Embed Size (px)
Citation preview

Initiation à la propagation des incertitudes
Pascal [email protected]
Laboratoire de Chimie Physique, OrsayRéseau National �Mesures, Modèles et Incertitudes�
April 2, 2013
P. Pernot () Propagation des incertitudes April 2, 2013 1 / 81

Mesures et incertitudes
Mesurer, c'est comparer une grandeur physique inconnue avec une grandeur demême nature prise comme référence, à l'aide d'une chaîne instrumentalecomportant un ou plusieurs capteurs.
C'est exprimer le résultat de cette comparaison à l'aide d'une valeur numérique,associée à une unité qui rappelle la nature de la référence, et assortie d'uneincertitude qui dépend à la fois des qualités de l'expérience e�ectuée, des outilsemployés et de la connaissance qu'on a de la référence et de ses conditionsd'utilisation.
M. Himbert (1993) Bulletin du Bureau National de Métrologie 93:1.
P. Pernot () Propagation des incertitudes April 2, 2013 2 / 81

L'incertitude, a quoi bon ?
Comparer un résultat à une limite ou à une consigne
Consigne Resultat
Comparer deux résultats
Resultat 1 Resultat 2
Quanti�er la �délité de mesure
Resultat
P. Pernot () Propagation des incertitudes April 2, 2013 3 / 81

La démarche �incertitudes�
Etape préliminaire 1. Dé�nition du mesurande
Etape préliminaire 2. Analyse du processus de mesure(Deux étapes �métier� nécessaires
à la désambiguation du mesurande)
Phase 1. Description du processus et calcul du mesurande
Phase 2. Phase "métrologique" - contribution des données d'entrée
Phase 3. Propagation des incertitudes (Comb. Var. ou Monte Carlo)
Phase 4. Analyse de sensibilité, hiérarchisation des contributions
Phase 5. Incertitude élargie - Présentation du résultat
P. Pernot () Propagation des incertitudes April 2, 2013 4 / 81

Etapes préliminaires - Exemple
Mesurer la surface de votre table...
P. Pernot () Propagation des incertitudes April 2, 2013 5 / 81

Incertitude et probabilité
Quanti�cation de l'incertitude (P-S. Laplace, ca. 1800)
on peut attribuer un �degré de con�ance� p(X = x)à chaque valeur possible x d'une quantité incertaine X
cohérence et normalisation ⇒p(X = x) obéit auxrègles de la théorie des probabilités
Cette démarche est adoptée dans le GUM (3.3.1)
l'incertitude de mesure re�ète le manque de connaissancesur la valeur exacte du mesurande.l'état des connaissance correspondant est décrit au mieux parune distribution sur l'ensemble des valeurs possibles du mesurande.
P. Pernot () Propagation des incertitudes April 2, 2013 6 / 81

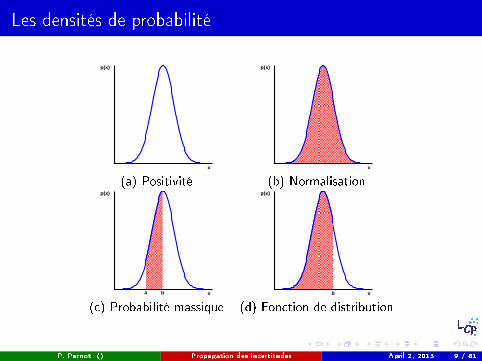
Les densités de probabilité
Si dx est un nombre réel positif in�niment petit, alors la probabilité que la valeurde la variable X soit incluse dans l'intervalle [x , x + dx ] est égale à p(x)dx , soit
P (x < X < x + dx) = p (x) dx
Pour une variable continue prenant ses valeurs dans l'intervalle [xmin, xmax ], ladensité de probabilité p(x) véri�e les propriétés suivantes :
positivitép(x) ≥ 0
normalisation à l'unité � xmax
xmin
dx p(x) = 1
P. Pernot () Propagation des incertitudes April 2, 2013 7 / 81

Les densités de probabilité
Quelques rappels:
probabilité (massique) pour que X se trouve dans un intervalle [a, b]
P(a ≤ X ≤ b) =
� b
a
dx p(x)
valeur moyenne
x = E(X ) =
� xmax
xmin
dx x p(x)
variance
σ2X =
� xmax
xmin
dx (x − x)2 p(x)
entropie de Shannon
H(p) = −� xmax
xmin
p(x) ln p(x) dx
P. Pernot () Propagation des incertitudes April 2, 2013 8 / 81
Les densités de probabilité
x
p(x)
x
p(x)
(a) Positivité (b) Normalisation
x
p(x)
a b x
p(x)
b
(c) Probabilité massique (d) Fonction de distribution
P. Pernot () Propagation des incertitudes April 2, 2013 9 / 81

Représenter un jeu d'informations par une pdfApproche statistique
Lorsqu'on dispose d'un échantillon représentatif de la variable X , on a plusieurssolutions pour dé�nir une densité de probabilité:
approche directe: construction d'une densité de probabilité approchée à partirde l'échantillon (nécessite un grand nombre de points):
histogrammesméthode des noyaux
approche inverse: inférer la densité de probabilité (en général supposéesimple) ayant permis de générer l'échantillon.
Remarque anticipée: pour la mise en oeuvre de la méthode de propagation desdistributions par Monte-Carlo, l'essentiel est de disposer d'un moyen numériquepour générer des échantillons représentatifs (il n'est pas nécessaire d'établir uneexpression analytique de la densité de probabilité).
P. Pernot () Propagation des incertitudes April 2, 2013 10 / 81

Approche statistique
-3 -2 -1 0 1 2 3
0.0
0.1
0.2
0.3
0.4
0.5
X
Den
sity
density(X)
Inferred Gaussian
True pdf
P. Pernot () Propagation des incertitudes April 2, 2013 11 / 81

Dé�nir une pdf à partir des informations disponiblesApproche informationnelle
Si on ne dispose que d'informations partielles (p. ex. une valeur moyenne et unécart type), il existe une in�nité de densités de probabilité pouvant les reproduire.
Le Principe du Maximum d'Entropie (Maxent) spéci�e que parmi toute cesdistributions, on doit retenir celle qui maximise l'entropie de Shannon
H(p) = −�
p(x) ln p(x) dx
avec les contraintes imposées par les informations disponibles. C'est la distributionla moins informative (celle qui minimise l'information statistique), compte tenudes contraintes.
Rq: la mise en oeuvre (analytique ou numérique) est hors du propos de laformation, mais nous mentionnerons ce principe à plusieurs occasions.
P. Pernot () Propagation des incertitudes April 2, 2013 12 / 81

Dé�nir une pdf à partir des informations disponiblesDocuments de référence
E.T. Jaynes (1957) Information theory and statistical mechanics. PhysicalReview 106:620�630.http://bayes.wustl.edu/etj/articles/theory.1.pdf
Le père fondateur...
S.Y. Park and A.K. Bera (2009). Maximum entropy autoregressiveconditional heteroskedasticity model. Journal of Econometrics 150:219�230.http://www.wise.xmu.edu.cn/UploadFiles/paper-masterdownload/
2009519932327055475115776.pdf
Contient une table pratique des densités d'entropie maximale les plus utiles.
sans oublier Wikipedia...
P. Pernot () Propagation des incertitudes April 2, 2013 13 / 81

