Embed Size (px)
Citation preview

Département de Mathématiques et Informatique
Abdelhamid El Mossadeq P rofesseur à l’E H T P
2006-2007

© A. El Mossadeq Juin 2006

TABLE DES MATIERES
Chapitre 1 : Statistique Descriptive
1. Concepts généraux de la statistique descriptive 3 2. Les types de caractères et de variables statistiques 3
2.1. Les caractères qualitatifs 3 2.2. Les caractères quantitatifs 3 2.2.1. Les variables statistiques discrètes 4 2.2.2. Les variables statistiques continues 4
3. Présentation générale des tableaux statistiques 4 4. Présentation des distributions à caractères qualitatifs 5 5. Présentation des distributions à caractères quantitatifs discrets 7 6. Présentation des distributions à caractères quantitatifs continus 9 7. Le résum é num érique d’une distribution statistique 12 8. Les caractéristiques de tendance centrale 13
8.1. Le mode 13 8.1.1. Détermination pratique 13
8.1.2. Propriétés 13 8.2. La médiane 14 8.2.1. Détermination pratique 14 8.2.2. Propriétés 15 8.3. La moyenne arithmétique 16 8.2.1. Calcul pratique 16 8.2.2. Propriétés 16 8.4. La moyenne géométrique 17 8.5. La moyenne harmonique 18 9. Les caractéristiques de dispersion 19
9.1. L’étendue 19 9.1.1. Calcul pratique 19
9.1.2. Propriétés 20 9.2. L’intervalle interquartile 20
9.2.1. Détermination pratique 20 9.2.2. Propriétés 21 9.2.3. Déciles et percentiles 21
9.3. L’écart absolu moyen 21 9.3.1. Calcul pratique 21
9.3.2. Propriétés 22

9.4. L’écart-type 22 9.4.1. Détermination pratique 22 9.4.2. Correction de W. F. Sheppard 23
9.4.3. Propriétés 23 10. Aplatissement et dissymétrie 23 10.1. Les m om ents d’ordre r 23 10.2.Le coefficient d’aplatissem ent 24 10.3. Le coefficient de dissymétrie 25
Chapitre 2 : Structures Statistiques et Estimation 1. Statistique et structure statistique 29 2. Fonction de vraisemblance 31 2.1. Structure statistique discrète 31 2.2. Structure statistique continue 31 3. Statistiques exhaustives 32 4. Information concernant un paramètre 38 4.1. M atrice d’information 38 4.2. Inégalité de Cramer-Rao 43 5. Estimateurs 45 6. L’estim ation par la m éthode de la vraisem lance 50 8. Exercices 54
Chapitre 3 : Les Procédures Usuelles des Tests d’Hypothèses : Les Fréquences
1. Fluctuations d’échantillonnage d’une fréquence 61 2. Les sondages 62 3. Test de com paraison d’une fréquence à une norm e 64 4. Test de comparaison de deux fréquences 65 5. Exercices 68
Chapitre 4 : Les Procédures Usuelles des Tests d’Hypothèses : Les Tests du Khi-Deux
1. Test de com paraison d’une proportion observée à une
proportion théorique 73 2. Test d’indépendance du Khi-deux 76 3. Exercices 82

Chapitre 5 : Les Procédures Usuelles des Tests d’Hypothèses : Moyennes et Variances
..1. Estim ation de la m oyenne et de la variance d’une population 91 2. Intervalle de confiance d’une variance 91 3. Intervalle de confiance d’une m oyenne 93
3.1. n30 93 3.2. n<30 94
..4. Test de com paraison d’une variance observée à une norme 95
..5. Test de com paraison d’une m oyenne observée à une norme 97 5.1. n30 97 5.2. n<30 98
6. Test de comparaison de deux variances 100 7. Test de comparaison de deux moyennes 102
7.1. n30 102 7.2. n<30 104
8. Exercices 107
Chapitre 6 : Le Modèle Linéaire Simple 1. Le modèle linéaire simple 115 2. Analyse du modèle linéaire simple par la méthode des
moindres carrés 117 3. Propriétés statistiques des estimateurs 120 3.1. Etude de 120 3.2. Etude de 121 3.3. Etude de 122 3.4. Etude de la covariance de et 123 4. Etude de la variance des estimateurs 124 5. Estimation de ² 128 6. Analyse de la variance 129 7. Tests et intervalles de confiance 130 7.1. Intervalle de confiance de ² 130 7.2. Région de confiance et tests concernant (,) 130 7.3. Intervalle de confiance et test concernant 131 7.4. Intervalle de confiance et test concernant 132
7.5. Intervalle de confiance de 134 7.6. Coefficient de corrélation 135 8. Le test de linéarité du modèle 136 9. Prédiction 140 10. Exemple 142 10.1. Estimation des paramètres du modèle 142 10.2. Validation du modèle 144 10.3 Intervalles de confiance 146


Chapitre 1
Statistique Descriptive


A. El Mossadeq Statistique Descriptive
1. CONCEPTS GÉNÉRAUX DE LASTATISTIQUE DESCRIPTIVE
Une population est l’ensemble des unités statistiques ou individus étudié par lestatisticien.Pour décrire une population, on s’efforce de classer les individus qui la composenten un certain nombre de sous ensembles.Cette opération aboutit à la confection de tableaux statistiques.Le classement peut se faire relativement à un ou plusieurs caractères.Le choix d’un caractère détermine le critère qui servira à classer les individus de lapopulation étudiées en deux ou plusieurs sous ensembles.Le nombre de ses sous ensembles correspond aux différentes situations possibles oumodalités de ce caractère.Les différentes modalités d’un caractère doivent être à la fois incompatibles et ex-haustives : un individu appartient à un et un seul des sous ensembles définis par cesmodalités.
2. LES TYPES DE CARACTÈRES ETDE VARIABLES STATISTIQUES
Un caractère peut être soit qualitatif soit quantitatif.Dans ce dernier cas, on lui associe une variable statistique.
2.1. LES CARACTÈRES QUALITATIFS
Un caractère qualitatif est un caractère dont les modalités échappent à la mesure.Elles peuvent seulement être constatées : le sexe, la nationalité et la profession sontdes caractères qualitatifs.
2.2. LES CARACTÈRES QUANTITATIFS
On dit qu’un caractère est quantitatif lorsqu’il est mesurable.A chaque unité statistique correspond alors un nombre qui est la mesure ou la valeurdu caractère.A ce nombre, on donne le nom de variable statistique.Elle peut être discrète ou continue.
3

Statistique Descriptive A. El Mossadeq
2.2.1. LES VARIABLES STATISTIQUES DISCRÈTESUne variable statistique est discrète lorsqu’elle ne prend que certaines valeursisolées : le nombre d’enfants à charge d’une famille, le nombre de ventes journalierd’un certain type d’appareils, le nombre de jours pluvieux dans une région donnée.
2.2.2. LES VARIABLES STATISTIQUES CONTINUESUne variable statistique est continue lorsqu’elle peut prendre toutes les valeurs àl’intérieur de son intervalle de variation : la taille, le poids, l’age d’une personne, lateneur en nickel d’un alliage, le débit d’une canalisation, la pression atmosphérique,la force du vent.Les valeurs d’une telle variable sont groupées en classes qui peuvent avoir une am-plitude constante ou variable.
3. PRÉSENTATION GÉNÉRALE DESTABLEAUX STATISTIQUES
Soit une population P comprenant n individus pour chacun desquels on a fait uneobservation concernant le caractère X qui comporte les modalités M1, ...,Mk.Le nombre ni d’individus présentant la modalité Mi est l’effectif de Mi.La fréquence fi de la modalité Mi est le rapport entre l’effectif de Mi et la taillede la population :
fi =nin
Un tableau statistique décrivant une populationP suivant un caractèreX se présenteen général comme suit :
Distribution de la population Psuivant le caractère X
Source : .......
Modalités de X Effectifs des modalités Fréquence des modalitésM1 n1 f1M2 n2 f2.. .. ..Mk nk fk
Total n =kPi=1
ni 1 =kPi=1
fi
Une première synthèse de l’information contenue dans un tableau statistique peutêtre fournie par sa traduction sous forme de graphe.
4
A. El Mossadeq Statistique Descriptive
4. PRÉSENTATION DESDISTRIBUTIONS A CARACTÈRES
QUALITATIFS
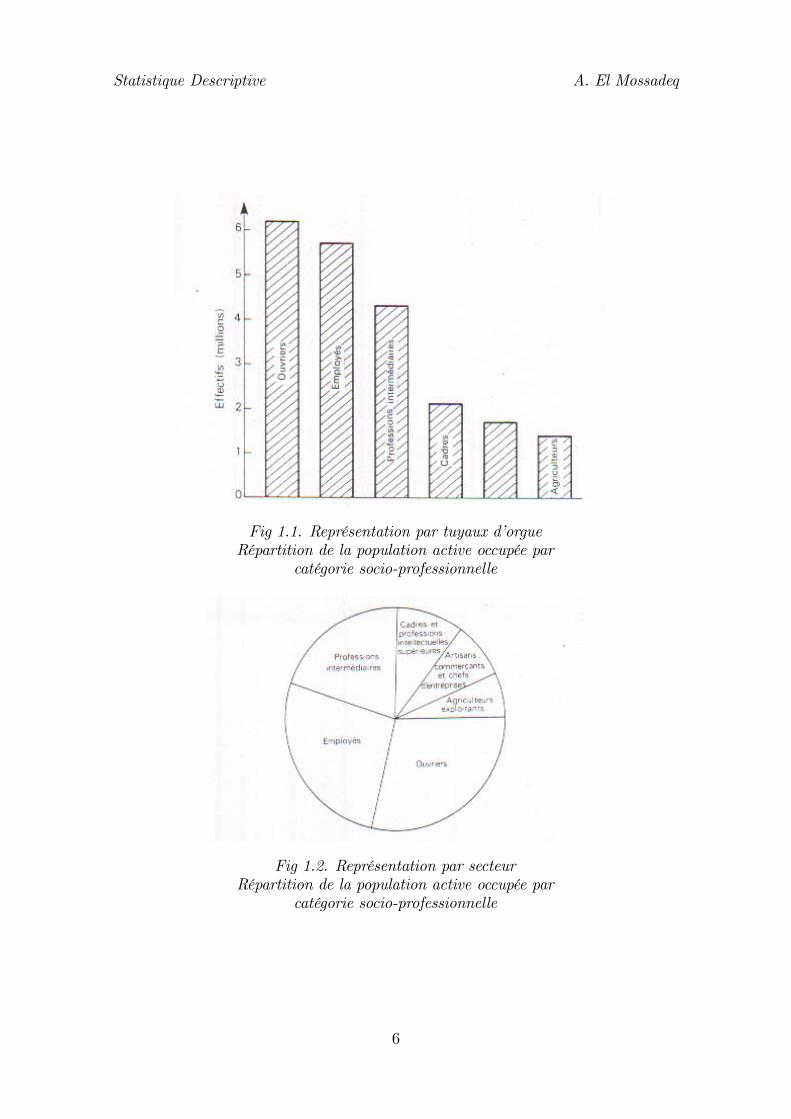
La présentation d’un tableau statistique concernant un tel caractère suit exactementles règles générales exposées ci-dessus.Deux types de représentation graphique sont surtout utilisés : les tuyaux d’orgueset les secteurs :• Dans la représentation par tuyaux d’orgues, les différentes modalités du car-actère sont figurées par des rectangles dont la base est constante et dont lahauteur, et l’air par conséquent, est proportionnelle aux effectifs. Très souvent,les modalités sont ordonnées sur le graphique dans le sens des effectifs croissantsou décroissants.• Dans la représentation par secteurs, ces derniers ont une aire, et par conséquentun angle au centre proportionnel aux effectifs des modalités correspondantes.Ce système de figuration permet de mieux visualiser la part de chaque modalité.
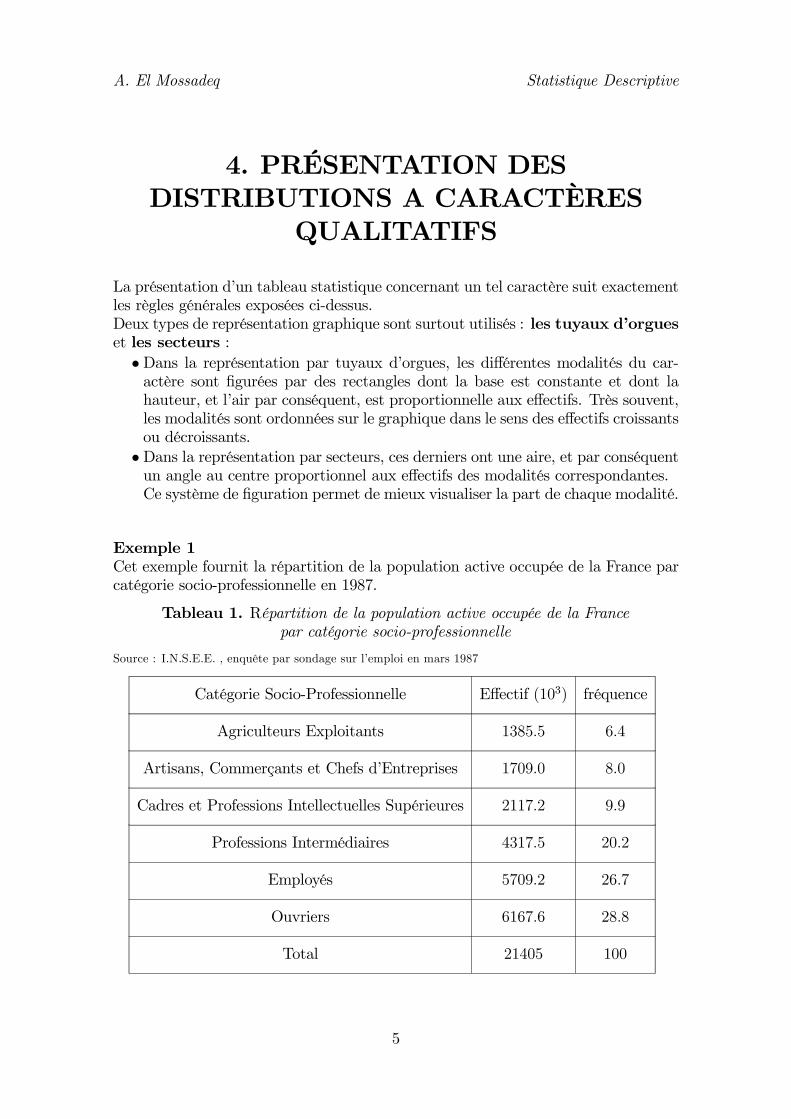
Exemple 1Cet exemple fournit la répartition de la population active occupée de la France parcatégorie socio-professionnelle en 1987.
Tableau 1. Répartition de la population active occupée de la Francepar catégorie socio-professionnelle
Source : I.N.S.E.E. , enquête par sondage sur l’emploi en mars 1987
Catégorie Socio-Professionnelle Effectif (103) fréquence
Agriculteurs Exploitants 1385.5 6.4
Artisans, Commerçants et Chefs d’Entreprises 1709.0 8.0
Cadres et Professions Intellectuelles Supérieures 2117.2 9.9
Professions Intermédiaires 4317.5 20.2
Employés 5709.2 26.7
Ouvriers 6167.6 28.8
Total 21405 100
5
Statistique Descriptive A. El Mossadeq
Fig 1.1. Représentation par tuyaux d’orgueRépartition de la population active occupée par
catégorie socio-professionnelle
Fig 1.2. Représentation par secteurRépartition de la population active occupée par
catégorie socio-professionnelle
6

A. El Mossadeq Statistique Descriptive
5. PRÉSENTATION DESDISTRIBUTIONS A CARACTÈRES
QUANTITATIFS DISCRETS
Les différentes modalités sont constituées par les valeurs possibles de la variablestatistique discrète.En face de chacune de ses valeurs xi, on fait figurer dans le tableau l’effectif ni, lafréquence fi, et la fréquence cumulée Fi :⎧⎪⎪⎪⎪⎨⎪⎪⎪⎪⎩
F1 = 0
F2 = f1
Fi = f1 + ...+ fi−1
Le tableau statistique d’une telle distribution se présente comme ci-après :
Tableau Statistique. Distribution Statistique Discrète
Source : .......
V aleurs xi Effectifs ni Frequences fi Frequences Cumulees Fi
x1 n1 f1 F1 = 0
x2 n2 f2 F2 = f1
: : : :
xk nk fk Fk = f1 + ...+ fk−1
Total n =kPi=1
ni 1 =kPi=1
fi
Il existe deux types de représentation graphique pour les séries statistiques à carac-tères quantitatifs discrets :• le diagramme différentiel ou diagramme en bâtons, qui correspond à lareprésentation des fréquences ou des effectifs,• le diagramme intégral ou courbe cumulative, qui correspond à la représen-tation des fréquences cumulées ou effectifs cumulés.
7
Statistique Descriptive A. El Mossadeq
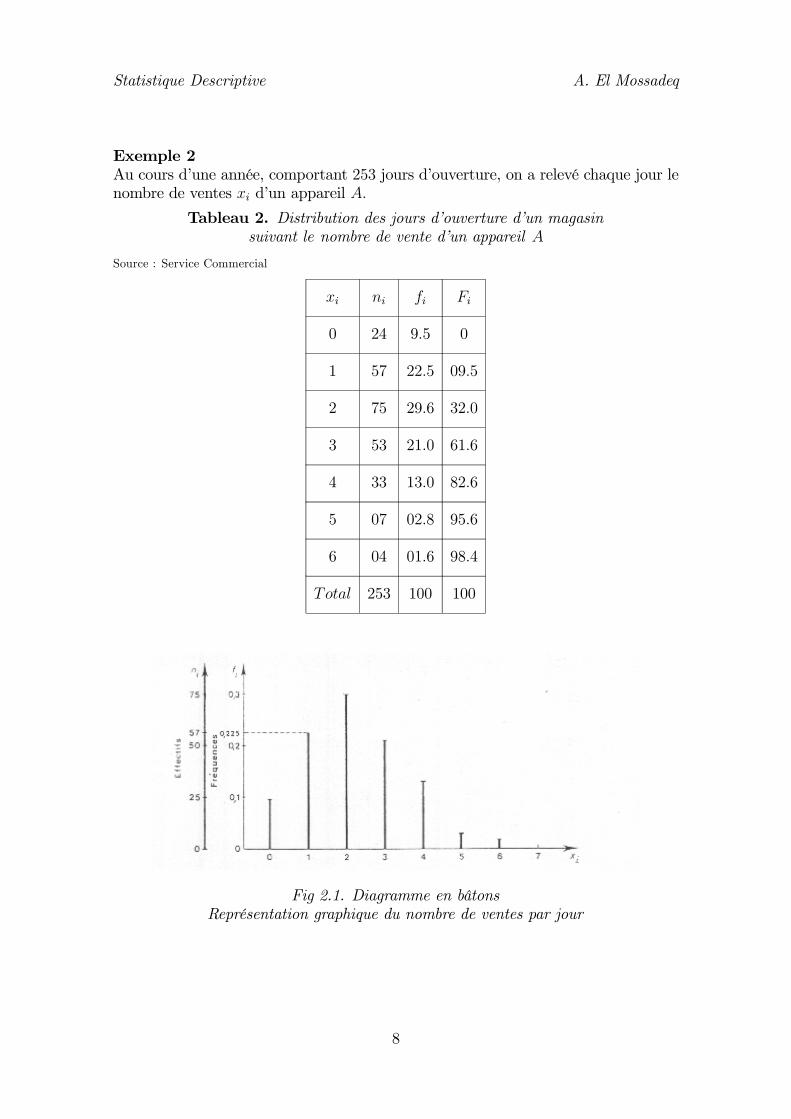
Exemple 2Au cours d’une année, comportant 253 jours d’ouverture, on a relevé chaque jour lenombre de ventes xi d’un appareil A.
Tableau 2. Distribution des jours d’ouverture d’un magasinsuivant le nombre de vente d’un appareil A
Source : Service Commercial
xi ni fi Fi
0 24 9.5 0
1 57 22.5 09.5
2 75 29.6 32.0
3 53 21.0 61.6
4 33 13.0 82.6
5 07 02.8 95.6
6 04 01.6 98.4
Total 253 100 100
Fig 2.1. Diagramme en bâtonsReprésentation graphique du nombre de ventes par jour
8

A. El Mossadeq Statistique Descriptive
Fig 2.2. Courbe cumulativeReprésentation graphique du nombre de ventes par jour
6. PRÉSENTATION DESDISTRIBUTIONS A CARACTÈRES
QUANTITATIFS CONTINUS
Les observations sont nécessairement regroupées par classe. Les modalités du car-actère sont constituées par les différentes classes.Si l’on désigne par xi−1 et xi les extrémités inférieure et supérieure de la ieme classe,celle-ci est généralement définie par :
xi−1 ≤ x < xi
En face de la ieme classe, on fait figurer, dans le tableau statistique, l’effectif ni, lafréquence fi et la fréquence cumulée Fi :⎧⎪⎪⎪⎪⎨⎪⎪⎪⎪⎩
F1 = 0
F2 = f1
Fi = f1 + ...+ fi−1
9

