Embed Size (px)
Citation preview

Livre Blanc
Gestion du cycle de vie analytique pour des décisions à haute fréquence : comment passer des données aux décisions le plus rapidement possible

ContentsIntroduction ........................................................................1
Des décisions à haute fréquence .................................2
La problématique .......................................................................2
Le cycle de vie analytique SAS® : les meilleures pratiques pour améliorer vos résultats de modélisation prédictive ..................................................4
Phase de découverte du cycle de vie analytique ........................................................................4
Phase de déploiement du cycle de vie analytique ........................................................................6
Du concept à l’action : comment créer un environnement analytique efficace .............................7
Quel est l’apport de SAS® tout au long du cycle de vie analytique ? ...........................................................8
Préparation et exploration des données : une approche systématique ....................................................8
Développement de modèles avec un workbench analytique novateur ...................................................................8
Mise en œuvre de modèles à partir d’un environnement convivial unique ............................................9
Action ! Implémenter vos résultats de modélisation le plus rapidement possible ....................................................10
Gestion et évaluation de modèles : un processus continu ................................................................10
Études de cas ..................................................................11
Institution financière britannique : moderniser son cycle de vie analytique ........................................................... 11
Orlando Magic : la magie derrière la magie ..................... 11
Pour plus d’informations ...............................................12

1
IntroductionImaginons le scénario suivant :
Une entreprise possède des centaines de modèles analy-tiques intégrés à ses systèmes de production et destinés à appuyer la prise de décisions dans les domaines du marketing, de la tarification, du risque de crédit, du risque opérationnel, de la fraude et des finances.
Les analystes des divers départements développent leurs modèles sans processus préalablement formalisé ou normalisé pour les stocker, les déployer et les gérer. Certains modèles ne sont accompagnés d’aucune docu-mentation indiquant le nom de leur propriétaire, leur objectif métier, leurs consignes d’utilisation ou d’autres informations nécessaires pour les gérer ou les expliquer aux organismes de réglementation.
Ainsi, les résultats communiqués aux décideurs provien-nent de modèles qui ont fait l’objet de peu de contrôles et d’exigences, et dont l’exactitude a été évaluée au travers de procédures de validation ou de backtesting minimales. De plus, comme ces modèles ont été créés à partir de variables et d’ensembles de données différents, les résultats sont disparates.
Les décisions sont alors prises en fonction de ces résul-tats, chacun espérant que tout se passe au mieux.
De nombreuses entreprises se reconnaîtront sans doute dans la confusion qui règne en matière de modélisation. Ainsi, dans un environnement de modélisation hétérogène et géré de manière peu rigoureuse, il peut s’avérer difficile de répondre à des questions essentielles sur les modèles analytiques prédictifs employés dans votre entreprise. Des questions du type :
• Qui a créé les modèles et pourquoi ?
• Quelles variables d’entrée sont utilisées pour effectuer des prévisions et, au final, prendre des décisions ?
• Comment sont utilisés les modèles ?
• Comment les modèles fonctionnent-ils, et à quand remonte leur dernière mise à jour ?
• Où se trouve la documentation associée ?
• Pourquoi la mise en production de modèles nouveaux ou actualisés est-elle si longue ?
L’entreprise qui n’est pas en mesure de répondre avec assurance à ces questions n’a aucune garantie que ses modèles analytiques apportent une réelle valeur ajoutée.
Or, les modèles analytiques sont au cœur des décisions métier critiques. Ils permettent d’identifier de nouvelles opportunités, d’établir de nouvelles relations avec les clients ou de les améliorer, et de gérer l’incertitude et le risque. Pour toutes ces raisons, et pour bien d’autres encore, ils doivent être créés et traités comme des atouts précieux de l’entreprise. Oui, mais comment ?
Utiliser vos modèles pour automatiser la prise de décisions
Les décisions opérationnelles se présentent à l’identique de façon récurrente, et sont souvent prises plusieurs fois par jour. Elles peuvent provenir de personnes (par exemple, des employés de centre d’appels qui effectuent par téléphone des ventes croisées ou incitatives), ou être totalement automatisées, reproduisant la logique déci-sionnelle humaine (par exemple, le rejet d’un achat par carte de crédit). Cependant, une décision opérationnelle ne porte pas nécessairement sur un seul client ; elle peut concerner l’envoi d’une offre ciblée à un groupe de clients. Des décisions de ce type sont remontées toutes les semaines ou tous les mois dans les outils de gestion de campagne. À partir du moment où des modèles d’analyse prédictive sont intégrés aux systèmes de production et où un processus métier utilise les résultats pour produire des réponses instantanées, on considère que vos modèles analytiques ont été efficacement déployés.

