Embed Size (px)
Citation preview

1
STATISTIQUES
LOGICIEL R
MODE D’EMPLOI
1ère année
Irina IOANNOU

Statistiques I
Les scripts fournis ne sont qu’un exemple de scripts possibles pour exécuter l’outil sur R. • Les Tables sur R
• Les tests paramétriques
• Statistiques Descriptives
• Test du Khi2
• Analyse de la variance
3
Les tables statistiques sur R
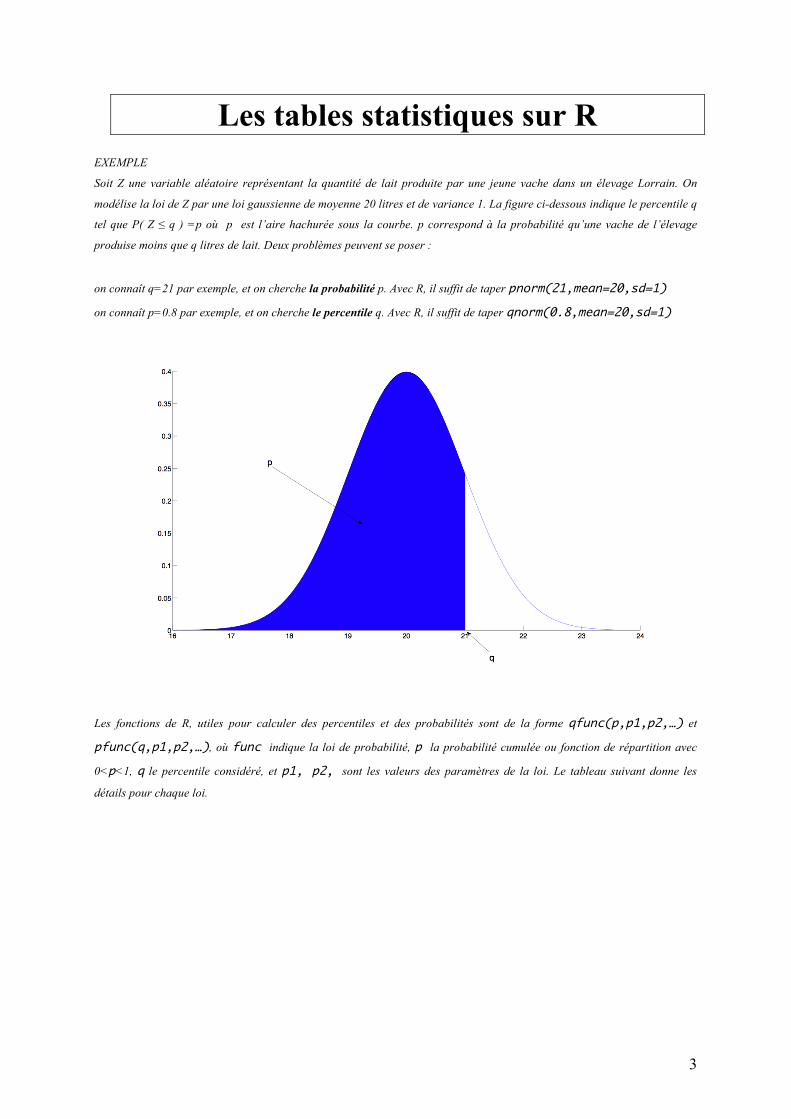
EXEMPLE
Soit Z une variable aléatoire représentant la quantité de lait produite par une jeune vache dans un élevage Lorrain. On
modélise la loi de Z par une loi gaussienne de moyenne 20 litres et de variance 1. La figure ci-dessous indique le percentile q
tel que P( Z ≤ q ) =p où p est l’aire hachurée sous la courbe. p correspond à la probabilité qu’une vache de l’élevage
produise moins que q litres de lait. Deux problèmes peuvent se poser :
on connaît q=21 par exemple, et on cherche la probabilité p. Avec R, il suffit de taper pnorm(21,mean=20,sd=1)
on connaît p=0.8 par exemple, et on cherche le percentile q. Avec R, il suffit de taper qnorm(0.8,mean=20,sd=1)
Les fonctions de R, utiles pour calculer des percentiles et des probabilités sont de la forme qfunc(p,p1,p2,…) et
pfunc(q,p1,p2,…), où func indique la loi de probabilité, p la probabilité cumulée ou fonction de répartition avec
0<p<1, q le percentile considéré, et p1, p2, sont les valeurs des paramètres de la loi. Le tableau suivant donne les
détails pour chaque loi.

