Embed Size (px)
Citation preview

Application de la logique floue à l’évaluation
des risques et à la prise de décisions
Commandité par CAS/ICA/SOA
Section conjointe de la gestion des risques
Préparé par
Kailan Shang1
Zakir Hossen2 Novembre 2013
©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries. Tous droits réservés.
Les opinions et conclusions exprimées dans les présentes sont celles des auteurs et ne représentent pas la
position officielle ni l’opinion des organismes commanditaires ou de leurs membres. Ces organismes ne font
aucune déclaration et n’offrent aucune garantie quant à l’exactitude de l’information.
1 Vous pouvez joindre Kailan Shang, FSA, CFA, PRM, SCJP, de Financière Manuvie, à
[email protected]. 2 Vous pouvez joindre Zakir Hossen, MA, de Banque Scotia, à [email protected].

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 2 de 67
Remerciements
Les auteurs tiennent à remercier les membres du Groupe de supervision du projet (GSP) pour leur aide, leurs examens, leurs commentaires et tout le soutien qu’ils ont accordé pendant la durée du projet. Le présent document n’aurait pas été aussi pertinent sans l’utile contribution du GSP. Les auteurs sont reconnaissants pour les fonds consentis par la Section conjointe de la gestion des risques de la Casualty Actuarial Society, de l’Institut canadien des actuaires et de la Society of Actuaries.
Les membres du Groupe de supervision du projet « Application de la logique floue à l’évaluation des risques et la prise de décisions » sont : • Andrei Titioura • Casey Malone • Christopher Coulter • Fred Tavan • Jason Sears • Joshua Parker • Mark Bergstrom • Mary Neumann • Steven Siegel • Zhiwei Zhu
Les auteurs remercient également Barbara Scott pour la coordination efficace de ce projet.

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 3 de 67
Sommaire La gestion du risque fait appel depuis fort longtemps à des modèles complexes
pour évaluer l’incertitude. En raison de la disponibilité croissante des ressources informatiques, on emploie de plus en plus des méthodes avancées telles la modélisation stochastique et la simulation de crise ou même l’utilisation de la modélisation stochastique sur stochastique aux fins des programmes de couverture. Bien que les professionnels de la gestion du risque s’efforcent de mieux comprendre les risques et qu’ils emploient pour ce faire des modèles complexes, un grand nombre de risques ne sont toujours pas bien compris. Certains restent inconnus, tandis que de nouveaux émergent. De nombreux types de risque ne peuvent encore être bien analysés au moyen des modèles classiques probabilistes. Le manque de données d’expérience, conjugué aux liens imbriqués de cause à effet, rend difficile l’appréciation du degré d’exposition à certains types de risque.
Les modèles classiques de risque reposent sur la théorie des probabilités et la
théorie classique des ensembles. Ils sont couramment employés pour évaluer les risques de marché, de crédit, d’assurance et de négociation. Par contraste, les modèles de logique floue s’appuient sur la théorie des ensembles flous et la logique floue et servent à analyser les risques lorsque les connaissances sont insuffisantes ou que les données sont imprécises. Ces derniers types de risque entrent d’habitude dans la catégorie des risques opérationnels ou des risques émergents.
La différence fondamentale entre la théorie classique des ensembles et la théorie
des ensembles flous réside dans la nature de l’inclusion des éléments de l’ensemble. Dans les ensembles classiques, les éléments sont soit inclus, soit exclus de l’ensemble. Dans un ensemble flou, les éléments sont inclus selon un degré de validité compris normalement entre 0 et 1. Les modèles de logique floue permettent à un objet d’appartenir à plus qu’un seul ensemble exclusif selon divers degrés de validité ou de confiance. La logique floue tient compte du manque de connaissances ou de l’absence de données précises et prend en compte explicitement la chaîne de cause à effet entre les variables. La plupart des variables étant décrites en termes linguistiques, les modèles de logique floue s’apparentent intuitivement au raisonnement humain. Ces modèles flous sont utiles pour démystifier, évaluer et mieux comprendre les risques qui ne sont pas bien compris.
Les systèmes de logique floue permettent de simplifier les cadres de gestion du
risque à grande échelle. Dans le cas des risques pour lesquels il n’existe pas de modèle probabiliste quantitatif approprié, un système de logique floue permet de modéliser les liens de cause à effet, d’évaluer le degré d’exposition aux risques et de classer par ordre les principaux risques de façon cohérente, en tenant compte des données disponibles et des opinions des experts. Dans le cas des entreprises ayant des activités diversifiées ainsi qu’une large exposition aux risques et des activités dans plusieurs régions géographiques, la longue liste des risques devant faire l’objet d’une

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 4 de 67
surveillance est telle qu’elle rendrait toute analyse approfondie des risques inabordable, surtout lorsque les liens entre les facteurs de risque sont imbriqués. Une telle analyse pourrait être onéreuse et extrêmement laborieuse sans le recours à un système de logique floue. De plus, les systèmes de logique floue comprennent des règles qui explicitent les liens, la dépendance et les relations entre les facteurs modélisés, ce qui facilite la recherche des pistes d’atténuation des risques. Les ressources peuvent ensuite servir à atténuer les risques pour lesquels le degré d’exposition est le plus élevé et le coût de couverture est relativement faible.
La théorie des ensembles flous et les modèles de logique floue peuvent aussi être
utilisés pour d’autres types de modèles de décision ou de reconnaissance de formes, notamment les réseaux bayésiens et les réseaux de neurones artificiels, ainsi que les modèles de Markov cachés et les modèles d’arbres de décision. Ces modèles élargis permettent éventuellement de résoudre des problèmes difficiles d’évaluation des risques.
Le présent document explore les domaines auxquels les modèles de logique floue
peuvent être appliqués pour améliorer l’évaluation des risques et la prise de décisions. On y traite de la méthode, du cadre et du processus d’utilisation des systèmes de logique floue aux fins de la gestion des risques. Le document étant truffé d’exemples pratiques, il est à espérer qu’il encouragera l’application judicieuse des modèles de logique floue à la modélisation des risques.

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 5 de 67
Table des matières
1. Introduction ............................................................................................................................. 6 2. Logique floue et théorie des ensembles flous .......................................................................... 7
2.1 Principes fondamentaux de la théorie des ensembles flous et de la logique floue ....... 7 2.2 Exemple numérique .................................................................................................... 17 2.3 Autres modèles ........................................................................................................... 21
3 Application de la théorie des ensembles flous et de la logique floue : Analyse documentaire .......................................................................................................... 30
4 Cadre d’évaluation des risques fondé sur la logique floue ..................................................... 35 4.1 Évaluation des risques et prise de décisions ............................................................... 35 4.2 Modèle du capital économique requis ........................................................................ 40
5 Considérations clés ................................................................................................................. 42 5.1 Opinions d’experts : Collecte et analyse .................................................................... 42 5.2 Sélection des fonctions d’appartenance ...................................................................... 43 5.3 Rôle des données d’expérience .................................................................................. 44 5.4 Examen du système de logique floue ......................................................................... 45 5.5 Liens avec la prise de décisions.................................................................................. 45
6 Études de cas .......................................................................................................................... 46 6.1 Identification et évaluation de l’opinion publique négative ....................................... 47 6.2 Agrégation des risques et budgétisation ..................................................................... 52
7 Conclusion .............................................................................................................................. 57 8 Bibliographie .......................................................................................................................... 59 Annexe. L’utilisation des données d’expérience ........................................................................ 63

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 6 de 67
1. Introduction
Les modèles probabilistes sont très répandus en quantification et en évaluation des risques. Ils sont devenus la pierre angulaire de la prise de décisions éclairées en matière de risque dans de nombreux domaines. Toutefois, un modèle probabiliste bâti sur la théorie classique des ensembles peut difficilement décrire certains risques d’une manière significative et pratique. Le manque de données d’expérience, conjugué aux liens imbriqués de cause à effet et à l’imprécision des données, compliquent l’appréciation du degré d’exposition à certains types de risque à l’aide des seuls modèles probabilistes classiques. Parfois, même en recourant à un modèle de risque quantitatif crédible étalonné pour tenir compte des données d’expérience, la cause du risque et ses caractéristiques peuvent être compris de façon incomplète. D’autres modèles, notamment un modèle de logique floue, le modèle de Markov caché et le modèle d’arbre de décision, de même que les réseaux bayésiens et les réseaux de neurones artificiels, tiennent compte explicitement des liens de cause à effet sous-jacents et en reconnaissent la complexité inconnue. Ces modèles plus nouveaux sont plus efficaces pour faire comprendre et évaluer certains risques, notamment le risque opérationnel.
Il est intéressant de préciser que même si les modèles quantitatifs complexes et bien
acceptés sont accessibles pour évaluer les risques de marché, de crédit et d’assurance, ils échappent habituellement au contrôle des gestionnaires des opérations. Par ailleurs, en appliquant des pratiques pertinentes d’identification et de contrôle des risques, le risque opérationnel peut être sensiblement atténué, malgré le manque de consensus au sujet des modèles quantitatifs à utiliser. Par conséquent, il pourrait être avantageux de construire et de mettre en œuvre des modèles plus pertinents de gestion du risque opérationnel à l’aide d’une nouvelle approche, notamment la logique floue.
Le présent rapport porte plus particulièrement sur le recours à la logique floue et à la
théorie des ensembles flous, appliquées à la gestion des risques pour la première en 1965 par le mathématicien Lotfi A. Zadeh. Contrairement à la théorie des probabilités, la théorie de la logique floue accepte de façon explicite l’incertitude entourant la certitude; elle peut également intégrer facilement l’information décrite en termes linguistiques. Les modèles de logique floue sont plus commodes pour intégrer différentes opinions d’expert et ils sont mieux adaptés aux cas renfermant des données insuffisantes et imprécises. Ils fournissent un cadre dans lequel l’apport des experts et les données d’expérience peuvent évaluer conjointement l’incertitude et identifier les problèmes importants. À partir d’approximations et de conclusions tirées de connaissances et de données ambiguës, les modèles de logique floue peuvent servir à modéliser les risques qui ne sont pas très bien compris. Certains risques opérationnels et émergents évoluent rapidement. Les gestionnaires de risques ne possèdent peut-être pas suffisamment de connaissances ou de données pour effectuer une évaluation exhaustive à l’aide de modèles fondés sur la théorie des probabilités. Les modèles de logique floue peuvent permettre d’évaluer l’exposition d’une entreprise à ces risques.

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 7 de 67
Le présent document se décline comme suit : • La section 2 (Logique floue et théorie des ensembles flous) présente le contexte
théorique du modèle de logique floue et elle le compare à d’autres modèles. • La section 3 (Application de la logique floue) porte sur l’application éventuelle
de la logique floue à la gestion des risques. • La section 4 (Cadre d’évaluation des risques fondé sur la logique floue) traite de
l’utilisation d’un modèle de logique floue pour l’identification, l’évaluation et la quantification des risques.
• La section 5 (Considérations clés) aborde certains facteurs clés d’un cadre pratique de gestion des risques fondé sur un modèle de logique floue.
• La section 6 (Études de cas) présente les processus d’identification des risques, d’évaluation des risques et de prise de décisions à un niveau microdimensionnel pour un certain type de risque et à un niveau global pour l’ensemble des risques de l’entreprise.
• La section 7 résume les points principaux de la présente étude et elle conclut la partie principale du rapport.
2. Logique floue et théorie des ensembles flous
La présente section propose quelques notions de base dans le domaine de la théorie des ensembles flous et une comparaison avec d’autres méthodes servant à évaluer les risques et à prendre des décisions. Les lecteurs possédant des antécédents en intelligence artificielle ou en génie des contrôles automatiques peuvent passer à la section suivante.
2.1 Principes fondamentaux de la théorie des ensembles flous et de la logique floue
Ensembles flous En théorie classique des ensembles, un objet est un élément, ou un non-élément, d’un
ensemble. Toutefois, en réalité, due à l’insuffisance des connaissances ou de l’imprécision des données, il n’est pas toujours évident de déterminer si un objet appartient ou non à un ensemble. Par contre, les ensembles flous interprètent l’incertitude d’une manière approximative. Au plan conceptuel, la théorie des ensembles flous permet à un objet d’appartenir à plusieurs ensembles exclusifs dans le cadre du raisonnement. À chaque ensemble correspond un degré de certitude selon lequel un objet appartient à un ensemble flou. Prenons l’exemple des cotes de crédit. Supposons qu’il existe trois niveaux de cote - faible, moyen, élevé – qui peuvent être considérés comme trois ensembles. Selon la théorie classique des ensembles, l’ensemble complet se compose de ces trois ensembles exclusifs. Dès que la cote de crédit est connue, son niveau est établi. La figure 1 présente un exemple d’ensemble classique de cotes de crédit. Si la cote s’établit à 3,5, il est certain à 100 % que la cote de crédit est élevée.
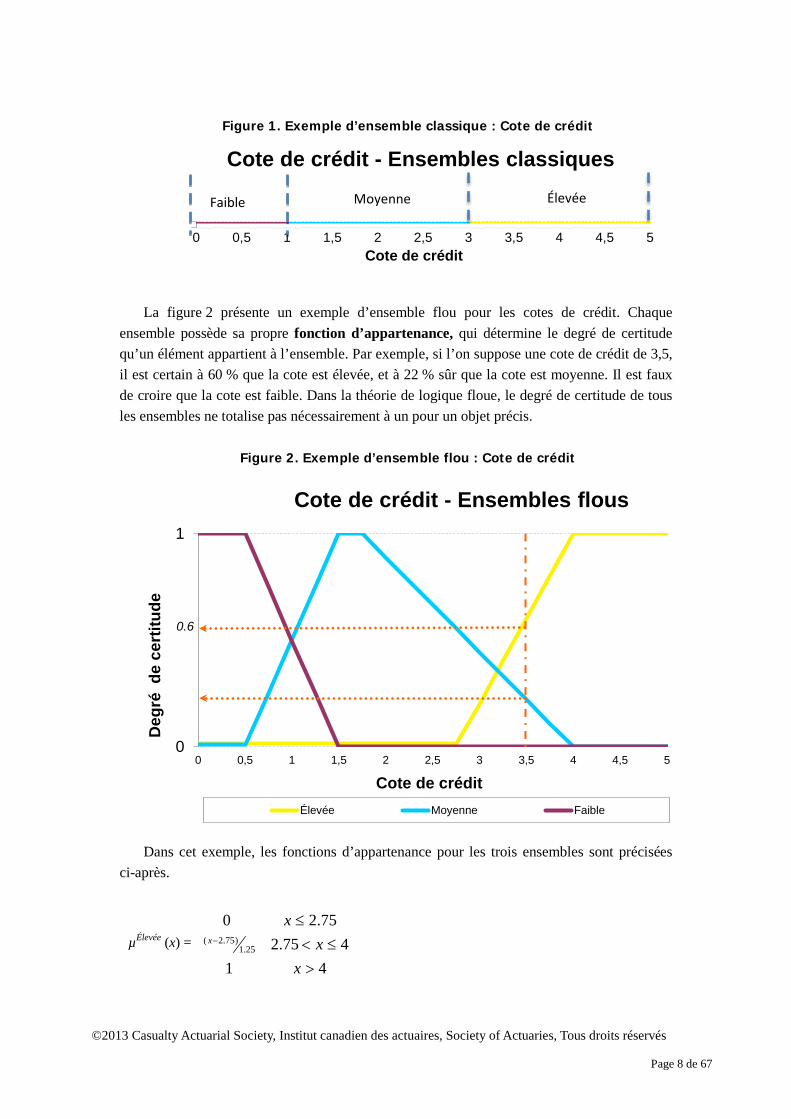
©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 8 de 67
Figure 1. Exemple d’ensemble classique : Cote de crédit
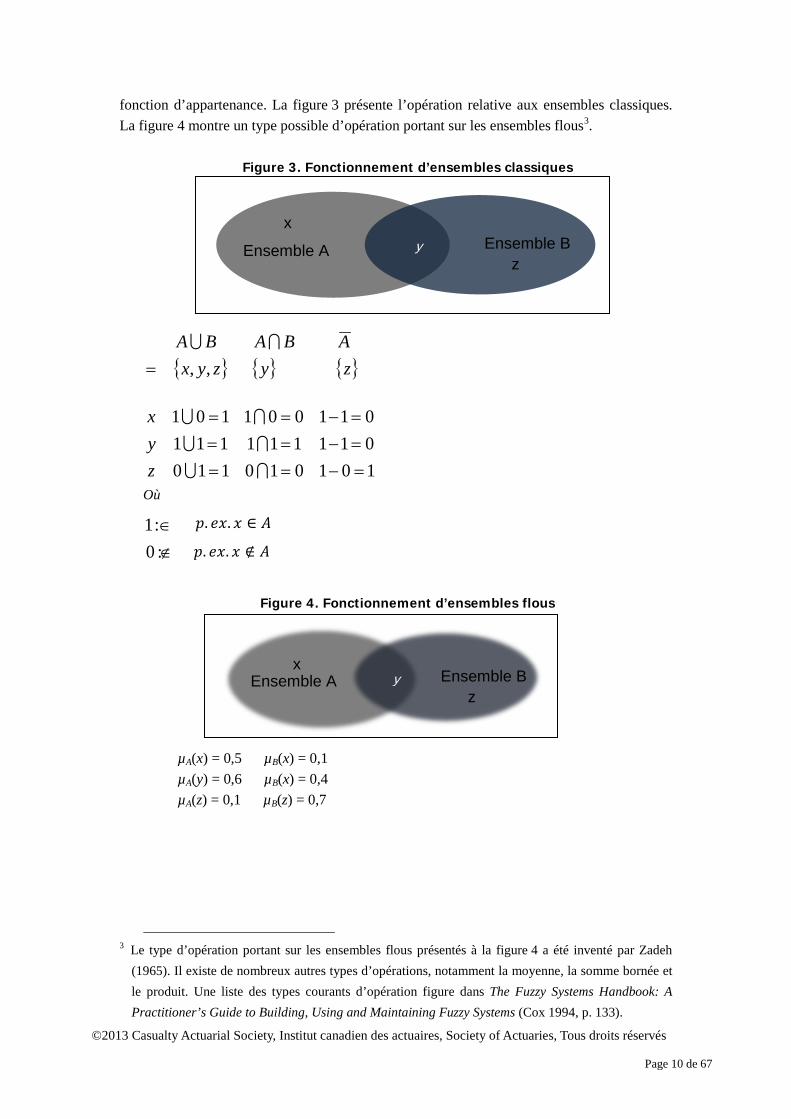
La figure 2 présente un exemple d’ensemble flou pour les cotes de crédit. Chaque
ensemble possède sa propre fonction d’appartenance, qui détermine le degré de certitude qu’un élément appartient à l’ensemble. Par exemple, si l’on suppose une cote de crédit de 3,5, il est certain à 60 % que la cote est élevée, et à 22 % sûr que la cote est moyenne. Il est faux de croire que la cote est faible. Dans la théorie de logique floue, le degré de certitude de tous les ensembles ne totalise pas nécessairement à un pour un objet précis.
Figure 2. Exemple d’ensemble flou : Cote de crédit
Dans cet exemple, les fonctions d’appartenance pour les trois ensembles sont précisées
ci-après.
0 0,5 1 1,5 2 2,5 3 3,5 4 4,5 5Cote de crédit
Cote de crédit - Ensembles classiques
Faible Moyenne Élevée
0
1
0 0,5 1 1,5 2 2,5 3 3,5 4 4,5 5
Deg
ré d
e ce
rtitu
de
Cote de crédit
Cote de crédit - Ensembles flous
Élevée Moyenne Faible
0.6
4475.2
75.2
1
0)( 25.1
)75.2(
>≤<
≤= −
xx
xx xHighµµÉlevée (x) =

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 9 de 67
Les ensembles flous présentent une caractéristique incontournable : il n’existe pas de
règles parfaites au sujet de la définition des fonctions d’appartenance. La forme mathématique de la fonction et ses paramètres dépendent de la contribution des experts. Dans la mesure où les fonctions d’appartenance sont cohérentes, si l’on procède par comparaison, la conclusion fondée sur les ensembles flous demeure significative. Par exemple, le degré de certitude d’une cote de crédit 4 qui appartient à l’ensemble flou « élevé » ne devrait pas être inférieur à celui d’une cote de crédit 3. Par ailleurs, une seule des fonctions d’appartenance peut augmenter pour une certaine fourchette de cotes de crédit. Il pourrait y avoir contradiction si le degré de certitude d’une cote de crédit 4 appartenant à l’ensemble flou « élevé » est supérieur à celui d’une cote de crédit 3, alors que le degré de certitude d’une cote de crédit 4 appartenant à l’ensemble flou « moyenne » est simultanément supérieur à celui d’une cote de crédit 3.
Les fonctions d’appartenance sont habituellement simples pour les ensembles flous. Elles
sont fréquemment linéaires et elles prennent souvent la forme d’un triangle trapézoïde, L ou r. Elles peuvent également être gaussiennes ou de type gamma. Des personnes différentes peuvent avoir leurs propres fonctions d’appartenance pour un ensemble flou en raison de niveaux de connaissances ou d’expérience différents. De façon générale, elles peuvent toutefois désigner des choses semblables lorsqu’elles font référence à un ensemble flou. Par exemple, on peut partager l’opinion selon laquelle la demande de crédit hypothécaire d’un postulant qui bénéficie d’une cote de crédit élevée est susceptible d’être approuvée à un taux d’emprunt relativement faible. Dans cet exemple, l’expression « cote de crédit élevée » correspond bien à la définition d’un ensemble flou. Mais les évaluateurs de risque en matière de crédit hypothécaire peuvent appliquer des fonctions d’appartenance différentes pour la « cote de crédit élevée » d’un ensemble flou. Les ensembles flous nous permettent de mettre au point un système en langage courant fondé sur nos méthodes de raisonnement habituelles.
Fonctionnement des ensembles flous
Comme en théorie classique des ensembles, les ensembles flous possèdent leurs propres
opérations, notamment l’union, l’intersection et le complément. Différentes de l’opération relative aux ensembles classiques, les opérations propres aux ensembles flous reposent sur la
4475.175.15.15.15.0
5.0
0
1
0
)(
25.2)4(
1)5.0(
Average
>≤<
≤<≤<
≤
=−
−
xx
xx
x
xx
x
µ
5.15.15.0
5.0
0
1)( 1
)5.1(
>≤<
≤= −
xx
xx xLowµ
µMoyenne (x) =
µFaible (x) =
©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 10 de 67
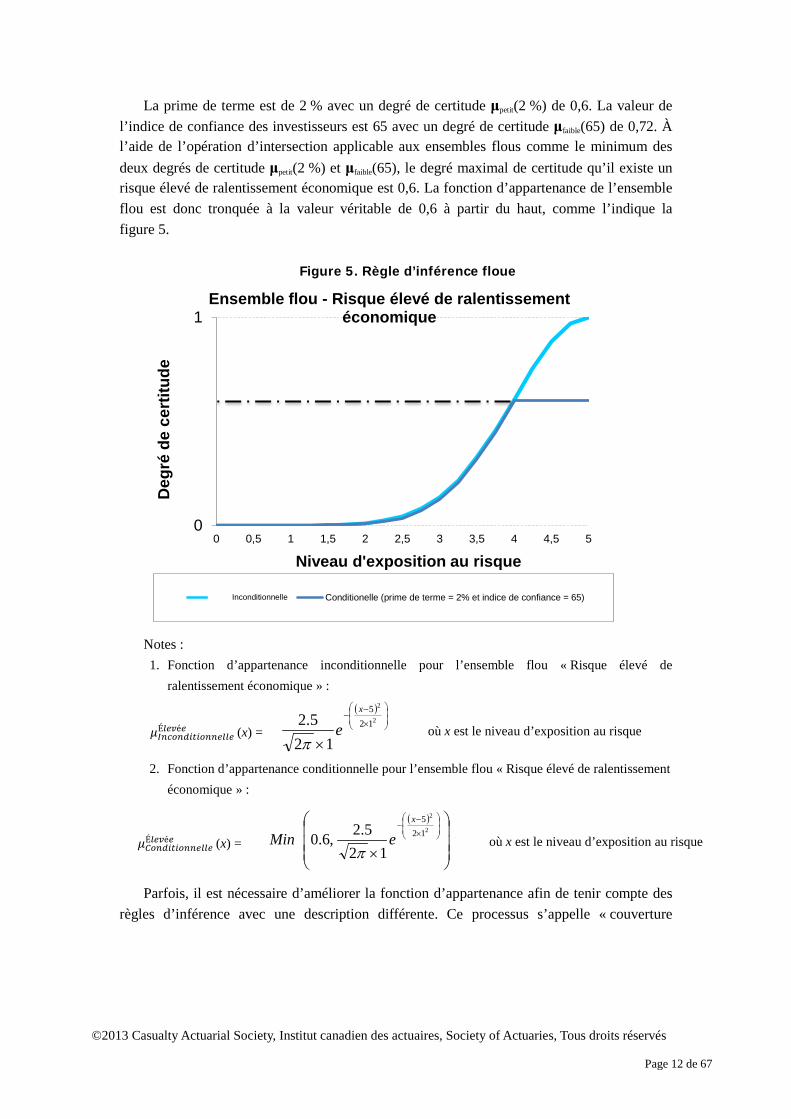
fonction d’appartenance. La figure 3 présente l’opération relative aux ensembles classiques. La figure 4 montre un type possible d’opération portant sur les ensembles flous3.
Figure 3. Fonctionnement d’ensembles classiques
Figure 4. Fonctionnement d’ensembles flous
3 Le type d’opération portant sur les ensembles flous présentés à la figure 4 a été inventé par Zadeh
(1965). Il existe de nombreux autres types d’opérations, notamment la moyenne, la somme bornée et le produit. Une liste des types courants d’opération figure dans The Fuzzy Systems Handbook: A Practitioner’s Guide to Building, Using and Maintaining Fuzzy Systems (Cox 1994, p. 133).
{ } { } { }
AxgeAxge
Wherezyx
zA
yBA
zyxBA
∉∉∈∈
=−===−===−==
=
..:0
..:1
101010110011111111011001101
,,
7.0)(1.0)(4.0)(6.0)(1.0)(5.0)(
======
zzyyxx
BA
BA
BA
µµµµµµ
x
Ensemble A Ensemble B z
y
x Ensemble A Ensemble B
z y
Où 𝑝. 𝑒𝑒. 𝑒 ∈ 𝐴
𝑝. 𝑒𝑒. 𝑒 ∉ 𝐴
µA(x) = 0,5 µB(x) = 0,1 µA(y) = 0,6 µB(x) = 0,4 µA(z) = 0,1 µB(z) = 0,7

