Embed Size (px)
Citation preview

La Méthode de mesure COSMIC de la taille fonctionnelle
Version 3.0.1
MMaannuueell ddee mmeessuurree
(Le Guide COSMIC d’implémentation pour ISO/IEC 19761: 2003).
août 2009 (français)
Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 2
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
RREEMMEERRCCIIEEMMEENNTTSS
Auteurs et Membres fondateurs de la Version 2.0 (ordre alphabétique) :
• Alain Abran, École de Technologie Supérieure – Université du Québec, • Jean-Marc Desharnais, Laboratoire de métriques appliquées en gestion du logiciel -
LMAGL, • Serge Oligny, Bell Canada • Denis St-Pierre, DSA Inc., • Charles Symons, Software Measurement Services Ltd.
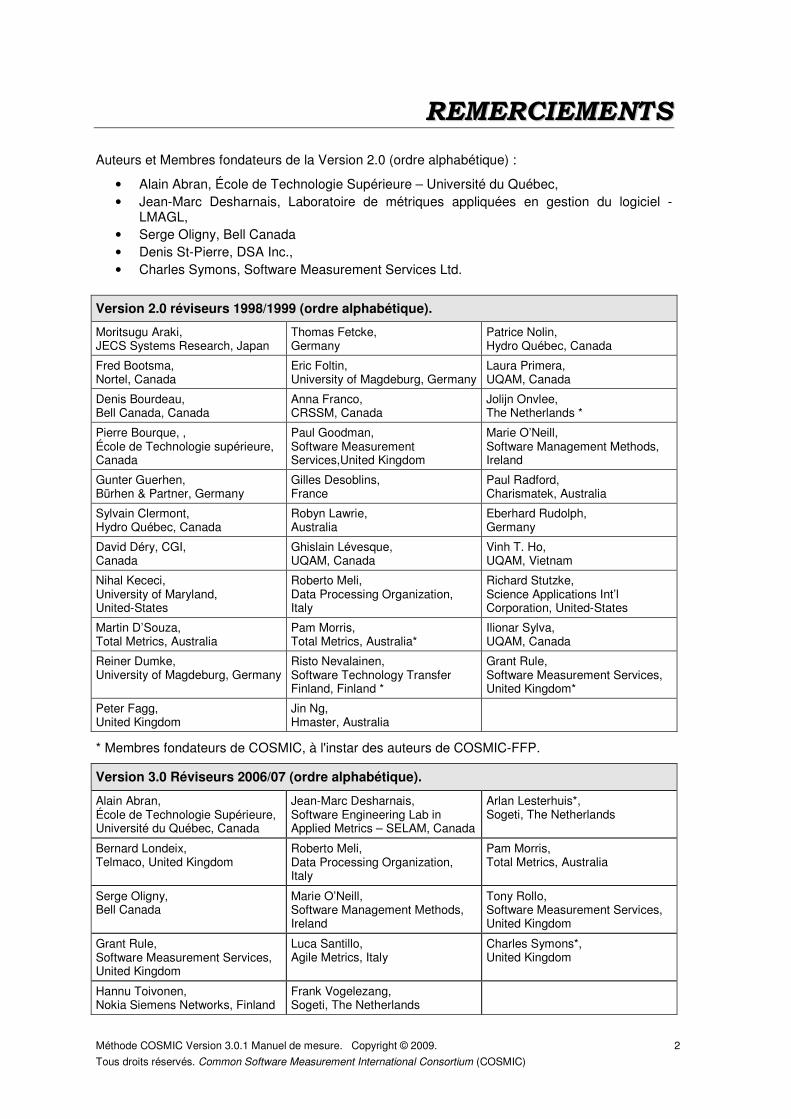
Version 2.0 réviseurs 1998/1999 (ordre alphabétique).
Moritsugu Araki, JECS Systems Research, Japan
Thomas Fetcke, Germany
Patrice Nolin, Hydro Québec, Canada
Fred Bootsma, Nortel, Canada
Eric Foltin, University of Magdeburg, Germany
Laura Primera, UQAM, Canada
Denis Bourdeau, Bell Canada, Canada
Anna Franco, CRSSM, Canada
Jolijn Onvlee, The Netherlands *
Pierre Bourque, , École de Technologie supérieure, Canada
Paul Goodman, Software Measurement Services,United Kingdom
Marie O’Neill, Software Management Methods, Ireland
Gunter Guerhen, Bürhen & Partner, Germany
Gilles Desoblins, France
Paul Radford, Charismatek, Australia
Sylvain Clermont, Hydro Québec, Canada
Robyn Lawrie, Australia
Eberhard Rudolph, Germany
David Déry, CGI, Canada
Ghislain Lévesque, UQAM, Canada
Vinh T. Ho, UQAM, Vietnam
Nihal Kececi, University of Maryland, United-States
Roberto Meli, Data Processing Organization, Italy
Richard Stutzke, Science Applications Int’l Corporation, United-States
Martin D’Souza, Total Metrics, Australia
Pam Morris, Total Metrics, Australia*
Ilionar Sylva, UQAM, Canada
Reiner Dumke, University of Magdeburg, Germany
Risto Nevalainen, Software Technology Transfer Finland, Finland *
Grant Rule, Software Measurement Services, United Kingdom*
Peter Fagg, United Kingdom
Jin Ng, Hmaster, Australia
* Membres fondateurs de COSMIC, à l'instar des auteurs de COSMIC-FFP.
Version 3.0 Réviseurs 2006/07 (ordre alphabétique).
Alain Abran, École de Technologie Supérieure, Université du Québec, Canada
Jean-Marc Desharnais, Software Engineering Lab in Applied Metrics – SELAM, Canada
Arlan Lesterhuis*, Sogeti, The Netherlands
Bernard Londeix, Telmaco, United Kingdom
Roberto Meli, Data Processing Organization, Italy
Pam Morris, Total Metrics, Australia
Serge Oligny, Bell Canada
Marie O’Neill, Software Management Methods, Ireland
Tony Rollo, Software Measurement Services, United Kingdom
Grant Rule, Software Measurement Services, United Kingdom
Luca Santillo, Agile Metrics, Italy
Charles Symons*, United Kingdom
Hannu Toivonen, Nokia Siemens Networks, Finland
Frank Vogelezang, Sogeti, The Netherlands

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 3
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
* Éditeurs de la version 3.0 et 3.0.1 de la Méthode COSMIC
Traduction Française 3.0 – 2007 (ordre alphabétique)
• Alain Abran, École de Technologie Supérieure – Université du Québec, Montréal, Canada ;
• Jean-Marc Desharnais, École de Technologie Supérieure – Université du Québec, Montréal, Canada ;
• Bernard Londeix, Telmaco Ltd, Londres, Grande-Bretagne ; • Anabel Stambollian, BTS Industrie - Conseil et Formation, Toulouse, France.
Traduction Française 3.0.1 – 2009 (ordre alphabétique)
• Jean-Marc Desharnais, École de Technologie Supérieure – Université du Québec, Montréal, Canada ;
• Bernard Londeix, Telmaco Ltd, Londres, Grande-Bretagne ; • Anabel Stambollian, BTS Industrie - Conseil et Formation, Toulouse, France.
Si vous avez des commentaires pour la traduction française, communiquez avec Jean-Marc Desharnais ([email protected])
Copyright 2009. Tous droits réservés. Le ‘Common Software Measurement International Consortium’ (COSMIC). Il est permis de copier ce document en tout ou en partie, sauf pour des avantages commerciaux, si le titre de la publication, sa date et ses auteurs sont cités et qu’une note indique que cette copie est faite avec la permission de COSMIC. Autrement, il est obligatoire d’obtenir une autorisation spécifique.
Une version publique de la documentation COSMIC, incluant les traductions, est disponible sur le site web suivant: www.gelog.etsmtl.ca/cosmic-ffp
Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 4
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
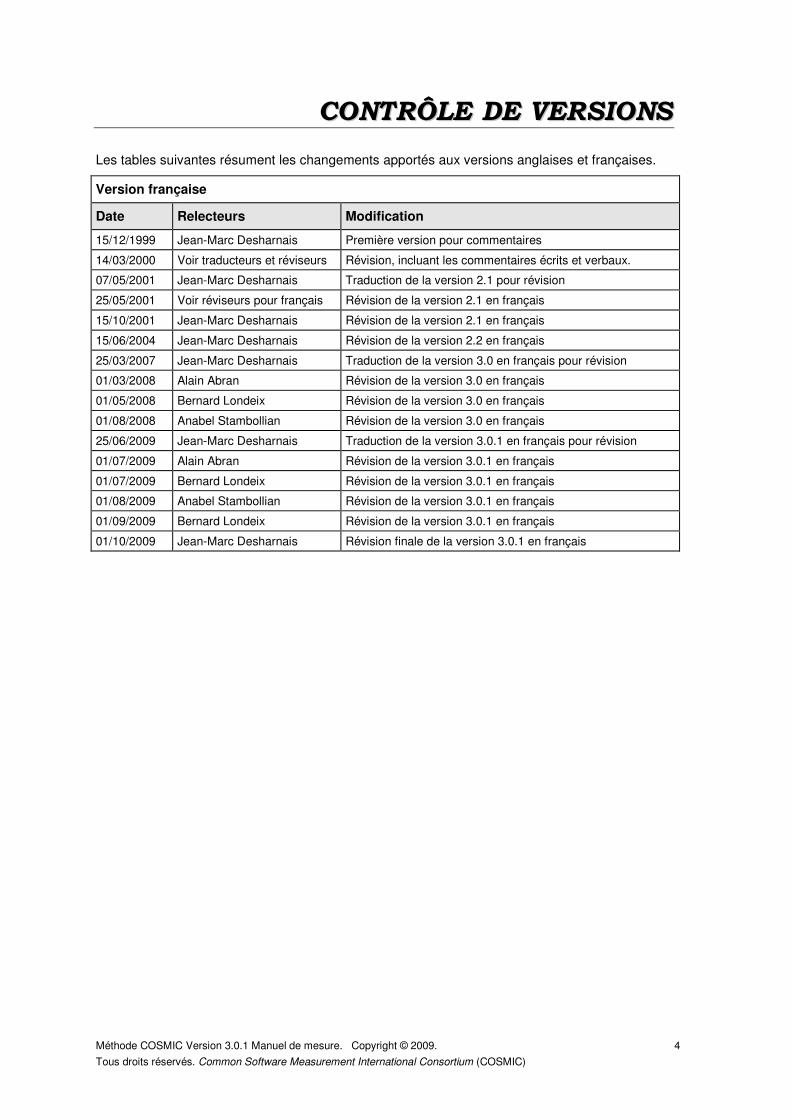
CCOONNTTRRÔÔLLEE DDEE VVEERRSSIIOONNSS
Les tables suivantes résument les changements apportés aux versions anglaises et françaises.
Version française
Date Relecteurs Modification
15/12/1999 Jean-Marc Desharnais Première version pour commentaires
14/03/2000 Voir traducteurs et réviseurs Révision, incluant les commentaires écrits et verbaux.
07/05/2001 Jean-Marc Desharnais Traduction de la version 2.1 pour révision
25/05/2001 Voir réviseurs pour français Révision de la version 2.1 en français
15/10/2001 Jean-Marc Desharnais Révision de la version 2.1 en français
15/06/2004 Jean-Marc Desharnais Révision de la version 2.2 en français
25/03/2007 Jean-Marc Desharnais Traduction de la version 3.0 en français pour révision
01/03/2008 Alain Abran Révision de la version 3.0 en français
01/05/2008 Bernard Londeix Révision de la version 3.0 en français
01/08/2008 Anabel Stambollian Révision de la version 3.0 en français
25/06/2009 Jean-Marc Desharnais Traduction de la version 3.0.1 en français pour révision
01/07/2009 Alain Abran Révision de la version 3.0.1 en français
01/07/2009 Bernard Londeix Révision de la version 3.0.1 en français
01/08/2009 Anabel Stambollian Révision de la version 3.0.1 en français
01/09/2009 Bernard Londeix Révision de la version 3.0.1 en français
01/10/2009 Jean-Marc Desharnais Révision finale de la version 3.0.1 en français

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 5
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
PPRRÉÉFFAACCEE
La Méthode COSMIC est une méthode normalisée de Mesure de la Taille Fonctionnelle d’un logiciel des domaines fonctionnels généralement désignés sous le nom logiciel d’application d'affaires (ou `MIS') et des logiciels temps réel ainsi que des hybrides de ces logiciels.
La Méthode COSMIC a été acceptée par ISO/IEC JTC1 SC7 en décembre 2002 en tant que norme internationale : ‘COSMIC-FFP:2003 – A functional size measurement method’ (ci-après désignée comme `ISO/IEC 19761').
Pour une plus grande clarté, ISO/IEC 19761 contient les définitions et les règles normatives fondamentales de la méthode. Le but du Manuel de mesure est non seulement de fournir ces règles et définitions, mais de fournir également davantage d'explications et beaucoup plus d'exemples afin d'aider les mesureurs à comprendre et à appliquer la méthode. Cependant, l’expérience des utilisateurs de la méthode s’est de plus en plus consolidée, nous avons jugé important d’ajouter des règles, des exemples et même des définitions plus élaborées pour certains concepts sous-jacents. COSMIC envisage de soumettre ces additions et améliorations à l'ISO pour les inclure dans ISO/IEC 19761 lors de la révision 2009/07.
Ce Manuel de mesure est l'un de quatre documents COSMIC qui définissent la version 3.0 de la méthode. Les autres documents sont :
• Vue d'ensemble de la documentation et glossaire (Le glossaire définit tous les termes qui sont communs à tous les documents COSMIC. Ce document décrit également d'autres documents de support tels que les études de cas et les directives des domaines spécifiques) ;
• Introduction à la méthode ; • Sujets spécialisés (Ce document traitera de sujets particuliers dans le but d'assurer la
comparabilité des mesures de taille et inclura des chapitres sur la mesure de la taille réalisée tôt dans le cycle de développement d’un logiciel ou la mesure de la taille conduite par approximation rapide. Il traitera aussi la convertibilité des mesures qui sont précédemment apparues dans la version 2.2 du Manuel de mesure).
Les lecteurs qui sont nouveaux en mesure de taille fonctionnelle, ou qui sont familiers avec une autre méthode de mesure de taille fonctionnelle, sont fortement conseillés de lire le document « Introduction à la méthode » avant de lire ce ‘Manuel de mesure’.
Principaux changements pour cette version 3.0 de la Méthode COSMIC.
Le changement de la désignation de la version de la Méthode COSMIC de 2.2 à 3.0 indique que cette version représente une avance significative par rapport à la version précédente. Cette version 3.0 de la Méthode COSMIC, contrairement à la version 2.2 du Manuel de mesure, comporte les principaux changements suivants:
• La version 3.0 de la méthode est maintenant définie dans quatre documents distincts comme mentionnés ci-dessus afin de rendre la documentation COSMIC plus facile à utiliser ;
• Les propositions des deux bulletins de mise à jour de la méthode qui ont été éditées depuis la dernière version 2.2 du Manuel de mesure ont été incorporées. Ce sont le MUB 1 ‘Améliorations proposées à la définition et aux caractéristiques d'une « couche logicielle »’ et le MUB 2 ‘Améliorations proposées à la définition d'un « objet d'intérêt »’. La version 3.0.1 ajoute trois MUB – voir annexe D);
• Une phase de « Stratégie de mesure » a été définie séparément comme la première phase du Processus de mesure. La phase de stratégie est également augmentée en présentant des conseils sur la façon de considérer le concept du "niveau de granularité" des FUR (Fonctionnalité Utilisateur Requises) du logiciel devant être mesuré, pour aider à assurer la comparabilité des mesures à travers différents morceaux de logiciel ;

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 6
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
• L'expérience a prouvé que les concepts "d'utilisateur final" et "points de vue du développeur pour la mesure", présentés dans le Manuel de mesure de la version 2.2, peuvent être remplacés par le concept plus simple "d'utilisateur fonctionnel". Ce dernier peut être librement défini en tant qu'émetteur ou destinataire des données des FUR du logiciel devant être mesuré. Toutes les mesures de taille d’un morceau de logiciel proviennent alors des fonctionnalités prévues pour les utilisateurs fonctionnels du logiciel, tel qu'identifié dans les FUR ;
• Le nom de l'unité de mesure de la méthode a été remplacé de la méthode de « mesure de la taille COSMIC (abrégé avec Cfsu) » en « Point de Fonction COSMIC (abrégé avec CFP) ». Ce changement a été fait pour faciliter la lecture et la prononciation, et pour permettre la conformité de la méthode avec d'autres méthodes de Points de Fonction. De plus, pour simplifier, le nom de la méthode a été changé de ‘COSMIC-FFP’ à ‘COSMIC’ ;
• Le glossaire a été mis à jour et augmenté pour améliorer la lisibilité et a été déplacé dans le nouveau document intitulé : Vue d'ensemble de la documentation et glossaire ;
• Une partie des informations, notamment celle concernant les concepts d'analyse de données, a été enlevée. Il est maintenant inclus dans le Guide pour évaluer la taille du logiciel d'application d'affaires en utilisant COSMIC, puisqu'il est très spécifique à ce domaine et n'est pas spécifique à la Méthode COSMIC ;
• Beaucoup d'améliorations et d’ajouts éditoriaux ont été apportés pour améliorer la cohérence de la terminologie et pour améliorer sa compréhension. Parmi ces derniers, une distinction a été faîte entre les 'principes’ et les ‘règles’ de la méthode, en adoptant une convention du domaine de la comptabilité à savoir que les 'règles’ existent pour aider l’application des définitions et des principes. Tant les ‘principes’ que les ‘règles’ devraient êtres considérés comme obligatoires. Par conséquent, la plupart des exemples ont été enlevés des énoncés de ces ‘principes’ et ‘règles’ dans le corps du texte ;
• Tous ces changements sont résumés dans l'annexe D.
Les lecteurs familiers avec la version 2.2 du Manuel de mesure verront le plus grand nombre de changements en cette version 3.0 à la nouvelle phase appelée : « stratégie de mesure ».
Conséquences des principaux changements sur les mesures de taille existantes.
Les principes originaux de la Méthode COSMIC sont demeurés inchangés depuis qu'ils ont été édités à la première ébauche du Manuel de mesure en 1999, même si des améliorations et des ajouts ont été nécessaires pour produire les versions internationales successives des normes (2.0, 2.1, 2.2, 3.0 et cette dernière version 3.0 du Manuel de mesure).
Les mesures de taille fonctionnelles, conformément aux principes et aux règles des version 3.0 et 3.0.1 du Manuel de mesure, peuvent différer des mesures de taille des versions antérieures seulement parce que les nouvelles règles visent accroître la précision de la mesure. Ainsi les mesureurs ont moins de pouvoir discrétionnaire pour interpréter les règles qu’auparavant. Les changements dans le domaine de la stratégie de mesure et le changement du nom de l'unité de mesure ont comme résultat des différences triviales dans les règles pour rapporter les résultats de mesure par rapport aux versions précédentes.
Explication des principaux changements de la version 2.2 à la version 3.0 du Manuel de mesure.
Nous devons d'abord souligner que l'unité de mesure COSMIC, le CFP, précédemment le Cfsu, demeure inchangée depuis sa première version publique du Manuel de mesure COSMIC-FFP en 1999. C'est l'équivalent COSMIC, d’une unité standard de longueur comme le mètre, par exemple. Mais la taille fonctionnelle d’un morceau de logiciel peut être mesurée de plusieurs manières et ceci est parfois un problème pour n'importe quelle méthode de Mesure de la Taille Fonctionnelle (MTF ou Functional Size Method), i.e. lorsque l’on veut répondre à la question : Quelle taille mesurons-nous?
Le premier problème connu est que n'importe quel morceau d’un logiciel fournit des fonctionnalités à différents types d’utilisateurs. Rappelons que le terme « utilisateur » est défini dans la terminologie de la norme ISO/IEC 14143/1 ('Principes du MTF') de la façon suivante : ‘tout ce qui interagit avec le logiciel mesuré'. Il s’ensuit que la taille fonctionnelle d'un morceau de logiciel dépend de ce qui (ou de quoi) est défini comme étant l’utilisateur(s).

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 7
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
Prenons par exemple une application de téléphone mobile. Si nous acceptons la définition ISO d'utilisateur littéralement, les utilisateurs d'une application d'un téléphone mobile pourraient inclure soit un humain qui utilise les boutons, soit les dispositifs de l’appareil (par exemple l'écran, les boutons, etc.) qui interagissent avec l'application; ou encore l’utilisateur pourrait être le système d'exploitation qui supporte l'application ou même les morceaux d’un logiciel séparés de même niveau, logiciel qui interagit avec l'application mesurée. Chacun des quatre types d'utilisateurs exige des fonctionnalités différentes (par conséquent la taille fonctionnelle diffère selon qui - ou quoi - est défini comme étant « utilisateur »). Alors comment, à partir d’une taille fonctionnelle particulière, savons-nous qui (personne ou chose) est l’utilisateur, c’est-à-dire quelles fonctionnalités ont été mesurées?
C'est cette problématique qui a incité le Comité de pratique des mesures ('CPM') COSMIC à présenter dans la version 2.2 du Manuel de mesure les concepts de ‘points de vue’ de l’utilisateur final et du développeur. Cependant, l'expérience a prouvé que ces définitions, en particulier la définition de la mesure du point de vue du développeur, n'étaient pas assez complètes pour aider à définir tous les besoins pour les fins de la mesure. Le CPM a conclu que l'approche correcte et la plus complète était de définir le concept d'un ‘utilisateur fonctionnel’ et que la taille fonctionnelle change selon qui (personne ou chose) est défini en tant qu'utilisateur fonctionnel. L'identification des utilisateurs fonctionnels dépend du but de la mesure. Les utilisateurs fonctionnels devraient normalement êtres identifiables à partir des Fonctionnalités Utilisateur Requises (FUR) du logiciel mesuré. L'idée de définir des points de vue spécifiques pour la mesure n'est donc plus nécessaire.
Le deuxième problème est que nous savons que les FUR évoluent pendant tout le projet et que, selon la façon dont la taille est mesurée, tout au long d’un projet cette taille peut sembler augmenter. La première version de la FUR pour un nouveau morceau de logiciel donne des spécifications de ‘haut niveau’. À mesure que le projet progresse et que les spécifications sont plus détaillées, les FUR sont aussi plus détaillés, ou sont défini à un niveau plus bas de détail. C’est alors que la taille peut sembler augmenter. Ces différents niveaux de détails sont appelés : 'niveaux de granularités'.
Ainsi, le problème qui doit être pris en compte maintenant est de se demander comment, de façon certaine, il est possible de savoir si deux mesures différentes ont été faites à un même niveau de granularité. Les versions 3.0 et 3.0.1 du Manuel de mesure fournissent des recommandations à ce sujet. Cette question est particulièrement importante quand la taille du logiciel est mesurée tôt dans le cycle de vie d'un projet logiciel alors que les FUR sont toujours en évolution. Ce sujet devient critique quand les différentes tailles du logiciel sont employées pour mesurer la performance. Les résultats des performances doivent être comparés à partir de différentes sources, entre autres, dans les exercices d’étalonnages (‘benchmarking’).
Il est important de souligner que ces nouveaux concepts « d'utilisateur fonctionnel » et de « niveau de granularité » ainsi que les procédés associés pour les déterminer tel que présentés dans la Stratégie de mesure, n'ont pas besoin d'être uniques à la Méthode COSMIC. Ils sont applicables à toutes les méthodes de mesures de taille fonctionnelle (MTF). Puisque la Méthode COSMIC est basée sur des principes établis du génie logiciel, et qu’elle est applicable à un plus grand nombre de domaines de logiciel que les méthodes de MTF de la '1ère génération ', le problème de définir correctement la taille mesurée a été reconnu et une solution a été trouvée.
La plupart des mesureurs utilisant COSMIC pour mesurer la performance (par exemple l’estimation, l’étalonnages, etc.), n'auront pas besoin de prendre trop de temps pour identifier les utilisateurs fonctionnels ni le niveau de la granularité de la mesure, puisqu'ils seront évidents. Mais pour les mesures où le choix peut ne pas être évident, la nouvelle documentation concernant 'la phase de Stratégie de la mesure' du Manuel de mesure, de même que le chapitre de la comparabilité des mesures de taille dans le document ‘Sujets spécialisés’, discutent de ces facteurs à approfondir.
Le Comité de pratique de la mesure COSMIC.
mai 2009

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 8
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
TTAABBLLEE DDEESS MMAATTIIÈÈRREESS
TABLE DES MATIÈRES
TABLE DES MATIÈRES ................................................................................................................. 8
INTRODUCTION. ........................................................................................................................... 11
1.1 Applicabilité de la Méthode COSMIC .................................................................................. 11
1.1.1 Domaines d’applicabilité. ........................................................................................... 11
1.1.2 Domaines de non applicabilité. .................................................................................. 11
1.1.3 Facteurs contribuant à la taille fonctionnelle : les limites. ......................................... 11
1.1.4 Mesure d’un très petit morceau du logiciel : les limites. ............................................ 12
1.2 Fonctionnalités Utilisateur Requises .................................................................................... 12
1.2.1 Dérivation des Fonctionnalités Utilisateur Requises pour un logiciel existant. .......... 13
1.2.2 Extraire ou dériver les Fonctionnalités Utilisateur Requises des artéfacts logiciels. .. 13
1.3 Le modèle contextuel de logiciel COSMIC .......................................................................... 14
1.4 Le modèle générique de logiciel COSMIC........................................................................... 14
1.5 Le processus de mesure COSMIC. ..................................................................................... 15
PHASE DE STRATÉGIE DE LA MESURE. .................................................................................. 16
2.1 Définir la raison d’être de la mesure. ................................................................................... 17
2.1.1 La raison d’être d'une mesure - une analogie. .......................................................... 17
2.1.2 Exemples: Raisons d’être typiques de la mesure. .................................................... 17
2.1.3 Importance des raisons d'être. .................................................................................. 18
2.2 Définition du périmètre de la mesure. .................................................................................. 18
2.2.1 Déterminer le morceau de logiciel mesuré à partir de sa raison d'être. .................... 19
2.2.2 Exemples type de morceau de logiciel. ..................................................................... 20
2.2.3 Niveau de décomposition. ......................................................................................... 20
2.2.4 Couches. .................................................................................................................... 20
2.2.5 Composants de même niveau. .................................................................................. 23
2.3 Identification des utilisateurs fonctionnels. .......................................................................... 24
2.3.1 La taille fonctionnelle varie selon les utilisateurs fonctionnels. ................................. 24
2.3.2 Utilisateurs fonctionnels. ............................................................................................ 24
2.4 Identification du niveau de granularité. ................................................................................ 26
2.4.1 Le besoin d’un niveau de granularité normalisé. ....................................................... 26
2.4.2 Clarification du niveau de granularité. ....................................................................... 27
2.4.3 La norme du niveau de granularité. ........................................................................... 28
2.5 Conclusions sur la phase de la stratégie de mesure. .......................................................... 31
PHASE D’ARRIMAGE. .................................................................................................................. 33
3.1 Application du modèle générique de logiciel. ...................................................................... 33
3.2 Identification des processus fonctionnels. ........................................................................... 34
3.2.1 Définitions. ................................................................................................................. 35
3.2.2 L’approche à l’identification d’un processus fonctionnel. .......................................... 36

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 9
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
3.2.3. Exemples dans le domaine des logiciels d’application des d’affaires. ...................... 37
3.2.4 Exemples dans le domaine des applications de type temps réel. ............................. 38
3.2.5 Autres informations sur les processus fonctionnels distincts. .................................... 38
3.2.6 Les processus fonctionnels de composants de même niveau.................................... 39
3.3 Identification des objets d’intérêts et des groupes de données. .......................................... 39
3.3.1 Définitions et principes. .............................................................................................. 39
3.3.2 À propos de la matérialisation des groupes de données. .......................................... 40
3.3.3 À propos de l’identification des objets d’intérêt et des groupes de données. ............ 40
3.3.4 Données ou groupes de données non éligible aux mouvements de données. ......... 42
3.3.5 L’utilisateur fonctionnel comme objet d’intérêt. .......................................................... 42
3.4 Identification des attributs (optionnel). ................................................................................. 42
3.4.1 Définition. ................................................................................................................... 42
3.4.2 À propos de l’association entre les attributs et les groupes de données. .................. 43
LA PHASE DE MESURE. .............................................................................................................. 44
4.1 Identification des mouvements de données. ........................................................................ 44
4.1.1 Définition des types de mouvement de données. ...................................................... 44
4.1.2 Identification des Entrées (E). .................................................................................... 46
4.1.3 Identification des Sorties (S). ..................................................................................... 47
4.1.4 Identification des Lectures (L). ................................................................................... 48
4.1.5 Identification des éCritures (C). ................................................................................. 48
4.1.6 Les manipulations des données associées aux mouvements de données. .............. 49
4.1.7 Unicité des mouvements de données et exceptions possibles14. .............................. 51
4.1.8 Lorsqu’un processus fonctionnel déplace des données de ou vers du stockage persistant. ................................................................................................................... 52
4.1.9 Lorsqu’un processus fonctionnel demande des données à un utilisateur fonctionnel. 55
4.1.10 Commandes de contrôle. ........................................................................................... 57
4.2 Appliquer la fonction de mesure. .......................................................................................... 58
4.3 Additivité des résultats de mesure. ...................................................................................... 58
4.3.1 Règles générales de l’addition. .................................................................................. 59
4.3.2 Informations supplémentaires sur l’additivité des tailles fonctionnelles. .................... 60
4.4 Informations supplémentaires sur la taille fonctionnelle de modifications logicielles ........... 60
4.4.1 Modification des fonctionnalités. ................................................................................ 61
4.4.2 Taille d’un logiciel fonctionnellement modifié. ............................................................ 62
4.5 Extension de la méthode de mesure COSMIC. ................................................................... 62
4.5.1 Introduction. ............................................................................................................... 62
4.5.2 Extension locale avec des algorithmes complexes. .................................................. 63
4.5.3 Extension locale avec des fractions d‘unité de mesure. ............................................ 63
RAPPORTER LA MESURE. .......................................................................................................... 64
5.1 Étiquetage. ........................................................................................................................... 64
5.2 Archivage des résultats de la mesure COSMIC. .................................................................. 65

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 10
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
ANNEXE A – DOCUMENTATION D’UNE MESURE DE TAILLE COSMIC. ............................... 66
ANNEXE B - SOMMAIRE DES PRINCIPES DE LA MÉTHODE COSMIC. ................................. 67
ANNEXE C – SOMMAIRE DES RÈGLES DE LA MÉTHODE COSMIC. ..................................... 71
ANNEXE D – HISTORIQUE DES MISES À JOUR DE LA MÉTHODE COSMIC. ....................... 79
De la version 2.2 à la version 3.0 ................................................................................................... 79
De la version 3.0 à la version 3.0.1 ................................................................................................ 82
Sommaire des modifications majeures .......................................................................................... 83
ANNEXE E - DEMANDE DE CHANGEMENTS ET COMMENTAIRES : PROCÉDURE. ............ 85

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 11
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
11 INTRODUCTION.
1.1 Applicabilité de la Méthode COSMIC
1.1.1 Domaines d’applicabilité.
La Méthode de mesure COSMIC a été conçue pour être appliquée aux fonctionnalités des logiciels des domaines suivants :
• Logiciels d’application d’affaires, tels les logiciels typiques aux domaines des banques, des assurances, de la comptabilité, du personnel, des achats, de la distribution et de la production, entre autres. Ce type de logiciel est « riche en données », et sa complexité est surtout liée au besoin de faire le lien entre les nombreuses données et événements du monde réel ;
• Logiciels de type temps réel, dont la tâche est de garder le contrôle des événements du monde réel. Voici quelques exemples : les logiciels d'échanges téléphoniques et d'interruptions des messages, les logiciels embarqués dans des dispositifs de contrôle de différents appareils, tels les appareils électroménagers ou encore les moteurs d'ascenseur ou d'automobiles, des logiciels servant au contrôle de processus et à l'acquisition de données automatiques, ou finalement, des logiciels à l'intérieur des systèmes d'exploitation des ordinateurs ;
• Logiciels hybrides (d’affaire & temps réel) tels les logiciels de réservations d'avions ou d'hôtels, en temps réel.
1.1.2 Domaines de non applicabilité.
La Méthode de mesure COSMIC n'a pas été conçue pour le moment, pour prendre en compte la taille fonctionnelle des logiciels ou morceaux de logiciels qui sont caractérisés par des algorithmes mathématiques complexes ou par d'autres règles spécialisées ou complexes telles que l'on peut trouver dans les systèmes experts, systèmes de simulation, systèmes d'auto apprentissage, systèmes de prévision de la météo, etc. Les variables de processus continus tels que les fichiers audio ou vidéo, comme ceux trouvés par exemple dans les jeux logiciels, dans les instruments de musique et ainsi de suite.
Pour des logiciels ayant ces fonctionnalités, il est possible de définir des extensions locales à la Méthode de mesure COSMIC. Le Manuel de mesure explique dans quels contextes ces extensions locales pourraient être utilisées et fournit un exemple d'une de ces règles. Lorsqu‘utilisées, ces règles d'extension locales doivent être documentées en suivant les conventions présentées dans le chapitre sur la documentation des mesures du Manuel de mesure.
1.1.3 Facteurs contribuant à la taille fonctionnelle : les limites.
De plus, dans son domaine d'applicabilité, la méthode de Mesure de la Taille Fonctionnelle COSMIC ne vise pas à mesurer tous les aspects possibles de la fonctionnalité contribuant à la ‘taille’ du logiciel. Cela dit, ni l'influence de la ‘complexité' (quel que soit sa définition), pas plus que l'influence du nombre d'attributs par mouvement de données sur la taille fonctionnelle du logiciel ne sont saisies par cette méthode de mesure (concernant le nombre d’attributs, voir le chapitre sur la phase de ‘mappage’ du Manuel de mesure). Tel que décrit dans la section 1.1.2, dans certains cas où c’est souhaitable, il est possible de tenir compte de tels aspects de taille fonctionnelle par des règles d’extension locales ajoutées à la méthode de mesure COSMIC.