2
Pour commencer, vous avez besoin de solutions puissantes et faciles à utiliser qui vous aideront à mettre en forme vos données et à créer rapidement de nombreux modèles prédictifs pertinents. Puis il vous faut de solides processus intégrés pour gérer vos modèles analytiques afin que leur performance reste optimale tout au long de leur cycle de vie. Les équipes informatiques et analyt-iques exigent des processus efficaces et répétables, ainsi qu’une architecture fiable pour gérer les données, communiquer les prin-cipes de base et suivre les modèles d’analyse prédictive pendant tout le cycle de déploiement.
Enfin, dernier point et non des moindres, la clé de la réussite consiste à transformer rapidement les données en connaissances puis en actions, ce qui implique d’intégrer efficacement aux systèmes de production des modèles prédictifs précis permettant d’automatiser la prise de décisions.
Face à la complexité et à l’ampleur croissantes que représente la gestion de centaines voire de milliers de modèles potentiels en constante évolution, les entreprises sont à l’orée d’une véri-table révolution en matière d’information. L’ancienne approche artisanale doit laisser la place à un processus automatisé plus efficace.
}}“Ce sont les décisions opérationnelles
qui matérialisent votre stratégie métier
et garantissent un fonctionnement
efficace de votre organisation.”
James Taylor et Neil Raden, Smart (Enough) Systems
Des décisions à haute fréquence Combien de décisions opérationnelles sont prises dans votre entreprise au quotidien ? Sans doute plus que vous ne l’imaginez. Prenons l’exemple d’un établissement financier. Combien de transactions de carte de crédit sont traitées par heure ? (Chez Visa, le taux de transactions peut atteindre le chiffre de 14 000 par seconde. Voir page 3.) Chacune de ces transactions représente une décision opérationnelle : il s’agit d’autoriser ou pas la poursuite de la transaction en fonction du calcul d’un score de risque de fraude. Et si chaque décision
opérationnelle ou transaction représente un risque peu élevé au niveau individuel, le grand nombre de décisions prises par heure ou par jour accroît d’autant le risque associé.
C’est pourquoi la capacité à produire très rapidement des déci-sions opérationnelles de qualité, tout en couvrant des volumes de données sans cesse plus élevés, peut faire la différence entre la présence et l’absence de fraude, et donc entre la réussite ou l’échec de l’entreprise.
Dans ce contexte, quels sont les éléments requis pour prendre rapidement et à bon escient un grand nombre de décisions opérationnelles pertinentes et alignées sur la stratégie globale, tout en permettant à l’entreprise de progresser avec entrain ?
1. Des applications opérationnelles exploitant les données pour produire des réponses qui permettront aux collaborateurs (ou aux systèmes) de prendre les mesures qui s’imposent.
2. Des modèles analytiques judicieux et à jour sur lesquels l’entreprise peut s’appuyer pour prendre les décisions optimales au bon moment.
3. L’intégration des règles métier et de l’analytique prédictive dans des flux de décisions opérationnelles qui fournissent les connaissances et les instructions nécessaires à la prise de décisions fiables et vérifiées.
4. Un moyen de gérer et surveiller les modèles analytiques pour s’assurer qu’ils fonctionnent correctement et continuent à fournir des réponses appropriées.
5. Une architecture et des processus capables d’évoluer pour répondre à de nouveaux besoins, tels que la transmission de données en continu et la création de modèles prédictifs détaillés dans des délais toujours plus courts.
La problématiqueMalheureusement, malgré l’abondance des données et le consensus général sur les besoins à satisfaire, il n’est pas facile de transformer des données volumineuses et éparses en infor-mations utiles générant de meilleures décisions automatisées. De nombreux défis se présentent :
• Délais. Les processus étant souvent manuels et ponctuels, la mise en œuvre d’un modèle dans les systèmes de produc-tion peut prendre plusieurs mois. Étant donné la longueur des phases de développement et de test, les modèles peuvent s’avérer périmés lorsqu’ils atteignent la phase de production. Parfois, ils ne sont même jamais déployés. Les problèmes de conformité internes et externes peuvent compliquer encore le processus.