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 11 de 67
Dans cet exemple, une règle max-min est utilisée. Le degré de certitude qu’un élément appartient à l’union de quelques ensembles flous correspond au maximum des degrés de certitude que l’élément appartient à chaque ensemble flou. Le degré de certitude qu’un élément appartient à l’intersection de quelques ensembles flous correspond au minimum des degrés de certitude que l’élément appartient à chaque ensemble flou. Le degré de certitude qu’un élément appartient au complément d’un ensemble flou est déduit par le degré de certitude que l’élément appartient à l’ensemble flou.
Règles d’inférence et couvertures floues
À l’aide d’opérations logiques portant sur des ensembles flous, des règles d’inférence
peuvent être créées pour établir des liens entre différentes variables. Un type de règle d’inférence floue s’appelle la règle d’inférence max-min4. Il s’agit de la règle max-min indiquée à la figure 4 qui est appliquée à l’inférence.
1. Si A et B, alors C.
Le degré maximal de certitude de C est le moindre du degré de certitude de A et du degré de certitude de B.
2. Si A ou B, alors C. Le degré maximal de certitude de C est le plus élevé du degré de certitude de A et du degré de certitude de B.
3. Si ce n’est pas A, alors C. Le degré maximal de certitude de C est celui qui est déduit du degré de certitude de A.
Par exemple, lorsque l’on évalue le risque d’un ralentissement économique, la prime de
terme5 et le niveau de confiance des investisseurs sont les deux principaux indicateurs. Une règle d’inférence possible est énoncée ci-après.
Si la prime de terme est faible et que le niveau de confiance des investisseurs est faible, le risque de ralentissement économique dans un avenir rapproché est élevé.
4 Outre la règle d’inférence max-min, il existe plusieurs autres règles d’inférence floues, notamment le
raisonnement monotone, la règle addictive floue, le minimum de corrélation et le produit de corrélation.
5 La prime de terme correspond à la différence entre le rendement des obligations à long terme et le rendement des obligations à court terme.
9.01.07.04.04.06.05.01.05.0
1),min(),max(
zyx
ABABA ABABA µµµµµ −===
©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 12 de 67
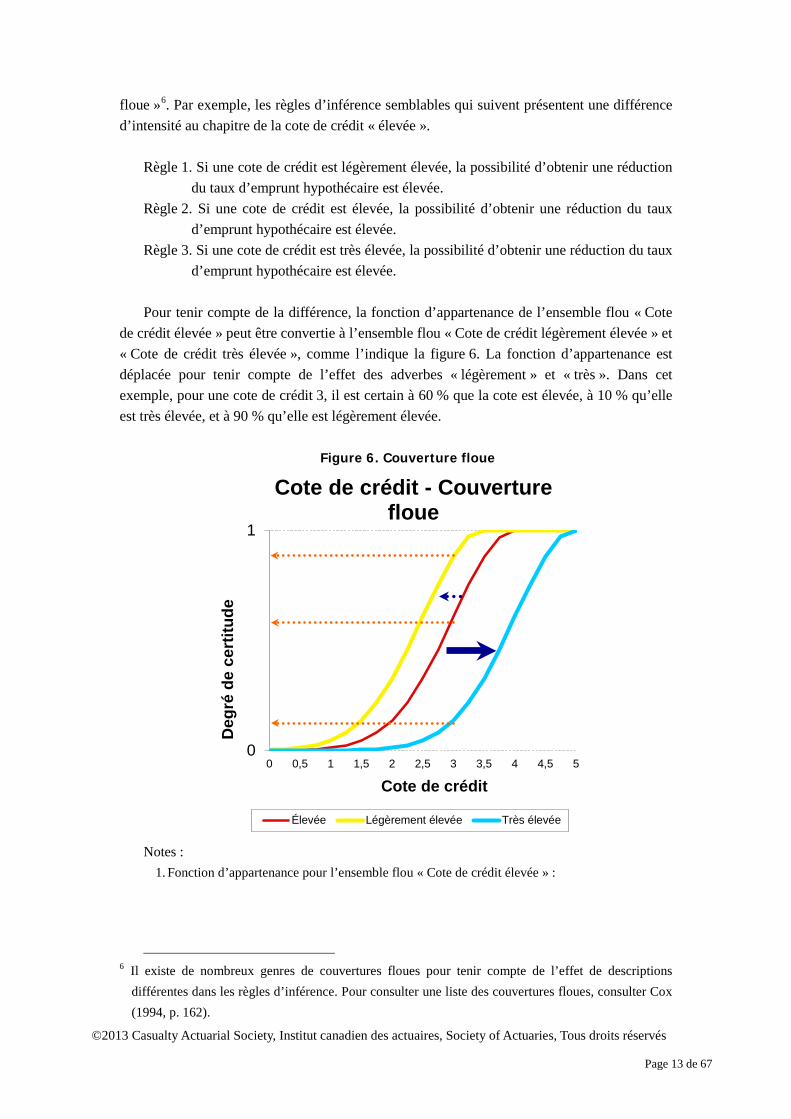
La prime de terme est de 2 % avec un degré de certitude μpetit(2 %) de 0,6. La valeur de l’indice de confiance des investisseurs est 65 avec un degré de certitude μfaible(65) de 0,72. À l’aide de l’opération d’intersection applicable aux ensembles flous comme le minimum des deux degrés de certitude μpetit(2 %) et μfaible(65), le degré maximal de certitude qu’il existe un risque élevé de ralentissement économique est 0,6. La fonction d’appartenance de l’ensemble flou est donc tronquée à la valeur véritable de 0,6 à partir du haut, comme l’indique la figure 5.
Figure 5. Règle d’inférence floue
Notes : 1. Fonction d’appartenance inconditionnelle pour l’ensemble flou « Risque élevé de
ralentissement économique » :
2. Fonction d’appartenance conditionnelle pour l’ensemble flou « Risque élevé de ralentissement économique » :
Parfois, il est nécessaire d’améliorer la fonction d’appartenance afin de tenir compte des règles d’inférence avec une description différente. Ce processus s’appelle « couverture
0
1
0 0,5 1 1,5 2 2,5 3 3,5 4 4,5 5
Deg
ré d
e ce
rtitu
de
Niveau d'exposition au risque
Ensemble flou - Risque élevé de ralentissement économique
Très élevée Conditionelle (prime de terme = 2% et indice de confiance = 65)
( )
level exposurerisk theis x where12
5.2)(2
2
125
×
−−
×=
x
Highnalunconditio ex
πµ
( )
level exposurerisk theis x where12
5.2,6.0)(2
2
125
×=
×
−−
x
Highlconditiona eMinx
πµ
𝜇𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼 É𝐼𝐼𝑙é𝐼 (x) = où x est le niveau d’exposition au risque
𝜇𝐶𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼 É𝐼𝐼𝑙é𝐼 (x) = où x est le niveau d’exposition au risque
Inconditionnelle
©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 13 de 67
floue »6. Par exemple, les règles d’inférence semblables qui suivent présentent une différence d’intensité au chapitre de la cote de crédit « élevée ».
Règle 1. Si une cote de crédit est légèrement élevée, la possibilité d’obtenir une réduction
du taux d’emprunt hypothécaire est élevée. Règle 2. Si une cote de crédit est élevée, la possibilité d’obtenir une réduction du taux
d’emprunt hypothécaire est élevée. Règle 3. Si une cote de crédit est très élevée, la possibilité d’obtenir une réduction du taux
d’emprunt hypothécaire est élevée. Pour tenir compte de la différence, la fonction d’appartenance de l’ensemble flou « Cote
de crédit élevée » peut être convertie à l’ensemble flou « Cote de crédit légèrement élevée » et « Cote de crédit très élevée », comme l’indique la figure 6. La fonction d’appartenance est déplacée pour tenir compte de l’effet des adverbes « légèrement » et « très ». Dans cet exemple, pour une cote de crédit 3, il est certain à 60 % que la cote est élevée, à 10 % qu’elle est très élevée, et à 90 % qu’elle est légèrement élevée.
Figure 6. Couverture floue
Notes :
1. Fonction d’appartenance pour l’ensemble flou « Cote de crédit élevée » :
6 Il existe de nombreux genres de couvertures floues pour tenir compte de l’effet de descriptions
différentes dans les règles d’inférence. Pour consulter une liste des couvertures floues, consulter Cox (1994, p. 162).
0
1
0 0,5 1 1,5 2 2,5 3 3,5 4 4,5 5
Deg
ré d
e ce
rtitu
de
Cote de crédit
Cote de crédit - Couverture floue
Élevée Légèrement élevée Très élevée

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 14 de 67
2. Fonction d’appartenance pour l’ensemble flou « Cote de crédit légèrement élevée » :
3. Fonction d’appartenance pour l’ensemble flou « Cote de crédit très élevée » :
Clarification
La clarification est le processus permettant d’estimer la valeur de la variable dépendante
d’après l’ensemble flou obtenu après l’application de la règle d’inférence floue. Trois méthodes de clarification types sont décrites ci-après :
1. Méthode de la moyenne : la valeur numérique moyenne de la variable dépendante
dans l’ensemble flou de sortie. 2. Méthode de la moyenne du maximum : la valeur numérique moyenne de la variable
dépendante avec le degré de certitude maximal dans l’ensemble flou de sortie. 3. Méthode centroïde : la valeur numérique moyenne pondérée de la variable
dépendante dans l’ensemble flou de sortie. Le coefficient de pondération est le degré de certitude.
Des méthodes différentes conviennent dans des situations différentes. Reprenons
l’exemple de la règle d’inférence à la figure 5. L’ensemble flou de sortie représente la zone entre la fonction d’appartenance conditionnelle et l’axe des x.
Fonction d’appartenance conditionnelle :
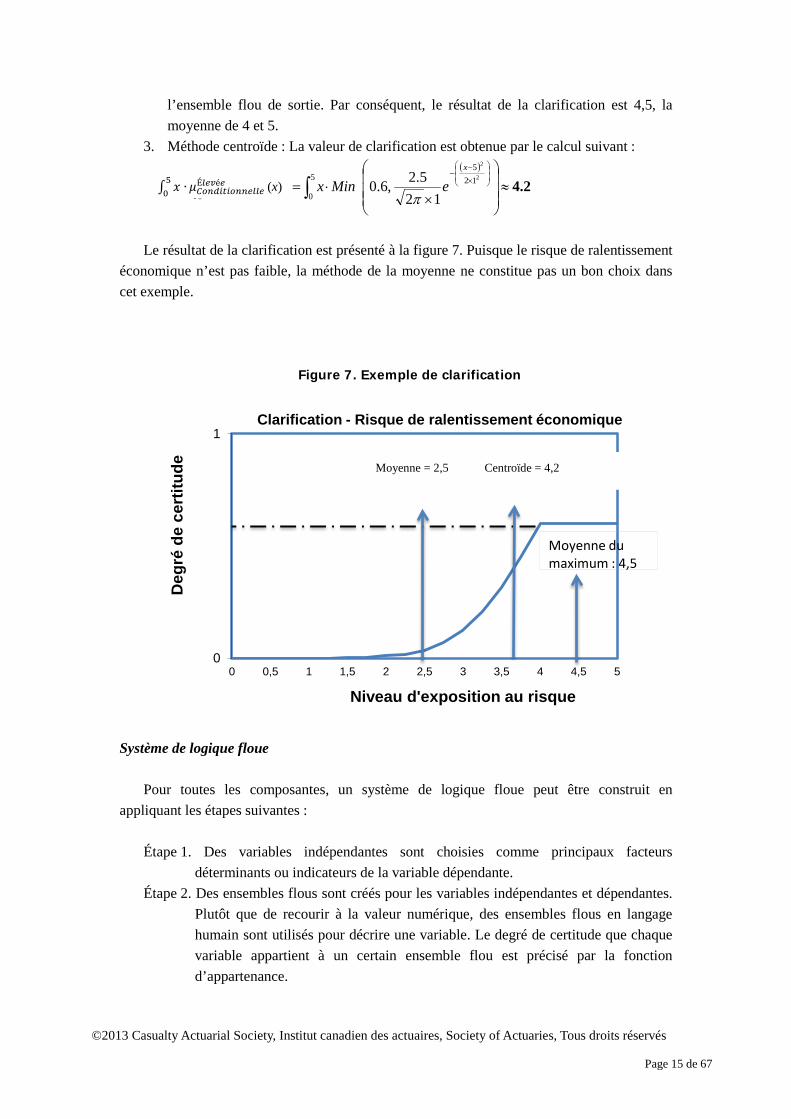
1. Méthode de la moyenne : La fourchette du niveau d’exposition au risque dans l’ensemble flou de sortie est [0,5]. Par conséquent, le résultat de la clarification est 2,5, la moyenne de 0 et 5.
2. Méthode de la moyenne du maximum : Lorsque x est supérieur à 4, la valeur de la fonction d’appartenance conditionnelle est 0,6, le degré maximal de certitude dans
( )
scorecredit theis x where541
4012
5.2
)(
2
2
124
≤<
≤≤×
=
×
−−
x
xe
x
x
Highπ
µ
( )
scorecredit theis x where55.31
5.3012
5.2
)(
2
2
125.3
≤<
≤≤×
=
×
−−
x
xe
x
x
Highπ
µ
( )
scorecredit theis x where50 12
5.2)(2
2
125
≤≤×
=
×
−−
xexx
High
πµ
( )
[ ] level exposurerisk theis 0,5 x where12
5.2,6.0)(2
2
125
∈
×=
×
−−
x
Highlconditiona eMinx
πµ
µÉlevée (x) =
µÉlevée (x) = où x est la cote de crédit
où x est la cote de crédit
où x est la cote de crédit µÉlevée (x) =
𝜇𝐶𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼 É𝐼𝐼𝑙é𝐼 (x) = Où x ∈ [0,5] est le niveau d’exposition au risque
©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 15 de 67
l’ensemble flou de sortie. Par conséquent, le résultat de la clarification est 4,5, la moyenne de 4 et 5.
3. Méthode centroïde : La valeur de clarification est obtenue par le calcul suivant :
Le résultat de la clarification est présenté à la figure 7. Puisque le risque de ralentissement
économique n’est pas faible, la méthode de la moyenne ne constitue pas un bon choix dans cet exemple.
Figure 7. Exemple de clarification
Système de logique floue Pour toutes les composantes, un système de logique floue peut être construit en
appliquant les étapes suivantes : Étape 1. Des variables indépendantes sont choisies comme principaux facteurs
déterminants ou indicateurs de la variable dépendante. Étape 2. Des ensembles flous sont créés pour les variables indépendantes et dépendantes.
Plutôt que de recourir à la valeur numérique, des ensembles flous en langage humain sont utilisés pour décrire une variable. Le degré de certitude que chaque variable appartient à un certain ensemble flou est précisé par la fonction d’appartenance.
( )
4.2≈
×⋅=⋅ ∫∫
×−
−5
0
125
5
0
2
2
125.2,6.0)(
x
Highlconditiona eMinxxx
πµ
0
1
0 0,5 1 1,5 2 2,5 3 3,5 4 4,5 5
Deg
ré d
e ce
rtitu
de
Niveau d'exposition au risque
Clarification - Risque de ralentissement économique
Moyenne du maximum : 4,5
∫ 𝑒 ∙50 𝜇𝐶𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼
É𝐼𝐼𝑙é𝐼 (x)
Moyenne = 2,5 Centroïde = 4,2

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 16 de 67
Étape 3. Des règles d’inférence sont intégrées au système. Une couverture floue peut être utilisée pour modifier légèrement la fonction d’appartenance selon la description des règles d’inférence.
Étape 4. L’ensemble flou de sortie de la variable dépendante est produit à partir des variables indépendantes et des règles d’inférence. Après clarification, une valeur numérique peut être utilisée pour représenter l’ensemble flou de sortie.
Étape 5. Le résultat est ensuite utilisé pour la prise de décisions éclairées.