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 12
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
1.1.4 Mesure d’un très petit morceau du logiciel : les limites.
Toutes les méthodes de Mesure de la Taille Fonctionnelles sont fondées sur l’hypothèse qu’un modèle de la fonctionnalité d’un logiciel simplifié est prévue tenir compte d’une fonctionnalité ‘moyenne’ pour son domaine d’application prévu. La prudence est donc de mise lors de la mesure, de la comparaison ou de l’utilisation (par exemple pour l’estimation) des tailles des morceaux d’un logiciel très petits, et plus particulièrement des changements très petits où l’hypothèse concernant cette 'moyenne' peut être fausse. Dans le cas de la Méthode COSMIC, ‘très petit’ veut dire qu’il s’agit de quelques mouvements de données.
1.2 Fonctionnalités Utilisateur Requises
La Méthode de mesure COSMIC implique qu’un ensemble de modèles, de principes, de règles et de processus soient appliqués aux Fonctionnalités Utilisateur Requises (FUR) d’un morceau de logiciel donné. Selon la Méthode COSMIC, le résultat est une 'valeur numérique d'une quantité' (tel que défini par ISO) représentant la taille fonctionnelle du morceau du logiciel.
La Méthode de mesure COSMIC a été conçue pour être indépendante des décisions de réalisation et de mise en œuvre telles qu’implémentées dans les artéfacts opérationnels du logiciel à mesurer. La fonctionnalité est concernée par 'le traitement de l'information que le logiciel doit exécuter pour ses utilisateurs’.
Plus précisément, une déclaration de FUR décrit la fonctionnalité que le logiciel doit offrir pour les utilisateurs fonctionnels, qui sont les émetteurs et les destinataires prévus des données qui vont et viennent du logiciel. Une description de FUR exclut toutes les conditions techniques ou de qualité qui indiquent 'comment’ le logiciel doit s’exécuter. (Pour la définition formelle de la FUR, voir la section 2.2.). Seulement les FUR sont prises en considération en mesurant la taille fonctionnelle.
Extraire, dans la pratique, les Fonctionnalités Utilisateur Requises à partir d’artéfacts logiciels.
En pratique, lors du développement de logiciels, il est rare de trouver les artéfacts logiciels pour lesquels les FUR soient clairement distingués des autres types d’exigences ou qui soient exprimés directement dans une forme appropriée à la mesure. Ceci signifie que le mesureur doit habituellement extraire les FUR des exigences existantes ou implicites, des artéfacts logiciels fournis, avant de les arrimer aux concepts de modèle de logiciel COSMIC.
Tels qu'illustrés à la figure 1.2.1 ci-dessous, les FUR peuvent être dérivées des artéfacts du génie logiciel qui sont produits avant même l'existence du logiciel (typiquement des artéfacts de l'architecture et de la conception). Ainsi, la taille fonctionnelle d'un logiciel peut être mesurée avant que le logiciel ne soit réalisé.
Figure 1.2.1 – Le modèle COSMIC avant l’implantation des FUR
Il est important de noter que les objets façonnés avant que le logiciel soit mis en application, par exemple pendant la collecte ou l'analyse des exigences, peuvent décrire le logiciel à différents ‘niveaux de granularité' alors que les conditions évoluent - voir la section 2.4 pour en savoir plus.
REMARQUE : Les exigences fonctionnelles des utilisateurs peuvent être produites avant qu'elles soient assignées au matériel ou au logiciel. Puisque la Méthode COSMIC vise à établir la taille de

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 13
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
la FUR d'un morceau d’un logiciel, seulement les FUR assignées au logiciel sont mesurées. Cependant, en principe, la Méthode COSMIC peut être appliquée à la FUR avant que les FUR soient assignées au logiciel ou au matériel, et ce, indépendamment de la décision d'attribution éventuelle. Par exemple, il est possible de classer assez directement les fonctionnalités d’une calculette avec COSMIC sans qu’il soit nécessaire de connaître le matériel ou le logiciel (si présent) impliqué. Cependant, l'affirmation que la Méthode COSMIC peut être utilisée pour évaluer la taille des FUR assignées au matériel, nécessite davantage d'essais pratiques avant de considérer sa validité sans qu’il soit nécessaire d’appliquer plus de règles.
1.2.1 Dérivation des Fonctionnalités Utilisateur Requises pour un logiciel existant.
Dans d'autres circonstances, une certaine partie existante du logiciel peut devoir être mesurée sans qu’il y ait, ou presque pas, d’artéfacts logiciel de disponible, soit d'architecture ou de conception, et la FUR pourrait ne pas être documentée (par exemple, pour des anciennes applications). Dans de telles circonstances il est encore possible de dériver les FUR des artéfacts installés sur le système informatique, i.e. après que le logiciel ait été mis en opération tel qu'illustré à la figure 1.2.2 ci-dessous. On peut les extraire des interfaces personne / machine, des rapports, ou encore en examinant les flux de données du logiciel en question.
Figure 1.2.2 – Le modèle COSMIC après l’implantation des FUR
1.2.2 Extraire ou dériver les Fonctionnalités Utilisateur Requises des artéfacts logiciels.
Le processus pour extraire une FUR changera évidemment selon les types d'artéfacts, soit directement à partir des artéfacts du logiciel fournis, soit dérivé à partir du logiciel installé, mais tous dans le but de les exprimer sous forme de modèle de logiciel COSMIC. De tels processus sont dépendants du domaine et changent trop souvent pour qu’ils puissent être traités par la Méthode COSMIC. COSMIC suppose que les FUR du logiciel à mesurer existent ou peuvent être extraites ou dérivées de ses artéfacts. Cependant, COSMIC suggère également des directives spécifiques à un domaine, en décrivant quelques techniques pour dériver les FUR.
La Méthode COSMIC se limite donc à décrire et à définir les concepts des modèles de logiciel COSMIC, c’est à dire, l’objectif principal du processus d'extraction ou de dérivation1. Ces concepts sont inclus dans les deux modèles de logiciel COSMIC : le modèle contextuel de logiciel et le modèle générique de logiciel.
Ces deux modèles sont décrits dans le document d’’Introduction à la Méthode COSMIC’. Les lecteurs ayant besoin d’une explication générale et d'une justification pour ces modèles pourront se référer á ce document. Les modèles sont copiés ci-dessous pour des raisons de commodité et sont élaborés en détail respectivement aux chapitres 2 et 3 du Manuel de mesure.
1 Le Guide de mesure de la taille des applications logicielles d’affaires utilisant COSMIC donne des conseils sur l’arrimage des données d’analyse et des exigences utilisées dans le domaine des applications d’affaires sur les concepts COSMIC.
Fonctionnalités Utilisateur Requises
(FUR)
DocumentDocumentProgrammes physiques
Manuels de procédures et d’opérations logiciels
Artefact de stockage physique des données

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 14
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
1.3 Le modèle contextuel de logiciel COSMIC
Un morceau de logiciel à mesurer, doit être défini avec soin (dans le périmètre de la mesure) et cette définition doit tenir compte du contexte de tous les logiciels et matériels avec lesquels il interagit. Ce modèle contextuel de logiciel introduit les principes et concepts nécessaires à cette définition.
REMARQUE: certains termes sont présentés en caractère gras lorsque utilisés pour la première fois dans les sections 1.3 et 1.4. La signification de ces termes peut être spécifique à la Méthode COSMIC. Pour les définitions formelles, voir le glossaire dans le document Vue d'ensemble de la documentation et glossaire. Tous ces termes sont expliqués en détail dans les chapitres 2, 3 et 4 du présent document.
Les concepts du ‘Modèle de contexte du logiciel’ sont élaborés dans le chapitre 2 du Manuel de mesure : Stratégie de la mesure.
PRINCIPES – Le modèle contextuel de logiciel COSMIC
a. Le logiciel est limité par le matériel ; b. Le logiciel est typiquement structuré en couches ; c. Une couche peut contenir un ou plusieurs morceaux de logiciel, de même niveau mais
distincts, et tout morceau de logiciel peut aussi être construit au moyen de composants de même niveau mais distincts ;
d. Tout morceau de logiciel à mesurer doit être défini par un périmètre de mesure, lequel doit aussi être entièrement compris à l’intérieur d’une seule couche de logiciel ;
e. La périmètre du morceau de logiciel à mesurer doit dépendre de la raison d’être de la mesure ;
f. Les utilisateurs fonctionnels doivent être identifiés à partir des Fonctionnalités Utilisateurs Requises (FUR) du morceau de logiciel à mesurer comme les émetteurs et/ou les destinataires visés pour les données ;
g. Un morceau de logiciel interagit avec ses utilisateurs fonctionnels via les mouvements de données à travers la frontière. Ce morceau de logiciel peut déplacer les données vers et à partir d’un stockage persistant situé à l’intérieur de la frontière du logiciel ;
h. La FUR d’un logiciel peut être exprimée à différents niveaux de granularité ; i. Le niveau de granularité auquel les mesures doivent normalement être effectuées, est celui
du processus fonctionnel (voire section 2.2.3) ; j. S’il n’est pas possible de mesurer à partir du niveau de granularité du processus fonctionnel,
alors la FUR du logiciel doit être mesurée d’une manière approximative, et échelonnée selon le niveau de granularité des processus fonctionnels2.
1.4 Le modèle générique de logiciel COSMIC
Après avoir interprété la FUR du logiciel à mesurer en fonction du modèle contextuel de logiciel, nous pouvons maintenant appliquer le Modèle Générique de logiciel à la FUR pour identifier les composants de la fonctionnalité à mesurer. Ce Modèle Générique sous-entend que les principes généraux suivants sont valables pour toute mesure du logiciel utilisant cette méthode. Voir le glossaire dans le document Vue d'ensemble de la documentation et glossaire pour la définition de tous les termes en caractère gras3.
Les concepts du Modèle Générique de logiciel sont élaborés dans le chapitre 3 (Phases d’Arrimage) du Manuel de mesure.
Quand les FUR devant être mesurées ont été arrimées à partir du modèle générique de logiciel, elles peuvent être mesurées en utilisant les processus expliqués dans ‘Phase de la mesure’ (chapitre 4). Les résultats de mesure doivent être rapportés selon les conventions de rapportage de la mesure (chapitre 5).
2 Le sujet d’échelonnage entre les différents niveaux de granularité est présenté dans le document : Sujets spécialisés de COSMIC

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 15
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
3 Comme mentionné dans le Glossaire, toute méthode de mesure de taille fonctionnelle vise à identifier les ‘types’ et non les ‘occurrences’ des données ou fonctions. Dans ce texte, le suffixe ‘type’ sera donc omis lorsque les concepts de base de COSMIC seront mentionnés, sauf lorsqu’il sera essentiel de distinguer les ‘types’ des ‘occurrences’.
1.5 Le processus de mesure COSMIC.
Le processus général de mesure COSMIC comprend trois phases:
• La phase de la stratégie de mesure (phase 1) : Dans laquelle le modèle contextuel de logiciel est appliqué au logiciel devant être mesuré (Chapitre 2) ;
• La phase d’arrimage (phase 2) : Dans laquelle le modèle générique de logiciel est appliqué au logiciel devant être mesuré (Chapitre 3) ;
• La phase de mesure (phase 3) : Dans laquelle les mesures de taille sont obtenues (Chapitre 4).
Les résultats obtenus après avoir appliqué le processus de mesure sur un morceau d’un logiciel est une mesure de taille fonctionnelle du logiciel, exprimée en Points de Fonction COSMIC (CFP).
Les relations entre les trois phases de la Méthode COSMIC sont montrées à la figure 1.5 :
Figure 1.5 – Structure de la Méthode COSMIC.
Fonctionnalité Utilisateur Requise (FUR) de l’artefact du logiciel devant être mesuré
CHAP. 3 Phase 1
Stratégie de mesure
Processus de Mesure
Model Générique de logiciel
Raison d’être de la mesure. Périmètre de chaque morceau de logiciel devant être mesuré
Buts
Model contextuel de logiciel
CHAP. 4 Phase 2
Arrimage
CHAP. 5 Phase 3 Mesure
FUR sous sa forme de Model Générique de logiciel
Taille fonctionnelle du logiciel mesuré
en unités CFP

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 16
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
22 PHASE DE STRATÉGIE DE LA MESURE.
Ce chapitre aborde les quatre principaux paramètres de la mesure de la taille fonctionnelle du logiciel qui doivent être considérés, et ce avant même de commencer le processus de la mesure. Ces quatre paramètres sont : la raison d’être de la mesure, le périmètre de la mesure, l'identification des utilisateurs fonctionnels et le niveau de granularité auquel la mesure doit être faite. La définition de ces paramètres aide à aborder les questions telles que… : Quelle est la taille qui devrait être mesurée? Ou encore, pour une mesure existante : Comment devrions-nous interpréter cette mesure?
Il est important de noter que ces quatre paramètres et leurs concepts associés ne sont pas spécifiques à la mesure de la taille fonctionnelle (MTF) de la méthode COSMIC , mais devraient être communs à toutes les méthodes de MTF.. Les autres méthodes de MTF pour leur part, ne distinguent pas, les différents types d'utilisateurs fonctionnels ou les différents niveaux de granularité, etc. Seule la méthode COSMIC, dont le champ d’action est plus étendu et plus flexible, exige que ces paramètres soient considérés avec davantage de précautions que pour les autres méthodes de MTF.
Il est très important d'enregistrer les données résultant de cette phase de stratégie de la mesure (énumérées dans la section 5.2) lors de l’enregistrement du résultat de n'importe quelle mesure. Manquer de définir et d’enregistrer ces paramètres uniformément mènera à des mesures qui ne peuvent pas être interprétées correctement et ne pouvant être comparées, ou encore, ne pouvant être employées comme entrée pour des processus tel l’estimation de l'effort d’un projet.
Les quatre sections de ce chapitre donnent les définitions formelles, les principes, les règles et quelques exemples pour chacun des paramètres principaux pour aider le mesureur à travers le processus de détermination de la stratégie de la mesure, tel que montrée au schéma 2.0 ci-dessous.
Chaque section donne des explications contextuelles sur la raison d’être de l’importance des paramètres clefs, en utilisant des analogies pour montrer pourquoi les paramètres ne sont pas questionnés dans d'autres domaines de la mesure, et par conséquent doivent également êtres considérés dans le domaine de la Mesure de la Taille Fonctionnelle du logiciel.
Figure 2.0 – Le processus de détermination de la stratégie de mesure.

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 17
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
2.1 Définir la raison d’être de la mesure.
DÉFINITION – Raison d’être de la mesure.
Un énoncé qui définit pourquoi une mesure est exigée, et comment le résultat sera employé.
2.1.1 La raison d’être d'une mesure - une analogie.
Il y a plusieurs raisons de vouloir mesurer la taille fonctionnelle d’un logiciel, tout comme il y a plusieurs raisons de vouloir mesurer par exemple, la superficie d'une maison. Quand la raison est d'estimer le coût d'un nouveau développement de logiciel, il pourrait être nécessaire de mesurer la taille fonctionnelle du logiciel avant son développement, tout comme il pourrait être nécessaire de mesurer la superficie d'une maison avant sa construction pour en estimer son coût. Dans un contexte différant par exemple, en devant comparer les coûts réels et estimés, il pourrait être nécessaire de mesurer la taille fonctionnelle du logiciel une fois mis en opération, juste il pourrait être utile de mesurer la superficie d'une maison après sa construction pour vérifier que les dimensions réelles s’apparentent aux plans. La raison pour laquelle une mesure est prise a donc un impact sur la mesure, quoique parfois subtile, sur ce qui est mesuré, sans affecter l'unité de mesure ou les principes de mesure.
Comme dans l'exemple de la superficie d’une maison ci-dessus, la mesure de la superficie avant la construction est évidemment basée sur les plans de bâtiment. Les dimensions exigées (longueur et largeur) sont extraites à partir des plans en utilisant des conventions préétablies de graduation et la superficie est calculée selon ces conventions bien établies.
De même, la Mesure de la Taille Fonctionnelle d’un logiciel avant son développement est basée sur les exigences fonctionnelles des utilisateurs du logiciel, qui sont dérivées de ses plans ; c’est-à-dire les artéfacts logiciels fabriqués avant son développement. Les Fonctionnalités Utilisateur Requises sont dérivées de ces artéfacts façonnés, en utilisant des conventions appropriées. Les dimensions exigées (le nombre de transferts de données) sont alors identifiées de sorte que la taille du logiciel puisse être calculée.
Pour poursuivre l'analogie de maison, mesurer sa superficie après sa construction nécessite un processus de mesure quelque peu différent d’avant sa construction. Maintenant, les dimensions exigées (longueur et largeur) sont extraites à partir du bâtiment, à l'aide d'un outil différent telle une bande de mesure. Cependant, bien que l'objet physique mesuré diffère (la « maison » plutôt que ses « plans »), les dimensions, l'unité de mesure ou toutes autres conventions (y compris la graduation) de même que tous les principes de mesure, restent inchangés.
Pareillement, la Mesure de la Taille Fonctionnelle du logiciel après que ce logiciel soit mis en production, nécessite un processus de mesure quelque peu différent. Les dimensions exigées sont extraites à partir de divers artéfacts du logiciel lui-même. Bien que la nature de ces artéfacts diffère, les dimensions, l'unité de mesure et les principes de mesure, demeurent les mêmes.
Il appartient au mesureur, compte tenu du but de sa mesure, de déterminer si l'objet à mesurer est la maison telle que décrite verbalement par son propriétaire, la maison telle que décrite par les plans ou la maison elle-même, et ce pour choisir l’artéfact les plus appropriés à la raison d’être de sa mesure. Dans cet exemple, il apparaît clairement que les trois tailles peuvent être différentes. Le même raisonnement s'applique à la mesure du logiciel.
2.1.2 Exemples: Raisons d’être typiques de la mesure.
Mesurer la taille d’une FUR comme elle se développe, en tant qu’entrée à un processus d’estimation ;
• Mesurer la taille des modifications apportées à une FUR après qu’elles aient été initialement acceptées, afin de contrôler l’ampleur des déviations incontrôlées dans un projet ;
• Mesurer la taille d’une FUR d’un logiciel livré pour l’utiliser comme entrée dans la mesure de la performance du développeur ;

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 18
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
• Mesurer la taille de la FUR de la totalité du logiciel livré, de même que la taille de la FUR du logiciel qui a été développée, afin obtenir une mesure de réutilisation fonctionnelle ;
• Mesurer la taille de la FUR d’un logiciel existant pour l’utiliser comme entrée dans la mesure de la performance des responsables de maintenance et support de ce logiciel ;
• Mesurer la taille de la FUR de certaines modifications apportées à un logiciel existant comme mesure de la taille du travail d'une équipe de projet en maintenance ;
• Mesurer la taille de la fonctionnalité d‘un logiciel existant fourni par des utilisateurs fonctionnels humains.
2.1.3 Importance des raisons d'être.
La raison d'être de la mesure est d'aider le mesureur à déterminer:
• Le périmètre de la mesure, et de là, les artéfacts qui seront utiles pour la mesure ; • L‘utilisateur fonctionnel : La taille fonctionnelle change selon la définition de l’utilisateur
fonctionnel (personne ou chose) tel qu’indiqué en 2.3 ; • Le moment dans le cycle de vie du projet quand la mesure aura lieu ; • La précision qui sera demandée et de là, si la Méthode COSMIC doit être employée, ou si
une version d’approximation locale, tirée de la méthode de COSMIC doit plutôt être employée (par exemple au début d’un cycle de vie d’un projet, avant que la FUR ne soit entièrement élaborée). Ces deux derniers points détermineront le niveau de granularité de la mesure du FUR.
2.2 Définition du périmètre de la mesure.
DÉFINITION – Périmètre de la mesure.
C’est l'ensemble des Fonctionnalités Utilisateur Requises (FUR) qui doivent être incluses dans une occurrence spécifique de mesure de taille fonctionnelle.
REMARQUE : une distinction doit être faite entre le ‘périmètre global’, i.e. tout le logiciel qui doit être mesuré selon la raison d’être de la mesure, et le ‘périmètre, de chaque morceau de logiciel à l’intérieur de cette raison d’être globale, et pour lequel la taille doit être mesurée séparément. Dans le Manuel de mesure, le terme ‘périmètre’ (ou l’expression ‘périmètre de la mesure’) sera relié à tout morceau de logiciel dont la taille doit être mesurée séparément.
Les Fonctionnalités Utilisateur Requises (FUR) sont définies de la façon suivante par ISO:
DÉFINITION – Fonctionnalités Utilisateur Requises (FUR).
Un sous-ensemble des besoins de l’utilisateur. Les besoins qui décrivent ce que le logiciel doit accomplir, en termes de tâches et service. Note : les Fonctionnalités Utilisateur Requises sont liées mais ne sont pas limitées au :
• Transfert de données (exemple: données d’entrée du client, envoyer un signal de contrôle) ;
• Transformation de données (exemple: calculer l’intérêt bancaire, déterminer la température moyenne) ;
• Stockage de données (exemple: emmagasiner la commande de l’usager, enregistrer la température ambiante sur une période) ;
• Extraction des données (exemple : liste (actuelle) des employés actuels, récupérer la position de l’avion).
Exemples de Requis Utilisateur qui ne sont pas des Fonctionnalités Utilisateur Requises qui incluent, mais ne sont pas limités, à des:
• Contraintes de qualité (exemple: utilisabilité, fiabilité, efficience et portabilité);
• Contraintes organisationnelles (exemple: locations pour opération, matériel cible et conformité aux normes) ;

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 19
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
• Contraintes environnementales (exemple: interopérabilité, sécurité, protection de la vie privée et sécurité) ;
• Contraintes d’implémentation (exemple: langage de développement, cédule de livraison).
RÈGLE – Périmètre.
a. Le périmètre d'une Mesure de la Taille Fonctionnelle (MTF) doit être dérivé de la raison d’être de la mesure ;
b. Le périmètre de toute mesure ne doit pas couvrir plus d'une couche du logiciel à mesurer.
2.2.1 Déterminer le morceau de logiciel mesuré à partir de sa raison d'être.
Il est important de définir le périmètre de la mesure avant de débuter un exercice particulier de mesure.
Pour continuer avec l'analogie de la construction d’une maison, il pourrait être nécessaire, si la raison d’être de la mesure est l’estimation du coût, de mesurer la taille des différentes parties de la maison séparément, par exemple les fondations, les murs et le toit, étant données que différentes méthodes de construction sont employées pour ces différentes parties. La même chose est vraie pour l’estimation des coûts de développement d’un logiciel.
Si le logiciel à développer se compose de morceaux qui résideront dans différentes couches de l'architecture d’un système, alors la taille du logiciel doit être mesurée séparément pour chacune des couches, c‘est à dire, que chaque morceau aura un périmètre distinct pour la mesure de la taille. Ceci découle du principe (d) du Modèle de contextuel de logiciel. (Pour en savoir plus sur les couches, voir la section 2.2.4 ci-dessous.)
De même, si le logiciel doit être développé comme un ensemble de composants de même niveau résidant dans une seule et même couche, chacun utilisant des technologies différentes, il sera alors nécessaire de définir un périmètre de mesure séparé pour chaque composant avant de mesurer leurs tailles. Ce sera nécessaire, par exemple, si les différentes technologies à être utilisées étaient associées à différents résultats de productivité de développement. (Pour en savoir plus sur des composants de même niveau voir la section 2.2.4 ci-dessous).
EXEMPLE 1: Si, pour chaque morceau d’un logiciel, on utilise une technologie ou un langage de développement différent et que l’on doit mesurer ce logiciel pour en estimer les efforts de développement, alors des périmètres de mesure différents devront aussi être définis pour chacun de ces morceaux de logiciel. Chaque résultat de MTF sera alors associé à un niveau de productivité de développement différent. (Pour plus d'informations sur les morceaux de même niveau, voir la section 2.2.5 ci-dessous.)
La raison d'être permettra également de décider quelles parties du logiciel devront être incluses et exclues du champ de la mesure du morceau du logiciel.
EXEMPLE 2: Si la raison d'être est de mesurer la taille fonctionnelle de l'ensemble des logiciels livrés par une équipe de projet, il sera d'abord nécessaire de définir les FUR de l'ensemble des différents morceaux ou composants de logiciel destinés à être livrés par l'équipe. Il pourrait s'agir de FUR d'un morceau de logiciel qui a été utilisée une seule fois pour convertir les données d'un logiciel par exemple.
EXEMPLE 3: Si la raison d'être est de mesurer la taille fonctionnelle d’un nouveau logiciel disponible et opérationnel, la taille du morceau de logiciel sera alors plus petite, puisque la FUR du logiciel opérationnel n’inclura pas le morceau de logiciel qui a été utilisée une seule fois pour convertir les données de l’exemple 2, dans son périmètre.
En résumé, la raison d’être de la mesure doit toujours être employée pour déterminer (a) quel logiciel est inclus ou exclus du périmètre global et (b) la manière dont le logiciel qui est inclus, peut devoir être divisé en morceaux séparés, chacun avec son propre périmètre, afin d’être mesuré séparément.

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 20
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
2.2.2 Exemples type de morceau de logiciel.
EXEMPLES:
• Un portfolio d’entreprise ; • Un énoncé d’exigences accepté contractuellement ; • Les livrables d’une équipe (c.-à-d. tout ce qui est obtenu en exploitant des paramètres
existants du logiciel livré, les produits logiciels achetés et le code réutilisable, tous les logiciels utilisés pour la conversion de données mais dont on a disposé par la suite, de même que les utilitaires et essais développés spécifiquement pour ce projet) ;
• Tous les logiciels d’une couche ; • Un progiciel ; • Une application ; • Un composant majeure de l‘application (de même niveau) ; • Une classe objet réutilisable ; • Tous les changements requis pour la nouvelle version d'un morceau de logiciel existant ;
Dans la pratique, un énoncé de périmètre doit être explicite plutôt que générique, par exemple le résultat du développement de l’équipe 'A' du projet, ou l'application 'B', ou le portfolio de l'entreprise 'C'. L’énoncé du périmètre peut également, pour la clarté, avoir besoin d'énoncer ce qui est exclu.
2.2.3 Niveau de décomposition.
Noter que certains périmètres 'de type générique’ énumérés plus tôt correspondent à différents 'niveaux de décomposition' du logiciel, définis comme suit ;
DÉFINITION – Niveau de décomposition.
N’importe quel niveau de logiciel résultant de la division d'un morceau de logiciel en plusieurs composants (de «Niveau 1», par exemple), puis par la division de composants en sous-composants («niveau 2»), puis par la division des sous-composants en sous-sous-composants (« niveau 3 »), etc.
NOTE 1: ne pas confondre avec le « niveau de granularité »
NOTE 2: Les mesures de la taille des composants d'un morceau de logiciel peuvent être directement comparables seulement pour les composants de même niveau, entre eux, c'est-à-dire des composants du même niveau de décomposition.
Par exemple, un portfolio d'applications pourrait être composé d'applications multiples, où chacune pourrait aussi se composer ‘de composants principaux’ (de même niveau), et ensuite encore, où chacun serait aussi composé de ‘classes réutilisables d'objets’.
La détermination du périmètre de la mesure peut donc être une question de retenir les fonctionnalités devant faire partie de la mesure. La décision peut également impliquer la notion de niveaux de décomposition du logiciel pour lequel on voudrait faire la mesure. C'est une décision importante de stratégie de mesure, dépendante de la raison d’être de la mesure. Une des conséquences de cette décision par exemple, est que des mesures prises à différents niveaux de décomposition ne peuvent être facilement comparées. Comme on le verra dans la section 4.3.1 règle g), ceci est dû au fait que la taille de tout morceau de logiciel ne peut pas être obtenue en faisant la somme des tailles de ses composants.
2.2.4 Couches.
Puisque le périmètre d'un morceau de logiciel à mesurer doit être confinée à une seule couche de logiciel, le processus de définir le périmètre peut exiger que le mesureur doive d’abord décider de ce que sont les couches de son système logiciel. Dans cette section nous définirons et discuterons des 'couches’ et des composants de même niveau du logiciel, puisque ces termes sont employés dans la Méthode COSMIC.

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 21
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
Il existe des raisons précises pour justifier ces définitions et ces règles. Les voici :
• Le mesureur peut avoir à mesurer un logiciel dans un environnement ‘hérité’ ou ‘patrimonial’4 qui a depuis évolué, et ce, sans jamais avoir été conçu selon un design d’architecture prédéfinie (appelé de façon triviale ‘architecture spaghetti'). Le mesureur peut donc avoir besoin de conseils sur la manière de distinguer des couches selon la terminologie COSMIC ;
• Les expressions 'couche', 'architecture en couche' et 'composant de même niveau' ne sont pas employés uniformément dans l'industrie du logiciel. Si le mesureur doit mesurer un logiciel décrit comme appartenant à une ‘architecture en couche', il est recommandé de vérifier que les 'couches’ de cette architecture soient définies de manière compatible à la définition de celle proposée par la Méthode COSMIC. À cette fin, le mesureur devra établir des équivalences entre, d’une part, les objets architecturaux spécifiques de son 'architecture en couche' et le concept de ‘couches’, tel que définis dans ce manuel.
Les couches peuvent être identifiées selon les définitions et principes suivants :
DÉFINITION – Couche.
Un partitionnement résultant d’une division fonctionnelle d'un système qui, ensemble, avec le matériel, forme un système informatique complet où :
• les couches sont organisées dans une hiérarchie; • il y a seulement une couche à chaque niveau dans la hiérarchie; • il y a une dépendance hiérarchique ‘supérieur/subordonné’ entre les
services fonctionnels fournis par le logiciel et n’importe quelle des deux couches du système logiciel qui échangent directement des données;
• le logiciel dans n’importe laquelle des deux couches du système logiciel qui échangent des données, interprètent de façon identique seulement une partie des données.
L’identification des couches est un processus itératif. Les couches à identifier seront raffinées au fur et à mesure que la phase d’arrimage du processus de mesure progresse. Une fois identifiée, chaque couche doit ensuite être conforme aux règles et aux principes suivants :
PRINCIPES – Couche.
a. Le logiciel d’une couche spécifique échange des données avec le logiciel d’une autre couche par l'intermédiaire de leurs processus fonctionnels respectifs ;
b. La ‘dépendance hiérarchique' entre les couches est telle que le logiciel d’une couche peut employer les services fonctionnels d’un logiciel d’une couche inférieure (subordonnée) de la hiérarchie. Là où il y a de tels rapports entre couches, la couche utilisant un logiciel est identifiée comme étant la couche 'supérieure' et celle fournissant le logiciel est identifiée comme étant la couche 'subordonnée'. Le logiciel d’une couche supérieure se fie sur les services des logiciels des couches subordonnées pour s’exécuter correctement; ces derniers se fiant, à leur tour, sur les logiciels des couches qui leur sont subordonnées, et ainsi de suite, jusqu’en bas de la hiérarchie. Réciproquement, un logiciel d’une couche subordonnée à une autre couche, peut s’exécuter sans avoir besoin des services d’un logiciel d’une couche supérieure hiérarchique ;
c. Le logiciel d’une couche supérieure n'utilise pas nécessairement toutes les fonctionnalités fournies par le logiciel d’une couche subordonnée ;
d. Les données qui sont échangées entre logiciels de deux couches sont définies et interprétées différemment par les FUR respectives des deux morceaux de logiciel communicants. En d’autres mots, pour chaque donnée échangée entre ces deux morceaux de logiciel, différents attributs et/ou de sous-groupes de données seront identifiés. Cependant, il doit y avoir un ou plusieurs attributs ou sous-groupes de données de définis, afin de permettre au logiciel de la couche de réception (supérieure) d'interpréter (selon ses besoins) les données qui ont été passées par le logiciel de la couche d'envoi (subordonnée).
4 De l’anglais « legacy software ».

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 22
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
RÈGLES – Couche.
a. Si un logiciel est conçu sur la base d'un concept architectural connu, selon le modèle COSMIC, alors les paradigmes de cette architecture peuvent être utilisés pour identifier les couches, en fonction de la raison d’être de la mesure ;
b. Dans le domaine des applications d'affaires et SIG (Système d'Information de Gestion), la couche 'supérieure' à la hiérarchie, i.e. la couche qui n'est pas subordonnée à aucune autre couche, est normalement désignée comme étant la couche ‘applicative’ ou ‘d’application’. Le logiciel de cette couche se fie sur les services des logiciels des autres couches pour s’exécuter correctement. Dans le domaine du logiciel de type ‘temps réel’, le logiciel de la couche ‘supérieure' est généralement désigné comme étant la couche 'système'. Exemples de logiciel de type ‘temps réel’ : le logiciel de système de contrôle des processus, le logiciel de circuit de commande de vol ;
c. Ne pas supposer que des logiciels ayant évolués sans design d’architecture prédéfinie ni structure apparente, puisse être partitionnés dans des couches selon le modèle COSMIC.
Les services fonctionnels de progiciels sont généralement considérés comme des couches distinctes : Bases de données, interfaces graphiques utilisateurs (GUI), systèmes d'exploitation, pilotes, etc.
Une fois identifiée, chaque couche peut être enregistrée comme 'composant' séparé dans la matrice du modèle générique de logiciel, avec une étiquette correspondante (voir l’annexe A).
Exemple 1: La structure physique type d'un logiciel avec une architecture en couche (soit le terme 'couche', tel que défini dans COSMIC) supportant des applications d’affaires est donnée en la Figure 2.2.4.1 ci-dessous.
DBMS 2
Logiciel 1 Couche applicative Logiciel 2 Logicie ‘N’
Couche intermédiaire (Utilités, services, etc.)
Couche système de gestion de base de donnés DBMS ‘N’ DBMS 1
Couche système d’exploitation
Couches logicielles
Couche matérielle
Pilote du clavier
Pilote de l’écran
Pilote de l’imprimante
Pilote de disque dur
Clavier Ecran Imprimante Disque dur Processeur central
Clé :
Couche supérieure
Repose sur
Couche subordonnée
Figure 2.2.4.1 – Architecture d’un logiciel/matériel en couches, typique des applications d’affaires et de logiciels SIG

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 23
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
Figure 2.2.4.2 – Architecture d’un logiciel/matériel en couches, typique des applications embarquée et de type temps réel.
2.2.5 Composants de même niveau.
Les composants de même niveau peuvent être identifiés selon les définitions et principes suivants:
DÉFINITION – Composant de même niveau.
Un composant (d'un ensemble de composants coopératifs tous de même niveau de décomposition), résultant de la division d'un morceau de logiciel provenant d'une seule couche et où chaque composant de cette couche répond à une partie des FUR de ce morceau de logiciel.
NOTE: Cette division d'un morceau de logiciel à partir de composants de même niveau peut être réalisé dans le but d’apporter une réponse aux besoins fonctionnels et / ou non fonctionnels des utilisateurs.
Une fois identifié, chaque composant de même niveau doit être conforme aux principes suivants
PRINCIPES – Composant de même niveau.
a. Dans un ensemble de composants de même niveau d'un morceau de logiciel d’une couche en particulier, il n'y a pas de dépendance hiérarchique entre ces composants. Chaque FUR des composants de même niveau d'un morceau de logiciel de n'importe quelle couche, est au même ‘niveau' dans cette hiérarchie des couches ;
b. Tous les composants de même niveau d'un morceau de logiciel doivent coopérer entre eux pour que ce morceau de logiciel puisse opérer correctement ;
c. Un groupe de données peut être échangées directement entre deux composants de même niveau d'un morceau de logiciel par l’entremise d’un processus fonctionnel. Un premier composant émet une donnée en Sortie qui est ensuite reçue par le processus fonctionnel du second composant, comme donnée en Entrée. L'échange peut aussi avoir lieu indirectement, par un processus fonctionnel d'un composant créant un groupe de données persistant (via une éCriture) qui ensuite est récupéré par le biais d'une Lecture de la part du processus fonctionnel du deuxième composant.
Une fois identifié, chaque composant de même niveau peut être enregistré comme composant individuel dans la matrice du modèle générique de logiciel, avec l'étiquette correspondante (voir annexe A).
Par exemple, lorsqu'une application d'affaires est développée, il peut y avoir trois composants principaux, à savoir : une interface utilisateur (application frontale ou front-end), une règle d'affaires et des services de données. Ces trois composants étant de même niveau.