Exemples
P. Pernot () Propagation des incertitudes April 2, 2013 14 / 81
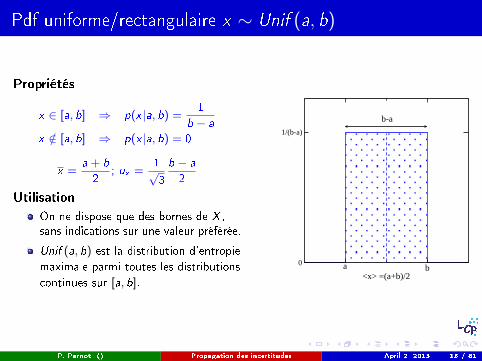
Pdf uniforme/rectangulaire x ∼ Unif (a, b)
Propriétés
x ∈ [a, b] ⇒ p(x |a, b) =1
b − a
x /∈ [a, b] ⇒ p(x |a, b) = 0
x =a + b
2; ux =
1√3
b − a
2
UtilisationOn ne dispose que des bornes de X ,sans indications sur une valeur préférée.
Unif (a, b) est la distribution d'entropie
maximale parmi toutes les distributions
continues sur [a, b].
a b<x> =(a+b)/2
0
1/(b-a)
b-a
P. Pernot () Propagation des incertitudes April 2, 2013 15 / 81
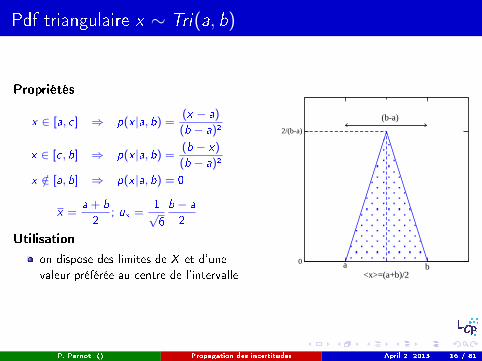
Pdf triangulaire x ∼ Tri(a, b)
Propriétés
x ∈ [a, c] ⇒ p(x |a, b) =(x − a)
(b − a)2
x ∈ [c, b] ⇒ p(x |a, b) =(b − x)
(b − a)2
x /∈ [a, b] ⇒ p(x |a, b) = 0
x =a + b
2; ux =
1√6
b − a
2
Utilisation
on dispose des limites de X et d'une
valeur préférée au centre de l'intervallea b
<x>=(a+b)/2
0
2/(b-a)
(b-a)
P. Pernot () Propagation des incertitudes April 2, 2013 16 / 81

Pdf triangulaire x ∼ Tri(a, b, c)
Propriétés
x ∈ [a, c] ⇒ p(x |a, b, c) =2(x − a)
(b − a)(c − a)
x ∈ [c, b] ⇒ p(x |a, b, c) =2(b − x)
(b − a)(b − c)
x /∈ [a, b] ⇒ p(x |a, b, c) = 0
x =a + b + c
3; ux =
√a2 + b2 + c2 − ab − ac − bc
3√2
Utilisation
on dispose des limites de X et d'une
valeur préféréea c b
<x>=(a+b+c)/3
0
2/(b-a)
P. Pernot () Propagation des incertitudes April 2, 2013 17 / 81
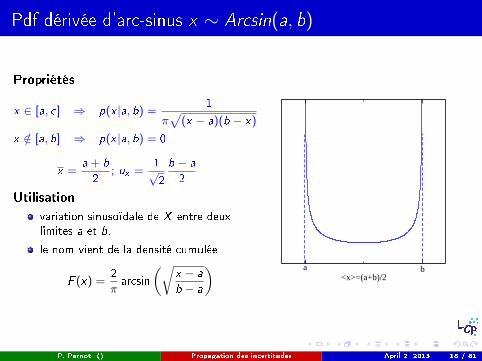
Pdf dérivée d'arc-sinus x ∼ Arcsin(a, b)
Propriétés
x ∈ [a, c] ⇒ p(x |a, b) =1
πp
(x − a)(b − x)
x /∈ [a, b] ⇒ p(x |a, b) = 0
x =a + b
2; ux =
1√2
b − a
2
Utilisationvariation sinusoïdale de X entre deuxlimites a et b.
le nom vient de la densité cumulée
F (x) =2
πarcsin
„rx − a
b − a
« a b<x>=(a+b)/2
P. Pernot () Propagation des incertitudes April 2, 2013 18 / 81
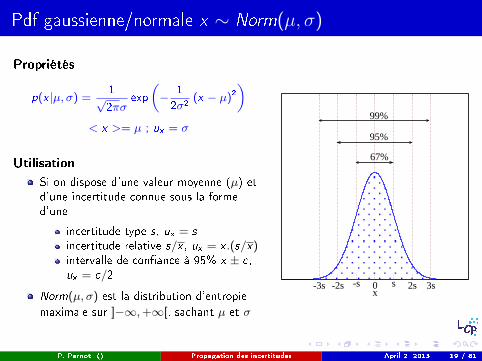
Pdf gaussienne/normale x ∼ Norm(µ, σ)
Propriétés
p(x |µ, σ) =1√2πσ
exp
„− 1
2σ2(x − µ)2
«< x >= µ ; ux = σ
UtilisationSi on dispose d'une valeur moyenne (µ) etd'une incertitude connue sous la formed'une
incertitude type s, ux = s
incertitude relative s/x , ux = x .(s/x)intervalle de con�ance à 95% x ± c,ux = c/2
Norm(µ, σ) est la distribution d'entropie
maximale sur ]−∞,+∞[, sachant µ et σ
-2s -s 0 s 2s-3s 3sx
67%
95%
99%
P. Pernot () Propagation des incertitudes April 2, 2013 19 / 81

Densités de probabilité multivariées
Lorsqu'on a plusieurs variables dépendantes, elles sont en général décrites à l'aidede leurs valeurs moyennes et d'une matrice de variance-covariance. Dans ce cas, ladensité de probabilité utilisée est la distribution normale multivariée, p. ex.
p(x , y |µX1 , µX2 ,Σ) ∝ (detΣ)−1/2 exp
(−12ETΣ−1E
)
E =
(x1 − µX1
x2 − µX2
); Σ =
(σ2X1
σ2X1X2
σ2X2X1σ2X2
)= STRS
S =
(σX1
σX2
); R =
(1 ρρ 1
)
Σ est la matrice de variance-covariance
R est la matrice de corrélation
P. Pernot () Propagation des incertitudes April 2, 2013 20 / 81

Densités de probabilité multivariées
-25 -24 -23 -22 -21 -20ln A
0
200
400
600
800
1000
E /
K
Nuages de points correspondant à des distributions normales bivariées:(a) cyan : variables non corrélées ;
(b) marron : variables fortement corrélées.
P. Pernot () Propagation des incertitudes April 2, 2013 21 / 81

Variables incertaines avec contraintes
Introduire le maximum de contraintes pertinentesdans la représentation des variables incertaines
Cas des lois de conservation
N variables telles quePN
i=1Xi = 1 et {Xi ≥ 0; i = 1,N},
on utilise la distribution de Dirichlet (Maxent)
{X1, . . . ,XN} ∼ Diri (γ ∗ (µ1, . . . , µN))
où γ > 0 est un facteur de précision (la précision augmente avec γ)
exemples: composition chimique, rapports de branchement...
mots-clés pour la littérature: Compositional Data Analysis
P. Pernot () Propagation des incertitudes April 2, 2013 22 / 81