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 17 de 67
Figure 8. Système de logique floue
2.2 Exemple numérique
Un système de logique floue simple7 utilisé pour évaluer le risque d’inconduite des conseillers est illustré dans cette section. Attirés par des commissions de vente élevées, les conseillers financiers peuvent être tentés de dissimuler de l’information au sujet des risques liés au produit, de fournir de l’information fausse ou même d’annoncer le produit de façon trompeuse. Trois principaux indicateurs de risques sont utilisés pour surveiller cette importante composante du risque d’atteinte à la réputation de l’entreprise :
1. Le coût de règlement au cours de la dernière année en raison de publicité fausse ou trompeuse
2. La complexité du produit, qui mesure le degré de difficulté des clients ou des conseillers à comprendre le produit vendu
3. Le niveau de rémunération des conseillers Des graphiques sur leurs fonctions d’appartenance sont reproduits ci-après.
7 Un fichier d’accompagnement (« Fuzzy Logic Examples.xls »), illustre le processus de calcul et ses
détails. Il peut être utilisé pour certains calculs de la logique floue simple.
Clarification
Opération d'ensemble flouCouvertures d'ensemble flou
Clarification
Variables indépendantes (valeur
Variables indépendantes
Règles d'inférence
Variable dépendante (Description
Prise de décisions Variable dépendante (valeur numérique)
Variables indépendantes
(valeur numérique)
Variables indépendantes
(description linguistique)
Variable dépendante
(description linguistique)
©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 18 de 67
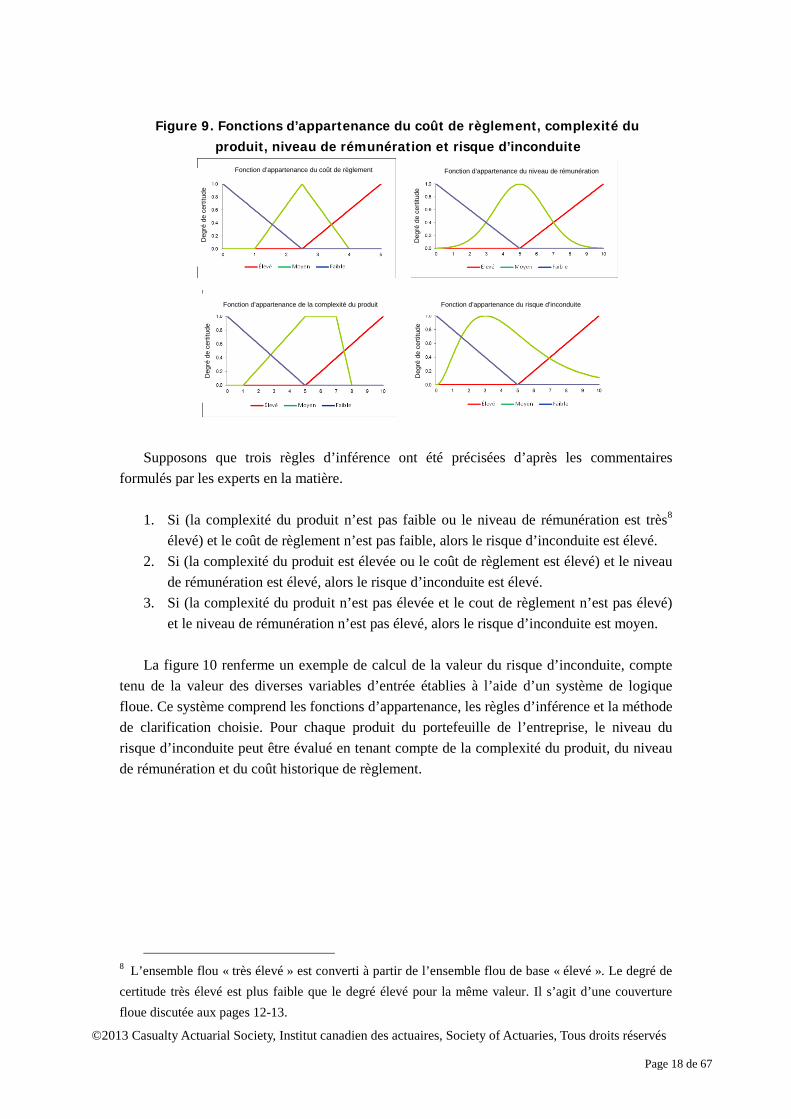
Figure 9. Fonctions d’appartenance du coût de règlement, complexité du
produit, niveau de rémunération et risque d’inconduite
Supposons que trois règles d’inférence ont été précisées d’après les commentaires
formulés par les experts en la matière. 1. Si (la complexité du produit n’est pas faible ou le niveau de rémunération est très8
élevé) et le coût de règlement n’est pas faible, alors le risque d’inconduite est élevé. 2. Si (la complexité du produit est élevée ou le coût de règlement est élevé) et le niveau
de rémunération est élevé, alors le risque d’inconduite est élevé. 3. Si (la complexité du produit n’est pas élevée et le cout de règlement n’est pas élevé)
et le niveau de rémunération n’est pas élevé, alors le risque d’inconduite est moyen. La figure 10 renferme un exemple de calcul de la valeur du risque d’inconduite, compte
tenu de la valeur des diverses variables d’entrée établies à l’aide d’un système de logique floue. Ce système comprend les fonctions d’appartenance, les règles d’inférence et la méthode de clarification choisie. Pour chaque produit du portefeuille de l’entreprise, le niveau du risque d’inconduite peut être évalué en tenant compte de la complexité du produit, du niveau de rémunération et du coût historique de règlement.
8 L’ensemble flou « très élevé » est converti à partir de l’ensemble flou de base « élevé ». Le degré de certitude très élevé est plus faible que le degré élevé pour la même valeur. Il s’agit d’une couverture floue discutée aux pages 12-13.
Deg
ré d
e ce
rtitu
de
Deg
ré d
e ce
rtitu
de
Deg
ré d
e ce
rtitu
de
Deg
ré d
e ce
rtitu
de
Fonction d’appartenance du coût de règlement Fonction d’appartenance du niveau de rémunération
Fonction d’appartenance de la complexité du produit Fonction d’appartenance du risque d’inconduite
©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 19 de 67
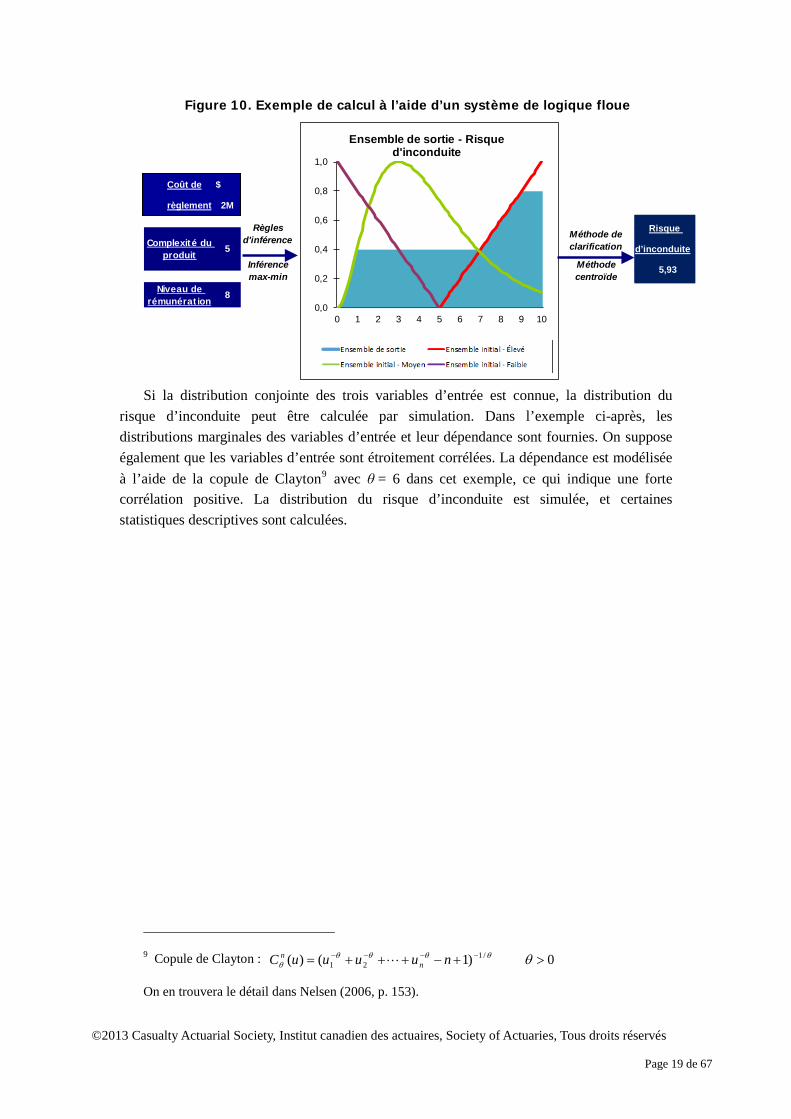
Figure 10. Exemple de calcul à l’aide d’un système de logique floue
Si la distribution conjointe des trois variables d’entrée est connue, la distribution du
risque d’inconduite peut être calculée par simulation. Dans l’exemple ci-après, les distributions marginales des variables d’entrée et leur dépendance sont fournies. On suppose également que les variables d’entrée sont étroitement corrélées. La dépendance est modélisée à l’aide de la copule de Clayton9 avec θ = 6 dans cet exemple, ce qui indique une forte corrélation positive. La distribution du risque d’inconduite est simulée, et certaines statistiques descriptives sont calculées.
9 Copule de Clayton :
On en trouvera le détail dans Nelsen (2006, p. 153).
Méthode de clarification
Inférence Méthodemax-min centroïde 5,93
Niveau de rémunération
8
Colût de règlement
2M $
Règles d'inférence
Risque d'inconduit
eComplexité du
produit5
0,0
0,2
0,4
0,6
0,8
1,0
0 1 2 3 4 5 6 7 8 9 10
Ensemble de sortie - Risque d'inconduite
Output Set Original Set - High
Original Set - Medium Original Set - Low
0)1()( /121 >+−+⋅⋅⋅++= −−−− θθθθθ
θ nuuuuC nn
Risque
d’inconduite
5,93
Coût de $
règlement 2M
©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 20 de 67
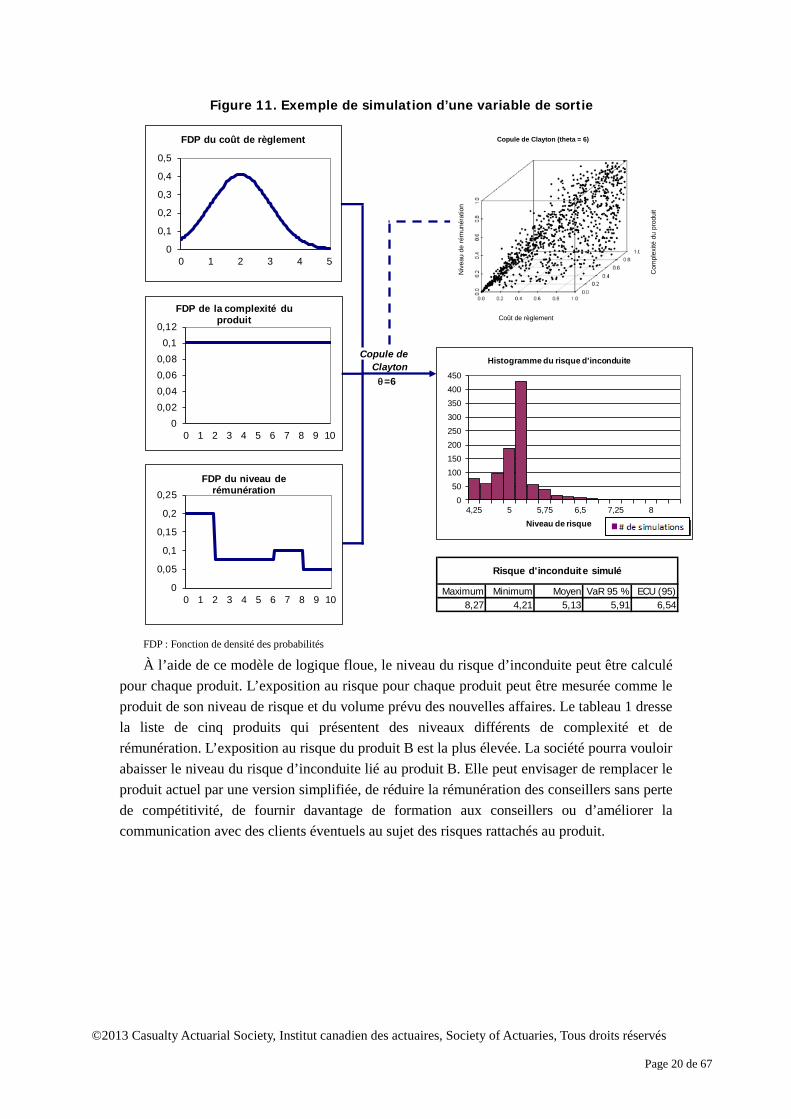
Figure 11. Exemple de simulation d’une variable de sortie
FDP : Fonction de densité des probabilités
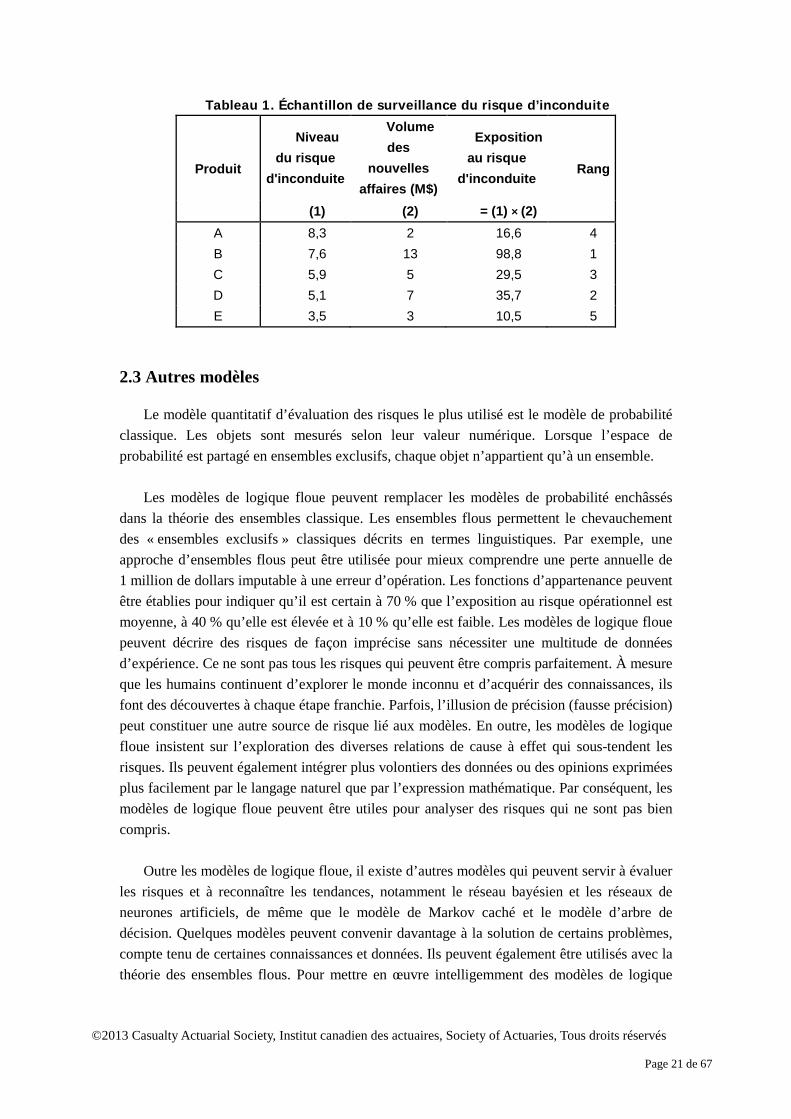
À l’aide de ce modèle de logique floue, le niveau du risque d’inconduite peut être calculé pour chaque produit. L’exposition au risque pour chaque produit peut être mesurée comme le produit de son niveau de risque et du volume prévu des nouvelles affaires. Le tableau 1 dresse la liste de cinq produits qui présentent des niveaux différents de complexité et de rémunération. L’exposition au risque du produit B est la plus élevée. La société pourra vouloir abaisser le niveau du risque d’inconduite lié au produit B. Elle peut envisager de remplacer le produit actuel par une version simplifiée, de réduire la rémunération des conseillers sans perte de compétitivité, de fournir davantage de formation aux conseillers ou d’améliorer la communication avec des clients éventuels au sujet des risques rattachés au produit.
Copule deClayton
θ=6
Maximum Minimum Moyen VaR 95 % ECU (95)8,27 4,21 5,13 5,91 6,54
Risque d'inconduite simulé
0
0,1
0,2
0,3
0,4
0,5
0 1 2 3 4 5
FDP du coût de règlement
00,020,040,060,08
0,10,12
0 1 2 3 4 5 6 7 8 9 10
FDP de la complexité du produit
0
0,05
0,1
0,15
0,2
0,25
0 1 2 3 4 5 6 7 8 9 10
FDP du niveau de rémunération
050
100150200250300350400450
4,25 5 5,75 6,5 7,25 8Niveau de risque
Histogramme du risque d'inconduite
# of Simulation
Copule de Clayton (theta = 6)
Niv
eau
de ré
mun
érat
ion
Com
plex
ité d
u pr
odui
t
Coût de règlement
©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 21 de 67
Tableau 1. Échantillon de surveillance du risque d’inconduite
Produit
Niveau du risque
d'inconduite
Volume des
nouvelles affaires (M$)
Exposition au risque
d'inconduite Rang
(1) (2) = (1) × (2) A 8,3 2 16,6 4 B 7,6 13 98,8 1 C 5,9 5 29,5 3 D 5,1 7 35,7 2 E 3,5 3 10,5 5
2.3 Autres modèles
Le modèle quantitatif d’évaluation des risques le plus utilisé est le modèle de probabilité classique. Les objets sont mesurés selon leur valeur numérique. Lorsque l’espace de probabilité est partagé en ensembles exclusifs, chaque objet n’appartient qu’à un ensemble.
Les modèles de logique floue peuvent remplacer les modèles de probabilité enchâssés
dans la théorie des ensembles classique. Les ensembles flous permettent le chevauchement des « ensembles exclusifs » classiques décrits en termes linguistiques. Par exemple, une approche d’ensembles flous peut être utilisée pour mieux comprendre une perte annuelle de 1 million de dollars imputable à une erreur d’opération. Les fonctions d’appartenance peuvent être établies pour indiquer qu’il est certain à 70 % que l’exposition au risque opérationnel est moyenne, à 40 % qu’elle est élevée et à 10 % qu’elle est faible. Les modèles de logique floue peuvent décrire des risques de façon imprécise sans nécessiter une multitude de données d’expérience. Ce ne sont pas tous les risques qui peuvent être compris parfaitement. À mesure que les humains continuent d’explorer le monde inconnu et d’acquérir des connaissances, ils font des découvertes à chaque étape franchie. Parfois, l’illusion de précision (fausse précision) peut constituer une autre source de risque lié aux modèles. En outre, les modèles de logique floue insistent sur l’exploration des diverses relations de cause à effet qui sous-tendent les risques. Ils peuvent également intégrer plus volontiers des données ou des opinions exprimées plus facilement par le langage naturel que par l’expression mathématique. Par conséquent, les modèles de logique floue peuvent être utiles pour analyser des risques qui ne sont pas bien compris.
Outre les modèles de logique floue, il existe d’autres modèles qui peuvent servir à évaluer
les risques et à reconnaître les tendances, notamment le réseau bayésien et les réseaux de neurones artificiels, de même que le modèle de Markov caché et le modèle d’arbre de décision. Quelques modèles peuvent convenir davantage à la solution de certains problèmes, compte tenu de certaines connaissances et données. Ils peuvent également être utilisés avec la théorie des ensembles flous. Pour mettre en œuvre intelligemment des modèles de logique

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 22 de 67
floue, il est important de bien comprendre d’autres options offertes et de ne s’en servir que lorsqu’ils sont pertinents.
Le réseau bayésien
Le réseau bayésien, également connu sous l’appellation « réseau de croyance bayésien »,
est un graphe acyclique dirigé qui est composé de sommets, d’arêtes et d’une distribution de probabilité conditionnelle. Reprenons l’exemple du risque d’inconduite que nous avons utilisé précédemment et appliquons-le à un réseau bayésien. Comme le montre la figure 12, ce réseau comporte cinq sommets (ou variables) désignés par les lettres A à E et cinq arêtes (dépendances conditionnelles) identifiées par les chiffres 1 à 5. La distribution de chaque variable est également indiquée, de façon conditionnelle ou inconditionnelle.
Figure 12. Exemple de réseau bayésien : risque d’inconduite
Les modèles de réseau bayésien utilisent les règles de Bayes et la probabilité
conditionnelle pour décrire la probabilité conjointe du réseau. La relation est enchâssée dans le système comme dépendante conditionnelle des parents et indépendante conditionnelle des non-défunts, compte tenu de la valeur des parents. Par conséquent, elle tient compte de la distribution des variables et de leur dépendance. Les modèles de réseau bayésien peuvent être utilisés pour calculer les probabilités conditionnelles, notamment la probabilité de publicité trompeuse si le produit n’est pas complexe et que le coût de la pénalité est élevé.
Compte tenu du nombre de relations et de probabilités conditionnelles qui doivent être
précisées dans un réseau bayésien, la production d’un tel modèle peut toutefois être très fastidieuse. L’inférence dans un gros réseau est également coûteuse. Il est nécessaire de posséder l’expertise au sujet des relations de cause à effet pour bâtir le système, qu’elle soit obtenue au moyen du raisonnement humain ou de données. Aussi, il existe une demande pour
Complexité du
Coût des pénalités
Mauvaise compréhension
Niveau de
Publicité
A
B D
E
1
34 5
2
P (Complexe) = 0,3
P (Élevé|Complexe) = 0,8P (Faible|Complexe) = 0,2
P (Élevé) = 0,5
P (Élevé|Complexe) = 0,65P (Faible|Complexe) = 0,35 P (Élevé|Élevé B & Élevé
C et Élevé D) = 0,95P (Faible|Élevé B et Élevé
C et Élevé D) = 0,05... ...
C
Produit
Niveau de
rémunération

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 23 de 67
des données précisant la probabilité conditionnelle. Toutes ces facettes font en sorte que le modèle de réseau bayésien convient bien aux problèmes de moindre envergure, pour lesquels nous possédons une connaissance suffisante des relations.
Par ailleurs, les systèmes à logique floue ne sont que légèrement contraints par la taille du
système. Ils permettent également le recours à un ensemble incomplet de règles ou de relations précisées dans le système d’inférence. Ainsi, le modèle de logique floue se prête davantage à l’analyse d’enjeux avec insuffisance de connaissances.
Certains efforts ont été déployés pour intégrer la théorie des ensembles flous et la logique
floue dans des modèles de réseau bayésien pour que les variables puissent disposer de valeurs discrètes et continues. Les ensembles flous ont été mis à l’essai pour améliorer le système d’inférence dans le réseau bayésien général. Ces réseaux bayésiens étendus sont habituellement désignés réseaux bayésiens flous10. Mais l’intégration d’ensembles flous aux réseaux bayésiens ne réduit pas nécessairement le besoin : a) de connaissances au sujet des relations de cause à effet et b) de données pour l’étalonnage de la probabilité conditionnelle.
Les réseaux de neurones artificiels
Les modèles fondés sur des réseaux de neurones artificiels sont utilisés pour apprendre la
relation entre les variables d’une manière semblable aux réseaux de neurones biologiques. Le réseau compte de nombreux neurones qui sont reliés de certaines façons, comme l’indique la figure 13. Il peut exister de multiples couches cachées entre l’ensemble d’entrée et l’ensemble de sortie. Il est nécessaire de posséder suffisamment de données de formation pour préciser la relation représentée par les fonctions f, g et h à l’aide de méthodes telles l’estimation du maximum de vraisemblance, du maximum a posteriori ou de la rétropropagation. Les modèles de réseaux de neurones artificiels peuvent être utilisés dans de nombreux domaines, notamment la reconnaissance, la prédiction et la classification des tendances. Parmi les applications possibles, mentionnons la détection des sinistres frauduleux en assurance automobile. Les renseignements d’entrée peuvent comprendre le sexe, la profession, le module voiture, le salaire, l’endroit, le montant des sinistres, les antécédents en matière de sinistres, par exemple la fréquence et la gravité, et la cause d’accident. Les données de sortie peuvent correspondre à la probabilité de fraude en assurance et le coût estimatif des enquêtes. D’après les données d’expérience au sujet de la fraude en assurance automobile, le réseau de neurones artificiels peut être formé pour déterminer une relation raisonnable entre l’entrée et la sortie à travers les couches cachées. Il peut ensuite être utile pour déterminer les sinistres susceptibles d’être faux et de préciser le coût prévu rattaché à l’enquête qui en découlera. La société pourra vouloir affecter les ressources aux sinistres les plus douteux présentant un coût d’enquête abordable.
10 On trouvera des exemples de réseaux bayésiens flous dans Pan (1988, pp. 6–22).

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 24 de 67
Figure 13. Exemple de réseau de neurones artificiels
Les modèles de réseau de neurones artificiels reposent sur de vastes ensembles de
données de formation pour produire une bonne estimation de la relation. Le calcul nécessaire exige bien des ressources. Il convient davantage aux systèmes complexes comportant suffisamment de données d’observation, mais des relations vagues ou inconnues. Ce modèle est très différent des systèmes de logique floue, à l’intérieur desquels des données dispersées ou imprécises sont souvent la norme, mais qui comportent certaines relations connues entre l’entrée et la sortie.
Les modèles de réseau de neurones ont été utilisés dans quelques systèmes de logique
floue, dont les règles d’inférence sont exprimées dans une certaine forme de fonctions utilisées dans les modèles de réseau de neurones artificiels, notamment Sortie = f (Entrée). Jang (1993) a lancé le système d’inférence neuro-floue adaptatif (ANFIS), dans lequel des réseaux de neurones sont utilisés pour modéliser et améliorer les fonctions d’appartenance d’ensembles flous. Le système ANFIS peut être utile lorsqu’il existe certaines données de formation pour le système de logique floue. Les règles d’inférence ou les fonctions d’appartenance peuvent être structurées de manière à mieux correspondre à l’expérience.
X1
...
X3
X2
a1
a2
a3
a4
b1
b2
bn-1
bn
Y1
Y1
Input OutputLayers
X1
...
X3
X2
a1
a2
a3
a4
b1
b2
bn-1
bn
Y1
Input OutputLayers
X1
...
X3
X2
a1
a2
a3
a4
b1
b2
bn-1
bn
Y2
Input OutputLayersInput OutputLayers
X1
...
X3
X2
a1
a2
a3
a4
b1
b2
bn-1
bn
Entrée SortieCouches cachées
ai=f(x1,x2,x3) bi=g(a1,...,a4) Yi=h(b1,...,bn)
©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 25 de 67
Cependant, ce système est plus compliqué et difficile à mettre en œuvre qu’un système pur de logique floue.
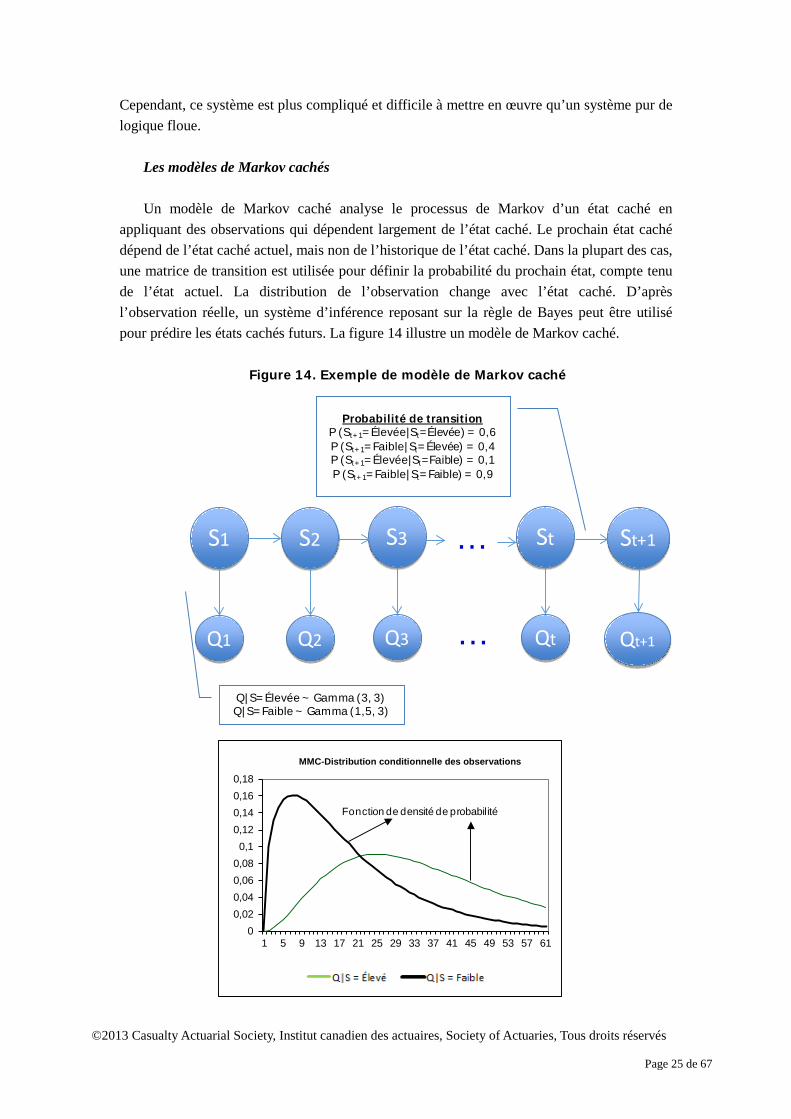
Les modèles de Markov cachés Un modèle de Markov caché analyse le processus de Markov d’un état caché en
appliquant des observations qui dépendent largement de l’état caché. Le prochain état caché dépend de l’état caché actuel, mais non de l’historique de l’état caché. Dans la plupart des cas, une matrice de transition est utilisée pour définir la probabilité du prochain état, compte tenu de l’état actuel. La distribution de l’observation change avec l’état caché. D’après l’observation réelle, un système d’inférence reposant sur la règle de Bayes peut être utilisé pour prédire les états cachés futurs. La figure 14 illustre un modèle de Markov caché.
Figure 14. Exemple de modèle de Markov caché
00,020,040,060,080,1
0,120,140,160,18
1 5 9 13 17 21 25 29 33 37 41 45 49 53 57 61
HMM - Conditional Distribution of Observation
Q|S=High Q|S=Low
Fonction de densité de probabilité
S1
Q1
Probabilité de transition P (St+1=Élevée|St=Élevée) = 0,6P (St+1=Faible|St=Élevée) = 0,4P (St+1=Élevée|St=Faible) = 0,1P (St+1=Faible|St=Faible) = 0,9
Q|S=Élevée ~ Gamma (3, 3)Q|S=Faible ~ Gamma (1,5, 3)
St
Qt
S2
Q2
S3
Q3
St+1
Qt+1...
...
MMC-Distribution conditionnelle des observations

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 26 de 67
Notes :
S : État caché. Il a deux valeurs, élevé et faible. La probabilité de transition est également exprimée.
Par exemple, si l’état actuel est faible, la possibilité de valeur élevée la prochaine fois est de 10 %.
Q : Observation. Un certain état a une distribution conditionnelle. Par exemple, si l’état est faible, la
sortie suit une distribution gamma avec les paramètres α=1,5 et β=3.
Par exemple, lorsque l’on prédit les dommages causés par un tremblement de terre, on
suppose que S est l’état du mouvement de la croûte terrestre; cette valeur présente une fréquence élevée ou une fréquence faible. Q représente le nombre de catastrophes naturelles, comme un tremblement de terre survenu au cours de l’année. Les données historiques sont utilisées pour établir une estimation de la probabilité de transition de S et la distribution conditionnelle de Q. Le gestionnaire des risques peut utiliser ce modèle de Markov caché pour établir une estimation de la probabilité de l’état caché futur, compte tenu de l’observation actuelle, notamment P(St+1 = Fréquence élevée| Qt=30). Si la probabilité d’un état de fréquence élevé est élevée, la société peut envisager de hausser la tarification de ses produits d’assurance ou d’accroître son capital pour survivre à des pertes plus graves en raison de catastrophes naturelles.
À l’instar de réseaux bayésiens, les modèles de Markov cachés ont besoin de données de
formation pour fixer la probabilité de transition pertinente et la distribution conditionnelle de l’observation fondée sur un certain état caché. Ces modèles soulignent également le caractère aléatoire de la transition d’un état à l’autre. Dans la réalité, ce type de transition peut être déterministe compte tenu des facteurs exogènes. Mais ces facteurs peuvent être négligés dans les modèles de Markov cachés en raison de leur complexité ou de l’incompréhension des relations de cause à effet qui favorisent la transition d’un état caché au suivant.
Contrairement aux modèles de logique floue, les modèles de Markov cachés exigent la
spécification de la relation entre les observations et l’état caché à l’aide de la probabilité conditionnelle plutôt que de règles d’inférence peut-être incomplètes. Ils insistent sur la prédiction des états futurs de façon formée mais incertaine. Ils conviennent davantage à la modélisation d’un système fondé sur une connaissance suffisante de la situation actuelle mais dont l’évolution est incertaine.
La théorie des ensembles flous a également été utilisée dans les modèles de Markov
cachés. La possibilité de l’état caché peut être décrite par des ensembles flous plutôt que des ensembles classiques11, sauf que les modèles flous de Markov cachés comportent les mêmes caractéristiques que les modèles de Markov cachés fondés sur la théorie des ensembles classiques.
11 Un exemple de modèle flou de Markov caché est donné par Zhang et Naghdy (2005, pp. 3–8).