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 24
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
NOTE: Deux morceaux de logiciel de même niveau, donc de même couche, qui échangent des données entre eux, peuvent échanger leurs données suivant les principes énoncés en ‘c’ ci-dessus.
Le diagramme suivant présente une situation illustrant cet exemple. Tous les logiciels (AppX et AppY) résident dans la même couche applicative. Les échanges entre : Les deux composants de même niveau (Comp 1, Comp 2 et Comp 3), et entre les deux morceaux de logiciel de même niveau (Comp 2 des applications X et Y) peuvent se réaliser via l'une ou l'autre des séquences définis dans le principe c, plus haut-mentionné.
Figure 2.2.5.1 – Relations entre les concepts 'même niveau', ‘composant’ et ‘composant de même niveau’
2.3 Identification des utilisateurs fonctionnels.
2.3.1 La taille fonctionnelle varie selon les utilisateurs fonctionnels.
Commençons par une analogie. La mesure de la surface des planchers d'un bureau peut être prise selon quatre conventions différentes, comme suit. (Noter que le périmètre - le bureau particulier - est le même pour chacune des quatre conventions.)
• Le propriétaire du bâtiment doit payer des taxes pour le bureau. Pour le propriétaire du bâtiment, la superficie est le nombre de 'mètre carré brut', déterminée à partir des dimensions externes et donc comprenant tous les vestibules publics, espaces occupés par des murs, etc. ;
• Le directeur de chauffage de bâtiment est intéressé par le 'mètre carré net ', i.e. les aires internes, y compris les aires publiques et l'espace occupé par les ascenseurs, mais en excluant l'épaisseur des murs ;
• L'entrepreneur de services de nettoyage employé par le locataire du bureau est intéressé par le 'mètre carré supernet plus', qui exclut les aires publiques, mais inclut les passages utilisés par le locataire ;
• Le directeur de planification de bureau est intéressé par le 'mètre carré supernet’, mais seulement l'espace utilisable par les bureaux.
Cette analogie permet de comprendre que différents types d'utilisateurs d'un objet peut voir différentes fonctionnalités et de là il est possible de mesurer différentes tailles de l'objet. Dans le cas du logiciel, les différents types d’utilisateurs fonctionnels peuvent exiger (via leur FUR) et employer des fonctionnalités différentes. Le logiciel obtiendra donc des tailles fonctionnelles qui varieront selon le choix de ces utilisateurs fonctionnels.
2.3.2 Utilisateurs fonctionnels.
Un 'utilisateur'5, est défini en pratique, comme étant 'n'importe quelle chose qui interagit avec le logiciel mesuré’.
Un utilisateur se défini aussi comme n’importe quelle personne et/ou n’importe chose communiquant ou interagissant avec le logiciel à n’importe quel moment. Cette définition est trop large pour les besoins de la Méthode COSMIC : le choix d’un utilisateur (ou des utilisateurs) est
App X App Y
Comp 1 Comp 2 Comp 3
Exchanges entre 2 composants de l’Application X
Exchanges entre 2 morceaux de logiciel de même niveau
Premier niveau de décomposition d’AppX
App X App Y
Comp 1 Comp 2 Comp 3
Application X est compose de 3 composants de même niveau, chacun devant être mesuré séparément

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 25
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
plutôt déterminé par la FUR qui doit être mesurée. Ce (type) d’utilisateur, connu sous le nom d’utilisateur fonctionnel, est défini de la façon suivante :
DÉFINITION – Utilisateur fonctionnel.
Un (type d’) utilisateur qui envoie et/ou est un récepteur de données des Fonctionnalités Utilisateurs Requises d'une partie du logiciel.
Dans la méthode COSMIC, il est essentiel d’identifier les utilisateurs fonctionnels parmi tous les d’utilisateurs potentiels du morceau de logiciel devant être mesurée.
EXEMPLE 1 : Considérer une application d'affaires. Ses utilisateurs fonctionnels vont inclure normalement les humains et d'autres applications de même niveau auxquels l'application se connecte grâce à une interface. Pour une application de type temps réel, les utilisateurs fonctionnels seraient normalement représentés par les équipements d’ingénierie ou tout autre logiciel d'interface de même niveau. Les FUR d'un tel logiciel sont normalement exprimées de telle sorte que les utilisateurs fonctionnels sont les émetteurs des données et/ou les destinataires prévus des données qui vont et viennent du logiciel.
L’ensemble des ‘utilisateurs’, i.e. 'n'importe quelle chose qui interagit avec le logiciel mesuré’', doit donc logiquement inclure le système d'exploitation comme utilisateur. Cependant, la FUR de n'importe quelle application ne l’inclurait jamais. C’est que toutes les contraintes que le système d'exploitation peut imposer à une application sont communes à toutes les applications, sont normalement manipulées par le compilateur ou l'interpréteur et sont invisibles aux autres utilisateurs fonctionnels de l'application. Dans la pratique de la mesure de la taille fonctionnelle, un système d'exploitation ne sera jamais considéré comme étant un utilisateur fonctionnel pour une application6.
Trouver un utilisateur fonctionnel n’est pas toujours évident.
EXEMPLE 2: Considérer une application sur téléphone mobile (déjà mentionné dans l'introduction). Bien que nous ayons éliminé le système d'exploitation du téléphone mobile en tant qu'utilisateur fonctionnel potentiel de l'application, les 'utilisateurs’ pourraient encore être soit (a) les humains qui appuient sur les touches, ou (b) les dispositifs câblés (par exemple l'écran, les clefs, etc..) et ses logiciels de même niveau qui interagissent directement avec l'application du téléphone. L'utilisateur humain, par exemple, verra seulement un sous-ensemble de toutes les fonctionnalités qui permettent à l'application du téléphone mobile de fonctionner. Ainsi, ces deux types d'utilisateurs verront différentes fonctionnalités; la taille fonctionnelle de la FUR pour l'utilisateur humain sera plus petite que la taille fonctionnelle de la FUR développée pour que le téléphone fonctionne7.
RÈGLES – Utilisateurs fonctionnels.
a. Les utilisateurs fonctionnels d'un morceau de logiciel à mesurer, doivent être dérivés de la raison d’être de la mesure ;
b. Lorsque la raison d’être d'une mesure d'un morceau de logiciel est liée à l'effort de développement ou à l’effort de modification d’un morceau de logiciel, alors les utilisateurs fonctionnels devraient être ceux pour qui la fonctionnalité nouvelle ou modifiée doit être fournie.
5 Voir le Glossaire pour la définition d’ISO/IEC 14143/1 :2007. 6 En réalité, bien sûr, l’inverse peut aussi être vrai. Les applications peuvent être des utilisateurs fonctionnels des systèmes d’exploitation. Les FUR d’un système d’exploitation sont définies en tenant compte des applications qui doivent être supportées par ses utilisateurs fonctionnels. 7 Toivonen, par exemple, compare les fonctionnalités disponibles à un utilisateur humain dans Defining measures for memory efficiency of the software in mobile terminals, International Workshop on Software Measurement, Magdeburg, Germany, October 2002
Après avoir identifié les utilisateurs fonctionnels, il est alors facile d’identifier la frontière, car elle se trouve tout simplement entre le morceau de logiciel à mesurer et ses utilisateurs fonctionnels. Nous ignorons tout autre matériel ou logiciel dans cet espace d’intervention8.
DÉFINITION – Frontière.
Une interface conceptuelle entre le logiciel à mesurer et ses utilisateurs

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 26
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
DÉFINITION – Frontière.
fonctionnels.
REMARQUE : La frontière d'un morceau de logiciel est la ligne conceptuelle séparant cette partie de l’environnement dans lequel il s’exécute, tel que perçu d’un point de vue externe par ses utilisateurs fonctionnels. La frontière permet à la personne qui mesure de distinguer, sans ambiguïté, ce qui est inclus dans le logiciel mesuré de ce qui fait partie de l’environnement dans lequel fonctionne ce logiciel.
NOTE : Cette définition de frontière est prise d'ISO/IEC 14143/1:2007, modifiée par l'addition du mot ‘fonctionnel' pour qualifier l''utilisateur'. Pour éviter toute ambiguïté, noter que la frontière ne devrait pas être confondue avec la délimitation tracée autour du logiciel à mesurer pour définir le périmètre de mesure. La frontière n'est en aucun cas employée pour définir le périmètre d'une mesure.
Les règles suivantes pourraient s’avérer utiles pour confirmer le statut d'une frontière :
RÈGLES – Frontière.
a. Identifier le (ou les) utilisateur(s) fonctionnel(s) qui interagissent avec le logiciel à mesurer. La frontière se trouve entre les utilisateurs fonctionnels et ce logiciel ;
b. Par définition, il y a une frontière entre deux couches identifiées de même niveau, où le logiciel d’une couche est l'utilisateur fonctionnel du logiciel de l’autre, i.e. le logiciel devant être mesuré ;
c. Il y a une frontière entre deux morceaux de logiciel, incluant parmi ces morceaux n'importe quels composants de même niveau. Dans ce cas-ci, chaque morceau de logiciel et/ou chaque composant peut être un utilisateur fonctionnel de son homologue.
La frontière permet de faire une distinction claire entre tout ce qui fait partie du morceau de logiciel à mesurer (i.e. du côté ‘logiciel’ de la frontière) et tout ce qui fait partie de l'environnement des utilisateurs fonctionnels (i.e. du côté des ‘utilisateurs fonctionnels’ de la frontière). Par exemple, le stockage persistant n'est pas considéré comme étant un utilisateur fonctionnel d’un logiciel et est donc considéré comme faisant parti du côté ‘logiciel’ de la frontière.
2.4 Identification du niveau de granularité.
2.4.1 Le besoin d’un niveau de granularité normalisé.
Quand un projet est lancé pour concevoir et construire une nouvelle maison, les premiers plans tracés par un architecte sont considérés comme étant de ‘haut niveau’, i.e. qu’ils montrent une ébauche et peu de détails. Alors que le projet progresse vers la phase de construction, des plans plus détaillés (de 'bas niveau') sont nécessaires.
C’est aussi le cas pour le logiciel. Aux étapes initiales d'un projet de développement d’un logiciel, les Fonctionnalités Utilisateur Requises (FUR) sont définies à ‘haut niveau’, soit à partir d’une ébauche, ou avec peu de détails. Alors que le projet progresse, les FUR seront raffinées, (par itération par exemple), montrant de plus en plus de détail jusqu’à ce qu’on arrive à des FUR de ‘bas niveau'. Ces différents niveaux de détails de la FUR sont représentés par différents 'niveaux de granularité ' (voir également la section 2.4.3 pour d'autres définitions qui pourraient être confondues celle-ci.)
8 En fait, si le mesureur a examiné la FUR afin d'identifier les émetteurs et les destinataires prévus des données, la frontière aura déjà été identifiée.
DÉFINITION – Niveau de granularité.
Tout niveau d’expansion de la description d’un seul morceau de logiciel (i.e. un énoncé d'une exigence, ou la description d’une structure d’un morceau de logiciel) tel que chaque niveau supérieur d’expansion, la description de la fonctionnalité du

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 27
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
morceau du logiciel est à un niveau supérieur et uniforme de détails.
REMARQUE: Les mesureurs doivent tenir compte de l'évolution précoce des exigences dans le cycle de vie d’un projet. À tout moment, différentes parties des fonctionnalités requises du logiciel seront typiquement documentées à différents niveaux de granularité.
Par exemple, il est facile de transposer les dimensions mesurées à partir de plans de construction d’une maison tracés à partir d’échelles normalisées, à d’autres dessins de différentes échelles. Par contre, il n'y a pas d’échelles normalisées pour les divers niveaux de granularité des spécifications d’un logiciel, ce qui permet difficilement d’affirmer que deux artéfacts décrivant une FUR soit au même niveau de granularité. Sans un accord sur un certain niveau de normalisation de la granularité applicable à la mesure (ou de savoir quelle échelle de mesure est utilisée) il est impossible de comparer avec certitude deux mesures de taille fonctionnelle. Les mesureurs doivent alors développer leur propre méthode d’étalonnage des mesures d’un niveau de granularité à un autre.
Pour illustrer le concept sous un autre angle, considérons cette analogie : Un ensemble de cartes routières indique les détails d’un réseau routier national à trois niveaux de granularité :
• La carte A montre les autoroutes et les routes principales ; • La carte B montre plutôt les autoroutes, les routes principales et les routes secondaires
(comme dans un atlas pour automobilistes) ; • La carte C montre toutes les routes avec le nom de chacune (équivalent des cartes
routières locales).
Si nous ne connaissions pas le concept de différents niveaux de granularité, ces trois cartes auraient indiqué différentes tailles du même réseau routier. Habituellement les cartes routières intègrent le concept et intègrent donc les différents niveaux de détails à différentes échelles normalisées pour interpréter la taille du réseau routier selon le niveau de granularité que l’on veut montrer. Le concept de 'niveau du granularité' se trouve derrière les échelles de ces différentes cartes.
Pour la mesure de logiciel, il y a seulement un niveau normalisé de granularité qu'il est possible de définir clairement. C'est le niveau de granularité auquel les processus fonctionnels ont été identifiés et les mouvements de données définis. Donc lorsque c’est possible, c’est selon ce niveau normalisé de granularité que les mesures devraient être faites (ou étalonnée) 10.
2.4.2 Clarification du niveau de granularité.
Avant de continuer, il est important de s'assurer que la signification du concept de ‘niveau de granularité’ de la Méthode COSMIC est bien assimilée. Tel que défini plus tôt, approfondir la ‘description’ de haut niveau d’un logiciel, à un niveau inférieur de granularité, implique qu’il existe une vision plus en profondeur des fonctionnalités et qu’on révèle plus de détails, sans toutefois changer le périmètre. Ce processus NE DEVRAIT PAS être confondu avec les processus suivants :
• Faire un zoom sur un artéfact descriptif du logiciel afin de montrer différents sous-ensembles de la fonctionnalité à livrer aux différents utilisateurs, limitant probablement ainsi la fonctionnalité à mesurer ;
• Zoomer sur un quelconque logiciel afin de révéler ses composants, sous-composants, etc (à différents niveaux de décomposition, voir section 2.2.2 ci-dessus). De tels zoom peuvent être nécessaires si la mesure nécessite d'obtenir de la raison d'être de la mesure des sous-divisions suivant la structure physique du logiciel;
•
10 Le sujet d'étalonnage des mesures d'un niveau de granularité à un autre a déjà été présenté dans la version 2.2 du Manuel de mesure au chapitre 7 dans le chapitre Approximation de la taille tôt dans le projet en utilisant COSMIC. (Ce sujet est aussi traité dans le volume Sujet spécialisé).
• De réaliser des artéfacts descriptifs du logiciel au fur et à mesure que celui-ci progresse dans son cycle de vie : Soit de réaliser un artéfact d’exigences, ensuite un artéfact de conception logique puis physique, par exemple. Quel que soit la phase du cycle dans lequel le logiciel se situe, nous sommes seulement intéressés aux FUR pour des fins de mesure.

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 28
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
Le concept de ‘niveau du granularité' est donc prévu pour être interprété comme s'appliquant seulement aux FUR du logiciel. D'autres manières de ‘zoomer’ ou de 'décomposer' le logiciel ou ses divers artéfacts descriptifs peuvent également être très importants lorsqu’on utilise ou on compare des mesures de taille fonctionnelles. Ce sujet sera traités dans le document Sujets spécialisés V 3.0 dans le chapitre intitulé Assurer la comparaison des mesures de taille.
2.4.3 La norme du niveau de granularité.
La norme du niveau de granularité ou le niveau de normalisation de la granularité pour la mesure est le ‘niveau d’un processus fonctionnel’ et est définit comme suit :
DÉFINITION – Niveau de granularité d’un processus fonctionnel
Un niveau de granularité de la description d’un morceau de logiciel pour lequel les utilisateurs fonctionnels :
• Sont des individus humains ou des objets d'ingénierie ou d’autres morceaux de logiciel (et non pas des groupes de ceux-ci) ET ;
• Détectent des occurrences uniques d’évènements auxquels un morceau du logiciel doit répondre (et pas au niveau où les groupes d’évènements sont définis).
REMARQUE 1: En pratique, la documentation du logiciel contenant les Fonctionnalités Utilisateurs Requises décrivent souvent les fonctionnalités à divers niveaux de granularité, plus particulièrement quand la documentation est toujours en cours d’élaboration.
REMARQUE 2: Les ‘Groupes ciblés (utilisateurs fonctionnels) peuvent être, par exemple, un ‘département’ dont les membres peuvent effectuer plusieurs types de processus fonctionnels, ou un ‘panneau de contrôle’ qui a plusieurs types d’instruments, ou des ‘systèmes centraux’.
REMARQUE 3: Les ‘Groupes d’évènements’ peuvent, par exemple, être exprimés dans l’énoncé d’une FUR à un haut niveau de granularité par un flux d’intrants pour un système comptable nommé ‘transactions de vente’ ou par un flux d’intrants à un logiciel avionique appelé ‘commande de pilotage’.
NOTE : La raison pour laquelle le nom de ‘niveau de granularité d’un processus fonctionnel’ a été choisi est qu’il s’agit du niveau pour lequel le processus fonctionnel et ses mouvements de données sont identifiés – voir la section 3.2 pour davantage d’information sur le processus fonctionnel.
Avec cette définition, nous pouvons maintenant définir les règles suivantes et une recommandation :
RÈGLES - Niveau de granularité d’un processus fonctionnel.
a) La mesure de la taille fonctionnelle doit être réalisée au niveau de granularité du processus fonctionnel ;
b) Lorsqu’une mesure de taille fonctionnelle est nécessaire pour une FUR qui n’est pas encore décrite au niveau où tous les processus fonctionnels ont été identifiés ou pour une FUR où tous les détails concernant ses mouvements de données n’ont pas encore été définis, la mesure de cette fonctionnalité devrait quand même être faite. Celle-ci sera par la suite mise à l’échelle du niveau de granularité des processus fonctionnels. (voir le document - Sujet spécialisés pour connaître la méthode d’approximation de la taille et d’estimation de la taille fonctionnelle d’un logiciel tôt dans le processus de description des FUR.).

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 29
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
En plus de ces règles, COSMIC recommande11 que le niveau de granularité du processus fonctionnel représente la norme à laquelle les mesures de la taille fonctionnelles doivent se conformer. Cette recommandation s’étend aux fournisseurs de services d’étalonnage, aux fournisseurs d’outils logiciel conçus pour supporter ou utiliser des mesures de taille fonctionnelles, utile à l’estimation de l’effort par exemple.
Exemple : Fonctionnalités à différents niveaux de granularité.
Voici un exemple provenant du domaine des applications d'affaires : un système de commande de marchandises par Internet, que nous appellerons 'Everest'. (Pour sa part, le document Sujets spécialisés donne un exemple provenant du domaine des logiciels de type temps réel.)
La description ci-dessous a été simplifiée afin d’illustrer les niveaux de granularité. La description couvre seulement la fonctionnalité disponible aux utilisateurs (clients) d'Everest. Elle exclut donc les fonctionnalités nécessaires au système pour réaliser, dans sa totalité : l'approvisionnement d’un client en marchandises, la fonctionnalité disponible au personnel d'Everest, aux fournisseurs de produit, aux annonceurs, aux fournisseurs de service de paiement, etc.
Le périmètre de la mesure est donc défini comme les 'morceaux du système d'application ‘Everest’ qui sont accessibles aux clients via Internet'. Nous supposons que la raison d’être de la mesure est de déterminer la taille fonctionnelle de l'application disponible aux clients comme 'utilisateurs fonctionnels’.
Au plus ‘haut niveau’ (niveau 1) de l'application, un artéfact descriptif d’une FUR du système de commande Everest serait représenté par un énoncé simple, tel que :
"Le système d'Everest doit permettre aux clients d’interroger, de sélectionner, de payer et d’obtenir la livraison de n'importe quel article de la gamme de produits offerts par Everest, y compris les produits fournis par les fournisseurs externes."
En réalisant un zoom sur cet énoncé de haut niveau, on peut constater que le prochain niveau (le niveau 2), consisterait en 4 sous-systèmes, tel que montré à la figure 2.4.3.1.
Figure 2.4.3.1 – Analyse partielle du système de commande Everest, montrant 4 niveaux d’analyse.
Sous-système d’interrogation de
commande
Processus d’ajout de moyens de
paiements
Niveau 1
S-S-Sys. Interrogation de processus de
commandes actuelles …
…
Sous-système de vérification de
paiement Sous-système de
vérification de commande
Sous-système de stockage des
comptes
S-S-Sys. Revue, maintenir, confirmer
commande S-S-Sys. Sélection
des options emballage/livraison
S-S-Sys. Paiement de commandes
S-S-Sys. Affichage, confirmation de commande par
courriel
Processus de gestion des
nouveaux clients
Processus de paiement d’une
commande
… Stocker des
données clients
Stocker les moyens de paiements
…
…
…
…
…
S-S-Sys. Interrogation de processus de
commandes historiques
…
S-S-Sys. de retour de marchandise
Processus de suppression de
moyens de paiements existants
Niveau 2
Niveau 3
Niveau 4
Système de commande EVEREST

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 30
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
11 La raison pour laquelle le niveau de granularité d’un processus fonctionnel est ‘recommandé’ plutôt que présenté comme une règle, est qu’elle s’applique non seulement à l’utilisateur de la méthode COSMIC mais aussi au réseau de fournisseurs, services et outils qui utilise les mesures de taille. COSMIC ne peut que faire des recommandations à l’ensemble de la communauté.
Les quatre sous-systèmes du niveau 2 sont:
• Le sous-système interrogation/commande permet à un client de trouver n’importe quel produit de la base de données d'Everest, aussi bien que son prix et sa disponibilité. Il permet aussi au client d’ajouter n’importe quel produit sélectionné, à son 'panier' d'achat. Ce sous-ensemble favorise également les ventes, car il présente des offres spéciales, des évaluations pour les articles choisis et permet aussi de répondre à des questions générales sur les conditions de livraison, etc. C'est un sous-ensemble très complexe et son analyse ne dépasse pas le niveau 2 pour les fins de cet exemple ;
• Le sous-système vérification/paiement permet au client de confirmer une commande et de payer les marchandises présentes dans sone panier ;
• Le sous-système suivi des commandes permet au client de connaître la progression de la livraison d’une de ses commande existante, de mettre à jour les informations relatives à sa commande (ex : modifier l’adresse de livraison) et de retourner les marchandises dont le client n’est pas satisfait ;
• Le sous-système maintenance des comptes permet à un client existant de mettre à jour les informations détaillées de son compte comme son adresse à domicile ou les modes de paiements préconisés, à titre d’exemple.
Un zoom a aussi été effectué en figure 2.4.3.1, ce qui permet de montrer plus de détails à travers les niveaux inférieurs, soit vers les sous-ensembles des FUR tels que : sous vérification/paiement, sous de suivi des commandes et sous maintenance des comptes. Lors du processus de zoomage il est important de noter que :
• nous n’avons pas changé le périmètre de mesure de l’application à mesurer ; • tous les niveaux de la description du système logiciel Everest montrent la fonctionnalité
disponible aux clients (en tant qu'utilisateurs fonctionnels). Un client peut donc 'voir' en entier la fonctionnalité du système, à tous ces niveaux de l'analyse.
La figure 2.4.3.1 indique également cela quand un zoom est effectué à des niveaux plus bas dans cette analyse particulière. Sous ces trois sous-systèmes, nous trouvons différents processus fonctionnels (au niveau 3), de même qu’au niveau 4 pour deux des sous-systèmes. Cet exemple démontre donc que, quand une certaine fonctionnalité est analysée dans une approche descendante, on ne peut pas supposer que la fonctionnalité d’un niveau particulier correspondra toujours au même 'niveau de granularité', tel que défini dans la Méthode COSMIC. La définition exige plutôt qu'à n'importe quel niveau de granularité, la fonctionnalité soit 'à un niveau comparable de détail'.
De plus, d'autres analystes pourraient dessiner le diagramme de la figure 2.4.3.1 différemment, montrant différents groupements de la même fonctionnalité, à chaque niveau du diagramme. Il n'y a pas une seule façon ‘correcte’ d'analyser la fonctionnalité d'un système complexe 12.
Puisque ce type de variation se produira inévitablement dans la pratique, un mesureur doit soigneusement examiner les divers niveaux d'un diagramme d'analyse afin de trouver les processus fonctionnels devant être mesurés. Là où, dans la pratique, ce n'est pas possible, c’est dans les cas où l'analyse n'a pas encore atteint le niveau où tous les processus fonctionnels ont été définis. Dans ce cas, la règle (b) de la sous-section 2.4.3 doit être appliquée. Pour illustrer ceci, examinons le cas du sous-système ‘mise à jour des informations client’ (niveau 3) de la figure 2.4.3.1 ci-dessus, sous la branche maintenance des comptes (niveau 2).
Pour un mesureur expérimenté, le terme ‘mise à jour' suggère un groupe d'événements ainsi qu’un groupe de processus fonctionnels qui restent invariables. Nous pouvons donc s’avancer sans trop de risques que ‘mettre à jour’ comprendra au moins trois processus fonctionnels, à savoir : Lire les informations client, écrire les informations client, et supprimer les informations client. (Le processus ‘création des informations client doit aussi exister, mais il se trouve dans une autre branche du système, soit lorsque le client commande pour la première fois. Il est en dehors de la portée de cet exemple.).

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 31
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
12 La figure 2.4.3.1 n’est pas un bon exemple de la meilleure pratique à adopter, mais représente plutôt un exemple typique de réalisation d’un tel diagramme.
En extrapolant un certain nombre de processus fonctionnels, un mesureur expérimenté devrait être en mesure de connaître instinctivement la taille d’un de ces sous-système en unité CFP (trois dans ce cas-ci) et en multipliant ce nombre par la taille moyenne d'un processus du système ou dans d'autres systèmes comparables. Des exemples de ce processus de calibration sont donnés dans le document Sujets spécialisés sur l’approximation de la taille. Il contient également d'autres exemples et approches pour estimer la taille.
Clairement, de telles méthodes d'approximation ont leurs limites. Si nous appliquons une telle approche à l’énoncé de niveau 1 de la FUR tel que donné ci-dessus ("Le système d'Everest doit permettre aux clients d’interroger, de sélectionner, de payer et d’obtenir la livraison de n'importe quel article de la gamme de produits offerts par Everest, y compris les produits fournis par les fournisseurs externes."), nous pourrions identifier peu de processus fonctionnels. Mais une analyse plus détaillée indiquerait que le vrai nombre de processus fonctionnels dans ce système complexe doit être beaucoup plus grand. C'est pourquoi les tailles fonctionnelles semblent habituellement augmenter au fur et à mesure que plus de détails sur les exigences sont établies, même sans changer de périmètre de mesure. Ces méthodes d'approximation doivent donc être employées avec précaution aux niveaux élevés de la granularité, quand peu de détails sont disponibles.
Le document Sujets spécialisés donne différents types d’exemples de mesure de la taille à différent niveaux de granularité à partir d’un exemple de logiciel faisant partie de l’architecture d’un système de télécommunication. Cet exemple est plus complexe que le cas Everest, puisque les utilisateurs fonctionnels du périmètre mesuré sont différents : le périmètre choisi est représenté par tous les autres processus fonctionnels et sous-systèmes utilisés par tous les autres utilisateurs fonctionnels du système (donc pas d’utilisateur ‘humain’). Cet exemple traite aussi des différents niveaux de décomposition de ce même logiciel, mais qui est cette fois de type ‘temps réel’.
2.5 Conclusions sur la phase de la stratégie de mesure.
Il est nécessaire de soigneusement considérer les quatre principaux paramètres du processus de stratégie de mesure avant de commencer la phase de mesure. Cela devrait permettre d‘assurer que la taille fonctionnelle résultante peut être valable et correctement interprétée. Ces quatre paramètres sont :
a. établir la raison d’être de la mesure ; b. définir le périmètre de mesure global du morceau de logiciel à mesurer et le périmètre des
morceaux à mesurer séparément, en considérant les couches et les composants de même niveau de l'architecture du logiciel ;
c. définir les utilisateurs fonctionnels du morceau de logiciel devant être mesuré ; d. définir le niveau de granularité des objets du logiciel à mesurer et comment, au besoin, on
pourra étalonner les tailles au niveau de la granularité du processus fonctionnel, de façon normalisée.
Quelques itérations peuvent être nécessaires pour les trois derniers paramètres, surtout quand les exigences évoluent et que de nouveaux détails indiquent qu’il faut raffiner la définition du périmètre.
La raison d’être la plus commune des mesures de taille fonctionnelles est souvent pour déterminer l'effort de développement, par exemple mesurer de performance d’un équipe, ou pour estimer les délais d’un projet. Dans ces situations, définir la stratégie de mesure devrait être assez simple. Ensuite, il est habituellement facile de définir le reste. La raison d’être et le périmètre de la mesure sont simple en soit à définir, les utilisateurs fonctionnels sont habituellement les utilisateurs pour qui le développeur doit fournir la fonctionnalité, et le niveau de granularité auquel les mesures sont habituellement exigées est celui auquel les utilisateurs fonctionnels perçoivent des événements / fonctionnalités de haut niveau.
Cependant, ce ne sont pas toutes les mesures qui s’adaptent à ce modèle commun; ainsi la stratégie de mesure devrait être définie selon le contexte.

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 32
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
Il est important de noter que les quatre principaux paramètres de la stratégie de mesure ne sont pas uniquement liés à la Méthode COSMIC, mais sont communs à toutes les méthodes de mesure de taille fonctionnelle. Les autres méthodes de mesure taille fonctionnelle emploient bien sûr d'autres termes, comme ‘processus élémentaires’ ou 'transaction logique’ plutôt que le terme ‘processus fonctionnels’ de COSMIC, mais ces mêmes concepts restent les mêmes. C'est une plus vaste portée et une plus grande flexibilité que la Méthode COSMIC promeut, ce qui justifie que ces quatre paramètres doivent être considérés plus soigneusement par le mesureur que pour les autres méthodes de mesure.

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 33
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
33 PHASE D’ARRIMAGE.
Ce chapitre présente les règles et la méthode du processus d’arrimage. La méthode générale d’arrimage du logiciel, au modèle générique de logiciel COSMIC, est schématisée dans la figure 3.0 :
Figure 3.0 – Méthode générale d’arrimage du processus de mesure COSMIC.
Chaque étape de cette méthode est discutée dans une section spécifique (indiquée par les titres des boîtes de la figure 3.0. où les définitions et les règles sont présentées, avec quelques principes de base et exemples.
La méthode générale décrite dans la figure 3.0 ci-dessus est conçue pour être applicable à une gamme très large d’artéfacts logiciels. Un processus plus systématique et plus détaillé aurait bien sûr fourni des règles d’arrimage plus précis consacrés à une gamme d’artéfacts logiciels plus spécifiques, et aurait aussi réduit les ambiguïtés éventuelles lors de la réalisation du modèle générique de logiciel COSMIC. Un tel processus, par définition, aurait fortement dépendu de la nature des artéfacts qui à leur tour, auraient dépendu de la méthodologie du génie logiciel de l’organisation qui mesure.
Le document Guide pour évaluer la taille du logiciel d'application d'affaires en utilisant COSMIC, donne des conseils sur l’arrimage à partir des différentes données d'analyse et des méthodes de définition des exigences d’un logiciel du domaine des affaires, vers les concepts de la Méthode COSMIC.
3.1 Application du modèle générique de logiciel.
PRINCIPE – Application du modèle générique de logiciel COSMIC.
Le modèle générique de logiciel COSMIC sera appliqué aux Fonctionnalités Utilisateurs Requises (FUR) de chacun des morceaux de logiciel pour lesquels un périmètre distinct de mesure a été défini.
Appliquer le 'modèle générique de logiciel COSMIC' signifie qu'il faut identifier l'ensemble des déclencheurs des événements perçus par chacun des – types – d’utilisateurs fonctionnels identifiés pour une FUR, puis, d’identifier les processus fonctionnels correspondant, l'objet d'intérêt, les groupes de données et finalement, les mouvements de données fonctionnels devant être fournis pour répondre à ces événements.
Phase d’Arrimage COSMIC
FUR provenant des artéfacts du logiciel à
mesurer
Chapitre 2 RAISON D’ÊTRE DE LA MESURE, PÉRIMÈTRE DE LA MESURE, UTILISATEURS FONCTIONNELS & NIVEAU DE GRANULARITÉ d’un morceau de logiciel à mesurer.
Section 3.1 IDENTIFIER LES PROCESSUS FONCTIONNELS Section 3.2
IDENTIFIER LES GROUPES DE DONNÉES
(*) Cette étape n’est pas une étape obligatoire de la Méthode COSMIC
FUR sous forme de Modèle générique de
logiciel COSMIC
Section 3.3 IDENTIFIER LES ATTRIBUTS DE DONNÉES *

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 34
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
Les figures 3.1.1 et 3.1.2 ci-dessous, illustrent l'application du principe (g) du modèle contextuel de logiciel et les principes du modèle générique de logiciel respectivement à (ces principes sont énumérés dans le document Introduction à la méthode COSMIC, section 2.2.2 et 2.2.3) : un morceau de logiciel d’une application d'affaires et à un morceau de logiciel de type temps réel/embarqué.
Considérant que les figures 2.2.4.1 et 2.2.4.2 vue plus haut ont montrées des vues physiques d’architectures de couches de ces types de logiciels respectifs, les figures 3.1.1 et 3.1.2 montrent une vue logique des interactions entre les divers concepts définis dans les deux modèles de logiciels COSMIC. Dans une vue logique, les utilisateurs fonctionnels interagissent avec le logiciel mesuré à travers la frontière via les mouvements de données, Entrées et Sorties. Le logiciel déplace les données à partir du stockage persistant par l'intermédiaire des mouvements de données éCritures et Lectures respectivement. Dans ces vues logiques, tout le matériel et logiciel permettant les interactions le entre morceau de logiciel mesuré et ses utilisateurs fonctionnels ou son stockage persistant, sont ignorés.
E
Lectures
S
S E
S E
Frontière Frontière
Utilisateur(s) fonctionnel(s)
de type « Humain »
Morceau de logiciel mesuré
Utilisateur(s) fonctionnel(s) de
type « Morceau de logiciel de même
niveau » Écritures
Stockage persistant
Cette illustration indique que l’extrant (issu d’un mouvement de données en sortie) traverse la frontière pour devenir un intrant (issu d’un mouvement de donnée en entrée)
Couche applicative
Entrées
Sorties
Figure 3.1.1 – Vue logique d’un morceau de logiciel d’application d'affaires interagissant avec deux utilisateur(s) fonctionnel(s) différents
Figure 3.1.2 – Vue logique d’un morceau de logiciel embarqué / de type temps réel, interagissant avec un utilisateur(s) fonctionnel(s)
3.2 Identification des processus fonctionnels.
Cette étape consiste à identifier l'ensemble des processus fonctionnels d’un morceau de logiciel à mesurer, à partir des FUR.
Utilisateur(s) fonctionnel(s) de type « dispositif physique »
Lectures
Frontière
Morceau de logiciel mesuré
Écritures
Stockage persistant
Entrées
Sorties Couche
applicative

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 35
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
3.2.1 Définitions.
DÉFINITION – Processus fonctionnel.
Un composant élémentaire d’un ensemble des Fonctionnalités Utilisateur Requises (FUR), comprenant un ensemble de mouvements de données unique, cohésif et indépendamment exécutable. Il est déclenché par un mouvement de données d’un utilisateur fonctionnel qui informe le morceau de logiciel à mesurer que l’utilisateur fonctionnel a identifié un évènement déclencheur. Il est complet lorsqu'il a exécuté tout ce qui est requis en réponse au type d’évènement déclencheur.
REMARQUE : En plus d’informer le morceau de logiciel que l’évènement est réalisé, l’Entrée, déclenchée par cet évènement, peut inclure des données à propos de l’objet d’intérêt associé à cet évènement.
DÉFINITION – Evénement déclencheur.
Type d’événement (quelque chose qui se produit) qui induit un utilisateur fonctionnel d’un morceau de logiciel à initier (‘déclencher’) un ou plusieurs types de processus fonctionnels. Dans un ensemble de Fonctionnalités Utilisateurs Requises (FUR), chaque type d’événement qui incite un utilisateur fonctionnel à déclencher un processus fonctionnel :
Ne peut pas être sous-divisé pour cet ensemble de FUR, et
Doit, soit survenir, ou n’est pas encore survenu.
REMARQUE : Une horloge et ses événements temporels peuvent être des événements déclencheurs.
Le rapport entre un événement déclencheur, l'utilisateur fonctionnel et les mouvements de données en entrée qui déclenche le processus fonctionnel est décrit à la figure 3.2.1 ci-dessous. L'interprétation de ce diagramme se résume ainsi: un événement est perçu par un utilisateur fonctionnel, et l'utilisateur fonctionnel déclenche un processus fonctionnel.
Frontière
Processus fonctionnel
Déclenchement en entrée
Est perçu par
Utilisateur fonctionnel
Évènement déclencheur
Figure 3.2.1 – Relation entre l’évènement déclencheur, l’utilisateur fonctionnel et le processus fonctionnel.
Le déclencheur en Entrée est normalement un message positif et non ambigu qui informe le logiciel que l'utilisateur fonctionnel a identifié un événement déclencheur. Le déclencheur en Entrée inclut également des données au sujet d'un objet d'intérêt lié à l'événement. Après que le déclenchement en Entrée ait eu lieu, un processus fonctionnel peut être exigé pour recevoir et traiter d'autres entrées décrivant d'autres objets d'intérêt.
Si un utilisateur fonctionnel envoie des données incorrectes, par exemple parce qu'un capteur fonctionne mal ou la saisie de donnée effectuée par un humain soit erronée, c'est habituellement la tâche du processus fonctionnel de déterminer si l'événement s'est vraiment produit et/ou si les données saisies sont vraiment invalides, et d'indiquer comment y répondre.

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 36
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
3.2.2 L’approche à l’identification d’un processus fonctionnel.
L'approche à l’identification des processus fonctionnels dépend des artéfacts logiciels qui sont disponibles au moment de la mesure. Ces derniers dépendent à leur tour de la phase du cycle de vie du logiciel à laquelle on se trouve au moment de la mesure, et dépendent aussi, finalement des méthodes d'analyse, de conception et de développement du logiciel utilisés. Puisque ces méthodes changent souvent d’une organisation à une autre, même dans des domaines équivalents du génie logiciel, il est hors de portée de ce Manuel de mesure de fournir un ou plusieurs processus généraux pour identifier des processus fonctionnels.
À la section 4.4 du Guide pour évaluer la taille du logiciel d'application d'affaires en utilisant COSMIC, on donne plus de règles et d'exemples sur la façon d'identifier et de distinguer les processus fonctionnels dans le domaine des logiciels d'application d'affaires.
Le conseil le plus utile est d'essayer d'identifier distinctement tous les événements auxquels le logiciel doit répondre, du monde des utilisateurs fonctionnels, puisque ce type d'événement provoque habituellement un, mais parfois plus, de processus fonctionnel. Des événements peuvent être identifiés dans des diagrammes d'état et dans des diagrammes du cycle de vie des entités, puisque chaque transaction à laquelle le logiciel doit répondre correspond à un événement.
Il est utile d’appliquer les règles suivantes pour vérifier que les processus fonctionnels ont été correctement identifiés :
RÈGLES – Processus fonctionnel.
a. Un processus fonctionnel est identifié à partir d’au moins une FUR appartenant au périmètre du logiciel à mesurer ;
b. Un processus fonctionnel est exécuté lorsqu'un événement déclencheur identifiable survient ;
c. Un événement spécifique (-type) peut déclencher un (ou plusieurs) processus fonctionnel(s) exécuté(s) en parallèle. Un processus fonctionnel spécifique (-type) peut être déclenché par plus d'un événement (-type) ;
d. Un processus fonctionnel contient au moins deux mouvements de données, une en Entrée plus une en Sortie et/ou une en éCriture ;
e. Un processus fonctionnel doit appartenir entièrement à un morceau logiciel dont le périmètre de mesure a été défini, et ce, pour une seule et unique couche ;
f. Dans le contexte d’un logiciel en temps réel, un processus fonctionnel doit être considéré comme terminé lorsqu'un état asynchrone d’attente a été atteint (i.e. que le processus fonctionnel doit avoir réalisé tout ce qui était requis, en réponse à un événement déclencheur, et attend que le prochain événement déclencheur arrive en Entrée) ;
g. Un processus fonctionnel (-type) doit être identifié, et ce, même si la FUR ne permet que ce processus fonctionnel puisse se produire avec différents sous-ensembles, du nombre maximum d'attributs en entrée, et que ces différentes valeurs de données puissent provoquer des chemins de traitement variés à travers ce processus fonctionnel ;
h. Des événements séparés (-types) donc des processus fonctionnels séparés (-types) doivent être distingués dans ces cas :
• Lorsque les décisions qui résultent en de évènements séparés qui demandent une décision en deux temps (i.e. entrer des données d’une commande aujourd'hui et plus tard confirmer l'acceptation de cette commande, demandant ainsi une décision séparée.) Ces événements demandant des décisions séparées sont deux processus fonctionnels séparés ;
• Lorsque les responsabilités inhérentes aux activités liées au logiciel sont séparées (i.e. le personnel responsable de la base de données du personnel d'une entreprise, par rapport au personnel responsable de maintenir la paie, indique des processus fonctionnels de différente nature; ou encore un système dont des fonctions distinctes sont offertes à l'administrateur de ce système qui doit maintenir les paramètres de ce produit, par rapport à des fonctions disponibles à l'utilisateur fonctionnel 'régulier' tel un client de

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 37
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
RÈGLES – Processus fonctionnel.
l’organisation en question).
3.2.3. Exemples dans le domaine des logiciels d’application des d’affaires.
a. Les événements déclencheurs d'une application d'affaires en ligne surviennent habituellement via des utilisateurs fonctionnels humains de l'application. L'utilisateur humain donne l'occurrence de l'événement à un processus fonctionnel en saisissant et captant les données par rapport à l'événement ;
EXEMPLE 1 : Dans une compagnie, une commande est reçue (déclencheur de l'événement), entraînant un employé (utilisateur fonctionnel) à saisir les données de la commande (événement déclencheur : données en Entrée de l’objet d'intérêt - 'commande'), peut être le premier mouvement de données du processus fonctionnel « d'enregistrement de commandes ».
b. Parfois, pour une application A, il peut y avoir une application B de même niveau, qui reçoit ou envoie des données à cette dernière. Dans ce cas, si l'application B déclenche un processus fonctionnel quand elle doit envoyer ou recevoir des données de l'application A, alors l'application B est un utilisateur fonctionnel de l'application A ;
EXEMPLE 2 : Supposons qu'à la réception de la commande de l'exemple a), l'application ‘commande’ est alors exigée pour envoyer les informations détaillées du client à une application centrale 'client-enregistrement', qui est mesurée. L'application ‘commande’ devient alors un utilisateur fonctionnel de l'application centrale. L'application ‘commande’ perçoit l'événement de réception des données du client et déclenche alors un processus fonctionnel dans l'application centrale ‘client-enregistrement’ pour enregistrer ces données, en envoyant des données au sujet de l'objet d'intérêt 'client' comme une Entrée, soit le déclenchement de l'application centrale.
c. En principe, il n'y a aucune différence entre l'analyse d'un processus fonctionnel qui se soit effectué en ligne (via Internet par exemple) et l'analyse d'un processus fonctionnel qui se soit effectué dans un lot. Choisir d’exécuter un traitement en lot représente une décision technique d'exécution, et tout ce qui doit être fait pendant cette exécution n’est normalement pas réalisé tant que le ‘processus de nuit’ n'est pas complété. Un traitement en lot se compose d'un ou plusieurs processus fonctionnels (-types), chaque processus devant être analysé du début à la fin, indépendamment de tout autre processus fonctionnel du même lot. Chaque processus fonctionnel a sa propre Entrée de déclenchement devant être mesurée ;
EXEMPLE 3 : Supposons que les commandes de l'exemple a) soient écrites en ligne, et qu’elles soient stockées pour le traitement automatique en différé pendant la nuit. L'utilisateur fonctionnel est toujours l'humain qui a écrit en ligne les commandes et l'Entrée de déclenchement est toujours les données des commandes. Il n’y a qu’un seul processus fonctionnel pour l'Entrée et le traitement des commandes.
d. Les signaux périodiques d'une horloge peuvent physiquement déclencher un processus fonctionnel ;
EXEMPLE 4 : Supposons une FUR pour le traitement en lot des résultats de fin d’année fiscale d’une entreprise, afin d’établir un bilan annuel et aussi, pour rétablir le point de départ du début de l'année suivante. Physiquement, l’horloge du système d'exploitation déclenche le traitement du lot une fois par an, ce dernier, composé d’un ou plusieurs processus fonctionnels. Ces processus fonctionnels faisant partie du lot utilisent des données d'Entrée de ces mêmes lots : Ils devraient être analysés de façon normale (par exemple, les données entrées dans un processus fonctionnel peut comporter une ou plusieurs Entrées : La première Entrée sera l’Entrée de déclenchement pour ce processus).
Cependant, supposons un processus fonctionnel particulier pour produire un ensemble de rapports, qui, dans le lot, n'exige aucune donnée en entrée. Physiquement, l'utilisateur fonctionnel (humain) a délégué au système d'exploitation la charge de déclencher ce processus fonctionnel. Puisque chaque processus fonctionnel doit avoir une Entrée de déclenchement, on peut considérer que l'horloge qui a déclenché la chaîne de lots joue ce rôle pour ce processus. Ce processus fonctionnel peut alors avoir besoin de plusieurs Lectures et beaucoup de Sorties pour produire ses rapports. Logiquement, l'analyse de cet exemple n'est aucunement différente du fait que l'utilisateur fonctionnel lance la production d'un ou plusieurs rapports en ligne, plutôt que de déléguer la production de rapports au système d’exploitation par l'intermédiaire d'un traitement en lots.

