin; #endif
static const int ARBRE_VIDE = 1;static const int ARBRE_PLEIN = 2;static const int TRUE = 1;static const int FALSE = 0;
extern void creerArbreBin(ArbreBin *); extern int estVide(ArbreBin);extern ArbreBin creerNoeud (ArbreBin, int, ArbreBin);extern int filsGauche (ArbreBin, ArbreBin *);extern int filsdroit (ArbreBin, ArbreBin * );extern int filsGauche (ArbreBin, ArbreBin *);extern ArbreBin pere(ArbreBin);extern int taille (ArbreBin);extern int hauteur (ArbreBin);
#endif
//ArbreBin.c
#include <malloc.h> // inclusion des bibliothèques utilisées#include <stdio.h>
#define _typeArbreBin_ // Vue du type ArbreBin interne au module
typedef struct cellule_{ struct cellule_ * fg; int valeur; struct cellule_ * fd; // ajout d'un champ père pour faciliter la remontée dans l'arbre struct cellule_ * pere;} Cellule;typedef Cellule * ArbreBin;
#include "essai.h"
void creerArbreBin (ArbreBin * a) { a = NULL;}int estVide (ArbreBin a){ if (a==NULL) return TRUE; return FALSE;
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

123
}ArbreBin creerNoeud (ArbreBin fg, int e, ArbreBin fd) { ArbreBin a = (ArbreBin) malloc(sizeof(Cellule)); a->fg = fg; a->fd = fd; a->valeur = e; a->pere = NULL; fg->pere = a; // effet de bord !! fd->pere = a; return a;} int filsGauche (ArbreBin a, ArbreBin * fg) { if (estVide(a)) return ARBRE_VIDE; (*fg) = a->fg; return TRUE;}int filsDroit (ArbreBin a, ArbreBin * fd) { if (estVide(a)) return ARBRE_VIDE; (*fd) = a->fd; return TRUE;}int racine (ArbreBin a, int * e) { if (estVide(a)) return ARBRE_VIDE; (*e) = a->valeur; return TRUE;}ArbreBin pere (ArbreBin n) { if (estVide(n)) return NULL; return (n->pere); }int taille (ArbreBin a) { if (estVide(a)) return 0; return (1 + taille(a->fg) + taille(a->fd));}int hauteur (ArbreBin n) { if (estVide(n)) return 0; return (1 + hauteur(n->pere));}
11.5.2 Arbre n-aire : Représentation chaînée
Pour représenter un Arbre n-aire, on utilisera une représentation du nœud également avec 3 champs dont la signification est la suivante : premierFils, valeur, frèreSuivant.
Exemple : représentation de l'arborescence Unix précédente :
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat
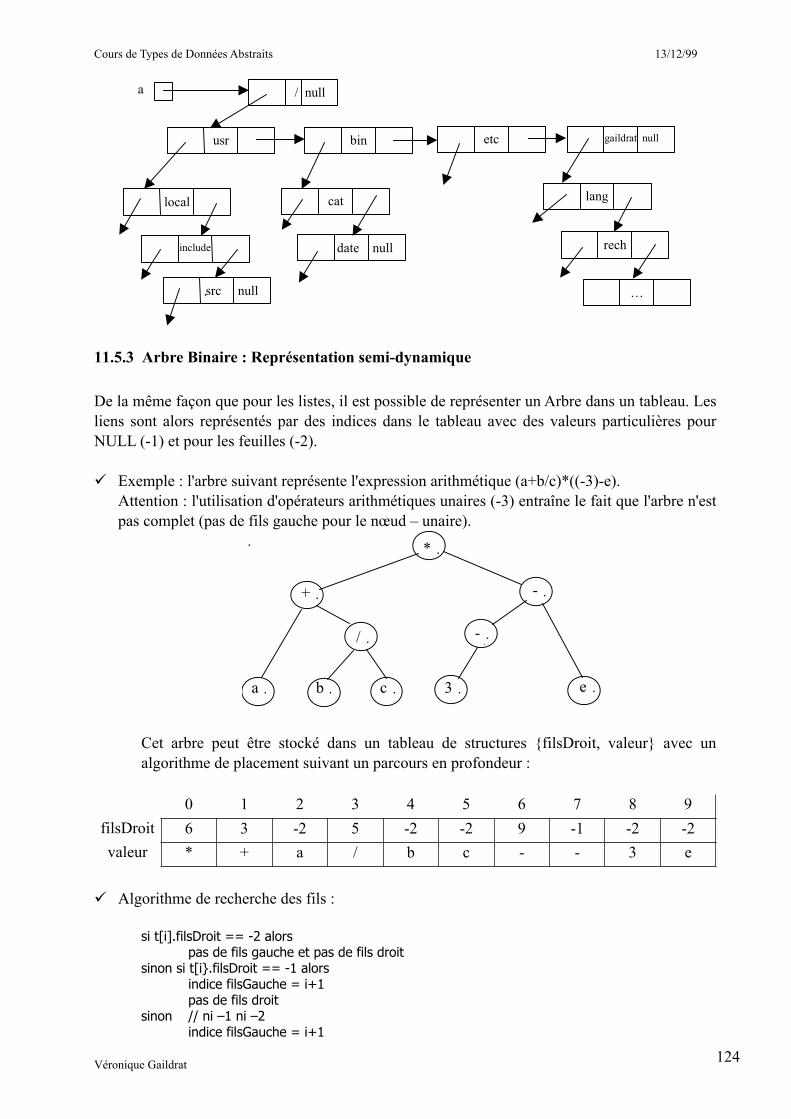
124
11.5.3 Arbre Binaire : Représentation semi-dynamique
De la même façon que pour les listes, il est possible de représenter un Arbre dans un tableau. Les liens sont alors représentés par des indices dans le tableau avec des valeurs particulières pour NULL (-1) et pour les feuilles (-2).