Distribution de Dirichlet
P. Pernot () Propagation des incertitudes April 2, 2013 23 / 81
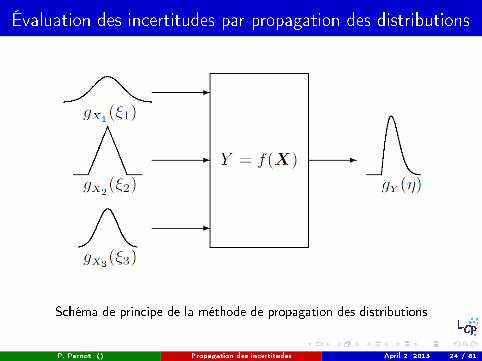
Évaluation des incertitudes par propagation des distributions
Schéma de principe de la méthode de propagation des distributions
P. Pernot () Propagation des incertitudes April 2, 2013 24 / 81

Théorie probabiliste de la propagation des incertitudes
(1) Formulation1 identi�cation des variables d'entrée incertaines X = {X1, ...,Xk}
2 dé�nition du modèle Y = f (X)
3 dé�nition de la densité de probabilité jointe des variables d'entréegX1,...,Xk
(ξ1, . . . , ξk)
(2) Propagation des distributions (Équation de Markov)1
gY (η) =
�dξ1 . . . dξk δ (η − f (ξ1, . . . , ξk)) gX1,...,Xk
(ξ1, . . . , ξk)
1Interprétation: on prend tous les points dans l'espace des ξξξ dont l'image par F vaut η, et onsomme leurs poids donnés par gX (ξξξ). La discrétisation de cette intégrale nous donne une recettepour bâtir un histogramme représentatif de gY .
P. Pernot () Propagation des incertitudes April 2, 2013 25 / 81

Théorie probabiliste de la propagation des incertitudes
(1) Formulation1 identi�cation des variables d'entrée incertaines X = {X1, ...,Xk}
2 dé�nition du modèle Y = f (X)
3 dé�nition de la densité de probabilité jointe des variables d'entréegX1,...,Xk
(ξ1, . . . , ξk)
(2) Propagation des distributions (Équation de Markov)1
gY (η) =
�dξ1 . . . dξk δ (η − f (ξ1, . . . , ξk)) gX1,...,Xk
(ξ1, . . . , ξk)
1Interprétation: on prend tous les points dans l'espace des ξξξ dont l'image par F vaut η, et onsomme leurs poids donnés par gX (ξξξ). La discrétisation de cette intégrale nous donne une recettepour bâtir un histogramme représentatif de gY .
P. Pernot () Propagation des incertitudes April 2, 2013 25 / 81

Évaluation des incertitudes par propagation des distributions
(3) Résumés statistiques de gY (η)
1 espérance statistique de Y et son écart type
E(Y ) =
� ∞−∞
dη η gY (η)
u(y) =pV (Y ) ; V (Y ) =
� ∞−∞
dη (η − E(Y ))2 gY (η)
2 et/ou intervalle de couverture 100p%, contenant Y avec une probabilité p
spéci�ée ˆG−1Y (α) ; G−1Y (p + α)
˜; 0 ≤ α ≤ 1− p
où GY (η) est la fonction de distribution de Y
GY (η) =
� η
−∞dz gY (z).
P. Pernot () Propagation des incertitudes April 2, 2013 26 / 81

Relation entre les résumés statistiques de gY et le GUM
Pour obtenir des statistiques de Y , il n'est pas nécessaire de calculer explicitementgY . Ainsi, pour l'espérance statistique, on a
E (Y ) =
� ∞−∞
dη η gY (η)
=
�dη η
�dξξξ δ (η − f (ξξξ)) gX (ξξξ)
=
�dξξξ
�dη η δ (η − f (ξξξ)) gX (ξξξ)
=
�dξξξ f (ξξξ) gX (ξξξ)
où on applique la relation de translation de la distribution δ de Dirac:
� +∞
−∞dx f (x) δ (x0 − x) = f (x0)
.
P. Pernot () Propagation des incertitudes April 2, 2013 27 / 81

Relation entre les résumés statistiques de gY et le GUM
Pour la variance, on applique le même type de développement:
V (Y ) =
� ∞−∞
dη (η − E (Y ))2 gY (η)
=
�dη (η − E (Y ))2
�dξξξ δ (η − f (ξξξ)) gX (ξξξ)
=
�dξξξ
�dη (η − E (Y ))2 δ (η − f (ξξξ)) gX (ξξξ)
=
�dξξξ (f (ξξξ)− E (Y ))2 gX (ξξξ)
On est donc ramené à des intégrales (multiples) sur les variables incertainesdu modèle.
P. Pernot () Propagation des incertitudes April 2, 2013 28 / 81

Le cas des modèles linéaires
Si on considère un modèle linéaire, ou bien le développement en série de Taylor aupremier ordre d'un modèle quelconque autour d'un point xxx0, on peut écrire
f (ξξξ) = f (xxx0) + JJJT .(ξξξ − xxx0) (1)
où les coe�cients de sensibilité Ji sont donnés par les dérivées premières dumodèle au point xxx0
Ji =∂f (ξξξ)
∂ξi
∣∣∣∣ξξξ=xxx0
d'où
E (Y ) =
�dξξξ[F (xxx0) + JJJT .(ξξξ − xxx0)
]gX (ξξξ)
= F (xxx0)
�dξξξ gX (ξξξ) +
∑i
Ji
�dξξξ (ξi − x0,i ) gX (ξξξ)
= F (xxx0) +∑i
Ji (E (Xi )− x0,i )
Si on choisit xxx0 = E (XXX ), on a E (Y ) = f (E (X)).P. Pernot () Propagation des incertitudes April 2, 2013 29 / 81

Le cas des modèles linéaires
Dans cette hypothèse, on peut dériver la variance
V (Y ) =
�dξξξ[f (E (X)) + JJJT .(ξξξ − E (X))− f (E (X))
]2gX (ξξξ)
=
�dξξξ[JJJT .(ξξξ − E (X))
]2gX (ξξξ)
=∑i,k
JiJk
�dξξξ (ξi − E (Xi )) (ξk − E (Xk)) gX (ξξξ)
=∑i,k
Ji u(Xi ,Xk) Jj
= JJJT .Σ.JJJ
où Σ est la matrice de variance-covariance des variables d'entrée, telle queΣi,j = u(Xi ,Xj).
Ce résultat est la notation matricielle de l'équation de combinaison des variances.
P. Pernot () Propagation des incertitudes April 2, 2013 30 / 81

Évaluation des incertitudes par propagation des distributions
Approximation linéaire de la propagation des incertitudes (modèle à 1 variable).From K.O. Arras (1998) An Introduction To Error Propagation.
Technical report Nº EPFL-ASL-TR-98-01 R3, EPF Lausanne.
P. Pernot () Propagation des incertitudes April 2, 2013 31 / 81

La méthode GUM de combinaison des variances
Procédure normalisée pour gérer les incertitudes associées à une mesure(Évaluation des données de mesure � Guide pour l'expression de l'incertitude demesure. JCGM 100:2008,http://www.bipm.org/utils/common/documents/jcgm/JCGM_100_2008_F.pdf).
1 Identi�er les sources d'incertitudeÉvaluation de l'ensemble des sources d'incertitudes a�ectant une mesure
2 Caractériser les incertitudesLes incertitudes sont de deux types :
1 Type A : incertitudes obtenues par analyse statistique d'un ensemble demesurages répétés d'un même mesurande
2 Type B : tout le reste
3 Estimer les incertitudes-type4 Propager/combiner les incertitudes
Estimation de l'incertitude sur le résultat de la mesure à partir des sourcesidenti�ées
P. Pernot () Propagation des incertitudes April 2, 2013 32 / 81
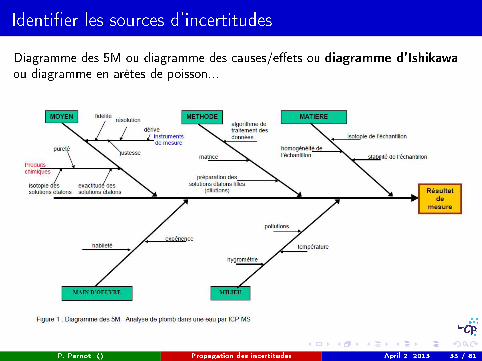
Identi�er les sources d'incertitudes
Diagramme des 5M ou diagramme des causes/e�ets ou diagramme d'Ishikawaou diagramme en arêtes de poisson...
P. Pernot () Propagation des incertitudes April 2, 2013 33 / 81