3
• Difficulté à définir des déclencheurs. L’étape consistant à traduire les réponses des modèles analytiques en actions soutenant des décisions opérationnelles exige des règles métier claires et établies. Ces règles doivent être intégrées à l’environnement géré car elles déterminent le mode d’utilisation des résultats des modèles. Par exemple, un modèle de détection de fraude peut renvoyer un score de risque de fraude sous la forme d’un nombre compris entre 100 et 1 000 (semblable à un score FICO). Il incombe alors à l’entreprise de déterminer le niveau de risque qui nécessi-tera une intervention. Si le déclencheur d’une alerte de fraude est trop haut, la fraude risque de passer inaperçue. À l’inverse, si la valeur définie est trop basse, les alertes créent de trop nombreux faux positifs. Dans les deux cas, l’intérêt des modèles et la confiance dans les résultats en sont dévalués.
• Résultats médiocres. Il arrive trop souvent que des modèles peu performants restent en production même s’ils génèrent des résultats inexacts conduisant à des décisions inappro-priées. Les résultats des modèles changent au fil de l’évolution des données selon de nouvelles conditions et de nouveaux comportements. Les principales causes de cette situation sont l’absence d’un référentiel central des modèles et le manque d’indicateurs cohérents permettant de déter-miner à quel moment un modèle doit être actualisé ou remplacé.
• Confusion. Les entreprises fonctionnent en mode réactif, répondant dans l’urgence aux échéances imposées par des organismes externes. Chaque groupe applique une approche différente en matière de manipulation et de vali-dation d’un modèle. Il en résulte des rapports uniques comportant divers niveaux de détail à consulter ou des modèles décrits de façon inégale, rendant ainsi difficile leur mise en œuvre informatique. Personne ne sait exactement pourquoi tel ou tel modèle a été retenu, comment un score a été calculé, ni ce qui régit les règles métier déclenchant le modèle.
• Manque de transparence. En matière de modèles, la visi-bilité sur les étapes du développement est faible. De même, il est difficile de connaître les différents intervenants au cours du cycle de vie d’un modèle. En conséquence, des hypothèses contradictoires apparaissent. Il faut alors faire appel à des réviseurs impartiaux pour valider les modèles lors de leur passage d’un groupe à l’autre, ce qui constitue un gaspillage de ressources considérable.
Visa : des milliards de décisions opérationnelles par an permettent d’améliorer l’expérience client et de réduire la fraude
Entreprise de renommée mondiale, Visa gère le transfert électronique de fonds par le biais de produits de marque commercialisés par des milliers d’établissements bancaires partenaires. La société a traité 64,9 milliards de transactions en 2014 ; la même année, des achats d’un montant total de 4,7 billions de dollars ont été effectués au moyen d’une carte Visa.
Visa détient la capacité nécessaire pour traiter 56 000 transactions par seconde, c’est-à-dire plus de quatre fois le taux effectif maximal de transactions constaté à ce jour. Visa ne se contente pas de traiter et de calculer ; la société utilise constamment l’analytique pour partager ses connaissances straté-giques et opérationnelles avec ses établissements financiers partenaires et les aider à améliorer leurs performances.
Cet objectif métier s’appuie sur un solide système de gestion de données. Visa aide également ses clients à améliorer leurs performances et à produire des connaissances analytiques approfondies. « Nous déterminons des schémas comportementaux en procédant à des opérations de classification et de segmentation à un niveau très pointu, et nous communiquons ces informations à nos partenaires financiers » indique Nathan Falkenborg, directeur de Visa Performance pour l’Asie du Nord.
Au cours d’une récente démonstration de fais-abilité, Visa a fait appel à une solution hautes performances de SAS qui repose sur le traitement en mémoire (« in-memory ») pour mettre en œuvre des algorithmes statistiques et d’apprentissage automatique, et présenter ensuite les informations visuellement. Ainsi, d’après Falkenborg, « le défi que nous devons relever, comme toute entreprise ayant à gérer et à manipuler d’énormes ensembles de données, consiste à utiliser toutes les informations nécessaires pour résoudre un problème métier – qu’il s’agisse d’améliorer nos modèles de fraude ou d’aider un partenaire à communiquer plus efficace-ment avec ses clients. »
En savoir plus
4
• Disparition de connaissances importantes sur les modèles. Lorsque les modèles sont mal documentés, la propriété intellectuelle réside en grande partie dans le cerveau de leurs propriétaires. Quand ceux-ci quittent l’entreprise, leurs connaissances sont perdues.
• Pénurie de compétences analytiques. En dépit du nombre croissant de data scientists, la pénurie de compétences analytiques pour la création et le déploiement de modèles demeure problématique pour de nombreuses entreprises.
Le cycle de vie analytique SAS® : les meilleures pratiques pour améliorer vos résultats de modélisation prédictive Les entreprises prospères reconnaissent le rôle essentiel des modèles analytiques, qui produisent des réponses et les trans-mettent aux systèmes de production pour renforcer les relations client, améliorer l’exploitation, augmenter les revenus et réduire les risques. C’est pourquoi elles cherchent à créer les meilleurs modèles possibles.
Cependant, peu d’entre elles gèrent entièrement les complex-ités du cycle de vie des modèles analytiques. En effet, cette tâche présente de multiples facettes.
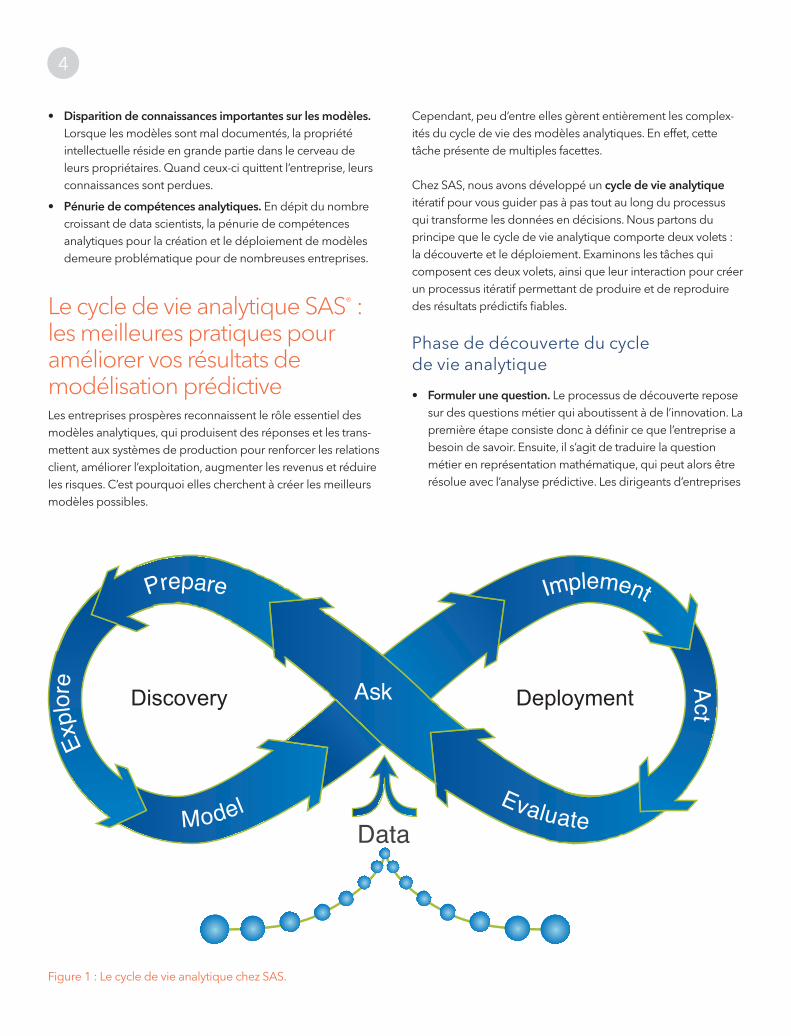
Chez SAS, nous avons développé un cycle de vie analytique itératif pour vous guider pas à pas tout au long du processus qui transforme les données en décisions. Nous partons du principe que le cycle de vie analytique comporte deux volets : la découverte et le déploiement. Examinons les tâches qui composent ces deux volets, ainsi que leur interaction pour créer un processus itératif permettant de produire et de reproduire des résultats prédictifs fiables.
Phase de découverte du cycle de vie analytique
• Formuler une question. Le processus de découverte repose sur des questions métier qui aboutissent à de l’innovation. La première étape consiste donc à définir ce que l’entreprise a besoin de savoir. Ensuite, il s’agit de traduire la question métier en représentation mathématique, qui peut alors être résolue avec l’analyse prédictive. Les dirigeants d’entreprises
Figure 1 : Le cycle de vie analytique chez SAS.
Ask
Prepare
Expl
ore Act
Model
Implement
Evaluate
DeploymentDiscovery