4
Comment retrouver les tables statistiques papier avec le logiciel R :
Loi Normale Centrée Réduite
Trouver p à partir de z p =P( Z ≤ Z )
Trouver z à partir de p
Loi Normale de moyenne m et d’écart
type s
Trouver p à partir de x p=P( X ≤ x )
Trouver x à partir de p
Loi Student à n ddl
Trouver p à partir de t p=P( T ≤ t )
Trouver t à partir de p
Loi Khi 2 à n ddl
Trouver p à partir de x p=P( X ≤ x )
Trouver x à partir de p
Loi Fisher à n1 et n2 ddl
Trouver p à partir de f p=P( F ≤ f )
Trouver f à partir de p
Loi binomiale de paramètres nbtirages
et PSuccès
Trouver p à partir de x p=P( X ≤ x )
Trouver x à partir de p

5
pfunc et qfunc sont très utiles pour trouver les valeurs critiques ou les p-valeurs de tests
statistiques.
EXEMPLE :
Les valeurs critiques au seuil de 5% pour un test bilatéral suivant une loi normale sont :
> qnorm(0.025)
[1] -1.959964
> qnorm(0.975)
[1] 1.959964
Pour la version unilatérale de ce test, qnorm(0.05) ou 1 - qnorm(0.95) sera utilisé, suivant la
forme de l'hypothèse alternative.
La p-valeur d'un test, disons chi_2 = 3.84 avec ddl = 1, est :
> 1 - pchisq(3.84, 1)
[1] 0.05004352
Toutes ces fonctions peuvent être utilisées en remplaçant la lettre p, ou q par r ou d, pour obtenir respectivement une
réalisation de la variable aléatoire (rfunc(x,…)), et la densité de probabilité (dfunc(x,…)).
Pour se familiariser avec ces fonctions, reprenons quelques exercices résolus en cours/TD :
Lois Continues – Exercice 6
* Soit une variable aléatoire de loi N(-2;2). Calculez
a. P(X≤-2)
b. P(X≥2.3)
c. Quelle est la valeur de a telle que P(X≥a)=0.65
Lois Continues – Exercice 9
* Soit T une variable aléatoire suivant une loi de student à 15 ddl. Déterminer :
P(T≥Tc)+P(T≤-Tc) = 5 %
P(T≥Tc) = 10 %
P(T≥2) = ?
* Soit F une variable aléatoire suivant une loi de Fisher à 6 et 4 ddl. Déterminer :
P(F≥Fc) = 5 %
P(F≤Fc) = 5 %
P(F≥1) = ?
* Soit X une variable aléatoire suivant une loi de Khi-deux à 9 ddl. Déterminer :
P(X≥Xc) = 1 %
P(X≤Xc) = 5 %
P(X≥8) = ?

6
Lois Discrètes – Exercice 4
* La compagnie pétrolière Wildcat Oil Exploration est à la recherche désespérée de nouveaux puits :
elle a consacré ses derniers fonds au financement de 12 forages. Dans cette région, chaque forage a
indépendamment des autres, 20 % de chances d'aboutir.
Pour éviter la banqueroute, il faut que trois forages au moins donnent du pétrole.
Quelle est la probabilité de cet événement?

7
Les tests paramétriques Les comparaisons de moyennes sur R utilisent la loi Student. Que faire si vous souhaitez effectuer un test de comparaison de moyennes de populations gaussiennes ? Les
différents tests de comparaison de moyennes sont les suivants :
TEST 1 :
Comparaison d’une moyenne à un standard (variance connue OU variance inconnue et grand effectif
OU variance inconnue et effectif faible),
TEST 2 :
Comparaison de 2 moyennes (variances connues OU variances inconnues et grands effectifs OU
variances inconnues et effectifs faibles),
TEST 3 :
Comparaison de 2 moyennes pour des données appariées.
Pour les comparaisons de variances, on ne réalisera que la comparaison de 2 variances.
Comment effectuer les tests d’hypothèses étudiés ?
• Rappels
Que représente l’hypothèse H1 ?
Quelles sont les règles de décision ?
• Comparaison de moyennes
Arguments Fonction : t.test
x Matrice 1 x à définir
y Matrice 2 y à définir, si la matrice 2
n’existe pas, écrire y=NULL.
alternative = "..."
Traduction de H1
Bilatéral ou unilatéral
two.sided less
greater mu = 0 Do ou standard Facultatif
paired = … Données indépendantes ou
appariées
FALSE ou TRUE (par défaut
false)
var.equal = Variances égales ou inégales FALSE ou TRUE
Ouvrir dans script le fichier : Test_student démo