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 27 de 67
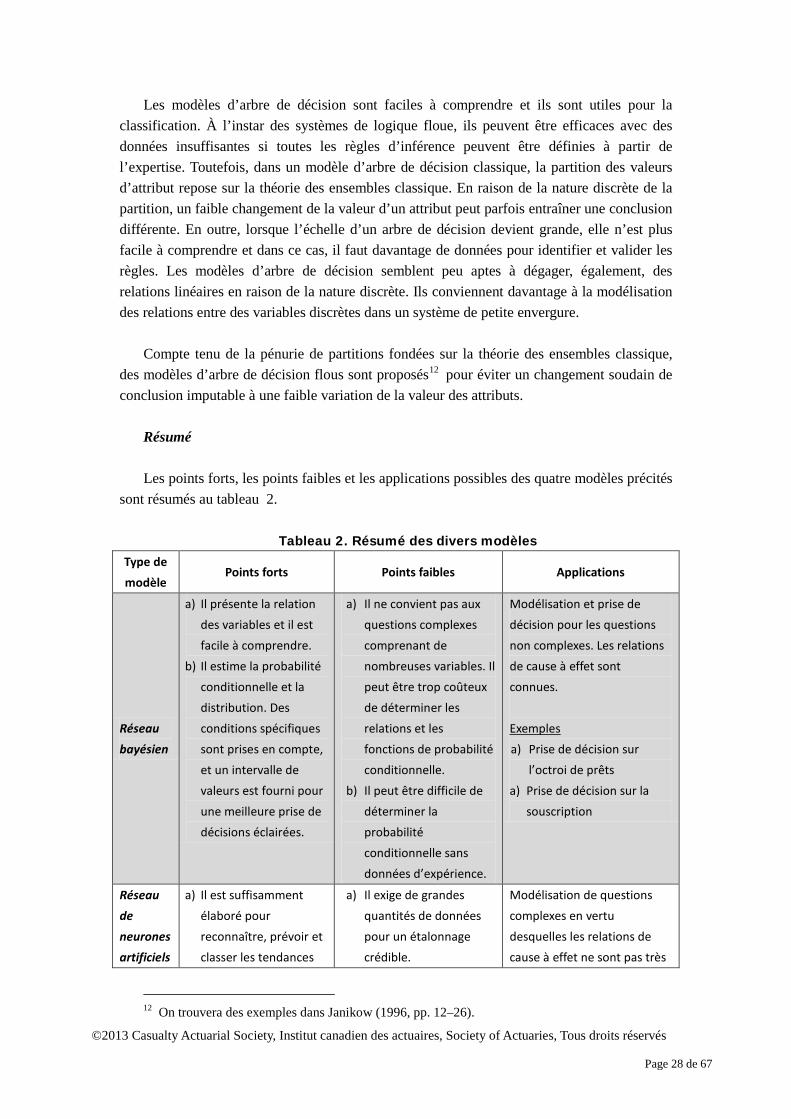
L’arbre de décision Un modèle d’arbre de décision est utilisé pour faciliter la prise de décisions à partir d’un
ensemble de règles présentées sous forme d’arbre. Il utilise les attributs des objets aux fins de classification et de décision. Par exemple, on peut construire un arbre qui permet de classifier le risque de crédit d’après le revenu, l’âge et d’autres facteurs. Contrairement à la plupart des techniques de modélisation de type boîte noire, en vertu desquelles la logique interne peut être difficile à établir, le processus de raisonnement qui sous-tend le modèle est clairement indiqué dans l’arbre. La figure 15 décrit un arbre de décision servant à classifier les clients d’une banque selon le niveau du risque de crédit d’après leur revenu, leur niveau de scolarité et leur logement. Il peut facilement être converti en un ensemble de règles utilisées pour classer un client afin de prendre une décision d’emprunt. Voir un exemple ci-après.
Si (revenu ≥ 92,5) et (statut de logement = non) et (scolarité = élevée), alors (niveau de risque de crédit faible = prêt accordé).
Figure 15. Exemple d’arbre de décision
Pour établir un arbre de décision, les données sont réparties en ensembles de formation et
de validation. Les données de formation sont utilisées pour identifier les règles pertinentes et trouver la meilleure partition de certains attributs à l’aide de techniques tel le partitionnement récursif. Les données de validation sont utilisées pour valider l’arbre de décision et lui apporter les rajustements nécessaires. Par exemple, les règles inutiles peuvent être éliminées à partir des données de validation.
Revenu
<92,5 >=92,5
Risque élevéStatut de logement
Non Oui
Scolarité Risque faible
Élevée Faible
Risque faible Risque élevé
©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 28 de 67
Les modèles d’arbre de décision sont faciles à comprendre et ils sont utiles pour la classification. À l’instar des systèmes de logique floue, ils peuvent être efficaces avec des données insuffisantes si toutes les règles d’inférence peuvent être définies à partir de l’expertise. Toutefois, dans un modèle d’arbre de décision classique, la partition des valeurs d’attribut repose sur la théorie des ensembles classique. En raison de la nature discrète de la partition, un faible changement de la valeur d’un attribut peut parfois entraîner une conclusion différente. En outre, lorsque l’échelle d’un arbre de décision devient grande, elle n’est plus facile à comprendre et dans ce cas, il faut davantage de données pour identifier et valider les règles. Les modèles d’arbre de décision semblent peu aptes à dégager, également, des relations linéaires en raison de la nature discrète. Ils conviennent davantage à la modélisation des relations entre des variables discrètes dans un système de petite envergure.
Compte tenu de la pénurie de partitions fondées sur la théorie des ensembles classique,
des modèles d’arbre de décision flous sont proposés12 pour éviter un changement soudain de conclusion imputable à une faible variation de la valeur des attributs.
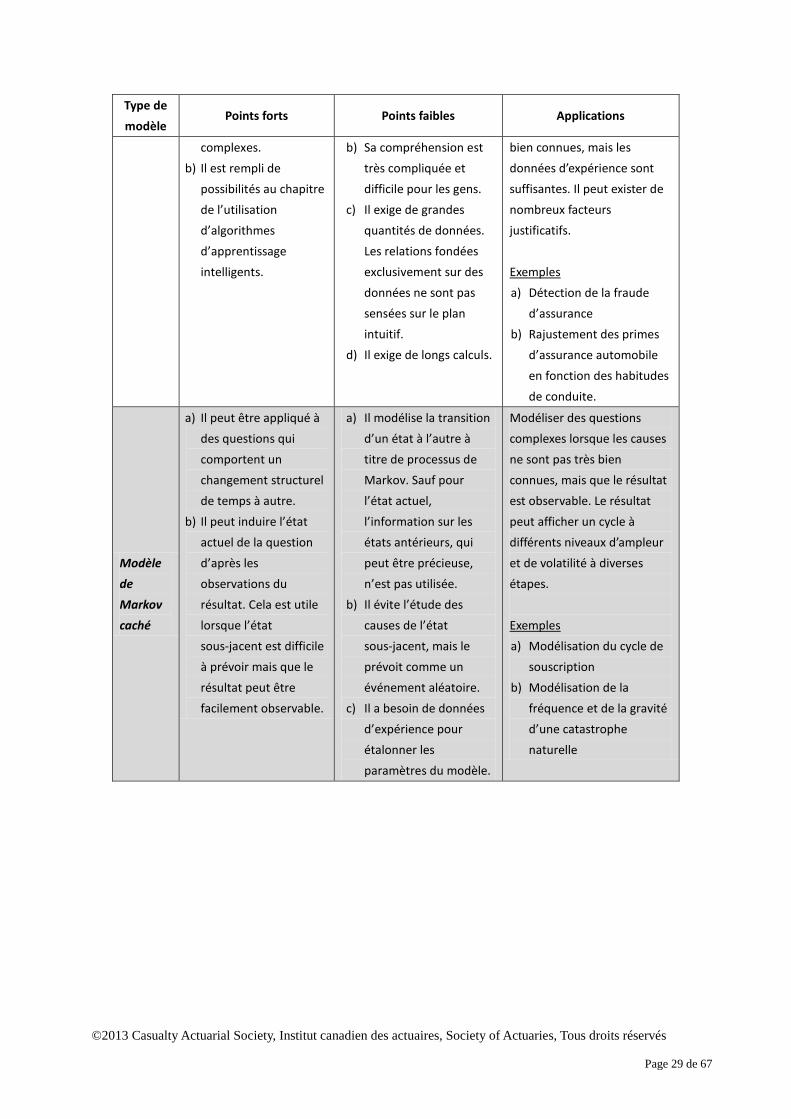
Résumé Les points forts, les points faibles et les applications possibles des quatre modèles précités
sont résumés au tableau 2.
Tableau 2. Résumé des divers modèles Type de modèle
Points forts Points faibles Applications
Réseau bayésien
a) Il présente la relation des variables et il est facile à comprendre.
b) Il estime la probabilité conditionnelle et la distribution. Des conditions spécifiques sont prises en compte, et un intervalle de valeurs est fourni pour une meilleure prise de décisions éclairées.
a) Il ne convient pas aux questions complexes comprenant de nombreuses variables. Il peut être trop coûteux de déterminer les relations et les fonctions de probabilité conditionnelle.
b) Il peut être difficile de déterminer la probabilité conditionnelle sans données d’expérience.
Modélisation et prise de décision pour les questions non complexes. Les relations de cause à effet sont connues.
Exemples a) Prise de décision sur
l’octroi de prêts a) Prise de décision sur la
souscription
Réseau de neurones artificiels
a) Il est suffisamment élaboré pour reconnaître, prévoir et classer les tendances
a) Il exige de grandes quantités de données pour un étalonnage crédible.
Modélisation de questions complexes en vertu desquelles les relations de cause à effet ne sont pas très
12 On trouvera des exemples dans Janikow (1996, pp. 12–26).
©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 29 de 67
Type de modèle
Points forts Points faibles Applications
complexes. b) Il est rempli de
possibilités au chapitre de l’utilisation d’algorithmes d’apprentissage intelligents.
b) Sa compréhension est très compliquée et difficile pour les gens.
c) Il exige de grandes quantités de données. Les relations fondées exclusivement sur des données ne sont pas sensées sur le plan intuitif.
d) Il exige de longs calculs.
bien connues, mais les données d’expérience sont suffisantes. Il peut exister de nombreux facteurs justificatifs. Exemples a) Détection de la fraude
d’assurance b) Rajustement des primes
d’assurance automobile en fonction des habitudes de conduite.
Modèle de Markov caché
a) Il peut être appliqué à des questions qui comportent un changement structurel de temps à autre.
b) Il peut induire l’état actuel de la question d’après les observations du résultat. Cela est utile lorsque l’état sous-jacent est difficile à prévoir mais que le résultat peut être facilement observable.
a) Il modélise la transition d’un état à l’autre à titre de processus de Markov. Sauf pour l’état actuel, l’information sur les états antérieurs, qui peut être précieuse, n’est pas utilisée.
b) Il évite l’étude des causes de l’état sous-jacent, mais le prévoit comme un événement aléatoire.
c) Il a besoin de données d’expérience pour étalonner les paramètres du modèle.
Modéliser des questions complexes lorsque les causes ne sont pas très bien connues, mais que le résultat est observable. Le résultat peut afficher un cycle à différents niveaux d’ampleur et de volatilité à diverses étapes. Exemples a) Modélisation du cycle de
souscription b) Modélisation de la
fréquence et de la gravité d’une catastrophe naturelle

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 30 de 67
Type de modèle
Points forts Points faibles Applications
Arbre de décision
a) Il est facile à comprendre.
b) Il traite efficacement les variables discrètes.
c) Il est simple pour la prise de décisions avec choix limités.
a) Il ne convient pas pour les questions complexes qui exigent de nombreux facteurs et relations.
b) Il a peine à dégager les relations linéaires en raison de sa nature discrète.
c) Il est conçu pour la prise de décisions mais non pour l’évaluation et la quantification des risques.
Prise de décision pour des questions non complexes. Les choix qui s’offrent aux décideurs sont limités et habituellement binaires (oui ou non). Les questions sont susceptibles de demeurer au niveau individuel.
Exemples b) Prise de décision sur
l’octroi de prêts c) Prise de décision sur la
souscription
3 Application de la théorie des ensembles flous et de la
logique floue : Analyse documentaire
Comme il a été question à la Section 2, la logique floue peut être exécutée en trois étapes principales, notamment la modification logique floue, l’inférence et/ou la clarification. Depuis le début de la contribution de Zadeh (1965) à ce nouveau domaine, le fonds documentaire à ce sujet est très riche : il embrasse la recherche universitaire et la mise en œuvre pratique dans presque chaque secteur, des sciences physiques jusqu’aux sciences sociales. L’analyse documentaire dans le présent rapport porte plus particulièrement sur les domaines liés—directement ou indirectement—à la gestion des risques. L’application est très diversifiée. Il peut s’agir de remplacer des ensembles classiques par des ensembles flous, de la mise en œuvre intégrale d’un système de logique floue ou d’un modèle hybride qui comprend un modèle de logique floue. L’objectif consiste à implanter une vaste gamme d’applications possibles de la logique floue et il ne se veut nullement exhaustif.
Gestion des risques
Pour prendre plus rapidement des décisions et réduire l’erreur humaine dans le processus
d’évaluation du crédit, les systèmes informatisés d’évaluation du risque de crédit jouent un rôle important. Lahsasna (2009) a construit et vérifié l’exactitude (pour permettre une évaluation correcte) et la transparence (pour comprendre le processus décisionnel) d’un modèle de notation du crédit à l’aide d’ensembles de données de l’Allemagne et de

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 31 de 67
l’Australie, et de deux types de modèle flou13. Les approches de modélisation proposées permettent à leurs utilisateurs d’exécuter une analyse approfondie, notamment définir les attributs des clients qui influencent la décision de souscription du crédit et quantifier les valeurs approximatives de ces attributs.
Constatant que les données déclarées dans les états financiers ne sont pas exactement
comparables en raison de différences au chapitre des pratiques comptables et qu’elles peuvent renfermer des inexactitudes au plan des nombres déclarés, Cheng et coll. (2006) ont soutenu que la valeur observée serait mieux prise en compte à titre de phénomène flou, mais non aléatoire. Ils ont donc utilisé un intervalle plutôt qu’une valeur unique aux fins des variables financières. Ils ont construit un modèle de pré-alerte pour difficultés financières à l’aide de la régression floue pour remplacer des méthodes bien connues, notamment l’analyse des discriminants, l’analyse logit et l’analyse des réseaux de neurones artificiels.
Matsatsinis et coll. (2003) ont constaté que les dépendances analytiques entre les
variables d’un processus ou d’un système sont souvent inconnues ou difficiles à établir. Ils ont donc utilisé des règles floues pour formuler les dépendances entre les variables dans le contexte de l’analyse de la classification appliquée à un modèle de faillite d’entreprise. Ils ont utilisé ces règles à la phase d’exploration des données afin de prédire la faillite de sociétés.
S’appuyant sur les conclusions relatives aux problèmes de classification touchant
l’analyse du risque financier et du risque de crédit, Li et coll. (2011) ont utilisé une méthode de classification de programmation linéaire floue dont les contraintes avaient été assouplies pour analyser le comportement des détenteurs de carte de crédit.
Cherubini et Lunga (2001) ont constaté, lors de l’établissement du coût des créances
éventuelles, que la mesure de probabilité utilisée n’est pas connue avec précision; ils ont donc utilisé une catégorie de mesures floues pour tenir compte de cette incertitude. Ils ont recouru à cette approche pour quantifier le risque de liquidité afin d’établir le coût d’un actif sur des marchés peu liquides, et ils ont par la suite appliqué cette démarche pour construire une version floue du modèle fondamental de risque de crédit de Merton.
Yu et coll. (2009) ont proposé un outil d’analyse des décisions fondé sur plusieurs critères
aux fins de l’évaluation du risque de crédit à partir de la théorie des ensembles flous. Cet outil est mis au point pour répartir initialement les résultats obtenus à partir d’autres techniques rivales d’évaluation du crédit prenant la forme d’opinions floues, puis ils les ont réunies pour obtenir un consensus et ils les ont clarifiées dans une valeur numérique discrète pour étayer une décision de crédit ultime. Le raisonnement humain, la connaissance d’un expert et l’information imprécise sont des éléments jugés valables pour l’estimation du risque opérationnel.
13 Les deux types sont Takagi-Sugeno (TS) et Mamdani. Pour plus de détails, consulter Hao et coll. (1998).

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 32 de 67
Reveiz et Leon (2009) ont étudié le risque opérationnel à l’aide du système d’inférence à logique floue (SILF) afin de tenir compte de l’interaction complexe et de l’absence de linéarité de ces éléments. Le choix du SILF permet d’utiliser des éléments qualitatifs et quantitatifs de manière saine et commode, et d’évaluer a priori les efforts d’atténuation des risques.
Gestion de l’actif-passif (GAP) et assurance
Brotons et Terceno (2011) ont utilisé la logique floue pour étudier les stratégies
d’immunisation visant à atténuer les mouvements du risque de taux d’intérêt dans un cadre de GAP où la combinaison du rendement attendu et du risque, choisie pour accroître la liquidité, est obtenue à partir du point milieu et de la largeur des nombres flous pertinents. Un tableau risque-rendement est créé à l’aide de cette approche pour tenir compte de l’aversion de l’investisseur pour le risque, ce qui permet à ce dernier de suivre l’écart de rendement de la stratégie adoptée pour un certain niveau de durée.
Huang et coll. (2009) ont étudié la probabilité de ruine ultime dans un cadre de risque
d’assurance en vertu duquel le montant d’un sinistre individuel est modélisé à titre de variable aléatoire floue distribuée de façon exponentielle et l’opération de règlement est caractérisée par un processus de Poisson.
Lai (2006) a effectué une étude empirique de la marge bénéficiaire de la souscription
d’une société d’assurance IARD de Taïwan, dans le cadre d’un modèle inter-temporel d’évaluation des actifs financiers (ICAPM)14. Il a constaté que les paramètres les plus pertinents des modèles peuvent être exprimés sous forme de nombre flou triangulaire asymétrique. Il a également indiqué de quelle façon les facteurs asymétriques obtenus pourraient être utilisés pour prévoir la marge bénéficiaire de souscription. Lai (2008) a élargi l’étude susmentionnée pour analyser le risque systématique découlant de la souscription de polices d’assurance pour les principaux modes de transport, à partir de l’assurance automobile jusqu’à l’assurance aviation.
De Andres Sanchez et Gomez (2003) ont appliqué des techniques de régression floues
pour analyser la structure des échéances des taux d’intérêt. Ils ont insisté sur la quantification des taux d’intérêt et ont étudié les applications à la tarification des contrats d’assurance-vie et des polices d’assurance IARD.
Lazzari et Moulia (2012) ont étudié certains paramètres qui décrivent le risque de maladie
cardiovasculaire en créant un modèle de diagnostic formulé dans un cadre flou, et ils ont proposé un cadre pour une stratégie d’expansion d’une société d’assurance-maladie.
Derrig et Ostaszewski (1996) ont étudié le fardeau fiscal d’une société d’assurance IARD
dans un cadre théorique où le passif d’assurance correctement évalué est utilisé comme
14 L’ICAPM est un modèle hybride en vertu duquel le modèle d’assurance algébrique est lié au CAPM pour tarifer les produits d’assurance.