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 38
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
e. Un événement unique peut déclencher un ou plusieurs processus fonctionnels qui s'exécutent indépendamment ;
EXEMPLE 5 : À la fin de la semaine, une horloge déclenche le processus de production de rapports de même que le processus de revue des échéances et délais, dans un système particulier de déroulement des opérations.
f. Le même processus fonctionnel peut être déclenché par plus d'un type d'événement déclencheur.
EXEMPLE 6 : Dans un système bancaire, un rapport complet pourrait être généré par un traitement d’un lot de processus de fin de mois, mais également par une demande spécifique effectuée par un client.
Pour accéder à plusieurs exemples distincts d'événements déclencheurs et des processus fonctionnels de traitement en lot, se référer au Guide pour mesurer la taille des applications d'affaires en utilisant COSMIC, à la section 4.6.3.
3.2.4 Exemples dans le domaine des applications de type temps réel.
a. Un événement déclencheur est typiquement détecté par un capteur ;
EXEMPLE 1 : Quand la température atteint une certaine valeur (événement déclencheur), un capteur (utilisateur fonctionnel) est contraint d’envoyer d'un signal (Entrée de déclenchement) au commutateur pour allumer un voyant d'alarme (processus fonctionnel).
EXEMPLE 2 : Un avion militaire possède un capteur qui détecte les événements 'approche de missiles'. Ce capteur est un utilisateur fonctionnel du logiciel embarqué qui doit répondre à la menace. Pour ce logiciel, un événement se produit seulement lorsque le capteur détecte quelque chose. C'est le capteur (utilisateur fonctionnel) qui déclenche un événement du logiciel, en lui envoyant un message (Entrée de déclenchement) disant, par exemple que 'le capteur 2 a détecté un missile'. Les données du message pourraient aussi indiquer la rapidité du missile et ses coordonnées. Le ‘missile’ est l'objet d'intérêt.
b. Les signaux périodiques d'une horloge peuvent déclencher un processus fonctionnel ;
EXEMPLE 3 : Dans certains logiciels de contrôle de processus de type temps réel, un signal périodique (événement déclencheur) d'une horloge (utilisateur fonctionnel) fait en sorte que l’horloge produise un autre signal (Entrée de déclenchement), soit un message d'un bit, qui demande à un processus fonctionnel de répéter un cycle de contrôle. Le processus fonctionnel lit alors les divers capteurs, recevant ainsi des données des objets d'intérêt, et prend alors toutes les actions nécessaires. Il n'y a pas d'autres données accompagnant le signal périodique de l'horloge.
c. Un événement peut déclencher un ou plusieurs processus fonctionnels qui s'exécutent indépendamment et en parallèle ;
EXEMPLE 4 : Un état d'urgence détecté dans une centrale nucléaire peut déclencher des processus fonctionnels indépendants dans différentes parties de l'usine pour abaisser les tiges de commande, commencer le refroidissement d'urgence, fermer les valves, sonner les alarmes pour avertir les opérateurs, etc.
d. Un processus fonctionnel unique peut être déclenché par plus d'un type d'événements déclencheur.
EXEMPLE 5 : La rétraction des roues d'un avion peut être déclenchée par le détecteur de 'poids à terre ', ou par une commande du pilote.
3.2.5 Autres informations sur les processus fonctionnels distincts.
Un logiciel distingue des événements et fournit les processus fonctionnels correspondants et ce, uniquement en fonction de la FUR activée. En évaluant la taille du logiciel, il peut parfois être difficile de décider quels sont les événements distincts que le logiciel doit reconnaître. C'est particulièrement le cas quand la FUR originale n'est plus disponible et quand, par exemple, le développeur a trouvé plus « économique » de combiner le code de plus d’une exigence. Il peut alors être utile d’examiner l'organisation des données en entrée (voir ci-dessous), ou encore, d’examiner les menus de certains logiciels déjà installés. Cela peut aider à distinguer les événements distincts que le logiciel doit exécuter avec les processus fonctionnels correspondants.
EXEMPLE 1 : Quand il y a une FUR permettant de traiter des crédits d'impôts pour un enfant additionnel et aussi, permettant de traiter des crédits d'impôts pour les familles à bas revenus, celles-ci représentent des exigences à deux

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 39
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
événements distincts pour les utilisateurs humains, et dont le logiciel doit répondre. Par conséquent, il devrait y avoir deux processus fonctionnels, et ce, même si un seul formulaire avait été conçu pour saisir les données de ces deux cas.
EXEMPLE 2 : Si le revenu dans un cas (pour une personne) dépasse la limite pour accéder au crédit d'impôt sur le travail, et que pour une personne différente ce ne soit pas le cas, cette différence ne provoque pas deux processus fonctionnels distincts. Cela indique plutôt deux conditions distinctes couvertes par le processus fonctionnel.
EXEMPLE 3 : Pour donner un exemple à la règle (g), supposons une occurrence d’un événement spécifique qui déclenche l’Entrée d’un groupe de données, composé des attributs A, B et C. supposons ensuite que la FUR permette aussi une autre occurrence à partir du même événement déclencheur, une Entrée d'un groupe de données composé des attributs A et B. Cet exemple ne crée pas deux processus fonctionnels (- types) distincts. Seulement une Entrée et un processus fonctionnel (- type) sont ici identifiés, déplaçant et manipulant les attributs A, B et C.
Une fois identifié, chaque processus fonctionnel peut être enregistré sur une ligne individuelle, à une couche ou un niveau qui lui sont appropriés, dans la matrice du modèle générique de logiciel (voir annexe A), sous l'étiquette correspondante.
3.2.6 Les processus fonctionnels de composants de même niveau.
Lorsque la raison d’être de la mesure est de mesurer la taille fonctionnelle de chaque composant de même niveau, un périmètre de mesure distinct doit être défini pour chacun de ces composants. Dans un tel cas, la taille fonctionnelle des processus fonctionnels de chaque composant suit toutes les mêmes règles telles que décrites précédemment.
Dans le cas où la procédure à suivre pour une mesure est respectée (soit, définir la portée, puis les utilisateurs fonctionnels, les frontières, etc...), il s'ensuit que, pour un logiciel étant constitué de deux ou plusieurs composants de même niveau, il ne pourra y avoir de chevauchement entre les périmètres de mesure de chacun d’eux. Effectivement, un périmètre de mesure doit définir un ensemble complet de processus fonctionnels pour chaque composant. Par exemple, un processus fonctionnel ne peut pas chevaucher deux composants de même niveau à la fois. De même, les processus fonctionnels d’un périmètre particulier et d’un composant particulier n'ont pas connaissance des processus fonctionnels provenant d'un autre composant et ce même si les deux composants s’échangeaient des messages (des données).
Les utilisateurs fonctionnels de chaque composant sont définis en vérifiant où se produisent les événements qui déclenchent les processus fonctionnels du composant en question. (Les événements déclencheurs ne peuvent que se produire dans le monde des utilisateurs fonctionnels.)
La figure 4.1.8.2 illustre les processus fonctionnels de deux composants de même niveau et leurs mouvements de données.
3.3 Identification des objets d’intérêts et des groupes de données.
3.3.1 Définitions et principes.
Cette étape consiste à identifier les groupes de données référencés par le morceau de logiciel à mesurer. Pour identifier les groupes de données, particulièrement dans le domaine des logiciels d'application d'affaires, il est habituellement utile d'identifier les objets d'intérêt et probablement aussi leurs attributs. Les groupes de données sont déplacés par des 'mouvements de données' tel que présenté dans le prochain chapitre.
DÉFINITION – Objet d’intérêt.
Toute ‘chose’ qui est identifiée du point de vue des Fonctionnalités Utilisateurs Requises (FUR). Ce peut être une chose physique, aussi bien qu'un objet conceptuel ou partie d’un objet conceptuel dans le monde de l’utilisateur fonctionnel pour lequel un logiciel est requis pour un traitement et/ou un stockage de données.
REMARQUE : Dans la méthode COSMIC, le terme ‘objet d’intérêt’ est utilisé pour éviter d’utiliser des termes reliés à des méthodologies spécifiques du génie logiciel. Le terme ne correspond pas nécessairement au terme ‘objet’ selon le sens utilisé dans les méthodes orientées objets.

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 40
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
DÉFINITION – Groupe de données.
Tout ensemble distinct, non vide, non ordonné et non redondant de types d’attributs de données où chaque type d’attribut de donnée décrit un aspect complémentaire du même objet d’intérêt.
DÉFINITION – Stockage persistant.
Un type de stockage qui permet à un processus fonctionnel de conserver des données au-delà de la vie du processus fonctionnel et/ou qui permet à un processus fonctionnel de retrouver une donnée stockée par un autre processus fonctionnel, ou stockée plus tôt au cours d’une occurrence du même processus fonctionnel ou stockée par un autre processus.
REMARQUE 1 : Dans le modèle COSMIC, puisque la partie de stockage persistant est du côté logiciel de la frontière, elle n’est pas considérée comme un utilisateur du logiciel mesuré.
REMARQUE 2 : Un exemple d’un autre type de stockage persistant est la fabrication de mémoires à lecture seulement.
Après avoir été identifié, chaque groupe de données doit se conformer aux principes suivants :
PRINCIPES – Groupe de données.
a. Chaque groupe de données identifié doit être unique quant à l’ensemble des attributs qu’il contient ;
b. Chaque groupe de données doit être directement lié à un objet d’intérêt décrit dans les FUR du logiciel à mesurer ;
c. Le groupe de données doit être matérialisé dans le système informatique supportant le logiciel.
Après avoir été identifié, chaque groupe de données est enregistré dans une colonne individuelle de la matrice du modèle générique de logiciel (voir annexe A), sous l'étiquette correspondante.
3.3.2 À propos de la matérialisation des groupes de données.
En pratique, la matérialisation d'un groupe de données peut prendre plusieurs formes, par exemple :
a. Comme structure physique d'un enregistrement sur un dispositif de stockage persistant (i.e. un dossier, une table de base de données, la mémoire morte (ROM), etc.) ;
b. Comme structure physique dans la mémoire vive (RAM), de l'ordinateur (i.e. la structure de données a assigné dynamiquement ou par un bloc pré-affecté d'espace mémoire) ;
c. Comme présentation groupée des attributs de données, fonctionnellement reliés sur un interface personne – machine (IPM) ou autre dispositif d’interfaçage (i.e. écran de visualisation, rapport imprimé, affichage de panneau de commande, etc.) ;
d. Comme message étant transmis entre un dispositifs physiques quelconque et un ordinateur, via un réseau, etc.
3.3.3 À propos de l’identification des objets d’intérêt et des groupes de données.
La définition et les principes supportant les objets d’intérêt et leurs groupes de données sont intentionnellement génériques en vue d'être applicable à un plus grand nombre possible de types de logiciels. Cette généricité a comme inconvénient de rendre plus difficile l'application de la mesure sur un morceau de logiciel particulier. Les règles suivantes issues de la pratique de la mesure fonctionnelle, peuvent aider à résoudre certains cas particuliers.
Lorsqu’on est confronté à un besoin d'analyser un groupe d'attributs de données déplacé à partir, ou vers un processus fonctionnel, ou encore déplacé par un processus fonctionnel à partir, ou vers un stockage persistant, il s’avère critique de déterminer si tous ces attributs communiquent

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 41
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
des données à un unique 'objet d'intérêt' car cet 'objet d'intérêt' déterminera le nombre de 'groupes de données' distincts tel que défini par la méthode COSMIC. Par exemple, si les attributs de données qui entrent dans un processus fonctionnel sont des attributs de trois objets d'intérêt distincts, alors on devra identifier trois mouvements de données en entrée distincts.
Objets d'intérêts et groupes de données dans le domaine des applications d'affaires
• Exemple 1: Dans le domaine des logiciels d'application d'affaires, supposons un logiciel permettant de stocker des données au sujet des employés ou des commandes : un objet d'intérêt pourrait alors être un 'employé d’entreprise' (individu physique) ou une 'commande d’articles' (conceptuel). Dans le cas de la 'commande', il arrive généralement qu’une FUR de commandes « multi lignes » soit à l’origine, i.e. qu’il y ait deux objets d'intérêt identifiés plutôt qu’une, soient: 'commande' et 'ligne de commande'. Les groupes de données correspondants pourraient alors être : 'données de commande', et 'ligne de donnée de commande’ ;
• Des groupes de données sont constitués toutes les fois qu'il y a une requête ad hoc qui demande des données sur une certaine 'chose'. La particularité est que ces données ne sont pas toujours contenues dans le stockage persistant, mais peuvent toutefois être dérivées des données contenues dans le stockage persistant. Les mouvements de données en entrée d’une requête ad hoc (soit les paramètres de choix pour dériver les données requises) ainsi que les mouvements de données en sortie (contenant les attributs désirés) déplacent toutes les deux des groupes de données à propos de cette 'chose'. Ce sont des groupes de données temporaires qui ne survivent pas à l'exécution du processus fonctionnel. Il reste que ces groupes de données sont valides parce qu'ils traversent la frontière entre le logiciel et son (ses) utilisateur(s).
EXEMPLE 2 : Considérons une requête ad hoc pour effectuer sur une base de données ‘d’employés’ qui extrait la liste des noms de tous les employés de plus de 35 ans. Le mouvement de données en entrée déplace un groupe de données contenant les paramètres choisis. Le mouvement de données sortie déplace un groupe de données contenant seulement l'attribut 'nom' ; l'objet d'intérêt (ou 'la chose') est représenté par 'tous les employés âgés plus de 35 ans'. Il est important en enregistrant le processus fonctionnel d'identifier clairement un groupe de données temporaire par rapport à son objet d'intérêt, plutôt que de le relier ce groupe de données à l'objet d'intérêt (ou aux objets) lui-même, duquel le résultat de la requête ad hoc est dérivé.
Pour une discussion détaillée sur les méthodes d'analyse des données pour déterminer des objets d'intérêt et des groupes de données distincts, le lecteur doit se référer au 'Guide pour mesurer la taille des applications d'affaires en utilisant COSMIC'.
Objets d'intérêts et groupes de données dans le domaine du temps réel
Exemple 3: Les mouvements de données qui sont en entrée de dispositifs physiques contiennent souvent des données sur l'état d'un objet d'intérêt, comme une valve dont l’état est « ouvert » ou « fermée » par exemple. Ces mouvements de données indiquent souvent, aussi, les délais signalant à court terme si des données temporaires sont valides ou non. Ces mêmes mouvements de données indiquent si un événement critique s'est produit, causant ainsi un blocage. Réciproquement, des mouvements de données en sortie, on obtient souvent des données au sujet d'un objet d'intérêt unique, comme une commande pour allumer ou éteindre voyant lumineux d'avertissement ;
• Un commutateur de messages peut recevoir un groupe de données en entrée et le transférer en sortie sans le modifier, selon les besoins de la FUR du morceau de logiciel en particulier. Les attributs de message du groupe de données peuvent être, par exemple, 'expéditeur, destinataire, code de route et contenu du message' ; l'objet d'intérêt de ce message est donc 'message' ;
• Une structure de données commune, représentant les objets d'intérêt qui sont mentionnés dans les FUR, laquelle peut être mise à jour par des processus fonctionnels, et pouvant être accessible par la plupart des processus fonctionnels trouvés dans le logiciel mesuré ;
• Une structure de données référencée, représentant des graphiques ou des tables avec des valeurs trouvées dans les FUR, qui sont conservées dans le stockage persistant (mémoire ROM, par exemple) et accessible par la plupart des processus fonctionnels du logiciel mesuré ;
• Fichiers généralement désignés comme 'Fichiers plats’, représentant des objets d'intérêt mentionnés dans les FUR qui sont conservés sur un dispositif de stockage persistant.

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 42
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
3.3.4 Données ou groupes de données non éligible aux mouvements de données.
Toute donnée apparaissant sur une interface d’entrée ou de sortie (écran, rapports) qui n’est pas liée à un objet d'intérêt d’un utilisateur fonctionnel, ne devrait pas faire part d’un mouvement de données, et ne devrait donc pas être mesurée.
Exemple 1: Des données de type ‘application générale’ telles que des en-têtes et titres de bas de page (nom de compagnie, nom d'application, date de système, etc.) apparaissant sur tous les écrans ;
Exemple 2: Des commandes de contrôle du logiciel (un concept défini seulement dans le domaine des logiciels d'application d'affaires) permettant à un utilisateur fonctionnel de contrôler son logiciel plutôt que de déplacer des données, telles que : des commandes permettant de feuilleter (page haut / page bas), des commandes de type « cliquer 'OK’ pour accepter un message d'erreur », etc. - voir aussi la section 4.1.10.
Le modèle générique de logiciel COSMIC suppose que toute manipulation de données dans un processus fonctionnel est associée à un des quatre types de mouvements de données. - voir la section 4.1.6. Par conséquent, aucun mouvement ou manipulation de données dans un processus fonctionnel ne peut être identifié comme étant un mouvement de données autres que : Entrées, Sorties, Lectures ou eCritures. (Pour des exemples manipulation et de mouvements de données qui pourraient être mal interprétées, voir la section 4.1.4, principe (c)) pour la Lecture, et la section 4.1.5 (d)) pour l’eCriture).
3.3.5 L’utilisateur fonctionnel comme objet d’intérêt.
Dans beaucoup de cas simples de systèmes type temps réel, tels que décrit à l'exemple 3 de la section 3.3.3, le dispositif physique - un utilisateur fonctionnel – ne se distingue pas de l'objet d'intérêt du mouvement de données qu'il envoie ou reçoit. Dans ces cas-là, cela ajoute peu d’intérêt de documenter un objet d'intérêt comme si c'était quelque chose de distinct de l'utilisateur fonctionnel. Il est important d'employer ces concepts quand c'est utile, afin de distinguer des groupes de données distincts et par conséquent, de séparer les mouvements de données.
EXEMPLE : Supposons un capteur de température 'A' qui, une fois interrogé par un processus fonctionnel, envoie la température courante de ce dernier. L'utilisateur fonctionnel est le capteur de température ‘A’ ; le nom de la donnée en entrée pourrait être 'la température courante A ' et finalement, l'objet d'intérêt de ce message pourrait également être considéré comme étant le capteur de température 'A'. Mais théoriquement, l'objet d'intérêt n'est pas le capteur de température 'A', mais bien 'la chose dont la température est mesurée par le capteur A'. En pratique cependant, effectuer ce type distinction raffinée ajoute peu de valeur, ce qui fait qu'il est peu ou pas intéressant d'identifier l'objet d'intérêt de manière distincte.
3.4 Identification des attributs (optionnel).
Cette section présente comment est réalisée une identification des attributs de données référencés, par le morceau de logiciel à mesurer. Dans cette version de la méthode de mesure, il n'est pas obligatoire d'identifier les attributs de données. Cependant, il peut être utile d'analyser et d'identifier des attributs de données lors du processus d'identification des groupes de données et des objets d'intérêt. Par exemple, des attributs de données pourraient être identifiés si une sous unité de mesure de taille était exigée, comme présenté dans la section 4.5 'Extension de méthode de mesure COSMIC'.
3.4.1 Définition.
DÉFINITION – Attribut de donnée.
La plus petite parcelle d’information codée, dans un groupe de données, possédant une signification dans la perspective des Fonctionnalités Utilisateurs Requises (FUR) du logiciel.
EXEMPLE 1 : Les attributs dans le contexte du domaine des logiciels d’applications d’affaires sort par exemple des éléments de donnés enregistrés dans un dictionnaire de données et les éléments de donnés apparaissant dans un modèle conceptuel ou dans un modèle logique de données.

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 43
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
EXEMPLE 2 : Les attributs dans le contexte du domaine des logiciels de type temps réel sont par exemple des éléments de donnés d’un signal reçu d’un capteur et des éléments de donnés d’un message transmis.
3.4.2 À propos de l’association entre les attributs et les groupes de données.
En théorie, un groupe de données ne pourrait contenir qu’un seul attribut de donnée, et ce serait suffisant du point de vue de la FUR, afin de décrire l'objet d'intérêt. Dans la pratique, de tels cas se produisent généralement dans des logiciels de type temps réel (par exemple : Un mouvement de données en Entrée véhiculant un signal périodique d'une horloge) et sont moins communs dans les logiciels d'application d'affaires.

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 44
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
44 LA PHASE DE MESURE.
Cette section présente maintenant les règles et procédures pertinentes à la phase de mesure. La procédure générale, pour mesurer un morceau de logiciel à partir du modèle générique de logiciel COSMIC, est résumée à la figure 4.0 ci-dessous.
Figure 4.0 – Processus général de la phase de mesure COSMIC.
Chaque étape de cette procédure fait l'objet d'une sous-section spécifique où les définitions et les principes à appliquer sont présentés, de même que certaines règles et exemples.
4.1 Identification des mouvements de données.
Cette étape consiste à identifier les mouvements de données (Entrée, Sortie, Lecture et éCriture) de chaque processus fonctionnel.
4.1.1 Définition des types de mouvement de données.
DÉFINITION – Mouvement de données.
Un composant fonctionnel de base qui déplace un seul type de groupe de données.
REMARQUE 1 : Il y a quatre sous-types de mouvements de données: entrée (E), sortie (S), lecture (L), écriture (C).
REMARQUE 2 : Pour le besoin de la mesure, chaque sous-type de mouvement de données est
Phase de Mesure COSMIC
Section 4.1 IDENTIFIER LES MOUVEMENTS DE DONNÉES
Section 4.2 APPLIQUER LES FONCTIONS DE MESURE
Section 4.3 ADDITIONNER LES RESULTATS DE MESURES
FUR sous forme de Modèle générique de
logiciel COSMIC
Taille fonctionnelle du logiciel mesuré
Tous les processus fonctionnels sont
mesurés
NON
OUI
Rapporter la mesure
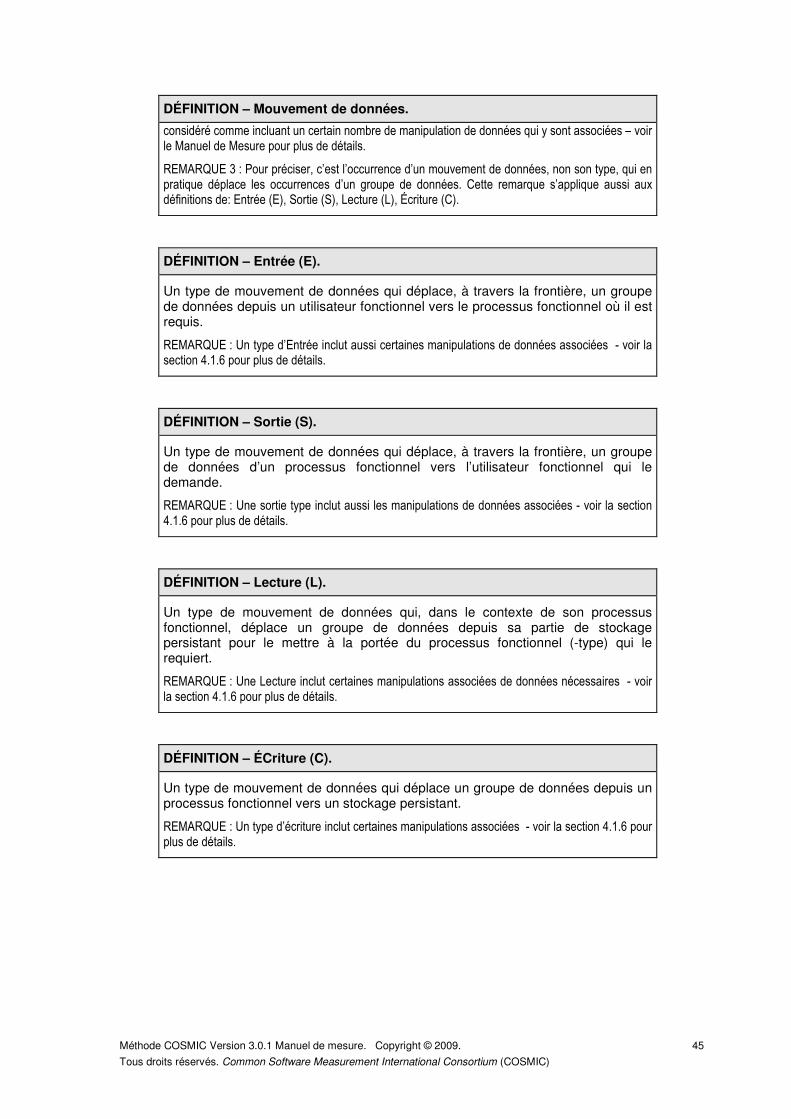
Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 45
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
DÉFINITION – Mouvement de données.
considéré comme incluant un certain nombre de manipulation de données qui y sont associées – voir le Manuel de Mesure pour plus de détails.
REMARQUE 3 : Pour préciser, c’est l’occurrence d’un mouvement de données, non son type, qui en pratique déplace les occurrences d’un groupe de données. Cette remarque s’applique aussi aux définitions de: Entrée (E), Sortie (S), Lecture (L), Écriture (C).
DÉFINITION – Entrée (E).
Un type de mouvement de données qui déplace, à travers la frontière, un groupe de données depuis un utilisateur fonctionnel vers le processus fonctionnel où il est requis.
REMARQUE : Un type d’Entrée inclut aussi certaines manipulations de données associées - voir la section 4.1.6 pour plus de détails.
DÉFINITION – Sortie (S).
Un type de mouvement de données qui déplace, à travers la frontière, un groupe de données d’un processus fonctionnel vers l’utilisateur fonctionnel qui le demande.
REMARQUE : Une sortie type inclut aussi les manipulations de données associées - voir la section 4.1.6 pour plus de détails.
DÉFINITION – Lecture (L).
Un type de mouvement de données qui, dans le contexte de son processus fonctionnel, déplace un groupe de données depuis sa partie de stockage persistant pour le mettre à la portée du processus fonctionnel (-type) qui le requiert.
REMARQUE : Une Lecture inclut certaines manipulations associées de données nécessaires - voir la section 4.1.6 pour plus de détails.
DÉFINITION – ÉCriture (C).
Un type de mouvement de données qui déplace un groupe de données depuis un processus fonctionnel vers un stockage persistant.
REMARQUE : Un type d’écriture inclut certaines manipulations associées - voir la section 4.1.6 pour plus de détails.

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 46
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
La figure 4.1.1 ci-dessous, illustre la relation entre chacun des quatre types de mouvement de données et le processus fonctionnel auquel il appartient de même que la frontière du logiciel mesuré.
Entrée
Frontière
Utilisateur(s) fonctionnel(s)
Processus fonctionnel
Stockage persistant
Lecture Écriture
Sortie
Sous-processus de type de « mouvement de données »
Manipulation
Figure 4.1.1 – Les composants d’un processus fonctionnel (les 4 types de mouvements de données) et certaines de leurs interrelations
4.1.2 Identification des Entrées (E).
Une fois identifié, chaque mouvement de données en Entrée doit répondre aux principes suivants :
PRINCIPES – Entrée (E).
a. Une Entrée déplacera un seul groupe de données décrivant un seul objet d'intérêt d'un utilisateur fonctionnel, à travers la frontière du logiciel vers le processus fonctionnel auquel cette Entrée fait partie. Si l'Entrée d’un processus fonctionnel comporte plus d'un groupe de données, il faudra identifier une seule Entrée pour chaque groupe de données. (voir également la section 4.1.7 sur ‘l'unicité des mouvements de données’ ;
b. Une Entrée ne doit pas sortir de données à travers la frontière du logiciel, ni lire, ni écrire des données ;
c. Une Entrée à un processus fonctionnel doit être comptée dans le cas où ce dernier est ‘demandeur d’une Entrée’ d’un utilisateur fonctionnel et que cet utilisateur fonctionnel n’a pas besoin qu’on lui précise la donnée à envoyer, ou que cet utilisateur fonctionnel ne soit pas en mesure de répondre à des messages lui étant destinés.
REMARQUE : Dans ce cas particulier en ‘c’, tout message provenant du processus fonctionnel et étant destiné à l’utilisateur fonctionnel pour faire une ‘demande d’Entrée’ ne devra pas être compté comme étant une ‘Sortie’ au processus fonctionnel. Toutefois, lorsque le processus fonctionnel est ‘demandeur d’une Entrée’ auprès de l’utilisateur fonctionnel, mais que ce processus fonctionnel doit fournir des données en Entrée à cet utilisateur fonctionnel pour préciser ce dont il a besoin, alors il faudra compté une ‘Sortie’ au processus fonctionnel, en plus de l’Entrée telle qu’envoyé à ce dernier par l’utilisateur fonctionnel (voir la section 4.1.9 pour plus de précisions)
Les règles suivantes aident à confirmer le statut ‘d’Entrée’ pour mouvement de données :
RÈGLES – Entrée (E).
a. Un groupe de données d'une Entrée de déclenchement peut comporter un seul attribut de données informant tout simplement le logiciel qu'un événement ‘Y’ est survenu. Très souvent, plus particulièrement pour les logiciels d'application d'affaires, le groupe de données de l’Entrée de déclenchement a plusieurs attributs de données qui informent le logiciel qu'un événement ‘Y’ s'est produit et présente ainsi les données au sujet de cet événement

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 47
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
RÈGLES – Entrée (E).
particulier ; b. Les signaux périodiques d’une l’horloge comme déclencheur d’événements sera toujours
‘extérieur’ au logiciel mesuré. Par conséquent lorsque qu’une horloge émet un signal périodique pour un événement se produisant toutes les 3 secondes, ce signal sera associé à une Entrée déplaçant un groupe de données d'un seul attribut de données. Noter qu'il n’y a aucune différence si l'événement déclencheur est produit périodiquement par du matériel ou par un autre morceau de logiciel en dehors de la frontière du logiciel mesuré ;
c. À moins qu'un processus fonctionnel spécifique soit nécessaire, le fait d’obtenir le temps d’une horloge d’un système ne sera pas considéré comme la cause suffisante de caractérisation d’un mouvement de données en Entrée ;
d. Si une occurrence d'un événement spécifique déclenche l'Entrée d'un groupe de données comportant 'N' attributs (d'un objet d'intérêt particulier), et que la FUR admet qu’une autre occurrence du même événement puisse déclencher une Entrée d'un groupe de données ayant les même valeurs pour un sous-ensemble de ces 'N' attributs, alors une seule Entrée sera identifiée : celle comportant tous les 'N' attributs.
Un exemple illustrant la règle (c) : lorsqu’un processus fonctionnel Écrit le résultat d'un horodateur, aucune Entrée n'est identifiée pour obtenir la valeur de l'horloge du système.
Une fois identifié, chaque mouvement de données en Entrée peut être enregistré en marquant un 'E' dans la cellule correspondante de la matrice du modèle générique de logiciel (voir en annexe A).
4.1.3 Identification des Sorties (S).
Une fois identifié, chaque mouvement de données en Sortie doit répondre aux principes suivants :
PRINCIPES – Sortie (S).
a. Une Sortie déplacera un seul groupe de données décrivant un seul objet d'intérêt d’un processus fonctionnel, à travers la frontière du logiciel vers un utilisateur fonctionnel. Si la Sortie d'un processus fonctionnel comprend plus d'un groupe de données, il faudra identifier une seule Sortie pour chaque groupe de données. (voir également la section 4.1.7 sur 'l'unicité des mouvements de données'.) ;
b. Une Sortie ne doit pas entrer des données à travers la frontière du logiciel, ni lire, ni écrire des données.
Les règles suivantes aident à confirmer le statut de ‘Sortie’ pour mouvement de données
RÈGLES – Sortie (S).
a. Tous les messages produits par le logiciel qui sortent sans la présence de données utilisateur (par exemple un ‘message d'erreur générique’) seront considérés comme des valeurs d'un attribut d'un seul objet d'intérêt (qui pourrait être appelés 'indication d’erreur'). Par conséquent, une seule Sortie sera identifiée pour représenter toutes ces occurrences de message, et ce pour chaque processus fonctionnel lorsque la FUR le nécessite ;
b. Si la Sortie d'un processus fonctionnel déplace un groupe de données comportant 'N' attributs (d'un objet d'intérêt particulier), et que la FUR admet qu’une autre occurrence du même événement puisse déclencher une Sortie d'un groupe de données ayant les même valeurs pour un sous-ensemble de ces 'N' attributs, alors une seule Sortie sera identifiée : celle comportant tous les 'N' attributs.
Voici quelques exemples qui illustrent la règle (a) :
EXEMPLE 1 : Dans un dialogue personne-machine, des messages d'erreur qui pourraient se manifester pendant la validation des données en Entrées pourraient être, par exemple : 'erreur de format', 'client non trouvé ', 'erreur : la case à cocher indique que les modalités et conditions n’ont pas été lues', 'la limite du crédit a été dépassé', etc. De tels messages d'erreur devraient être considérés comme étant des occurrences d’une seule Sortie pour chaque processus fonctionnel où de tels messages doivent exister. Ils pourraient être appelés des 'messages d'erreur' de manière générique.