Statistique Descriptive A. El Mossadeq
Tableau Statistique. Distribution Statistique Continue
Source : .......
V aleurs xi Effectifs ni Frequences fi Frequences Cumulees Fi
(x0, x1[ n1 f1 F1 = 0
[x1, x2[ n2 f2 F2 = f1
: : : :
[xk−1, xk) nk fk Fk = f1 + ...+ fk−1
Total n =kPi=1
ni 1 =kPi=1
fi
Deux types de représentation graphique sont possibles pour les séries statistiquescontinues :• le diagramme différentiel appelé histogramme,• le diagramme intégral appelé courbe cumulative.
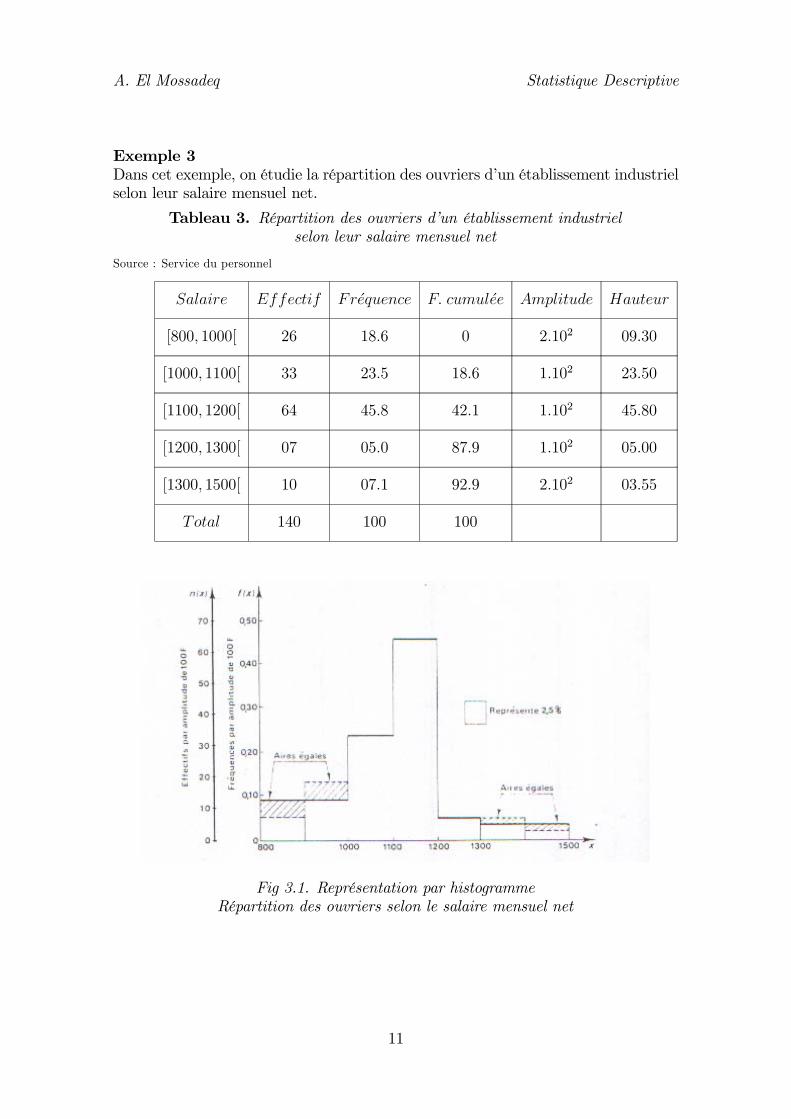
L’histogramme est la représentation graphique de la distribution des effectifs ou desfréquences de la variable statistique continue.A chaque classe de valeurs de la variable, portée en abscisse, on fait correspondreun rectangle basé sur cette classe.Or deux fréquences ne sont directement comparables que s’ils concernent des classesde même amplitude.Dans le cas d’une série dont les amplitudes des classes sont inégales, on choisit uneamplitude de classe u (pour simplifier les calculs, on retiendra le plus grand commundiviseur des diverses amplitudes).L’expression des amplitudes dans cette nouvelle unité est :
ai =xi − xi−1
u
La hauteur hi des rectangles représentatifs de chaque classe est alors :
hi =fiai
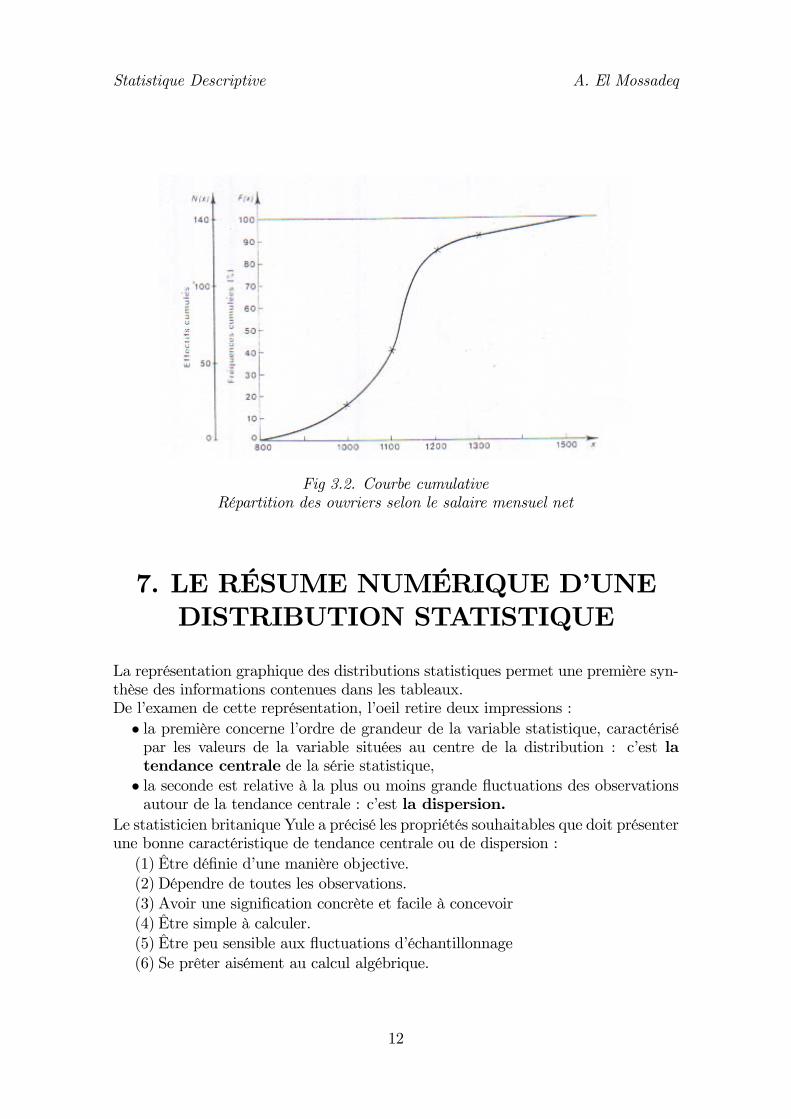
La courbe cumulative, comme pour les variables statistiques discrètes, est la représen-tation graphique de la fonction cumulative F (fonction de répartition).Les observations étant groupées par classe [xi, xi+1[, la valeur de F en xi est :½
F (x1) = 0F (xi) = f1 + ...+ fi−1 , 2 ≤ i ≤ n
10
A. El Mossadeq Statistique Descriptive
Exemple 3Dans cet exemple, on étudie la répartition des ouvriers d’un établissement industrielselon leur salaire mensuel net.
Tableau 3. Répartition des ouvriers d’un établissement industrielselon leur salaire mensuel net
Source : Service du personnel
Salaire Effectif Frequence F. cumulee Amplitude Hauteur
[800, 1000[ 26 18.6 0 2.102 09.30
[1000, 1100[ 33 23.5 18.6 1.102 23.50
[1100, 1200[ 64 45.8 42.1 1.102 45.80
[1200, 1300[ 07 05.0 87.9 1.102 05.00
[1300, 1500[ 10 07.1 92.9 2.102 03.55
Total 140 100 100
Fig 3.1. Représentation par histogrammeRépartition des ouvriers selon le salaire mensuel net
11
Statistique Descriptive A. El Mossadeq
Fig 3.2. Courbe cumulativeRépartition des ouvriers selon le salaire mensuel net
7. LE RÉSUME NUMÉRIQUE D’UNEDISTRIBUTION STATISTIQUE
La représentation graphique des distributions statistiques permet une première syn-thèse des informations contenues dans les tableaux.De l’examen de cette représentation, l’oeil retire deux impressions :• la première concerne l’ordre de grandeur de la variable statistique, caractérisépar les valeurs de la variable situées au centre de la distribution : c’est latendance centrale de la série statistique,• la seconde est relative à la plus ou moins grande fluctuations des observationsautour de la tendance centrale : c’est la dispersion.
Le statisticien britanique Yule a précisé les propriétés souhaitables que doit présenterune bonne caractéristique de tendance centrale ou de dispersion :(1) Être définie d’une manière objective.(2) Dépendre de toutes les observations.(3) Avoir une signification concrète et facile à concevoir(4) Être simple à calculer.(5) Être peu sensible aux fluctuations d’échantillonnage(6) Se prêter aisément au calcul algébrique.
12

A. El Mossadeq Statistique Descriptive
8. LES CARACTÉRISTIQUES DETENDANCE CENTRALE
Les caractéristiques de tendance centrale les plus utilisées sont :• le mode,• la médiane,• la moyenne arithmétique.
On peut leur ajouter :• la moyenne géométrique,• la moyenne harmonique
dont l’usage s’impose dans certains cas particuliers.
8.1. LE MODE
C’est la valeur de la variable statistique pour laquelle la fréquence est la plus élevée.C’est donc la valeur de la variable qui se rencontre le plus fréquemment dans la sériestatistique.
8.1.1. DÉTERMINATION PRATIQUELorsque la variable est discrète, le mode est défini avec précision.Ainsi, dans l’exemple 2, le mode est égal à 2 appareils.Si deux valeurs successives de la variable statistique ont la fréquence maximum, ily a un intervalle modal dont les extrémités correspondent à ces valeurs.Lorsque la variable est continue, la détermination du mode est beaucoup moinsprécise : on peut définir la classe modale comme la classe dont la fréquence parunité d’intervalle est la plus élevée.Ainsi dans l’exemple 3, le salaire modale de la distribution des ouvriers est comprisentre 1100 et 1200.
8.1.2. PROPRIÉTÉSLe principal avantage du mode c’est d’avoir une signification immédiate.Si son calcul dans le cas discret est très facile, par contre, sa détermination dans lecas d’une variable statistique continue n’est pas absolument précise : elle dépend enpartie du découpage en classes retenu.Il ne dépend des observations que par leur fréquence et non par leur valeur.Il se prête mal au calcul algébrique et est très sensible aux fluctuations d’échantillonnage.Il sera surtout utilisé lorsqu’on désire se faire rapidement une première idée de latendance centrale d’une série statistique.
13

Statistique Descriptive A. El Mossadeq
Les distributions statistiques les plus répandues n’ont qu’un seul mode : distribu-tion unimodale, mais il arrive de rencontrer des distributions présentant deux ouplusieurs mode : distribution bimodale ou plurimodale. Chacun d’eux, corre-spond à un maximum local de la courbe de fréquence.Généralement, la présence de plusieurs modes indique que la population observée est,en réalité, hétérogène et composée de sous-populations ayant des caractéristiques detendace centrale différentes.
8.2. LA MÉDIANE
C’est la valeur M da la variable statistique pour laquelle la fréquence cumulée est
égale à1
2:
F (M) =1
2
Elle partage donc en deux effectifs égaux les observations constituant la série préal-ablement rangée par ordre croissant ou décroissant du caractère.
8.2.1. DÉTERMINATION PRATIQUE• Si la variable est discrète, alors dans une série comportant (2k + 1) observa-tions ordonnées dans le sens croissant ou décroissant, la valeur de la (k + 1)eme
observation correspond à la médiane.Si la série comporte 2k observations, les extrémités de l’intervalle médiancorrespondent à la keme et la (k + 1)eme observation.Lorsque à certaines valeurs de la variable statistique correspondent plusieursobservations, l’équation :
F (M) =1
2
peut ne pas avoir de solution.On convient de retenir pour la valeur médiane, la valeur xi telle que :
F (xi−) <1
2< F (xi+)
c’est à dire telle que :
f1 + ...+ fi−1 <1
2< f1 + ...+ fi
On peut aussi déterminer la médiane en utilisant la courbe des fréquences cu-mulée.
14

A. El Mossadeq Statistique Descriptive
Ainsi, dans l’exemple 2, il y a 253 observations, la médiane correspond à lavaleur de la 127eme observations. La valeur de la médiane est 2.Il n’y a que 38.4% des observations dont la valeur soit supérieure à la médiane.
• Dans le cas d’une variable statistique continue, la médiane est toujours stricte-ment définie.On détermine d’abord la classe médiane [xi, xi+1[ telle que :
f1 + ...+ fi−1 <1
2< f1 + ...+ fi
L’estimation de la valeur précise de la médiane s’obtient par interpolationlinéaire :∗ si n est impair égal à 2k + 1 alors :
M = xi + (xi+1 − xi)
Ãk + 1−
i−1Pj=1
nj
!ni
∗ si n est pair égal à 2k alors les extrémités de l’intervalle médian sont :
M1 = xi + (xi+1 − xi)
Ãk −
i−1Pj=1
nj
!ni
M2 = xi + (xi+1 − xi)
Ãk + 1−
i−1Pj=1
nj
!ni
On peut aussi déterminer la valeur de la médiane graphiquement en utilisant lacourbe des fréquences cumulées.Il est préférable de retenir cette valeur puisque celle-ci n’implique pas d’hypothèsede répartition uniforme à l’intérieur de la classe médiane.
8.2.2. PROPRIÉTÉSL’inconvénient principal de la médiane est de ne pas satisfaire la dernière conditionde Yule : définie comme la racine d’une équation, elle ne se prête pas au calcul al-gébrique., la médiane d’une série constituée par le mélange de plusieurs populationsne peut être déduite des médianes des séries composantes.Son emploi n’est pas recommandé dans le cas de séries statistiques discrètes présen-tants des sauts importants ou dans le cas de séries statistiques continues ne com-portant que peu d’observations, car sa signification devient alors très incertaines.
15

Statistique Descriptive A. El Mossadeq
8.3. LA MOYENNE ARITHMÉTIQUE
8.3.1. CALCUL PRATIQUE• Soit une variable statistique discrète prenant les valeurs x1, ..., xk auxquellescorrespondent respectivement les effectifs n1, ..., nk, et n = n1 + ...+ nk.la moyenne arithmétique de cette série est :
m =1
n
kXi=1
nixi
Ainsi, dans l’exemple 2, le nombre moyen de ventes de l’appareil A par jourd’ouverture est 2.2.
• Soit une variable statistique continue où x1, ..., xk sont respectivement les cen-tres des classes [c1, c2[ , ..., [ck, ck+1[ auquelles correspondent les effectifs n1, ..., nkrespectivement, et n = n1 + ...+ nk.la moyenne arithmétique de cette série est :
m =1
n
kXi=1
nixi
Ainsi, dans l’exemple 3, la salaire moyen net des ouvriers de l’établissement est1103F .
8.3.2. PROPRIÉTÉSLa moyenne arithmétique satisfait assez bien les conditions de Yule.Son principal mérite est d’avoir une signification concrète, simple et se prête au cal-cul algébrique.Elle possède les propriétés suivantes :
(1) On a :
1
n
kXi=1
ni (xi −m) = 0
c’est à dire, l’écart moyen des observations par rapport à la moyenne arith-métique est nulle.
(2) La quantité :
S (t) =
vuut1
n
kXi=1
ni (xi − t)2
16

A. El Mossadeq Statistique Descriptive
est minimal pour :
t = m
c’est à dire, la distance moyenne des observations à la moyenne arithmétiqueest minimale.
(3) Si des populations P1, ..., Pk d’effectifs n1, ..., nk ont pour moyennes arithmé-tiques m1, ...,mk alors la population P constituée des populations P1, ..., Pk
a pour moyenne arithmétique :
m =1
n
kXi=1
nimi
8.4. LA MOYENNE GÉOMÉTRIQUE
Soit une série statistique prenant les valeurs x1, ..., xk auxquelles correspondentrespectivement les effectifs n1, ..., nk, et n = n1 + ...+ nk.la moyenne géométrique de cette série est :
G = n
vuut kYi=1
xnii
On a :
lnG =1
n
kXi=1
ni lnxi
lnG est donc la moyenne arithmétique de la série statistique lnx1, ..., lnxk.
Exemple 4Trois équipes se sont succédées à la direction d’une entreprise.Pendant la première période, qui a durée trois ans, les bénifices réalisés ont augmentéde 5.6% par an. Pendant la seconde période de deux ans, de 4.5% et pendant ladernière période de cinq, de 11.3%.Calculons l’indice moyen d’accroissement des bénifices pendant ces dix ans.Soit B0 le bénifice réalisé pendant l’année précédente, alors :
Bi = Bi−1 + 0.056Bi−1 = 1.056Bi−1 =105.6
100Bi−1 , 1 ≤ i ≤ 3
Bi = Bi−1 + 0.045Bi−1 = 1.045Bi−1 =104.5
100Bi−1 , 4 ≤ i ≤ 5
Bi = Bi−1 + 0.113Bi−1 = 1.113Bi−1 =111.3
100Bi−1 , 6 ≤ i ≤ 10
17

Statistique Descriptive A. El Mossadeq
On en déduit :
B10 =
µ105.6
100
¶3µ104.5
100
¶2µ111.3
100
¶5B0
Soit bm l’indice moyen annuel de variation des bénifices pendant ces dix années.On a :
B10 =
µbm100
¶10B0
d’où :
bm =10
q(105.5)3 (104.5)2 (111.3)5 = 108.2
8.5. LA MOYENNE HARMONIQUE
Soit une série statistique prenant les valeurs x1, ..., xk auxquelles correspondent re-spectivement les effectifs n1, ..., nk, et n = n1 + ...+ nk.la moyenne harmonique de cette série est :
H =n
kPi=1
nixi
On a :
1
H=1
n
kXi=1
nixi
1
Hest donc la moyenne arithmétique de la série statistique
1
x1, ...,
1
xk.
Exemple 5Une entreprise a n camions qui font la rotation Casablanca et Rabat.Au cours d’une de celle-ci, le trajet Casablanca-Rabat (distance D) a été couvertpar ces véhicules aux vitesses moyennes :
v1 pour n1 camionsv2 pour n2 camionsv3 pour n3 camions
où
n1 + n2 + n3 = n
Déterminons la vitesse moyenne vm mise pour parcourir cette distance.
18

A. El Mossadeq Statistique Descriptive
Le temps mis est :
t1 =D
v1pour n1 camions
t2 =D
v2pour n2 camions
t3 =D
v3pour n3 camions
La distance totale parcourue par les n camions est nD alors que le temps total misest :
t = n1t1 + n2t2 + n3t3
Pour l’ensemble des camions, la vitesse moyenne est :
vm =nD
t
=n
n1v1+
n2v2+
n3v3
9. LES CARACTÉRISTIQUES DEDISPERSION
Les caractéristiques de dispersion les plus utilisées sont :• l’étendue,• l’intervalle interquartile,• l’écart absolu moyen,• l’écart-type.
9.1. L’ÉTENDUE
9.1.1. CALCUL PRATIQUESoit une série statistique prenant les valeurs x1, ..., xk auxquelles correspondent re-spectivement les effectifs n1, ..., nk.L’étendue ω est la différence entre la plus grande et la plus petite des valeursobservées :
ω =kmaxi=1
xi −k
mini=1
xi
19

Statistique Descriptive A. El Mossadeq
9.1.2. PROPRIÉTÉSLa signification de l´étendue est claire et son calcul est extrêmement rapide.Ces avantages la font fréquemment utiliser dans le contrôle de fabrication indus-trielle où l’on préfère effectuer un plus grand nombre d’observations plutôt que deconfier, compte tenu des conditions de travail d’un atelier, des calculs complexes àdes agents sans formation statistique.Mais cette caractéristique présente des inconvénients sérieux qui conduisent à l’écarterchaque fois que cela est possible.Ne dépendant que des termes extrêmes, qui sont souvent exceptionnels, voir abér-rants, et non de tous les termes, elle est sujette à des fluctuations considérables d’unéchantillon à l’autre.C’est une caractéristique de dispersion très imparfaite.
9.2. L’INTERVALLE INTERQUARTILE
Les trois quartiles Q1, Q2 et Q3 sont les valeurs de la variables pour lesquels la
fréquence cumulée est respectivement1
4,1
2et3
4:⎧⎪⎪⎪⎪⎨⎪⎪⎪⎪⎩
F (Q1) =1
4
F (Q2) =1
2
F (Q3) =3
4
Le 2eme quartile est la médiane.Q3 − Q1 est appelé l’intervalle interquartile. C’est l’intervalle qui contient 50%des observations en laissant 25% à droite et 25% à gauche.
9.2.1. DÉTERMINATION PRATIQUELes quartiles se déterminent à la manière de la médiane, soit par le calcul, soitgraphiquement à partir de la courbe des fréquences cumulées.• Pour l’exemple 2, la variable étant discrète, en utilisant les mêmes conventionsque pour la médiane, on trouve :⎧⎪⎪⎨⎪⎪⎩
Q1 = 1Q2 = 2Q3 = 3Q3 −Q1 = 2
Comme pour la médiane, la signification des quartiles dans le cas discret esttrès incertaines : dans cet exemple, l’intervalle interquartile contient 73% etnon 50% des observations.
20

A. El Mossadeq Statistique Descriptive
• Pour l’exemple 3, l’interpolation linéaire à l’intérieur des intervalles contenantQ1 et Q3, à savoir les intervalles [1000, 1100[ et [1100, 1200[ respectivement,conduit à :
Q1 = 1000 +
(1100− 1000)µ140
4− 26
¶33
= 1027F
Q3 = 1100 +
(1200− 1100)µ3× 1404
− 59¶
64= 1172F
La détermination graphique fournit des évaluations peu différentes mais plusprécises :
Q1 = 1040F , Q3 = 1150F
50% des ouvriers se trouvent dans cet intervalle.
9.2.2. PROPRIÉTÉSLes avantages de l’intervalle interquartile sont la rapidité de son calcul et la simplicitéde sa signification.Mais il ne tient compte que de l’ordre des observations et non de leurs valeurs etdes écarts qui existe entre elles. En outre, sa détermination dans le cas discret n’estpas précise et il ne se prête pas au calcul algébrique. C’est une caractéristique trèsimparfaite qui ne convient qu’à des mesures de dispersion élémentaires.
9.2.3. DÉCILES ET PERCENTILES• Les 9 déciles D1, ...,D9 sont définies de manière analogue par :
F (Dk) =k
10, 1 ≤ k ≤ 9
L’intervalleD9−D1, qui contient 80% des observations, est utilisé parfois commemesure de dispersion.• Les 99 percentiles P1, ..., P99 divisent l’effectif de la série en 100 partie égales :
F (Pk) =k
100, 1 ≤ k ≤ 99
9.3. L’ÉCART ABSOLU MOYEN
9.3.1. DÉTERMINATION PRATIQUESoit une variable statistiqueX prenant les valeurs x1, ..., xk auxquelles correspondentrespectivement les effectifs n1, ..., nk, et n = n1 + ...+ nk.L’écart absolu moyen e [X] est la moyenne arithmétique des valeurs absolues des
21

Statistique Descriptive A. El Mossadeq
écarts à la moyenne arithmétique :
e [X] =1
n
kXi=1
ni |xi −m|
où m est la moyenne arithmétique da la variable.Ainsi, dans l’exemple 3, l’écart absolu moyen est
e = 100.26F
9.3.2. PROPRIÉTÉSL’écart absolu moyen satisfait assez bien aux premières conditions de Yule, mais seprête mal au calcul algébrique puisqu’il fait intervenir des valeurs absolues.
9.4. L’ÉCART-TYPE
9.4.1. DÉTERMINATION PRATIQUESoit une variable statistique X prenant les valeurs x1, ..., xk auquelles correspondentrespectivement les effectifs n1, ..., nk, et n = n1 + ...+ nk.
• La variance V [X] de la variable statistique X est :
V [X] =1
n
kXi=1
ni (xi −m)2 =1
n
kXi=1
nixi2 −m2
où m est la moyenne arithmétique da la variable.C’est la moyenne arithmétique des carrés des écarts à la moyenne arithmétique.• L’écart-type σ [X] est la racine carrée de la variance :
σ [X] =pV [X]
C’est une sorte de distance moyenne des observations à la moyenne arithmé-tique.
Ainsi, dans l’exemple 2 :
m [X] = 2.2
V [X] = 1.8
σ [X] = 1.34
et pour l’exemple 3 :
m [X] = 1102.95F
V [X] = 19719.5
σ [X] = 129.3
22

A. El Mossadeq Statistique Descriptive
9.4.2. CORRECTION DE W. F. SHEPPARDLorsque les observations sont groupées par classe, l’hypothèse de la concentrationdes observations au centre de chaque classe entraine une approximation dans lecalcul.Si toutes les classes ont une même amplitude a et si la courbe de distribution estunimodale et se raccorde, en ses extrémités, tangentiellement à l’axe des abscisses,alors on introduit la correction suivante de l’écart-type σ, dite la correction deSheppard :
σcorrige =
rσ2 − a2
12
9.4.3. PROPRIÉTÉSL’écart-type satisfait assez bien les conditions de Yule.Sa signification n’apparait clairement que dans l’étude des distributions d’échantillonnages.Il jouera un rôle essentiel dans les applications pratiques.
10. APLATISSEMENT ETDISSYMÉTRIE
10.1. LES MOMENTS D’ORDRE r
Soit une variable statistiqueX prenant les valeurs x1, ..., xk auxquelles correspondentrespectivement les effectifs n1, ..., nk, et n = n1 + ...+ nk.
• Le moment d’ordre r de X est :
mr =1
n
kXi=1
nixri
• Le moment d’ordre r de X par rapport à α est :
mr (α) =1
n
kXi=1
ni (xi − α)r
• Le moment centré d’ordre r de X est :
μr =1
n
kXi=1
ni (xi −m1)r
23