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 33 de 67
instrument de couverture. Les paramètres pertinents ont été modélisés à l’aide de nombre flous pour tenir compte de l’incertitude du taux d’imposition, du taux de rendement et du passif de couverture.
Économie et finances
Horgby (1999) propose une introduction aux techniques d’inférence floue pour les
applications en économie. À l’aide d’une série d’exemples, il montre la façon d’assimiler l’information qui, de par sa nature, est floue, et d’induire des conclusions à partir d’un ensemble de règles floues de type « si-alors ». Caleiro (2003) a mené une étude intéressante dans laquelle il tente de déterminer de quelle façon des mesures subjectives comme la confiance des consommateurs peuvent se rapprocher de mesures économiques objectives comme le taux de chômage à l’aide de la logique floue. Blavatksyy (2011) a étudié l’aversion pour le risque lorsque les résultats ne sont pas mesurables en termes monétaires et que les gens affichent des préférences floues pour la loterie, c’est-à-dire une préférence pour la loterie exprimée de manière probabiliste.
Ng et coll. (2002) ont établi une fonction d’appartenance floue des critères de sélection
des acquisitions au moyen d’une étude empirique menée en Australie; dans cette étude, ils reconnaissaient que de nombreux critères de sélection— notamment la rapidité, la complexité, la souplesse, la responsabilité, le niveau de qualité, la répartition des risques et la concurrence des prix—sont de nature floue. Xu et coll. (2011) ont élargi cette approche en mettant au point un modèle pratique d’évaluation des risques pour les projets d’acquisition en partenariat public-privé, en vertu duquel les facteurs de risque sous-jacents sont établis à l’aide de la technique de sondage Delphi et de la théorie des ensembles flous. Le modèle d’évaluation des risques est élaboré à l’aide d’une approche d’évaluation synthétique floue.
Oliveira et Silva (2004) ont étudié la réglementation environnementale, lorsque le lien
imparfait entre la réglementation et les processus polluants sont modélisés à l’aide d’une approche logique floue. Pour faciliter la prise de décisions efficaces, l’étude vise à fournir une compréhension raisonnable de la complexité des interactions, ce qui peut entraîner une réglementation coûteuse, de la corruption et des excès de pollution, et un comportement de «recherche de rente» de la part du législateur, notamment l’attribution de privilèges de monopole.
Sun et van Kooten (2005) ont appliqué la logique floue à l’évaluation conditionnelle des
équipements environnementaux et biens publics à l’aide d’un cadre d’optimisation aléatoire floue des services publics (FRUM). À l’aide de données de la Suède, ils ont effectué une étude empirique pour mesurer l’empressement de résidents sollicités à payer pour des services améliorés de conservation des forêts.
Cai et coll. (2009) ont produit un modèle de programmation à intervalles aléatoires flous
(FRIP) pour dégager les stratégies optimales de planification des systèmes de gestion de l’énergie, compte tenu de nombreuses incertitudes causées par des facteurs économiques,

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 34 de 67
environnementaux et politiques. Ils ont construit leur modèle FRIP en intégrant la programmation linéaire à intervalle, la programmation stochastique floue et la programmation linéaire mixte en nombres entiers pour traiter les incertitudes présentées dans les intervalles de valeurs.
Tucha et Brem (2006) ont proposé une approche quantitative pour analyser les fonctions
et les modèles de risque des prix de transfert internationaux à l’aide du cadre flou. Dow et Ghosh (2004) ont étudié la demande spéculative d’argent à l’aide d’un cadre de logique floue. Ils y intègrent différentes opinions et reconnaissent que les attentes peuvent différer lorsque la nature du problème empêche une description précise et définitive des variables sous-jacentes.
Lin et coll. (2008) ont présenté un modèle hybride de prédiction de crise de monnaie en
recourant à l’approche de la modélisation neuro-floue. Ils intègrent la capacité d’apprentissage des réseaux de neurones au mécanisme d’inférence de la logique floue pour découvrir les relations de cause à effet entre les variables. Gulick (2010) a étudié le problème d’affectation à l’aide d’un cadre flou fondé sur la théorie des jeux. Gulick a analysé plusieurs applications, allant de décisions d’investissement coopératif jusqu’à l’affectation de capital de risque pour les banques et les sociétés d’assurances. Leon et Machado (2011) ont proposé un indice établi à l’aide d’un système d’inférence fondé sur la logique floue pour effectuer une évaluation relative générale de l’importance systématique d’une institution financière. L’indice proposé utilise certains indicateurs importants clés de la taille de l’institution, son interdépendance et sa substituabilité. Une expertise sert à combiner ces indicateurs.
Caetano et Caleiro (2005) ont étudié l’influence de la corruption sur les décisions
relatives à l’investissement étranger direct en appliquant une approche logique floue qui reconnaît qu’un certain niveau de corruption perçue peut être assujetti à des évaluations subjectives différentes effectuées par les investisseurs. Brochado et Martins (2005) ont étudié la variation des indicateurs politiques d’un bout à l’autre du pays et leur association au niveau des indicateurs de développement économique, humain et sexospécifique à l’aide d’un algorithme de classification floue des k moyennes. L’exercice avait pour but de mieux comprendre l’hétérogénéité des comportements en ce qui touche les indicateurs politiques. Sveshnikov et Bocharnikov (2009) ont élaboré un modèle pour étudier le risque politico-économique international lorsque des points de vue contradictoires et opposés des pays au sujet des décisions relatives aux enjeux politiques, économiques, internes et internationaux sont groupés à l’aide de mesures floues et d’intégrales. Ils ont effectué une étude empirique pour estimer le risque politico-économique en Ukraine.
Magni et coll. (2006) ont étudié une autre méthode d’évaluation ferme reposant sur la
logique floue et les systèmes experts. Dans cette étude, l’analyse des flux monétaires actualisés prévoyait des variables quantitatives et qualitatives, p.ex. les volets financiers, stratégiques et opérationnels, de même que leur intégration mutuelle au moyen de règles « si-alors » utilisées pour coter et classer les entreprises, et pour évaluer l’impact des décisions prises par les cadres au sujet de la création de valeur et la qualité de la gouvernance de la société. Smimou (2006) a effectué une étude empirique du marché à terme canadien sur

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 35 de 67
les produits de base à l’intérieur du modèle d’évaluation des actifs financiers (CAPM) à l’aide d’une méthode de régression floue. Smimou a fourni une analyse comparative pour démontrer la supériorité de l’application d’une approche floue pour saisir la prime de risque dans les contrats à terme sur produits de base sur d’autres approches rivales. Giovanis (2009) a étendu le cadre de régression floue pour l’appliquer à la modélisation autorégressive conditionnelle généralisée d’hétéroscédasticité (GARCH) et il a étudié l’effet du jour de la semaine sur quatre grandes bourses. Le but principal consistait à intégrer des non-linéarités dans les finances et le comportement humain, et éviter le recours à une classification binaire dans ce contexte. Su et Fen (2011) ont construit une stratégie de négociation à l’aide d’un système d’inférence floue contrôlable au plan des risques qui est bâti sur la modélisation d’équations structurelles, et ils ont confirmé sa supériorité sur la stratégie « acheter et conserver ».
Tarification des options
Muzzioli et Torricelli (2001) ont proposé un modèle binomial de tarification des options
(OPM) d’une période, fondé sur une technique d’évaluation à risque neutre. Ils ont intégré différents niveaux d’information sur le marché tout en modélisant le paiement des options au moyen de nombres flous triangulaires. Lee et coll. (2005) ont appliqué la théorie des ensembles flous au modèle de taux d’intérêt de Cox, Ross et Rubinstein (CRR) pour élaborer un OPM binomial flou qui permet aux investisseurs de mettre à jour leur stratégie de portefeuille d’après leurs préférences personnelles en matière de risque. Le modèle proposé prévoit des fourchettes raisonnables de prix d’option qui offrent aux investisseurs la possibilité de les utiliser aux fins d’arbitrage ou de couverture. Une étude empirique fondée sur des options de l’indice S&P 500 est également effectuée pour appuyer leurs résultats théoriques. Dans le contexte d’un modèle de valeur des options réelles, Zmeskal (2010) a observé que souvent, les données d’entrée requises ne sont pas de qualité; il a donc déterminé deux types d’incertitude liée aux données d’entrée : le risque et l’imprécision. Puisque le risque est de nature stochastique et que l’imprécision découle de la nature floue inhérente des intrants déclarés, l’auteur a proposé un modèle américain réel d’option flou-stochastique en vertu duquel les intrants sont utilisés sous forme de nombres flous et la valeur des options est déterminée à titre d’ensemble flou.
4 Cadre d’évaluation des risques fondé sur la logique floue
4.1 Évaluation des risques et prise de décisions
Une plateforme d’évaluation des risques et de prise de décisions construite à partir d’un système de logique floue peut garantir la cohérence aux fins de l’analyse des risques lorsque les données et les connaissances sont limitées. Elle permet de se concentrer sur le fondement de l’évaluation des risques, qui englobe la relation de cause à effet entre les principaux facteurs, de même que l’exposition à chaque risque individuel. Plutôt que de constituer un intrant direct de la probabilité et de la gravité éventuelle d’un événement de risque, elle encourage le raisonnement humain, à partir des faits et des connaissances jusqu’à la

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 36 de 67
conclusion et ce, d’une manière cohérente et bien documentée. Le graphique qui suit montre un échantillon du processus d’évaluation des risques fondé sur le système de logique floue. Il s’agit d’une structure ascendante qui repose sur chaque risque individuel. L’exposition au risque est ensuite agrégée au niveau de l’unité opérationnelle et de la société afin de dépister les principaux risques.

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 37 de 67
Figure 16. Structure hiérarchique de l’évaluation des risques
Pour garantir la comparabilité entre tous les types de risques, la même mesure doit être
adoptée pour évaluer l’exposition à chaque risque. L’une des mesures possibles est le montant estimatif des pertes dans le cadre d’événements extrêmes. Si la distribution de la perte peut être simulée à l’aide d’un modèle de logique floue, compte tenu de la distribution des variables indépendantes, la mesure pourrait se situer aux environs du 99,5e centile de la distribution de la perte (un événement en 200 ans). En utilisant le montant de la perte comme variable de sortie, il est possible de classer les risques selon le résultat de la clarification, une valeur numérique qui mesure le niveau de l’exposition au risque. L’opération s’apparente au classement fondé sur le degré de certitude que l’exposition au risque est élevée. La figure 17 illustre le classement des risques d’après le montant estimatif de perte dans le cadre d’événements extrêmes. Le montant des pertes peut être évalué à partir du résultat de la clarification à l’aide d’un modèle de logique floue. Ce modèle peut utiliser le montant des pertes comme variable de sortie. La valeur des variables d’entrée en vertu d’un événement extrême est insérée dans le modèle pour obtenir le montant estimatif des pertes pour un certain risque. Une autre méthode consiste à utiliser une simulation, comme l’indique la figure 11. La distribution du montant des pertes peut être simulée, et la valeur au centile désigné peut être utilisée pour représenter l’exposition au risque.
Exposition à chaque risque
Exposition à chaque risque
Exposition à chaque risque
Exposition à chaque risque
Exposition à chaque risque
Exposition à chaque risque
Total de la société
Principaux risques 1. 2. … 10.
Unité opérationnelle Unité opérationnelle Unité opérationnelle Unité opérationnellePrincipaux risques 1. 2. … 10.
Principaux risques 1. 2. … 10.
Principaux risques 1. 2. … 10.
Principaux risques 1. 2. … 10.
Modèles de logique floue (indicateurs de risque, fonctions d'appartenance et règles d'inférence)
Opinions d'expert
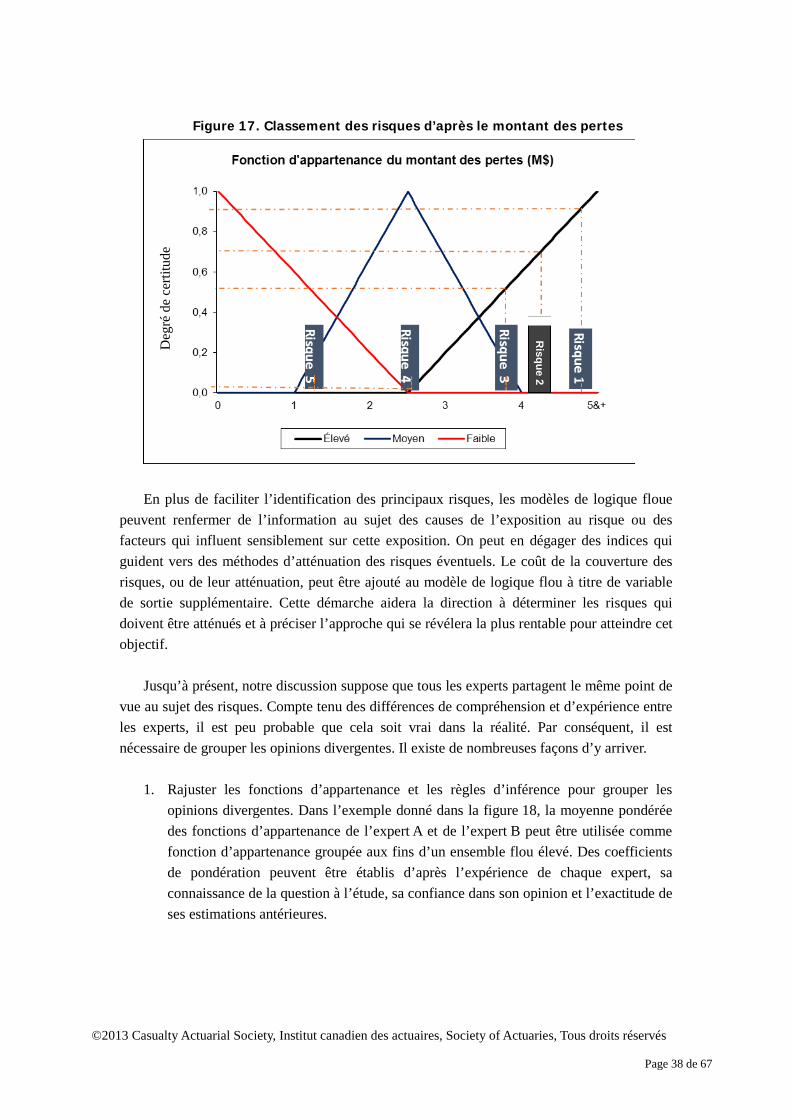
©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 38 de 67
Figure 17. Classement des risques d’après le montant des pertes
En plus de faciliter l’identification des principaux risques, les modèles de logique floue
peuvent renfermer de l’information au sujet des causes de l’exposition au risque ou des facteurs qui influent sensiblement sur cette exposition. On peut en dégager des indices qui guident vers des méthodes d’atténuation des risques éventuels. Le coût de la couverture des risques, ou de leur atténuation, peut être ajouté au modèle de logique flou à titre de variable de sortie supplémentaire. Cette démarche aidera la direction à déterminer les risques qui doivent être atténués et à préciser l’approche qui se révélera la plus rentable pour atteindre cet objectif.
Jusqu’à présent, notre discussion suppose que tous les experts partagent le même point de
vue au sujet des risques. Compte tenu des différences de compréhension et d’expérience entre les experts, il est peu probable que cela soit vrai dans la réalité. Par conséquent, il est nécessaire de grouper les opinions divergentes. Il existe de nombreuses façons d’y arriver.
1. Rajuster les fonctions d’appartenance et les règles d’inférence pour grouper les
opinions divergentes. Dans l’exemple donné dans la figure 18, la moyenne pondérée des fonctions d’appartenance de l’expert A et de l’expert B peut être utilisée comme fonction d’appartenance groupée aux fins d’un ensemble flou élevé. Des coefficients de pondération peuvent être établis d’après l’expérience de chaque expert, sa connaissance de la question à l’étude, sa confiance dans son opinion et l’exactitude de ses estimations antérieures.
Risque 2
Deg
ré d
e ce
rtitu
de
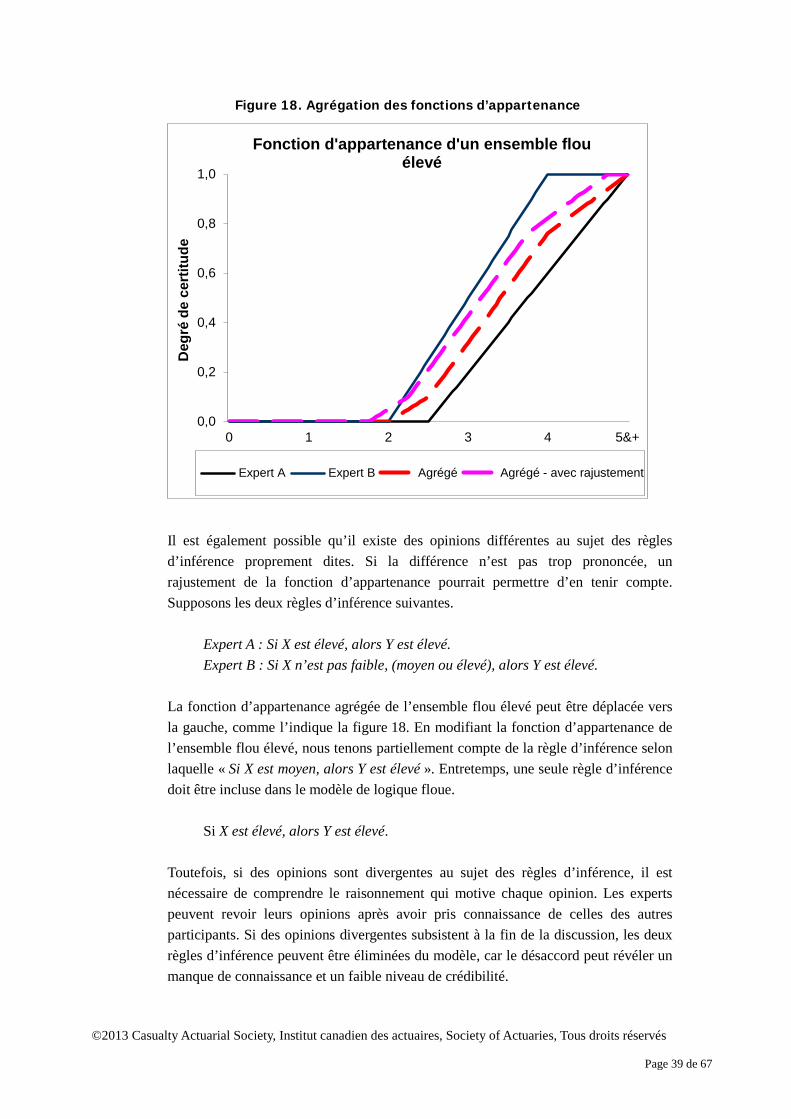
©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 39 de 67
Figure 18. Agrégation des fonctions d’appartenance
Il est également possible qu’il existe des opinions différentes au sujet des règles d’inférence proprement dites. Si la différence n’est pas trop prononcée, un rajustement de la fonction d’appartenance pourrait permettre d’en tenir compte. Supposons les deux règles d’inférence suivantes.
Expert A : Si X est élevé, alors Y est élevé. Expert B : Si X n’est pas faible, (moyen ou élevé), alors Y est élevé.
La fonction d’appartenance agrégée de l’ensemble flou élevé peut être déplacée vers la gauche, comme l’indique la figure 18. En modifiant la fonction d’appartenance de l’ensemble flou élevé, nous tenons partiellement compte de la règle d’inférence selon laquelle « Si X est moyen, alors Y est élevé ». Entretemps, une seule règle d’inférence doit être incluse dans le modèle de logique floue.
Si X est élevé, alors Y est élevé.
Toutefois, si des opinions sont divergentes au sujet des règles d’inférence, il est nécessaire de comprendre le raisonnement qui motive chaque opinion. Les experts peuvent revoir leurs opinions après avoir pris connaissance de celles des autres participants. Si des opinions divergentes subsistent à la fin de la discussion, les deux règles d’inférence peuvent être éliminées du modèle, car le désaccord peut révéler un manque de connaissance et un faible niveau de crédibilité.
0,0
0,2
0,4
0,6
0,8
1,0
0 1 2 3 4 5&+
Deg
ré d
e ce
rtitu
de
Fonction d'appartenance d'un ensemble flou élevé
Expert A Expert B Agrégé Agrégé - avec rajustement

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 40 de 67
2. Chaque expert peut posséder son propre modèle de logique floue comportant des fonctions d’appartenance et des règles d’inférence exclusives. Le résultat global de l’évaluation des risques correspond simplement à la moyenne pondérée des résultats produits par les différents modèles. Contrairement à la première approche, qui rajuste les intrants du modèle, la seconde rajuste les extrants du modèle en les fusionnant.
3. Un exemple précis de la seconde approche consiste à attribuer une pondération égale à toutes les opinions que l’on retrouve dans l’ensemble des documents sur les modèles de logique floue. Cette démarche est habituellement utilisée en présence d’un petit nombre d’experts, lorsque le but consiste à établir un classement d’après le niveau de risque. Par exemple, on compte n experts qui donnent leur point de vue sur le niveau de risque de A et B. Si plus de n/2 experts optent pour A comme l’élément le plus risqué, A sera réputé plus risqué que B. Cette démarche peut permettre de repérer les cas les plus risqués pour un risque individuel précis; mais elle ne se prête pas très bien à l’agrégation à l’échelle de l’unité opérationnelle et pour l’ensemble de la société.
4.2 Modèle du capital économique requis
La détermination du capital économique requis (CER) pour les risques à l’aide de données d’expérience insuffisantes pose un défi. En raison de l’insuffisance de données historiques pertinentes sur les pertes, et de la vaste portée ainsi que l’intervalle possible des pertes qui pourraient découler de ces risques, il est difficile de quantifier l’exposition à ces risques. Certaines sociétés ont recours à des modèles réglementaires ou à des modèles d’agences de notation du crédit. D’autres évaluent l’exposition en se reportant au CER de leurs pairs pour le risque opérationnel. Toutefois, ces méthodes représentent habituellement des approches factorielles de haut niveau, notamment x % du revenu/des primes, des gains, de l’actif ou du capital requis pour un autre type de risque. De tels facteurs ne parviennent pas toujours à tenir compte complètement de la différence au chapitre des pratiques réelles d’exposition au risque et de gestion des risques entre les diverses sociétés.
Même à défaut de données suffisantes sur les pertes aux fins de quantification, les
systèmes de logique floue peuvent faciliter l’évaluation du CER pour certains risques à l’aide d’une approche ascendante, en supposant une contribution suffisante de la part des experts en la matière. Comme l’indique la Section 2.2 Exemple numérique, la variable de sortie peut être simulée pour obtenir la distribution, la valeur à risque (VaR) et l’espérance conditionnelle unilatérale (ECU). Si la variable de sortie correspond à la perte annuelle liée au risque, le CER peut représenter, par exemple, le 99,5e centile15 de la distribution de la perte simulée moins la perte moyenne. Une autre façon consiste à établir la différence entre la perte estimative en vertu d’un événement extrême et la perte attendue. Le CER au niveau agrégé peut être évalué de deux façons.
15 Le 99,5e centile équivaut à un événement aux 200 ans. Le centile peut être choisi selon la propension de la société à prendre des risques.

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 41 de 67
1. Agréger le CER de chaque risque individuel à l’aide d’une matrice de corrélation, comme dans l’exemple de trois coefficients de risque ci-après.
( )
=
3
2
1
2313
2312
1312
321Total
11
1CER
CERCERCER
CERCERCERρρ
ρρρρ
Notations CERTotal : Capital économique requis agrégé CERi : Capital économique requis pour coefficient de risque i ρij: Coefficient de corrélation des coefficients de risque i et j
2. Produire des valeurs corrélées pour toutes les variables d’entrée et exécuter la simulation pour obtenir la distribution de la perte agrégée, puis le CER agrégé, comme il est indiqué ci-après.
Figure 19. CER agrégé à l’aide d’une simulation
Notations PIR : Principaux indicateurs de risque CERTotal : Capital économique requis agrégé CERi : Capital économique requis pour coefficient de risque i
Il n’est pas facile de déterminer la corrélation du CER pour chaque risque. Dans bien des
cas où le modèle de logique floue est utilisé, les données d’expérience sont insuffisantes. Il sera encore plus difficile d’établir la corrélation pertinente entre les différents risques, car
1er coeff. de risque 2e coeff. de risque 3e coeff. de risque
PIR(1) PIR(2) … … … … PIR(n)
Exposition au risque
agrégée
Exposition à chaque risque
Principaux indicateurs de risque
CER1CER2 CER3
CERTotal Simulation fondée sur des
systèmes de logique floue

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 42 de 67
cette tâche exige habituellement une série chronologique de données de panel aux fins d’étalonnage. En outre, la corrélation entre les CER pour différents risques n’est pas la même que celle des risques proprement dits. Une approche plus raisonnable au plan théorique consiste à intégrer la corrélation ou la dépendance à la base du système de logique floue, c’est-à-dire au niveau des variables d’entrée. La distribution des pertes à des niveaux différents peut être simulée, et le CER peut être calculé d’après cette distribution. C’est pourquoi la deuxième méthode convient davantage au calcul du CER dans un système de logique floue. Un exemple de calcul du CER et de son agrégation figure à la Section 6 Études de cas.
5 Considérations clés
Dans le cadre de l’application des systèmes de logique floue à l’évaluation des risques et à la prise de décisions, vous serez confrontés à nombre de questions et défis d’ordre pratique. Même si le système repose sur des bases théoriques solides, sa réussite dépend de nombreux facteurs, notamment la qualité des opinions formulées par les experts, sa crédibilité et ses liens avec les décisions de la direction. La présente section porte sur les principaux facteurs à prendre en compte pour l’élaboration et l’application d’un système pratique de logique floue.
5.1 Opinions d’experts : Collecte et analyse
Les opinions formulées par les experts en la matière ou les gestionnaires des opérations constituent la principale source d’information d’un système de logique floue. Il ne s’agit pas d’un effort ponctuel, mais plutôt d’un processus itératif. Un échantillon de ce processus est reproduit ci-après.
Étape 1. La demande d’opinions au sujet d’une question ou d’un risque est envoyée. Elle
peut comprendre des questions concernant les principaux facteurs qui peuvent entraîner un événement lié au risque, la valeur de chaque facteur lié à des polices en vigueur, les relations de cause à effet connues, les mesures du risque qui peuvent être utilisées et la relation avec d’autres types de risque. Cela peut se faire de façon électronique, dans le cadre d’entrevues avec chaque expert ou par discussion de groupe. Si la question est nouvelle et compliquée, il est plus efficace d’effectuer une présentation et de tenir une discussion.
Étape 2. Les opinions recueillies sont agrégées et analysées. Si des opinions sont
contraires, une explication supplémentaire des experts peut être requise pour bien comprendre la pensée qui les sous-tend. Par la suite, un modèle de logique floue comportant des variables, des fonctions d’appartenance et des règles d’inférence précises est proposé aux experts pour obtenir leurs commentaires et leur approbation.