Modèle de mesure
Mesure directeX = x + C
X : valeur du mesurandex : indication(valeur mesurée)C : corrections (justesse, quanti�cation...)
Propriétés dérivéesY = f (X1, ...,Xk)
P. Pernot () Propagation des incertitudes April 2, 2013 34 / 81

Incertitudes de type A
La caractérisation d'un échantillon de mesures se fait par un ensemble de résumésstatistiques. Typiquement une valeur moyenne et une incertitude-type :
Valeur moyenne
x =
(N∑i=1
xi
)/n
Variance
s2X =n∑i=1
(xi − x)2/(n − 1)
Incertitude-type sur xuX = sX/
√n
Rq: ces estimateurs, notamment l'incertitude-type, ne sont pertinents que si ladistribution des erreurs est raisonnablement symétrique. Une étape préalabled'Analyse Exploratoire des Données est donc toujours judicieuse.
P. Pernot () Propagation des incertitudes April 2, 2013 35 / 81

Incertitude sur l'incertitude
Comment l'estimation de la variance dépend de la taille de l'échantillon
s2X =∑n
i=1(xi − x)2/(n − 1) est un estimateur de la variance de X , σ2X
on veut estimer l'erreur relative sur l'écart type: r = usX /sx
si X suit une loi normale, la variable (n − 1)s2X/σ2
X suit une loi du χ2 à(n − 1) degrés de liberté, dont on tire
r ' 1/√2(n − 1)
n 2 5 10 50 100 5000r = usX /sx 0.70 0.35 0.24 0.10 0.07 0.01
P. Pernot () Propagation des incertitudes April 2, 2013 36 / 81

Incertitudes de type B
En absence de mesurages répétés, on est en général contraint d'utiliser desinformations collectées sous des formes diverses, tirées de di�érentes sources :
notice des instruments
certi�cats de calibration
limitations d'a�chage...
Le problème est ici de dé�nir une incertitude-type à partir de ces informationssouvent partielles.
La technique recommandée est de dé�nir une densité de probabilité pourreprésenter la distribution plausible des erreurs, et d'utiliser l'incertitude-typecorrespondant à cette densité.
P. Pernot () Propagation des incertitudes April 2, 2013 37 / 81

Exemple: erreur de justesse du mètre à ruban
la précision des mètres ruban est normalisée: la classe de précision(I, II ou III) est indiquée sur le ruban.
les erreurs maximales tolérées sont dé�nies par EMT = ±(a + c + bL) mm
L est la longueur mesurée arrondie en excès au nombre entier de mètresa, b et c sont dé�nis pour chaque classe de précision (c 6= 0 est pris encompte lorsque le mètre se termine par un crochet, et qu'on l'utilise...)
Classe a b c
I 0.1 0.1 0.1II 0.2 0.3 0.2III 0.6 0.4 0.3
Ex: longueur mesurée L = 1 652mm avec un mètre de classe II + crochet
EMT = ±1.0 mm (0.2 + 0.2 + 0.3*2)représentation par une distribution uniforme Unif (−1, 1) mml'erreur de justesse est donc caractérisée par une correction nulle Cj = 0 et uneincertitude type sur la correction uCj = 1√
3
2
2= 0.58 mm
P. Pernot () Propagation des incertitudes April 2, 2013 38 / 81

Combinaison des variances
Pour obtenir l'incertitude combinée, on applique les formues suivantes
y = f (x1, ..., xk)
u2Y =∑i
(∂Y∂Xi
)2
xi
u2Xi+∑i 6=j
(∂Y∂Xi
)xi
(∂Y∂Xj
)xj
cov(Xi ,Xj)
= JTΣJ
P. Pernot () Propagation des incertitudes April 2, 2013 39 / 81

Exemple: surface de la table
Modèle S = LA × LB
Mesure d'une longueur avec le mètre à ruban
on e�ectue 5 mesures réparties uniformément sur un côtéLx,i = lx,i + Cq,i + Cj + CT
Cq : correction de l'erreur de quanti�cation (lecture)Cj : correction de l'erreur de justesse pour la longueur mesuréeCT = Lnomα∆T : correction de température due à la dilatation éventuelle dumètre.
Lx =1
5
5Xi=1
(lx,i + Cq,i ) + Cj + Lx,nomα∆T
u2(Lx) = u2(lx) +1
5u2(Cq) + u2(Cj ) +
L2x,nom`α2u2(∆T ) + ∆T 2u2(α)
´P. Pernot () Propagation des incertitudes April 2, 2013 40 / 81
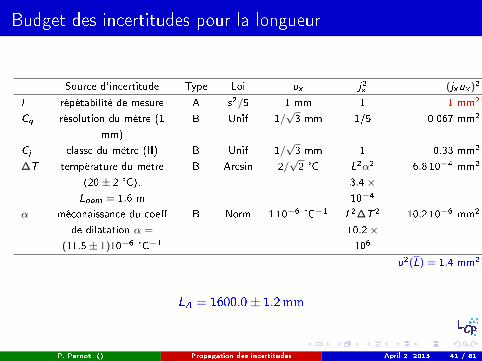
Budget des incertitudes pour la longueur
Source d'incertitude Type Loi ux j2x (jxux )2
l répétabilité de mesure A s2/5 1 mm 1 1 mm2
Cq résolution du mètre (1
mm)
B Unif 1/√3 mm 1/5 0.067 mm2
Cj classe du mètre (II) B Unif 1/√3 mm 1 0.33 mm2
∆T température du mètre
(20± 2 °C),
Lnom = 1.6 m
B Arcsin 2/√2 °C L2α2
3.4×10−4
6.8 10−4 mm2
α méconaissance du coe�
de dilatation α =
(11.5± 1)10−6 °C−1
B Norm 1 10−6 °C−1 L2∆T 2
10.2×106
10.2 10−6 mm2
u2(L) = 1.4 mm2
LA = 1600.0± 1.2mm
P. Pernot () Propagation des incertitudes April 2, 2013 41 / 81
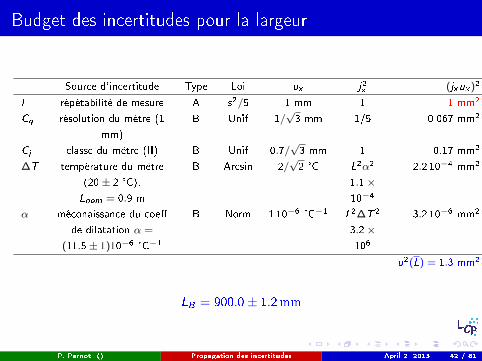
Budget des incertitudes pour la largeur
Source d'incertitude Type Loi ux j2x (jxux )2
l répétabilité de mesure A s2/5 1 mm 1 1 mm2
Cq résolution du mètre (1
mm)
B Unif 1/√3 mm 1/5 0.067 mm2
Cj classe du mètre (II) B Unif 0.7/√3 mm 1 0.17 mm2
∆T température du mètre
(20± 2 °C),
Lnom = 0.9 m
B Arcsin 2/√2 °C L2α2
1.1×10−4
2.2 10−4 mm2
α méconaissance du coe�
de dilatation α =
(11.5± 1)10−6 °C−1
B Norm 1 10−6 °C−1 L2∆T 2
3.2×106
3.2 10−6 mm2
u2(L) = 1.3 mm2
LB = 900.0± 1.2mm
P. Pernot () Propagation des incertitudes April 2, 2013 42 / 81
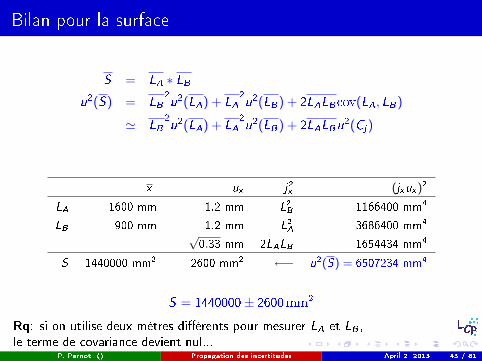
Bilan pour la surface
S = LA ∗ LBu2(S) = LB
2
u2(LA) + LA2
u2(LB) + 2LALBcov(LA, LB)
' LB2
u2(LA) + LA2
u2(LB) + 2LALBu2(Cj)
x ux j2x (jxux)2
LA 1600 mm 1.2 mm L2B 1166400 mm4
LB 900 mm 1.2 mm L2A 3686400 mm4
√0.33 mm 2LALB 1654434 mm4
S 1440000 mm2 2600 mm2 ←− u2(S) = 6507234 mm4
S = 1440000± 2600mm2
Rq: si on utilise deux mètres di�érents pour mesurer LA et LB ,le terme de covariance devient nul...
P. Pernot () Propagation des incertitudes April 2, 2013 43 / 81