8
TEST 1
# Comparaison des notes de Al à la note standard 13 (test unilatéral). Al<-c(14,8,12,17,10) #on considère pour l'instant la normalité t.test(Al,y=NULL,mu=13,"greater”)
TEST 2
# Comparaison des notes de deux étudiants Al<-c(14,8,12,17,10) Jo<-c(12,13,14,12,13) #on considère pour l'instant la normalité et l'égalité des variances de même que l'indépendance des variables t.test(Al,Jo,mu=0,"two.sided", paired=FALSE,var.equal = ?)
TEST 3
# Comparaison des performances de deux étudiants travaillant en binôme (échantillons appariés). # On suppose la normalité des variables. Al<-c(14,8,12,17,10) Jo<-c(12,13,14,12,13) t.test(Al,Jo,mu=0,"two.sided", paired=TRUE)
• Comparaison de variances
La fonction est : var.test(Vecteur1,Vecteur2).
• Résoudre sur R Exercice 5 (Tests d’hypothèses ) Une usine de conditionnement de jus de fruit dispose de 2 chaînes d'embouteillage distinctes. Le responsable de
production désire savoir si les deux chaînes ont des performances semblables ou pas. Pour cela, il effectue sur
chacune des lignes de production 15 prélèvements pour lesquels il relève la quantité réelle du produit. Les
résultats des observations sont les suivants : Echantillon 1 1.00 1.02 0.99 1.01 0.98 1.02 0.98 0.99
Echantillon 1 0.99 1 0.98 1 1 1.01 1
Echantillon 2 0.98 1 1.01 1.02 0.98 1 0.98 0.99
Echantillon 2 0.97 1 1 1.01 0.98 0.99 1
On supposera que la distribution des deux populations est normale. Peut-on dire que les moyennes des deux
populations sont égales ? On prendra un niveau de 5%.
9
Résoudre sur R Exercice 3 (Tests d’hypothèses) Sept experts ont jugé la fiabilité des productions de deux nouvelles usines. A partir des données ci-dessous, il y
a-t-il une différence significative entre les scores moyens de ces deux usines?
Expert A B C D E F G
Usine X 15 12 14 17 11 16 15
Usine Y 14 14 15 14 11 14 13
Résoudre sur R Exercice 4 (Examen Statistiques) Une expérience est réalisée dans le but de déterminer si le fait de" fumer modifie la sensibilité des personnes à
percevoir la saveur sucrée dans une boisson citronnée. Pour cela, on présente à 7 fumeurs et 5 non-fumeurs, 10
échantillons contenant des quantités de sucre différentes. Chaque personne doit comparer chacun des 10
échantillons à un échantillon standard et dire lequel des deux est le moins sucré. Le nombre d'identifications
correctes par personne est donné ci-dessous :
Non-fumeurs : 7 9 8 10 9
Fumeurs : 4 7 5 3 6 4 8
A quelle conclusion vous conduit cette expérience en supposant que les scores "nombre d'identifications
correctes" proviennent de distributions normales.

10
Statistiques Descriptives • Paramètres numériques
Fonctions sur R
L’écart type peut se calculer avec la fonction sd(x). summary(x) permet de donner un ‘résumé d’informations statistiques’ sur l’échantillon x • Représentations graphiques ! Histogramme
Fonction : hist(namefile$var) EXEMPLE : Ouvrir le script démo_histo. # Version simple t3var <- read.table("t3var.txt", h = T) hist(t3var$tai) # Version complète hist(t3var$tai, col = grey(0.9), main = "Taille des étudiants", xlab = "Taille [cm]", ylab = "Effectifs", labels = TRUE, ylim = c(0, 15))

11
#Avec ajustement à la loi normale hist(t3var$tai, col = grey(0.9), main = "Taille des étudiants", xlab = "Taille [cm]", proba = TRUE) x <- seq(from = min(t3var$tai), to = max(t3var$tai), length = 100) lines(x, dnorm(x, mean(t3var$tai), sd(t3var$tai))) mtext("Ajustement (moyen) a une loi normale") # Ajout de la densité de probabilité réelle dst <- density(t3var$tai) lines(dst$x, dst$y, col=”red”) # Imposer les limites de classes hist(t3var$tai, breaks=c(150,160,170,180,190,200))
! Tracé de courbes
Fonction : plot()
EXEMPLE (voir d’autres exemples dans le polycopié d’introduction à R) : #Relation de type X Y plot(t3var$tai, t3var$poi) #Plus sophistiqué plot(t3var$tai, t3var$poi, pch = ifelse(t3var$sex =="h", 1, 19)) legend("topleft", c("Homme", "Femme"), pch = c(1, 19)) ! Boxplot Fonction : boxplot()
EXEMPLE :
# Tracé d'une boxplot boxplot(t3var$tai ~ t3var$sex, col = c("lightpink", "lightblue"), main = "Comparaison taille Homme-Femme", ylab = "Taille")