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 48
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
EXEMPLE 2 : Des messages d'erreur conçus pour des utilisateurs fonctionnels humains qui n’ont pas été générés par le logiciel, devraient être ignorés. Un tel message proviendrait du système d'exploitation par exemple, et pourrait se manifester de cette façon : 'imprimante X ne répond pas'.
EXEMPLE 3 : Dans un dialogue personne-machine, si un message se produit dans des situations d'erreur mais qui contient des données d’un utilisateur fonctionnel, alors il devrait être considéré comme étant une Sortie du processus fonctionnel où l’erreur s’est manifesté. Un exemple d'un tel message pourrait être : 'avertissement : le montant que l’on souhaite retirer dépasse la limite de découvert de $100.00' (où $100.00 est une variable calculée). Dans cet exemple, la Sortie contient le groupe de données comportant des attributs du compte bancaire du client.
EXEMPLE 4 : Dans un logiciel de type temps réel, un processus fonctionnel qui vérifie périodiquement le bon fonctionnement de dispositifs câblés pourrait émettre un message qui indique que la ‘sonde ‘X’ a échoué’, où 'X' est une variable. Ce message devrait être identifié comme étant un mouvement de données en Sortie pour ce processus fonctionnel (indépendamment de la valeur de 'X').
EXEMPLE 5 : Considérer les processus fonctionnels ‘A’ et ‘B’. 'A' peut potentiellement émettre deux messages distincts de confirmation et cinq messages d'erreur à ses utilisateurs fonctionnels. 'B' pour sa part, peut potentiellement émettre huit messages d'erreur à ses utilisateurs fonctionnels. Dans cet exemple, une seule Sortie sera identifiée dans le processus fonctionnel 'A' (manipulant 5 + 2 = 7 messages) et une Sortie séparée sera identifiée pour le processus fonctionnel 'B' (manipulant pour sa part, 8 messages).
Une fois identifié, chaque mouvement de données en Sortie peut être enregistré en marquant un 'S' dans la cellule correspondante de la matrice du modèle générique de logiciel (voir en annexe A).
4.1.4 Identification des Lectures (L).
Une fois identifié, chaque mouvement de données en Lecture doit répondre aux principes suivants :
PRINCIPES – Lecture (L).
a. La Lecture déplacera un seul groupe de données décrivant un seul objet d'intérêt d’un stockage persistant, à travers la frontière du logiciel, vers le processus fonctionnel auquel cette Lecture fait partie. Si le processus fonctionnel doit lire plus d'un groupe de données à partir du stockage persistant, il faudra identifier une seule Lecture pour chaque groupe de données à lire. (voir également la section 4.1.7 sur ‘l'unicité des mouvements de données') ;
b. La Lecture ne doit pas recevoir de données à travers la frontière du logiciel, ni sortir, ni écrire des données ;
c. Le mouvement (ou la manipulation) des donnés qui ne proviennent pas d’une FUR mais qui sont internes à un processus fonctionnel et qui peuvent être changé seulement par : un programmeur, par un calcul de résultats intermédiaires, ou à partir de données conservées par un autre processus fonctionnel résultant de l’implantation, ne sera pas considéré comme étant un mouvement de données en Lecture ;
d. Un mouvement de données en Lecture inclura toujours toutes fonctionnalités de 'demande de Lecture'. Ainsi un mouvement de données additionnel ne sera jamais nécessaire pour représenter une éventuelle fonctionnalité distincte de 'demande de Lecture'. Voir également la section 4.1.9.
Une fois identifié, chaque mouvement de données en Lecture peut être enregistré en marquant un 'L' dans la cellule correspondante de la matrice du modèle générique de logiciel (voir en annexe A).
4.1.5 Identification des éCritures (C).
Une fois identifié, chaque mouvement de données en éCriture doit répondre aux principes suivants :
PRINCIPES – éCriture (C).
a. Une éCriture déplacera un seul groupe de données décrivant un seul objet d'intérêt d’un processus fonctionnel duquel l'éCriture fait partie, à travers la frontière du logiciel, vers le 'stockage persistant'. Si le processus fonctionnel doit écrire plus d'un groupe de données dans le stockage persistant, il faudra identifier une seule éCriture pour chaque groupe de données à

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 49
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
PRINCIPES – éCriture (C).
écrire. (voir également la section 4.1.7 sur ‘l'unicité des mouvements de données’.) ; b. Une éCriture ne doit pas recevoir de données à travers la frontière du logiciel, ni sortir, ni lire
des données ; c. Une manipulation de données de suppression d’un groupe de données du 'stockage
persistant' ne sera mesurée que par un seul mouvement de données en éCriture ; d. Le mouvement (ou la manipulation) des données qui ne persistent pas quand le processus
fonctionnel est complété, et qui ne met pas à jour des variables qui sont internes au processus fonctionnel, et qui ne produit pas de résultats intermédiaires à partir d'un calcul, ne sera pas considéré comme étant un mouvement de données en éCriture.
Une fois identifié, chaque mouvement de données en éCriture peut être enregistré en marquant un 'C' dans la cellule correspondante de la matrice du modèle générique de logiciel (voir en annexe A).
4.1.6 Les manipulations des données associées aux mouvements de données.
Les sous-processus sont soit des mouvements de données, soit des manipulations de données, tel que défini dans le principe (d) du modèle générique de logiciel (voir la section 1.4). Cependant, actuellement, par une convention COSMIC (voir le principe (j) du générique de logiciel), l'existence de sous-processus distincts de manipulation de données n'est pas reconnue.
DÉFINITION –Manipulation des données.
Tout ce qui survient aux données autre qu’un mouvement de données vers l’intérieur ou l’extérieur d’un processus fonctionnel, ou entre un processus fonctionnel et un stockage persistant.
Le principe suivant détermine comment la méthode COSMIC traite la manipulation des données :
PRINCIPE – Manipulation des données associées aux mouvements de données.
Toute manipulation de données d’un processus fonctionnel sera associée aux quatre types de mouvements de données (E, S, L, et C). Par convention, on suppose que les mouvements de données d'un processus fonctionnel représentent des manipulations de données pour le même processus fonctionnel.
La nécessité de savoir quel genre de manipulations de données est associé à quel type de mouvement de données ne survient que lorsqu’on mesure les modifications apportées à un logiciel (voir la section 4.4). Une demande de modification typique affecte le plus souvent le déplacement des attributs que la manipulation liée à un mouvement de données, mais il peut aussi seulement affecter la manipulation de données, (sans toucher au mouvement de données). Une telle modification doit alors être identifiée et mesurée. Ainsi, quand il y a une exigence visant à modifier la manipulation des données dans un processus fonctionnel, le mesureur doit identifier quel mouvement de données est associé au changement de manipulation des données.
Ci-dessous sont présentées des directives permettant d’identifier des manipulations de données, chacune représentée par des mouvements de données.
Mouvement de données en Entrée.
Une Entrée inclut toutes les manipulations de données… :
• pour permettre à un utilisateur fonctionnel de saisir un groupe de données en Entrée (ex : des manipulations de type formatage ou de présentation) et/ou ;
…mais aucune manipulation de données impliquant un autre mouvement de données, ni une manipulation de données après que le groupe de données soit écrit et validé ne sont inclus.
EXEMPLE: une Entrée inclut toutes les manipulations de type formatage ou présentation sur un écran de saisie, excepté toute Lecture(s) qui pourrait être exigée pour valider les entrées de codes ou pour obtenir quelques descriptions associées.

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 50
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
Un mouvement de données en Entrée inclut toute fonctionnalité de 'demande d'Entrée' excepté lorsque le de processus fonctionnel doit informer l'utilisateur fonctionnel sur les données à lui envoyer (voir la section 4.1.9 sur les données à envoyer et 4.1.10 pour le traitement d'un écran d'entrée vide).
Mouvement de données en Sortie.
Une Sortie inclut toutes les manipulations de données… :
• Pour créer les attributs de donnée d'un groupe de données à sortir et/ou ; • Pour permettre à un groupe de données de sortir (ex. : des manipulations de type
formatage ou de présentations) pour ensuite être dirigé vers un utilisateur fonctionnel ciblé.
• Mais aucune autre manipulation de données impliquant un autre mouvement de données n’est incluse.
EXEMPLE : Une Sortie inclut tous les traitements permettant de formater et de préparer l'impression de certains attributs de données, y compris les champs d'en-têtes13 lisibles par un utilisateur fonctionnel humain, mais n’inclut AUCUN mouvement de donnée de type Lecture ou Entrée qui pourraient être exigées pour fournir de telles valeurs ou attributs de données.
Mouvement de données en Lecture.
Une Lecture inclut tous les traitements et/ou calculs requis en vue de retrouver un groupe de données provenant d’un stockage persistant. Par contre, aucune manipulation de données impliquant un autre type de mouvement de données, ni les manipulations survenant après que la Lecture ait été complétée avec succès sont inclus.
Par exemple, la Lecture inclut tous les calculs mathématiques et traitements logiques nécessaires pour rechercher un groupe de données dans un stockage persistant, mais n’inclut pas une manipulation des attributs de données après que le groupe de données ait été trouvé.
La Lecture inclut également toutes les fonctionnalités de 'demande de Lecture' (voir la section 4.1.9).
Mouvement de données en Écriture.
Une éCriture inclut tous les traitements et/ou calculs requis en vue de créer et d’écrire un groupe de données, sans toutefois inclure une manipulation de données impliquant un autre type de mouvement de données, ni une manipulation de données après que l'éCriture ait été complétée avec succès.
EXEMPLE : une éCriture inclut tous les calculs mathématiques et traitements logiques nécessaires pour créer, mettre à jour, ou à supprimer un groupe de données, mais n’inclut AUCUN mouvement de donnée de type Lecture ou Entrée qui pourraient être exigées pour fournir de telles valeurs ou attributs de données du groupe de données à écrire ou à être supprimé.
13 Cet exemple s'applique à la mesure d'un logiciel utilisé par des utilisateurs fonctionnels humains, quelque soit le domaine. Il ne s'appliquerait pas pour la mesure de la taille d’objets réutilisables pour l’affichage de différents champs d’écrans par exemple.

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 51
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
4.1.7 Unicité des mouvements de données et exceptions possibles14.
Le modèle générique de logiciel suppose que normalement, pour tout processus fonctionnel, toutes les données décrivant un objet d'intérêt doit prendre part dans au moins un mouvement de données, soit : être saisi en Entrée et/ou lu par mouvement de données de Lecture et/ou écrit par un mouvement de données en éCriture et/ou sorti au moyen d’un mouvement de données en Sortie. De plus, le modèle suppose aussi que toute manipulation de données (modification, ajout, suppression) exercée sur un groupe de données spécifique ainsi déplacé, est associée à son propre mouvement de données.
EXEMPLE : illustrant ces hypothèses: considérons deux occurrences d'un processus fonctionnel donné (- type). Supposons que dans la première occurrence, les valeurs de quelques attributs de données à déplacer mènent à un sous-processus de manipulation de données (- type) 'A'. Supposons aussi que dans l’autre occurrence du même processus fonctionnel, la valeur des attributs mènent à un sous-processus différent de manipulation de données (- type) 'B'. Dans de telles circonstances, les sous-processus 'A' et ‘B’ de manipulation de données doivent être associés au même mouvement de données et par conséquent, seulement un mouvement de données devra normalement être identifié et compté dans ce processus fonctionnel.
Il existe cependant des circonstances exceptionnelles dans lesquelles différents types de groupe de données (décrivant un objet d'intérêt), peuvent être demandés (par la FUR) à être déplacés par un mouvement de données de même type (C, L, E, S) dans le même processus fonctionnel. Alternativement, et encore exceptionnellement, il peut être demandé que le même groupe de données soit déplacé dans le même type de mouvement de données (C, L, E, S) dans le même processus fonctionnel, mais avec des manipulations de données différente.
Les règles suivantes et les exemples couvrent les cas normaux, quelques exceptions et exemples qui apparaissent comme étant des cas valides, mais qui ne le sont pas.
RÈGLES – Unicité des mouvements de données et exceptions possibles.
a. Sauf si la FUR l’indique autrement, tous les attributs de données décrivant un objet d'intérêt et qui est exigé dans un processus fonctionnel, de même que toutes les manipulations de données associées, seront identifiées et comptées comme étant des mouvements de données en Entrée (-type) ;
REMARQUE : Un processus fonctionnel pourrait, en principe, manipuler de multiples Entrées (-type), chacune déplaçant un groupe de données décrivant un objet d'intérêt (-type) distinct ;
b. La règle équivalente s'applique à tout mouvement de données en Lecture, en éCriture ou en Sortie, dans tout processus fonctionnel donné ;
c. Dans les cas où il existe plus d'un mouvement de données en Entrée (-type), déplaçant chacun un même groupe de données, décrivant ainsi le même objet d'intérêt (-type) dans un même processus fonctionnel donné (-type) peuvent être identifiés et comptés s'il y a une FUR pour ces entrées multiples. De même, dans les cas où il existe plus d'une Entrée (-type) déplaçant chacune le même groupe de données (-type) dans le même processus fonctionnel, mais chacune ayant différentes manipulations de données (-types) associées, peuvent être identifiées et comptées s'il y a une FUR pour ces entrées multiples ;
d. Une telle FUR peut exister quand des Entrées multiples d'un processus fonctionnel, proviennent de plusieurs utilisateurs fonctionnels qui saisissent plusieurs groupes de données (chacun décrivant le même objet d'intérêt) ;
e. La même règle s'applique à la Lecture, l'éCriture ou la Sortie d'un mouvement de données dans n'importe quel processus fonctionnel donné ;
f. Plusieurs occurrences d'un même type de mouvement de données (i.e. déplaçant le même groupe de données avec la même manipulation de données) ne seront pas identifiées ou comptées plus d'une fois dans tout le processus fonctionnel ;
g. Dans le cas où des occurrences multiples d'un mouvement de données (associés à un processus fonctionnel donné), diffèreraient dans leur manipulation de données en raison des différentes valeurs des attributs du groupe de données, cela résulterait dans le suivi de différents chemins de traitement. Ce type de mouvement de données ne sera pas identifié et compté plus d’une fois dans ce processus.
14 Cette section s’appelait ‘Déduplication des mouvements de données’ dans la version 2.2 du Manuel de mesure. Le
terme ‘déduplication’ n’a pas été perçu comme utile, sa terminologie a été changée.

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 52
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
Les exemples suivants expliquent les règles ci-dessus.
EXEMPLE 1 : (pour la règle (a)) Toute Lecture de données déplaçant un objet d'intérêt particulier peut être logiquement considéré comme déplaçant tous les attributs de données requis de cet objet d'intérêt (i.e. la totalité du 'vecteur d'état' de cet objet d'intérêt). Par conséquent et habituellement, seulement une Lecture (de n'importe quel attribut, et de n'importe quel objet d'intérêt), est fonctionnellement nécessaire et devrait être identifiée et comptée dans tout processus fonctionnel.
EXEMPLE 2 : (pour les règles (a) et (b)) Suite à l'exemple 1, étant donnée toutes les données devant être lues, celles-ci doivent aussi être reconnues comme étant des données persistantes provenant d'une éCriture. Il est donc normal dans ce cas (règle a), qu’une éCriture identifiée comme étant celle qui déplace tous les attributs du groupe de données d’un objet d’intérêt, soit nécessairement persistants dans un processus fonctionnel donné (selon la règle (a)). Exceptionnellement cependant, il est possible qu’une FUR d'un processus fonctionnel unique écrive deux groupes de données différents, décrivant le même objet d'intérêt. Un exemple d'application de la règle b) serait quand un unique processus fonctionnel A est requis pour extraire deux sous-ensembles de données d'un fichier d'un compte de banque courant pour une utilisation ultérieure dans des programmes séparés. Le premier sous-ensemble est le détail de «compte à découvert" "(qui comprend les attributs du solde négatif). Le deuxième sous-ensemble est le détail de «compte de grande valeur " (qui ne comprend que le nom et l'adresse du titulaire du compte destinés au marketing par courriel). Un processus fonctionnel aura deux écritures, un pour chaque sous-ensemble.
EXEMPLE 3 : (pour la règle (b)) Supposons un processus fonctionnel A, devant extraire deux sous-groupes de données d’un fichier de « comptes courants » bancaires, pour une utilisation ultérieure, par un autre logiciel. Le premier groupe de données traite des « comptes en souffrance » et le second, des « comptes à haut rendement ». Dans ce cas précis, le processus fonctionnel A fera deux éCritures : une pour chaque sous-groupe de données.
EXEMPLE 4 : (pour la règle (b)) Il est possible qu’une FUR exige qu’un processus fonctionnel produise deux Sorties déplaçant des groupes de données différents destinés à différents utilisateurs fonctionnels, mais qui décrivent le même objet d'intérêt. Par exemple, un nouvel employé se joint à une nouvelle compagnie : un rapport est alors produit pour que l'employé révise ses données personnelles afin de les valider. Un message est alors envoyé à la sécurité pour autoriser cet employé à entrer dans les bâtiments de l’organisation.
EXEMPLE 5 : (pour la règle (c)) Supposons qu’une Lecture soit exigée par la FUR qui en pratique, requiert plusieurs occurrences de Lecture, pour une recherche dans un fichier. Pour les fins de la mesure, on doit identifier qu’une seule Lecture.
EXEMPLE 6 : (pour la règle (c)) Supposons un processus fonctionnel de types temps réel, dont la FUR requière des données devant être saisies par un dispositif câblé (utilisateur fonctionnel). Cette FUR requiert donc des données deux fois à intervalle de temps fixe, afin de mesurer un taux de changement, ou, de contrôler si une valeur a changé pendant le processus. Si les deux Entrées sont identiques en termes de groupes de données déplacés et en termes de manipulation de données associée, seulement une Entrée devra être identifiée. (Se référer à la section 4.1.6 pour les types de manipulation de données qui sont considérés comme étant associés à une Entrée.)
EXEMPLES 7 : (pour la règle (c)) Voir la section 4.1.2, règle (d) pour les mouvements de données en Entrées, et la section 4.1.3, règle (b) pour les mouvements de données en Sorties.
EXEMPLE 8 : (pour la règle (d)) Supposons qu'un processus fonctionnel fournisse une diversité de manipulation de données selon les valeurs des attributs de données d'une Entrée. Pour les fins de la mesure, on doit identifier qu’une seule Entrée.
EXEMPLE 9 : Supposons qu’un groupe de données soit exigé en Lecture par une FUR, mais que le développeur informatique décide de réaliser cette fonctionnalité en deux commandes. Le développeur veut ainsi faire afin de retrouver deux sous-ensembles différents d'attributs de données appartenant au même objet d'intérêt, à partir d’un stockage persistant et ce, à différents moment dans le processus fonctionnel. Pour les fins de la mesure, on doit identifier qu’une seule Lecture.
4.1.8 Lorsqu’un processus fonctionnel déplace des données de ou vers du stockage persistant.
Cette section explique les mouvements de données impliqués lorsqu’un processus fonctionnel d'un morceau de logiciel déplace des données de ou vers du stockage persistant, quand ce stockage est local ou distribué. Les exemples présentés ici montrent aussi comment les besoins de stockages d’une l'application sont manipulés par d’autres logiciels qui supportent l'application dans une autre couche, tels que des pilotes pour un dispositif de stockage persistant.
Les exemples illustrent aussi l'application du principe (g) du modèle contextuel de logiciel et les principes du model générique de logiciel. La clef pour comprendre ces cas est que ces principes doivent être appliqués séparément à chaque morceau de logiciel devant être mesuré.

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 53
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
Le premier exemple traite des mouvements de données d'une requête d’une application, où l’exigence de rechercher (ou Lire) des données persistantes provient d’un pilote situé dans une autre couche que l’application. Le deuxième exemple montre comment les mouvements de données diffèrent quand la recherche est d'abord satisfaite par un morceau de logiciel de même niveau et provenant de la même couche que l'application.
En pratique, les exemples sont applicables quand la tâche consiste à mesurer la taille fonctionnelle de deux morceaux de logiciel qui ont un rapport hiérarchique (i.e. quand les deux morceaux sont dans différentes couches) ou qui ont un rapport client/serveur (i.e. quand les deux morceaux sont dans la même couche). Ces exemples montrent comment les mouvements de données qui sont physiquement échangés entre les deux morceaux de logiciel à mesurer sont modelés.
Les exemples sont illustrés en utilisant les diagrammes de séquences normalisés. Voici la notation utilisée pour ces diagrammes :
• La flèche verticale en « gras » se dirigeant vers le bas, représente un processus fonctionnel ;
• Les flèches horizontales représentent des mouvements de données, marqués E, S, L ou C pour l'Entrée, la Sortie, la Lecture et l'éCriture, respectivement. Les Entrées et Lectures sont représentés par des flèches entrant dans le processus fonctionnel, et les Sorties et éCritures sont représentés par des flèches sortantes ; elles apparaissent dans l'ordre séquentiel exigé par le processus fonctionnel, de haut en bas ;
• La ligne pointillée verticale représente la frontière.
Exemple 1 : Un processus fonctionnel déplaçant des données de ou vers un stockage persistant local.
Cet exemple implique deux morceaux distincts de logiciel : le morceau de logiciel 'A' et le morceau de logiciel 'B' qui représente le pilote du périphérique pour le dispositif de stockage persistant que le logiciel ‘A’ utilise. (Nous ignorons la présence probable d'un système d’exploitation pour simplifier la situation ; le système d’exploitation transmet effectivement des requêtes au pilote du périphérique et retourne ces résultats.)
Le concept de couches nous indique que les deux morceaux de logiciel sont dans différentes couches : la couche de l’application et la couche du pilote. Il y a, physiquement, un rapport hiérarchique entre les deux morceaux de logiciel et aussi une interface physique entre les logiciels des deux couches (tout en ignorant le logiciel d'exploitation), tel que montré par l’exemple de la figure 2.2.4.1.
Normalement, la FUR du morceau de logiciel 'A' indiquera les processus fonctionnels nécessaires pour combler les exigences de Lectures et d’éCritures concernant le stockage persistant. Par contre, le morceau de logiciel 'A' ne sera pas concerné par la façon dont ces Lectures et ÉCritures seront manipulées par les autres infrastructures logicielles.
En appliquant les modèles COSMIC aux deux morceaux de logiciel, les utilisateurs fonctionnels du morceau de logiciel 'A' de la couche application pourraient être, par exemple, des utilisateurs humains, tandis que l'utilisateur fonctionnel du morceau de logiciel 'B' de la couche du pilote, est le morceau de morceau de logiciel 'A' (tout en ignorant le logiciel d'exploitation).
Supposons une requête exigeant un mouvement de données en Lecture provenant d’un processus fonctionnel du logiciel A de la couche application ‘PF ‘A’’. La figure 4.1.8.1 (a) montre le modèle COSMIC du logiciel A qui a effectué cette requête. La récupération physique des données demandées à partir du stockage persistant est manipulée par un processus fonctionnel ‘PF ‘B’’ du logiciel B provenant de la couche du pilote du périphérique. La figure 4.1.8.1 (b) montre le modèle pour ce processus fonctionnel du pilote de ce périphérique.

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 54
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
Figures 4.1.8.1 (a) et (b) – Solution à un problème de Lecture de la couche applicative ‘A’ vers la couche du pilote de stockage persistant ‘B’
La figure 4.1.8.1 (a) montre la requête logiciel ‘A’ en Entrée (E), suivie d'une Lecture (L) et puis d'une Sortie (S) avec, en bout de ligne, le résultat de la requête. Le processus fonctionnel ‘PF ‘A’’ n'a aucune connaissance de la provenance des données recherchées, et ne sait pas non plus que la Lecture est attribuée à un logiciel pilote du périphérique.
La figure 4.1.8.1 (b) montre que fonctionnellement la requête de Lecture du logiciel ‘A’ est reçue comme un déclencheur en Entrée pour le processus fonctionnel ‘PF ‘B’’, qui alors recherche les données demandées dans le stockage persistant physique de la couche pilote via une Entrée/Sortie, et renvoie les données au logiciel ‘A’ en Sortie. Le logiciel ‘A’ et le stockage persistant physique ont ainsi un utilisateur fonctionnel du logiciel ‘B’.
La disparité apparente entre le nombre de mouvements de données en Lecture de la couche application et la paire de mouvements de données en Entrée/Sortie de la couche pilote du périphérique, est due au fait que par convention, un mouvement de données en Lecture est considéré comme incluant toutes les fonctionnalités de requête pour cette Lecture.
Des modèles analogues s'appliqueraient si le processus fonctionnel ‘PF ‘A’’ demandait de rendre quelques données persistantes par l'intermédiaire d'un mouvement de données en éCriture. Dans cet exemple, la Sortie du processus fonctionnel ‘FP ‘B’’ du pilote du périphérique pourrait contenir un 'code de retour' ou un ‘message d'erreur’.
Exemple 2 : Un processus fonctionnel doit obtenir des données d’un morceau de logiciel de même niveau.
Pour cet exemple, on émet l’hypothèse que les deux morceaux de logiciel à mesurer qui sont de même niveau ont une relation de 'client/serveur ', i.e. où l'un des morceaux de logiciel, le client, obtient des services et/ou des données de l'autre morceau de logiciel, le serveur dans la même couche. La figure 4.1.8.2 montre un exemple d'une telle relation, dans lequel les deux morceaux de logiciel sont les composants principaux de même niveau et de la même application. Le même rapport existerait et le même diagramme s'appliquerait si les deux morceaux étaient des applications distinctes de même niveau, où l’une demanderait des données à l'autre.
Physiquement, les deux composants de même niveau pourraient s'exécuter sur des processeurs distincts ; dans un tel cas, dans une architecture de logiciel telle que montré à la figure 2.2.4.1, ils échangeraient des données par l'intermédiaire de systèmes d'exploitation respectifs de même que par l'intermédiaire des couches intermédiaires de leurs processeurs. Mais logiquement, appliquant les modèles COSMIC, les deux composants échangent des données par l'intermédiaire des paires ‘d’Entrée/Sortie'. Tous les logiciels et le matériel qui interviennent sont ignorés dans ce modèle (comme montré sur le côté droit de la figure. 3.1.1).
La figure. 4.1.8.2 montre qu'un processus fonctionnel ‘PF ‘C1’’ du composant client ‘C1’ est déclenché par son utilisateur fonctionnel qui envoie une Entrée qui comporte des paramètres de
Couche ‘A’ : Couche de l’application
Couche ‘B’ : Couche du pilote de stockage persistant
E E
E
S
S
S
L Dispositif
physique de stockage
persistant (utilisateur
fonctionnel)
Utilisateur fonctionnel de l’application de la couche ‘B’ = (application de la couche ‘A’)
Utilisateur fonctionnel de l’application de la couche ‘A’
‘PF ‘A’’ ‘PF ‘B’’

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 55
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
la requête. La FUR du composant ‘C1’ reconnaîtra que ce composant doit demander au composant du serveur ‘C2’ les données requises, et doit lui dire quelles données sont requises.
Ainsi, pour obtenir les données requises, ‘PF ‘C1’’ transmet en Sortie les paramètres de la requête au composant ‘C2’. Le composant ‘C1’ est maintenant un utilisateur fonctionnel du composant ‘C2’. Par conséquent, une frontière existe entre les deux composants. Ce mouvement de données en Sortie, traverse la frontière entre ‘C1’ et ‘C2’ et devient ainsi un déclencheur en Entrée d'un processus fonctionnel ‘C2’ dans le composant ‘PF ‘C2’’. Le processus fonctionnel ‘PF ‘C2’’ du composant ‘C2’ obtient les données demandées, par l'intermédiaire d'une Lecture, et envoie les données de nouveau à ‘C1’ par l'intermédiaire d'une Sortie. Le processus fonctionnel ‘PF ‘C1’’ du composant ‘C1’ reçoit ce mouvement de données en Entrée. Le processus ‘C1’ transmet alors les données en Sortie pour satisfaire la requête de son utilisateur fonctionnel. Cette requête de l’exemple 2 exige donc 7 mouvements de données pour satisfaire la requête dans la couche logiciel. Ceci est à comparer avec les 3 mouvements de données (1 x E, 1 x L et 1 x S) qui auraient été exigés dans la couche logiciel si le composant ‘C1’ avait pu rechercher les données du stockage persistant 'local 'comme montré en figure 4.1.8.1 (a).
Figure 4.1.8.2 – Échange de données entre des composants de même niveau dans une même couche.
Le composant ‘C2’ utilisera probablement les services d’un logiciel pilote quelconque dans une couche inférieure de l'architecture du logiciel pour rechercher les données du matériel, comme dans le Cas 1.
En comparant les exemples 1 et 2, nous voyons dans l'exemple 1 que les modèles de l'application ‘A’ et le pilote du dispositif de ‘B’ ne pourraient pas être combinés comme dans L'exemple 2. C'est parce qu’une Lecture ne traverse pas une frontière. La figure 4.1.8.1 (b) montre que l'application ‘A’ est un utilisateur fonctionnel du pilote ‘B’. Mais l'inverse n'est pas vrai, démontrant de ce fait la nature hiérarchique du logiciel dans ces différentes couches.
En revanche, la figure 4.1.8.2 peut montrer les deux composants dans un même modèle, simplement parce qu'ils échangent des données au même niveau, i.e. en tant qu’égaux hiérarchique. Le composant ‘C1’ est un utilisateur fonctionnel du composant ‘C2’, et vice-versa, et ils partagent dans la même couche, de plus, une frontière commune.
NOTE : Dans ces deux exemples nous avons ignoré, pour des fins de simplifications, la génération d'un message d'erreur en Sortie par l'application A ou le composant C1 (en plus de la Sortie contenant le résultat de la requête) pourrait résulter en un "message d'erreur" accompagnant le mouvement de données en Lecture.
4.1.9 Lorsqu’un processus fonctionnel demande des données à un utilisateur fonctionnel.
Selon le principe (c) d’une Entrée (voir la section 4.1.2), dans le cas où un processus fonctionnel devait obtenir des données d'un utilisateur fonctionnel, il existerait deux cas possibles. Si le processus fonctionnel n'a pas besoin d'indiquer à l'utilisateur fonctionnel quelles données il a besoins, une simple Entrée est suffisante (par objet d'intérêt). Si le processus fonctionnel doit indiquer à l'utilisateur fonctionnel quelles données il a besoin, une paire d’Entrée/Sortie est alors nécessaire. Les règles suivantes s'appliquent :
Composant ‘C1’ : Client
Utilisateur fonctionnel du
composant ‘C1’
S
E ‘PF ‘C1’’
Composant ‘C2’ : Serveur
S
E
C
‘PF ‘C2’’
E
S

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 56
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
RÈGLES – Lorsqu’un processus fonctionnel demande des données à un utilisateur fonctionnel.
a. Un processus fonctionnel doit obtenir un groupe de données via un mouvement de données en Entrée provenant d’un utilisateur fonctionnel, et ce, dans le seul cas où le processus fonctionnel n’a pas besoin de préciser à cet utilisateur, de quelle donnée il s’agit. Voici certains de ces cas, soit :
• Quand un utilisateur fonctionnel envoie un déclenchement en Entrée qui initie le processus fonctionnel ;
• Quand un processus fonctionnel, ayant déjà commencé, attend une prochaine Entrée de l'utilisateur fonctionnel (typique dans les logiciels d'application d'affaires, où utilisateur fonctionnel est un humain) ;
• Quand un processus fonctionnel, ayant déjà commencé, demande à l'utilisateur fonctionnel d’envoyer des données maintenant s’il en a : L'utilisateur fonctionnel envoie alors ses données (typiquement connues sous les termes ‘d’invitation à émettre’ ou de ‘scrutation’ dans les logiciels de type temps réel) ;
• Quand un processus fonctionnel, ayant déjà commencé, inspecte l'état de l’utilisateur fonctionnel et récupère les données dont il a besoin.
REMARQUE : Dans les deux derniers cas (en général, se produisant des le cas de logiciel de type temps réel), par convention, aucune Sortie du processus fonctionnel ne sera comptépour obtenir la donnée requise. Le processus fonctionnel enverra plutôt un message à l’utilisateur fonctionnel pour l’obtention de cette donnée et ce message sera considéré comme faisant partie de l’Entrée. Par contre, en aucun cas ce message sera comptabilisée comme étant une Entrée en soit : une seule Entrée sera comptabilisée dans ce cas, soit la donnée qui était attendue.
b. Dans le cas où un processus fonctionnel requiert les services d'un utilisateur fonctionnel (par exemple, pour obtenir des données) et que cet utilisateur fonctionnel a besoin qu’on lui précise la donnée à envoyer (par exemple, quand cet utilisateur fonctionnel provient d’un autre morceau de logiciel ne faisant pas parti du périmètre de la mesure), une paire de mouvements de données en ‘Sortie et Entrée’ devra être compté. La Sortie contient la donnée de « demande de données » spécifiques et l'Entrée contient les données renvoyées.
EXEMPLE 1 de la règle ‘a.’, premier et deuxième points : Supposons un processus fonctionnel offrant un affichage d’écran pour la saisie de données par un utilisateur fonctionnel humain. Cet affichage de l’écran est ordinairement ‘vide’, sauf pour d'éventuelles valeurs par défaut comme par exemple l’affichage d’un logo pour une application d’affaire. Cet écran d’affichage dit 'vide' ne doit pas être compté comme une donnée en Sortie. Seuls les écrans dont l’affichage est significatif peuvent-ils être considérés comme pouvant créer des mouvements de données en Entrées au processus fonctionnel. (Voir également la section 4.1.10.)
EXEMPLE 2 de la règle ‘a.’, troisième et quatrième points : Supposons un processus fonctionnel d’un logiciel de contrôle de type temps réel devant recenser les informations provenant d’une table de capteurs passifs. Ce processus fonctionnels obtient donc ses données via un seul mouvement de données en Entrée (type) puisque les capteurs sont identiques, et qu’une seule Entrée (type) est identifiée et compté (bien qu'il y ait de multiples événements). Supposons ensuite que ces données en Entrée doivent être passées à une couche inférieure de l’architecture logicielle, sur un pilote de périphérique, qui lui obtient physiquement ses données des capteurs comme illustré dans la figure 2.2.4.1. Les processus fonctionnels du logiciel de contrôle des pilotes de périphérique et des logiciels des capteurs passifs sont présentés dans les figures. 4.1.9.1 (a) et (b) ci-dessous.

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 57
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
Figures 4.1.9.1 (a) et (b) – Solution au problème d’une Entrée transmise par le logiciel ‘A’ de la couche applicative où logiciel de contrôle de traitements se situe, vers le logiciel ‘B’
de la couche du pilote du dispositif où le logiciel du capteur non intelligent se situe.
La Figure 4.1.9.1 (a) montre que le processus fonctionnel ‘PF ‘A’’ du logiciel de contrôle de traitements est déclenché par une Entrée ‘E1‘, par un signal d'horloge. Le processus fonctionnel reçoit alors l'Entrée ’E2’ par le réseau de sondes non intelligentes par les occurrences multiples de lectures de sonde. Ces sondes non intelligentes sont également les utilisateurs fonctionnels des traitements du logiciel de contrôle,
La figure 4.1.9.1 (b) montre que le logiciel qui commande le réseau de sondes non intelligentes reçoit un déclenchement en Entrée (probablement par l'intermédiaire d'un système d'exploitation) par le processus fonctionnel ’PF ‘B’’. Ce processus fonctionnel obtient une Entrée de son utilisateur fonctionnel (-type), la sonde non intelligente (-type) pour obtenir les données sur les sondes qui sont ensuite è nouveau déplacées au logiciel de contrôle de traitements en Sortie. Le processus fonctionnel du logiciel de contrôle de traitements continue alors son traitement de données provenant des sondes. Le fait qu'il y ait des occurrences multiples de ce cycle de scrutation de données de sondes identiques est ignoré dans la modélisation.
La disparité apparente entre l'Entrée du logiciel de contrôle de traitements et la paire d'Entrée/Sortie du logiciel pilote, est due à la convention qu'une Entrée doit être considérée comme incluant toute fonctionnalité de demande d’Entrée.
EXEMPLE 3 de la règle (b) : Supposons un processus fonctionnel envoyant, à un de ses utilisateurs fonctionnels, un dispositif 'intelligent' ou un morceau de logiciel distinct de même niveau, des paramètres pour une requête ou des paramètres pour un calcul, ou encore quelques données à compresser. La réponse des utilisateurs fonctionnels serait obtenue par l'intermédiaire d'une paire d’Entrée/Sortie, comme décrit dans la section 4.1.8, exemple 2.
4.1.10 Commandes de contrôle.
Une 'commande de contrôle' est une catégorie spéciale de mouvement de données qui est identifiée seulement dans le domaine des logiciel d’application d'affaires et qui doit être ignorée lorsqu’on mesure une taille fonctionnelle. Voici sa définition :
DÉFINITION – Commande de contrôle.
Une commande qui permet à un utilisateur fonctionnel de contrôler l’utilisation du logiciel mais qui n’implique pas de mouvement de données des objets d’intérêt.
REMARQUE : Le terme ‘commande de contrôle’ est utilisé SEULEMENT dans le contexte de la mesure d’un logiciel d’application d’affaires. Dans ce contexte, une commande de contrôle n’est pas un mouvement de données parce que la commande ne déplace pas des données d’un objet d’intérêt. Exemples : commande de feuilletage ‘page haut/bas’, le fait d’appuyer sur la clef Tab (Tabulation) ou sur la clef Enter (Retour de Chariot), cliquer sur ‘OK’ avec la souris pour confirmer
Couche ‘B’ : Couche du pilote de la sonde non-intelligente
Utilisateur fonctionnel de la couche ‘B’ = (application de le couche ‘A’)
Dispositif physique : sonde non-intelligente
S
E
E
‘PF ‘B’’
Dispositif physique : sonde non-intelligente
Couche ‘A’ : Couche du logiciel de contrôle de traitements
Utilisateur fonctionnel
de la couche ‘A’
E1
E2
‘PF ‘A’’
(etc.)

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 58
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
DÉFINITION – Commande de contrôle.
une action, etc.
RÈGLE – Commande de contrôle dans le domaine des logiciels d’applications d’affaires.
Dans le domaine des logiciels d’application d'affaires, la 'commande de contrôle' doit être ignorée puisqu’elle n'implique pas de mouvement de données des objets d'intérêt.
Des exemples de 'commandes de contrôle' dans le domaine des logiciels d'application d'affaires pourraient être les fonctions qui permettent à un utilisateur fonctionnel de commander l'affichage d'un en-tête ou de totaux partiels ayant été calculés, de passer d’un écran d’affichage à un autre, de cliquer sur 'OK' avec un souris pour reconnaître un message d'erreur ou pour confirmer des données saisies, etc. Les commandes de contrôle incluent donc également les commandes de menu qui permettent à l'utilisateur fonctionnel de passer d’un ou plusieurs processus fonctionnels spécifiques à d’autres processus, ou des commandes pour afficher un écran vierge pour la saisie de données, mais qui par elles-mêmes, ces commandes n’initient aucun processus fonctionnel.
REMARQUE : En dehors du domaine d'application d'affaires, le concept de 'commande de contrôle' n'a pas de signification spéciale et tout signal ou mouvement des données au sujet d'un objet d'intérêt venant d'un utilisateur fonctionnel doit être considéré, c’est à dire doit être mesuré.
4.2 Appliquer la fonction de mesure.
Cette étape consiste à appliquer la fonction de mesure COSMIC à chacun des mouvements de données identifié dans chaque processus fonctionnel.
DÉFINITION – Fonction de mesure COSMIC.
Fonction mathématique qui assigne une valeur numérique à sa variable sur la base de l’étalon de mesure COSMIC. La variable de la fonction de mesure COSMIC est le type de mouvement de données.
DÉFINITION – Étalon de mesure COSMIC.
L’étalon de mesure COSMIC, soit 1 CFP (COSMIC Function Point), est défini comme la taille d’un mouvement de données.
REMARQUE : L’étalon de mesure était désigné précédemment comme un ‘Cfsu’ (COSMIC functional size unit)
Selon cette fonction de mesure, chaque instance d'un mouvement de données (Entrée, Sortie, Lecture ou éCriture) (identifié selon la section 4.1) où la donnée déplacée doit subir une manipulation de données telle que : un ajout, une modification ou une suppression, doit se voir attribuer une taille fonctionnelle d’un point numérique CFP.
4.3 Additivité des résultats de mesure.
Cette étape consiste à regrouper les résultats de la fonction de mesure, telle qu'appliquée à tous les mouvements de données identifiés, en un seul nombre représentant la taille fonctionnelle. Cette étape se réalise selon les règles suivantes.