Combinaison des variances vs. combinaison des incertitudes
Pourquoi on n'utilise pas une formule de la forme uY =∑
i
∣∣∣ ∂Y∂Xi
∣∣∣xi
uXipour
combiner des erreurs aléatoires ?
Théorème de la limite centrée : la somme de variables aléatoires indépendanteset de variance �nie converge vers une loi Normale.
Comme illustré ci-dessous, dès qu'on combine quelques variables aléatoires, unetendance centrale se dégage, et les valeurs extrêmes deviennent nonreprésentatives.
X1 X1 + X2 X1 + X2 + X3 X1 + . . .+ X6
Illustration du théorème de la limite centrée : addition de variables uniformes
Xi ∼ Unif (0, 1)
P. Pernot () Propagation des incertitudes April 2, 2013 44 / 81

Exemples - variables dépendantes
On s'intéresse ici à la di�érence de deux variables Y = X1 − X2. La formulestandard nous donne
uY =√
u2x1 + u2x2 − 2 ∗ cov(X1,X2)
avec cov(X1,X2) = uX1 ∗ uX2 ∗ corr(X1,X2).
Pour illustrer l'e�et de la corrélation supposons que les variables soient de mêmeécart-type (uX1 = uX2). Selon la valeur du coe�cient de corrélation, on obtientdes résultats très di�érents, allant du doublement de l'incertitude standard, à lacompensation totale des erreurs :
corr(X1,X2) -1 0 1uY 2 ∗ uX1
√2 ∗ uX1 0
P. Pernot () Propagation des incertitudes April 2, 2013 45 / 81

Exemples - variables dépendantes
On remarquera que, compte tenu des limites du coe�cient de corrélation, onvéri�e toujours
0 ≤ uY =√
u2X1+ u2X2
− 2 ∗ uX1 ∗ uX2 ∗ corr(X1,X2) ≤ uX1 + uX2
Plus généralement
0 ≤ uY ≤∑i
∣∣∣∣ ∂Y∂Xi
∣∣∣∣xi
uXi
La combinaison des incertitudes fournit donc seulement une limite supérieureabsolue à l'incertitude-type obtenue par la combinaison des variances, et non uneestimation de cet écart-type.
P. Pernot () Propagation des incertitudes April 2, 2013 46 / 81

La méthode GUM de propagation des distributionsDocuments de référence
Évaluation des données de mesure � Supplément 1 du �Guide pourl'expression de l'incertitude de mesure� � Propagation de distributions parune méthode de Monte Carlo. JCGM 101:2008.http://www.bipm.org/fr/publications/guides/gum.html
M. Désenfant, N. Fischer, B. Blanquart, N. Bédiat (2007). Évaluation del'incertitude en utilisant les simulations de Monte Carlo. Actes du 13èmeCongrès de Métrologie, Lille.http://www.lne.fr/publications/13e-congres-metrologie/actes/
117-desenfant-incertitude-simulations-monte-carlo.pdf
P. Pernot () Propagation des incertitudes April 2, 2013 47 / 81

Les limites du GUM - Linéarité
Hypothèse de linéarité
La formule de combinaison des variances du GUM est basée sur uneapproximation linéaire du modèle de la mesure au voisinage de la valeur moyennedes variables incertaines
E [f (X )] ' f [E (X )]
qui est valide tant que les écarts à la linéarité sont faibles devant les incertitudes.
Dans le cas de modèles linéaires, il n'y a aucune restriction de validité pour lecalcul des valeurs moyennes E (Y ) et incertitudes standard u(y).
P. Pernot () Propagation des incertitudes April 2, 2013 48 / 81

Les limites du GUM - Linéarité
Pour les modèles non-linéaires, des problèmes sont susceptibles de se produiredès que les incertitudes relatives des variables d'entrée dépassent 20-30 %. Onpeut alors avoir recours à des développements de Taylor du modèle à des ordressupérieurs, mais plusieurs points doivent alors être véri�és:
F doit être continûment dérivable jusqu'à un ordre approprié, en toutes lesvariables au voisinage de E (X);
les Xi impliqués dans des termes d'ordre supérieur du développement deTaylor de f (X) sont indépendantes et les pfds attribuées à ces variables sontnormales/gaussiennes;
les termes ignorés de la série de Taylor de f (X) sont négligeables.
P. Pernot () Propagation des incertitudes April 2, 2013 49 / 81

Les limites du GUM - Intervalles de con�ance
L'estimation des intervalles de con�ance préconisée par le GUM (multiplication del'incertitude standard par un facteur de couverture dépendant d'un nombre dedegrés de liberté) présente également des limites:
la connaissance du nombre de degrés de liberté pour chacune des sourcesd'incertitude (comment faire pour celles de Type B ?);
le facteur de couverture implique un intervalle de con�ance symétrique autourde la valeur estimée, hypothèse qui peut devenir invalide si les densités deprobabilité attachées aux variables d'entrée in�uentes ne sont pas symétriques(p.ex. à cause de contraintes de positivité)...
P. Pernot () Propagation des incertitudes April 2, 2013 50 / 81

Les réponses apportées par la propagation des distributions
La méthode de propagation des distributions permet de s'a�ranchir depratiquement toutes les restrictions liées à la formule de combinaison desvariances:
pas de restrictions sur la linéarité du modèle;
pas de restriction sur la forme des densités de probabilité;
calcul direct des intervalles de con�ance, même assymétriques...
Même si l'approche GUM reste valide dans une grande majorité de cas pratiques,la méthode de propagation des distributions peut aussi être un outil de validationpour la mise en place d'une démarche GUM pour un nouveau dispositif de mesure.
P. Pernot () Propagation des incertitudes April 2, 2013 51 / 81