Statistique Descriptive A. El Mossadeq
En particulier :
m1 = m [X] = m
μ1 = 0
m2 =1
n
kXi=1
nix2i = m
£X2¤
μ2 =1
n
kXi=1
ni (xi −m)2 = σ2 = m£X2¤−m2
On peut aussi, dans les mêmes conditions que pour l’écart-type, introduire lescorrections de Sheppard :
μ3 (corrige) = μ3
μ4 (corrige) = μ4 −1
2a2σ2corrige −
7
240a4
où a est l’amlitude de classe.
10.2. LE COEFFICIENT D’APLATISSEMENT
Le coefficient d’aplatissement peut être défini selon le sens de Fisher (β2F )ou selon le sens de Paerson (β2P ) :
β2F =μ4σ4
β2P =μ4σ4− 3 = β2F − 3
Pour une loi normale :
μ4 = 3σ4
et par suite :
β2F = 3
β2P = 0
Le coefficient d’aplatissement permet de comparer l’aplatissement d’une courbede fréquence à celui d’une courbe de Gauss de même écart-type : lorsqueβ2P > 0, la courbe de fréquence est moins aplatie que celle de Gauss; c’estl’inverse lorsque β2P < 0.
24
A. El Mossadeq Statistique Descriptive
10.3. LE COEFFICIENT DE DISSYMÉTRIE
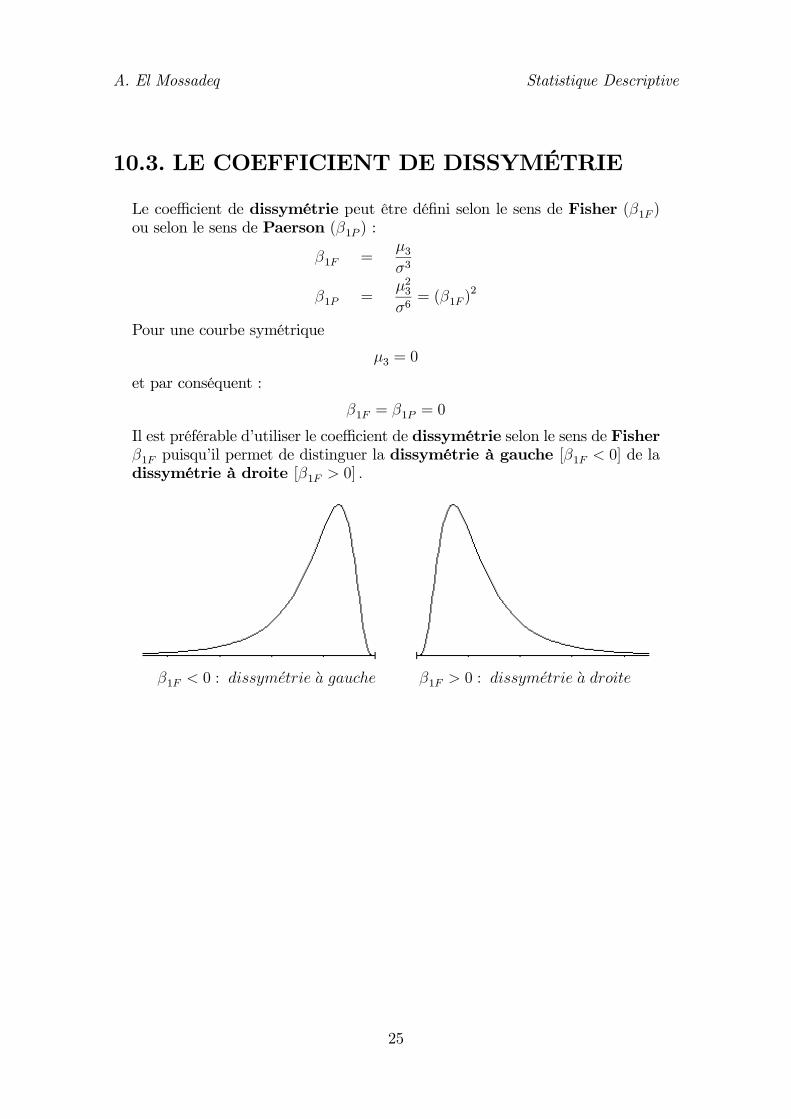
Le coefficient de dissymétrie peut être défini selon le sens de Fisher (β1F )ou selon le sens de Paerson (β1P ) :
β1F =μ3σ3
β1P =μ23σ6= (β1F )
2
Pour une courbe symétrique
μ3 = 0
et par conséquent :
β1F = β1P = 0
Il est préférable d’utiliser le coefficient de dissymétrie selon le sens de Fisherβ1F puisqu’il permet de distinguer la dissymétrie à gauche [β1F < 0] de ladissymétrie à droite [β1F > 0] .
β1F < 0 : dissymetrie a gauche β1F > 0 : dissymetrie a droite
25


Chapitre 2
Structure Statistique et
Estimation


A. El Mossadeq Structures Statistiques et Estimation
1. STATISTIQUE ET STRUCTURESTATISTIQUE
Définition 1Soit X un aléa défini sur un espace probabilisé (Ω, T ,P ) à valeurs dans un espaceprobabilisable (E ,B) .(X1, ...,Xn) est un échantillon de taille n de variable parente X, ou plussimplement un n-échantillon issu de X, si X1, ..., Xn sont n aléas indépendantsqui suivent la même loi que X.
Définition 2Soit (X1, ...,Xn) un n-échantillon issu d’un aléa X défini sur un espace probabilisé(Ω, T ,P ) à valeurs dans un espace probabilisable (E ,B) et soit g un aléa défini sur(E ,B)n .L’aléa g (X1, ...,Xn) est appelé une statistique.La loi de g (X1, ..., Xn) est appelé une distribution d’échantillonnage.
Exemple 1Soit (X1, ...,Xn) un n-échantillon issu d’une variables aléatoire X.Les variables aléatoires : ⎧⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎩
M =1
n
nXi=1
Xi
S2 =1
n
nXi=1
(Xi −M)2
sont des statistiques.M est la moyenne empirique et S2 est la variance empirique.
Définition 3Soit P une famille de lois de probabilité sur un espace probabilisable (Ω,T ).Le triplet (Ω,T ,P) est appelé une structure statistique.
29

Structures Statistiques et Estimation A. El Mossadeq
Remarque 1Le plus souvent, la famille de lois de probabilité P est décrite à l’aide d’un paramètreθ appartenant à un sous ensemble Θ de Rp, p ≥ 1. On écrit alors :
P = Pθ | θ ∈ Θ
et la structure statistique s’écrit :
(Ω,T , Pθ | θ ∈ Θ)
Exemple 2Soit X une variable aléatoire de Poisson de paramètre θ, θ > 0 :
pθ (ω) =θω
ω!e−θ
où ω ∈ N.La structure statistique associée est (N, pθ | θ > 0) .
Exemple 3Soit X une variable aléatoire exponentielle de paramètre θ, θ > 0 :
fθ (x) =
⎧⎨⎩ 0 si x ≤ 0
θ exp−θx si x > 0
La structure statistique associée est (R,BR, fθ | θ > 0) .
Définition 4On appelle un r-échantillon d’une structure statistique (Ω,T , Pθ | θ ∈ Θ), lastructure produit :
(Ω,T , Pθ | θ ∈ Θ)r = (Ωr,⊗rT , ⊗rPθ | θ ∈ Θ)
30

A. El Mossadeq Structures Statistiques et Estimation
2. FONCTION DE VRAISEBLANCE
2.1. STRUCTURE STATISTIQUE DISCRÈTE
Définition 5Soit (Ω, pθ | θ > 0) une structure statistique discrète.On appelle fonction de vraisemblance, de cette structure, la fonction numériqueL définie pour tout (θ;x) ∈ Θ×Ω par :
L (θ;x) = pθ (x)
La fonction de vraisemblance d’un r-échantillon de cette structure est définiepour tout (θ;x1, ..., xr) ∈ Θ× Ωr par :
L (θ;x1, ..., xr) =rY
i=1
pθ (xi)
Exemple 4Si (X1, ...,Xr) est un r-échantillon issu d’une variables aléatoire de Poisson deparamètre θ, θ > 0, sa fonction de vraisemlance est :
L (θ;ω1, ..., ωr) =rY
i=1
pθ (ωi)
=θ
rPi=1
ωi
ω1!...ωr!e−rθ
2.2. STRUCTURE STATISTIQUE CONTINUE
Définition 6Soit (Rn,BRn, Pθ | θ > 0) une structure statistique dans laquelle les probabilitésPθ sont définies à partir de densité fθ.On appelle fonction de vraisemblance, de cette structure, la fonction numériqueL définie pour tout (θ;x) ∈ Θ×Rn par :
L (θ;x) = fθ (x)
31

Structures Statistiques et Estimation A. El Mossadeq
La fonction de vraisemblance d’un r-échantillon de cette structure est définiepour tout (θ;x1, ..., xr) ∈ Θ× (Rn)r par :
L (θ;x1, ..., xr) =rY
i=1
fθ (xi)
Exemple 5Si (X1, ...,Xr) est un r-échantillon issu d’une variables aléatoire exponentielle deparamètre θ, θ > 0, sa fonction de vraisemlance est :
L (θ;x1, ..., xr) =rY
i=1
fθ (xi)
= θr exp−θrX
i=1
xi , xi > 0 , 1 ≤ i ≤ r
Exemple 6Si (X1, ..., Xr) est un r-échantillon issu d’une variables aléatoire qui suit la loi uni-forme sur l’intervalle [0, θ], θ > 0, sa fonction de vraisemlance est :
L (θ;x1, ..., xr) =rY
i=1
fθ (xi)
=1
θr, xi ∈ [0, θ] , 1 ≤ i ≤ r
3. STATISTIQUES EXHAUSTIVES
Soit (Ω, T ,P ) un espace probabilisé et T ∗ une sous-tribu de T .Si A est un événement de T et χA la fonction caractéristique de A, l’espérenceconditionnelle E [χA | T ∗], que l’on note P [A | T ∗], s’appelle la probabilitéconditionnelle de A relativement à la sous-tribu T ∗.P [A | T ∗] est une variable aléatoire définie sur (Ω,T ∗) d’une façon unique(P -p.p) par : Z
B
P [A | T ∗] dP =
ZB
χAdP
= P [AB]
32

A. El Mossadeq Structures Statistiques et Estimation
pour tout B ∈ T ∗.Si T ∗ est la sous-tribu engendrée par une partition A1, ..., Ar de Ω, alors :
P [A | T ∗] = P [A | Ai] sur Ai
c’est à dire :
P [A | T ∗] =rX
i=1
P [A | Ai]χAi
Si T est un aléa défini sur un espace probabilisé (Ω,T ,P ) à valeurs dans unespace probabilisable (E ,B), on définit la probabilité conditionnelle de Arelativement à T par :
P [A | T ] = P£A | T−1 (B)
¤et comme :
P [A | T ] = u T = u (T )
alors :
P [A | T = t] = u (t)
Définition 7Soit (Ω, T , Pθ | θ ∈ Θ) une structure statistique.Une sous-tribu T ∗ de T est dite exhaustive pour la famille Pθ | θ ∈ Θ si pourtout A dans T , la probabilité conditionnelle Pθ [A | T ∗] est indépendante de θ.
Définition 8On dit que la statistique T définie sur (Ω,T , Pθ | θ ∈ Θ) à valeurs dans unespace probabilisable (E ,B) est exhaustive pour la famille Pθ | θ ∈ Θ si la soustribu T−1 (B) est exhaustive pour cette famille.Une statistique exhaustive est appelée aussi un résumé exhaustif.
Proposition 1Soit (Ω, pθ | θ ∈ Θ) une structure statistique discrète.Une statistique T définie sur (Ω, T , Pθ | θ ∈ Θ) à valeurs dans un espace probabil-isable (E ,B) est exhaustive pour la famille Pθ | θ ∈ Θ si et seulement si il existeune fonction positive g définie sur Θ × Ω et une fonction h définie sur Ω telle quepour tout (θ;ω) ∈ Θ×Ω on ait :
pθ (ω) = g (θ;T (ω))h (ω)
33

Structures Statistiques et Estimation A. El Mossadeq
Preuve 1• Supposons T exhaustif.
∗ Si :Pθ [T = T (ω)] = 0
il suffit de prendre :
g (θ;T (ω)) = 0
et :
h (ω) = 0
∗ Si :Pθ [T = T (ω)] 6= 0
alors :
pθ (ω) = Pθ [ω ∩ T = T (ω)]= Pθ [T = T (ω)]Pθ [ω | T = T (ω)]
On peut poser donc :
g (θ;T (ω)) = Pθ [T = T (ω)]
et :
h (ω) = Pθ [ω | T = T (ω)]
puisque d’après l’exhaustuvité, cette probabilité conditionnelle ne dépendpas de θ.
• Inversement, supposons que pour tout (θ;ω) ∈ Θ×Ω on a :
pθ (ω) = g (θ;T (ω))h (ω)
Il suffit de prouver que pour tout (ω, t) ∈ Ω × E , la probabilité Pθ [ω | T = t]ne dépend pas de θ.En effet, supposons :
Pθ [T = t] 6= 0
∗ si :T (ω) 6= t
alors :
Pθ [ω | T = t] =Pθ [ω ∩ T = t]
Pθ [T = t]= 0
34

A. El Mossadeq Structures Statistiques et Estimation
∗ si :T (ω) = t
alors :
Pθ [ω | T = t] =Pθ [ω ∩ T = t]
Pθ [T = t]
=g (θ;T (ω))h (ω)P
ω∈Ω|T (ω)=tg (θ;T (ω))h (ω)
=h (ω)P
ω∈Ω|T (ω)=th (ω)
Exemple 7Soit (Ω, pθ | θ ∈ Θ) une structure statistique discrète.Les familles de lois exponentielles :
pθ (ω) = exp
"kXi=1
αi (θ) ai (ω) + β (θ) + b (ω)
#admettent des résumés exhaustifs.
Exemple 8Soit X une variable aléatoire de Bernouilli de paramètre θ, 0 < θ < 1 :
pθ (ω) = exp [(1− ω) ln (1− θ) + ω ln θ]
Si (X1, ...,Xr) est un r-échantillon de cette structure alors :
pθ (ω1, ..., ωr) = exprX
i=1
[(1− ωi) ln (1− θ) + ωi ln θ]
Posons :
T (ω1, ..., ωr) =1
r
rXi=1
ωi
alors :
pθ (ω1, ..., ωr) = exprX
i=1
[(1− ωi) ln (1− θ) + ωi ln θ]
= exp r [(1− T (ω1, ..., ωr)) ln (1− θ) + T (ω1, ..., ωr) ln θ]
= g [θ;T (ω1, ..., ωr)]
35

Structures Statistiques et Estimation A. El Mossadeq
T est alors un résumé exhaustif pour la famille des lois de Bernouilli de paramètreθ, 0 < θ < 1.
Proposition 2Soit (Rn,BRn, Pθ | θ > 0) une structure statistique dans laquelle les probabilitésPθ sont définies à partir de densité fθ.Une statistique T définie sur (Rn,BRn, Pθ | θ > 0) à valeurs dans (Rs,BRs) estexhaustive pour la famille Pθ | θ ∈ Θ si et seulement si il existe une fonction pos-itive g définie sur Θ×Rs mesurable pour tout θ fixé dans Θ et une fonction positiveet mesurable h définie sur Rn telle que pour tout (θ;x) ∈ Θ× Rn on ait :
fθ (x) = g (θ;T (x))h (x)
Preuve 2Admis
Exemple 9Soit (Rn,BRn, Pθ | θ > 0) une structure statistique dans laquelle les probabilitésPθ sont définies à partir de densité fθ.Les familles de lois exponentielles :
fθ (x) = exp
"kXi=1
αi (θ) ai (x) + β (θ) + b (x)
#admettent des résumés exhaustifs.
Exemple 10Soit X une variable aléatoire exponentielle de paramètre θ, θ > 0 :
fθ (x) =
⎧⎨⎩ 0 si x ≤ 0
θ exp−θx si x > 0
Si (X1, ...,Xr) un r-échantillon de cette structure alors :
fθ (x1, ..., xr) =
⎧⎪⎪⎨⎪⎪⎩θr exp−θ
rPi=1
xi si xi > 0 , 1 ≤ i ≤ r
0 ailleurs
36

A. El Mossadeq Structures Statistiques et Estimation
Posons :
T (x1, ..., xr) =1
r
rXi=1
xi
alors :
fθ (ω1, ..., ωr) = θr exp−θrX
i=1
xi
= θr exp−rθT (x1, ..., xr)= g [θ;T (x1, ..., xr)]
T est alors un résumé exhaustif pour la famille des lois exponentielles de paramètresθ, θ > 0.
Exemple 11Soit X une variable aléatoire normale de paramètres μ ∈ R et σ2, σ > 0 :
f (μ, σ;x) =1
σ√2πexp− 1
2σ2(x− μ)2
Si (X1, ...,Xr) est un r-échantillon de cette structure alors :
f (μ, σ;x1, ..., xr) =1¡
σ√2π¢r exp− 1
2σ2
rXi=1
(xi − μ)2
Posons :
M (x1, ..., xr) =1
r
nXi=1
xi
S2 (x1, ..., xr) =1
r
nXi=1
[xi −M (x1, ..., xr)]2
On a :
f (μ, σ;x1, ..., xr) =1¡
σ√2π¢r exp− r
2σ2£S2 (x1, ..., xr) + (M (x1, ..., xr)− μ)2
¤= g
£μ, σ;M (x1, ..., xr) , S
2 (x1, ..., xr)¤
puisque :rX
i=1
(xi − μ)2 = r£S2 (x1, ..., xr) + (M (x1, ..., xr)− μ)2
¤(M,S2) est alors un résumé exhaustif pour la famille des lois normales de paramètresμ ∈ R et σ2, σ > 0.
37

Structures Statistiques et Estimation A. El Mossadeq
4. INFORMATION CONCERNANTUN PARAMÈTRE
Dans tout ce paragraphe, on suppose donné un vecteur aléatoire à n dimen-sions défini sur une structure statistique (Ω,T , Pθ | θ ∈ Θ), ce qui permetde trasporter la structure statistique sur Rn.Par abus, on note Pθ, la loi (Pθ)X du vecteur aléatoire X, et on suppose quePθ possède une densité fθ.On désigne par Dθ le domaine :
Dθ = x ∈ Rn | f (θ;x) > 0
4.1. MATRICE D’INFORMATION
Proposition 3Soit (Rn,BRn , Pθ | θ ∈ Θ), Θ ⊂ Rk, une structure statistique dans laquelle lesprobabilités Pθ sont définies à partir des densités fθ.Sous réserve de légitimité de dérivations sous le signe intégrale et en supposant ledomaine :
Dθ = x ∈ Rn | f (θ;x) > 0indépendant de θ, pour tout θ ∈ Θ, le vecteur aléatoire :∙
∂
∂θjln f (θ;X)
¸1≤i≤k
est centré.
Preuve 3Puisque : Z
Rnf (θ, x) dx = 1
alors, en supposant légitimes les dérivations sous le signe d’intégration et le domaineDθ indépendant de θ, pour tout θ ∈ Θ, on obtient :Z
Rn
∂
∂θjf (θ, x) dx =
ZRn
∙∂
∂θjln f (θ, x)
¸f (θ, x) dx
= 0
pour tout j, 1 ≤ j ≤ k.
38

A. El Mossadeq Structures Statistiques et Estimation
Définition 9La matrice des variances et covariances du vecteur aléatoire :∙
∂
∂θjln f (θ;X)
¸1≤i≤k
est appelée, lorsqu’elle existe, la matrice d’information concernant le paramètreθ fourni par la structure statistique (Rn,BRn, Pθ | θ ∈ Θ).On la note I [X, θ] .Lorsque n = 1, I [X, θ] n’a qu’un seul élément appelé la quantité d’informationde Fisher.
Pour calculer les éléments de la matrice I [X, θ] = [Iij], partons de la relation :ZRn
f (θ, x) dx = 1
donc, pour tout j, 1 ≤ j ≤ n, on a :
∂
∂θj
ZRn
f (θ, x) dx = 0
Sous reserve de validité des dérivations sous le signe intégrale et en supposantle domaine :
Dθ = x ∈ Rn | f (θ;x) > 0indépendant de θ, on obtient :Z
Rn
∂
∂θjf (θ, x) dx =
ZRn
∙∂
∂θjln f (θ, x)
¸f (θ, x) dx
= 0
Sous les mêmes conditions on a :ZRn
∙∂2
∂θi∂θjln f (θ, x)
¸f (θ, x) dx+
∙∂
∂θiln f (θ, x)
¸ ∙∂
∂θjln f (θ, x)
¸f (θ, x) dx = 0
d’où :
Iij = E
∙∂
∂θiln f (θ,X)
∂
∂θjln f (θ,X)
¸= −E
∙∂2
∂θi∂θjln f (θ,X)
¸
39

Structures Statistiques et Estimation A. El Mossadeq
Remarque 2En tant que matrice des variances et covariances, I [X, θ] est symétrique et positive.
Exemple 12Soit X une variable aléatoire normale de paramètres μ ∈ R et σ2, σ > 0.La matrice d’information concernant les paramètres μ et σ est donnée par :
I [X;μ, σ] =
⎡⎢⎢⎣1
σ20
02
σ2
⎤⎥⎥⎦
Remarque 3Lorsque n = 1, la quantité d’information de Fisher est :
I [X, θ] = E
"µ∂
∂θln f (θ,X)
¶2#
= −E∙∂2
∂θ2ln f (θ,X)
¸
Proposition 4Soit I [X, θ] la matrice d’information de la structure statistique (Rn,BRn, Pθ | θ ∈ Θ),où Θ ⊂ Rk et les probabilités Pθ sont définies à partir des densités fθ, et soitI [X1, ..., Xr; θ] un r-échantillon de cette structure.
40

A. El Mossadeq Structures Statistiques et Estimation
Sous reserve de légétimité de dérivations sous le signe intégrale et en supposant ledomaine :
Dθ = x ∈ Rn | f (θ;x) > 0indépendant de θ, pour tout θ ∈ Θ, alors :
I [X1, ..., Xr; θ] = rI [X, θ]
Preuve 4Puisque :
L (θ;x1, ..., xr) =rY
i=1
f (θ, xi)
alors :
E
∙∂2
∂θi∂θjlnL (θ;X1, ...,Xr)
¸= E
"∂2
∂θi∂θjln
rYi=1
f (θ;Xi)
#
=rX
i=1
E
∙∂2
∂θi∂θjln f (θ;Xi)
¸= rE
∙∂2
∂θi∂θjln f (θ;X)
¸
Exemple 13Soit X une variable aléatoire normale de paramètres μ ∈ R et σ2, σ > 0. On supposeque σ est connu.
I [X,μ] = E
"µ∂
∂μln f (μ,X)
¶2#
= E
∙1
σ4(X − μ)2
¸=
1
σ2
Si X1, ...,Xr est un r-échantillon de cette structure, alors :
I [X1, ..., Xr;μ] = rI [X,μ]
=r
σ2
41

Structures Statistiques et Estimation A. El Mossadeq
Proposition 5Soit T1, ..., Ts un système de s statistiques définies sur un r-échantillon de la structurestatistique (Rn,BRn, Pθ | θ ∈ Θ), s ≤ r.On suppose qu’il existe des statistiques Ts+1, ..., Tr telles que les équations :
ti = Ti (x1, ..., xr) , 1 ≤ i ≤ r
définissent un changement de variables continument différentiable.Sous réserve de légétimité de dérivations sous le signe intégrale et en supposant ledomaine :
Dθ = x ∈ Rn | f (θ;x) > 0indépendant de θ, pour tout θ ∈ Θ, la matrice :
I [X1, ..., Xr; θ]− I [T1, ..., Ts; θ]
est positive.Elle est nulle si et seulement si T1, ..., Ts est un résumé exhaustif.
Preuve 5Le changement de variables :
ti = Ti (x1, ..., xr) , 1 ≤ i ≤ r
permet d’écrire :
L (θ;x1, ..., xr) = g (θ; t1, ..., ts) g (θ; ts+1, ..., tr | t1, ..., ts)¯D (t1, ..., tr)
D (x1, ..., xr)
¯d’où :
− ∂2
∂θi∂θjlnL (θ;x1, ..., xr) = −
∂2
∂θi∂θjln g (θ; t1, ..., ts)−
∂2
∂θi∂θjln g (θ; ts+1, ..., tr | t1, ..., ts)
Il en découle que :
I [X1, ...,Xr; θ] = I [T1, ..., Ts; θ] + J
La matrice J est positive puisqu’elle s’obtient comme moyenne des matrices desvariances et covariances associées à :
∂
∂θiln g (θ; ts+1, ..., tr | t1, ..., ts)
Elle est nulle si et seulement si la fonction :
g (θ; ts+1, ..., tr | t1, ..., ts)
est indépendant de θ, donc si et seulement si (T1, ..., Ts) est un résumé exaustif.
42