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 59
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
4.3.1 Règles générales de l’addition.
RÈGLES – Additivité des résultats de mesure.
a. Pour chaque processus fonctionnel, la taille fonctionnelle des mouvements de données est regroupée en une seule valeur de taille fonctionnelle par l’intermédiaire d’une addition arithmétique du nombre de mouvements de données ;
Taille CFP ( processus fonctionnel ) =
Σ taille ( Entrée i ) + Σ taille ( Sortie i ) +
Σ taille ( Lecture i ) + Σ taille ( éCriture i )
b. Pour chaque processus fonctionnel, la taille fonctionnelle de chaque modification de FUR est additionnée à la somme des tailles fonctionnelles des mouvements de données, pour qui les données ont subit une manipulation de donnée par l’entremise d’un processus fonctionnel. Voici la formule :
Taille CFP ( modification ( processus fonctionnel i ) ) =
Σ taille ( mouv. de donnée i --> manip. ‘ajouté’ ) +
Σ taille ( mouv. de donnée i --> manip. ‘modifié’ ) +
Σ taille ( mouv. de donnée i --> manip. 'supprimé’ )
Pour en savoir plus sur l'additivité de la taille fonctionnelle, voir la section 4.3.2. Pour mesurer la taille d’un morceau de logiciel modifié, voir la section 4.4.
c. La taille d'un morceau de logiciel pour un périmètre défini doit être obtenue en additionnant les tailles fonctionnelles des processus fonctionnels de ce morceau, selon les règles (e) et (f) ci-dessous ;
d. La taille d’une modification d’un morceau logiciel d’un périmètre donné doit être obtenue en additionnant les tailles fonctionnelles de toutes les modifications de tous les processus fonctionnels de ce morceau, selon les règles (e) et (f) ci-dessous ;
e. La taille de chaque morceau de logiciel à mesurer dans une couche peut être obtenue en les additionnant, mais seulement au même niveau de granularité des processus fonctionnels de leur FUR ;
f. Les tailles des morceaux de logiciel et/ou des modifications apportées à un morceau de logiciel dans leur couche respective ou dans des couches différentes, ne devraient pas être additionnées entre elles, sauf si il est logique de le faire, pour les fins de la mesure ;
g. La taille d'un morceau de logiciel ne peut pas être obtenue en additionnant les tailles de ses composants (quelques soit le mode de décomposition) à moins que la taille des mouvements de données entre ces composants soient éliminée du calcul;
h. Si la méthode COSMIC est étendue localement (par exemple pour mesurer certains aspects de la taille non couverte par la méthode normalisée), alors la taille mesurée en utilisant une extension locale doit être rapportée séparément tel que décrit dans la section 5.2, et ne peut pas être additionné pour obtenir une taille selon l‘étalon de mesure COSMIC (voir la section 4.5).
EXEMPLE pour les règles (b) et (c) : Des modifications apportées à un morceau de logiciel pourraient être : d’ajouter un nouveau processus fonctionnel de taille 6 CFP, d’ajouter un mouvement de données dans un autre processus fonctionnel, de faire des modifications dans trois autres mouvements de données et de supprimer deux mouvements de données. La taille totale de ces modifications serait 6 + 1 +3 +2 = 12 CFP.
EXEMPLE pour la règle (f) : Si plusieurs parties importantes d’un morceau de logiciel étaient développées en utilisant des technologies différentes, développées aussi par des équipes de projets différentes, il pourrait ne pas y avoir de valeur ajoutée significative que d’additionner leur taille respective.
EXEMPLE pour la règle (g) : Si un morceau de logiciel était :
• Mesuré comme un tout, i.e. provenant d’un seul périmètre de mesure ; • Et qu’ensuite, la taille de chacun de ses composants était mesurée séparément, i.e. chacun
dans son propre périmètre de mesure ;

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 60
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
La taille fonctionnelle obtenue en additionnant toutes les tailles des composants séparés (au deuxième point) aurait la conséquence suivante : La taille mesurée dans ce cas dépasserait la taille mesurée du logiciel pris comme un tout (premier point). Ceci est due au fait que la taille de tous les mouvements de données entre les composants ont été comptés plus d’une fois. Ces mouvements de données inter-composants ne sont pas visibles quand le morceau de logiciel est mesuré comme un tout et ces derniers doivent donc être éliminés de l’équation de la mesure des composants séparés pour obtenir la vraie taille de l’ensemble. Voir aussi l’exemple de la section traitant de la mesure à différent niveau de granularité d’une architecture logiciel, dans le document Sujet spécialisés.
Il est à noter que, dans chaque couche identifiée, le processus de l’addition est complètement extensible. De cette façon, un sous-total peut être généré pour chaque processus fonctionnel individuel ou pour un logiciel complet d’une couche en particulier, et ce, en fonction de la raison d’être et du périmètre de chaque exercice de mesure et aussi suivant les règles (d), (e), et (f) ci-dessus.
4.3.2 Informations supplémentaires sur l’additivité des tailles fonctionnelles.
Dans un contexte où la taille fonctionnelle doit être utilisée comme variable dans un modèle, pour estimer l’effort d’un logiciel de plus d’une couche ou de composants de même niveau par exemple, une addition sera habituellement pratiquée par couche ou par composant de même niveau, et ce même si souvent, il ne sont pas développés avec la même technologie.
Exemple1: considérons un logiciel où la couche applicative doit être réalisée en utilisant un langage de troisième génération et une bibliothèque de programmes existante, tandis qu’une couche contenant un pilote doit être réalisée en utilisant un langage assembleur. L’unité d’effort associé à la construction de chaque couche sera, très probablement, différente, et par conséquent, l’estimation de l’effort sera calculée distinctement pour chacune des couches en tenant compte de leur taille respective.
EXEMPLE 2: si une équipe de projet doit développer un certain nombre de morceaux de logiciel d’importances et que cette équipe est intéressée par sa performance globale, elle peut additionner les heures de travail nécessaires pour développer chaque morceau. De la même manière, cette équipe peut additionner les tailles des morceaux majeurs de logiciel qu’elle a développé si (et seulement si) ces tailles satisfont les règles ci-dessus.
La raison pour laquelle les tailles des morceaux majeurs de logiciel de différentes couches d’une architecture à couches standard, mesurées au même niveau de granularité de processus fonctionnel, peuvent être additionnées ensemble, est qu’une telle architecture possède un ensemble d’utilisateurs fonctionnels définis de manière cohérente. Chaque couche est un utilisateur fonctionnel des couches inférieures qu’elle utilise, et tout morceau de logiciel d’une couche en particulier peut être un utilisateur fonctionnel de son autre morceau de logiciel de même niveau . La seule chose qu’une telle architecture requiert est que les FUR de tous les morceaux de logiciel échangent des messages. Il est donc logique et raisonnable que les tailles de ces morceaux de logiciels puissent être additionnées ensemble, toujours assujetties aux règles (d), (e) et (f) ci-dessus. Cependant, à l’opposé, la taille d’un morceau de logiciel ne pourrait pas être obtenue en additionnant les tailles de ses composants réutilisables séparément, à moins que les mouvements de données inter-composants soient éliminés, en référence à la règle (f) ci-dessus.
L’additivité des résultats de la mesure par type de mouvement de données pourrait être utile pour analyser la contribution de chaque type (de mouvement de données) à la taille totale d’une couche et pourrait ainsi aider à caractériser la nature fonctionnelle de la couche mesurée.
4.4 Informations supplémentaires sur la taille fonctionnelle de modifications logicielles
Une ‘modification fonctionnelle’ d’un logiciel existant est interprétée par la méthode COSMIC comme étant ‘toute combinaison d’ajouts de nouveaux mouvements de données ou modifications ou suppressions de mouvements de données existants’. Les termes ‘amélioration’ et ‘maintenance’15 sont le plus souvent utilisés comme synonyme de ‘modification fonctionnelle’.
15. Par convention, la taille fonctionnelle d'un logiciel ne doit pas changer si ce logiciel doit être modifié pour corriger un défaut de manière à ce que ce logiciel se remette en ligne avec la FUR d’origine. La taille fonctionnelle du logiciel change uniquement s’il faut corriger la FUR.

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 61
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
Le besoin de modifier un logiciel peut provenir… :
• D’une nouvelle FUR (i.e. que des ajouts à une fonctionnalité existante), ou ; • D’une modification dans la FUR (pouvant être accompagné d’ajouts, de modifications
et/ou de suppressions) ou ; • D’un besoin de ‘maintenance’ pour éliminer un/des défauts.16
Les règles de mesure liées aux modifications mentionnées ci-dessus sont les mêmes, mais le mesureur doit être vigilant afin de distinguer le contexte dans lequel ces mesures et estimations seront faîtes.
Lorsqu’un morceau de logiciel est complètement remplacé par un autre, par exemple, en réécrivant le code avec ou sans extension (ou omission) de fonctionnalité, la taille fonctionnelle de ce morceau de logiciel sera la taille du logiciel de remplacement, mesuré d’après les règles usuelles de mesure. Ce cas ne sera pas revisité dans cette section. Cependant, le mesureur devrait être conscient qu’il est nécessaire de distinguer les projets de développement d’un nouveau logiciel, des projets de ‘redéveloppement’ ou de ‘remplacement’ d’un logiciel existant, lors de la réalisation d’une mesure de performance ou d’estimation.
Souvent, les parties obsolètes d’une application sont supprimées (où ‘déconnectée’) en laissant le code du programme en place (en enlevant seulement le lien vers ces parties obsolètes). Lorsque la fonctionnalité de la partie obsolète atteint 100 CFP mais que le code qui a été modifié pour effectuer cette déconnection est de, disons, 2 mouvements de données, il faut compter 100 (et non pas 2) mouvements de données pour la taille de la modification fonctionnelle. Nous mesurons la taille de la FUR, et non pas la taille de la modification. 17
Notons la différence entre la taille de la modification fonctionnelle et le changement dans la taille fonctionnelle du logiciel. Habituellement, elles sont différentes : La taille de cette dernière est adressée en section 4.4.3.
4.4.1 Modification des fonctionnalités.
Tout mouvement de données de type E, S, L, et C implique deux types de fonctionnalités : il déplace un seul groupe de données et il possède une certaine quantité de manipulation de données (pour ce dernier, voir la section 4.1.6). Donc, pour les fins de la mesure, un mouvement de données est considéré comme étant fonctionnellement modifié si :
• le groupe de données se déplace et/ou ; • les manipulations de données associées sont modifiées de quelque façon que ce soit.
Un groupe de données est modifié si :
• des nouveaux attributs sont ajoutés à ce groupe de données et/ou ; • les attributs existants sont supprimés du groupe de données et/ou ; • un ou plusieurs attributs existants sont modifiés, c'est-à-dire selon leur signification, type
ou format (en excluant les valeurs de ces attributs).
Une manipulation de données est modifiée si elle est fonctionnellement changée de quelque façon que ce soit, par exemple en changeant les calculs, le formatage spécifique, la présentation, et/ou la validation des données. La ‘présentation’ peut signifier, par exemple la police de caractère, la couleur de l’arrière plan, la longueur des champs, le nombre de décimales, etc.
16. Normalement, par convention, la taille fonctionnelle d’un logiciel ne change pas si le logiciel doit être modifié pour corriger un défaut lié à la logique de ses fonctionnalités. Mais, la taille fonctionnelle changera si la modification est réalisée sur la FUR elle-même.
Les commandes de contrôle et les données générales d’application ne sont pas concernées par les mouvements de données, car il n’y a pas de données appartenant à un objet d’intérêt qui soit

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 62
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
déplacée. En conséquence, les modifications affectant les commandes de contrôle et les données générales d’application ne doivent pas être comptés. Par exemple, si la couleur d’écran était changée pour tous les écrans, ce changement ne devrait pas être compté. (Voir la section 4.1.10 pour plus de détails sur les commandes de contrôle et les données générales d’application.)
RÈGLES – Modification d’un mouvement de données.
a. Si un mouvement de données devait être modifié suite à un changement dans une manipulation de données associée et/ou suite à un changement du nombre ou du type d’attributs de données déplacé par ce mouvement de données, un CFP (modification) devra être mesuré, quelque soit le nombre réel de modifications dans ce mouvement de données ;
b. Si un groupe de données devait être modifié, les mouvements de données déplaçant ce groupe, dont la fonctionnalité n’est pas affectée par cette modification ne sera pas identifiés comme étant un mouvement de données modifié.
REMARQUE 1 : Le changement de la valeur actuelle d’un attribut, telle que la modification d’un code d’un groupe de données dont les valeurs des attributs est représenté par un système de codes, n’est pas une modification de ‘signification, type ou format’ d’attribut.
REMARQUE 2 : Une modification de toute donnée qui apparaît sur des écrans d’entrée ou de sortie qui ne représentent pas d’objet d’intérêt pour un utilisateur fonctionnel ne devrait pas être identifiée comme un CFP de modification (Voir section 3.3.4 pour des exemples d’une telle donnée).
EXEMPLE pour les règles (a) et (b) : Supposons une requête visant à ajouter ou modifier des attributs d'un groupe de données ‘D1’, telle sorte qu’après la modification, le groupe de données devienne ‘D2’. Dans le processus fonctionnel 'A' où cette modification a été demandée, tous les mouvements de données affectés par cette modification devraient être identifiés et comptés comme étant modifiés. Ainsi, selon la règle (a), si le groupe de données modifié ‘D2’ a été envoyé vers un stockage persistant et/ou est sortie du processus fonctionnel ‘A’, il faudra identifier et compter respectivement des mouvements de données en éCriture et/ou en Sortie comme étant modifiés. Cependant, il est possible que d'autres processus fonctionnels fassent entrer et/ou lisent ce même groupe de données ‘D2’, mais leur fonctionnalité reste inchangée par la modification, car ils n’utilisent pas les attributs de données modifiés. Ces processus fonctionnels continuent à traiter le groupe de données déplacé comme si c'était toujours ‘D1’. Ainsi, selon la règle (b), ces mouvements de données des autres processus fonctionnels qui ne sont pas affectés par la modification du(des) mouvement(s) de données du processus fonctionnel ‘A’, ne doivent pas être identifiés et comptés comme étant modifiés.
4.4.2 Taille d’un logiciel fonctionnellement modifié.
Après avoir fonctionnellement modifié un morceau de logiciel, sa nouvelle taille totale est la même que la taille originale, plus (+) la taille fonctionnelle de tous les mouvements de données supplémentaires, moins (-) la taille fonctionnelle de tous les mouvements de données supprimés. Les mouvements de données modifiés n'ont aucune influence sur la taille de ce morceau de logiciel car ils existaient déjà avant et après que les modifications aient été faites.
4.5 Extension de la méthode de mesure COSMIC.
4.5.1 Introduction.
La méthode de mesure de taille fonctionnelle COSMIC ne prétends pas mesurer tous les aspects de la taille du logiciel. Aujourd’hui, la méthode de mesure COSMIC n'est pas conçue pour fournir une manière standard de mesurer la taille de certains types de FUR, tel que la mesure d’algorithmes mathématiques complexes ou des FUR comportant des règles complexes telles que l’on en trouve dans les systèmes experts, par exemple. Aussi, l'influence du nombre d'attributs de données par mouvement de données sur la taille fonctionnelle d’un logiciel n'est pas prise en compte par la méthode de mesure. D’un autre côté, l'influence de la manipulation de données des sous-processus sur la taille fonctionnelle n’est prise en compte par l'intermédiaire d’une simplification des règles qui est valide que pour certains domaines de logiciel, comme défini dans la section 2.1 sur l'applicabilité de la méthode.
D'autres paramètres tels que la 'complexité' (quel que soit sa définition) pourraient être considérés influençant la taille fonctionnelle. Une discussion constructive sur cette question exigerait un accord commun sur les définitions des autres éléments mal connu influençant la taille

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 63
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
du logiciel. De telles définitions font toujours l’objet de nouvelles recherches et de nombreuses discussions.
Néanmoins, la mesure de la taille COSMIC est considérée comme étant bon moyen pour les fins visés et le domaine d'applicabilité de la méthode. Il est possible que dans le contexte d’une organisation où la méthode de mesure COSMIC est utilisée, que l’on puisse tenir compte de différents types de fonctionnalité de la méthode, de manière à ce qu’elle soit significative dans le cadre de la norme locale de l’organisation. Pour cette raison, la méthode de mesure COSMIC prévoit des adaptations locales. Dans le cas où de telles adaptations ou extensions locales sont utilisées, les résultats de la mesure doivent être rapportés selon la convention utilisée, telle que présentée dans la section 5.1.
Les sections suivantes montrent comment ‘étendre’ la méthode à une norme locale.
4.5.2 Extension locale avec des algorithmes complexes.
Si l’organisation juge nécessaire de tenir compte des algorithmes complexes, une norme locale peut être établie pour cette fonctionnalité exceptionnelle. Dans n'importe quel processus fonctionnel où il y a un sous-processus fonctionnel comportant des manipulations de données anormalement complexes, le mesureur est libre d’assigner ses propres points de fonction localement déterminés.
EXEMPLE : Une extension d'une norme locale pourrait être dans notre organisation, un point de fonction local assigné pour des algorithmes mathématiques comme (liste d'exemples ou de règles locales significatifs et bien compris). Deux points de fonction sont assignés à (une autre liste d'exemples de règles locales), etc."
4.5.3 Extension locale avec des fractions d‘unité de mesure.
Lorsqu’il faut davantage de précision pour la mesure des mouvements de données, alors une fraction de l’unité de mesure peut être définie. Par exemple, un mètre peut être subdivisé en 100 centimètres ou 1000 millimètres. Par analogie, le mouvement d'un attribut de données simple peut être utilisé comme une fraction d’unité de mesure. Des mesures sur un petit échantillon de logiciel lors des essais COSMIC indiquent que, dans un échantillon de mesure, le nombre moyen d’attributs par mouvement de données ne varie pas beaucoup d’un mouvement de données à un autre pour les quatre types de mouvements de données. Pour cette raison et pour conserver la logique de la mesure, l'unité de la mesure COSMIC 1 CFP, a été fixée au niveau d'un mouvement de données. Cependant, il faut être prudent lorsqu’on compare des tailles fonctionnelles CFP, de deux morceaux de logiciel différents où le nombre moyen d'attributs de données par mouvement de données diffère drastiquement entre les deux morceaux de logiciel.
Si l’on souhaite raffiner la méthode COSMIC en présentant une fraction d’unité de mesure il est possible de le faire, mais on doit indiquer clairement que les résultats qui résultent d’une telle méthode de mesure de taille fonctionnelle ne sont pas exprimées en points de fonction CFP selon les normes COSMIC.

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 64
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
55 RAPPORTER LA MESURE.
Le modèle générique de logiciel peut être présenté sous forme de matrice où les rangées peuvent représenter les processus fonctionnels (qui peuvent être groupés par couches), les colonnes ; des groupes de données et les cellules ; d'identifier les mouvements de données (Entrée, Sortie, Lecture et éCriture). Cette représentation du modèle générique de logiciel est présentée en annexe A.
Les résultats de la mesure COSMIC sont donc rapportés et archivés selon les conventions suivantes :
5.1 Étiquetage.
Lorsque de la taille fonctionnelle COSMIC est rapportée, l'étiquetage devrait suivre la convention suivante, selon la norme ISO/IEC 14143-1: 2007.
RÈGLE – Étiquetage de la mesure COSMIC.
Les résultats de la mesure COSMIC seront notés comme suit, « x CFP (v.y) », où :
• “x”: représente la valeur numérique de la taille fonctionnelle ; • “v.y”: représente l'identification de la version de la norme de la méthode COSMIC utilisée
pour obtenir la valeur numérique “x”.
EXEMPLE : Le résultat obtenu en utilisant la règle de ce Manuel de mesure sera noté comme « x CFP (v3.0) ».
REMARQUE : Si une méthode locale d'approximation est utilisée pour obtenir la mesure, l'utilisation de la méthode devra être notée ailleurs - voir la section 5.2. Toutefois, si la mesure a été faite en utilisant les conventions d'une version COSMIC normalisé, la convention d'étiquetage ci-dessus reste applicable.
EXEMPLE : Un résultat obtenu en utilisant les règles du Manuel de mesure est noté comme ‘x CFP (v3.0.1)’
Lorsque les extensions locales sont utilisées, telles que définies à la section 5.2, le résultat de la mesure doit être rapporté tel que défini ci-dessous :
RÈGLE – Étiquetage des extensions locales COSMIC.
Un résultat de la mesure COSMIC utilisant des extensions locales doit être noté de la façon suivante, « x CFP (v. y) + z Local FP », où:
• “x”: représente la valeur numérique obtenue en additionnant tous les résultats des mesures individuelles selon la norme de la méthode COSMIC, version v.y ;
• “v.y”: représente l'identification de la version de la norme de la méthode COSMIC utilisée pour obtenir la valeur numérique fonctionnelle “x” ;
• “z”: représente la valeur numérique obtenue en additionnant tous les résultats des mesures individuelles à partir des extensions locales de la méthode COSMIC.

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 65
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
5.2 Archivage des résultats de la mesure COSMIC.
Lorsqu’on archive les résultats de la mesure COSMIC, les informations suivantes doivent être conservées pour s'assurer que les résultats sont toujours interprétables :
RÈGLE– Rapporter la mesure COSMIC.
En plus des résultats de mesure tels qu’enregistrés dans la section 5.1, les caractéristiques suivantes doivent être enregistrées pour chaque mesure :
a. Une identification du composant logiciel mesuré (nom, numéro de version ou numéro de configuration) ;
b. Le nom des sources d'information utilisées pour identifier la FUR pour la mesure ; c. Le domaine d’applicabilité du logiciel mesuré ; d. Un énoncé de la raison d’être de la mesure ; e. Une description du périmètre de la mesure, et sa relation avec les autres périmètres de
mesures, s’il y a lieu. (Voir la section 2.2) ; f. Les utilisateurs fonctionnels du logiciel ; g. Le niveau de granularité de la FUR et le niveau de décomposition du logiciel ; h. La phase du cycle de vie du projet à laquelle la mesure a été faîte (particulièrement si la
mesure est une estimation réalésée sur une FUR inachevée, ou sur des fonctionnalités déjà livrées) ;
i. La cible ou la marge d'erreur de la mesure que l'on croit viser ; j. Des indications sur si la méthode de mesure COSMIC standard a été employée, et/ou si une
approximation locale de la méthode standard a été appliquée, et/ou si des extensions locales ont été employés (voir la section 4.5). Employer les conventions d'étiquetage des sections 5.1 ou 5.2 ;
k. Une indication sur si l'on mesure une fonctionnalité développé ou déjà livrée (la fonctionnalité 'développée' est obtenue en créant un nouveau logiciel ; la fonctionnalité ‘déjà livrée’ inclut la fonctionnalité 'développée' en plus d'autres fonctionnalités comme par exemple toutes formes de réutilisation de logiciels existants ou d'utilisation de paramètres existants pour ajouter ou modifier la fonctionnalité, etc.) ;
l. Une indication sur si la mesure provient d'une fonctionnalité nouvellement fournie ou si elle est le résultat d'une activité de ‘maintenance’ ou 'd'amélioration' (i.e. la somme des ajouts, modification et suppressions - voir 4.4) ;
m. Une description de l'architecture du logiciel, les couches pour lesquelles les mesures sont réalisées, s’il y a lieu ;
n. Le nombre de composants majeurs dont les tailles ont été additionnées ensemble pour obtenir la taille totale telle qu’enregistrée, s’il y a lieu ;
o. Saisir, pour chaque périmètre de logiciel du le périmètre global de la mesure, une matrice de mesure, telle qu'indiqué dans l'annexe A ;
p. Le nom du mesureur et toutes ses qualifications et certifications COSMIC.

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 66
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
AANNNNEEXXEE AA.. ANNEXE A – DOCUMENTATION D’UNE MESURE DE TAILLE COSMIC.
La matrice ci-dessous peut être employée pour tenir à jour les résultats de la mesure pour chaque composant identifié, d'un périmètre global qui a été retracé à partir du modèle générique de logiciel. Chaque périmètre du périmètre global de mesure doit posséder sa propre matrice.
Figure A – Matrice du modèle générique de logiciel
Phase d’arrimage.
• Chaque groupe de données identifié est enregistré dans la colonne ; • Chaque processus fonctionnel est enregistré sur une ligne spécifique, selon la couche auquel
il appartient.
Phase de mesure.
• Pour chaque processus fonctionnel identifié, les mouvements de données identifiés sont notés dans la cellule correspondante en utilisant la convention suivante: “E” pour une Entrée, “S” pour une Sortie, “L” pour une Lecture and “C” pour une éCriture ;
• Pour chaque processus fonctionnel identifié, chacun des mouvements de données sont comptabilisés par type, et chacune des sommes doit être enregistrée dans la colonne appropriée, à droite de la matrice ;
• La somme des mesures peut alors être calculée et enregistrée dans les cellules de chaque couche, sur la ligne « TOTAL ».
Groupes de donnˇes
Couches FUNCTIONAL PROCESSES Gro
up
e d
e d
on
nˇe
s 1
É É É É É É Gro
up
e d
e d
on
nˇe
s n
EN
TR�
E (
E)
SO
RT
IE (
X)
LE
CT
UR
E (
R)
�C
RIT
UR
E (
W)
Couche "A"
Functional process aFunctional process bFunctional process cFunctional process dFunctional process e
TOTAL - Couche ACouche "B"
Functional process fFunctional process gFunctional process h
TOTAL - Couche B