Le cas des modèles complexes
Ces modèles font en général appel à un ensemble de paramètres qui proviennentde mesures expérimentales (p.ex. simulations mécaniques par éléments �nis,problèmes de chimie-transport...)
Il est primordial d'évaluer l'impact des incertitudes de ces paramètres sur laprécision des prédictions des modèles. Les situations où on a plusieurs centaines,voire milliers de paramètres à gérer ne sont pas rares. La démarche GUM présentaalors deux problèmes:
1 il est pratiquement impossible de déterminer à l'avance les paramètresin�uents; et
2 la formule de propagation des variances devient vite inadaptée si on n'a pasune expression analytique des coe�cients de sensibilité ou si les paramètresincertains sont susceptibles de mettre en évidence les non-linéarités dumodèle.
Dans ce type de situation la méthode de propagation des distributions est un outilprécieux qui doit être combiné avec une étape d'analyse de sensibilité permettantd'identi�er les paramètres in�uents et éventuellement de simpli�er le modèle.
P. Pernot () Propagation des incertitudes April 2, 2013 52 / 81

Principes de base
1 Formulation
1 identi�cation des variables d'entrée incertaines X = {X1, ...,Xk}2 dé�nition du modèle Y = f (X)3 dé�nition de la densité de probabilité jointe des variables d'entrée gX (ξξξ)
2 Propagation des distributions (Équation de Markov)
gY (η) =
�dξξξ δ (η − f (ξξξ)) gX (ξξξ)
3 Résumés statistiques de gY (η)
P. Pernot () Propagation des incertitudes April 2, 2013 53 / 81

L'approche Monte Carlo
on obtient directement les résumés statistiques sur Y à l'aide d'intégralesimpliquant F (X) et gX
le calcul de telles intégrales peut rarement être mené de manière analytique.On a donc recours à des méthodes numériques:
les méthodes d'intégration basées sur une discrétisation des variables d'entréesont ingérables dès qu'il y a plus de quelques variables: le nombre d'évaluationsdu modèle augmente comme une puissance du nombre de variables
l'intégration stochastique par la méthode de Monte Carlo ne présente pas cedésavantage.
P. Pernot () Propagation des incertitudes April 2, 2013 54 / 81

Approximation d'intégrales par Monte CarloPrincipe
la pdf gX (ξξξ) est remplacée par un échantillon représentatif{ξξξ(i); i = 1,N
}le calcul d'intégrale est remplacé par une moyenne arithmétique
�dξξξ F (ξξξ) gX (ξξξ) ' 1
N
N∑i=1
F(ξξξ(i))
point positif: la précision de l'intégrale calculée ne dépend pas du nombre dedimensions de l'espace des paramètre incertains.
Si lesnξξξ(i); i = 1,N
orésultent de tirages indépendants, l'incertitude sur la
valeur de l'intégrale évolue en N−1/2 (Théorème de la limite centrée).
P. Pernot () Propagation des incertitudes April 2, 2013 55 / 81

Application à la propagation des distributions
1 Dé�nir les densités de probabilité pour toutes les variables incertaines(type A et type B) gX (ξξξ)
2 Générer un échantillon représentatif de chacune des variables ou groupes devariables corrélées (à l'aide de générateurs de nombres aléatoires)
3 Calculer le résultat du modèle pour chaque point de l'échantillonη(i) = F (ξξξ(i)); i = 1,N
4 Produire les résumés statistiques adéquats: E (Y ), u(y) et intervalle decon�ance à 100p%
P. Pernot () Propagation des incertitudes April 2, 2013 56 / 81

Propagation des distributions par Monte CarloÉtape 1: génération d'un échantillon représentatif des entrées
gX (ξξξ)↓︷ ︸︸ ︷ f
ξ(1)1 ξ
(1)2 ... ξ
(1)n → η(1)
ξ(2)1 ξ
(2)2 ... ξ
(2)n → η(2)
......
......
ξ(m)1 ξ
(m)2 ... ξ
(m)n → η(m)
↓gY (η)
P. Pernot () Propagation des incertitudes April 2, 2013 57 / 81

Propagation des distributions par Monte CarloÉtape 2: application du modèle à chacun des points de l'échantillon
gX (ξξξ)↓︷ ︸︸ ︷ f
ξ(1)1 ξ
(1)2 ... ξ
(1)n → η(1)
ξ(2)1 ξ
(2)2 ... ξ
(2)n → η(2)
......
......
ξ(m)1 ξ
(m)2 ... ξ
(m)n → η(m)
↓gY (η)
P. Pernot () Propagation des incertitudes April 2, 2013 58 / 81

Propagation des distributions par Monte CarloÉtape 3: analyse statistique de l'échantillon des sorties du modèle
gX (ξξξ)↓︷ ︸︸ ︷ f
ξ(1)1 ξ
(1)2 ... ξ
(1)n → η(1)
ξ(2)1 ξ
(2)2 ... ξ
(2)n → η(2)
......
......
ξ(m)1 ξ
(m)2 ... ξ
(m)n → η(m)
↓gY (η)
P. Pernot () Propagation des incertitudes April 2, 2013 59 / 81

Limites sur la propagation des distribution par Monte Carlo
La seule condition pour pouvoir e�ectuer le calcul de propagation est que lafonction F doit être continue au voisinage de E (X).
Des restrictions plus sévères s'appliquent pour assurer la validité des résumésstatistiques:
pour pouvoir évaluer de manière univoque des intervalles de con�ance, il estnécessaire que la fonction de distribution GY soit continue et monotonementcroissantepour la détermination de l'intervalle de con�ance à 100p% le plus court, descontraintes s'appliquent sur la pdf gY : continuité, unimodalitéE (Y ) et V (Y ) doivent existerun nombre de tirages M su�sant doit être réalisé.
Le principe de la méthode de Monte Carlo est donc très simple et elle a un champd'application très large. Il nous laisse cependant avec deux problèmes techniques:
comment générer un échantillon représentatif d'une densité de probabilité ?combien de tirages sont nécessaires pour atteindre une précision spéci�ée surles résumés statistiques ?
P. Pernot () Propagation des incertitudes April 2, 2013 60 / 81

Générer des nombres aléatoires de distribution prescrite
Dispositifs capables de produire une séquence de nombres dont on ne peut pasfacilement tirer des propriétés déterministes:
Générateurs reposant sur des phénomènes imprévisibles: les dés, laroulette, le tirage au sort (loto et autres), les di�érentes méthodes de mélangedes cartes, le pile ou face... ( souvent biaisés ou insu�samment sûrs)
Générateurs reposant sur des phénomènes physiques: radioactivité ;bruits thermiques ; bruits électromagnétiques ; mécanique quantique (a prioriles meilleurs générateurs, mais ils ne sont pas faciles à mettre en place). Desséquences nombres aléatoires physiques sont téléchargeables à partird'internet : www.random.org, www.randomnumbers.info
Générateurs reposant sur des algorithmes
un algorithme est déterministe, à l'opposé de ce que l'on recherchecertaines opérations sont su�samment imprévisibles pour donner des résultatsqui semblent aléatoiresles nombres ainsi obtenus sont appelés pseudo-aléatoiresplus facile et plus e�cace à produire que par d'autres méthodes
P. Pernot () Propagation des incertitudes April 2, 2013 61 / 81