12
• Découper la fenêtre graphique (pour avoir plusieurs graphiques visibles)
par(mfcol=c(nb de lignes, nb de colonnes))
Exemple : par(mfcol=c(2,3)) ici on peut afficher 6 graphiques sur la même feuille.
Résoudre sur R : Exercice1 (Statistiques Descriptives). Pour vérifier s'il est vrai qu'une nouvelle sorte de pile dure plus longtemps, une association de consommateurs
teste un échantillon aléatoire de 20 de ces piles. Chacune est soumise à un usage identique jusqu'à son extinction.
Les durées de vie (en minutes) suivantes ont été observées :
65.1 58.4 64.9 76 67.8 78.1 76.7 64.2 74.9 77.6 58 68 73.3
75.4 76 59.4 65.4 74.7 76.6 81.3
Tracer l’histogramme et le commenter.

13
Test du Khi2
• Sur données quantitatives (Test d’ajustement)
Fonction : chisq.test(effobs,p=ptheo)
Arguments : effobs (matrice contenant les effectifs observés),
ptheo (probabilités théoriques à calculer d’après la loi à tester).
EXEMPLE : Ouvrir le script démo_khi2.
Soit une question à choix multiples, X la variable mesurant le nombre de personnes ayant répondu A,
B, C et D à la question.
Un échantillon de 80 personnes a répondu à la question, les résultats sont les suivants : 26 A, 18 B, 20
C et 16 D.
Peut-on considérer que les personnes au répondu au hasard à la question ? Autrement dit peut-on
considérer que X suit une loi uniforme ?
SCRIPT
effobs <- c(26, 18, 20, 16)
probtheo <- c(1/4, 1/4, 1/4, 1/4)
chisq.test(effobs, p= probtheo)
Les effectifs observés ne sont pas toujours fournis, il faut pouvoir les trouver. De même les
probabilités théoriques seront à calculer.
Détermination des effectifs observés :
Il s’agit de déterminer les classes et de comptabiliser le nombre de valeurs présentes dans
chaque classe.
EXEMPLE
X<-c(1,2,3,4,5,8,9,10)
Class<-c(1,2,4,6,8,10)
x<- cut(X,breaks=Class,include.lowest=TRUE)
Eff<-table(x)
Eff

14
Calcul des probabilités théoriques :
Pour cela, vous devez connaître la loi théorique ainsi que les paramètres estimés de la loi.
EXEMPLE : loi normale(5,2).
Il faut dans ce cas utiliser pnorm.
• Sur données qualitatives (Test d’indépendance)
Fonction : chisq.test(matrice)
Arguments : matrice (matrice contenant le tableau de contingence).
EXEMPLE
Soit X la réponse à une question, celle-ci peut prendre les modalités suivantes « oui, peut-être, non ».
Soit un échantillon de 300 personnes référencées selon une variable Y catégories d’age « enfant, ado,
adulte ».
Peut-on considérer que X et Y sont indépendantes ? Autrement dit les effectifs du tableau de
contingence sont-ils répartis de façon uniforme ?
SCRIPT
ki2 =matrix(c(10,20,30,20,30,40,40,50,60),byrow=T,nrow=3)
colnames(ki2)<-c("enfant","ado","adulte" )
rownames(ki2)<-c("oui","peut-être", "non")
ki2
chisq.test(ki2)

15
Résoudre sur R : Exercice 6 (Tests d’hypothèses) En grande distribution, un contrôle est porté sur le poids des Steak hachés. A partir des prélèvements ci-dessous,
montrer que le poids des Steak Hachés suit une loi normale de paramètres 100 grammes et d’écart type 1.
Poids en grammes de 20 Steak Hachés :
100,8 101,1 100,4 99,8 101,5 99,3 100,0 100,2 100,4 99,9
99,6 99,9 100,2 99,1 99,7 100,3 100,4 99,9 100,0 99,5
Résoudre sur R : Exercice 7 (Tests d’hypothèses) Pour tester l’efficacité de deux vaccins A et B, on inocule à un groupe d’animaux,le vaccin A et à un autre
groupe d’animaux le vaccin B. On comptabilise ensuite le nombre d’animaux sains et le nombre atteints par la
maladie :
Vaccin Nombre d’animaux sains Nombre d’animaux malades
A 180 16
B 98 8
Les deux vaccins ont-ils la même efficacité ?