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 67
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
AANNNNEEXXEE BB.. ANNEXE B - SOMMAIRE DES PRINCIPES DE LA MÉTHODE COSMIC.
Le tableau ci-dessous identifie chaque principe de la méthode de mesure COSMIC, dans le but de faciliter la référence.
ID NOM DESCRIPTION DES PRINCIPES.
P-01
Le modèle contextuel de logiciel COSMIC
a. Le logiciel est limité par le matériel ; b. Le logiciel est typiquement structuré en couches ; c. Une couche peut contenir un ou plusieurs morceaux de logiciel, de
même niveau mais distincts, et tout morceau de logiciel peut aussi être construit de composants de même niveau mais distincts ;
d. Tout morceau de logiciel à mesurer doit être défini par un périmètre de mesure, lequelle doit aussi être entièrement compris à l’intérieur d’une seule couche de logiciel ;
e. Le périmètre du morceau de logiciel à mesurer doit dépendre de la raison d’être de la mesure ;
f. Les utilisateurs fonctionnels doivent être identifiés à partir des Fonctionnalités Utilisateurs Requises (FUR) du morceau de logiciel à mesurer comme les émetteurs et/ou les destinataires visés pour les données ;
g. Un morceau de logiciel interagit avec ses utilisateurs fonctionnels via les mouvements de données à travers la frontière. Ce morceau de logiciel peut déplacer les données vers et à partir d’un stockage persistant situé à l’intérieur de la frontière du logiciel ;
h. La FUR d’un logiciel peut être exprimée à différents niveaux de granularité ;
i. Le niveau de granularité auquel les mesures doivent normalement être effectuées, est celui du processus fonctionnel (voire section 2.2.3) ;
j. S’il n’est pas possible de mesurer à partir du niveau de granularité du processus fonctionnel, alors la FUR du logiciel doit être mesurée d’une manière approximative, et échelonnée selon le niveau de granularité des processus fonctionnels2.
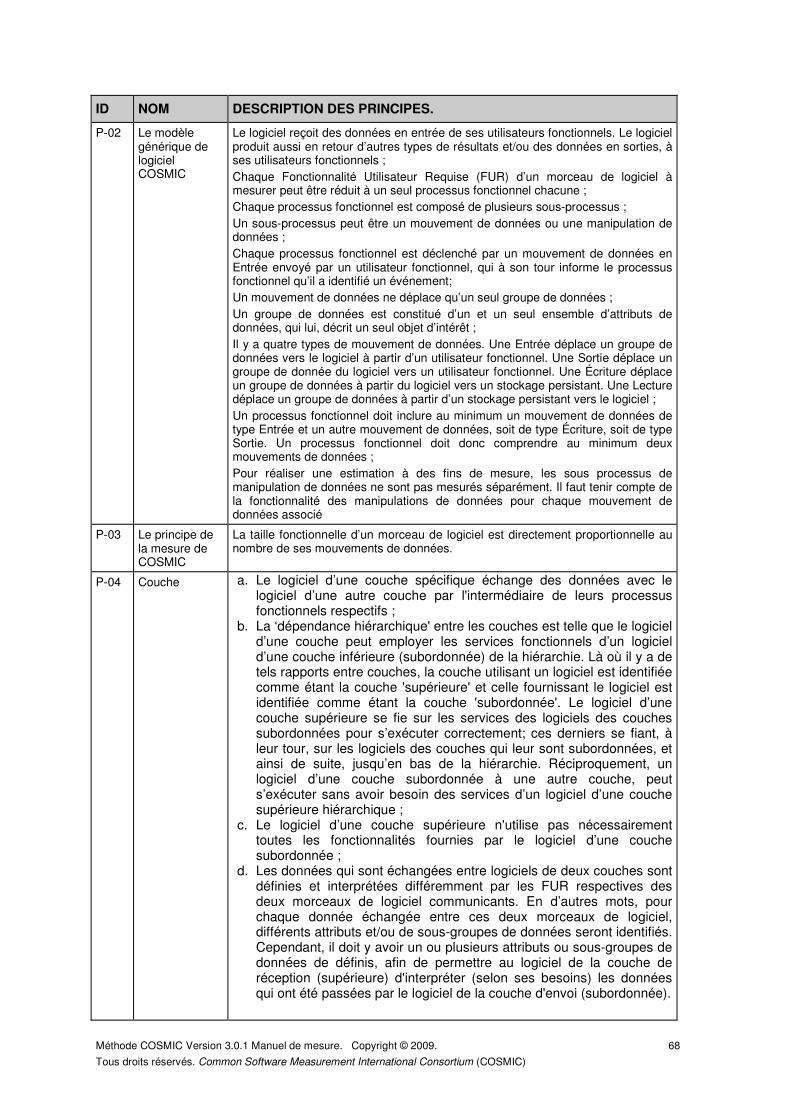
Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 68
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
ID NOM DESCRIPTION DES PRINCIPES.
P-02
Le modèle générique de logiciel COSMIC
Le logiciel reçoit des données en entrée de ses utilisateurs fonctionnels. Le logiciel produit aussi en retour d’autres types de résultats et/ou des données en sorties, à ses utilisateurs fonctionnels ; Chaque Fonctionnalité Utilisateur Requise (FUR) d’un morceau de logiciel à mesurer peut être réduit à un seul processus fonctionnel chacune ; Chaque processus fonctionnel est composé de plusieurs sous-processus ; Un sous-processus peut être un mouvement de données ou une manipulation de données ; Chaque processus fonctionnel est déclenché par un mouvement de données en Entrée envoyé par un utilisateur fonctionnel, qui à son tour informe le processus fonctionnel qu’il a identifié un événement; Un mouvement de données ne déplace qu’un seul groupe de données ; Un groupe de données est constitué d’un et un seul ensemble d’attributs de données, qui lui, décrit un seul objet d’intérêt ; Il y a quatre types de mouvement de données. Une Entrée déplace un groupe de données vers le logiciel à partir d’un utilisateur fonctionnel. Une Sortie déplace un groupe de donnée du logiciel vers un utilisateur fonctionnel. Une Écriture déplace un groupe de données à partir du logiciel vers un stockage persistant. Une Lecture déplace un groupe de données à partir d’un stockage persistant vers le logiciel ; Un processus fonctionnel doit inclure au minimum un mouvement de données de type Entrée et un autre mouvement de données, soit de type Écriture, soit de type Sortie. Un processus fonctionnel doit donc comprendre au minimum deux mouvements de données ; Pour réaliser une estimation à des fins de mesure, les sous processus de manipulation de données ne sont pas mesurés séparément. Il faut tenir compte de la fonctionnalité des manipulations de données pour chaque mouvement de données associé
P-03 Le principe de la mesure de COSMIC
La taille fonctionnelle d’un morceau de logiciel est directement proportionnelle au nombre de ses mouvements de données.
P-04 Couche a. Le logiciel d’une couche spécifique échange des données avec le logiciel d’une autre couche par l'intermédiaire de leurs processus fonctionnels respectifs ;
b. La ‘dépendance hiérarchique' entre les couches est telle que le logiciel d’une couche peut employer les services fonctionnels d’un logiciel d’une couche inférieure (subordonnée) de la hiérarchie. Là où il y a de tels rapports entre couches, la couche utilisant un logiciel est identifiée comme étant la couche 'supérieure' et celle fournissant le logiciel est identifiée comme étant la couche 'subordonnée'. Le logiciel d’une couche supérieure se fie sur les services des logiciels des couches subordonnées pour s’exécuter correctement; ces derniers se fiant, à leur tour, sur les logiciels des couches qui leur sont subordonnées, et ainsi de suite, jusqu’en bas de la hiérarchie. Réciproquement, un logiciel d’une couche subordonnée à une autre couche, peut s’exécuter sans avoir besoin des services d’un logiciel d’une couche supérieure hiérarchique ;
c. Le logiciel d’une couche supérieure n'utilise pas nécessairement toutes les fonctionnalités fournies par le logiciel d’une couche subordonnée ;
d. Les données qui sont échangées entre logiciels de deux couches sont définies et interprétées différemment par les FUR respectives des deux morceaux de logiciel communicants. En d’autres mots, pour chaque donnée échangée entre ces deux morceaux de logiciel, différents attributs et/ou de sous-groupes de données seront identifiés. Cependant, il doit y avoir un ou plusieurs attributs ou sous-groupes de données de définis, afin de permettre au logiciel de la couche de réception (supérieure) d'interpréter (selon ses besoins) les données qui ont été passées par le logiciel de la couche d'envoi (subordonnée).
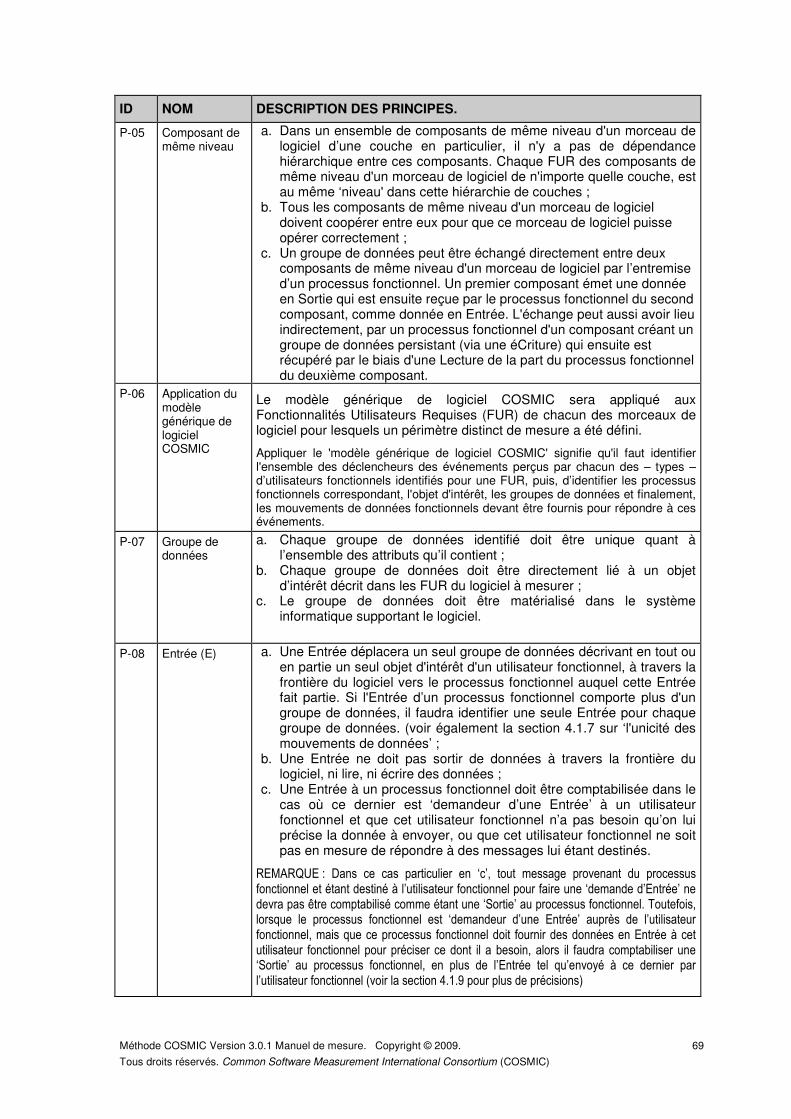
Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 69
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
ID NOM DESCRIPTION DES PRINCIPES.
P-05
Composant de même niveau
a. Dans un ensemble de composants de même niveau d'un morceau de logiciel d’une couche en particulier, il n'y a pas de dépendance hiérarchique entre ces composants. Chaque FUR des composants de même niveau d'un morceau de logiciel de n'importe quelle couche, est au même ‘niveau' dans cette hiérarchie de couches ;
b. Tous les composants de même niveau d'un morceau de logiciel doivent coopérer entre eux pour que ce morceau de logiciel puisse opérer correctement ;
c. Un groupe de données peut être échangé directement entre deux composants de même niveau d'un morceau de logiciel par l’entremise d’un processus fonctionnel. Un premier composant émet une donnée en Sortie qui est ensuite reçue par le processus fonctionnel du second composant, comme donnée en Entrée. L'échange peut aussi avoir lieu indirectement, par un processus fonctionnel d'un composant créant un groupe de données persistant (via une éCriture) qui ensuite est récupéré par le biais d'une Lecture de la part du processus fonctionnel du deuxième composant.
P-06
Application du modèle générique de logiciel COSMIC
Le modèle générique de logiciel COSMIC sera appliqué aux Fonctionnalités Utilisateurs Requises (FUR) de chacun des morceaux de logiciel pour lesquels un périmètre distinct de mesure a été défini.
Appliquer le 'modèle générique de logiciel COSMIC' signifie qu'il faut identifier l'ensemble des déclencheurs des événements perçus par chacun des – types – d’utilisateurs fonctionnels identifiés pour une FUR, puis, d’identifier les processus fonctionnels correspondant, l'objet d'intérêt, les groupes de données et finalement, les mouvements de données fonctionnels devant être fournis pour répondre à ces événements.
P-07
Groupe de données
a. Chaque groupe de données identifié doit être unique quant à l’ensemble des attributs qu’il contient ;
b. Chaque groupe de données doit être directement lié à un objet d’intérêt décrit dans les FUR du logiciel à mesurer ;
c. Le groupe de données doit être matérialisé dans le système informatique supportant le logiciel.
P-08
Entrée (E) a. Une Entrée déplacera un seul groupe de données décrivant en tout ou en partie un seul objet d'intérêt d'un utilisateur fonctionnel, à travers la frontière du logiciel vers le processus fonctionnel auquel cette Entrée fait partie. Si l'Entrée d’un processus fonctionnel comporte plus d'un groupe de données, il faudra identifier une seule Entrée pour chaque groupe de données. (voir également la section 4.1.7 sur ‘l'unicité des mouvements de données’ ;
b. Une Entrée ne doit pas sortir de données à travers la frontière du logiciel, ni lire, ni écrire des données ;
c. Une Entrée à un processus fonctionnel doit être comptabilisée dans le cas où ce dernier est ‘demandeur d’une Entrée’ à un utilisateur fonctionnel et que cet utilisateur fonctionnel n’a pas besoin qu’on lui précise la donnée à envoyer, ou que cet utilisateur fonctionnel ne soit pas en mesure de répondre à des messages lui étant destinés.
REMARQUE : Dans ce cas particulier en ‘c’, tout message provenant du processus fonctionnel et étant destiné à l’utilisateur fonctionnel pour faire une ‘demande d’Entrée’ ne devra pas être comptabilisé comme étant une ‘Sortie’ au processus fonctionnel. Toutefois, lorsque le processus fonctionnel est ‘demandeur d’une Entrée’ auprès de l’utilisateur fonctionnel, mais que ce processus fonctionnel doit fournir des données en Entrée à cet utilisateur fonctionnel pour préciser ce dont il a besoin, alors il faudra comptabiliser une ‘Sortie’ au processus fonctionnel, en plus de l’Entrée tel qu’envoyé à ce dernier par l’utilisateur fonctionnel (voir la section 4.1.9 pour plus de précisions)
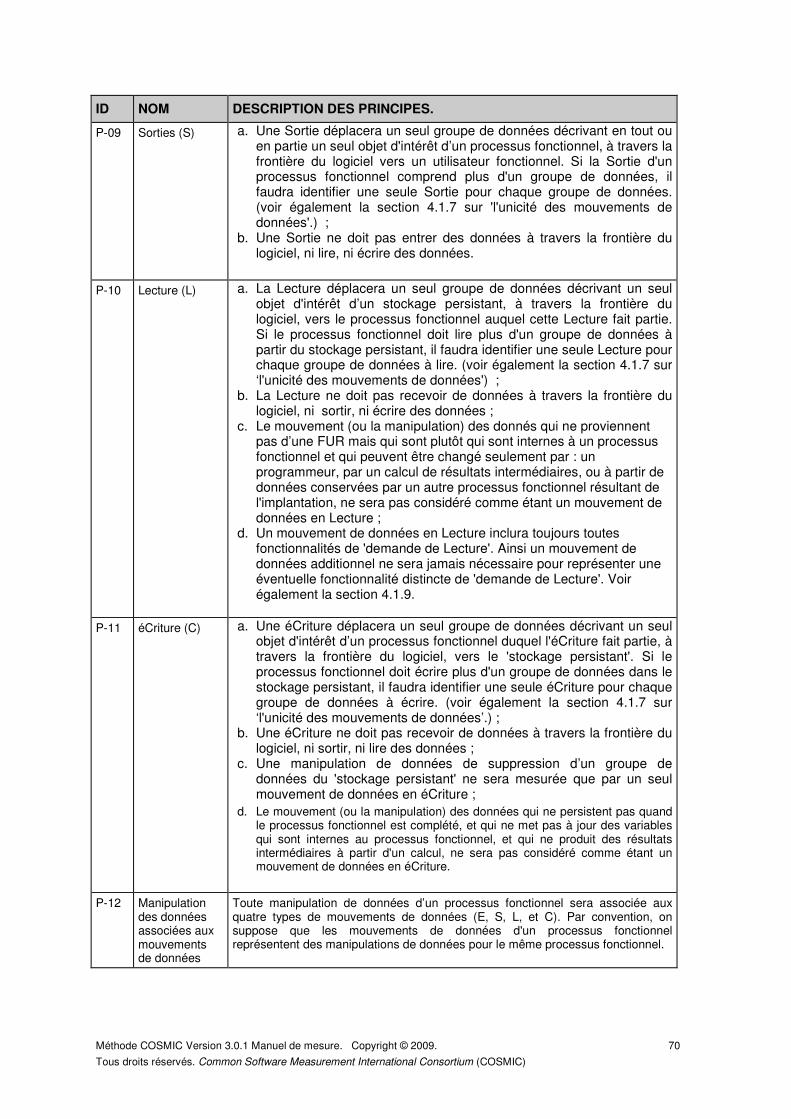
Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 70
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
ID NOM DESCRIPTION DES PRINCIPES.
P-09
Sorties (S) a. Une Sortie déplacera un seul groupe de données décrivant en tout ou en partie un seul objet d'intérêt d’un processus fonctionnel, à travers la frontière du logiciel vers un utilisateur fonctionnel. Si la Sortie d'un processus fonctionnel comprend plus d'un groupe de données, il faudra identifier une seule Sortie pour chaque groupe de données. (voir également la section 4.1.7 sur 'l'unicité des mouvements de données'.) ;
b. Une Sortie ne doit pas entrer des données à travers la frontière du logiciel, ni lire, ni écrire des données.
P-10
Lecture (L) a. La Lecture déplacera un seul groupe de données décrivant un seul objet d'intérêt d’un stockage persistant, à travers la frontière du logiciel, vers le processus fonctionnel auquel cette Lecture fait partie. Si le processus fonctionnel doit lire plus d'un groupe de données à partir du stockage persistant, il faudra identifier une seule Lecture pour chaque groupe de données à lire. (voir également la section 4.1.7 sur ‘l'unicité des mouvements de données') ;
b. La Lecture ne doit pas recevoir de données à travers la frontière du logiciel, ni sortir, ni écrire des données ;
c. Le mouvement (ou la manipulation) des donnés qui ne proviennent pas d’une FUR mais qui sont plutôt qui sont internes à un processus fonctionnel et qui peuvent être changé seulement par : un programmeur, par un calcul de résultats intermédiaires, ou à partir de données conservées par un autre processus fonctionnel résultant de l'implantation, ne sera pas considéré comme étant un mouvement de données en Lecture ;
d. Un mouvement de données en Lecture inclura toujours toutes fonctionnalités de 'demande de Lecture'. Ainsi un mouvement de données additionnel ne sera jamais nécessaire pour représenter une éventuelle fonctionnalité distincte de 'demande de Lecture'. Voir également la section 4.1.9.
P-11
éCriture (C) a. Une éCriture déplacera un seul groupe de données décrivant un seul objet d'intérêt d’un processus fonctionnel duquel l'éCriture fait partie, à travers la frontière du logiciel, vers le 'stockage persistant'. Si le processus fonctionnel doit écrire plus d'un groupe de données dans le stockage persistant, il faudra identifier une seule éCriture pour chaque groupe de données à écrire. (voir également la section 4.1.7 sur ‘l'unicité des mouvements de données’.) ;
b. Une éCriture ne doit pas recevoir de données à travers la frontière du logiciel, ni sortir, ni lire des données ;
c. Une manipulation de données de suppression d’un groupe de données du 'stockage persistant' ne sera mesurée que par un seul mouvement de données en éCriture ;
d. Le mouvement (ou la manipulation) des données qui ne persistent pas quand le processus fonctionnel est complété, et qui ne met pas à jour des variables qui sont internes au processus fonctionnel, et qui ne produit des résultats intermédiaires à partir d'un calcul, ne sera pas considéré comme étant un mouvement de données en éCriture.
P-12 Manipulation des données associées aux mouvements de données
Toute manipulation de données d’un processus fonctionnel sera associée aux quatre types de mouvements de données (E, S, L, et C). Par convention, on suppose que les mouvements de données d'un processus fonctionnel représentent des manipulations de données pour le même processus fonctionnel.
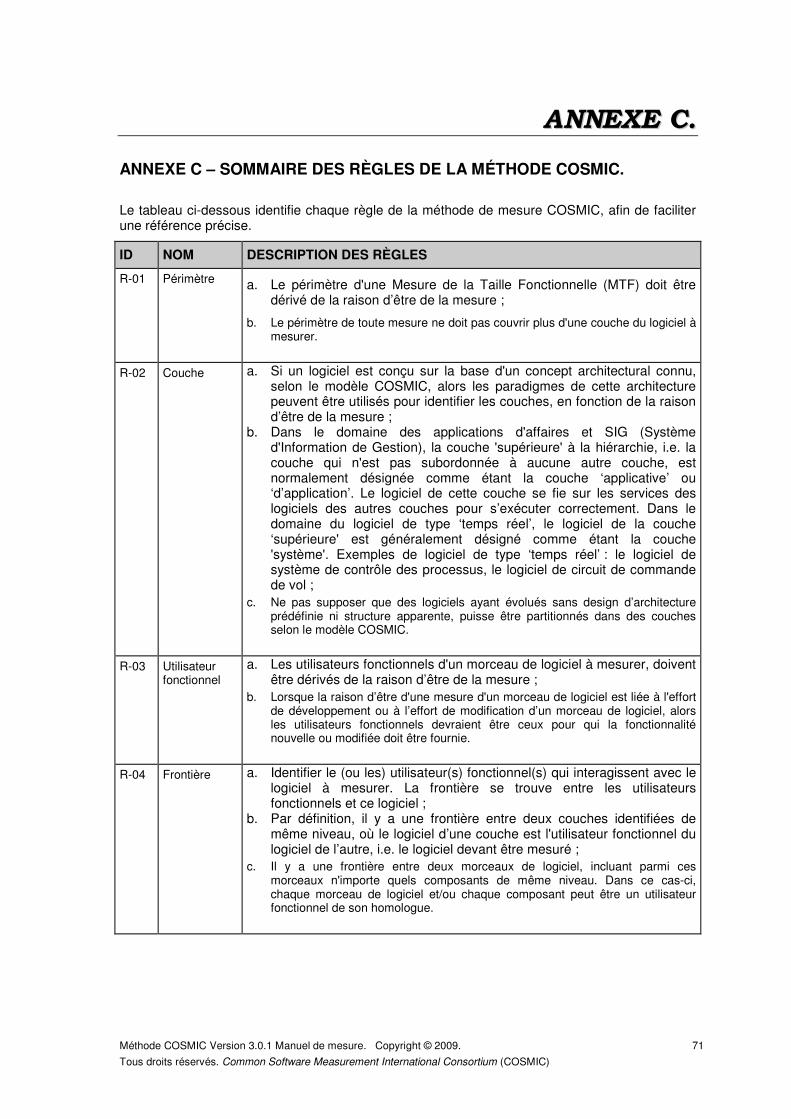
Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 71
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
AANNNNEEXXEE CC.. ANNEXE C – SOMMAIRE DES RÈGLES DE LA MÉTHODE COSMIC.
Le tableau ci-dessous identifie chaque règle de la méthode de mesure COSMIC, afin de faciliter une référence précise.
ID NOM DESCRIPTION DES RÈGLES
R-01 Périmètre a. Le périmètre d'une Mesure de la Taille Fonctionnelle (MTF) doit être dérivé de la raison d’être de la mesure ;
b. Le périmètre de toute mesure ne doit pas couvrir plus d'une couche du logiciel à mesurer.
R-02 Couche a. Si un logiciel est conçu sur la base d'un concept architectural connu, selon le modèle COSMIC, alors les paradigmes de cette architecture peuvent être utilisés pour identifier les couches, en fonction de la raison d’être de la mesure ;
b. Dans le domaine des applications d'affaires et SIG (Système d'Information de Gestion), la couche 'supérieure' à la hiérarchie, i.e. la couche qui n'est pas subordonnée à aucune autre couche, est normalement désignée comme étant la couche ‘applicative’ ou ‘d’application’. Le logiciel de cette couche se fie sur les services des logiciels des autres couches pour s’exécuter correctement. Dans le domaine du logiciel de type ‘temps réel’, le logiciel de la couche ‘supérieure' est généralement désigné comme étant la couche 'système'. Exemples de logiciel de type ‘temps réel’ : le logiciel de système de contrôle des processus, le logiciel de circuit de commande de vol ;
c. Ne pas supposer que des logiciels ayant évolués sans design d’architecture prédéfinie ni structure apparente, puisse être partitionnés dans des couches selon le modèle COSMIC.
R-03 Utilisateur fonctionnel
a. Les utilisateurs fonctionnels d'un morceau de logiciel à mesurer, doivent être dérivés de la raison d’être de la mesure ;
b. Lorsque la raison d’être d'une mesure d'un morceau de logiciel est liée à l'effort de développement ou à l’effort de modification d’un morceau de logiciel, alors les utilisateurs fonctionnels devraient être ceux pour qui la fonctionnalité nouvelle ou modifiée doit être fournie.
R-04 Frontière a. Identifier le (ou les) utilisateur(s) fonctionnel(s) qui interagissent avec le logiciel à mesurer. La frontière se trouve entre les utilisateurs fonctionnels et ce logiciel ;
b. Par définition, il y a une frontière entre deux couches identifiées de même niveau, où le logiciel d’une couche est l'utilisateur fonctionnel du logiciel de l’autre, i.e. le logiciel devant être mesuré ;
c. Il y a une frontière entre deux morceaux de logiciel, incluant parmi ces morceaux n'importe quels composants de même niveau. Dans ce cas-ci, chaque morceau de logiciel et/ou chaque composant peut être un utilisateur fonctionnel de son homologue.
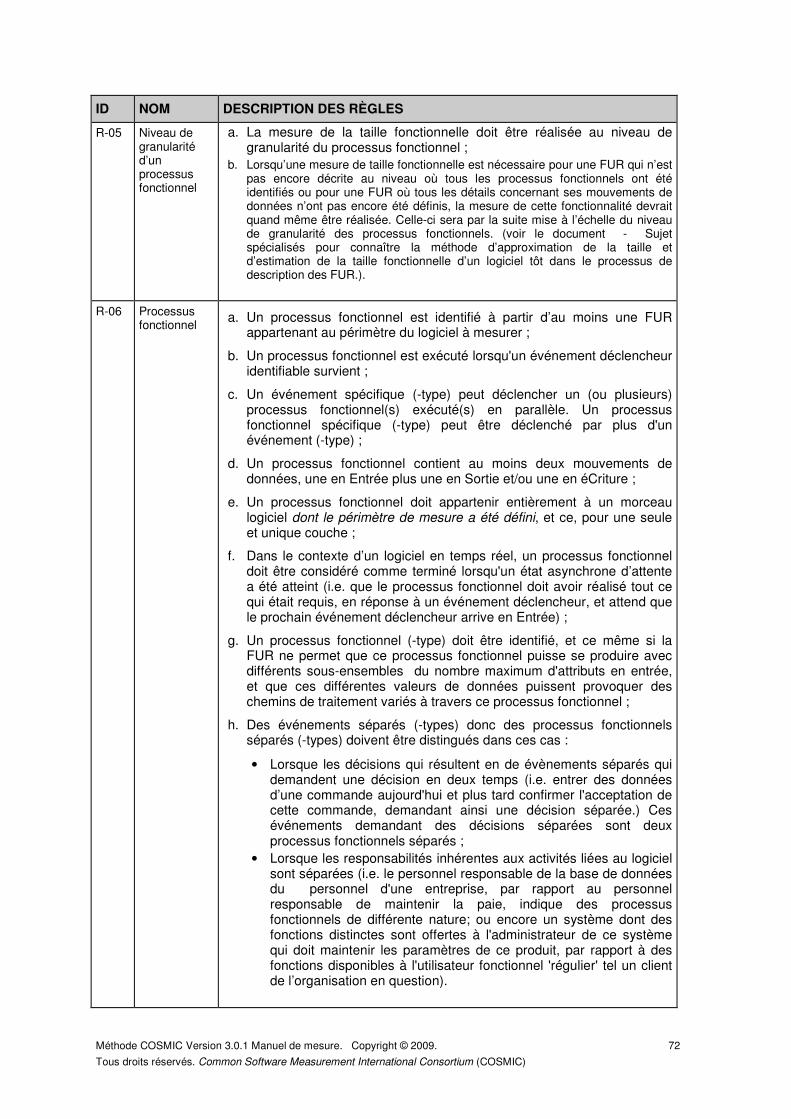
Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 72
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
ID NOM DESCRIPTION DES RÈGLES
R-05 Niveau de granularité d’un processus fonctionnel
a. La mesure de la taille fonctionnelle doit être réalisée au niveau de granularité du processus fonctionnel ;
b. Lorsqu’une mesure de taille fonctionnelle est nécessaire pour une FUR qui n’est pas encore décrite au niveau où tous les processus fonctionnels ont été identifiés ou pour une FUR où tous les détails concernant ses mouvements de données n’ont pas encore été définis, la mesure de cette fonctionnalité devrait quand même être réalisée. Celle-ci sera par la suite mise à l’échelle du niveau de granularité des processus fonctionnels. (voir le document - Sujet spécialisés pour connaître la méthode d’approximation de la taille et d’estimation de la taille fonctionnelle d’un logiciel tôt dans le processus de description des FUR.).
R-06 Processus fonctionnel
a. Un processus fonctionnel est identifié à partir d’au moins une FUR appartenant au périmètre du logiciel à mesurer ;
b. Un processus fonctionnel est exécuté lorsqu'un événement déclencheur identifiable survient ;
c. Un événement spécifique (-type) peut déclencher un (ou plusieurs) processus fonctionnel(s) exécuté(s) en parallèle. Un processus fonctionnel spécifique (-type) peut être déclenché par plus d'un événement (-type) ;
d. Un processus fonctionnel contient au moins deux mouvements de données, une en Entrée plus une en Sortie et/ou une en éCriture ;
e. Un processus fonctionnel doit appartenir entièrement à un morceau logiciel dont le périmètre de mesure a été défini, et ce, pour une seule et unique couche ;
f. Dans le contexte d’un logiciel en temps réel, un processus fonctionnel doit être considéré comme terminé lorsqu'un état asynchrone d’attente a été atteint (i.e. que le processus fonctionnel doit avoir réalisé tout ce qui était requis, en réponse à un événement déclencheur, et attend que le prochain événement déclencheur arrive en Entrée) ;
g. Un processus fonctionnel (-type) doit être identifié, et ce même si la FUR ne permet que ce processus fonctionnel puisse se produire avec différents sous-ensembles du nombre maximum d'attributs en entrée, et que ces différentes valeurs de données puissent provoquer des chemins de traitement variés à travers ce processus fonctionnel ;
h. Des événements séparés (-types) donc des processus fonctionnels séparés (-types) doivent être distingués dans ces cas :
• Lorsque les décisions qui résultent en de évènements séparés qui demandent une décision en deux temps (i.e. entrer des données d’une commande aujourd'hui et plus tard confirmer l'acceptation de cette commande, demandant ainsi une décision séparée.) Ces événements demandant des décisions séparées sont deux processus fonctionnels séparés ;
• Lorsque les responsabilités inhérentes aux activités liées au logiciel sont séparées (i.e. le personnel responsable de la base de données du personnel d'une entreprise, par rapport au personnel responsable de maintenir la paie, indique des processus fonctionnels de différente nature; ou encore un système dont des fonctions distinctes sont offertes à l'administrateur de ce système qui doit maintenir les paramètres de ce produit, par rapport à des fonctions disponibles à l'utilisateur fonctionnel 'régulier' tel un client de l’organisation en question).
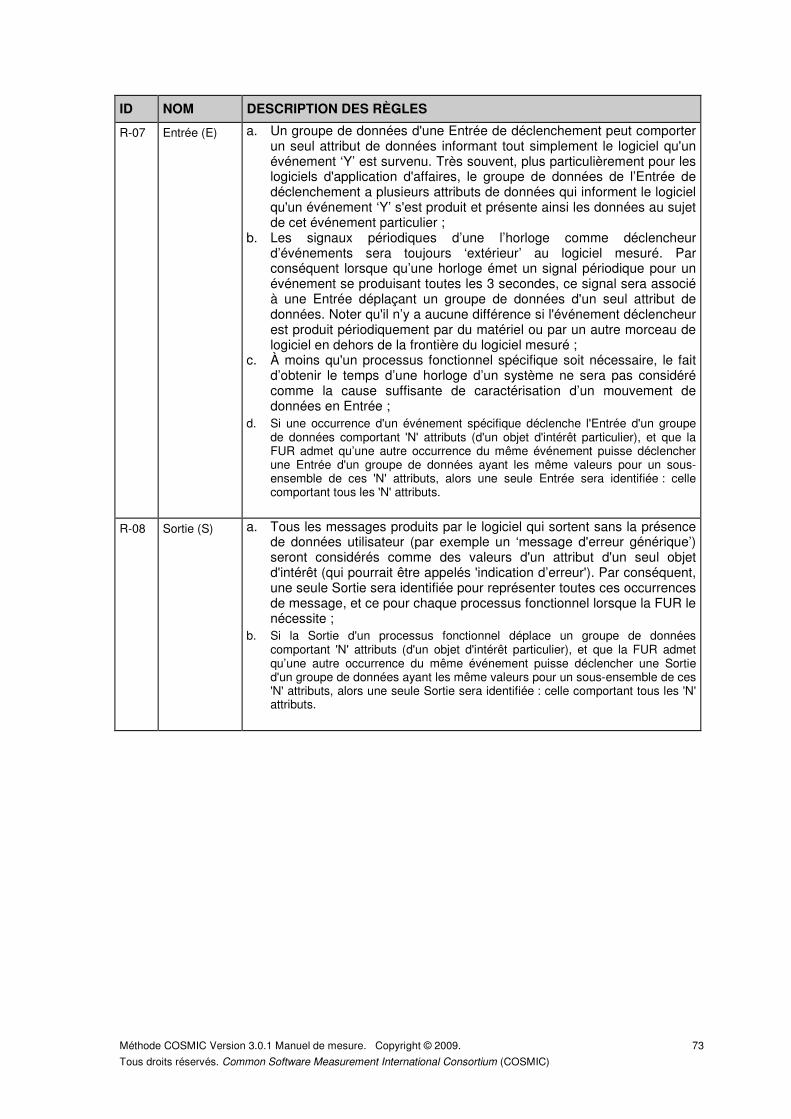
Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 73
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
ID NOM DESCRIPTION DES RÈGLES
R-07 Entrée (E) a. Un groupe de données d'une Entrée de déclenchement peut comporter un seul attribut de données informant tout simplement le logiciel qu'un événement ‘Y’ est survenu. Très souvent, plus particulièrement pour les logiciels d'application d'affaires, le groupe de données de l’Entrée de déclenchement a plusieurs attributs de données qui informent le logiciel qu'un événement ‘Y’ s'est produit et présente ainsi les données au sujet de cet événement particulier ;
b. Les signaux périodiques d’une l’horloge comme déclencheur d’événements sera toujours ‘extérieur’ au logiciel mesuré. Par conséquent lorsque qu’une horloge émet un signal périodique pour un événement se produisant toutes les 3 secondes, ce signal sera associé à une Entrée déplaçant un groupe de données d'un seul attribut de données. Noter qu'il n’y a aucune différence si l'événement déclencheur est produit périodiquement par du matériel ou par un autre morceau de logiciel en dehors de la frontière du logiciel mesuré ;
c. À moins qu'un processus fonctionnel spécifique soit nécessaire, le fait d’obtenir le temps d’une horloge d’un système ne sera pas considéré comme la cause suffisante de caractérisation d’un mouvement de données en Entrée ;
d. Si une occurrence d'un événement spécifique déclenche l'Entrée d'un groupe de données comportant 'N' attributs (d'un objet d'intérêt particulier), et que la FUR admet qu’une autre occurrence du même événement puisse déclencher une Entrée d'un groupe de données ayant les même valeurs pour un sous-ensemble de ces 'N' attributs, alors une seule Entrée sera identifiée : celle comportant tous les 'N' attributs.
R-08 Sortie (S) a. Tous les messages produits par le logiciel qui sortent sans la présence de données utilisateur (par exemple un ‘message d'erreur générique’) seront considérés comme des valeurs d'un attribut d'un seul objet d'intérêt (qui pourrait être appelés 'indication d’erreur'). Par conséquent, une seule Sortie sera identifiée pour représenter toutes ces occurrences de message, et ce pour chaque processus fonctionnel lorsque la FUR le nécessite ;
b. Si la Sortie d'un processus fonctionnel déplace un groupe de données comportant 'N' attributs (d'un objet d'intérêt particulier), et que la FUR admet qu’une autre occurrence du même événement puisse déclencher une Sortie d'un groupe de données ayant les même valeurs pour un sous-ensemble de ces 'N' attributs, alors une seule Sortie sera identifiée : celle comportant tous les 'N' attributs.

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 74
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
ID NOM DESCRIPTION DES RÈGLES
R-09 Unicité des mouvements de données et exceptions possibles
a. Sauf si la FUR l’indique autrement, tous les attributs de données décrivant un objet d'intérêt et qui est exigé dans un processus fonctionnel, de même que toutes les manipulations de données associées, seront identifiées et comptées comme étant des mouvements de données en Entrée (-type) ;
REMARQUE : Un processus fonctionnel pourrait, en principe, manipuler de multiples Entrées (-type), chacune déplaçant un groupe de données décrivant un objet d'intérêt (-type) distinct ;
b. La règle équivalente s'applique à tout mouvement de données en Lecture, en éCriture ou en Sortie, dans tout processus fonctionnel donné ;
c. Dans les cas où il existe plus d'un mouvement de données en Entrée (-type), déplaçant chacun un même groupe de données, décrivant ainsi le même objet d'intérêt (-type) dans un même processus fonctionnel donné (-type) peuvent être identifiés et comptés s'il y a une FUR pour ces entrées multiples. De même, dans les cas où il existe plus d'une Entrée (-type) déplaçant chacune le même groupe de données (-type) dans le même processus fonctionnel, mais chacune ayant différentes manipulations de données (-types) d’associées, peuvent être identifiées et comptées s'il y a une FUR pour ces entrées multiples ;
d. Une telle FUR peut exister quand des Entrées multiples d'un processus fonctionnel, proviennent de plusieurs utilisateurs fonctionnels qui saisissent plusieurs groupes de données (chacun décrivant le même objet d'intérêt) ;
e. La même règle s'applique à la Lecture, l'éCriture ou la Sortie d'un mouvement de données dans n'importe quel processus fonctionnel donné ;
f. Plusieurs occurrences d'un même type de mouvement de données (i.e. déplaçant le même groupe de données avec la même manipulation de données) ne seront pas identifiées ou comptées plus d'une fois dans tout le processus fonctionnel ;
g. Dans le cas où des occurrences multiples d'un mouvement de données (associés à un processus fonctionnel donné), diffèreraient dans leur manipulation de données en raison des différentes valeurs des attributs du groupe de données, cela résulterait dans le suivi de différents chemins de traitement. Ce type de mouvement de données ne sera pas identifié et compté plus d’une fois dans ce processus.
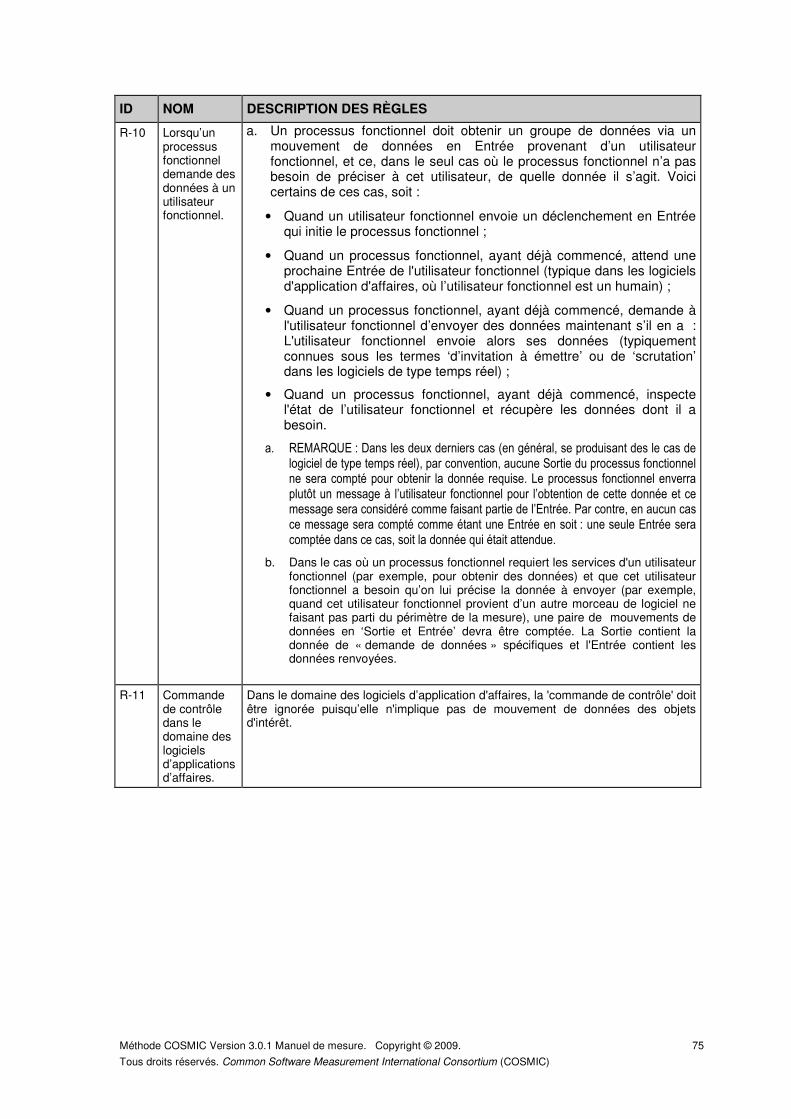
Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 75
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
ID NOM DESCRIPTION DES RÈGLES
R-10 Lorsqu’un processus fonctionnel demande des données à un utilisateur fonctionnel.
a. Un processus fonctionnel doit obtenir un groupe de données via un mouvement de données en Entrée provenant d’un utilisateur fonctionnel, et ce, dans le seul cas où le processus fonctionnel n’a pas besoin de préciser à cet utilisateur, de quelle donnée il s’agit. Voici certains de ces cas, soit :
• Quand un utilisateur fonctionnel envoie un déclenchement en Entrée qui initie le processus fonctionnel ;
• Quand un processus fonctionnel, ayant déjà commencé, attend une prochaine Entrée de l'utilisateur fonctionnel (typique dans les logiciels d'application d'affaires, où l’utilisateur fonctionnel est un humain) ;
• Quand un processus fonctionnel, ayant déjà commencé, demande à l'utilisateur fonctionnel d’envoyer des données maintenant s’il en a : L'utilisateur fonctionnel envoie alors ses données (typiquement connues sous les termes ‘d’invitation à émettre’ ou de ‘scrutation’ dans les logiciels de type temps réel) ;
• Quand un processus fonctionnel, ayant déjà commencé, inspecte l'état de l’utilisateur fonctionnel et récupère les données dont il a besoin.
a. REMARQUE : Dans les deux derniers cas (en général, se produisant des le cas de logiciel de type temps réel), par convention, aucune Sortie du processus fonctionnel ne sera compté pour obtenir la donnée requise. Le processus fonctionnel enverra plutôt un message à l’utilisateur fonctionnel pour l’obtention de cette donnée et ce message sera considéré comme faisant partie de l’Entrée. Par contre, en aucun cas ce message sera compté comme étant une Entrée en soit : une seule Entrée sera comptée dans ce cas, soit la donnée qui était attendue.
b. Dans le cas où un processus fonctionnel requiert les services d'un utilisateur fonctionnel (par exemple, pour obtenir des données) et que cet utilisateur fonctionnel a besoin qu’on lui précise la donnée à envoyer (par exemple, quand cet utilisateur fonctionnel provient d’un autre morceau de logiciel ne faisant pas parti du périmètre de la mesure), une paire de mouvements de données en ‘Sortie et Entrée’ devra être comptée. La Sortie contient la donnée de « demande de données » spécifiques et l'Entrée contient les données renvoyées.
R-11 Commande de contrôle dans le domaine des logiciels d’applications d’affaires.
Dans le domaine des logiciels d’application d'affaires, la 'commande de contrôle' doit être ignorée puisqu’elle n'implique pas de mouvement de données des objets d'intérêt.

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 76
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
ID NOM DESCRIPTION DES RÈGLES
R-12 Additivité des résultats de mesure.
a. Pour chaque processus fonctionnel, la taille fonctionnelle des mouvements de données est regroupée en une seule valeur de taille fonctionnelle par l’intermédiaire d’une addition arithmétique du nombre de mouvements de données ;
Taille CFP ( processus fonctionnel ) =
Σ taille ( Entrée i ) + Σ taille ( Sortie i ) +
Σ taille ( Lecture i ) + Σ taille ( éCriture i )
b. Pour chaque processus fonctionnel, la taille fonctionnelle de chaque modification de FUR est additionnée à la somme des tailles fonctionnelles des mouvements de données, pour qui les données ont subit une manipulation de donnée par l’entremise d’un processus fonctionnel. Voici la formule :
Taille CFP ( modification ( processus fonctionnel i ) ) =
Σ taille ( mouv. de donnée i --> manip. ‘ajouté’ ) +
Σ taille ( mouv. de donnée i --> manip. ‘modifié’ ) +
Σ taille ( mouv. de donnée i --> manip. 'supprimé’ )
Pour en savoir plus sur l'additivité de la taille fonctionnelle, voir la section 4.3.2. Pour mesurer la taille d’un morceau de logiciel modifié, voir la section 4.4.
c. La taille d'un morceau de logiciel pour un périmètre défini doit être obtenue en additionnant les tailles fonctionnelles des processus fonctionnels de ce morceau, selon les règles (e) et (f) ci-dessous ;
d. La taille d’une modification d’un morceau logiciel d’un périmètre donné doit être obtenue en additionnant les tailles fonctionnelles de toutes les modifications de tous les processus fonctionnels de ce morceau, selon les règles (e) et (f) ci-dessous ;
e. La taille de chaque morceau de logiciel à mesurer dans une couche peut être obtenue en les additionnant, mais seulement au même niveau de granularité des processus fonctionnels de leur FUR ;
f. Les tailles des morceaux de logiciel et/ou des modifications apportées à un morceau de logiciel dans leur couche respective ou dans des couches différentes, ne devraient pas être additionnées entre elles, sauf si il est logique de le faire, pour les fins de la mesure ;
g. La taille d'un morceau de logiciel ne peut pas être obtenue en additionnant les tailles de ses composants (quelques soit le mode de décomposition) à moins que la taille des mouvements de données entre ces composants soient éliminée du calcul;
h. Si la méthode COSMIC est étendue localement (par exemple pour mesurer certains aspects de la taille non couverte par la méthode normalisée), alors la taille mesurée en utilisant une extension locale doit être rapportée séparément tel que décrit dans la section 5.2, et ne peut pas être additionné pour obtenir une taille selon l‘étalon de mesure COSMIC (voir la section 4.5).
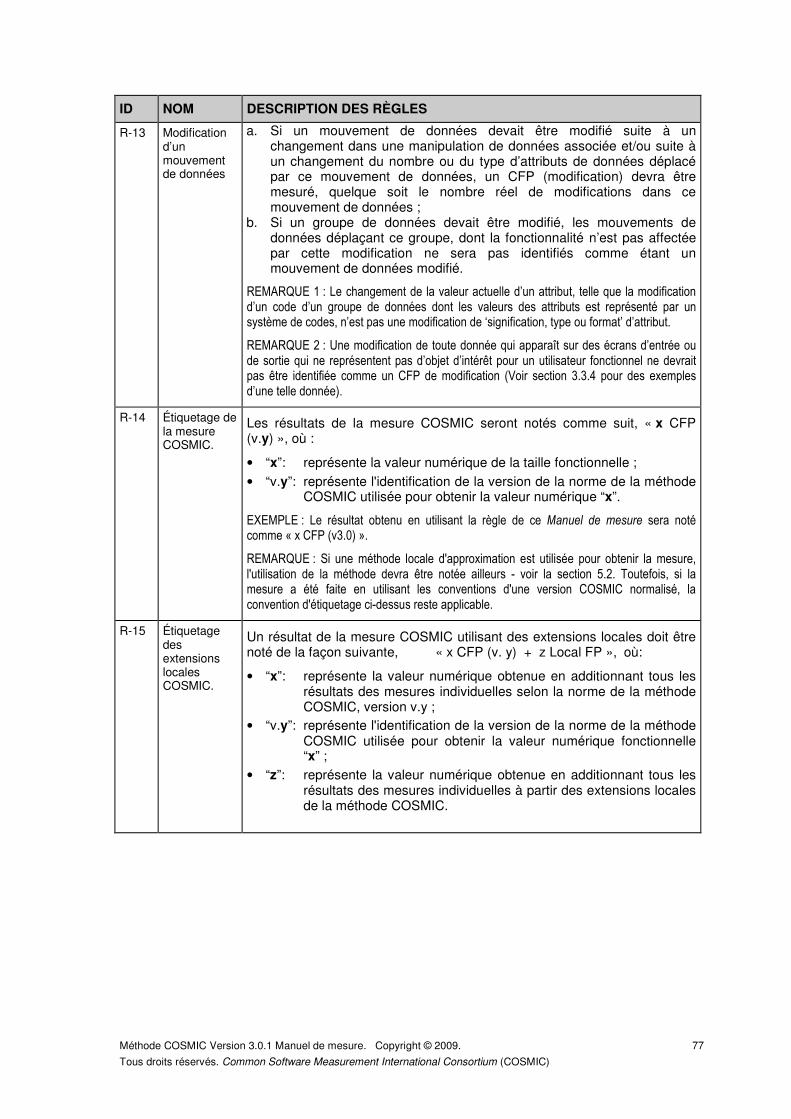
Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 77
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
ID NOM DESCRIPTION DES RÈGLES
R-13 Modification d’un mouvement de données
a. Si un mouvement de données devait être modifié suite à un changement dans une manipulation de données associée et/ou suite à un changement du nombre ou du type d’attributs de données déplacé par ce mouvement de données, un CFP (modification) devra être mesuré, quelque soit le nombre réel de modifications dans ce mouvement de données ;
b. Si un groupe de données devait être modifié, les mouvements de données déplaçant ce groupe, dont la fonctionnalité n’est pas affectée par cette modification ne sera pas identifiés comme étant un mouvement de données modifié.
REMARQUE 1 : Le changement de la valeur actuelle d’un attribut, telle que la modification d’un code d’un groupe de données dont les valeurs des attributs est représenté par un système de codes, n’est pas une modification de ‘signification, type ou format’ d’attribut.
REMARQUE 2 : Une modification de toute donnée qui apparaît sur des écrans d’entrée ou de sortie qui ne représentent pas d’objet d’intérêt pour un utilisateur fonctionnel ne devrait pas être identifiée comme un CFP de modification (Voir section 3.3.4 pour des exemples d’une telle donnée).
R-14 Étiquetage de la mesure COSMIC.
Les résultats de la mesure COSMIC seront notés comme suit, « x CFP (v.y) », où :
• “x”: représente la valeur numérique de la taille fonctionnelle ; • “v.y”: représente l'identification de la version de la norme de la méthode
COSMIC utilisée pour obtenir la valeur numérique “x”.
EXEMPLE : Le résultat obtenu en utilisant la règle de ce Manuel de mesure sera noté comme « x CFP (v3.0) ».
REMARQUE : Si une méthode locale d'approximation est utilisée pour obtenir la mesure, l'utilisation de la méthode devra être notée ailleurs - voir la section 5.2. Toutefois, si la mesure a été faite en utilisant les conventions d'une version COSMIC normalisé, la convention d'étiquetage ci-dessus reste applicable.
R-15 Étiquetage des extensions locales COSMIC.
Un résultat de la mesure COSMIC utilisant des extensions locales doit être noté de la façon suivante, « x CFP (v. y) + z Local FP », où:
• “x”: représente la valeur numérique obtenue en additionnant tous les résultats des mesures individuelles selon la norme de la méthode COSMIC, version v.y ;
• “v.y”: représente l'identification de la version de la norme de la méthode COSMIC utilisée pour obtenir la valeur numérique fonctionnelle “x” ;
• “z”: représente la valeur numérique obtenue en additionnant tous les résultats des mesures individuelles à partir des extensions locales de la méthode COSMIC.