5
parvenir plus rapidement à des résultats et d’augmenter la productivité des équipes analytiques. Par le passé, les data miners et data scientists ne pouvaient créer que quelques modèles par semaine ou par mois, à l’aide d’outils manuels. Grâce à des logiciels améliorés et à des ordinateurs plus rapides, le processus de création de modèles s’est accéléré, de sorte qu’il est aujourd’hui possible d’élaborer des centaines voire des milliers de modèles dans les mêmes délais. Mais un autre problème se pose alors : dans cette multitude, comment identifier rapidement et de façon fiable le modèle qui fonctionnera le mieux ? Des « concours » de modèles permettent de comparer de nombreux algorithmes concurrents et de choisir celui qui offre les meilleurs résultats pour un ensemble de données particulier. Tout ce processus est devenu plus fluide grâce aux concours automatisés d’algorithmes d’apprentissage automatique et aux indica-teurs bien précis identifiant le modèle « champion ». Les analystes et data scientists peuvent ainsi se consacrer à des questions et investigations plus stratégiques.
doivent également définir le besoin, la portée, les conditions du marché et les objectifs liés à la question métier à laquelle ils essaient de répondre. C’est cette démarche qui les aide à choisir les techniques de modélisation les plus appropriées.
• Préparer les données. Grâce à des technologies comme Hadoop et à des ordinateurs plus rapides et moins coûteux, il est désormais possible de stocker et d’exploiter beaucoup plus de données et de types de données. Mais ces progrès n’ont fait qu’accroître la nécessité de regrouper des données de différents formats et différentes sources, et de trans-former les données brutes afin de pouvoir les utiliser en modélisation prédictive. Avec de nouveaux types de données issus d’appareils connectés, telles que les données de capteurs de machines ou les fichiers journaux des interac-tions en ligne, la phase de préparation des données s’avère de plus en plus complexe. Ainsi, de nombreuses entreprises constatent que cette tâche est toujours aussi fastidieuse, représentant parfois jusqu’à 80 pour cent de la phase de découverte. Or, l’essentiel de cette phase devrait être consacré à l’exploration et à la création de modèles plutôt qu’à la préparation des données.
• Explorer les données. Les outils de visualisation interactifs en libre-service doivent être accessibles à toutes sortes d’utilisateurs (de l’analyste métier sans connaissances statis-tiques au data scientist féru d’analytique) et leur permettre de rechercher facilement des relations, des tendances et des schémas afin d’acquérir une meilleure compréhension des données. Cette étape sert à affiner la question et l’approche ébauchées au cours de la phase initiale de « questionnement » du projet. Il s’agit de développer et de tester des idées visant à aborder la problématique métier sous un angle analytique. En examinant les données, vous serez sans doute amené à ajouter, supprimer ou combiner diverses variables pour créer des modèles plus ciblés. Enfin, des outils interac-tifs rapides permettent de rendre ce processus itératif, condi-tion essentielle pour identifier les questions et les réponses les plus pertinentes.
• Modéliser les données. Cette étape consiste à traiter les données en appliquant de nombreux algorithmes de modé-lisation analytique et d’apprentissage automatique afin de trouver la meilleure représentation des relations entre les données, qui permettra de répondre à la question métier. Les outils analytiques recherchent une combinaison de données et de techniques de modélisation visant à prévoir de façon fiable un résultat souhaité. Il n’existe aucun algo-rithme unique qui fonctionne dans tous les cas. Le « meilleur » algorithme pour résoudre la problématique métier dépend des données. Dans ce contexte, l’expérimentation constitue le meilleur moyen de trouver la réponse la plus fiable. De même, la création automatisée de modèles permet de

6
formelle, il est facile d’effectuer des mises à jour et des réglages en cas de changements. L’agilité et la gouvernance métier en sont ainsi améliorées. Une fois le modèle approuvé pour la production, l’outil de decision manage-ment l’applique à de nouvelles données opérationnelles, générant les informations prédictives nécessaires pour entre-prendre de meilleures actions.
• Évaluer les résultats. L’étape suivante – probablement la plus importante – consiste à évaluer les résultats des actions générées par le modèle analytique. Les prévisions issues de votre modèle sont-elles justes ? Avez-vous enregistré des résultats tangibles, comme une augmentation du chiffre d’affaires ou une diminution des coûts ? En suivant et en mesurant constamment les performances de votre modèle en fonction d’indicateurs normalisés, vous pouvez en évaluer les bénéfices pour votre activité. Cette évaluation vient à son tour alimenter l’itération suivante du modèle, le tout en circuit fermé pour un apprentissage en continu. Si un modèle analytique perd en précision, vous pouvez définir la stratégie optimale pour l’actualiser, afin qu’il continue de produire les résultats escomptés. Face à la multiplication des modèles analytiques, l’automatisation est indispensable pour repérer rapidement ceux qui nécessitent le plus d’attention, et procéder à un recalibrage automatique.
• Reformuler la problématique. Les modèles prédictifs ne durent qu’un temps. Les prévisions d’un modèle doivent intégrer l’évolution des facteurs, le changement des clients et de la concurrence, ou encore les nouvelles données disponibles. Même les modèles les plus précis doivent être actualisés, obligeant les entreprises à reitérer les étapes de découverte et de déploiement. C’est un processus en constante évolution. Si un modèle se dégrade, vous pouvez le ré-étalonner en modifiant ses coefficients ou le recréer en y ajoutant de nouvelles caractéristiques tout en conservant certaines d’entre elles. Lorsqu’un modèle ne répond plus aux besoins d’une entreprise, il est retiré. Les multiples raisons pouvant conduire ce processus à l’échec sont faciles à imaginer. Il faut souvent des mois aux entreprises pour mener ce processus à bien, parfois même des années. Les facteurs de complication sont nombreux :
• Les données doivent parfois être intégrées et nettoyées à plusieurs reprises pour répondre à divers impératifs analytiques.
• La conversion manuelle des modèles dans différents langages de programmation pour assurer leur intégration avec les principaux systèmes d’exploitation – dont des systèmes fonctionnant par lots et en temps réel – peut prendre beaucoup de temps.
Phase de déploiement du cycle de vie analytique
• Mettre en œuvre vos modèles. L’objectif de cette phase est de mettre en application les connaissances acquises au cours de la phase de découverte au travers de processus automatisés et répétables. Dans nombre d’entreprises, on assiste à ce stade à un ralentissement considérable du processus de modélisation analytique, car il n’existe aucune transition définie entre découverte et déploiement, ni aucune collaboration entre les développeurs de modèles et les architectes du déploiement informatique, et encore moins d’automatisation optimisée. L’environnement de déploiement de la plupart des entreprises est très différent de l’environnement de découverte, en particulier quand les modèles prédictifs appuient la prise de décisions opéra-tionnelles. En effet, le département informatique doit souvent appliquer des règles de gouvernance strictes à cet environnement pour garantir ses accords de niveau de service avec l’entreprise. Par conséquent, en intégrant les phases de découverte et de déploiement, vous pouvez créer une transition automatisée, à la fois souple et répétable, qui débouche sur de meilleures décisions opérationnelles. Par ailleurs, un processus piloté et transparent est important pour tous, notamment les auditeurs. Une fois généré, le modèle est enregistré, testé ou validé, approuvé et déclaré prêt à être utilisé avec les données de production (intégré aux systèmes opérationnels).
• Agir en fonction des nouvelles informations. Deux types de décisions peuvent être prises sur la base de résultats analyt-iques. Les décisions stratégiques sont prises par des personnes qui étudient les résultats et passent à l’action, en se tournant généralement vers l’avenir. Les décisions opéra-tionnelles sont automatisées (par exemple, les scores de crédit ou les recommandations de meilleures offres). Elles n’exigent aucune intervention humaine car les règles qui seraient appliquées par des humains peuvent être program-mées dans les systèmes de production. De plus en plus d’entreprises cherchent à automatiser les décisions opéra-tionnelles et à produire des résultats en temps réel afin de réduire les temps de latence dans la prise de décisions. Reposant sur les réponses de modèles analytiques, ces déci-sions opérationnelles sont objectives, cohérentes, répétables et mesurables. Par ailleurs, l’intégration de modèles à une solution de decision management permet d’élaborer des flux complets de décisions opérationnelles. Il s’agit de combiner des modèles analytiques à des déclencheurs basés sur des règles métier pour produire des décisions automatisées optimales. Et comme ce mécanisme est défini au sein de la solution de decision management de manière