A. El Mossadeq Structures Statistiques et Estimation
Remarque 4Dans ces conditions, il est équivalent de travailler avec le r-échantillon ou le résuméexhaustif.
Remarque 5Lorsque θ est un paramètre réel, la quantité d’information fournie par un résumé Tdéfini sur un r-échantillon est majorée par celle qui est fournie par le r-échantillon :
I [T ; θ] ≤ I [X1, ...,Xr; θ]
L’égalité a lieu si et seulement si T est un résumé exhaustif.
Exemple 14Soit X une variable aléatoire normale de paramètres μ ∈ R et σ2, σ > 0.On suppose que σ est connu.Considérons la statistique :
M =1
r
rXi=1
Xi
où X1, ...,Xr est un r-échantillon issu de X.
Puisque M est une variable aléatoire normale de paramètres μ etσ2
r, alors :
I [M,μ] =r
σ2
M est alors un résumé exhaustif pour μ concernant la structure statistique consid-érée.
4.2. INÉGALITÉ DE CRAMER-RAO
Proposition 6Soit (Rn,BRn , Pθ | θ ∈ Θ), Θ ⊂ Rk, une structure statistique dans laquelle lesprobabilités Pθ sont définies à partir des densités fθ.Considérons un r-échantillon de cette structure et notons L sa fonction de vraise-blance.
43

Structures Statistiques et Estimation A. El Mossadeq
Soit :
T = Φ (X1, ..., Xr)
un résumé exhaustif de cette structure.On suppose que :(1) la variance σ2 [T ] = V [T ] existe,
(2)∂
∂θL (θ;x1, ..., xr) et Φ (x1, ..., xr)
∂
∂θL (θ;x1, ..., xr) existent et sont intégrables,
(3) la quantité d’information de Fisher existe,(4) le domaine Dθ est indépendant de θ, pour tout θ ∈ Θ.Alors sous reserve de légétimité de dérivations sous le signe d’intégration on a :
V [T ] ≥
∙∂
∂θE [T ]
¸I [X1, ...,Xr; θ]
de plus, l’égalité a lieu si et seulement si :
∂
∂θlnL (θ;X1, ..., Xr) = γ (θ) [T − E [T ]]
C’est l’inégalité de Cramer-Rao.
Preuve 6D’après ce qui précède, la variable aléatoire
∂
∂θlnL (θ;X1, ...,Xr) est centrée, c’est
à dire :
E
∙∂
∂θlnL (θ;X1, ...,Xr)
¸= 0
et donc :
E
∙E [T ]
∂
∂θlnL (θ;X1, ...,Xr)
¸= 0
Par définition :
E [T ] =
ZRnr
Φ (x1, ..., xr)L (θ;x1, ..., xr) dx1...dxr
Les hypothèses permettent d’écrire :
∂
∂θE [T ] =
ZRnr
Φ (x1, ..., xr)∂
∂θL (θ;x1, ..., xr) dx1...dxr
= E
∙T∂
∂θlnL (θ;X1, ...,Xr)
¸= E
∙(T −E [T ])
∂
∂θlnL (θ;X1, ..., Xr)
¸
44

A. El Mossadeq Structures Statistiques et Estimation
Il s’en suit par application de l’inégalité de Schwarz :∙∂
∂θE [T ]
¸2≤ E
£(T −E [T ])2
¤E
"µ∂
∂θlnL (θ;X1, ...,Xr)
¶2#≤ V [T ] I [X1, ..., Xr; θ]
d’où :
V [T ] ≥
∙∂
∂θE [T ]
¸2I [X1, ...,Xr; θ]
De plus légalité a lieu si et seulement si :
∂
∂θlnL (θ;X1, ..., Xr) = γ (θ) [T − E [T ]]
5. ESTIMATEURS
Définition 10Soit (Ω, T , Pθ | θ ∈ Θ) une structure statistique et considérons un aléa :
h : (Θ,W) −→ (E ,B)
où W est une tribu de P (Θ) .On appelle estimateur de h (θ), θ ∈ Θ, toute statistique à valeurs dans (E ,B).
Définition 11Soit T un estimateur de h (θ), θ ∈ Θ.
1. T est dit sans biais si :
E [T ] = h (θ)
2. T est dit asymptoquement sans biais si :
limr→∞
E [T ] = h (θ)
3. T est dit convergent si :
limr→∞
V [T ] = 0
45

Structures Statistiques et Estimation A. El Mossadeq
Exemple 15Soit (X1, ..., Xr) un r-échantillon issu d’une variable aléatoire X de moyenne μ etde variance σ2.
1. La statistique :
M =1
r
rXi=1
Xi
est un estimateur sans biais et convergent de la moyenne μ :
E [M ] = E
"1
r
rXi=1
Xi
#
=1
r
rXi=1
E [Xi]
= μ
2. La statistique :
S21 =1
r
rXi=1
(Xi − μ)2
est un estimateur sans biais de la variance σ2.En effet :
E£S21¤
= E
"1
r
rXi=1
(Xi − μ)2#
=1
r
rXi=1
E£(Xi − μ)2
¤=
1
r
rXi=1
V [Xi]
= σ2
Donc S21 est un estimateur sans biais de σ2.
3. La statistique :
S22 =1
r
rXi=1
(Xi −M)2
est un estimateur biaisé de la variance σ2.
46

A. El Mossadeq Structures Statistiques et Estimation
En effet :rX
i=1
(Xi −M)2 =rX
i=1
[(Xi − μ)− (M − μ)]2
=rX
i=1
(Xi − μ)2 − 2rX
i=1
(Xi − μ) (M − μ) +rX
i=1
(M − μ)2
=rX
i=1
(Xi − μ)2 − r (M − μ)2
d’où :
E
"rX
i=1
(Xi −M)2#
= E
"rX
i=1
(Xi − μ)2#− rE
£(M − μ)2
¤= (r − 1)σ2
On en déduit :
E£S22¤=
r − 1r
σ2
d’où S22 est biasé.
4. La statistique :
S2 =1
r − 1
rXi=1
(Xi −M)2
est un estimateur sans biais de la variance σ2.En effet, puisque :
S2 =r
r − 1S22
on en déduit :
E£S2¤= σ2
Remarque 6Si T un estimateur sans biais de h (θ), on a en vertu de l’inégalité de Cramer-Rao :
V [T ] ≥ [h0 (θ)]2
I [X1, ...,Xr; θ]
Si de plus h (θ) = θ, alors :
V [T ] ≥ 1
I [X1, ...,Xr; θ]
47

Structures Statistiques et Estimation A. El Mossadeq
Remarque 7Soit T l’ensemble des estimateurs sans biais de h (θ), vérifiant l’inégalité de Cramer-Rao.On a :
infT∈T
V [T ] ≥ [h0 (θ)]2
I [X1, ...,Xr; θ]
Définition 12Un estimateur T0 de T est dit de variance minimale si :
V [T0] = infT∈T
V [T ]
Définition 13Si :
infT∈T
V [T ] =[h0 (θ)]2
I [X1, ...,Xr; θ]
on appelle efficacité d’un estimateur T0 de T, le rapport :
e [T0] =infT∈T
V [T ]
V [T0]
T0 est dit efficace lorsque son efficacité est égale à 1 :
e [T0] = 1
Proposition 7Soit T = Φ (X1, ..., Xr) un estimateur de T.Les trois conditions suivantes sont équivalentes :
(1) T est efficace
(2)∂
∂θlnL (θ;x1, ..., xr) = γ (θ) [Φ (x1, ..., xr)− h (θ)]
(3) T un résumé exhaustif dont la densité de probabilité g (θ; t) est telle que :
∂
∂θln g (θ;x) = γ (θ) [t− h (θ)]
48

A. El Mossadeq Structures Statistiques et Estimation
Preuve 7• (1)⇐⇒ (2)D’après la définition de l’efficacité, T est efficace si et seulement si l’inégalité deCramer-Rao est une égalité, donc si et seulement si :
∂
∂θlnL (θ;X1, ..., Xr) = γ (θ) [T − h (θ)]
• (1) =⇒ (3)T est efficace donc :
V [T ] =[h0 (θ)]2
I [X1, ...,Xr; θ]
=[h0 (θ)]2
I [T ; θ]
d’où :
I [X1, ...,Xr; θ] = I [T ; θ]
et par conséquent T est un résumé exhaustif concernant θ et on a :
∂
∂θln g (θ;x) = γ (θ) [t− h (θ)]
par application de l’inégalité de Cramer-Rao (qui est une égalité dans ce cas) àT .
• (3) =⇒ (2)Si T est un résumé exhaustif concernant θ, alors d’après le théorème de factori-sation :
L (θ;X1, ..., Xr) = g (θ; t) s (X1, ...,Xr)
D’où :
∂
∂θlnL (θ;X1, ...,Xr) =
∂
∂θln g (θ;x)
= γ (θ) [T − h (θ)]
49

Structures Statistiques et Estimation A. El Mossadeq
6. L’ESTIMATION PAR LAMÉTHODE DE LAVRAISEMBLANCE
La méthode du maximum de vraisemblance a pour but de fournir un moyenefficace pour choisir un estimateur d’un paramètre.
Définition 14Soit L (θ;X1, ...,Xr) la fonction de vraisemlance d’un r-échantillon X1, ...,Xr.Si pour (x1, ..., xr) donné :
θ = Φ (x1, ..., xr)
réalise le maximum strict de la fonction :
θ 7−→ L (θ;X1, ...,Xr)
on dit que :
θ = Φ (X1, ...,Xr)
est l’estimateur du maximum de vraisemlance de θ.
Exemple 16Soit X1, ...,Xr un r-échantillon d’une variable aléatoire de Poisson de paramètre θ,θ > 0. Sa fonction de vraisemlance est :
L (θ;ω1, ..., ωr) =θ
rPi=1
ωi
ω1!...ωr!e−rθ
Cette fonction atteint son maximum strict pour :
θ =1
r
rXi=1
ωi
Donc, l’estimateur du maximum de vraisemlance de θ est :
θ =1
r
rXi=1
Xi
θ est un estimateur sans biais et convergent du paramètre θ de la loi de Poisson.θ représente la moyenne empirique du n-échantillon.
50

A. El Mossadeq Structures Statistiques et Estimation
Exemple 17Soit (X1, ...,Xr) un r-échantillon d’une variable aléatoire qui suit une loi normalede paramètres μ ∈ R et σ2, σ > 0.On suppose σ connu.La fonction de vraisemlance de ce r-échantillon est :
L (μ;x1, ..., xr) =1¡
σ√2π¢r exp− 1
2σ2
rXi=1
(xi − μ)2
Cette fonction atteint son maximum strict pour :
μ =1
r
rXi=1
xi
Donc, l’estimateur du maximum de vraisemlance de μ est :
μ =1
r
rXi=1
Xi
Et comme :
V [μ] =σ2
ret :
I [X1, ...,Xr;μ] =r
σ2
donc :
e [μ] = 1
μ est alors un estimateur efficace de μ.
Exemple 18Soit (X1, ...,Xr) un r-échantillon d’une variable aléatoire qui suit une loi normalede paramètres μ ∈ R et σ2, σ > 0.On suppose μ connu.L’estimateur du maximum de vraisemlance de σ2 est :
σ2 =1
r
rXi=1
(Xi − μ)2
σ2 est un estimateur sans biais de σ2.
51

Structures Statistiques et Estimation A. El Mossadeq
Exemple 19Soit (X1, ...,Xr) un r-échantillon d’une variable aléatoire qui suit une loi normalede paramètres μ ∈ R et σ2, σ > 0.Les estimateurs du maximum de vraisemlance de μ et σ2 sont :⎧⎪⎪⎪⎨⎪⎪⎪⎩
μ =1
r
rXi=1
Xi
σ2 =1
r
rXi=1
(Xi − μ)2
σ2 est un estimateur biaisé de σ2.
Proposition 8S’il existe un résumé exhaustif T1, ..., Ts alors tout estimateur de θ par le maximumde vraisemlance est fonction de T1, ..., Ts.
Preuve 8Si (T1, ..., Ts) est un résumé exhaustif alors :
L (θ;x1, ..., xr) = g (θ; t1, ..., ts)h (x1, ..., xr)
Donc, maximiser L revient à maximiser g.
Proposition 9Supposons les hypothèses de l’inégalité de Cramer-Rao vérifiées.S’il existe un estimateur sans biais et efficace T de h (θ), alors toute fonctionθ (x1, ..., xr) telle que :
T (x1, ..., xr) = h³θ´
est solution de l’équation de vraisemlance et réalise le maximum strict de la vraisem-lance.
Preuve 9Si T est un estimateur sans biais et efficace de h (θ) alors :
∂
∂θlnL (θ;x1, ..., xr) = γ (θ) [t− h (θ)]
Donc, pour (x1, ..., xr) donné, toute fonction θ telle que :
t (x1, ..., xr) = h³θ´
52

A. El Mossadeq Structures Statistiques et Estimation
est solution de l’équation de vraisemblance.D’autre part :
∂2
∂θ2lnL (θ;x1, ..., xr) = γ0 (θ) [t− h (θ)]− γ (θ)h0 (θ)
et :
I [X1, ...,Xr; θ] = −E∙∂2
∂θ2lnL (θ;X1, ..., Xr)
¸= γ (θ)h0 (θ)
Or :
I [X1, ..., Xr; θ] = E
"µ∂
∂θlnL (θ;X1, ...,Xr)
¶2#= [γ (θ)]2 V [T ]
donc :
γ (θ)h0 (θ) > 0
d’où, pour θ = θ :
∂2
∂θ2lnL
³θ;x1, ..., xr
´= γ
³θ´h0³θ´
est strictement négatif, ce qui assure que θ réalise le maximum strict.
53

Structures Statistiques et Estimation A. El Mossadeq
7. EXERCICES
Exercice 1Déterminer et étudier les propriétés de l’estimateur du maximum de vraisemlanced’un r-échantillon pour :
1. le paramètre p d’une loi de Bernouilli2. le paramètre p d’une loi geometrique3. le paramètre p d’une loi binomiale d’ordre n4. le paramètre α d’une loi de Poisson5. le paramètre λ d’une loi exponentielle6. les paramètres μ et σ2 d’une loi normale7. le paramètre θ d’une loi uniforme sur l’intervalle [0, θ]
Exercice 2Soit X une variable aléatoire dont la densité de probabilité f est définie par :
f (x) =1
θexp−x
θ, x > 0
où θ est un paramètre réel strictement positif.
1. Déterminer l’estimateur du maximum de vraisemlance θ de θ d’un r-échantillonde variable parente X.
2. θ est-il un résumé exhaustif ?3. Calculer l’espérance mathématique et la variance de θ.Que peut-on conclure ?
4. Calculer la quantité d’information de Fisher.En déduire que θ est efficace.
Exercice 3Soit X une variable aléatoire dont la densité de probabilité f est définie par :
f (x) =λ
θkxk−1 exp−x
θ, x > 0
où θ est un paramètre réel strictement positif , k un entier naturel non nul et λ uneconstante réel.
1. Déterminer la constante λ.2. Déterminer l’estimateur du maximum de vraisemlance θ de θ d’un r-échantillonde variable parente X.
54

A. El Mossadeq Structures Statistiques et Estimation
3. θ est-il un résumé exhaustif ?4. Calculer l’espérance mathématique et la variance de θ.Que peut-on conclure ?
5. Calculer la quantité d’information de Fisher.En déduire que θ est efficace.
Exercice 4Soit X une variable aléatoire dont la densité de probabilité f est définie par :
f (x) =
⎧⎪⎨⎪⎩0 si x /∈ [0, θ]
1
θsi x ∈ [0, θ]
où θ est un paramètre réel.
1. Déterminer la fonction de répartition de X.2. Calculer la quantité d’information de Fisher.3. Déterminer l’estimateur du maximum de vraisemlance θ de θ d’un r-échantillonde variable parente X.
4. Calculer l’espérance mathématique et la variance de θ.Que peut-on conclure ?
5. Dans le cas où θ est biasé, proposer un estimateur sans biais de θ.
Exercice 5Soit X une variable aléatoire dont la densité de probabilité f est définie par :
f (x) =
⎧⎨⎩ 0 si x < θ
exp θ − x si x ≥ θ
où θ est un paramètre réel.
1. Déterminer la fonction de répartition de X.2. Calculer la quantité d’information de Fisher.3. Déterminer l’estimateur du maximum de vraisemlance θ de θ d’un r-échantillonde variable parente X.
4. Calculer l’espérance mathématique et la variance de θ.Que peut-on conclure ?
5. Dans le cas où θ est biasé, proposer un estimateur sans biais de θ.
55

Structures Statistiques et Estimation A. El Mossadeq
Exercice 6Les éléments d’une population possédent un caractère X qui suit une loi de Poissonde paramètre inconnu α.Une suite de r expériences a fourni les valeurs k1, ..., kr.
1. Déterminer l’estimateur du maximum de vraisemlance α de α et étudier lespropriétés de cet estimateur.
2. α est-il un résumé exhaustif ?3. On désire estimer la quantité :
δ = P [X = 0]
Déterminer l’estimateur du maximum de vraisemlance δ de δ.Que remarquez-vous ?
Exercice 7Soit α un réel appartenant à ]1,+∞[ et X une variable aléatoire telle que :
P [X = k] =1
α
µ1− 1
α
¶k−1, k ∈ N∗
1. Calculer l’espérance mathématique et la variance de X.2. Déterminer l’estimateur du maximum de vraisemlance α de α d’un r-échantillonde variable parente X et étudier ses propriétés.
3. α est-il un résumé exhaustif ?
Exercice 8Soit X une variable aléatoire qui suit une loi de Pareto dont la densité de probabilitéf est définie par :
f (x) =
⎧⎪⎨⎪⎩0 si x < a
αaα
xα+1si x ≥ a
où X représente le revenu par habitant, a le revenu minimum et α, α > 2, uncoefficient dépendant du type du pays où l’on se place.
1. Vérifier que f est bien une densité de probabilité.2. Calculer l’espérance mathématique et la variance de X.3. Calculer la fonction de répartition de X.4. Déterminer l’estimateur du maximum de vraisemlance a de a d’un r-échantillonissu X.
5. Dans le cas où a est biasé, proposer un estimateur sans biais de a.
56

A. El Mossadeq Structures Statistiques et Estimation
Exercice 9Soit X une variable aléatoire dont la densité de probabilité f est définie par :
f (x) =
⎧⎪⎨⎪⎩0 si x ≤ θ
1
αexp
(θ − x)
αsi x > θ
où θ est un paramètre réel et α un paramètre réel strictement positif.
1. Vérifier que f est bien une densité de probabilité.2. Calculer l’espérance mathématique et la variance de X.3. Calculer la fonction de répartition de X.4. On suppose θ connu et α inconnu.
(a) Déterminer l’estimateur du maximum de vraisemlance α de α d’un r-échantillon issu X.
(b) Etudier les propriétés de α.(c) Dans le cas où α est biasé, proposer un estimateur sans biais de α.
5. On suppose α connu et θ inconnu.
(a) Déterminer l’estimateur du maximum de vraisemlance θ de θ d’un r-échantillon issu de X.
(b) Etudier les propriétés de θ(c) Dans le cas où θ est biasé, proposer un estimateur sans biais de θ.
6. On suppose que θ et α sont tous les deux inconnus.
(a) Déterminer l’estimateur du maximum de vraisemlance³α, θ
´de (α, θ)
d’un r-échantillon issu de X.(b) Etudier les propriétés de
³α, θ
´(c) Proposer un estimateur sans biais de (α, θ) .
Exercice 10Soient X et Y deux variables aléatoires indépendantes, la première prenant lesvaleurs 1 et 0 avec les probabilités respectives α et 1−α, et la deuxième prenant lesvaleurs 1 et 0 avec les probabilités respectives P et 1− P . On suppose α inconnueet P connue, P > 0.5.On définit la variable aléatoire Z par :⎧⎨⎩ Z = 1 si X = Y
Z = 0 si X 6= Y
57

Structures Statistiques et Estimation A. El Mossadeq
On considère un n-échantillon ((X1, Y1) , ..., (Xn, Yn)) de (X,Y ) et on définit Zi,1 ≤ i ≤ n, à partir de Xi et Yi comme on a défini Z à partir de X et Y .
1. Montrer que (Z1, ..., Zn) est un n-échantillon de Z.2. Etudier les propriétés de l’estimateur :
T =1
n(Z1 + ...+ Zn)
3. Proposer alors un estimateur sans biais S de α.4. Etudier la variance de S en fonction de P .5. Indiquer un intervalle de confiance pour α lorsque n est grand, en supposant
qu’on dispose d’une observation p de1
n(Z1 + ...+ Zn).
6. Voyez-vous une application de ce qui précède dans le domaine des sondages ?
58

Chapitre 3
Tests d’H ypothèses Les Fréquences


A. El Mossadeq Tests : Les Fréquences
1. FLUCTUATIONSD’ECHANTILLONNAGE D’UNE
FRÉQUENCE
On considère une population où le caractère étudié ne prend que les valeurs 0 et 1,c’est à dire X est une variable aléatoire de Bernouilli.On désigne par p la proportion des individus de la population de caractère 1 :
p = P [X = 1]
c’est à dire le paramètre de la loi de Bernouilli.On extrait de cette population un échantillon de taille n sur lequel on observe unefréquence f du caractère 1 qui diffère plus ou moins de p.Le hasard de l’échantillonnage peut produire une quelconque composition, et lafréquence f est susceptible de prendre des valeurs variant de 0 à 1, mais un grandécart entre f et p reste peu probable.D’après le theoreme centrale limite, et pourvu que np et n (1− p) soient supérieursou égaux à 5 (n est considéré dans ces conditions assez grand), la quantité :
t =f − prp (1− p)
n
peut être considérée comme une réalisation de la variable aléatoire normale centréeréduite :
N =F − prp (1− p)
n
où F est la fréquence empirique du n-échantillon :
F =1
n
nXi=1
Xi
Ainsi, pour tout α ∈ [0, 1], il existe t1−α/2 ∈ R tel que :
P£|N | < t1−α/2
¤= 1− α
c’est à dire : Z t1−α/2
−t1−α/2
1√2πexp−t
2
2dt = 1− α
61

Tests : Les Fréquences A. El Mossadeq
ou encore : Z t1−α/2
−∞
1√2πexp−t
2
2dt = 1− α
2
On dit que :
F ∈"p− t1−α/2
rp (1− p)
n, p+ t1−α/2
rp (1− p)
n
#à 1− α ou au seuil α.Cet intervalle est appelé l’intervalle de pari à 1− α.
Exemple 1Une urne contient quarante boules noires et soixante boules blanches.Dans quelles limites peut varier le nombre de boules blanches si l’on tire de l’urnetrente boules avec remise ?
Construisons d’obord l’intervalle de pari, pour un échantillon de taille n = 30,correspondant à la probabilité d’obtenir une boule blanche p = 0.6.Au seuil α, cet intervalle est défini par :"
p− t1−α/2
rp (1− p)
n, p+ t1−α/2
rp (1− p)
n
#Pour α = 5%, on a :
t.975 = 1.96
on obtient alors l’intervalle :
[.42, .78]
Il en résulte que sur les trente boules tirées, le nombre de boules blanches seraitcompris, à 95%, entre 13 et 23.
2. LES SONDAGES
Le plus souvent, la proportion p est inconnue du fait que l’examen de toute lapopulation est impossible.Puisque F est un estimateur sans biais de p, on peut extraire un échantillon de taillen sur lequel on observe une fréquence f qui constitue une estimation ponctuelle dep, puis on assigne à p un intervalle de variation appelé intervalle de confianceavec une probabilité 1− α, 0 ≤ α ≤ 1.
62