Exemple : l'arbre suivant représente l'expression arithmétique (a+b/c)*((-3)-e).Attention : l'utilisation d'opérateurs arithmétiques unaires (-3) entraîne le fait que l'arbre n'est pas complet (pas de fils gauche pour le nœud – unaire).
Cet arbre peut être stocké dans un tableau de structures {filsDroit, valeur} avec un algorithme de placement suivant un parcours en profondeur :
0 1 2 3 4 5 6 7 8 9filsDroit 6 3 -2 5 -2 -2 9 -1 -2 -2valeur * + a / b c - - 3 e
Algorithme de recherche des fils :
si t[i].filsDroit == -2 alors pas de fils gauche et pas de fils droitsinon si t[i}.filsDroit == -1 alors indice filsGauche = i+1 pas de fils droitsinon // ni –1 ni –2 indice filsGauche = i+1
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

125
indice filsDroit = t[i].filsDroitfsi
11.5.4 ArbreBinaire en largeur : représentation dans un tableau
Cette technique est encore plus directe si l'arbre considéré est un arbre en largeur, c'est à dire un arbre binaire dont à chaque niveau, les champs sont remplis de gauche à droite et tous les champs doivent être remplis à un niveau de profondeur donné avant d'insérer une valeur le plus à gauche du niveau suivant.
Pour créer un arbre en largeur il faut ajouter à la spécification précédente du type ArbreBin une méthode :
• insérerEnLargeur (ArbreBin, Elément) qui place l'élément au premier emplacement disponible dans l'arbre.
• estEnLargeur (ArbreBin) return boolean qui teste si un ArbreBin est bien un arbre en largeur.
On peut donc définir les axiomes suivants :• (1) estEnLargeur(creerArbreBin( )) == true• (2) filsGauche(insérerEnLargeur(créerArbreBin( ), e)) == e• (3) filsDroit(insérerEnLargeur(insérerEnLargeur(créerArbreBin( ), e), f)) == f• (4) si estEnLargeur(a) alors estEnLargeur(insérerEnLargeur(a, e)) == true
Algorithme de recherche des fils :
t[i].filsDroit == i * 2 t[i].filsGauche == i * 2 + 1père de t[i] == i / 2
Exemple d'utilisation : tri de tableau par utilisation d'un arbre binaire :
T [6, 2, 5, 8, 7, 4, 9, 5, 9]
procédure triTab (t: in out tableau[Eléments])debut
créerArbre (a);pour i := t'first , i <= t'last, i++ fre insérerEnLargeurTrié(a, t[i]);fpour
fin
L'opération insérerEnLargeurTrié va appeler insérerEnLargeur de façon à ce que estEnLargeur(a) soit vrai après l'insertion.Ensuite, la branche va être triée pour que la valeur d'un nœud père soit < à la valeur d'un nœud fils et ce de la feuille à la racine.