7
Ils obtiennent ainsi différents modèles au gré des étapes de développement, mais aussi des modèles adaptés aux gammes de produits et aux problématiques métier. Une entreprise peut ainsi se retrouver rapidement avec des milliers de modèles à gérer.
Qui plus est, l’environnement de modélisation est tout sauf statique. Les modèles sont constamment modifiés, à chaque test ou nouvelle découverte de résultats et de données. Le but est de créer les meilleurs modèles prédictifs possible, en se servant des meilleures données disponibles.
Pour les entreprises, les modèles prédictifs sont de précieux atouts dont l’efficacité ne repose pas uniquement sur la tech-nologie. Elles doivent se préoccuper de leurs collaborateurs et processus. Par exemple, il est important d’améliorer constam-ment les compétences commerciales, techniques et analytiques pour identifier les principales problématiques métier et appli-quer les enseignements analytiques aux processus opérationnels.
Le cycle de vie analytique est intrinsèquement itératif et collabo-ratif. Ainsi, les collaborateurs possédant des expériences et des compétences différentes sont impliqués aux divers stades du processus. Un responsable commercial doit clairement identi-fier un problème qui nécessite une réponse analytique, puis prendre la décision appropriée et surveiller les réactions qu’entraîne sa décision. Un analyste dirige l’exploration et la visualisation des données et s’efforce d’identifier les variables clés qui influent sur les résultats. Les équipes informatiques et de gestion des données contribuent à la préparation des données puis au déploiement et à la surveillance des modèles. Un data scientist ou un data miner procède à des opérations plus complexes d’analyse exploratoire, de segmentation descriptive et de modélisation prédictive.
• Les entreprises peuvent mettre du temps à s’apercevoir qu’un modèle doit être changé, si bien qu’elles prennent des décisions erronées, fondées sur les résultats d’un modèle obsolète.
• La majorité des étapes du cycle analytique sont intrin-sèquement itératives et il est parfois nécessaire de revenir en arrière pour ajouter ou actualiser des données.
• La diversité des profils d’utilisateur augmente la complexité du processus, ce qui rend la collaboration et la documentation essentielles. Dans la plupart des entre-prises, le service informatique s’occupe de la préparation des données lors de la phase de découverte, les analystes métier et data scientists se chargent ensuite de l’exploration des données et du développement de modèles. Puis l’informatique effectue leur déploiement, notamment lorsque les modèles doivent être intégrés aux processus métier opérationnels (même si cette équipe IT peut être différente de la première, qui assure la gestion et la mise à disposition des données).
Les modèles censés produire des informations utiles sont alors à l’origine de décisions hasardeuses, d’occasions manquées et de mesures peu judicieuses. Il n’y a pourtant pas de fatalité !
Du concept à l’action : comment créer un environnement analytique efficace Dans un environnement analytique efficace, les données sont créées et accessibles rapidement, dans une structure adaptée à l’exploration et au développement de modèles. Ces derniers sont développés, testés, puis déployés dans un environnement de production en un minimum de temps. Ceux-ci produisent très vite des résultats fiables. Leurs performances sont constam-ment surveillées, et les moins efficaces sont remplacés sans délai par des modèles plus récents.
En bref, une stratégie analytique efficace ne se résume pas à la création d’un modèle puissamment prédictif ; elle consiste à gérer chaque étape du cycle analytique de manière globale, que ce soit pour un modèle spécifique ou l’ensemble des modèles. Ce qui n’est pas simple.
Les analystes et data scientists ne se contentent pas de dével-opper un modèle pour résoudre une problématique métier. Ils développent un ensemble de modèles concurrents et utilisent différentes techniques pour traiter des problèmes complexes.