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 43 de 67
Étape 3. La rétroaction au sujet du modèle proposé est analysée et prise en compte dans la version finale du modèle. Cette étape peut s’étendre sur plusieurs séries de communication.
Étape 4. Une fois la version finale du modèle achevée, un processus pertinent de collecte
de données et de surveillance des risques doit être mis en place. Des rapports périodiques au sujet de l’exposition actuelle au risque sont préparés d’après le modèle de logique floue. Ces rapports sont distribués aux experts aux fins de commentaire et d’information. D’après les résultats du modèle, l’expérience acquise, l’évolution du contexte ou une meilleure compréhension, les experts peuvent revoir leurs opinions, ce qui exige un examen régulier et la mise à jour du modèle.
Pour favoriser la contribution des experts au système de logique floue, il est essentiel de
présenter le produit fini et de leur en faire rapport pour qu’ils puissent saisir le résultat de leurs efforts. Les experts sont habituellement des gestionnaires des opérations. Si le modèle peut leur fournir de l’information au sujet de l’exposition au risque de leurs activités opérationnelles actuelles ou de leurs stratégies éventuelles futures, ils seront plus susceptibles d’y consacrer davantage de temps parce qu’ils en tireront un avantage pour leurs décisions d’affaires.
5.2 Sélection des fonctions d’appartenance
La fonction d’appartenance est un intrant essentiel pour le système de logique floue. Il peut être facile d’élaborer des règles d’inférence, mais il en va tout autrement de la conception de fonctions d’appartenance parce qu’il faut convertir la description qualitative en une mesure quantitative. Plusieurs approches peuvent être utilisées à cette fin.
1. Demander aux experts en la matière de fournir des intrants. Les modèles de logique
floue dépendent dans une large mesure du raisonnement humain. Lorsque les opinions sont recueillies auprès des experts, il est important de demander à ces derniers de définir ce qu’ils entendent par les notions « élevé, moyen, faible ». Prenons l’exemple de la cote de crédit, dont nous avons déjà discuté. Des énoncés tels « toute cote supérieure à 1,5 n’est pas faible » ou « toute cote inférieure à 0,5 est absolument faible », sont utiles pour créer la fonction d’appartenance. Une fonction d’appartenance raisonnable pour l’ensemble flou de la cote de crédit faible pourrait se lire comme suit :
La fonction d’appartenance choisie doit être communiquée à ces experts pour obtenir leur approbation. Il s’agit d’un processus fastidieux qui exige la formation des personnes qui fourniront leur contribution au système de logique floue. Des experts différents peuvent avoir des opinions différentes au sujet de la fonction d’appartenance. Il est nécessaire de grouper différentes opinions et de trouver une
5.15.15.0
5.0
0
1)( 1
)5.1(
>≤<
≤= −
xx
xx xLowµ µFaible (x) =

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 44 de 67
façon de les agréger. La manière la plus simple consiste à ajouter un coefficient de pondération à l’opinion de chaque personne et d’utiliser la fonction d’appartenance moyenne pondérée. Par contre, la façon de calculer le coefficient de pondération et d’en maintenir la simplicité relève de l’art plutôt que de la science.
2. Si des données d’expérience sont disponibles, la fonction d’appartenance peut parfois
être partiellement étalonnée. Cette étape est habituellement franchie après l’utilisation du système de logique floue pendant une certaine période. Il pourrait exister certains renseignements concernant l’efficacité du système par rapport à ce qui s’est vraiment passé. Il serait peut-être possible d’améliorer la fonction d’appartenance en se fondant sur l’expérience. La pondération de l’opinion de chaque expert peut aussi être rajustée.
3. D’autres modèles peuvent être utilisés conjointement avec le modèle de logique floue
de manière à permettre l’étalonnage des fonctions d’appartenance. Le système d’inférence neuro-floue adaptatif (ANFIS), qui marie le réseau neuronal artificiel et le modèle de logique floue, est un exemple. Toutefois, il exige un très vaste ensemble de données de formation qui n’est habituellement pas applicable au risque opérationnel.
5.3 Rôle des données d’expérience
Pour la plupart des risques traités à l’aide de modèles de logique, il n’existe peut-être pas suffisamment de données. Le caractère raisonnable du modèle relève principalement des experts ou des gestionnaires des opérations. Les commentaires sur les règles d’inférence ou sur les fonctions d’appartenance peuvent exercer une influence importante sur le résultat d’une évaluation des risques. Toutefois, le contrôle ex post des données d’expérience (pour autant qu’elles soient disponibles) peut servir à valider ou à améliorer les modèles. La comparaison de l’expérience actuelle et du modèle représente une option qui peut être utilisée après la mise en œuvre du système de logique floue. Fondées sur les données d’expérience, les fonctions d’appartenance peuvent être rajustées ou étalonnées pour mieux prédire la variable de sortie. Le suivi des intrants effectué par chaque expert peut également révéler leur niveau de correspondance avec les données d’expérience; la pondération des opinions de chaque expert peut être rajustée en conséquence. En outre, lorsque des données suffisantes ont été recueillies, elles peuvent également influer sur la compréhension du sujet par les experts et elles peuvent aussi modifier ces intrants, y compris les règles d’inférence et les fonctions d’appartenance. En bout de ligne, si les données sont suffisantes, des modèles de logique floue peuvent être convertis en modèles fondés sur la théorie des probabilités, mais pas nécessairement16.
Contrairement à certains modèles fondés sur les données, le poids exercé sur les données
d’expérience lorsque l’on précise un modèle de logique floue n’est pas lourd dans la plupart des cas.
16 Un exemple simple d’utilisation des données d’expérience est présenté à l’annexe.

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 45 de 67
1. Les données d’expérience recueillies ne sont peut-être pas crédibles au plan statistique pour revoir les paramètres actuels du modèle et les règles d’inférence. Il est probable que des données pertinentes ne seront recueillies d’une manière significative qu’après la mise en œuvre du modèle de logique floue.
2. Pour la gestion des risques, le renseignement le plus utile a trait aux événements extrêmes. Il sera encore plus difficile de recueillir des données sur ces événements.
3. Les liens explicites de cause à effet fondés sur le modèle de logique floue empêchent le modèle de changer uniquement en fonction des données d’expérience, contrairement à certains modèles d’exploration des données. À moins que l’expérience ne soit analysée et très bien comprise, elle pourrait ne pas causer de changement au sein du modèle.
L’analyse des données d’expérience offre des occasions d’améliorer nos connaissances
sur les risques et d’accroître l’exactitude du modèle de logique floue. Les données peuvent renfermer des renseignements contraires aux règles d’inférence présumées. En analysant les données, on peut corriger un malentendu, découvrir de nouveaux facteurs sous-jacents et revoir les règles d’inférence.
5.4 Examen du système de logique floue
À l’instar d’autres outils de gestion des risques, notamment la propension à prendre des risques, les systèmes de logique floue doivent être examinés et mis à jour de temps à autre.
1. Il se peut que de nouveaux risques doivent être inclus dans le système en raison de
nouvelles affaires ou d’un changement du contexte des affaires. 2. Il se pourrait que l’on comprenne mieux la question d’après de récents travaux de
recherche universitaire ou l’expérience des pertes enregistrées récemment. 3. Il se peut que la société ait modifié sa stratégie. Dans ce cas, l’exposition de la société
à chaque risque doit être mise à jour. Selon la portée du système de logique floue, il pourrait s’avérer difficile de produire une
mise à jour intégrale. Pour optimiser le temps consacré par les experts, il faut garantir un équilibre. Il importe de faire en sorte que le processus de mise à jour soit aussi facile et valorisant que possible. Une interface conviviale pourrait permettre aux experts de mettre à jour leurs opinions. Des rapports périodiques au sujet de l’exposition au risque et les répercussions d’éventuelles stratégies de gestion des risques maintiennent l’intérêt et l’empressement à participer au processus continu.
5.5 Liens avec la prise de décisions
Un système d’évaluation des risques a pour but ultime d’aider les décideurs à prendre des décisions éclairées en matière de risque. Même si un système de logique floue peut être utilisé pour évaluer l’exposition au risque du point de vue quantitatif, c’est la classification des

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 46 de 67
risques qui représente l’élément vraiment significatif. Ainsi, les décideurs peuvent repérer les principaux risques et ils acquièrent une meilleure compréhension de l’ampleur relative des risques. Dans la mesure où les hypothèses et les approches utilisées pour évaluer les risques sont cohérentes, la classification fondée sur le modèle de logique floue est significative. En outre, les systèmes de logique floue peuvent servir à évaluer le coût de l’atténuation des risques.
1. Au niveau du risque individuel : pour chaque risque individuel, les principaux
facteurs qui alimentent l’exposition au risque peuvent être identifiés par le modèle de logique floue. Par exemple, le risque d’inconduite lié à chaque produit d’une société peut être évalué et classifié. Les produits exposés à un risque d’inconduite élevé peuvent ensuite être surveillés et même examinés si l’expérience des mauvais risques se prolonge sur une longue période. Les mesures appliquées peuvent englober une formation plus poussée pour les conseillers, un régime rajusté de rémunération des conseillers qui pénalise la publicité trompeuse, ou une simplification du produit. Un autre exemple porte sur l’identification des principaux événements qui peuvent ternir la réputation d’une société. Une liste des événements présentant des risques éventuels peut être dressée à partir de l’évaluation effectuée par la société ou de l’analyse des opinions publiques. Un modèle de logique floue peut être utilisé pour classifier ces événements et les mesures nécessaires peuvent être prises pour gérer le risque.
2. Au niveau de l’unité opérationnelle : Les principaux risques peuvent être identifiés
par le système de logique floue; à ce moment, les mesures nécessaires de surveillance et de gestion des risques peuvent être prises dans les unités opérationnelles. Outre les risques existants, l’exposition aux risques émergents et aux nouveaux risques susceptibles d’être imputables à de nouvelles stratégies d’affaires peuvent être évaluées par le système de logique floue. Le résultat peut ensuite être intégré au processus décisionnel de sorte que les stratégies d’affaires futures comprennent un examen suffisant des risques éventuels.
3. Au niveau de l’entreprise : Au haut de la pyramide, en plus de l’identification et de
l’évaluation des risques, les systèmes de logique floue peuvent jouer un rôle important au plan de la planification stratégique et ils peuvent influer sur les nouveaux plans d’affaires et sur la gestion stratégique du capital. Les décideurs peuvent obtenir un point de vue plus général des risques de l’entreprise dans le cadre de la planification de son avenir.
6 Études de cas
La présente section renferme deux exemples d’application de modèles de logique floue à la gestion des risques, l’un au niveau microdimensionnel et l’autre au niveau macrodimensionnel.

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 47 de 67
6.1 Identification et évaluation de l’opinion publique négative
L’opinion publique au sujet de la performance d’une entreprise ou de sa contribution à la société est importante pour la gestion du risque d’atteinte à la réputation. L’opinion peut également influer directement sur la performance boursière à court terme. Par conséquent, la collecte et l’analyse de l’opinion publique sont utiles. Cette démarche est parfois désignée « exploration de l’opinion » ou « analyse psychologique ». De nombreuses sociétés scrutent l’opinion publique en consultant les médias sociaux, les journaux, l’actualité en ligne, les blogues, Twitter, etc. Habituellement, cette tâche est exécutée de façon ponctuelle ou manuellement, ce qui pourrait être insuffisant (trop peu, trop tard), plus particulièrement pour les grandes sociétés d’envergure mondiale. Un cadre permettant d’identifier et d’évaluer l’opinion publique sur une base plus fréquente, voire quotidienne, est idéal car l’information se répand à la vitesse de l’éclair et l’impact d’une opinion publique négative sur le cours des actions peut être immédiat. À l’aide de ce type d’information, l’équipe de direction peut prendre rapidement des mesures pour atténuer ou même éviter des répercussions négatives. Les modèles de logique floue peuvent convenir parce que les éléments de référence au sujet de l’opinion publique sont généralement exprimés sous forme linguistique. Le schéma d’un cadre d’identification et d’évaluation fondé sur un modèle de logique floue figure ci-après.
Figure 20. Schéma du suivi de l’opinion publique
Les modèles de logique floue peuvent servir à identifier et à évaluer les opinions
publiques négatives qui seront portées à l’attention de la haute direction. Après l’analyse de l’information recueillie à l’aide d’un moteur d’exploration textuelle pour dégager une liste de problèmes éventuels, le modèle de logique floue peut aider à identifier les opinions les plus problématiques. Plutôt que d’attribuer une valeur numérique à chaque variable indépendante, des règles d’inférence fondées sur une description linguistique des variables indépendantes peuvent être utilisées à cette étape. Cela s’apparente au processus de raisonnement humain, à la différence qu’en l’occurrence, l’intrant prend la forme d’opinions décrites en termes qualitatifs. Lorsque l’on évalue le risque lié aux problèmes identifiés, on peut utiliser un modèle de logique floue différent et plus complexe, qui repose sur les répercussions
Médias sociaux JournauxActualités en ligne Blogues
Tw itter FacebookLinkedIn Google+
Évaluer l'impact négatif éventuel pour déterminer les principaux
problèmesÉvaluation des risques
Mesures de la directionClarif ication, atténuation des
risques, mesures réparatrices
Moteur de recherche Sources d'informationChercher la raison sociale ou la cote
boursière
Dégager des opinions importantes au sujet de la société
Moteur d'exploration textuelle
Modèle de logique floue
©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 48 de 67
éventuelles sur la valeur de la franchise. Par ailleurs, un modèle de logique floue combiné peut être utilisé pour regrouper l’identification et l’évaluation en une seule étape, mais une telle démarche pourrait entraîner un plus long délai de traitement, car un modèle de logique floue plus complexe doit traiter tous les renseignements recueillis.
Un exemple simplifié est reproduit ci-bas pour illustrer le processus d’élaboration et
d’utilisation d’un tel cadre de gestion du risque d’atteinte à la réputation.
Étape 1. Recueillir les opinions publiques au sujet de la Société XYZ auprès de sources diverses, notamment les médias sociaux, les journaux, les blogues et les réseaux sociaux, dont Twitter, Facebook, LinkedIn et Google+.
Étape 2. Utiliser des techniques avancées d’exploration de textes pour résumer chaque
opinion en une phrase ou un court paragraphe. Un exemple de liste est fourni ci-après. Dans la réalité, cette liste peut être bien plus longue.
Tableau 3. Exemple de liste d’opinions publiques
No Description de l’« opinion »
Source d’information
Nombre de commentaires
Catégorie Opinions
divergentes
1
Il N’EST PAS bon pour XYZ d’acheter ABC en raison de l’ampleur de l’exigence de capital.
Twitter 4 Stratégie d’affaires
50 %
2 XYZ ne cesse de majorer le taux de prime, ce qui complique la vente.
Blogues 5 Compétitivité des produits
0 %
3
XYZ a aidé les collectivités locales à améliorer la santé des enfants et l’éducation.
Journaux 10 Responsabilité
sociale 0 %
4
Les gains de XYZ au prochain trimestre seront vraisemblablement plus faibles que prévu.
Blogues 17 Rendement des
actions 60 %
5
Des investisseurs prévoient de poursuivre XYZ pour perte imputable à une gestion inadéquate.
Twitter 14 Rendement des
actions 0 %
6
Le programme de couverture mis en place par XYZ semble trop prudent pour que les investisseurs espèrent un
Blogues et Twitter
18 Rendement des
actions 40 %
©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 49 de 67
rendement positif de leur avoir.
7
Certains clients craignent que les ventes croisées de XYZ ne causent une fuite de leurs renseignements personnels et privés.
Bulletin de nouvelles télévisé
18 Protection des
renseignements personnels
0 %
8
XYZ prévoit d’élargir son marché en Asie au cours des cinq prochaines années.
Journaux 1 Stratégie d’affaires
0 %
9
J’ai été piégé pour acheter un produit de XYZ comportant une très faible valeur garantie.
Twitter 3 Fausse publicité 0 %
10
Il est possible que XYZ vende son unité de services des régimes de retraite au prochain trimestre.
Twitter 5 Renseignements
d’initiés 0 %
Étape 3. Utiliser un modèle de logique floue pour trouver des opinions importantes au
sujet de la société. Un exemple suit. Table 4. Exemple de modèle de logique floue : Publicité négative
Publicité négative Principaux indicateurs de risque
1. Source d’information : Les types de sources peuvent être classés selon leur importance. Par exemple, une nouvelle à la télévision est vraisemblablement plus importante qu’un commentaire sur Twitter.
2. Popularité du sujet : Elle peut être mesurée d’après le nombre de fois où le sujet a été abordé.
3. Degré d’uniformité des opinions : Cet élément pourrait englober la question de savoir s’il existe des opinions contraires et laquelle jouit du meilleur appui.
4. Objet de l’opinion : Performance boursière, compétitivité du produit, protection des renseignements personnels, fausse publicité, renseignements d’initiés, etc. La société peut avoir sa propre liste reposant sur le type d’activité et sa stratégie de gestion des risques.
Règles d’inférence
1. Si [(le niveau d’information est important) ou (le sujet est populaire)] et (le sujet figure sur la liste de priorité), alors le risque est élevé.
2. Si (le degré d’uniformité n’est pas élevé) et (le sujet ne figure pas sur la liste de priorité), alors le risque est faible.
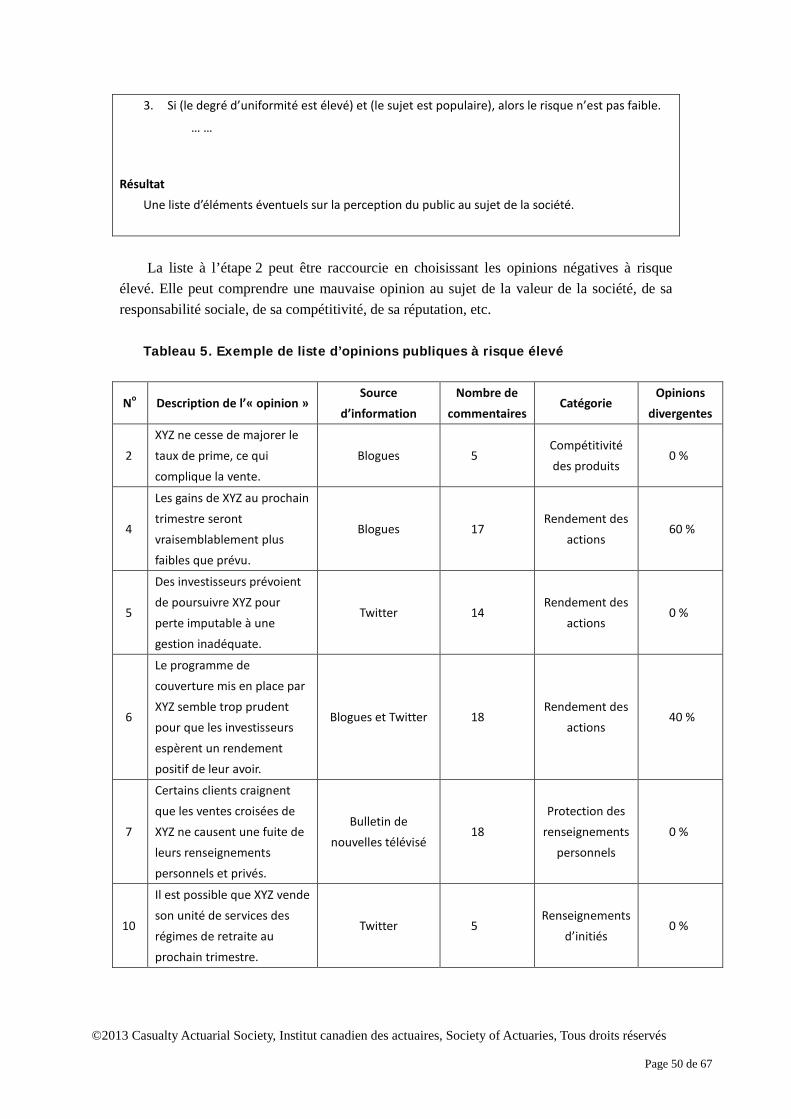
©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 50 de 67
3. Si (le degré d’uniformité est élevé) et (le sujet est populaire), alors le risque n’est pas faible.
… …
Résultat
Une liste d’éléments éventuels sur la perception du public au sujet de la société.
La liste à l’étape 2 peut être raccourcie en choisissant les opinions négatives à risque
élevé. Elle peut comprendre une mauvaise opinion au sujet de la valeur de la société, de sa responsabilité sociale, de sa compétitivité, de sa réputation, etc.
Tableau 5. Exemple de liste d’opinions publiques à risque élevé
No Description de l’« opinion » Source
d’information Nombre de
commentaires Catégorie
Opinions divergentes
2 XYZ ne cesse de majorer le taux de prime, ce qui complique la vente.
Blogues 5 Compétitivité des produits
0 %
4
Les gains de XYZ au prochain trimestre seront vraisemblablement plus faibles que prévu.
Blogues 17 Rendement des
actions 60 %
5
Des investisseurs prévoient de poursuivre XYZ pour perte imputable à une gestion inadéquate.
Twitter 14 Rendement des
actions 0 %
6
Le programme de couverture mis en place par XYZ semble trop prudent pour que les investisseurs espèrent un rendement positif de leur avoir.
Blogues et Twitter 18 Rendement des
actions 40 %
7
Certains clients craignent que les ventes croisées de XYZ ne causent une fuite de leurs renseignements personnels et privés.
Bulletin de nouvelles télévisé
18 Protection des
renseignements personnels
0 %
10
Il est possible que XYZ vende son unité de services des régimes de retraite au prochain trimestre.
Twitter 5 Renseignements
d’initiés 0 %