Générateurs de séquences de nombres aléatoires
tous les générateurs ne sont pas égaux entre eux
s'assurer avant tout que les générateurs aléatoires utilisés ont des propriétéssatisfaisantes pour:
la période de récurrence du générateurla corrélation séquentielle
des algorithmes sophistiqués combinant plusieurs générateurs (MersenneTwister, Wichmann-Hill...) sont aujourd'hui la norme. A condition d'êtrecorrectement programmés et paramétrés, ils fournissent des séquences avecdes périodes couvrant la majorité des besoins en propagation des distribution.
P. Pernot () Propagation des incertitudes April 2, 2013 62 / 81

E�cacité statistique
L'utilisation d'une chaîne de Markov, ou d'une dynamique fait que les pointssuccessifs de l'échantillon ne sont plus indépendants. Il faut alors estimerl'e�cacité statistique de l'échantillon:
1 estimer µ = x and σ2 = 1
N−1∑
(xi − x)2
2 calculer la fonction d'autocorrélation
A(l) =1
σ2 (N − l − 1)
N−l∑i=1
(xi − x)(xi+l − x); l ≥ 0
et estimer la longueur de corrélation τ (intégrale de A(l) ou ajustementmonoexponentiel A(l) = exp(−l/τ))
3 on obtient alors ρ = (1 + 2τ)−1, l'e�cacité statistique de la chaîne(0 < ρ < 1) et l'incertitude type sur l'estimation de la valeur moyenne est
µ = x ± σ√Nρ
.
Certains packages de R (coda) fournissent directement la taille e�ective Nρ del'échantillon et/ou l'incertitude type corrigée.
P. Pernot () Propagation des incertitudes April 2, 2013 63 / 81

Convergence des estimateurs
On n'est pas capable de prévoir le nombre de tirages nécessaires pour atteindreune précision prescrite sur tous les estimateurs d'une séquence aléatoire. Onutilise une approche adaptative: augmenter le nombre de tirages jusqu'à lastabilisation statistique des estimateurs.
0 2000 4000 6000 8000 10000
-0.10
-0.05
0.00
0.05
0.10
x
Deviationdes
estimateurs
cumulatifs
Moyenne
Limites exactes
Q05
P. Pernot () Propagation des incertitudes April 2, 2013 64 / 81

Méthode Monte Carlo adaptative
Cette procédure doit nous fournir pour une variable Y des valeurs véri�ant latolérance prédé�nie: l'espérance statistique y , l'incertitude standard u(y) et leslimites ylow et yhigh d'un intervalle de con�ance de couverture spéci�ée 100p %.
1 dé�nir ndig à une valeur appropriée (typiquement ndig = 1 ou 2)2 calculer le nombre de tirages élémentaire M = max(ceiling(100/(1− p)), 104)3 initialiser le compteur d'itération h = 14 calculer M tirages Monte Carlo de Y = f (X)
5 calculer les estimateurs pour ces M valeurs: y (h), u(y (h)), y(h)low et y
(h)high
6 si h = 1, incrémenter h et aller à l'étape 4.7 calculer l'écart type associé aux valeurs moyennes des di�érents estimateurs sur les
itérations s2y = 1
h(h−1)
Phr=1
“y (r) − y
”2
, avec y = 1
h
Phr=1
y (r). Idem pour u(y),ylow et yhigh.
8 utiliser toutes les M × h valeurs de Y pour estimer u(y)9 calculer la tolérance numérique δ pour u(y)10 si une valeur parmi 2sy , 2su(y), 2sylow et 2syhigh dépasse δ, incrémenter h et aller à
l'étape 4.11 le calcul a convergé : utiliser les M × h valeurs de Y pour les estimations
statistiques �nales
P. Pernot () Propagation des incertitudes April 2, 2013 65 / 81

La tolérance numérique
Soit ndig le nombre de chi�res considérés comme signi�catifs pour une valeurnumérique x . La tolérance numérique δ associée à x est dé�nie par:
1 mettre x sous la forme c × 10l , où c est un entier à ndig chi�res et l un entier;2 on a alors δ = 0.5× 10l
Exemple
numtol(12345,ndig=1) = 5000
numtol(12345,ndig=2) = 500
P. Pernot () Propagation des incertitudes April 2, 2013 66 / 81

Analyse de sensibilité
Objectifs
Repérer a posteriori les variables in�uentes en analysant les échantillons de X etY .
Cette partie n'est pas explicitement abordée par le GUM-Supp1, mais on peutconsidérer c'est un complément pratiquement indispensable à l'approche parMonte Carlo.
Documents de référence
J.C. Helton, J.D. Johnson, C.J. Salaberry, and C.B. Storlie (2006) Survey ofsampling based methods for uncertainty and sensitivity analysis. ReliabilityEngineering and System Safety 91:1175�1209.
A. Saltelli, S. Tarantola, F. Campolongo and M. Ratto (2004). SensitivityAnalysis in Practice: A Guide to Assessing Scienti�c Models. John Wiley andSons.
P. Pernot () Propagation des incertitudes April 2, 2013 67 / 81

Corrélation entrées/sortie
les échantillons générés pour la propagation des distributions peuvent êtredirectement utilisés pour calculer des indices de sensibilité.
une méthode simple à mettre en oeuvre est le calcul des coe�cients decorrélation entre les échantillons de Y et de X.
dans le cas d'un modèle linéaire, on a l'analogue Monte Carlo du calcul descoe�cients de sensibilité Ji = df (X )/dXi .pour ne pas être trop dépendant d'une hypothèse de linéarité, on utilise engénéral la corrélation de rang (Spearman), plutôt que la corrélation linéaire(Pearson).
dans certaines limites, en particulier la variation monotone de Y en fonctionde X, la valeur absolue du coe�cient de corrélation ρi = cor(Y ,Xi ) traduitl'importance de l'in�uence de Xi sur Y .
P. Pernot () Propagation des incertitudes April 2, 2013 68 / 81

Exemple SA 1
Si Y ne varie pas monotonement en fonction d'un paramètre, même une fortedépendance peut se traduire par un coe�cient de corrélation nul.
X1 <- rnorm(1000, 0, 1)X2 <- rnorm(1000, 0, 0.1)Y <- X1^2 + X2^2# Comparaison des correlations lineaires (Pearson) et de rang# (Spearman) entre la sortie et les entrees du modeleX <- cbind(X1, X2)cor(Y, X, method = "pearson")
## X1 X2## [1,] -0.03531 -0.04242
cor(Y, X, method = "spearman")
## X1 X2## [1,] 0.0134 -0.04971
ces cas ne sont pas forcément aisés à repérer lorsqu'on a des modèles avecdes centaines de paramètres...
P. Pernot () Propagation des incertitudes April 2, 2013 69 / 81
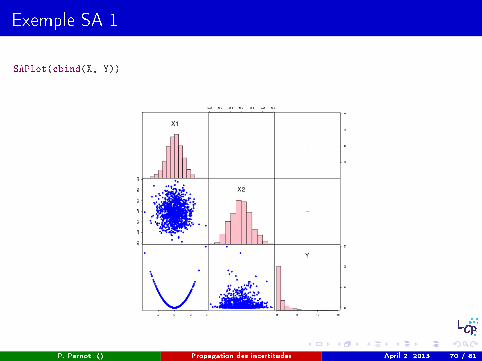
Exemple SA 1
SAPlot(cbind(X, Y))
P. Pernot () Propagation des incertitudes April 2, 2013 70 / 81

Exemple SA 2
Même modèle, paramètres d'entrée di�érents
X1 <- rnorm(1000, 1, 1)X2 <- rnorm(1000, 1, 0.1)Y <- X1^2 + X2^2# Comparaison des correlations linéaires (Pearson) et de rang# (Spearman) entre la sortie et les entrees du modeleX <- cbind(X1, X2)cor(Y, X, method = "pearson")
## X1 X2## [1,] 0.817 0.09588
cor(Y, X, method = "spearman")
## X1 X2## [1,] 0.8938 0.1684
P. Pernot () Propagation des incertitudes April 2, 2013 71 / 81