A. El Mossadeq Tests : Les Fréquences
En effet, en estimantp (1− p)
npar
f (1− f)
n, et pourvu que np et n (1− p) soient
supérieurs ou égaux à 5, la quantité :
t =f − prf (1− f)
n
peut être considérée comme une réalisation de la variable aléatoire normale centréeréduite :
N =F − prf (1− f)
n
Ainsi, pour tout α ∈ [0, 1], il existe t1−α/2 ∈ R tel que :
P£|N | < t1−α/2
¤= 1− α
L’intervalle : "f − t1−α/2
rf (1− f)
n, f + t1−α/2
rf (1− f)
n
#est appelé l’intervalle de confiance de p à 1− α ou au seuil α.
Exemple 2A la veille d’une consultation électorale, on a intérrogé cent électeurs constituant unéchantillon au hasard. Soixante ont déclaré avoir l’intention de voter pour le candi-dat C.En quelles limites, au moment du sondage, la proportion du corps électoral favor-able à C se situe-t-elle ?
Construisons l’intervalle de confiance correspondant à la fréquence f = 0.6 du corpsélectoral favorable à C observée sur un échantillon de taille n = 100.Au seuil α, cet intervalle est défini par :"
f − t1−α/2
rf (1− f)
n, f + t1−α/2
rf (1− f)
n
#Pour α = 5%, on a :
t.975 = 1.96
on obtient alors l’intervalle :
[.504, .696]
A 95%, le candidat C serait élu.
63

Tests : Les Fréquences A. El Mossadeq
3. TEST DE COMPARAISON D’UNEFRÉQUENCE À UNE NORME
On dispose d’une population où le caractère étudié présente une proportion p.Sur un échantillon de taille n, on observe une fréquence f.La différence entre p et f est-elle significative ou est-elle dûe seulement au hasardde l’échantillonnage ?Soit donc à tester l’hypothèse nulle :
H0 : ”f = p”
contre l’hypothèse alternative :
H0 : ”f 6= p”
au seuil α.Sous l’hypothèse nulle H0 et pourvu que np et n (1− p) soient supérieurs ou égauxà 5, la quantité :
t =f − prp (1− p)
n
peut être considérée comme une réalisation de la variable aléatoire normale centréeréduite :
N =F − prp (1− p)
n
Ainsi, pour tout α ∈ [0, 1], il existe t1−α/2 ∈ R tel que :
P£|N | < t1−α/2
¤= 1− α
On rejette l’hypothèse nulle H0, au seuil α, dès que :
|t| > t1−α/2
Exemple 3Une machine à former des pilules fonctionne de façon satisfaisante si la proportionde pilules non réussies est de 1 pour 1000.Sur un échantillon de 10000 pilules, on a trouvé 15 pilules défectueuses.Que faut-il conclure ?
64

A. El Mossadeq Tests : Les Fréquences
Ici on a : ⎧⎨⎩ n = 104
f = 15× 10−4p = 10−3
Testons, au seuil α, l’hypothèse nulle :
H0 : ”la machine est bien réglée”
Sous cette hypothèse, la quantité :
t =f − prp (1− p)
n
peut être considérée comme une réalisation d’une variable aléatoire normale centréeréduite.Pour α = 5%, on a :
t.975 = 1.96
et comme :
t =f − prp (1− p)
n
= 1.58
on accepte donc l’hypothèse nulle H0 au seuil α = 5%, c’est à dire, qu’au seuilα = 5%, la machine fonctionne de façon satisfaisante.
4. TEST DE COMPARAISON DEDEUX FRÉQUENCES
On dispose de deux échantillons indépendants de tailles respectives n1 et n2 surlesquels le caractère étudié présente les fréquences f1 et f2 respectivement.On se demande si ces deux échantillons proviennent d’une même population.Soit donc à tester l’hypothèse nulle :
H0 : ”p1 = p2”
contre l’hypothèse alternative :
H0 : ”p1 6= p2”
au seuil α.
65

Tests : Les Fréquences A. El Mossadeq
Si les deux échantillons proviennent d’une même population définie par la proportionp = p1 = p2 (souvent inconnue) du caractère étudié, f1 et f2 peuvent être considéréescomme des réalisations des variables aléatoires normales centrées réduites :
N1 =F1 − prf1 (1− f1)
n1
N2 =F2 − prf2 (1− f2)
n2
respectivement, pourvu que n1p1, n1 (1− p1), n2p2 et n2 (1− p2) soient tous supérieursou égaux à 5.En conséquence , la quantité :
t =f1 − f2r
f1 (1− f1)
n1+
f2 (1− f2)
n2
peut être considérée comme une réalisation d’une variable aléatoire normale centréeréduite.On rejette l’hypothèse nulle H0, au seuil α, dès que :
|t| > t1−α/2
Exemple 4Avant de procéder au lancement d’un produit, une entreprise a fait procéder à uneenquête portant sur deux régions géographiques A et B.Sur 1800 réponses provenant de la région A, 630 se déclarent intéressées par le pro-duit.En provenance de B, 150 réponses sur 600 se déclarent favorables.Tester, au seuil de 5%, l’hypothèse de l’identité des opinions des régions A et Bquant au produit considéré.
Ici on : ⎧⎪⎪⎨⎪⎪⎩nA = 1800 , fA =
7
20
nB = 600 , fB =1
4
Testons, au seuil α, l’hypothèse nulle :
H0 : ”les opinions des régions A et B sont identiques”
66

A. El Mossadeq Tests : Les Fréquences
Sous cette hypothèse, la quantité :
t =fA − fBr
fA (1− fA)
nA+
fB (1− fB)
nB
peut être considérée comme une réalisation d’une variable aléatoire normale centréeréduite.Pour α = 5%, on a :
t.975 = 1.96
et comme :
t =fA − fBr
fA (1− fA)
nA+
fB (1− fB)
nB= 4.77
on rejette donc l’hypothèse nulle H0 à 95% (et même à 99.98%), cest à dire, les deuxrégions A et B ont des opinions différentes.
67

Tests : Les Fréquences A. El Mossadeq
5. EXERCICES
Exercice 1A la veille d’une consultation électorale, on a intérrogé cent électeurs constituantun échantillon au hasard. Soixante ont déclaré avoir l’intention de voter pour lecandidat C.En quelles limites, au moment du sondage, la proportion du corps électoral favorableà C se situe-t-elle ?
Exercice 2On sait que le taux de mortalité d’une certaine maladie est de 30%.Sur 200 malades testés, combien peut-on envisager de décès ?
Exercice 3Dans une pré-enquête, on selectionne, par tirage au sort cent dossiers.Quinze d’entre eux sont incomplets.Combien de dossiers incomplets trouvera-t-on sur dix milles dossiers ?
Exercice 4Dans une maternité, on fait le point de la proportion de filles toutes les cent nais-sances.Comment peut varier cette proportion d’une fois à l’autre si l’on admet qu’il naiten moyenne 51% de filles ?
Exercice 5Une machine à former des pilules fonctionne de façon satisfaisante si la proportionde pilules non réussies est de 1 pour 1000.Sur un échantillon de 10000 pilules, on a trouvé 15 pilules défectueuses.Que faut-il conclure ?
Exercice 6Sur un échantillon de 600 sujets atteints du cancer des poumons, on a trouvé 550fumeurs.Que peut-on dire du pourcentage de fumeurs parmi les cancéreux ?
68

A. El Mossadeq Tests : Les Fréquences
Exercice 7Avant de procéder au lancement d’un produit, une entreprise a fait procéder à uneenquête portant sur deux régions géographiques A et B.Sur 1800 réponses provenant de la région A, 630 se déclarent intéressées par leproduit.En provenance de B, 150 réponses sur 600 se déclarent favorables.Tester, au seuil de 5%, l’hypothèse de l’identité des opinions des régions A et Bquant au produit considéré.
Exercice 8Dans un groupe de 200 malades atteints du cancer du col de l’utérus, un traitementpar application locale du radium a donné 50 guérisons.Un autre groupe de 150 sujets atteints de la même maladie a été traité par chirurgie,on a trouvé 50 guérisons.Que peut-on conclure ?
Exercice 9Aux guichets d’une gare parisienne, sur les 350 billets vendus vendredi après-midi,95 étaient des billets de 1ere classe. Sur les 250 billets vendus la matinée du lundisuivant, 55 étaient de 1ere classe.Peut-on considérer qu’il y a une différence entre les proportions de vente de parcoursen 1ere classe pour les fins et débuts de semaines ?
Exercice 10On a lancé cent fois une pièce de monnaie et l’on a obtenu soixante fois ”pile” etquarante fois ”face”.Tester au seuil de 5%, puis 1%, l’hypothèse de la loyauté de la pièce.
Exercice 11Un échantillon de taille n a donné lieu au calcul d’une fréquence observée f corre-spondant à l’intervalle de confiance [.22− .34] au seuil α = 5%.
1. Calculer n.2. Par rapport à la proportion p = 0.3, l’écart est-il significatif au seuil α = 5% ?3. Déterminer l’intervalle de confiance de |f − p| au seuil α = 5%.
69

Tests : Les Fréquences A. El Mossadeq
Exercice 12L’étude du taux de défectuosités afférentes aux caractéristiques de traitements ther-miques d’une même pièce, traitée par deux fours différents, a donné lieu aux résultatssuivants :* Pour le premier four, 20 pièces défectueuses sur un échantillon de 200 piècestraitées.* Pour le second four, 120 pièces défectueuses sur un échantillon de 800 piècestraitées.Que peut-on conclure ?
Exercice 13Un questionnaire auquel on ne peut répondre que par ”oui” ou par ”non”, a étérempli par un échantillon de taille n.L’intervalle de confiance de la fréquence observée f des réponses ”oui” est (0.35− 0.43)au seuil α = 5%.
1. Quelle est la taille n de l’échantillon.2. Par rapport à la proportion p = 0.4, l’écart est-il significatif au seuil α = 5% ?3. Déterminer l’intervalle de confiance de |f − p| au seuil α = 5%.
Exercice 14Parmi 470 sujets exposés à une infection, 370 n’ayant pas été immunisés.Parmi ces derniers, 140 contractent la malidie ainsi que 25 sujets immunisés.Le traitement donne-t-il une protection significative ?
70

Chapitre 4
Les Tests du Khi-deux


A. El Mossadeq Les Tests du Khi-Deux
1. TEST DE COMPARAISON D’UNERÉPARTITION OBSERVÉE À UNE
RÉPARTITION THÉORIQUE
On considère un caractère à k classes différentes en proportion p1, ..., pk.Comme p1+ ...+pk = 1, la composition de la population est entièrement déterminéepar k − 1 de ces proportions.On extrait de cette populations un échantillon de taille n.Si la composition de cet échantillon était identique à celle de la population, il con-tiendrait :
t1 = np1 du caractère 1:
tk = npk du caractère k
ce sont les effectifs calculés ou les effectifs théoriques.En réalité, on observe des effectifs :
o1 du caractère 1:
ok du caractère k
différant plus ou moins des effectifs théoriques. Ce sont les effectifs observés.Le problème est de décider si l’écart entre ces effectifs est significatif ou il est dûseulement au hasard de l’échantillonnage.Soit donc à tester, au seuil α, l’hypothèse nulle :
H0 : ”o1 = t1 , ... , ok = tk”
contre l’hypothèse alternative H0.Sous l’hypothèse nulleH0, et pourvu que tous les effectifs théoriques soient supérieursou égaux à 5, la quantité :
χ2 =kXi=1
(oi − ti)2
ti
est une réalisation d’une variable du Khi-deux à k − 1 degrés de liberté : χ2k−1.α étant donné, il existe χ2k−1;1−α ∈ R tel que :
P£χ2 < χ2k−1;1−α
¤= 1− α
On rejette alors l’hypothèse nulle H0 à 1− α dès que :
χ2 > χ2k−1;1−α
73

Les Tests du Khi-Deux A. El Mossadeq
Exemple 1On a croisé deux types de plantes différant par deux caractères A et B.La première génération est homogène.La seconde fait apparaitre quatre types de plantes dont les génotypes sont notés :AB , Ab , aB , ab.Si les caractères se trasmettent selon les lois de Mendel, les proportions théoriques
des quatre génotypes sont :9
16,3
16,3
16,1
16respectivement.
Sur un échantillon de 160 plantes, on a observé les effectifs :
100 pour AB28 pour Ab24 pour aB8 pour ab
Au vu de ces résultats, les lois de Mendel sont-elles applicables ?
Testons alors, au seuil α, l’hypothèse nulle :
H0 : ”les lois de Mendel sont applicables”
Si H0 est vraie, la répartition des 160 plantes sur les quatre génotypes devrait êtrecomme suit :
t1 = 90 pour ABt2 = 30 pour Abt3 = 30 pour aBt4 = 10 pour ab
On résume toutes les données dans le tableau suivant :
Genotypes Repartition Observee Repartition Theorique
AB 100 90
Ab 28 30
aB 24 30
ab 8 10
Total 160 160
74

A. El Mossadeq Les Tests du Khi-Deux
Sous l’hypothèse nulle H0, et vu que tous les effectifs théoriques sont supérieursou égaux à 5, la quantité :
χ2 =4X
i=1
(oi − ti)2
ti
est une réalisation d’une variable du Khi-deux à :
4− 1 = 3
degrés de liberté : χ23.Pour α = 5%, on a :
χ23;.95 = 7.81
et comme :
χ2 =4X
i=1
(oi − ti)2
ti
= 2.84
On accepte alors l’hypothèse nulle H0 au seuil de 5%, c’est à dire, les transmissionsgénétiques de ce type de plantes se font selon les lois de Mendel.
Remarque 1Si pour l’ajustement par une loi théorique dépendant de paramètres, on utilise lesestimations de s parmi ces paramètres, et non leurs valeurs réelles, alors le nombrede degrés de liberté, dans ce cas, est :
(k − 1)− s = k − s− 1
Ainisi , par exemple :
(1) si, pour l’ajustement par une loi de Poisson, on utilise l’estimation de sonparamètre, supposé inconnu, alors le nombre de degrés de liberté est :
(k − 1)− 1 = k − 2
(2) si, pour l’ajustement par une loi normale, on utilise l’estimation de la moyenneet de la variance, supposées toutes les deux inconnues, alors le nombre dedegrés de liberté est :
(k − 1)− 2 = k − 3
75

Les Tests du Khi-Deux A. El Mossadeq
2. TEST D’INDÉPENDANCE DUKHI-DEUX
On considère deux caractères X et Y à n et m classes respectivement.Le tableau suivant résume les observations faites sur un échantillon de taille Nconcernant le couple de caractères (X,Y ) :
Tableau des effectifs observes
XÂY 1 2 . . m Total
1 o11 o12 . . o1m o1.
2 o21 o22 . . o2m o2.
: : : : : : :
n on1 on2 . . onm on.
Total o.1 o.2 . . o.m N
où :
oi. =mXk=1
oik
o.j =nX
k=1
okj
et :nXi=1
oi. =mXj=1
o.j =nXi=1
mXj=1
oij = N
Au vu de ces résultats, Il s’agit de décider si les deux caractère X et Y sont in-dépendants.Soit à tester, au seuil α, l’hypothèse nulle :
H0 : ”Xet Y sont indépendants”
contre l’hypothèse alternative H0.Si X et Y étaient indépendants, alors pour tout (i, j) ∈ 1, ..., n × 1, ...,m :
P [X = i, Y = j] = P [X = i]P [Y = j]
76

A. El Mossadeq Les Tests du Khi-Deux
et l’échantillon contiendrait en conséquence :
tij =oi.o.jN
individus possédant le caractère [X = i, Y = j]. Ce sont les effectifs théoriquesou les effectifs calculés.
Tableau des effectifs theoriques
XÂY 1 2 . . m Total
1 t11 t12 . . t1m o1.
2 t21 t22 . . t2m o2.
: : : : : : :
n tn1 tn2 . . tnm on.
Total o.1 o.2 . . o.m N
Sous l’hypothèse nulleH0, et pourvu que tous les effectifs théoriques soient supérieursou égaux à 5, la quantité :
χ2 =nXi=1
mXj=1
(oij − tij)2
tij
est une réalisation d’une variable du Khi-deux à (n− 1) (m− 1) degrés de liberté :χ2(n−1)(m−1).α étant donné, il existe χ2(n−1)(m−1);1−α ∈ R tel que :
P£χ2 < χ2(n−1)(m−1);1−α
¤= 1− α
On rejette alors l’hypothèse nulle H0 à 1− α dès que :
χ2 > χ2(n−1)(m−1);1−α
Exemple 2On se propose de comparer les réactions produites par deux vaccins A et B.Un groupe de 348 individus a été divisé, par tirage au sort, en deux séries qui ontété vaccinées l’une par A et l’autre par B.Les réactions ont été lues par une personne ignorant le vaccin utilisé.Le problème est de décider si les réactions observées sont indépendantes du vaccinutilisé.
77

Les Tests du Khi-Deux A. El Mossadeq
Tableau des effectifs observes
V accinÂReaction legere moyenne ulceration abces Total
A 12 156 8 1 177
B 29 135 6 1 171
Total 41 291 14 2 348
Soit à tester, au seuil α = 5%, l’hypothèse nulle d’indépendanceH0 contre l’hypothèsealternative H0.Si les réactions étaient indépendantes du vaccin utilisé, les probabilités correspon-dantes aux réactions seraient alors :
p1 =41
348, pour une réaction légère
p2 =291
348, pour une réaction moyenne
p3 =14
348, pour une ulcération
p4 =2
348, pour un abcès
On détermine les effectifs théoriques du premier échantillon de 177 sujets puis ceuxdu second échantillon de 171 sujets :
Tableau des effectifs theoriques
V accinÂReaction legere moyenne ulceration abces Total
A 20.9 148 7.1 1 177
B 20.1 143 6.9 1 171
Total 41 291 14 2 348
Une légère difficulté apparait cependant sur cet exemple : les effectifs théoriquesdans la colonne ”Abces” sont inférieurs à 5 ce qui empêche l’application d’un testdu Khi-deux.On peut remédier à cet état en opérant le groupement ”logique” des classes ”Ulceration”et ”Abces”.
78

A. El Mossadeq Les Tests du Khi-Deux
Les tableaux des effectifs observés et théoriques obtenus après regroupement sont :
Tableau des effectifs observes
V accinÂReaction legere moyenne ulceration ou abces Total
A 12 156 9 177
B 29 135 7 171
Total 41 291 16 348
Tableau des effectifs theoriques
V accinÂReaction legere moyenne ulceration ou abces Total
A 20.9 148 8.1 177
B 20.1 143 7.9 171
Total 41 291 16 348
On calcule alors la quantité χ2 à partir des nouveaux tableaux :
χ2 =2X
i=1
3Xj=1
(oij − tij)2
tij
Le nombre de degrés de liberté est :
(2− 1) (3− 1) = 2
Et comme :
χ22;.95 = 5.99
et :
χ2 =2X
i=1
3Xj=1
(oij − tij)2
tij
= 8.8
on rejette alors, à 95%, l’hypothèse selon laquelle les deux vaccins A et B provoquentles mêmes réactions.
79

Les Tests du Khi-Deux A. El Mossadeq
Remarque 2Lorsque l’hypothèse nulle est rejetée, il est souhaitable de préciser l’intensité de laliaison entre les deux caractères X et Y .On introduit alors le coefficient suivant, dit coefficient de Tschuprov :
T 2 =χ2
Np(n− 1) (m− 1)
1. Si les deux caractères X et Y sont indépendants alors :
χ2 = 0
puisque pour tout (i, j) ∈ 1, .., n × 1, ...,m :
oij = tij
d’où :
T 2 = 0
2. Si les deux caractèresX et Y sont en liason fonctionnelle (bijection), alors n = met par une permutation sur les lignes ou sur les colonnes, on peut ramener letableau des effectifs observés à un tableau diagonal.On a :
oi. = o.i = oii
d’où :
χ2 =nXi=1
nXj=1
(oij − tij)2
tij
=nXi=1
(oii − tii)2
tii+Xi6=j
(oij − tij)2
tij
Or :
nXi=1
(oii − tii)2
tii= N (n− 2) +
nXi=1
o2ii
et :
80

A. El Mossadeq Les Tests du Khi-Deux
Xi6=j
(oij − tij)2
tij=
Xi6=j
tij
=Xi6=j
oi. × o.jN
=1
N
nXi=1
oi. (N − o.i)
= N − 1
N
nXi=1
o2i.
donc :
χ2 = N (n− 1)Il en résulte que :
|T | = 1
3. Dans les autres cas, on admet que :
(a) Si :
0 < T < 0.3
on dit que la liaison est faible.(b) Si :
0.3 < T < 0.5
on dit que la liaison est moyenne.(c) Si :
0.5 < T < 1
on dit que la liaison est forte.
81

Les Tests du Khi-Deux A. El Mossadeq
3. EXERCICES
Exercice 1Avant de procéder au lancement d’un produit, une entreprise a fait procéder à uneenquête portant sur deux régions géographiques A et B.Sur 1800 réponses provenant de la région A, 630 se déclarent intéressées par leproduit.En provenance de B, 150 réponses sur 600 se déclarent favorables.Tester, au seuil de 5%, l’hypothèse de l’identité des opinions des régions A et Bquant au produit considéré.
Exercice 2Dans un groupe de 200 malades atteints du cancer du col de l’utérus, un traitementpar application locale du radium a donné 50 guérisons.Un autre groupe de 150 sujets atteints de la même maladie a été traité par chirurgie,on a trouvé 54 guérisons.Que peut-on conclure ?
Exercice 3Aux guichets d’une gare parisienne, sur les 350 billets vendus vendredi après-midi,95 étaient des billets de 1ere classe. Sur les 250 billets vendus la matinée du lundisuivant, 55 étaient de 1ere classe.Peut-on considérer qu’il y une différence entre les proportions de vente de parcoursen 1ere classe pour les fins et débuts de semaines ?
Exercice 4On a lancé cent fois une pièce de monnaie et l’on a obtenu soixante fois ”pile” etquarante fois ”face”.Tester au seuil de 5% puis 1%, l’hypothèse de la loyauté de la pièce.
82

A. El Mossadeq Les Tests du Khi-Deux
Exercice 5On veut savoir si la réussite (R) d’un traitement est indépendantes du niveaux dela tension artérielle du malade (T ).On dispose pour cela de 250 observations réparties comme suit :
TÂR echec succes
basse 21 104
elevee 29 96
Que peut-on conclure ?
Exercice 6On veut savoir s’il y a une liason entre la localisation (L) du cancer du poumon(périphérique , non périphérique) et le côté (C) de la lésion (poumon gauche ,poumon droit). L’étude a porté sur 1054 malades :
LÂC gauche droit
peripherique 26 62
non peripherique 416 550
Que peut-on conclure ?
Exercice 7De nombreuses observations cliniques ont montré que jusque là :
• 30% des malades atteints de M ont une survie inférieure à un an• 50% ont une survie entre un an et deux ans• 10% ont une survie entre deux ans et cinq ans• 10% ont une survie supérieure à cinq ans.
On applique un nouveau traitement à 80 malades atteint de la maladie M et onconstate :
• 12 ont une survie inférieure à un an• 56 ont une survie entre un an et deux ans• 8 ont une survie entre deux ans et cinq ans• 4 ont une survie supérieure à cinq ans.
Que peut-on conclure ?
83

Les Tests du Khi-Deux A. El Mossadeq
Exercice 8On suppose pouvoir classer les malades atteints d’une maladieM en trois catégoriescliniques : A , B , C.On se demande si ces trois catégories diffèrent par leurs survies à un an.Les effectifs observés sont les suivants :
SurvieÂCategorie A B C
survie a un an 5 20 45
deces avant un an 15 50 145
Que peut-on conclure ?
Exercice 975 enfants sont vus en consultation pour un asthme. On relève chez eux les deuxsymptômes suivants :* Intensité de la maladie asmathique : légère , moyenne , forte* Existence ou absence d’un eczéma au moment de l’observation ou dans le passé.On peut classer les enfants selon la répartition suivante :
EÂA fort moyen leger
present 8 2 2
passe 11 11 3
jamais 6 18 14
Existe-t-il une association entre l’intensité de l’asthme et l’existence d’un eczéma ?
Exercice 10Une étude statistique relative aux résultats d’admission du concours d’une grandeécole fait ressortir la répartition des admis selon la profession des parents lorsquecelle-ci est connue :
84