procédure insérerEnLargeurTrié (a : in out ArbreBinLargeur, e : Elément) début insérerEnLargeur(a, e); i := a'first + taille(a) - 1; // pour commencer au début // trier la branche tq (i < a'first) and then (a[i].valeur < a[i/2].valeur) fre
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat
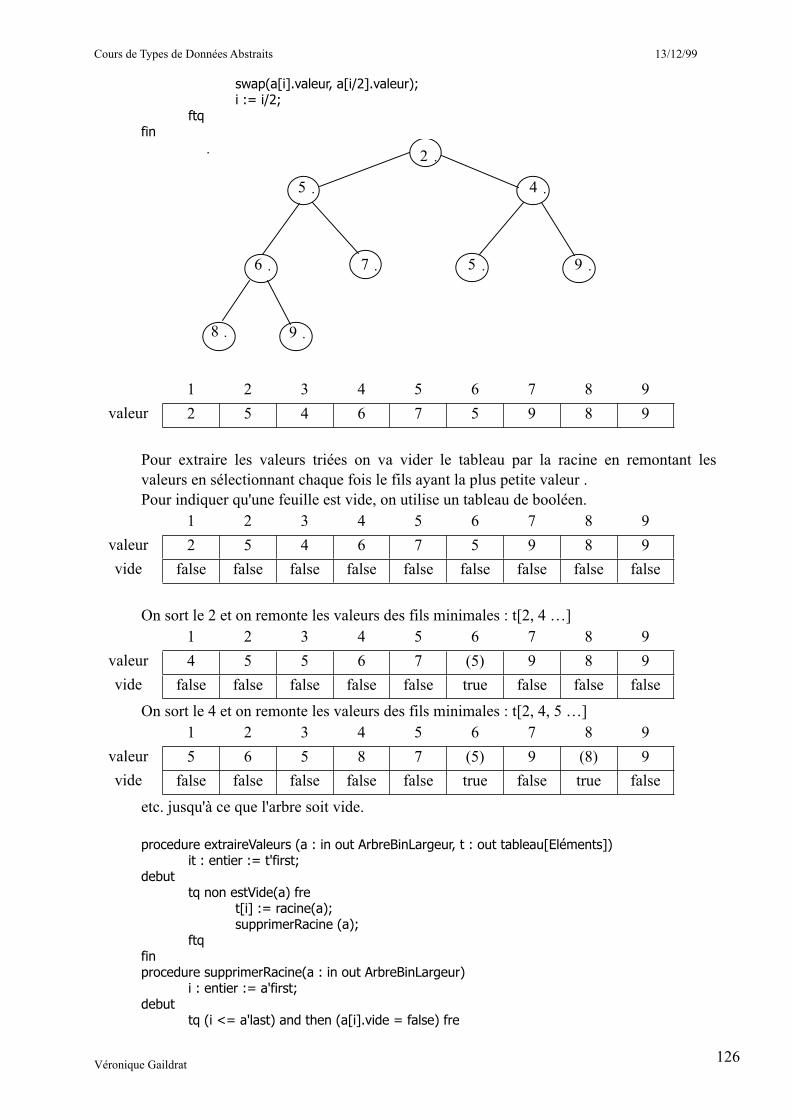
126
swap(a[i].valeur, a[i/2].valeur); i := i/2; ftqfin
1 2 3 4 5 6 7 8 9valeur 2 5 4 6 7 5 9 8 9
Pour extraire les valeurs triées on va vider le tableau par la racine en remontant les valeurs en sélectionnant chaque fois le fils ayant la plus petite valeur .Pour indiquer qu'une feuille est vide, on utilise un tableau de booléen.