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 51 de 67
Étape 4. Utiliser le modèle de logique floue pour évaluer l’impact sur la valeur de franchise et le coût des mesures d’atténuation des risques. Le modèle de logique floue peut constituer une version étendue du modèle mentionné à l’étape 3. Parmi les autres variables d’entrée qui peuvent être incluses, mentionnons la question de savoir si l’opinion au sujet de l’entreprise est négative et si l’impact est négatif dans la mesure où l’opinion est fausse. Les variables de sortie peuvent comprendre le montant estimatif de la perte et le coût de l’atténuation des risques.
a. Montant de la perte = Montant de base × Coefficient de risque de publicité
négative 1. Un coefficient de risque de publicité négative peut être choisi pour tenir
compte d’un niveau de confiance conforme à la propension de l’entreprise à prendre des risques. Par exemple, un événement survenant aux 200 ans peut être sélectionné plutôt qu’un événement aux 100 ans pour une entreprise très prudente.
2. Le montant de base peut être déterminé à l’aide de l’expérience, au niveau de l’entreprise ou la moyenne pour le secteur. Il peut être difficile de déterminer le montant de base. Les pertes historiques imputables à la publicité négative peuvent donner un aperçu d’une fourchette raisonnable du montant de base, que l’on peut envisager comme le coût d’un événement de risque avec coefficient de risque 1. Au plan conceptuel, le processus est semblable à la façon dont certaines sociétés calculent le capital économique requis pour le risque opérationnel, notamment l’utilisation du produit d’un coefficient de niveau de risque et les gains en vertu des principes comptables généralement reconnus (PCGR) ou le capital requis pour d’autres risques. Les gains selon les PCGR ou le capital requis pour d’autres risques peuvent être envisagés comme un élément correspondant du « montant de base » et le coefficient s’apparente au « coefficient de risque de publicité négative ». À défaut d’expérience, il convient d’obtenir une estimation des experts.
b. Le coût d’atténuation des risques peut être évalué d’après la source
d’information et l’objet de l’opinion. Étape 5. Vérifier les opinions choisies par rapport aux faits. Étape 6. Prendre des décisions au sujet de la gestion des principales questions relevées.
Parmi les mesures possibles, il y aurait lieu de préciser les faits au moyen d’un communiqué de presse ou d’une séance d’information.
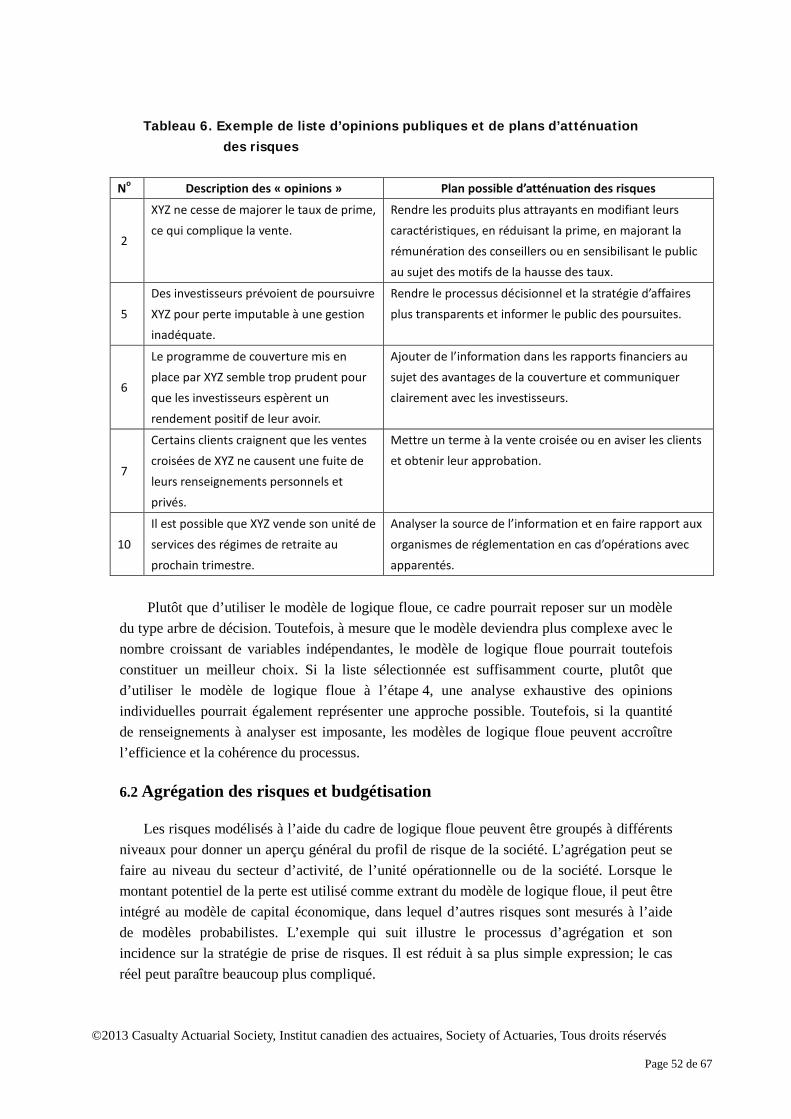
©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 52 de 67
Tableau 6. Exemple de liste d’opinions publiques et de plans d’atténuation
des risques
No Description des « opinions » Plan possible d’atténuation des risques
2
XYZ ne cesse de majorer le taux de prime, ce qui complique la vente.
Rendre les produits plus attrayants en modifiant leurs caractéristiques, en réduisant la prime, en majorant la rémunération des conseillers ou en sensibilisant le public au sujet des motifs de la hausse des taux.
5 Des investisseurs prévoient de poursuivre XYZ pour perte imputable à une gestion inadéquate.
Rendre le processus décisionnel et la stratégie d’affaires plus transparents et informer le public des poursuites.
6
Le programme de couverture mis en place par XYZ semble trop prudent pour que les investisseurs espèrent un rendement positif de leur avoir.
Ajouter de l’information dans les rapports financiers au sujet des avantages de la couverture et communiquer clairement avec les investisseurs.
7
Certains clients craignent que les ventes croisées de XYZ ne causent une fuite de leurs renseignements personnels et privés.
Mettre un terme à la vente croisée ou en aviser les clients et obtenir leur approbation.
10 Il est possible que XYZ vende son unité de services des régimes de retraite au prochain trimestre.
Analyser la source de l’information et en faire rapport aux organismes de réglementation en cas d’opérations avec apparentés.
Plutôt que d’utiliser le modèle de logique floue, ce cadre pourrait reposer sur un modèle
du type arbre de décision. Toutefois, à mesure que le modèle deviendra plus complexe avec le nombre croissant de variables indépendantes, le modèle de logique floue pourrait toutefois constituer un meilleur choix. Si la liste sélectionnée est suffisamment courte, plutôt que d’utiliser le modèle de logique floue à l’étape 4, une analyse exhaustive des opinions individuelles pourrait également représenter une approche possible. Toutefois, si la quantité de renseignements à analyser est imposante, les modèles de logique floue peuvent accroître l’efficience et la cohérence du processus.
6.2 Agrégation des risques et budgétisation
Les risques modélisés à l’aide du cadre de logique floue peuvent être groupés à différents niveaux pour donner un aperçu général du profil de risque de la société. L’agrégation peut se faire au niveau du secteur d’activité, de l’unité opérationnelle ou de la société. Lorsque le montant potentiel de la perte est utilisé comme extrant du modèle de logique floue, il peut être intégré au modèle de capital économique, dans lequel d’autres risques sont mesurés à l’aide de modèles probabilistes. L’exemple qui suit illustre le processus d’agrégation et son incidence sur la stratégie de prise de risques. Il est réduit à sa plus simple expression; le cas réel peut paraître beaucoup plus compliqué.

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 53 de 67
La société XYZ est une société d’assurances IARD active dans deux régions du monde, l’Amérique du Nord et le Moyen-Orient. Ses principales branches d’activité sont l’assurance automobile et l’assurance de propriétaire-occupant. XYZ a été fondée il y a 50 ans et possède une grande expérience interne de données au sujet du risque d’assurance. Elle utilise un cadre de capital économique pour mesurer son exposition au risque. Dans le cas des types de risque pour lesquels il existe suffisamment de données d’expérience réelles, notamment sur le risque de marché, de crédit et d’assurance, la société utilise des modèles quantitatifs fondés sur la théorie des probabilités. Toutefois pour les autres risques, pour lesquels XYZ ne possède pas une expérience suffisante ou de ressources suffisantes pour construire des modèles quantitatifs, la société utilise des modèles de logique floue pour mesurer son exposition au risque. Les principaux risques traités par le cadre de logique floue portent sur les changements climatiques, la cybersécurité, la publicité négative, l’instabilité régionale et le terrorisme. Un échantillon de modèles de logique floue est présenté ci-après au titre de ces risques, à l’exception du risque de publicité négative, qui a été abordé à la Section 6.1.
Tableau 7. Exemple de modèle de logique floue : Changements climatiques
Changements climatiques Principaux indicateurs de risque
1. Fréquence : Tendance à la hausse des récentes inondations 2. Gravité : Tendance à la hausse des récentes inondations 3. Le lieu des polices souscrites
Règles d’inférence 1. Si (la tendance de l’augmentation de la gravité est élevée) et (les biens assurés sont situés
dans la zone à haut risque), alors le risque est élevé. 2. Si (la tendance de l’augmentation de la gravité n’est pas élevée) et (la tendance de
l’augmentation de la fréquence est élevée) et (les biens assurés sont situés dans la zone à haut risque), alors le risque est moyen.
3. Si (les biens assurés ne sont pas situés dans la zone à haut risque), alors le risque est faible.
… …
Montant de la perte = Somme assurée × Coefficient de risque de changements climatiques Notes
1. Le coefficient de risque de changements climatiques peut être choisi pour tenir compte d’un niveau de confiance conforme à la propension de la société à prendre des risques.
2. L’évaluation des risques peut être effectuée pour l’ensemble des polices en vigueur ou pour chaque nouvelle police prévue, puis les données sont regroupées.

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 54 de 67
Tableau 8. Exemple de modèle de logique floue : Cybersécurité
Cybersécurité Principaux indicateurs de risque
1. Technologie de la cybersécurité 2. Normes de cybersécurité 3. Portée de l’information privée recueillie 4. Impact des incidents antérieurs
Règles d’inférence 1. Si (la technologie est avancée) et (la norme est élevée), alors le risque n’est pas élevé. 2. SI (l’impact des incidents antérieurs est élevé), alors le risque n’est pas faible. 3. Si (la portée n’est pas étroite), alors le risque n’est pas faible.
… …
Montant de la perte = Somme assurée × Coefficient de risque de cybersécurité
Notes 1. Le coefficient de risque de cybersécurité peut être choisi pour tenir compte d’un niveau de
confiance conforme à la propension de la société à prendre des risques.
2. Le montant de base peut être déterminé à l’aide de l’expérience ou de l’apport des experts.
Tableau 9. Exemple de modèle de logique floue : Instabilité régionale
Instabilité régionale Principaux indicateurs de risque
1. Lieu des polices souscrites 2. Pertes imputables à la guerre 3. Intervention extérieure
Règles d’inférence 1. Si (les biens assurés sont situés dans une zone à haut risque) et (les répercussions de
l’intervention extérieure sont élevées), alors le risque est élevé. 2. Si (les pertes imputables à la guerre sont élevées), alors le risque n’est pas faible. 3. Si (les biens assurés ne sont pas situés dans la zone à haut risque), alors le risque est faible.
… …
Montant de la perte = Somme assurée × Coefficient de risque d’instabilité régionale
Notes 1. Le coefficient de risque d’instabilité régionale peut être choisi pour tenir compte d’un niveau
de confiance conforme à la propension de la société à prendre des risques. 2. Somme assurée couverte : La somme assurée couverte en cas de guerre, d’agitation
politique, de chaos, etc.
3. L’évaluation des risques peut être effectuée pour l’ensemble des polices en vigueur ou pour

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 55 de 67
chaque nouvelle police prévue, puis les données sont regroupées. Tableau 10. Exemple de modèle de logique floue : Terrorisme
Terrorisme Principaux indicateurs de risque
1. Lieu des polices souscrites 2. Pertes imputables au terrorisme 3. Système de sécurité
Règles d’inférence 1. Si (les biens assurés sont situés dans une zone à haut risque), alors le risque est élevé. 2. Si (les pertes imputables au terrorisme sont élevées), alors le risque n’est pas faible. 3. Si (les biens assurés ne sont pas situés dans la zone à haut risque) et (le système de sécurité
est bon), alors le risque est faible.
… …
Montant de la perte = Somme assurée × Coefficient de risque de terrorisme
Notes 1. Le coefficient de risque de terrorisme peut être choisi pour tenir compte d’un niveau de
confiance conforme à la propension de la société à prendre des risques. 2. Somme assurée couverte : La somme assurée couverte en cas de terrorisme.
3. L’évaluation des risques peut être effectuée pour l’ensemble des polices en vigueur ou pour chaque nouvelle police prévue, puis les données sont regroupées.
À l’aide du modèle de logique floue, le capital économique requis estimatif au niveau de
confiance du 99,5e centile (un événement aux 200 ans) pour chaque risque individuel figure au tableau 11. Il est obtenu comme suit :
a. Le 99,5e centile de la distribution de la perte simulée moins la perte moyenne; ou b. La perte estimative dans le cadre d’un événement extrême (historique ou
hypothétique) moins la perte prévue.
Tableau 11. Exemple de capital économique requis pour chaque risque
Millions $US
Amérique du
Nord Moyen-Orient
Changements climatiques 100 20
Cybersécurité 40 35
Publicité négative 60 50
Instabilité régionale 15 120
Terrorisme 50 100
Comme il est indiqué à la Section 4.2, deux approches sont appliquées à l’agrégation.
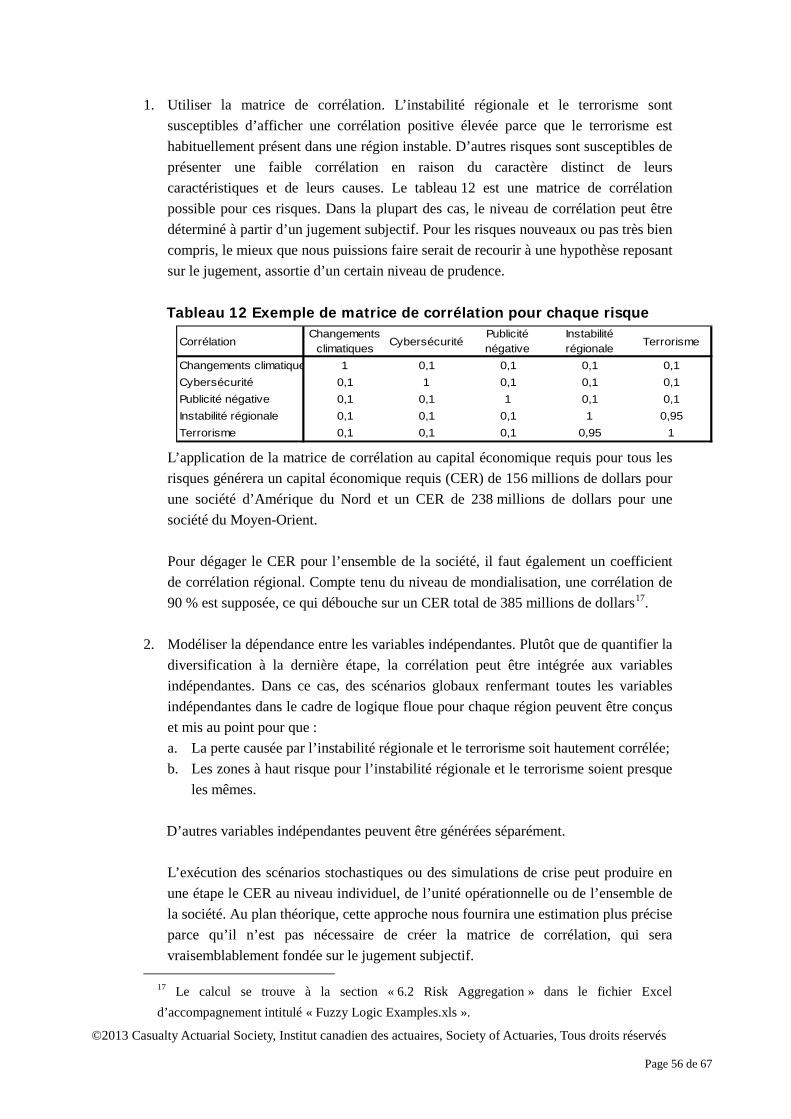
©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 56 de 67
1. Utiliser la matrice de corrélation. L’instabilité régionale et le terrorisme sont susceptibles d’afficher une corrélation positive élevée parce que le terrorisme est habituellement présent dans une région instable. D’autres risques sont susceptibles de présenter une faible corrélation en raison du caractère distinct de leurs caractéristiques et de leurs causes. Le tableau 12 est une matrice de corrélation possible pour ces risques. Dans la plupart des cas, le niveau de corrélation peut être déterminé à partir d’un jugement subjectif. Pour les risques nouveaux ou pas très bien compris, le mieux que nous puissions faire serait de recourir à une hypothèse reposant sur le jugement, assortie d’un certain niveau de prudence.
Tableau 12 Exemple de matrice de corrélation pour chaque risque
L’application de la matrice de corrélation au capital économique requis pour tous les risques générera un capital économique requis (CER) de 156 millions de dollars pour une société d’Amérique du Nord et un CER de 238 millions de dollars pour une société du Moyen-Orient.
Pour dégager le CER pour l’ensemble de la société, il faut également un coefficient de corrélation régional. Compte tenu du niveau de mondialisation, une corrélation de 90 % est supposée, ce qui débouche sur un CER total de 385 millions de dollars17.
2. Modéliser la dépendance entre les variables indépendantes. Plutôt que de quantifier la
diversification à la dernière étape, la corrélation peut être intégrée aux variables indépendantes. Dans ce cas, des scénarios globaux renfermant toutes les variables indépendantes dans le cadre de logique floue pour chaque région peuvent être conçus et mis au point pour que : a. La perte causée par l’instabilité régionale et le terrorisme soit hautement corrélée; b. Les zones à haut risque pour l’instabilité régionale et le terrorisme soient presque
les mêmes.
D’autres variables indépendantes peuvent être générées séparément.
L’exécution des scénarios stochastiques ou des simulations de crise peut produire en une étape le CER au niveau individuel, de l’unité opérationnelle ou de l’ensemble de la société. Au plan théorique, cette approche nous fournira une estimation plus précise parce qu’il n’est pas nécessaire de créer la matrice de corrélation, qui sera vraisemblablement fondée sur le jugement subjectif.
17 Le calcul se trouve à la section « 6.2 Risk Aggregation » dans le fichier Excel d’accompagnement intitulé « Fuzzy Logic Examples.xls ».
CorrélationChangements
climatiques CybersécuritéPublicité négative
Instabilité régionale Terrorisme
Changements climatique 1 0,1 0,1 0,1 0,1Cybersécurité 0,1 1 0,1 0,1 0,1Publicité négative 0,1 0,1 1 0,1 0,1Instabilité régionale 0,1 0,1 0,1 1 0,95Terrorisme 0,1 0,1 0,1 0,95 1

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 57 de 67
Les risques mesurés au moyen de modèles de logique floue peuvent être groupés avec les
risques mesurés par des modèles probabilistes. L’utilisation de la matrice de corrélation représente une approche plus facile parce que les scénarios requis par la seconde approche peuvent exiger le recours simultané à un trop grand nombre de variables. Puisque la plupart des risques traités au moyen de modèles de logique floue peuvent être des risques opérationnels ou émergents, l’hypothèse de corrélation entre le risque opérationnel et d’autres types de risque peut être utilisée. Cette hypothèse peut exister dans le cadre de capital économique actuel de la société, dans des modèles de capital réglementaire comme la directive Solvabilité II de l’Union européenne, des modèles de capital d’agences de notation du crédit et dans des rapports de recherche sectoriels.
À l’aide du capital économique requis, par exemple, les risques analysés au moyen de
modèles de logique floue peuvent être comparés aux risques analysés à l’aide de modèles quantitatifs axés sur des données en appliquant un même fondement. Par le passé, ces risques opérationnels et émergents n’étaient habituellement pas pris en compte dans le processus de gestion du capital et de budgétisation des risques. Toutefois, ils peuvent maintenant s’arrimer au cadre existant et faire partie d’un plus vaste profil de risque. La plupart des risques modélisés par des modèles de logique floue ne sont pas négociables; il est donc difficile d’obtenir un rendement élevé du processus de prise de risque. Au cours du processus d’examen et de budgétisation des risques, l’accent est davantage placé sur l’évitement des risques et sur l’atténuation des risques pour en réduire l’exposition. Par exemple, XYZ est largement exposée aux risques d’instabilité régionale et de terrorisme sur le marché du Moyen-Orient. La société peut envisager de couvrir ces deux risques en recourant à la réassurance ou en modifiant les caractéristiques du produit pour réduire le montant assuré pour pertes causées par la guerre, l’agitation politique, le terrorisme, etc.
7 Conclusion
À titre de complément des modèles probabilistes, les modèles de logique floue peuvent être appliqués afin d’évaluer les risques pour lesquels les données sont insuffisantes et les connaissances sont incomplètes. La logique floue fournit un cadre en vertu duquel le raisonnement humain et les données imprécises peuvent contribuer à l’analyse des risques. La portée des applications possibles est vaste pour les systèmes de logique floue. Plusieurs risques sont hors contrôle, ne sont pas bien compris ou sont même inconnus, comme en fait foi la liste des risques émergents qui ne cesse de s’allonger.
À l’aide d’un système de logique floue convenable, il est possible d’analyser
constamment plusieurs risques qui ne sont pas bien compris. L’exposition à chaque risque peut être évaluée et classifiée. Les principaux risques peuvent être identifiés et gérés. Les ressources peuvent être utilisées pour surveiller et atténuer ces principaux risques qui présentent une exposition élevée. Les règles d’inférence dans un modèle de logique floue

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 58 de 67
peuvent aider non seulement à identifier la cause d’un certain risque, mais également à concevoir des plans d’atténuation efficients et efficaces.
Les systèmes de logique floue nous aident de deux façons à mieux connaître les risques. 1. Les systèmes libèrent les gestionnaires de risque et les experts du volet inférence de
plusieurs risques et leur permettent de se concentrer sur les relations de cause à effet d’après leurs connaissances.
2. Les résultats de l’évaluation des risques sont intégrés au processus de prise de
décisions sur les risques, et le résultat des décisions peut ensuite être réinséré dans le système afin d’améliorer les ensembles flous, les règles et la compréhension.
Les modèles de logique floue peuvent être utilisés de concert avec d’autres modèles de
risque, notamment les arbres de décision et les réseaux de neurones artificiels pour modéliser les questions compliquées liées aux risques, comme le comportement des titulaires de police.

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 59 de 67
8 Bibliographie
Blavatskyy, Pavlo R. « Probabilistic Risk Aversion with an Arbitrary Outcome Set », dans Economics Letters 112, no 1, juillet 2011, pp. 34–37.
Brochado, Ana Margarida Oliveira, et Francisco Vitorino Martins. « Democracy and Economic Development: A Fuzzy Classification Approach », FEP Working Paper 180, Universidade do Porto, Faculdade de Economia do Porto, Portugal, 2005. http://www.fep.up.pt/investigacao/workingpapers/05.07.04_WP180_ana.pdf.
Brotons, Jose M., et Antonio Terceno. « Return Risk Map in a Fuzzy Environment », dans Fuzzy Economic Review 16, no 2, novembre 2011, p. 33.
Caetano, Jose Manuel Martins, et Antonio Caleiro. « Corruption and Foreign Direct Investment: What Kind of Relationship is There? », Economics Working Paper 18, University of Evora, Department of Economics, Portugal, 2005 http://hdl.handle.net/10174/8434.
Cai, Y.P., G. H. Huang, Z. F. Yang et Q. Tan. « Identification of Optimal Strategies for Energy Management Systems Planning Under Multiple Uncertainties », dans Applied Energy 86, no 4, avril 2009, pp. 480–495.
Caleiro, Antonio. « A Subjective Versus Objective Economic Measures: A Fuzzy Logic Exercise », Economics Working Paper 11, University of Evora, Department of Economics, Portugal, 2003. http://dspace.uevora.pt/rdpc/bitstream/10174/8397/1/wp_2003_11.pdf.
Cheng, Wen-Ying, Ender Su et Sheng-Jung Li. « A Financial Distress Prewarning Study by Fuzzy Regression Model of TSE-Listed Companies », dans Asian Academy of Management Journal of Accounting and Finance 2, no 2, 2006, pp. 75–93. http://web.usm.my/journal/aamjaf/vol%202-2/2-2-5.pdf.
Cherubini, Umberto, et Giovanni Della Lunga. « Liquidity and Credit Risk », dans Applied Mathematical Finance 8, no 2, pp 79–95.
Cox, Earl. The Fuzzy Systems Handbook: A Practitioner’s Guide to Building, Using and Maintaining Fuzzy Systems, Boston: AP Professional, 1994, pp. 107–268.
de Andres Sanchez, Jorge, et Antonio Terceno Gomez. « Applications of Fuzzy Regression in Actuarial Analysis », dans The Journal of Risk and Insurance 70, no 4, 2003, pp. 665–699.
Derrig, Richard, et Krysztof Ostaszewski. « Hedging the Tax Liability of a Property-Liability Insurance Company », Center for Financial Institutions Working Paper 96-30, Wharton School Center for Financial Institutions, University of Pennsylvania, Philadelphia, mai 1996.
Dow, Sheila C., et Dipak Ghosh. « Variety of Opinion and the Speculative Demand for Money: An Analysis in Terms of Fuzzy Concepts », SCEME Working Papers: Advances in Economic Methodology No. 007/2004, Scottish Centre for Economic Methodology, Adam Smith Business School, University of Glasgow, 2004.