8
des modèles à l’aide de procédures et technologies cohérentes diminuent les risques inhérents au processus de modélisation tout en favorisant la collaboration et la gouvernance entre les parties prenantes des principaux services et du service informatique.
Préparation et exploration des données : une approche systématique
• Préparation des données. SAS® Data Management vous permet de profiler et de nettoyer les données, ainsi que de créer des routines ETL (Extract Transform Load) qui produisent des magasins de données analytiques en util-isant uniquement les données requises dans la base de données. Ces données sont transférées provisoirement dans la base pour accélérer leur chargement, formatées en une structure compatible à la création de modèles, puis agrégées pour créer des champs dérivés. Tous ces processus peuvent être automatisés et planifiés par lots ou exécutés ponctuellement et en temps réel, selon l’étape du cycle de vie analytique. Des solutions de préparation et de manipulation des données en libre-service comme SAS® Data Loader for Hadoop aident les analystes métier et data scientists à rationaliser l’accès aux données, ainsi qu’à fusi-onner et à nettoyer ces dernières sans surcharger le service informatique. SAS peut traiter d’importants volumes de flux d’événements, à raison de centaines de millions d’événements par seconde, avec des temps de réponse à faible latence. Ces débits vous permettent d’identifier les événements qui nécessitent une intervention immédiate, ceux qu’il est possible d’ignorer et ceux qui doivent être conservés. Enfin, un traitement au sein de la base de données (in-database) est utilisé pour limiter les transferts de données et améliorer les performances.
• Exploration des données. SAS® Visual Analytics facilite la tâche des analystes. Ces derniers peuvent découvrir d’importantes relations entre les données et cibler instan-tanément les domaines susceptibles de créer des opportu-nités ou de poser des problèmes, révéler des schémas inattendus, examiner la répartition des données, observer la prévalence de valeurs extrêmes et identifier des variables importantes à incorporer au processus de développement de modèles.
Développement de modèles avec un workbench analytique novateur Les analystes peuvent créer des modèles prédictifs à l’aide de divers outils SAS qui comprennent une grande variété d’algorithmes pour l’analyse de données structurées et non structurées.
En résumé, pour obtenir les meilleurs résultats analytiques, les entreprises doivent s’entourer de personnes dotées des compétences appropriées et leur permettre de collaborer pour remplir leurs fonctions respectives.
Quel est l’apport de SAS® tout au long du cycle de vie analytique ? SAS utilise des composants intégrés pour réduire le seuil de rentabilité (time-to-value) du cycle de vie de la modélisation, éliminant ainsi les étapes redondantes et favorisant la cohésion tout au long de la chaîne d’informations, des données au decision management. Le développement et le déploiement
Figure 2 : SAS DataLoader utilise des instructions intégrées pour réduire les besoins en formation. Voici un exemple de directive « match-merge data », qui permet de fusionner deux tables en une seule et s’exécute au sein de Hadoop pour de meilleures performances.
Figure 3 : Explorez les données depuis un environnement de visualisation interactif.

9
Greenplum, Teradata, Oracle et SAP HANA) et du matériel standard équipé de Hadoop. La rapidité de ce traitement permet d’alimenter des modèles itératifs de statistiques et d’apprentissage automatique à partir de sources de données extrêmement vastes.
Mise en œuvre de modèles à partir d’un environnement convivial unique SAS® Enterprise Decision Manager joue un rôle clé dans l’amélioration de la phase de déploiement. En effet, cette appli-cation fournit un environnement web partagé permettant de gérer le cycle de vie et d’assurer la gouvernance de vos ressources de modélisation. Elle s’adresse aussi bien aux utilisa-teurs métier qu’au service informatique. Les analystes sélection-nent des données et modèles dans un référentiel centralisé, tout en définissant en parallèle des règles métier dans le contexte de leurs modèles. Grâce à cette infrastructure, il devient facile de suivre les activités de modélisation, d’effectuer des modifications et de procéder à des tests en continu dans un environnement unique.
• Enregistrement de modèles. À l’issue du développement de modèles, les analystes enregistrent un package contenant le modèle, y compris toutes les transformations de données, imputations, etc., ainsi que toutes les sorties et la documen-tation associées. Ce package permet de s’assurer que les étapes appropriées ont été suivies et qu’un modèle adapté et performant est publié dans l’environnement de produc-tion. Il aide également les entreprises à normaliser le processus de création, de gestion, de déploiement et de surveillance des modèles analytiques.
• Gouvernance. La gestion du risque associé aux modèles fait intervenir des indicateurs de suivi et des rapports de gestion des versions fournissant des informations sur les auteurs des modifications, les dates de transfert du contrôle d’un domaine à un autre, etc. Le référentiel centralisé, les analyses du cycle de vie et le contrôle des versions offrent une visi-bilité des processus analytiques et permettent de les auditer pour s’assurer de leur conformité aux règles de gouvernance internes et aux réglementations externes.
• Référentiel de modèles. Le référentiel sécurisé et centralisé comprend une documentation fournie sur le modèle, son code de scoring et les métadonnées associées. Ainsi, les modélisateurs peuvent aisément collaborer et réutiliser le code d’un modèle. Leurs activités font l’objet d’un suivi via une authentification des utilisateurs/groupes, un contrôle des versions et des audits.
• Automatisation du processus de modélisation. SAS® Factory Miner offre un environnement de modélisation prédictive interactif qui simplifie la création, la modification et l’évaluation de centaines, voire de milliers, de modèles en un temps record. Quelques clics suffisent pour accéder à vos données, les modifier et les transformer, choisir les tech-niques d’apprentissage automatique à appliquer et exécuter les modèles dans un environnement de comparaison automatisée afin d’identifier rapidement le meilleur d’entre eux. Il est possible de créer et de partager avec d’autres util-isateurs des scenarii de modélisation respectant les contraintes et meilleures pratiques et ce, sans écrire une seule ligne de code.
• Modélisation prédictive et data mining. SAS® Enterprise MinerTM rationalise le processus de data mining, vous permettant ainsi de créer rapidement des modèles prédictifs et descriptifs optimisés basés sur de grands volumes de données. Grâce à un environnement de flux de processus interactif et autodocumenté, vos data miners et statisticiens passent moins de temps à développer les modèles. Ils peuvent faire une évaluation visuelle, utiliser des indicateurs de validation, ou comparer plusieurs modèles.
• Text mining. SAS® Text Analytics offre de nombreux outils permettant de découvrir et d’extraire des concepts et des connaissances à partir de documents texte, comme des contenus web, des notes de centres d’appels, des livres, etc. Les informations recueillies peuvent être ajoutées à vos modèles analytiques pour enrichir leurs capacités prédictives.
• Analytique en mémoire (in-memory). Le traitement analyt-ique en mémoire distribué de SAS tire parti de l’extrême évolutivité et fiabilité d’une infrastructure analytique compre-nant des appliances de base de données (telles que Pivotal
Figure 4 : Les techniques d’évaluation personnalisables de SAS Factory Miner vous permettent de générer des modèles champions pour chaque segment de données.