A. El Mossadeq Les Tests du Khi-Deux
Profession des Parents Candidats Admis
Fontionnaires et Assimiles 2224 180
Commerce et Industrie 998 89
Professions Liberales 575 48
Proprietaires Rentiers 423 37
Proprietaires Agricoles 287 13
Artisans 210 18
Banques et Assurances 209 17
1. La profession des parents a-t-elle une influence sur l’accès à cette école ?2. Cette conclusion persiste-t-elle lorsqu’on tient compte pour compléter la statis-tique précédente de 961 candidats dont l’origine socio-professionnelle est incon-nue et qui ont obtenus 43 succès ?
Exercice 11Sur un échantillon de 84 prématurés, on cherche s’il existe une liaison entre lasurvenue d’une hypoglycémie et la survenue d’un ictère :
• sur 43 enfants n’ayant pas d’ictère, 23 sont hypoglycémiques• sur 20 enfants ayant un ictère modéré, 6 sont hypoglycémiques• sur 21 enfants ayant un ictère intense, 4 sont hypoglycémiques
Que peut-on conclure ?
Exercice 12Un médicament essayé sur 42 patients est contrôlé quant aux effets secondaires qu’ilpeut avoir sur le poids des malades. On peut considérer que :
• quinze d’entre eux ont maigri• dix sept n’ont pas changé de poids• dix ont grossi
En supposant que la maladie est sans effet sur les variations de poids, le médicamenta-t-il un effet significatif sur le poids ?
85

Les Tests du Khi-Deux A. El Mossadeq
Exercice 13Pour étudier la densité de poussières dans un gaz, on a procédé à une série d’observationsde petits échantillons de gaz au moyen d’un microscope.On a ainsi effectué 143 observations et les résultats sont les suivants :
Nombre de particules en suspension Nombre d0echantillons de gaz
0 34
1 46
2 38
3 19
4 4
5 2
> 5 0
Peut-on admettre, au seuil α = 5%, que le nombre de particules en suspension estune variable de Poisson ?
Exercice 14Le tableau ci-après concerne le nombre annuel de cyclones tropicaux ayant atteintla côte orientale des Etats-Unis entre 1887 et 1956 :
Nombre annuel de cyclones Nombre d0annees
0 11 62 103 164 195 56 87 38 19 1> 9 0
Peut-on admettre, au seuil α = 5%, que ce nombre annuel de cyclones est unevariable de Poisson ?
86

A. El Mossadeq Les Tests du Khi-Deux
Exercice 15Le tableau suivant indique le résultat de l’examen de 124 sujets, classés d’après lacouleur de leurs yeux (Y ) et la couleur de leus cheveux (C) :
YÂC Blonds Bruns Noirs Roux
Bleus 25 9 3 7
Gris ou V erts 13 17 10 7
Marrons 7 13 8 5
Existe-t-il une liason entre ces deux caractères ?
Exercice 16On considère les familles de quatre enfants.Sur un échantillon de cent familles à quatre enfants, la répartition suivante a été ob-servée :
Nombre de filles Nombre de familles
0 7
1 20
2 41
3 22
4 10
Peut-on considérer que la probabilité qu’un enfant soit une fille est1
2?
Exercice 17On distribue un jeu de quarante cartes à quatre joueurs : A , B , C , D ; chacunreçevant dix cartesUn statisticien a élaboré un programme de distribution de donnes par ordinateur.Pour un ensemble de deux cents donnes, obtenues à partir de ce programme, ilobserve le nombre de donnes où le joueur A reçoit k as, 0 ≤ k ≤ 4.
87

Les Tests du Khi-Deux A. El Mossadeq
Les résultats sont les suivants :
Nombre d0as Nombre de donnes
0 64
1 74
2 52
3 8
4 2
Le programme du statisticien est-il fiable ?
88

Chapitre 5
Tests d’H ypothèses Moyennes et Variances


A. El Mossadeq Tests : Moyennes et Variances
1. ESTIMATION DE LA MOYENNEET DE LA VARIANCE D’UNE
POPULATION
Soit X une variable aléatoire continue de moyenne μ et de variance σ2.Si (X1, ...,Xn) est un n-échantillon issu de X, alors les statistiques :
M =1
n
nXi=1
Xi
S2 =1
n− 1
nXi=1
(Xi −M)2
constituent des estimateurs sans biais de μ et σ2 respectivement.Si :
m =1
n
nXi=1
xi
et :
s2 =1
n− 1
nXi=1
(xi −m)2
sont des réalisations de M et S2, alors m et s2 sont des estimations ponctuelles deμ et σ2.
2. INTERVALLE DE CONFIANCED’UNE VARIANCE
Si X suit une loi normale de moyenne μ et de variance σ2, alors la quantité :
χ2 =(n− 1) s2
σ2
est une réalisation d’une variable χ2n−1 du Khi-deux à (n− 1) degrés de liberté.Ainsi, pour tout α ∈ [0, 1], il existe χ2n−1;α/2 et χ2n−1;1−α/2 dans R tels que :
P£χ2n−1;α/2 < χ2 < χ2n−1;1−α/2
¤= 1− α
91

Tests : Moyennes et Variances A. El Mossadeq
où χ2n−1;α/2 et χ2n−1;1−α/2 vérifient :⎧⎪⎪⎨⎪⎪⎩
Kn−1
³χ2n−1;α/2
´=
α
2
Kn−1
³χ2n−1;1−α/2
´= 1− α
2
Kn−1 étant la fonction de répartition de χ2n−1.Il en résulte que :
P
"(n− 1) s2χ2n−1;1−α/2
< σ2 <(n− 1) s2χ2n−1;α/2
#= 1− α
L’intervalle : "(n− 1) s2χ2n−1;1−α/2
,(n− 1) s2χ2n−1;α/2
#est appelé l’intervalle de confiance de la variance σ2 à 1− α ou au seuil α.L’intervalle de confiance de l’écart-type σ à 1− α est alors donné par :"s
(n− 1)χ2n−1;1−α/2
s,
s(n− 1)χ2n−1;α/2
s
#
Exemple 1La force de rupture d’un certain type de cable peut être assimilée à une variablealéatoire normale.Des essais portant sur dix cables ont donné une variance empirique s2 de 1560N2.Construire un intervalle de confiance, à 95%, de l’écart-type de cette force de rupture.
Au seuil α, l’intervalle de confiace de l’écart-type est défini par :"s(n− 1)
χ2n−1;1−α/2s,
s(n− 1)χ2n−1;α/2
s
#Pour α = 5% : ⎧⎨⎩ χ29;.025 = 2.7
χ29;.975 = 19
d’où l’intervalle de confiace de l’écart-type à 95% :
[27.18N, 72.11N]
92

A. El Mossadeq Tests : Moyennes et Variances
3. INTERVALLE DE CONFIANCED’UNE MOYENNE
3.1. n ≥ 30La taille de l’échantillon est assez grande, d’après le théorème centrale limite, laquantité :
t =m− μσ√n
peut être considérée comme une réalisation de la variable aléatoire normale centréeréduite :
N =M − μ
σ√n
Ainsi, pour tout α ∈ [0, 1], il existe t1−α/2 ∈ R tel que :
P£|N | < t1−α/2
¤= 1− α
c’est à dire : Z t1−α/2
−t1−α/2
1√2πexp−t
2
2dt = 1− α
ou encore : Z t1−α/2
−∞
1√2πexp−t
2
2dt = 1− α
2
On dit que :
μ ∈∙m− t1−α/2
σ√n,m+ t1−α/2
σ√n
¸à 1− α ou au seuil α.Cet intervalle est appelé l’intervalle de confiance de la moyenne μ à 1− α.Si la variance σ2 est inconnue, on la remplace sans inconvénient par son estimations2.
Exemple 2D’une population de variance σ2 = 25, on extrait un échantillon de taille n = 100sur lequel on observe une moyenne empirique m = 12.5.Quel intervalle peut-on assigner à la moyenne μ de la population ?
93

Tests : Moyennes et Variances A. El Mossadeq
Au seuil α, l’intervalle de confiace de la moyenne est défini par :∙m− t1−α/2
σ√n,m+ t1−α/2
σ√n
¸Pour α = 5%, on a :
t.975 = 1.96
d’où l’intervalle de confiance à 95% :
[11.52, 13.48]
3.2. n < 30
Si X suit une loi normale de moyenne μ et de variance σ2, alors la quantité :
t =m− μ
s√n
est une réalisation de la variable aléatoire de Student à (n− 1) degrés de liberté :
Tn−1 =M − μ
S√n
Ainsi, pour tout α ∈ [0, 1], il existe tn−1;1−α/2 ∈ R tel que :
P£|Tn−1| < tn−1;1−α/2
¤= 1− α
où tn−1;1−α/2 vérifie :
Fn−1¡tn−1;1−α/2
¢= 1− α
2
Fn−1 étant la fonction de répartition de Tn−1.On dit que :
μ ∈∙m− tn−1;1−α/2
s√n,m+ tn−1;1−α/2
s√n
¸à 1− α ou au seuil α.Cet intervalle est appelé l’intervalle de confiance de la moyenne μ à 1− α.
Exemple 3Pour déterminer le point de fusion moyen μ d’un certain alliage, on a procédé à neufobservations qui ont données une moyenne m = 1040 C et un écart-type s = 16 C.Construire un intervalle de confiance de la moyenne μ à 95%.
94

A. El Mossadeq Tests : Moyennes et Variances
Ici on a :
n = 9
m = 1040 C
s = 16 C
Au seuil α, l’intervalle de confiace d’une telle moyenne est défini par :∙m− tn−1;1−α/2
s√n,m+ tn−1;1−α/2
s√n
¸Pour α = 5%, on a :
t8;.975 = 2.31
d’où l’intervalle de confiance à 95% :
[1027.68 C, 1052.32 C]
4. TEST DE COMPARAISON D’UNEVARIANCE OBSERVÉE À UNE
NORME
Si X suit une loi normale de moyenne μ et de variance σ2, alors sous l’hypothèsenulle :
H0 : ”s2 = σ2”
la quantité :
χ2 =(n− 1) s2
σ2
est une réalisation d’une variable χ2n−1 du Khi-deux à (n− 1) degrés de liberté.Ainsi, pour tout α ∈ [0, 1], il existe χ2n−1;α/2 et χ2n−1;1−α/2 dans R tels que :
P£χ2n−1;α/2 < χ2 < χ2n−1;1−α/2
¤= 1− α
où χ2n−1;α/2 et χ2n−1;1−α/2 vérifient :⎧⎨⎩ Kn−1
³χ2n−1;α/2
´=
α
2Kn−1
³χ2n−1;1−α/2
´= 1− α
2
95

Tests : Moyennes et Variances A. El Mossadeq
Kn−1 étant la fonction de répartition de χ2n−1.On rejette alors l’hypothèse nulle H0, à 1− α, dès que :
(n− 1) s2σ2
/∈£χ2n−1;α/2 − χ2n−1;1−α/2
¤
Exemple 4La force de rupture d’un certain type de cable peut être assimilée à une variablealéatoire normale.Un vendeur de ce type de cable affirme que cette force de rupture a pour varianceσ2 = 2000N2.Des essais portant sur dix cables ont donné une variance empirique s2 de 1560N2.Que peut-on conclure ?
Ici on a : ⎧⎨⎩ n = 10σ2 = 2000N2
s2 = 1560N2
Testons l’hypothèse nulle :
H0 : ”la variance de la force de rupture du cable est σ2=2000N2”
Sous cette hypothèse, la quantité :
χ2 =(n− 1) s2
σ2
est une réalisation d’une variable du Khi-deux à :
(10− 1) = 9
degrés de liberté : χ29Pour α = 5% : ⎧⎨⎩ χ29;.025 = 2.7
χ29;.975 = 19
et comme :
χ2 =(n− 1) s2
σ2
= 7.02
on accepte l’hypothèse nulle H0, au seuil α = 5%, c’est à dire, la force de rupturede ce type de cable a pour variance :
σ2 = 2000N2
96

A. El Mossadeq Tests : Moyennes et Variances
5. TEST DE COMPARAISON D’UNEMOYENNE OBSERVÉE À UNE
NORME
5.1. n ≥ 30Sous l’hypothèse nulle :
H0 : ”m = μ”
la quantité :
t =m− μσ√n
peut être considérée comme une réalisation de la variable aléatoire normale centréeréduite :
N =M − μ
σ√n
Ainsi, pour tout α ∈ [0, 1], il existe t1−α/2 ∈ R tel que :
P£|N | < t1−α/2
¤= 1− α
c’est à dire : Z t1−α/2
−t1−α/2
1√2πexp−t
2
2dt = 1− α
ou encore : Z t1−α/2
−∞
1√2πexp−t
2
2dt = 1− α
2
On rejette alors l’hypothèse nulle H0, à 1− α, dès que :
|t| > t1−α/2
Si la variance σ2 est inconnue, on la remplace par son estimation s2.
Exemple 5D’une population, on extrait un échantillon de taille n = 40 sur lequel on observeune moyenne m = 7.5 et une variance s2 = 80.Tester l’hypothèse selon laquelle cet échantillon est extrait d’une population demoyenne μ = 10.
97

Tests : Moyennes et Variances A. El Mossadeq
Ici on a :
n = 40 μ = 10 m = 7.5 s2 = 80
Testons l’hypothèse nulle :
H0 : ”la moyenne de la population est μ = 10”
Sous cette hypothèse, la quantité :
t =m− μ
s√n
peut être considérée comme une réalisation d’une variable aléatoire normale centréeréduite.Pour α = 5%, on a :
t.975 = 1.96
et comme :
t =m− μ
s√n
= −1.77
on accepte l’hypothèse nulleH0 au seuil α = 5%, c’est à dire, l’échantillon est extraitd’une population de moyenne μ = 10.
5.2. n < 30
Si X suit une loi normale de moyenne μ et de variance σ2, alors sous l’hypothèsenulle :
H0 : ”m = μ”
la quantité :
t =m− μ
s√n
est une réalisation de la variable aléatoire de Student à (n− 1) degrés de liberté :
Tn−1 =M − μ
s√n
Ainsi, pour tout α ∈ [0, 1], il existe tn−1;1−α/2 ∈ R tel que :
P£|Tn−1| < tn−1;1−α/2
¤= 1− α
98

A. El Mossadeq Tests : Moyennes et Variances
où tn−1;1−α/2 vérifie :
Fn−1¡tn−1;1−α/2
¢= 1− α
2
Fn−1 étant la fonction de répartition de Tn−1.On rejette alors l’hypothèse nulle H0, à 1− α, dès que :
|t| > tn−1;1−α/2
Exemple 6Un fabriquant de corde affirme que les objets qu’il produit ont une tension de rupturemoyenne de trois cents Kilogrammes.Peut-on admettre le bien fondé de cette affirmation si des expériences faites sur dixcordes ont permis de constater les forces de rupture suivantes :
251 247 255 305 341 326 329 345 392 289
Avant de tester l’hypothèse nulle :
H0 : ”la tension de rupture moyenne de la corde est 300 kg”
Calculons les estimations m et s2 sur cet échantillon de taille n = 10.On a :
m =1
10
10Xi=1
xi = 308 kg
et :
s2 =1
9
10Xi=1
(xi −m)2 = 2269.8 kg2
Sous l’hypothèse nulle H0, la quantité :
t =m− μ
s√n
est une réalisation d’une variable aléatoire de Student à :
n− 1 = 9
degrés de liberté :T9.Pour α = 5%, on a :
t9;.975 = 2.26
99

Tests : Moyennes et Variances A. El Mossadeq
et comme :
t =m− μ
s√n
= .531
on accepte l’hypothèse nulle H0 au seuil α = 5%, c’est à dire, la tension de rupturemoyenne de la corde est 300 kg.
6. TEST DE COMPARAISON DEDEUX VARIANCES
On considère deux populations dans lesquelles le caractère étudié est distribué selondes lois normales de variances σ21 et σ
22 inconnues.
Il s’agit de décider si les variances de ces deux populations sont égales.Soit à tester, au seuil α, l’hypothèse nulle :
H0 : ”σ21 = σ22”
On extrait de ces deux populations, deux échantillons indépendants de taille n1 etn2 respectivement, sur lesquels on calcule les estimations s21 de σ
21 et s
22 de σ
22.
Sous l’hypothèse nulle H0, la quantité :
f =s21s22
est une réalisation d’une variable aléatoire Fn1−1,n2−1 de Fisher à (n1 − 1, n2 − 1)degrés de liberté.Ainsi, pour tout α ∈ [0, 1], il existe Fn1−1,n2−1;α/2 ∈ R et Fn1−1,n2−1;1−α/2 ∈ R telsque :
P£Fn1−1,n2−1;α/2 < f < Fn1−1,n2−1;1−α/2
¤= 1− α
On rejette alors l’hypothèse nulle H0, à 1− α, dès que :
f /∈£Fn1−1,n2−1;α/2 − Fn1−1,n2−1;1−α/2
¤En pratique, on rejette l’hypothèse nulle H0, à 1− α, dès que :⎧⎪⎪⎪⎪⎨⎪⎪⎪⎪⎩
s21s22
> Fn1−1,n2−1;1−α/2 si s21 > s22
s22s21
> Fn2−1,n1−1;1−α/2 si s22 > s21
100

A. El Mossadeq Tests : Moyennes et Variances
Exemple 7Sur deux échantillons indépendants de tailles n1 = 9 et n2 = 21, extraits de deuxpopulations gaussiennes, les variances ont été estimées par s21 = 16 et s
22 = 12.
Peut-on admettre, au seuil α = 10%, que les deux populations considérées ont lamême variance ?
Ici on a : ½n1 = 9 s21 = 16n2 = 21 s22 = 12
Testons au seuil α, l’hypothèse nulle :
H0 : ”σ21 = σ22”
Sous cette hypothèse, la quantité :
f =s21s22
est une réalisation d’une variable aléatoire de Fisher à
(n1 − 1, n2 − 1) = (8, 20)
degrés de liberté : F8,20Pour α = 10%, on a :
F8,20;.95 = 2.45
et comme :
f =s21s22
=4
3
on accepte l’hypothèse nulle H0 au seuil α = 10%.
Exemple 8Sur deux échantillons indépendants de tailles n1 = 17 et n2 = 21, extraits de deuxpopulations gaussiennes, les variances ont été estimées par s21 = 36 et s
22 = 45.
Peut-on admettre, au seuil α = 2%, que ces deux populations ont la même variance ?
Ici on a : ½n1 = 17 s21 = 36n2 = 21 s22 = 45
Testons au seuil α, l’hypothèse nulle :
H0 : ”σ21 = σ22”
101

Tests : Moyennes et Variances A. El Mossadeq
Sous cette hypothèse, la quantité :
f =s22s21
est une réalisation d’une variable aléatoire de Fisher à
(n2 − 1, n1 − 1) = (20, 16)
degrés de liberté : F20,16Pour α = 2, on a :
F20,16;.99 = 3.25
et comme :
f =s22s21
= 1.25
on accepte l’hypothèse nulle H0 au seuil α = 2%.
7. TEST DE COMPARAISON DEDEUX MOYENNES
On considère deux populations dans lesquelles le caractère étudié est défini par(μ1, σ
21) et(μ2, σ
22) respectivement.
On extrait de ces deux populations, deux échantillons indépendants de taille n1 et n2respectivement, sur lesquels on calcule les estimations (m1, s
21) de (μ1, σ
21) et (m2, s
22)
de (μ2, σ22).
7.1. n1 ≥ 30 et n2 ≥ 30Sous l’hypothèse nulle :
H0 : ”μ1 = μ2”
la quantité :
t =m1 −m2rσ21n1+
σ22n2
peut être considérée comme une réalisation de la variable aléatoire normale centrée
102

A. El Mossadeq Tests : Moyennes et Variances
réduite :
N =M1 −M2rσ21n1+
σ22n2
Ainsi, pour tout α ∈ [0, 1], il existe t1−α/2 ∈ R tel que :
P£|N | < t1−α/2
¤= 1− α
On rejette alors l’hypothèse nulle H0, à 1− α, dès que :
|t| > t1−α/2
Si σ21 ou σ22 est inconnue, on peut remplacer sans inconvénient l’une ou l’autre parson estimation.
Exemple 9Chez cent sujet normaux, on dose l’acide urique, les résultats sont :⎧⎨⎩ m1 = 53.3mg/ l
s1 = 9.1mg/ l
Chez cent sujet atteints de la maladie de goutte, le même dosage fournit les résultatssuivants : ⎧⎨⎩ m2 = 78.6mg/ l
s2 = 13.1mg/ l
Que peut-on conclure ?
Testons au seuil α, l’hypothèse nulle :
H0 : ”la maladie de goutte n’a pas d’influence sur la dose de l’acide urique.”
Sous cette hypothèse, la quantité :
t =m1 −m2rs21n1+
s22n2
peut être considérée comme une réalisation d’une variable aléatoire normale centréeréduite.Pour α = 5%, on a :
t.975 = 1.96
103

Tests : Moyennes et Variances A. El Mossadeq
et comme :
t =m1 −m2rs21n1+
s22n2
= 15.862
on rejette l’hypothèse nulle H0 à 95% (même à 99.99%), c’est à dire, la maladie degoutte a une influence sur la dose de l’acide urique.
7.2. n1 < 30 ou n2 < 30
Si le caractère étudié est distribué dans les deux populations selon des lois normalesde même variance σ2 = σ21 = σ22 (pour vérifier cette hypothèse, on peut faire un testde comparaison de deux variances) estimée par :
s2 =(n1 − 1) s21 + (n2 − 1) s22
n1 + n2 − 2alors sous l’hypothèse nulle :
H0 : ”μ1 = μ2”
la quantité :
t =m1 −m2
s
r1
n1+1
n2
est une réalisation de la variable aléatoire Tn1+n2−2 de Student à (n1 + n2 − 2) degrésde liberté.Ainsi, pour tout α ∈ [0, 1], il existe tn1+n2−2;1−α/2 ∈ R tel que :
P£|Tn1+n2−2| < tn1+n2−2;1−α/2
¤= 1− α
On rejette alors l’hypothèse nulle H0, à 1− α, dès que :
|t| > tn1+n2−2;1−α/2
Exemple 10On étudie l’effet d’une substance sur la croissance d’une tumeur greffée.Les résultats sont consignés sur le tableau ci-dessous donnant la surface de la tumeurau 20eme jour après sa greffe :
104

A. El Mossadeq Tests : Moyennes et Variances
Surface 5.5 6 6.5 7 7.5 8T emoins 1 2 3 8 4 3Traites 4 4 8 3 1 1
Le traitement a-t-il un effet significatif sur la surface tumorale ?On suppose que la surface tumorale est distribuée selon des lois normales N (μ1, σ21)et N (μ2, σ22) chez les témoins et les traités respectivement.
Calculons les estimations (m1, s21) de (μ1, σ
21) et (m2, s
22) de (μ2, σ
22).
On a : ⎧⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎩m1 =
1
21
6Xi=1
n1ixi = 7
s21 =1
20
6Xi=1
n1i (xi −m1)2 = .45
et : ⎧⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎩m2 =
1
21
6Xi=1
n2ixi = 6.4048
s22 =1
20
6Xi=1
n2i (xi −m2)2 = .87972
Testons d’abord, au seuil α = 2%, l’hypothèse nulle d’égalité des variances dessurfaces tumorales chez les populations des témoins et des traités.Sous cette hypothèse, la quantité :
f =s22s21
est une réalisation d’une variable aléatoire de Fisher à :
(n2 − 1, n1 − 1) = (20, 20)
degrés de liberté.Pour α = 2%, on a :
F20,20;.99 = 2.94
et comme :
f =s22s21
= 1.9549
105