1 2 3 4 5 6 7 8 9valeur 2 5 4 6 7 5 9 8 9vide false false false false false false false false false
On sort le 2 et on remonte les valeurs des fils minimales : t[2, 4 …]1 2 3 4 5 6 7 8 9
valeur 4 5 5 6 7 (5) 9 8 9vide false false false false false true false false false
On sort le 4 et on remonte les valeurs des fils minimales : t[2, 4, 5 …]1 2 3 4 5 6 7 8 9
valeur 5 6 5 8 7 (5) 9 (8) 9vide false false false false false true false true false
etc. jusqu'à ce que l'arbre soit vide.
procedure extraireValeurs (a : in out ArbreBinLargeur, t : out tableau[Eléments]) it : entier := t'first;debut tq non estVide(a) fre t[i] := racine(a); supprimerRacine (a); ftqfinprocedure supprimerRacine(a : in out ArbreBinLargeur) i : entier := a'first;debut tq (i <= a'last) and then (a[i].vide = false) fre
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

127
si ((i*2 <= a'last) and then (a[i*2].vide = false)) and ((i*2+1 < a'last) and then (a[i*2+1].vide = false)) alors
si a[i*2].valeur < a[i*2+1].valeur alors a[i].valeur := a[i*2].valeur; i := i*2; sinon a[i].valeur := a[i*2+1].valeur; i := i*2+1; fsi sinon si ((i*2 <= a'last) and then (a[i*2].vide = false)) alors a[i].valeur := a[i*2].valeur; i := i*2; sinon si ((i*2+1 < a'last) and then (a[i*2+1].vide = false)) alors a[i].valeur := a[i*2+1].valeur; i := i*2+1; sinon a[i].vide := true; // arrêt quand aucun autre cas trouvé fsi ftqfin
11.5.5 Arbre Binaire de recherche
Les Arbres Binaires de Recherche sont des Arbres Binaires particuliers : Un nœud est composé de
(fg : ArbreBinRech, e : Elément, fd : ArbreBinRech, père : ArbrebinRech)avec Elément qui peut contenir une clé pour faciliter la recherche et donner un critère de classement
Sur lesquelles on applique les opérations suivantes :
° rechercher : ArbreBin x Elément ArbreBin // identifie le Nœud contenant un élément♦ en entrée : a : ArbreBin, e : Elément♦ en sortie : n : Arbrebin♦ pré-conditions : aucune♦ post-conditions : n est le Nœud contenant l'élément, null si a est vide ou si non
trouvé
° minimum : ArbreBin ArbreBin // retourne le Nœud qui contient la valeur min♦ en entrée : a : ArbreBin, ♦ en sortie : min : Arbrebin♦ pré-conditions : aucune♦ post-conditions : min est le Nœud qui contient la valeur minimum de l'arbre
° maximum : ArbreBin ArbreBin // retourne le Nœud qui contient la valeur max♦ en entrée : a : ArbreBin, ♦ en sortie : max : Arbrebin♦ pré-conditions : aucune♦ post-conditions : max est le Nœud qui contient la valeur maximum de l'arbre
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

128
° successeur : ArbreBin ArbreBin // retourne le Nœud qui contient la valeur immédiatement supérieure (suivante)♦ en entrée : a : ArbreBin, ♦ en sortie : succ : Arbrebin♦ pré-conditions : aucune♦ post-conditions : succ est le Nœud qui contient la valeur suivante
° prédécesseur : ArbreBin ArbreBin // retourne le Nœud qui contient la valeur immédiatement inférieure (précédente)♦ en entrée : a : ArbreBin, ♦ en sortie : pred : Arbrebin♦ pré-conditions : aucune♦ post-conditions : pred est le Nœud qui contient la valeur précédente
° insérer : ArbreBin x Elément ArbreBin // insère la valeur dans l'arbre♦ en entrée : a : ArbreBin, e : Elément, ♦ en sortie : a' : Arbrebin♦ pré-conditions : aucune♦ post-conditions : e est inséré de façon à conserver l'arbre trié
° supprimer : ArbreBin x Elément ArbreBin // supprime la valeur de l'arbre♦ en entrée : a : ArbreBin, e : Elément♦ en sortie : a' : Arbrebin♦ pré-conditions : aucune♦ post-conditions : e est supprimé de façon à conserver l'arbre trié
Les arbres de recherche peuvent servir aussi bien pour trier un tableau d'entiers, que de dictionnaire ou de file de priorité.On peut associer aux données stockées dans un Nœud une clé qui servira à l'identification de l'élément.Pour obtenir les éléments stockés dans l'arbre de recherche dans l'ordre où ils ont été insérés il faut effectuer un parcours infixé qui permettra d'obtenir les valeurs < valeur racine, puis la valeur racine, puis les valeurs >= valeur racine.