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 60 de 67
Giovanis, Eleftherios. « Bootstrapping Fuzzy-GARCH Regressions on the Day of the Week Effect in Stock Returns: Applications in MATLAB », MPRA Working Paper 22326, Munich Personal RePEc Archive, 2009.
Gulick, Gerwald van. « Game Theory and Applications in Finance », thèse de doctorat, Tilburg University, Pays-Bas, 2010.
Hao, Ying, Yongsheng Ding, Shaokuan Li et Shihuang Shao. « Typical Takagi-Sugeno and Mamdani Fuzzy Systems as Universal Approximators: Necessary Conditions and Comparison », dans 1998 IEEE International Congress on Fuzzy Systems Proceedings, Institute of Electrical and Electronics Engineers (IEEE) World Congress on Computational Intelligence, Alaska, mai 1998, vol. 1, pp. 824–828.
Horgby, Per-Johan. « An Introduction to Fuzzy Inference in Economics », dans Homo Oeconomicus 15, 1999, pp. 543–559.
Huang, Tao, Ruiqing Zhao et Wansheng Tang. « Risk Model with Fuzzy Random Individual Claim Amount », dans European Journal of Operational Research 192, no 3, 2009, pp 879–890.
Jang, J.-S.R. « ANFIS: Adaptive-Network-Based Fuzzy Inference System », dans IEEE Transactions on Systems, Man and Cybernetics 23, no 3, 1993, pp. 665–685.
Jang, J.-S.R. et C.-T. Sun. « Neuro-Fuzzy Modeling and Control », dans Proceedings of the IEEE 83, no 3, 1995, pp. 378–406.
Janikow, Cezary Z. « Fuzzy Decision Trees: Issues and Methods », University of Missouri–St. Louis, Department of Mathematics and Computer Science, 1996, pp. 12–26. http://www.cs.umsl.edu/~janikow/fid/fid34/papers/fid.ieeesmc.pdf.
Klir, George J., et Bo Yuan. Fuzzy Sets and Fuzzy Logic Theory and Applications. Upper Saddle River, New Jersey, Prentice Hall, 1995, pp. 367–377 et 390–415.
Lahsasna, Adel. « Evaluation of Credit Risk Using Evolutionary-Fuzzy Logic Scheme », thèse de maîtrise, Faculty of Computer Science and Information Technology, University of Malaya, 2009.
Lai, Li-Hua. « An Evaluation of Fuzzy Transportation Underwriting Systematic Risk », dans Transportation Research Part A: Policy and Practice 42, no 9, 2008, pp. 1231–1237.
———. « Underwriting Profit Margin of P/L Insurance in the Fuzzy-ICAPM », dans Geneva Risk and Insurance 31, no 1, 2006, pp. 23–34.
Lazzari, Luisa L., et Patricia I. Moulia. « Fuzzy Sets Application to Healthcare Systems », dans Fuzzy Economic Review 17, no 2, 2012, pp. 43–58.
Lee, Cheng, Gwo-Hshiung Tzeng et Shin-Yun Wang. « A Fuzzy Set Approach for Generalized CRR Model: An Empirical Analysis of S&P 500 Index Options », dans Review of Quantitative Finance and Accounting 25, no 3, 2005, pp. 255–275.
Leon, Carlos, et Clara Machado. « Designing an Expert Knowledge-Based Systemic Importance Index for Financial Institutions », Borradores de Economia 669, 2011.
Li, Aihua, Yong Shi, Jing He et Yanchun Zhang. « A Fuzzy Linear Programming-Based Classification Method », dans International Journal of Information Technology and Decision Making 10, no 6, 2011, pp. 1161–1174.

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 61 de 67
Lin, Chin-Shien, Haider A. Khan, Ying-Chieh Wang et Ruei-Yuan Chang. « A New Approach to Modeling Early Warning Systems for Currency Crises: Can a Machine-Learning Fuzzy Expert System Predict the Currency Crises Effectively? », dans Journal of International Money and Finance 27, no 7, 2008, pp. 1098–1121.
Magni, Carlo Alberto, Stefano Malagoli et Giovanni Mastroleo. « An Alternative Approach to Firms’ Evaluation: Expert Systems and Fuzzy Logic », dans International Journal of Information Technology and Decision Making 5, no 1, 2006, pp. 195–225.
Matsatsinis, M., K. Kosmidou, M. Doumpos et C. Zopounidis. « A Fuzzy Decision Aiding Method for the Assessment of Corporate Bankruptcy », dans Fuzzy Economic Review 3, no 1, 2003, pp. 13–23.
Mitchell, Tom M. Machine Learning. New York: McGraw-Hill, 1997, pp. 52–127 et 154–200.
Muzzioli, Silvia, et Constanza Torricelli. « A Model for Pricing an Option with a Fuzzy Payoff », dans Fuzzy Economic Review 6, no 1, 2001, pp. 49–87.
Nelsen, Roger B. An Introduction to Copulas. 2nd ed. Springer Series in Statistics. Springer, New York, 2006, pp. 109–155.
Ng, S. Thomas, Duc Thanh Luu, Swee Eng Chen et Ka Chi Lam. « Fuzzy Membership Functions of Procurement Selection Criteria », dans Construction Management and Economics 20, no 2, 2002, pp. 285–296.
Oliveira, Elizabeth Real de, et Manuela Castro e Silva. « A Political Economy Model of Regulation Explained Through Fuzzy Logics », European Regional Science Association Conference Paper ersa04p189, 2004. http://www-sre.wu-wien.ac.at/ersa/ersaconfs/ersa04/PDF/189.pdf.
Pan, Heping. « Fuzzy Bayesian Networks: A General Formalism for Representation, Inference and Learning with Hybrid Bayesian Networks », 1998, pp. 6–22. http:/perso.telecom-paristech.fr/~chollet/Biblio/Articles/Domaines/BayésianNet/fuzzy-bayésian-networks-a.pdf.
Pokoadi, Laszlo. « Fuzzy Logic-Based Risk Assessment », dans Academic and Applied Research in Military Science 1, no 1, 2002, pp. 63–73.
Reveiz, Alejando, et Carlos Leon. « Operational Risk Management using a Fuzzy Logic Inference System », dans Borradores de Economia 574, 2009, pp. 9–24 http://papers.ssrn.com/sol3/papers.cfm?abstract_id=1473614.
Shah, Samir. « Measuring Operational Risks using Fuzzy Logic Modeling », 2003, pp. 1-8.
Sivanandam, S. N., S. Sumathi et S. N. Deepa. Introduction to Fuzzy Logic using MATLAB , Springer, Berlin, 2007, pp. 277–320.
Smimou, Kamal. « Estimation of Canadian Commodity Market Risk Premiums Under Price Limits: Two-Phase Fuzzy Approach », dans Omega 34, no 5, 2006, pp. 477–491.
Su, EnDer et Yu-Gin Fen. « Applying the Structural Equation Model Rule-Based Fuzzy System with Genetic Algorithm for Trading in Currency Market », MPRA Working Paper 35474, Munich Personal RePEc Archive, 2011. http://mpra.ub.uni-muenchen.de/35474/1/MPRA_paper_35474.pdf.

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 62 de 67
Sun, Lili, et G. Cornelis van Kooten. « Fuzzy Logic and Preference Uncertainty in Non-Market Valuation », Working Paper 2005-11, Resource Economics and Policy Analysis (REPA) Research Group, Department of Economics, University of Victoria, 2005. https://web.uvic.ca/~repa/publications/REPA%20working%20papers/WorkingPaper2005-11.pdf.
Sveshnikov, Sergey, et Victor Bocharnikov. « Modeling Risk of International Country Relations », MPRA Working Paper 15745, Munich Personal RePEc Archive, 2009. http://mpra.ub.uni-muenchen.de/15745/1/MPRA_paper_15745.pdf.
Tucha, Thomas, et Markus Brem. « Fuzzy Transfer Pricing World: On the Analysis of Transfer Pricing with Fuzzy Logic Techniques », IIMA Working Paper 2005-12-03, Indian Institute of Management, Ahmedabad, Inde, 2006.
Xu, Yelin, Yujie Lu, Albert P. C. Chan, Miroslaw J. Skibniewski et John F. Y. Yeung. « A Computerized Risk Evaluation Model for Public-Private Partnership (PPP) Projects and Its Application », dans International Journal of Strategic Property Management 16, no 2, 2012, pp. 277–297.
Yu, Lean, Shouyang Wang et Kin Keung Lai. « An Intelligent-Agent-Based Fuzzy Group Decision-Making Model for Financial Multicriteria Decision Support: The Case of Credit Scoring », dans European Journal of Operational Research 195, no 3, 2009, pp. 942–959.
Zadeh, Lotfi A. « Fuzzy Sets », dans Information and Control 8, 1965, pp. 338–353.
———. « Probability Measures of Fuzzy Events », dans Journal of Mathematical Analysis and Applications 23, no 2, 1968, pp. 421–427.
Zhang, X., et F. Naghdy. « Human Motion Recognition through Fuzzy Hidden Markov Model », Research Online, University of Wollongong, 2005, pp. 3–8. http://ro.uow.edu.au/cgi/viewcontent.cgi?article=1468.
Zmeskal, Zdenek. « Generalised Soft Binomial American Real Option Pricing Model (Fuzzy-Stochastic Approach) », dans European Journal of Operational Research 207, no 2, 2010, pp. 1096–1103.

©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 63 de 67
Annexe. L’utilisation des données d’expérience
La Section 5.3 renferme une analyse du rôle des données d’expérience. Dans cette section, un exemple simple illustre la façon d’utiliser les données d’expérience pour améliorer les paramètres du modèle ou même passer à un nouveau modèle lorsque les données sont suffisantes. L’exemple et l’hypothèse utilisés ne sont pas sensés dans la réalité, mais ils ont été choisis pour faciliter la compréhension.
La société ABC prévoit d’offrir à sa clientèle des services de prêt hypothécaire personnel.
En raison de son manque d’expérience, elle utilise un modèle de logique floue fondé sur les conseils d’analystes financiers expérimentés pour prendre des décisions concernant les prêts.
À l’aide de renseignements tels l’âge, le sexe, le revenu, le niveau d’endettement actuel et
l’emploi, chaque demandeur obtient une cote de crédit. Cette cote est ensuite introduite dans le modèle de logique floue pour évaluer le risque de défaut et prendre une décision au sujet du prêt. La structure initiale du modèle est indiquée ci-après.
Variable d’entrée : Cote de crédit Fonctions d’appartenance
5330
)(2
)3( ≤<≤
=− x
xx
xHighµ
44332
0
20
)(1
)4(
1)2(
Medium
>≤<≤<
≤
= −
−
xxx
x
x x
x
µ
3030
)( 3)3(
>≤≤
=−
xx
xx
Lowµ
µÉlevée (x) =
µMoyen (x) =
µFaible (x) =
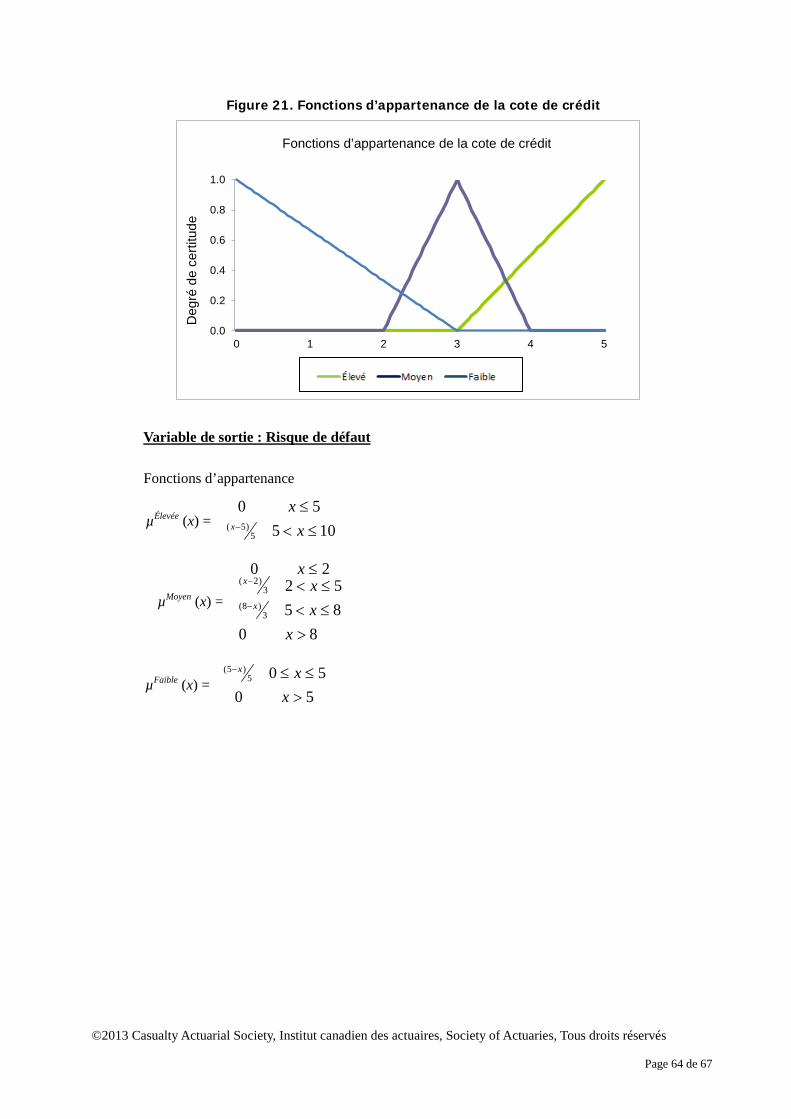
©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 64 de 67
Figure 21. Fonctions d’appartenance de la cote de crédit
Variable de sortie : Risque de défaut Fonctions d’appartenance
0.0
0.2
0.4
0.6
0.8
1.0
0 1 2 3 4 5
Deg
ree
of T
ruth
Membership Function of Credit Score
High Medium Low
10550
)(5
)5( ≤<≤
=− x
xx
xHighµ
88552
0
20
)(3
)8(
3)2(
Medium
>≤<≤<
≤
= −
−
xxx
x
x x
x
µ
5050
)( 5)5(
>≤≤
=−
xx
xx
Lowµ
µÉlevée (x) =
µMoyen (x) =
µFaible (x) =
Fonctions d’appartenance de la cote de crédit
Deg
ré d
e ce
rtitu
de
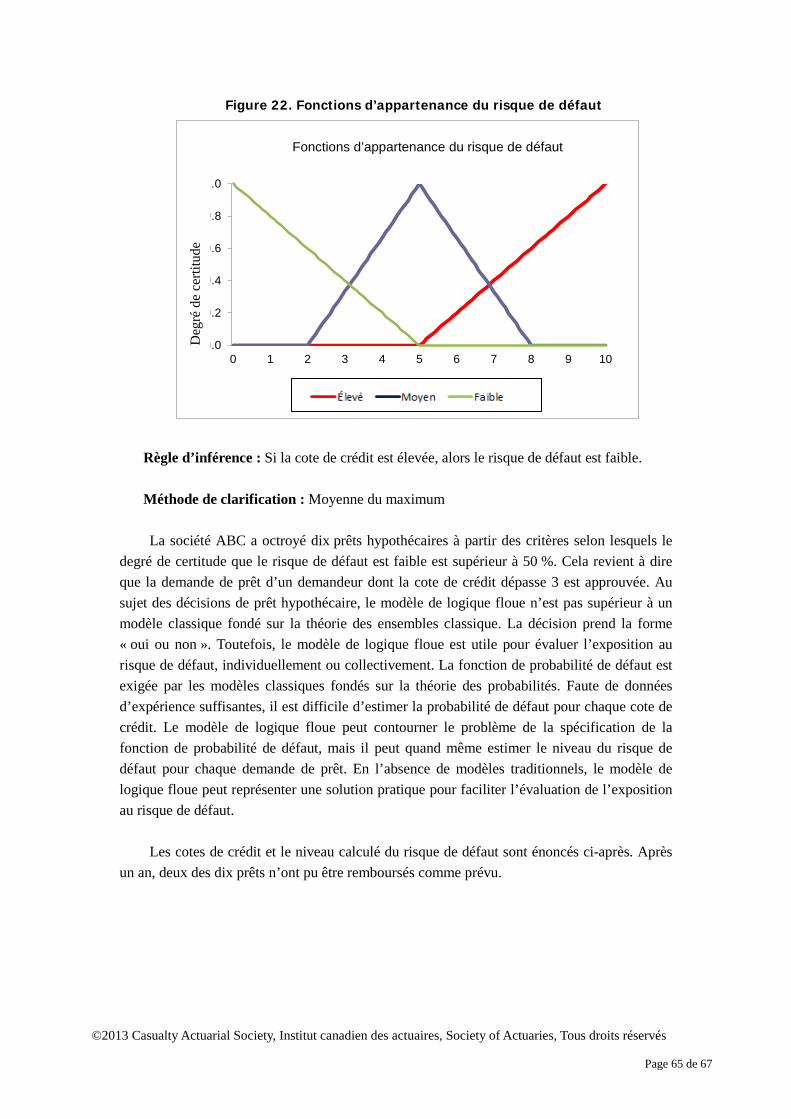
©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 65 de 67
Figure 22. Fonctions d’appartenance du risque de défaut
Règle d’inférence : Si la cote de crédit est élevée, alors le risque de défaut est faible. Méthode de clarification : Moyenne du maximum La société ABC a octroyé dix prêts hypothécaires à partir des critères selon lesquels le
degré de certitude que le risque de défaut est faible est supérieur à 50 %. Cela revient à dire que la demande de prêt d’un demandeur dont la cote de crédit dépasse 3 est approuvée. Au sujet des décisions de prêt hypothécaire, le modèle de logique floue n’est pas supérieur à un modèle classique fondé sur la théorie des ensembles classique. La décision prend la forme « oui ou non ». Toutefois, le modèle de logique floue est utile pour évaluer l’exposition au risque de défaut, individuellement ou collectivement. La fonction de probabilité de défaut est exigée par les modèles classiques fondés sur la théorie des probabilités. Faute de données d’expérience suffisantes, il est difficile d’estimer la probabilité de défaut pour chaque cote de crédit. Le modèle de logique floue peut contourner le problème de la spécification de la fonction de probabilité de défaut, mais il peut quand même estimer le niveau du risque de défaut pour chaque demande de prêt. En l’absence de modèles traditionnels, le modèle de logique floue peut représenter une solution pratique pour faciliter l’évaluation de l’exposition au risque de défaut.
Les cotes de crédit et le niveau calculé du risque de défaut sont énoncés ci-après. Après
un an, deux des dix prêts n’ont pu être remboursés comme prévu.
0.0
0.2
0.4
0.6
0.8
1.0
0 1 2 3 4 5 6 7 8 9 10
Deg
ree
of T
ruth
Membership Function of Default Risk
High Medium Low
Fonctions d’appartenance du risque de défaut
Deg
ré d
e ce
rtitu
de
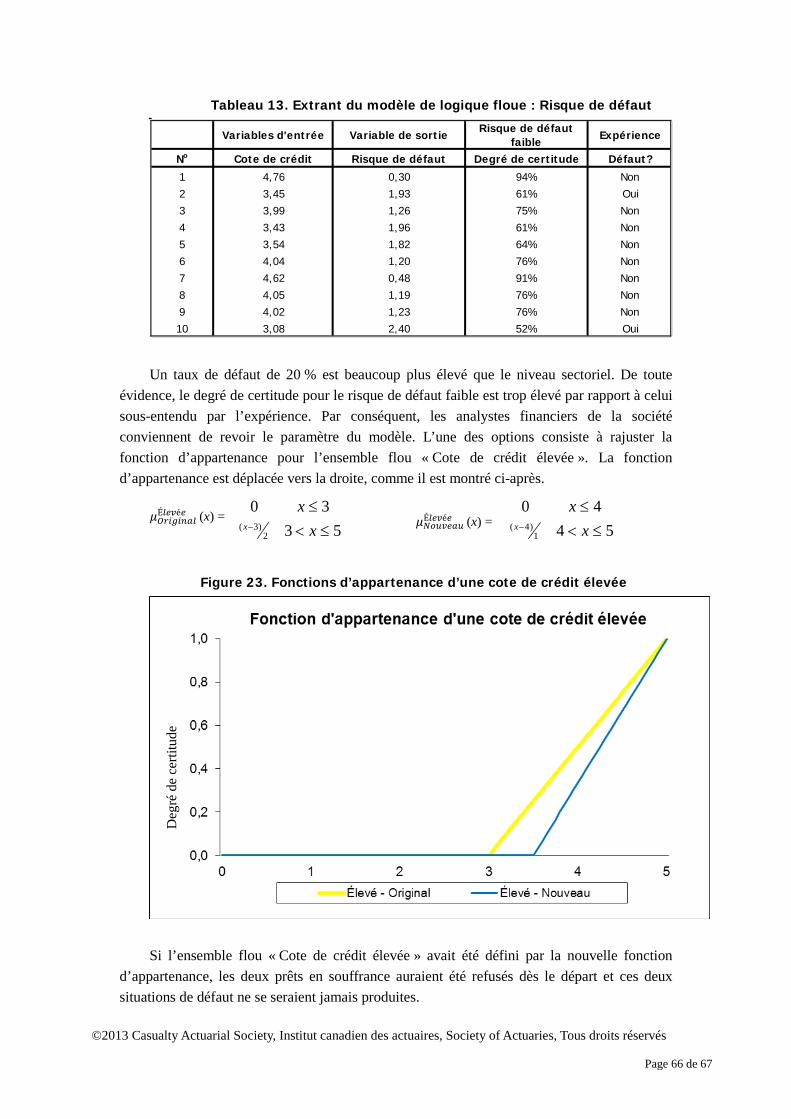
©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 66 de 67
Tableau 13. Extrant du modèle de logique floue : Risque de défaut
Un taux de défaut de 20 % est beaucoup plus élevé que le niveau sectoriel. De toute
évidence, le degré de certitude pour le risque de défaut faible est trop élevé par rapport à celui sous-entendu par l’expérience. Par conséquent, les analystes financiers de la société conviennent de revoir le paramètre du modèle. L’une des options consiste à rajuster la fonction d’appartenance pour l’ensemble flou « Cote de crédit élevée ». La fonction d’appartenance est déplacée vers la droite, comme il est montré ci-après.
Figure 23. Fonctions d’appartenance d’une cote de crédit élevée
Si l’ensemble flou « Cote de crédit élevée » avait été défini par la nouvelle fonction
d’appartenance, les deux prêts en souffrance auraient été refusés dès le départ et ces deux situations de défaut ne se seraient jamais produites.
Variables d'entrée Variable de sortie Risque de défaut faible Expérience
No Cote de crédit Risque de défaut Degré de certitude Défaut?
1 4,76 0,30 94% Non2 3,45 1,93 61% Oui3 3,99 1,26 75% Non4 3,43 1,96 61% Non5 3,54 1,82 64% Non6 4,04 1,20 76% Non7 4,62 0,48 91% Non8 4,05 1,19 76% Non9 4,02 1,23 76% Non10 3,08 2,40 52% Oui
5330
)(2
)3( ≤<≤
=− x
xx
xHighOriginalµ
5440
)(1
)4( ≤<≤
=− x
xx
xHighNewµ𝜇𝑂𝑂𝐼𝑂𝐼𝐼𝑂𝐼 É𝐼𝐼𝑙é𝐼 (x) = 𝜇𝑁𝐼𝑁𝑙𝐼𝑂𝑁
É𝐼𝐼𝑙é𝐼 (x) =
Deg
ré d
e ce
rtitu
de
©2013 Casualty Actuarial Society, Institut canadien des actuaires, Society of Actuaries, Tous droits réservés
Page 67 de 67
Tableau 14. Extrant du modèle de logique floue revu : Risque de défaut
D’autres options pour le rajustement du modèle comprennent l’ajustement des fonctions
d’appartenance pour l’ensemble de sortie et l’amélioration des règles d’inférence en ajoutant une couverture floue ou de nouvelles règles. Toutefois, le but devrait demeurer le même dans ce cas : réduire le degré de certitude pour le risque de défaut faible sous-entendu par le modèle.
Lorsque les données d’expérience suffisantes sont disponibles, davantage de modèles
améliorés pourront être utilisés pour la prise de décision concernant les prêts. Par exemple, plutôt que de s’en remettre aux opinions des experts au sujet des fonctions d’appartenance, les modèles peuvent être entièrement étalonnés selon les données d’expérience.
Passons à une autre étape. Les modèles fondés sur la théorie des probabilités peuvent
être utilisés pour remplacer le modèle de logique floue. La probabilité de défaut peut être modélisée comme fonction de la cote de crédit, ce qui permet de supprimer du modèle de logique floue le processus de modification logique floue et de clarification. La décision de prêt peut être prise d’après l’estimation de la probabilité de défaut. Par exemple, chaque prêt affichant une probabilité de défaut inférieure à 1 % peut être octroyé.
Variables d'entrée Variable de sortie Risque de défaut faible Expérience
No Cote de crédit Risque de défaut Degré de certitude Défaut?
1 4,76 0,40 92% Non2 3,45 5,00 0% Oui3 3,99 1,68 66% Non4 3,43 5,00 0% Non5 3,54 2,43 51% Non6 4,04 1,60 68% Non7 4,62 0,63 87% Non8 4,05 1,58 68% Non9 4,02 1,63 67% Non10 3,08 5,00 0% Oui





