Tests : Moyennes et Variances A. El Mossadeq
on accepte donc l’hypothèse d’égalité des variances des deux populations.Calculons maintenant l’estimation commune s2 de cette variance :
s2 =(n1 − 1) s21 + (n2 − 1) s22
n1 + n2 − 2= .66486
et testons l’hypothèse nulle :
H0 : ”le traitement est sans effet sur la croissance de la surface tumorale”
Sous cette hypothèse, la quantité :
t =m1 −m2
s
r1
n1+1
n2
est une réalisation de la variable aléatoire de Student à :
n1 + n2 − 2 = 40
degrés de liberté.Pour α = 2%, on a :
t40;.99 = 2.42
et comme :
t =m1 −m2
s
r1
n1+1
n2= 2.831
on rejette l’hypothèse nulle H0 à 98%, c’est à dire, le traitement a une influence surla croissance de la surface tumorale.
106

A. El Mossadeq Tests : Moyennes et Variances
8. EXERCICES
Exercice 1Une série de cent mesures a donné comme résultat :⎧⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎩
100Xi=1
xi = 5200
100Xi=1
"xi −
1
100
100Pj=1
xj
#2= 396
1. Estimer la moyenne et la variance.2. Quel est, à 95%, l’intervalle de confiance de la moyenne ?3. En supposant la variable mesurée gaussienne, déterminer, à 95%, l’intervalle deconfiance de la variance.
Exercice 2La force de rupture d’un certain type de cable peut être assimilée à une variablealéatoire normale.Des essais portant sur dix cables ont donné une variance empirique s2 de 1560N2.Construire un intervalle de confiance, à 95%, de l’écart-type de cette force de rupture.
Exercice 3Une enquête statistique effectuée sur cent sujets permet de définir, à 95%, l’intervallede confiance de la moyenne :
[49.6− 50.4]Dans quelles conditions aurait-il été possible que le résultat fût à 95% :
[49.8− 50.2]
Exercice 4Pour déterminer le point de fusion moyen μ d’un certain alliage, on a procédé à neufobservations qui ont données une moyenne m = 1040 C et un écart-type s = 16 C.Construire un intervalle de confiance de la moyenne μ à 95%.
107

Tests : Moyennes et Variances A. El Mossadeq
Exercice 5La taille de 1200 conscrits du bureau de recrutementX a pour moyenne X = 172 cmet pour écart-type sX = 6 cm.Les mêmes mesures effectuées sur les 250 conscrits du bureau de recrutement Y ontdonné pour moyenne Y = 170 cm et pour écart-type sY = 5 cm.Que peut-on conclure ?
Exercice 6On se propose de comparer le poids à la naissance chez une série de primapares(série 1) et une série de multipares (série 2) :
Serie 1 : n1 = 95 m1 = 3197 g s21 = 210100 g2
Serie 2 : n2 = 105 m2 = 3410 g s22 = 255400 g2
Que peut-on conclure ?
Exercice 7Chez cent sujet normaux, on dose l’acide urique, les résultats sont :⎧⎨⎩ m1 = 53.3mg/ l
s1 = 9.1mg/ l
Chez cent sujet atteints de la maladie de goutte, le même dosage de l’acide uriquefournit les résultats suivants :⎧⎨⎩ m2 = 78.6mg/ l
s2 = 13.1mg/ l
Que peut-on conclure ?
Exercice 8On admet que la valeur moyenne de la glycémie du sujet normal est 1 g/ l.Sur 17 sujets, on a trouvé une moyenne de .965 g/ l et un écart-type estimé de.108 g/ l.Cette valeur peut-elle être considérée comme différente du taux normal ?
108

A. El Mossadeq Tests : Moyennes et Variances
Exercice 9Dans un échantillon de 17 prématurés, la moyenne du Na-plasmatique est :½
m1 = 133s21 = 81.2
Soit un autre échantillon de 25 dysmaturés, dans lequel la moyenne duNa-plasmatiqueest : ½
m2 = 136s22 = 56.57
Que peut-on conclure ?
Exercice 10Lorqu’une machine est bien réglée, elle produit des pièces dont le diamètre D estune variable gaussienne de moyenne 25mm.Deux heures après le réglage de la machine, on a prélevé au hasard neuf pièces.Leurs diamètres ont pour mesure en mm :
22 23 21 25 24 23 22 26 21
Que peut-on conclure quant à la qualité du réglage après deux heures de fonction-nement de la machine ?
Exercice 11Si l’écart-type de la durée de vie d’un modèle de lampe électrique est estimé à centheures, quelle doit être la taille de l’échantillon à prélever pour que l’erreur surl’estimation de la durée de vie moyenne n’exède pas vingt heures et ce avec uneprobabilité de 95% puis 99% ?
Exercice 12Une machine fabrique des rondelles dont le diamètre D est une variable guassienne.On prélève au hasard un échantillon de huit rondelles.Leurs diamètres ont pour mesure en mm :
20.1 19.9 19.7 20.2 20.1 23.1 22.6 19.8
Construire à 95% puis 99% les intervalles de confiance de la moyenne et de la vari-ance.
109

Tests : Moyennes et Variances A. El Mossadeq
Exercice 13On effectue un dosage par deux méthodes différentes A et B.On obtient les résultats suivants :
Methode A .6 .65 .7 .7 .7 .7 .75 .8 .8
Methode B .6 .6 .65 .65 .7 .6 .75 .8 .8
Peut-on considérer que les deux méthodes sont équivalentes ?
Exercice 14Dans deux types de forêts, on a mesuré les hauteurs de treize et quatorze peuple-ments choisis au hasard et indépendamment dans le but de vérifier si les hauteursde ces deux types d’arbres sont ou ne sont pas égales. Les résultats sont les suivants :
Type 1 : 22.5 22.9 23.7 24.0 24.4 24.5 26.0
26.2 26.4 26.7 27.4 28.6 28.7
Type 2 : 23.4 24.4 24.6 24.9 25.0 26.2 26.3
26.8 26.8 26.9 27.0 27.6 27.7 27.8
On admet que les hauteurs de ces deux types d’arbres sont des variables gaussiennesN (μ1, σ21) et N (μ2, σ22).Que peut-on conclure ?
Exercice 15On considère deux variétés de maïsM1 etM2 dont les rendements sont des variablesaléatoires gaussiennes N (μ1, σ21) et N (μ2, σ22).Afin de comparer les rendements de ces deux variétés de maïs, on a choisi de cultiverdans neuf stations différentes des parcelles voisines encemencées de l’une ou l’autredes deux variétés.On a observé les rendements suivants :
110

A. El Mossadeq Tests : Moyennes et Variances
Station 1 2 3 4 5 6 7 8 9
V ariete 1 39.6 32.4 33.1 27 36 32 25.9 32.4 33.2
V ariete 2 39.2 33.1 32.4 25.2 33.1 29.5 24.1 29.2 34.1
Que peut-on conclure ?
Exercice 16Le relevé des températures journalières minimales de deux stations S1 et S2, aucours de neuf journées consécutives a fourni les valeurs suivantes en C:
Station 1 12 8 9 10 11 13 10 7 10
Station 2 7 11 10 6 8 11 12 9 7
On admet que la distribution des températures journalières minimales des deuxstations S1 et S2 sont des variables gaussiennes N (μ1, σ21) et N (μ2, σ22).1. Déterminer les estimations des moyennes et des variances des températuresjournalières minimales des deux stations S1 et S2.
2. Construire, au seuil α = 5%, les intervalles de confiance de ces estimations.3. Peut-on admettre, au seuil α = 10%, l’hypothèse selon laquelle les températuresjournalières minimales moyennes des deux stations S1 et S2 sont identiques ?
Exercice 17On étudie l’effet d’une substance sur la croissance d’une tumeur greffée.Les résultats sont consignés sur le tableau ci-dessous donnant la surface de la tumeurau 20eme jour après sa greffe :
Surface 5.5 6 6.5 7 7.5 8T emoins 1 2 3 8 4 3Traites 4 4 8 3 1 1
Le traitement a-t-il un effet significatif sur la surface tumorale ?On suppose que la surface tumorale est distribuée selon des lois normales N (μ1, σ21)et N (μ2, σ22) chez les témoins et les traités respectivement.
111


Chapitre 6
Le Modèle Linéaire


A. El Mossadeq Le Modèle Linéaire
1. LE MODÈLE LINÉAIRE SIMPLE
Etant données deux variables x et y, on désire savoir si la variable y est fonction dex, ou encore si la connaissance de x fournit une certaine information sur y.On peut aussi s’intéresser à la forme de la relation entre x et y, ou à des prédictionsde y connaissant x.Pour répondre à ces besoins, on est amené à effectuer une régression de y sur x.En agronomie, par exemple, la production du maïs, peut être décrite par la régressiondu rendement de maïs selon la dose de l’engrais utilisé.La variable y est appelée : variable expliquée ou réponse ou variable exogène oucontrôle ...Quant à la variable x, elle est appelée : variable explicative ou variable endogène oucontrôle ...
Définition 1Soit η une variable (réponse) dépendant de variables indépendantes z1, ..., zs :
η = f (z1, ..., zs)
On dit que η obéit à un modèle linéaire si :
η =kX
j=1
βjxj (z1, ..., zs)
où les xj, 1 ≤ j ≤ k, sont des fonctions de (z1, ..., zs) seulement et β1, ..., βk sontdes paramètres souvent inconnus.
Exemple 1Le modèle :
η = α0 + α1z + α2z2 + ...+ αrz
r
est un modèle linéaire.En effet, si l’on pose : ⎧⎪⎪⎨⎪⎪⎩
s = 1k = r + 1βj = αj−1xj = xj (z) = zj−1
le modèle précédent s’écrit alors :
η =kX
j=1
βjxj
115

Le Modèle Linéaire A. El Mossadeq
Définition 2Un modèle linéaire est dit simple si :
η = α+ βz
C’est le cas où :s = 1 , z1 = zβ1 = α , β2 = β
x1 (z) = 1 , x2 (z) = z
Exemple 2Le modèle
γ = δ expβz
où δ > 0, est un modèle linéaire simple.En effet, si l’on pose :
η = ln γ , α = ln δ
le modèle s’écrit :
η = α+ βz
Exemple 3Le modèle
η = α+ β sin 2πz
est un modèle linéaire.En effet, si l’on pose :
s = 1 , k = 2β1 = α , β2 = β
x1 (z) = 1 , x2 (z) = sin 2πz
le modèle s’écrit :
η = β1x1 + β2x2
Exemple 4Le modèle :
η =1
β2 − β1[exp (−β1z)− exp (−β2z)]
n’est pas un modèle linéaire.
116

A. El Mossadeq Le Modèle Linéaire
Remarque 1De ces exemples, on déduit que la linéarité du modèle doit être envisagée commeune linéarité par rapport aux paramètres du modèle.
2. ANALYSE DU MODÈLELINÉAIRE SIMPLE PAR LAMÉTHODE DES MOINDRES
CARRÉS
Suposons qu’on s’intéresse à la relation entre les variations de la température (x) etles variations du volume d’un gaz (y).Lorsqu’on applique au gaz une température xi (qui peut être choisie au hasard oufixée par l’expérimentateur), le volume du gaz résultant est une variable aléatoireyi.Supposons que, l’erreur expérimentale mise à part, la relation entre x et y soitlinéaire, de telle manière que l’espérance conditionnelle de y relativement à x, qu’onappelle la fonction de régression de y en x, est de la forme :
E [y | x] = ηx = α+ βx
où α et β sont des paramètres qu’on se propose d’estimer.Supposons aussi que pour tout x, le volume observé contient la même erreur expéri-mentale donnée par :
V [y | x] = σ2
On appelle erreur aléatoire la variable :
ε = y − (α+ βx)
Pour tout x, ε a une même distribution de moyenne nulle et de variance σ2 :⎧⎨⎩ E [ε] = 0
V [ε] = σ2
Considérons maintenant n réalisations indépendantes y1, ..., yn sous x1, ..., xn respec-tivement.
117

Le Modèle Linéaire A. El Mossadeq
Pour tout i, 1 ≤ i ≤ n, on a :
yi = α+ βxi + εi
où : ⎧⎪⎪⎪⎪⎨⎪⎪⎪⎪⎩E [εi] = 0
V [εi] = σ2
Cov [εi, εj] = 0 si i 6= j
Posons :
Q (α, β) =nXi=1
(yi − α− βxi)2
=nXi=1
ε2i
La méthode des moindres carrés consiste à estimer le couple (α, β) par le couple³α, β
´minimisant Q (α, β) :
Q³α, β
´= min
(α,β)Q (α, β)³
α, β´sont appelés les estimateurs des moindres carrés de (α, β).
On obtient :
α = y − βx
β =S (x, y)
S (x2)
où :
x =1
n
nXi=1
xi
y =1
n
nXi=1
yi
118
A. El Mossadeq Le Modèle Linéaire
et :
S (x, y) =nXi=1
(xi − x) (yi − y)
=nXi=1
xiyi − nxy
S (x, x) = S¡x2¢
Un estimateur η de η est alors donné par :
η = α+ βx
Posons :
ei = yi − ηi
= yi −³α+ βxi
´On a :
nXi=1
ei =nXi=1
³yi − α− βxi
´=
nXi=1
h(yi − y)− β (xi − x)
i= 0
La droite des moindres carrés η = α+ βxet les résidus ei = yi − ηi
119

Le Modèle Linéaire A. El Mossadeq
3. PRORIÉTÉS STATISTIQUES DESESTIMATEURS
Posons :
ci =(xi − x)
S (x2)
On a : ⎧⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎩
nXi=1
ci = 0
nXi=1
c2i =1
S (x2)
nXi=1
cixi = 1
3.1. ETUDE DE β
Puisque :
S (x, y) =nXi=1
(xi − x) (yi − y) =nXi=1
(xi − x) yi
on en déduit :
β =S (x, y)
S (x2)
=
nXi=1
(xi − x) yi
S (x2)
=nXi=1
ciyi
120

A. El Mossadeq Le Modèle Linéaire
d’où :
Ehβi
= E
"nXi=1
ciyi
#
=nXi=1
ciE [yi]
=nXi=1
ci (α+ βxi)
= β
et :
Vhβi
= V
"nXi=1
ciyi
#
=nXi=1
c2iV [yi]
=σ2
S (x2)
Proposition 1β est un estimateur sans biais de β de variance :
Vhβi=
σ2
S (x2)
3.2. ETUDE DE α
Puisque :
α = y − βx
On a :
E [α] = Ehy − βx
i= E [y]−E
hβix
= α+ βx− βx
= α
121

Le Modèle Linéaire A. El Mossadeq
et comme :
β =nXi=1
ciyi
alors :
α = y − βx
= y −Ã
nXi=1
ciyi
!x
=nXi=1
µ1
n− xci
¶yi
d’où :
V [α] = V
"nXi=1
µ1
n− xci
¶yi
#
=nXi=1
µ1
n− xci
¶2V [yi]
= σ2∙1
n+
x2
S (x2)
¸
Proposition 2α est un estimateur sans biais de α de variance :
V [α] = σ2∙1
n+
x2
S (x2)
¸
3.3. ETUDE DE η
On a :
η = α+ βx
=nXi=1
µ1
n− xci
¶yi +
nXi=1
ciyix
=nXi=1
∙1
n+ ci (x− x)
¸yi
122

A. El Mossadeq Le Modèle Linéaire
d’où :
E [η] = Ehα+ βx
i= E [α] +E
hβix
= α+ βx
et :
V [η] = V
"nXi=1
∙1
n+ ci (x− x)
¸yi
#
=nXi=1
∙1
n+ ci (x− x)
¸2V [yi]
= σ2
"1
n+(x− x)2
S (x2)
#
Proposition 3η est un estimateur sans biais de η de variance :
V [η] = σ2
"1
n+(x− x)2
S (x2)
#
3.4. ETUDE DE LA COVARIANCE DE α ET β
On a :
β − β =nXi=1
ci (yi − ηi)
α− α =nX
j=1
µ1
n− xcj
¶¡yj − ηj
¢
123

Le Modèle Linéaire A. El Mossadeq
donc :
(α− α)³β − β
´=
nXi=1
³cin− xc2i
´(yi − ηi)
2 +
Xi6=j
µ1
n− xci
¶cj (yi − ηi)
¡yj − ηj
¢=
nXi=1
³cin− xc2i
´(yi − ηi)
2 +Xi6=j
µ1
n− xci
¶cjεiεj
d’où :
Covhα, β
i= E
h(α− α)
³β − β
´i= σ2
nXi=1
³cin− xc2i
´= −σ2 x
S (x2)
Proposition 4La covariance de α et β est donnée par :
Covhα, β
i= −σ2 x
S (x2)
4. ETUDE DE LA VARIANCE DESESTIMATEURS
Soient a et b deux réels donnés et considérons l’estimateur des moindres carrés :
τ = aα+ bβ
de :
τ = aα+ bβ
124

A. El Mossadeq Le Modèle Linéaire
Comme :
E [τ ] = Ehaα+ bβ
i= aα+ bβ
= τ
τ est donc un estimateur sans biais de τ .
D’autre part, puisque :
τ = aα+ bβ
=nXi=1
han+ (b− ax) ci
iyi
on en déduit :
V [τ ] = V
"nXi=1
han+ (b− ax) ci
iyi
#
=nXi=1
han+ (b− ax) ci
i2V [yi]
= σ2
"a2
n+(b− ax)2
S (x2)
#
Considérons un estimateur t de τ sans biais et linéaire en yi :
t =nXi=1
diyi
Puisque :
E [t] = τ
alors : ⎧⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎩
nXi=1
di = a
nXi=1
dixi = b
125

Le Modèle Linéaire A. El Mossadeq
Calculons la covariance de τ et t :
τ −E [τ ] =nXi=1
han+ (b− ax) ci
i(yi − ηi)
=nXi=1
han+ (b− ax) ci
iεi
t− E [t] =nX
j=1
dj¡yj − ηj
¢=
nXj=1
djεj
d’où :
Cov [τ , t] = E [(τ − τ) (t− τ)]
=nXi=1
nXj=1
han+ (b− ax) ci
idjCov [εi, εj]
=nXi=1
han+ (b− ax) ci
idiV [εi]
= σ2
"a2
n+ (b− ax)
nXi=1
cidi
#
Et comme :nXi=1
cidi =nXi=1
xi − x
S (x2)di
=1
S (x2)
"nXi=1
xidi − xnXi=1
di
#
=(b− ax)
S (x2)
on obtient alors :
Cov [τ , t] = σ2
"a2
n+ (b− ax)
nXi=1
cidi
#
= σ2
"a2
n+(b− ax)2
S (x2)
#= V [τ ]
126

A. El Mossadeq Le Modèle Linéaire
Or :
V [τ − t] = V [τ ] + V [t]− 2Cov [τ , t]= V [t]− V [τ ]
et :
V [τ − t] ≥ 0on en déduit :
V [τ ] ≤ V [t]
Proposition 5Parmi tous les estimateurs sans biais de :
τ = aα+ bβ
linéaires en yi, l’estimateur des moindres carrés :
τ = aα+ bβ
est de variance minimale.
Corollaire 1Parmi tous les estimateurs sans biais de α, linéaires en yi, l’estimateur des moindrescarrés α est de variance minimale.
Corollaire 2Parmi tous les estimateurs sans biais de β, linéaires en yi, l’estimateur des moindrescarrés β est de variance minimale.
Corollaire 3Parmi tous les estimateurs sans biais de :
η = α+ βx
linéaires en yi, l’estimateur des moindres carrés :
η = α+ βx
est de variance minimale.
127

Le Modèle Linéaire A. El Mossadeq
5. ESTIMATION DE σ2
On appelle somme des carrés des résidus la quantité :
SSe =nXi=1
e2i
où
ei = yi − ηi
= yi − α− βxi
En remplaçant, on obtient :
SSe =nXi=1
e2i
=nXi=1
³yi − α− βxi
´2=
nXi=1
y2i −"α
nXi=1
yi + βnXi=1
xiyi
#Posons :
SSr = αnXi=1
yi + βnXi=1
xiyi
alors :
SSr = nα2 + 2αβnXi=1
xi + β2
nXi=1
x2i
=nXi=1
η2i
d’où :
SSe =nXi=1
y2i − SSr
128

A. El Mossadeq Le Modèle Linéaire
Et comme :
E£α2¤
= V [α] +E [α]2
Ehβ2i
= Vhβi+E
hβi2
Ehαβi
= Covhα, β
i+E [α]E
hβi
E [y2i ] = V [yi] +E [yi]2 = σ2 + (α+ βxi)
2
alors :
E [SSr] = 2σ2 +
"nα2 + 2αβ
nXi=1
xi + β2nXi=1
x2i
#d’où :
E [SSe] = E
"nXi=1
y2i
#−E [SSr]
= (n− 2)σ2
Proposition 6La statistique :
1
n− 2SSe
est un estimateur sans biais de σ2.
6. ANALYSE DE LA VARIANCE
On a :nXi=1
y2i = SSe + SSr
nXi=1
y2i se décompose en la somme de deux carrés :
• le premier, SSe, donnant une information sur l’erreur,• le second, SSr, donnant une information sur les paramètres de la fonction derégression.
129

Le Modèle Linéaire A. El Mossadeq
Nous résumons l’analyse dans le tableau suivant, appelé table de l’analyse de la vari-ance :
Source d.d.l SS SS/ddl Esperance
Regression 2 SSrSSr2
σ2 +1
2
∙nα2 + 2αβx+ β2
nPi=1
x2i
¸Residu n− 2 SSe
SSen− 2 σ2
Total nnPi=1
y2i
7. TESTS ET INTERVALLES DECONFIANCE
On suppose, dans ce paragraphe, que pour tout i, 1 ≤ i ≤ n, yi est une variablenormale de moyenne α+ βxi et de variance σ2.
Proposition 7Le couple d’estimateurs
³α, β
´a pour densité la fonction :
f (x, y) = nS (x2)
2πσ2exp− 1
2σ2
"n (x− α)2 + 2 (x− α) (y − β)
nXi=1
xi + (y − β)2nXi=1
x2i
#
7.1. INTERVALLE DE CONFIANCE DE σ2
Proposition 8La variable :
SSeσ2
suit une loi du khi-deux à (n− 2) degrés de liberté : χ2n−2.
130

A. El Mossadeq Le Modèle Linéaire
Un intervalle de confiance de σ2 à 1− δ est alors donné par :"SSe
χ2n−2;1−δ/2,
SSeχ2n−2;δ/2
#
7.2. RÉGION DE CONFIANCE ET TESTSCONCERNANT (α, β)
Proposition 9La variable :
T (α, β) = n (α− α)2 + 2 (α− α)³β − β
´ nXi=1
xi +³β − β
´2 nXi=1
x2i
est telle que la variable :1
σ2T (α, β)
suit une loi du Khi-deux à deux degrés de liberté χ22 indépendamment de SSe.
Supposons qu’on veut tester l’hypothèse :
H0 : ” (α, β) = (α0, β0) ”
Si H0 est vraie, alors la variable aléatoire :
1
σ2T (α0, β0)
suit une loi du Khi-deux à deux degrés de liberté χ22 indépendamment de la variablealéatoire :
SSeσ2
qui suit une loi du khi-deux à (n− 2) degrés de liberté : χ2n−2.Considérons la statistique:
F =T (α0, β0) /2
SSe/n− 2Sous l’hypothèse nulle H0, F est une variable de Fisher-Snedecor à (2, n− 2) degrésde liberté F2,n−2.On rejette l’hypothèse nulle H0, au seuil δ, dès que :
F < F2,n−2;δ/2 ou F > F2,n−2;1−δ/2
131