Exemple d'arbre de recherche possédant une valeur clé en chaque nœud.
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat
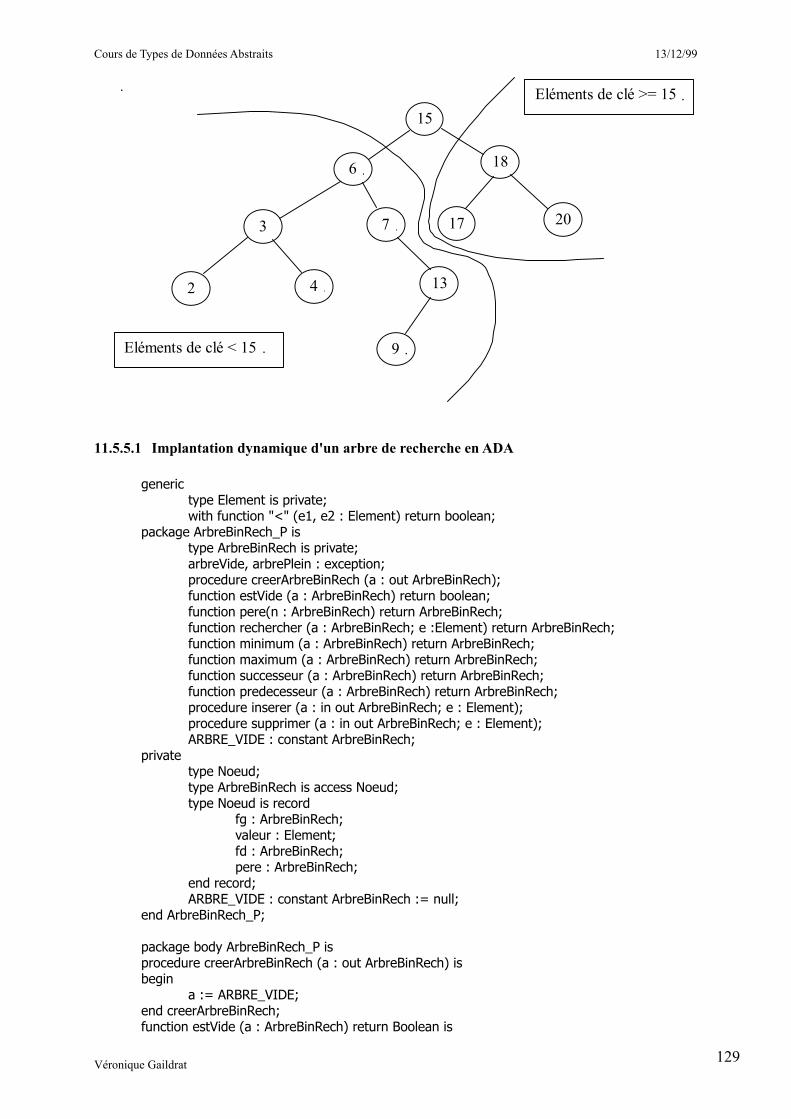
129
11.5.5.1 Implantation dynamique d'un arbre de recherche en ADA
generic type Element is private; with function "<" (e1, e2 : Element) return boolean;package ArbreBinRech_P is
type ArbreBinRech is private;arbreVide, arbrePlein : exception;procedure creerArbreBinRech (a : out ArbreBinRech);function estVide (a : ArbreBinRech) return boolean;function pere(n : ArbreBinRech) return ArbreBinRech;function rechercher (a : ArbreBinRech; e :Element) return ArbreBinRech;function minimum (a : ArbreBinRech) return ArbreBinRech;function maximum (a : ArbreBinRech) return ArbreBinRech;function successeur (a : ArbreBinRech) return ArbreBinRech;function predecesseur (a : ArbreBinRech) return ArbreBinRech;procedure inserer (a : in out ArbreBinRech; e : Element);procedure supprimer (a : in out ArbreBinRech; e : Element);ARBRE_VIDE : constant ArbreBinRech;
private type Noeud; type ArbreBinRech is access Noeud; type Noeud is record fg : ArbreBinRech; valeur : Element; fd : ArbreBinRech; pere : ArbreBinRech; end record;
ARBRE_VIDE : constant ArbreBinRech := null;end ArbreBinRech_P;
package body ArbreBinRech_P isprocedure creerArbreBinRech (a : out ArbreBinRech) isbegin a := ARBRE_VIDE;end creerArbreBinRech;function estVide (a : ArbreBinRech) return Boolean is
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

130
begin return a = null;end estVide;function feuille (a : ArbreBinRech) return Boolean isbegin if estVide(a) then raise arbreVide; end if; return (estVide(a.fd) and estVide(a.fg));end feuille;function pere(n : ArbreBinRech) return ArbreBinRech isbegin if estVide(n) then return null; end if; return (n.pere);end pere;function rechercher (a : ArbreBinRech; e :Element) return ArbreBinRech isbegin if (estVide(a) or (a.valeur = e)) then return a; end if; if (e < a.valeur) then return rechercher (a.fg, e); else return rechercher (a.fd, e); end if;end rechercher;function minimum (a : ArbreBinRech) return ArbreBinRech isbegin if estVide(a) then return a; end if; if estVide(a.fg) then return a; end if; return minimum (a.fg);end minimum;function maximum (a : ArbreBinRech) return ArbreBinRech isbegin if estVide(a) then return a; end if; if estVide(a.fd) then return a; end if; return maximum (a.fd);end maximum;function successeur (a : ArbreBinRech) return ArbreBinRech is courant, p : ArbreBinRech;begin if estVide(a) then return a; end if; if not estVide(a.fd) then return minimum (a.fd); end if;