10
Action ! Implémenter vos résultats de modélisation le plus rapidement possible Avec SAS, vous avez le choix entre plusieurs options de déploi-ement pour intégrer vos modèles champions à vos systèmes de production, afin qu’ils produisent des résultats analytiques le plus rapidement possible. Le déploiement intégré et automa-tisé fourni par SAS® Scoring Accelerator peut dynamiser les performances de déploiement de modèles de diverses façons.
• Déploiement plus rapide. Déployez des informations et des processus analytiques avec une infrastructure et des coûts minimes. La conversion de l’ensemble du code de scoring analytique en services web légers ou en langages natifs pour un traitement in-database s’effectue automatiquement. Ce qui évite de devoir convertir et valider manuellement le code de scoring des modèles pour différents environnements.
• Déploiement souple. Au niveau des différents systèmes opérationnels, il n’y a pas de solution unique. Cependant, les mêmes modèles peuvent être déployés sans changement sur des systèmes fonctionnant en mode “batch” et en temps réel. Les analystes n’ont plus à les adapter à chaque envi-ronnement en modifiant les paramètres, le code de scoring ou les programmes personnalisés.
• Processus de scoring plus rapides et mieux gérés. Le modèle étant scoré directement au sein de la base de données, la tâche d’exécution tire parti de l’évolutivité et de la vitesse de traitement offertes par la base. Ainsi, les tâches qui auparavant prenaient des heures, voire des journées, peuvent désormais être effectuées en quelques minutes. Par ailleurs, les transferts de données sont réduits car le scoring analytique peut s’effectuer là où résident les données. Et comme elles n’ont pas besoin de quitter l’environnement organisationnel, leur gouvernance est sécurisée. Même dans un environnement tel que Hadoop, il peut être très avanta-geux en termes de performances d’éviter tout transfert et duplication de données.
Gestion et évaluation de modèles : un processus continu Une fois déployé en environnement de production et exécuté pour fournir des réponses, le modèle champion est soumis à une surveillance centralisée via divers rapports reposant sur des indicateurs de performance clés (KPI) normalisés. Lorsque les performances du modèle commencent à se dégrader jusqu’à passer en dessous du niveau acceptable (par rapport aux éléments d’apprentissage de modèle gérés centralement), il est possible de ré-étalonner le modèle ou de le remplacer par un autre modèle.
• Scoring. Dès qu’un modèle a été vérifié, approuvé et déclaré prêt à la mise en production, il devient « champion ». Il est alors possible, en un seul clic, de transformer tout le workflow de votre modèle champion en un code de scoring qui peut être déployé dans SAS, des bases de données tierces, Hadoop et des services web.
• Validation. La logique de scoring fait l’objet d’une validation avant la mise en production des modèles, par l’intermédiaire d’une console d’administration visant à enregistrer chaque test auquel est soumis le moteur de scoring. Il s’agit ainsi de s’assurer que la logique intégrée au modèle champion est correcte.
Figure 5 : SAS Decision Manager vous aide à accélérer le processus de déploiement de modèles. Il intègre l’automatisation du développement de modèles à SAS Factory Miner et accélère les tâches manuelles courantes (définition de règles métier, par exemple) et la génération automatique des lexiques.