Exemple SA 2
SAPlot(cbind(X, Y))
P. Pernot () Propagation des incertitudes April 2, 2013 72 / 81

Warning: corrélation vs. dépendance
P. Pernot () Propagation des incertitudes April 2, 2013 73 / 81

Au delà des corrélations
comme le montrent ces exemples, il ne faut jamais se contenter deschi�res, et il est toujours utile de tracer des diagrammes de paires entre lesvariables pour repérer d'éventuelles anomalies.
en cas de doute à propos de la méthode des corrélations, il existe desméthodes plus sophistiquées:
nécessitent la génération d'échantillons spéci�ques, où les variables sontperturbées de façon optimale pour repérer les in�uences
elles sortent du cadre de cette formation...
pour en savoir plus, consulter les ouvrages cités plus haut, ainsi que le packagesensitivity de R, qui fournit la plupart de ces méthodes.
P. Pernot () Propagation des incertitudes April 2, 2013 74 / 81

Exemple Sobol sur Y = X 21 + X 2
2 en x1 = x2 = 0
# Run de la methode de Sobolz <- soboljansen(model = sq.fun, X1 = X1, X2 = X2, nboot = 100)print(z)
#### Call:## soboljansen(model = sq.fun, X1 = X1, X2 = X2, nboot = 100)#### Model runs: 200000#### First order indices:## original bias std. error min. c.i. max. c.i.## x1 0.99990 -1.711e-08 2.025e-06 0.99989 0.99990## x2 -0.00759 2.186e-03 1.220e-02 -0.03624 0.01158#### Total indices:## original bias std. error min. c.i. max. c.i.## x1 1.007590 -2.186e-03 1.220e-02 9.884e-01 1.0362350## x2 0.000101 1.711e-08 2.025e-06 9.694e-05 0.0001053
P. Pernot () Propagation des incertitudes April 2, 2013 75 / 81

Comment reporter un résultat
notation standardY /U = y ± uY
où Y est le mesurande, U l'unité, y le résultat de mesure et uY l'incertitudetype associée.p. ex., si on a mesuré y = 1.2345 kg avec uY = 0.0011 kg, on notera
Y /kg = 1.2345± 0.0011
on trouvera aussi souvent la notation condensée
Y /kg = 1.2345(11)
où l'ordre de grandeur des 2 chi�res entre parenthèses correspond à celui des2 derniers chi�res signi�catifs du résultat.
NB: dans le cas de plusieurs résultats avec des incertitudes corrélées, il fautégalement fournir la matrice de variance/covariance, ou la matrice decorrélation.
P. Pernot () Propagation des incertitudes April 2, 2013 76 / 81

Incertitude élargie
déterminer k tel que si Y est estimé par y avec une incertitude (élargie)U(y) = ku(y), on peut a�rmer que
y − U(y) ≤ Y ≤ y + U(y)
avec une probabilité p proche de 1. [y − U(y), y + U(y)] est alors unintervalle de con�ance à p %.
il faut connaître la pdf, ce qui peut poser des problèmes avec la méthode decombinaison des variances
dans le cas idéal (modèle raisonnablement linéaire, plusieurs sourcesd'incertitude avec des in�uences comparables...) la pdf de Y est Normale, eton peut utiliser les propriétés correspondantes ( k = 2 pour p ' 0.95 ou k = 3pour p ' 0.99...)
P. Pernot () Propagation des incertitudes April 2, 2013 77 / 81

Incertitude élargie
sinon, il faut identi�er les sources principales d'incertitude (hyp: modèleapprox. linéaire)
type A avec peu (moins de 10) de répétitions: utiliser les coe�cients deStudent (k = tp)
n 3 4 5 6 7 8 9 10
t95% 4.30 3.18 2.78 2.57 2.45 2.37 2.31 2.26t99% 9.93 5.84 4.60 4.03 3.71 3.50 3.36 3.25
Ex: mesure de la surface de la table
type B non Normal: se baser sur les propriétés de la pdf
sinon, Monte Carlo....
P. Pernot () Propagation des incertitudes April 2, 2013 78 / 81

Combien de chi�res signi�catifs?
cela dépend de l'incertitude sur ce résultat, mais aussi de la destination de cerésultat:
résultats intermédiaires d'un calcul : en garder le maximum pour éviterl'accumulation d'erreurs d'arrondi;résultat �nal: conserver 2 chi�res signi�catifs pour l'incertitude et tronquer
le résultat au même niveau. p. ex., si y = 1.23456789U et uY = 0.0045U,on reportera Y /U = 1.2345± 0.0045.
d'une manière générale, il vaut mieux reporter trop de chi�res que trop peu.Dans ce dernier cas, on causerait une dégradation préjudiciable del'information. Cependant, ne pas exagérer, et avoir toujours en tête un ordrede grandeur des incertitudes associées à la mesure ou à la méthode de calculutilisée.
NB: pour la matrice de variance/covariance, choisir un nombre de chi�resigni�catifs assurant que la matrice tronquée est bien dé�nie positive.
P. Pernot () Propagation des incertitudes April 2, 2013 79 / 81

Méthode d'arrondissage
Pour arrondir les résultats de mesure et les incertitudes au bon nombre de chi�ressigni�catif:
résultat de mesure
si le dernier chi�re est supérieur à 5, l'avant-dernier chi�re est arrondi auchi�re supérieurex: 101.28 −→ 101.3si le dernier chi�re est strictement inférieur à 5, l'avant-dernier chi�re estarrondi au chi�re inférieurex: 101.23 −→ 101.2
incertitudequelque soit le dernier chi�re, on arrondit toujours au chi�re supérieur pourne pas risquer de minimiser l'incertitudeex: 1.01 −→ 1.1 et 1.09 −→ 1.1
P. Pernot () Propagation des incertitudes April 2, 2013 80 / 81
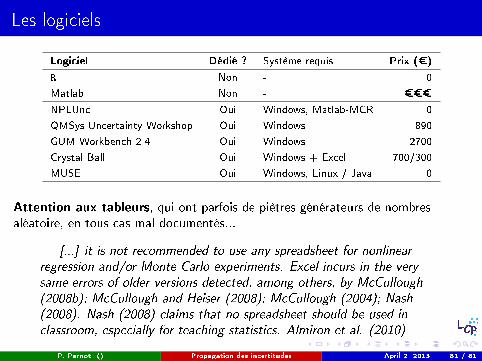
Les logiciels
Logiciel Dédié ? Système requis Prix (¿)
R Non - 0
Matlab Non - ¿¿¿
NPLUnc Oui Windows, Matlab-MCR 0
QMSys Uncertainty Workshop Oui Windows 890
GUM Workbench 2.4 Oui Windows 2700
Crystal Ball Oui Windows + Excel 700/300
MUSE Oui Windows, Linux / Java 0
Attention aux tableurs, qui ont parfois de piètres générateurs de nombresaléatoire, en tous cas mal documentés...
[...] it is not recommended to use any spreadsheet for nonlinearregression and/or Monte Carlo experiments. Excel incurs in the verysame errors of older versions detected, among others, by McCullough(2008b); McCullough and Heiser (2008); McCullough (2004); Nash(2008). Nash (2008) claims that no spreadsheet should be used inclassroom, especially for teaching statistics. Almiron et al. (2010)
P. Pernot () Propagation des incertitudes April 2, 2013 81 / 81