16
Analyse de la variance Les scripts se situent dans scripts_ANOVA, vous avez besoin des fichiers txt : Anova1facteur.txt et
Anova2facteur.txt
Attention, les données doivent être disposées en colonnes, une colonne par facteur, une colonne
pour la réponse.
• Analyse de la variance à 1 facteur
#Anova 1 facteur rm(list=ls()) adv1F <- read.table("Anova1facteur.txt", h=T) names(adv1F) <- c("facteur", "rep") adv1F$facteur <- as.factor(adv1F$facteur) summary(adv1F) lm1 <- lm(rep ~ facteur , data = adv1F) anova(lm1)
• Analyse de la variance à 2 facteurs sans répétition d’expériences
#Anova 2 facteurs sans répétition d'expériences rm(list=ls()) adv2F <- read.table("Anova2facteur.txt", h=T) names(adv2F) <- c("fact1","fact2", "rep") adv2F$fact1 <- as.factor(adv2F$fact1) adv2F$fact2 <- as.factor(adv2F$fact2) summary(adv2F) lm2 <- lm(rep ~ fact2+fact1 , data = adv2F) anova(lm2)
17
Résoudre sur R : Exercice 1 (Analyse de la variance) Les teneurs en azote de 6 fromages différents sont comparées. Ces teneurs sont évaluées en g/kg.
Quel est l'effet du facteur fromage sur la teneur en azote?
Molle Persillé Ferme Dure Fondu Chèvre
36.7 29.3 35.5 46 25.6 17.4
32.1 31.7 36.1 56 26.3 28.6
26.8 28.4 38.7 45.8 19.5 25
32.3 32.3 40.9 41.7 12.1 26.4
Résoudre sur R : Exercice 8 (Pour Entrainement) L’effet de fertilisation potassique et magnésienne sur le rendement de la pomme de terre, de la variété fourchette,
a été étudié par Giroux (1982). Le dispositif comportait 4 doses de potassium (0 à 240 Kg/Ha de K) et 4 doses de
magnésium (0 à 80 Kg/Ha de Mg). L’engrais a été appliqué par bande au moment de la plantation et les bandes
ont été sélectionnées aléatoirement. Les résultats de rendement sont les suivants :
Dose K Total Moyenne
Dose Mg
0 80 160 240 0 203 253 257 261 974 243,5
20 206 247 270 267 990 247,5 40 204 244 266 276 990 247,5 80 179 252 265 259 955 238,75
Total 792 996 1058 1063 3909
Moyenne 198 249 264,5 265,75 244,31 Les fertilisations potassique et magnésienne conduisent-elles à un accroissement du rendement ?
Résoudre sur R : Exercice 3 (Examen Statistiques) On sait que certaines bactéries du système uro-génital inhibent la croissance de la bactérie pathogène Neisseria
gonorrhoeae. Toutefois, on ne sait pas si l'action de ces bactéries est due à une diminution du pH qu'elles
induisent ou à un autre mode d'inhibition. Pour le vérifier, Morin et coll. (1980) ont réalisé les expériences
suivantes :
- Six milieux de culture différents ont été préparés avec six pH différents : 5.3;5.8;6.3;7.0;7.5;8.1.
- Trois microgouttes de 20 microlitres de suspension de la souche G1 de Neisseria gonorrhoeae ont
été déposées sur les milieux de culture et les colonies de G1 ont été dénombrées après une période
d'incubation.
pH 5.3 5.8 6.3 7.0 7.5 8.1
Nombre de colonies par
goutte
0 20 85 75 33 64
0 22 101 73 52 66
0 16 88 60 51 54
Total 0 58 274 208 136 184 860
Peut-on dire que le pH n'a aucun effet sur la croissance des colonies G1?













![IECL | Institut Élie Cartan de Lorraine - EXERCICES …Gerard.Eguether/zARTICLE/...Cela définit également des normes sur les espaces de polynômes R[X] et C[X] car la nullité](https://img.pdfslide.fr/doc/110x75/5e5f2f578f13a1097f2c5a6a/iecl-institut-lie-cartan-de-lorraine-exercices-gerardeguetherzarticle.jpg)