Le Modèle Linéaire A. El Mossadeq
La région de confiance de (α, β) à 1− δ est donnée par :½(α, β) | T (α, β) ≤ 2 SSe
n− 2F2,n−2;1−δ/2¾
C’est une région limitée par une ellipse centrée en³α, β
´.
7.3. INTERVALLE DE CONFIANCE ET TESTCONCERNANT β
Proposition 10La variable aléatoire β est distribuée selon une loi normale de moyenne :
Ehβi
= β
et de variance :
Vhβi
=σ2
S (x2)
indépendamment de SSe.
Ainsi, la variable :
X =
³β − β
´pS (x2)
σ
est distribuée selon une loi normale centrée réduite.Et comme la variable :
Y =SSeσ2
suit une loi du khi-deux à (n− 2) degrés de liberté : χ2n−2, il en résulte que la statis-tique :
T (β) =Xp
Y/n− 2
=³β − β
´s(n− 2)S (x2)SSe
suit une loi de Student à (n− 2) degrés de liberté : Tn−2.
132

A. El Mossadeq Le Modèle Linéaire
L’intervalle de confiance de β à 1− δ est donné par :
"β − tn−2;1−δ/2
sSSe
(n− 2)S (x2) , β + tn−2;1−δ/2
sSSe
(n− 2)S (x2)
#Afin de tester l’hypothèse nulle :
H0 : ”β = β0”
on compare T (β0) à tn−2;1−δ/2.
7.4. INTERVALLE DE CONFIANCE ET TESTCONCERNANT α
Proposition 11La variable aléatoire α est distribuée selon une loi normale de moyenne :
E [α] = α
et de variance :
V [α] = σ2
nPi=1
x2i
nS (x2)
indépendamment de SSe.
Posons :
γ2 =
nPi=1
x2i
nS (x2)
Ainsi, la variable :
Z =(α− α)
σγ
est distribuée selon une loi normale centrée réduite.
133

Le Modèle Linéaire A. El Mossadeq
Et comme la variable :
Y =SSeσ2
suit une loi du khi-deux à (n− 2) degrés de liberté : χ2n−2, il en résulte que lastatistique :
T (α) =Zp
Y/n− 2
=(α− α)
γ
s(n− 2)SSe
suit une loi de Student à (n− 2) degrés de liberté : Tn−2.
L’intervalle de confiance de α à 1− δ est donné par :"α− tn−2;1−δ/2γ
sSSe(n− 2) , α+ tn−2;1−δ/2γ
sSSe(n− 2)
#
Afin de tester, au seuil δ, l’hypothèse nulle :
H0 : ”α = α0”
on compare T (α0) à tn−2;1−δ/2.
7.5. INTERVALLE DE CONFIANCE DE η
Proposition 12La variable aléatoire ηx est distribuée selon une loi normale de moyenne :
E [ηx] = ηx
et de variance :
V [ηx] = σ2
"1
n+(x− x)2
S (x2)
#indépendamment de SSe.
Ainsi, la variable :
U =(ηx − ηx)
σ [ηx]
134

A. El Mossadeq Le Modèle Linéaire
est distribuée selon une loi normale centrée réduite.Et comme la variable :
Y =SSeσ2
suit une loi du khi-deux à (n− 2) degrés de liberté : χ2n−2, il en résulte que la statis-tique :
T (ηx) =Up
Y/n− 2
=(ηx − ηx)r
SSen− 2
s1
n+(x− x)2
S (x2)
suit une loi de Student à (n− 2) degrés de liberté : Tn−2.
L’intervalle de confiance de ηx à 1− δ est donné par :
ηx ∓ tn−2;1−δ/2
sSSe(n− 2)
s1
n+(x− x)2
S (x2)
7.6. COEFFICIENT DE CORRÉLATION
Par définition , le coefficient de corrélation de x et y est donnée par :
ρ =Cov [x, y]
σ [x]σ [y]
=S (x, y)p
S (x2)pS (y2)
Il en résulte que :
ρ2 =β2S (x2)
S (y2)
Or :
SSe = S¡y2¢− β
2S¡x2¢
135

Le Modèle Linéaire A. El Mossadeq
donc :
SSeS (y2)
= 1− β2S (x2)
S (y2)
= 1− ρ2
En utilisant les résultats précédents, on obtient :
Proposition 13La variable aléatoire :
T (ρ) =(n− 2) ρp1− ρ2
suit une loi de Student à n− 2 degrés de liberté : Tn−2.
Afin de tester, au seuil δ, l’hypothèse nulle :
H0 : ”ρ = 0”
c’est à dire :
”il n’y a pas de relation linéaire entre x et y”
on compare T (ρ) à tn−2;1−δ/2.
8. LE TEST DE LINÉARITÉ DUMODÈLE
Dans toute l’analyse que nous avons menée, nous avons supposé l’existence d’unerelation linéaire entre x et y de la forme :
E [y | x] = ηx = α+ βx
c’est à dire, que le modèle étudié, est un modèle linéaire simple.Il s’agit, maintenant de vérifier si cette hypothèse est vraie, autrement dit :
le modèle est-il réellement linéaire ?
Soient x1, ..., xm m valeurs fixée de x, m ≥ 3, telles que :
x1 < ... < xm
136

A. El Mossadeq Le Modèle Linéaire
Pour chaque xj, 1 ≤ j ≤ m, supposons qu’on dispose de nj, nj ≥ 1, observations¡y1j, ..., ynjj
¢de y et que l’un au moins des nj est strictement supérieur à 1.
Soit :
n =mXj=1
nj
et pour tout j, 1 ≤ j ≤ m, posons :
y.j =1
nj
njXi=1
yij
La méthode des moindres carrés nous fournit la droite :
η = α+ βx
avec :
α = y − βx
β =S (x, y)
S (x2)
où :
x =1
n
mXi=1
nixi
y =1
n
mXj=1
nj y.j =1
n
mXj=1
njXi=1
yij
S (x, y) =mXj=1
nj (xj − x) (y.j − y) =mXj=1
njXi=1
(xj − x) (yij − y)
S¡x2¢=
mXj=1
nj (xj − x)2
Il est clair que :
SSe =mXj=1
njXi=1
e2ij =mXj=1
njXi=1
¡yij − ηij
¢2où pour tout j ∈ 1, ...,m :
ηij = α+ βxj , 1 ≤ i ≤ nj
137

Le Modèle Linéaire A. El Mossadeq
Intuitivement, si la relation entre x et y n’est pas linéaire, alors les résidus eijcontiennet une information autre que celle liée à l’erreur.Dans ce cas, il faut s’attendre à ce que la somme des carrés des résidus SSe contient,en plus de l’information sur σ2, une information sur l’écart à la vraie relation entrex et y.Posons :
SST =mXj=1
njXi=1
(yij − y)2
SSB =mXj=1
(yij − y.j)2
SSW =mXj=1
njXi=1
(yij − y.j)2
alors on a :
SST = SSB + SSW
• SST représente la variation totale,• SSB représente la variation inter-groupe,• SSW représente la variation intra-groupe.
Puisque pour tout j ∈ 1, ...,m, y1j, ..., ynjj sont identiquement distribués selonune loi d’espérace mathématique α+ βxj et de variance σ2, alors :
E
"njXi=1
(yij − y.j)2
#= (nj − 1)σ2
et :
E [SSW ] = (n−m)σ2
On conclut que la statistique :
SSWn−m
est un estimateur sans biais de σ2.Cet estimateur est indépendant de la relation linéaire pouvant exister entre x et ycontrairement au précédent estimateur :
SSen− 2
Posons :
SSL = SSB − SSr (β)
138

A. El Mossadeq Le Modèle Linéaire
où :
SSr (β) = β2S¡x2¢
On démontre que, sous l’hypothèse de linéarité du modèle on a :
E [SSL] = (m− 2)σ2
sinon :
E [SSL] = (m− 2)σ2 + Λ2
où Λ2 dépend de la nature de la relation entre x et y de telle sorte que :
Λ2 = 0⇐⇒ η = α+ βx
Il en résulte que si les yij, 1 ≤ i ≤ nj et 1 ≤ j ≤ m, sont identiquement distribuésselon une même loi normale, alors sous l’hypothèse nulle :
H0 : ”le modèle est linéaire”
la statistique :
FL =SSL/ (m− 2)SSW/ (n−m)
est distribuée selon une loi de Ficher à (m− 2, n−m) degrés de liberté : Fm−2,n−m.
On rejette l’hypothèse nulle H0, au seuil δ, dès que :
FL > Fm−2,N−m;δ
On résume les différents résultats dans la table suivante où g (Λ2) est une fonctionde Λ2 telle que :
g (0) = 0
Source d.d.l SS E [SS/ddl]
InterÁmodele
Ânon linearite
1
m−2m− 1
SSr(β)
SSL
SSBσ2+β2S(x2)+g(Λ2)
σ2+g(Λ2)/(m−2)Intra n−m SSW σ2
Total n− 1 SST
Lorsque l’hypothèse de la linéarité du modèle est acceptée, il devient intéressantd’examiner l’hypothèse nulle :
H0 : ”β = 0”
c’est à dire, la réponse est une fonction constante.
Sous l’hypothèse de linéarité du modèle, c’est à dire :
Λ = 0
139

Le Modèle Linéaire A. El Mossadeq
et sous l’hypothèse nulle :
H0 : ”β = 0”
la statistique :
Fβ =SSr (β)
SSe/ (n− 2)est distribuée selon une loi de Ficher à (1, n− 2) degrés de liberté : F1,n−2.
9. PREDICTION
Souvent, le but d’une expérimentation est de pouvoir, pour une valeur donnée x0 dela variable explicative x, prédire la valeur de la variable à expliquer y.Supposons que la relation entre x et y soit linéaire :
E [y | x] = ηx = α+ βx
et supposons qu’après validation du modèle, par les données (xi, yi)1≤i≤n, on a :
ηx = α+ βx
où³α, β
´sont les estimateurs des moindres carrés de (α, β).
Nous souhaitons maintenant prédire la valeur ”future” de la réponse y, indépen-dante des observations précédantes, lorsque x = x0.
Quel prédicteur yx0, basé seulement sur les observations (xi, yi)1≤i≤n, doit-on alorsutiliser pour prédire la réponse indépendante y qui serait observée en x = x0 ?
Intuitivement, il parait raisonnable de considérer le prédicteur :
yx0 = α+ βx0
On a :
E [yx0 | (xi, yi) , 1 ≤ i ≤ n] = E [y | x0] = ηx0
donc, tous les prédicteurs, de la réponse indépendante y en x = x0, ont la même es-pérance mathématique.
140

A. El Mossadeq Le Modèle Linéaire
Le choix de ce prédicteur se justifie par le fait que si t est un prédicteur de y, alors :
Eh¡tx0 − y
¢2 | (xi, yi)1≤i≤ni = Eh¡tx0 − ηx0
¢2 | (xi, yi)1≤i≤ni+E
h¡y − ηx0
¢2 | (xi, yi)1≤i≤nile terme représentant la covariance est nulle vue l’hypothèse de l’indépendance.Lorsqu’on ne considère que les prédicteurs linéaires en y, alors d’après le Corollaire3 de la Proposition 5, l’espérance :
Eh¡tx0 − ηx0
¢2 | (xi, yi)1≤i≤niest minimum lorsque :
tx0 = yx0
Si les yi, 1 ≤ i ≤ n, sont indépendantes et distribuées selon des lois de moyennesα+ βxi et de variances σ2, et si y est indépendante des yi, 1 ≤ i ≤ n, est distribuéeselon une loi de moyenne α+ βx0 et de variance σ2, alors :
E£(yx0 − y)2 | (xi, yi)1≤i≤n
¤= σ2
"1 +
1
n+(x0 − x)2
S (x2)
#Si en plus la distribution est normale, alors :
Tn−2 =yx0 − yr
SSen− 2
s1 +
1
n+(x0 − x)2
S (x2)
est distribuée selon une loi de student à n− 2 degrés de liberté.
Un intervalle de prédiction de y en x = x0, à 1− δ, est donné par :
yx0 ∓ tn−2;1−δ/2
rSSen− 2
s1 +
1
n+(x0 − x)2
S (x2)
141

Le Modèle Linéaire A. El Mossadeq
10. EXEMPLE
On injecte à trente patients des doses différentes (x) d’une solution (mg/ml), et onobserve leur tension arterielle (y).Les résultats sont résumés dans le tableau suivants, où 15 ≤ x ≤ 70 :
no patient x y no patient x y no patient x y
01 39 144 11 64 162 21 36 13602 47 220 12 56 150 22 50 14203 45 138 13 59 140 23 39 12004 47 145 14 34 110 24 21 12005 65 162 15 42 128 25 44 16006 46 142 16 48 130 26 53 15807 67 170 19 45 135 27 63 14408 42 124 18 17 114 28 29 13009 67 158 19 20 116 29 25 12510 56 154 20 19 124 30 69 175
10.1. ESTIMATION DES PARAMÈTRES DUMODÈLE
La taille de l’échantillon, ici, est :
n = 30
On a :30Xi=1
xi = 1354 ,30Xi=1
yi = 4276
30Xi=1
x2i = 67894 ,30Xi=1
y2i = 624260
30Xi=1
xiyi = 199576
et :
S¡x2¢=
30Xi=1
x2i −
µ30Pi=1
xi
¶230
= 6783.47
142
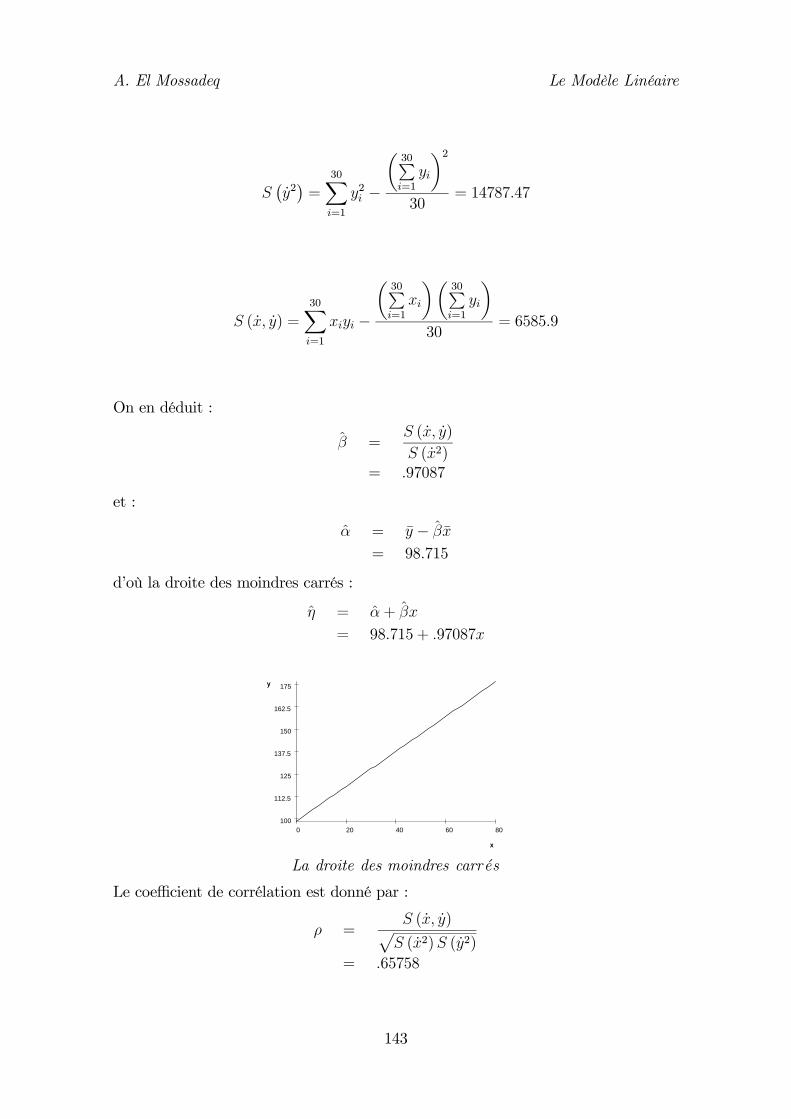
A. El Mossadeq Le Modèle Linéaire
S¡y2¢=
30Xi=1
y2i −
µ30Pi=1
yi
¶230
= 14787.47
S (x, y) =30Xi=1
xiyi −
µ30Pi=1
xi
¶µ30Pi=1
yi
¶30
= 6585.9
On en déduit :
β =S (x, y)
S (x2)= .97087
et :
α = y − βx
= 98.715
d’où la droite des moindres carrés :
η = α+ βx
= 98.715 + .97087x
806040200
175
162.5
150
137.5
125
112.5
100
x
y
x
y
La droite des moindres carr es
Le coefficient de corrélation est donné par :
ρ =S (x, y)p
S (x2)S (y2)
= .65758
143

Le Modèle Linéaire A. El Mossadeq
On a :
SSr = αnXi=1
yi + βnXi=1
xiyi
= 615870
SSe =nXi=1
y2i − SSr
= 8393.45
D’où la table de l’analyse de la variance :
Source d.d.l SS SS/ddl E [SS/ddl]
Regression 2 SSrSSr2
σ2 +1
2
∙30α2 + 2αβx+ β2
nPi=1
x2i
¸Erreur 28 SSe
SSe28
σ2
Total 3030Pi=1
y2i
10.2. VALIDATION DU MODÈLE
Afin de valider le modèle, on prend en compte les six valeurs suivantes de x, pourlesquelles une deuxième observations a été faite :
x 39 42 45 47 56 67y 120 128 135 220 150 158
Pour calculer SSW , il suffit de remarquer que :⎧⎪⎪⎪⎪⎨⎪⎪⎪⎪⎩
njPi=1
(yij − y.j)2 = 0 si nj = 1
njPi=1
(yij − y.j)2 =
(y1j−y2j)2
2si nj = 2
d’où :
SSW =mXj=1
njXi=1
(yij − y.j)2
= 3193
144

A. El Mossadeq Le Modèle Linéaire
Comme :
SSr (β) = β2S¡x2¢
= 6394.02
on en déduit :
SSL = SST − SSW − SSr (β)
= 5200.45
d’où la table d’analyse :
Source d.d.l SSModele 1 SSr (β) = 6394.02
Non linearite 22 SSL = 5200.45Erreur pure 6 SSW = 3193
Total 29 SST = 14787.47
On en déduit :
FL =SSL/ (m− 2)SSW/ (n−m)
= .44
et comme :
F22,6;.95 = 3.85
l’hypothèse de la linéarité du modèle est accepté au seuil δ = 5%.On peut maintenant examiner l’hypothèse nulle :
H0 : ”β = 0”
c’est à dire, la réponse est une fonction constante.On a :
Fβ =SSr (β)
SSe/ (n− 2)= 21.33
et comme :
F1,28;.95 = 4.2
on rejette H0 à 95%.
145

Le Modèle Linéaire A. El Mossadeq
10.3. INTERVALLES DE CONFIANCE
(1) L’intervalle de confiance de σ2, au seuil δ, est défini par :"SSe
χ2n−2;1−δ/2,
SSeχ2n−2;δ/2
#Pour δ = 5%, on a : ⎧⎨⎩ χ228;.025 = 15.3
χ228;.975 = 44.5
d’où l’intervalle :
[188.62, 548.59]
(2) L’intervalle de confiance de β, au seuil δ, est défini par :"β − tn−2;1−δ/2
sSSe
(n− 2)S (x2) , β + tn−2;1−δ/2
sSSe
(n− 2)S (x2)
#Pour δ = 5%, on a :
t28;.975 = 2.05
d’où l’intervalle :
[.5405, 1.4015]
(3) L’intervalle de confiance de α, au seuil δ, est défini par :"α− tn−2;1−δ/2γ
sSSe(n− 2) , α+ tn−2;1−δ/2γ
sSSe(n− 2)
#Pour δ = 5%, on a :
t28;.975 = 2.05
d’où l’intervalle :
[78.21, 119.21]
(4) L’intervalle de confiance de ηx à 1− δ est donné par :
ηx ∓ tn−2;1−δ/2
sSSe(n− 2)
s1
n+(x− x)2
S (x2)
Pour δ = 5%, on a :
t28;.975 = 2.05
146
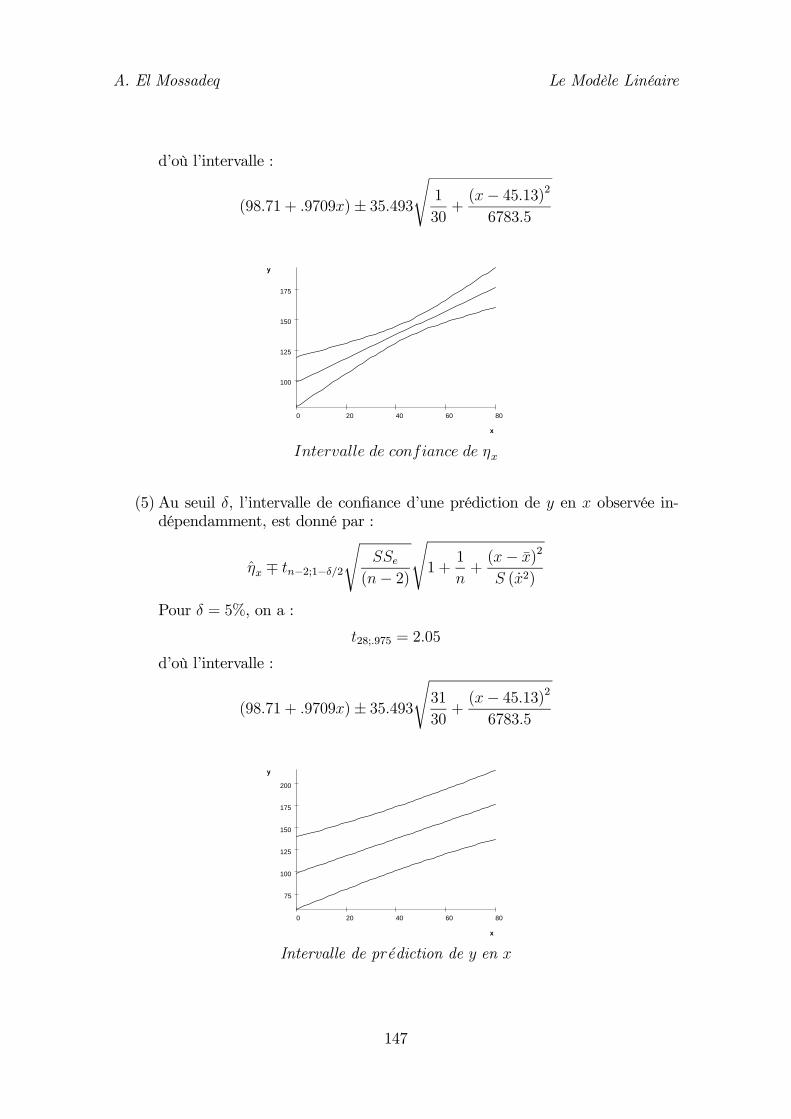
A. El Mossadeq Le Modèle Linéaire
d’où l’intervalle :
(98.71 + .9709x)± 35.493
s1
30+(x− 45.13)2
6783.5
806040200
175
150
125
100
x
y
x
y
Intervalle de confiance de ηx
(5) Au seuil δ, l’intervalle de confiance d’une prédiction de y en x observée in-dépendamment, est donné par :
ηx ∓ tn−2;1−δ/2
sSSe(n− 2)
s1 +
1
n+(x− x)2
S (x2)
Pour δ = 5%, on a :
t28;.975 = 2.05
d’où l’intervalle :
(98.71 + .9709x)± 35.493
s31
30+(x− 45.13)2
6783.5
806040200
200
175
150
125
100
75
x
y
x
y
Intervalle de pr ediction de y en x
147

Le Modèle Linéaire A. El Mossadeq
(6) La région de confiance de (α, β) à 1− δ est donnée par :
C (α, β) =
½(α, β) | T (α, β) ≤ 2 SSe
n− 2F2,n−2;1−δ/2¾
= (α, β) | T (α, β) ≤ 2002.4
où :
T (α, β) = 30 (α− 98.71)2+2708 (α− 98.71) (β − .971)+67894 (β − .971)2−2002.4
148