11
Avec l’aide de SAS et du fournisseur d’entrepôts de données Teradata, l’institution a conçu une plate-forme analytique prédictive souple en intégrant la gestion des données, le dével-oppement et le déploiement de modèles via la technologie in-database. Cette plate-forme exploite l’évolutivité de l’environnement Teradata pour le scoring de modèles et la puis-sance analytique de SAS pour leur création.
Grâce à cette nouvelle organisation, plus de 55 millions d’enregistrements peuvent être soumis à un scoring dans Teradata plusieurs fois par jour, une prouesse impossible avec l’ancien processus. Ainsi, le délai requis pour pousser un modèle en production est tombé de trois mois à quelques jours. De même, le temps de préparation des données a chuté de 40%, tandis que la productivité des analystes a augmenté de 50%.
Orlando Magic : la magie derrière la magie PLes équipes sportives professionnelles évoluant sur des marchés restreints ont souvent du mal à générer suffisamment de recettes pour rivaliser avec les adversaires issus de marchés plus importants. En utilisant SAS® Analytics et SAS® Data Management, la franchise des Magic d’Orlando est devenue l’une de celles qui génèrent le plus de recettes au sein de la NBA, malgré leur classement au 20ème rang.
Les Magic ont accompli cet exploit en étudiant le marché de revente des billets afin de mieux fixer leurs prix, de prévoir quels détenteurs de billets pour la saison sont susceptibles de faire faux bond - et de les faire changer d’avis - et d’analyser les franchises et les ventes de produits dérivés afin d’offrir aux supporters les produits qu’ils attendent dès leur arrivée au stade. Le club utilise également SAS pour aider les entraîneurs à aligner la meilleure formation.
À défaut d’une boule de cristal, les Magic ont SAS® Enterprise Miner™, qui leur a permis de mieux comprendre leurs données et de développer des modèles analytiques pour prévoir les renouvellements des abonnements annuels. Les outils de data mining ont aidé l’équipe à effectuer un scoring plus précis, qui a fait la différence (en améliorant le marché) dans son approche marketing et sur le plan de la fidélisation des clients.
En savoir plus
• Workflow automatisé. Une console de workflow web permet d’automatiser davantage le processus de gestion, de le rendre répétable, collaboratif et réglementé. L’entreprise (et ses auditeurs) peuvent ainsi suivre chaque étape d’un projet de modélisation, de l’exposé du problème à l’abandon du projet, en passant par son développement et son déploiement.
• Gestion globale du cycle de vie. Toutes les étapes du cycle de vie d’un modèle sont coordonnées de manière holis-tique, grâce à l’utilisation de matrices préconçues et définies par le client, adaptées aux processus métier de l’entreprise.
• Surveillance automatisée des modèles. Les tâches d’exécution peuvent être planifiées de façon récurrente (et les résultats contrôlés régulièrement), que ce soit pour un modèle isolé ou pour un ensemble de modèles complet. Il est alors possible de publier ces résultats dans des tableaux de bord et de définir des seuils de performance. En cas de dépassement de seuils, les analystes reçoivent des alertes portant sur les modèles qui nécessitent leur intervention. Ce processus permet de gagner du temps et de l’argent.
Avec un cadre de gestion formel, les meilleurs modèles passent plus rapidement en production au service de l’entreprise. Cette dernière peut générer des modèles de meilleure qualité, en plus grand nombre, reposant sur des méthodes analytiques plus variées et ce, avec moins de ressources. Continuellement surveillés et affinés, les modèles analytiques sont en perma-nence à jour et pertinents. Tout le processus de découverte et de déploiement devient plus transparent et mieux géré ; il est ainsi plus facile d’expliquer les décisions analytiques aux dirige-ants et aux organismes de réglementation.
Études de cas L’approche reposant sur un cycle de vie analytique et prédictif donne une toute autre perspective au mode opératoire habituel et crée un avantage concurrentiel significatif..
Institution financière britannique : moderniser son cycle de vie analytique Un important établissement financier du Royaume-Uni s’est aperçu que le temps de cycle qui s’écoulait entre la création d’un modèle et son déploiement, ne répondait pas aux impéra-tifs du 21e siècle. Le processus manuel, sujet aux erreurs et vorace en ressources, ne comportait en outre pratiquement aucun mécanisme de surveillance permettant d’identifier la dégradation d’un modèle.

12
Pour plus d’informations Pour en savoir plus sur la phase de découverte du cycle de vie analytique, lisez le document Le data mining de A à Z : tirer de nouveaux enseignements pour s’offrir de meilleures perspectives.
Sur la phase de déploiement, reportez-vous à From Data to Decision: How SAS Decision Manager Automates Operational Decisions.

13
Les particularités de SAS® • Une plate-forme intégrée unique permet la préparation
des données à analyser, l’exploration et la découverte interactives des données, le développement de modèles modernes, le déploiement, la surveillance et la gestion des modèles.
• Plusieurs disciplines analytiques (data mining, machine learning, prévision, analyse et optimisation de texte) sont intégrées pour une plus grande souplesse de dével-oppement de modèles et la résolution de probléma-tiques métier plus complexes.
• Des fonctions d’automatisation intelligente et des matrices personnalisables de modélisation prédictive et de machine learning intégrant les meilleures pratiques constituent des outils d’apprentissage hautement productifs et collaboratifs destinés à divers types d’utilisateurs.
• SAS peut gérer de nombreux modèles complexes comprenant des variables virtuellement illimitées et portant sur d’énormes volumes de données.
• Un environnement web automatisé de concours de modèles améliore la productivité en permettant aux modélisateurs de tester rapidement, facilement et simul-tanément de nombreuses approches par le biais d’un apprentissage automatique et d’algorithmes statistiques.
• Grâce aux fonctionnalités de workflow web, les utilisa-teurs peuvent aisément définir des processus person-nalisés, les gérer de bout en bout jusqu’à leur achèvement, favoriser la collaboration par des notifica-tions, et établir des normes d’entreprise.
• La traçabilité de la modélisation depuis la source des données jusqu’aux résultats analytiques assure une gouvernance essentielle, déterminante pour le respect de la réglementation ou d’exigences strictes en matière de reporting.
• Des tableaux de bord graphiques intuitifs permettent un suivi des performances des modèles dans plusieurs projets ; les équipes peuvent ainsi se consacrer en priorité aux projets nécessitant une attention immédiate afin d’éviter toute détérioration des modèles.
• L’interopérabilité avec des outils de modélisation tiers permet, à partir d’un référentiel central, d’importer, de gérer et de surveiller les éléments de modélisation créés à l’aide de SAS et d’autres outils (par exemple, les modèles PMML, R).
• Des fonctions de scoring in-database peuvent être exécutées sur des bases de données largement utilisées telles que Teradata, Aster Data, EMC Greenplum, IBM Netezza, IBM DB2 et Oracle.
• Les métadonnées SAS couvrent à la fois la gestion et l’analyse des données, de sorte que les transformations opérées sur les données au cours de la phase de décou-verte peuvent être réutilisées lors du déploiement.
• Enfin, SAS partage son immense savoir-faire technique et commercial dans le cadre d’une assistance avant-vente et après-vente, vous aidant à améliorer votre renta-bilisation et votre retour sur investissement.

Pour prendre contact avec votre bureau SAS local, visitez le site : sas.com/offices
SAS Institute s. a. s. – DOMAINE DE GREGY - GREGY-SUR-YERRES - 77257 BRIE COMTE ROBERT - FRANCE
TEL. : +33(0) 1 60 62 11 11 FAX : +33(0) 1 60 62 11 99 www.sas.com/france
SAS et tout autre nom de produit et de service de SAS Institute Inc. sont des marques déposées de SAS Institute Inc. pour les
USA et tous les autres pays. ® indique un dépôt aux USA. Les autres marques et noms de produits sont des marques
déposées de leurs entreprises respectives. Copyright © 2016 SAS Institute Inc. Tous droits réservés. S152615.0316