-- si pas de fils droit, le successeur est le premier ancêtre de a -- dont le fils gauche est aussi un ancêtre de a
courant := a; p := a.pere; while (not estVide(p) and (courant = p.fd)) loop courant := p; p := p.pere; end loop; return p;end successeur;function predecesseur (a : ArbreBinRech) return ArbreBinRech is courant, p : ArbreBinRech;begin if estVide(a) then return a; end if; if not estVide(a.fg) then
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

131
return maximum (a.fg); end if;
-- si pas de fils gauche, le predecesseur est le premier ancêtre de a -- dont le fils droit est aussi un ancêtre de a
courant := a; p := a.pere; while (not estVide(p) and (courant = p.fg)) loop courant := p; p := p.pere; end loop; return p;end predecesseur;procedure inserer (a : in out ArbreBinRech; e : Element) isbegin if estVide(a) then a := new Noeud'(ARBRE_VIDE, e, ARBRE_VIDE, ARBRE_VIDE); elsif (e < a.valeur) then if estVide(a.fg) then a.fg := new Noeud'(ARBRE_VIDE, e, ARBRE_VIDE, a); else inserer (a.fg, e); end if; else if estVide(a.fd) then a.fd := new Noeud'(ARBRE_VIDE, e, ARBRE_VIDE, a); else inserer (a.fd, e); end if; end if;end inserer;procedure supprimerPt (a : in out ArbreBinRech; n : in out ArbreBinRech) is p, m : ArbreBinRech;begin if not estVide(n) then -- si n null on ne fait rien -- recherche du pointeur qui pointe sur n if not estVide(n.pere) then if (n.pere.fg = n) then p := n.pere.fg; else p := n.pere.fd; end if; else p := null; end if; if feuille(n) then p := null; -- n est supprimé de l'arbre elsif estVide(n.fg) then -- fils droit seul p := n.fd; -- on raccroche le fils droit n.fd.pere := n.pere; elsif estVide(n.fd) then -- fils gauche seul p := n.fg; -- on raccroche le fils gauche n.fg.pere := n.pere; else -- il existe 2 fils m := maximum(n.fg); -- on recherche le max des min supprimerPt(n, m); -- on le supprime n.valeur := m.valeur; -- on place sa valeur dans m end if; end if;end supprimerPt;procedure supprimer (a : in out ArbreBinRech; e : Element) is
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

132
n : ArbreBinRech;begin n := rechercher (a, e); if not estVide(n) then supprimerPt (a, n); end if;end supprimer;end ArbreBinRech_P;
11.5.5.2 Utilisation d'un Arbre Binaire de Recherche pour trier un tableau
Insertion des éléments du tableau dans l'arbre de recherche :
creerArbreBinRech(a);Pour i := t'first, i <= t'last, i++ fre inserer(a, t[i]);fpour
m := minimum(a);Pour i := t'first, i <= t'last, i++ fre
t[i] := racine(m);m := successeur(m);
fpour
11.5.6 Arbre équilibré