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 78
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
ID NOM DESCRIPTION DES RÈGLES
R-16 Rapporter la mesure COSMIC
En plus des résultats de mesure tels qu’enregistrés dans la section 5.1, les caractéristiques suivantes doivent être enregistrées pour chaque mesure :
a. Une identification du composant logiciel mesuré (nom, numéro de version ou numéro de configuration) ;
b. Le nom des sources d'information utilisées pour identifier la FUR pour la mesure ;
c. Le domaine d’applicabilité du logiciel mesuré ; d. Un énoncé de la raison d’être de la mesure ; e. Une description du périmètre de la mesure, et sa relation avec les
autres périmètres de mesures, s’il y a lieu. (Voir la section 2.2) ; f. Les utilisateurs fonctionnels du logiciel ; g. Le niveau de granularité de la FUR et le niveau de décomposition du
logiciel ; h. La phase du cycle de vie du projet à laquelle la mesure a été faîte
(particulièrement si la mesure est une estimation réalésée sur une FUR inachevée, ou sur des fonctionnalités déjà livrées) ;
i. La cible ou la marge d'erreur de la mesure que l'on croit viser ; j. Des indications sur si la méthode de mesure COSMIC standard a été
employée, et/ou si une approximation locale de la méthode standard a été appliquée, et/ou si des extensions locales ont été employés (voir la section 4.5). Employer les conventions d'étiquetage des sections 5.1 ou 5.2 ;
k. Une indication sur si l'on mesure une fonctionnalité développé ou déjà livrée (la fonctionnalité 'développée' est obtenue en créant un nouveau logiciel ; la fonctionnalité ‘déjà livrée’ inclut la fonctionnalité 'développée' en plus d'autres fonctionnalités comme par exemple toutes formes de réutilisation de logiciels existants ou d'utilisation de paramètres existants pour ajouter ou modifier la fonctionnalité, etc.) ;
l. Une indication sur si la mesure provient d'une fonctionnalité nouvellement fournie ou si elle est le résultat d'une activité de ‘maintenance’ ou 'd'amélioration' (i.e. la somme des ajouts, modification et suppressions - voir 4.4) ;
m. Une description de l'architecture du logiciel, les couches pour lesquelles les mesures sont réalisées, s’il y a lieu ;
n. Le nombre de composants majeurs dont les tailles ont été additionnées ensemble pour obtenir la taille totale telle qu’enregistrée, s’il y a lieu ;
o. Saisir, pour chaque périmètre de logiciel le périmètre global de la mesure, une matrice de mesure, telle qu'indiqué dans l'annexe A ;
p. Le nom du mesureur et toutes ses qualifications et certifications COSMIC.

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 79
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
AANNNNEEXXEE DD.. ANNEXE D – HISTORIQUE DES MISES À JOUR DE LA MÉTHODE COSMIC.
Cette annexe contient un résumé des principaux changements fait lors du passage de la version 3.0 et version 3.0.1 de la méthode de mesure fonctionnelle COSMIC. La version 2.2 de la méthode est décrite dans le ‘Manuel de mesure v2.2’ (abréviation ‘MM’). Mais à partir de la version 3.0 la documentation est distribué dans quatre (4) documents, un seul étant nommé ‘Manuel de mesure’.
Le but de cette annexe est de permettre au lecteur familier avec le MM v2.2 version de retracer les changements qui ont été fait dans les versions 3.0 et 3.01 et comprendre leur justification. (Pour les changements du passage de la version 2.2 à la version 2.1, voir la version 2.2 du Manuel de mesure, annexe E).
De la version 2.2 à la version 3.0
Dans les tables ci-dessous montrant les principaux changements à partir de la version 2.2 à la version 3.0., il y a deux références dans le tableau des changements ci-dessous, chacune est reliée a une mise-à-jour par bulletin (appelé ‘Method Update Bulletins’ – MUB18). Un MUB est publié par COSMIC pour proposer des améliorations à la méthode sans attendre les mise-à-jour majeures de la définition de la méthode. Les deux MUB sont :
• MUB 1 : Améliorations à la définition et caractéristiques proposées à la « couche » logicielle. Publié en mai 2003.
• MUB 2 “ Améliorations proposées à la définition d’un « objet d’intérêt » , publié en mars 2005.
Dans le processus de mise-à-jour de la méthode de v2.2 à v3.0, un effort a été fait pour rationaliser les explications entre les ‘principes’ et les ‘règles’ et pour séparer les exemples des principes et des règles. De tels changements et plusieurs améliorations de type éditoriales ne sont pas décrits dans le tableau suivant.
Réf. V2.2
Réf. V3.0
Modification
COSMIC Restructuration de la méthode
2.2, 2.7, 3.1, 3.2
1.5, Chapitre2
La phase de ‘stratégie de la mesure’ a été créée et séparée de la première phase, ce qui nous donne une méthode à trois phases. La phase de stratégie de la mesure inclue maintenant des considérations sur les ‘couches’, les ‘frontières’ et les utilisateurs (fonctionnel), lesquels sont considérés comme faisant partie de la phase d’arrimage du MM v2.2.
18 Il n’y a pas d’équivalent pour le terme anglophone ‘MUB’ en français. Tous les bulletins sont en anglais.

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 80
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
Réf. V2.2 Réf. V3.0 Modification
Manuel de mesure, restructuration
En produisant la v3.0 de la méthode COSMIC, le MM V2.2 a été séparé en 4 documents pour faciliter son utilisation :
• ‘La méthode COSMIC v3.0: Vue d’ensemble de la documentation et glossaire des termes’’ (nouveau)
• ‘La méthode COSMIC v3.0: Vue d’ensemble de la méthode’ (Chapitres 1 et 2 du MM v2.2)
• ‘La méthode COSMIC v3.0: Manuel de mesure’ (Chapitres 3, 4 et 5 et les annexes du MM v2.2
• ‘La méthode COSMIC v3.0: Sujets spécialisés’ (Chapitres 6 et 7 du MM v2.2)
Les références aux origines et les documents de recherches ont été enlevé du MM. Ils sont maintenant disponibles au www.gelog.etsmtl.ca/cosmic-ffp. Les seules références restantes dans les quatre (4) documents sont placées en bas de page.
Chapitre 4 Chapitre 4 Le chapitre sur la ‘phase de mesure’ a été considérablement restructuré pour permettre une présentation plus logique.
Ann. D -- Cette Annexe concernant ‘Further information on software layers’ a été retirée, car elle était incompatible avec le MUB 1 et aussi elle n’ajoutait que peu d’intérêt. Voir aussi les notes ci-dessous sur les changements à prendre en compte dans cette MUB 1.
Changements des noms et terminologie
Général Le nom de la méthode ‘COSMIC-FFP’ s’appelle maintenant la méthode ‘COSMIC’.
5.1 4.2 Le nom de l’unité de mesure, ‘COSMIC functional size unit’ (sous l’abréviation ‘Cfsu’) a été changé par ‘COSMIC Function Point’ (sous l’abréviation ‘CFP’). Voir la préface du MM v3.0 pour une explication de ce changement.
4.1 4.1.7 La règles de ‘dé-duplication du mouvement de donnée’ a été renommée la règle du ‘mouvement de donnée unique’.
Concepts nouveaux, remplacés et enlevés
2.7 2.3 Les concepts ‘d’abstraction’, de ‘point de vue’, de ‘point de vue de la mesures’, de ‘point de vue de la mesure de l’utilisateur final’ et de ‘point de vue de la mesure du développeur’ ont été enlevés. Ils sont remplacés par le concept plus générique à l’effet que la taille fonctionnelle d’un morceau de logiciel devant être mesuré dépend de la fonctionnalité qui doit être fournie à ‘l’utilisateur(s) fonctionnel’ du logiciel. Celles-ci doivent pouvoir être identifiées dans les FUR du logiciel devant être mesuré. La définition de ‘l’utilisateur fonctionnel’ devient un pré-requis pour définir quelle taille doit être mesurée ou pour interpréter la mesure de la taille existante. Voir la préface du MM v3.0 pour une explication de ce changement.
3.2 2.3 Le concept ‘d’utilisateur’ (tel que défini dans ISO/IEC 14143/1) a été remplacé par le concept ‘d’utilisateur fonctionnel’ qui est un concept plus limitatif. Voir la préface du MM v3.0 pour une explication de ce changement. Dans 2.3.2, deux exemples ont été introduits documentant une variation de la taille fonctionnelle pour deux types d’utilisateurs fonctionnels identifiés dans la FUR, l’un pour un téléphone mobile et l’autre pour une application d’affaires dans un produit-programme.
-- 2.2.2 Le ‘niveau de décomposition’ du logiciel devant être mesuré a été introduit dans le débat du périmètre de la mesure.
-- 2.4 Le ‘niveau de granularité’ de la FUR du logiciel devant être mesuré a été introduit dans le débat de la stratégie de mesure. Un exemple exhaustif est présenté. Voir la préface du MM v3.0 pour une explication de ce changement.
-- 2.4.3 Un ‘niveau de granularité du processus fonctionnel’ a été défini et des règles et recommandations proposées.
3.4 4.2 Le concept de ‘groupe de données persistant’ incluant trois niveau de persistance, soit ‘transitoire’, ‘court’ et ‘indéfini’ a été enlevé puisqu’inutile. Le concept de ‘stockage persistant’’ a été introduit.
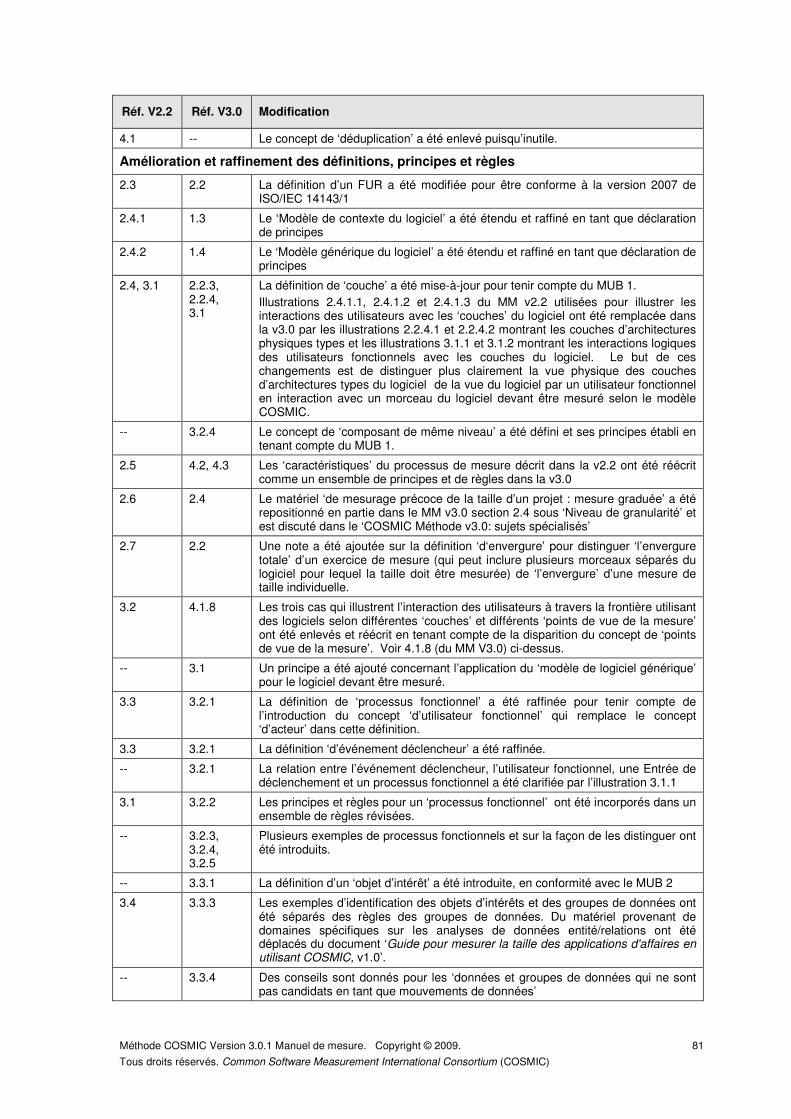
Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 81
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
Réf. V2.2 Réf. V3.0 Modification
4.1 -- Le concept de ‘déduplication’ a été enlevé puisqu’inutile.
Amélioration et raffinement des définitions, principes et règles
2.3 2.2 La définition d’un FUR a été modifiée pour être conforme à la version 2007 de ISO/IEC 14143/1
2.4.1 1.3 Le ‘Modèle de contexte du logiciel’ a été étendu et raffiné en tant que déclaration de principes
2.4.2 1.4 Le ‘Modèle générique du logiciel’ a été étendu et raffiné en tant que déclaration de principes
2.4, 3.1 2.2.3, 2.2.4, 3.1
La définition de ‘couche’ a été mise-à-jour pour tenir compte du MUB 1. Illustrations 2.4.1.1, 2.4.1.2 et 2.4.1.3 du MM v2.2 utilisées pour illustrer les interactions des utilisateurs avec les ‘couches’ du logiciel ont été remplacée dans la v3.0 par les illustrations 2.2.4.1 et 2.2.4.2 montrant les couches d’architectures physiques types et les illustrations 3.1.1 et 3.1.2 montrant les interactions logiques des utilisateurs fonctionnels avec les couches du logiciel. Le but de ces changements est de distinguer plus clairement la vue physique des couches d’architectures types du logiciel de la vue du logiciel par un utilisateur fonctionnel en interaction avec un morceau du logiciel devant être mesuré selon le modèle COSMIC.
-- 3.2.4 Le concept de ‘composant de même niveau’ a été défini et ses principes établi en tenant compte du MUB 1.
2.5 4.2, 4.3 Les ‘caractéristiques’ du processus de mesure décrit dans la v2.2 ont été réécrit comme un ensemble de principes et de règles dans la v3.0
2.6 2.4 Le matériel ‘de mesurage précoce de la taille d’un projet : mesure graduée’ a été repositionné en partie dans le MM v3.0 section 2.4 sous ‘Niveau de granularité’ et est discuté dans le ‘COSMIC Méthode v3.0: sujets spécialisés’
2.7 2.2 Une note a été ajoutée sur la définition ‘d‘envergure’ pour distinguer ‘l’envergure totale’ d’un exercice de mesure (qui peut inclure plusieurs morceaux séparés du logiciel pour lequel la taille doit être mesurée) de ‘l’envergure’ d’une mesure de taille individuelle.
3.2 4.1.8 Les trois cas qui illustrent l’interaction des utilisateurs à travers la frontière utilisant des logiciels selon différentes ‘couches’ et différents ‘points de vue de la mesure’ ont été enlevés et réécrit en tenant compte de la disparition du concept de ‘points de vue de la mesure’. Voir 4.1.8 (du MM V3.0) ci-dessus.
-- 3.1 Un principe a été ajouté concernant l’application du ‘modèle de logiciel générique’ pour le logiciel devant être mesuré.
3.3 3.2.1 La définition de ‘processus fonctionnel’ a été raffinée pour tenir compte de l’introduction du concept ‘d’utilisateur fonctionnel’ qui remplace le concept ‘d’acteur’ dans cette définition.
3.3 3.2.1 La définition ‘d’événement déclencheur’ a été raffinée.
-- 3.2.1 La relation entre l’événement déclencheur, l’utilisateur fonctionnel, une Entrée de déclenchement et un processus fonctionnel a été clarifiée par l’illustration 3.1.1
3.1 3.2.2 Les principes et règles pour un ‘processus fonctionnel’ ont été incorporés dans un ensemble de règles révisées.
-- 3.2.3, 3.2.4, 3.2.5
Plusieurs exemples de processus fonctionnels et sur la façon de les distinguer ont été introduits.
-- 3.3.1 La définition d’un ‘objet d’intérêt’ a été introduite, en conformité avec le MUB 2
3.4 3.3.3 Les exemples d’identification des objets d’intérêts et des groupes de données ont été séparés des règles des groupes de données. Du matériel provenant de domaines spécifiques sur les analyses de données entité/relations ont été déplacés du document ‘Guide pour mesurer la taille des applications d'affaires en utilisant COSMIC, v1.0’.
-- 3.3.4 Des conseils sont donnés pour les ‘données et groupes de données qui ne sont pas candidats en tant que mouvements de données’
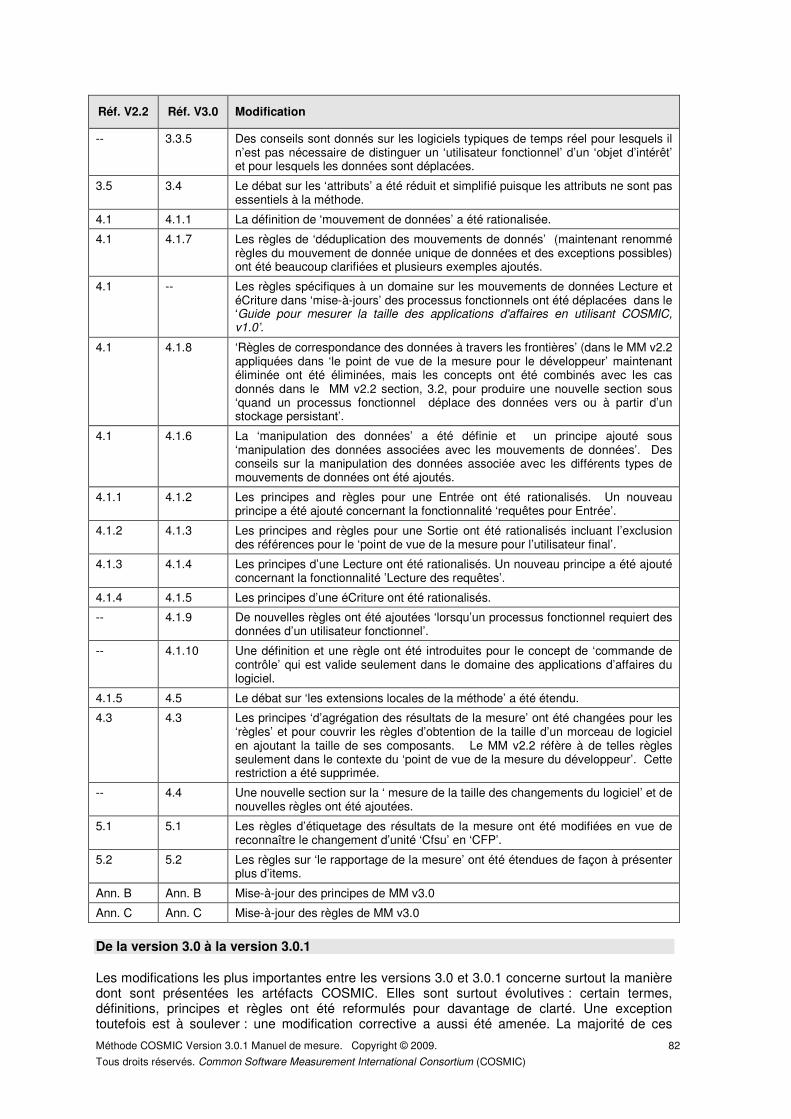
Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 82
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
Réf. V2.2 Réf. V3.0 Modification
-- 3.3.5 Des conseils sont donnés sur les logiciels typiques de temps réel pour lesquels il n’est pas nécessaire de distinguer un ‘utilisateur fonctionnel’ d’un ‘objet d’intérêt’ et pour lesquels les données sont déplacées.
3.5 3.4 Le débat sur les ‘attributs’ a été réduit et simplifié puisque les attributs ne sont pas essentiels à la méthode.
4.1 4.1.1 La définition de ‘mouvement de données’ a été rationalisée.
4.1 4.1.7 Les règles de ‘déduplication des mouvements de donnés’ (maintenant renommé règles du mouvement de donnée unique de données et des exceptions possibles) ont été beaucoup clarifiées et plusieurs exemples ajoutés.
4.1 -- Les règles spécifiques à un domaine sur les mouvements de données Lecture et éCriture dans ‘mise-à-jours’ des processus fonctionnels ont été déplacées dans le ‘Guide pour mesurer la taille des applications d'affaires en utilisant COSMIC, v1.0’.
4.1 4.1.8 ‘Règles de correspondance des données à travers les frontières’ (dans le MM v2.2 appliquées dans ‘le point de vue de la mesure pour le développeur’ maintenant éliminée ont été éliminées, mais les concepts ont été combinés avec les cas donnés dans le MM v2.2 section, 3.2, pour produire une nouvelle section sous ‘quand un processus fonctionnel déplace des données vers ou à partir d’un stockage persistant’.
4.1 4.1.6 La ‘manipulation des données’ a été définie et un principe ajouté sous ‘manipulation des données associées avec les mouvements de données’. Des conseils sur la manipulation des données associée avec les différents types de mouvements de données ont été ajoutés.
4.1.1 4.1.2 Les principes and règles pour une Entrée ont été rationalisés. Un nouveau principe a été ajouté concernant la fonctionnalité ‘requêtes pour Entrée’.
4.1.2 4.1.3 Les principes and règles pour une Sortie ont été rationalisés incluant l’exclusion des références pour le ‘point de vue de la mesure pour l’utilisateur final’.
4.1.3 4.1.4 Les principes d’une Lecture ont été rationalisés. Un nouveau principe a été ajouté concernant la fonctionnalité ’Lecture des requêtes’.
4.1.4 4.1.5 Les principes d’une éCriture ont été rationalisés.
-- 4.1.9 De nouvelles règles ont été ajoutées ‘lorsqu’un processus fonctionnel requiert des données d’un utilisateur fonctionnel’.
-- 4.1.10 Une définition et une règle ont été introduites pour le concept de ‘commande de contrôle’ qui est valide seulement dans le domaine des applications d’affaires du logiciel.
4.1.5 4.5 Le débat sur ‘les extensions locales de la méthode’ a été étendu.
4.3 4.3 Les principes ‘d’agrégation des résultats de la mesure’ ont été changées pour les ‘règles’ et pour couvrir les règles d’obtention de la taille d’un morceau de logiciel en ajoutant la taille de ses composants. Le MM v2.2 réfère à de telles règles seulement dans le contexte du ‘point de vue de la mesure du développeur’. Cette restriction a été supprimée.
-- 4.4 Une nouvelle section sur la ‘ mesure de la taille des changements du logiciel’ et de nouvelles règles ont été ajoutées.
5.1 5.1 Les règles d’étiquetage des résultats de la mesure ont été modifiées en vue de reconnaître le changement d’unité ‘Cfsu’ en ‘CFP’.
5.2 5.2 Les règles sur ‘le rapportage de la mesure’ ont été étendues de façon à présenter plus d’items.
Ann. B Ann. B Mise-à-jour des principes de MM v3.0
Ann. C Ann. C Mise-à-jour des règles de MM v3.0
De la version 3.0 à la version 3.0.1
Les modifications les plus importantes entre les versions 3.0 et 3.0.1 concerne surtout la manière dont sont présentées les artéfacts COSMIC. Elles sont surtout évolutives : certain termes, définitions, principes et règles ont été reformulés pour davantage de clarté. Une exception toutefois est à soulever : une modification corrective a aussi été amenée. La majorité de ces
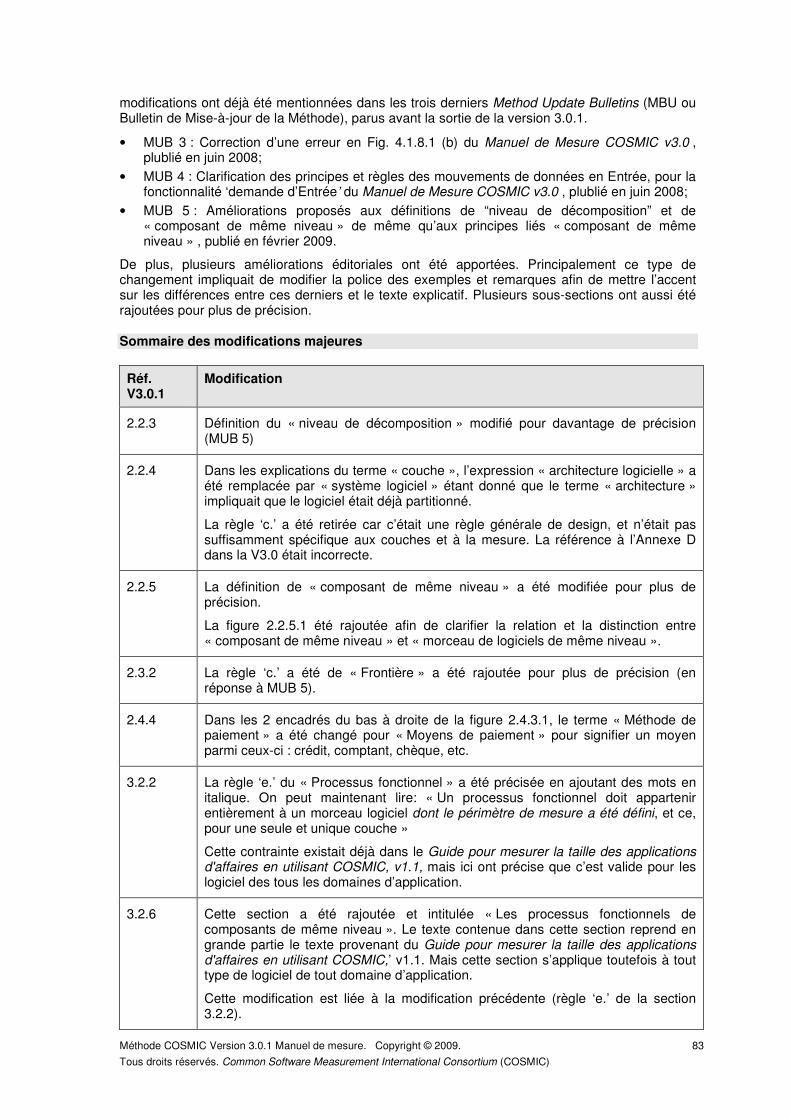
Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 83
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
modifications ont déjà été mentionnées dans les trois derniers Method Update Bulletins (MBU ou Bulletin de Mise-à-jour de la Méthode), parus avant la sortie de la version 3.0.1.
• MUB 3 : Correction d’une erreur en Fig. 4.1.8.1 (b) du Manuel de Mesure COSMIC v3.0 , plublié en juin 2008;
• MUB 4 : Clarification des principes et règles des mouvements de données en Entrée, pour la fonctionnalité ‘demande d’Entrée’ du Manuel de Mesure COSMIC v3.0 , plublié en juin 2008;
• MUB 5 : Améliorations proposés aux définitions de “niveau de décomposition” et de « composant de même niveau » de même qu’aux principes liés « composant de même niveau » , publié en février 2009.
De plus, plusieurs améliorations éditoriales ont été apportées. Principalement ce type de changement impliquait de modifier la police des exemples et remarques afin de mettre l’accent sur les différences entre ces derniers et le texte explicatif. Plusieurs sous-sections ont aussi été rajoutées pour plus de précision.
Sommaire des modifications majeures
Réf. V3.0.1
Modification
2.2.3 Définition du « niveau de décomposition » modifié pour davantage de précision (MUB 5)
2.2.4 Dans les explications du terme « couche », l’expression « architecture logicielle » a été remplacée par « système logiciel » étant donné que le terme « architecture » impliquait que le logiciel était déjà partitionné.
La règle ‘c.’ a été retirée car c’était une règle générale de design, et n’était pas suffisamment spécifique aux couches et à la mesure. La référence à l’Annexe D dans la V3.0 était incorrecte.
2.2.5 La définition de « composant de même niveau » a été modifiée pour plus de précision.
La figure 2.2.5.1 été rajoutée afin de clarifier la relation et la distinction entre « composant de même niveau » et « morceau de logiciels de même niveau ».
2.3.2 La règle ‘c.’ a été de « Frontière » a été rajoutée pour plus de précision (en réponse à MUB 5).
2.4.4 Dans les 2 encadrés du bas à droite de la figure 2.4.3.1, le terme « Méthode de paiement » a été changé pour « Moyens de paiement » pour signifier un moyen parmi ceux-ci : crédit, comptant, chèque, etc.
3.2.2 La règle ‘e.’ du « Processus fonctionnel » a été précisée en ajoutant des mots en italique. On peut maintenant lire: « Un processus fonctionnel doit appartenir entièrement à un morceau logiciel dont le périmètre de mesure a été défini, et ce, pour une seule et unique couche »
Cette contrainte existait déjà dans le Guide pour mesurer la taille des applications d'affaires en utilisant COSMIC, v1.1, mais ici ont précise que c’est valide pour les logiciel des tous les domaines d’application.
3.2.6 Cette section a été rajoutée et intitulée « Les processus fonctionnels de composants de même niveau ». Le texte contenue dans cette section reprend en grande partie le texte provenant du Guide pour mesurer la taille des applications d'affaires en utilisant COSMIC,’ v1.1. Mais cette section s’applique toutefois à tout type de logiciel de tout domaine d’application.
Cette modification est liée à la modification précédente (règle ‘e.’ de la section 3.2.2).

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 84
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
Réf. V3.0.1
Modification
4.1.2 Le principe ‘c.’ d’une « Entrée » a été modifié pour prendre en compte la fonctionnalité de ‘demande d’Entrée’ (MUB 4).
4.1.7 La première phrase de cette section « Unicité des mouvements de données et exceptions possibles » a été modifié pour davantage de clarté et pour être en accord avec le règle ‘a.’ de l’« Unicité des mouvements de données et exceptions possibles »
L’EXEMPLE 2 a aussi été modifié considérablement.
4.1.8 La figure 4.1.8.1 (b) a été modifiée pour corriger une erreur concernant l’interaction entre le logiciel de pilote périphérique et le matériel lui-même.
4.1.9 Les règles de « Lorsqu’un processus fonctionnel demande des données à un utilisateur fonctionnel » de même que les exemples qui y sont associés ont été modifiés pour davantage de clarté. (MUB 4)

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 85
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
AANNNNEEXXEE EE.. ANNEXE E - DEMANDE DE CHANGEMENTS ET COMMENTAIRES : PROCÉDURE.
Le comité des pratiques de la mesure COSMIC est très ouvert à recevoir des commentaires et suggestions et si nécessaire, des demandes de changement à la méthode COSMIC. Cette annexe établit la procédure de communication avec le comité des pratiques de la mesure COSMIC.
Toutes les communications avec ce comité des pratiques de la mesure COSMIC doivent être faites par courriel à cette adresse :
Remarques informelles générales et commentaires
Tous commentaires informels, remarques ou réactions à propos de la documentation de COSMIC, doivent être envoyés par courriel à la même adresse courriel, telle que mentionnée ci-dessus. Les commentaires peuvent être de tout type, tels que des difficultés compréhension du texte ou des difficultés d’application de la méthode COSMIC, de même que des suggestions d’améliorations générales, etc. sont les bienvenues. Les messages seront conservés et un accusé de réception sera envoyé dans les deux semaines suivant la réception du message. Le comité ne peut cependant pas garantir que des actions seront entreprises concernant des commentaires généraux.
Demandes formelles de changement
Lorsqu’un lecteur de la documentation COSMIC détecte une erreur dans le texte ou que le texte semble avoir besoin de clarifications ou encore d’amélioration, une demande formelle de changement peut être soumise.
Les demandes formelles de changement sont conservées et un accusé de réception est envoyé au demandeur dans un délai de deux semaines suivant la réception du message. Un numéro séquentiel est alloué à chaque demande de changement et la demande est communiquée à un groupe d’experts répartis à travers le monde, soit aux membres du comité des pratiques de la mesure COSMIC. Le cycle de révision normal peut prendre un mois au minimum, mais ce délai peut être plus long lorsque le comité fait face à des demandes de changement qui présentent des défis important quant à la solution à apporter.
Le résultat ou la solution trouvée suite au processus de révision peut être de nature diverse. Le comité peut décider d’accepter, de refuser ou mettre en suspend la décision finale pour en discuter davantage (par exemple, dans le cas où il y aurait une dépendance par rapport à une autre demande de changement). Le résultat est communiqué dès que possible au demandeur.
Une demande formelle de changement n’est acceptée que si elle est accompagnée des informations suivantes :
• Nom, titre et organisation de la personne soumettant la demande de changement ; • Les coordonnées nécessaires pour communiquer avec la personne soumettant la demande
de changement ; • Date de la soumission de la demande de changement ; • Déclaration générale de la raison d’être de la demande de changement (i.e. « nécessité
d’améliorer le texte … »); • Le texte actuel qui a besoin d’être changé, remplacé ou enlevé (ou une référence à ce texte) : • Le texte de remplacement ou le texte additionnel proposé : • Une description détaillée expliquant pourquoi le changement est nécessaire ;

Méthode COSMIC Version 3.0.1 Manuel de mesure. Copyright © 2009. 86
Tous droits réservés. Common Software Measurement International Consortium (COSMIC)
Il est nécessaire de saisir le formulaire de « demande de changement » pour soumettre une demande. Celui-ci est disponible à cette adresse : www.cosmicon.com
La décision du comité des pratiques de la mesure COSMIC suivant le processus de révision de la demande, de même que la version du texte COSMIC à laquelle ce changement s’applique, sont définitives.
Questions sur l’application de la méthode COSMIC
Le comité des pratiques de la mesure COSMIC regrette de ne pouvoir répondre directement aux questions portant l’utilisation ou l’application de la méthode de mesure COSMIC. Plusieurs organisations de nature commerciales œuvre dans la formation et le support (certaines proposent parfois des outils) de la méthode COSMIC. Il est possible d’obtenir plus de détails sur ces organisations à cette adresse : www.cosmicon.com.
Commentaires pour la version française : contacter Jean-Marc Desharnais à l’adresse courriel suivante : [email protected].
























![Mesure et instruments de mesure (1960) [Dunod].pdf](https://img.pdfslide.fr/doc/110x75/577cd1601a28ab9e789449c9/mesure-et-instruments-de-mesure-1960-dunodpdf.jpg)