Un arbre est dit équilibré si en tout nœud, les hauteurs des sous-arbres gauche et droit diffèrent au plus de 1.Sinon l'arbre est dit déséquilibré.
Arbre équilibré Arbre déséquilibré
11.6 Isomorphisme liste-arbre
Il est possible de représenter des listes à l'aide de structures d'arbres et vice-versa. Les deux structures ont en effet des caractéristiques suffisamment proches pour cela. Pour représenter une liste sous forme d'arbre, on utilise généralement une structure d'arbre binaire dont les nœuds non-terminaux ne comportent pas d'informations particulières. La transformation que l'on peut adopter sera de mettre le premier élément de la liste (car) comme sous-arbre gauche de la racine et le reste de la liste (cdr) comme sous-arbre droit de la racine. Le processus est réitéré pour chaque morceau de liste qui reste. Un élément de la liste deviendra une feuille de l'arbre et une sous-liste deviendra un sous-arbre droit (algorithme récursif).
Exemple :
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat

133
Transformation d'une liste en arbre binaire.
Il serait possible de représenter une liste sous forme d'arbre n-aire. Pour représenter un arbre n-aire sous forme de liste, on peut adopter la convention selon laquelle le contenu du nœud racine est mis en première position de la liste et chacun de ses sous-arbres constituera une sous-liste de la liste principale (algorithme récursif).
Exemple :
Transformation d'un arbre n-aire en liste.
Pour représenter un arbre binaire ordonné sous forme de liste, on peut d'une manière similaire adopter la convention selon laquelle le contenu du nœud racine est mis en première position de la liste et chacun de ses sous-arbres constituera une sous-liste de la liste principale (algorithme récursif). Si un sous-arbre est inexistant, on lui fera correspondre une liste vide.
Exemple
Transformation d'un arbre binaire en liste.
Cours de Types de Données Abstraits 13/12/99
Véronique Gaildrat











![TDA/H - Longueuil · TDA/H, la boîte à outils : stratégies et techniques pour gérer le TDA/H Hébert, Ariane. [2015]. Boucherville, Québec : Éditions de Mortagne, 169 p. Cote](https://img.pdfslide.fr/doc/110x75/5f0e58d87e708231d43ecd9c/tdah-longueuil-tdah-la-bote-outils-stratgies-et-techniques-pour-grer.jpg)
![76 UMLV Types abstraits Types de base entiers, réels, booléens, caractères, pointeurs (adresses),… Constructeurs puissanceE n type_E... […] produit cartésienE](https://img.pdfslide.fr/doc/110x75/551d9db6497959293b8dafe9/76-umlv-types-abstraits-types-de-base-entiers-reels-booleens-caracteres-pointeurs-adresses-constructeurs-puissancee-n-typee-produit-cartesiene.jpg)
















